Sound Event Detection in Underground Parking Garage Using Convolutional Neural Network


Abstract
1. Introduction
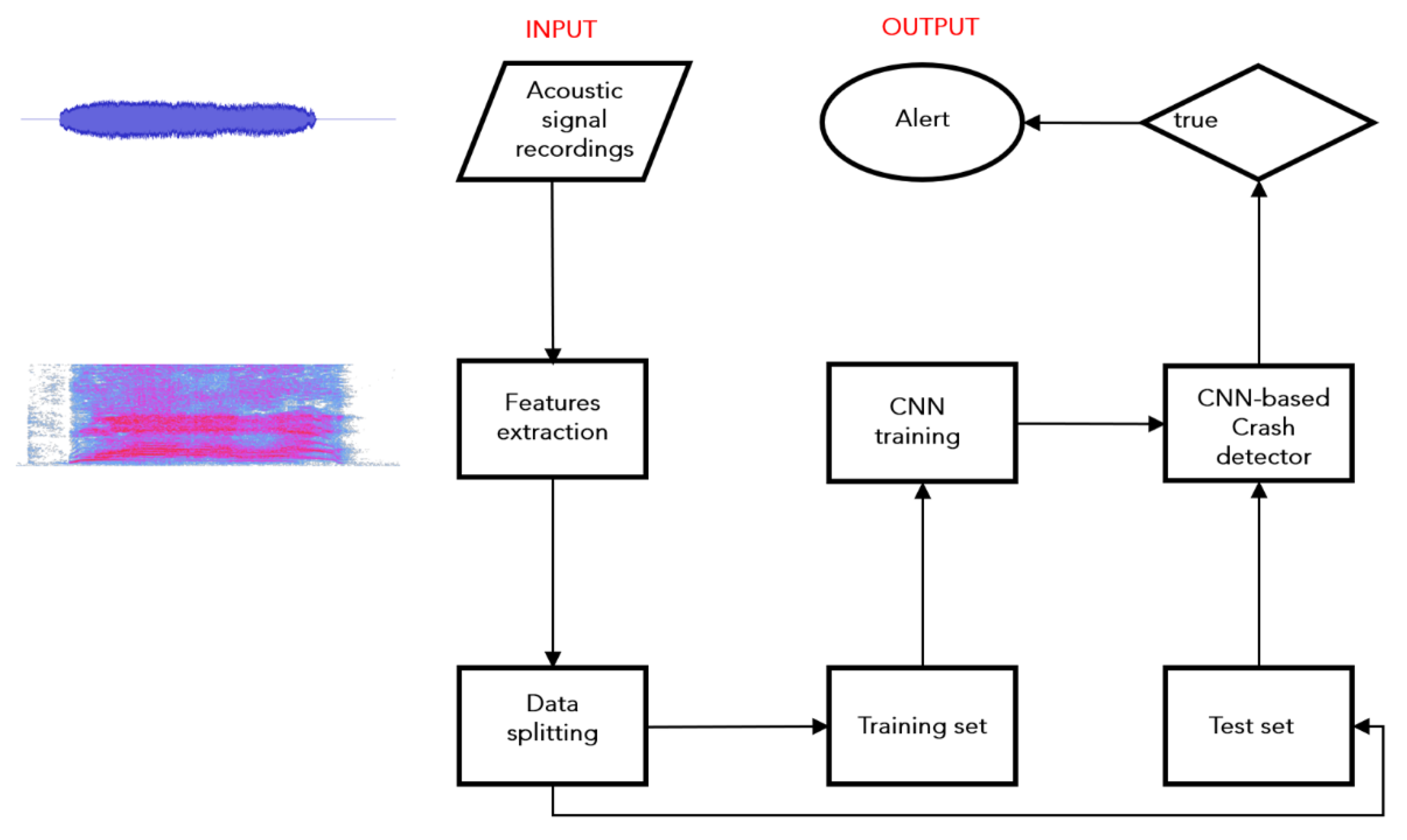
2. Methodology
2.1. Acoustical Signal Recordings
2.2. Signal Descriptor Selection
- f(x) is a real function of the real variable t.
- F is the Fourier transform of f(x).
2.3. Convolutional Neural Network
2.3.1. Convolutional Layer
2.3.2. ReLU Layer
2.3.3. Pooling Layer
2.3.4. Fully Connected Layer (FC)
2.3.5. Softmax Layer
3. Results and Discussion
3.1. Processing of Recorded Signals
- p is the root mean square of the pressure level.
- p0 is a reference value for sound pressure, which, in air, assumes the standard value of 20 µPa.
3.2. Feature Extraction
3.3. Sound Event Classification Using Convolutional Neural Network
4. Conclusions
- The characterization of the crash noise between cars did not highlight any trends in the time domain, meaning that an analysis in this domain is not able to identify the event.
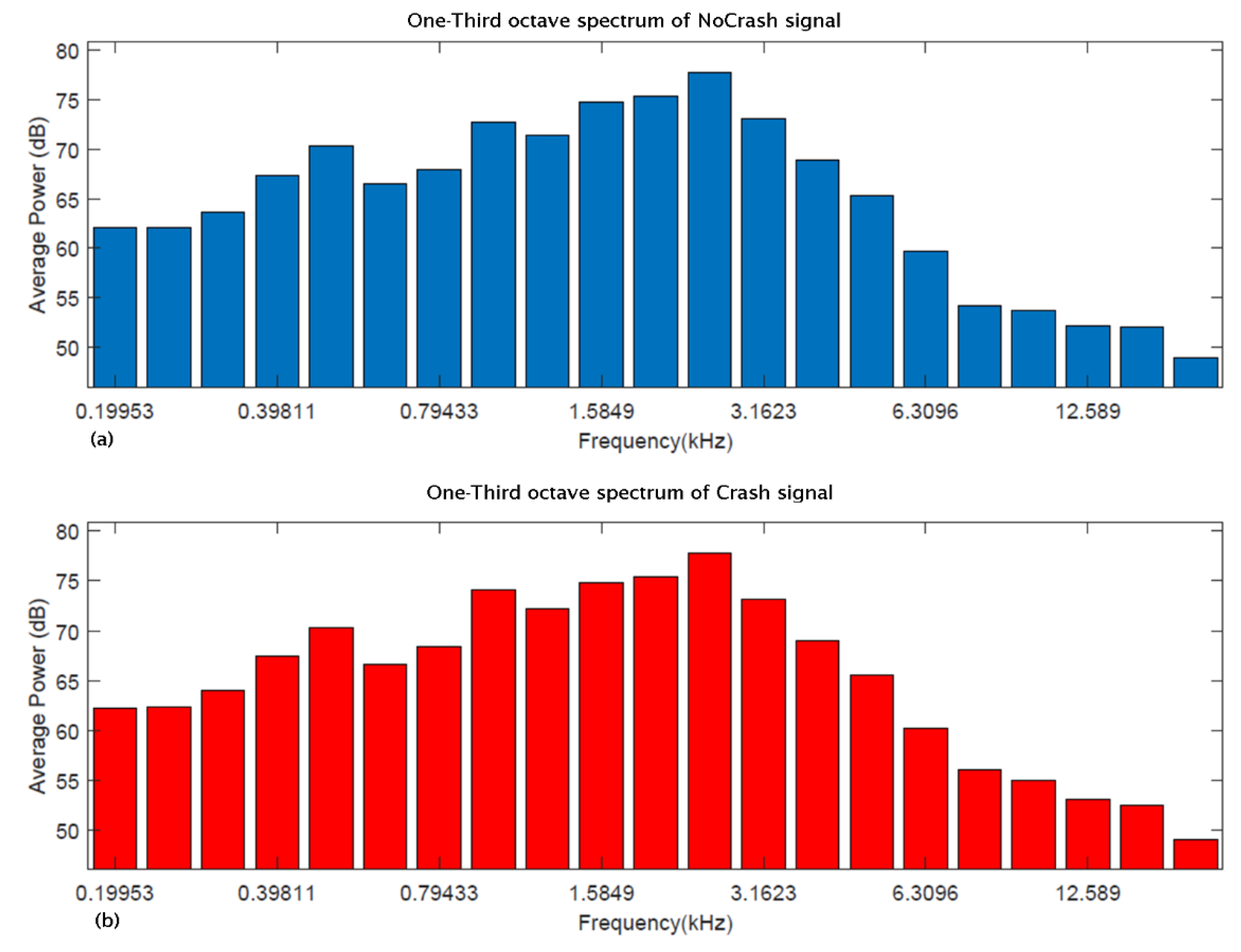
- The comparison between the spectra in the frequency domain in the one-third octave band during the two scenarios (NoCrash, Crash) shows that the two signals are comparable and no tonal components are highlighted. This confirms that the ambient noise in such scenarios is so complex that it is not possible to distinguish between the different acoustic sources, even using this descriptor.
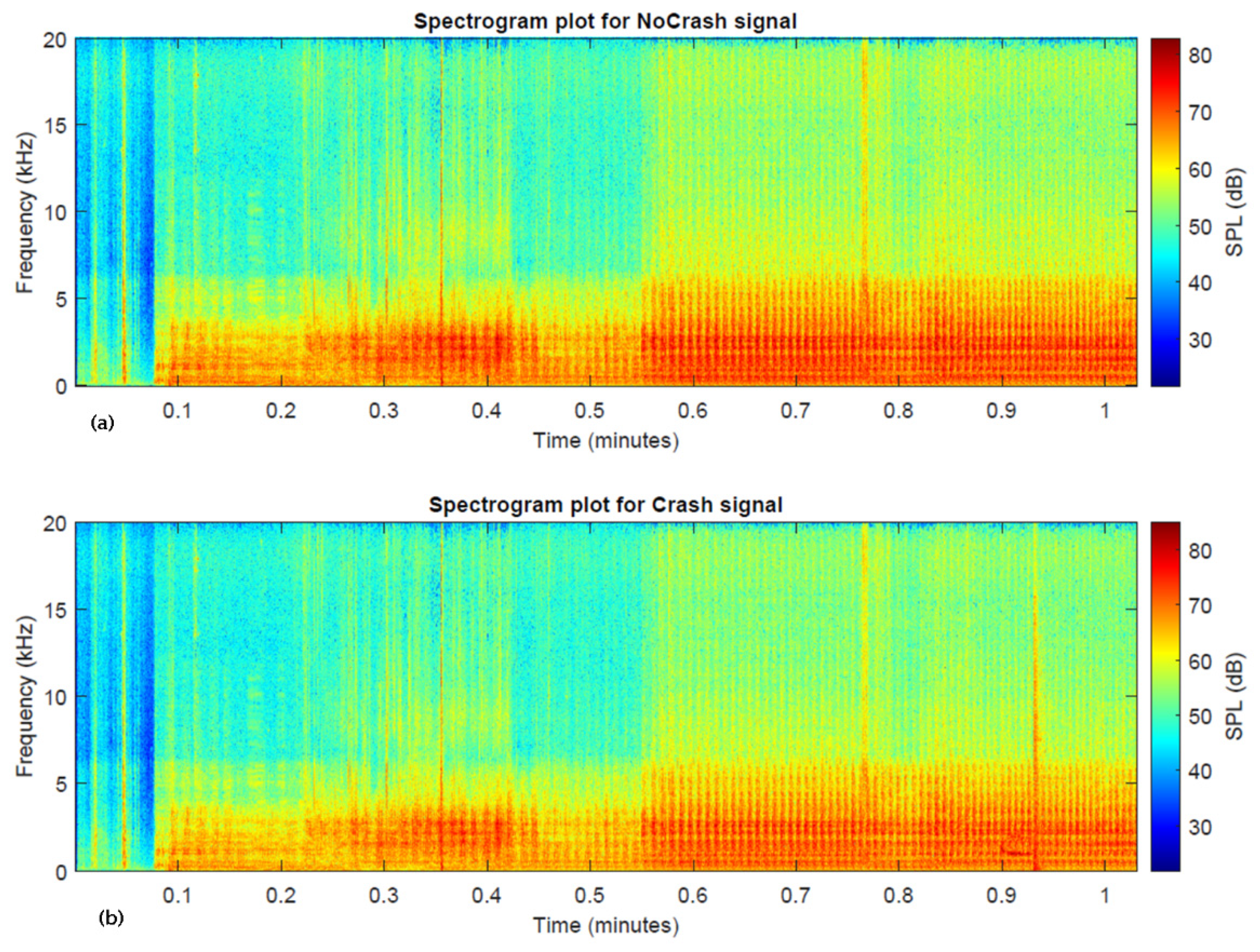
- The comparison between the spectrograms of the two scenarios demonstrated a broadband component at the event. This indicates that the spectrogram is a descriptor capable of discriminating between the two scenarios.
- A CNN-based rating system has proven to be able to identify the occurrence of a crash between cars with an accuracy of 0.87, demonstrating the strength of the procedure for identifying an accident in an underground parking garage.
Funding
Conflicts of Interest
References
- Chrest, A.P.; Smith, M.S.; Bhuyan, S.; Iqbal, M.; Monahan, D.R. Parking Structures: Planning, Design, Construction, Maintenance and Repair; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Chu, C.P.; Tsai, M.T. A study of an environmental-friendly parking policy. Transp. Res. Part D Transp. Environ. 2011, 16, 87–91. [Google Scholar] [CrossRef]
- Hoyt, H. Suburban Shopping Center Effects on Highways and Parking. Traffic Q. 1956, 10, 181–189. [Google Scholar]
- Albanese, B.; Matlack, G. Utilization of parking lots in Hattiesburg, Mississippi, USA, and impacts on local streams. Environ. Manag. 1998, 24, 265–271. [Google Scholar] [CrossRef] [PubMed]
- Guerra, E.; Morris, E.A. Cities, Automation, and the Self-parking Elephant in the Room. Plan. Theory Pract. 2018, 19, 291–297. [Google Scholar] [CrossRef]
- Pala, Z.; Inanc, N. Automation with RFID technology as an application: Parking lot circulation control. J. Sci. Technol. 2008, 2, 235–245. [Google Scholar]
- Tian, Y.L.; Brown, L.; Hampapur, A.; Lu, M.; Senior, A.; Shu, C.F. IBM smart surveillance system (S3): Event based video surveillance system with an open and extensible framework. Mach. Vis. Appl. 2008, 19, 315–327. [Google Scholar] [CrossRef]
- Zhang, T.; Chowdhery, A.; Bahl, P.; Jamieson, K.; Banerjee, S. The design and implementation of a wireless video surveillance system. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking, Paris, France, 7–11 September 2015; pp. 426–438. [Google Scholar]
- Lao, W.; Han, J.; De With, P.H. Automatic video-based human motion analyzer for consumer surveillance system. IEEE Trans. Consum. Electron. 2009, 55, 591–598. [Google Scholar] [CrossRef]
- Muller-Schneiders, S.; Jager, T.; Loos, H.S.; Niem, W. Performance evaluation of a real time video surveillance system. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005. [Google Scholar]
- Baltrënas, P.; Kazlauskas, D.; Petraitis, E. Testing on noise level prevailing at motor vehicle parking lots and numeral simulation of its dispersion. J. Environ. Eng. Landsc. Manag. 2004, 12, 63–70. [Google Scholar] [CrossRef]
- Mrkajic, V.; Stamenkovic, M.; Males, M.; Vukelic, D.; Hodolic, J. Proposal for reducing problems of the air pollution and noise in the urban environment. Carpathian J. Earth Environ. Sci. 2010, 5, 49–56. [Google Scholar]
- Shaffer, G.S.; Anderson, L.M. Perceptions of the security and attractiveness of urban parking lots. J. Environ. Psychol. 1985, 5, 311–323. [Google Scholar] [CrossRef]
- Anderson, L.M.; Stokes, G.S. Planting in parking lots to improve perceived attractiveness and security. J. Arboric. 1989, 15, 7–10. [Google Scholar]
- Chow, W.K. On safety systems for underground car parks. Tunn. Undergr. Space Technol. 1998, 13, 281–287. [Google Scholar] [CrossRef]
- Hill, J.; Rhodes, G.; Vollar, S.; Whapples, C. Car Park Designers′ Handbook; Thomas Telford: London, UK; Reston, VA, USA,, 2005. [Google Scholar]
- Idris, M.I.; Leng, Y.Y.; Tamil, E.M.; Noor, N.M.; Razak, Z. Car park system: A review of smart parking system and its technology. Inf. Technol. J. 2009, 8, 101–113. [Google Scholar] [CrossRef]
- Mingqiang, Y.; Kidiyo, K.; Joseph, R. A survey of shape feature extraction techniques. Pattern Recognit. 2008, 15, 43–90. [Google Scholar]
- Nussbaumer, H.J. The fast Fourier transform. In Fast Fourier Transform and Convolution Algorithms; Springer: Berlin/Heidelberg, Germany, 1981; pp. 80–111. [Google Scholar]
- Van Loan, C. Computational Frameworks for the Fast Fourier Transform; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1992. [Google Scholar]
- Brigham, E.O.; Morrow, R.E. The Fast Fourier Transform. IEEE Spectr. 1967, 4, 63–70. [Google Scholar] [CrossRef]
- Zue, V.; Cole, R. Experiments on spectrogram reading. In Proceedings of the ICASSP′79. IEEE International Conference on Acoustics, Speech, and Signal Processing, Washington, DC, USA, 2–4 April 1979; IEEE: Piscataway, NJ, USA, 1979; Volume 4, pp. 116–119. [Google Scholar]
- Fraser, G.; Boashash, B. Multiple window spectrogram and time-frequency distributions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP′94, Adelaide, Australia, 19–22 April 1994; IEEE: Piscataway, NJ, USA, 1994; Volume 4, pp. IV-293–IV-296. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Sainath, T.N.; Mohamed, A.R.; Kingsbury, B.; Ramabhadran, B. Deep convolutional neural networks for LVCSR. In Proceedings of the 2013 IEEE international Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 8614–8618. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Xu, L.; Ren, J.S.; Liu, C.; Jia, J. Deep convolutional neural network for image deconvolution. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 1790–1798. [Google Scholar]
- Sedghi, H.; Gupta, V.; Long, P.M. The singular values of convolutional layers. arXiv 2018, arXiv:1805.10408. [Google Scholar]
- He, J.; Li, L.; Xu, J.; Zheng, C. ReLU deep neural networks and linear finite elements. arXiv 2018, arXiv:1807.03973. [Google Scholar]
- Jaapar, R.M.Q.R.; Mansor, M.A. Convolutional Neural Network Model in Machine Learning Methods and Computer Vision for Image Recognition: A Review. J. Appl. Sci. Res. 2018, 14, 23–27. [Google Scholar]
- Ma, W.; Lu, J. An equivalence of fully connected layer and convolutional layer. arXiv 2017, arXiv:1712.01252. [Google Scholar]
- Yuan, B. Efficient hardware architecture of softmax layer in deep neural network. In Proceedings of the 2016 29th IEEE International System-on-Chip Conference (SOCC), Seattle, WA, USA, 6–9 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 323–326. [Google Scholar]
- Bardou, D.; Zhang, K.; Ahmad, S.M. Lung sounds classification using convolutional neural networks. Artif. Intell. Med. 2018, 88, 58–69. [Google Scholar] [CrossRef] [PubMed]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Chen, B.H.; Shi, L.F.; Ke, X. A robust moving object detection in multi-scenario big data for video surveillance. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 982–995. [Google Scholar] [CrossRef]
- Xu, H.; Caramanis, C.; Sanghavi, S. Robust PCA via outlier pursuit. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2010; pp. 2496–2504. [Google Scholar]
- Guan, N.; Tao, D.; Luo, Z.; Shawe-Taylor, J. MahNMF: Manhattan non-negative matrix factorization. arXiv 2012, arXiv:1207.3438. [Google Scholar]
- Iannace, G.; Ciaburro, G.; Trematerra, A. Modelling sound absorption properties of broom fibers using artificial neural networks. Appl. Acoust. 2020, 163, 107239. [Google Scholar] [CrossRef]
- Iannace, G.; Ciaburro, G.; Trematerra, A. Wind turbine noise prediction using random forest regression. Machines 2019, 7, 69. [Google Scholar] [CrossRef]
- Iannace, G.; Ciaburro, G.; Trematerra, A. Heating, ventilation, and air conditioning (HVAC) noise detection in open-plan offices using recursive partitioning. Buildings 2018, 8, 169. [Google Scholar] [CrossRef]
- Iannace, G.; Ciaburro, G.; Trematerra, A. Fault diagnosis for UAV blades using artificial neural network. Robotics 2019, 8, 59. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Junio Guimarães, A.; Vitor de Campos Souza, P.; Jonathan Silva Araújo, V.; Silva Rezende, T.; Souza Araújo, V. Pruning fuzzy neural network applied to the construction of expert systems to aid in the diagnosis of the treatment of cryotherapy and immunotherapy. Big Data Cogn. Comput. 2019, 3, 22. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Description | Shape |
|---|---|---|
| Input | Spectrogram image (800 × 800) png format | (800 × 800 × 3) |
| 1° Hidden | 2D spatial convolution for images | (399 × 399 × 32) |
| Max pooling operation for 2D spatial data | (199 × 199 × 32) | |
| ReLu activation function | (199 × 199 × 32) | |
| 2° Hidden | 2D spatial convolution for images | (199 × 199 × 64) |
| Max pooling operation for 2D spatial data | (99 × 99 × 64) | |
| ReLu activation function | (99 × 99 × 64) | |
| 3° Hidden | 2D spatial convolution for images | (99 × 99 × 64) |
| Max pooling operation for 2D spatial data | (49 × 49 × 64) | |
| ReLu activation function | (49 × 49 × 64) | |
| Flatten | Dimensionality reduction using a flatten operation | (153,664) |
| Random deactivation of some neurons via dropout | (153,664) | |
| Fully connected | Layer of neurons interconnected with each other | (64) |
| ReLu activation function | (64) | |
| Random deactivation of some neurons via dropout | (64) | |
| Output | Densely- Layer of neurons interconnected with each other | (2) |
| Softmax activation function | (2) |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ciaburro, G. Sound Event Detection in Underground Parking Garage Using Convolutional Neural Network. Big Data Cogn. Comput. 2020, 4, 20. https://doi.org/10.3390/bdcc4030020
Ciaburro G. Sound Event Detection in Underground Parking Garage Using Convolutional Neural Network. Big Data and Cognitive Computing. 2020; 4(3):20. https://doi.org/10.3390/bdcc4030020
Chicago/Turabian StyleCiaburro, Giuseppe. 2020. "Sound Event Detection in Underground Parking Garage Using Convolutional Neural Network" Big Data and Cognitive Computing 4, no. 3: 20. https://doi.org/10.3390/bdcc4030020
APA StyleCiaburro, G. (2020). Sound Event Detection in Underground Parking Garage Using Convolutional Neural Network. Big Data and Cognitive Computing, 4(3), 20. https://doi.org/10.3390/bdcc4030020