Replacing Rules by Neural Networks A Framework for Agent-Based Modelling


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methods
2.1. Artificial Neural Networks
2.2. A Framework for Agent-Based Modelling
- Save all the sensory inputs in a vector .
- Calculate current score from utility function and save as .
- Perform a random action a from the list of available actions.
- Calculate the new score and save as .
- Rate the decision and save as r: good if , bad otherwise.
- Add an entry to the experience database: .
- Save all the sensory inputs in a vector .
- For each action available action , use as an input for the neural network.
- Rank all actions according to the certainty that they are good decisions.
- Perform the action which was ranked highest.
2.3. Applying the Framework
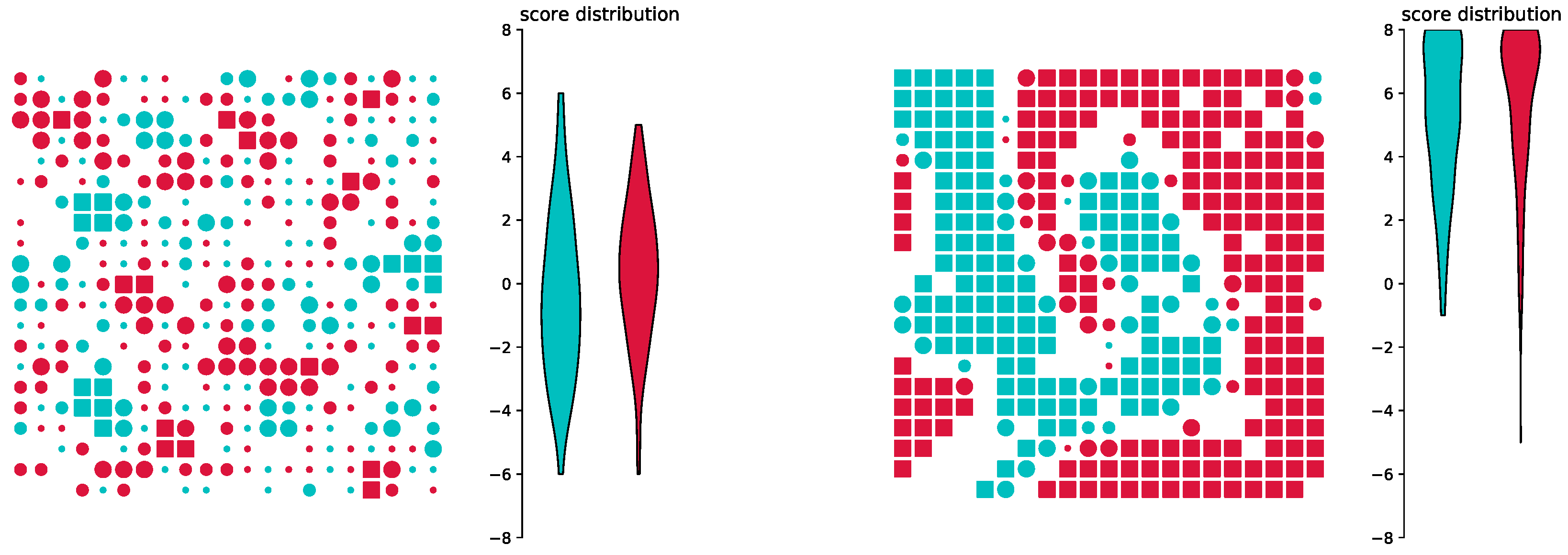
3. Results
3.1. Reproducing the Original Model
3.2. Training in a Different Environment
3.3. Truncating Input during Training
4. Discussion
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Gilbert, N. Agent-Based Models; Number 153; Sage: Thousand Oaks, CA, USA, 2008. [Google Scholar]
- Chen, X.; Zhan, F.B. Agent-based modelling and simulation of urban evacuation: Relative effectiveness of simultaneous and staged evacuation strategies. J. Oper. Res. Soc. 2008, 59, 25–33. [Google Scholar] [CrossRef]
- Chen, B.; Cheng, H.H. A review of the applications of agent technology in traffic and transportation systems. IEEE Trans. Intell. Transp. Syst. 2010, 11, 485–497. [Google Scholar] [CrossRef]
- Balmer, M.; Cetin, N.; Nagel, K.; Raney, B. Towards truly agent-based traffic and mobility simulations. In Proceedings of the Third International Joint Conference on Autonomous Agents and Multiagent Systems-Volume 1; IEEE Computer Society: Washington, DC, USA, 2004; pp. 60–67. [Google Scholar]
- Hofer, C.; Jäger, G.; Füllsack, M. Large scale simulation of CO2 emissions caused by urban car traffic: An agent-based network approach. J. Clean. Prod. 2018, 183, 1–10. [Google Scholar] [CrossRef]
- Batty, M. Cities and Complexity: Understanding Cities With Cellular Automata, Agent-Based Models, and Fractals; The MIT press: Cambridge, MA, USA, 2007. [Google Scholar]
- Davidsson, P. Agent based social simulation: A computer science view. J. Artif. Soc. Soc. Simul. 2002, 5, 1–7. [Google Scholar]
- Epstein, J.M. Agent-based computational models and generative social science. Complexity 1999, 4, 41–60. [Google Scholar] [CrossRef]
- Bonabeau, E. Agent-based modeling: Methods and techniques for simulating human systems. Proc. Natl. Acad. Sci. USA 2002, 99, 7280–7287. [Google Scholar] [CrossRef]
- Judson, O.P. The rise of the individual-based model in ecology. Trends Ecol. Evol. 1994, 9, 9–14. [Google Scholar] [CrossRef]
- Axelrod, R.M. The Complexity of Cooperation: Agent-Based Models of Competition and Collaboration; Princeton University Press: Princeton, NJ, USA, 1997. [Google Scholar]
- Amman, H.M.; Tesfatsion, L.; Kendrick, D.A.; Judd, K.L.; Rust, J. Handbook of Computational Economics; Elsevier: Amsterdam, The Netherlands, 1996; Volume 2. [Google Scholar]
- Tesfatsion, L. Agent-based computational economics: Growing economies from the bottom up. Artif. Life 2002, 8, 55–82. [Google Scholar] [CrossRef]
- Tesfatsion, L. Agent-based computational economics: A constructive approach to economic theory. Handb. Comput. Econ. 2006, 2, 831–880. [Google Scholar]
- Deissenberg, C.; Van Der Hoog, S.; Dawid, H. EURACE: A massively parallel agent-based model of the European economy. Appl. Math. Comput. 2008, 204, 541–552. [Google Scholar] [CrossRef]
- Farmer, J.D.; Foley, D. The economy needs agent-based modelling. Nature 2009, 460, 685–686. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, G.; Hamill, L. Social circles: A simple structure for agent-based social network models. J. Artif. Soc. Soc. Simul. 2009, 12, 1–3. [Google Scholar]
- Andrei, A.L.; Comer, K.; Koehler, M. An agent-based model of network effects on tax compliance and evasion. J. Econ. Psychol. 2014, 40, 119–133. [Google Scholar] [CrossRef]
- Simon, H.A. Theories of bounded rationality. Decis. Organ. 1972, 1, 161–176. [Google Scholar]
- Gilbert, N.; Terna, P. How to build and use agent-based models in social science. Mind Soc. 2000, 1, 57–72. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998; Volume 2. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Schelling, T.C. Models of segregation. Am. Econ. Rev. 1969, 59, 488–493. [Google Scholar]
- Schelling, T.C. Dynamic models of segregation. J. Math. Sociol. 1971, 1, 143–186. [Google Scholar] [CrossRef]
- Yao, X. Evolving artificial neural networks. Proc. IEEE 1999, 87, 1423–1447. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef]
- Da Silva, I.N.; Spatti, D.H.; Flauzino, R.A.; Liboni, L.H.B.; dos Reis Alves, S.F. Artificial Neural Networks; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems; 2014; pp. 3104–3112. Available online: https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf (accessed on 9 October 2019).
- Günther, F.; Fritsch, S. neuralnet: Training of neural networks. R J. 2010, 2, 30–38. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P.N. A survey of randomized algorithms for training neural networks. Inf. Sci. 2016, 364, 146–155. [Google Scholar] [CrossRef]
- Sutskever, I.; Hinton, G. Training Recurrent Neural Networks; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.P. Training deep neural networks with low precision multiplications. arXiv 2014, arXiv:1412.7024. [Google Scholar]
- Mirjalili, S.; Hashim, S.Z.M.; Sardroudi, H.M. Training feedforward neural networks using hybrid particle swarm optimization and gravitational search algorithm. Appl. Math. Comput. 2012, 218, 11125–11137. [Google Scholar] [CrossRef]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 2377–2385. [Google Scholar]
- Blank, T.; Brown, S. Data processing using neural networks. Anal. Chim. Acta 1993, 277, 273–287. [Google Scholar] [CrossRef]
- Huang, G.B.; Saratchandran, P.; Sundararajan, N. A generalized growing and pruning RBF (GGAP-RBF) neural network for function approximation. IEEE Trans. Neural Netw. 2005, 16, 57–67. [Google Scholar] [CrossRef] [PubMed]
- Adya, M.; Collopy, F. How effective are neural networks at forecasting and prediction? A review and evaluation. J. Forecast. 1998, 17, 481–495. [Google Scholar] [CrossRef]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef]
- Gauvin, L.; Vannimenus, J.; Nadal, J.P. Phase diagram of a Schelling segregation model. Eur. Phys. J. B 2009, 70, 293–304. [Google Scholar] [CrossRef]
- Clark, W.A.; Fossett, M. Understanding the social context of the Schelling segregation model. Proc. Natl. Acad. Sci. USA 2008, 105, 4109–4114. [Google Scholar] [CrossRef] [PubMed]
- Weisstein, E.W. Moore Neighborhood. From MathWorld—A Wolfram Web Resource. 2005. Available online: http://mathworld.wolfram.com/MooreNeighborhood.html (accessed on 9 September 2019).
- Guyon, I.; Gunn, S.; Nikravesh, M.; Zadeh, L.A. Feature Extraction: Foundations and Applications; Springer: Berlin/Heidelberg, Germany, 2008; Volume 207. [Google Scholar]
- Helbing, D. Agent-based modeling. In Social Self-Organization; Springer: Berlin/Heidelberg, Germany, 2012; pp. 25–70. [Google Scholar]
- Thrun, S. Monte carlo pomdps. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 1064–1070. [Google Scholar]
- Lazaric, A.; Restelli, M.; Bonarini, A. Reinforcement learning in continuous action spaces through sequential monte carlo methods. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2008; pp. 833–840. [Google Scholar]
- Thrun, S. Efficient Exploration in Reinforcement Learning; Technical Report; Carnegie Mellon University: Pittsburgh, PA, USA, 1992. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Stanley, K.O.; Miikkulainen, R. Efficient reinforcement learning through evolving neural network topologies. In Proceedings of the 4th Annual Conference on Genetic and Evolutionary Computation, New York, NY, USA, 9–13 July 2002; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2002; pp. 569–577. [Google Scholar]
- Jennings, N.R. Agent-Based Computing: Promise and Perils. In Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 31 July–6 August 1999; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1999; pp. 1429–1436. [Google Scholar]
- Galán, J.M.; Izquierdo, L.R.; Izquierdo, S.S.; Santos, J.I.; Del Olmo, R.; López-Paredes, A.; Edmonds, B. Errors and artefacts in agent-based modelling. J. Artif. Soc. Soc. Simul. 2009, 12, 1. [Google Scholar]
- Leombruni, R.; Richiardi, M. Why are economists sceptical about agent-based simulations? Phys. A Stat. Mech. Its Appl. 2005, 355, 103–109. [Google Scholar] [CrossRef]
- Elliott, E.; Kiel, L.D. Exploring cooperation and competition using agent-based modeling. Proc. Natl. Acad. Sci. USA 2002, 99, 7193–7194. [Google Scholar] [CrossRef] [PubMed]
- Müller, J.P. A cooperation model for autonomous agents. In Proceedings of the International Workshop on Agent Theories, Architectures, and Languages; Springer: Berlin/Heidelberg, Germany, 1996; pp. 245–260. [Google Scholar]
- Parsons, S.D.; Gymtrasiewicz, P.; Wooldridge, M. Game Theory and Decision Theory in Agent-Based Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 5. [Google Scholar]
- Adami, C.; Schossau, J.; Hintze, A. Evolutionary game theory using agent-based methods. Phys. Life Rev. 2016, 19, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Semsar-Kazerooni, E.; Khorasani, K. Multi-agent team cooperation: A game theory approach. Automatica 2009, 45, 2205–2213. [Google Scholar] [CrossRef]
- Conte, R.; Edmonds, B.; Moss, S.; Sawyer, R.K. Sociology and social theory in agent based social simulation: A symposium. Comput. Math. Organ. Theory 2001, 7, 183–205. [Google Scholar] [CrossRef]
- Bianchi, F.; Squazzoni, F. Agent-based models in sociology. Wiley Interdiscip. Rev. Comput. Stat. 2015, 7, 284–306. [Google Scholar] [CrossRef]
- Macy, M.W.; Willer, R. From factors to actors: Computational sociology and agent-based modeling. Annu. Rev. Sociol. 2002, 28, 143–166. [Google Scholar] [CrossRef]
- Squazzoni, F. Agent-Based Computational Sociology; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]






© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jäger, G. Replacing Rules by Neural Networks A Framework for Agent-Based Modelling. Big Data Cogn. Comput. 2019, 3, 51. https://doi.org/10.3390/bdcc3040051
Jäger G. Replacing Rules by Neural Networks A Framework for Agent-Based Modelling. Big Data and Cognitive Computing. 2019; 3(4):51. https://doi.org/10.3390/bdcc3040051
Chicago/Turabian StyleJäger, Georg. 2019. "Replacing Rules by Neural Networks A Framework for Agent-Based Modelling" Big Data and Cognitive Computing 3, no. 4: 51. https://doi.org/10.3390/bdcc3040051
APA StyleJäger, G. (2019). Replacing Rules by Neural Networks A Framework for Agent-Based Modelling. Big Data and Cognitive Computing, 3(4), 51. https://doi.org/10.3390/bdcc3040051