Viability in Multiplex Lexical Networks and Machine Learning Characterizes Human Creativity



Abstract
:1. Introduction
1.1. Previous Research: Assessing Creativity with Cognitive Networks
1.1.1. Semantic Networks Capture Knowledge Structure and Search as Related to Creativity
1.1.2. Studying Cognitive Search with the Semantic Fluency Task
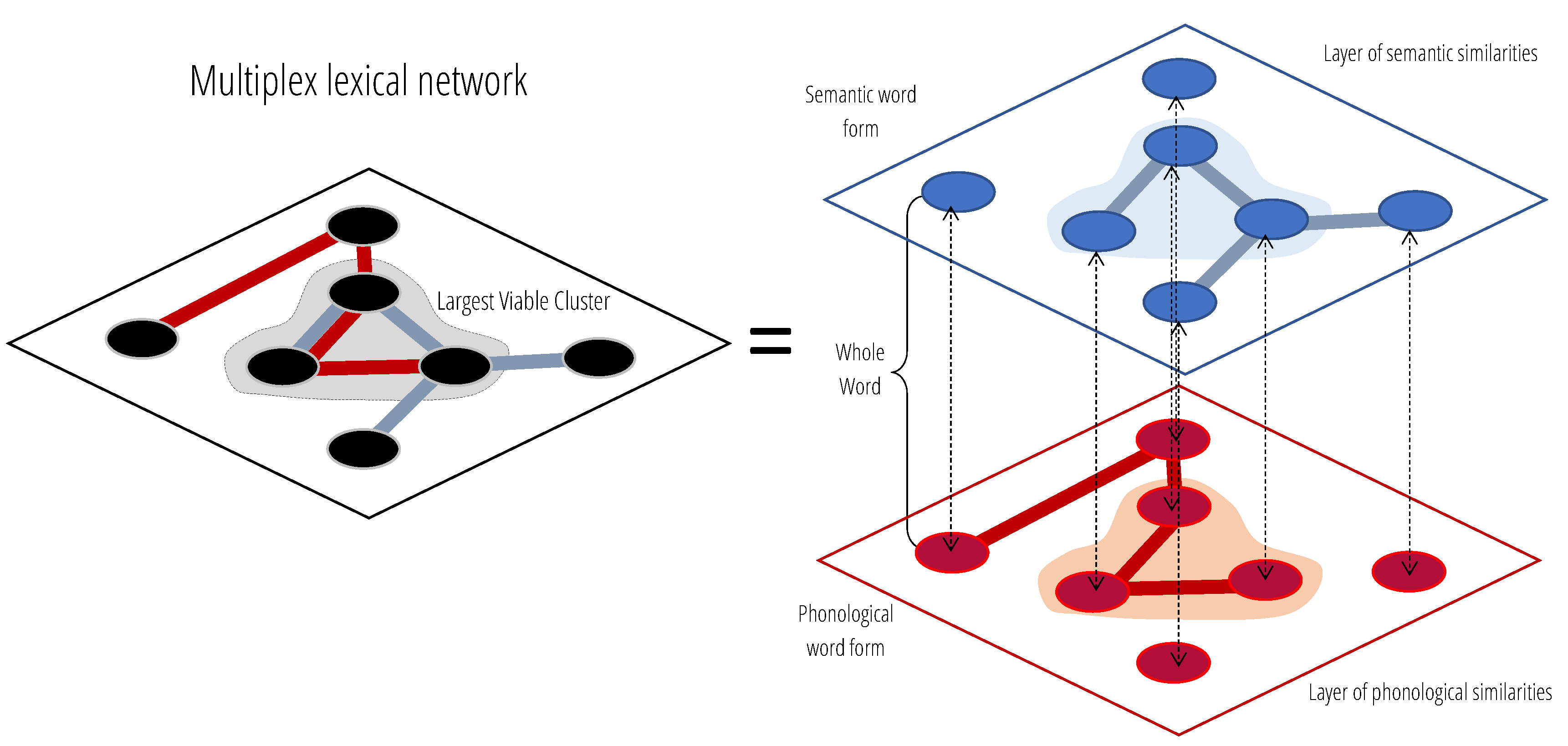
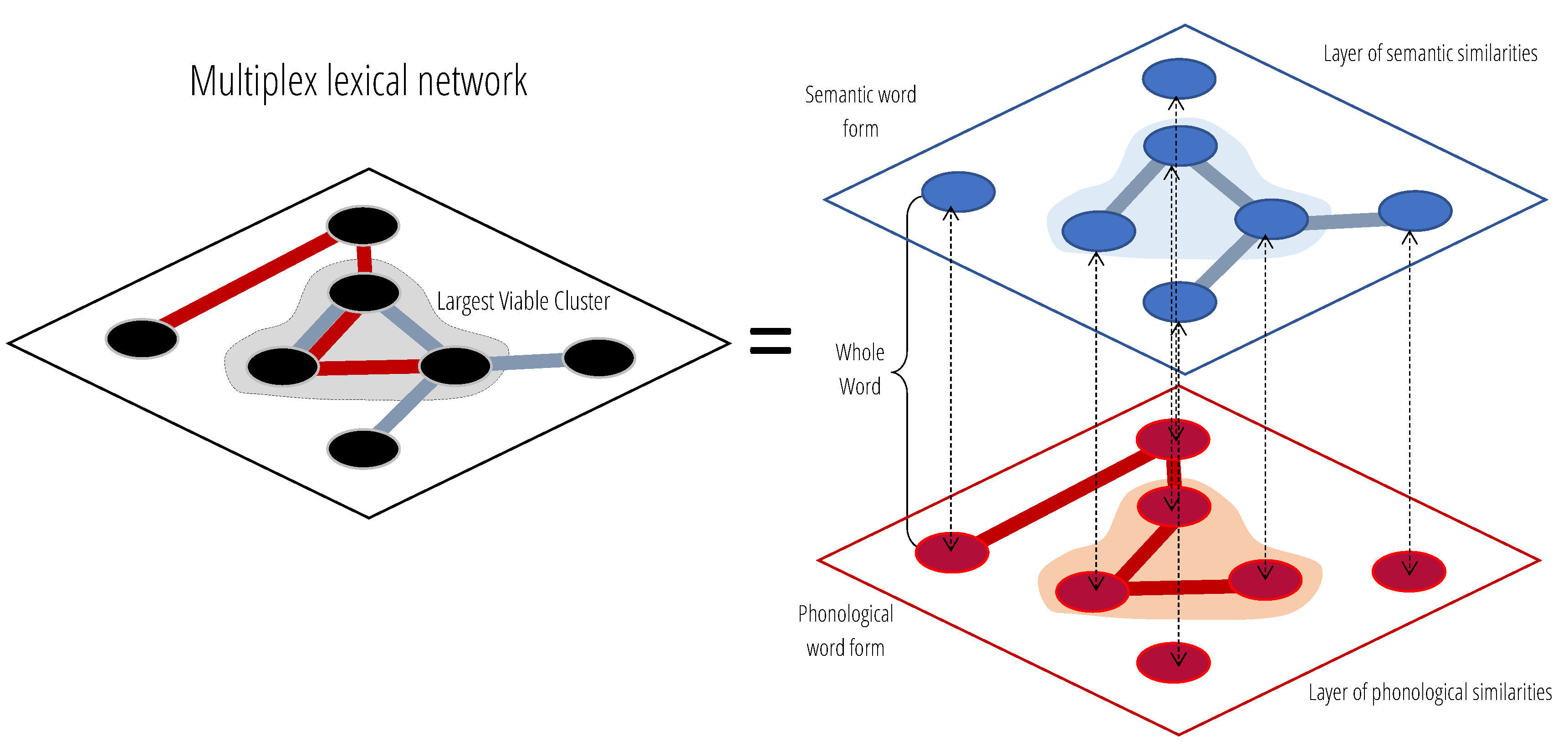
1.2. Beyond Semantics: A Multiplex Approach to Study the Mental Lexicon
1.3. Current Research: Outlook and Aims
2. Materials and Methods
2.1. Participants
2.2. Behavioral Tasks
2.3. Construction of the Multiplex Lexical Network
- Free associations [59,60,61], indicating empirical conceptual associations elicited by participants to a cognitive task (e.g., reading “bed” elicited the concept “sleep” x times). The data for this layer was gathered from the Small World of Words project by De Deyne and colleagues [59]. Only links elicited more than times were considered, in order for the association layer to feature the same link density of other multiplex layers. This layer is treated as undirected, as in previous approaches in cognitive network science [14,51].
- Synonyms [62], indicating overlap in meaning between concepts (e.g., “character” can mean also “font”). This layer is undirected by definition.
- Generalizations [62], representing which words are a special/more general type of concepts (e.g., “hawk” is a type of “bird”). These relationships are treated as undirected, as in previous approaches in cognitive network science.
2.4. Multiplex Lexical Networks and Viable Clusters
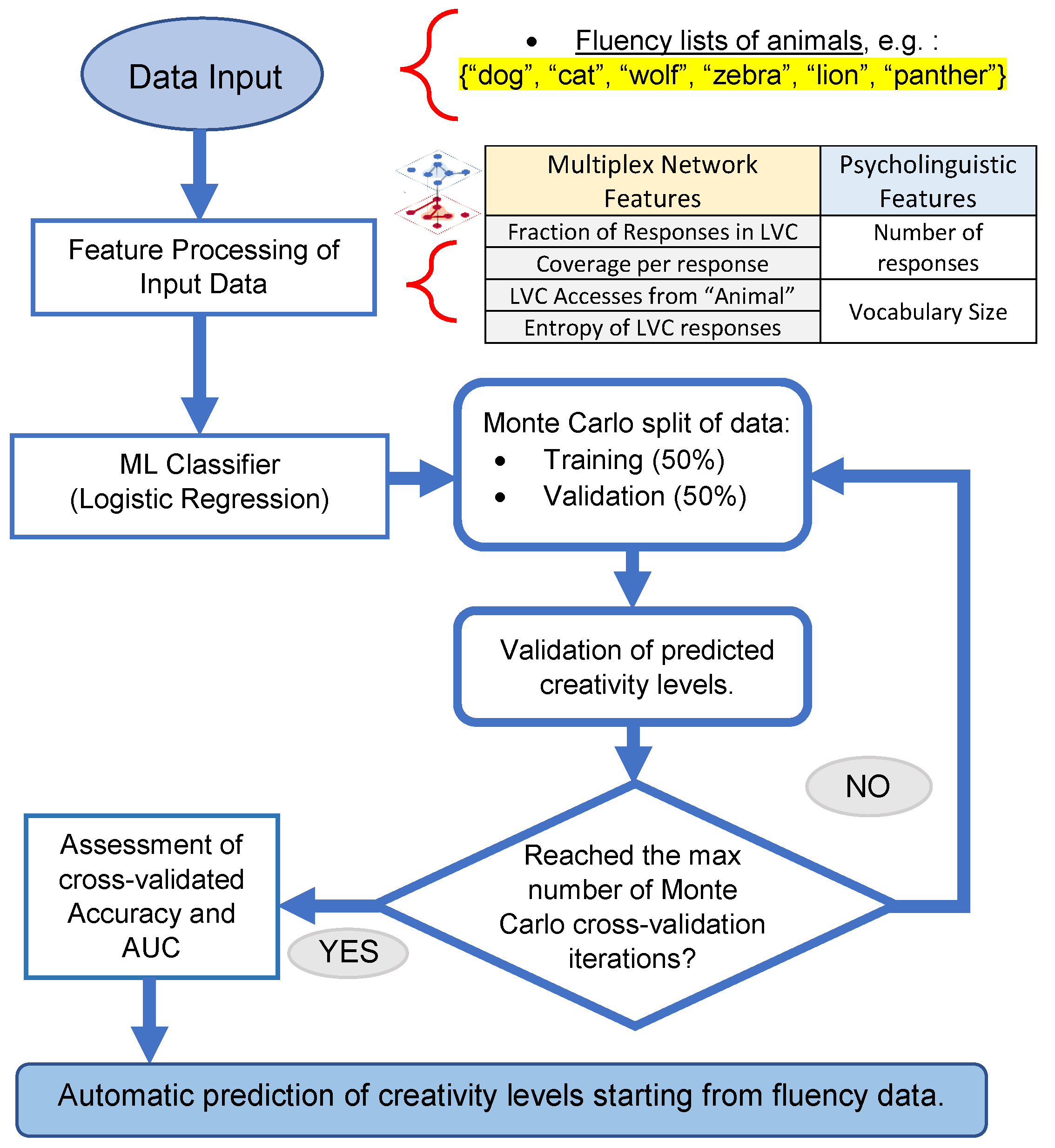
2.5. Mental Navigation Modelling of Fluency Data over Multiplex Lexical Networks
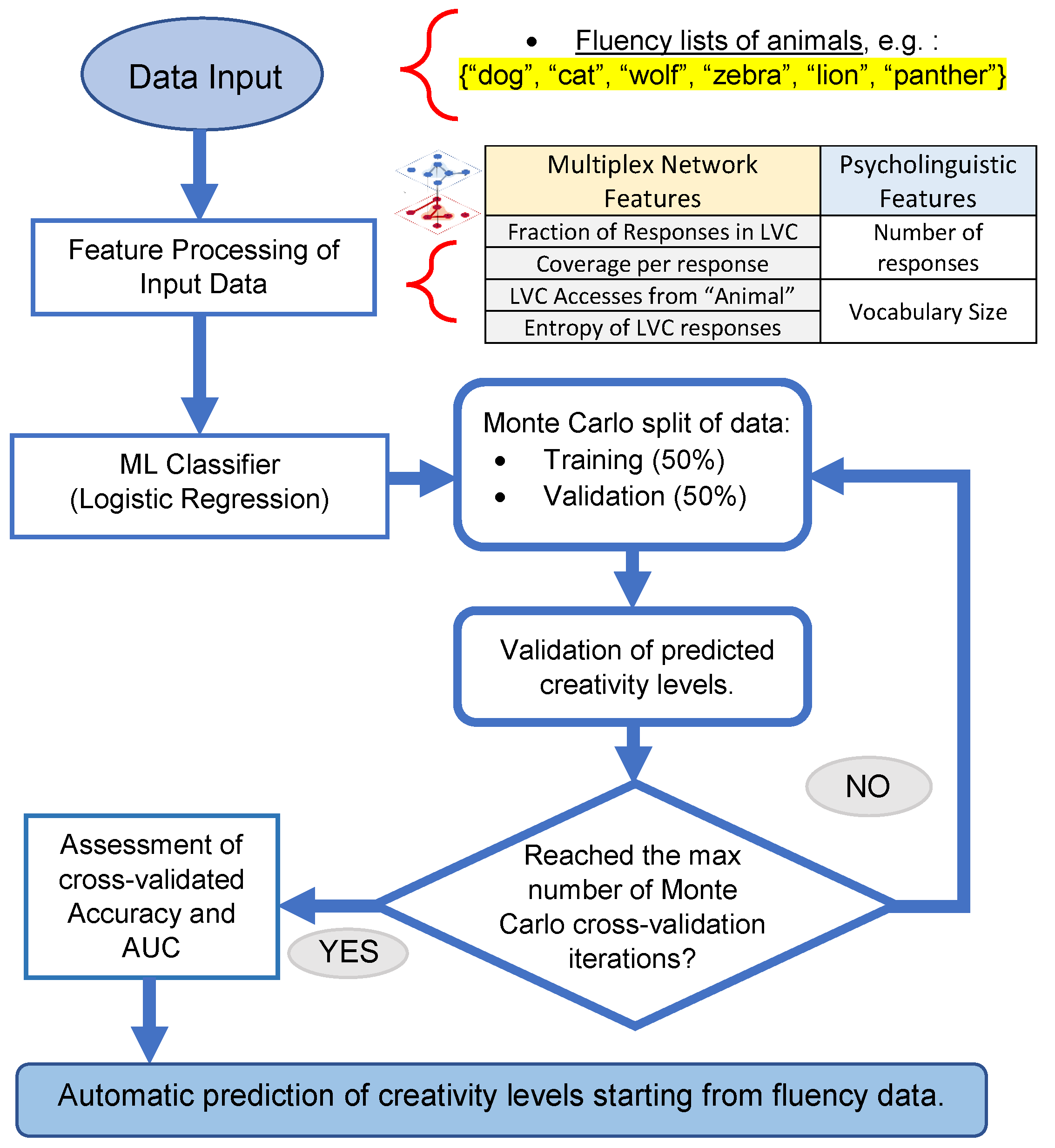
2.6. Machine Learning Classification of Low and High Creativity Individuals
3. Results
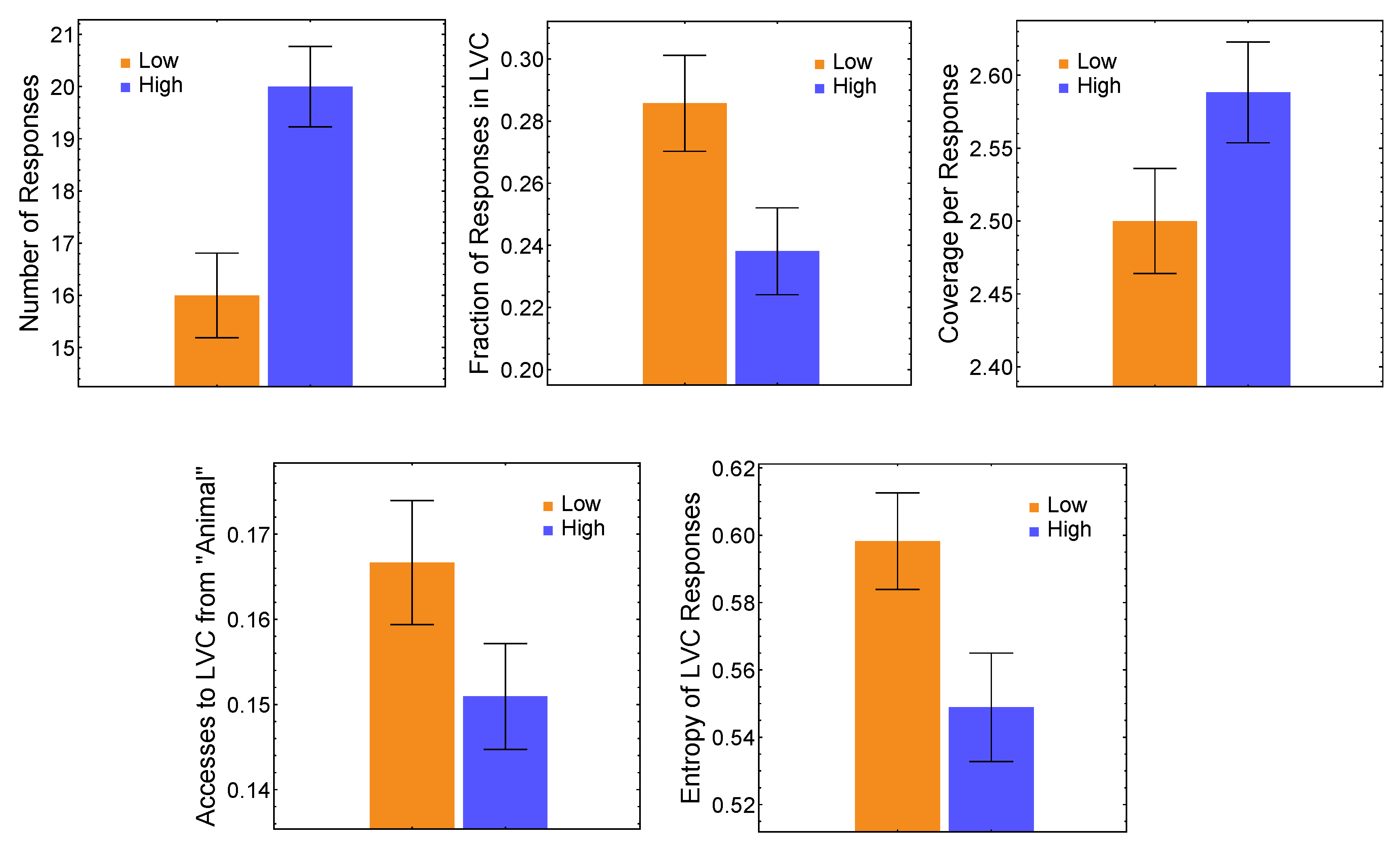
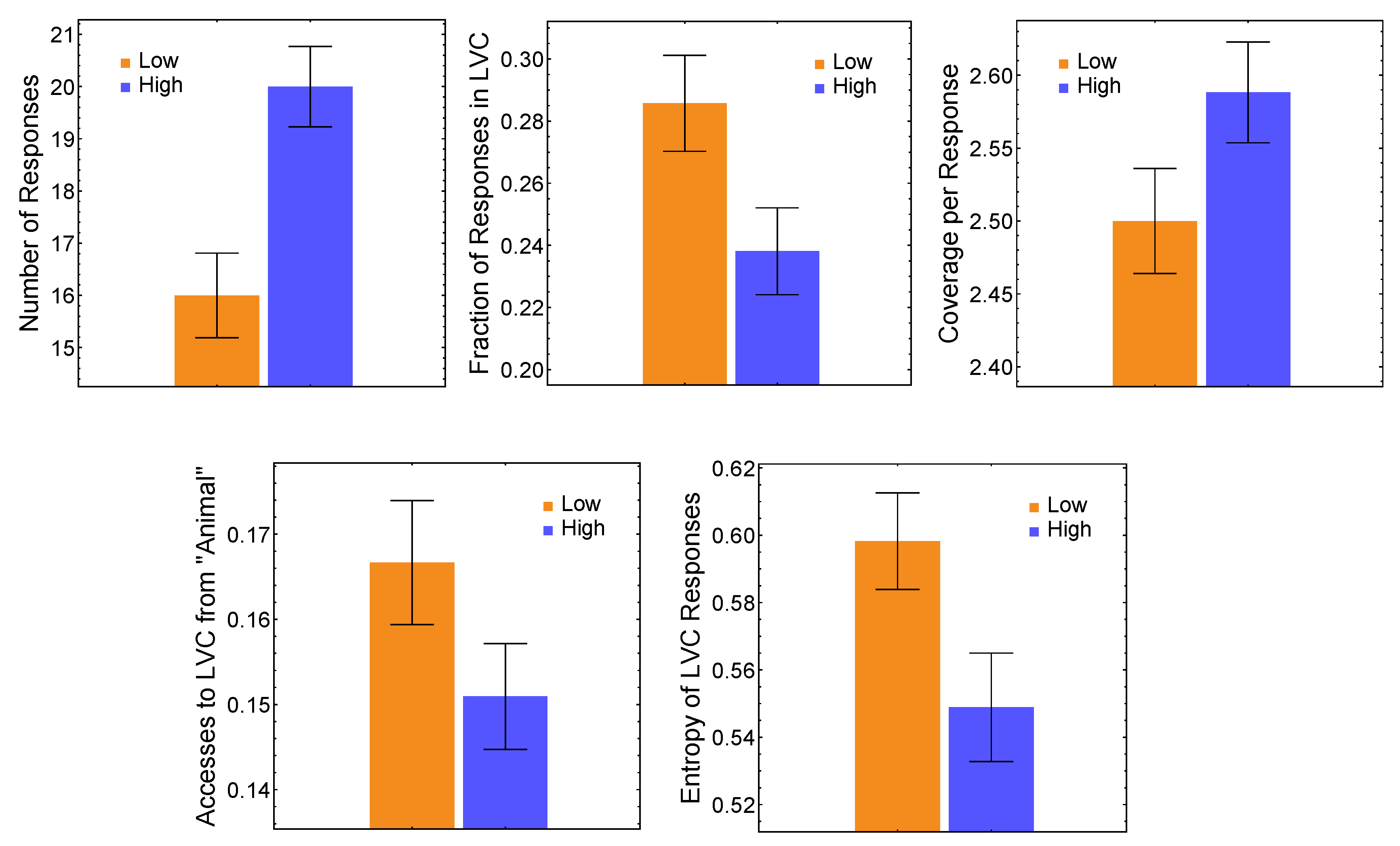
3.1. Distinct Features of Multiplex Core Relate to Low/High Creativity Levels
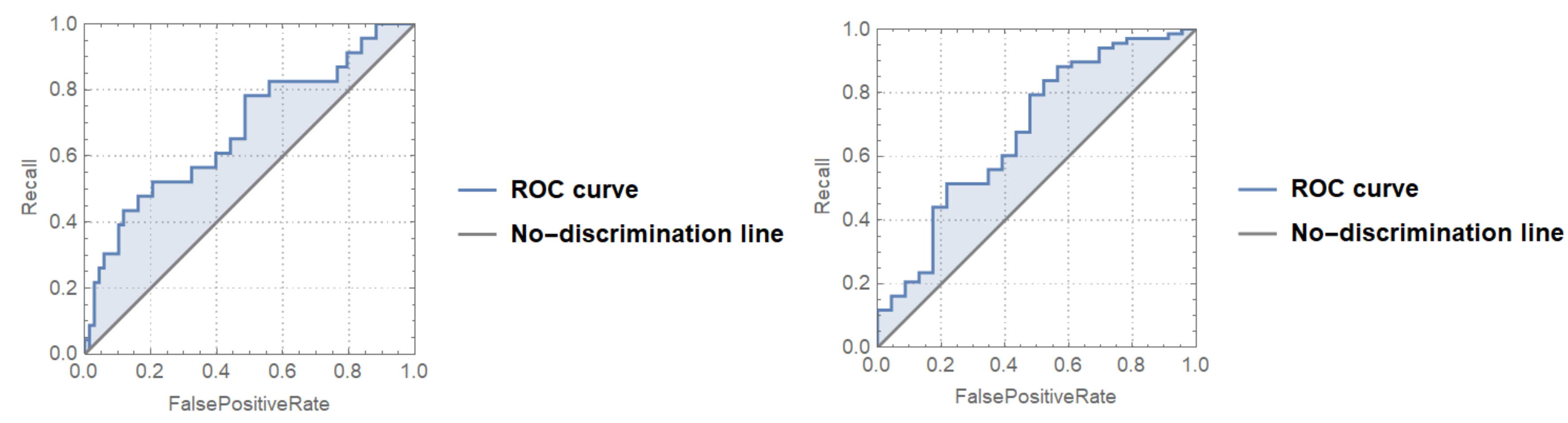
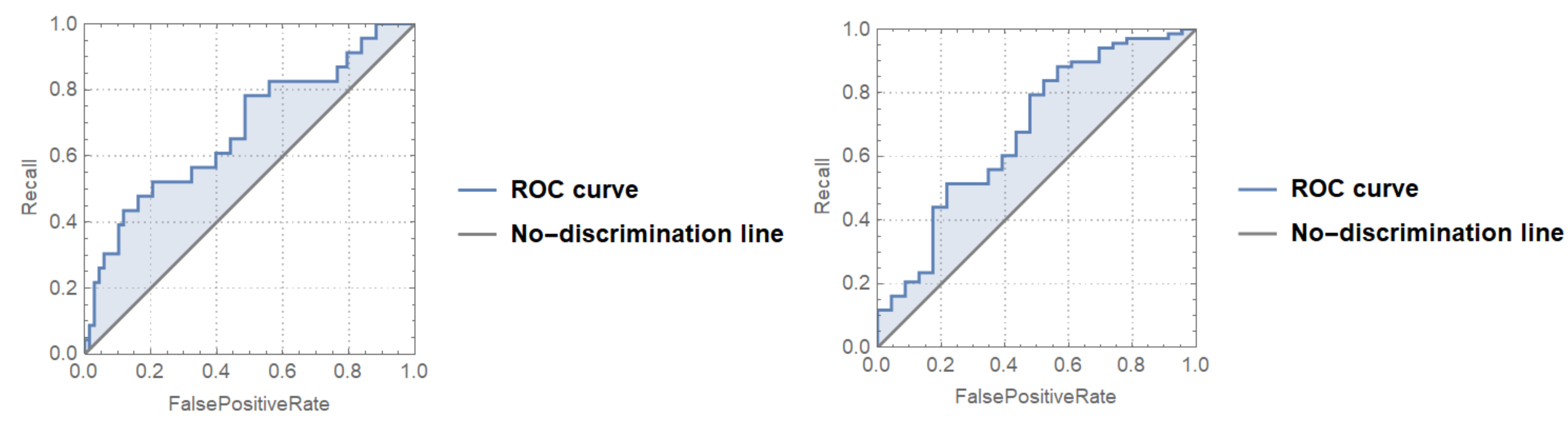
3.2. Multiplex-Based Machine Learning Classification of Low/High Creativity Levels
4. Discussion
Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kenett, Y.N. Going the extra creative mile: The role of semantic distance in creativity—Theory, research, and measurement. In The Cambridge Handbook of the Neuroscience of Creativity; Jung, R.E., Vartanian, O., Eds.; Cambridge University Press: New York, NY, USA, 2018; pp. 233–248. [Google Scholar]
- Beaty, R.E.; Silvia, P.J.; Nusbaum, E.C.; Jauk, E.; Benedek, M. The roles of associative and executive processes in creative cognition. Mem. Cogn. 2014, 42, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Benedek, M.; Neubauer, A.C. Revisiting Mednick’s model on creativity-related differences in associative hierarchies. Evidence for a common path to uncommon thought. J. Creat. Behav. 2013, 47, 273–289. [Google Scholar] [CrossRef] [PubMed]
- Kenett, Y.N. Investigating creativity from a semantic network perspective. In Exploring Transdisciplinarity in Art and Sciences; Kapoula, Z., Volle, E., Renoult, J., Andreatta, M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 49–75. [Google Scholar]
- Kenett, Y.N.; Faust, M. A semantic network cartography of the creative mind. Trends Cogn. Sci. 2019, 23, 271–274. [Google Scholar] [CrossRef] [PubMed]
- Mednick, S.A. The associative basis of the creative process. Psychol. Rev. 1962, 69, 220–232. [Google Scholar] [CrossRef] [PubMed]
- Volle, E. Associative and controlled cognition in divergent thinking: Theoretical, experimental, neuroimaging evidence, and new directions. In The Cambridge Handbook of the Neuroscience of Creativity; Jung, R.E., Vartanian, O., Eds.; Cambridge University Press: New York, NY, USA, 2018; pp. 333–362. [Google Scholar]
- Jones, M.N.; Willits, J.; Dennis, S. Models of semantic memory. In Oxford Handbook of Mathematical and Computational Psychology; Busemeyer, J., Townsend, J., Eds.; Oxford University Press: Oxford, UK, 2015; pp. 232–254. [Google Scholar]
- Stella, M.; Beckage, N.M.; Brede, M. Multiplex lexical networks reveal patterns in early word acquisition in children. Sci. Rep. 2017, 7, 46730. [Google Scholar] [CrossRef] [PubMed]
- Stella, M.; Beckage, N.M.; Brede, M.; De Domenico, M. Multiplex model of mental lexicon reveals explosive learning in humans. Sci. Rep. 2018, 8, 2259. [Google Scholar] [CrossRef] [PubMed]
- Siew, C.S.; Wulff, D.U.; Beckage, N.M.; Kenett, Y.N. Cognitive Network Science: A review of research on cognition through the lens of network representations, processes, and dynamics. Complexity 2019, 2019, 2108423. [Google Scholar] [CrossRef]
- Beckage, N.M.; Colunga, E. Language networks as models of cognition: Understanding cognition through language. In Towards a Theoretical Framework for Analyzing Complex Linguistic Networks; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–28. [Google Scholar]
- Vitevitch, M.S.; Castro, N. Using network science in the language sciences and clinic. Int. J. Speech-Lang. Pathol. 2015, 17, 13–25. [Google Scholar] [CrossRef]
- Kenett, Y.N.; Levi, E.; Anaki, D.; Faust, M. The semantic distance task: Quantifying semantic distance with semantic network path length. J. Exp. Psychol. Learn. Mem. Cogn. 2017, 43, 1470. [Google Scholar] [CrossRef] [PubMed]
- Stella, M.; Ferrara, E.; De Domenico, M. Bots increase exposure to negative and inflammatory content in online social systems. Proc. Natl. Acad. Sci. USA 2018, 115, 12435–12440. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christensen, A.P.; Kenett, Y.N.; Cotter, K.N.; Beaty, R.E.; Silvia, P.J. Remotely close associations: Openness to experience and semantic memory structure. Eur. J. Personal. 2018, 32, 480–492. [Google Scholar] [CrossRef]
- Hass, R.W. Tracking the dynamics of divergent thinking via semantic distance: Analytic methods and theoretical implications. Mem. Cogn. 2017, 45, 233–244. [Google Scholar] [CrossRef]
- Heinen, D.J.P.; Johnson, D.R. Semantic distance: An automated measure of creativity that is novel and appropriate. Psychol. Aesthet. Creat. Arts 2018, 12, 144–156. [Google Scholar] [CrossRef]
- Oltețeanu, A.M.; Schultheis, H. What determines creative association? Revealing two factors which separately influence the creative process when solving the Remote Associates Test. J. Creat. Behav. 2017. [Google Scholar] [CrossRef]
- Kenett, Y.N. What can quantitative measures of semantic distance tell us about creativity? Curr. Opin. Behav. Sci. 2019, 27, 11–16. [Google Scholar] [CrossRef]
- Benedek, M.; Kenett, Y.N.; Umdasch, K.; Anaki, D.; Faust, M.; Neubauer, A.C. How semantic memory structure and intelligence contribute to creative thought: A network science approach. Think. Reason. 2017, 23, 158–183. [Google Scholar] [CrossRef]
- Kenett, Y.N.; Anaki, D.; Faust, M. Investigating the structure of semantic networks in low and high creative persons. Front. Hum. Neurosci. 2014, 8, 1–16. [Google Scholar] [CrossRef]
- Kenett, Y.N.; Beaty, R.E.; Silvia, P.J.; Anaki, D.; Faust, M. Structure and flexibility: Investigating the relation between the structure of the mental lexicon, fluid intelligence, and creative achievement. Psychol. Aesthet. Creat. Arts 2016, 10, 377–388. [Google Scholar] [CrossRef]
- Abbott, J.T.; Austerweil, J.L.; Griffiths, T.L. Random walks on semantic networks can resemble optimal foraging. Psychol. Rev. 2015, 122, 558–569. [Google Scholar] [CrossRef]
- Capitán, J.A.; Borge-Holthoefer, J.; Gómez, S.; Martinez-Romo, J.; Araujo, L.; Cuesta, J.A.; Arenas, A. Local-based semantic navigation on a networked representation of information. PLoS ONE 2012, 7, e43694. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Steyvers, M.; Firl, A. Google and the mind: Predicting fluency with PageRank. Psychol. Sci. 2007, 18, 1069–1076. [Google Scholar] [CrossRef]
- Bourgin, D.D.; Abbott, J.T.; Griffiths, T.L.; Smith, K.A.; Vul, E. Empirical evidence for markov chain monte carlo in memory search. In Proceedings of the 36th Annual Conference of the Cognitive Science Society, Quebec City, QC, Canada, 23–26 July 2014. [Google Scholar]
- Smith, K.A.; Huber, D.E.; Vul, E. Multiply-constrained semantic search in the Remote Associates Test. Cognition 2013, 128, 64–75. [Google Scholar] [CrossRef]
- Smith, K.A.; Vul, E. The Role of Sequential Dependence in Creative Semantic Search. Top. Cogn. Sci. 2015, 7, 543–546. [Google Scholar] [CrossRef]
- Kenett, Y.N.; Austerweil, J.L. Examining Search Processes in Low and High Creative Individuals with Random Walks. CogSci. 2016, 8, 313–318. [Google Scholar]
- Gray, K.; Anderson, S.; Chen, E.E.; Kelly, J.M.; Christian, M.S.; Patrick, J.; Huang, L.; Kenett, Y.N.; Lewis, K. “Forward flow”: A new measure to quantify free thought and predict creativity. Am. Psychol. 2019. [Google Scholar] [CrossRef]
- Abbott, J.T.; Austerweil, J.L.; Griffiths, T.L. Human memory search as a random walk in a semantic network. Adv. Neural Inf. Process. Syst. 2012, 25, 3050–3058. [Google Scholar]
- Hills, T.T.; Jones, M.N.; Todd, P.M. Optimal foraging in semantic memory. Psychol. Rev. 2012, 119, 431–440. [Google Scholar] [CrossRef]
- Hills, T.T.; Todd, P.M.; Jones, M.N. Foraging in semantic fields: How we search through memory. Top. Cogn. Sci. 2015, 7, 513–534. [Google Scholar] [CrossRef]
- Wulff, D.U.; Hills, T.T.; Hertwig, R. Worm holes in memory: Is memory one representation or many? In Proceedings of the Annual Meeting of the Cognitive Science Society, Berlin, Germany, 31 July–3 August 2013; Volume 35. [Google Scholar]
- Ardila, A.; Ostrosky-Solís, F.; Bernal, B. Cognitive testing toward the future: The example of semantic verbal fluency (ANIMALS). Int. J. Psychol. 2006, 41, 324–332. [Google Scholar] [CrossRef]
- Bousfield, W.A.; Sedgewick, C.H.W. An analysis of sequences of restricted associative responses. J. Gen. Psychol. 1944, 30, 149–165. [Google Scholar] [CrossRef]
- Goñi, J.; Arrondo, G.; Sepulcre, J.; Martincorena, I.; Vélez de Mendizábal, N.; Corominas-Murtra, B.; Bejarano, B.; Ardanza-Trevijano, S.; Peraita, H.; Wall, D.; et al. The semantic organization of the animal category: Evidence from semantic verbal fluency and network theory. Cogn. Process. 2011, 12, 183–196. [Google Scholar] [CrossRef]
- Zemla, J.C.; Austerweil, J.L. Estimating semantic networks of groups and individuals from fluency data. Comput. Brain Behav. 2018, 1, 36–58. [Google Scholar] [CrossRef]
- Zemla, J.C.; Austerweil, J.L. Analyzing Knowledge Retrieval Impairments Associated with Alzheimer’s Disease Using Network Analyses. Complexity 2019, 2019, 4203158. [Google Scholar] [CrossRef]
- Troyer, A.K.; Moscovitch, M.; Winocur, G. Clustering and switching as two components of verbal fluency: Evidence from younger and older healthy adults. Neuropsychology 1997, 11, 138–146. [Google Scholar] [CrossRef]
- Goñi, J.; Martincorena, I.; Corominas-Murtra, B.; Arrondo, G.; Ardanza-Trevijano, S.; Villoslada, P. Switcher-random-walks: A cognitive-inspired mechanism for network exploration. Int. J. Bifurc. Chaos 2010, 20, 913–922. [Google Scholar] [CrossRef]
- Brown, R.; Mcniell, D. The “tip-of-the-tongue” phenomenon. J. Verbal Learn. Verbal Behav. 1966, 5, 325–337. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Chan, K.Y.; Goldstein, R. Insights into failed lexical retrieval from network science. Cogn. Psychol. 2014, 68, 1–32. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Chan, K.Y.; Roodenrys, S. Complex network structure influences processing in long-term and short-term memory. J. Mem. Lang. 2012, 67, 30–44. [Google Scholar] [CrossRef] [Green Version]
- Crutch, S.J.; Warrington, E.K. Abstract and concrete concepts have structurally different representational frameworks. Brain 2004, 128, 615–627. [Google Scholar] [CrossRef] [Green Version]
- Collins, A.M.; Loftus, E.F. A spreading-activation theory of semantic processing. Psychol. Rev. 1975, 82, 407. [Google Scholar] [CrossRef]
- Erdeljac, V.; Sekulić, M. Syntactic-semantic relationships in the mental lexicon of aphasic patients. Clin. Linguist. Phon. 2008, 22, 795–803. [Google Scholar] [CrossRef]
- Baxter, G.J.; Cellai, D.; Dorogovtsev, S.N.; Goltsev, A.V.; Mendes, J.F. A unified approach to percolation processes on multiplex networks. In Interconnected Networks; Springer: Berlin/Heidelberg, Germany, 2016; pp. 101–123. [Google Scholar]
- Stella, M. Modelling Early Word Acquisition through Multiplex Lexical Networks and Machine Learning. Big Data Cogn. Comput. 2019, 3, 10. [Google Scholar] [CrossRef]
- Castro, N.; Stella, M. The multiplex structure of the mental lexicon influences picture naming in people with aphasia. J. Complex Netw. 2019. [Google Scholar] [CrossRef]
- Stella, M.; De Domenico, M. Distance entropy cartography characterises centrality in complex networks. Entropy 2018, 20, 268. [Google Scholar] [CrossRef]
- Stella, M. Cohort and rhyme priming emerge from the multiplex network structure of the mental lexicon. Complexity 2018, 2018, 6438702. [Google Scholar] [CrossRef]
- Carroll, J.B. Human Cognitive Abilities: A Survey of Factor Analytic Studies; Cambridge University Press: New York, NY, USA, 1993. [Google Scholar]
- Ekstrom, R.B.; French, J.W.; Harman, H.H.; Dermen, D. Manual for Kit of Factor-Referenced Cognitive Tests; Educational Testing Service: Princeton, NJ, USA, 1976. [Google Scholar]
- Thurstone, L.I. Primary Mental Abilities; University of Chicago Press: Chicago, IL, USA, 1938. [Google Scholar]
- Carson, S.H.; Peterson, J.B.; Higgins, D.M. Reliability, validity, and factor structure of the creative achievement questionnaire. Creat. Res. J. 2005, 17, 37–50. [Google Scholar] [CrossRef]
- Silvia, P.J.; Wigert, B.; Reiter-Palmon, R.; Kaufman, J.C. Assessing creativity with self-report scales: A review and empirical evaluation. Psychol. Aesthet. Creat. Arts 2012, 6, 19–34. [Google Scholar] [CrossRef]
- De Deyne, S.; Navarro, D.J.; Perfors, A.; Brysbaert, M.; Storms, G. The “Small World of Words” English word association norms for over 12,000 cue words. Behav. Res. Methods 2019, 51, 987–1006. [Google Scholar] [CrossRef]
- De Deyne, S.; Kenett, Y.N.; Anaki, D.; Faust, M.; Navarro, D.J. Large-scale network representations of semantics in the mental lexicon. In Frontiers of Cognitive Psychology. Big Data in Cognitive Science; Routledge/Taylor & Francis Group: New York, NY, USA, 2016. [Google Scholar]
- Kenett, Y.N.; Kenett, D.Y.; Ben-Jacob, E.; Faust, M. Global and local features of semantic networks: Evidence from the Hebrew mental lexicon. PLoS ONE 2011, 6, e23912. [Google Scholar] [CrossRef]
- Sigman, M.; Cecchi, G.A. Global organization of the Wordnet lexicon. Proc. Natl. Acad. Sci. USA 2002, 99, 1742–1747. [Google Scholar] [CrossRef] [Green Version]
- Vitevitch, M.S. What can graph theory tell us about word learning and lexical retrieval? J. Speech Lang. Hear. Res. 2008. [Google Scholar] [CrossRef]
- Stella, M.; Brede, M. Patterns in the English language: Phonological networks, percolation and assembly models. J. Stat. Mech. Theory Exp. 2015, 2015, P05006. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Newman, M.E. Communities, modules and large-scale structure in networks. Nat. Phys. 2012, 8, 25. [Google Scholar] [CrossRef]
- Jones, C.M.; Athanasiou, T. Summary receiver operating characteristic curve analysis techniques in the evaluation of diagnostic tests. Ann. Thorac. Surg. 2005, 79, 16–20. [Google Scholar] [CrossRef]
- Goldstein, R.; Vitevitch, M.S. The influence of closeness centrality on lexical processing. Front. Psychol. 2017, 8, 1683. [Google Scholar] [CrossRef]
- Lydon-Staley, D.M.; Zhou, D.; Blevins, A.S.; Zurn, P.; Bassett, D.S. Hunters, busybodies, and the knowledge network building associated with curiosity. PsyArXiv 2019. [Google Scholar] [CrossRef] [Green Version]
- Cancho, R.F.I.; Solé, R.V. The small world of human language. Proc. R. Soc. Lond. Ser. Biol. Sci. 2001, 268, 2261–2265. [Google Scholar] [CrossRef] [Green Version]
- Runco, M.A.; Jaeger, G.J. The standard definition of creativity. Creat. Res. J. 2012, 24, 92–96. [Google Scholar] [CrossRef]
- Benedek, M.; Fink, A.; Neubauer, A.C. Enhancement of ideational fluency by means of computer-based training. Creat. Res. J. 2006, 18, 317–328. [Google Scholar] [CrossRef]
- Kenett, Y.N.; Levy, O.; Kenett, D.Y.; Stanley, H.E.; Faust, M.; Havlin, S. Flexibility of thought in high creative individuals represented by percolation analysis. Proc. Natl. Acad. Sci. USA 2018, 115, 867–872. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Yao, L.; Wang, X.; Monaghan, J.; Mcalpine, D. A Survey on Deep Learning based Brain Computer Interface: Recent Advances and New Frontiers. arXiv 2019, arXiv:1905.04149. [Google Scholar]
- Cress, U.; Kimmerle, J. A systemic and cognitive view on collaborative knowledge building with wikis. Int. J. Comput.-Support. Collab. Learn. 2008, 3, 105. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Psycholinguistic Feature | Median in LVC | Median Outside the LVC | Test Statistics |
|---|---|---|---|
| Word Length | 4 | 7 | KW, 1546, |
| Log Frequency | 7.71 | 5.66 | KW, 957, |
| Age of Acquisition | 6.22 yrs | 8.95 yrs | KW, 720, |
| Concreteness | 3.97 | 3.26 | KW, 293, |
| Reaction Time | 552 s | 605 s | KW, 560, |
| Number of Meanings | 7 | 2 | KW, 1560, |
| Name | Definition | Example Value |
|---|---|---|
| Number of responses | Number of responses in the list. | 14 |
| Number of repeated words | Number of words repeated at least once. | 0 |
| Number of all repetitions | Total number of repetitions of all repeated words. | 0 |
| Coverage per response | Average number of visited nodes in the multiplex shortest paths from one response to the next one. | 16/7 |
| Fraction of responses in LVC | Fraction of words in the list being part of the LVC. | 2/7 |
| LVC Coverage per response | Average number of visited nodes being part of the LVC in the multiplex shortest paths from one response to the next one (collective walk). | 9/32 |
| Entropy of LVC Coverage | Entropy of the collective walk , including nodes not in l but in the multiplex lexical network and being inside or outside the LVC | 0.621 |
| Entropy of LVC Responses | Entropy of nodes inside/outside the LVC as contained in the list l | 0.598 |
| Maximum Permanence in LVC | Maximum number of visited nodes in the collective walk being consecutively in the LVC | 15 |
| Median Permanence in LVC | Median number of nodes in all the visits to the LVC during the collective walk | 3 |
| Coverage from “animal” per response | Average number of visited nodes in the multiplex shortest path between a response and “animal” | 37/14 |
| Accesses to LVC from “animal” | Average number of visited nodes in the LVC in the multiplex shortest path between a response and “animal” | 6/37 |
| Graph distance entropy from “animal” | Graph distance entropy of all multiplex shortest paths between responses and “animal” | 1.0582 |
| Start in the LVC? | Flag for the first response being in the LVC | True |
| Contains typos? | Flag for any response containing mistakes or typos | False |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stella, M.; Kenett, Y.N. Viability in Multiplex Lexical Networks and Machine Learning Characterizes Human Creativity. Big Data Cogn. Comput. 2019, 3, 45. https://doi.org/10.3390/bdcc3030045
Stella M, Kenett YN. Viability in Multiplex Lexical Networks and Machine Learning Characterizes Human Creativity. Big Data and Cognitive Computing. 2019; 3(3):45. https://doi.org/10.3390/bdcc3030045
Chicago/Turabian StyleStella, Massimo, and Yoed N. Kenett. 2019. "Viability in Multiplex Lexical Networks and Machine Learning Characterizes Human Creativity" Big Data and Cognitive Computing 3, no. 3: 45. https://doi.org/10.3390/bdcc3030045
APA StyleStella, M., & Kenett, Y. N. (2019). Viability in Multiplex Lexical Networks and Machine Learning Characterizes Human Creativity. Big Data and Cognitive Computing, 3(3), 45. https://doi.org/10.3390/bdcc3030045