A Machine Learning Approach for Air Quality Prediction: Model Regularization and Optimization

Abstract
1. Introduction
2. Related Work
3. Data Collection and Preprocessing
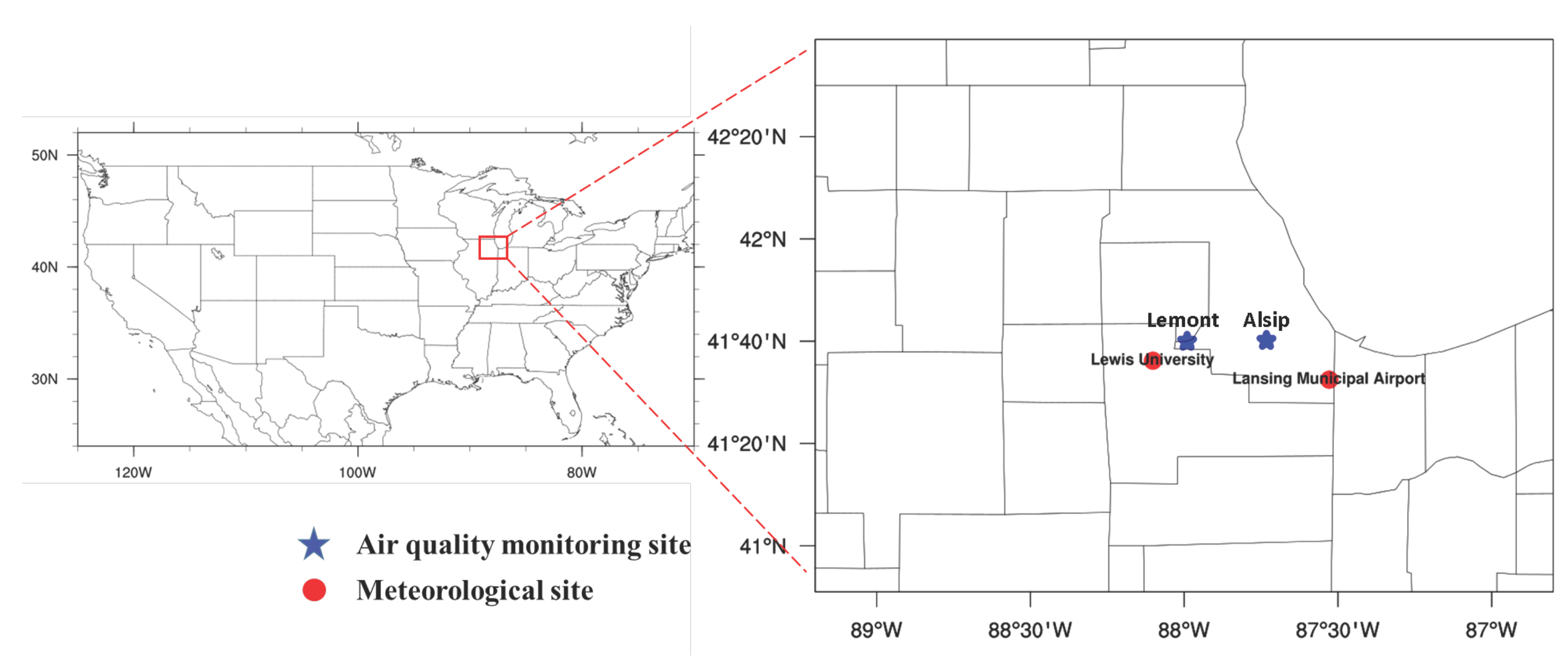
3.1. Data Collection
3.2. Preprocessing
4. Machine Learning Approaches for Air Pollution Prediction
4.1. A General Formulation
- Baseline Model. The first model is a baseline model that has been considered in existing studies and has the fewest number of parameters. In particular, the prediction of the air pollutant concentration is given bywhere is a basis vector with 1 at only the kth position and 0 at other positions; are the model parameters, where is the bias term. We denote this model by . It is notable that this model predicts the hourly concentration on the basis of the same hourly historical data of the previous day and that it has parameters. This simple model assumes that all 24 h share the same model parameter.
- Heavy Model. The second model takes all the data of the previous day into account when predicting the concentration of every hour of the second day. In particular, for the kth hour, the prediction is given bywhere and . This model is defined byWe note that each column of W corresponds to the prediction model for each hour. There are a total of (24 parameters. It is notable that the baseline model is a special case by enforcing all columns of W to be the same and because each has only one non-zero element at the kth position.
- Light Model. The third model is between the baseline model and the heavy model. It considers the 24 h pattern of the air pollutants in the previous day and the same hourly meteorological data of the previous day to predict the concentration at a particular hour. The prediction is given bywhere and . This model is defined byIt is also notable that each column corresponds to the predictive model for one hour and that W has a total of parameters.
4.2. Regularization of Model Parameters
- Frobenius norm regularization. Frobenius norm regularization is a generalization of standard Euclidean norm regularization to the matrix case, for whichwhere is a regularization parameter.
- -norm regularization. -norm regularization has been used for feature selection in MTL. The norm is formed by first computing the -norm of each row of the W matrix (across different tasks) and then computing the -norm of the resulting vector. In particular, for ,where denotes the jth row of W. We consider a -norm regularizer .
- Nuclear norm regularization. The nuclear norm is defined as the sum of singular values of a matrix, which is a standard regularization for enforcing a matrix to have a low rank. The motivation for using a low-rank matrix is that models for consecutive hours are highly correlated, which could render the matrix W to be low rank. We denote by the nuclear norm of a matrix W; the regularization is .
- Consecutive close (CC) regularization. Finally, we propose a useful regularization for the considered problem that explicitly enforces the predictive models for two consecutive hours to be close to each other. The intuition is that usually the concentrations of air pollutants for two consecutive hours are close to each other. We denote the model by and by . The CC regularization is given bywhere or .
4.3. Stochastic Optimization Algorithms for Different Formulations
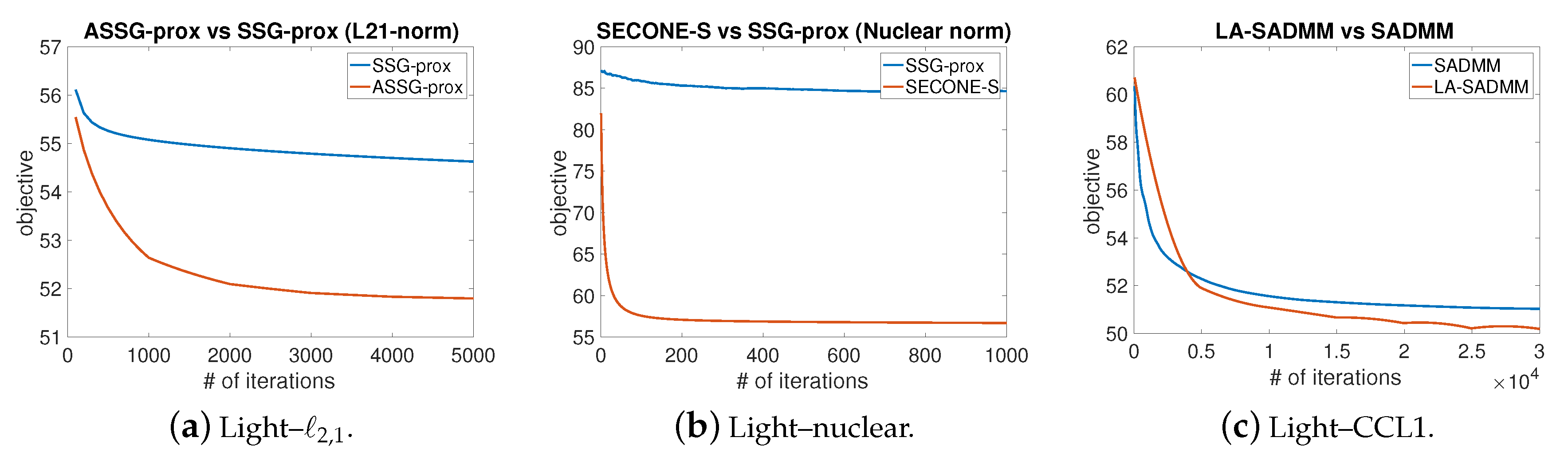
4.3.1. Optimizing -Norm Regularized Model
| Algorithm 1: ASSG method with proximal mapping solving -norm regularized model. |
Input: X, Y, , , S, and T |
4.3.2. Optimizing Nuclear Norm Regularized Model
| Algorithm 2: SECONE-S solving nuclear norm regularized model. |
Input: X, Y, T, , and  |
4.3.3. Optimizing Consecutive Close Regularized Model
| Algorithm 3: LA-SADMM solving consecutive close (CC) regularized problem with -norm. |
Input: X, Y, , , , , , S, and T |
4.4. Extensive Discussion
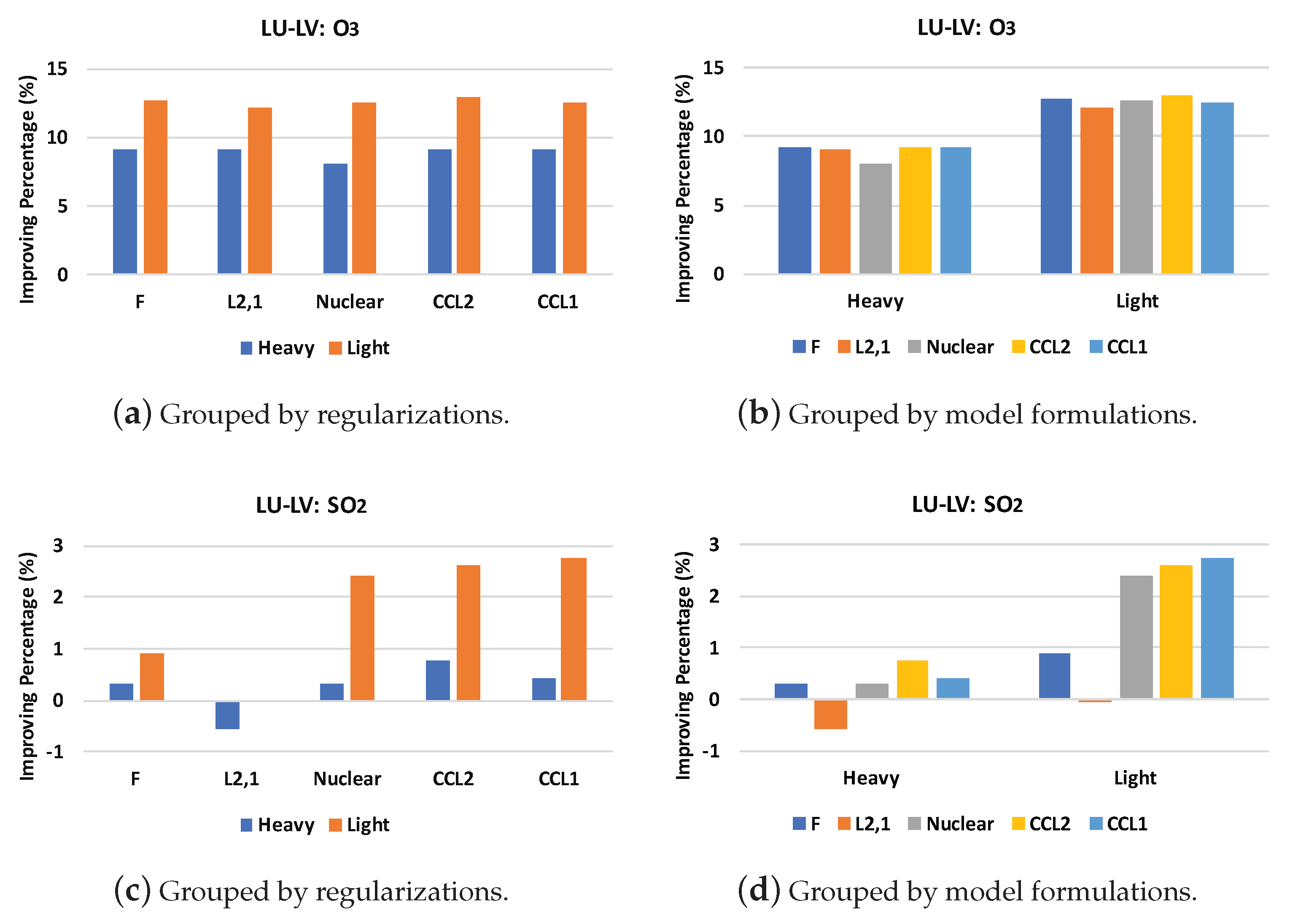
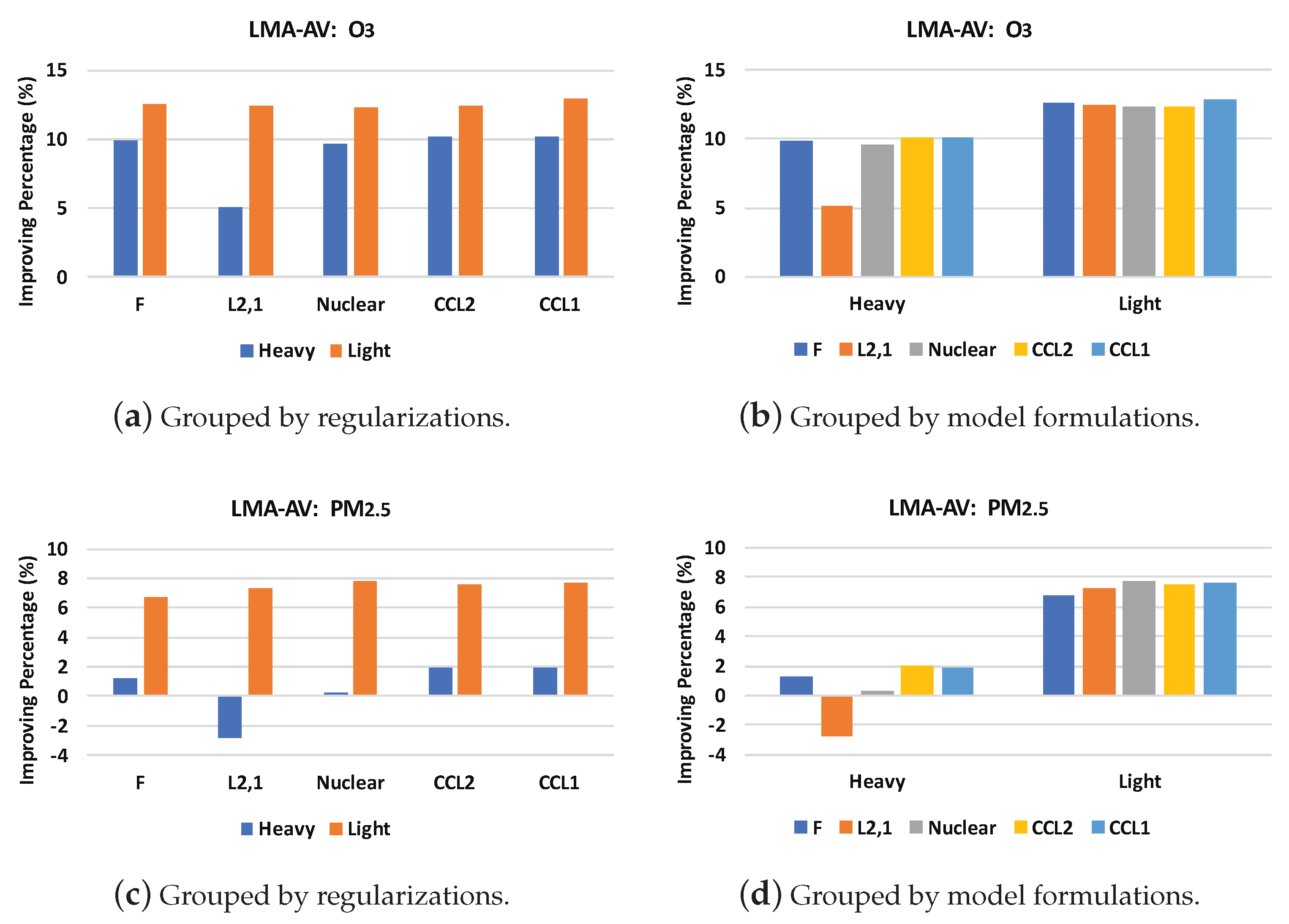
5. Experiments
- Baseline: the baseline model with standard Frobenius norm regularization.
- Heavy–F: the heavy model with standard Frobenius norm regularization.
- Light–F: the heavy model with standard Frobenius norm regularization.
- Heavy–: the heavy model with -norm regularization.
- Heavy–nuclear: the heavy model with nuclear-norm regularization.
- Heavy–CCL2: the heavy model with CC regularization using the -norm.
- Heavy–CCL1: the heavy model with CC regularization using the -norm.
- Light–: the light model with -norm regularization.
- Light–nuclear: the light model with nuclear-norm regularization.
- Light–CCL2: the light model with CC regularization using the -norm.
- Light–CCL1: the light model with CC regularization using the -norm.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Curtis, L.; Rea, W.; Smith-Willis, P.; Fenyves, E.; Pan, Y. Adverse health effects of outdoor air pollutants. Environ. Int. 2006, 32, 815–830. [Google Scholar] [CrossRef] [PubMed]
- Mayer, H. Air pollution in cities. Atmos. Environ. 1999, 33, 4029–4037. [Google Scholar] [CrossRef]
- Samet, J.M.; Zeger, S.L.; Dominici, F.; Curriero, F.; Coursac, I.; Dockery, D.W.; Schwartz, J.; Zanobetti, A. The national morbidity, mortality, and air pollution study. Part II: Morbidity and mortality from air pollution in the United States. Res. Rep. Health Eff. Inst. 2000, 94, 5–79. [Google Scholar] [PubMed]
- Dockery, D.W.; Schwartz, J.; Spengler, J.D. Air pollution and daily mortality: Associations with particulates and acid aerosols. Environ. Res. 1992, 59, 362–373. [Google Scholar] [CrossRef]
- Schwartz, J.; Dockery, D.W. Increased mortality in Philadelphia associated with daily air pollution concentrations. Am. Rev. Respir. Dis. 1992, 145, 600–604. [Google Scholar] [CrossRef] [PubMed]
- American Lung Association. State of the Air Report; ALA: New York, NY, USA, 2007; pp. 19–27. [Google Scholar]
- Environmental Protection Agency (EPA). Region 5: State Designations, as of September 18, 2009. Available online: https://archive.epa.gov/ozonedesignations/web/html/region5desig.html (accessed on 17 December 2017).
- Hinds, W.C. Aerosol Technology: Properties, Behavior, and Measurement of Airborne Particles; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Soukup, J.M.; Becker, S. Human alveolar macrophage responses to air pollution particulates are associated with insoluble components of coarse material, including particulate endotoxin. Toxicol. Appl. Pharmacol. 2001, 171, 20–26. [Google Scholar] [CrossRef] [PubMed]
- Environmental Protection Agency (EPA). CFR Parts 50, 51, 52, 53, and 58-National Ambient Air Quality Standards for Particulate Matter: Final Rule. Fed. Regist. 2013, 78, 3086–3286. [Google Scholar]
- Schwartz, J. Short term fluctuations in air pollution and hospital admissions of the elderly for respiratory disease. Thorax 1995, 50, 531–538. [Google Scholar] [CrossRef] [PubMed]
- De Leon, A.P.; Anderson, H.R.; Bland, J.M.; Strachan, D.P.; Bower, J. Effects of air pollution on daily hospital admissions for respiratory disease in London between 1987-88 and 1991-92. J. Epidemiol. Community Health 1996, 50 (Suppl. 1), s63–s70. [Google Scholar] [CrossRef]
- Birmili, W.; Wiedensohler, A. New particle formation in the continental boundary layer: Meteorological and gas phase parameter influence. Geophys. Res. Lett. 2000, 27, 3325–3328. [Google Scholar] [CrossRef]
- Lee, J.-T.; Kim, H.; Song, H.; Hong, Y.C.; Cho, Y.S.; Shin, S.Y.; Hyun, Y.J.; Kim, Y.S. Air pollution and asthma among children in Seoul, Korea. Epidemiology 2002, 13, 481–484. [Google Scholar] [CrossRef] [PubMed]
- Cai, C.; Zhang, X.; Wang, K.; Zhang, Y.; Wang, L.; Zhang, Q.; Duan, F.; He, K.; Yu, S.-C. Incorporation of new particle formation and early growth treatments into WRF/Chem: Model improvement, evaluation, and impacts of anthropogenic aerosols over East Asia. Atmos. Environ. 2016, 124, 262–284. [Google Scholar] [CrossRef]
- Kalkstein, L.S.; Corrigan, P. A synoptic climatological approach for geographical analysis: Assessment of sulfur dioxide concentrations. Ann. Assoc. Am. Geogr. 1986, 76, 381–395. [Google Scholar] [CrossRef]
- Comrie, A.C. A synoptic climatology of rural ozone pollution at three forest sites in Pennsylvania. Atmos. Environ. 1994, 28, 1601–1614. [Google Scholar] [CrossRef]
- Eder, B.K.; Davis, J.M.; Bloomfield, P. An automated classification scheme designed to better elucidate the dependence of ozone on meteorology. J. Appl. Meteorol. 1994, 33, 1182–1199. [Google Scholar] [CrossRef]
- Zelenka, M.P. An analysis of the meteorological parameters affecting ambient concentrations of acid aerosols in Uniontown, Pennsylvania. Atmos. Environ. 1997, 31, 869–878. [Google Scholar] [CrossRef]
- Laakso, L.; Hussein, T.; Aarnio, P.; Komppula, M.; Hiltunen, V.; Viisanen, Y.; Kulmala, M. Diurnal and annual characteristics of particle mass and number concentrations in urban, rural and Arctic environments in Finland. Atmos. Environ. 2003, 37, 2629–2641. [Google Scholar] [CrossRef]
- Jacob, D.J.; Winner, D.A. Effect of climate change on air quality. Atmos. Environ. 2009, 43, 51–63. [Google Scholar] [CrossRef]
- Holloway, T.; Spak, S.N.; Barker, D.; Bretl, M.; Moberg, C.; Hayhoe, K.; Van Dorn, J.; Wuebbles, D. Change in ozone air pollution over Chicago associated with global climate change. J. Geophys. Res. Atmos. 2008, 113. [Google Scholar] [CrossRef]
- Akbari, H. Shade trees reduce building energy use and CO2 emissions from power plants. Environ. Pollut. 2002, 116, S119–S126. [Google Scholar] [CrossRef]
- DeGaetano, A.T.; Doherty, O.M. Temporal, spatial and meteorological variations in hourly PM 2.5 concentration extremes in New York City. Atmos. Environ. 2004, 38, 1547–1558. [Google Scholar] [CrossRef]
- Elminir, H.K. Dependence of urban air pollutants on meteorology. Sci. Total Environ. 2005, 350, 225–237. [Google Scholar] [CrossRef] [PubMed]
- Natsagdorj, L.; Jugder, D.; Chung, Y.S. Analysis of dust storms observed in Mongolia during 1937–1999. Atmos. Environ. 2003, 37, 1401–1411. [Google Scholar] [CrossRef]
- Seinfeld, J.H.; Pandis, S.N. Atmospheric Chemistry and Physics: From Air Pollution to Climate Change; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Appel, B.R.; Tokiwa, Y.; Hsu, J.; Kothny, E.L.; Hahn, E. Visibility as related to atmospheric aerosol constituents. Atmos. Environ. (1967) 1985, 19, 1525–1534. [Google Scholar] [CrossRef]
- Deng, X.; Tie, X.; Wu, D.; Zhou, X.; Bi, X.; Tan, H.; Li, F.; Jiang, C. Long-term trend of visibility and its characterizations in the Pearl River Delta (PRD) region, China. Atmos. Environ. 2008, 42, 1424–1435. [Google Scholar] [CrossRef]
- Twomey, S. The influence of pollution on the shortwave albedo of clouds. J. Atmos. Sci. 1977, 34, 1149–1152. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, F.; Hsieh, H.-P. U-Air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013. [Google Scholar]
- Kalapanidas, E.; Avouris, N. Short-term air quality prediction using a case-based classifier. Environ. Model. Softw. 2001, 16, 263–272. [Google Scholar] [CrossRef]
- Kurt, A.; Oktay, A.B. Forecasting air pollutant indicator levels with geographic models 3 days in advance using neural networks. Expert Syst. Appl. 2010, 37, 7986–7992. [Google Scholar] [CrossRef]
- Kleine Deters, J.; Zalakeviciute, R.; Gonzalez, M.; Rybarczyk, Y. Modeling PM2.5 urban pollution using machine learning and selected meteorological parameters. J. Electr. Comput. Eng. 2017, 2017, 5106045. [Google Scholar] [CrossRef]
- Bougoudis, I.; Demertzis, K.; Iliadis, L.; Anezakis, V.-D.; Papaleonidas, A. FuSSFFra, a fuzzy semi-supervised forecasting framework: The case of the air pollution in Athens. In Neural Computing and Applications; Springer: Berlin, Germany, 2017; pp. 1–14. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhou, X.; Yang, T.; Tamerius, J.; Mantilla, R. Predicting Traffic Accidents Through Heterogeneous Urban Data: A Case Study. In Proceedings of the 6th International Workshop on Urban Computing (UrbComp 2017), Halifax, NS, Canada, 14 August 2017. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar]
- Fan, J.; Gao, Y.; Luo, H. Integrating concept ontology and multitask learning to achieve more effective classifier training for multilevel image annotation. IEEE Trans. Image Process. 2008, 17, 407–426. [Google Scholar] [CrossRef] [PubMed]
- Widmer, C.; Leiva, J.; Altun, Y.; Rätsch, G. Leveraging sequence classification by taxonomy-based multitask learning. In Annual International Conference on Research in Computational Molecular Biology; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Kshirsagar, M.; Carbonell, J.; Klein-Seetharaman, J. Multitask learning for host-pathogen protein interactions. Bioinformatics 2013, 29, i217–i226. [Google Scholar] [CrossRef] [PubMed]
- Lindbeck, A.; Snower, D.J. Multitask learning and the reorganization of work: From tayloristic to holistic organization. J. Labor Econ. 2000, 18, 353–376. [Google Scholar] [CrossRef]
- Foley, K.M.; Roselle, S.J.; Appel, K.W.; Bhave, P.V.; Pleim, J.E.; Otte, T.L.; Mathur, R.; Sarwar, G.; Young, J.O.; Gilliam, R.C.; et al. Incremental testing of the Community Multiscale Air Quality (CMAQ) modeling system version 4.7. Geosci. Model Dev. 2010, 3, 205–226. [Google Scholar] [CrossRef]
- Yahya, K.; Wang, K.; Campbell, P.; Chen, Y.; Glotfelty, T.; He, J.; Pirhalla, M.; Zhang, Y. Decadal application of WRF/Chem for regional air quality and climate modeling over the US under the representative concentration pathways scenarios. Part 1: Model evaluation and impact of downscaling. Atmos. Environ. 2017, 152, 562–583. [Google Scholar] [CrossRef]
- Horel, J.; Splitt, M.; Dunn, L.; Pechmann, J.; White, B.; Ciliberti, C.; Lazarus, S.; Slemmer, J.; Zaff, D.; Burks, J.; et al. Mesowest: Cooperative mesonets in the western United States. Bull. Am. Meteorol. Soc. 2002, 83, 211–225. [Google Scholar] [CrossRef]
- Athanasiadis, I.N.; Kaburlasos, V.G.; Mitkas, P.A.; Petridis, V. Applying machine learning techniques on air quality data for real-time decision support. In Proceedings of the First international NAISO Symposium on Information Technologies in Environmental Engineering (ITEE’2003), Gdansk, Poland, 24–27 June 2003. [Google Scholar]
- Corani, G. Air quality prediction in Milan: Feed-forward neural networks, pruned neural networks and lazy learning. Ecol. Model. 2005, 185, 513–529. [Google Scholar] [CrossRef]
- Fu, M.; Wang, W.; Le, Z.; Khorram, M.S. Prediction of particular matter concentrations by developed feed-forward neural network with rolling mechanism and gray model. Neural Comput. Appl. 2015, 26, 1789–1797. [Google Scholar] [CrossRef]
- Jiang, D.; Zhang, Y.; Hu, X.; Zeng, Y.; Tan, J.; Shao, D. Progress in developing an ANN model for air pollution index forecast. Atmos. Environ. 2004, 38, 7055–7064. [Google Scholar] [CrossRef]
- Ni, X.Y.; Huang, H.; Du, W.P. Relevance analysis and short-term prediction of PM 2.5 concentrations in Beijing based on multi-source data. Atmos. Environ. 2017, 150, 146–161. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. In Learning to Learn; Springer: Boston, MA, USA, 1998; pp. 95–133. [Google Scholar]
- Liu, J.; Ji, S.; Ye, J. Multi-task feature learning via efficient l 2, 1-norm minimization. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009. [Google Scholar]
- Recht, B.; Fazel, M.; Parrilo, P.A. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 2010, 52, 471–501. [Google Scholar] [CrossRef]
- Argyriou, A.; Micchelli, C.A.; Pontil, M. On spectral learning. J. Mach. Learn. Res. 2010, 11, 935–953. [Google Scholar]
- Maurer, A. Bounds for linear multi-task learning. J. Mach. Learn. Res. 2006, 7, 117–139. [Google Scholar]
- Zhang, T. Solving large scale linear prediction problems using stochastic gradient descent algorithms. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004. [Google Scholar]
- Xu, Y.; Lin, Q.; Yang, T. Stochastic Convex Optimization: Faster Local Growth Implies Faster Global Convergence. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, Z.; Yang, T.; Zhang, L. SVD-free convex-concave approaches for nuclear norm regularization. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australian, 19–25 August 2017. [Google Scholar]
- Xu, Y.; Liu, M.; Lin, Q.; Yang, T. ADMM without a Fixed Penalty Parameter: Faster Convergence with New Adaptive Penalization. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurement Sites | Variables |
|---|---|
| Alsip Village (AV) | Ozone concentration and PM concentration |
| Lemont Village (LV) | Ozone concentration and sulfur dioxide concentration |
| Lansing Municipal Airport (LMA) | Temperature, relative humidity, wind speed and direction, wind gust, precipitation accumulation, visibility, dew point, wind cardinal direction, pressure, and weather conditions |
| Lewis University (LU) | The same as for LMA site |
| Approaches | LMA-AV: | LMA-AV: | LU-LV: | LU-LV: |
|---|---|---|---|---|
| Baseline | 0.1324 | 0.0399 | 0.0971 | 0.0334 |
| Heavy–F | 0.1193 | 0.0394 | 0.0882 | 0.0333 |
| Heavy– | 0.12569 | 0.041 | 0.0883 | 0.033591 |
| Heavy–nuclear | 0.1197 | 0.0398 | 0.0893 | 0.0333 |
| Heavy–CCL2 | 0.11896 | 0.0391 | 0.0882 | 0.033148 |
| Heavy–CCL1 | 0.11897 | 0.039134 | 0.0882 | 0.033261 |
| Light–F | 0.1158 | 0.0372 | 0.0848 | 0.0331 |
| Light– | 0.11591 | 0.037 | 0.085376 | 0.033411 |
| Light–nuclear | 0.1161 | 0.0368 | 0.0849 | 0.0326 |
| Light–CCL2 | 0.116 | 0.0369 | 0.0845 | 0.03253 |
| Light–CCL1 | 0.11535 | 0.03684 | 0.085 | 0.03248 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, D.; Cai, C.; Yang, T.; Zhou, X. A Machine Learning Approach for Air Quality Prediction: Model Regularization and Optimization. Big Data Cogn. Comput. 2018, 2, 5. https://doi.org/10.3390/bdcc2010005
Zhu D, Cai C, Yang T, Zhou X. A Machine Learning Approach for Air Quality Prediction: Model Regularization and Optimization. Big Data and Cognitive Computing. 2018; 2(1):5. https://doi.org/10.3390/bdcc2010005
Chicago/Turabian StyleZhu, Dixian, Changjie Cai, Tianbao Yang, and Xun Zhou. 2018. "A Machine Learning Approach for Air Quality Prediction: Model Regularization and Optimization" Big Data and Cognitive Computing 2, no. 1: 5. https://doi.org/10.3390/bdcc2010005
APA StyleZhu, D., Cai, C., Yang, T., & Zhou, X. (2018). A Machine Learning Approach for Air Quality Prediction: Model Regularization and Optimization. Big Data and Cognitive Computing, 2(1), 5. https://doi.org/10.3390/bdcc2010005