
Interactive Content Retrieval in Egocentric Videos Based on Vague Semantic Queries

 , , , and
, , , and 
Abstract
1. Introduction
- RQ1:
- What interaction techniques and design guidelines can assist users in effectively retrieving relevant content from egocentric videos based on vague semantic queries?
- RQ2:
- How do users navigate egocentric video content based on vague semantic queries?
- We propose novel video interaction methods leveraging zero-shot content retrieval and incremental query building within a user-centered framework to support navigation in egocentric videos based on vague semantic queries;
- We extract user strategies for vague scenario-based video navigation based on interaction logs and structured observations and derive design implications that highlight the importance of hybrid navigation patterns, precision-first behaviors, and semantic visual feedback for supporting ambiguity and incompleteness in user queries.
2. Literature Review
2.1. Interactive Video Navigation
2.2. Zero-Shot Content Retrieval in Video Tasks
2.3. Content Retrieval in Egocentric Videos
2.4. Vague Semantic Queries in Content Retrieval
3. Materials and Methods
- Specific query: all retrieved moments are relevant;
- Vague query: the retrieved set contains a mix of relevant and irrelevant moments; and
- Erroneous query: None of the retrieved moments are relevant.
3.1. Factors of Vagueness
- Absent-mindedness (lack of attention) and transience (memory fading over time) may lead to the occlusion of certain information on events and thus to under-specified, incomplete queries.
- Blocking (memory retrieval failure) may prevent users from finding the exact terms to describe a concept or an event, leading to incomplete queries if no specific terms are employed or ambiguous queries when synonyms and paraphrasing are employed.
- Misattribution and bias may cause ambiguous queries referring to several scenes or even erroneous queries referring to incorrect or irrelevant scenes.
- Ambiguous query represents a polysemous natural language query, i.e., a query that can describe more than one single concrete object/action/scene/concept depicted in the target video. (For example,“Where did I put my keys after returning home?”, possible ambiguity on “keys” if several exist in the footage—house keys, car keys, etc.);
- Incomplete query represents a natural language query that does not describe the intended concrete object/action/scene/concept depicted in the target video sufficiently to identify it in a unique manner (for example, “Where are my car keys?” requires specification if the keys appear several times in the footage, but only the most recent occurrence is truly relevant).
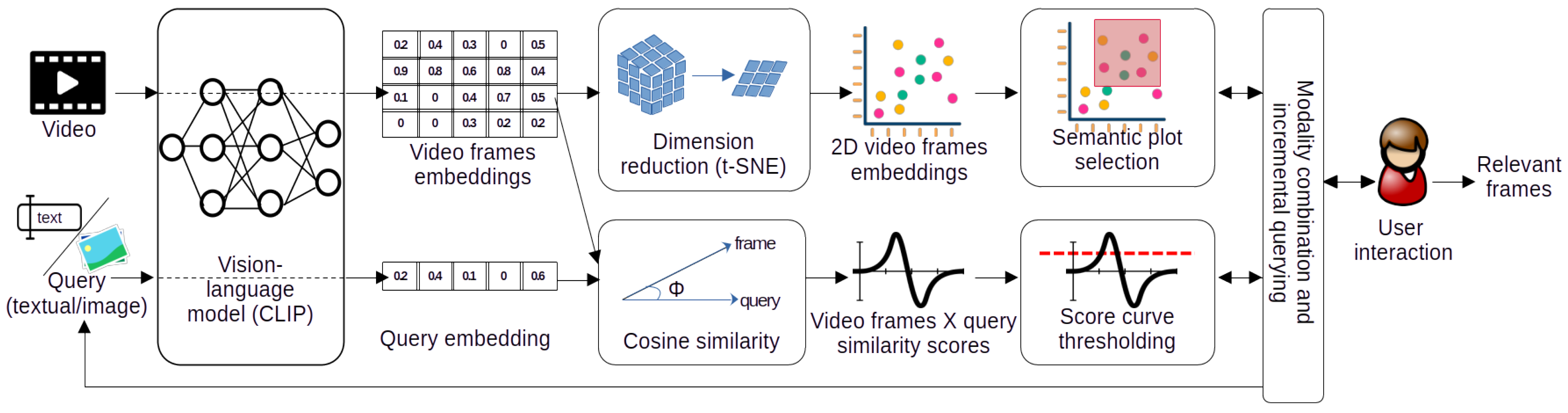
3.2. Video Content Retrieval Approach
3.3. Interaction Design
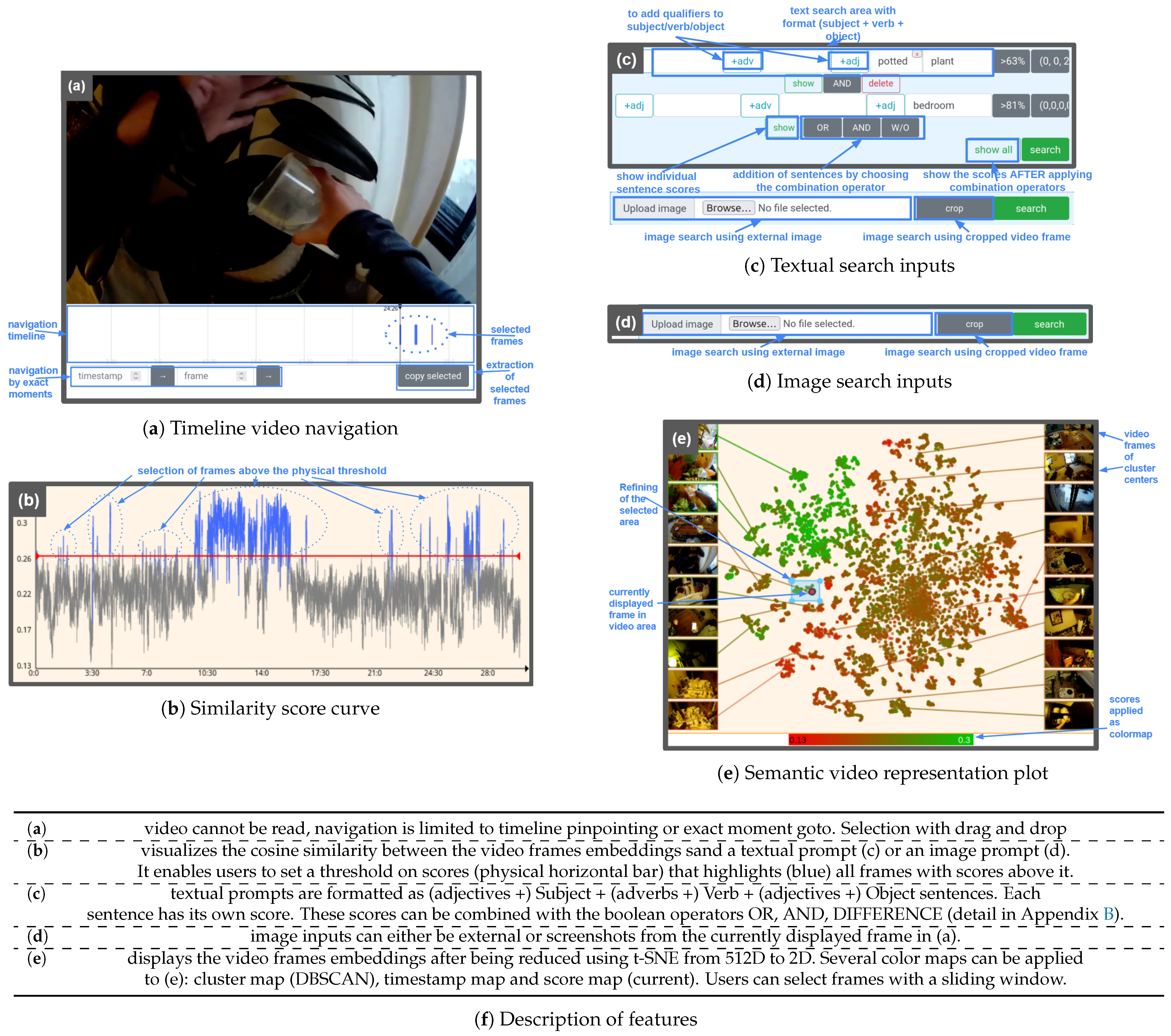
3.3.1. Sequential Navigation of Videos
3.3.2. Textual Search
3.3.3. Similarity Score Interactions
3.3.4. Image Search
3.3.5. Interaction with Hyperspace Representation of Encoded Video Frames
- Selection (base): highlights the frames selected by users. It can help users filter outliers out of a selection based on a vague semantic query.
- Clusters: highlights DBSCAN computed clusters. It can help users identify global semantic areas in the video.
- Timestamps: applies a two color gradient on the 2D projection where darker points indicate frames at the (temporal) beginning of the video recording and lighter points indicates frames at the end of the recording. It helps users link the temporal and semantic representation of the video.
- Scores: if scores are computed, applies a two color gradient on the 2D projection where green points show frames with higher scores and red points show frame with lower scores. It can help users filter outliers through high score frame clusters.
3.4. Mechanisms of Vagueness Resolution
3.4.1. Disambiguation
3.4.2. Incompleteness Refinement
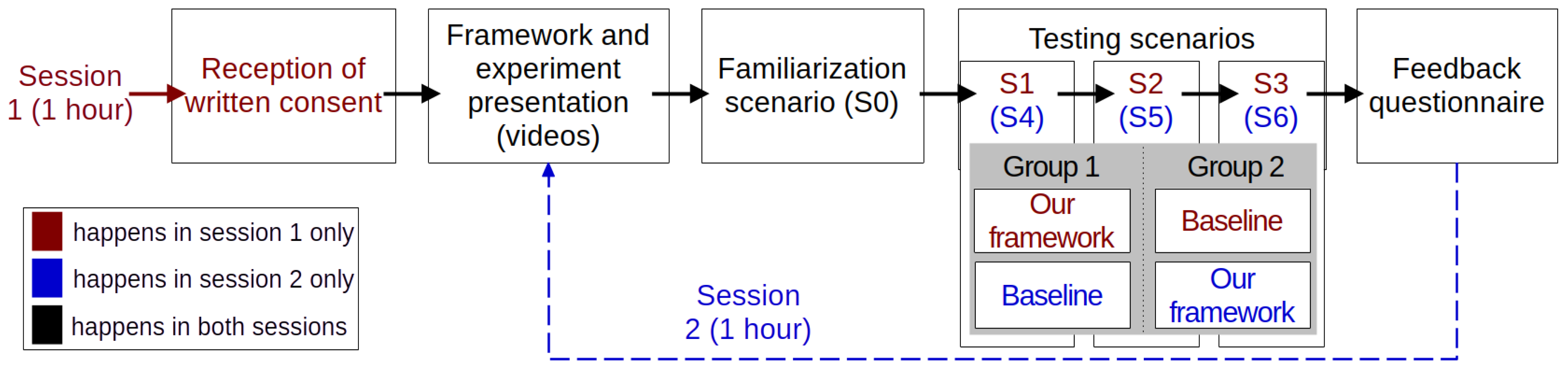
4. Experimental Validation
4.1. Scenario Design and Use Cases
- The title of the scenario;
- A short, textual description to describe the context of the scenario;
- A timeline showing a few snapshots of the video. The snapshots were representative images taken from the middle of each annotated segment (the description annotations of the Ego4d dataset); and
- The instruction that needs to be matched with video moments.
- Egocentricity and simulated memory: We aim to understand how human users navigate through egocentric videos based on vague semantic queries. For that, ideally, participants would navigate their own egocentric video recordings. However, such a setup introduces uncontrollable variability as to the level of detail remembered by each participant as well as the content and length of the videos, which complicates comparison. Thus, we aimed for a more controlled experimental setup where we simulate the same level of familiarity for all participants with already existing egocentric videos from the Ego4d dataset through contextual cues and image snapshots that come with each scenario.
- Vagueness in query formulation and navigation: Without any knowledge of the video, navigation would be entirely random, as participants would have no clue about where or how to search. Conversely, perfect awareness of the video content would eliminate ambiguity, allowing participants to directly locate the matching moment. To ensure this balance, participants were asked beforehand about their familiarity with the dataset, and all confirmed they had never encountered it.To create a sense of vagueness, participants were provided with approximate video segments, representative images, and rough segment descriptions, encouraging strategic exploration rather than precise targeting or random navigation.
4.2. Data Collection and Analysis
- Completion Time: Automatically recorded via framework logs. Only interaction time is accounted for (any loading pre-computation time is ignored for both frameworks)
- Retrieved Moments: Participants submitted responses via a web form for comparison with expert annotations.
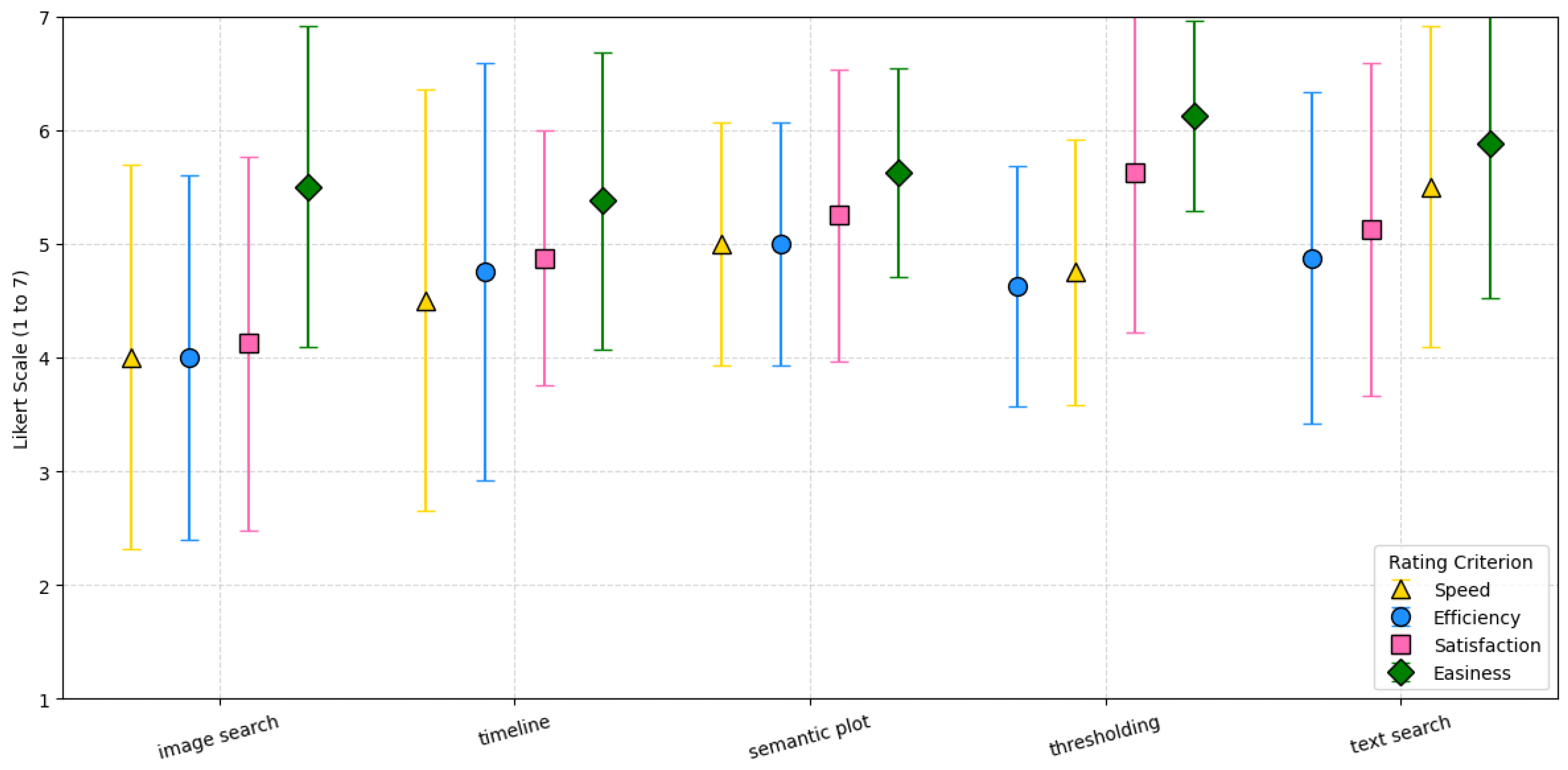
- Participants’ feedback: Participants used a seven-point Likert scale to evaluate intuitiveness, efficiency, satisfaction, and likelihood of recommending each framework, as well as the ease of use, speed, efficiency, and satisfaction of each feature.
4.3. Implementation Details and Computational Cost
5. Results
5.1. Quantitative Results
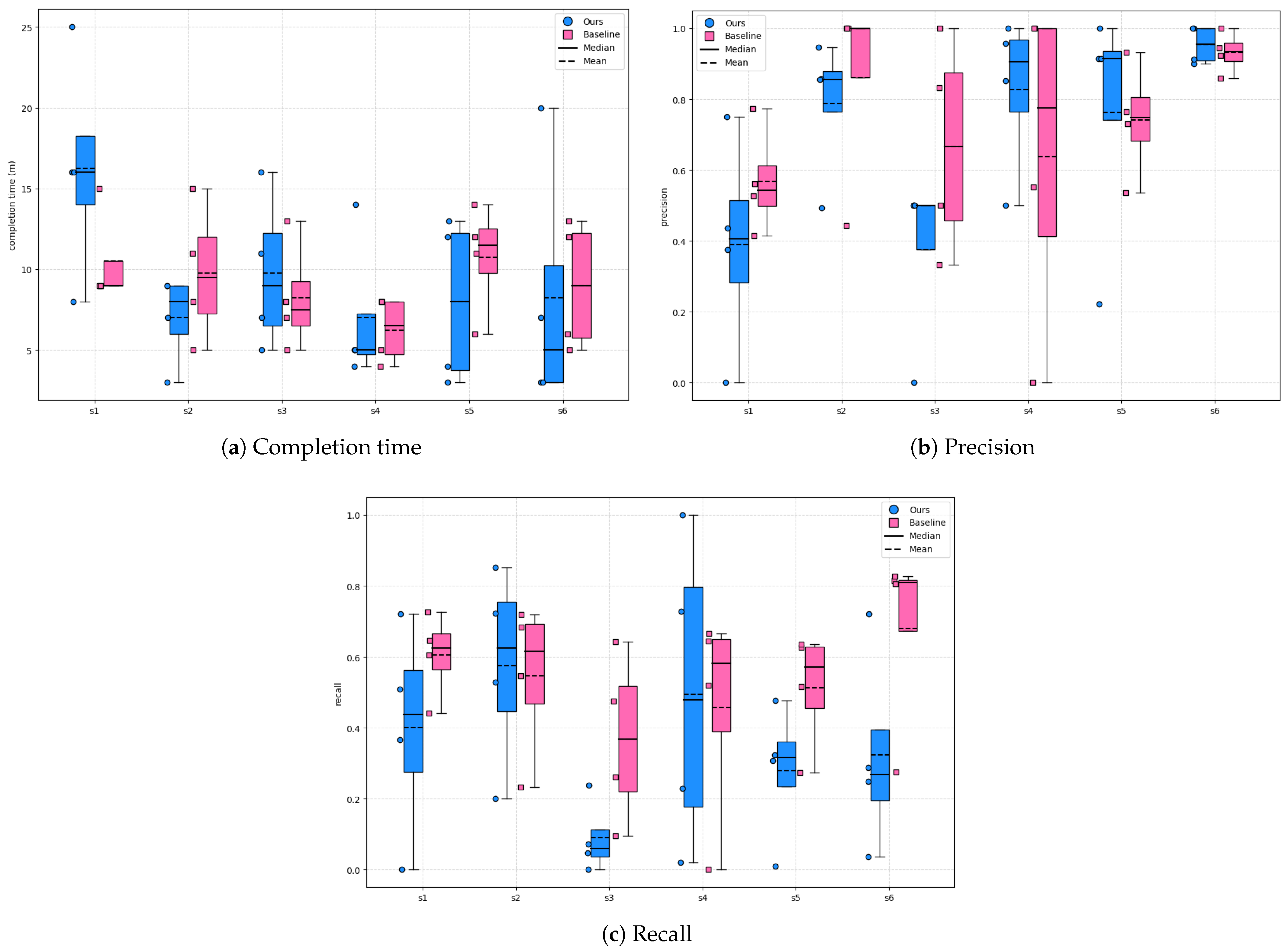
5.1.1. Completion Time
5.1.2. Precision and Recall
5.1.3. Participants’ Feedback for Framework Comparison
5.1.4. Participants’ Feedback for Feature Comparison
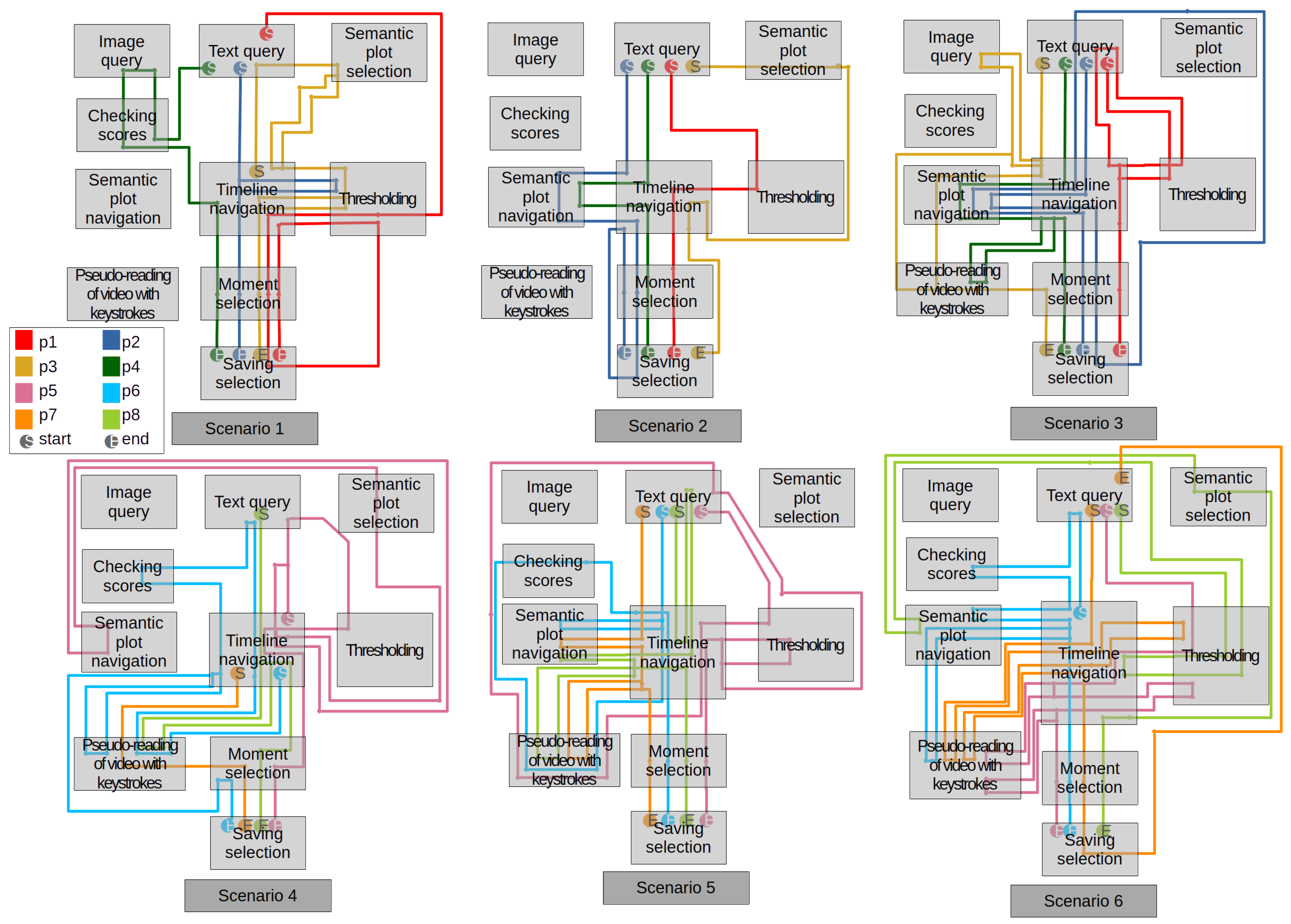
5.2. Analysis of Participants Search Strategies
- Search initiation: Participants started 79% of scenarios with textual querying while the other 21% of scenarios were initiated with temporal navigation. While the Graphical User Interface (GUI) may have influenced participants’ initial choice, this shows the immediacy of textual querying and its accessibility in the design.
- Query refinement: Several strategies were employed for refining the initially entered textual queries.
- Thresholding + temporal navigation: a strategy used in 42% of the workflows (across participants and scenarios) that consisted of a back and forth between setting a manual threshold on scores and temporally navigating the frames with scores above said threshold. This strategy was sufficient for P2 for answering Scenario 1, it was used alongside iterative textual querying by P1 for answering Scenario 3 and P5 for answering scenarios 5 and 6 and P7 for answering Scenario 6, and it was augmented by semantic navigation in the other cases.
- Checking scores + temporal navigation: Two participants chose to manually infer the frames to temporally navigate and select from the shape of the score curve instead of using the horizontal bar tool to set a physical threshold that automatically highlights the frames with high scores as shown in Figure 2b. While P4 did not understand the feature, P6 made a deliberate choice to bypass it. This suggests that the manual curve inspection held perceived advantages in clarity or control over the more automated threshold mechanism.
- Semantic navigation: This emerged as a key strategy in 45% of workflows. Some participants used it to supplement temporal methods (P5, P6, P7 and P8), while others (P2 and P4) completely abandoned the temporal score curve for the semantic representation to visualize scores on frames and search for the objects specific to each scenario.
- Full temporal navigation: In Scenario 4, P7 solely relied on temporal navigation, i.e., they navigated the video in a standard way (no incremental querying), while P8 attempted a textual query but later relied only on temporal navigation.
- Moment selection: Four strategies were observed for moment selection before copying them to the answering web page:
- Full reliance on manual, temporal-guided moment selection for all relevant moments, then copying (P2, P4, P6, P7, P8);
- Using the automatic threshold selection function, then refining the results through addition or deletion of specific moments (mainly deletion), then copying (P1, P2 in S1, P5, P7 in S6, P8 is S6);
- Using the semantic plot selection feature, then refining the results through addition or deletion of specific moments (mainly deletion), then copying (P3, P5);
- Full reliance on manual, temporal-guided moment selection for a portion of relevant moment, then copying, then repeating the process every time a new textual query and query refinement iteration is performed (P1 in S1).
These varied moment selection strategies reflect differing levels of trust in the system’s automatic highlighting and the importance of providing a flexible and multimodal framework for exploratory and verification tasks. - Reliance on temporal navigation: It persisted in 62% of interactions, often in conjunction with other features. P3 thinks that a hybrid video navigation method that combines features of both frameworks would be more efficient, while P6 would have preferred to sequentially navigate the video for some scenarios. This highlights the influence standard video navigation has on users even after the familiarization scenario and the limitations put in the GUI to minimize this effect.
- Strategies of semantic navigation: Semantic navigation was used at least once for each scenario with diverse strategies: while P2 and P4 used the semantic plot to pinpoint specific moments or objects, P3 selected areas with a high density of high scores, P5 relied on the semantic plot clusters to identify similar frames, P6 used it as a progression checkpoint, and P8 tried to identify frames with a specific camera angle. This highlights the expression power of the semantic space.
- Under-reliance on image querying: Scenario S0 aside, participants hardly ever used image querying, which corroborates the results of Section 5.1.4. P1 and P2 think that it is counter-intuitive, while P5 and P7 were dissatisfied with the returned scores. This confirms that the feature needs to be improved for better disambiguation efficiency.
6. Discussion
6.1. Framework Design
- Engineering prompts to improve the accuracy of queries, especially image-based queries. Multi-sentence textual queries can be divided into several smaller queries and an aggregated score can be computed ([43]). Image queries can benefit from upscaling or transformation into text with generative AI to ensure same modality encoding.
- Sound modality: Most videos are audio-visual and a great deal of information is found within the audio modality. The framework would benefit from encoding sound and including it when querying videos.
- Refining score computing using, for instance, image segmentation techniques like SAM [95] to identify and encode individual objects within video frames separately and then computing an aggregated score measure.
- Improving interaction design such as image search or thresholding to function as intended or removing limits on timeline navigation to have a hybrid framework, as mentioned by participants.
Privacy and Security Concerns
6.2. Experimental Validation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Experimental Setup

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n° | Title | Ego4D Video ID |
|---|---|---|
| 0 | Camping | b8b4fc74-e036-4731-ae03-4bfab7fd47b9 |
| 1 | Fire alarm triggers | 1bec800a-c3cf-431f-bf0a-7632ad53bcb7 |
| 2 | Water the plants | 24a27df2-892b-4630-909a-6e1b1d3cf043 |
| 3 | Where are my papers? | 1bec800a-c3cf-431f-bf0a-7632ad53bcb7 |
| 4 | Who won? | 915a7fd2-7446-4884-b777-35e6b329f063 |
| 5 | Diet | e837708f-8276-4d2b-88b3-319cddabbf74 |
| 6 | Warmups | 6395f964-0122-4f16-b036-337c28488504 |
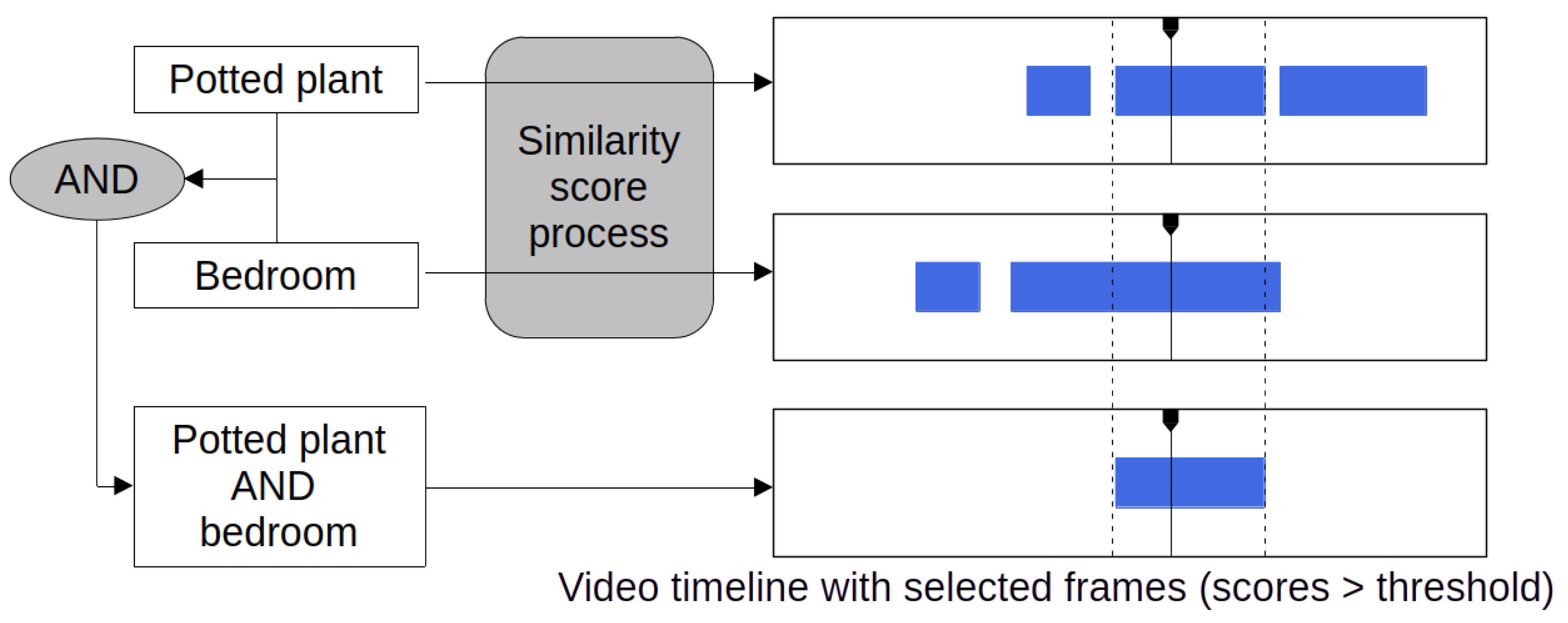
Appendix B. Textual Query Combination Logic
References
- Rodin, I.; Furnari, A.; Mavroeidis, D.; Farinella, G.M. Predicting the future from first person (egocentric) vision: A survey. Comput. Vis. Image Underst. 2021, 211, 103252. [Google Scholar] [CrossRef]
- Huang, S.; Wang, W.; He, S.; Lau, R.W. Egocentric hand detection via dynamic region growing. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2017, 14, 1–17. [Google Scholar] [CrossRef]
- Thakur, S.K.; Beyan, C.; Morerio, P.; Del Bue, A. Predicting gaze from egocentric social interaction videos and imu data. In Proceedings of the 2021 International Conference on Multimodal Interaction, Ottawa, ON, Canada, 18–22 October 2021; pp. 717–722. [Google Scholar]
- Legel, M.; Deckers, S.R.; Soto, G.; Grove, N.; Waller, A.; Balkom, H.v.; Spanjers, R.; Norrie, C.S.; Steenbergen, B. Self-Created Film as a Resource in a Multimodal Conversational Narrative. Multimodal Technol. Interact. 2025, 9, 25. [Google Scholar] [CrossRef]
- Yin, H. From Virality to Engagement: Examining the Transformative Impact of Social Media, Short Video Platforms, and Live Streaming on Information Dissemination and Audience Behavior in the Digital Age. Adv. Soc. Behav. Res. 2024, 14, 10–14. [Google Scholar] [CrossRef]
- Patra, S.; Aggarwal, H.; Arora, H.; Banerjee, S.; Arora, C. Computing Egomotion with Local Loop Closures for Egocentric Videos. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 454–463. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, S.; Stent, S.; Shi, J. Fine-Grained Egocentric Hand-Object Segmentation: Dataset, Model, and Applications. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 127–145. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Furnari, A.; Ma, J.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100. Int. J. Comput. Vis. (IJCV) 2022, 130, 33–55. [Google Scholar] [CrossRef]
- Mueller, F.; Mehta, D.; Sotnychenko, O.; Sridhar, S.; Casas, D.; Theobalt, C. Real-time hand tracking under occlusion from an egocentric rgb-d sensor. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; pp. 1154–1163. [Google Scholar]
- Liu, X.; Zhou, S.; Lei, T.; Jiang, P.; Chen, Z.; Lu, H. First-Person Video Domain Adaptation With Multi-Scene Cross-Site Datasets and Attention-Based Methods. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7774–7788. [Google Scholar] [CrossRef]
- Duane, A.; Zhou, J.; Little, S.; Gurrin, C.; Smeaton, A.F. An Annotation System for Egocentric Image Media. In MultiMedia Modeling; Amsaleg, L., Guomundsson, G.B., Gurrin, C., Jónsson, B.B., Satoh, S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 442–445. [Google Scholar]
- Wang, M.; Ni, B.; Hua, X.S.; Chua, T.S. Assistive tagging: A survey of multimedia tagging with human-computer joint exploration. ACM Comput. Surv. (CSUR) 2012, 44, 1–24. [Google Scholar] [CrossRef]
- Pourpanah, F.; Abdar, M.; Luo, Y.; Zhou, X.; Wang, R.; Lim, C.P.; Wang, X.Z.; Wu, Q.J. A review of generalized zero-shot learning methods. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4051–4070. [Google Scholar] [CrossRef]
- Grauman, K.; Westbury, A.; Byrne, E.; Chavis, Z.; Furnari, A.; Girdhar, R.; Hamburger, J.; Jiang, H.; Liu, M.; Liu, X.; et al. Ego4d: Around the world in 3000 hours of egocentric video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18995–19012. [Google Scholar]
- Zhu, C.; Xiao, F.; Alvarado, A.; Babaei, Y.; Hu, J.; El-Mohri, H.; Culatana, S.; Sumbaly, R.; Yan, Z. Egoobjects: A large-scale egocentric dataset for fine-grained object understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 20110–20120. [Google Scholar]
- Xue, Z.; Song, Y.; Grauman, K.; Torresani, L. Egocentric video task translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2310–2320. [Google Scholar]
- Dai, G.; Shu, X.; Wu, W.; Yan, R.; Zhang, J. GPT4Ego: Unleashing the potential of pre-trained models for zero-shot egocentric action recognition. IEEE Trans. Multimed. 2024, 27, 401–413. [Google Scholar] [CrossRef]
- Lin, K.Q.; Wang, J.; Soldan, M.; Wray, M.; Yan, R.; Xu, E.Z.; Gao, D.; Tu, R.C.; Zhao, W.; Kong, W.; et al. Egocentric video-language pretraining. Adv. Neural Inf. Process. Syst. 2022, 35, 7575–7586. [Google Scholar]
- Hong, H.; Wang, S.; Huang, Z.; Wu, Q.; Liu, J. Why only text: Empowering vision-and-language navigation with multi-modal prompts. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, Jeju, Republic of Korea, 3–9 August 2024; pp. 839–847. [Google Scholar]
- Zhang, Y.; Li, Y.; Cui, L.; Cai, D.; Liu, L.; Fu, T.; Huang, X.; Zhao, E.; Zhang, Y.; Chen, Y.; et al. Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models. arXiv 2023, arXiv:2309.01219. [Google Scholar]
- Esfandiarpoor, R.; Menghini, C.; Bach, S. If CLIP Could Talk: Understanding Vision-Language Model Representations Through Their Preferred Concept Descriptions. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 9797–9819. [Google Scholar]
- Furnas, G.W.; Landauer, T.K.; Gomez, L.M.; Dumais, S.T. The vocabulary problem in human-system communication. Commun. ACM 1987, 30, 964–971. [Google Scholar] [CrossRef]
- Song, R.; Luo, Z.; Wen, J.R.; Yu, Y.; Hon, H.W. Identifying ambiguous queries in web search. In Proceedings of the 16th International Conference on World Wide Web, New York, NY, USA, 8–12 May 2007; pp. 1169–1170. [Google Scholar]
- Asai, A.; Choi, E. Challenges in information-seeking QA: Unanswerable questions and paragraph retrieval. In Proceedings of the ACL-IJCNLP 2021—59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021. [Google Scholar] [CrossRef]
- Zarka, M.; Ben Ammar, A.; Alimi, A.M. Fuzzy reasoning framework to improve semantic video interpretation. Multimed. Tools Appl. 2016, 75, 5719–5750. [Google Scholar] [CrossRef]
- Chae, J.; Kim, J. Uncertainty-based Visual Question Answering: Estimating Semantic Inconsistency between Image and Knowledge Base. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Pajua, Italy, 18–23 July 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Chang, M.; Huh, M.; Kim, J. Rubyslippers: Supporting content-based voice navigation for how-to videos. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–14. [Google Scholar]
- Pérez Ortiz, M.; Bulathwela, S.; Dormann, C.; Verma, M.; Kreitmayer, S.; Noss, R.; Shawe-Taylor, J.; Rogers, Y.; Yilmaz, E. Watch less and uncover more: Could navigation tools help users search and explore videos? In Proceedings of the 2022 Conference on Human Information Interaction and Retrieval, New York, NY, USA, 14–18 March 2022; pp. 90–101. [Google Scholar]
- Zhou, Z.; Ye, L.; Cai, L.; Wang, L.; Wang, Y.; Wang, Y.; Chen, W.; Wang, Y. Conceptthread: Visualizing threaded concepts in MOOC videos. IEEE Trans. Vis. Comput. Graph. 2024, 31, 1354–1370. [Google Scholar] [CrossRef]
- Fong, M.; Miller, G.; Zhang, X.; Roll, I.; Hendricks, C.; Fels, S.S. An Investigation of Textbook-Style Highlighting for Video. In Proceedings of the Graphics Interface, Victoria, BC, Canada, 1–3 June 2016; pp. 201–208. [Google Scholar]
- Dragicevic, P.; Ramos, G.; Bibliowitcz, J.; Nowrouzezahrai, D.; Balakrishnan, R.; Singh, K. Video browsing by direct manipulation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 5–10 April 2008; pp. 237–246. [Google Scholar]
- Clarke, C.; Cavdir, D.; Chiu, P.; Denoue, L.; Kimber, D. Reactive video: Adaptive video playback based on user motion for supporting physical activity. In Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology, New York, NY, USA, 20–23 October 2020; pp. 196–208. [Google Scholar]
- Lilija, K.; Pohl, H.; Hornbæk, K. Who put that there? temporal navigation of spatial recordings by direct manipulation. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–11. [Google Scholar]
- Wu, Y.; Xie, X.; Wang, J.; Deng, D.; Liang, H.; Zhang, H.; Cheng, S.; Chen, W. Forvizor: Visualizing spatio-temporal team formations in soccer. IEEE Trans. Vis. Comput. Graph. 2018, 25, 65–75. [Google Scholar] [CrossRef] [PubMed]
- Chan, G.Y.Y.; Nonato, L.G.; Chu, A.; Raghavan, P.; Aluru, V.; Silva, C.T. Motion Browser: Visualizing and understanding complex upper limb movement under obstetrical brachial plexus injuries. IEEE Trans. Vis. Comput. Graph. 2019, 26, 981–990. [Google Scholar] [CrossRef]
- He, J.; Wang, X.; Wong, K.K.; Huang, X.; Chen, C.; Chen, Z.; Wang, F.; Zhu, M.; Qu, H. Videopro: A visual analytics approach for interactive video programming. IEEE Trans. Vis. Comput. Graph. 2023, 30, 87–97. [Google Scholar] [CrossRef]
- Xian, Y.; Schiele, B.; Akata, Z. Zero-shot learning-the good, the bad and the ugly. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4582–4591. [Google Scholar]
- Yang, A.; Miech, A.; Sivic, J.; Laptev, I.; Schmid, C. Zero-Shot Video Question Answering via Frozen Bidirectional Language Models Cross-modal Training. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Yang, A.; Miech, A.; Sivic, J.; Laptev, I.; Schmid, C. Learning to Answer Visual Questions from Web Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 47, 3202–3218. [Google Scholar] [CrossRef]
- Wang, Y.; Li, K.; Li, X.; Yu, J.; He, Y.; Chen, G.; Pei, B.; Zheng, R.; Wang, Z.; Shi, Y.; et al. InternVideo2: Scaling Foundation Models for Multimodal Video Understanding. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 396–416. [Google Scholar]
- Ma, K.; Zang, X.; Feng, Z.; Fang, H.; Ban, C.; Wei, Y.; He, Z.; Li, Y.; Sun, H. LLaViLo: Boosting Video Moment Retrieval via Adapter-Based Multimodal Modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 2798–2803. [Google Scholar]
- Panta, L.; Shrestha, P.; Sapkota, B.; Bhattarai, A.; Manandhar, S.; Sah, A.K. Cross-modal Contrastive Learning with Asymmetric Co-attention Network for Video Moment Retrieval. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 4–8 January 2024. [Google Scholar]
- Luo, D.; Huang, J.; Gong, S.; Jin, H.; Liu, Y. Zero-Shot Video Moment Retrieval from Frozen Vision-Language Models. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2024. [Google Scholar]
- Jiang, X.; Zhou, Z.; Xu, X.; Yang, Y.; Wang, G.; Shen, H.T. Faster video moment retrieval with point-level supervision. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1334–1342. [Google Scholar]
- Ma, Y.; Qing, L.; Li, G.; Qi, Y.; Sheng, Q.Z.; Huang, Q. Retrieval Enhanced Zero-Shot Video Captioning. arXiv 2024, arXiv:2405.07046. [Google Scholar]
- Wu, G.; Lin, J.; Silva, C.T. IntentVizor: Towards Generic Query Guided Interactive Video Summarization. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 10493–10502. [Google Scholar] [CrossRef]
- Pang, Z.; Nakashima, Y.; Otani, M.; Nagahara, H. Unleashing the Power of Contrastive Learning for Zero-Shot Video Summarization. J. Imaging 2024, 10, 229. [Google Scholar] [CrossRef]
- Ahmad, S.; Chanda, S.; Rawat, Y.S. Ez-clip: Efficient zeroshot video action recognition. arXiv 2023, arXiv:2312.08010. [Google Scholar]
- Yu, Y.; Cao, C.; Zhang, Y.; Lv, Q.; Min, L.; Zhang, Y. Building a Multi-modal Spatiotemporal Expert for Zero-shot Action Recognition with CLIP. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 9689–9697. [Google Scholar]
- Zhao, X.; Chang, S.; Pang, Y.; Yang, J.; Zhang, L.; Lu, H. Adaptive multi-source predictor for zero-shot video object segmentation. Int. J. Comput. Vis. 2024, 132, 3232–3250. [Google Scholar] [CrossRef]
- Chu, W.H.; Harley, A.W.; Tokmakov, P.; Dave, A.; Guibas, L.; Fragkiadaki, K. Zero-Shot Open-Vocabulary Tracking with Large Pre-Trained Models. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 4916–4923. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Westminster, UK, 18–24 July 2021; PMLR, Proceedings of Machine Learning Research. Volume 139, pp. 8748–8763. [Google Scholar]
- Tang, H.; Liang, K.J.; Grauman, K.; Feiszli, M.; Wang, W. Egotracks: A long-term egocentric visual object tracking dataset. Adv. Neural Inf. Process. Syst. 2023, 36, 75716–75739. [Google Scholar]
- Akiva, P.; Huang, J.; Liang, K.J.; Kovvuri, R.; Chen, X.; Feiszli, M.; Dana, K.; Hassner, T. Self-supervised object detection from egocentric videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 5225–5237. [Google Scholar]
- Hao, S.; Chai, W.; Zhao, Z.; Sun, M.; Hu, W.; Zhou, J.; Zhao, Y.; Li, Q.; Wang, Y.; Li, X.; et al. Ego3DT: Tracking Every 3D Object in Ego-centric Videos. In Proceedings of the MM 2024 32nd ACM International Conference on Multimedia. Association for Computing Machinery, Melbourne, Australia, 28 October–1 November 2024; pp. 2945–2954. [Google Scholar] [CrossRef]
- Cartas, A.; Dimiccoli, M.; Radeva, P. Detecting Hands in Egocentric Videos: Towards Action Recognition. In Computer Aided Systems Theory—EUROCAST 2017; Moreno-Díaz, R., Pichler, F., Quesada-Arencibia, A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 330–338. [Google Scholar]
- Liu, S.; Tripathi, S.; Majumdar, S.; Wang, X. Joint hand motion and interaction hotspots prediction from egocentric videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3282–3292. [Google Scholar]
- Xu, B.; Wang, Z.; Du, Y.; Song, Z.; Zheng, S.; Jin, Q. Do Egocentric Video-Language Models Truly Understand Hand-Object Interactions? In Proceedings of The Thirteenth International Conference on Learning Representations, Singapore, 24–28 April 2025.
- Xu, Y.; Li, Y.L.; Huang, Z.; Liu, M.X.; Lu, C.; Tai, Y.W.; Tang, C.K. Egopca: A new framework for egocentric hand-object interaction understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 5273–5284. [Google Scholar]
- Ng, E.; Xiang, D.; Joo, H.; Grauman, K. You2me: Inferring body pose in egocentric video via first and second person interactions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9890–9900. [Google Scholar]
- Khirodkar, R.; Bansal, A.; Ma, L.; Newcombe, R.; Vo, M.; Kitani, K. Ego-humans: An ego-centric 3d multi-human benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 19807–19819. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the IEEE 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Abreu, S.; Do, T.D.; Ahuja, K.; Gonzalez, E.J.; Payne, L.; McDuff, D.; Gonzalez-Franco, M. Parse-ego4d: Personal action recommendation suggestions for egocentric videos. arXiv 2024, arXiv:2407.09503. [Google Scholar]
- Fan, C. Egovqa-an egocentric video question answering benchmark dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Bärmann, L.; Waibel, A. Where did i leave my keys?-episodic-memory-based question answering on egocentric videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1560–1568. [Google Scholar]
- Di, S.; Xie, W. Grounded question-answering in long egocentric videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 12934–12943. [Google Scholar]
- Jiang, H.; Ramakrishnan, S.K.; Grauman, K. Single-stage visual query localization in egocentric videos. Adv. Neural Inf. Process. Syst. 2023, 36, 24143–24157. [Google Scholar]
- Pramanick, S.; Song, Y.; Nag, S.; Lin, K.Q.; Shah, H.; Shou, M.Z.; Chellappa, R.; Zhang, P. Egovlpv2: Egocentric video-language pre-training with fusion in the backbone. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 5285–5297. [Google Scholar]
- Hummel, T.; Karthik, S.; Georgescu, M.I.; Akata, Z. Egocvr: An egocentric benchmark for fine-grained composed video retrieval. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 1–17. [Google Scholar]
- Sanderson, M. Ambiguous queries: Test collections need more sense. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008; pp. 499–506. [Google Scholar]
- Dhole, K.D.; Agichtein, E. Genqrensemble: Zero-shot llm ensemble prompting for generative query reformulation. In Proceedings of the European Conference on Information Retrieval, Glasgow, UK, 24–28 March 2024; pp. 326–335. [Google Scholar]
- Hambarde, K.A.; Proença, H. Information Retrieval: Recent Advances and Beyond. IEEE Access 2023, 11, 76581–76604. [Google Scholar] [CrossRef]
- Woo, S.; Jeon, S.Y.; Park, J.; Son, M.; Lee, S.; Kim, C. Sketch-based video object localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2024; pp. 8480–8489. [Google Scholar]
- Miyanishi, T.; Hirayama, J.i.; Kong, Q.; Maekawa, T.; Moriya, H.; Suyama, T. Egocentric video search via physical interactions. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Lee, D.; Kim, S.; Lee, M.; Lee, H.; Park, J.; Lee, S.W.; Jung, K. Asking Clarification Questions to Handle Ambiguity in Open-Domain QA. Proceedings of The 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023. [Google Scholar]
- Nakano, Y.; Kawano, S.; Yoshino, K.; Sudoh, K.; Nakamura, S. Pseudo ambiguous and clarifying questions based on sentence structures toward clarifying question answering system. In Proceedings of the Second DialDoc Workshop on Document-grounded Dialogue and Conversational Question Answering, Dublin, Ireland, 26 May 2022; pp. 31–40. [Google Scholar]
- Gao, J.; Sun, C.; Yang, Z.; Nevatia, R. Tall: Temporal activity localization via language query. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; pp. 5267–5275. [Google Scholar]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Regneri, M.; Rohrbach, M.; Wetzel, D.; Thater, S.; Schiele, B.; Pinkal, M. Grounding action descriptions in videos. Trans. Assoc. Comput. Linguist. 2013, 1, 25–36. [Google Scholar] [CrossRef]
- Rothe, A.; Lake, B.M.; Gureckis, T.M. Do people ask good questions? Comput. Brain Behav. 2018, 1, 69–89. [Google Scholar] [CrossRef]
- Liu, S.; Yu, C.; Meng, W. Word sense disambiguation in queries. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, CIKM ’05, New York, NY, USA, 31 October–5 November 2005; pp. 525–532. [Google Scholar] [CrossRef]
- Wang, Y.; Agichtein, E. Query ambiguity revisited: Clickthrough measures for distinguishing informational and ambiguous queries. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 361–364. [Google Scholar]
- Aliannejadi, M.; Zamani, H.; Crestani, F.; Croft, W.B. Asking clarifying questions in open-domain information-seeking conversations. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 475–484. [Google Scholar]
- Keyvan, K.; Huang, J.X. How to approach ambiguous queries in conversational search: A survey of techniques, approaches, tools, and challenges. ACM Comput. Surv. 2022, 55, 1–40. [Google Scholar] [CrossRef]
- Hodges, S.; Williams, L.; Berry, E.; Izadi, S.; Srinivasan, J.; Butler, A.; Smyth, G.; Kapur, N.; Wood, K. SenseCam: A retrospective memory aid. In Proceedings of the UbiComp 2006: Ubiquitous Computing: 8th International Conference, UbiComp 2006, Orange County, CA, USA, 17–21 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 177–193. [Google Scholar]
- Gurrin, C.; Smeaton, A.F.; Doherty, A.R. Lifelogging: Personal big data. Found. Trends® Inf. Retr. 2014, 8, 1–125. [Google Scholar] [CrossRef]
- Schacter, D.L. The seven sins of memory: Insights from psychology and cognitive neuroscience. Am. Psychol. 1999, 54, 182. [Google Scholar] [CrossRef] [PubMed]
- Diwan, A.; Peng, P.; Mooney, R. Zero-shot Video Moment Retrieval with Off-the-Shelf Models. In Proceedings of the Transfer Learning for Natural Language Processing Workshop, PMLR; 2023; pp. 10–21. Available online: https://proceedings.mlr.press/v203/diwan23a.html (accessed on 28 April 2025).
- Sultan, M.; Jacobs, L.; Stylianou, A.; Pless, R. Exploring CLIP for Real World, Text-based Image Retrieval. In Proceedings of the 2023 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 27–29 September 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Chen, J.; Mao, J.; Liu, Y.; Zhang, F.; Zhang, M.; Ma, S. Towards a better understanding of query reformulation behavior in web search. In Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 743–755. [Google Scholar]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16901–16911. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 4015–4026. [Google Scholar]
- Huang, X.; Gao, Y.; He, S.; Xie, X.; Wang, Y.; Zhang, Y.; Liu, X.; Li, B.; Liu, Y. Exploring Clean-Label Backdoor Attacks and Defense in Language Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 12345–12354. [Google Scholar]
- St, L.; Wold, S. Analysis of variance (ANOVA). Chemom. Intell. Lab. Syst. 1989, 6, 259–272. [Google Scholar]


| n° | Title | Expected Query Type | Context | Instruction |
|---|---|---|---|---|
| 0 | Camping | Specific | A group of friends went camping. Afterwards, the person who brought the barbecue cannot find the bottle of oil and wonders if a friend took it by mistake. | - Find all moments where a bottle of oil is visible. |
| 1 | Fire alarm triggers | Specific | A security inspector is responsible for seeing if security protocols are being followed in an office. Among the things they must check is to ensure that fire extinguishers and fire alarm triggers are in place. | - Find all moments that contain fire alarm triggers in the workplace only. |
| 2 | Water the plants | Vague | A person regularly waters their plants at home. When they got home, this person forgot whether they had already watered all their plants or not, especially those in their bedroom. | - Find all moments where the person waters the plants. - Did they water the plants in the bedroom? |
| 3 | Where are my papers? | Vague | A person prints papers for later use. When it comes to using the papers (after returning home), the person no longer remembers where they put the papers. | - Find the last location of the printed papers. - When did they end up there? |
| 4 | Who won? | Vague | A group of friends gathered one evening for a party where they played games. While reminiscing about the event, they cannot agree on who won. | - Find when the first game ended. - Who won? The person filming or their opponent? |
| 5 | Diet | Vague | A person goes to the doctor and is informed that they have to undergo a low-sugar diet. The person struggles to remember every high-sugar substance they regularly consume. | - Find all moments that show high-sugar food that the person consumes or will consume. |
| 6 | Warmups | Vague | A person particularly enjoys the warmup exercises they performed before climbing. The person would like to reproduce them in another course. | - Find all moments where the group performs warmups before climbing. |
| Consumption in | Video Loading | Model Loading | Video Embeddings | Text/Image Embedding | Inference |
|---|---|---|---|---|---|
| Time | 60 ms | 0.35 s | 55.85 s | 3.503 ms | 0.813 ms |
| Memory | 5.75 MB (RAM) 183 MB (SSD) | 1.18 GB (GRAM) | 2.456 GB (RAM) | 8 MB (RAM) | / |
| Framework | Completion Time (m) | Precision | Recall |
|---|---|---|---|
| Ours | 9.375 | 0.632 | 0.398 |
| Baseline | 9.042 | 0.63 | 0.514 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ablaoui, L.; Marcilio-Jr, W.E.; Ng, L.X.; Jouffrais, C.; Hurter, C. Interactive Content Retrieval in Egocentric Videos Based on Vague Semantic Queries. Multimodal Technol. Interact. 2025, 9, 66. https://doi.org/10.3390/mti9070066
Ablaoui L, Marcilio-Jr WE, Ng LX, Jouffrais C, Hurter C. Interactive Content Retrieval in Egocentric Videos Based on Vague Semantic Queries. Multimodal Technologies and Interaction. 2025; 9(7):66. https://doi.org/10.3390/mti9070066
Chicago/Turabian StyleAblaoui, Linda, Wilson Estecio Marcilio-Jr, Lai Xing Ng, Christophe Jouffrais, and Christophe Hurter. 2025. "Interactive Content Retrieval in Egocentric Videos Based on Vague Semantic Queries" Multimodal Technologies and Interaction 9, no. 7: 66. https://doi.org/10.3390/mti9070066
APA StyleAblaoui, L., Marcilio-Jr, W. E., Ng, L. X., Jouffrais, C., & Hurter, C. (2025). Interactive Content Retrieval in Egocentric Videos Based on Vague Semantic Queries. Multimodal Technologies and Interaction, 9(7), 66. https://doi.org/10.3390/mti9070066