
Semantic Interest Modeling and Content-Based Scientific Publication Recommendation Using Word Embeddings and Sentence Encoders


Abstract
1. Introduction
2. Related Work
2.1. Interest Model Generation
2.2. Content-Based Scientific Publication Recommendation
2.2.1. Item Representation
2.2.2. User Modeling
2.2.3. Recommendation Generation
3. RIMA Application
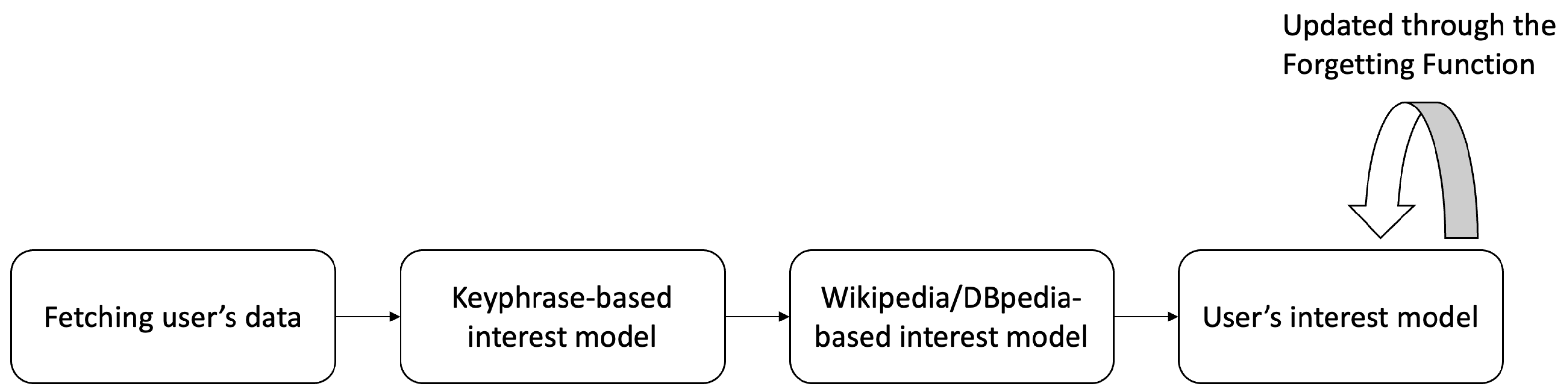
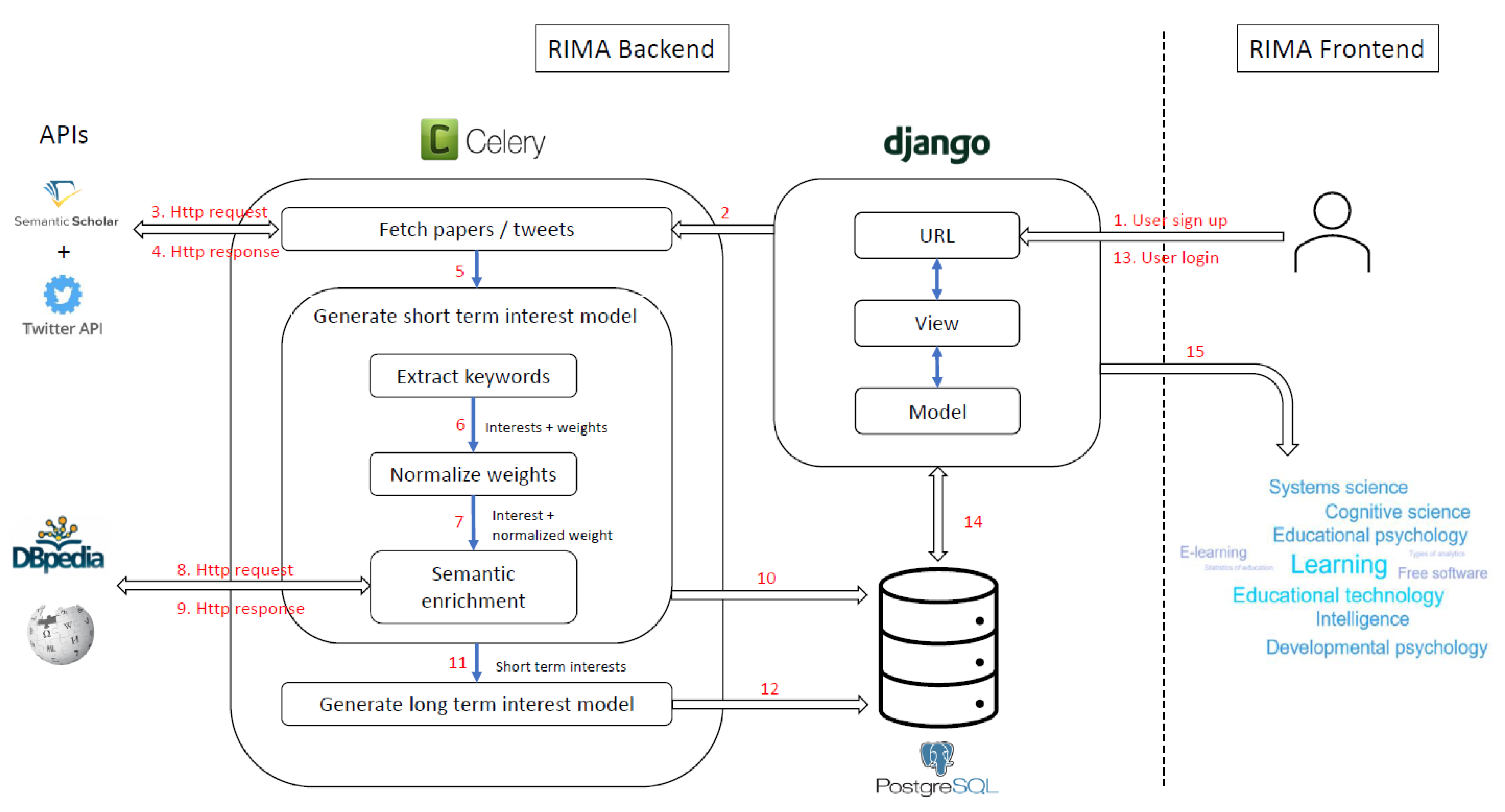
3.1. Interest Model Generation
3.1.1. Conceptual Pipeline
3.1.2. Technical Pipeline
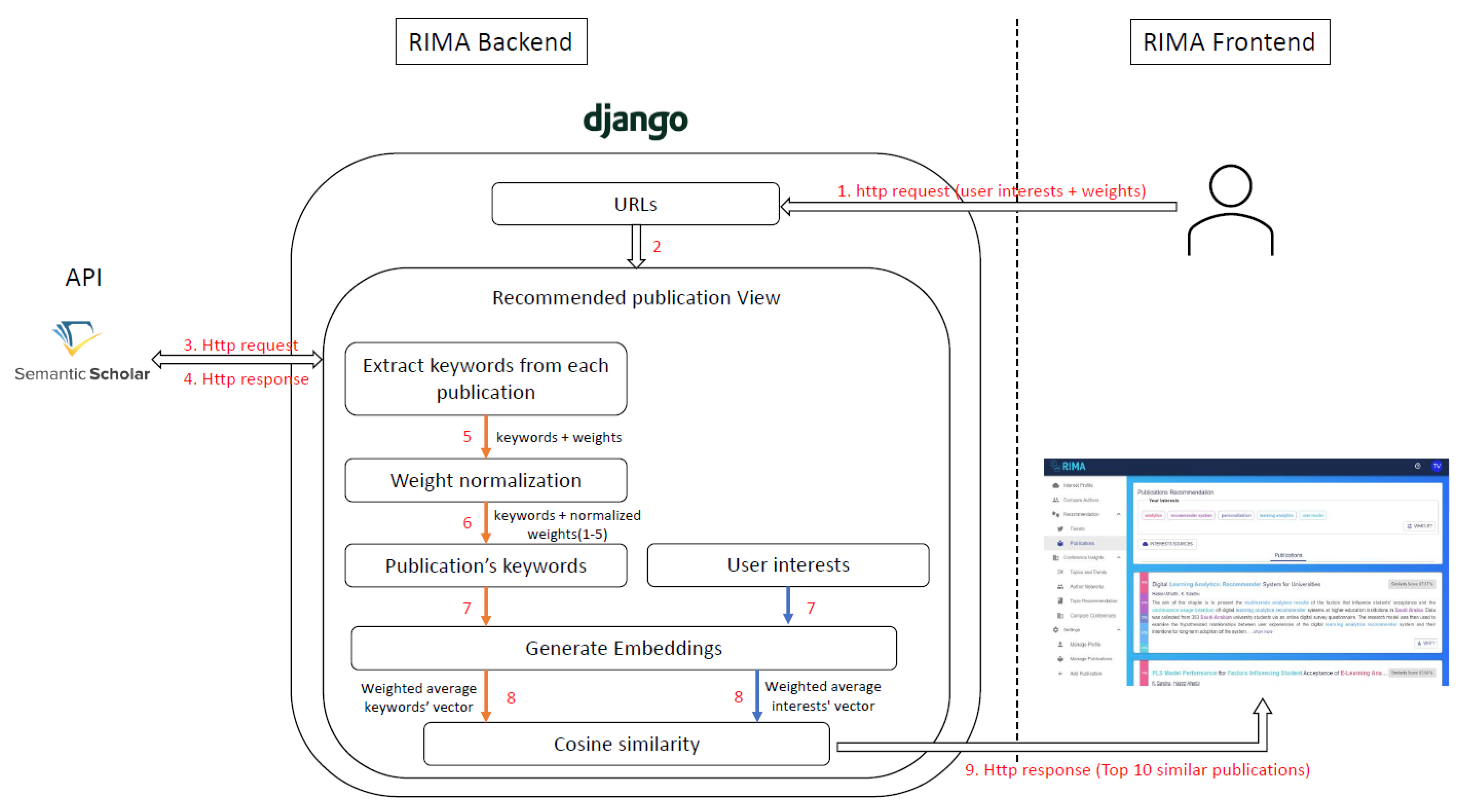
3.2. Recommendation Generation
3.2.1. Conceptual Pipeline
3.2.2. Technical Pipeline
4. Evaluation
4.1. Interest Model Generation
4.1.1. Participants
4.1.2. Procedure
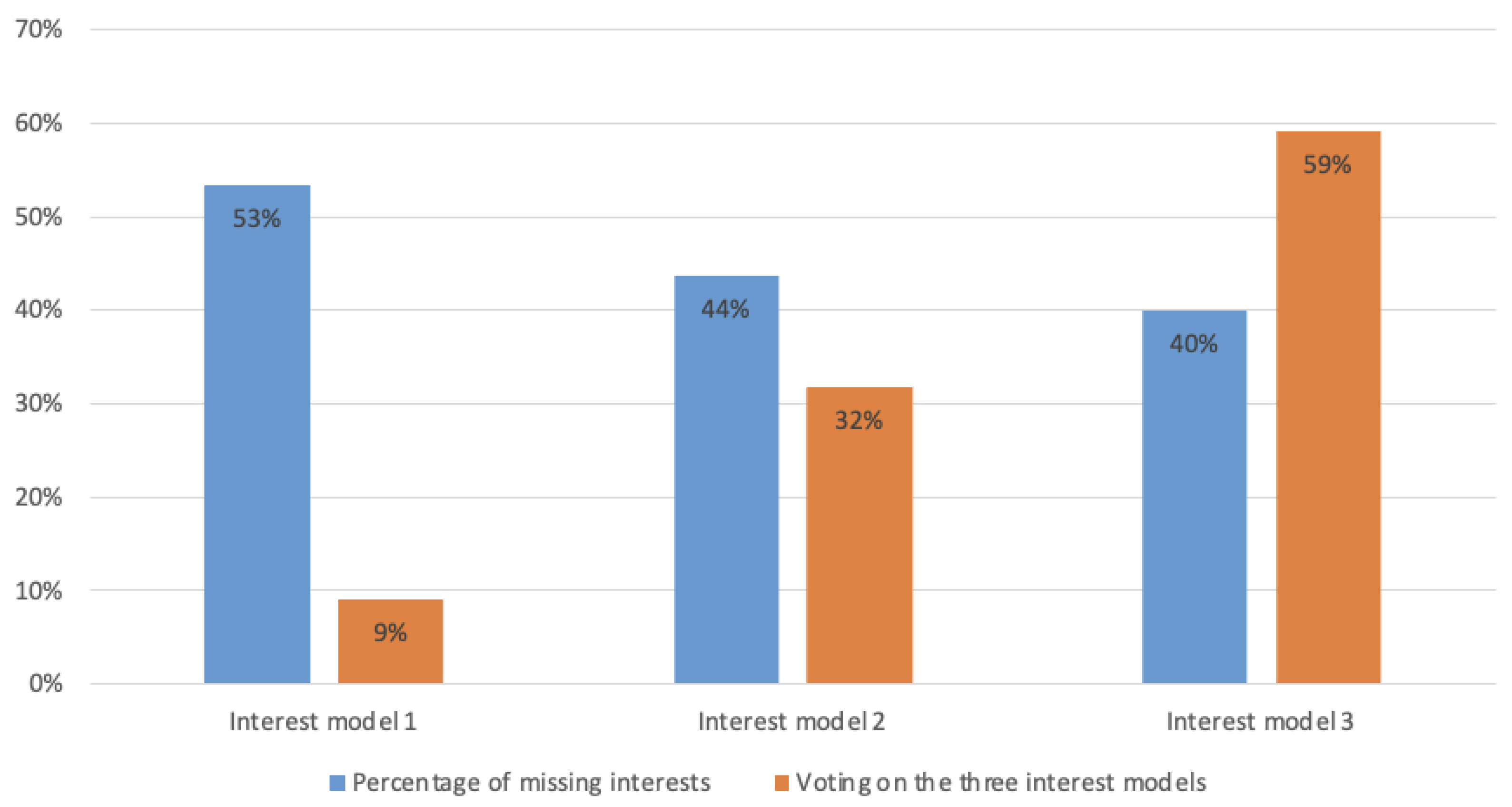
4.1.3. Analysis and Results
4.2. Recommendation Generation
4.2.1. Offline Evaluation
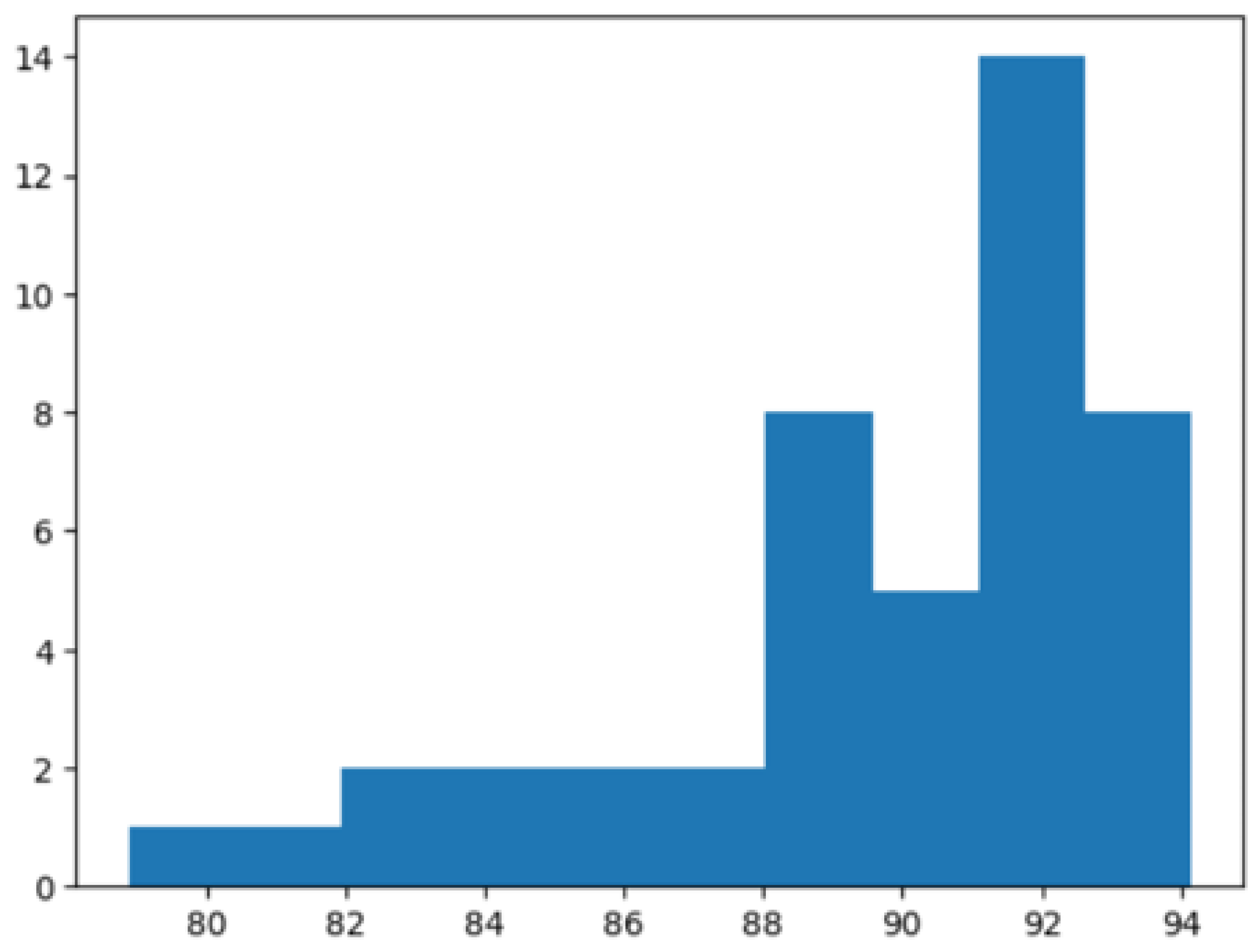
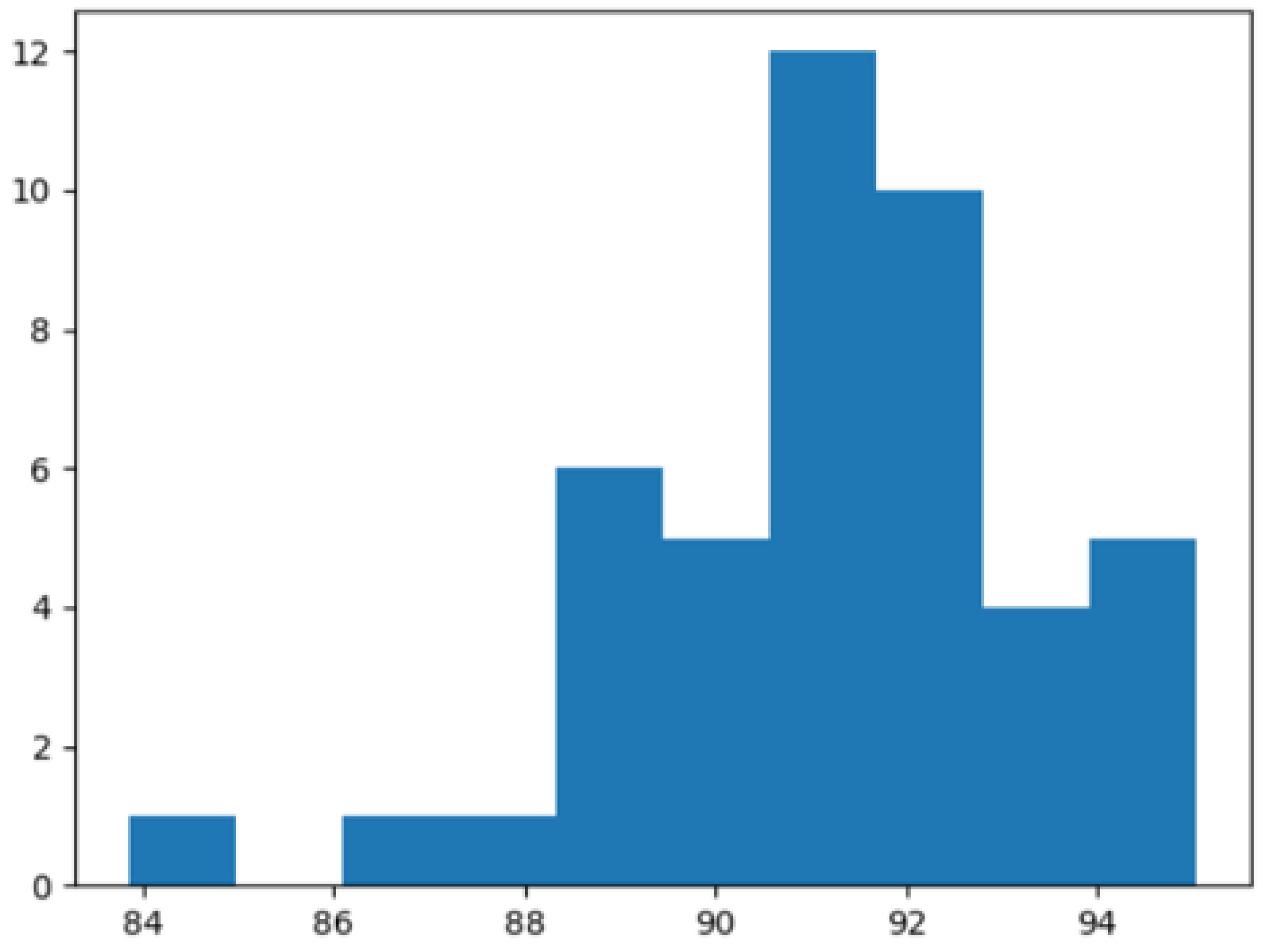
4.2.2. Analysis and Results
4.2.3. Online Evaluation
5. Limitations
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Isinkaye, F.O.; Folajimi, Y.O.; Ojokoh, B.A. Recommendation systems: Principles, methods and evaluation. Egypt. Inform. J. 2015, 16, 261–273. [Google Scholar] [CrossRef]
- Bulut, B.; Gündoğan, E.; Kaya, B.; Alhajj, R.; Kaya, M. User’s Research Interests Based Paper Recommendation System: A Deep Learning Approach. In Putting Social Media and Networking Data in Practice for Education, Planning, Prediction and Recommendation; Kaya, M., Birinci, Ş., Kawash, J., Alhajj, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 117–130. [Google Scholar] [CrossRef]
- Beel, J.; Gipp, B.; Langer, S.; Breitinger, C. Paper recommender systems: A literature survey. Int. J. Digit. Libr. 2016, 17, 305–338. [Google Scholar] [CrossRef]
- Bai, X.; Wang, M.; Lee, I.; Yang, Z.; Kong, X.; Xia, F. Scientific paper recommendation: A survey. IEEE Access 2019, 7, 9324–9339. [Google Scholar] [CrossRef]
- Yue, W.; Wang, Z.; Zhang, J.; Liu, X. An overview of recommendation techniques and their applications in healthcare. IEEE/CAA J. Autom. Sin. 2021, 8, 701–717. [Google Scholar] [CrossRef]
- Kreutz, C.K.; Schenkel, R. Scientific paper recommendation systems: A literature review of recent publications. Int. J. Digit. Libr. 2022, 23, 335–369. [Google Scholar] [CrossRef]
- Chen, T.T.; Lee, M. Research paper recommender systems on big scholarly data. In Proceedings of the Knowledge Management and Acquisition for Intelligent Systems: 15th Pacific Rim Knowledge Acquisition Workshop, PKAW 2018, Nanjing, China, 28–29 August 2018; Springer International Publishing: New York, NY, USA, 2018; Volume 15, pp. 251–260. [Google Scholar]
- Sakib, N.; Ahmad, R.B.; Haruna, K. A Collaborative Approach Toward Scientific Paper Recommendation Using Citation Context. IEEE Access 2020, 8, 51246–51255. [Google Scholar] [CrossRef]
- Hassan, H.A.M. Personalized research paper recommendation using deep learning. In Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization, Taichung City, Taiwan, 13–16 November 2017; pp. 327–330. [Google Scholar]
- Nair, A.M.; Benny, O.; George, J. Content based scientific article recommendation system using deep learning technique. In Proceedings of the Inventive Systems and Control: ICISC, Divnomorskoe, Russia, 5–10 September 2021; Springer: Singapore, 2021; pp. 965–977. [Google Scholar]
- Singh, R.; Gaonkar, G.; Bandre, V.; Sarang, N.; Deshpande, S. Scientific Paper Recommendation System. In Proceedings of the 2023 IEEE 8th International Conference for Convergence in Technology (I2CT), Shanghai, China, 28–30 October 2023; pp. 1–4. [Google Scholar]
- Tanner, W.; Akbas, E.; Hasan, M. Paper recommendation based on citation relation. In Proceedings of the 2019 IEEE International Conference on Big Data, Belgrade, Serbia, 25–27 November 2019; pp. 3053–3059. [Google Scholar]
- Liu, H.; Kou, H.; Yan, C.; Qi, L. Keywords-driven and popularity-aware paper recommendation based on undirected paper citation graph. Complexity 2020, 2020, 817. [Google Scholar] [CrossRef]
- Sinha, A.; Shen, Z.; Song, Y.; Ma, H.; Eide, D.; Hsu, B.J.; Wang, K. An overview of microsoft academic service (mas) and applications. In Proceedings of the 24th International Conference on World Wide Web, Vancouver, BC, Canada, 26–31 May 2015; pp. 243–246. [Google Scholar]
- Beel, J.; Aizawa, A.; Breitinger, C.; Gipp, B. Mr. DLib: Recommendations-as-a-service (RaaS) for academia. In Proceedings of the 2017 ACM/IEEE Joint Conference on Digital Libraries (JCDL), Toronto, ON, Canada, 19–23 June 2017; pp. 1–2. [Google Scholar]
- Mataoui, M.; Sebbak, F.; Sidhoum, A.H.; Harbi, T.E.; Senouci, M.R.; Belmessous, K. A hybrid recommendation system for researchgate academic social network. Soc. Netw. Anal. Min. 2023, 13, 53. [Google Scholar] [CrossRef]
- Gündoğan, E.; Kaya, M. A novel hybrid paper recommendation system using deep learning. Scientometrics 2022, 127, 3837–3855. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Sarma, M.; Samanta, D. SHARE: Designing multiple criteria-based personalized research paper recommendation system. Inf. Sci. 2022, 617, 41–64. [Google Scholar] [CrossRef]
- Mohamed, H.A.I.M. Deep Learning Models for Research Paper Recommender Systems. Ph.D. Thesis, Roma Tre University, Roma, Italy, 2020. [Google Scholar]
- Zhi, L.; Zou, X. A Review on Personalized Academic Paper Recommendation. Comput. Inf. Sci. 2019, 12, 33–43. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2010; pp. 1–35. [Google Scholar]
- Zarrinkalam, F.; Faralli, S.; Piao, G.; Bagheri, E. Extracting, Mining and Predicting Users’ Interests from Social Media. Found. Trends Inf. Retr. 2020, 14, 445–617. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Samanta, D.; Sarma, M. Modeling user behaviour in research paper recommendation system. arXiv 2021, arXiv:2107.07831. [Google Scholar]
- Hassan, H.A.M.; Sansonetti, G.; Gasparetti, F.; Micarelli, A.; Beel, J. Bert, elmo, use and infersent sentence encoders: The panacea for research-paper recommendation? In Proceedings of the RecSys (Late-Breaking Results), Kuching, Malaysia, 19–21 December 2019; pp. 6–10. [Google Scholar]
- Guo, G.; Chen, B.; Zhang, X.; Liu, Z.; Dong, Z.; He, X. Leveraging title-abstract attentive semantics for paper recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Hong Kong, China, 8–11 December 2020; Volume 34, pp. 67–74. [Google Scholar]
- Sun, Y.; Qiu, H.; Zheng, Y.; Wang, Z.; Zhang, C. SIFRank: A New Baseline for Unsupervised Keyphrase Extraction Based on Pre-Trained Language Model. IEEE Access 2020, 8, 10896–10906. [Google Scholar] [CrossRef]
- Iandola, F.N.; Shaw, A.E.; Krishna, R.; Keutzer, K.W. SqueezeBERT: What can computer vision teach NLP about efficient neural networks? arXiv 2020, arXiv:2006.11316. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. DBpedia—A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia. Semant. Web J. 2014, 6, 140134. [Google Scholar] [CrossRef]
- Chatti, M.A.; Ji, F.; Guesmi, M.; Muslim, A.; Singh, R.K.; Joarder, S.A. Simt: A semantic interest modeling toolkit. In Proceedings of the 29th ACM Conference on User Modeling, Adaptation and Personalization, Adjunct Proceedings, Singapore, 22–24 May 2021; pp. 75–78. [Google Scholar]
- Piao, G.; Breslin, J.G. Inferring user interests in microblogging social networks: A survey. User Model. User-Adapt. Interact. 2018, 28, 277–329. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Ning, H. Mining user interest based on personality-aware hybrid filtering in social networks. Knowl.-Based Syst. 2020, 206, 106227. [Google Scholar] [CrossRef]
- Liu, K.; Chen, W.; Bu, J.; Chen, C.; Zhang, L. User modeling for recommendation in blogspace. In Proceedings of the 2007 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology-Workshops, Fukuoka, Japan, 10–15 October 2007; pp. 79–82. [Google Scholar]
- Pratama, B.Y.; Sarno, R. Personality classification based on Twitter text using Naive Bayes, KNN and SVM. In Proceedings of the 2015 International Conference on Data and Software Engineering (ICoDSE), Yogyakarta, Indonesia, 25–26 November 2015; pp. 170–174. [Google Scholar] [CrossRef]
- Stern, M.; Beck, J.; Woolf, B.P. Naive Bayes Classifiers for User Modeling; Center for Knowledge Communication, Computer Science Department, University of Massachusetts: Boston, MA, USA, 1999. [Google Scholar]
- Michelson, M.; Macskassy, S.A. Discovering users’ topics of interest on twitter: A first look. In Proceedings of the Fourth Workshop on Analytics for Noisy Unstructured Text Data, Brisbane, Australia, 14–18 July 2010; pp. 73–80. [Google Scholar]
- Pu, X.; Chatti, M.A.; Schroeder, U.; Pratama, B.Y.; Sarno, R. Wiki-lda: A mixed-method approach for effective interest mining on twitter data. In Proceedings of the 8th International Conference on Computer Supported Education (CSEDU), Singapore, 12–14 May 2016; Scitepress: Rome, Italy, 2016; Volume 1, pp. 426–433. [Google Scholar]
- Caragea, C.; Bulgarov, F.; Godea, A.; Gollapalli, S.D. Citation-enhanced keyphrase extraction from research papers: A supervised approach. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Kuala Lumpur, Malaysia, 27–29 November 2014; pp. 1435–1446. [Google Scholar]
- Bennani-Smires, K.; Musat, C.; Hossmann, A.; Baeriswyl, M.; Jaggi, M. Simple unsupervised keyphrase extraction using sentence embeddings. arXiv 2018, arXiv:1801.04470. [Google Scholar]
- Liu, Z.; Huang, W.; Zheng, Y.; Sun, M. Automatic Keyphrase Extraction via Topic Decomposition. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Wuhan, China, 30 October–1 November 2010; pp. 366–376. [Google Scholar]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic keyword extraction from individual documents. In Text Mining: Applications and Theory; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2010; pp. 1–20. [Google Scholar]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.M.; Nunes, C.; Jatowt, A. Yake! collection-independent automatic keyword extractor. In Proceedings of the Advances in Information Retrieval: 40th European Conference on IR Research, ECIR 2018, Grenoble, France, 26–29 March 2018; Springer: Cham, Germany, 2018; Volume 40, pp. 806–810. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 21–23 May 2004; pp. 404–411. [Google Scholar]
- Wan, X.; Xiao, J. CollabRank: Towards a Collaborative Approach to Single-Document Keyphrase Extraction. In Proceedings of the COLING, Manchester, UK, 18–22 August 2008. [Google Scholar]
- Wan, X.; Xiao, J. Single Document Keyphrase Extraction Using Neighborhood Knowledge. In Proceedings of the 23rd National Conference on Artificial Intelligence, AAAI’08, Santa Clara, CA, USA, 13 July 2008; AAAI Press: Chicago, IL, USA, 2008; Volume 2, pp. 855–860. [Google Scholar]
- Florescu, C.; Caragea, C. PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 1–4 July 2017; Volume 1, pp. 1105–1115. [Google Scholar] [CrossRef]
- Bougouin, A.; Boudin, F.; Daille, B. Topicrank: Graph-based topic ranking for keyphrase extraction. In Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP), Cluj-Napoca, Romania, 28–30 October 2013; pp. 543–551. [Google Scholar]
- Boudin, F. Unsupervised keyphrase extraction with multipartite graphs. arXiv 2018, arXiv:1803.08721. [Google Scholar]
- Manrique, R.; Herazo, O.; Mariño, O. Exploring the use of linked open data for user research interest modeling. In Proceedings of the Advances in Computing: 12th Colombian Conference, CCC 2017, Cali, Colombia, 19–22 September 2017; Springer: Cham, Germany, 2017; Volume 12, pp. 3–16. [Google Scholar]
- Liang, Y.; Zaki, M.J. Keyphrase Extraction Using Neighborhood Knowledge Based on Word Embeddings. arXiv 2021, arXiv:2111.07198v1. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, PMLR, Xi’an, China, 5 November 2014; pp. 1188–1196. [Google Scholar]
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised Learning of Sentence Embeddings Using Compositional n-Gram Features. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New York, NY, USA, 1–6 June 2018; Volume 1. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 4–8 May 2018; Volume 1, pp. 2227–2237. [Google Scholar] [CrossRef]
- Arora, S.; Liang, Y.; Ma, T. A Simple but Tough-to-Beat Baseline for Sentence Embeddings. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Di Tommaso, G.; Faralli, S.; Stilo, G.; Velardi, P. Wiki-MID: A very large multi-domain interests dataset of Twitter users with mappings to Wikipedia. In Proceedings of the The Semantic Web–ISWC 2018: 17th International Semantic Web Conference, Monterey, CA, USA, 8–12 October 2018; Springer: Cham, Germany, 2018; Volume 17, pp. 36–52. [Google Scholar]
- Narducci, F.; Musto, C.; Semeraro, G.; Lops, P.; De Gemmis, M. Leveraging encyclopedic knowledge for transparent and serendipitous user profiles. In Proceedings of the International Conference on User Modeling, Adaptation, and Personalization, Atlantic City, NJ, USA, 24–27 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 350–352. [Google Scholar]
- Jadhav, A.S.; Purohit, H.; Kapanipathi, P.; Anantharam, P.; Ranabahu, A.H.; Nguyen, V.; Mendes, P.N.; Smith, A.G.; Cooney, M.; Sheth, A.P. Twitris 2.0: Semantically Empowered System for Understanding Perceptions from Social Data. 2010. Available online: https://corescholar.libraries.wright.edu/cgi/viewcontent.cgi?article=1253&context=knoesis (accessed on 3 April 2023).
- Jean-Louis, L.; Gagnon, M.; Charton, E. A knowledge-base oriented approach for automatic keyword extraction. Comput. Sist. 2013, 17, 187–196. [Google Scholar]
- Lu, C.; Lam, W.; Zhang, Y. Twitter user modeling and tweets recommendation based on wikipedia concept graph. In Proceedings of the Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence, Shanghai, China, 4–6 December 2012. [Google Scholar]
- Xu, T.; Oard, D.W. Wikipedia-based topic clustering for microblogs. Proc. Am. Soc. Inf. Sci. Technol. 2011, 48, 1–10. [Google Scholar] [CrossRef]
- Besel, C.; Schlötterer, J.; Granitzer, M. On the quality of semantic interest profiles for onine social network consumers. ACM SIGAPP Appl. Comput. Rev. 2016, 16, 5–14. [Google Scholar] [CrossRef]
- Piao, G.; Breslin, J.G. User modeling on Twitter with WordNet Synsets and DBpedia concepts for personalized recommendations. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 2057–2060. [Google Scholar]
- Piao, G.; Breslin, J.G. Analyzing aggregated semantics-enabled user modeling on Google+ and Twitter for personalized link recommendations. In Proceedings of the 2016 Conference on User Modeling Adaptation and Personalization, Phoenix, AZ, USA, 25–28 September 2016; pp. 105–109. [Google Scholar]
- Piao, G.; Breslin, J.G. Exploring dynamics and semantics of user interests for user modeling on Twitter for link recommendations. In Proceedings of the 12th International Conference on Semantic Systems, Singapore, 20–22 August 2016; pp. 81–88. [Google Scholar]
- Degemmis, M.; Lops, P.; Semeraro, G. A content-collaborative recommender that exploits WordNet-based user profiles for neighborhood formation. User Model. User-Adapt. Interact. 2007, 17, 217–255. [Google Scholar] [CrossRef]
- Lops, P.; de Gemmis, M.; Semeraro, G.; Musto, C.; Narducci, F.; Bux, M. A semantic content-based recommender system integrating folksonomies for personalized access. In Web Personalization in Intelligent Environments; Springer: Berlin/Heidelberg, Germany, 2009; pp. 27–47. [Google Scholar]
- Abel, F.; Herder, E.; Houben, G.J.; Henze, N.; Krause, D. Cross-system user modeling and personalization on the social web. User Model. User-Adapt. Interact. 2013, 23, 169–209. [Google Scholar] [CrossRef]
- Yu, X.; Ma, H.; Hsu, B.J.; Han, J. On building entity recommender systems using user click log and freebase knowledge. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, Warsaw, Poland, 11–14 August 2014; pp. 263–272. [Google Scholar]
- Manrique, R.; Mariño, O. How does the size of a document affect linked open data user modeling strategies? In Proceedings of the International Conference on Web Intelligence, Poznan, Poland, 21–23 June 2017; pp. 1246–1252. [Google Scholar]
- Abel, F.; Hauff, C.; Houben, G.J.; Tao, K. Leveraging user modeling on the social web with linked data. In Proceedings of the Web Engineering: 12th International Conference, ICWE 2012, Berlin, Germany, 23–27 July 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 12, pp. 378–385. [Google Scholar]
- Shen, W.; Wang, J.; Luo, P.; Wang, M. Linking named entities in tweets with knowledge base via user interest modeling. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Fuzhou, China, 8–10 July 2013; pp. 68–76. [Google Scholar]
- Renuka, S.; Raj Kiran, G.; Rohit, P. An unsupervised content-based article recommendation system using natural language processing. In Proceedings of the Data Intelligence and Cognitive Informatics ICDICI, Kyoto, Japan, 22–24 August 2020; Springer: Singapore, 2021; pp. 165–180. [Google Scholar]
- Subathra, P.; Kumar, P. Recommending research article based on user queries using latent dirichlet allocation. In Proceedings of the 2nd ICSCSP Soft Computing and Signal Processing, Alcala de Henares, Spain, 3–5 October 2019; Springer: Singapore, 2020; pp. 163–175. [Google Scholar]
- Tao, M.; Yang, X.; Gu, G.; Li, B. Paper recommend based on LDA and PageRank. In Proceedings of the Artificial Intelligence and Security: 6th International Conference, ICAIS 2020, Hohhot, China, 17–20 July 2020; Springer: Singapore, 2020; Volume 6, pp. 571–584. [Google Scholar]
- Collins, A.; Beel, J. Document embeddings vs. keyphrases vs. terms for recommender systems: A large-scale online evaluation. In Proceedings of the 2019 ACM/IEEE Joint Conference on Digital Libraries (JCDL), Chapel Hill, NC, USA, 11–15 June 2019; pp. 130–133. [Google Scholar]
- Zhao, X.; Kang, H.; Feng, T.; Meng, C.; Nie, Z. A hybrid model based on LFM and BiGRU toward research paper recommendation. IEEE Access 2020, 8, 188628–188640. [Google Scholar] [CrossRef]
- Ali, Z.; Qi, G.; Muhammad, K.; Ali, B.; Abro, W.A. Paper recommendation based on heterogeneous network embedding. Knowl.-Based Syst. 2020, 210, 106438. [Google Scholar] [CrossRef]
- Bereczki, M. Graph neural networks for article recommendation based on implicit user feedback and content. arXiv 2021. [Google Scholar] [CrossRef]
- Rios, F.; Rizzo, P.; Puddu, F.; Romeo, F.; Lentini, A.; Asaro, G.; Rescalli, F.; Bolchini, C.; Cremonesi, P. Recommending Relevant Papers to Conference Participants: A Deep Learning Driven Content-based Approach. In Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization, Adjunct Proceedings, Omaha, NE, USA, 13–16 October 2022; pp. 52–57. [Google Scholar]
- Ferrara, F.; Pudota, N.; Tasso, C. A keyphrase-based paper recommender system. In Proceedings of the Digital Libraries and Archives: 7th Italian Research Conference, IRCDL 2011, Pisa, Italy, 20–21 January 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 14–25. [Google Scholar]
- Chaudhuri, A.; Sinhababu, N.; Sarma, M.; Samanta, D. Hidden features identification for designing an efficient research article recommendation system. Int. J. Digit. Libr. 2021, 22, 233–249. [Google Scholar] [CrossRef]
- Hong, K.; Jeon, H.; Jeon, C. UserProfile-based personalized research paper recommendation system. In Proceedings of the 2012 8th International Conference on Computing and Networking Technology (INC, ICCIS and ICMIC), Shanghai, China, 21–23 September 2012; pp. 134–138. [Google Scholar]
- Hong, K.; Jeon, H.; Jeon, C. Personalized research paper recommendation system using keyword extraction based on UserProfile. J. Converg. Inf. Technol. 2013, 8, 106. [Google Scholar]
- Gautam, J.; Kumar, E. An improved framework for tag-based academic information sharing and recommendation system. In Proceedings of the World Congress on Engineering, Wuhan, China, 19–20 December 2012; Volume 2, pp. 1–6. [Google Scholar]
- Beel, J.; Langer, S.; Genzmehr, M.; Nürnberger, A. Introducing Docear’s research paper recommender system. In Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries, Cologne, Germany, 20–24 June 2013; pp. 459–460. [Google Scholar]
- Beel, J.; Langer, S.; Gipp, B.; Nürnberger, A. The Architecture and Datasets of Docear’s Research Paper Recommender System. D-Lib Mag. 2014, 20, 1045. [Google Scholar] [CrossRef][Green Version]
- Jomsri, P.; Sanguansintukul, S.; Choochaiwattana, W. A framework for tag-based research paper recommender system: An IR approach. In Proceedings of the 2010 IEEE 24th International Conference on Advanced Information Networking and Applications Workshops, Perth, WA, Australia, 20–23 April 2010; pp. 103–108. [Google Scholar]
- Al Alshaikh, M.; Uchyigit, G.; Evans, R. A research paper recommender system using a Dynamic Normalized Tree of Concepts model for user modelling. In Proceedings of the 2017 11th International Conference on Research Challenges in Information Science (RCIS), Auckland, New Zealand, 24–27 October 2017; pp. 200–210. [Google Scholar]
- Lee, J.; Lee, K.; Kim, J.G. Personalized academic research paper recommendation system. arXiv 2013, arXiv:1304.5457. [Google Scholar]
- Sugiyama, K.; Kan, M.Y. Scholarly paper recommendation via user’s recent research interests. In Proceedings of the 10th Annual Joint Conference on Digital Libraries, Houston, TX, USA, 23–26 October 2010; pp. 29–38. [Google Scholar]
- Nishioka, C.; Hauke, J.; Scherp, A. Influence of tweets and diversification on serendipitous research paper recommender systems. PeerJ Comput. Sci. 2020, 6, e273. [Google Scholar] [CrossRef] [PubMed]
- Nishioka, C.; Hauke, J.; Scherp, A. Research paper recommender system with serendipity using tweets vs. diversification. In Proceedings of the Digital Libraries at the Crossroads of Digital Information for the Future: 21st International Conference on Asia-Pacific Digital Libraries, ICADL 2019, Kuala Lumpur, Malaysia, 4–7 November 2019; Springer: Cham, Germany, 2019; Volume 21, pp. 63–70. [Google Scholar]
- Nishioka, C.; Hauk, J.; Scherp, A. Towards serendipitous research paper recommender using tweets and diversification. In Proceedings of the Digital Libraries for Open Knowledge: 23rd International Conference on Theory and Practice of Digital Libraries, TPDL 2019, Oslo, Norway, 9–12 September 2019; Springer: Cham, Germany, 2019; Volume 23, pp. 339–343. [Google Scholar]
- Bulut, B.; Kaya, B.; Alhajj, R.; Kaya, M. A paper recommendation system based on user’s research interests. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2018; pp. 911–915. [Google Scholar]
- Bulut, B.; Kaya, B.; Kaya, M. A Paper Recommendation System Based on User Interest and Citations. In Proceedings of the 2019 1st International Informatics and Software Engineering Conference (UBMYK), Ankara, Turkey, 6–7 November 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, J.; Ban, Z. Academic paper recommendation based on clustering and pattern matching. In Proceedings of the Artificial Intelligence: Second CCF International Conference, ICAI 2019, Xuzhou, China, 22–23 August 2019; Springer: Singapore, 2019; Volume 2, pp. 171–182. [Google Scholar]
- Amami, M.; Pasi, G.; Stella, F.; Faiz, R. An LDA-Based Approach to Scientific Paper Recommendation. In Proceedings of the International Conference on Applications of Natural Language to Data Bases, Boston, MA, USA, 11–14 December 2016. [Google Scholar]
- Lin, S.J.; Lee, G.; Peng, S.L. Academic article recommendation by considering the research field trajectory. In Proceedings of the International Conference on Innovative Computing and Cutting-Edge Technologies, Uttarakhand, India, 14–16 March 2020; Springer: Cham, Germany, 2020; pp. 447–454. [Google Scholar]
- Philip, S.; Shola, P.; Ovye, A. Application of content-based approach in research paper recommendation system for a digital library. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 051006. [Google Scholar] [CrossRef]
- Nascimento, C.; Laender, A.H.; da Silva, A.S.; Gonçalves, M.A. A source independent framework for research paper recommendation. In Proceedings of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries, Toronto, ON, Canada, 19 May 2011; pp. 297–306. [Google Scholar]
- Hanyurwimfura, D.; Bo, L.; Havyarimana, V.; Njagi, D.; Kagorora, F. An effective academic research papers recommendation for non-profiled users. Int. J. Hybrid Inf. Technol. 2015, 8, 255–272. [Google Scholar] [CrossRef]
- Guesmi, M.; Chatti, M.A.; Sun, Y.; Zumor, S.; Ji, F.; Muslim, A.; Vorgerd, L.; Joarder, S.A. Open, Scrutable and Explainable Interest Models for Transparent Recommendation. In Proceedings of the IUI Workshops, Rome, Italy, 15–18 June 2021. [Google Scholar]
- Guesmi, M.; Chatti, M.A.; Vorgerd, L.; Joarder, S.; Zumor, S.; Sun, Y.; Ji, F.; Muslim, A. On-demand personalized explanation for transparent recommendation. In Proceedings of the Adjunct Proceedings of the 29th ACM Conference on User Modeling, Adaptation and Personalization, Uxbridge, UK, 17–18 December 2021; pp. 246–252.
- Guesmi, M.; Chatti, M.A.; Vorgerd, L.; Joarder, S.A.; Ain, Q.U.; Ngo, T.; Zumor, S.; Sun, Y.; Ji, F.; Muslim, A. Input or Output: Effects of Explanation Focus on the Perception of Explainable Recommendation with Varying Level of Details. In Proceedings of the IntRS@ RecSys, Amsterdam, The Netherlands, 27 September–1 October 2021; pp. 55–72. [Google Scholar]
- Guesmi, M.; Chatti, M.A.; Ghorbani-Bavani, J.; Joarder, S.; Ain, Q.U.; Alatrash, R. What if Interactive Explanation in a Scientific Literature Recommender System. arXiv 2022. [Google Scholar] [CrossRef]
- Chatti, M.A.; Guesmi, M.; Vorgerd, L.; Ngo, T.; Joarder, S.; Ain, Q.U.; Muslim, A. Is More Always Better? The Effects of Personal Characteristics and Level of Detail on the Perception of Explanations in a Recommender System. In Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization, Nanjing, China, 27–29 June 2022; pp. 254–264. [Google Scholar]
- Guesmi, M.; Chatti, M.A.; Vorgerd, L.; Ngo, T.; Joarder, S.; Ain, Q.U.; Muslim, A. Explaining User Models with Different Levels of Detail for Transparent Recommendation: A User Study. In Proceedings of the Adjunct Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization, Turin, Italy, 4–8 July 2022; pp. 175–183.
- Guesmi, M.; Chatti, M.A.; Tayyar, A.; Ain, Q.U.; Joarder, S. Interactive visualizations of transparent user models for self-actualization: A human-centered design approach. Multimodal Technol. Interact. 2022, 6, 42. [Google Scholar] [CrossRef]
- Guesmi, M.; Chatti, M.A.; Joarder, S.; Ain, Q.U.; Siepmann, C.; Ghanbarzadeh, H.; Alatrash, R. Justification vs. Transparency: Why and How Visual Explanations in a Scientific Literature Recommender System. Information 2023, 14, 401. [Google Scholar] [CrossRef]
- Guesmi, M.; Siepmann, C.; Chatti, M.A.; Joarder, S.; Ain, Q.U.; Alatrash, R. Validation of the EDUSS Framework for Self-Actualization Based on Transparent User Models: A Qualitative Study. In Proceedings of the Adjunct Proceedings of the 31st ACM Conference on User Modeling, Adaptation and Personalization, London, UK, 3–6 December 2023; pp. 229–238. [Google Scholar]
- Bougouin, A.; Boudin, F.; Daille, B. TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction. In Proceedings of the IJCNLP, Nagoya, Japan, 14–18 October 2013. [Google Scholar]
- Jardine, J.G.; Teufel, S. Topical PageRank: A Model of Scientific Expertise for Bibliographic Search. In Proceedings of the EACL, Gothenburg, Sweden, 26–30 April 2014. [Google Scholar]
- Boudin, F. Unsupervised Keyphrase Extraction with Multipartite Graphs. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 3–10 June 2018; pp. 667–672. [Google Scholar] [CrossRef]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.M.; Nunes, C.; Jatowt, A. YAKE! Keyword extraction from single documents using multiple local features. Inf. Sci. 2020, 509, 257–289. [Google Scholar] [CrossRef]
- Hulth, A. Improved automatic keyword extraction given more linguistic knowledge. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Sapporo, Japan, 11–12 July 2003; pp. 216–223. [Google Scholar]
- Yu, P.; Wang, X. BERT-Based Named Entity Recognition in Chinese Twenty-Four Histories. In Proceedings of the International Conference on Web Information Systems and Applications, Cham, Switzerland, 16 August 2020; pp. 289–301. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 866. [Google Scholar]
- Mendes, P.; Jakob, M.; García-Silva, A.; Bizer, C. DBpedia spotlight: Shedding light on the web of documents. In Proceedings of the 7th International Conference on Semantic Systems, New York, NY, USA, 2–9 September 2011; pp. 1–8. [Google Scholar] [CrossRef]
- Cheng, Y.; Qiu, G.; Bu, J.; Liu, K.; Han, Y.; Wang, C.; Chen, C. Model bloggers’ interests based on forgetting mechanism. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 1129–1130. [Google Scholar]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised learning of universal sentence representations from natural language inference data. arXiv 2017, arXiv:1705.02364. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A pretrained language model for scientific text. arXiv 2019, arXiv:1903.10676. [Google Scholar]
- Hill, F.; Reichart, R.; Korhonen, A. SimLex-999: Evaluating Semantic Models with (Genuine) Similarity Estimation. Comput. Linguist. 2015, 41, 665–695. [Google Scholar] [CrossRef]
- Asaadi, S.; Mohammad, S.; Kiritchenko, S. Big BiRD: A large, fine-grained, bigram relatedness dataset for examining semantic composition. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MI, USA, 4–8 June 2019; Volume 1, pp. 505–516. [Google Scholar]
- Cer, D.; Diab, M.; Agirre, E.; Lopez-Gazpio, I.; Specia, L. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv 2017, arXiv:1708.00055. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | K = 5 | K = 10 | K = 15 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | P | R | F | |
| TextRank | 18.15 | 7.10 | 9.79 | 16.15 | 9.58 | 11.51 | 14.88 | 10.15 | 11.48 |
| SingleRank | 30.96 | 13.60 | 17.99 | 26.95 | 22.04 | 23.02 | 23.57 | 27.01 | 24.03 |
| TopicRank | 26.97 | 11.52 | 15.38 | 21.86 | 17.31 | 18.41 | 19.53 | 21.24 | 19.51 |
| TopicalPageRank | 30.36 | 13.37 | 17.67 | 26.31 | 21.44 | 22.47 | 23.34 | 26.43 | 23.69 |
| PositionRank | 32.12 | 13.82 | 18.38 | 25.45 | 20.79 | 21.77 | 22.79 | 25.80 | 23.15 |
| MultipartitieRank | 28.60 | 12.11 | 16.20 | 21.99 | 17.83 | 18.70 | 19.76 | 22.75 | 20.20 |
| Rake | 20.02 | 9.13 | 11.87 | 21.54 | 18.27 | 18.75 | 18.42 | 21.57 | 18.97 |
| YAKE! | 24.80 | 11.14 | 14.59 | 20.32 | 17.70 | 17.88 | 17.86 | 22.78 | 18.96 |
| Percentage Improvement (%) | - | - | - | 2.4 | 2.7 | 2.4 | 0.9 | 2.1 | 1.4 |
| Precision@k | MRR | MAP | |
|---|---|---|---|
| Interest model 1 (SingleRank + Wikipedia) | 0.62 | 0.64 | 0.65 |
| Interest model 2 ( + Wikipedia) | 0.69 | 0.86 | 0.78 |
| Interest model 3 ( + DBpedia) | 0.73 | 0.81 | 0.78 |
| Models | SimLex999 | BiRD | STS | |||
|---|---|---|---|---|---|---|
| Pearson Correlation | Time | Pearson Correlation | Time | Pearson Correlation | Time | |
| USE | 0.51 | 396 ms | 0.61 | 2.27 s | 0.78 | 1.12 s |
| SciBERT | 0.07 | 33.7 s | 0.45 | 2 min 10 s | 0.44 | 2 min 59 s |
| all-mpnet-base-v2 | 0.54 | 34.1 s | 0.67 | 1 min 52 s | 0.84 | 2 min 52 s |
| all-distilroberta-v1 | 0.31 | 26.1 s | 0.63 | 1 min 9 s | 0.83 | 1 min 23 s |
| all-MiniLM-L12-v2 | 0.51 | 14.9 s | 0.64 | 36.8 s | 0.83 | 51.3 s |
| msmarco-distilbert-base-tas-b | 0.55 | 25.1 s | 0.59 | 1 min 16 s | 0.79 | 1 min 23 s |
| Model | Time | Similarity Scores |
|---|---|---|
| USE | 24 s | 62–53% |
| SciBERT | 1 m 8 s | 95–80% |
| all-mpnet-base-v2 | 1 m 11 s | 76–40% |
| all-distilroberta-v1 | 56 s | 80–41% |
| all-MiniLM-L12-v2 | 45 s | 81–41% |
| msmarco-distilbert-base-tas-b | 47 s | 95–81% |
| Model | Time | Similarity Scores |
|---|---|---|
| USE | 3 s | 59–53% |
| SciBERT | 24 s | 72–53% |
| all-mpnet-base-v2 | 22 s | 70–41% |
| all-distilroberta-v1 | 13 s | 66–40% |
| all-MiniLM-L12-v2 | 6 s | 71–41% |
| msmarco-distilbert-base-tas-b | 12 s | 89–70% |
| Precision@k | MRR | MAP | Voting on the Better List | |
|---|---|---|---|---|
| Recommendation list 1 (Our approach) | 0.42 | 0.72 | 0.60 | 63% |
| Recommendation list 2 (Semantic Scholar) | 0.39 | 0.63 | 0.58 | 38% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guesmi, M.; Chatti, M.A.; Kadhim, L.; Joarder, S.; Ain, Q.U. Semantic Interest Modeling and Content-Based Scientific Publication Recommendation Using Word Embeddings and Sentence Encoders. Multimodal Technol. Interact. 2023, 7, 91. https://doi.org/10.3390/mti7090091
Guesmi M, Chatti MA, Kadhim L, Joarder S, Ain QU. Semantic Interest Modeling and Content-Based Scientific Publication Recommendation Using Word Embeddings and Sentence Encoders. Multimodal Technologies and Interaction. 2023; 7(9):91. https://doi.org/10.3390/mti7090091
Chicago/Turabian StyleGuesmi, Mouadh, Mohamed Amine Chatti, Lamees Kadhim, Shoeb Joarder, and Qurat Ul Ain. 2023. "Semantic Interest Modeling and Content-Based Scientific Publication Recommendation Using Word Embeddings and Sentence Encoders" Multimodal Technologies and Interaction 7, no. 9: 91. https://doi.org/10.3390/mti7090091
APA StyleGuesmi, M., Chatti, M. A., Kadhim, L., Joarder, S., & Ain, Q. U. (2023). Semantic Interest Modeling and Content-Based Scientific Publication Recommendation Using Word Embeddings and Sentence Encoders. Multimodal Technologies and Interaction, 7(9), 91. https://doi.org/10.3390/mti7090091