
Is Natural Necessary? Human Voice versus Synthetic Voice for Intelligent Virtual Agents



Abstract
:1. Introduction
2. Related Work
2.1. Anthropomorphism and Co-Presence
2.2. Anthropomorphism and Congruence
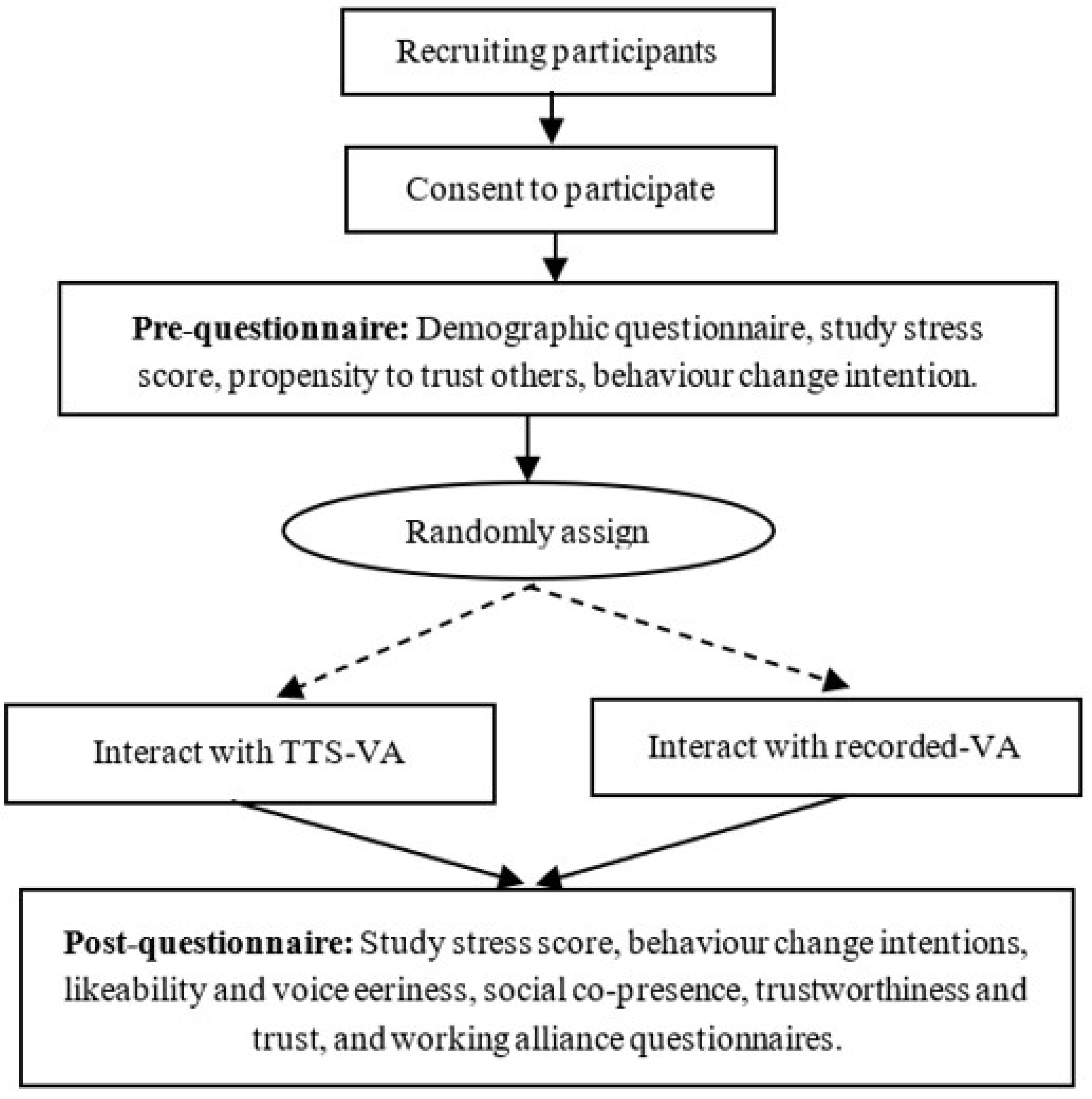
3. Methodology
3.1. Study Design and Materials
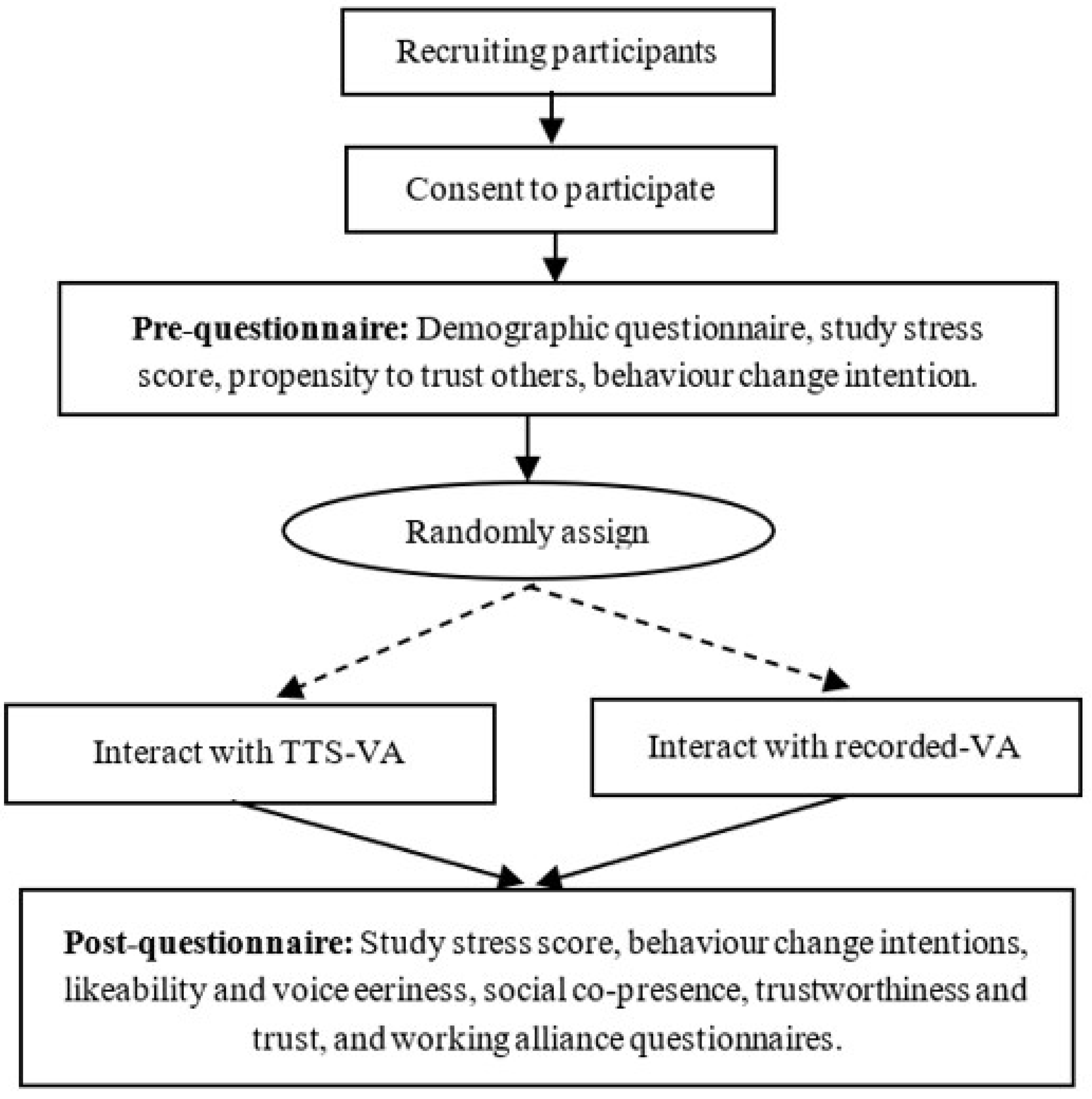
3.2. Recruitment, Instruments, and Procedure
4. Results
4.1. Study-Related Stress
4.2. Social Co-Presence
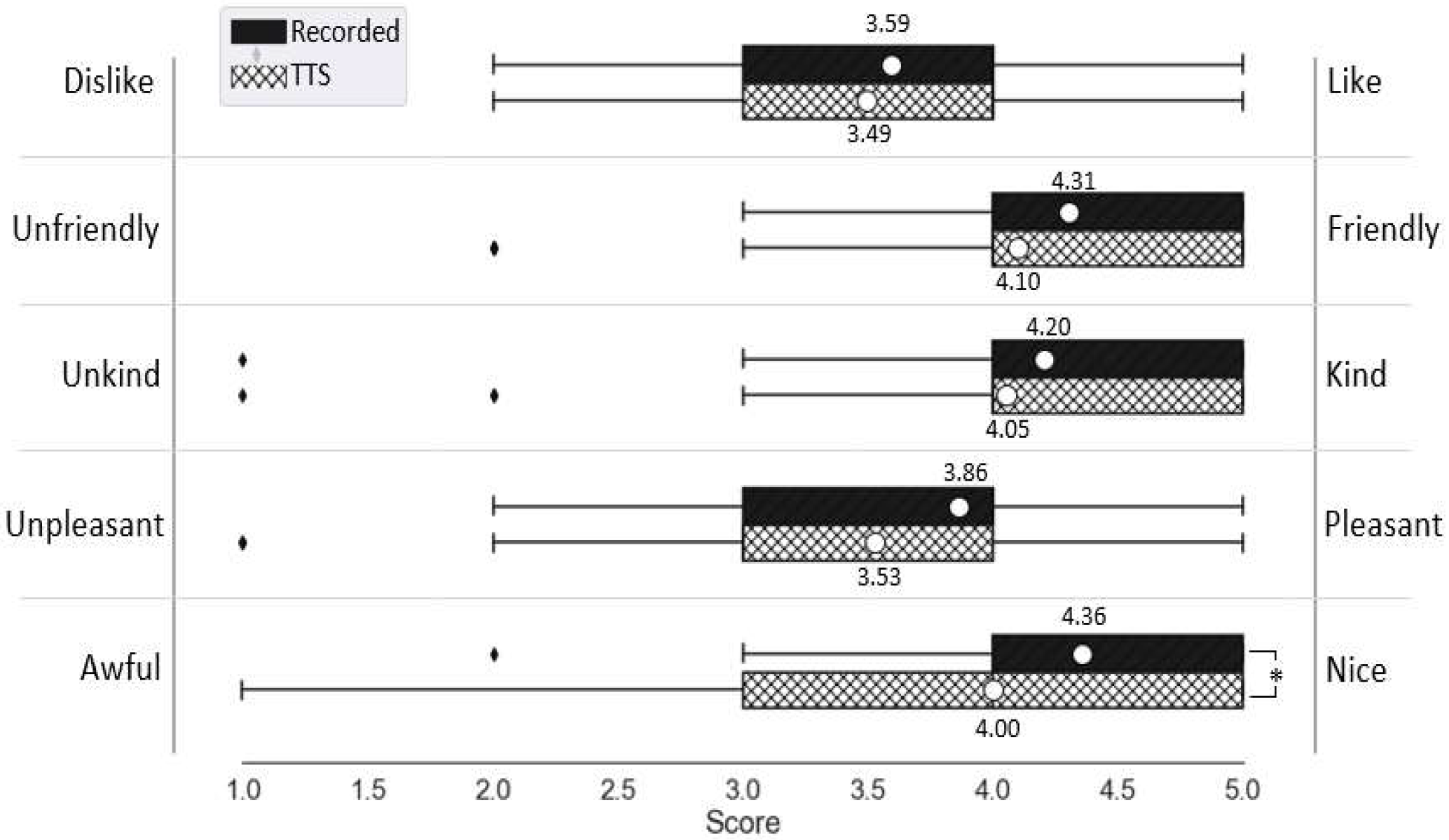
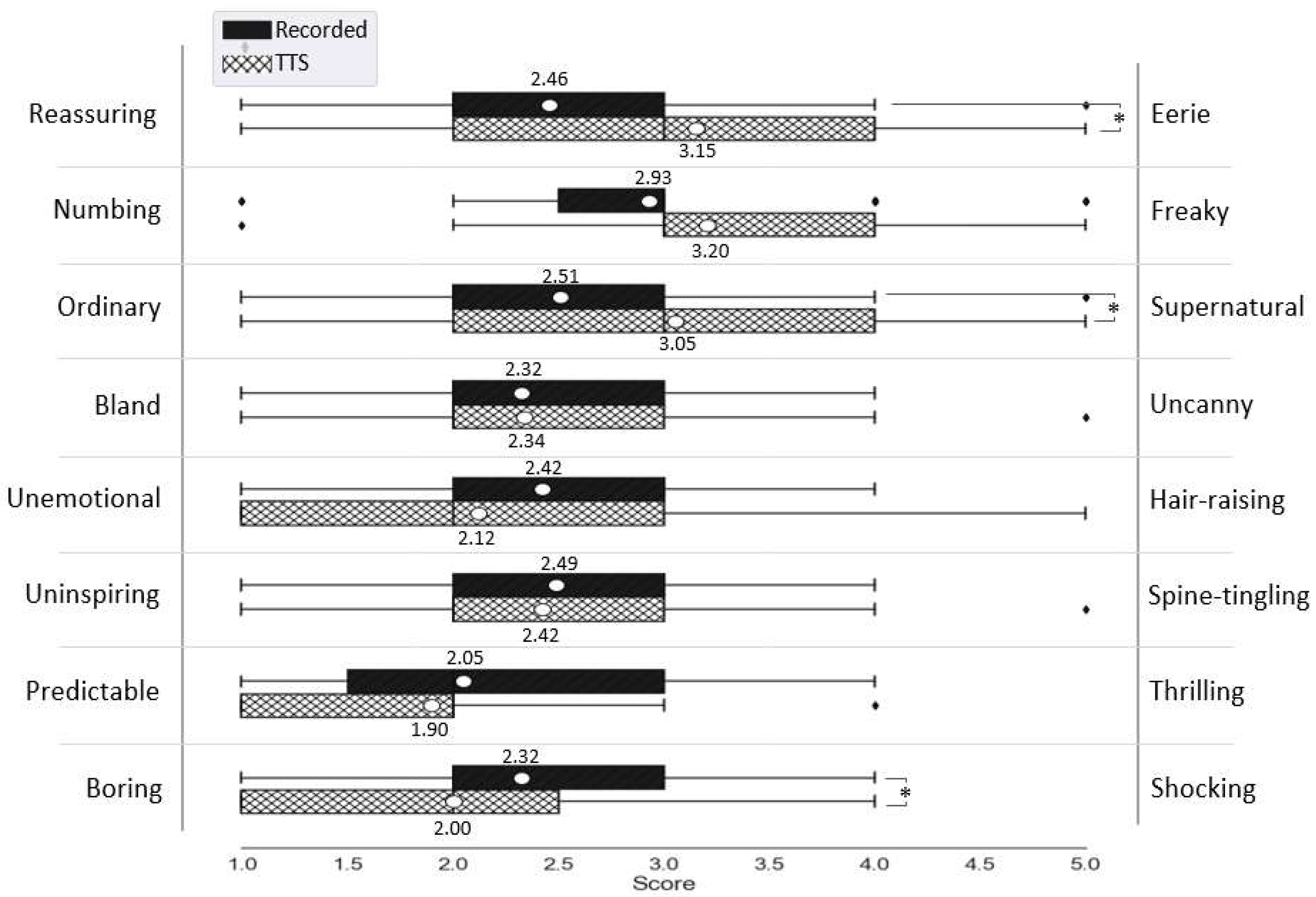
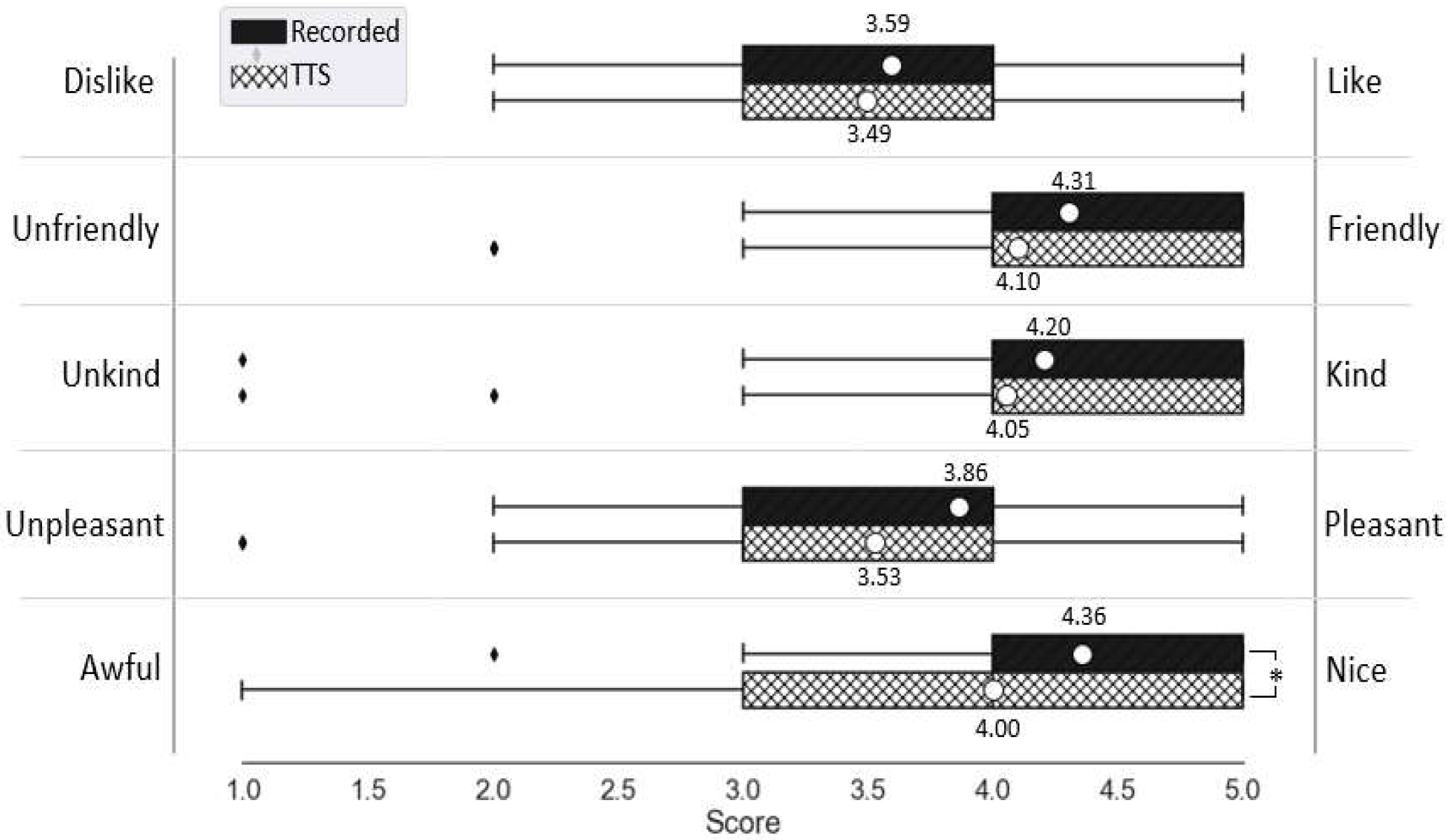
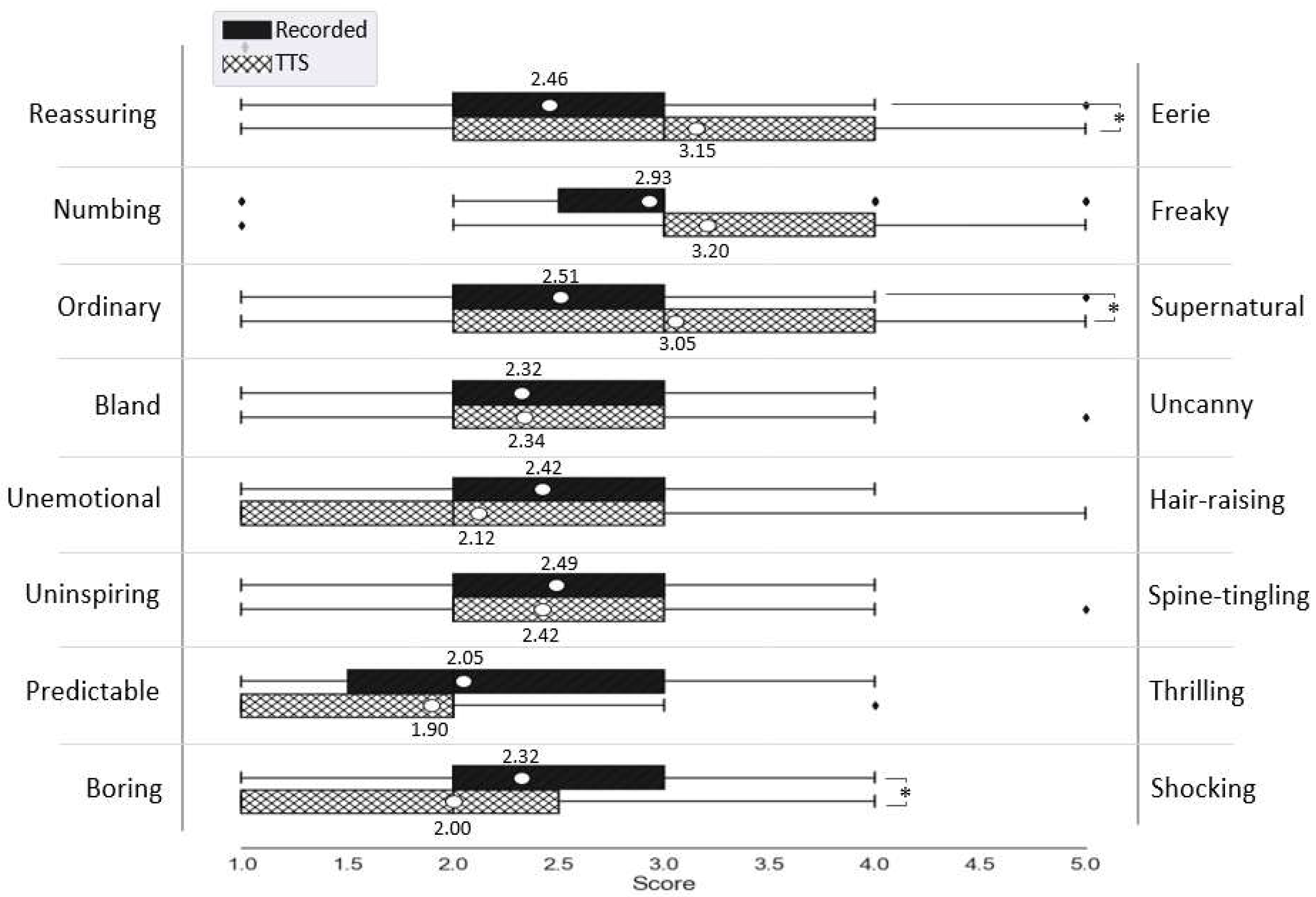
4.3. Character Likeability and Voice Eeriness
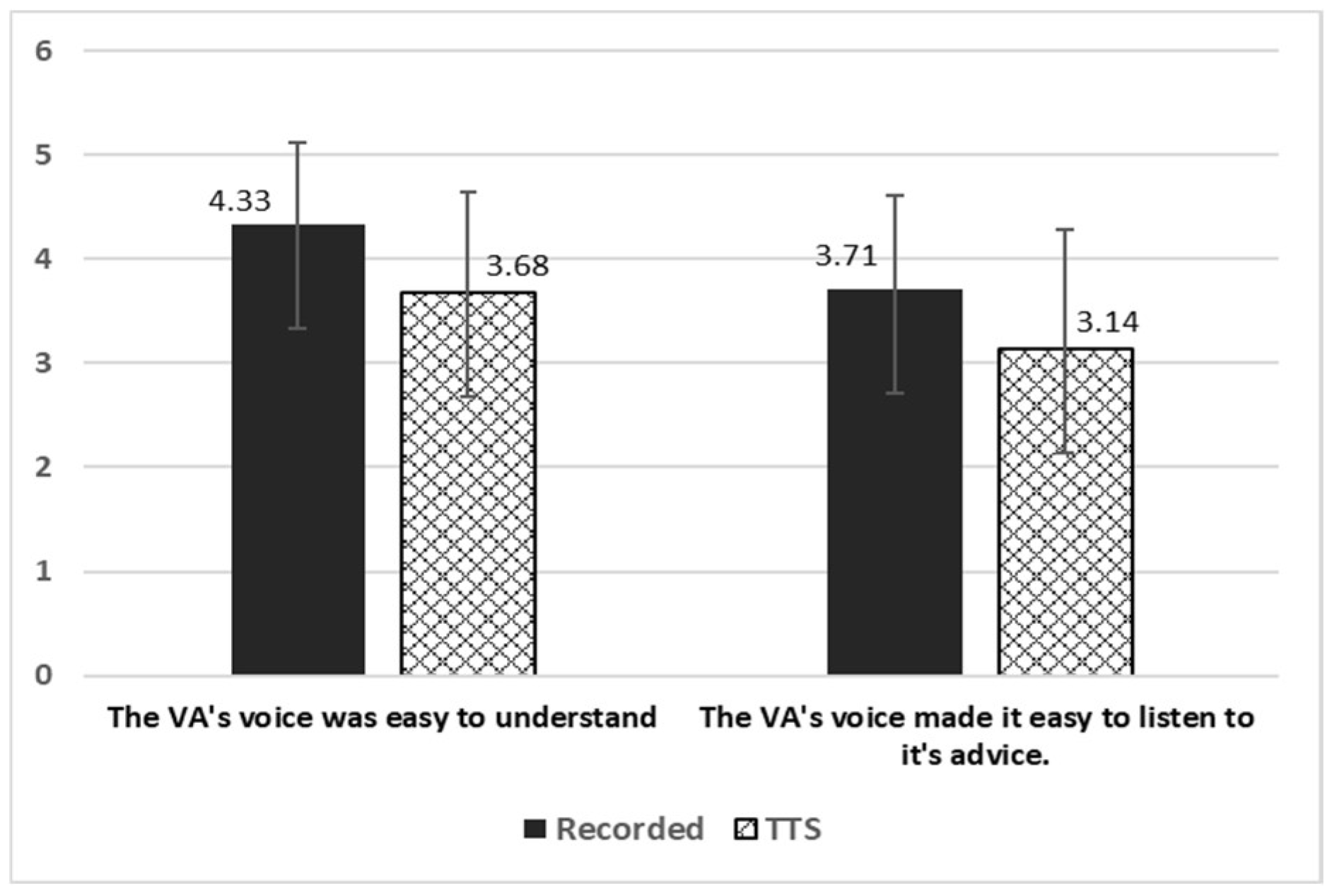
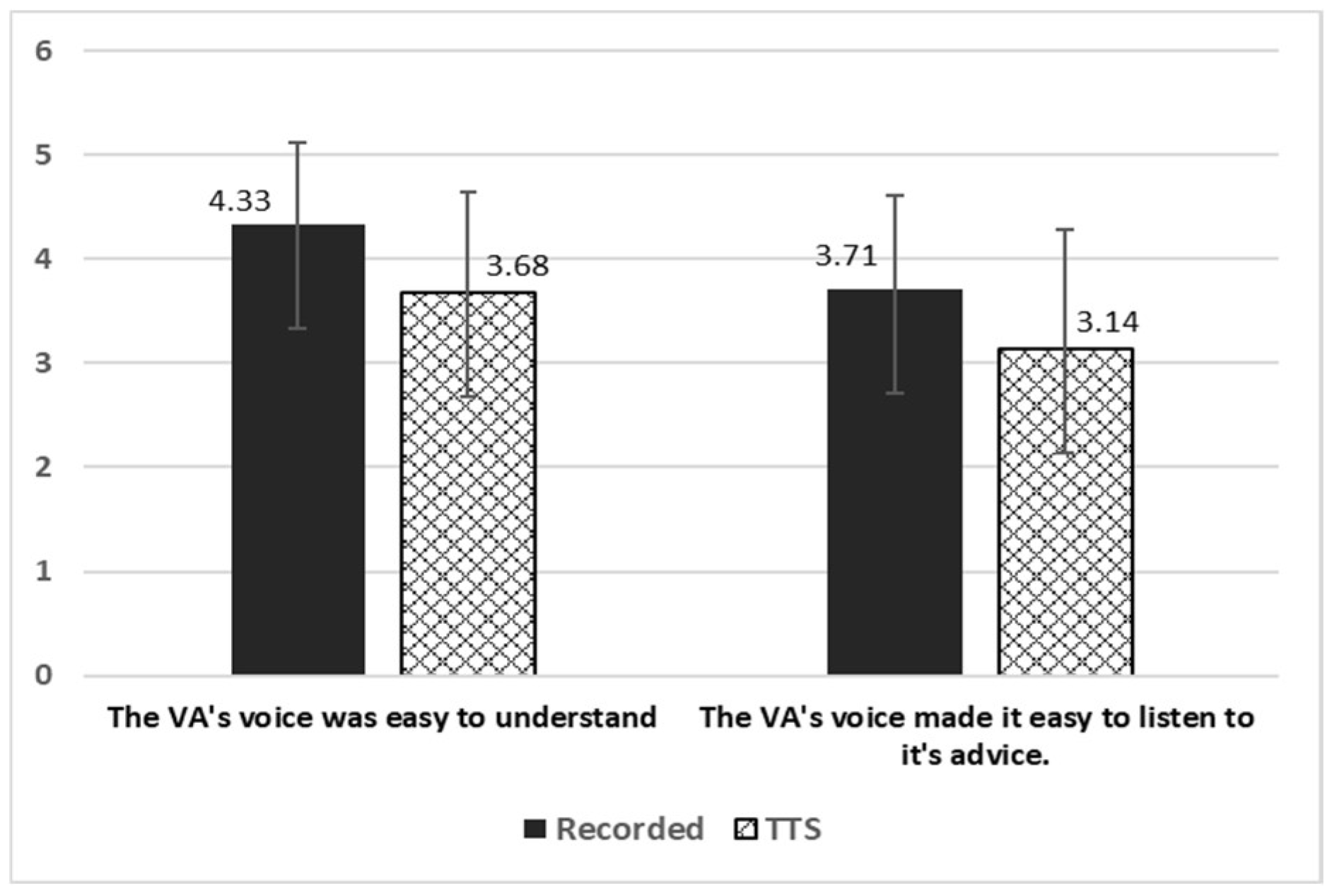
4.4. Trustworthiness, Trust, and Working Alliance
4.5. Behavior Change Intention
5. Discussion
6. Limitations, Future Work, and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yuan, X.; Chee, Y.S. Design and evaluation of Elva: An embodied tour guide in an interactive virtual art gallery. Comput. Animat. Virtual Worlds 2005, 16, 109–119. [Google Scholar] [CrossRef]
- Aljameel, S.S.; O’Shea, J.D.; Crockett, K.A.; Latham, A.; Kaleem, M. Development of an Arabic conversational intelligent tutoring system for education of children with ASD. In Proceedings of the 2017 IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Paris, France, 26–28 June 2017; pp. 24–29. [Google Scholar]
- Provoost, S.; Lau, H.M.; Ruwaard, J.; Riper, H. Embodied conversational agents in clinical psychology: A scoping review. J. Med. Internet Res. 2017, 19, e151. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isbister, K.; Nass, C. Consistency of personality in interactive characters: Verbal cues, non-verbal cues, and user characteristics. Int. J. Hum. Comput. Stud. 2000, 53, 251–267. [Google Scholar] [CrossRef] [Green Version]
- Diederich, S.; Brendel, A.B.; Kolbe, L.M. Towards a Taxonomy of Platforms for Conversational Agent Design. In Proceedings of the International Conference on Wirtschaftsinformatik, Siegen, Germany, 24–27 February 2019. [Google Scholar]
- Clore, G.L.; Ortony, A. Psychological construction in the OCC model of emotion. Emot. Rev. 2013, 5, 335–343. [Google Scholar] [CrossRef] [PubMed]
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Vaidyam, A.N.; Wisniewski, H.; Halamka, J.D.; Kashavan, M.S.; Torous, J.B. Chatbots and conversational agents in mental health: A review of the psychiatric landscape. Can. J. Psychiatry 2019, 64, 456–464. [Google Scholar] [CrossRef] [PubMed]
- Reeves, B.; Nass, C.I. The Media Equation: How People Treat Computers, Television, and New Media Like Real People and Places; Cambridge University Press: Cambridge, England, 1996. [Google Scholar]
- Schultze, U.; Brooks, J.A.M. An interactional view of social presence: Making the virtual other “real”. Inf. Syst. J. 2019, 29, 707–737. [Google Scholar] [CrossRef]
- Van Pinxteren, M.M.; Pluymaekers, M.; Lemmink, J.G. Human-like communication in conversational agents: A literature review and research agenda. J. Serv. Manag. 2020, 31, 203–225. [Google Scholar] [CrossRef]
- Mori, M. the uncanny valley. Energy 1970, 7, 33–35. [Google Scholar] [CrossRef]
- Nowak, K. Defining and differentiating copresence, social presence and presence as transportation. In Proceedings of the Presence 2001 Conference, Philadelphia, PA, USA, 21 May 2001; pp. 1–23. [Google Scholar]
- Oh, C.S.; Bailenson, J.N.; Welch, G.F. A Systematic Review of Social Presence: Definition, Antecedents, and Implications. Front. Robot. AI 2018, 5, 114. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Suh, A. Machinelike or Humanlike? A Literature Review of Anthropomorphism in AI-Enabled Technology. In Proceedings of the 54th Hawaii International Conference on System Sciences (HICSS 2021), Maui, HI, USA, 5–8 January 2021; pp. 4053–4062. [Google Scholar] [CrossRef]
- Kang, H.; Kim, K.J. Feeling Connected to Smart Objects? A Moderated Mediation Model of Locus of Agency, Anthropomorphism, and Sense of Connectedness. Int. J. Hum. Comput. Stud. 2020, 133, 45–55. [Google Scholar] [CrossRef]
- Kim, S.; Lee, J.; Gweon, G. Comparing data from chatbot and web surveys: Effects of platform and conversational style on survey response quality. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Xie, Y.; Chen, K.; Guo, X. Online anthropomorphism and consumers’ privacy concern: Moderating roles of need for interaction and social exclusion. J. Retail. Consum. Serv. 2020, 55, 102119. [Google Scholar] [CrossRef]
- Schmitt, A.; Zierau, N.; Janson, A.; Leimeister, J.M. Voice as a contemporary frontier of interaction design. In Proceedings of the European Conference on Information Systems (ECIS), Virtual, 22 May 2021. [Google Scholar]
- Brenton, H.; Gillies, M.; Ballin, D.; Chatting, D. The uncanny valley: Does it exist. In Proceedings of the Conference of Human Computer Interaction, Workshop on Human Animated Character Interaction, Las Vegas, NV, USA, 22–27 July 2005. [Google Scholar]
- Rothstein, N.; Kounios, J.; Ayaz, H.; de Visser, E.J. Assessment of Human-Likeness and Anthropomorphism of Robots: A Literature Review. In Proceedings of the International Conference on Applied Human Factors and Ergonomics, San Diego, CA, USA, 16–20 July 2020; pp. 190–196. [Google Scholar]
- Jia, H.; Wu, M.; Jung, E.; Shapiro, A.; Sundar, S.S. When the tissue box says “Bless You”: Using speech to build socially interactive objects. In Proceedings of the CHI ’13 Extended Abstracts on Human Factors in Computing Systems, Paris, France, 27 April 2013; pp. 1635–1640. [Google Scholar]
- Higgins, D.; Zibrek, K.; Cabral, J.; Egan, D.; McDonnell, R. Sympathy for the digital: Influence of synthetic voice on affinity, social presence and empathy for photorealistic virtual humans. Comput. Graph. 2022, 104, 116–128. [Google Scholar] [CrossRef]
- Abdulrahman, A.; Richards, D. Modelling working alliance using user-aware explainable embodied conversational agents for behavior change: Framework and empirical evaluation. In Proceedings of the 40th International Conference on Information Systems, ICIS 2019, Atlanta, GA, USA, 15–18 December 2019; pp. 1–17. [Google Scholar]
- Abdulrahman, A.; Richards, D.; Bilgin, A.A. Exploring the influence of a user-specific explainable virtual advisor on health behaviour change intentions. Auton. Agents Multi-Agent Syst. 2022, 36, 25. [Google Scholar] [CrossRef] [PubMed]
- Abdulrahman, A.; Richards, D.; Ranjbartabar, H.; Mascarenhas, S. Verbal empathy and explanation to encourage behaviour change intention. J. Multimodal User Interfaces 2021, 15, 189–199. [Google Scholar] [CrossRef]
- Goffman, E. The Presentation of Self in Everyday Life; Harmondsworth: London, UK, 1978. [Google Scholar]
- Nowak, K.L.; Biocca, F. The Effect of the Agency and Anthropomorphism on Users’ Sense of Telepresence, Copresence, and Social Presence in Virtual Environments. Presence Teleoperators Virtual Environ. 2003, 12, 481–494. [Google Scholar] [CrossRef]
- Blascovich, J.; Loomis, J.; Beall, A.C.; Swinth, K.R.; Hoyt, C.L.; Bailenson, J.N. Immersive Virtual Environment Technology as a Methodological Tool for Social Psychology. Psychol. Inq. 2002, 13, 103–124. [Google Scholar] [CrossRef]
- MacDorman, K.F.; Ishiguro, H. The uncanny advantage of using androids in cognitive and social science research. Interact. Stud. 2006, 7, 297–337. [Google Scholar] [CrossRef]
- Ciechanowski, L.; Przegalinska, A.; Magnuski, M.; Gloor, P. In the Shades of the Uncanny Valley: An Experimental Study of Human–chatbot Interaction. Future Gener. Comput. Syst. 2019, 92, 539–548. [Google Scholar] [CrossRef]
- Nass, C.; Steuer, J. Voices, Boxes, and Sources of Messages: Computers and Social Actors. Hum. Commun. Res. 1993, 19, 504–527. [Google Scholar] [CrossRef]
- Mullennix, J.W.; Stern, S.E.; Wilson, S.J.; Dyson, C.-l. Social perception of male and female computer synthesized speech. Comput. Hum. Behav. 2003, 19, 407–424. [Google Scholar] [CrossRef]
- de Visser, E.J.; Monfort, S.S.; McKendrick, R.; Smith, M.A.; McKnight, P.E.; Krueger, F.; Parasuraman, R. Almost human: Anthropomorphism increases trust resilience in cognitive agents. J. Exp. Psychol. Appl. 2016, 22, 331. [Google Scholar] [CrossRef] [PubMed]
- Zanbaka, C.; Goolkasian, P.; Hodges, L. Can a virtual cat persuade you?: The role of gender and realism in speaker persuasiveness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Gaithersburg, MD, USA, 15–17 March 2006; pp. 1153–1162. [Google Scholar]
- Mitchell, W.J.; Szerszen Sr, K.A.; Lu, A.S.; Schermerhorn, P.W.; Scheutz, M.; MacDorman, K.F.J.i.-P. A mismatch in the human realism of face and voice produces an uncanny valley. iPerception 2011, 2, 10–12. [Google Scholar] [CrossRef] [PubMed]
- Cowan, B.R.; Branigan, H.P.; Obregón, M.; Bugis, E.; Beale, R. Voice Anthropomorphism, Interlocutor Modelling and Alignment Effects on Syntactic Choices in Human-Computer Dialogue. Int. J. Hum. Comput. Stud. 2015, 83, 27–42. [Google Scholar] [CrossRef] [Green Version]
- Barcelos, R.H.; Dantas, D.C.; Sénécal, S. Watch Your Tone: How a Brand’s Tone of Voice on Social Media Influences Consumer Responses. J. Interact. Mark. 2018, 41, 60–80. [Google Scholar] [CrossRef]
- Smith, B. Foundations of Gestalt Theory; Philosophia Verlag: Munich, Germany, 1988. [Google Scholar]
- Stroop, J.R. Studies of interference in serial verbal reactions. J. Exp. Psychol. 1935, 18, 643. [Google Scholar] [CrossRef]
- Green, E.J.; Barber, P.J. An Auditory Stroop Effect with Judgments of Speaker Gender. Percept. Psychophys. 1981, 30, 459–466. [Google Scholar] [CrossRef] [Green Version]
- Gong, L.; Nass, C. When a Talking-Face Computer Agent Is Half-Human and Half-Humanoid: Human Identity and Consistency Preference. Hum. Commun. Res. 2007, 33, 163–193. [Google Scholar] [CrossRef]
- Moore, R.K. A Bayesian Explanation of the ‘Uncanny Valley’ Effect and Related Psychological Phenomena. Sci. Rep. 2012, 2, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Torre, I.; Latupeirissa, A.B.; McGinn, C. How context shapes the appropriateness of a robot’s voice. In Proceedings of the 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; pp. 215–222. [Google Scholar]
- Chérif, E.; Lemoine, J.-F. Anthropomorphic virtual assistants and the reactions of Internet users: An experiment on the assistant’s voice. Rech. Et Appl. En Mark. (Engl. Ed.) 2019, 34, 28–47. [Google Scholar] [CrossRef]
- Lee, E.-J. The more humanlike, the better? How speech type and users’ cognitive style affect social responses to computers. Comput. Hum. Behav. 2010, 26, 665–672. [Google Scholar] [CrossRef]
- Walters, M.L.; Syrdal, D.S.; Koay, K.L.; Dautenhahn, K.; Te Boekhorst, R. Human approach distances to a mechanical-looking robot with different robot voice styles. In Proceedings of the RO-MAN 2008-The 17th IEEE International Symposium on Robot and Human Interactive Communication, Munich, Germany, 1–3 August 2008; pp. 707–712. [Google Scholar]
- Dickerson, R.; Johnsen, K.; Raij, A.; Lok, B.; Stevens, A.; Bernard, T.; Lind, D.S. Virtual patients: Assessment of synthesized versus recorded speech. Stud. Health Technol. Inf. 2006, 119, 114–119. [Google Scholar]
- Noah, B.; Sethumadhavan, A.; Lovejoy, J.; Mondello, D. Public Perceptions Towards Synthetic Voice Technology. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2021, 65, 1448–1452. [Google Scholar] [CrossRef]
- Black, A.W.; Lenzo, K.A. Limited Domain Synthesis; Carnegie-Mellon University Pittsburgh Pa Inst of Software Research Internat: Pittburgh, PA, USA, 2000. [Google Scholar]
- Georgila, K.; Black, A.W.; Sagae, K.; Traum, D.R. Practical Evaluation of Human and Synthesized Speech for Virtual Human Dialogue Systems. In Proceedings of the LREC, Istanbul, Turkey, 21 May 2012; pp. 3519–3526. [Google Scholar]
- Seaborn, K.; Miyake, N.P.; Pennefather, P.; Otake-Matsuura, M. Voice in Human–Agent Interaction: A Survey. ACM Comput. Surv. 2021, 54, 1–43. [Google Scholar] [CrossRef]
- Cambre, J.; Colnago, J.; Maddock, J.; Tsai, J.; Kaye, J. Choice of Voices: A Large-Scale Evaluation of Text-to-Speech Voice Quality for Long-Form Content. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–13. [Google Scholar]
- ter Stal, S.; Broekhuis, M.; van Velsen, L.; Hermens, H.; Tabak, M. Embodied Conversational Agent Appearance for Health Assessment of Older Adults: Explorative Study. JMIR Hum. Factors 2020, 7, e19987. [Google Scholar] [CrossRef] [PubMed]
- Abdulrahman, A.; Richards, D.; Bilgin, A.A. Reason Explanation for Encouraging Behaviour Change Intention. In Proceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021), Online, 3–7 May 2021; IFAAMAS: County of Richland, SC, USA, 2021; p. 10. [Google Scholar]
- Mascarenhas, S.; Guimarães, M.; Prada, R.; Santos, P.A.; Dias, J.; Paiva, A. FAtiMA Toolkit: Toward an Accessible Tool for the Development of Socio-emotional Agents. ACM Trans. Interact. Intell. Syst. 2022, 12, 1–30. [Google Scholar] [CrossRef]
- Wagner, P.; Beskow, J.; Betz, S.; Edlund, J.; Gustafson, J.; Henter, G.E.; Le Maguer, S.; Malisz, Z.; Székely, É.; Tånnander, C. Speech Synthesis Evaluation: State-of-the-Art Assessment and Suggestion for a Novel Research Program. In Proceedings of the 10th Speech Synthesis Workshop (SSW10), Vienna, Austria, 20–22 September 2019. [Google Scholar]
- Ning, Y.; He, S.; Wu, Z.; Xing, C.; Zhang, L.-J. A Review of Deep Learning Based Speech Synthesis. Appl. Sci. 2019, 9, 4050. [Google Scholar] [CrossRef] [Green Version]
- Sisman, B.; Zhang, M.; Sakti, S.; Li, H.; Nakamura, S. Adaptive Wavenet Vocoder for Residual Compensation in GAN-Based Voice Conversion. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 282–289. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar]
- Bartneck, C.; Kulić, D.; Croft, E.; Zoghbi, S. Measurement instruments for the anthropomorphism, animacy, likeability, perceived intelligence, and perceived safety of robots. Int. J. Soc. Robot. 2009, 1, 71–81. [Google Scholar] [CrossRef] [Green Version]
- Ho, C.-C.; MacDorman, K.F. Revisiting the uncanny valley theory: Developing and validating an alternative to the Godspeed indices. Comput. Hum. Behav. 2010, 26, 1508–1518. [Google Scholar] [CrossRef]
- Mayer, R.C.; Davis, J.H. The effect of the performance appraisal system on trust for management: A field quasi-experiment. J. Appl. Psychol. 1999, 84, 123. [Google Scholar] [CrossRef]
- Horvath, A.O.; Greenberg, L.S. Development and validation of the Working Alliance Inventory. J. Couns. Psychol. 1989, 36, 223. [Google Scholar] [CrossRef]
- Hatcher, R.L.; Gillaspy, J.A. Development and validation of a revised short version of the Working Alliance Inventory. Psychother. Res. 2006, 16, 12–25. [Google Scholar] [CrossRef]
- Gong, L. Human and Humanoid don’t’match: Consistency preference and impact on users’ trust. In Proceedings of the Human-computer Interaction, INTERACT’03: IFIP TC13 International Conference on Human-Computer Interaction, Zurich, Switzerland, 1–5 September 2003; p. 160. [Google Scholar]
- Ranjbartabar, H.; Richards, D.; Bilgin, A.A.; Kutay, C.; Mascarenhas, S. Adapting a Virtual Advisor’s Verbal Conversation Based on Predicted User Preferences: A Study of Neutral, Empathic and Tailored Dialogue. Multimodal Technol. Interact. 2020, 4, 55. [Google Scholar] [CrossRef]
- Nelekar, S.; Abdulrahman, A.; Gupta, M.; Richards, D. Effectiveness of embodied conversational agents for managing academic stress at an Indian University (ARU) during COVID-19. Br. J. Educ. Technol. 2022, 53, 491–511. [Google Scholar] [CrossRef]
- Richards, D.; Caldwell, P. Improving Health Outcomes Sooner Rather Than Later via an Interactive Website and Virtual Specialist. IEEE J. Biomed. Health Inform. 2018, 22, 1699–1706. [Google Scholar] [CrossRef]
- McNaughton, H.; Weatherall, M.; McPherson, K.; Fu, V.; Taylor, W.J.; McRae, A.; Thomson, T.; Gommans, J.; Green, G.; Harwood, M.; et al. The effect of the Take Charge intervention on mood, motivation, activation and risk factor management: Analysis of secondary data from the Taking Charge after Stroke (TaCAS) trial. Clin. Rehabil. 2021, 35, 1021–1031. [Google Scholar] [CrossRef] [PubMed]
- Pitardi, V.; Marriott, H.R. Alexa, she’s not human but… Unveiling the drivers of consumers’ trust in voice-based artificial intelligence. Psychol. Mark. 2021, 38, 626–642. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Female | Male | Total |
|---|---|---|---|
| TTS | 44 | 15 | 59 |
| Recorded | 36 | 23 | 59 |
| Total | 80 | 38 | 118 |
| Group | Stress Level Before Interaction | Stress Level After Interaction | Paired Samples t-Test (Before vs. After) | |||
|---|---|---|---|---|---|---|
| Mean | SDT | Mean | SDT | t | p | |
| TTS | 6.51 | 1.746 | 5.86 | 1.634 | 3.703 | <0.001 |
| Recorded | 7.24 | 1.675 | 5.64 | 1.836 | 7.707 | <0.001 |
| Items | Recorded | TTS | ||
|---|---|---|---|---|
| Mean | SDT | Mean | STD | |
| I did not want a deeper relationship with the agent * | 2.37 | 0.981 | 2.32 | 0.973 |
| I wanted to maintain a sense of distance between us * | 2.95 | 0.753 | 2.73 | 0.827 |
| I was unwilling to share personal information with the agent * | 3.31 | 1.178 | 3.36 | 0.905 |
| I wanted to make the conversation more intimate | 2.74 | 0.965 | 2.71 | 1.001 |
| I tried to create a sense of closeness between us | 2.66 | 0.843 | 2.64 | 0.846 |
| I was interested in talking to the agent | 3.22 | 0.966 | 3.25 | 1.03 |
| Average | 2.88 | 0.599 | 2.84 | 0.540 |
| Measure | Recorded | TTS | ||
|---|---|---|---|---|
| VA’s likeability (the construct) | 0.380 | 0.003 | 0.511 | <0.001 |
| Dislike—Like | 0.482 | <0.001 | 0.486 | <0.001 |
| Unfriendly—Friendly | 0.201 | 0.127 | 0.402 | 0.002 |
| Unkind—Kind | 0.058 | 0.663 | 0.258 | 0.048 |
| Unpleasant—Pleasant | 0.225 | 0.086 | 0.350 | 0.007 |
| Awful—Nice | 0.303 | 0.020 | 0.398 | 0.002 |
| VA’s voice impression (the construct) | 0.176 | 0.181 | −0.301 | 0.020 |
| Reassuring—Eerie | −0.375 | 0.003 | −0.356 | 0.006 |
| Numbing—Freaky | −0.095 | 0.473 | −0.400 | 0.002 |
| Ordinary—Supernatural | −0.146 | 0.270 | −0.127 | 0.337 |
| Bland—Uncanny | 0.113 | 0.392 | 0.104 | 0.431 |
| Unemotional—Hair-raising | 0.042 | 0.751 | 0.025 | 0.849 |
| Uninspiring—Spine-tingling | 0.381 | 0.003 | −0.045 | 0.735 |
| Predictable—Thrilling | 0.367 | 0.004 | 0.103 | 0.437 |
| Boring—Shocking | 0.359 | 0.005 | 0.143 | 0.280 |
| Construct | #Items | Recorded | TTS | ||||
|---|---|---|---|---|---|---|---|
| NA | Mean | STD | NA | Mean | STD | ||
| Trustworthiness | |||||||
| Ability | 5 | 0 (0%) | 3.30 | 0.794 | 0 (0%) | 3.28 | 0.622 |
| Benevolence * | 2 | 0 (0%) | 3.25 | 1.001 | 0 (0%) | 2.87 | 0.940 |
| Integrity | 2 | 0 (0%) | 3.72 | 0.665 | 0 (0%) | 3.82 | 0.700 |
| Trust | 4 | 0 (0%) | 2.95 | 0.884 | 4 (2%) | 2.85 | 0.682 |
| Working Alliance | |||||||
| Task | 4 | 15 (6%) | 2.76 | 1.169 | 5 (2%) | 2.84 | 0.928 |
| Goal | 4 | 24 (10%) | 2.81 | 1.230 | 11 (5%) | 2.79 | 0.859 |
| Bond | 4 | 51 (22%) | 3.01 | 1.105 | 42 (18%) | 2.75 | 1.103 |
| Behavior | VA-Recorded | VA-TTS | ||||||
|---|---|---|---|---|---|---|---|---|
| Before Interaction | After Interaction | Paired Sample t-Test | Before Interaction | After Interaction | Paired Sample t-Test | |||
| Mean (STD) | Mean (STD) | t(58) | p | Mean (STD) | Mean (SDT) | t(58) | p | |
| Participate in a study group | 2.15 (1.00) | 2.42 (0.95) | −2.734 | <0.01 | 2.05 (1.01) | 2.54 (0.97) | −3.959 | <0.001 |
| Do physical activity | 2.34 (1.21) | 2.39 (1.05) | −1.524 | 0.133 | 2.31 (1.24) | 2.54 (1.15) | −2.188 | 0.033 |
| Meet new people | 2.66 (0.99) | 2.83 (0.95) | −0.369 | 0.713 | 2.68 (0.99) | 2.88 (1.00) | −1.651 | 0.104 |
| Consume caffeinated food/drink | 3.51 (1.15) | 3.00 (1.17) | 5.046 | <0.001 | 3.54 (1.10) | 2.93 (1.17) | 5.788 | <0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulrahman, A.; Richards, D. Is Natural Necessary? Human Voice versus Synthetic Voice for Intelligent Virtual Agents. Multimodal Technol. Interact. 2022, 6, 51. https://doi.org/10.3390/mti6070051
Abdulrahman A, Richards D. Is Natural Necessary? Human Voice versus Synthetic Voice for Intelligent Virtual Agents. Multimodal Technologies and Interaction. 2022; 6(7):51. https://doi.org/10.3390/mti6070051
Chicago/Turabian StyleAbdulrahman, Amal, and Deborah Richards. 2022. "Is Natural Necessary? Human Voice versus Synthetic Voice for Intelligent Virtual Agents" Multimodal Technologies and Interaction 6, no. 7: 51. https://doi.org/10.3390/mti6070051
APA StyleAbdulrahman, A., & Richards, D. (2022). Is Natural Necessary? Human Voice versus Synthetic Voice for Intelligent Virtual Agents. Multimodal Technologies and Interaction, 6(7), 51. https://doi.org/10.3390/mti6070051