ODO: Design of Multimodal Chatbot for an Experiential Media System

Abstract
:1. Introduction
1.1. Contributions
- Design of a conversational interface that facilitates storytelling and interaction through a deep learning-based universal encoder [4] and utterance-intent modeling.
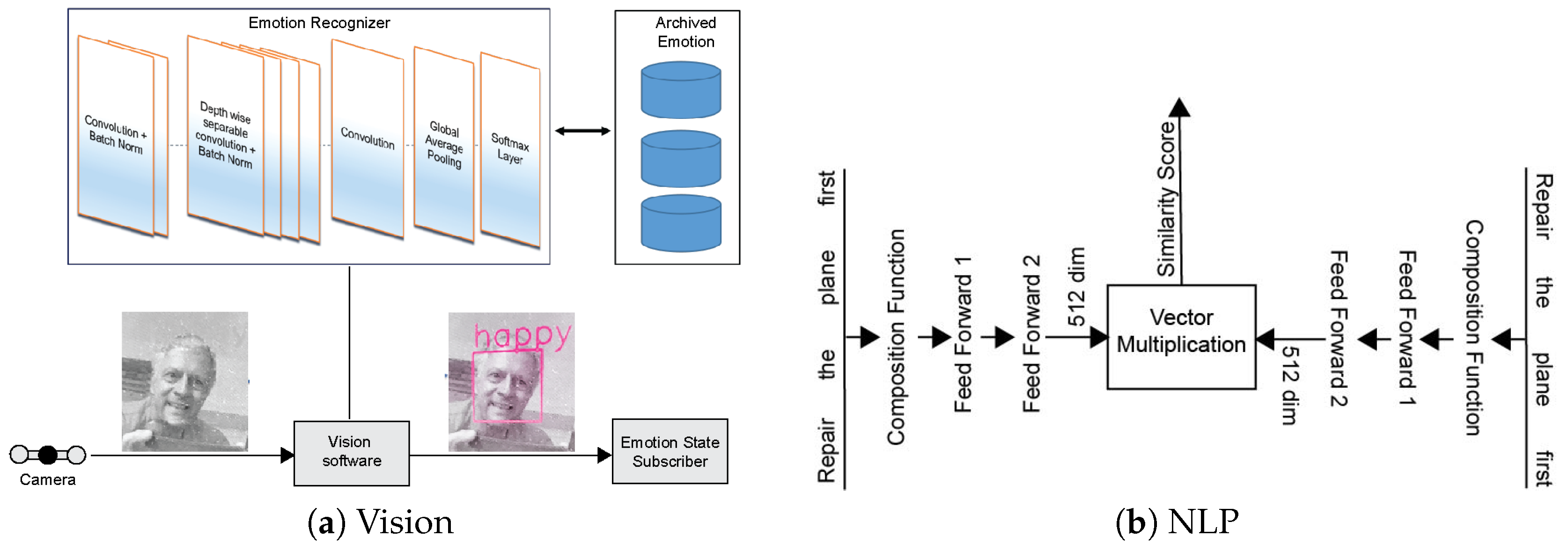
- A vision system consisting of face detection as well as emotion classification [5] using neural networks.
- Custom user position tracking via mobile devices to enable crowd index and other aggregate motion information for the system.
- A communication protocol via Open Sound Control (OSC) [6] and Transmission Control Protocol (TCP) to embedded computing platforms.
1.2. ODO Character and Story
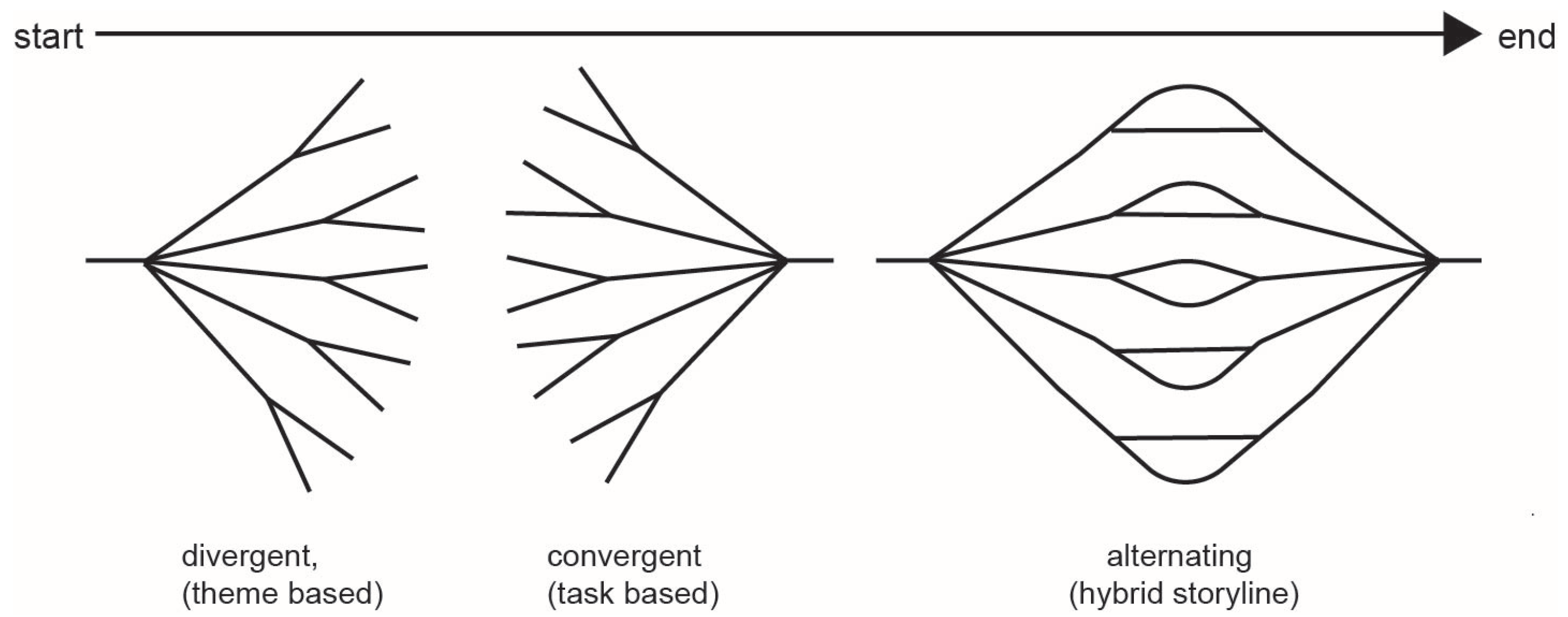
1.3. Related Work and Context
2. System Overview
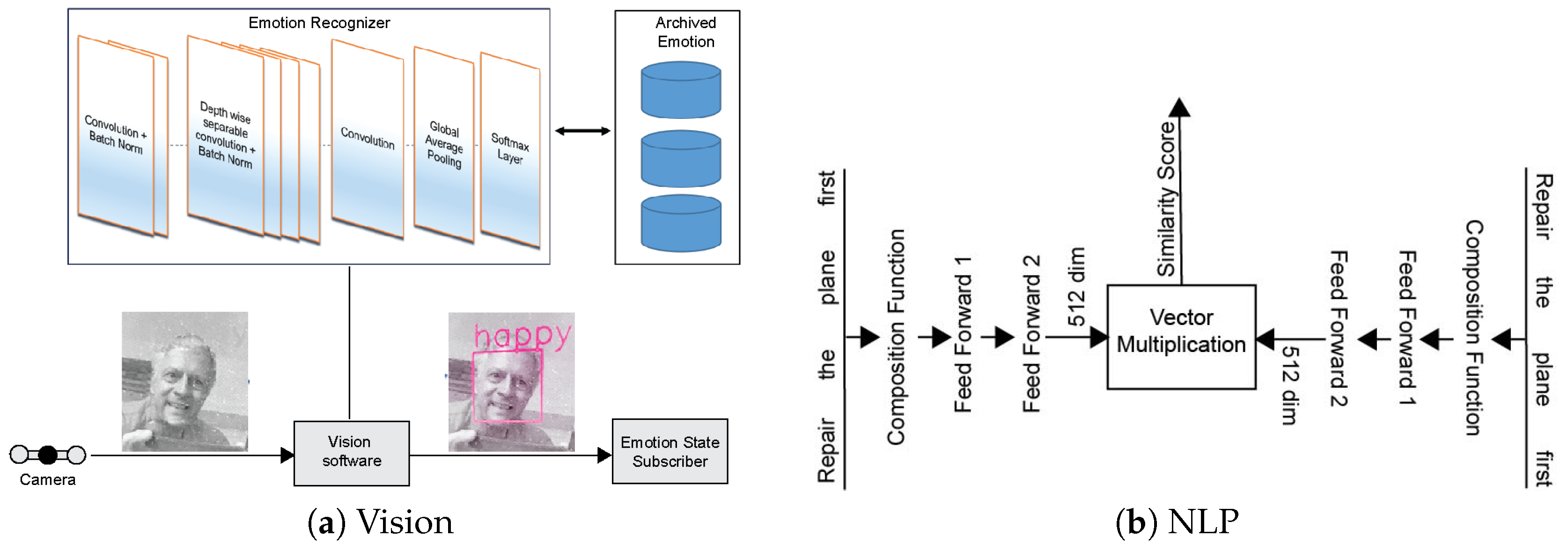
2.1. Chatbot
2.2. Vision Sub-System
2.3. Crowd Tracking via Mobile Devices
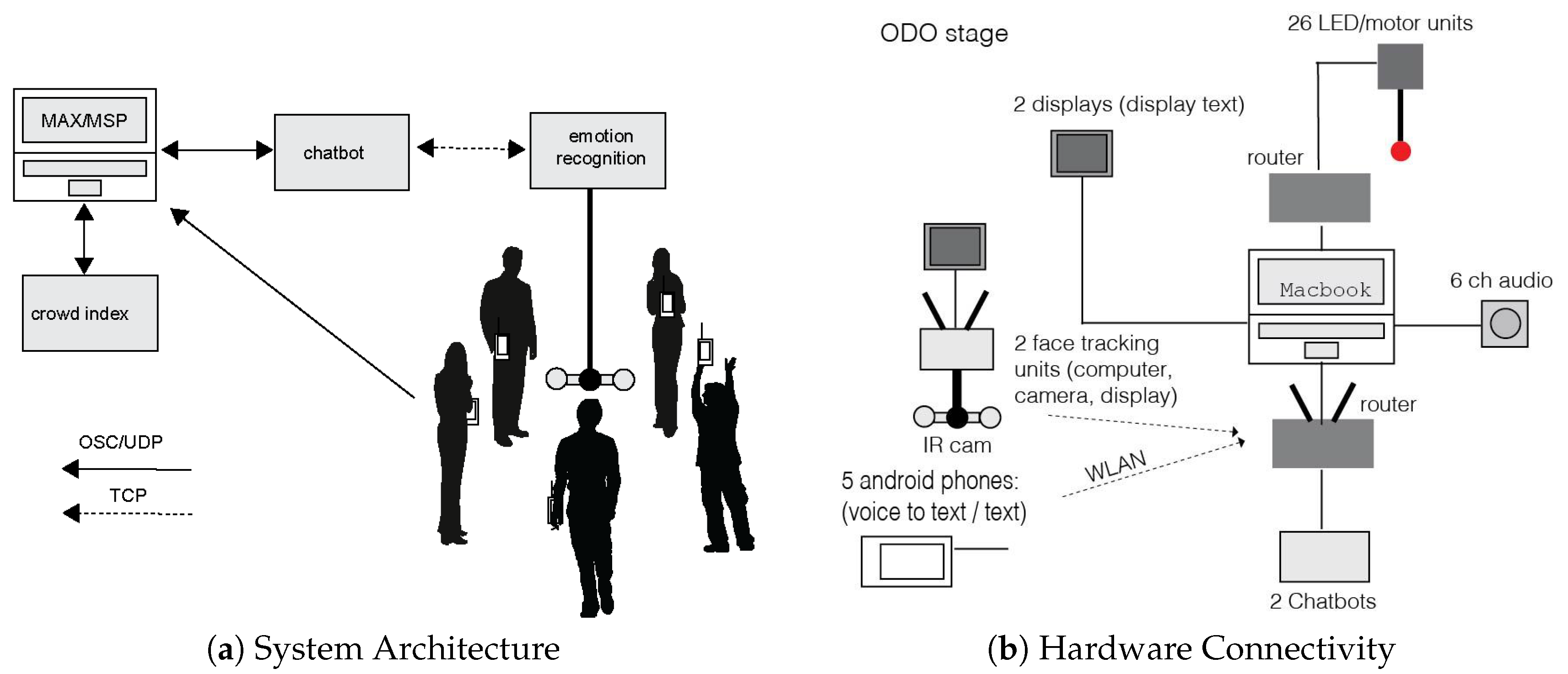
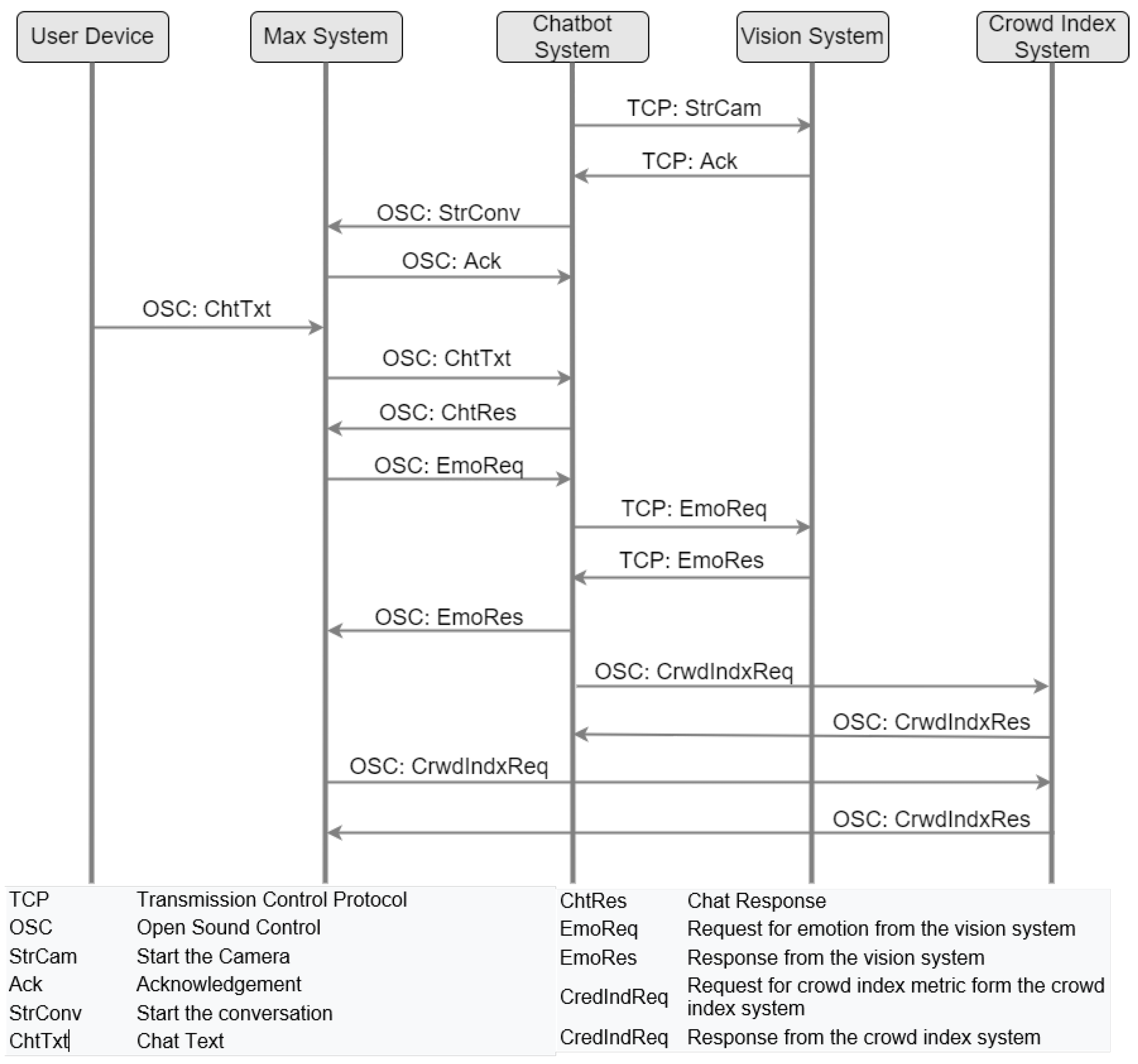
2.4. System Communication via Max/MSP
3. Implementation
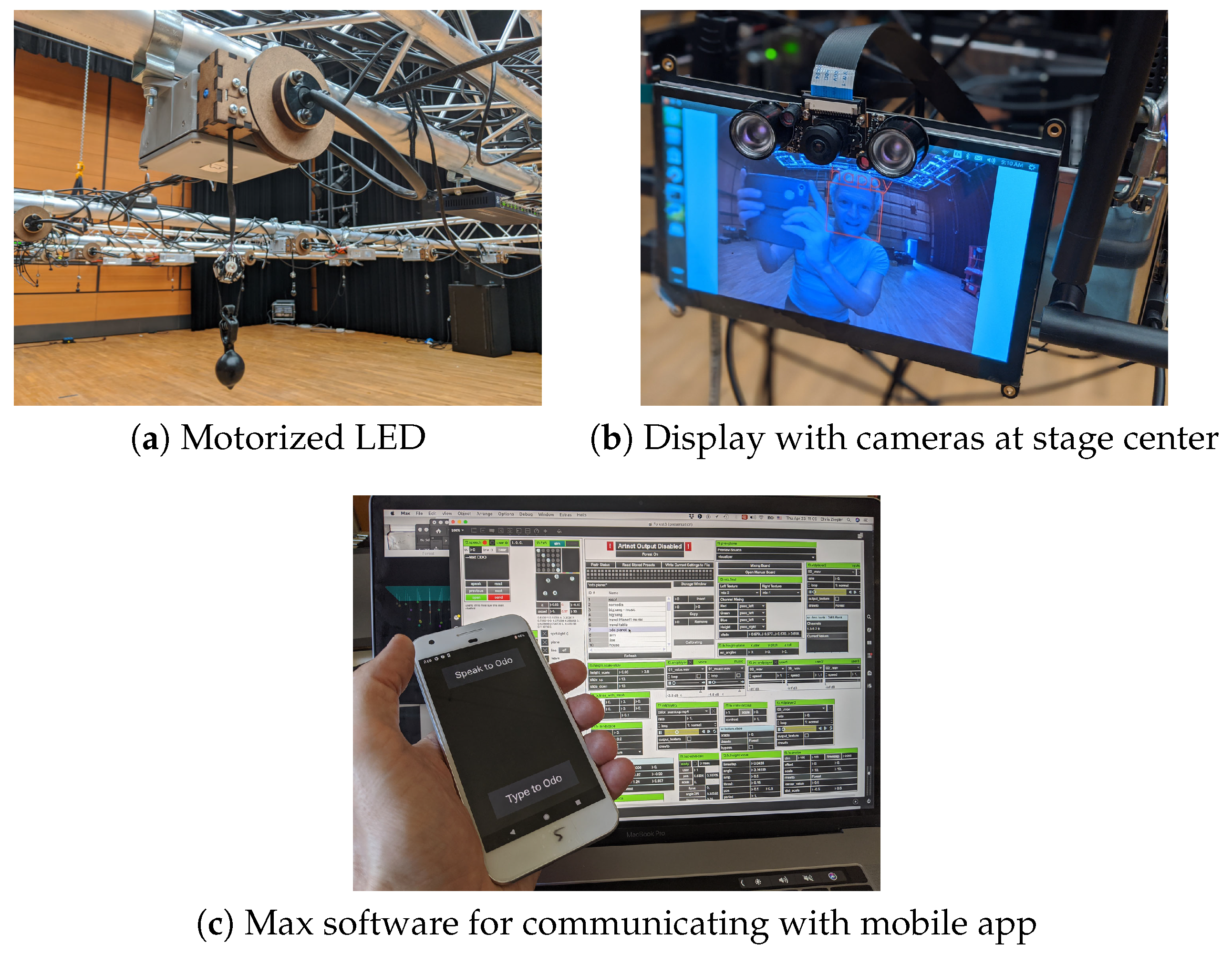
3.1. Stage Hardware
3.2. Algorithm Details
4. System Performance
4.1. Interaction and Games
- POINT Game: One user controls the z/height of one light by using position and z/height information via magnetic/pressure sensor information.
- LINE Game: Two users generate a line of lights between them controls the z/height of both ends of the line.
- WAVES game: The acceleration (x,y,z) information of all users is averaged and mapped to the speed of a Perlin noise generator controling motion movement of all 26 lights.
- PLANE game: Three users control the 3D orientation of a flat plane of lights. The host receives the x and y position of each user and z/height information via magnetic/pressure sensor information.
- LANDSCAPE game: Up to five users can move into the center field of stage between the 26 lights and build valleys and mountains using a terrain builder algorithm, which uses the user’s x and y position and z/height information via magnetic/pressure sensor information in the APP to shape a 3D landscape terrain model.
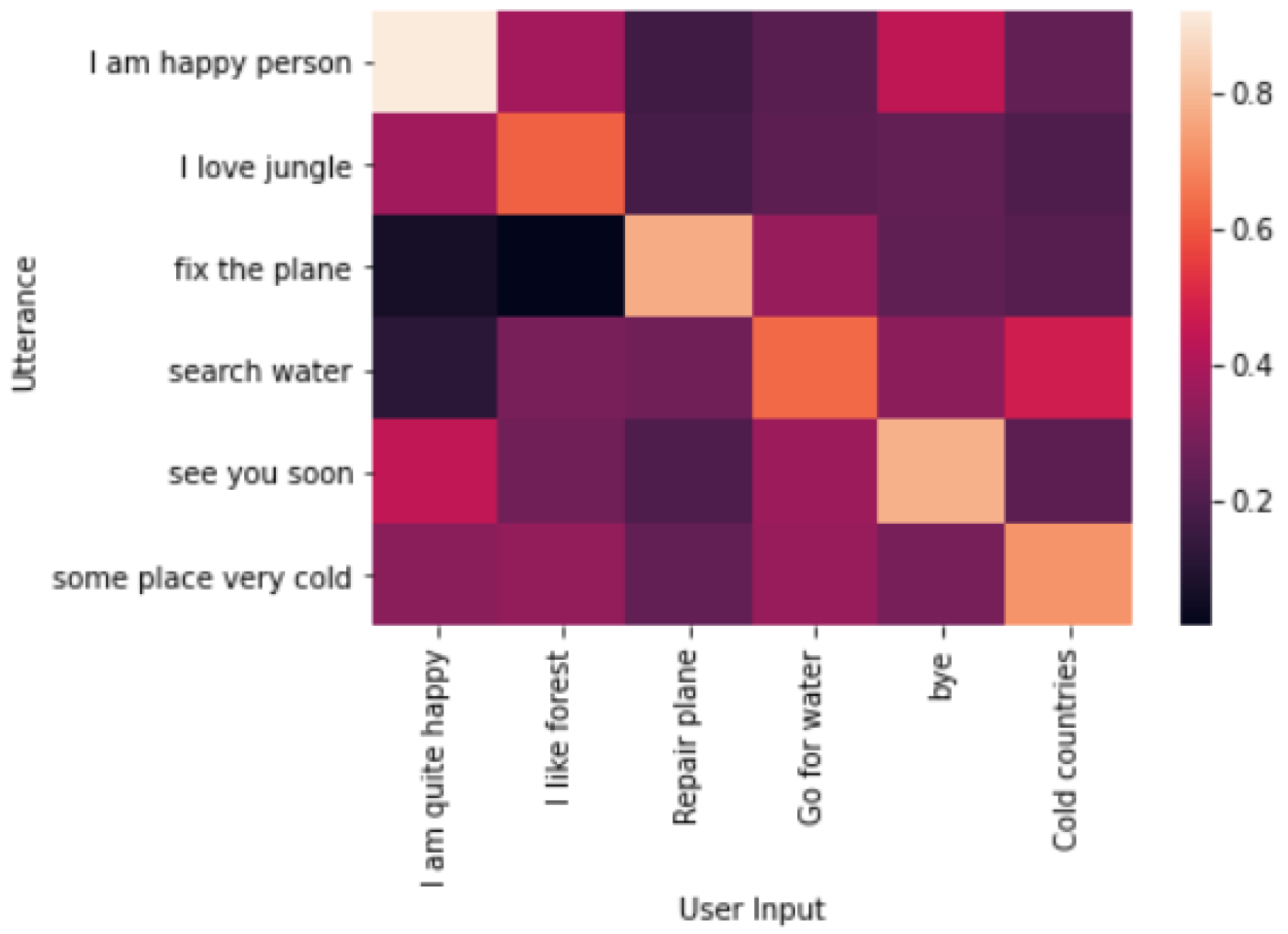
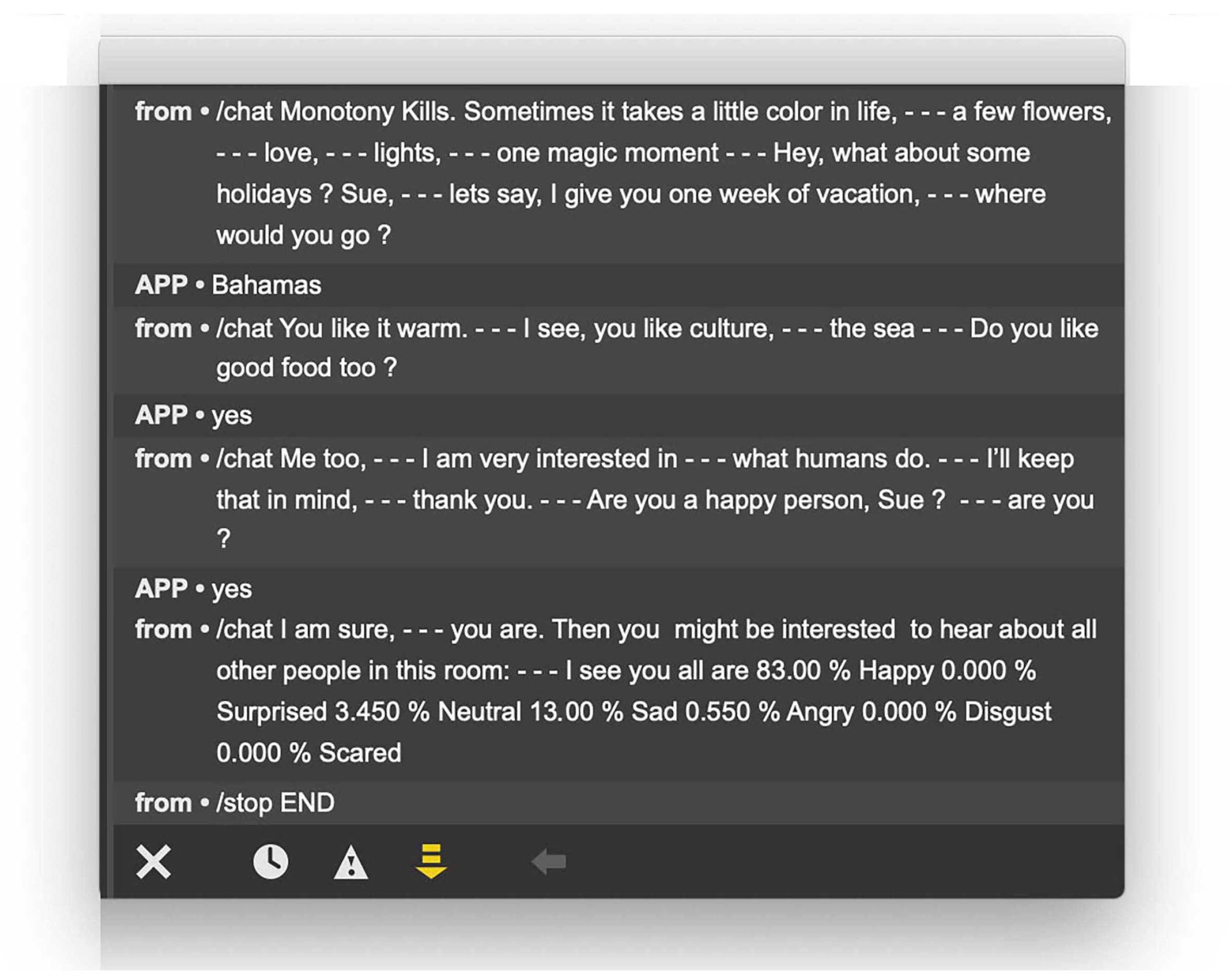
4.2. ODO Conversation
4.3. Latency
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Catania, F.; Spitale, M.; Fisicaro, D.; Garzotto, F. CORK: A COnversational agent framewoRK exploiting both rational and emotional intelligence. In Proceedings of the IUI Workshops, Los Angeles, CA, USA, 20 March 2019. [Google Scholar]
- Zhou, L.; Gao, J.; Li, D.; Shum, H.Y. The design and implementation of xiaoice, an empathetic social chatbot. Comput. Linguist. 2020, 46, 53–93. [Google Scholar] [CrossRef]
- Yin, J.; Chen, Z.; Zhou, K.; Yu, C. A Deep Learning Based Chatbot for Campus Psychological Therapy. arXiv 2019, arXiv:1910.06707. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Arriaga, O.; Valdenegro-Toro, M.; Plöger, P. Real-time convolutional neural networks for emotion and gender classification. arXiv 2017, arXiv:1710.07557. [Google Scholar]
- Freed, A. Open sound control: A new protocol for communicating with sound synthesizers. In Proceedings of the International Computer Music Conference (ICMC), Thessaloniki, Greece, 25–30 September 1997. [Google Scholar]
- Lehmann, H.T. Postdramatic Theatre; Routledge: Abingdon-on-Thames, UK, 2006. [Google Scholar]
- Sarikaya, R. The technology behind personal digital assistants: An overview of the system architecture and key components. IEEE Signal Process. Mag. 2017, 34, 67–81. [Google Scholar] [CrossRef]
- Greenshoot Labs. Available online: https://www.opendialog.ai/ (accessed on 1 May 2020).
- Sabharwal, N.; Agrawal, A. Introduction to Google Dialogflow. In Cognitive Virtual Assistants Using Google Dialogflow; Springer: Berlin/Heidelberg, Germany, 2020; pp. 13–54. [Google Scholar]
- Sabharwal, N.; Barua, S.; Anand, N.; Aggarwal, P. Bot Frameworks. In Developing Cognitive Bots Using the IBM Watson Engine; Springer: Berlin/Heidelberg, Germany, 2020; pp. 39–46. [Google Scholar]
- Mayo, J. Programming the Microsoft Bot Framework: A Multiplatform Approach to Building Chatbots; Microsoft Press: Redmond, WA, USA, 2017. [Google Scholar]
- Williams, S. Hands-On Chatbot Development with Alexa Skills and Amazon Lex: Create Custom Conversational and Voice Interfaces for Your Amazon Echo Devices and Web Platforms; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Gao, J.; Galley, M.; Li, L. Neural approaches to conversational ai. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 1371–1374. [Google Scholar]
- Serban, I.V.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Sordoni, A.; Galley, M.; Auli, M.; Brockett, C.; Ji, Y.; Mitchell, M.; Nie, J.Y.; Gao, J.; Dolan, B. A neural network approach to context-sensitive generation of conversational responses. arXiv 2015, arXiv:1506.06714. [Google Scholar]
- Vinyals, O.; Le, Q. A neural conversational model. arXiv 2015, arXiv:1506.05869. [Google Scholar]
- Dale, R. The return of the chatbots. Nat. Lang. Eng. 2016, 22, 811–817. [Google Scholar] [CrossRef] [Green Version]
- Brandtzaeg, P.B.; Følstad, A. Why people use chatbots. In Proceedings of the International Conference on Internet Science, Thessaloniki, Greece, 22–24 November 2017; pp. 377–392. [Google Scholar]
- Følstad, A.; Brandtzæg, P.B. Chatbots and the new world of HCI. Interactions 2017, 24, 38–42. [Google Scholar] [CrossRef]
- Purington, A.; Taft, J.G.; Sannon, S.; Bazarova, N.N.; Taylor, S.H. “Alexa is my new BFF” Social Roles, User Satisfaction, and Personification of the Amazon Echo. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 2853–2859. [Google Scholar]
- Ciechanowski, L.; Przegalinska, A.; Magnuski, M.; Gloor, P. In the shades of the uncanny valley: An experimental study of human–chatbot interaction. Future Gener. Comput. Syst. 2019, 92, 539–548. [Google Scholar] [CrossRef]
- Hill, J.; Ford, W.R.; Farreras, I.G. Real conversations with artificial intelligence: A comparison between human–human online conversations and human–chatbot conversations. Comput. Hum. Behav. 2015, 49, 245–250. [Google Scholar] [CrossRef]
- Sundaram, H. Experiential media systems. ACM Trans. Multimed. Comput. Commun. Appl. 2013, 9, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Jain, R. Experiential computing. Commun. ACM 2003, 46, 48–55. [Google Scholar] [CrossRef]
- Davis, M. Theoretical foundations for experiential systems design. In Proceedings of the 2003 ACM SIGMM Workshop on Experiential Telepresence, Berkeley, CA, USA, 7 November 2003; pp. 45–52. [Google Scholar]
- Chen, Y.; Sundaram, H.; Rikakis, T.; Ingalls, T.; Olson, L.; He, J. Experiential Media Systems—The Biofeedback Project. In Multimedia Content Analysis; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–34. [Google Scholar]
- Johnson, G.L.; Peterson, B.J.; Ingalls, T.; Wei, S.X. Lanterns: An Enacted and Material Approach to Ensemble Group Activity with Responsive Media. In Proceedings of the 5th International Conference on Movement and Computing, MOCO’ 18, Genoa, Italy, 28–30 June 2018. [Google Scholar] [CrossRef]
- Pinhanez, C.S.; Bobick, A.F. “It/I”: A theater play featuring an autonomous computer character. Presence Teleoperators Virtual Environ. 2002, 11, 536–548. [Google Scholar] [CrossRef]
- Knight, H. Eight lessons learned about non-verbal interactions through robot theater. In Proceedings of the International Conference on Social Robotics, Amsterdam, The Netherlands, 24–25 November 2011; pp. 42–51. [Google Scholar]
- Hoffman, G.; Kubat, R.; Breazeal, C. A hybrid control system for puppeteering a live robotic stage actor. In Proceedings of the RO-MAN 2008—The 17th IEEE International Symposium on Robot and Human Interactive Communication, Munich, Germany, 1–3 August 2008; pp. 354–359. [Google Scholar]
- Mazalek, A.; Nitsche, M.; Rébola, C.; Wu, A.; Clifton, P.; Peer, F.; Drake, M. Pictures at an exhibition: A physical/digital puppetry performance piece. In Proceedings of the 8th ACM Conference on Creativity and Cognition, Atlanta, GA, USA, 3–6 November 2011; pp. 441–442. [Google Scholar]
- Meyer, T.; Messom, C. Improvisation in theatre rehearsals for synthetic actors. In Proceedings of the International Conference on Entertainment Computing, Eindhoven, The Netherlands, 1–3 September 2004; pp. 172–175. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: Lake Tahoe, NV, USA, 2013; pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pandorabot. Mitusku. Available online: https://www.pandorabots.com/mitsuku/ (accessed on 1 May 2020).
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Cycling74. Max/MSP. 1997. Available online: https://cycling74.com/ (accessed on 22 May 2020).
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the SIGKDD Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Ziegler, C.; Sayaka Kaiwa, T.S.; Paquete, H. COSMOS. Presented at ZKM Center for Art and Media, Karlsruhe in 2018. Available online: https://zkm.de/en/event/2018/03/cosmos (accessed on 1 May 2020).
- Art-Net. 2020 Artistic Licence Holdings Ltd., United Kingdom. Available online: https://art-net.org.uk/ (accessed on 1 May 2020).
- Iyyer, M.; Manjunatha, V.; Boyd-Graber, J.; Daumé, H., III. Deep unordered composition rivals syntactic methods for text classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1: Long Papers. pp. 1681–1691. [Google Scholar]
- Ayman, O. Emotion-Recognition. 2019. Available online: https://github.com/omar178/Emotion-recognition (accessed on 1 May 2020).
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; pp. 117–124. [Google Scholar]
- Tirumala, A.; Qin, F.; Dugan, J.M.; Ferguson, J.A.; Gibbs, K.A. iPerf: TCP/UDP Bandwidth Measurement Tool. 2005. Available online: https://iperf.fr/ (accessed on 1 May 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Latency and Bandwidth of the System | |
|---|---|
| Max-Chatbot | 10 ms |
| Max-Sentence Matching | 02 ms |
| Max-Haiku Poem | 60 ms |
| Max-Emotions | 42 ms |
| Max-Crowd Index | 1470 ms * |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhushan, R.; Kulkarni, K.; Pandey, V.K.; Rawls, C.; Mechtley, B.; Jayasuriya, S.; Ziegler, C. ODO: Design of Multimodal Chatbot for an Experiential Media System. Multimodal Technol. Interact. 2020, 4, 68. https://doi.org/10.3390/mti4040068
Bhushan R, Kulkarni K, Pandey VK, Rawls C, Mechtley B, Jayasuriya S, Ziegler C. ODO: Design of Multimodal Chatbot for an Experiential Media System. Multimodal Technologies and Interaction. 2020; 4(4):68. https://doi.org/10.3390/mti4040068
Chicago/Turabian StyleBhushan, Ravi, Karthik Kulkarni, Vishal Kumar Pandey, Connor Rawls, Brandon Mechtley, Suren Jayasuriya, and Christian Ziegler. 2020. "ODO: Design of Multimodal Chatbot for an Experiential Media System" Multimodal Technologies and Interaction 4, no. 4: 68. https://doi.org/10.3390/mti4040068
APA StyleBhushan, R., Kulkarni, K., Pandey, V. K., Rawls, C., Mechtley, B., Jayasuriya, S., & Ziegler, C. (2020). ODO: Design of Multimodal Chatbot for an Experiential Media System. Multimodal Technologies and Interaction, 4(4), 68. https://doi.org/10.3390/mti4040068