1. Introduction
Tele-guidance systems for equipment maintenance have been extensively investigated. Such systems enable a remote helper to provide guidance to a local worker, while perceiving the local conditions. Typically, the local worker holds a mobile camera-display device or wears a headset, or a combination of a head-mounted display (HMD) and a camera. The local worker observes the helper’s gestures on a tele-pointer superimposed on the image of the target object.
Most of these studies consider a relatively small workspace, such as a desktop that can be captured within a single camera’s field of view. However, there are many cases wherein a target workspace is large and the local worker has to move their head around, or move around while receiving guidance with regard to repairs and facilities maintenance tasks at an industrial plant. In such cases, it is difficult for the remote helper to ask the local worker to move to an appropriate place and perform their gestures toward an intended target.
Based on social science studies, we assumed that the anticipation of an interlocutor’s actions in communication is key to overcoming this problem. For example, during face-to-face communication, both the helper and the worker can move around in the workspace and observe each other’s movement and gestures using their peripheral vision. Thus, they can anticipate where the next target area will be, or the direction toward which the helper will point the worker. Such anticipation is quite important for the helper and worker to coordinate their work without delay.
In this study, we propose an augmented reality (AR) tele-guidance system that supports the anticipation of an interlocutor’s actions during communication. Our system enables the helper and worker to anticipate each other’s actions by allowing them to move around the workspace freely, while facilitating the observation of each other’s non-verbal cues (e.g., body motions and other gestures) through an HMD. We conducted an experiment to compare the effectiveness of our proposed method with that of existing methods (a simple tele-pointer) supporting the anticipation of an interlocutor’s actions during communication.
2. Related Work
Various studies have investigated remote collaboration in a real-world environment. For example, Kuzuoka and colleagues have developed GestureMan-3 [
1], which is a robot equipped with a laser pointer and a pointing stick to allow a remote helper to identify objects in the local environment through the robot. Additionally, this experiment synchronized the orientation of the robot’s head with the helper’s head motion such that the worker could recognize the helper’s gaze direction. Because the robot requires sufficient space to move around, this experiment is not appropriate for an environment wherein the space is too narrow or where the floor is not sufficiently flat.
To address this workspace problem, Sakata and colleagues developed a wearable pointing device named WACL/CWD (Wearable Active Camera-Laser pointer/Chest Worn Display) [
2]. This device consists of a motor-actuated camera with a laser pointer attached to the shoulder of the local worker. The remote helper observes the workspace through the camera and points at objects using the laser pointer.
However, Fussell and colleagues reported that the pointing technique is not sufficient to represent the remote helper’s movements in some situations [
3]. This resulted in increased interest toward tele-guidance systems using AR technology. These studies have demonstrated that both pointing and non-verbal information, such as hand gestures, can be used to guide the worker. One such example is MobileHelper [
4]. In this system, a worker wears a helmet with a small camera, and a remote helper observes the local environment on a tablet device. The device captures the helper’s hand gestures by using its rear camera. Then, the hand gestures and the worker’s near-eye display are superimposed.
Another example is BeThere [
5], where a worker captures three-dimensional (3D) information from a local workspace by using a depth camera attached to his/her handheld device and sends the information to the helper’s mobile device. The helper can observe the transmitted 3D workspace from an arbitrary angle by moving the device as if he/she is looking at the environment through a small window. In return, the device captures the 3D shape of the helper’s hand gesture and sends it back to the worker’s location, where the gesture of the helper is displayed on the worker’s mobile device.
All of these systems impose requirements on the worker. For example, the worker must hold a mobile device in one hand, which hinders his/her operations. Collaboration systems that do not require helpers and workers to hold devices have been investigated. Tecchia and colleagues [
6] and Huang and colleagues [
7] developed systems that superimpose 3D hand gestures from a remote helper to a workspace view. By using depth cameras, these systems can capture the 3D information of a local tabletop and a 3D model of the remote helper’s hand gestures. The worker can see the image, onto which the helper’s hand gesture and the local workspace are superimposed, displayed on a monitor local to the worker. However, these systems have been developed for tabletop tasks. Thus, it is difficult to use them in cases wherein the worker must move freely within a wider workspace.
The system developed by Gauglitz and colleagues can be applied to a larger workspace, such as the workspace surrounding a car’s bonnet, by using a mobile device. This system uses vision-based simultaneous localization and mapping to capture the 3D information of the workspace and the worker’s position in real-time [
8,
9]. This 3D information is shared between the helper and the worker, who can then observe the workspace freely. Moreover, the remote helper is able to navigate the scene, create annotations, and send these images to the local user in AR through a touch display. If the annotations reside outside of the local worker’s current field of view, an arrow appears along the edge of the screen and indicates the direction of the annotation. In any case, the user cannot anticipate the next position toward which the helper will point and determining the helper’s instructions becomes time consuming. Thus, in such a large workspace, non-verbal cues have a positive effect on the efficiency and quality of the operation [
10].
For example, in a face-to-face situation, first, a helper provides an explanation regarding the target object. During this explanation, the helper turns his/her face toward the next target to prepare for the next explanation. Prior to the completion of the explanation, the worker can anticipate the next target by observing the helper’s motion. This non-verbal information (body motion, hand gestures, body position, and direction of gaze and body) during communication are referred to as non-verbal cues. Previously, it has been noted that non-verbal cues are important for communication [
11]. This is particularly true within social science, where the relationship of body orientation and the anticipation of an interlocutor’s actions during communication is important [
12].
In this study, we propose an AR tele-guidance system that supports the anticipation of communication in a larger workspace. To enable hands-free operation, both the worker and the helper wore an HMD. Moreover, to support the anticipation of actions by both the helper and the worker, our system provided non-verbal cues from both the helper and the worker (e.g., body transitions and other gestures) through their respective HMDs.
Smith and Neff evaluated participants’ communication behavior in VR, and found that using full-body avatars provided a high level of social presence and that the participants’ conversation patterns were very similar to those shown in face-to-face conditions [
13]. The results indicate that our AR tele-guidance system has similar capabilities. In other words, by presenting the helper’s avatar to the worker, the system can improve the efficiency of the task and reduce the worker’s mental workload.
3. AR Tele-Guidance System
We developed an experimental tele-guidance system that enables the helper and the worker to anticipate the actions of each other by facilitating the observation of each other’s whole body actions (e.g., body transitions and other gestures) through an HMD.
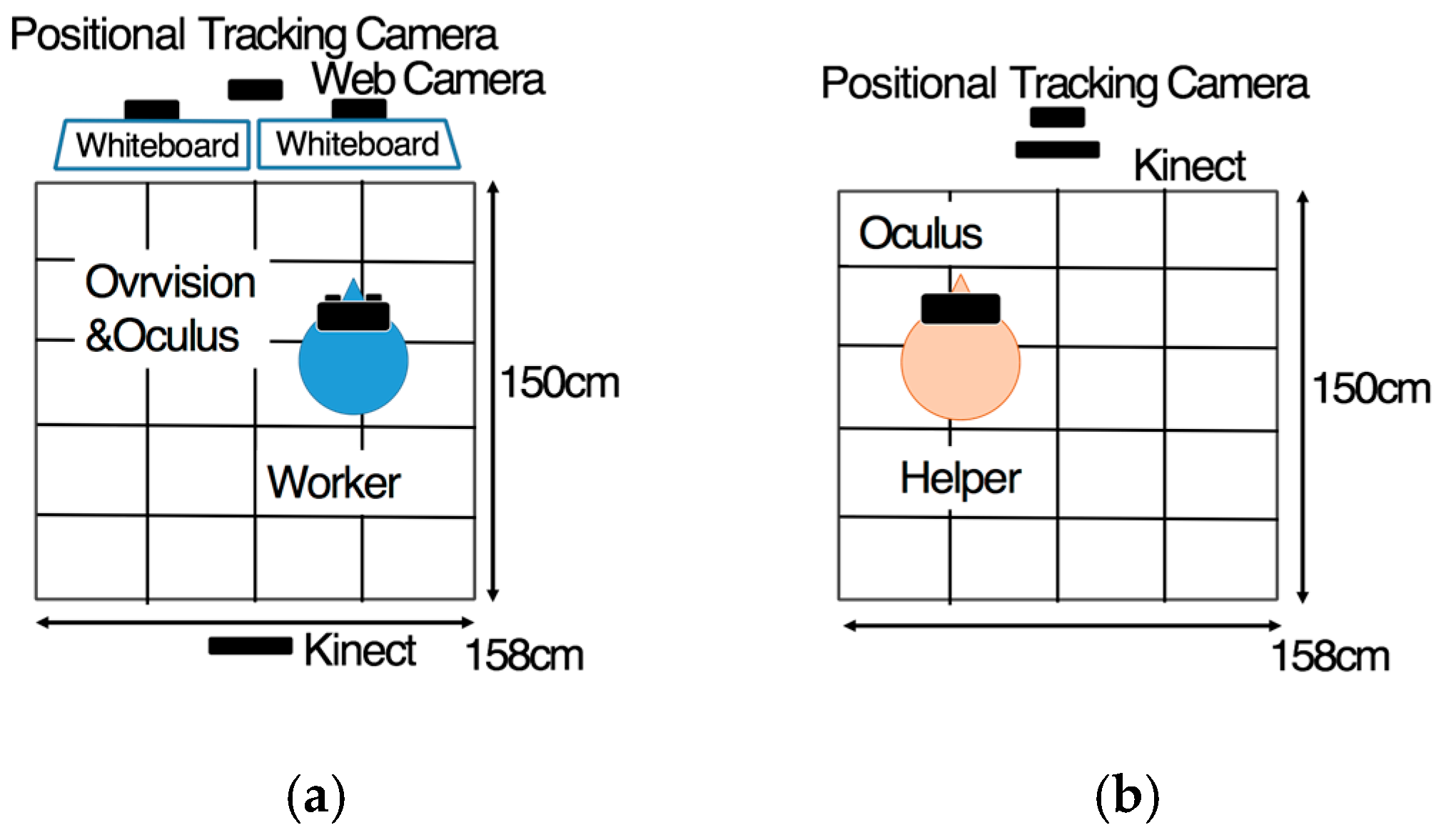
Figure 1 shows an overview of our system. A remote helper gives instructions to a local worker through the system.
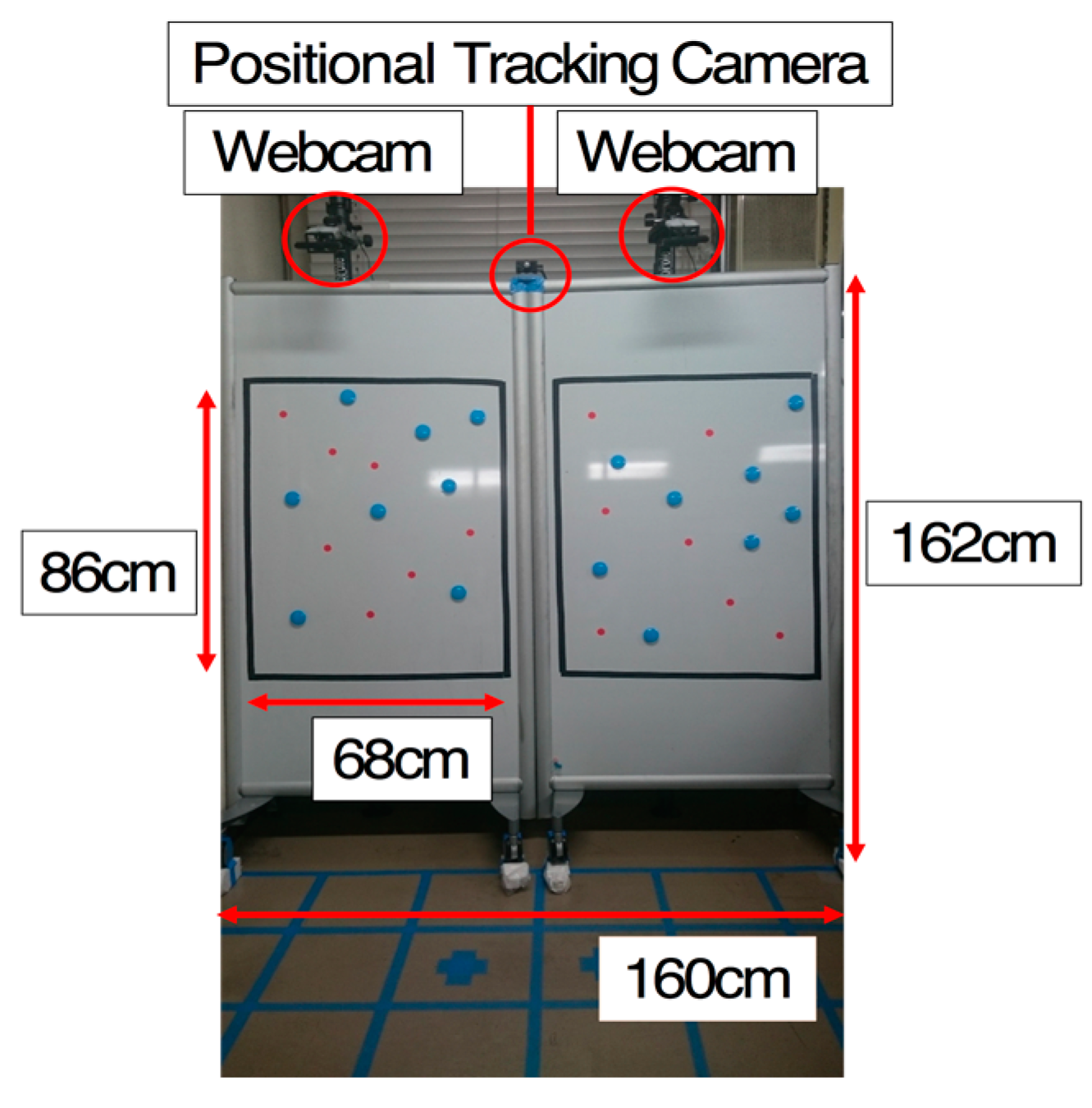
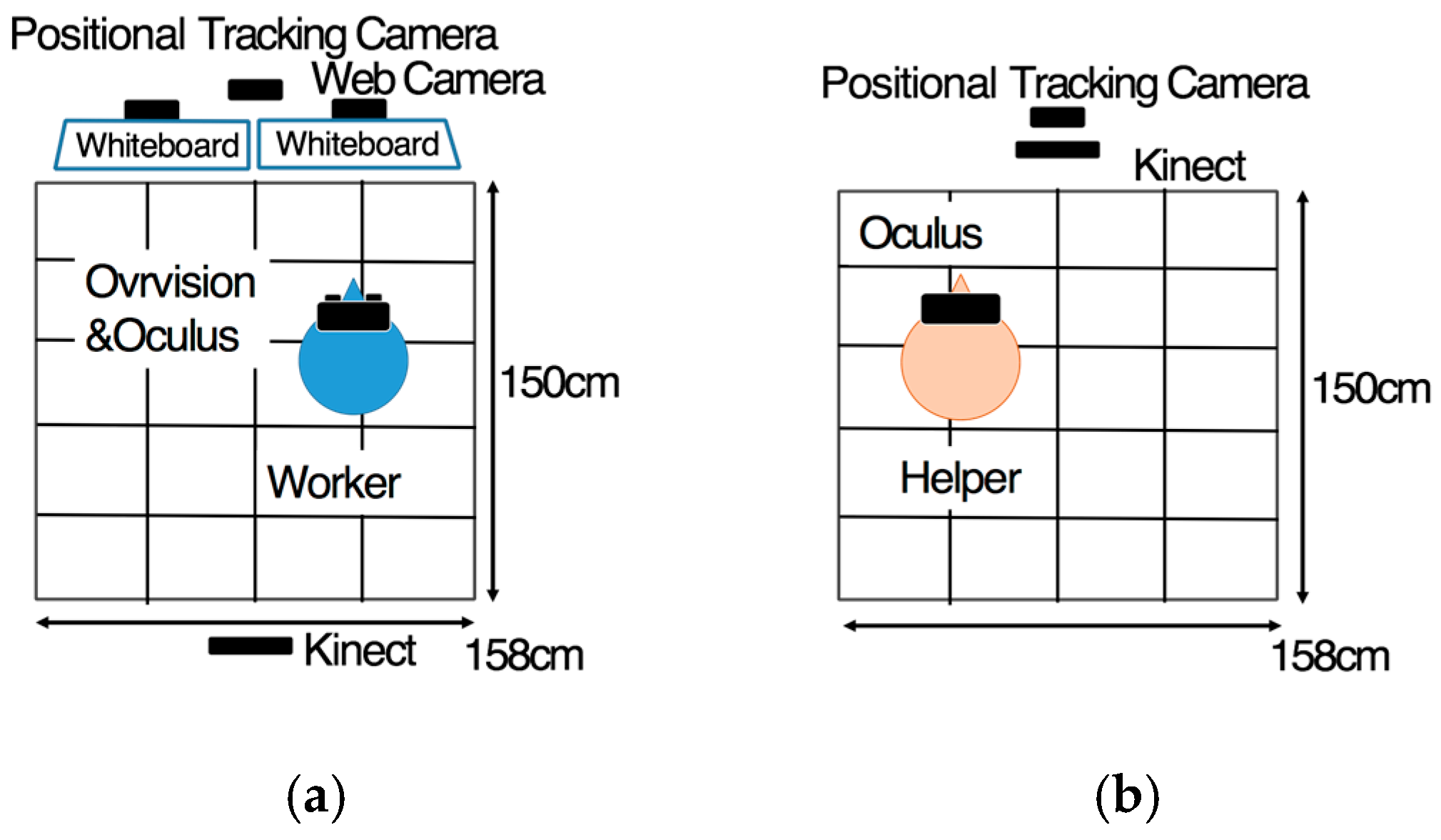
On the worker’s side, there are two whiteboards, whose top sides face the worker with webcams (iBUFFALO, BSW20KM11BK) (
Figure 2). This webcam captured the surface images of these whiteboards and sent them to the helper’s side. Additionally, a positional tracking camera (Oculus Rift, DK2) was adopted to track the worker’s head motion, and a motion-tracking camera (Kinect for Windows) was adopted to track the worker’s motion from his/her back. The captured images were sent to the helper’s personal computer (PC).
On the helper’s side, a positional tracking camera and a motion-tracking camera were mounted onto a tripod in front of the helper. The captured images of the helper’s motion were sent to the worker’s PC. Through the HMD (Oculus Rift, DK2), the worker could not only observe the workspace using a stereo camera (Ovrvision), but could also receive AR instructions from the helper.
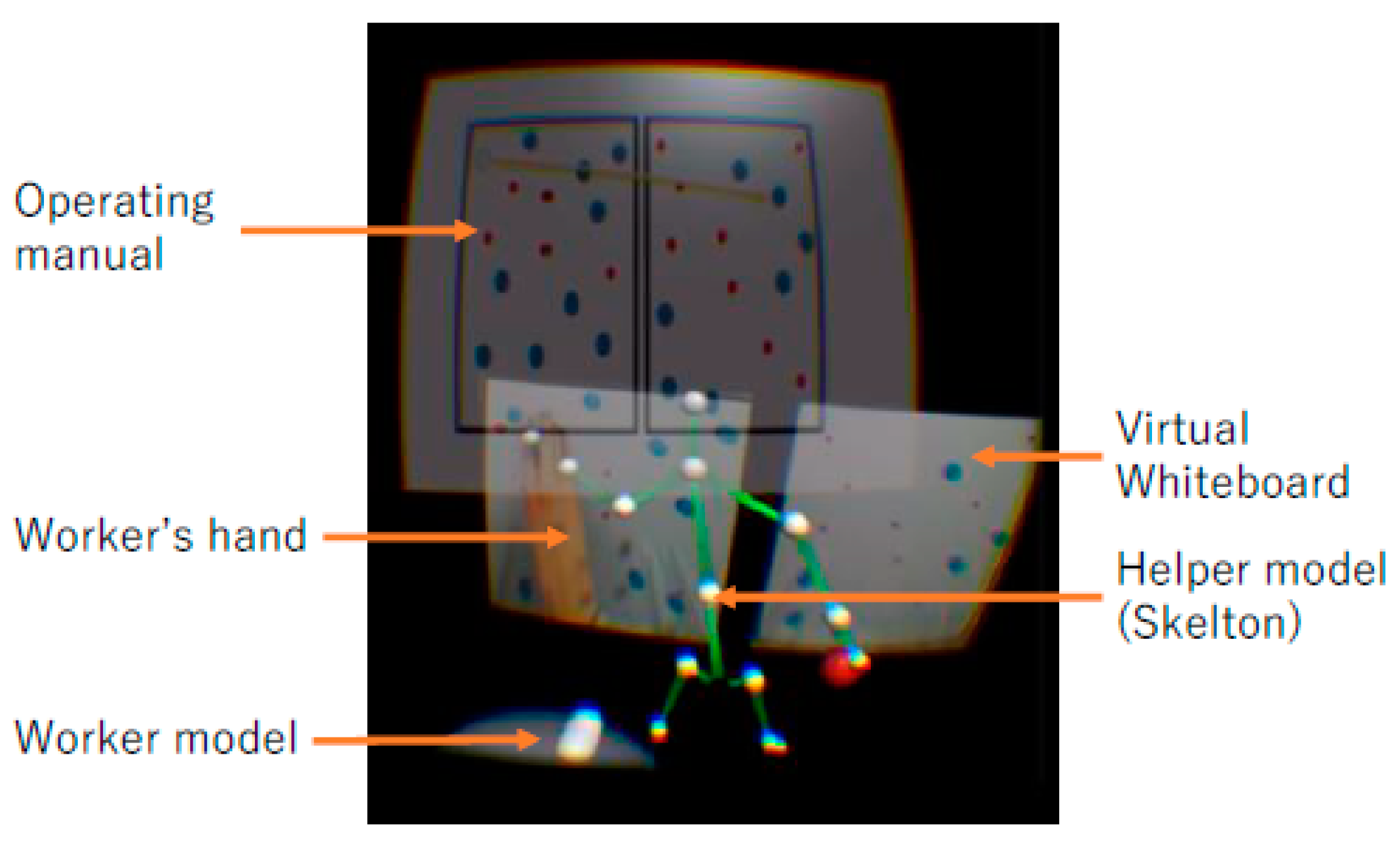
Figure 3a shows the worker’s view. The worker could observe the virtual helper’s full-body model. The motion of the helper model was synchronized with the helper’s actual movement using the motion-tracking camera on the helper’s side.
Figure 3b shows the actual workspace with the worker.
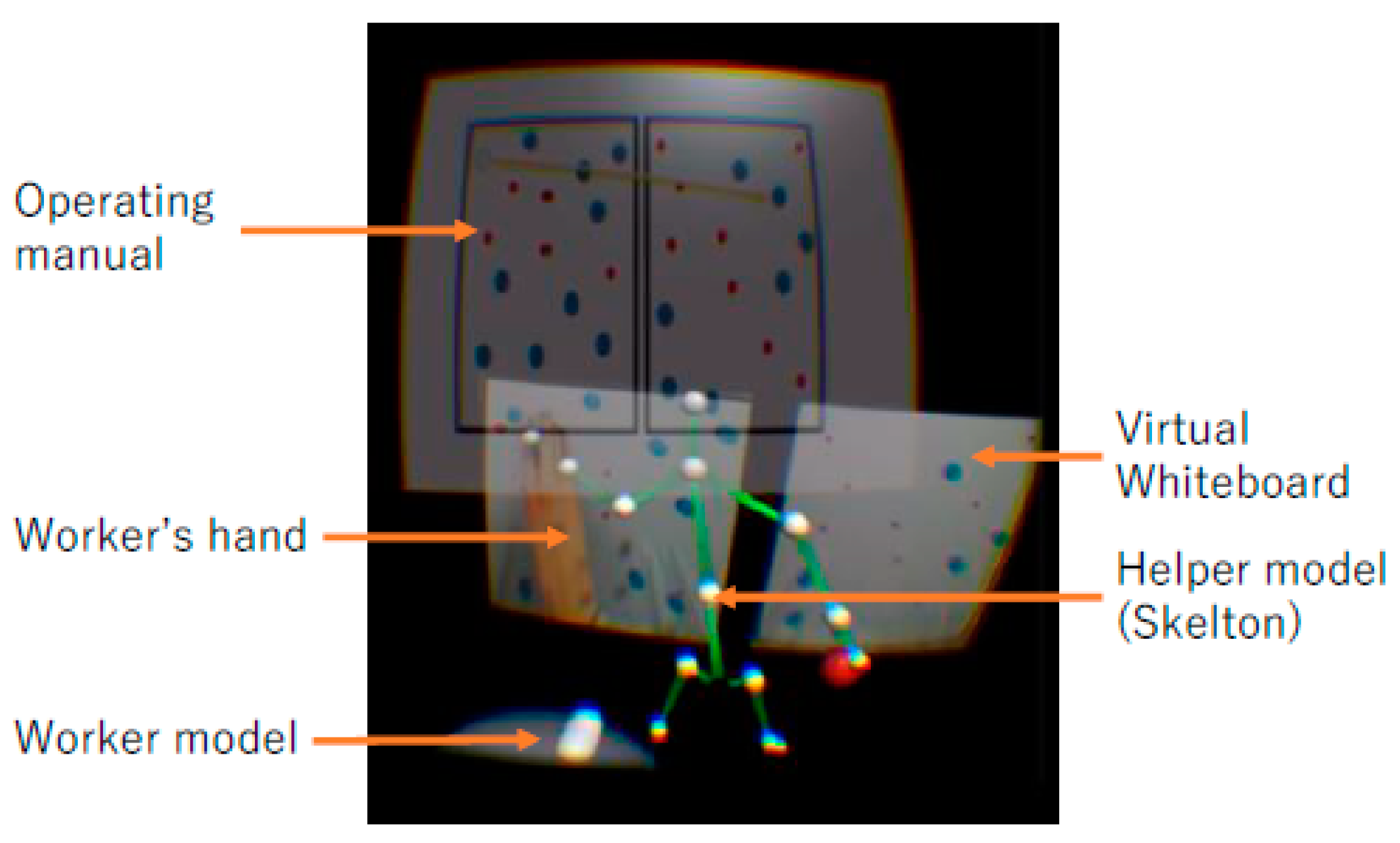
Figure 4 shows the helper’s view. The helper could observe the virtual whiteboards in the Augmented Virtual space. The surface images from the actual whiteboards within the workspace were captured and updated in real-time from images generated by the local web cameras. The system renders the information as a texture of a virtual whiteboard using a projection-transform. Additionally, the helper can also observe the worker’s virtual avatar and the helper’s own skeleton model, which is synchronized with his/her body motion. Note that the helper observed his/her skeleton from a third-person view. This design is based on the study by Wong and Gutwin [
14]. In their study, they found that, in a VR environment, the pointing task become easier when the participants could observe their own avatars from the third-person view. For the worker, however, since he/she has to actually manipulate physical objects, we decided to employ the first-person view.
4. Experiment
4.1. Objective
We conducted an experiment to evaluate the effect of non-verbal cues on task completion time by measuring the number of observed errors, and the impact of mental workload on both the helper and worker. Then, we compared the results obtained by our proposed method with those obtained by existing methods.
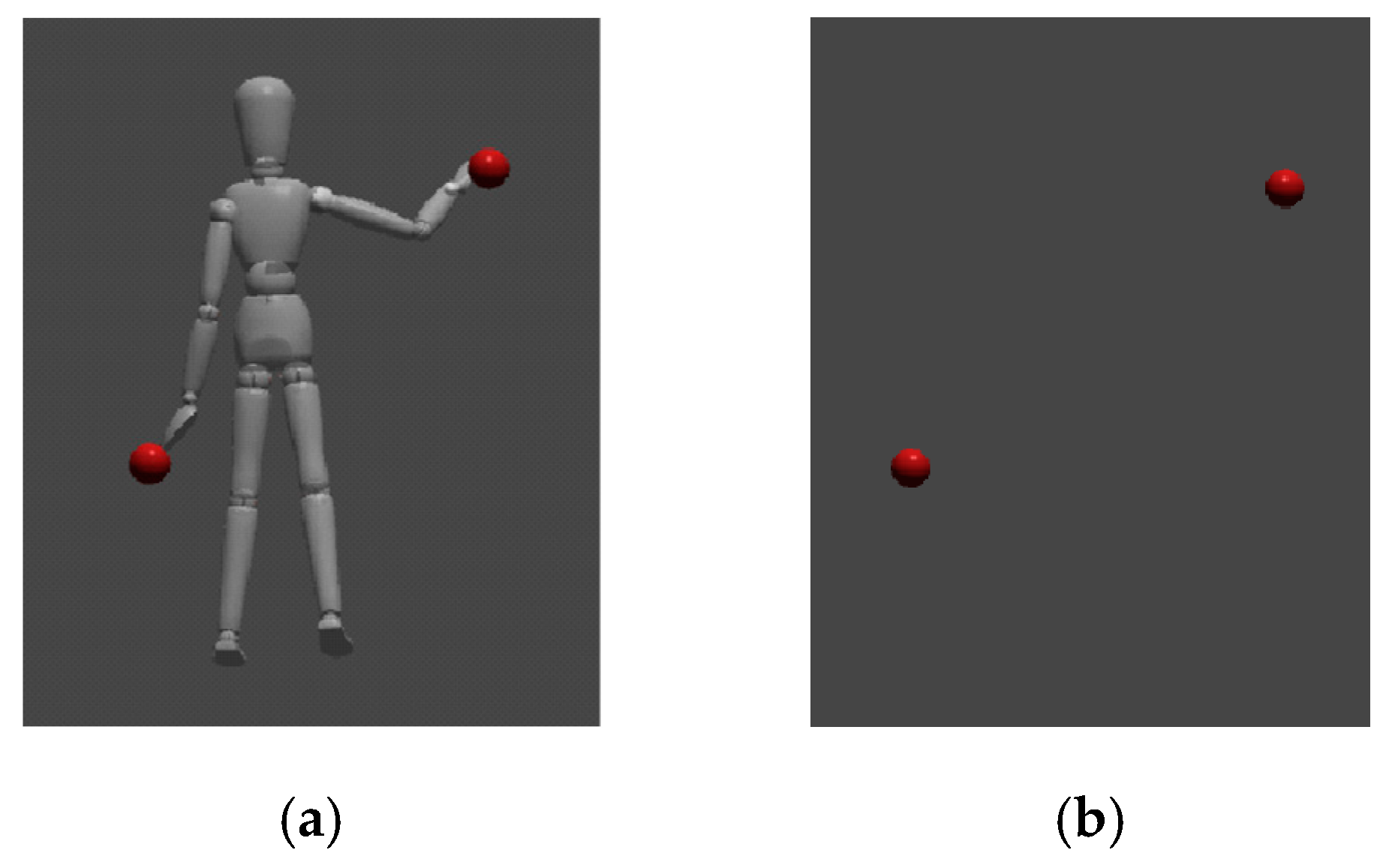
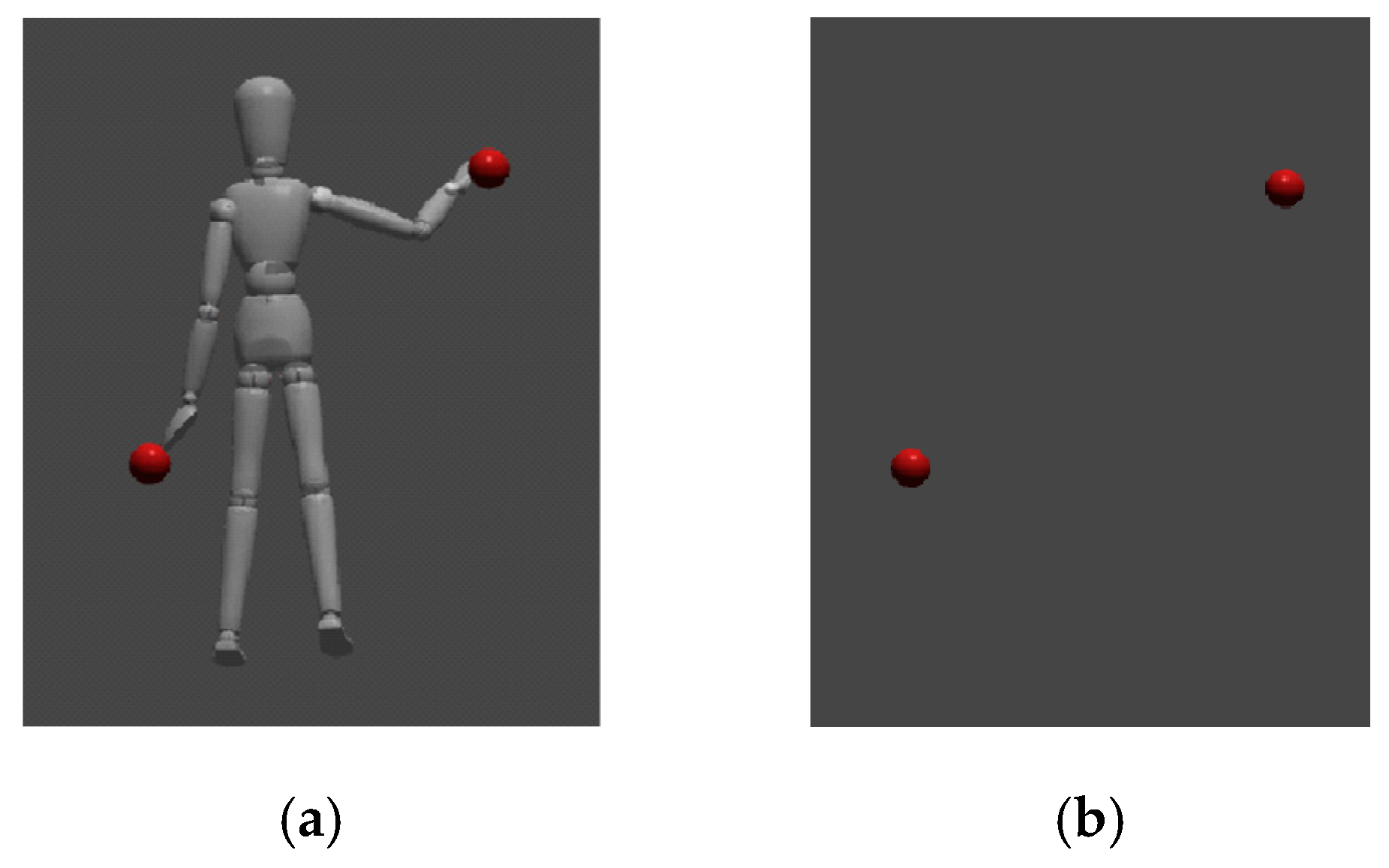
Condition 1 (proposed method): during the task, the worker observed the 3D model of helper’s entire body by using the red spherical pointers on the model’s fingertips
Figure 5a. The helper was also able to observe the 3D model of the helper’s entire body (
Figure 6).
Condition 2 (existing method): The only portion of the helper’s body that was visible was their fingertips, which are represented by red spherical pointers
Figure 5b. In this case, the worker could not observe the helper’s full-body avatar, and we assumed that this would also occur when using existing methods relying on superimposing hand gestures or using simple pointers.
4.2. Task
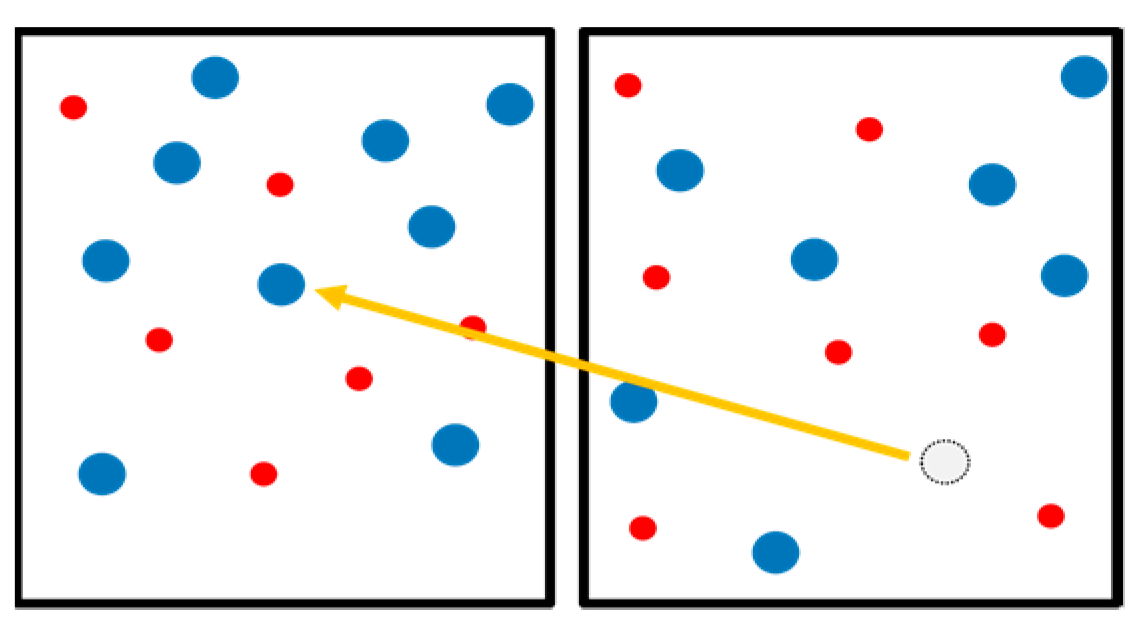
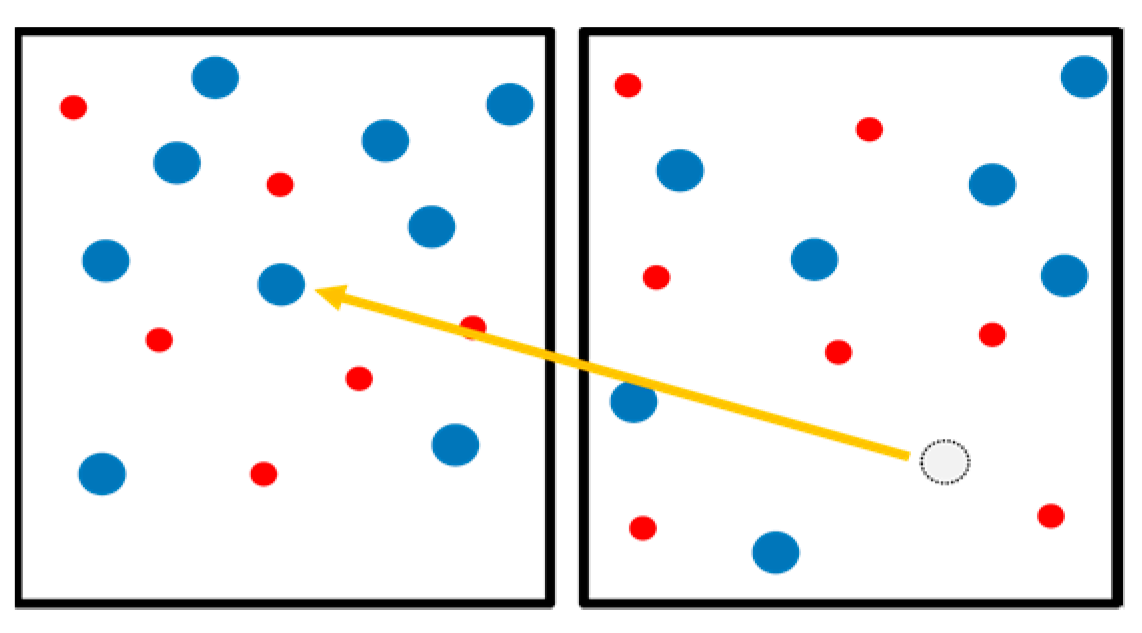
Thirty red dots were randomly placed on a whiteboard and blue magnets were placed over 16 of these dots, thus leaving 14 red dots visible. During this task, the helper asked the worker to move 10 magnets to different red dot positions. The helper followed a virtual operating manual (
Figure 7), which was rendered as semi-transparent in front of them (
Figure 4). The helper held a mouse in his/her hand and by clicking the left mouse button, he/she could toggle between a visible and an invisible manual. Furthermore, by rotating the scroll wheel, he/she could go forward and backward in the manual. This experiment was a within-subject design and each participant moved 10 magnets for each of the two conditions, which amounts to twenty moves. The participants consisted of 16 students (eight workers and eight helpers) from the University of Tsukuba (all male) aged between 21 and 30.
4.3. Procedure
The experiment consisted of the following five procedures:
- (1)
Explanation of proposed tele-guidance system: We explained the proposed tele-guidance system to each participant and described how the worker and the helper would observe the workspace from their respective positions, while their bodies are represented in virtual space. We also explained both experimental conditions.
- (2)
Explanation of the task: We explained the task to be performed (described in
Section 4.2) to each participant.
- (3)
Practice: Either worker or helper was assigned to each participant. Once a role was assigned, each participant practiced under the two experimental conditions until he/she thought they fully understood the requirements of his/her role. We prepared practice tasks which are used only for this practice phase.
- (4)
Experience the baseline modes: The participants executed the task in two baseline modes:
They did not use the system, so the helper and worker were side-by-side, the task was executed using the tele-guidance system, which was modified to exclude the models representing the helper and worker. The worker executed the task according to vocal instructions from the helper. We also prepared different practice tasks for this phase. Each participant used the experiences with these modes as reference points when evaluating the two conditions. We considered that (a) was the best case and (b) was the worst case. The details of the evaluation are discussed in (6).
- (5)
Conducting the experiment: The participants performed the task in two conditions, condition 1 and condition 2. The order of the conditions was counterbalanced. We also included two movement patterns that were not used in previous phases, and the order of these patterns were also counterbalanced. We recorded the behaviors of the worker and helper, captured the view from their HMDs, and counted their movement errors, which occurred if the worker touched an incorrect magnet or moved the magnet to an incorrect position. Based on the video analysis, we measured the task completion time.
- (6)
Questionnaire and interview: The participants were given a questionnaire to be answered upon completing each condition. Questions Q1 through Q6 are based on NASA-TLX [
15]. The content of question Q7 was “how much did you feel the presence of your co-worker during the task?” (
Table 1). We used a 7-point Likert scale (1: Lowest, 7: Highest) for questions Q1 through Q7. Finally, we used visual analogue scale (VAS) for Q8 [
16]. In this question, we asked him/her to rate the usefulness of the two techniques on a 100 mm line: The evaluations of the side-by-side technique were placed on the left, while the evaluations of using a tele-guidance system without a helper and worker model were placed on the right. These are the conditions mentioned in (4). Finally, we interviewed the participants after the experiment. The entire process lasted approximately 90 min.
4.4. Results
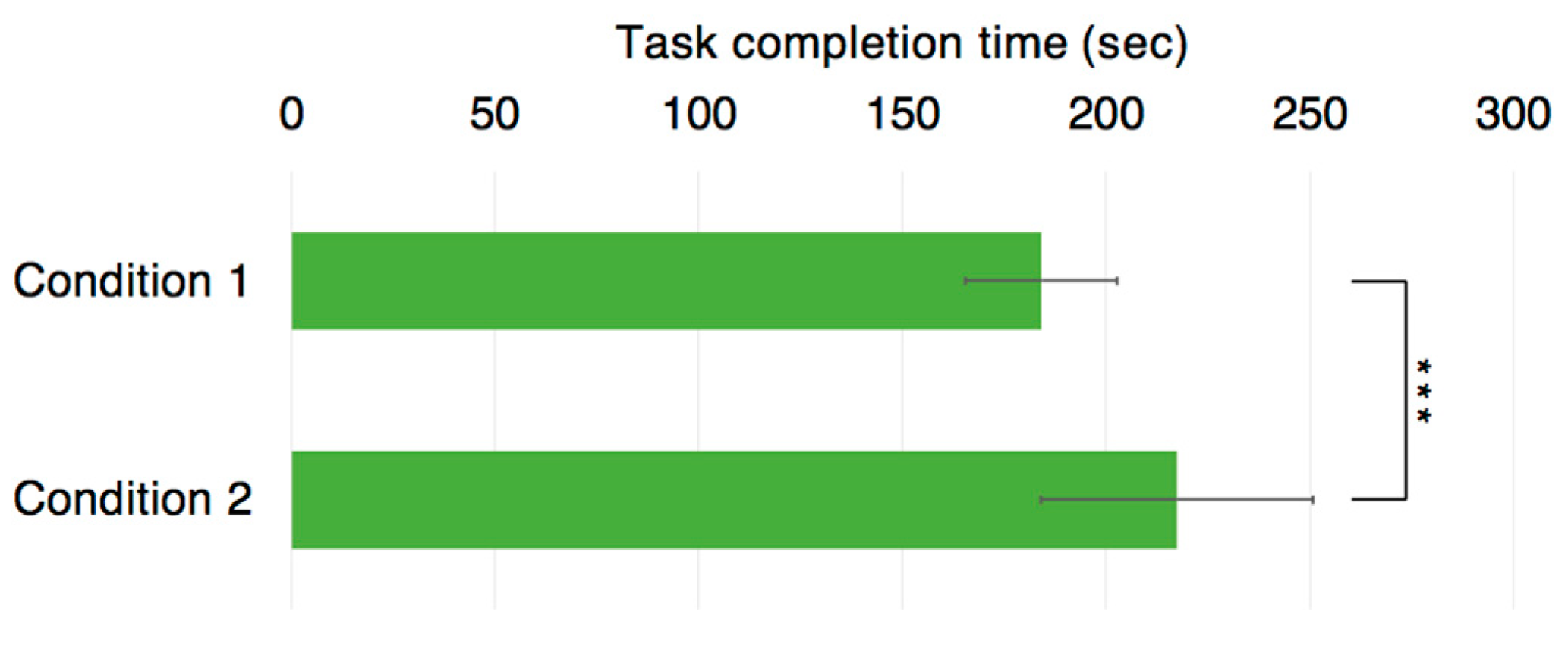
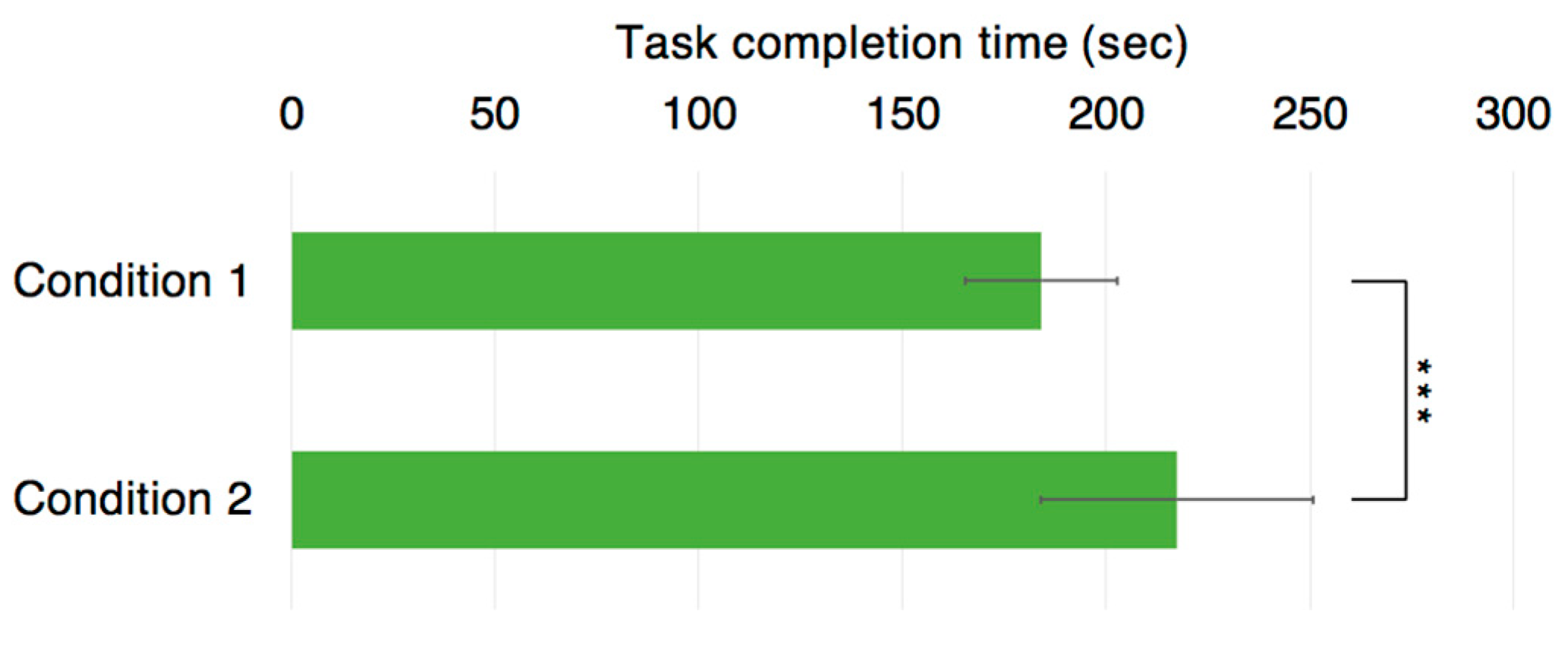
We compared the results obtained by the proposed method (Condition1) with the results obtained by existing methods (Condition2). The task completion time (
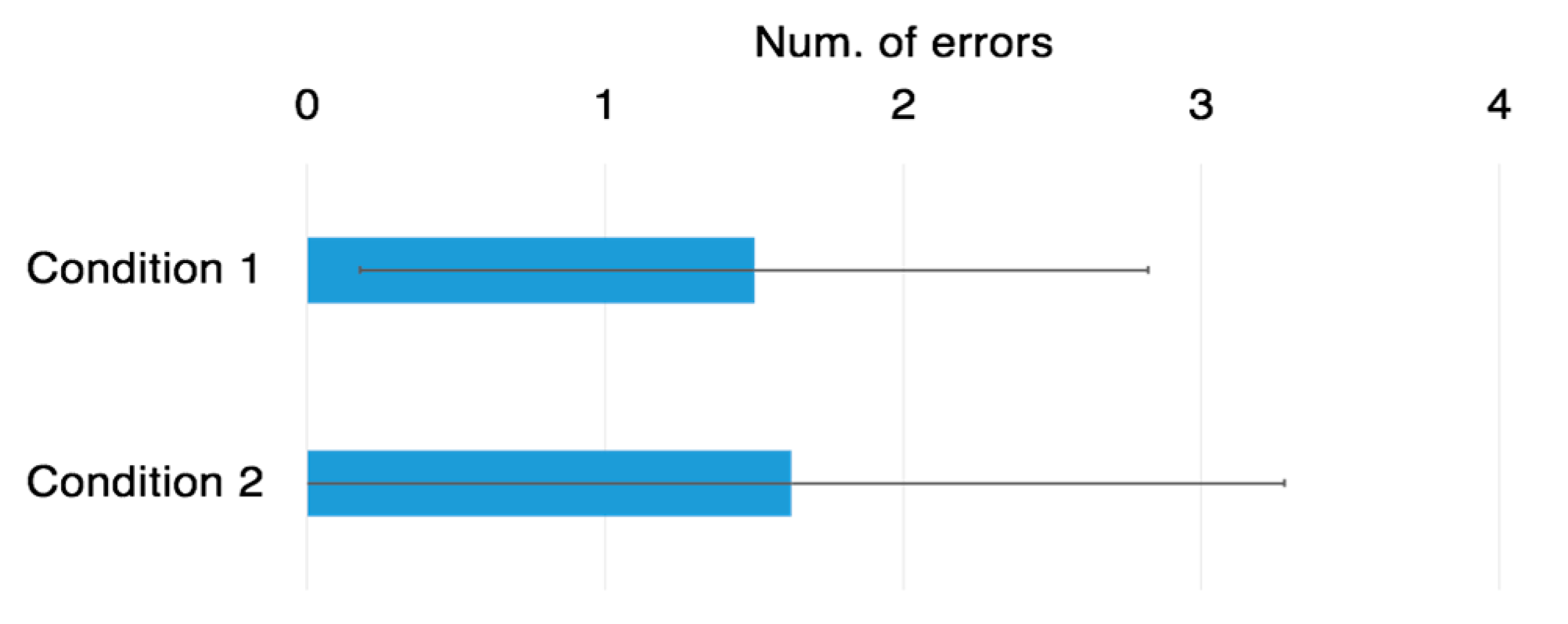
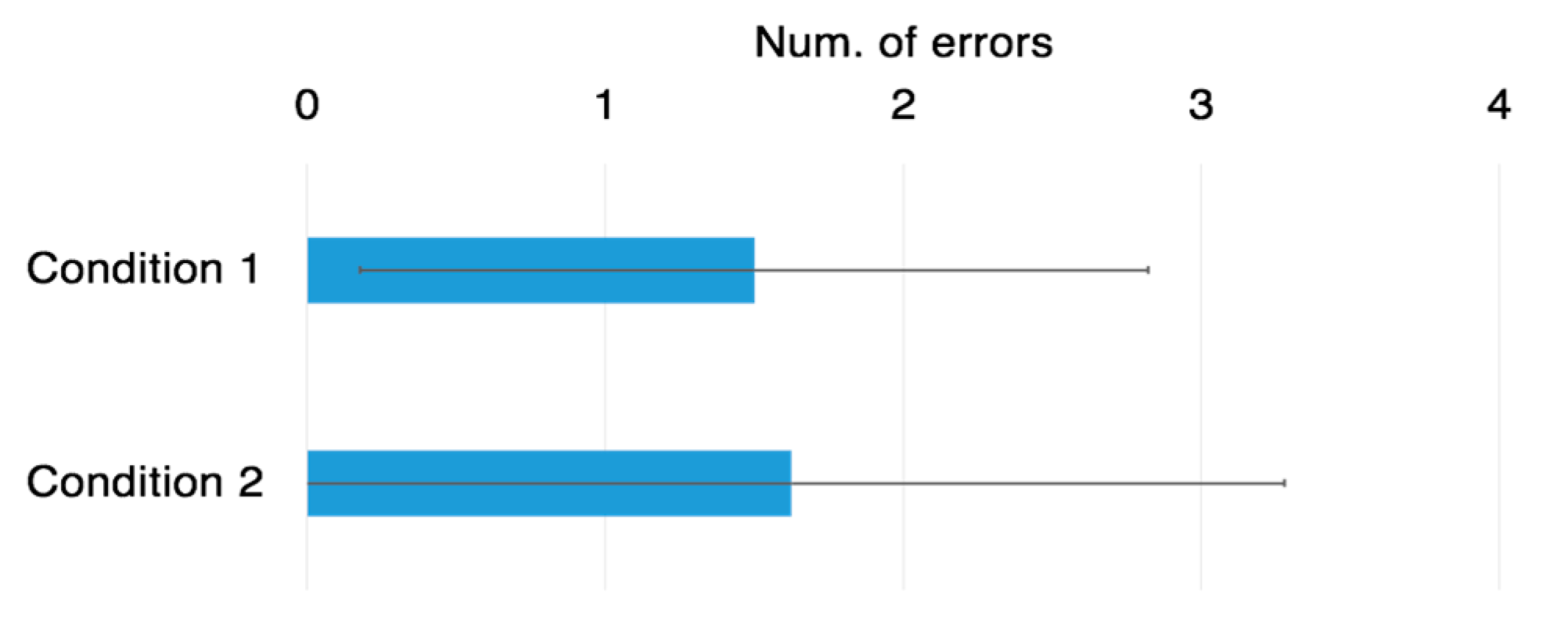
Figure 8), average number of errors (
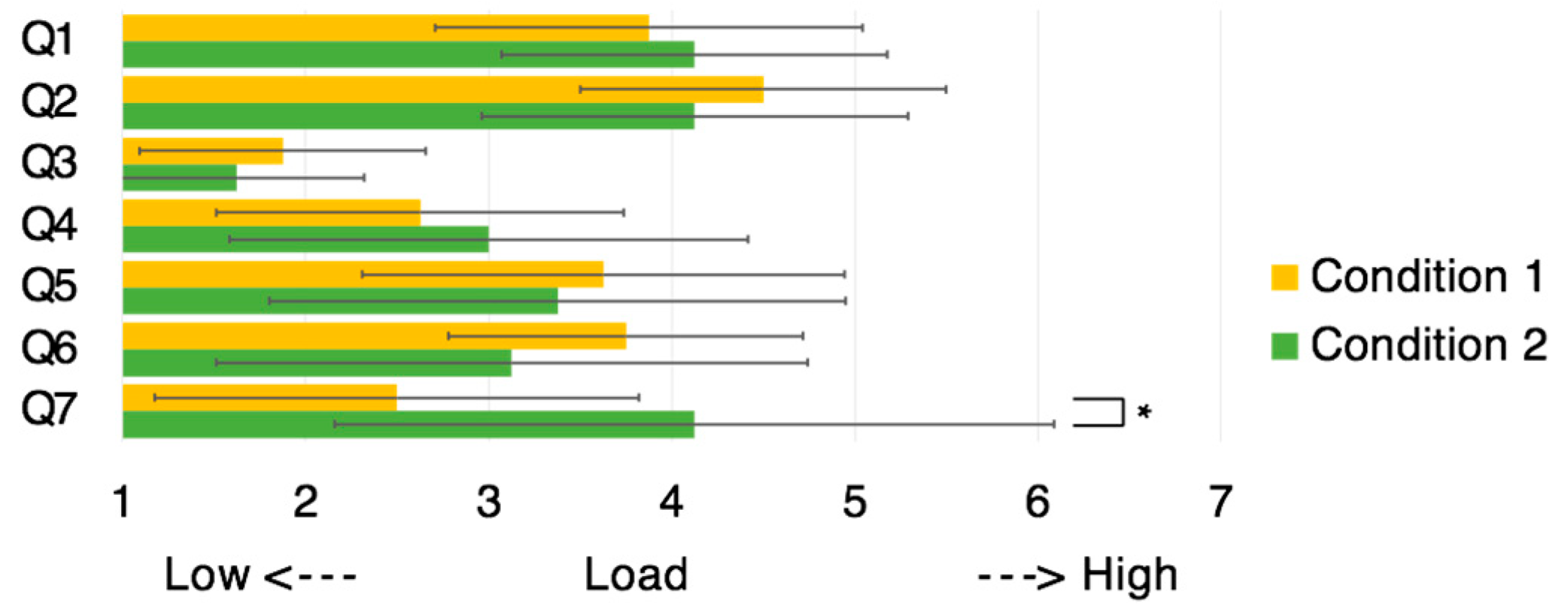
Figure 9), average score of mental workload recorded from Q1–Q7 (
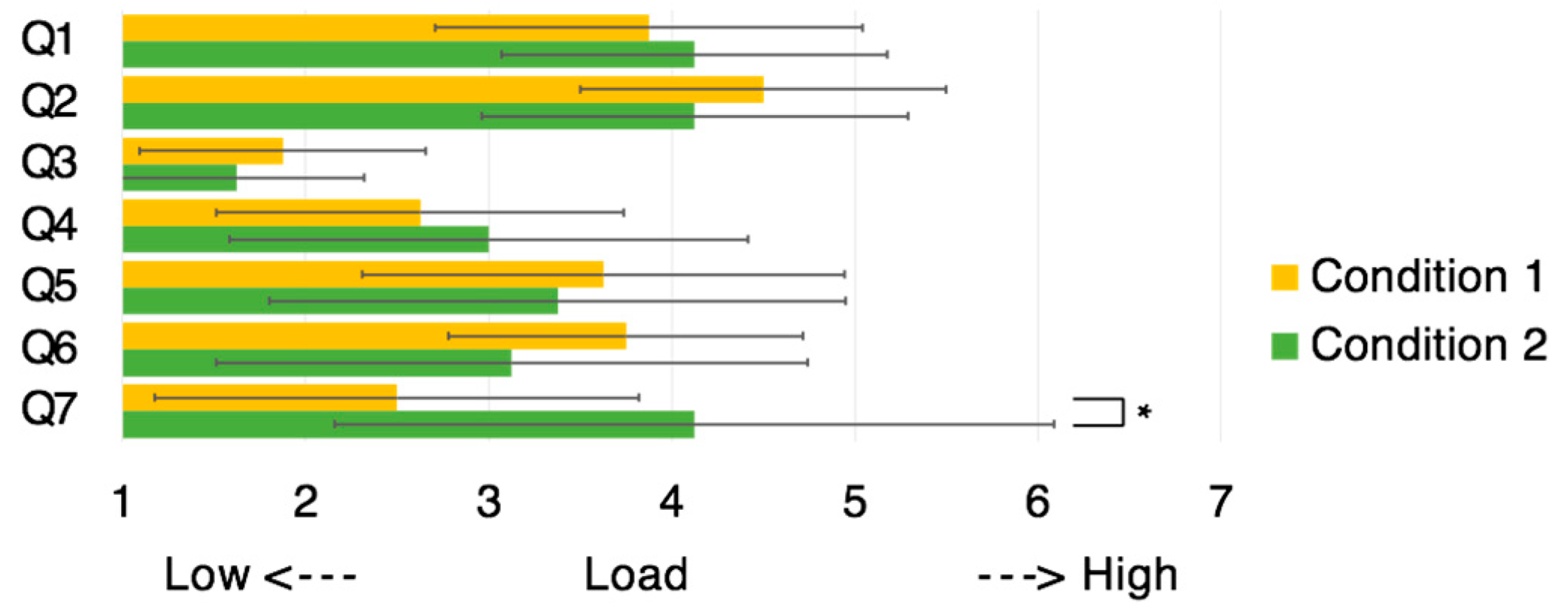
Figure 10 shows the helpers’ responses and
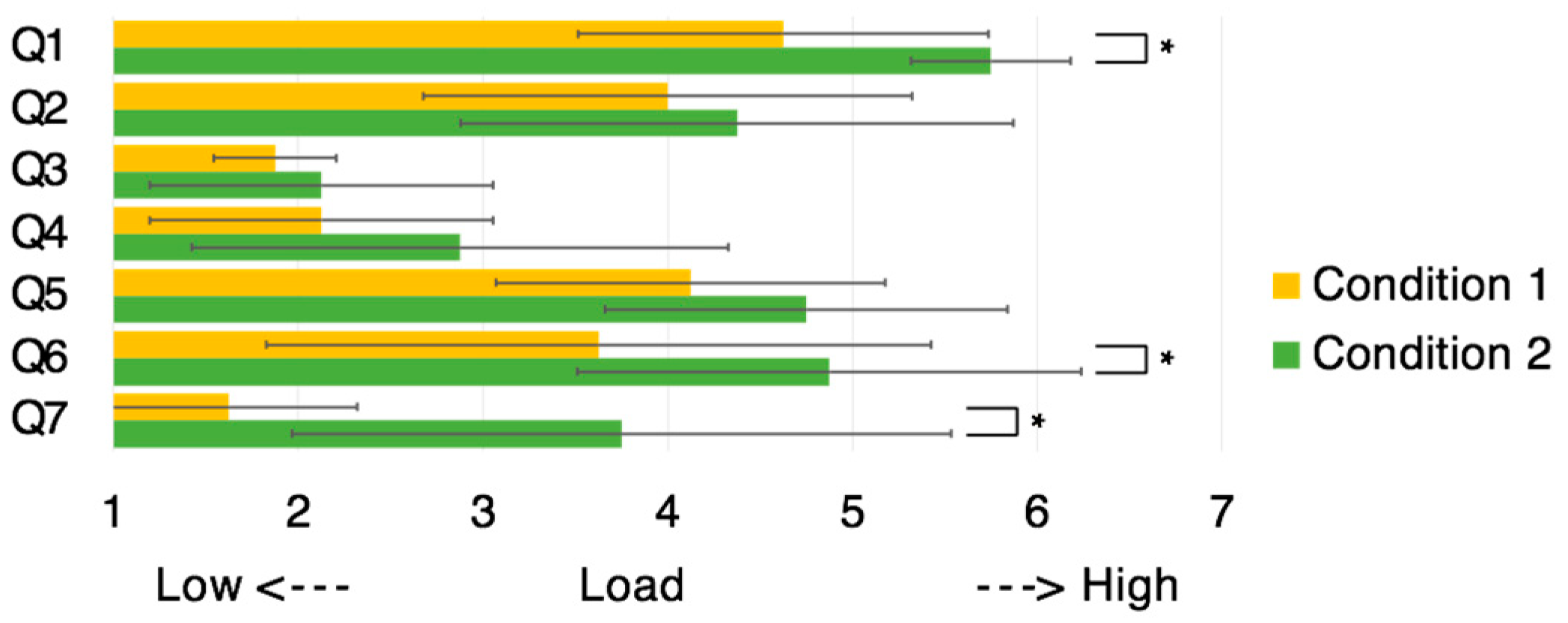
Figure 11 shows the workers’ responses), and average score of proposed system’s usefulness (Q8) (
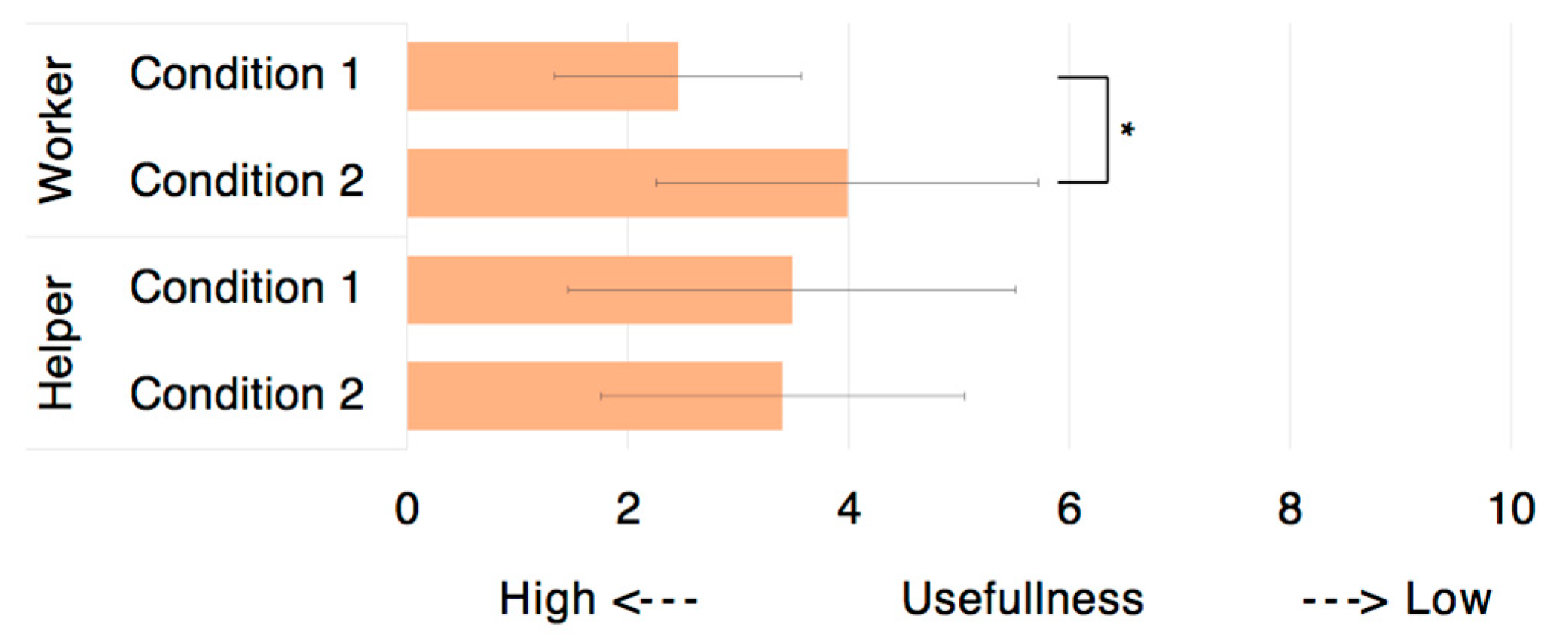
Figure 12) were considered in the comparison.
We analyzed the data using a paired t-test. As a result, the average task completion time of the condition 1 (proposed method) was significantly faster than that of condition 2 (p < 0.01). Conversely, the average number of errors was not significantly different between the two conditions.
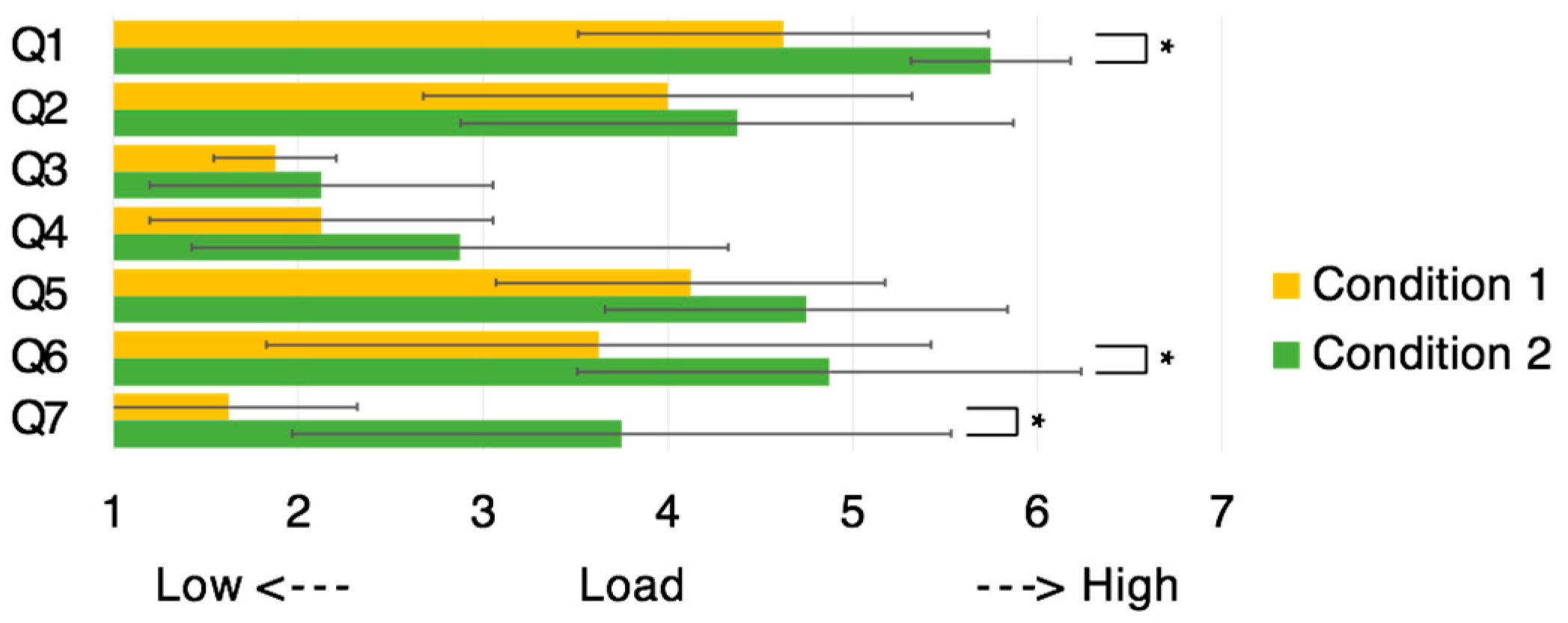
Regarding the helper questionnaire, only the responses from a single question, namely, Q7, were significantly different between the two conditions (p < 0.05).
The responses to the worker questionnaire exhibited significant differences (p < 0.05) for questions Q1, Q6, and Q7 (how much did you feel the presence of your co-worker during the task?). There was a marginal difference (p < 0.1) for question Q4.
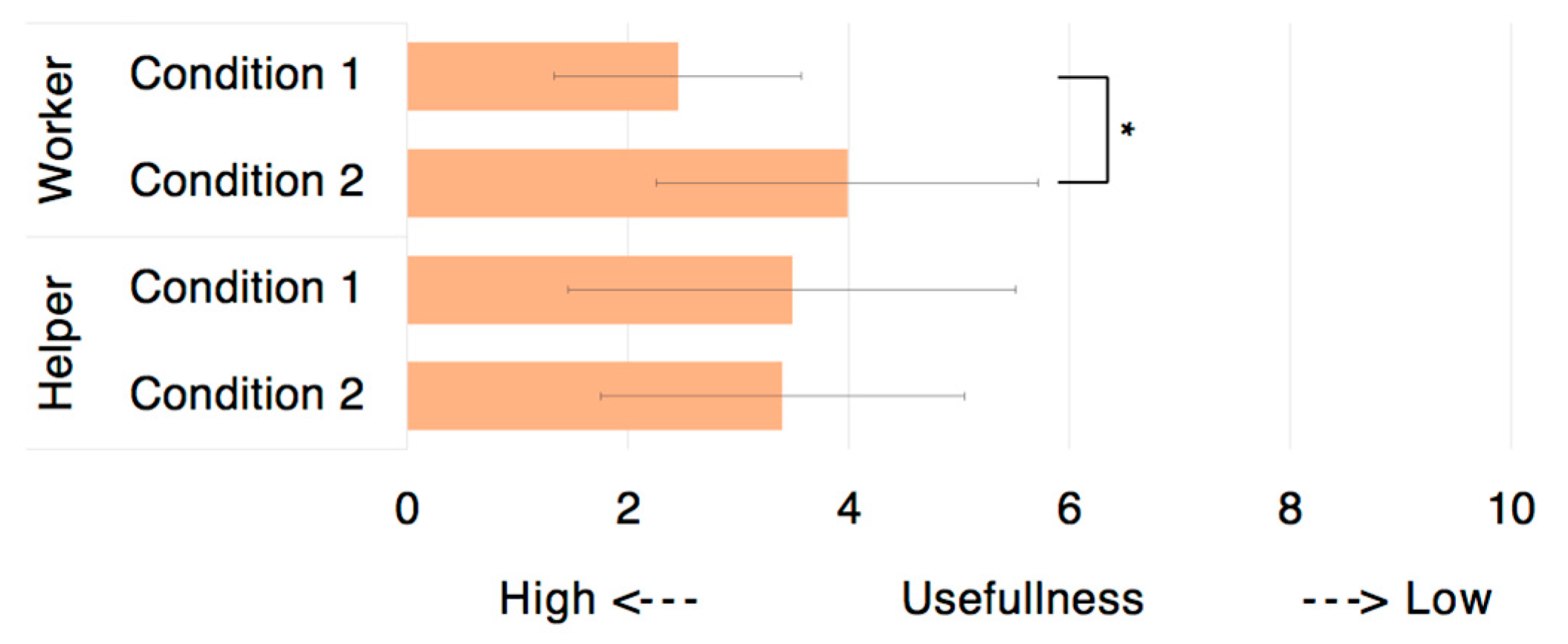
Regarding Q8 the proposed tele-guidance system was perceived to be significantly better only for the worker (p < 0.05).
5. Discussion
5.1. The Task Completion Time
We conducted our remote collaboration experiment using a wide workspace. We compared the case that used the proposed method and the case that used only pointers and voices, and evaluated the effect of non-verbal cues on task efficiency, the impression toward the interlocutors, and mental workload.
Figure 8 shows that the average task completion time for condition 1 (the proposed method) was significantly shorter (
p < 0.01) than that of condition 2 (the existing method). The difference between the two conditions was the representation of the helper model (full-body avatar or pointer) and the existence of the worker model (existent or non-existent). We discuss the aspect of mental workload in the following subsection as we assume if affects task efficiency.
5.2. Effect of Showing a Worker Model to a Helper
We first take a look at the helper’s mental workload. As shown in
Figure 11, the existence of a worker model, which was presented in the helper’s view, did not affect the mental workload of the helper (Q1–Q6). Conversely, the responses to Q7 indicates that the sense of the worker’s presence was significantly stronger when the worker’s model was shown.
Interestingly, however, in the interview, when we asked the helpers if they noticed any difference between the two conditions during the task, all helpers answered “no difference” or “not much difference”. Additionally, four helpers commented: “I felt the presence of the worker during the task but I thought it was not significant for task completion.”
The size of the workspace may explain the answer to the previous question. In this study, we assumed that workers move freely in the workspace during the task. However, because the workspace (two whiteboards) was 160 cm wide, the workers could complete all tasks while moving within less than 160 cm. When the helpers indicated any point on the whiteboards and the helper believed that the worker was close to him/her (regardless of the presence of the worker’s model) the worker was able to reach the target point immediately. Thus, in this experimental environment, it did not matter if the helpers were unable to feel the worker’s presence. Additionally, because the worker model indicated the location of the worker’s body but not body motion, it is possible that the helpers could not feel the presence of the worker.
In other comments, three helpers remarked that “the worker model frequently occluded the whiteboards”. Thus, in this experimental environment, the worker model may have disturbed the performance of a task.
5.3. Effect of Showing a Helper Model to a Worker
Next, we discuss the effect of the helper’s model that we presented to the worker. As discussed in
Section 5.2, because the existence or non-existence of the worker model was not effective for the reduction of the Helper’s mental work load, it is possible that it was mainly the helper model that reduced the task completion time.
The worker questionnaire responses (
Figure 10) show significant differences (
p < 0.05) for questions Q1, Q6, and Q7. These results revealed that the existence of the helper’s model partially reduced the mental workload. Additionally, regarding Q8, the system was significantly more useful (
p < 0.05) under the condition of the worker being able to observe the helper model.
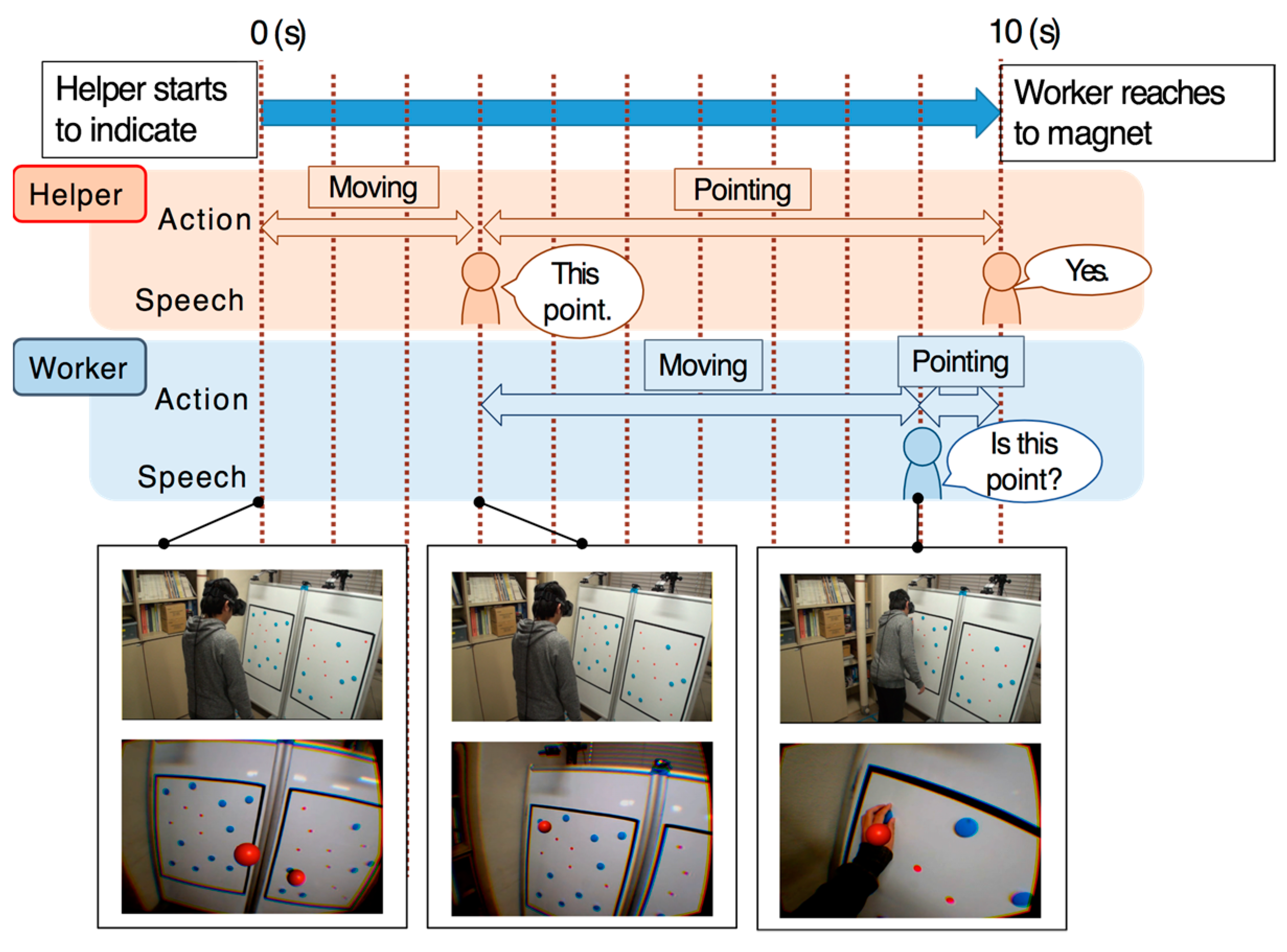
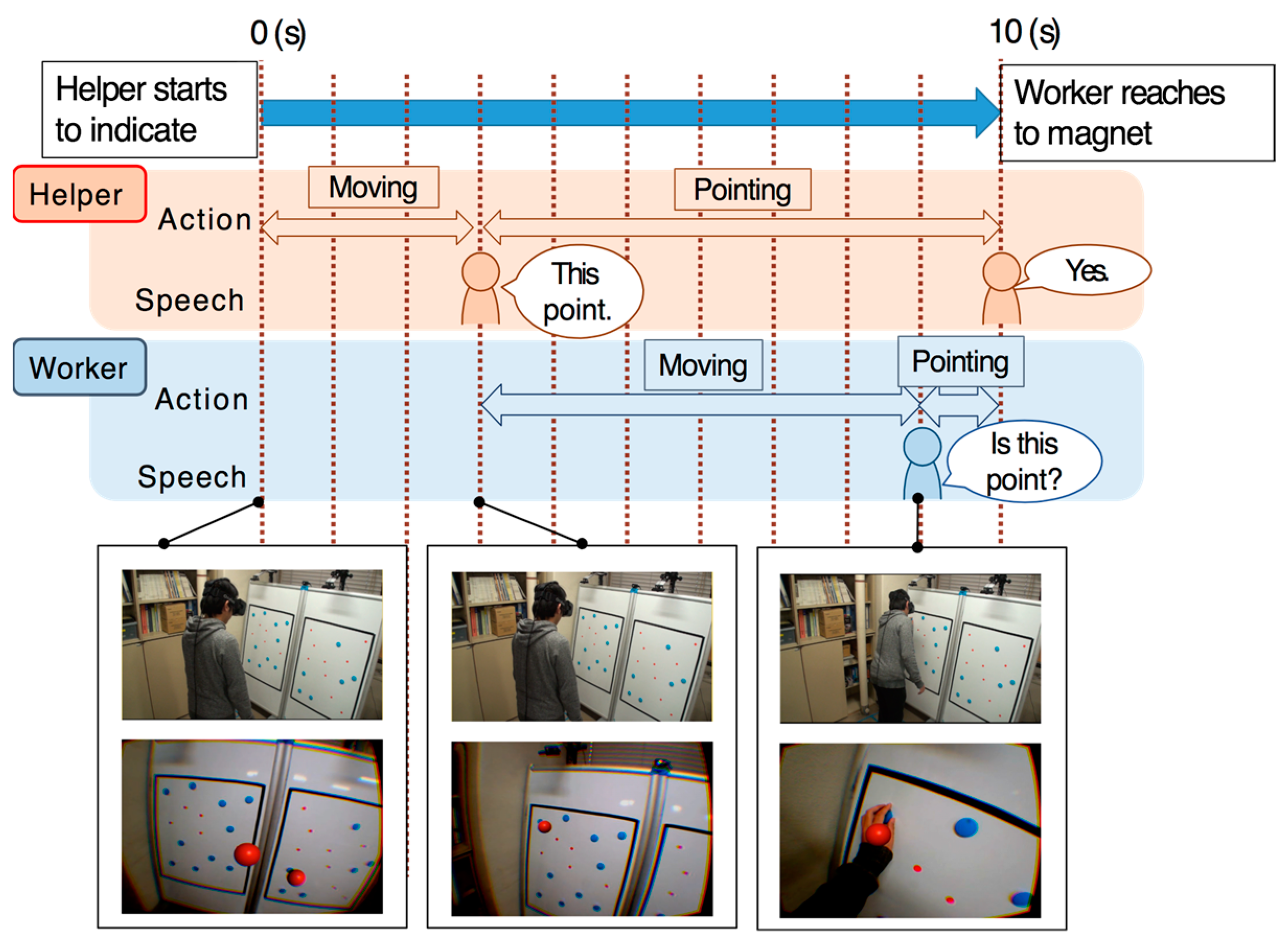
The results obtained by this experiment indicate that the system can improve the efficiency of task execution and reduce the worker’s mental workload by providing the helper’s model to the worker. Additionally, when we interviewed the participants after the task was completed, seven workers commented that they were able to identify the helper’s orientation more easily when they could observe the helper model. Based on video analysis of condition 2, the workers tended to confirm the indicated point to the helper (
Figure 13). The conversation between the helper and the worker is presented below.
(The helper points at the target)
Helper: “this point.”
(The worker moves toward the target)
Worker: “here?” (points at the target)
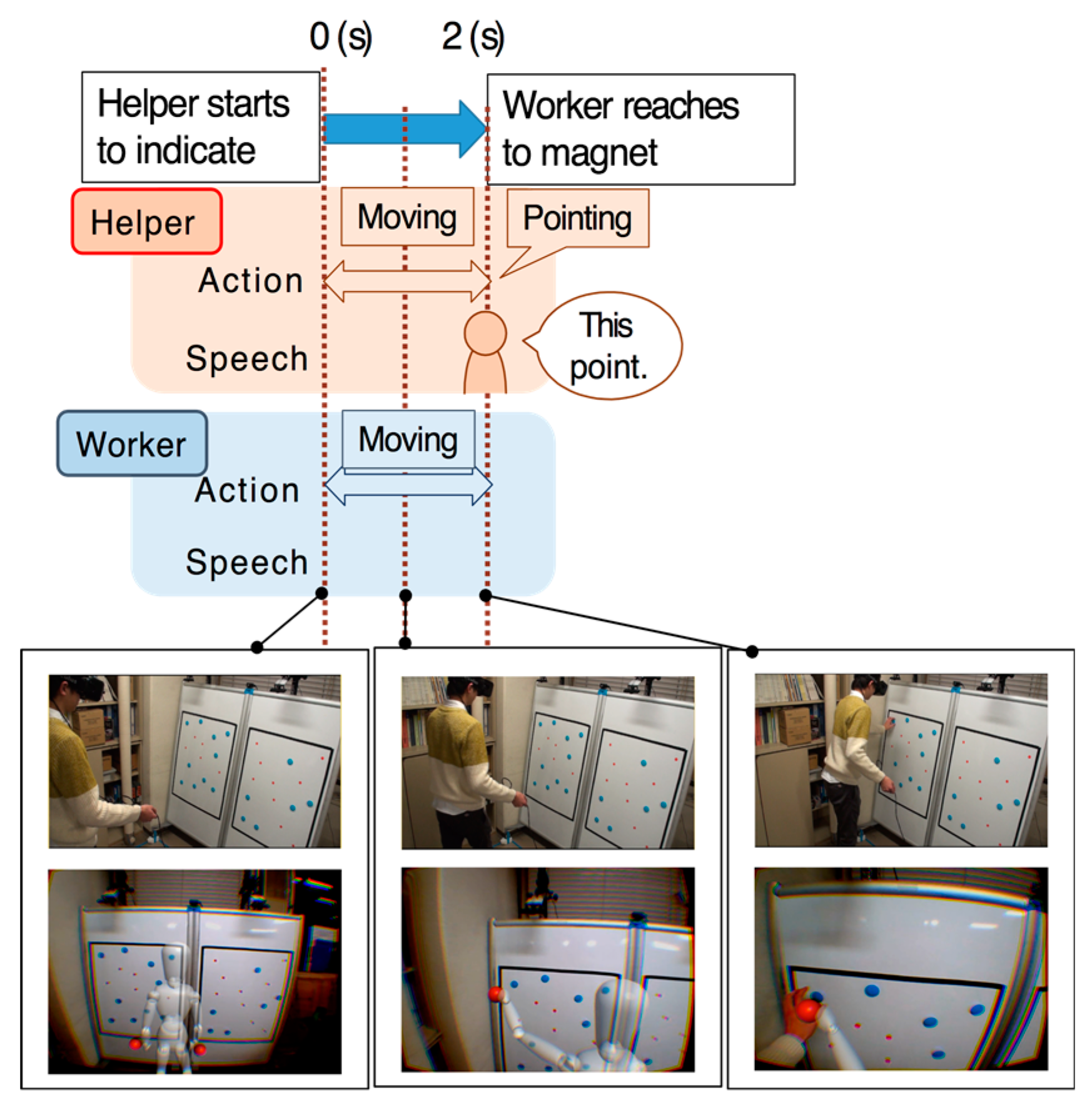
Under condition 1, the worker tended to start moving toward the target almost at the same time that the helper began to reach out to the target (
Figure 14). We are assuming that, under condition 1, the worker was able to realize the helper’s body position and anticipate the helper’s next move by observing the body motion of the helper. Conversely, under condition 2, the worker was not able to realize the helper’s orientation, and began to move only after receiving verbal indication from the helper.
Additionally, in condition 2, two pointers of the helper model were always visible. Seven workers commented that they were confused when identifying the pointer used when the helper said “this point”. This fact indicates the effectiveness of enabling to observe the helper’s body orientation by presenting his/her full-body avatar.
Based on these results, we believe that our proposed system is particularly effective for workers, owing to its overall impact on task completion, which results from understanding the helper’s non-verbal cues such as body motion, orientation, and location.
7. Conclusions and Future Work
In this study, we proposed an AR tele-guidance system that supports communication in a relatively large workspace. Our system enables a helper and a worker to anticipate each other’s actions by assisting both of them in observing each other’s non-verbal cues. We conducted an experiment to compare the effectiveness of our proposed method with the effectiveness of existing methods (a simple tele-pointer) with regard to supporting the anticipation of an interlocutor’s actions during communication. The result revealed that a task can be completed in a more efficient manner and reduce the worker’s mental workload by using a helper model to demonstrate the helper’s non-verbal cues, such as body motion, orientation, and location, which have a positive impact on the task efficiency.
In our planned future work, we will improve the worker’s model to represent full body gestures. We are also planning to test our method within a larger and more complex 3D environment. Furthermore, related works have given us ideas to improve our system. For example, Piumsombon and colleagues have showed the effect of visualizing the interlocutors’ field of view [
17,
18]. Gauglitz and colleagues showed that additional visual annotations such as arrow cursors and drawings by a helper are effective in improving the remote collaboration [
8,
9]. We are interested in incorporating these features into our system. However, because too many annotations may obscure other important visual information (e.g., real objects) or increase the mental workload, we have to figure out the appropriate quantity of information to improve the remote collaboration most efficiently.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}