Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation



Abstract
1. Introduction
2. Related Work
3. Feature Transformation
4. Experiment
4.1. Pilot
- Visualisation generated by PCA. This is the same as the first condition in the final experiment (as described in Section 4.2).
- Static Feature Transformation. The visualisation in this condition included the distortion introduced by the feature transformation. However, the user was not allowed to change the level of distortion, so the visualisation was static.
- Interactive Feature Transformation. This is similar to the previous condition, but users could interactively change the level of distortion introduced by feature transform. This is achieved through a slider that changes the value.
- Both Feature Transformation conditions performed better than the PCA condition. However, this is partly due to the fact that they utilise the clustering information, whereas PCA does not. We believe that this gave the two Feature Transformation conditions unfair advantage. As a result, we decided to introduce a new DR technique that also uses the clustering information.
- There was large variation in the performance of the interaction feature transformation condition. One participant always set the to the maximum value. As a result, each cluster transformed into a single point and the tasks became trivial. To avoid this scenario, we removed the interactive feature transformation condition, and replaced it with two static feature transformation conditions that have low and high level of distortion respectively.
4.2. Conditions
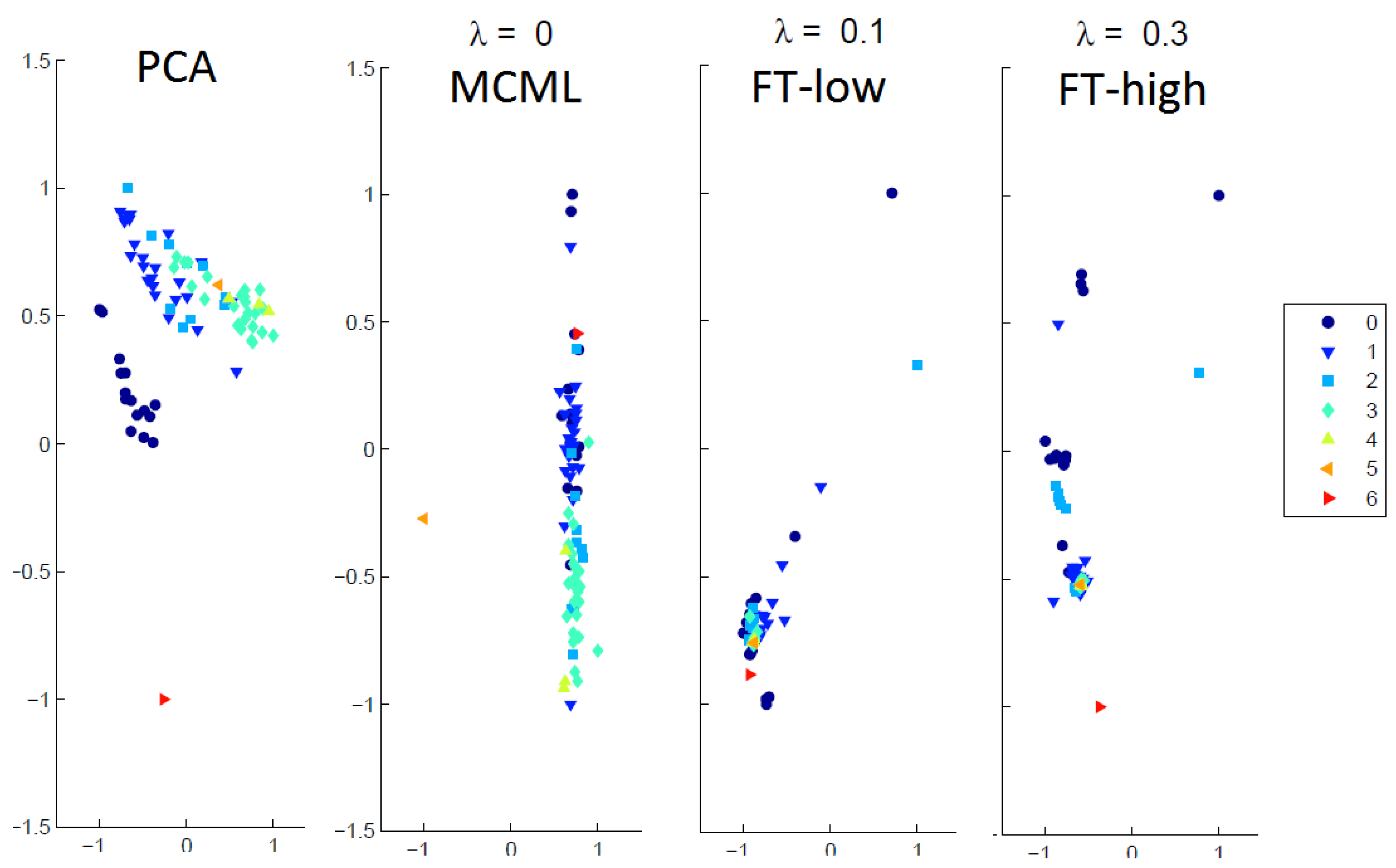
- Visualisation generated by PCA. The PCA is used as an example of DR technique that does not utilize clustering information. While it is possible to include additional DR method such as MDS, it will make the experiment overly long (it is close to one hour already with the four conditions) and it is not the focus of this study to compare DR techniques that do and do not use clustering information.
- Visualisation generated by MCML. This represents supervised techniques that take into account the class labels information during dimension reduction, since feature transformation also requires class information. This should produce visually more separated results than PCA because of the additional class labels information. Because feature transformation is independent of the DR technique used, any technique that uses class label can be used, so long as it is also used in the two feature transformation conditions.
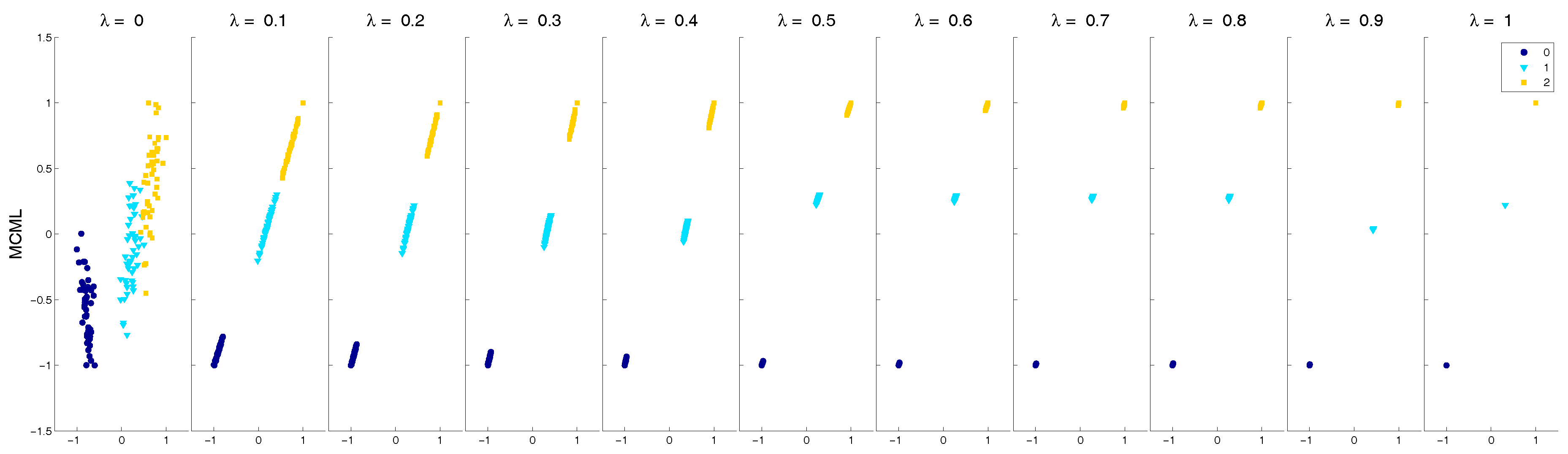
- Visualisation generated by low-level feature transformation distortion (FT-low), based on the results of MCML. The visualisation in this condition includes low level distortion introduced by the feature transform, and the user was not allowed to change the level of distortion. A small value was selected manually to ensure considerable visual difference from the MCML condition. This is to emulate the scenario when a low level of distortion is introduced through interactive feature transformation.
- Visualisation generated by high-level feature transformation distortion (FT-high), based on the results of MCML. This is similar to the last condition except that the distortion level was higher. A larger value was selected manually to (1) ensure considerable visual difference from the FT-low condition; and (2) avoid reducing the question to a trivial task, e.g., every cluster is reduced to a single point. This is to emulate the scenario when a high level of distortion is introduced through interactive feature transformation.
4.3. Tasks
- Clustering: The participants were asked to identify visually the number of clusters in the display. This is to test how well the resulting visualisation reveals the clustering structure within the original high-dimensional dataset.
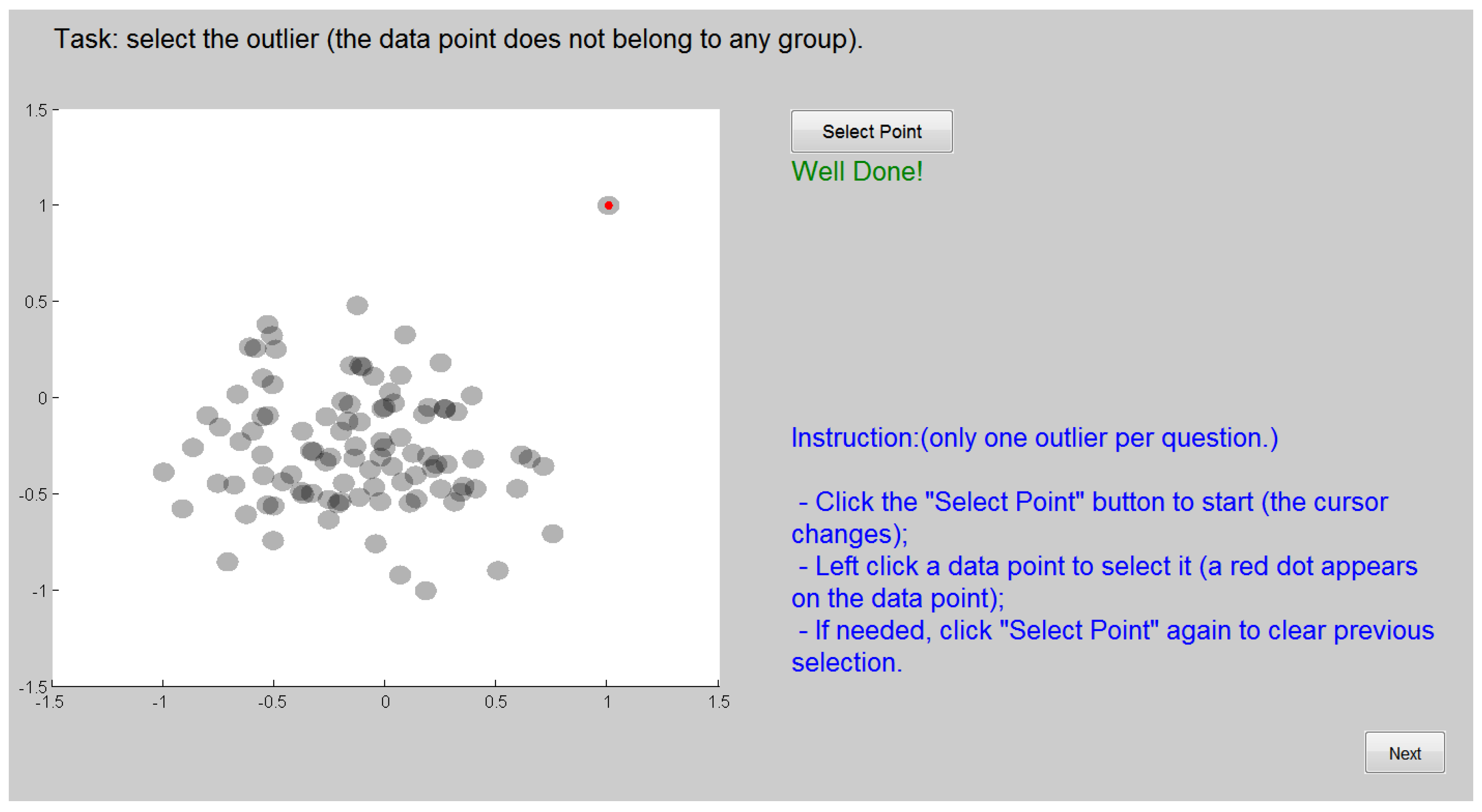
- Outlier: Similarly, this task requires participants to identify visually an outlier within the original dataset, which is another important property of high-dimensional data. To simplify the accuracy measurement, each dataset has exactly one outlier, so the answer can be either correct or incorrect. This avoids the case of ‘partially correct’ answers when there are two or more outliers.
4.4. Datasets
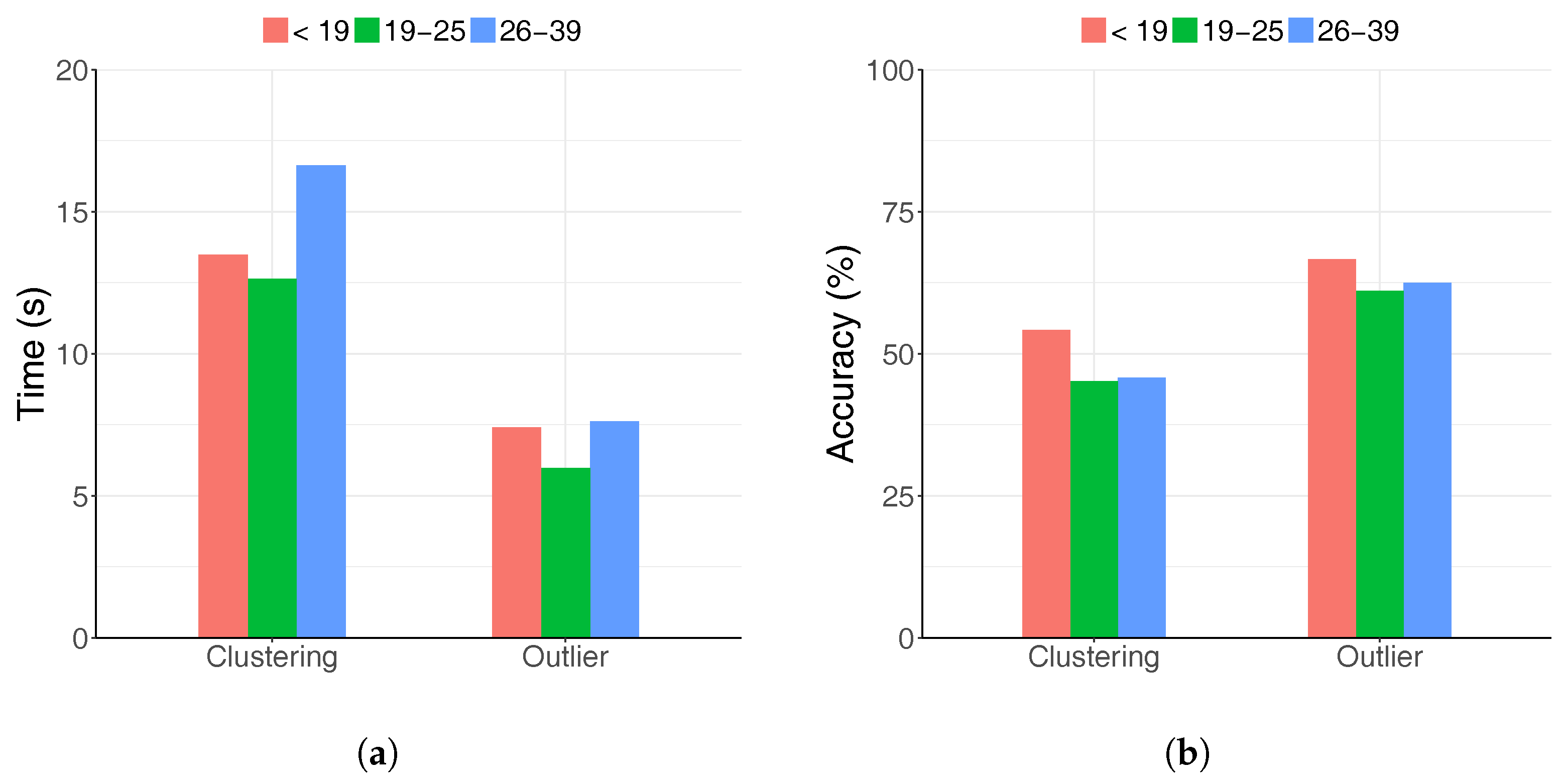
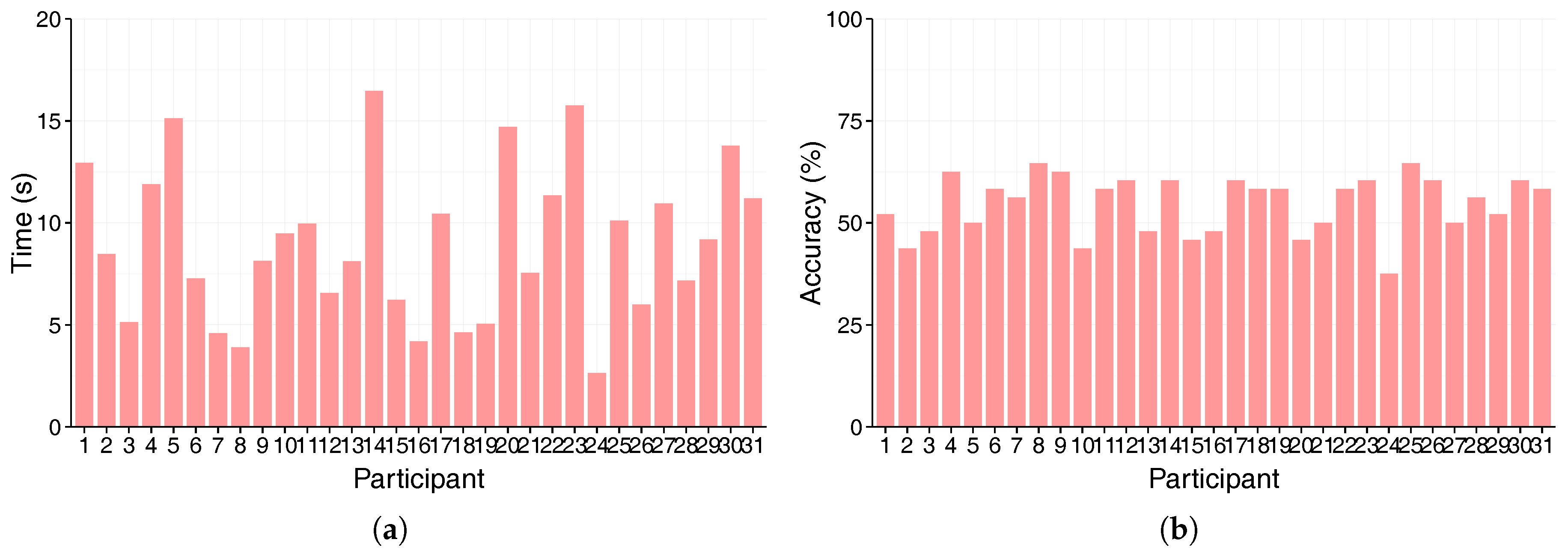
4.5. Participants and Procedure
4.6. Hypotheses
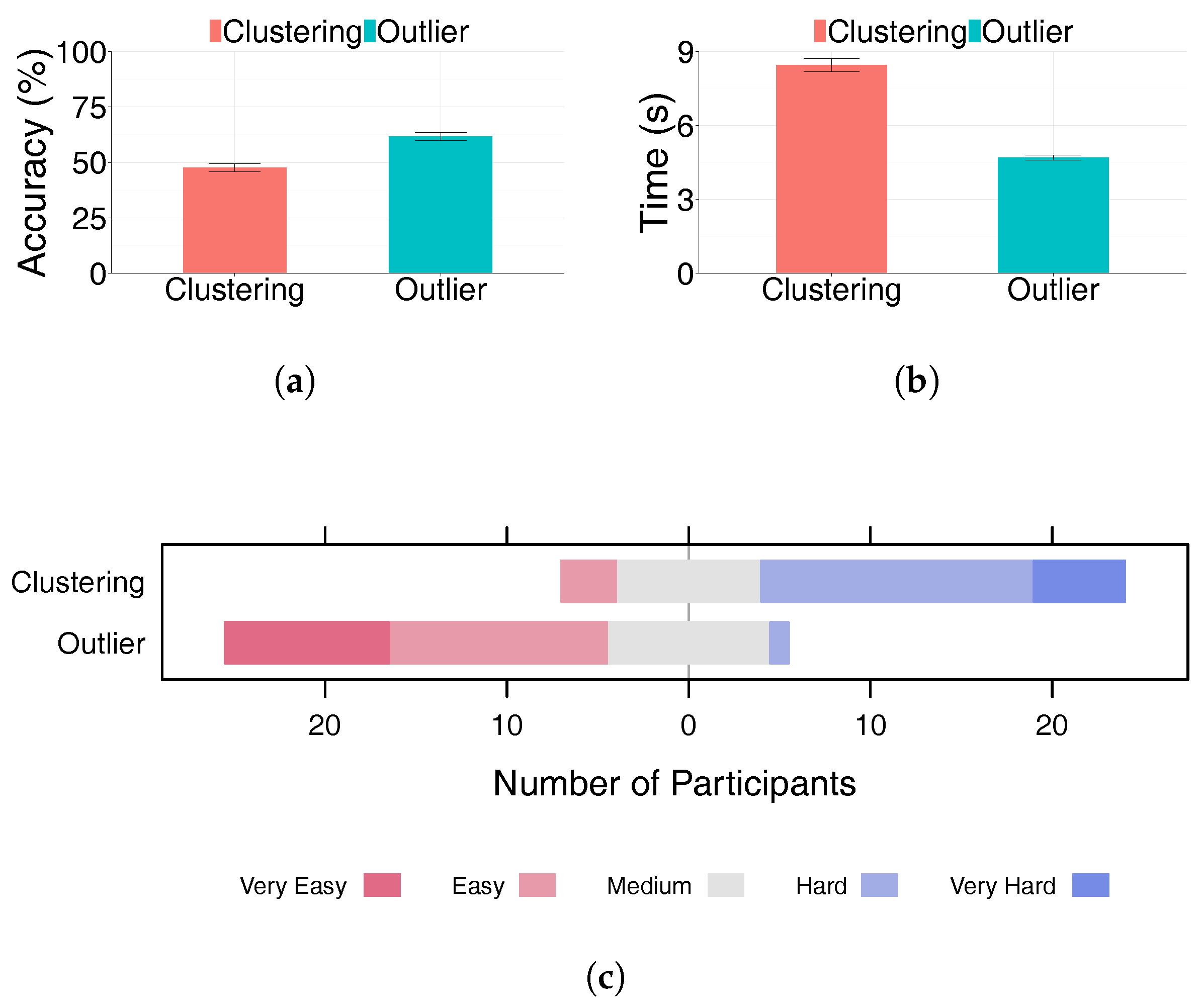
5. Results
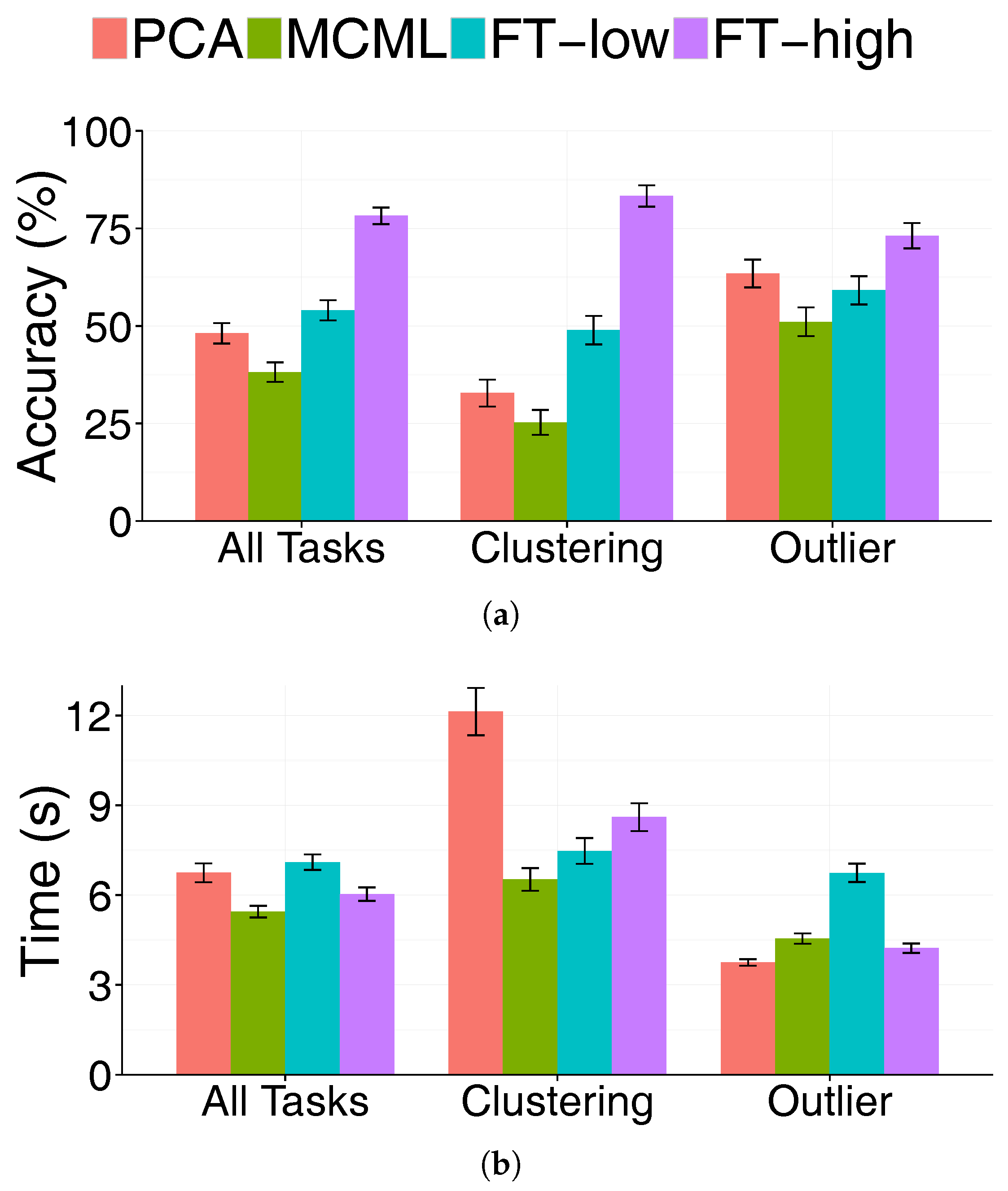
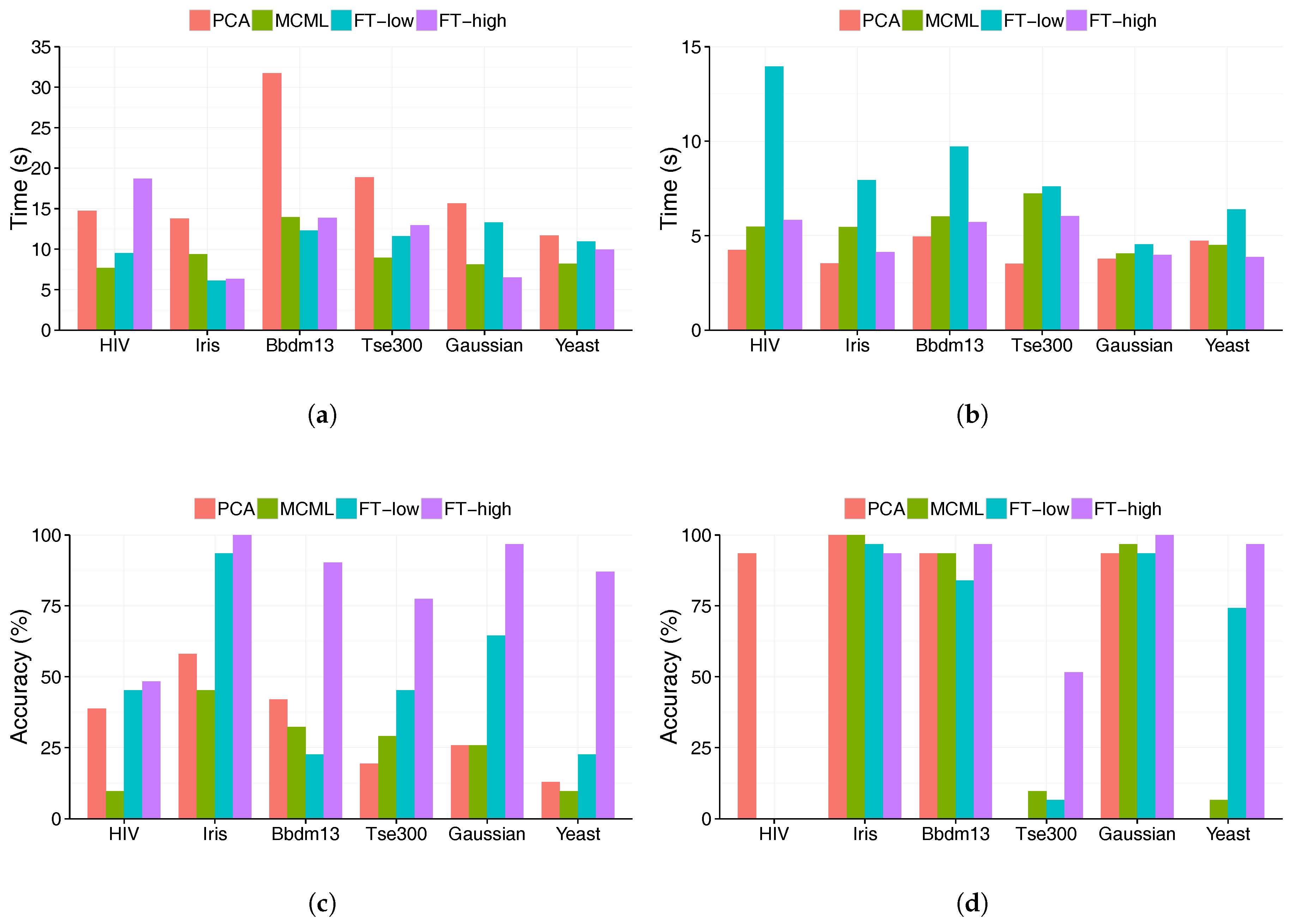
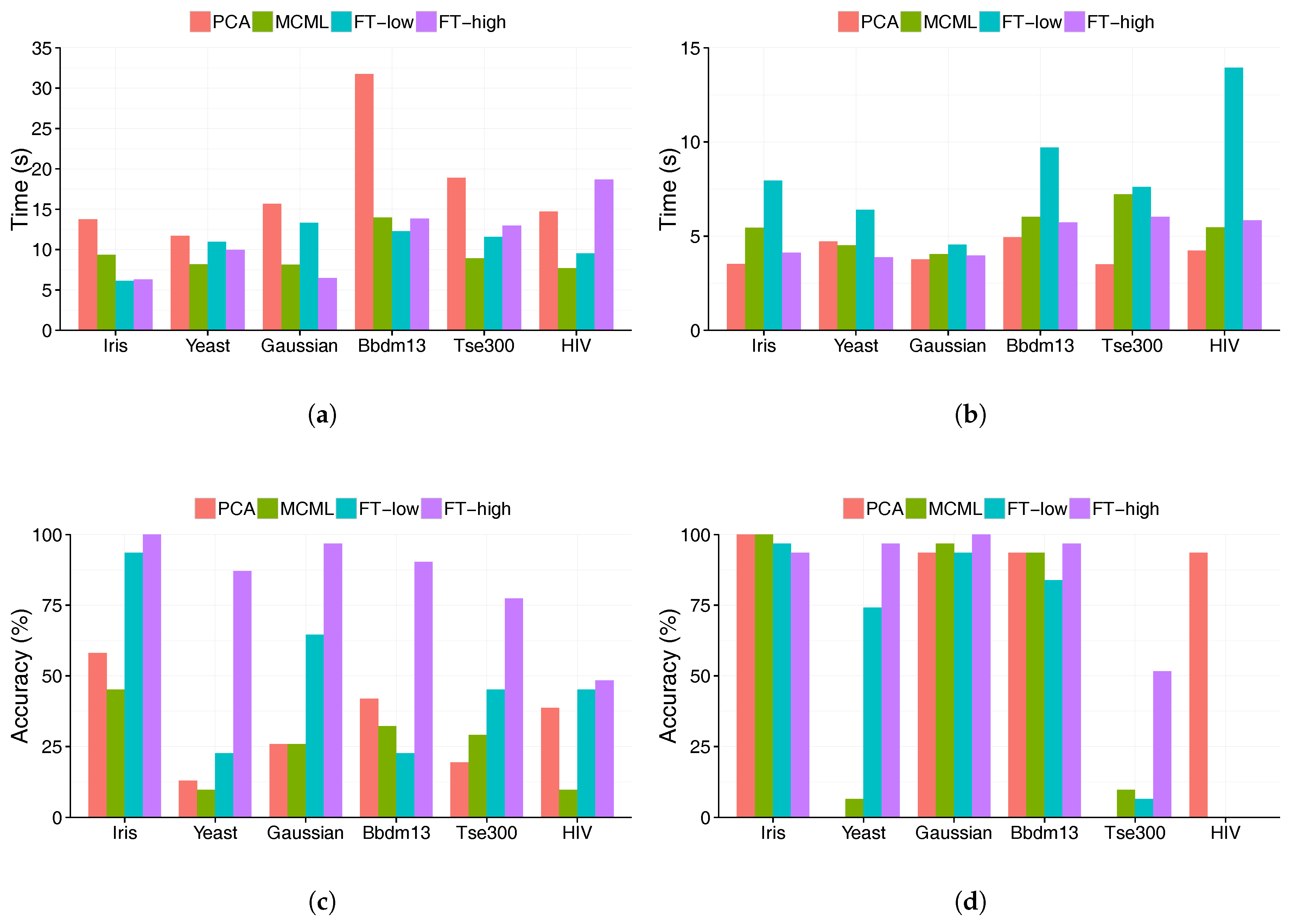
5.1. Accuracy
5.2. Time
6. Discussions
6.1. Methods
6.2. Data Size and Dimensionality
6.3. Tasks and Participants
6.4. Limitations
7. Conclusions
7.1. Techniques
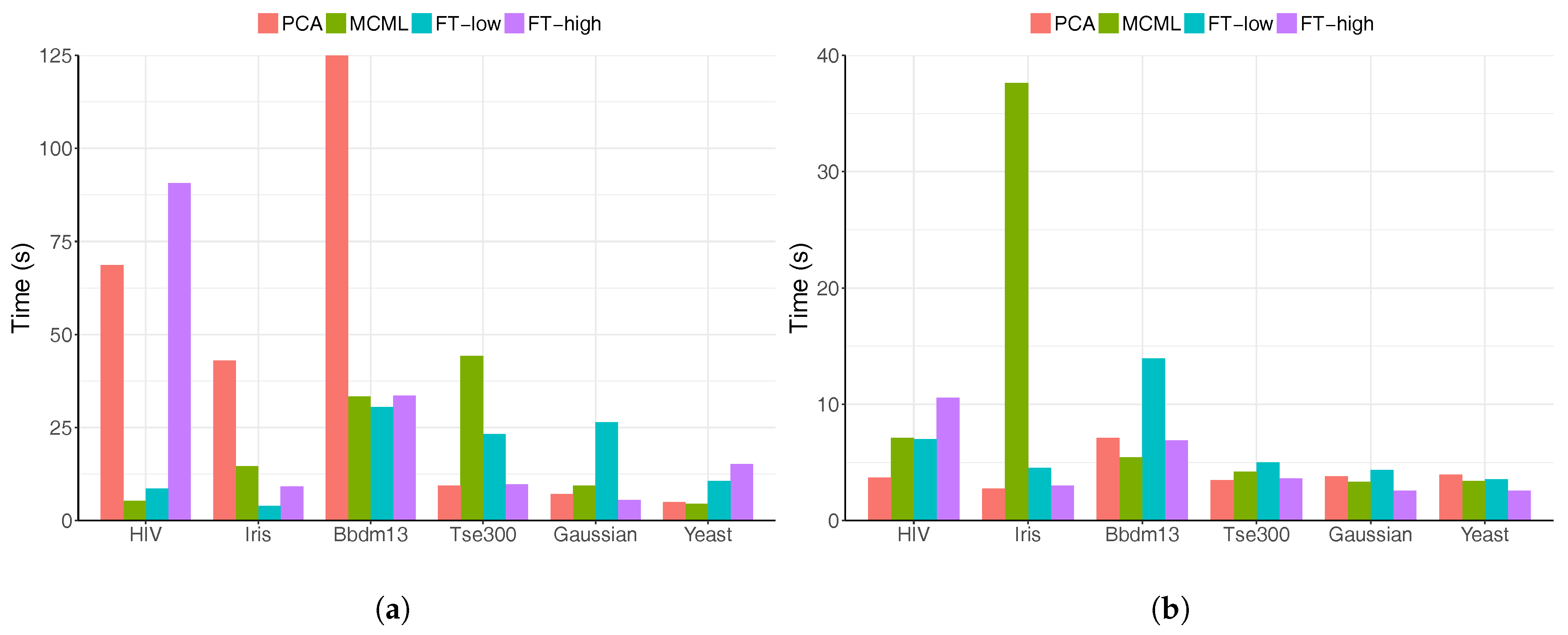
- There is a strong case for the feature transformation technique. Participants performed best with the visualisation produced with high-level feature transform (FT-high), in term of both accuracy and completion time. The improvements over other techniques were substantial, particularly in the case of the accuracy of the clustering task.
- Low-level feature transformation has a lesser impact on visualisation readability, and as a result does not have a clear advantage over existing techniques, represented by MCML (supervised DR) and PCA (un-supervised DR).
- Very high dimensional data seems to be a challenge for all the techniques, but particularly MCML and to certain extend FT-low. MCML performed poorly with the HIV dataset, which has a much higher dimensionality (139) than the rest of the data sets.
- The results of PCA were better than expected; its performance was close to that of the FT-low and MCML. Also, it performed surprisingly well on the very high-dimensional HIV dataset, matching the results of FT-high.
7.2. Scalability
- All the visualisation methods scaled well with data size, particularly with completion time. There is no apparent increase in completion time as the number of data points grow (20 fold difference between the size of the smallest and largest dataset). This is the result of human pre-attentative visual processing, which requires constant time regardless of data size. This makes visualisation an effective tool for understanding large data.
- The data dimensionality appears to have a larger impact on the user performance than the data size. It leads to an increase in completion time as the data dimensionality grows. The effect on the accuracy is less clear, with the performance of a certain method changes dramatically between data sets. This indicates that the suitability of a visualisation method to a particular data set can be the dominant factor for task accuracy.
7.3. Tasks and Participants
- Clustering is a more difficult task than outlier identification. Its accuracy is significantly lower and took significantly longer to complete. Except for FT-high, all techniques led to accuracy of only around 25%. This demonstrates that it is almost impossible to perform visual clustering analysis without feature transformation.
- Outlier detection is the relatively easier task, with faster completion time and higher accuracy. However, its accuracy varies dramatically between data sets and techniques. One technique can have close to 100% accuracy on one dataset, but 0% on another data set with similar size and dimensionality. Therefore, selecting an effective visualisation method is important for a successful analysis.
- Participants perceived clustering as the significantly more difficult task, but there was only a weak correlation between user preference and actual performance. There is a larger variation among the individual completion time than that of the task accuracy.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lee, J.; Verleysen, M. Nonlinear Dimensionality Reduction; Springer: Berlin, Germany, 2007. [Google Scholar]
- Van der Maaten, L. An introduction to dimensionality reduction using matlab. Available online: https://pdfs.semanticscholar.org/a082/e615d1d6676808eaf061819180114a4eb250.pdf (accessed on 31 May 2017).
- Donoho, D.L. High-dimensional data analysis: The curses and blessings of dimensionality. In Proceedings of the American Mathematical Society Conf. Math Challenges of the 21st Century, Los Angeles, CA, USA, 6–11 August 2000. [Google Scholar]
- Etemadpour, R.; Motta, R.; de Souza Paiva, J.; Minghim, R.; Ferreira de Oliveira, M.; Linsen, L. Perception-Based Evaluation of Projection Methods for Multidimensional Data Visualization. IEEE Trans. Vis. Comput. Gr. 2015, 21, 81–94. [Google Scholar] [CrossRef] [PubMed]
- Paulovich, F.; Silva, C.; Nonato, L. User-Centered Multidimensional Projection Techniques. Comput. Sci. Eng. 2012, 14, 74–81. [Google Scholar]
- Jeong, D.H.; Ziemkiewicz, C.; Fisher, B.; Ribarsky, W.; Chang, R. iPCA: An Interactive System for PCA-based Visual Analytics. Comput. Gr. Forum 2009, 28, 767–774. [Google Scholar] [CrossRef]
- Choo, J.; Lee, H.; Kihm, J.; Park, H. iVisClassifier: An interactive visual analytics system for classification based on supervised dimension reduction. In Proceedings of the 2010 IEEE Symposium on Visual Analytics Science and Technology (VAST), Salt Lake City, UT, USA, 25–26 October 2010; pp. 27–34. [Google Scholar]
- Schäfer, M.; Zhang, L.; Schreck, T.; Tatu, A.; Lee, J.A.; Verleysen, M.; Keim, D.A. Improving projection-based data analysis by feature space transformations. In IS & T/SPIE Electronic Imaging; International Society for Optics and Photonics: Burlingame, CA, USA, 2013; p. 86540H. [Google Scholar]
- Pérez, D.; Zhang, L.; Schaefer, M.; Schreck, T.; Keim, D.; Díaz, I. Interactive feature space extension for multidimensional data projection. Neurocomputing 2015, 150 Pt B, 611–626. [Google Scholar] [CrossRef][Green Version]
- Kwon, B.C.; Kim, H.; Wall, E.; Choo, J.; Park, H.; Endert, A. AxiSketcher: Interactive Nonlinear Axis Mapping of Visualizations through User Drawings. IEEE Trans. Vis. Comput. Gr. 2017, 23, 221–230. [Google Scholar] [CrossRef] [PubMed]
- Sacha, D.; Zhang, L.; Sedlmair, M.; Lee, J.A.; Peltonen, J.; Weiskopf, D.; North, S.C.; Keim, D.A. Visual Interaction with Dimensionality Reduction: A Structured Literature Analysis. IEEE Trans. Vis. Comput. Gr. 2017, 23, 241–250. [Google Scholar] [CrossRef] [PubMed]
- Keim, D.A.; Kohlhammer, J.; Ellis, G.; Mansmann, F. Mastering The Information Age—Solving Problems with Visual Analytics. Available online: http://www.vismaster.eu/wp-content/uploads/2010/11/title-page-to-chapter-1.pdf (accessed on 31 May 2017).
- Pérez, D.; Zhang, L.; Schaefer, M.; Schreck, T.; Keim, D.; Díaz, I. Interactive Visualization and Feature Transformation for Multidimensional Data Projection. Available online: http://homepage.tudelft.nl/19j49/eurovis2013/papers/0103-paper.pdf (accessed on 31 May 2017).
- Jolliffe, I. Principal Component Analysis; Spring: New York, NY, USA, 1986. [Google Scholar]
- Torgerson, W. Multidimensional scaling: I. Theory and method. Psychometrika 1952, 17, 401–419. [Google Scholar] [CrossRef]
- Sammon, J.W., Jr. A nonlinear mapping for data structure analysis. IEEE Trans. Comput. 1969, 100, 401–409. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. In Proceedings of the NIPS, Vancouver, BC, Canada, 3–8 December 2001; Volume 14, pp. 585–591. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.-Y.; Zha, H.-Y. Principal manifolds and nonlinear dimensionality reduction via tangent space alignment. J. Shanghai Univ. (Engl. Ed.) 2004, 8, 406–424. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Goldberger, J.; Roweis, S.; Hinton, G.; Salakhutdinov, R. Neighbourhood components analysis. In Proceedings of the NIPS’04, Vancouver, BC, Canada, 13–18 December 2004. [Google Scholar]
- Globerson, A.; Roweis, S. Metric learning by collapsing classes. In Proceedings of the NIPS, Vancouver, BC, Canada, 5–8 December 2005; Volume 18, pp. 451–458. [Google Scholar]
- Blum, A.L.; Langley, P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Ingram, S.; Munzner, T.; Irvine, V.; Tory, M.; Bergner, S.; Möller, T. DimStiller: Workflows for dimensional analysis and reduction. In Proceedings of the 2010 IEEE Symposium on Visual Analytics Science and Technology (VAST), Salt Lake City, UT, USA, 25–26 October 2010; pp. 3–10. [Google Scholar]
- Brown, E.T.; Liu, J.; Brodley, C.E.; Chang, R. Dis-function: Learning distance functions interactively. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; pp. 83–92. [Google Scholar]
- Lee, J.A.; Verleysen, M. Scale-independent quality criteria for dimensionality reduction. Pattern Recognit. Lett. 2010, 31, 2248–2257. [Google Scholar] [CrossRef]
- Bertini, E.; Tatu, A.; Keim, D. Quality Metrics in High-Dimensional Data Visualization: An Overview and Systematization. IEEE Trans. Vis. Comput. Gr. 2011, 17, 2203–2212. [Google Scholar] [CrossRef] [PubMed]
- Rensink, R.A.; Baldridge, G. The perception of correlation in scatterplots. Comput. Gr. Forum 2010, 29, 1203–1210. [Google Scholar] [CrossRef]
- Sedlmair, M.; Tatu, A.; Munzner, T.; Tory, M. A taxonomy of visual cluster separation factors. Comput. Gr. Forum 2012, 31, 1335–1344. [Google Scholar] [CrossRef]
- Albuquerque, G.; Eisemann, M.; Magnor, M. Perception-based visual quality measures. In Proceedings of the 2011 IEEE Conference on Visual Analytics Science and Technology (VAST), Providence, RI, USA, 23–28 October 2011; pp. 13–20. [Google Scholar]
- Lewis, J.M.; Van Der Maaten, L.; de Sa, V. A behavioral investigation of dimensionality reduction. In Proceedings of the 34th Conference of the Cognitive Science Society (CogSci), 1–4 August 2012; pp. 671–676. [Google Scholar]
- Frank, A.; Asuncion, A. UCI Machine Learning Repository; School of Information and Computer Science, University of California: Irvine, CA, USA, 2010; Volume 213. [Google Scholar]
- Sips, M.; Neubert, B.; Lewis, J.P.; Hanrahan, P. Selecting good views of high-dimensional data using class consistency. Comput. Gr. Forum 2009, 28, 831–838. [Google Scholar] [CrossRef]
- Statistical Data and Software Help. 2011. Available online: http://www.umass.edu/statdata/statdata/ (accessed on 31 May 2017 ).
- VisuMap Data Repository. 2011. Available online: http://www.visumap.net/ (accessed on 31 May 2017 ).
- Ware, C. Information Visualization: Perception for Design, 2nd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2004. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, K.; Zhang, L.; Pérez, D.; Nguyen, P.H.; Ogilvie-Smith, A. Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation. Multimodal Technol. Interact. 2017, 1, 13. https://doi.org/10.3390/mti1030013
Xu K, Zhang L, Pérez D, Nguyen PH, Ogilvie-Smith A. Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation. Multimodal Technologies and Interaction. 2017; 1(3):13. https://doi.org/10.3390/mti1030013
Chicago/Turabian StyleXu, Kai, Leishi Zhang, Daniel Pérez, Phong H. Nguyen, and Adam Ogilvie-Smith. 2017. "Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation" Multimodal Technologies and Interaction 1, no. 3: 13. https://doi.org/10.3390/mti1030013
APA StyleXu, K., Zhang, L., Pérez, D., Nguyen, P. H., & Ogilvie-Smith, A. (2017). Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation. Multimodal Technologies and Interaction, 1(3), 13. https://doi.org/10.3390/mti1030013