1. Introduction
Railway infrastructure plays a pivotal role in modern transportation systems, necessitating continuous innovation and precise management and maintenance [
1]. The integration of advanced technologies, such as mobile LiDAR (Light Detection and Ranging), into railway applications has introduced transformative capabilities to the industry. To fully leverage these technologies, data processing methods, like semantic segmentation, are essential for understanding the complex and dynamic railway environment. Semantic segmentation, a fundamental component of computer vision, enables the categorization of each pixel in an image or point in a point cloud into predefined classes, facilitating scene understanding. In this context, machine learning has emerged as a promising approach. Deep neural networks, known for their ability to extract intricate patterns and representations from extensive datasets, offer the potential to automate critical tasks within the railway domain [
2,
3].
However, the effective application of machine learning in the railway environment depends on a crucial factor: the availability of annotated data. Unlike urban contexts, where several annotated datasets and benchmark are available [
4,
5,
6,
7,
8], the railway environment lacks comprehensive benchmarks and annotated datasets tailored specifically to railway applications. The lack of annotated data presents a significant challenge for machine learning models development and evaluation. To train and validate semantic segmentation models effectively, labelled data, representing the diverse range of objects and structures found along railway tracks, including tracks, signals, poles, overhead wires, vegetation, and more, are required [
9,
10].
Moreover, as railways turn to machine learning (ML), there is a rising need for models that are accurate and easy to interpret. Using complex models, especially in safety-critical areas like railways, raises concerns about interpretation. Traditional ML models are vital for building trust, especially in tasks like semantic segmentation, in the railway environment. Additionally, the challenge extends beyond data labelling; it also involves the establishment of benchmarks that enable researchers and practitioners to objectively assess model performance. Benchmarks serve as standardized metrics for the quantitative evaluation and comparison of novel algorithms. In the absence of a railway-specific benchmark, the assessment of model performance becomes subjective and ad hoc, hindering progress and the adoption of machine learning solutions in railway applications.
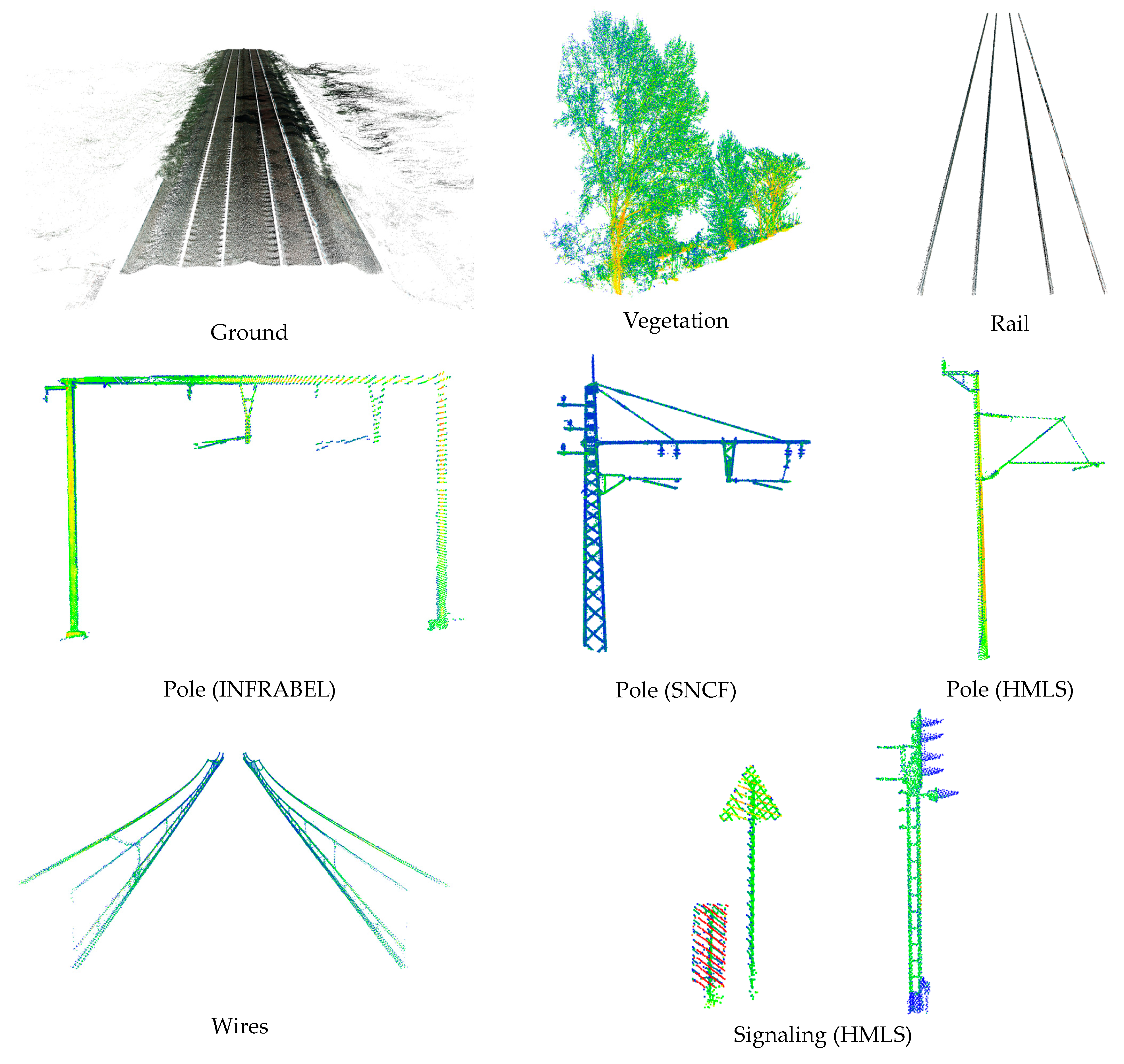
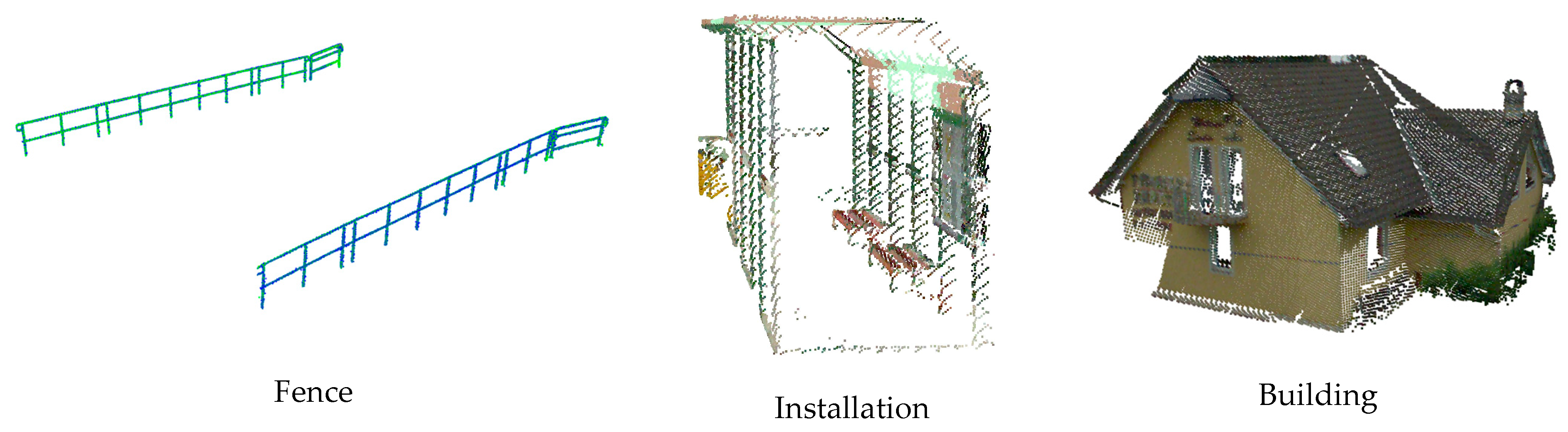
In response to this challenge, we introduce the Rail3D dataset, which aims to address the shortage of annotated data specifically tailored to railway applications. Rail3D comprises extensive point cloud data collected across diverse railway contexts in Hungary, France, and Belgium, covering approximately 5.8 km. This dataset not only mitigates the lack of annotated data but also serves as a foundational benchmark for semantic segmentation. The public availability of Rail3D represents a significant step toward fostering collaboration and innovation in the railway industry. We invite researchers, practitioners, and enthusiasts to explore, enhance, and contribute to this dataset, advancing the development of deep learning solutions that enhance the safety, efficiency, and sustainability of railway infrastructure on a global scale.
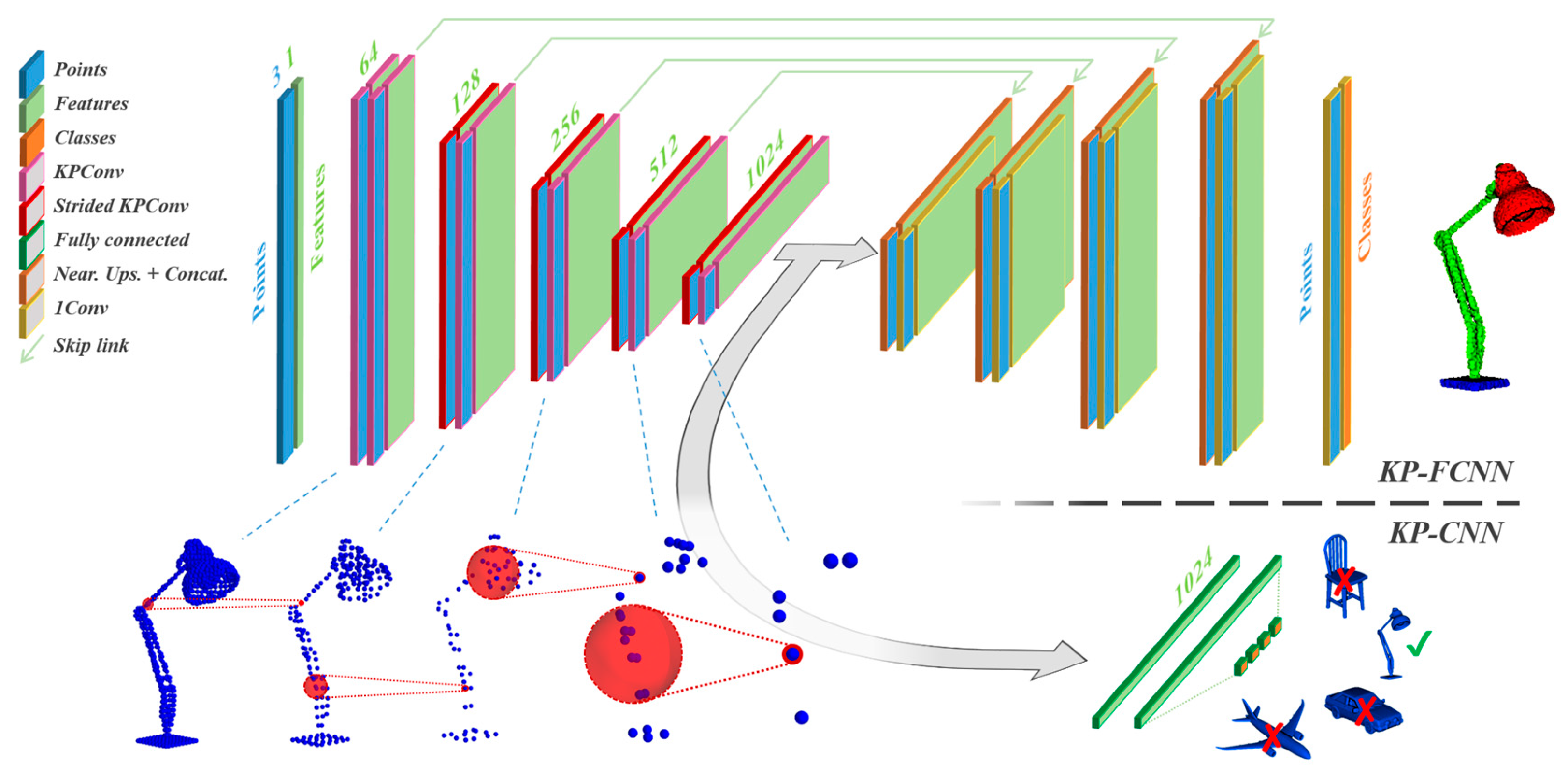
In the railway sector, where decision-makers might not be machine learning experts, the clarity and reliability of models are paramount [
10]. Benchmarking LightGBM, Random Forest, and the deep-learning-based KPConv allows us to assess the effectiveness of both traditional machine learning and advanced deep learning techniques. This comparative analysis is vital for selecting a model that not only delivers high performance but is also interpretable and aligns with safety-critical standards in railway applications. Through this benchmarking process, we aim to identify a model that combines accuracy and efficiency, ensuring it can be effectively used and trusted in the context of railway infrastructure management.
The main objective of this paper is to develop a large scale and multi-context 3D point cloud dataset for railway semantic segmentation tasks and assess models’ performance on it. The contributions of our work are as follows:
Present a multi-context railway point cloud dataset for semantic segmentation: We introduce Rail3D, a unique dataset for railway environments. Its special because it covers a wide range of railway scenes from three countries, helping to fill the gap in available data for training machine learning models in this field.
Evaluate three state-of-the-art semantic segmentation models: We compare three state-of-the-art models for understanding railway scenes: KPConv, LightGBM, and Random Forest. This helps find the best tool for the task, considering what is most important in railways: accuracy and safety.
Assess the generalization capabilities of the best performing model: We check how well the best model works in different places. This is important to make sure the model is reliable and can be used in other real-world railway settings.
The rest of the paper is organized as follows:
Section 2 presents current semantic segmentation techniques, with a special focus on railway applications and available datasets.
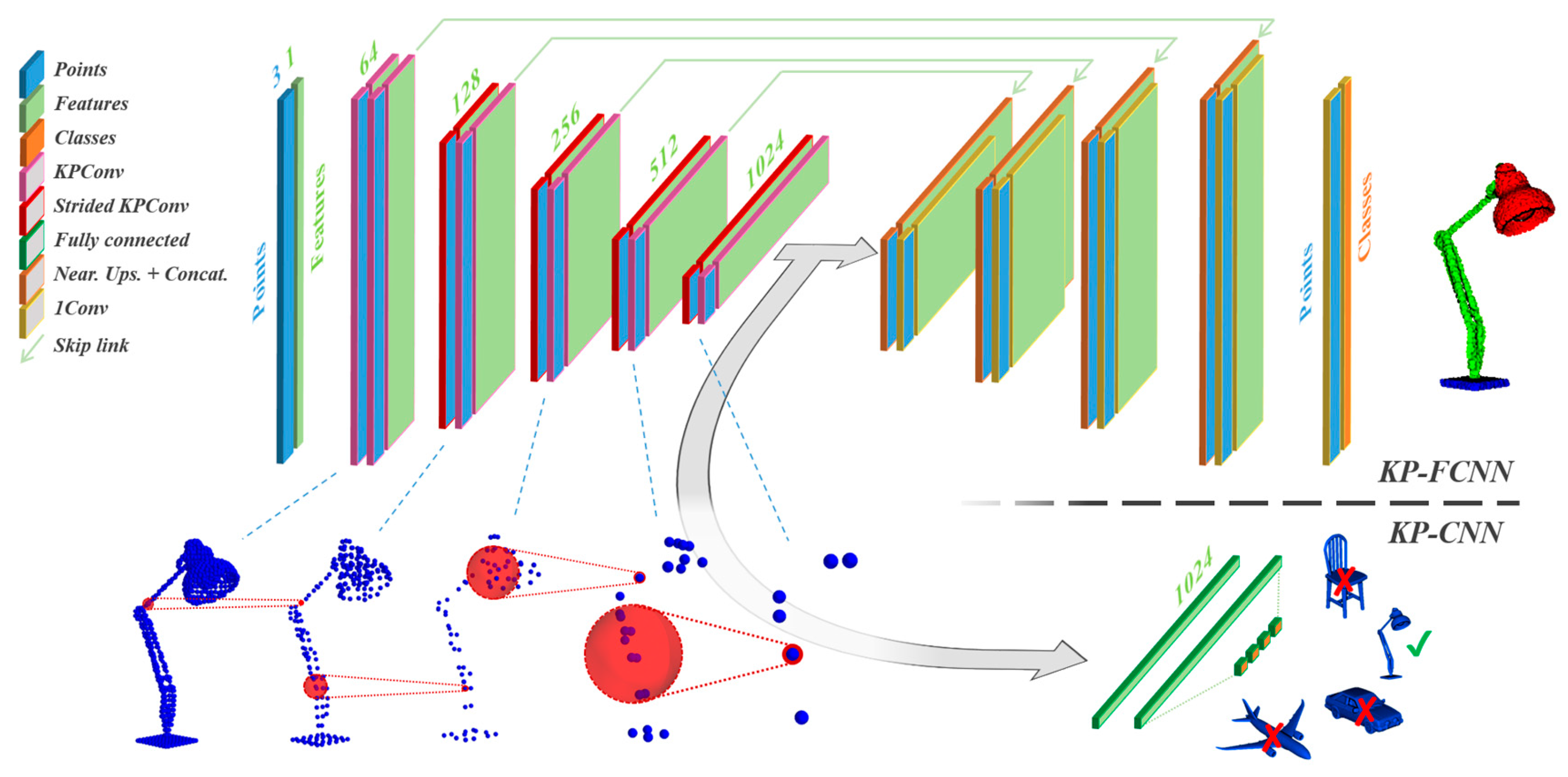
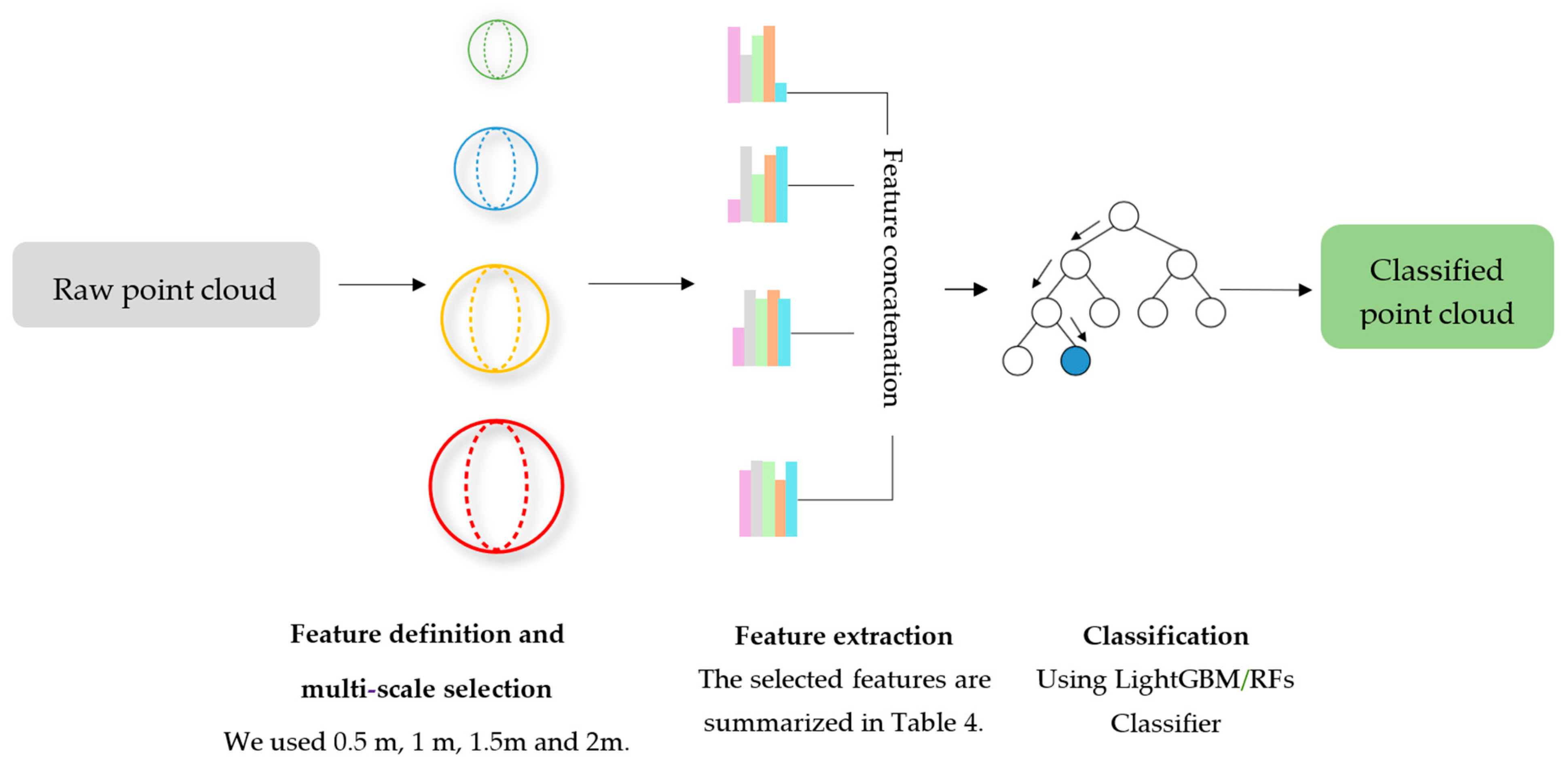
Section 3 outlines the specifics of the subset we curated to develop Rail3D, explains how we annotated the data, and introduces the three baseline methods selected for our analysis.
Section 4 details the experiments we conducted and their outcomes.
Section 5 discusses what we found and ideas for future research.
2. Related Works
The availability of datasets for training has so far played a key role in the progress and comparison of ML models. These allow scene understanding across several tasks, including classification, semantic/instance/panoptic segmentation, and object detection, etc. In the following subsections, we summarize the state of the art of semantic segmentation, we investigate the existing application in railway contexts, and present the available datasets.
2.1. Semantic Segmentation
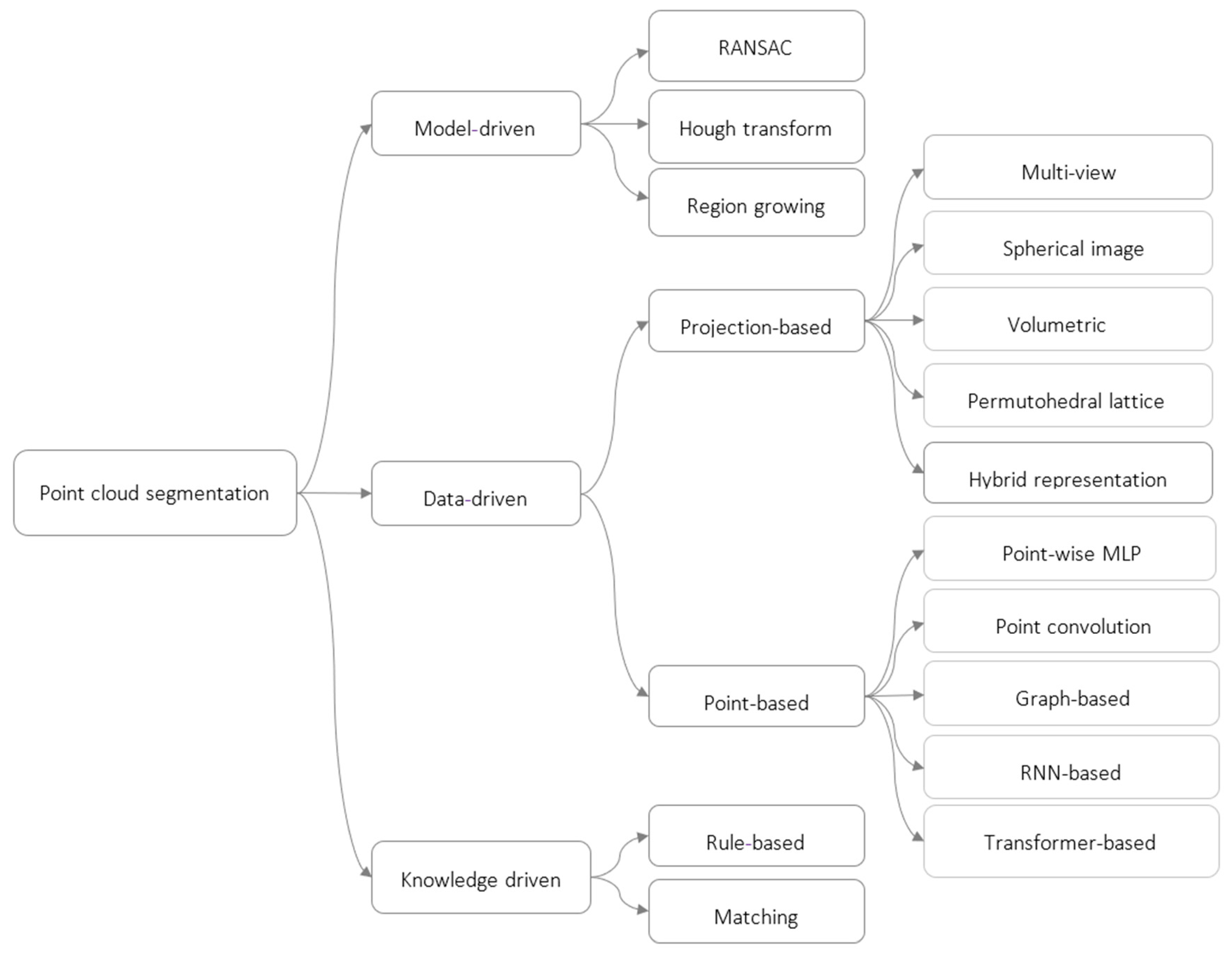
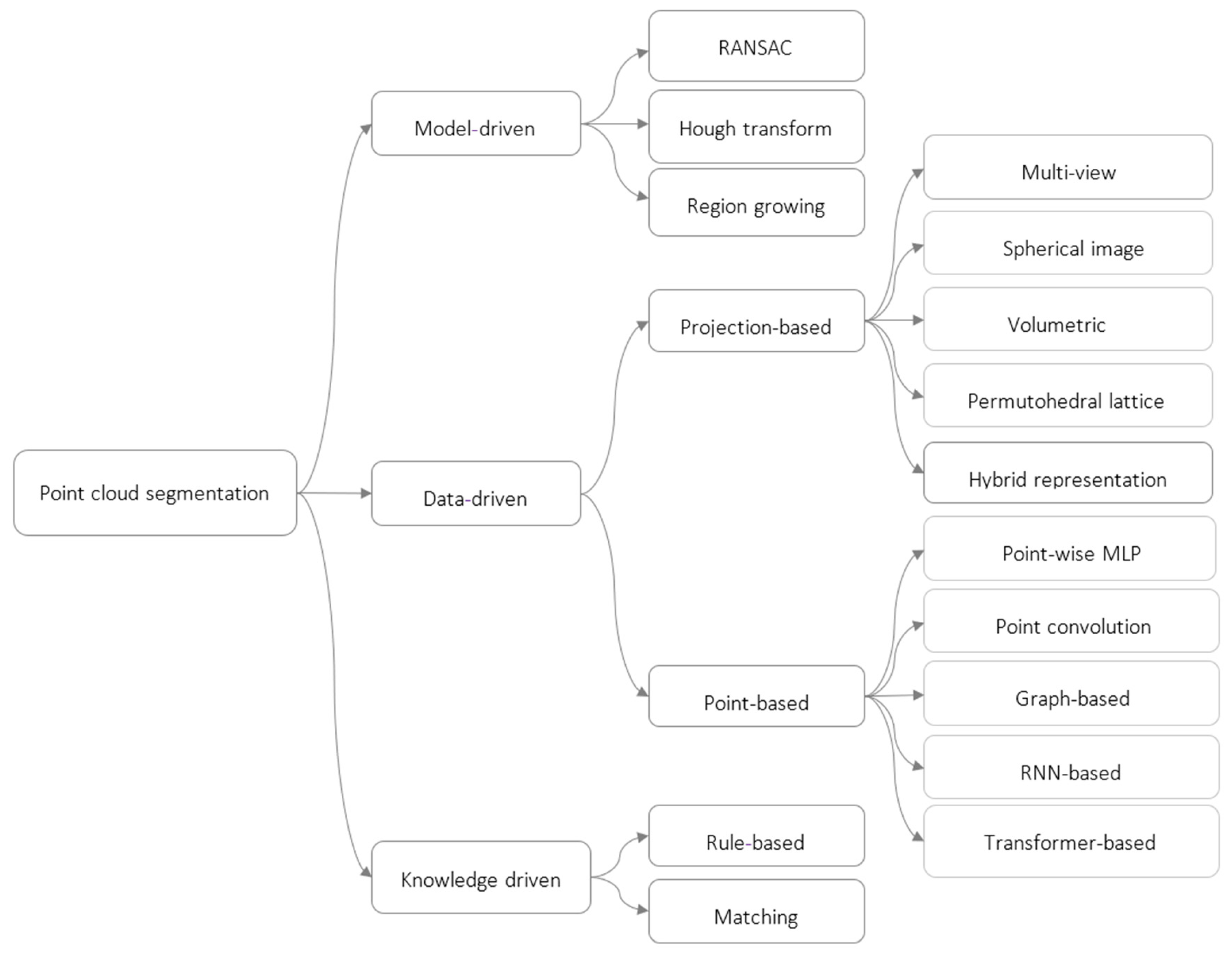
In the dynamic field of 3D point cloud semantic segmentation, significant advancements have been made through various approaches [
11]. Model-driven methods, including RANSAC [
12], Hough Transform, and region growing, continue to provide a solid foundation for segmenting point clouds, offering robustness in fitting geometric shapes and handling locally homogeneous properties. Meanwhile, knowledge-driven methods [
13,
14], incorporating explicit rules and matching strategies, are often used to enhance segmentation results in tandem with other approaches. Rule-based algorithms follow a set of predefined rules to categorize points, offering simplicity and computational efficiency [
15]. Matching-based methods, on the other hand, excel in accuracy and robustness by matching the point cloud to a database of 3D models. These methods are particularly useful in scenarios where precise object recognition is essential, but they can be computationally intensive and require extensive model databases. Knowledge-driven methods often complement data-driven and model-driven approaches by refining segmentation results, ensuring that the identified objects align with domain-specific knowledge or predefined rules.
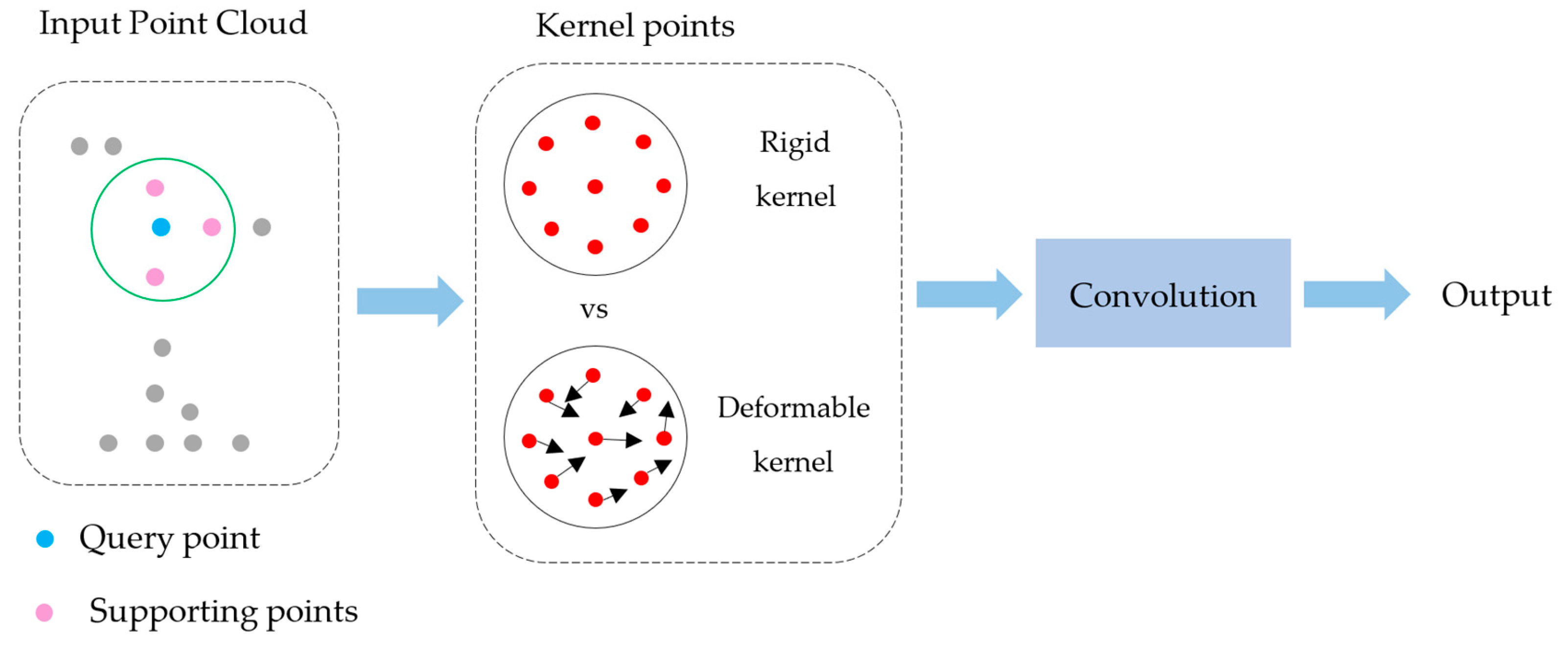
Finally, data-driven methods [
11] have gained popularity, using machine and deep learning techniques to extract features and classify points. These data-driven methods span projection-based strategies, including multi-view [
16,
17,
18,
19,
20,
21], and spherical image approaches [
22,
23,
24,
25], as well as volumetric [
26,
27,
28,
29] and lattice-based representations [
30,
31,
32], with hybrid representations combining their strengths. Point-based methods have made significant strides, introducing neural network architectures like PointNet and PointNet++ [
33,
34], point convolution networks [
35,
36], and Graph Neural Networks [
37,
38,
39,
40] to capture complex relationships and dependencies within point clouds. Recently, transformer-based methods [
41,
42,
43,
44] have emerged as state-of-the-art, using attention mechanisms to model global dependencies in point clouds.
Figure 1 summarize these semantic segmentation methods.
The most recent advances in 3D semantic segmentation include self-supervised learning, multi-task learning, transformer networks, foundation models, and 3D-LLMs. Self-supervised learning methods can train models without the need for labelled data [
45]. This can be helpful for reducing the cost and effort of training 3D semantic segmentation models, especially for large-scale applications. Multi-task learning methods train models to perform multiple tasks simultaneously, such as object detection and scene understanding [
46]. This can help 3D semantic segmentation models to learn better representations of the data, which can lead to improved performance on all the tasks. Transformer networks are a type of neural network architecture that has been shown to be effective for 3D semantic segmentation [
41]. They can learn long-range dependencies in point clouds, which can be helpful for better results. Foundation models, such as SAM [
47], are Large Visual Models (LVMs) that have been trained on a massive dataset of images and text. Foundation models can be used to train 3D semantic segmentation models in a variety of ways, such as by training a downstream model on top of the foundation model. Finally, the 3D-LLMs [
48] is a new type of large language model that is specifically designed to understand and reason 3D data. 3D-LLMs can be used to perform a variety of 3D-related tasks, such as 3D captioning, 3D questions answering, and 3D-assisted dialog.
2.2. Semantic Segmentation for Railways
Even if semantic segmentation has gained progress, particularly in urban environment, applications in the railway context remain limited. Arastounia [
49] developed an automated method to recognize key components of railroad infrastructure from 3D LiDAR data. The used dataset covers a 550 m section of Austrian rural railroad and contains thirty-one keys element with only XYZ coordinate information. The method segmented rail tracks, contact cables, catenary cables, return current cables, masts, and cantilevers based on their physical characteristics and spatial relationships. Recognition involved analyzing local neighborhoods, objects shape, topological relationships, and employing algorithms like KD tree’s structure [
50] and FLANN’s nearest neighbor search [
51] for computational efficiency. The approach achieved 96.4% accuracy and an average of 97.1% precision at point level. Despite the high metrics, this methodology cannot be generalized, the parameters need to be adjusted, and it remains particularly sensitive to occlusion. Additionally, the used data is not publicly available.
Heuristic methods have a long history, but learning-based approaches are becoming more prevalent. The latter aim to lessen reliance on parameters and enhance generalization capabilities. Chen et al. [
52] proposed a method for automatically classifying railway electrification assets using mobile laser scanning data. They used a multi-scale Hierarchical Conditional Random Field (HiCRF) model to capture spatial relationships, improving classification accuracy compared to local methods. The model achieved an overall accuracy of 99.67% for ten objects classes. The authors in [
53] proposed a deep learning-based methodology for the semantic segmentation of railway infrastructure from 3D point clouds. PointNet++ and KPConv were evaluated in four diverse scenarios, exhibiting a remarkable ability to adapt to varying data quality and density conditions. Notably, it achieved a mean accuracy of 90% when assessed on a 90 km long railway dataset used for both training and testing. They also evaluated the pros and cons of their approach, identifying the impact of intensity values as input features on segmentation results. Their best-performing tested architecture achieves a mean Intersection over Union (mIoU) of 74.89%. Furthermore, the methodology demonstrated its versatility by maintaining robust performance across different assets, such as rails, cables, and traffic lights, with an F1-score above 90% in all cases. Bram et al. [
54] used PointNet++, SuperPoint Graph, and Point Transformer as three main deep learning models to perform semantic segmentation of railways catenary arches. The models were trained and assessed on the Railways Catenary Arches dataset with 14 labelled classes. PointNet++ achieved the best performance with over 71% in Intersection over Union (IoU).
The common disadvantage of these studies is that they do not evaluate their methods on the same dataset, in the same context, or with the same number of classes. This makes it almost impossible to make a fair comparison between all these studies, which do not, in general, make their data publicly available.
2.3. Railways Dataset
In the context of railway scene understanding, several image datasets have been developed. RailSem19 [
55] offers 8500 annotated sequences from a train’s perspective, including crossings and tram scenes. FRSign (French Railway Signaling) [
56] contains over one hundred thousand images annotated over six French railway traffic lights with acquisition details (time, date, sensors information, and bounding boxes). RAWPED [
57,
58] is dedicated to pedestrian detection in railway scenes. GERALD [
59] features five thousand images and annotations for German railway signals. OSDaR23 [
60], a multi-sensor dataset, captures various railway scenes with an array of sensors. These datasets are vital for developing and testing algorithms for railway scene analysis, promoting safety and automation in the industry. Compared to image datasets, there is a shortage of open 3D point cloud datasets. To date, we found the following:
WHU-Railway3D: Introduced by Wuhan University of Science and Technology in 2023, this is a new railway point cloud dataset. It covers 30 km, contains four billion points, and is annotated using 11 classes. Its great advantage is that it covers three different environments, including urban, rural, and plateau. Each environment covers approximately 10 km: the urban railway dataset spans 10.7 km, captured using Optech’s Lynx Mobile Mapper System in central China; the rural railway dataset, covering approximately 10.6 km, was collected through an MLS system with dual HiScan-Z LiDAR sensors; and, lastly, the plateau railway dataset, spanning around 10.4 km, was obtained using a Rail Mobile Measurement System equipped with a 32-line LiDAR sensor [
61].
Catenary Arch Dataset: Covering an 800 m stretch of railway track near Delft, Netherlands, this dataset captures fifteen catenary arches in high detail [
62]. The data collection process involved the use of a Trimble TX8 Terrestrial Laser Scanner (TLS). This dataset provides the XYZ coordinates of points but does not include color information, intensity, or normal for the points. It is referenced within the Rijksdriehoeksstelsel coordinate system using meters as units. The number of points per arch varies from 1.6 million to 11 million, and each point is manually labelled into 14 distinct classes [
62].
OSDaR23: The Open Sensor Data for Rail 2023 dataset offers a comprehensive multi-sensor perspective of the railway environment, recorded in Hamburg, Germany during September 2021 [
60,
63]. It uses a railway vehicle equipped with an array of sensors, including lidar, high and low resolution RGB cameras, an InfraRed camera, and a radar. The data were acquired through a Velodyne HDL-64E lidar sensor operating at a 10 Hz frequency. These lidar data are further enriched with annotations of various object classes (20), such as trains, rail tracks, catenary poles, signs, vegetation, buildings, persons, vehicles, etc.
Others dataset: Several other datasets have been used for railway scene understanding tasks, but they are not publicly available or irrelevant. They include the Austrian rural railroad [
49], UA_L-DoTT [
64], Vigo dataset [
2,
53], TrainSim [
65], INFRABEL-5 [
66], Railway SLAM Dataset [
67], MUIF [
68] by the Italian Railways Network Enterprise (RFI), and MOMIT [
69].
Existing 3D point cloud datasets for railway scene understanding are often restricted in size, variety, and semantic class, limiting their practical applicability. Our Rail3D dataset addresses these limitations by providing a comprehensive collection of railway environments from Hungary, France, and Belgium. This multi-context approach includes diverse railway landscapes, with various railway types, track conditions, and densities.
Table 1 summarizes the datasets and their key specifications.
5. Discussion
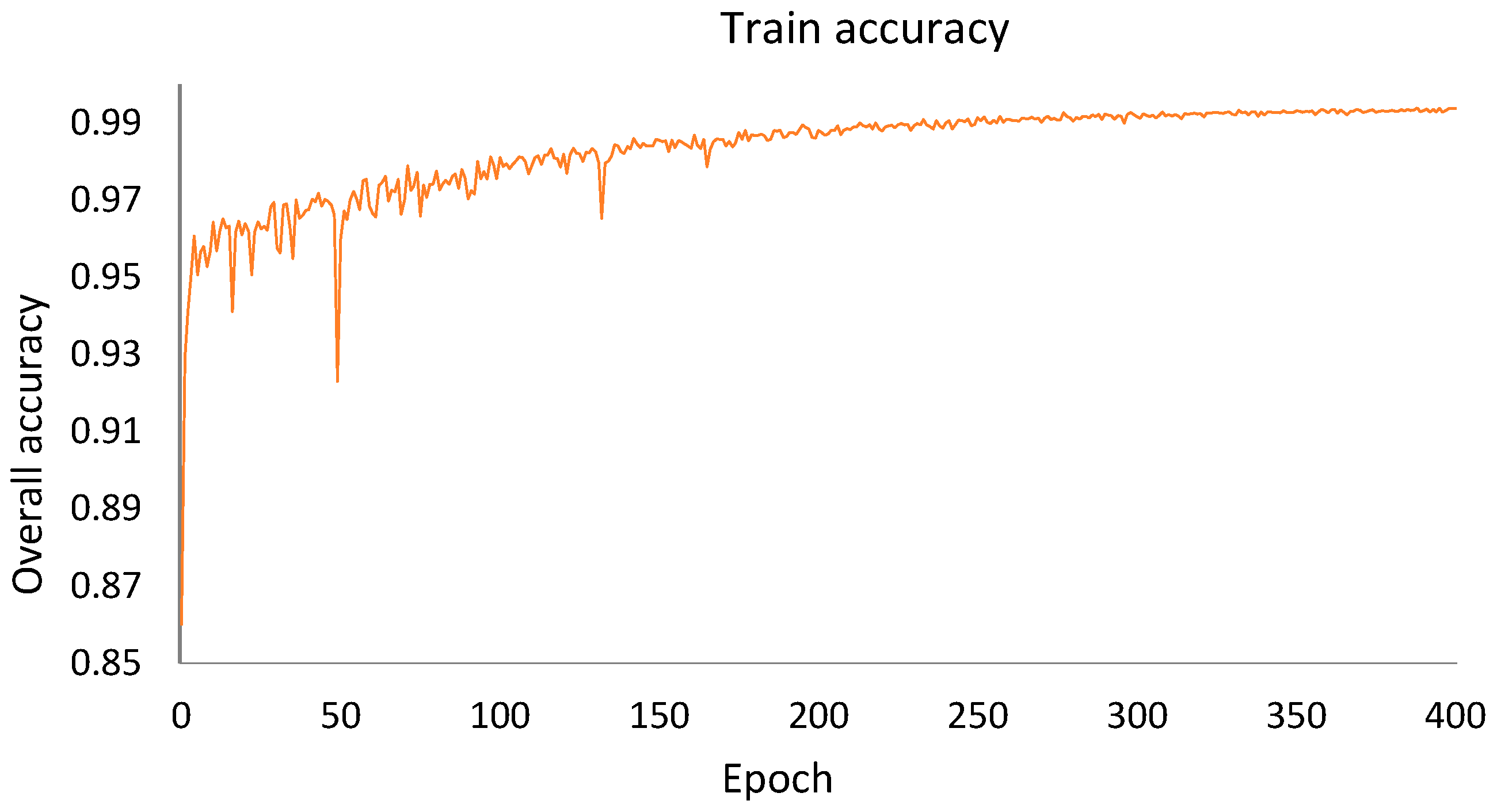
This work addresses two complementary aspects: firstly, the proposal of three subset representing different contexts of railway environments and, secondly, the introduction of three baselines to addressing semantic segmentation challenges. Regarding the proposed dataset, it presents the first comprehensive dataset for semantic segmentation in railway environments, covering three distinct railway contexts from Hungary, France, and Belgium. These datasets provide rich resources for applications in railway environments. With a significant annotation of over 288 million points, the created datasets stand out in both size and diversity compared to existing datasets. This extensive volume of annotated points enhances the dataset’s ability to cover a wide range of situations and variations within railway environments. Furthermore, the datasets developed across these railway environments ensure effective learning for machine learning models, confirming their generalization to different contexts. This was confirmed by the results obtained in
Table 8.
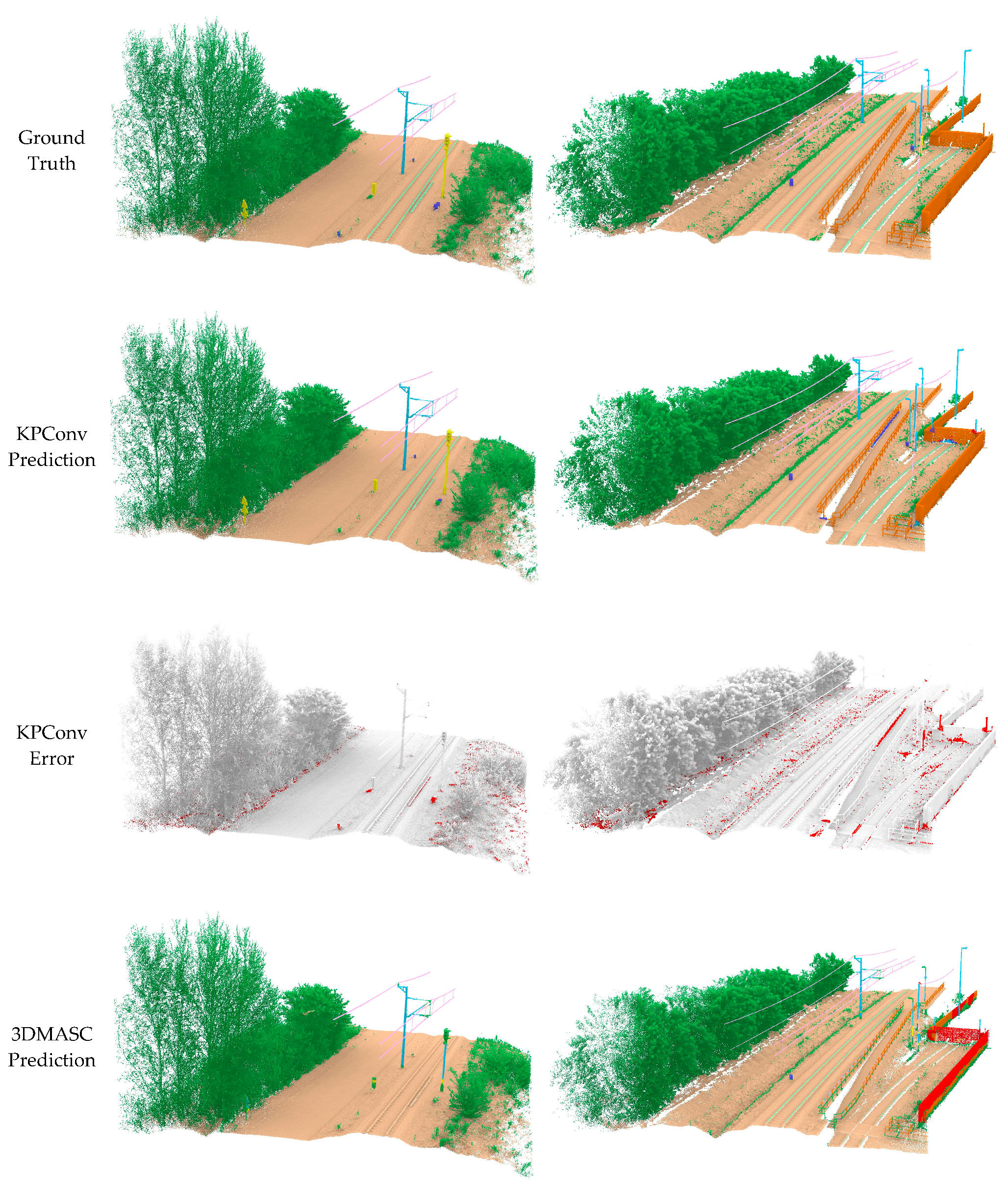
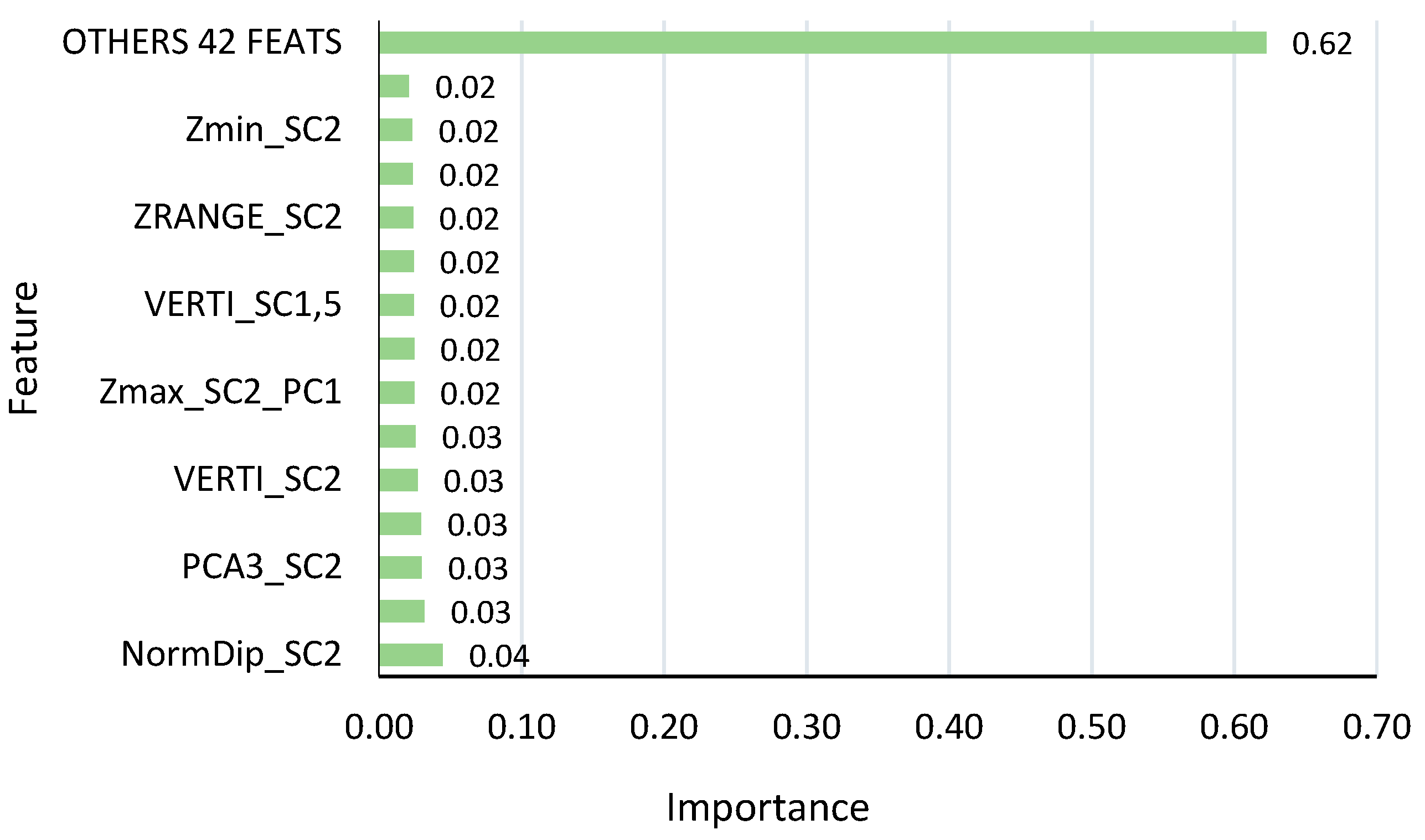
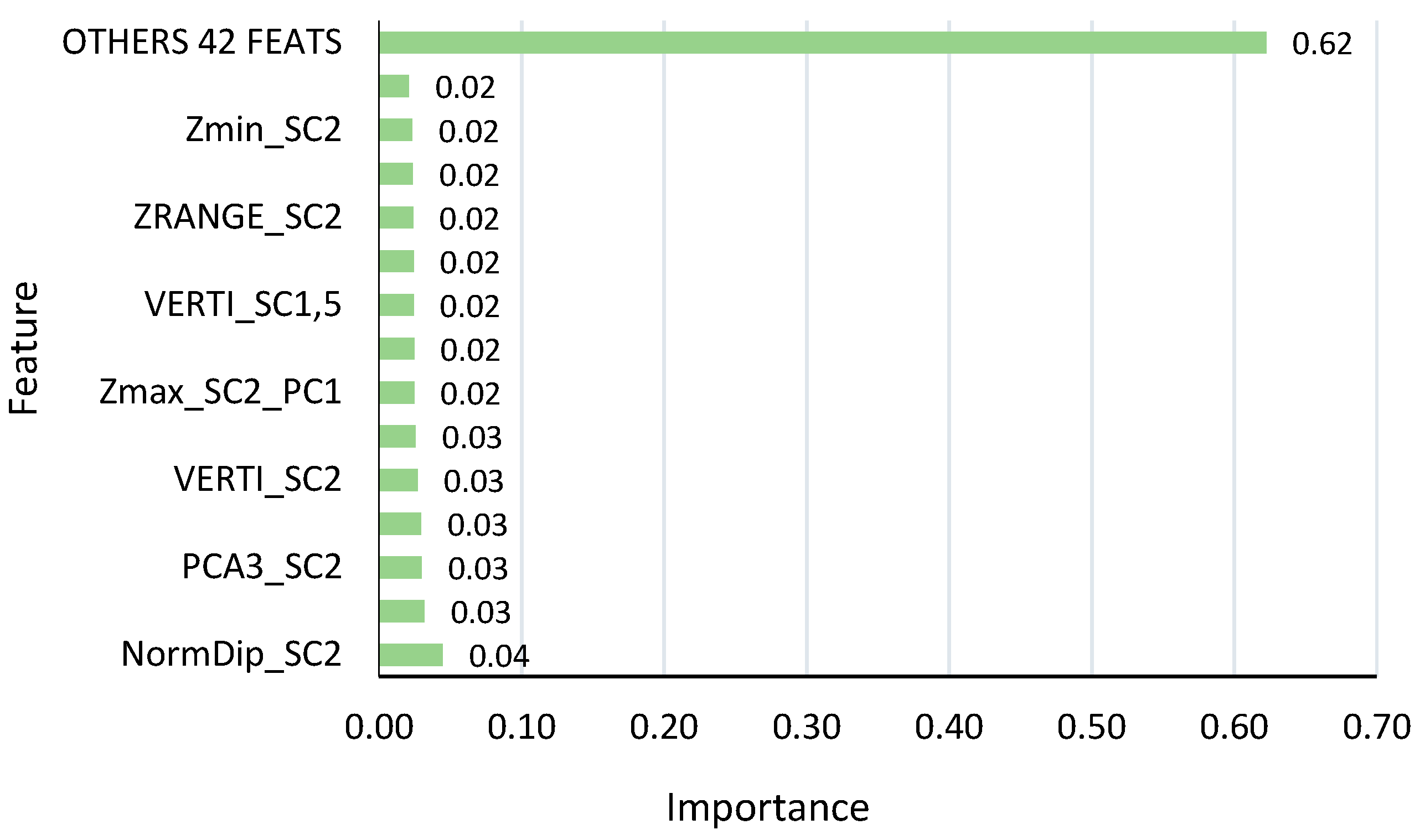
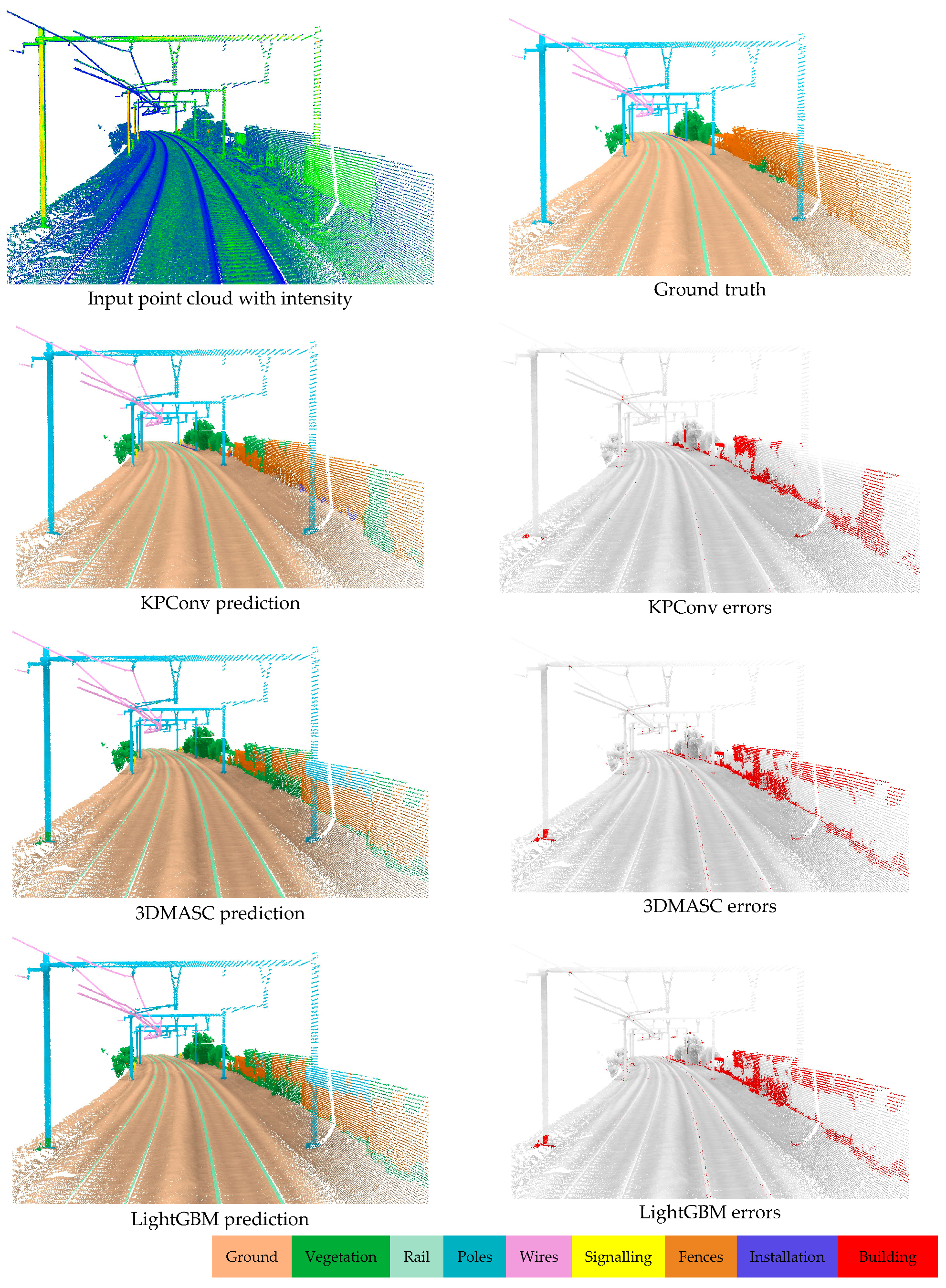
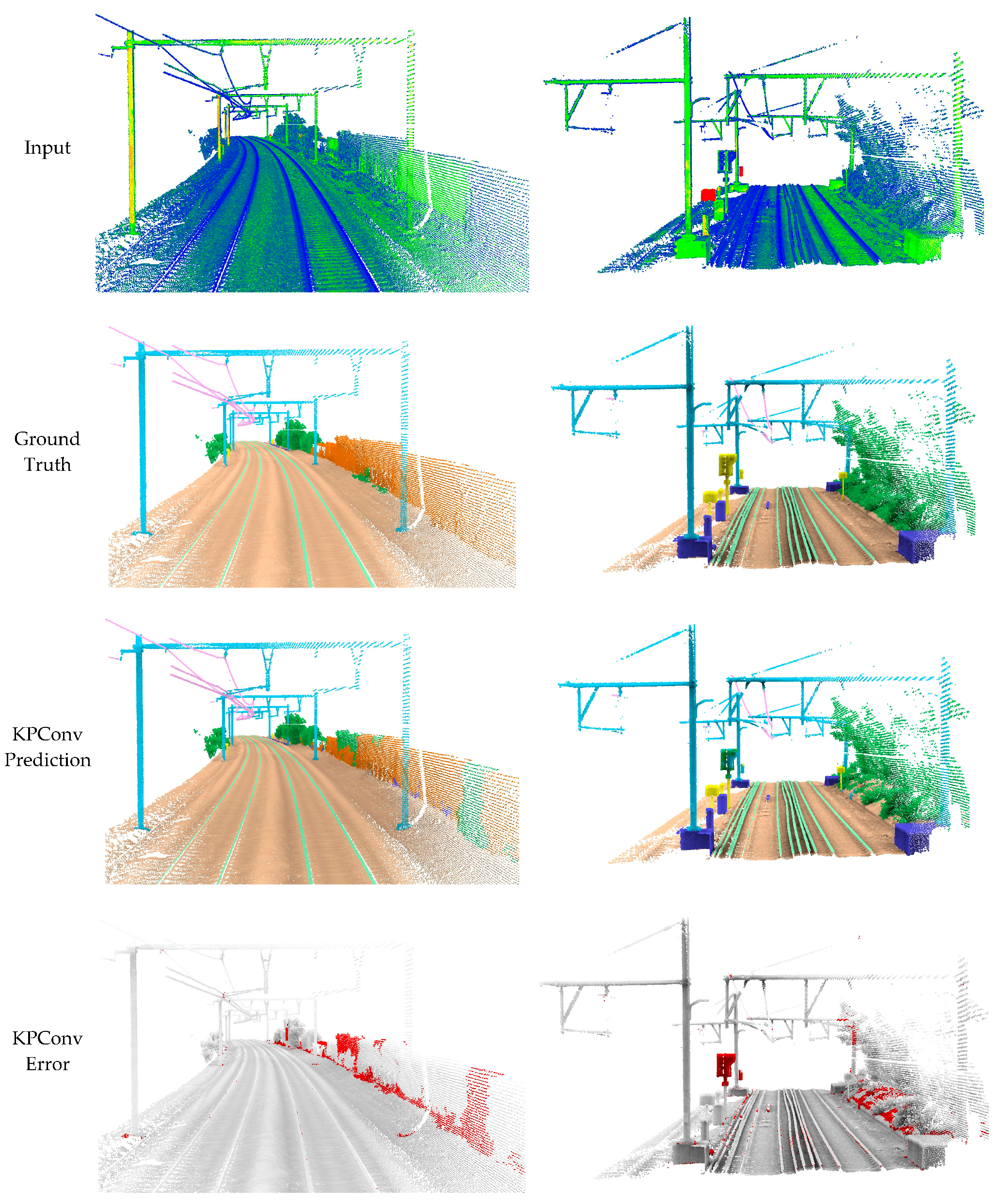
The comparison between KPConv-, 3DMASC-, and LightGBM-based results provides valuable insights about the performance of different classification methods for large-scale rail borne point cloud data. The results of the comparison indicate that, while KPConv may excel in capturing intricate local geometric features, LightGBM highlights promising performance in handling large-scale datasets with its computational efficiency. 3DMASC, although a reliable method, may exhibit limitations in dealing with the complexity and unbalanced nature of railways point cloud data. Furthermore, LightGBM offers superior computational efficiency and faster training times compared to traditional Random Forests. The performance of different methods was assessed through a combination of qualitative and quantitative evaluations. Across
Table 5,
Table 6 and
Table 7, the LightGBM method consistently gave good performance in semantic segmentation, with overall accuracies (OAs) ranging from 0.93 to 0.97 and mean Intersection over Union (mIoU) values from 0.60 to 0.71. Notably, the LightGBM approach highlights efficient results within a brief timeframe, 100 time faster than 3DMASC, emphasizing its practical applicability. This is because LightGBM is designed to be highly parallelizable while 3DMASC is not. Parallelization allows LightGBM to divide the training task into multiple smaller tasks, which can be run on multiple cores or CPUs simultaneously. While demonstrating competitive accuracy, particularly excelling in classes like Rail, Vegetation, and Wires, the machine learning method consistently falls slightly behind the performance of KPConv. The latter’s superior accuracy, especially in specific classes, suggests areas for potential refinement in the handcrafted feature method, highlighting the ongoing challenge of balancing speed and precision in semantic segmentation tasks. The qualitative results obtained using various methods have confirmed the quantitative findings. The traditional ML methods yielded qualitative results closely aligned with the ground truth across all three subsets. This underscores the good selection of geometric features, indicating a positive impact on differentiating railway objects. While color and intensity are often valuable features that can enhance classification performance, we opted to exclude them from our study for two primary reasons. Firstly, the color data acquired exhibited inferior quality due to variations in acquisition times and seasons, leading to heterogeneity between contexts. Secondly, the intensity values lacked calibration across the three contexts, as different lidar sensors were employed. To validate our choice of relying exclusively on spatial coordinates (x, y, and z) as input, we conducted a test using KPConv that verified the adverse effect of color and intensity on classification accuracy within our specific case study (refer to
Figure 13). One solution to correct this sky-colored points effect would be to perform a pre-processing step, as suggested in [
81].
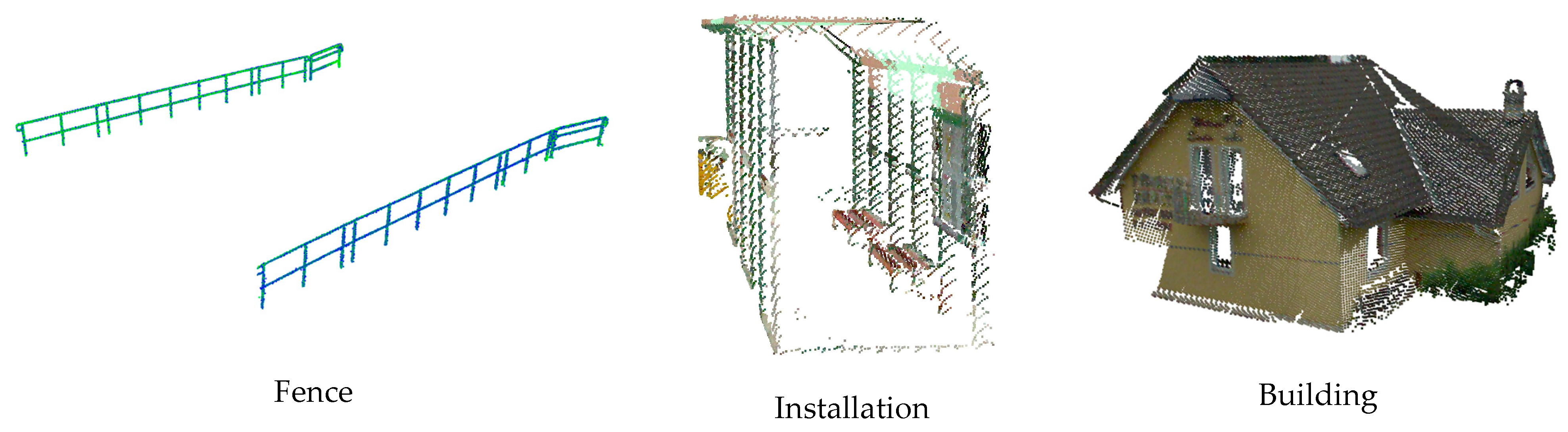
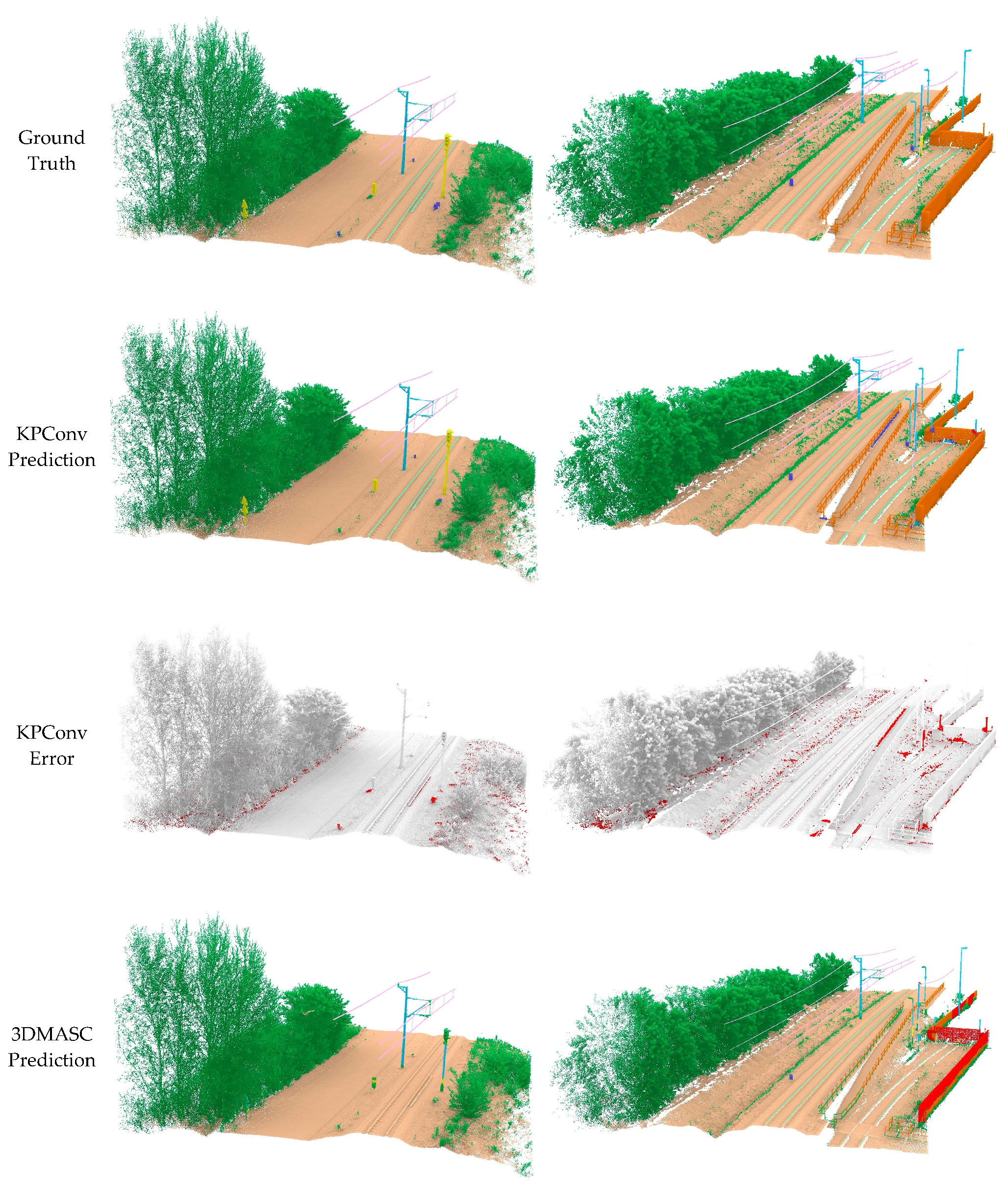
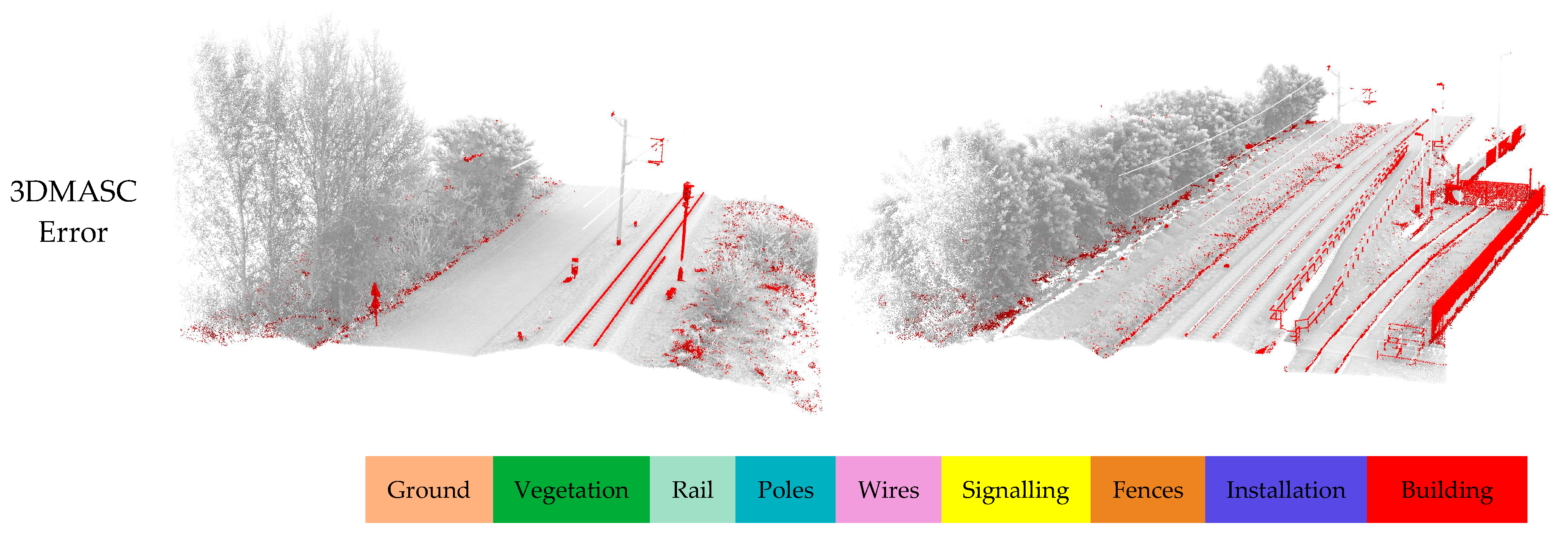
In addition, misclassification occurred where signaling poles were mistakenly categorized as catenary poles. This is due to the strong resemblance between the two and the lack of use of intensity or a specific color or geometric shape for these signs. In other cases, as shown in
Figure 12, LightGBM and 3DMASC were unable to extract the Fence class correctly, given the strong similarity with the Building class. However, KPConv was able to classify it correctly. This led to a further experiment on KPConv to assess its generalizability. The use of a multi-context dataset, encompassing railways from three different countries, was shown to be crucial for boosting the generalizability of semantic segmentation models. By training on data from diverse railway environments, the model develops a more robust representation of railway structures and can better adapt to unseen contexts. This was demonstrated in our experiments, where the KPConv model trained on our multi-context dataset achieved significantly higher mIoU scores (0.76 and 0.64) on the SNCF and INFRABEL datasets compared to the model trained on the HMLS dataset alone (0.61 and 0.55). This suggests that our dataset can generalize to unseen railway environments, making it a valuable resource for developing robust semantic segmentation models for railway applications.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}