
An Agglomerative Clustering Combined with an Unsupervised Feature Selection Approach for Structural Health Monitoring

 , , ,
, , ,  ,
,  ,
,  , ,
, ,  , and
, and 
Abstract
1. Introduction
- Introducing an unsupervised feature selection technique that identifies relevant features, improving cluster interpretation and reducing data size;
- Validating the proposed method through diverse case studies, including experimental and benchmark datasets, to demonstrate its effectiveness;
- Providing detailed insights into the identified clusters to better understand structural behaviors and anomalies.
2. Related Works
3. Materials and Methods
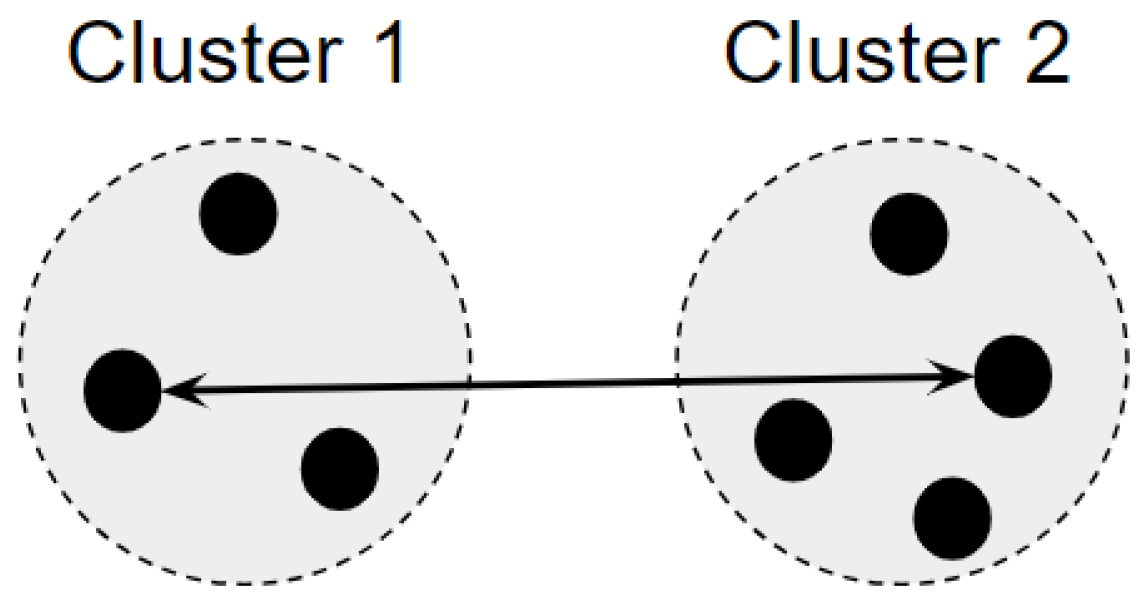
3.1. Agglomerative Clustering



3.2. Principal Component Analysis
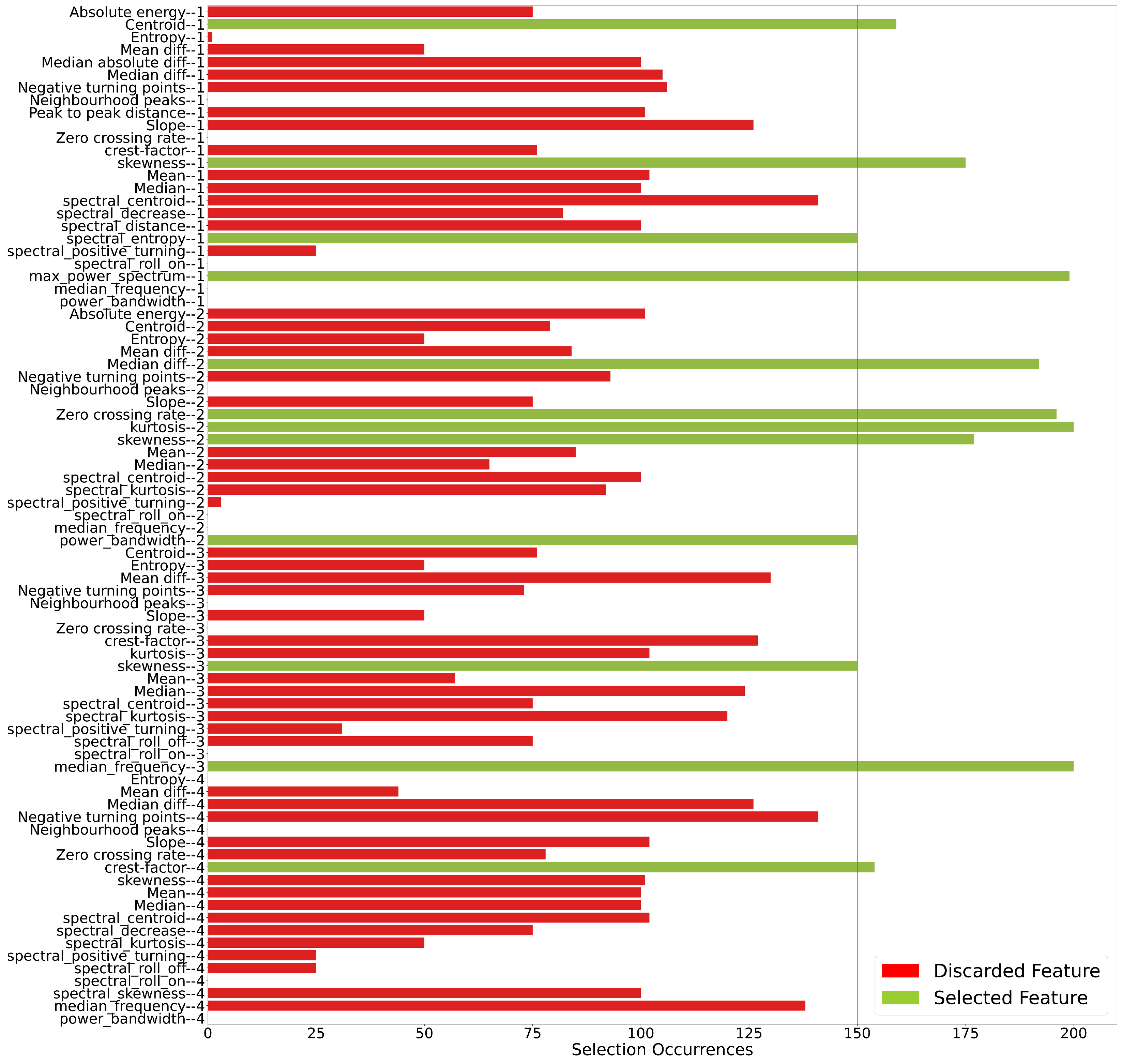
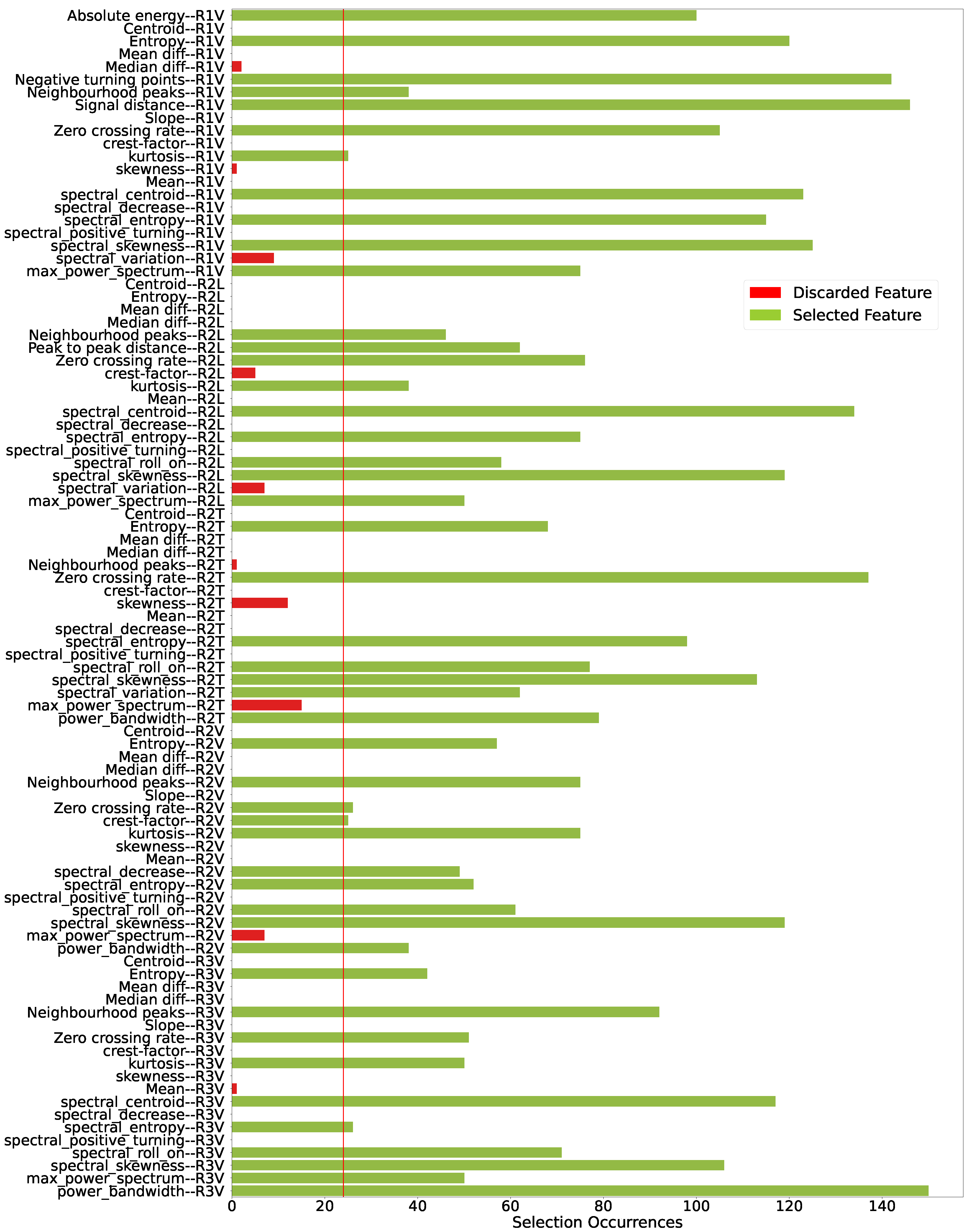
3.3. Feature Selection Approach
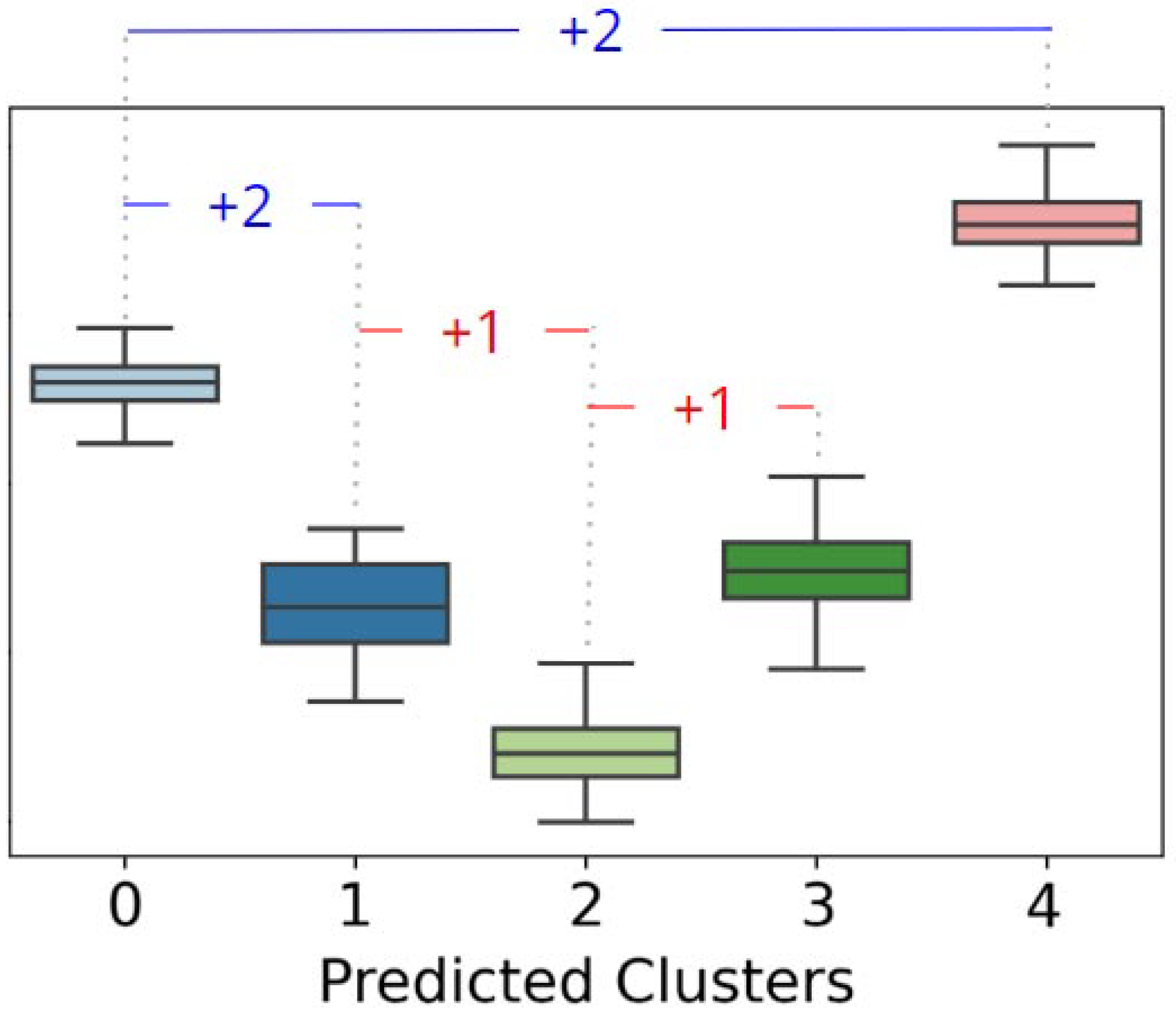
- Assigning scores: This stage begins by evaluating the interquartile ranges of all the clusters. The existence of at least one null interval invalidates the attribute for further scoring analyses. If there is no null iqr, the algorithm carries out a pairwise check of the clusters for a given feature, first comparing the lower limit of one cluster with the upper limit of the other and then the first quartile with the third quartile of the respective clusters. The first check consists of assessing whether the minimum value of the distribution of one cluster (reference) is greater than or equal to the maximum value of the distribution of the other cluster under analysis. If this is met, the algorithm bonuses the feature with 2 points and breaks the iteration, moving on to the next reference cluster. Otherwise, the second evaluation is carried out, checking whether the Q1 of the reference cluster is greater than the Q3 of the other cluster under analysis. In this case, the algorithm bonuses the feature with just 1 point and also breaks the repetition structure to continue analyzing the next reference cluster. In other cases where none of these behaviors are observed, there is no bonus for the feature.
| Algorithm 1 Algorithm for assigning weights in the process of identifying the relevance of features. |
|
3.4. Extrinsic Performance Metrics
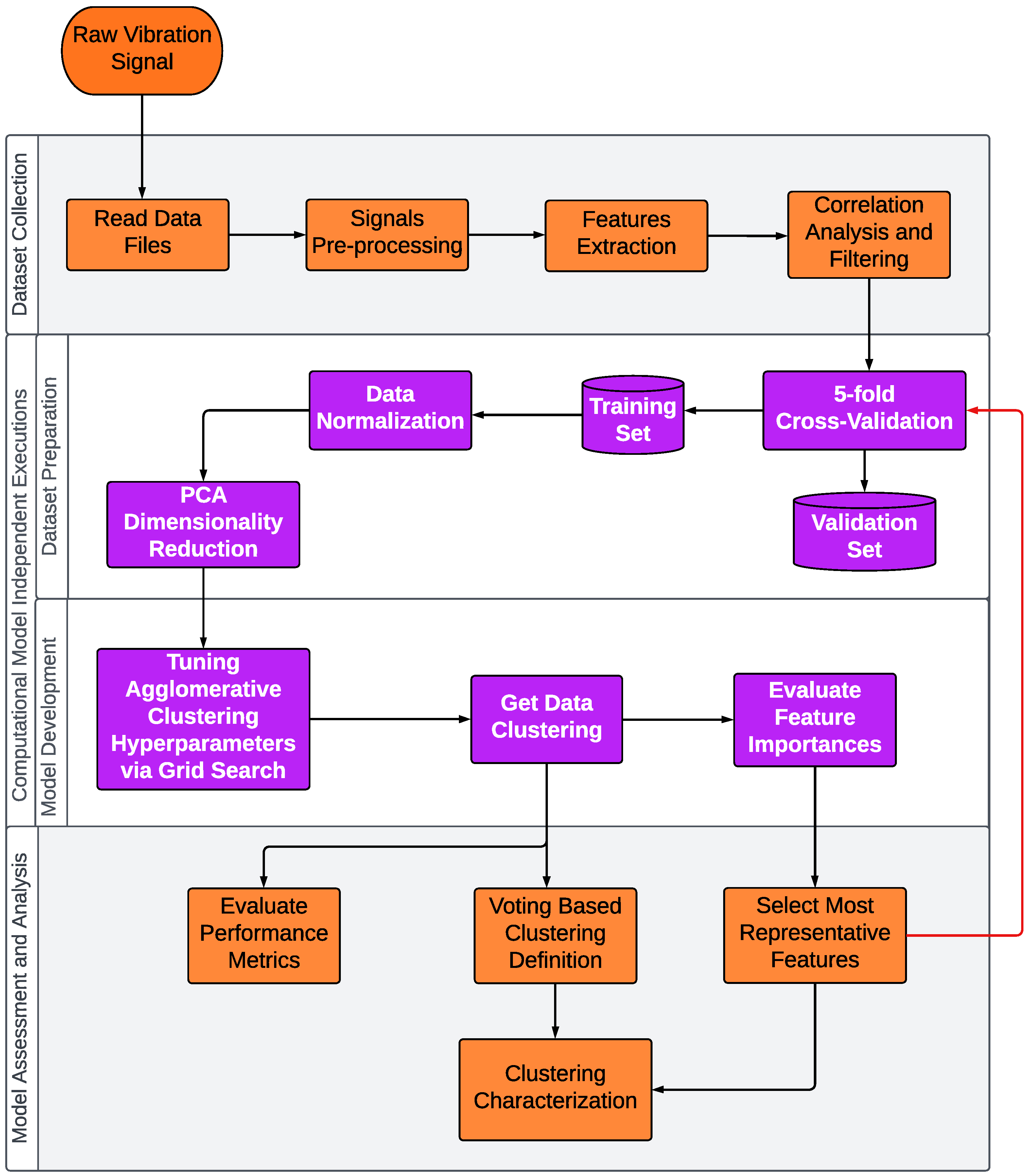
4. Proposed Approach
5. Computational Experiments
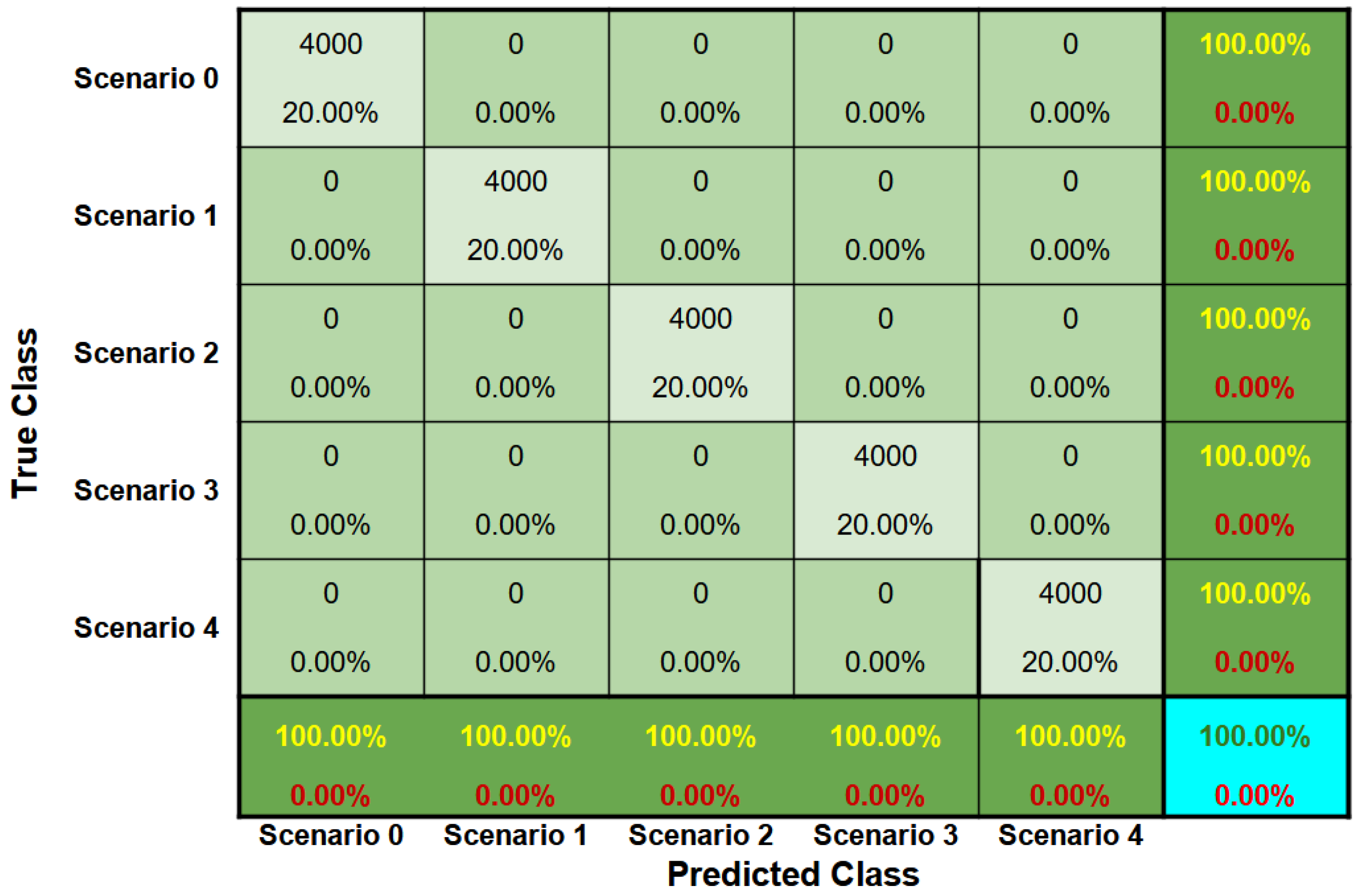
5.1. Two-Story Slender Aluminum Frame
- Scenario 0: Structure in original condition. No additional mass is attached to the structure ().
- Scenario 1: Only one additional 7.81 g mass is attached to the structure on the upper horizontal bar ( = 7.81 g and ).
- Scenario 2: Two additional 7.81 g masses are attached to the structure on the upper horizontal bar ( 15.62 g and ).
- Scenario 3: Three additional 7.81 g masses are attached to the structure: two on the upper horizontal bar and one in the lower horizontal bar ( = 15.62 g and 7.81 g).
- Scenario 4: Four additional 7.81 g masses are attached to the structure: two on the upper horizontal bar and two in the lower horizontal bar ( = 15.62 g and = 15.62 g).
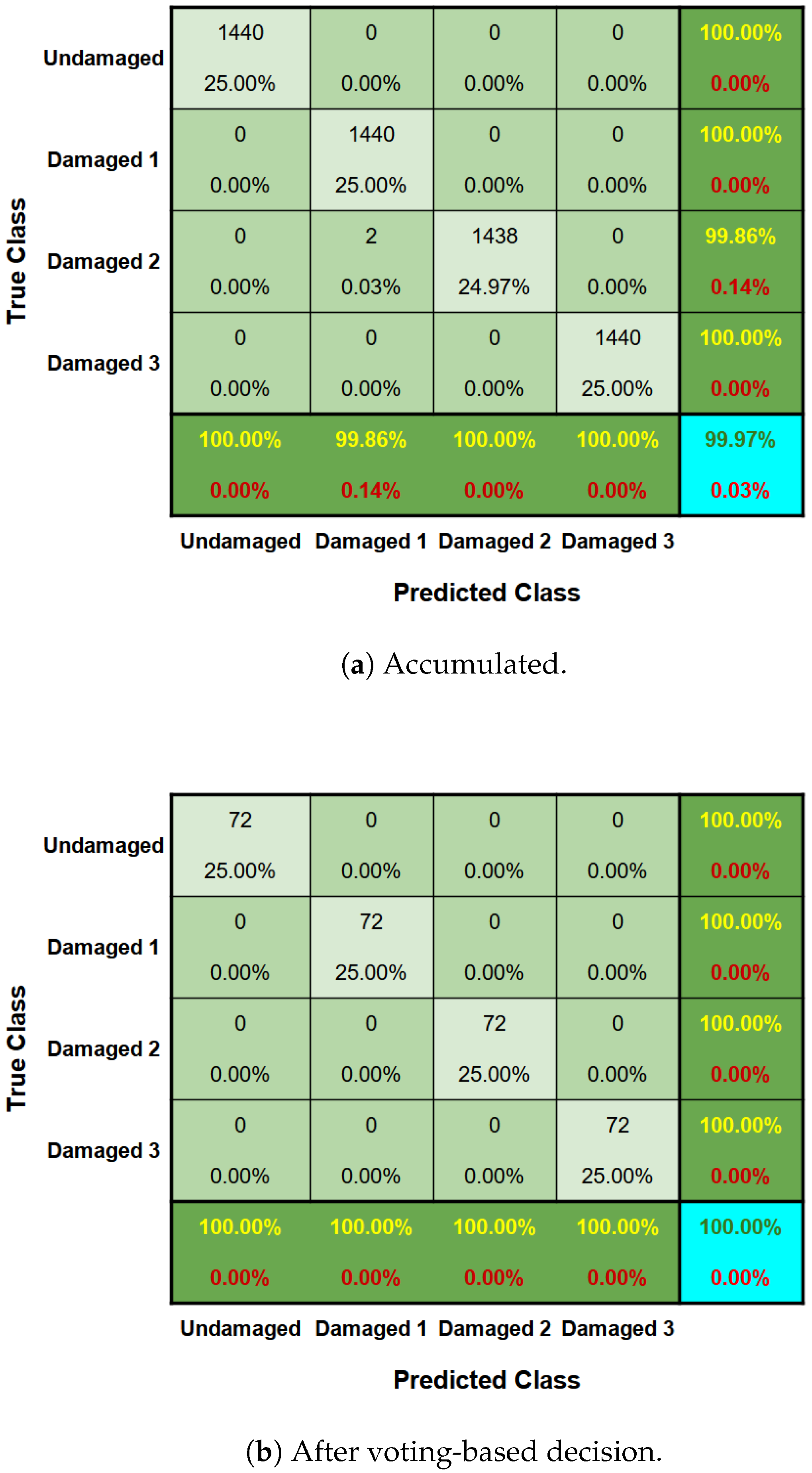
5.2. Wall Monitoring via Smartphone’s Vibration Response
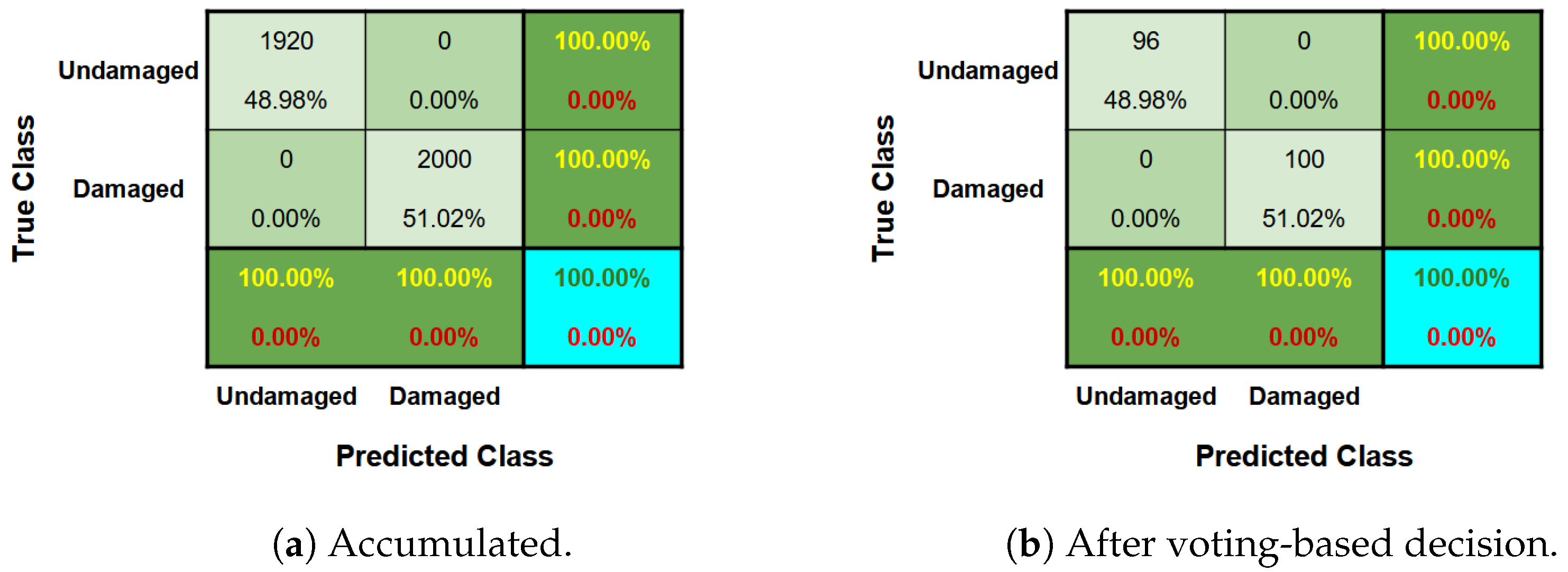
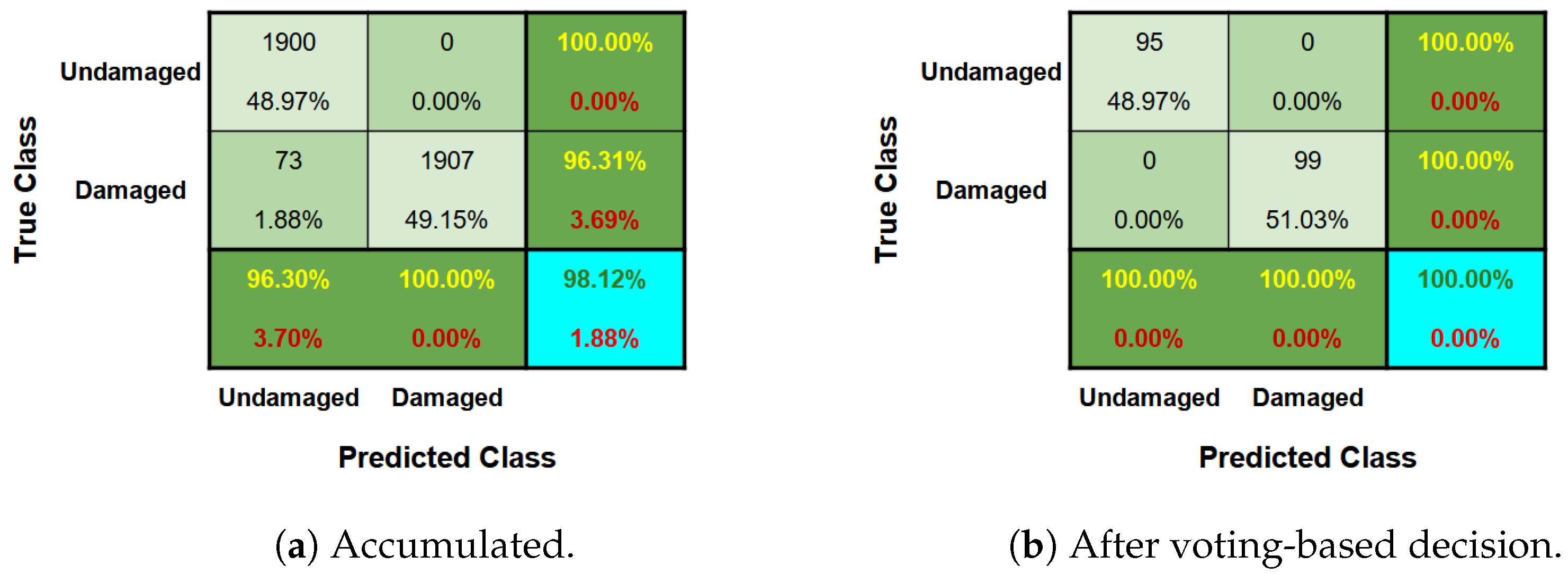
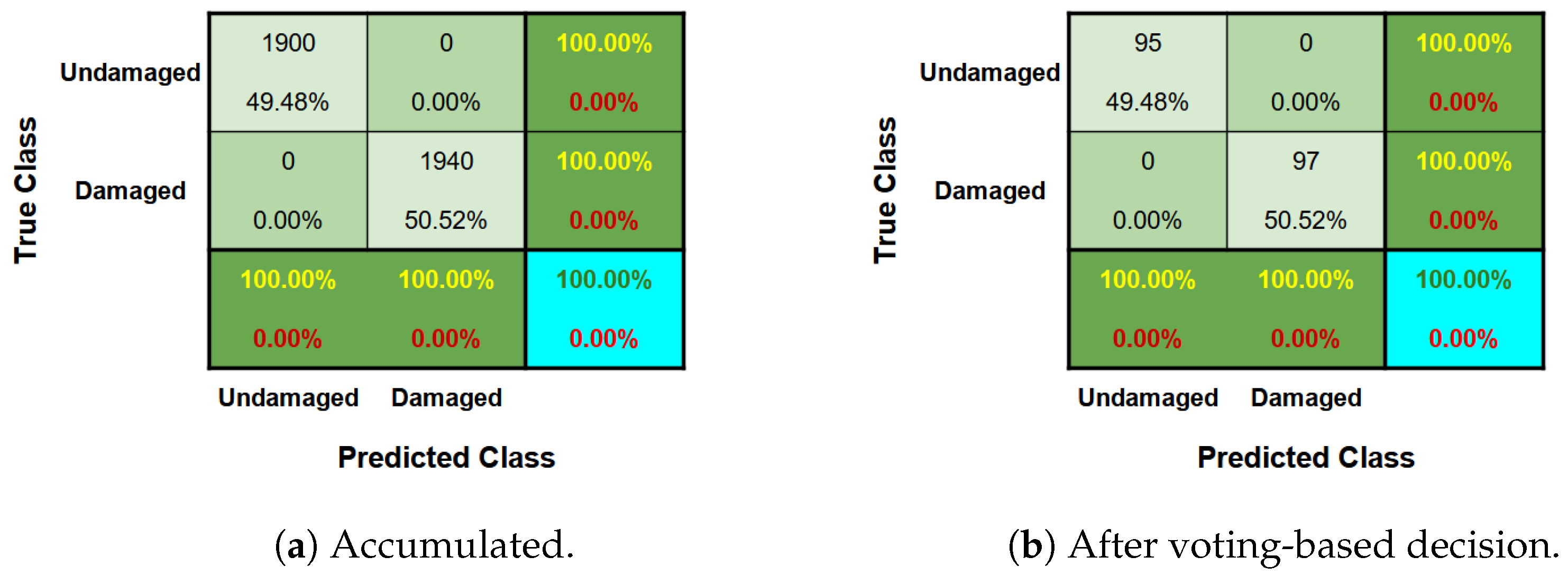
5.2.1. Anomaly Detection
5.2.2. Damage Severity Identification
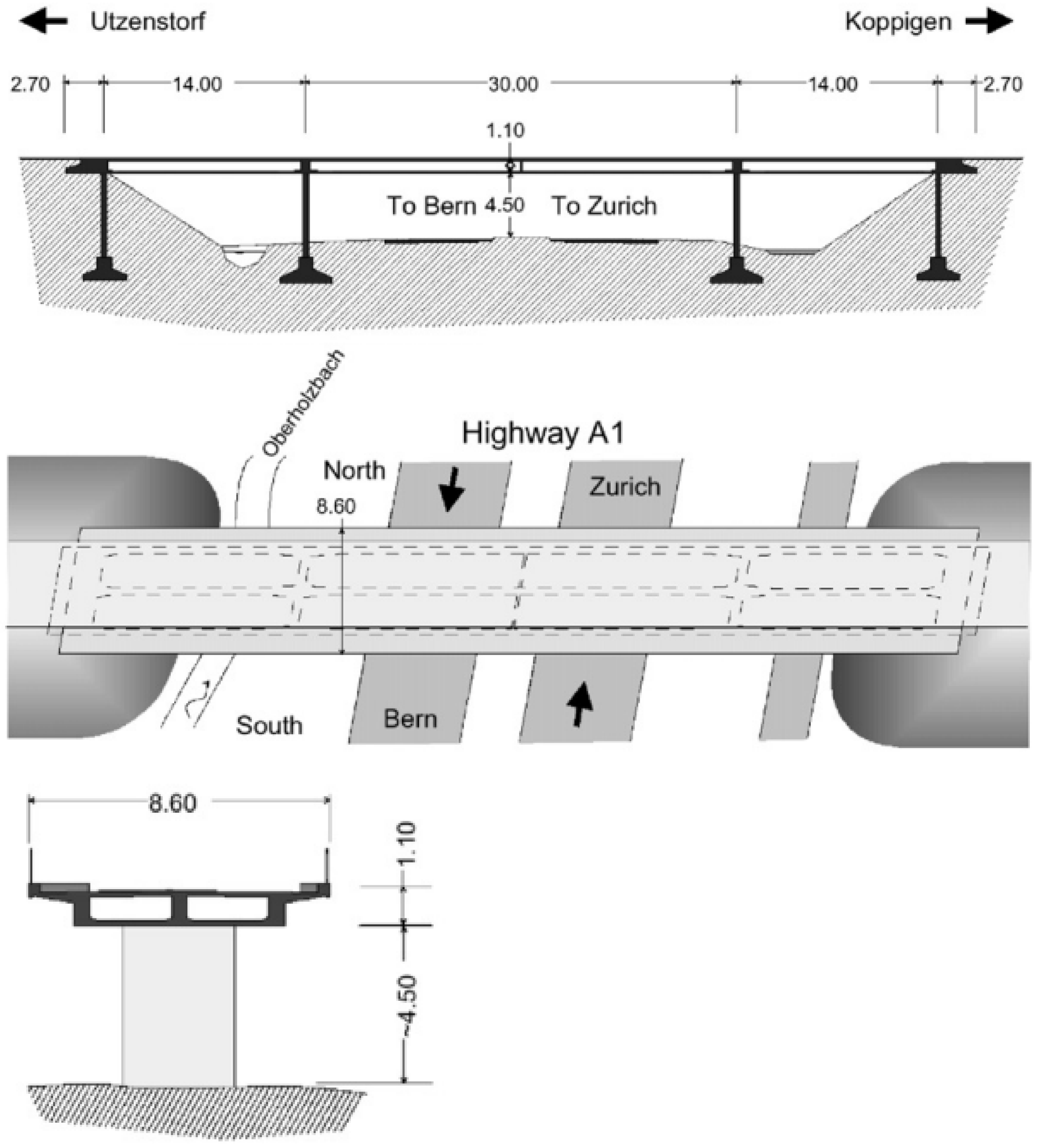
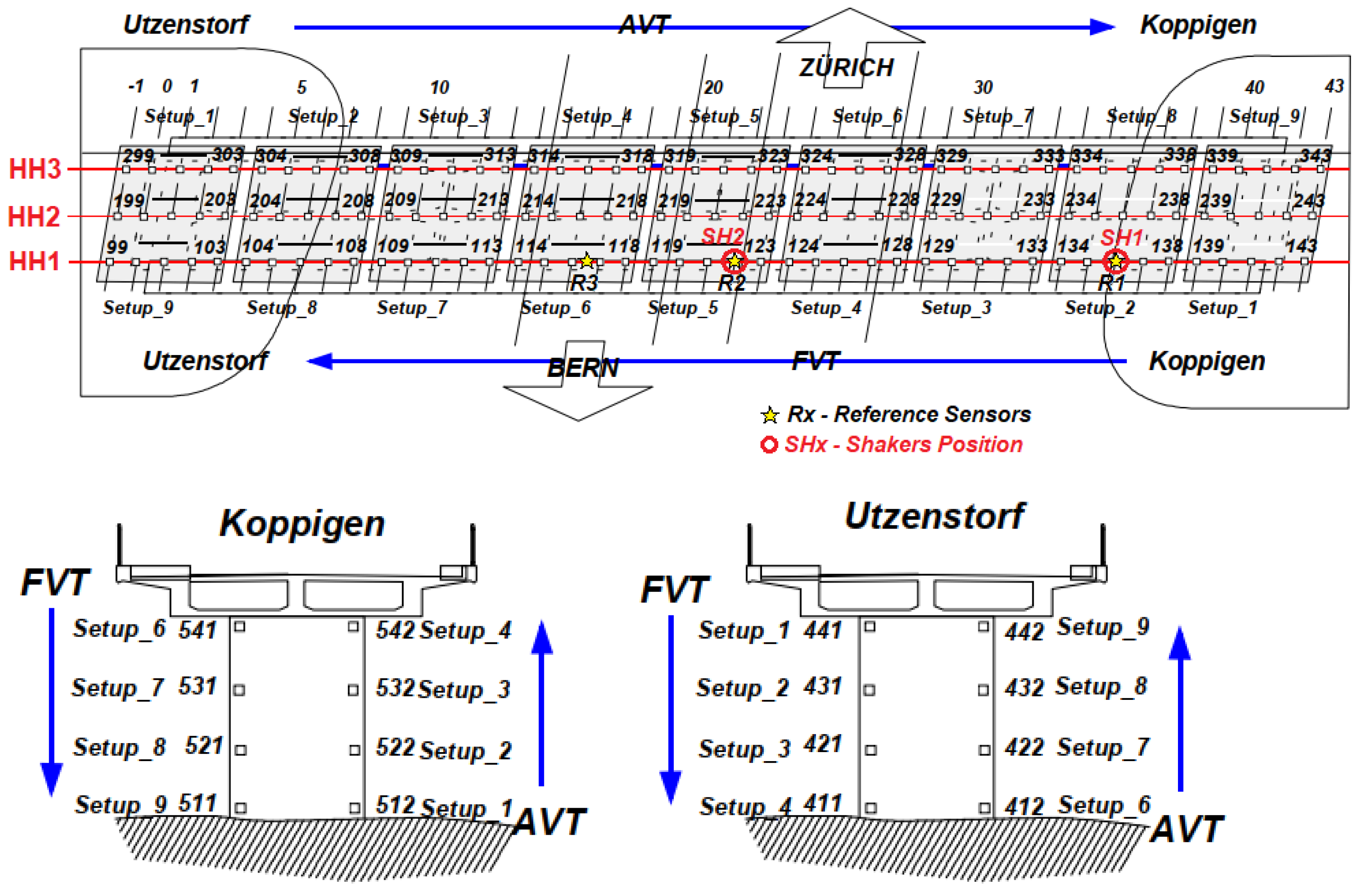
5.3. Z24 Bridge Benchmark
6. Analysis of the Results
6.1. Two-Story Slender Aluminum Frame
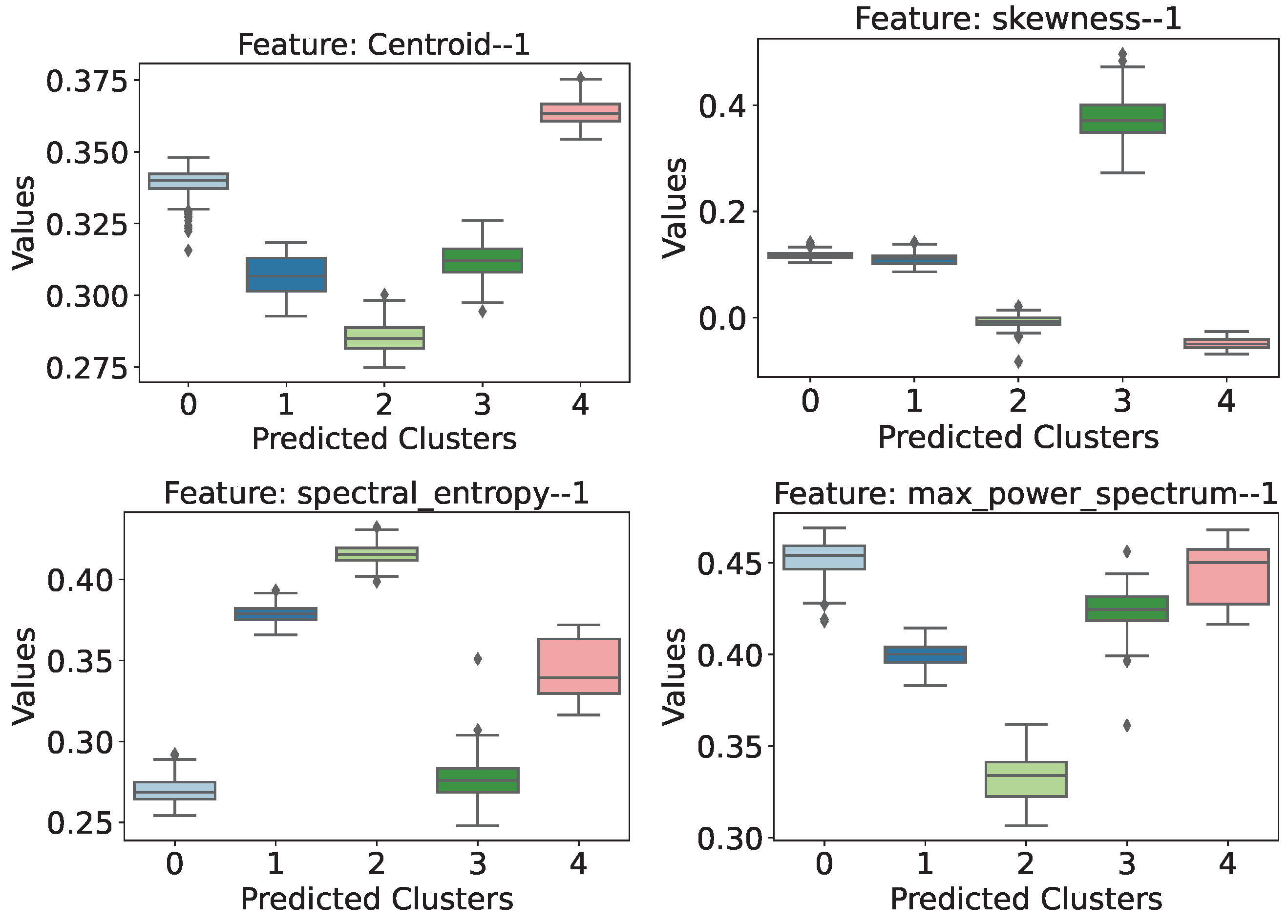
- Centroid: This attribute showed that the structure with the highest load (cluster 4) is associated with higher temporal centroid values and stands out because there is no interval overlap with the other cases.
- Skewness: The same behavior is identified in this attribute, with the difference that the highlight is cluster 3 ( = 15.62 g and = 7.81 g) and with an even greater difference between the intervals.
- Spectral Entropy: In this case, it is possible to identify that there is a difference in the behavior of the attribute for the cases of a structure with loading. At first, this attribute could be useful in trying to localize the loading on the structure, as the introduction of weights in the upper portion of the frame (scenarios 1 and 2) have higher values and distributions than scenarios 3 and 4, which have both top and bottom loading. The addition of a mass, both from case 1 to 2 and from scenario 3 to 4, causes an increase in the entropy value of the signal power spectrum.
- Maximum Power Spectrum: Scenario 2 ( = 15.62 g and = 0) is the cluster that stands out the most in this attribute, showing the lowest distribution of values.
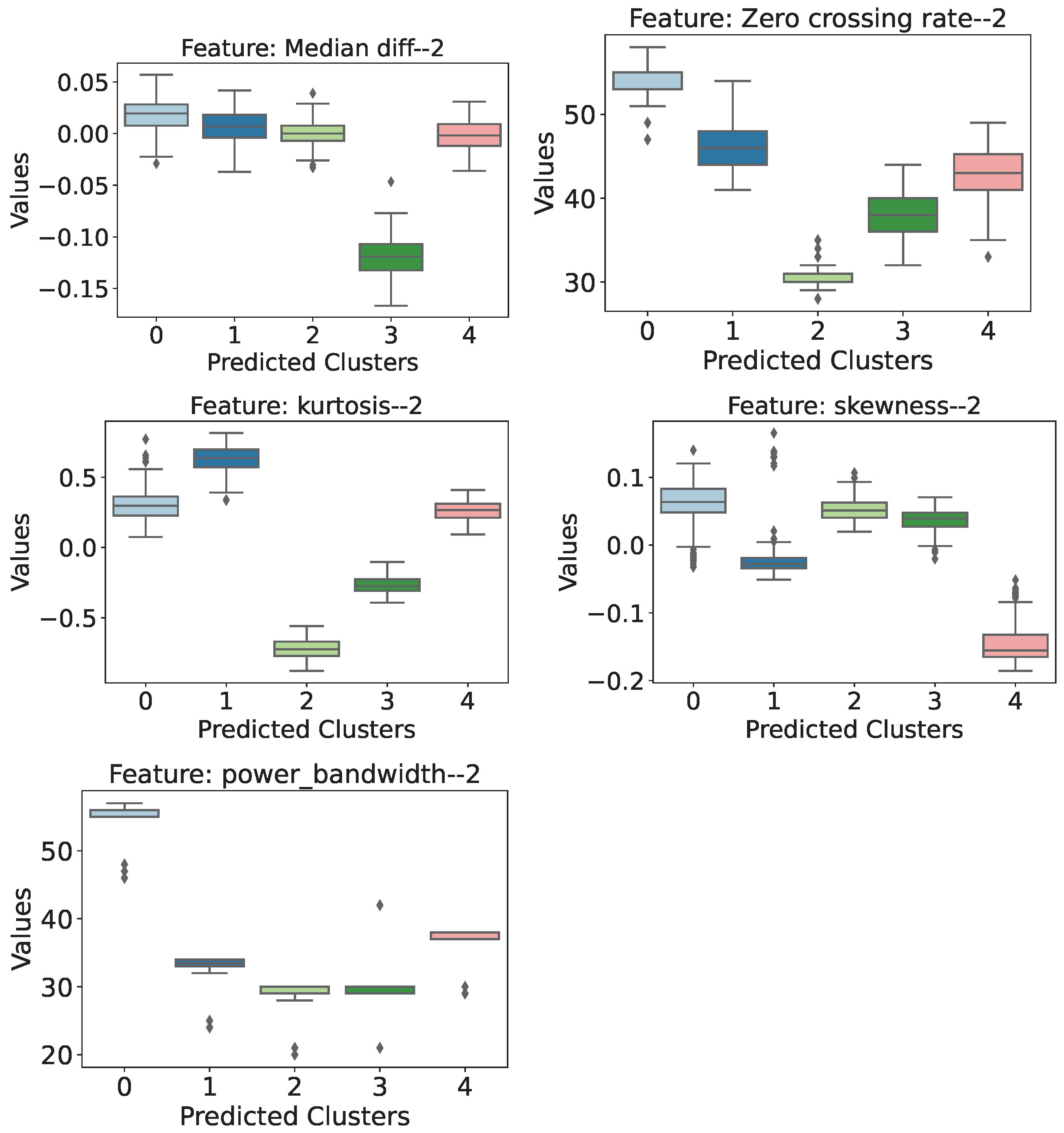
- Median of Signal Differences: In this attribute, it can be seen that cluster 3 stands out from the others, with the lowest values and no overlapping intervals.
- Zero Crossing Rate: Scenario 1 does not seem to be as well identified as a structure subject to external loading. On the other hand, when looking at scenarios 2, 3, and 4, there is a tendency for the value of the attribute to increase as the external load on the structure increases.
- Kurtosis: This feature shows that scenarios 2 and 3 do not overlap with any other grouping. It can also be seen that both scenarios have negative kurtosis values, which is more intense for scenario 2.
- Skewness: Cluster 4 stands out among the others, with the lowest skewness values, which are always negative.
- Power Bandwidth: This attribute is particularly noteworthy, as it seems to identify and represent a clear difference in behavior between an unloaded and loaded structure at any level. Even when taking into account the distribution’s outliers, it can be seen that a bandwidth above approximately 44 units identifies the structure as unloaded, while values below this threshold classify it as a structure subject to external loading.
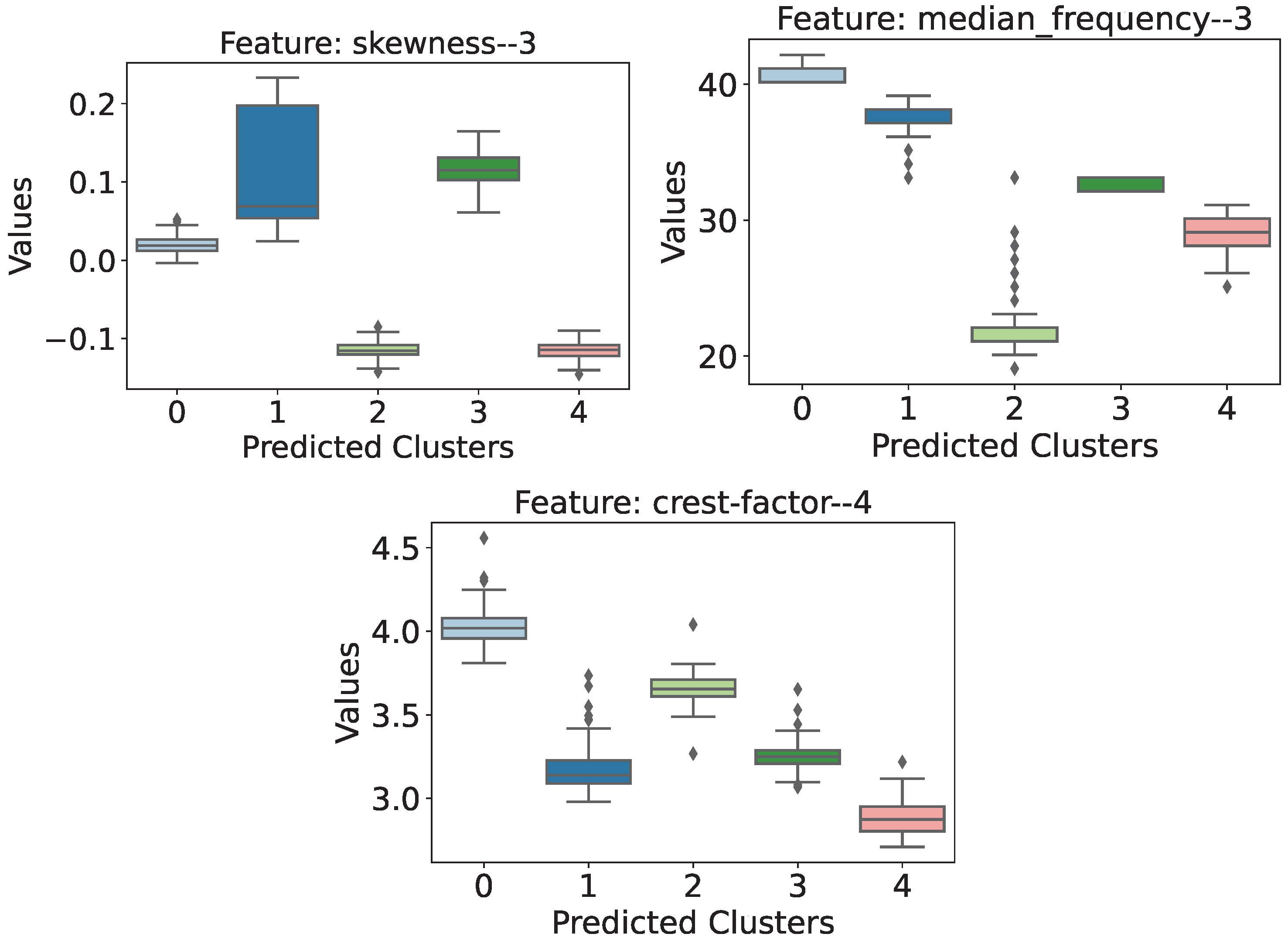
- Skewness (): It can be seen in this case that the unloaded structure has a distribution of values very close to zero, while scenarios 1 and 3 have exclusively positive skewness values, in contrast to scenarios 2 and 4, whose values were strictly negative.
- Median Frequency (): In this feature, the unloaded structure showed the highest distribution of values and no overlapping of ranges among the other scenarios.
- Crest Factor (): Even though the intervals overlap, this seems to be an attribute that helps identify the unloaded scenario from the cases in which the structure is loaded. In general, the unloaded structure showed higher wave crest factor values, so the addition of external loads caused the crest factor values to drop.
6.2. Wall Monitoring via Smartphone’s Vibration Response
6.2.1. Anomaly Detection
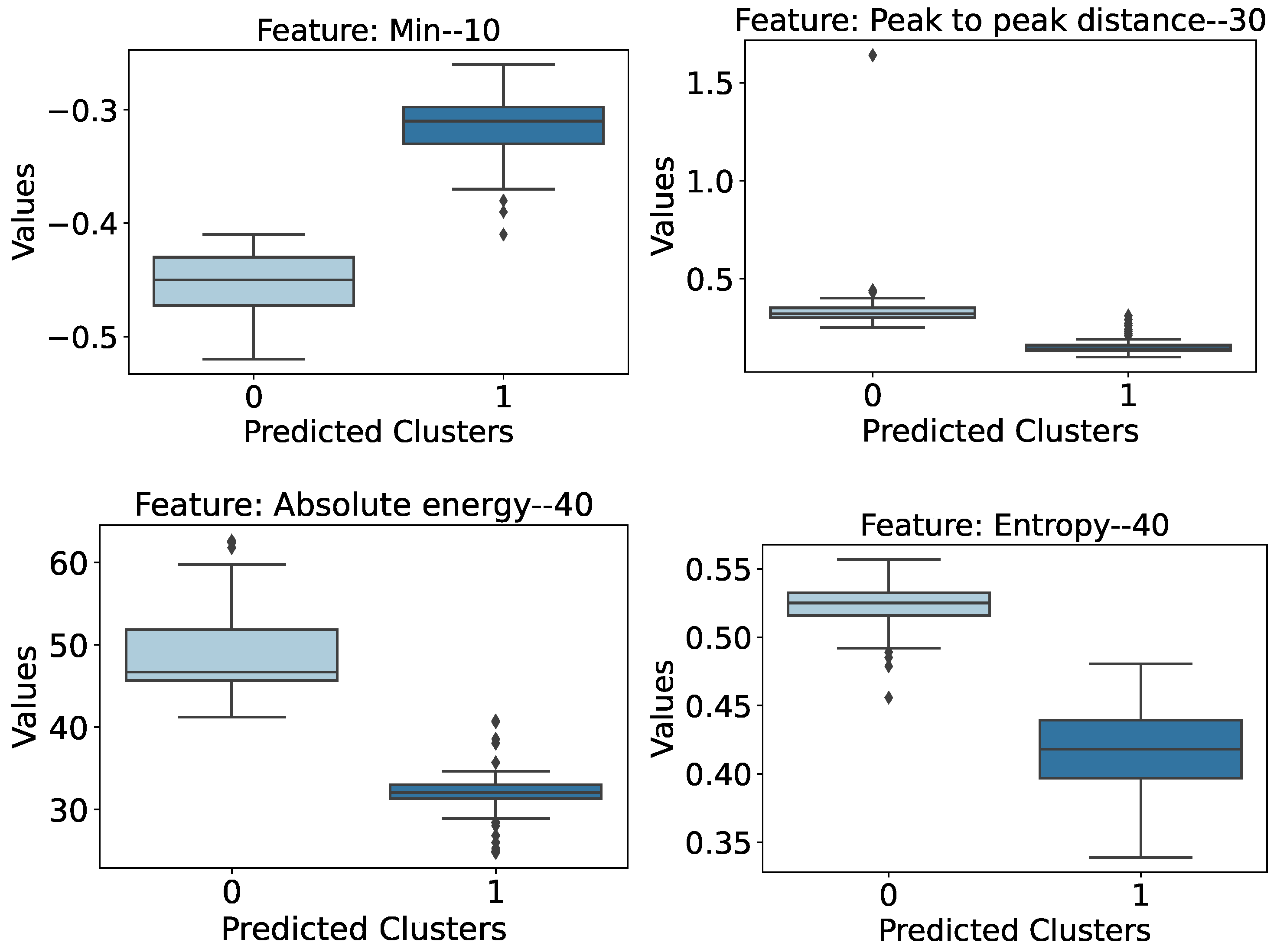
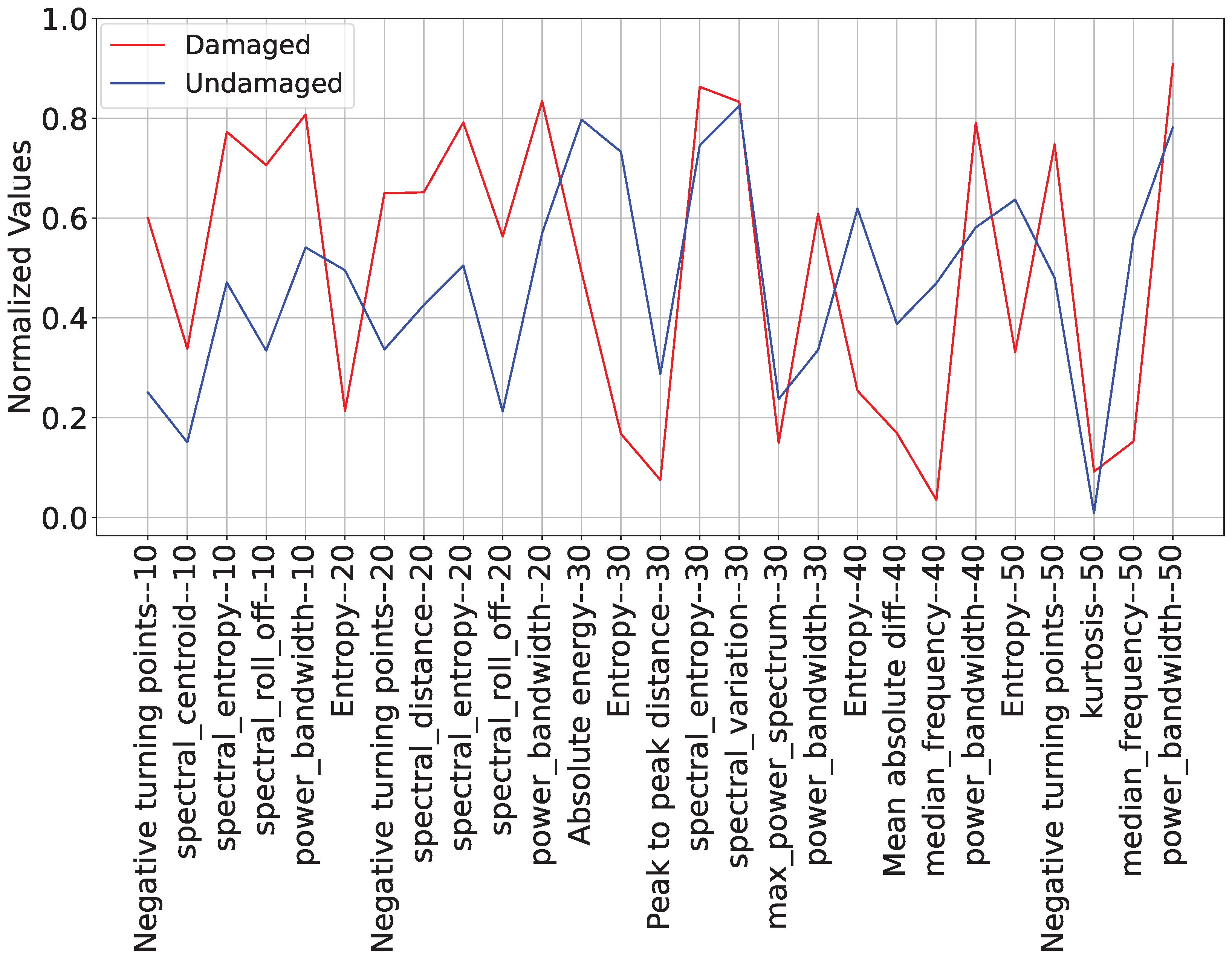
- Entropy (30 and 40 Hz): They show a difference of 56.5% and 36.5%, respectively, between the average values of the different wall conditions. In addition, the damaged cases have lower entropy values than the case of the wall in intact condition.
- Median Frequency (40 and 50 Hz): They show a difference of over 40.8% between the average values of the different wall conditions. Also, the damaged cases have lower values than the case of the wall in intact condition, as was expected, as, according to [61], damaged structures tend to have a lower natural frequency.
- Spectral Roll-Off (10 and 20 Hz): They show a difference of over 35.0% between the average values of the different wall conditions.
- Negative Turning Points (10 and 20 Hz): They show a difference of over 31.3% between the average values of the different wall conditions.
6.2.2. Damage Severity Identification
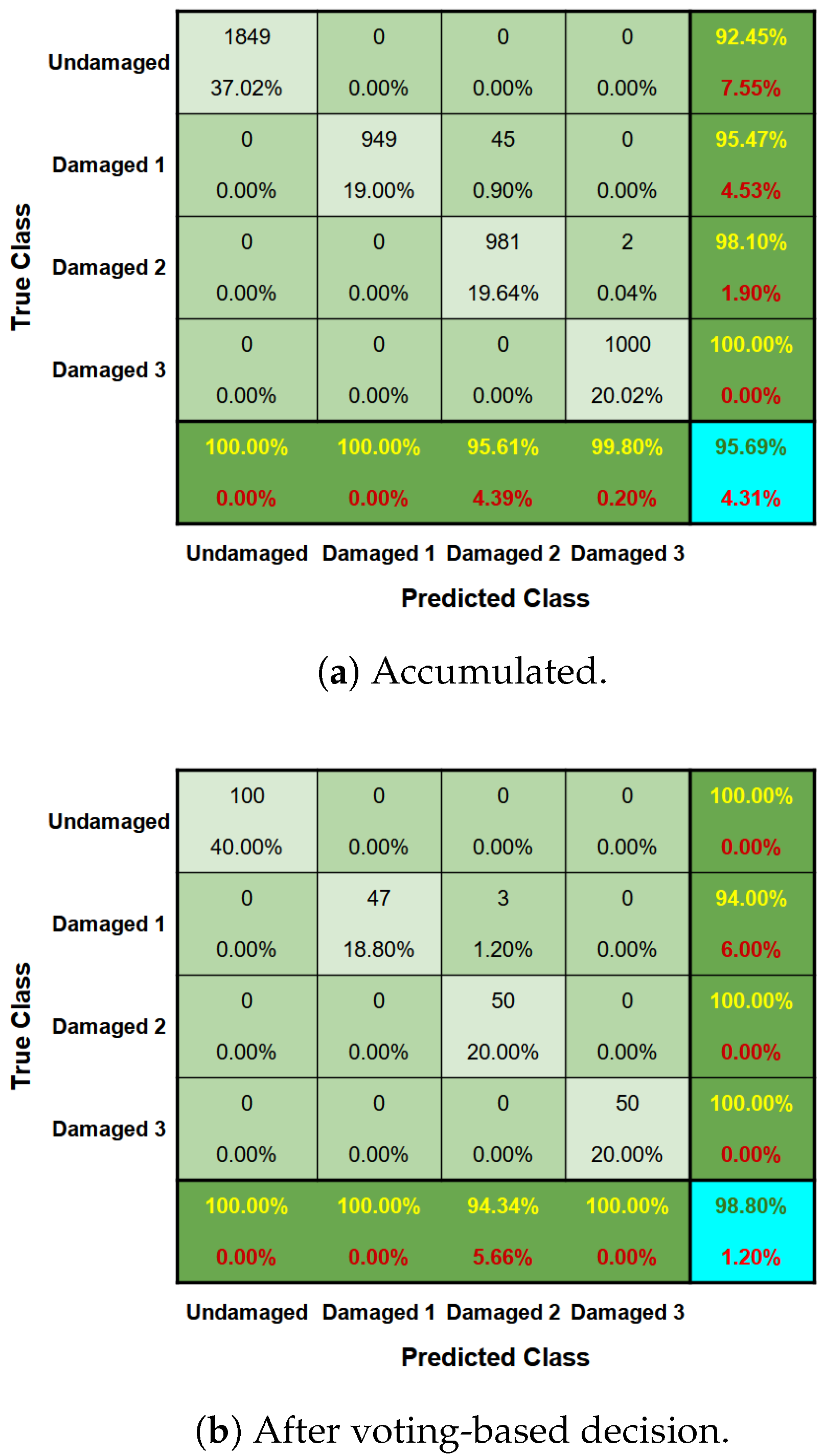
6.3. Z24 Bridge Benchmark
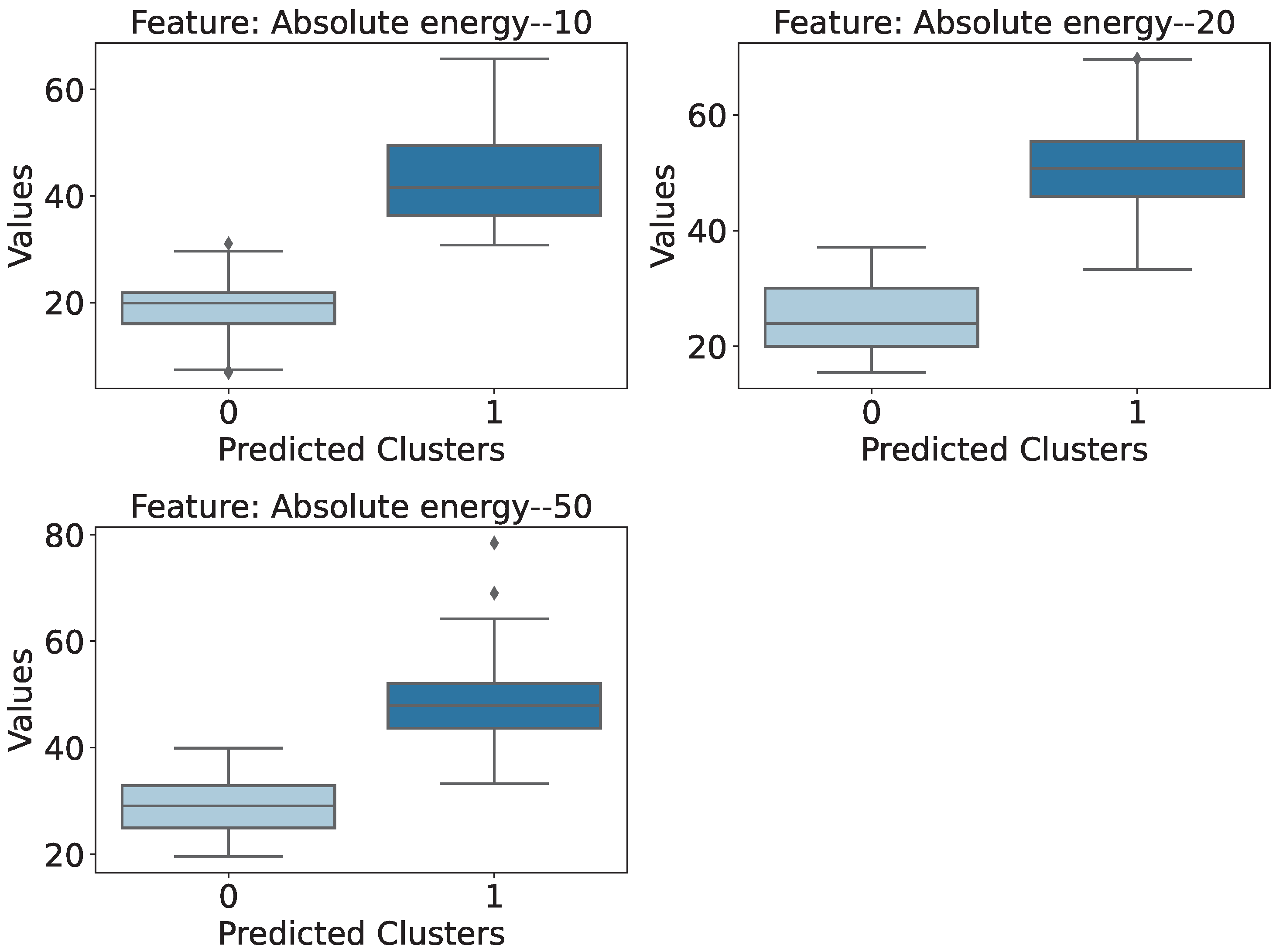
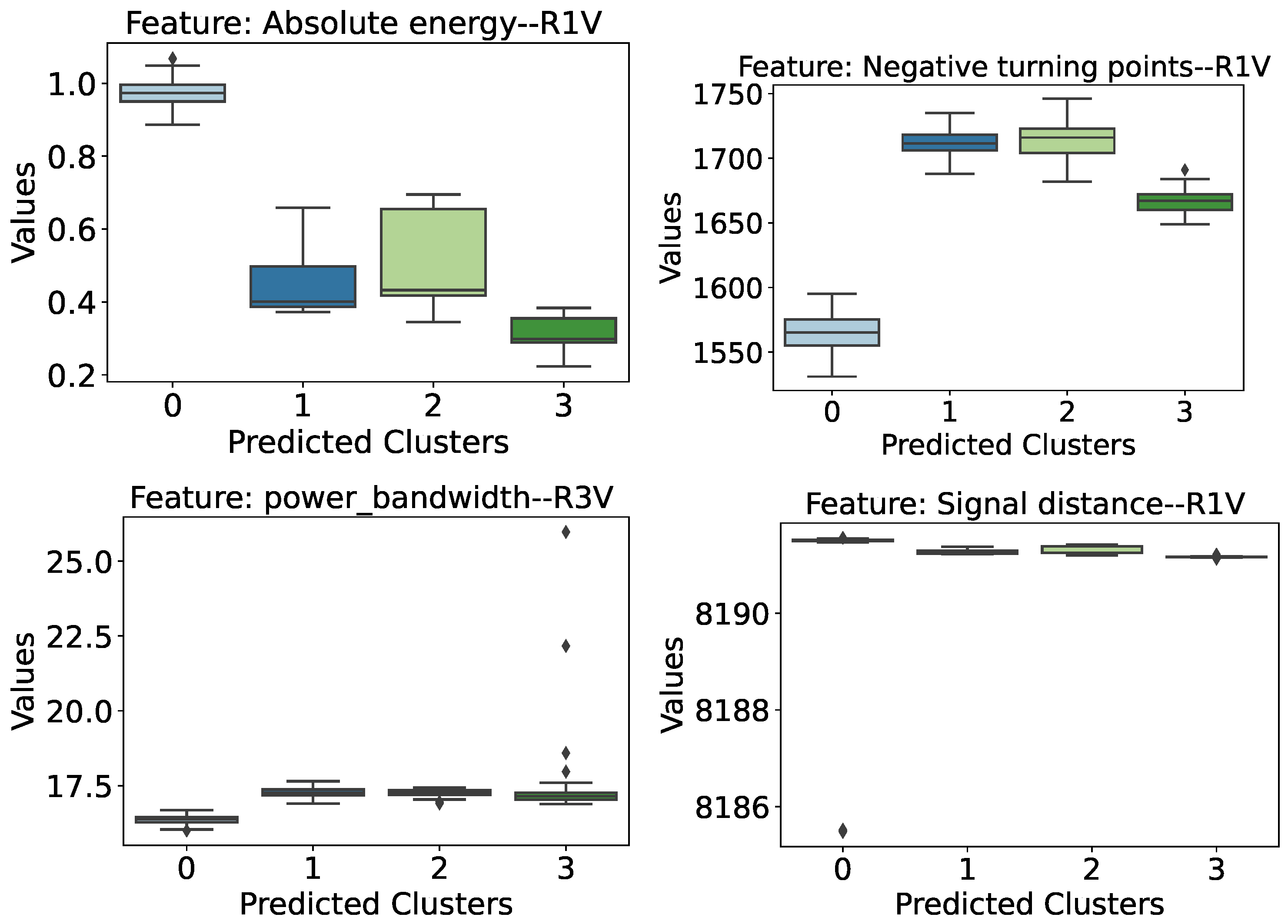
- Absolute Energy (R1 Sensor): This feature indicates that there is a distinction between the damaged and intact bridge scenarios. Higher absolute energy values tend to be associated with a healthy structure, while lower values of this attribute refer to one of the cases of lower damage assessed.
- Negative turning points (R1 Sensor): As with absolute energy, this characteristic extracted from the signals also appears to indicate healthy or damaged conditions. However, the behavior of this attribute is the opposite: lower values are associated with undamaged conditions, while higher values indicate the presence of one of the damages assessed.
- Power Bandwidth (R3 Sensor): This is yet another case where it is possible to separate anomalous structures from healthy ones, albeit with a narrow margin. In this case, we can again see the behavior where the attribute values are lower when the structure is healthy and higher in cases of damage.
- Signal Distance (R1 Sensor): This feature was highlighted in the preliminary analysis because it showed similar behavior to the previous cases, except for an outlier in the healthy structure (cluster 0) distribution. However, in general, separability occurs with the healthy structure, showing higher values for this attribute compared to the damaged cases.
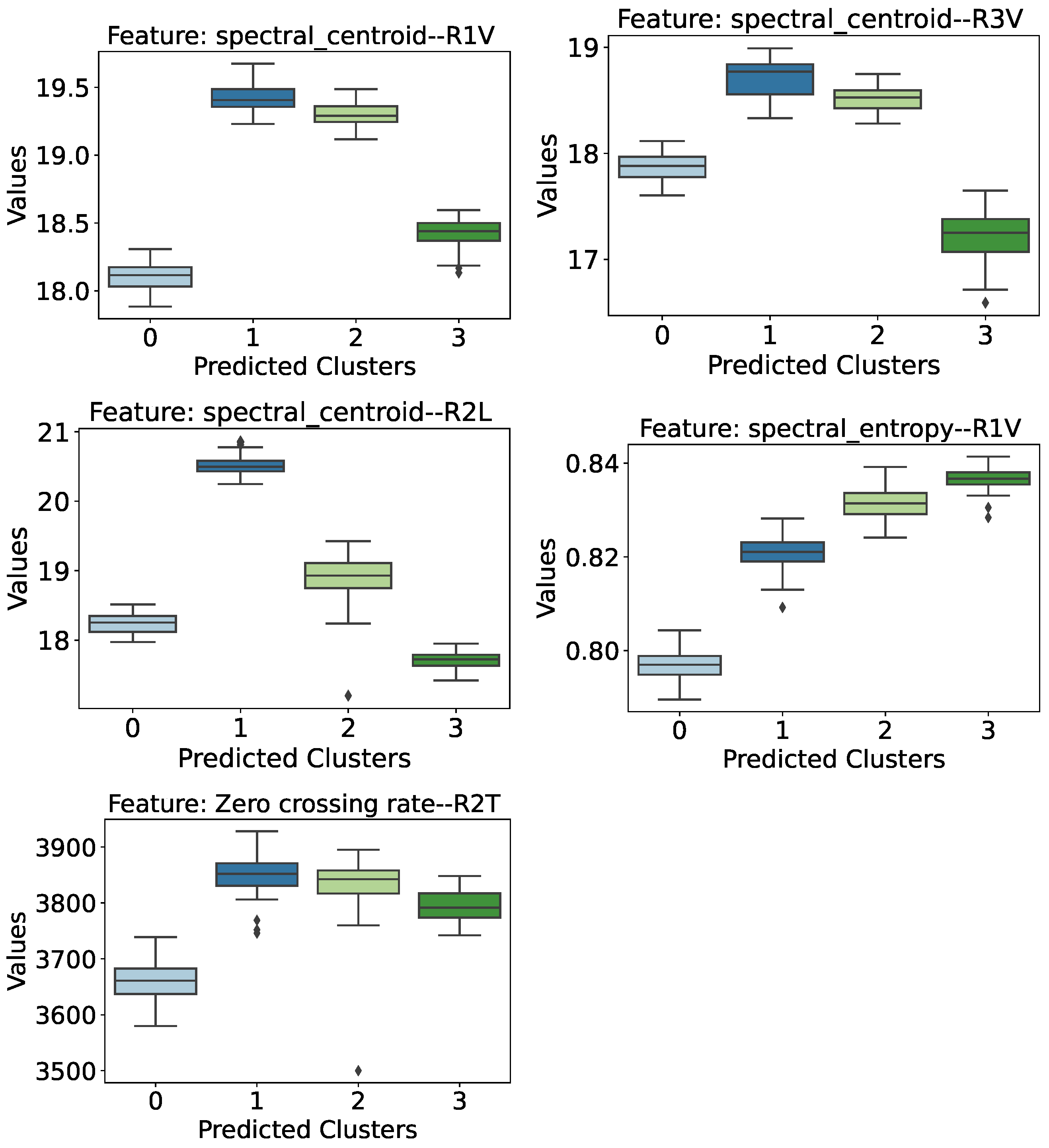
- Spectral Centroid (R1 Sensor): This attribute also shows near-separability between the cases of intact and damaged structures, except for a small overlap of intervals between the distribution of the intact structure (cluster 0) and the structure with the greatest severity of damage (cluster 3). However, if we analyze only the damaged cases, there is a certain tendency for the spectral centroid values to decrease as the severity of the damage increases.
- Spectral Centroid (R3 Sensor): The spectral centroid from the perspective of the R3 sensor shows almost total separability of the clusters, except for cluster 0 (healthy structure) having a small overlapping interval with the distribution of cluster 3 (lowering of 95 mm). Despite this, the behavior of the damaged structure cases is similar to that observed by the R1 sensor, i.e., the spectral centroid medians show a downward trend as the severity of the structure increases.
- Spectral Centroid (R2 Longitudinal Sensor): When analyzing the spectral centroids again, this time from the perspective of the R2 Longitudinal (R2L) Sensor, and discarding the distribution referring to the healthy structure, it is possible to see a clear trend and separability between the three levels of damage to the structure. Thus, when considering a damaged structure from the perspective of the R2L accelerometer, the greater the degree of severity of the damage, the lower its spectral centroid value tends to be.
- Spectral Entropy (R1 Sensor): This attribute deserves to be highlighted, because as well as being able to identify the presence of damage to the structure with a relatively safe margin, the behavior of the distributions also reveals a tendency for spectral entropy to increase as the degree of severity of the damage increases. Thus, the healthy structure of the Z24 bridge has low spectral entropy values, while the introduction of damage causes an increase in this value in proportion to its severity, i.e., the greater the severity of the damage, the higher the spectral entropy values.
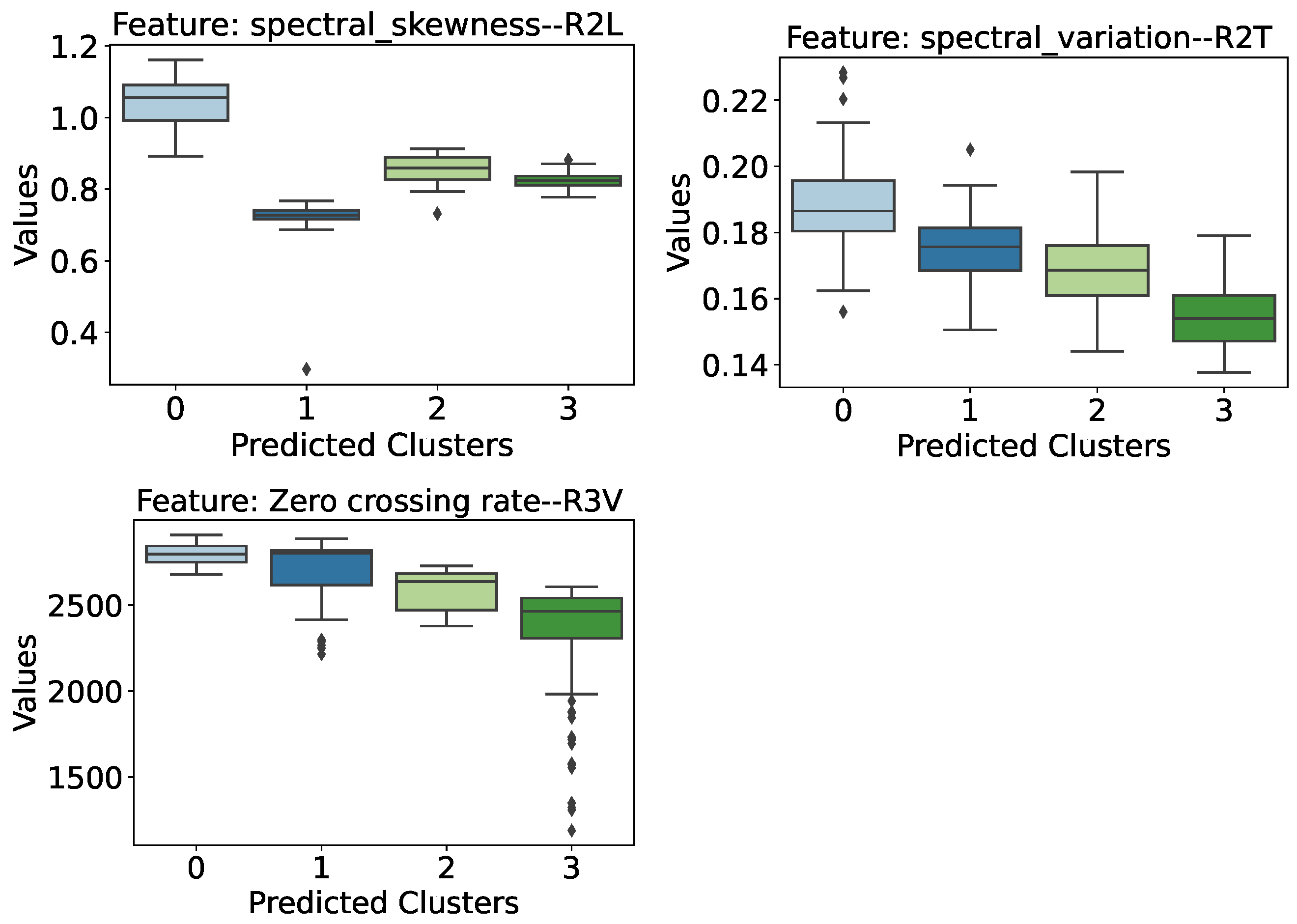
- Zero Crossing Rate (R2 Transversal Sensor): This feature manages to separate cases of intact structure from cases of damaged structure, albeit with a narrower margin of difference. Thus, the bridge’s healthy structure is associated with lower Zero Crossing Rate values, while damaged structures have higher values. Furthermore, it is possible to see a certain trend in the damaged cases, so that the greater the severity of the damage, the lower the rate at which the vibration signal crosses the abscissa axis (coordinate axis equal to 0).
6.4. Performance Comparison
6.5. Model Strengths and Limitations
7. Concluding Remarks and Future Works
- The agglomerative clustering combined with the unsupervised feature selection approach proved to be an effective unsupervised model for SHM tasks;
- The introduced unsupervised feature selection approach proved to be an efficient process for reducing data dimensionality and improving both clustering performance and interpretation.
- Theoretical improvements: Develop a more robust theoretical framework to enhance the stability and reliability of the clustering algorithm under diverse conditions.
- Adaptive automation: Investigate adaptive thresholding techniques for feature selection, enabling a fully automated process that minimizes user intervention and enhances scalability.
- Real-world validation: Conduct extensive evaluations of the method in specific application scenarios, such as bridge monitoring and industrial machinery health tracking, to validate its applicability and performance in practical settings.
- Integration with other techniques: Explore the integration of the proposed method with other machine learning techniques, such as semi-supervised and reinforcement learning, to address a wider range of SHM problems.
- Scalability studies: Examine the performance of the method on large and complex datasets to ensure its suitability for real-time SHM systems.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AC | Agglomerative clustering |
| AVT | Ambient vibration test |
| CNN | Convolution neural network |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| FE | Finite element |
| FRF | Frequency response function |
| FVT | Forced vibration test |
| GMM | Gaussian mixture model |
| Inf-FSU | Unsupervised infinite feature selection |
| k-NN | k-Nearest neighbors |
| LL | Lower limit |
| LSTM | Long short-term memory |
| MSD | Mahalanobis squared distance |
| PCA | Principal component analysis |
| SAE | Sparse autoencoder |
| SDA | Symbolic data analysis |
| SHM | Structural health monitoring |
| SVM | Support vector machines |
| TSFEL | Time Series Feature Extraction Library |
| UL | Upper limit |
| WCC | Waveform chain code |
References
- Farrar, C.R.; Worden, K. An introduction to structural health monitoring. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2007, 365, 303–315. [Google Scholar] [CrossRef]
- Rytter, A. Vibrational Based Inspection of Civil Engineering Structures. Ph.D. Thesis, Aalborg University, Aalborg, Denmark, 1993; 206p. [Google Scholar]
- Sarmadi, H.; Entezami, A.; Ghalehnovi, M. On model-based damage detection by an enhanced sensitivity function of modal flexibility and LSMR-Tikhonov method under incomplete noisy modal data. Eng. Comput. 2020, 38, 111–127. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, Y.; Wu, J.; Deng, C.; Hu, K. Sensor data-driven structural damage detection based on deep convolutional neural networks and continuous wavelet transform. Appl. Intell. 2021, 51, 5598–5609. [Google Scholar] [CrossRef]
- Alves, V.; Cury, A. An automated vibration-based structural damage localization strategy using filter-type feature selection. Mech. Syst. Signal Process. 2023, 190, 110145. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, Y.; Tan, X. Review on Vibration-Based Structural Health Monitoring Techniques and Technical Codes. Symmetry 2021, 13, 1998. [Google Scholar] [CrossRef]
- Xu, N.; Zhang, Z.; Liu, Y. 14—Spatiotemporal fractal manifold learning for vibration-based structural health monitoring. In Structural Health Monitoring/Management (SHM) in Aerospace Structures; Yuan, F.G., Ed.; Woodhead Publishing Series in Composites Science and Engineering; Woodhead Publishing: Cambridge, UK, 2024; pp. 409–426. [Google Scholar] [CrossRef]
- Kauss, K.; Alves, V.; Barbosa, F.; Cury, A. Semi-supervised structural damage assessment via autoregressive models and evolutionary optimization. Structures 2024, 59, 105762. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer series in statistics; Springer: Cham, Switzerland, 2009. [Google Scholar]
- Omori Yano, M.; Figueiredo, E.; da Silva, S.; Cury, A. Foundations and applicability of transfer learning for structural health monitoring of bridges. Mech. Syst. Signal Process. 2023, 204, 110766. [Google Scholar] [CrossRef]
- Bodini, M. A Review of Facial Landmark Extraction in 2D Images and Videos Using Deep Learning. Big Data Cogn. Comput. 2019, 3, 14. [Google Scholar] [CrossRef]
- Krishnanunni, C.G.; Raj, R.S.; Nandan, D.; Midhun, C.K.; Sajith, A.S.; Ameen, M. Sensitivity-based damage detection algorithm for structures using vibration data. J. Civ. Struct. Health Monit. 2018, 9, 137–151. [Google Scholar] [CrossRef]
- Mekjavić, I.; Damjanović, D. Damage Assessment in Bridges Based on Measured Natural Frequencies. Int. J. Struct. Stab. Dyn. 2017, 17, 1750022. [Google Scholar] [CrossRef]
- Ciambella, J.; Pau, A.; Vestroni, F. Modal curvature-based damage localization in weakly damaged continuous beams. Mech. Syst. Signal Process. 2019, 121, 171–182. [Google Scholar] [CrossRef]
- Finotti, R.P.; Souza Barbosa, F.; Cury, A.A.; Gentile, C. A novel natural frequency-based technique to detect structural changes using computational intelligence. Procedia Eng. 2017, 199, 3314–3319. [Google Scholar] [CrossRef]
- Salawu, O. Detection of structural damage through changes in frequency: A review. Eng. Struct. 1997, 19, 718–723. [Google Scholar] [CrossRef]
- Resende, L.; Finotti, R.; Barbosa, F.; Garrido, H.; Cury, A.; Domizio, M. Damage identification using convolutional neural networks from instantaneous displacement measurements via image processing. Struct. Health Monit. 2023, 23, 1627–1640. [Google Scholar] [CrossRef]
- Abdeljaber, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Sony, S.; Gamage, S.; Sadhu, A.; Samarabandu, J. Vibration-based multiclass damage detection and localization using long short-term memory networks. Structures 2022, 35, 436–451. [Google Scholar] [CrossRef]
- Finotti, R.P.; Barbosa, F.S.; Cury, A.A.; Pimentel, R.L. Numerical and Experimental Evaluation of Structural Changes Using Sparse Auto-Encoders and SVM Applied to Dynamic Responses. Appl. Sci. 2021, 11, 11965. [Google Scholar] [CrossRef]
- Finotti, R.P.; Gentile, C.; Barbosa, F.; Cury, A. Structural novelty detection based on sparse autoencoders and control charts. Struct. Eng. Mech. 2022, 81, 647–664. [Google Scholar] [CrossRef]
- Finotti, R.P.; Barbosa, F.S.; Cury, A.A.; Pimentel, R.L. Novelty Detection Using Sparse Auto-Encoders to Characterize Structural Vibration Responses. Arab. J. Sci. Eng. 2022, 47, 13049–13062. [Google Scholar] [CrossRef]
- Spínola Neto, M.; Finotti, R.; Barbosa, F.; Cury, A. Structural Damage Identification Using Autoencoders: A Comparative Study. Buildings 2024, 14, 2014. [Google Scholar] [CrossRef]
- Finotti, R.P.; Cury, A.A.; Barbosa, F.S. An SHM approach using machine learning and statistical indicators extracted from raw dynamic measurements. Lat. Am. J. Solids Struct. 2019, 16, e165. [Google Scholar] [CrossRef]
- Pan, H.; Azimi, M.; Yan, F.; Lin, Z. Time-Frequency-Based Data-Driven Structural Diagnosis and Damage Detection for Cable-Stayed Bridges. J. Bridge Eng. 2018, 23, 04018033. [Google Scholar] [CrossRef]
- Yang, Y.; Nagarajaiah, S. Blind identification of damage in time-varying systems using independent component analysis with wavelet transform. Mech. Syst. Signal Process. 2014, 47, 3–20. [Google Scholar] [CrossRef]
- Kankanamge, Y.; Hu, Y.; Shao, X. Application of wavelet transform in structural health monitoring. Earthq. Eng. Eng. Vib. 2020, 19, 515–532. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Gabbouj, M.; Inman, D.J. A review of vibration-based damage detection in civil structures: From traditional methods to Machine Learning and Deep Learning applications. Mech. Syst. Signal Process. 2021, 147, 107077. [Google Scholar] [CrossRef]
- Abu-Mahfouz, I.; Banerjee, A. Crack Detection and Identification Using Vibration Signals and Fuzzy Clustering. Procedia Comput. Sci. 2017, 114, 266–274. [Google Scholar] [CrossRef]
- Lucà, F.; Manzoni, S.; Cerutti, F.; Cigada, A. A Damage Detection Approach for Axially Loaded Beam-like Structures Based on Gaussian Mixture Model. Sensors 2022, 22, 8336. [Google Scholar] [CrossRef]
- Entezami, A.; Shariatmadar, H.; Karamodin, A. Improving feature extraction via time series modeling for structural health monitoring based on unsupervised learning methods. Sci. Iran. 2020, 27, 1001–1018. [Google Scholar] [CrossRef]
- Alves, V.; Cury, A.; Roitman, N.; Magluta, C.; Cremona, C. Novelty detection for SHM using raw acceleration measurements. Struct. Control. Health Monit. 2015, 22, 1193–1207. [Google Scholar] [CrossRef]
- Khoa, N.L.; Zhang, B.; Wang, Y.; Chen, F.; Mustapha, S. Robust dimensionality reduction and damage detection approaches in structural health monitoring. Struct. Health Monit. 2014, 13, 406–417. [Google Scholar] [CrossRef]
- Entezami, A.; Sarmadi, H.; Behkamal, B. Long-term health monitoring of concrete and steel bridges under large and missing data by unsupervised meta learning. Eng. Struct. 2023, 279, 115616. [Google Scholar] [CrossRef]
- Delgadillo, R.M.; Casas, J.R. SHM of Bridges by Improved Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (ICEEMDAN) and Clustering. Struct. Health-Monit.-Int. J. 2019. [Google Scholar] [CrossRef]
- Civera, M.; Sibille, L.; Zanotti Fragonara, L.; Ceravolo, R. A DBSCAN-based automated operational modal analysis algorithm for bridge monitoring. Measurement 2023, 208, 112451. [Google Scholar] [CrossRef]
- Roveri, N.; Milana, S.; Culla, A.; Conte, P.; Pepe, G.; Mezzani, F.; Carcaterra, A. Machine learning and sensor swarm for structural health monitoring of a bridge. In Proceedings of the ISMA 2020—International Conference on Noise and Vibration Engineering and USD 2020—International Conference on Uncertainty in Structural Dynamics, Virtual, 7–9 September 2020; pp. 2817–2824. [Google Scholar]
- Diez, A.; Khoa, N.L.D.; Makki Alamdari, M.; Wang, Y.; Chen, F.; Runcie, P. A clustering approach for structural health monitoring on bridges. J. Civ. Struct. Health Monit. 2016, 6, 429–445. [Google Scholar] [CrossRef]
- Chen, S.; Ong, Z.C.; Lam, W.H.; Lim, K.S.; Lai, K.W. Unsupervised Damage Identification Scheme Using PCA-Reduced Frequency Response Function and Waveform Chain Code Analysis. Int. J. Struct. Stab. Dyn. 2020, 20, 2050091. [Google Scholar] [CrossRef]
- Siow, P.Y.; Ong, Z.C.; Khoo, S.Y.; Lim, K.S. Damage Sensitive PCA-FRF Feature in Unsupervised Machine Learning for Damage Detection of Plate-Like Structures. Int. J. Struct. Stab. Dyn. 2021, 21, 2150028. [Google Scholar] [CrossRef]
- Diday, E.; Noirhomme-Fraiture, M. Symbolic Data Analysis and the SODAS Software; Wiley-Interscience: Hoboken, NJ, USA, 2008. [Google Scholar]
- Hassan Daneshvar, M.; Sarmadi, H. Unsupervised learning-based damage assessment of full-scale civil structures under long-term and short-term monitoring. Eng. Struct. 2022, 256, 114059. [Google Scholar] [CrossRef]
- Ackermann, M.R.; Blömer, J.; Kuntze, D.; Sohler, C. Analysis of Agglomerative Clustering. Algorithmica 2012, 69, 184–215. [Google Scholar] [CrossRef]
- Tokuda, E.K.; Comin, C.H.; Costa, L.d.F. Revisiting agglomerative clustering. Phys. A Stat. Mech. Its Appl. 2022, 585, 126433. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis; Springer Verlag: New York, NY, USA, 2002. [Google Scholar]
- Vyas, S.; Kumaranayake, L. Constructing socio-economic status indices: How to use principal components analysis. Health Policy Plan. 2006, 21, 459–468. [Google Scholar] [CrossRef]
- Rosenberg, A.; Hirschberg, J. V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 410–420. [Google Scholar]
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time Series Feature Extraction Library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Crutchfield, J.P.; Feldman, D.P. Regularities unseen, randomness observed: Levels of entropy convergence. Chaos Interdiscip. J. Nonlinear Sci. 2003, 13, 25–54. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M.L. seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Finotti, R.P.; Silva, C.F.; Oliveira, P.H.E.; Barbosa, F.S.; Cury, A.A.; Silva, R.C. Novelty detection on a laboratory benchmark slender structure using an unsupervised deep learning algorithm. Lat. Am. J. Solids Struct. 2023, 20, e512. [Google Scholar] [CrossRef]
- Sun, W. VibWall: Smartphone’s Vibration Challenge-response for Wall Crack Detection. ACM J. Comput. Sustain. Soc. 2023, 1, 1–24. [Google Scholar] [CrossRef]
- Maeck, J.; De Roeck, G. Description of Z24 benchmark. Mech. Syst. Signal Process. 2003, 17, 127–131. [Google Scholar] [CrossRef]
- Roeck, G.D.; Peeters, B.; Maeck, J. Dynamic monitoring of civil engineering structures. In Proceedings of the Computational Methods for Shell and Spatial Structures IASS-IACM 2000, Chania, Greece, 4–7 June 2000. [Google Scholar]
- Sinou, J.J. A Review of Damage Detection and Health Monitoring of Mechanical Systems from Changes in the Measurement of Linear and Non-linear Vibrations. In Mechanical Vibrations: Measurement, Effects and Control; Nova Science: Hauppauge, NY, USA, 2009; pp. 643–702. [Google Scholar]
- Eltouny, K.; Gomaa, M.; Liang, X. Unsupervised Learning Methods for Data-Driven Vibration-Based Structural Health Monitoring: A Review. Sensors 2023, 23, 3290. [Google Scholar] [CrossRef]
- Silva, M.; Santos, A.; Figueiredo, E.; Santos, R.; Sales, C.; Costa, J.C. A novel unsupervised approach based on a genetic algorithm for structural damage detection in bridges. Eng. Appl. Artif. Intell. 2016, 52, 168–180. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; AAAI Press: Washington, DC, USA, 1996; pp. 226–231. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| Absolute energy of the signal *. | |
| Area under the signal curve computed with trapezoid rule *. | |
| Autocorrelation of the signal *. | |
| Centroid along the time axis *. | |
| Entropy of the signal using the Shannon Entropy ** | |
| Mean absolute differences of the signal. | |
| Mean of differences of the signal. | |
| Median absolute differences of the signal. | |
| Median of signal differences. | |
| Number of negative turning points of the signal. | |
| Number of peaks from a defined signal neighborhood. | |
| Peak to peak distance *. | |
| Number of positive signal turning points *. | |
| Signal traveled distance *. | |
| Slope of the signal *. | |
| Sum of absolute differences of the signal *. | |
| Total energy of the signal *. | |
| Computes the zero-crossing rate of the signal *. |
| Feature | Description |
|---|---|
| Compute the interquartile range of the data along the specified axis **. | |
| Computes crest-factor of the signal. | |
| Computes kurtosis of the signal *. | |
| Computes skewness of the signal *. | |
| Computes the maximum value of the signal *. | |
| Computes the minimum value of the signal *. | |
| Computes root mean square of the signal *. | |
| Computes mean value of the signal *. | |
| Computes median of the signal *. | |
| Computes standard deviation of the signal *. |
| Feature | Description |
|---|---|
| Barycenter of the spectrum *. | |
| Represents the amount of decreasing of the spectra amplitude *. | |
| Computes the signal spectral distance. Distance of the signal’s cumulative sum of the FFT elements to the respective linear regression *. | |
| Computes the spectral entropy of the signal based on Fourier transform *. | |
| Measures the flatness of a distribution around its mean value *. | |
| Computes the number of positive turning points of the FFT magnitude signal *. | |
| Computes the spectral roll-off of the signal. The spectral roll-off corresponds to the frequency where 95% of the signal magnitude is contained below this value *. | |
| Computes the spectral roll-on of the signal. The spectral roll-on corresponds to the frequency where 5% of the signal magnitude is contained below this value *. | |
| Measures the asymmetry of a distribution around its mean value *. | |
| Computes the spectral slope. The spectral slope is computed by finding constants m and b of the function aFFT = mf + b, obtained by linear regression of the spectral amplitude *. | |
| Measures the spread of the spectrum around its mean value *. | |
| Computes the amount of variation of the spectrum along time. Spectral variation is computed from the normalized cross-correlation between two consecutive amplitude spectra *. | |
| Computes maximum power spectrum density of the signal *. | |
| Computes maximum frequency of the signal *. | |
| Computes median frequency of the signal *. | |
| Computes power spectrum density bandwidth of the signal. It corresponds to the width of the frequency band in which 95% of its power is located *. |
| Parameters | Possible Values |
|---|---|
| Linkage | Ward, Complete, Average, Single |
| Metric | Euclidean, L1, L2, Manhattan, Cosine |
| Number of Clusters | [2, 3, 4, 5, 6, 7, 8] |
| Performance Metric | Before Feature Selection | After Feature Selection |
|---|---|---|
| Homogeneity | 1.0 (0.0) | 1.0 (0.0) |
| Completeness | 1.0 (0.0) | 1.0 (0.0) |
| Adjusted Rand score | 1.0 (0.0) | 1.0 (0.0) |
| V-measure | 1.0 (0.0) | 1.0 (0.0) |
| Performance Metric | Baker Bricks | Baker Hall | Office Wall |
|---|---|---|---|
| Homogeneity | 0.9921 (0.018) | 0.8529 (0.0415) | 0.9762 (0.0439) |
| Completeness | 0.9921 (0.0182) | 0.6139 (0.0342) | 0.9765 (0.0432) |
| Adjusted Rand score | 0.9959 (0.0094) | 0.7302 (0.0375) | 0.9855 (0.0283) |
| V-measure | 0.9921 (0.0181) | 0.7137 (0.0354) | 0.9764 (0.0435) |
| Performance Metric | Baker Bricks | Baker Hall | Office Wall |
|---|---|---|---|
| Homogeneity | 1.0 (0.0) | 1.0 (0.0) | 1.0 (0.0) |
| Completeness | 1.0 (0.0) | 1.0 (0.0) | 1.0 (0.0) |
| Adjusted Rand score | 1.0 (0.0) | 1.0 (0.0) | 1.0 (0.0) |
| V-measure | 1.0 (0.0) | 1.0 (0.0) | 1.0 (0.0) |
| Performance Metric | Before Feature Selection | After Feature Selection |
|---|---|---|
| Homogeneity | 0.9111 (0.0326) | 0.9686 (0.0104) |
| Completeness | 0.7052 (0.0248) | 0.9171 (0.0657) |
| Adjusted Rand score | 0.7413 (0.0314) | 0.9251 (0.0680) |
| V-measure | 0.7949 (0.0259) | 0.9410 (0.0363) |
| Performance Metric | Before Feature Selection | After Feature Selection |
|---|---|---|
| Homogeneity | 0.9925 (0.0087) | 0.9987 (0.0043) |
| Completeness | 0.9926 (0.0086) | 0.9987 (0.0043) |
| Adjusted Rand score | 0.9944 (0.0066) | 0.9991 (0.0031) |
| V-measure | 0.9926 (0.0087) | 0.9987 (0.0043) |
| Adjusted | ||||
|---|---|---|---|---|
| Case Study | Homogeneity | Completeness | Rand Score | V-Measure |
| Aluminum Frame | 1.0/1.0 | 1.0/1.0 | 1.0/1.0 | 1.0/1.0 |
| Wall Monitoring (I) | ||||
| Baker Bricks | 0.9804/1.0 | 0.8974/1.0 | 0.9536/1.0 | 0.9337/1.0 |
| Baker Hall | 0.6541/1.0 | 0.5796/7107 | 0.6387/0.8450 | 0.6042/0.8308 |
| Office Wall | 0.9809/0.9798 | 0.8839/0.8801 | 0.9637/0.9531 | 0.9244/0.9255 |
| Wall Monitoring (II) | ||||
| Damage Severity | 0.8783/0.9258 | 0.6784/0.7217 | 0.7189/0.7810 | 0.7651/0.8108 |
| Z24 Bridge | 0.8293/0.8196 | 0.9957/0.9880 | 0.8026/0.7959 | 0.9003/0.8884 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boratto, T.; Bernardino, H.S.; Vieira, A.B.; Gontijo, T.S.; Bodini, M.; Martyushev, D.A.; Saporetti, C.M.; Cury, A.; Barbosa, F.; Goliatt, L. An Agglomerative Clustering Combined with an Unsupervised Feature Selection Approach for Structural Health Monitoring. Infrastructures 2025, 10, 32. https://doi.org/10.3390/infrastructures10020032
Boratto T, Bernardino HS, Vieira AB, Gontijo TS, Bodini M, Martyushev DA, Saporetti CM, Cury A, Barbosa F, Goliatt L. An Agglomerative Clustering Combined with an Unsupervised Feature Selection Approach for Structural Health Monitoring. Infrastructures. 2025; 10(2):32. https://doi.org/10.3390/infrastructures10020032
Chicago/Turabian StyleBoratto, Tales, Heder Soares Bernardino, Alex Borges Vieira, Tiago Silveira Gontijo, Matteo Bodini, Dmitriy A. Martyushev, Camila Martins Saporetti, Alexandre Cury, Flávio Barbosa, and Leonardo Goliatt. 2025. "An Agglomerative Clustering Combined with an Unsupervised Feature Selection Approach for Structural Health Monitoring" Infrastructures 10, no. 2: 32. https://doi.org/10.3390/infrastructures10020032
APA StyleBoratto, T., Bernardino, H. S., Vieira, A. B., Gontijo, T. S., Bodini, M., Martyushev, D. A., Saporetti, C. M., Cury, A., Barbosa, F., & Goliatt, L. (2025). An Agglomerative Clustering Combined with an Unsupervised Feature Selection Approach for Structural Health Monitoring. Infrastructures, 10(2), 32. https://doi.org/10.3390/infrastructures10020032