

Enhancing Neural Machine Translation Quality for Kannada–Tulu Language Pairs through Transformer Architecture: A Linguistic Feature Integration


Abstract
1. Introduction
- Rule-Based Machine Translation (RBMT): It uses dictionary and grammatical rules specific to language pairs for translation. However, more post-editing is required for the translated output. The initial machine translation models were built using rule-based approaches and deducing rules was a time-consuming task.
- Statistical Machine Translation (SMT): It uses statistical models to analyse massive parallel data and generate the target language text by aligning words present in the source language. Though SMT is good for basic translations, it does not capture the context very well, so the translation can be wrong at times.
- Hybrid Machine Translation (HMT): It combines RBMT and SMT. It uses a translation memory and produces good-quality translations and requires editing from human translators.
- Neural Machine Translation (NMT): This type of translation uses neural models, parallel corpora and deductive reasoning to determine the correlation between source and target language words. Nowadays, most MT systems are neural, due to ease of use, and open-source architectures which are applicable to high-resource languages.
2. Literature Survey
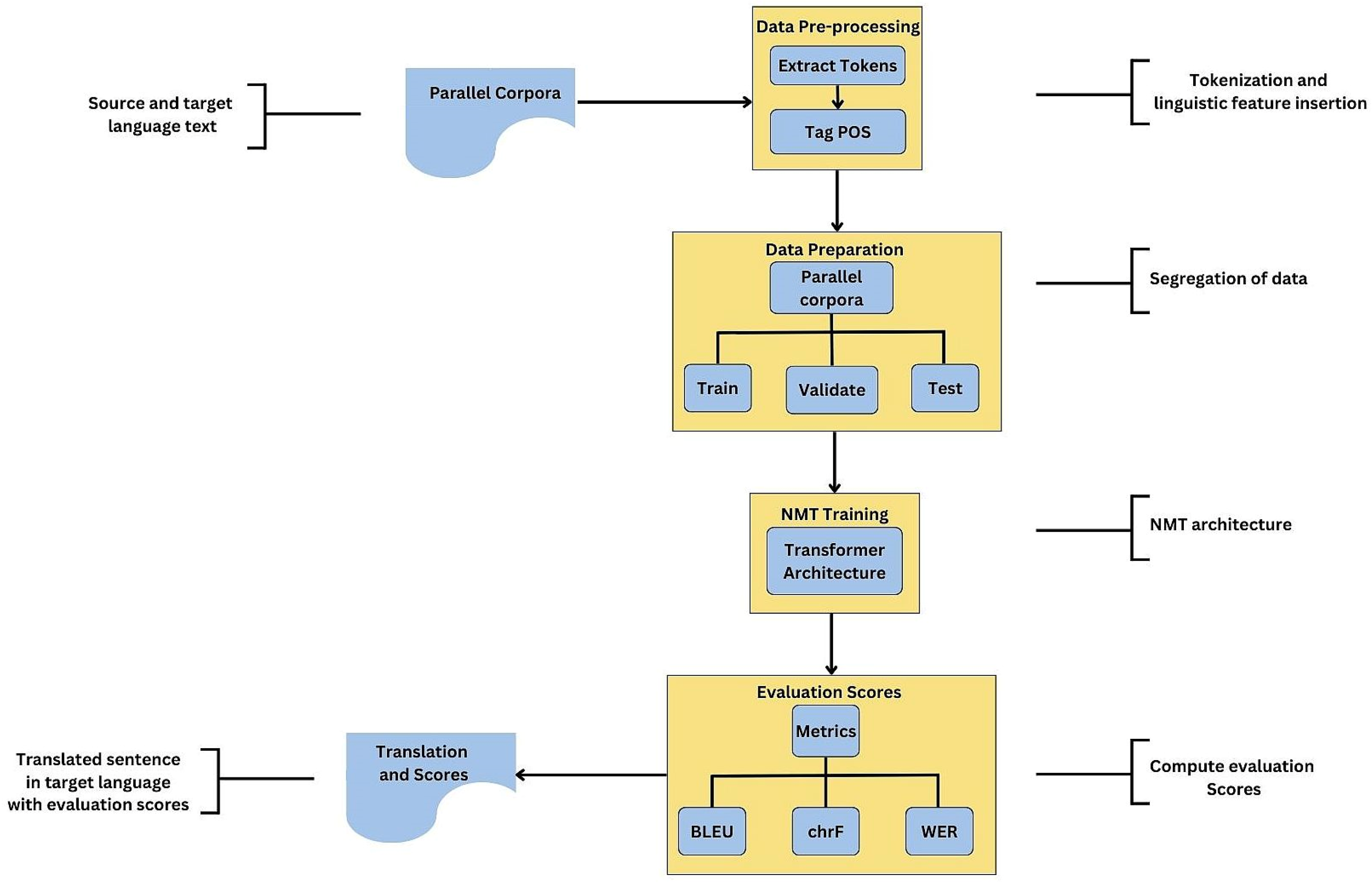
3. Proposed Methodology
3.1. Data Pre-Processing
3.2. Data Preparation
3.3. Training NMT Model Using Transformer Architecture
3.4. Translating Text from Kannada to Tulu
| Algorithm 1: Linguistic-Feature-Integrated NMT | |||
| Data: | |||
| Source file: sentences in Kannada language | |||
| Target file: sentences in Tulu language | |||
| Variables: | |||
| SP= [‘!’, ‘@’, ‘#’, ‘$’, ‘%’, ‘&’, ‘(’, ‘)’] | |||
| data: parallel corpora | |||
| Functions: | |||
| remove_Duplicate(file, temp): takes source and target files,removes duplicate sentences and returns temporary files temp_src and temp_tgt | |||
| split(s,a): splits s on special character ‘a’ | |||
| delete(k): removes the token ‘k’ | |||
| tagPOS(): return POS concatenated with token | |||
| Output: Translated text and evaluation scores | |||
| 1 | Data Pre-processing | ||
| 2 | d← split(data,newline) | ||
| 3 | for i in d do | ||
| 4 | temp ← remove_Duplicate(src,s1) | ||
| 5 | end | ||
| #tokenisation of line based on space | |||
| 6 | for i in d do | ||
| 7 | token ← split(i,space) | ||
| 8 | if token == tab || token == [0-9]+ || token ==SP then | ||
| 9 | delete(token) | ||
| 10 | end | ||
| 11 | token.tagPOS() | ||
| 12 | end | ||
| 13 | Data Preparation | ||
| 14 | train ← 0.8 * d | ||
| 15 | validation ← 0.1 * d | ||
| 16 | test ← 0.1 * d | ||
| 17 | Train NMT model using Transformer architecture | ||
| 18 | Write output to file f | ||
| 19 | Compute BLEU score, chrF and WER as per equations 2, 3 and 4 | ||
| 20 | Display output scores | ||
| 21 | End | ||
4. Results and Experimental Analysis
4.1. Experimental Setup
4.2. Performance Metrics
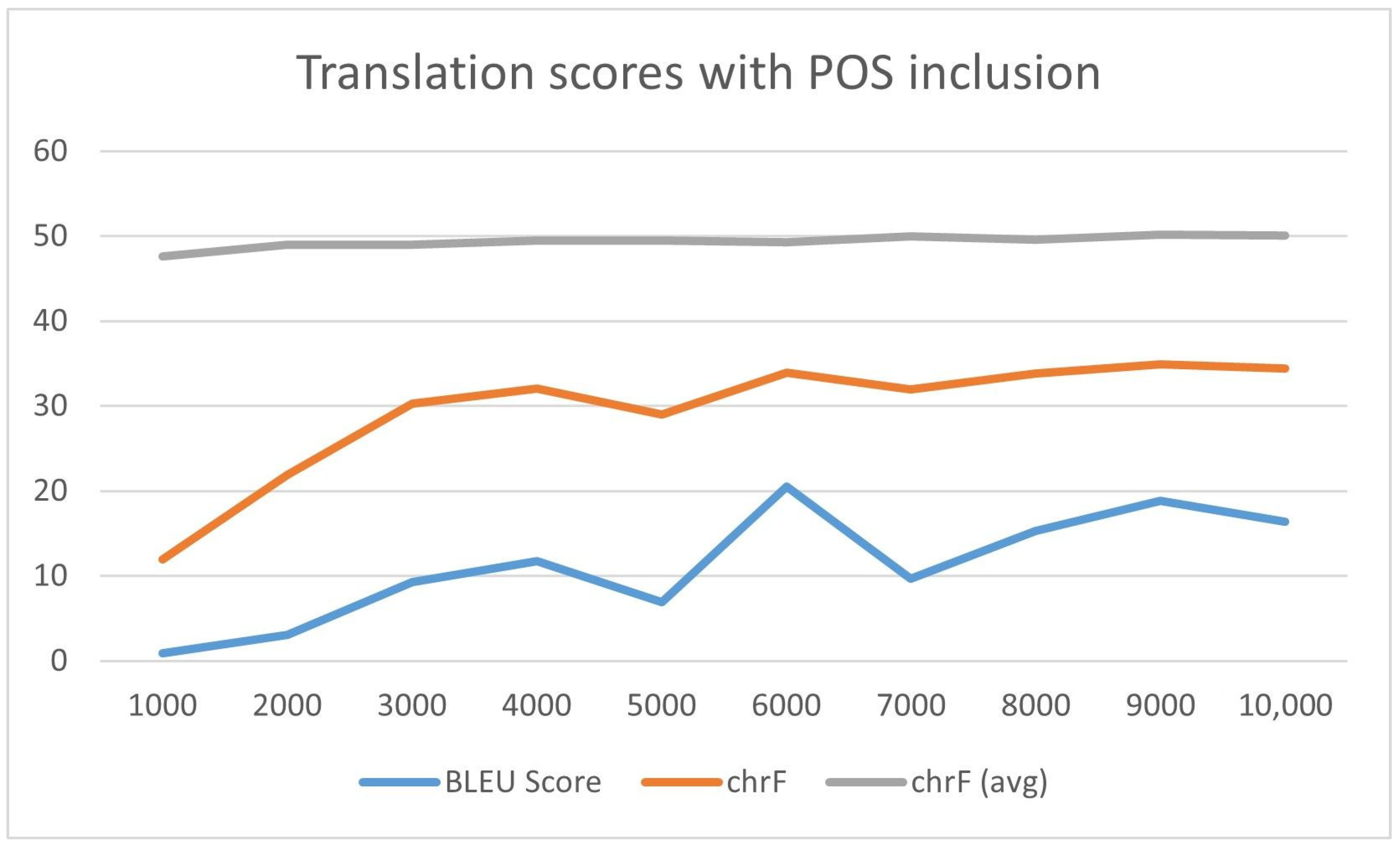
4.3. Result Analysis
4.4. Experimental Analysis and Discussions
5. Conclusions and Future Scope
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bhattacharyya, P.; Joshi, A. Natural Language Processing; Wiley: Chennai, India, 2023; pp. 183–201. [Google Scholar]
- Imami, T.R.; Mu’in, F. Linguistic and Cultural Problems in Translation. In Proceedings of the 2nd International Conference on Education, Language, Literature, and Arts (ICELLA 2021), Banjarmasin, Indonesia, 10–11 September 2021; Atlantis Press: Amsterdam, The Netherlands, 2021. [Google Scholar]
- Koehn, P. Statistical Machine Translation; Cambridge University Press: Cambridge, UK, 2010; pp. 14–20. [Google Scholar]
- Encyclopaedia Britannica. Indian Languages, In Encyclopaedia Britannica. Available online: https://www.britannica.com/topic/Indian-languages (accessed on 17 February 2023).
- Steever, S.B. The Dravidian Languages; Routledge: London, UK, 1998; p. 1. [Google Scholar]
- Caldwell, R. A Comparative Grammar of the Dravidian or South-Indian Family of Languages; University of Madras: Madras, India, 1956; p. 35. [Google Scholar]
- Brigel, J. A Grammar of the Tulu Language; Basel Mission Press: Mangalore, India, 1872; pp. 28–30. [Google Scholar]
- Tulu Language. Available online: https://en.wikipedia.org/wiki/Tulu_language?variant=zh-tw (accessed on 24 May 2024).
- Sridhar, S.N. Modern Kannada Grammar; Manohar Publishers: Delhi, India, 2007; pp. 156–157. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 261–272. [Google Scholar]
- Im, S.K.; Chan, K.H. Neural Machine Translation with CARU-Embedding Layer and CARU-Gated Attention Layer. Mathematics 2024, 12, 997. [Google Scholar] [CrossRef]
- Chan, K.H.; Ke, W.; Im, S.K. CARU: A Content-Adaptive Recurrent Unit for the Transition of Hidden State in NLP. In Neural Information Processing; Yang, H., Pasupa, K., Leung, A.C.S., Kwok, J.T., Chan, J.H., King, I., Eds.; ICONIP 2020. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12532, pp. 123–135. [Google Scholar] [CrossRef]
- O’Brien, S. How to deal with errors in machine translation: Postediting. Mach. Transl. Everyone: Empower. Users Age Artif. Intell. 2022, 18, 105. [Google Scholar]
- DravidianLangTech-2022 the Second Workshop on Speech and Language Technologies for Dravidian Languages. GithubIO. Available online: https://dravidianlangtech.github.io/2022/ (accessed on 23 January 2024).
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Popović, M. chrF++: Words helping character n-grams. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; pp. 612–618. [Google Scholar]
- Zechner, K.K.; Waibel, A. Minimizing word error rate in textual summaries of spoken language. In Proceedings of the 1st Meeting of the North American Chapter of the Association for Computational Linguistics, Seattle, WA, USA, 29 April–4 May 2000. [Google Scholar]
- Sennrich, R.; Haddow, B. Linguistic input features improve neural machine translation. arXiv 2016, arXiv:1606.02892. [Google Scholar]
- Mujadia, V.; Sharma, D.M. Nmt based similar language translation for hindi-marathi. In Proceedings of the Fifth Conference on Machine Translation, Online, 19–20 November 2020; pp. 414–417. [Google Scholar]
- Goyal, P.; Supriya, M.; Dinesh, U.; Nayak, A. Translation Techies@ DravidianLangTech-ACL2022-Machine Translation in Dravidian Languages. In Proceedings of the Second Workshop on Speech and Language Technologies for Dravidian Languages, Dublin, Ireland, Online, 26 May 2022; pp. 120–124. [Google Scholar]
- Vyawahare, A.; Tangsali, R.; Mandke, A.; Litake, O.; Kadam, D. PICT@ DravidianLangTech-ACL2022: Neural machine translation on dravidian languages. arXiv 2022, arXiv:2204.09098. [Google Scholar]
- Hegde, A.; Shashirekha, H.L.; Madasamy, A.K.; Chakravarthi, B.R. A Study of Machine Translation Models for Kannada-Tulu. In Congress on Intelligent Systems; Springer Nature: Singapore, 2022; pp. 145–161. [Google Scholar]
- Rodrigues, A.P.; Vijaya, P.; Fernandes, R. Tulu Language Text Recognition and Translation. IEEE Access 2024, 12, 12734–12744. [Google Scholar]
- Hochreiter, S. Long short-term memory. Neural Comput. 2010, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chakrabarty, A.; Dabre, R.; Ding, C.; Utiyama, M.; Sumita, E. Low-resource Multilingual Neural Translation Using Linguistic Feature-based Relevance Mechanisms. ACM Trans. Asian Low-Resource Lang. Inf. Process. 2023, 22, 1–36. [Google Scholar] [CrossRef]
- El Marouani, M.; Boudaa, T.; Enneya, N. Incorporation of linguistic features in machine translation evaluation of Arabic. In Big Data, Cloud and Applications: Third International Conference, BDCA-2018, Kenitra, Morocco, Revised Selected Papers 3; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 500–511. [Google Scholar]
- Agrawal, R.; Shekhar, M.; Misra, D. Integrating knowledge encoded by linguistic phenomena of Indian languages with neural machine translation. In Mining Intelligence and Knowledge Exploration: 5th International Conference, MIKE-2017, Hyderabad, India, Proceedings 5; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 287–296. [Google Scholar]
- Hlaing, Z.Z.; Thu, Y.K.; Supnithi, T.; Netisopakul, P. Improving neural machine translation with POS-tag features for low-resource language pairs. Heliyon 2022, 8, e10375. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Su, J.; Wen, H.; Zeng, J.; Liu, Y.; Chen, Y. Pos tag-enhanced coarse-to-fine attention for neural machine translation. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2019, 18, 46. [Google Scholar] [CrossRef]
- Kannada Shallow Parser. LTRC. Available online: https://ltrc.iiit.ac.in/analyzer/kannada/ (accessed on 23 January 2024).
- Tandon, J.; Sharma, D.M. Unity in diversity: A unified parsing strategy for major indian languages. In Proceedings of the Fourth International Conference on Dependency Linguistics, Pisa, Italy, 18–20 September 2017; pp. 255–265. [Google Scholar]
- Popović, M.; Ney, H. Towards automatic error analysis of machine translation output. Comput. Linguist. 2011, 37, 657–688. [Google Scholar] [CrossRef]
- OpenNMT-py. Available online: https://opennmt.net/OpenNMT-py/ (accessed on 22 July 2024).
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. Opennmt: Open-source toolkit for neural machine translation. arXiv 2017, arXiv:1701.02810. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisbon, Portugal, 17–18 September 2015; pp. 392–395. [Google Scholar]
- Tilde Custom Machine Translation. LetsMT. Available online: https://www.letsmt.eu/Bleu.aspx (accessed on 24 January 2024).
- Moslem, Y. WER Score for Machine Translation. Available online: https://blog.machinetranslation.io/compute-wer-score/ (accessed on 24 February 2024).
- Krishnamurti, B. The Dravidian Languages; Cambridge University Press: Cambridge, UK, 2003; p. 24. [Google Scholar]
- Kekunnaya, P. A Comparative Study of Tulu Dialects; Rashtrakavi Govinda Pai Research Centre Udupi: Udupi, India, 1997; pp. 168–169. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Input | ಶ್ಯಾಮನು ಆ ಭೂಮಿಯ ಮಾಲೀಕನಾಗಿದ್ದಾನೆ |
| POS tagged input | N_NNP|ಶ್ಯಾಮನು DM_DMD|ಆ N_NN|ಭೂಮಿಯ V_VM_VF|ಮಾಲೀಕನಾಗಿದ್ದಾನೆ |
| Category | Sentence Count | |
|---|---|---|
| Kannada | Tulu | |
| Training | 8300 | 8300 |
| Validation | 1000 | 1000 |
| Test | 1000 | 1000 |
| Source Text | ರಾಜನು ಯುದ್ಧ ಮಾಡುತ್ತಾನೆ (Rājanu yud’dha māḍuttāne) |
| Translated Text | ರಾಜೆ ಲಡಾಯಿ ಮಲ್ಪುವೆ (Rāje laḍāyi malpuve) |
| Hyper Parameters | Values |
|---|---|
| Word vector size | 512 |
| Encoding layers | 6 |
| Decoding layers | 6 |
| Heads | 8 |
| Learning rate | 2 |
| Batch size | 2048 |
| Train steps | 10,000 |
| Encoder type | Transformer |
| Label smoothing | 0.1 |
| Hardware Requirements | Software Requirements | ||
|---|---|---|---|
| GPU | NVIDIA A100 | Python | 3.11.7 |
| RAM | 32 GB | OpenNMT Py | 3.4.3 |
| SSD | 1.92 TB | Ubuntu Operating System | 22.04.4 |
| Memory | 80 GB | ||
| Sl No. | Source Text (Kannada) | Remarks on Source Text | Target Text (Tulu) | Generated Output in Target Language (Tulu) | Remarks on Translation | |
|---|---|---|---|---|---|---|
| With POS | Without POS | |||||
| 1 | ಆಕಾಶನು ನೇತೃತ್ವ-ವಹಿಸುತ್ತಾನೆ (Ākāśanu nētr̥tva-vahisuttāne) | Short sentence | ಆಕಾಶೆ ಮುತಾಲಿಕೆನ್-ವಹಿಸುವೆ (Ākāśe mutāliken-vahisuve) | ಆಕಾಶೆ ಮುತಾಲಿಕೆನ್-ವಹಿಸುವೆ (Ākāśe mutāliken-vahisuve) | ಆಕಾಶೆ ಮುತಾಲಿಕೆನ್-ವಹಿಸುವೆ (Ākāśe mutāliken-vahisuve) | Accurate for both with POS and without POS embedding |
| 2 | ಮನೆ ನೋಡಕೊಳ್ಳಬೇಕು ತಮ್ಮ (Mane nōḍakoḷḷabēku tam’ma) | Short sentence | ಇಲ್ಲ್ ತೂವೊಡು ತಗೆ (Ill tūvoḍu tage) | ಇಲ್ಲ್ ಇಲ್ಲಗ್ ಬೈಲುದ್ದೊಗು ಬರೊಂದಿತ್ತಿನ ಆಟಿ ಕಳೆಂಜನ್ ಜೋಕುಲು ಮಲ್ಲಕುಲುಂದು ಮಾತೆರ್ಲ ಕಾತೊಂದಿತ್ತೆರ್ (Ill illag bailuddogu barondittina āṭi kaḷejan jōkulu mallakulundu māterla kātonditter) | ಇಲ್ಲ ಯೆಡ್ಡೆಪ್ಪುಡೆ ಸಾಗೊಡಾಂಡ ಪೊಂಜೆನಕ್ಲೆ ಪೊಲಬು ಮೂಡೊಡು (Illa yeḍḍeppuḍe sāgoḍāṇḍa pojenakle polabu mūḍoḍu) | Translation with POS embedding is better |
| 3 | ಅನೂಪನು ತೊಟ್ಟಿದ್ದಾನೆ (Anūpanu toṭṭiddāne) | Short sentence | ಅನೂಪೆ ಪಾಡ್ದೆ (Anūpe pāḍde) | ಅನೂಪೆ ಪಾಡ್ದೆ (Anūpe pāḍde) | ಅನೂಪೆ ಪಾಡ್ದೆ (Anūpe pāḍde) | Accurate for both with POS and without POS embedding |
| 4 | ಆ ವಠಾರದಲ್ಲಿ ದೀಪದ ಬೆಳಕಿಗೆ ಮಿನುಗುವ ಒಂದು ಕೋಣೆಯಲ್ಲಿ (Ā vaṭhāradalli dīpada beḷakige minuguva ondu kōṇeyalli) | Incomplete sentence | ಆ ವಠಾರೊಡು ಸಾನಾದಿಗೆದ ಬೊಲ್ಪುಡು ಮೆನ್ಕುನ ಒಂಜಿ ಅದೆಟ್ (Ā vaṭhāroḍu sānādigeda bolpuḍu menkuna oji adeṭ) | ಮೆನ್ಕುನ ರಡ್ಡ್ ಕಣ್ಣ್ (Menkuna raḍḍ kaṇṇ) | ಮರಿಯಲೊಡು ಗುಡ್ಡೆಡ್ <unk> ಪರ್ಂದ್ <unk> <unk> ಕಾಯಿ (Mariyaloḍu guḍḍeḍ <unk> parnd <unk> <unk> kāyi) | Translation with POS embedding is better |
| 5 | ರಾಜನು ಯುದ್ಧ ಮಾಡುತ್ತಾನೆ (Rājanu yud’dha māḍuttāne) | Long sentence | ರಾಜೆ ಲಡಾಯಿ ಮಲ್ಪುವೆ (Rāje laḍāyi malpuve) | ರಾಜೆ ಲಡಾಯಿ ಮಲ್ಪುವೆ (Rāje laḍāyi malpuve) | ರಾಜೆ ಲಡಾಯಿ ಮಲ್ಪುವೆ (Rāje laḍāyi malpuve) | Accurate for both with POS and without POS embedding |
| 6 | ಇಂತಹ ಚಂದ ನೋಡಲಿಕ್ಕೂ ಭಾಗ್ಯ ಬೇಕು (Intaha canda nōḍalikkū bhāgya bēku) | Long sentence | ಇಂಚಿನ ಪೊರ್ಲು ತುವರೆಗ್ಲಾ ಭಾಗ್ಯ ಬೋಡು (Icina porlu tuvareglā bhāgya bōḍu) | ಇಂಚಿನ ತೂಯೆರೆಲಾ ಬಾರೀ ಪೊರ್ಲು (Icina tūyerelā bārī porlu) | ತೂಯೆರೆಲಾ ಬಾರೀ ಪೊರ್ಲು (Tūyerelā bārī porlu) | Translation with POS embedding is better |
| 7 | ಹಾಸುಕಲ್ಲಿನ ಮೇಲೆ ಹದಿನಾರು ಗೆರೆ ಹಾಕುತ್ತೀರಿ (Hāsukallina mēle hadināru gere hākuttīri) | Long sentence | ಹಾಸಿಕಲ್ಲುದ ಮಿತ್ತ್ ಪದಿನಾಜಿ ಗೆರೆ ಪಾಡುವರ್ (Hāsikalluda mitt padināji gere pāḍuvar) | ಪದಿನಾಜಿ ಗೆರೆ ಒಯ್ತಿನ ಕಾರ್ನಿಕೊದ ಸತ್ಯೊ (Padināji gere oytina kārnikoda satyo) | ಮಿತ್ತ್ <unk> <unk> ಗೆರೆ (Mitt <unk> <unk> gere) | |
| Model | BLEU Score | chrF | Average chrF |
|---|---|---|---|
| With POS | 21.99 | 35.2771 | 50.7802 |
| Without POS | 20.53 | 34.8844 | 50.2007 |
| Model | Corpus WER Score | Corpus BLEU Score |
|---|---|---|
| With POS | 0.8806 | 11.3996 |
| Without POS | 1.3025 | 11.1935 |
| Sl No. | Existing Approaches by Researcher | Model | Evaluation Scores | Comparison with Proposed Approach | ||
|---|---|---|---|---|---|---|
| BLEU | chrF | WER | ||||
| 1 | Goyal et al. [20] | LSTM | 0.6149 | - | - | Inclusion of linguistic feature could enhance the translation quality. |
| 2 | Vyawahare et al. [21] | Transformer | 0.8123 | - | - | The low BLEU score might be due to a different set of hyper parameters set on Transformers. |
| 3 | Hegde et al. [22] | Transformer | 22.89 | - | - | Inclusion of a linguistic feature could enhance the translation quality. |
| Transformer + BPE | 23.06 | - | - | |||
| ATG + Transformer | 41.02 | - | - | Leads to a biased translation. | ||
| ATG + Transformer + BPE | 41.82 | - | - | |||
| 4 | Proposed approach | Transformer + POS | 21.99 | 35.2771 | 50.7802 | Generic and can be adopted to any language pairs along with chrF and WER score. |
| Baseline | Transformer | 20.53 | 34.8844 | 50.2007 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Supriya, M.; Acharya, U.D.; Nayak, A. Enhancing Neural Machine Translation Quality for Kannada–Tulu Language Pairs through Transformer Architecture: A Linguistic Feature Integration. Designs 2024, 8, 100. https://doi.org/10.3390/designs8050100
Supriya M, Acharya UD, Nayak A. Enhancing Neural Machine Translation Quality for Kannada–Tulu Language Pairs through Transformer Architecture: A Linguistic Feature Integration. Designs. 2024; 8(5):100. https://doi.org/10.3390/designs8050100
Chicago/Turabian StyleSupriya, Musica, U Dinesh Acharya, and Ashalatha Nayak. 2024. "Enhancing Neural Machine Translation Quality for Kannada–Tulu Language Pairs through Transformer Architecture: A Linguistic Feature Integration" Designs 8, no. 5: 100. https://doi.org/10.3390/designs8050100
APA StyleSupriya, M., Acharya, U. D., & Nayak, A. (2024). Enhancing Neural Machine Translation Quality for Kannada–Tulu Language Pairs through Transformer Architecture: A Linguistic Feature Integration. Designs, 8(5), 100. https://doi.org/10.3390/designs8050100