
Safety in Traffic Management Systems: A Comprehensive Survey


_Wang.png)
Abstract
1. Introduction
- A thorough examination of the literature published within the last five years is conducted, allowing for an accurate depiction of the prevailing research trends during this period.
- The literature collection exclusively focuses on top-tier venues, ensuring that the selected works are highly representative of both the domain field and computer science field. This provides valuable insights for researchers interested in traffic safety applications.
- We categorize the works into two distinct categories of analysis and control and provide corresponding summaries that outline the research objectives and limitations. This categorization offers inspiration and guidance for future researchers in the field.
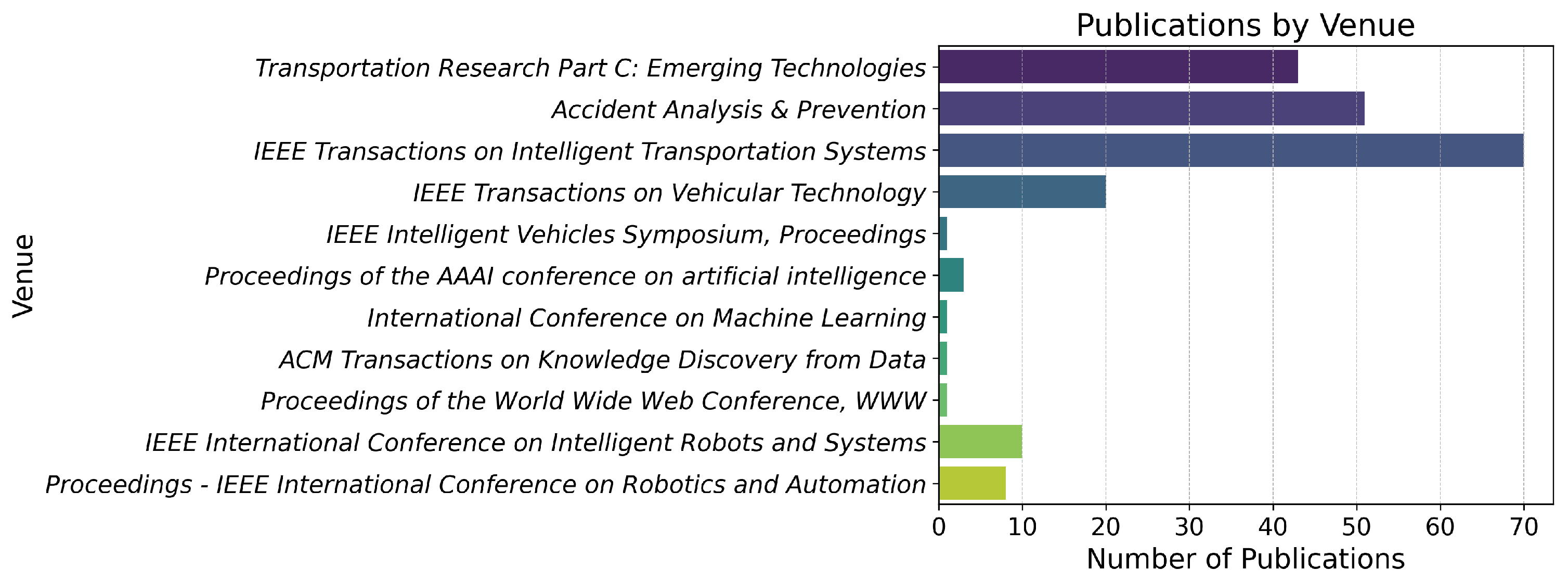
2. Review Method
3. Surveying the Literature: An In-Depth Exploration
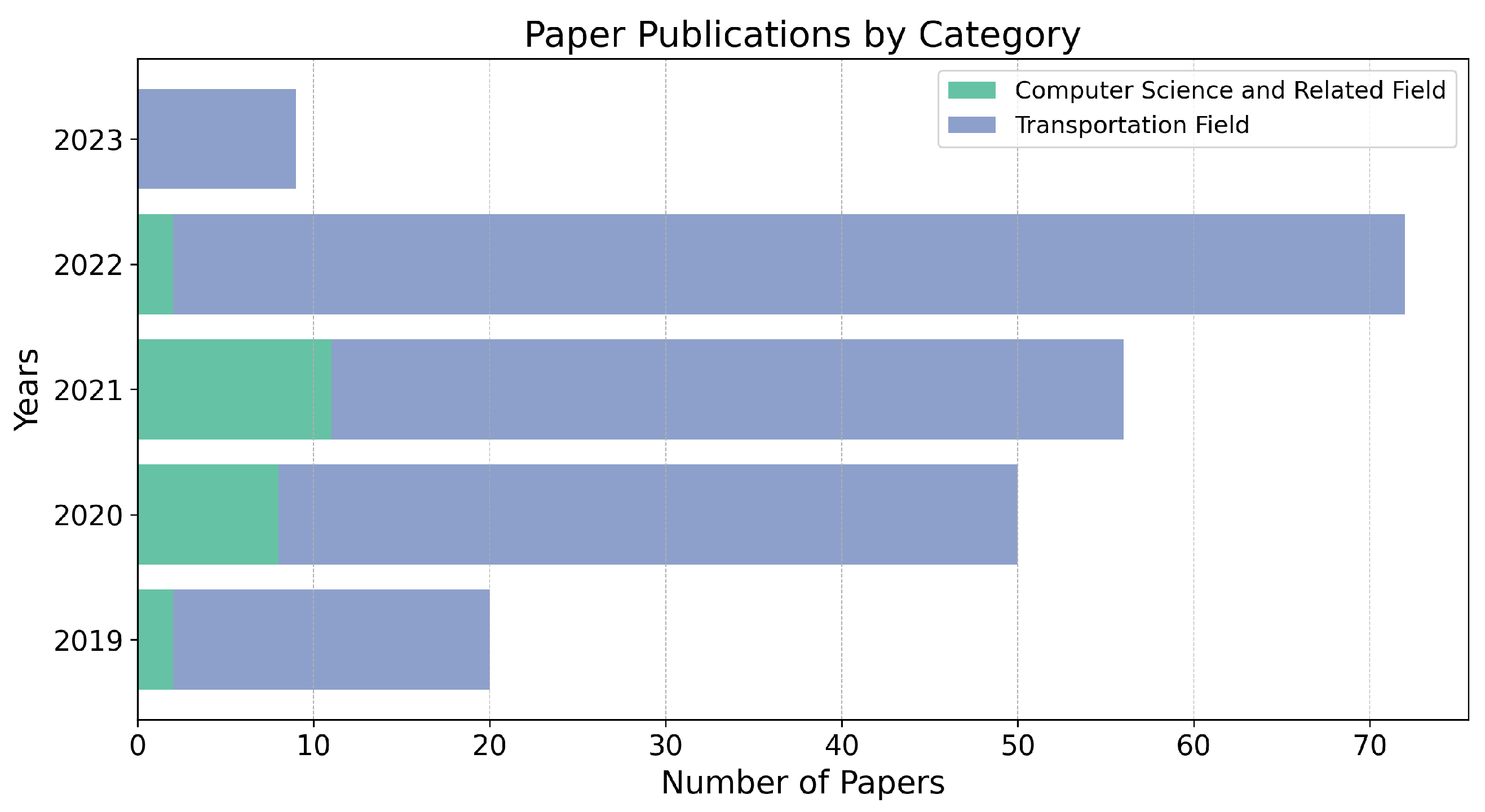
3.1. Ongoing Funded Research Projects
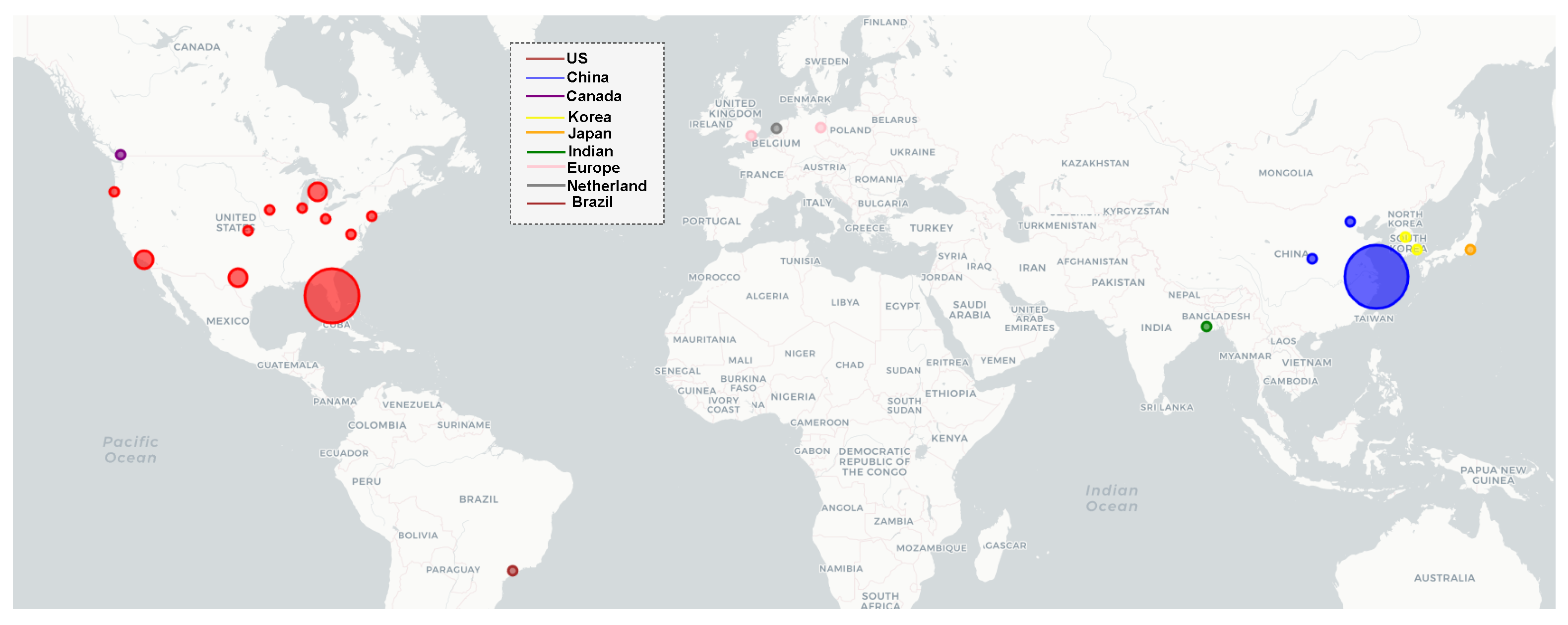
3.2. Geographical Distribution of the Study Area
4. Analysis
4.1. Method
- Case Selection: Identify cases, which are crash incidents that occurred during evacuation events. These could include traffic accidents, collisions, or any other crash-related incidents that occurred during the evacuation process.
- Control Selection: Select controls, which are non-crash events during the same evacuation scenario. Controls should be chosen to be comparable to cases in terms of the relevant characteristics, such as location, time, weather conditions, and traffic volume. The objective is to create pairs of cases and controls that are similar in terms of these matched criteria.
- Data Collection: Gather data on both cases and controls. This includes information about the evacuation scenario, road conditions, traffic management measures, driver behavior, vehicle characteristics, and any other relevant variables that may influence crash occurrences during evacuations. The data collection process can involve crash reports, eyewitness accounts, interviews, video footage, or other available sources.
- Matching Criteria: Determine the matching criteria to create pairs of cases and controls. This could involve factors such as location, time of day, weather conditions, road type, or any other factors specific to the evacuation scenario that may contribute to crash occurrences.
- Statistical Analysis: Perform statistical analysis to compare the exposure or risk factors between cases and controls within each matched pair. Common statistical techniques used in matched case-control studies include conditional logistic regression, which takes into account the matching and provides adjusted estimates of the association between the exposure variables and crash occurrences.
- Interpretation: Interpret the results to identify the significant risk factors or exposures associated with crash occurrences during evacuations. The analysis should account for confounding variables and assess the strength of the associations between the identified factors and the likelihood of crashes during evacuations.
- Outcome Variable: First, define the outcome variable, which is typically a binary variable indicating whether an event of interest has occurred or not. For road safety analysis, the outcome variable could be a binary indicator representing whether a road accident occurred (1) or did not occur (0) for each observation or case.
- Risk Factors: Identify the hypothesized risk factors or independent variables that are linked to the outcome variable (e.g., road conditions, driver characteristics, vehicle type, weather conditions, etc.). These risk factors can be categorical (e.g., sex and road type) or continuous (e.g., vehicle speed and age).
- Data Collection: Gather data on the outcome variable and risk factors for each observation or case. This can involve collecting information from accident reports, police records, surveys, or any other relevant sources.
- Model Estimation: Fit a logistic regression model to the data to estimate the relationship between the risk factors and the outcome variable. Logistic regression estimates the probability of the outcome (e.g., road accident occurrence) based on the values of the risk factors. It models the log odds or logit of the probability as a linear combination of the risk factors, using a logistic function to map the linear combination to the probability scale.
- Interpretation of Coefficients: Estimate the coefficients for each risk factor, along with their standard errors and significance levels. These coefficients represent the log-odds ratio, indicating the direction and magnitude of the association between each risk factor and the likelihood of the outcome occurring. A positive coefficient suggests an increased likelihood of the outcome, while a negative coefficient suggests a decreased likelihood, with significance indicating the strength of the association.
- Model Evaluation: Assess the goodness of fit of the logistic regression model and evaluate its predictive performance. Various statistical measures, such as the Hosmer–Lemeshow test, likelihood ratio test, or AIC/BIC values, can be used to evaluate the model’s fit to the data.
- Conclusion and Inference: Based on the logistic regression results, draw conclusions about the significance and impact of the risk factors on road safety. Identify the risk factors that have a statistically significant association with the outcome variable and determine their relative importance in explaining the occurrence of road accidents.
- Null hypothesis (H0): The distributions of the two samples are equal. Alternative hypothesis (Ha): The distributions of the two samples are not equal.
- Combine the data from both groups and rank them in ascending order. Assign ranks to each observation, with the lowest value assigned a rank of 1, the next lowest value assigned a rank of 2, and so on.
- Calculate the sum of ranks (U) for each group. U1 represents the sum of ranks for one group, and U2 represents the sum of ranks for the other group.
- Calculate the test statistic U, which is the smaller of U1 and U2. The test statistic is used to determine the p-value.
- Determine the critical value or p-value associated with the test statistic. The critical value or p-value is obtained from a reference table or statistical software.
- Compare the calculated test statistic with the critical value or p-value. If the calculated test statistic is less than the critical value or if the p-value is less than the predetermined significance level (e.g., = 0.05), the null hypothesis is rejected, indicating that the two groups have a significant difference. If the calculated test statistic is greater than the critical value or if the p-value is greater than the significance level, the null hypothesis is not rejected, suggesting that there is no significant difference between the two groups.
4.2. Research Outcomes
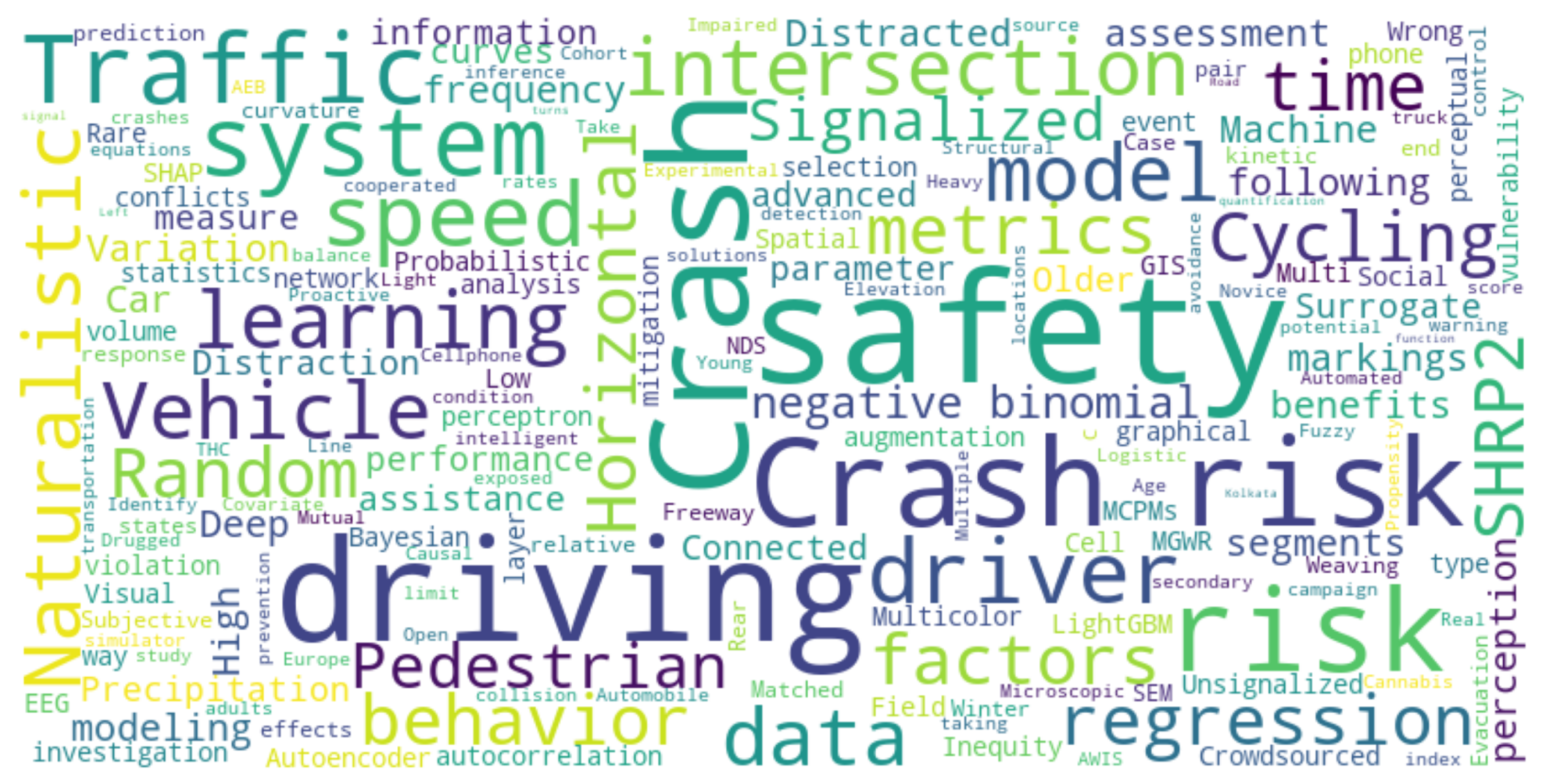
4.3. Comparative Analysis of the Literature: Commonalities and Variations
- Crash risk assessment: Several titles focused on assessing crash risk using different methodologies, such as data-driven Bayesian networks, quantification of risk factors, and identification of high-risk segments.
- Impact of driving behavior: Multiple titles explored the effects of various driving behaviors on crash risk, including evasive behavior, distraction, impaired driving, and subjective risk perception.
- Utilization of data: Many titles utilized real-world data or simulation platforms to predict collision cases, examine crash risks, and identify high-risk locations.
- Specific contexts: Some titles investigated crash risk in specific contexts, such as urban cycling, freeway segments with horizontal curvature, and signalized intersections.
- Methods and techniques: Each title employed different methods and techniques for crash risk assessment, ranging from Bayesian networks and deep reinforcement learning to empirical observations and structural equation modeling.
- Focus areas: The titles covered a wide range of topics within the domain of crash risk, including individual driver assessment, roadway segment crashes, intersection safety, driving behaviors, and the impact of factors like distraction and precipitation.
- Data sources: The titles made use of diverse data sources, such as traffic violation and crash records, EEG metrics, naturalistic driving data, connected vehicle systems data, and SHRP2 NDS data.
- Risk Analysis and Safety Assessment: Several studies focused on analyzing driving risks, crash avoidance, and safety evaluation in different contexts, such as variable speed limit systems, automated driving strategies, and vehicular safety applications.
- Driving Behavior Analysis: Several studies explored driving behavior patterns, habitual driving behaviors, and driver interactions with vehicle systems, aiming to understand their impact on crash risk and safety.
- Comparative Analysis and Evaluation: Several studies compared and evaluated different algorithms, models, or features related to safety applications, such as LiDAR-based contour estimation, driver drowsiness monitoring, and vehicular communications.
5. Operation or Control
5.1. Method
5.2. Research Outcomes
5.3. Comparative Analysis of the Literature: Commonalities and Variations
6. Crash Risk Prediction
7. Challenges and Limitations
7.1. Sparseness of Data
7.2. Model Interpretability
7.3. Real-World Generalizability
7.4. Limited Data Source
8. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alanazi, F. A Systematic Literature Review of Autonomous and Connected Vehicles in Traffic Management. Appl. Sci. 2023, 13, 1789. [Google Scholar] [CrossRef]
- Chia, W.M.D.; Keoh, S.L.; Goh, C.; Johnson, C. Risk Assessment Methodologies for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16923–16939. [Google Scholar] [CrossRef]
- Nascimento, A.M.; Vismari, L.F.; Molina, C.B.S.T.; Cugnasca, P.S.; Camargo, J.B.; de Almeida, J.R.; Inam, R.; Fersman, E.; Marquezini, M.V.; Hata, A.Y. A systematic literature review about the impact of artificial intelligence on autonomous vehicle safety. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4928–4946. [Google Scholar] [CrossRef]
- Muhammad, K.; Ullah, A.; Lloret, J.; Del Ser, J.; de Albuquerque, V.H.C. Deep learning for safe autonomous driving: Current challenges and future directions. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4316–4336. [Google Scholar] [CrossRef]
- Mehra, A.; Mandal, M.; Narang, P.; Chamola, V. ReViewNet: A fast and resource optimized network for enabling safe autonomous driving in hazy weather conditions. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4256–4266. [Google Scholar] [CrossRef]
- Tobin, D.M.; Kumjian, M.R.; Black, A.W. Effects of precipitation type on crash relative risk estimates in Kansas. Accid. Anal. Prev. 2021, 151, 105946. [Google Scholar] [CrossRef] [PubMed]
- Rahman, R.; Bhowmik, T.; Eluru, N.; Hasan, S. Assessing the crash risks of evacuation: A matched case-control approach applied over data collected during Hurricane Irma. Accid. Anal. Prev. 2021, 159, 106260. [Google Scholar] [CrossRef] [PubMed]
- Trirat, P.; Lee, J.G. Df-tar: A deep fusion network for citywide traffic accident risk prediction with dangerous driving behavior. In Proceedings of the Web Conference 2021, Online, 12–23 April 2021; pp. 1146–1156. [Google Scholar]
- Mantouka, E.G.; Vlahogianni, E.I. Deep reinforcement learning for personalized driving recommendations to mitigate aggressiveness and riskiness: Modeling and impact assessment. Transp. Res. Part C Emerg. Technol. 2022, 142, 103770. [Google Scholar] [CrossRef]
- Huang, T.; Wang, S.; Sharma, A. Highway crash detection and risk estimation using deep learning. Accid. Anal. Prev. 2020, 135, 105392. [Google Scholar] [CrossRef]
- Das, L.C.; Won, M. Saint-acc: Safety-aware intelligent adaptive cruise control for autonomous vehicles using deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 2445–2455. [Google Scholar]
- Zhao, J.; Liu, P.; Xu, C.; Bao, J. Understand the impact of traffic states on crash risk in the vicinities of Type A weaving segments: A deep learning approach. Accid. Anal. Prev. 2021, 159, 106293. [Google Scholar] [CrossRef]
- Ma, Q.; Yang, H.; Wang, Z.; Xie, K.; Yang, D. Modeling crash risk of horizontal curves using large-scale auto-extracted roadway geometry data. Accid. Anal. Prev. 2020, 144, 105669. [Google Scholar] [CrossRef] [PubMed]
- Ghoul, T.; Sayed, T. Real-time signal-vehicle coupled control: An application of connected vehicle data to improve intersection safety. Accid. Anal. Prev. 2021, 162, 106389. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Wang, Z.; Han, K.; Gupta, R.; Tiwari, P.; Wu, G.; Barth, M.J. Personalized car following for autonomous driving with inverse reinforcement learning. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2891–2897. [Google Scholar]
- Han, J.; Zhang, J.; He, C.; Lv, C.; Hou, X.; Ji, Y. Distributed finite-time safety consensus control of vehicle platoon with senor and actuator failures. IEEE Trans. Veh. Technol. 2022, 72, 162–175. [Google Scholar] [CrossRef]
- Zheng, Q.; Xu, C.; Liu, P.; Wang, Y. Investigating the predictability of crashes on different freeway segments using the real-time crash risk models. Accid. Anal. Prev. 2021, 159, 106213. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Wang, L.; Lu, Z.; Chu, X.; Shi, Z.; Deng, J.; Su, T.; Shou, G.; Wen, X. SRL-TR2: A Safe Reinforcement Learning Based TRajectory TRacker Framework. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5765–5780. [Google Scholar] [CrossRef]
- Du, W.; Ye, J.; Gu, J.; Li, J.; Wei, H.; Wang, G. SafeLight: A Reinforcement Learning Method toward Collision-free Traffic Signal Control. In Proceedings of the AAAI Conference on Artificial Intelligence, Montreal, QC, Canada, 8–10 August 2023. [Google Scholar]
- Atwood, J.; Noh, E.Y.; Craig, M.J. Female crash fatality risk relative to males for similar physical impacts. Traffic Inj. Prev. 2023, 24, S1–S8. [Google Scholar] [CrossRef]
- Devane, K.; Chan, H.; Albert, D.; Kemper, A.; Gayzik, F.S. Response of small female and midsize male models with active musculature in pre-crash maneuvers and low-speed impacts. Traffic Inj. Prev. 2023, 24, S9–S15. [Google Scholar] [CrossRef]
- Bolte IV, J.; Fibbi, C.; Tesny, A.C.; Kang, Y.S.; Agnew, A.M.; Shurtz, B.K.; Pipkorn, B.; Rhule, H.; Moorhouse, K. Analysis of injury mechanism and thoracic response of elderly, small female PMHS in near-side impact scenarios. Traffic Inj. Prev. 2023, 24, S23–S31. [Google Scholar] [CrossRef]
- Schwarz, C.; Gaspar, J.; Yousefian, R. Multi-sensor driver monitoring for drowsiness prediction. Traffic Inj. Prev. 2023, 24, S100–S104. [Google Scholar] [CrossRef] [PubMed]
- Kullgren, A.; Amin, K.; Tingvall, C. Effects on crash risk of automatic emergency braking systems for pedestrians and bicyclists. Traffic Inj. Prev. 2023, 24, S111–S115. [Google Scholar] [CrossRef]
- Breitlauch, P.; Erbsmehl, C.T.; van Ratingen, M.; Mallada, J.L.; Sandner, V.; Ferson, N.; Urban, M. A novel method for the automated simulation of various vehicle collisions to estimate crash severity. Traffic Inj. Prev. 2023, 24, S116–S123. [Google Scholar] [CrossRef] [PubMed]
- de Gelder, E.; Op den Camp, O. How certain are we that our automated driving system is safe? Traffic Inj. Prev. 2023, 24, S131–S140. [Google Scholar] [CrossRef]
- Baikejuli, M.; Shi, J.; Hussain, M. A study on the probabilistic quantification of heavy-truck crash risk under the influence of multi-factors. Accid. Anal. Prev. 2022, 174, 106771. [Google Scholar] [CrossRef]
- Yang, K.; Quddus, M.; Antoniou, C. Developing a new real-time traffic safety management framework for urban expressways utilizing reinforcement learning tree. Accid. Anal. Prev. 2022, 178, 106848. [Google Scholar] [CrossRef] [PubMed]
- Wu, K.F.K.; Wang, L. Exploring the combined effects of driving situations on freeway rear-end crash risk using naturalistic driving study data. Accid. Anal. Prev. 2021, 150, 105866. [Google Scholar] [CrossRef]
- Cicchino, J.B. Effects of automatic emergency braking systems on pedestrian crash risk. Accid. Anal. Prev. 2022, 172, 106686. [Google Scholar] [CrossRef]
- Arvin, R.; Khattak, A.J. Driving impairments and duration of distractions: Assessing crash risk by harnessing microscopic naturalistic driving data. Accid. Anal. Prev. 2020, 146, 105733. [Google Scholar] [CrossRef]
- Olszewski, P.; Szagała, P.; Rabczenko, D.; Zielińska, A. Investigating safety of vulnerable road users in selected EU countries. J. Saf. Res. 2019, 68, 49–57. [Google Scholar] [CrossRef] [PubMed]
- Hua, C.; Fan, W.D. Injury severity analysis of time-of-day fluctuations and temporal volatility in reverse sideswipe collisions: A random parameter model with heterogeneous means and heteroscedastic variances. J. Saf. Res. 2023, 84, 74–85. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, S.; Wang, J.; Sulaj, D.; Hao, W.; Kuang, A. Risk factors affecting crash injury severity for different groups of e-bike riders: A classification tree-based logistic regression model. J. Saf. Res. 2021, 76, 176–183. [Google Scholar] [CrossRef]
- Zhang, C.; He, J.; King, M.; Liu, Z.; Chen, Y.; Yan, X.; Xing, L.; Zhang, H. A crash risk identification method for freeway segments with horizontal curvature based on real-time vehicle kinetic response. Accid. Anal. Prev. 2021, 150, 105911. [Google Scholar] [CrossRef]
- Branion-Calles, M.; Götschi, T.; Nelson, T.; Anaya-Boig, E.; Avila-Palencia, I.; Castro, A.; Cole-Hunter, T.; de Nazelle, A.; Dons, E.; Gaupp-Berghausen, M.; et al. Cyclist crash rates and risk factors in a prospective cohort in seven European cities. Accid. Anal. Prev. 2020, 141, 105540. [Google Scholar] [CrossRef] [PubMed]
- Abdel-Aty, M.; Cai, Q. Crash analysis and development of safety performance functions for Florida roads in the framework of the context classification system. J. Saf. Res. 2021, 79, 1–13. [Google Scholar]
- Wang, D.; Liu, Q.; Ma, L.; Zhang, Y.; Cong, H. Road traffic accident severity analysis: A census-based study in China. J. Saf. Res. 2019, 70, 135–147. [Google Scholar] [CrossRef] [PubMed]
- Jiang, F.; Yuen, K.K.R.; Lee, E.W.M. Analysis of motorcycle accidents using association rule mining-based framework with parameter optimization and GIS technology. J. Saf. Res. 2020, 75, 292–309. [Google Scholar] [CrossRef]
- Lu, D.; Guo, F.; Li, F. Evaluating the causal effects of cellphone distraction on crash risk using propensity score methods. Accid. Anal. Prev. 2020, 143, 105579. [Google Scholar] [CrossRef]
- Wen, X.; Xie, Y.; Wu, L.; Jiang, L. Quantifying and comparing the effects of key risk factors on various types of roadway segment crashes with LightGBM and SHAP. Accid. Anal. Prev. 2021, 159, 106261. [Google Scholar] [CrossRef]
- Hu, J.; Huang, M.C.; Yu, X. Efficient mapping of crash risk at intersections with connected vehicle data and deep learning models. Accid. Anal. Prev. 2020, 144, 105665. [Google Scholar] [CrossRef]
- Son, S.o.; Jeong, J.; Park, S.; Park, J. Effects of advanced warning information systems on secondary crash risk under connected vehicle environment. Accid. Anal. Prev. 2020, 148, 105786. [Google Scholar] [CrossRef]
- Török, Á. Do Automated Vehicles Reduce the Risk of Crashes–Dream or Reality? IEEE Trans. Intell. Transp. Syst. 2022, 24, 718–727. [Google Scholar] [CrossRef]
- Nguyen-Phuoc, D.Q.; De Gruyter, C.; Oviedo-Trespalacios, O.; Ngoc, S.D.; Tran, A.T.P. Turn signal use among motorcyclists and car drivers: The role of environmental characteristics, perceived risk, beliefs and lifestyle behaviours. Accid. Anal. Prev. 2020, 144, 105611. [Google Scholar] [CrossRef] [PubMed]
- Ding, N.; Jiao, N.; Zhu, S.; Liu, B. Structural equations modeling of real-time crash risk variation in car-following incorporating visual perceptual, vehicular, and roadway factors. Accid. Anal. Prev. 2019, 133, 105298. [Google Scholar] [CrossRef]
- Kwon, J.H.; Cho, G.H. An examination of the intersection environment associated with perceived crash risk among school-aged children: Using street-level imagery and computer vision. Accid. Anal. Prev. 2020, 146, 105716. [Google Scholar] [CrossRef] [PubMed]
- Mitra, S.; Bhowmick, D. Status of signalized intersection safety-A case study of Kolkata. Accid. Anal. Prev. 2020, 141, 105525. [Google Scholar] [CrossRef]
- Essa, M.; Sayed, T. Full Bayesian conflict-based models for real time safety evaluation of signalized intersections. Accid. Anal. Prev. 2019, 129, 367–381. [Google Scholar] [CrossRef] [PubMed]
- Zafian, T.; Ryan, A.; Agrawal, R.; Samuel, S.; Knodler, M. Using SHRP2 NDS data to examine infrastructure and other factors contributing to older driver crashes during left turns at signalized intersections. Accid. Anal. Prev. 2021, 156, 106141. [Google Scholar] [CrossRef] [PubMed]
- Mattas, K.; Makridis, M.; Botzoris, G.; Kriston, A.; Minarini, F.; Papadopoulos, B.; Re, F.; Rognelund, G.; Ciuffo, B. Fuzzy Surrogate Safety Metrics for real-time assessment of rear-end collision risk. A study based on empirical observations. Accid. Anal. Prev. 2020, 148, 105794. [Google Scholar] [CrossRef]
- Rowe, R.; Stride, C.B.; Day, M.R.; Thompson, A.R.; McKenna, F.P.; Poulter, D.R. Why are newly qualified motorists at high crash risk? Modelling driving behaviours across the first six months of driving. Accid. Anal. Prev. 2022, 177, 106832. [Google Scholar] [CrossRef]
- Lin, Q.; Li, S.; Ma, X.; Lu, G. Understanding take-over performance of high crash risk drivers during conditionally automated driving. Accid. Anal. Prev. 2020, 143, 105543. [Google Scholar] [CrossRef]
- Ko, J.; Jang, J.; Oh, C. A multi-agent driving simulation approach for evaluating the safety benefits of connected vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4512–4524. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, W.; Zhang, W.; Zhao, J.L. SafeDrive: A new model for driving risk analysis based on crash avoidance. IEEE Trans. Intell. Transp. Syst. 2020, 23, 2116–2129. [Google Scholar] [CrossRef]
- Li, P.; Abdel-Aty, M.; Yuan, J. Real-time crash risk prediction on arterials based on LSTM-CNN. Accid. Anal. Prev. 2020, 135, 105371. [Google Scholar] [CrossRef]
- Li, P.; Abdel-Aty, M. A hybrid machine learning model for predicting real-time secondary crash likelihood. Accid. Anal. Prev. 2022, 165, 106504. [Google Scholar] [CrossRef] [PubMed]
- Gong, Y.; Abdel-Aty, M.; Yuan, J.; Cai, Q. Multi-objective reinforcement learning approach for improving safety at intersections with adaptive traffic signal control. Accid. Anal. Prev. 2020, 144, 105655. [Google Scholar] [CrossRef] [PubMed]
- Zhu, M.; Wang, Y.; Pu, Z.; Hu, J.; Wang, X.; Ke, R. Safe, efficient, and comfortable velocity control based on reinforcement learning for autonomous driving. Transp. Res. Part C Emerg. Technol. 2020, 117, 102662. [Google Scholar] [CrossRef]
- Cao, Z.; Xu, S.; Jiao, X.; Peng, H.; Yang, D. Trustworthy safety improvement for autonomous driving using reinforcement learning. Transp. Res. Part C Emerg. Technol. 2022, 138, 103656. [Google Scholar] [CrossRef]
- Man, C.K.; Quddus, M.; Theofilatos, A.; Yu, R.; Imprialou, M. Wasserstein Generative Adversarial Network to Address the Imbalanced Data Problem in Real-Time Crash Risk Prediction. IEEE Trans. Intell. Transp. Syst. 2022, 23, 23002–23013. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, Y.; Xie, X.; Chen, L.; Liu, H. RiskOracle: A minute-level citywide traffic accident forecasting framework. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1258–1265. [Google Scholar]
- Wang, B.; Lin, Y.; Guo, S.; Wan, H. GSNet: Learning spatial-temporal correlations from geographical and semantic aspects for traffic accident risk forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 4402–4409. [Google Scholar]
- Xie, K.; Yang, D.; Ozbay, K.; Yang, H. Use of real-world connected vehicle data in identifying high-risk locations based on a new surrogate safety measure. Accid. Anal. Prev. 2019, 125, 311–319. [Google Scholar] [CrossRef]
- Peng, Y.; Li, C.; Wang, K.; Gao, Z.; Yu, R. Examining imbalanced classification algorithms in predicting real-time traffic crash risk. Accid. Anal. Prev. 2020, 144, 105610. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, F.; Wolshon, B.; Sheng, Y. Virtual Traffic Signals: Safe, Rapid, Efficient and Autonomous Driving without Traffic Control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6954–6966. [Google Scholar] [CrossRef]
- Kim, H.; Lee, K.; Hwang, G.; Suh, C. Crash to not crash: Learn to identify dangerous vehicles using a simulator. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 978–985. [Google Scholar]
- Zheng, L.; Sayed, T. A novel approach for real time crash prediction at signalized intersections. Transp. Res. Part C Emerg. Technol. 2020, 117, 102683. [Google Scholar] [CrossRef]
- Gu, Y.; Liu, D.; Arvin, R.; Khattak, A.J.; Han, L.D. Predicting intersection crash frequency using connected vehicle data: A framework for geographical random forest. Accid. Anal. Prev. 2022, 179, 106880. [Google Scholar] [CrossRef]
- Lin, D.J.; Chen, M.Y.; Chiang, H.S.; Sharma, P.K. Intelligent Traffic Accident Prediction Model for Internet of Vehicles with Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2340–2349. [Google Scholar] [CrossRef]
- Basso, F.; Basso, L.J.; Bravo, F.; Pezoa, R. Real-time crash prediction in an urban expressway using disaggregated data. Transp. Res. Part C Emerg. Technol. 2018, 86, 202–219. [Google Scholar] [CrossRef]
- Cai, Q.; Abdel-Aty, M.; Yuan, J.; Lee, J.; Wu, Y. Real-time crash prediction on expressways using deep generative models. Transp. Res. Part C Emerg. Technol. 2020, 117, 102697. [Google Scholar] [CrossRef]
- Guo, M.; Zhao, X.; Yao, Y.; Yan, P.; Su, Y.; Bi, C.; Wu, D. A study of freeway crash risk prediction and interpretation based on risky driving behavior and traffic flow data. Accid. Anal. Prev. 2021, 160, 106328. [Google Scholar] [CrossRef]
- Roy, A.; Hossain, M.; Muromachi, Y. A deep reinforcement learning-based intelligent intervention framework for real-time proactive road safety management. Accid. Anal. Prev. 2022, 165, 106512. [Google Scholar] [CrossRef]
- Chen, J.; Wu, Z.; Zhang, J. Driving Safety Risk Prediction Using Cost-Sensitive with Nonnegativity-Constrained Autoencoders Based on Imbalanced Naturalistic Driving Data. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4450–4465. [Google Scholar] [CrossRef]
- Mahajan, V.; Katrakazas, C.; Antoniou, C. Crash Risk Estimation Due to Lane Changing: A Data-Driven Approach Using Naturalistic Data. IEEE Trans. Intell. Transp. Syst. 2022, 23, 3756–3765. [Google Scholar] [CrossRef]
- Li, Z.N.; Huang, X.H.; Mu, T.; Wang, J. Attention-Based Lane Change and Crash Risk Prediction Model in Highways. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22909–22922. [Google Scholar] [CrossRef]
- Chen, T.; Shi, X.; Wong, Y.D.; Yu, X. Predicting lane-changing risk level based on vehicles’ space-series features: A pre-emptive learning approach. Transp. Res. Part C Emerg. Technol. 2020, 116, 102646. [Google Scholar] [CrossRef]
- Karim, M.M.; Li, Y.; Qin, R.; Yin, Z. A Dynamic Spatial-Temporal Attention Network for Early Anticipation of Traffic Accidents. IEEE Trans. Intell. Transp. Syst. 2022, 23, 9590–9600. [Google Scholar] [CrossRef]
- Formosa, N.; Quddus, M.; Ison, S.; Timmis, A. A New Modeling Approach for Predicting Vehicle-Based Safety Threats. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18175–18185. [Google Scholar] [CrossRef]
- Arbabzadeh, N.; Jafari, M. A Data-Driven Approach for Driving Safety Risk Prediction Using Driver Behavior and Roadway Information Data. IEEE Trans. Intell. Transp. Syst. 2018, 19, 446–460. [Google Scholar] [CrossRef]
- Wang, X.; Liu, J.; Qiu, T.; Mu, C.; Chen, C.; Zhou, P. A Real-Time Collision Prediction Mechanism With Deep Learning for Intelligent Transportation System. IEEE Trans. Veh. Technol. 2020, 69, 9497–9508. [Google Scholar] [CrossRef]
- Elamrani Abou Elassad, Z.; Mousannif, H.; Al Moatassime, H. A real-time crash prediction fusion framework: An imbalance-aware strategy for collision avoidance systems. Transp. Res. Part C Emerg. Technol. 2020, 118, 102708. [Google Scholar] [CrossRef]
- Hao, W.; Rong, D.; Zhang, Z.; Wu, Q.; Byon, Y.J.; Yi, K.; Tang, J.; Lyu, N. Development of a Safety Prediction Method for Arterial Roads Based on Big-Data Technology and Stacked AutoEncoder-Gated Recurrent Unit. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20110–20122. [Google Scholar] [CrossRef]
- von Stülpnagel, R.; Lucas, J. Crash risk and subjective risk perception during urban cycling: Evidence for congruent and incongruent sources. Accid. Anal. Prev. 2020, 142, 105584. [Google Scholar] [CrossRef] [PubMed]
- Shangguan, Q.; Fu, T.; Wang, J.; Fang, S.; Fu, L. A proactive lane-changing risk prediction framework considering driving intention recognition and different lane-changing patterns. Accid. Anal. Prev. 2022, 164, 106500. [Google Scholar] [CrossRef]
- Islam, Z.; Abdel-Aty, M.; Cai, Q.; Yuan, J. Crash data augmentation using variational autoencoder. Accid. Anal. Prev. 2021, 151, 105950. [Google Scholar] [CrossRef]
- Basso, F.; Pezoa, R.; Varas, M.; Villalobos, M. A deep learning approach for real-time crash prediction using vehicle-by-vehicle data. Accid. Anal. Prev. 2021, 162, 106409. [Google Scholar] [CrossRef]
- Ahmadi, A.; Machiani, S.G. Drivers’ performance examination using a personalized adaptive curve speed warning: Driving simulator study. Int. J. Hum.–Comput. Interact. 2019, 35, 996–1007. [Google Scholar] [CrossRef]
- Huang, Y.; Yan, X.; Li, X.; Yang, J. Using a multi-user driving simulator system to explore the patterns of vehicle fleet rear-end collisions occurrence under different foggy conditions and speed limits. Transp. Res. Part F Traffic Psychol. Behav. 2020, 74, 161–172. [Google Scholar] [CrossRef]
- Gratzer, A.L.; Thormann, S.; Schirrer, A.; Jakubek, S. String Stable and Collision-Safe Model Predictive Platoon Control. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19358–19373. [Google Scholar] [CrossRef]
- Kim, G.; Kang, J.; Sohn, K. A meta–reinforcement learning algorithm for traffic signal control to automatically switch different reward functions according to the saturation level of traffic flows. Comput.-Aided Civ. Infrastruct. Eng. 2022, 38, 779–798. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topics | |
|---|---|
|
|
|
|
| Investigated Locations | |
|---|---|
|
|
| Considered Entities | |
|
|
| Techniques | |
|
|
| Data | |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, W.; Dash, A.; Li, J.; Wei, H.; Wang, G. Safety in Traffic Management Systems: A Comprehensive Survey. Designs 2023, 7, 100. https://doi.org/10.3390/designs7040100
Du W, Dash A, Li J, Wei H, Wang G. Safety in Traffic Management Systems: A Comprehensive Survey. Designs. 2023; 7(4):100. https://doi.org/10.3390/designs7040100
Chicago/Turabian StyleDu, Wenlu, Ankan Dash, Jing Li, Hua Wei, and Guiling Wang. 2023. "Safety in Traffic Management Systems: A Comprehensive Survey" Designs 7, no. 4: 100. https://doi.org/10.3390/designs7040100
APA StyleDu, W., Dash, A., Li, J., Wei, H., & Wang, G. (2023). Safety in Traffic Management Systems: A Comprehensive Survey. Designs, 7(4), 100. https://doi.org/10.3390/designs7040100