1. Introduction
In recent years, deep learning, target detection, and other technologies have gone deep into various fields, but the technology has not been well applied in the field of fishery detection, fishery ecological monitoring, fishery diversity research, and intelligent aquaculture, and other related fields urgently need the support of target detection and other technologies. Fish object detection technology aims to distinguish and locate fish in images or videos in multiple scenes and is the technical core of the automatic monitoring of fish growth status [
1]. At the same time, assessing fish species diversity and monitoring changes in aquatic species are also key tasks of related research [
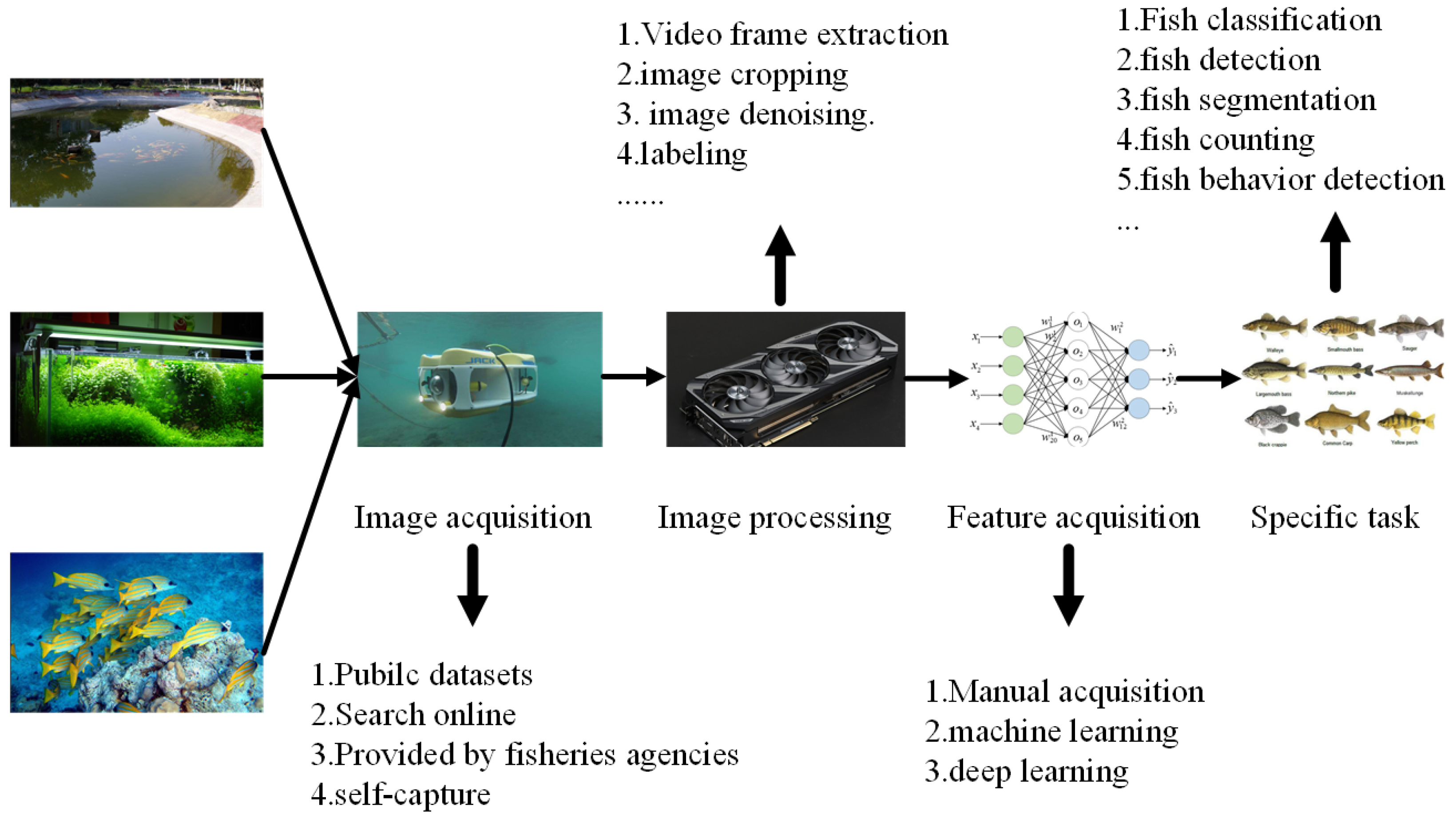
2]. In addition, the technology can monitor fish species in an intelligent way to achieve the protection of fish diversity, and low-cost, high-performance, high-precision fish detection technology that has almost no adverse impact on the living environment of fish has become the basis for fish behavior analysis and growth state measurement. At present, the main research process in this field is shown in
Figure 1 below. Firstly, image and video data are obtained from various scenarios, followed by data processing, feature extraction, and model training to achieve specific downstream tasks so as to realize research in specific fields, and then the intelligent perception, identification, and classification of fish species and quantity are realized so as to effectively prevent illegal overfishing. The sustainable development of fishery resources is protected and the fishery intelligence of the whole industry chain is realized.
Combining many factors, such as model size, detection speed, and deployment difficulty, we proposed a multi-scale, multi-level, multi-stage cross-domain feature fusion discrimination model
TMFD (triple the multi-scale/multi-layer/multi-stage fish detection) based on fish data images in different scenes. In view of the large differences in size and color of fish in multi-scene images, we deepened the depth of the model from the original three layers to the current five layers. Secondly, in the neck stage, in order to reduce the loss of a large number of high-dimensional features caused by direct use of the 1*1 convolution between the backbone and neck, we introduce the
MCB (multiple convolution batch normalization) module to segment the depth features through splitting, and then obtain a new output through the convolution operation using the output on one side as the residual edge. The other side repeats the above work as a new input. After several splits, the final output is concat spliced to further obtain a unified output channel. At the same time, in the neck stage, a comparison of FPN [
3], PANet [
4], BiFPN [
5], and our neck structure
MMCFPN (multi-stage, multi-level and cross-domain) is proposed, and the
DBMFormer (DPConv combines binary additive attention with MLP Former) attention mechanism is added after multi-level feature splicing in the first stage, which effectively utilizes the feature information of different channels in the same spatial position. The feature interaction between different stages and different levels is realized, and the feature information at all levels is efficiently integrated, which further enhances the detection effect of the model and improves the discriminability of the whole model. Finally, in order to avoid the mutual influence of the required features among different subtasks, we completely decouple the three subtasks of classification, positioning, and regression, which further improves the detection results of the model.
Our contributions are as follows:
In this paper, a novel multi-scale, multi-level, and multi-stage cross-domain feature fusion discrimination model TMFD is proposed to detect fish targets in different scenarios, thus effectively preventing illegal overfishing.
The multi-layer segmentation residual fusion module MCB and a new neck structure MMCFPN are introduced to solve the problem of multi-channel deep features losing a large amount of feature information when the number of feature channels is unified. At the same time, multi-scale, multi-level, and multi-stage features are integrated across domains, improving the feature integration ability of the model.
In the neck fusion process of the model, we introduce DBMFormer, a Q and K binary fusion attention mechanism, which further processes the fused features, strengthens the features, and thus improves the detection ability.
The remaining sections of this article are structured as follows:
Section 3 provides a description of the pertinent materials and data sets utilized in our study. In
Section 4, we present our approach, also referred to as the model. It begins by introducing the overall model and subsequently elaborates on the relevant technical modules and innovations employed. Additionally, it outlines the loss function used. Moving on to
Section 5, we introduce our specific experiments, encompassing experiment details, and demonstrate the superiority of our model through comparative experiments, ablation experiments, and visualizations.
Section 6 delves into discussing challenges encountered in current research work along with future research directions. Finally, in
Section 7, we conclude by summarizing the relevant findings from this study.
2. Related Work
With the further development of fishery intelligence, fish classification, segmentation, target detection, and other related tasks have gradually introduced deep learning, which can automatically extract more abundant features from massive information and can constantly learn the difference between the actual value and the predicted value according to the needs. In the early stage of fishery resource target detection, machine learning is mainly relied on, which can effectively classify and locate fish targets and provide key data for related industries. As a reliable and economical technology, machine learning has the advantages of non-contact monitoring, a wide application range, and long-term stable operation [
6]. Lee et al. [
7] used the global shape matching method to further identify fish by testing descriptors such as Fourier, polygon approximation, and line segments, achieving an accuracy of more than 90% for four species in aquariums. Fouad MM et al. [
8] used feature extraction techniques based on scale invariant feature transform (SIFT) and accelerated robust feature (SURF) algorithms in combination with support vector machines (SVMs) to automatically classify Nile tilapia, which was superior to other machine learning techniques, such as artificial neural networks (ANNs) and the K-nearest neighbor (K-CNN) algorithm. Spampinato et al. [
9] improved the fish detection effect by combining local feature extraction, patch coding, and pooling operations with the background modeling method of multi-scale feature aggregation in the later stage. Ravanbakhsh et al. [
10] used an automated method for fish detection based on a shape-based level set framework to model the shape of fish through principal component analysis (PCA) to achieve the detection of fish. In previous relevant studies [
11,
12], the texture, color, shape, and other local features of the target were manually designed and selected through appropriate feature extraction algorithms to ensure that the selected features could accurately represent different objects. However, the characteristics selected by this method rely too much on manual techniques, and the characteristics depend on human subjective judgment, which has a great influence on the final detection. At the same time, in addition to the traditional manual monitoring methods, there are also sense-based [
13] and acoustic [
14] methods. However, due to the large differences in different scenes and complex environment, the layout of sensors and acoustic methods is difficult, the cost is high, and the efficiency is low, so it is difficult to further study and develop. Therefore, the traditional fish target detection algorithm that relies on machine learning cannot meet the needs of the actual situation.
At present, the two-stage object detection algorithm is applied to the fishery scene. The first stage is to classify the foreground and background in the image and screen out the candidate frame from a large number of anchor frames; the second stage is to adjust the position of the candidate frame and classify the objects in the candidate frame. Rauf et al. [
15] further deepened the network on the basis of VGG and used deep convolutional neural networks to realize the automatic recognition of fish based on visual features. Maløy et al. [
16] proposed a two-flow cyclic network (DSRN) based on deep learning by integrating spatial networks and 3D convolutional motion networks to automatically capture the spatiotemporal behavior of salmon during swimming. Manda et al. [
17] first introduced Faster RCNN into the field of fish detection and achieved an accuracy rate of 82.4% on the data set of remote underwater video stations. Labao et al. [
18] used numerous convolutional networks on the basis of RPN, connected them through long- and short-term memory networks and cascading structures, and introduced an automatic correction mechanism to further improve the detection accuracy of the model. Salman et al. [
19] used a region-based convolutional neural network to detect freely moving fish in an unconstrained underwater environment. They used background subtraction and optical flow to make use of the fish movement information in the video, and then combined the results with the original images to generate corresponding candidate regions to further improve the effect of the model. Liu et al. [
20] improved the Faster RCNN by embedding a convolutional kernel adaptive selection unit in the backbone to enhance the feature extraction capability of the network and solve the detection problem of small densely distributed benthic creatures under overlapping and occlusion images. Peng et al. [
21] proposed a two-stage detection network named S-FPN that added a fast connection structure to FPN and proposed a new segmented focal length loss (PFL) function to reduce the interference of a large number of unrelated background samples, thereby improving the detection of objects at different scales. Although the two-stage algorithm has high detection accuracy, its reasoning speed is slow, and it needs to occupy many resources, so it cannot be well deployed on edge devices.
Compared with the two-stage algorithm, the first-stage algorithm has been vigorously developed because of characteristics such as its faster reasoning speed, lower resource occupation, and easy deployment. For application scenarios requiring detection speed, the first-stage detector is more suitable. It does not have the stage of classifying the foreground and background, but directly generates the classification probability and positioning coordinate value of the target in one stage, determines the positioning and classification of the predicted object according to the grid unit where the central point of the object is located, and then directly regresses the classification probability and positioning coordinates of the target to achieve the prediction effect. Wang et al. [
22] proposed that, by improving the up-sampling operator based on the YOLOV5 model, problems such as a small detection target and fuzzy detection can be effectively solved. Based on YOLOV3, Wei et al. [
23] added an SE attention module to learn the relationship between channels, enhance the semantic information of depth features, and enhance the detection effect of small targets. Jalal et al. [
2] combined the optical flow and Gaussian mixture model with YOLO, eliminating the problem that YOLO was initially only used to capture static and clearly visible fish targets, and expanding the detection range. Wageeh et al. [
24] used the multi-scale Retinex algorithm to enhance the cloudy underwater image, and then used YOLO combined with the optical flow algorithm to detect fish and obtain the activity trajectories of fish. Hu et al. [
25] used YOLOV3-Lite to improve the blocking and loss functions of fish schools so as to better identify fish behaviors. Yu et al. [
26] extracted fish contour features based on the attentional full convolutional instance segmentation network (CAM-Decoupled SOLO), and combined pixel position information with a channel attention mechanism to realize the fusion of target position information and channel dimension information. Zhao et al. [
27] made improvements to YOLOV4, replacing the original backbone with MobileNetV3 and standard convolution with deep separable convolution, thus achieving a significant reduction in network parameters and computation. Kandimalla et al. [
28] integrated the Norfair tracking algorithm with YOLOv4 to track fish in video data, thus improving the effect of fish detection. Wang et al. [
29] improved YOLOV5 by adding multilevel features, adding feature mapping, and adding a SiamRPN structure to detect and track target fish. Yu et al. [
30] designed a novel multi-attention path aggregation network named APAN that combines coordinate competing attention and spatial supplementary attention and a double-transmission underwater image enhancement algorithm to further enhance the detection effect of the model. Xu et al. [
31] proposed a new refined marine object detector based on the attention spatial pyramid pool network (SA-SPPN) and bidirectional feature fusion strategy to detect fine marine objects. Jia et al. [
32] proposed a new marine organism target detection model EfficientDet-Reved (EDR) that reconstructs MBConvBlock by adding a channel shuffle module to realize information exchange between the channel of the element layer. Xu et al. [
33] proposed a new scale perception feature pyramid structure SA-FPN in order to enrich the semantic features of prediction and further improve the marine target detection performance. In order to further improve the detection accuracy of underwater fish in complex underwater environments, Liu et al. [
34] proposed a dual-path (DP) pyramid vision converter (PVT) feature extraction network DP-FishNET. The model enhances the ability of extracting global and local features from underwater images and enhances the feature reusability. The detection system proposed by Dharshana et al. [
35] based on the YOLO framework focuses on changes in fish scales and location and looks for distinguishing traits to distinguish fish.
Whether it is a one-stage algorithm or a two-stage algorithm, it predicts the category of the target and the center point offset and then obtains the actual prediction results based on the anchor frame, but there are some problems in this approach, such as how to find the appropriate size of the anchor frame, how to allocate positive and negative samples, how to choose different anchor frames, and so on. In order to solve the above problems, our model abandoned the traditional idea of an anchor frame and directly predicted the distance of the point to the left (l: left), upper (t: top), right (r: right), and lower (b: bottom) sides of the target in each position of the prediction feature map; this idea is not only simple but also more effective, as shown in
Figure 2.
Our model is similar to the FCOS model, which simplifies the process of target detection through the design of no anchor points. Combined with the relevant data in
Table 1, it can be found that, compared with the traditional method with anchor points, our model has a better effect than other models when the proportion of data sets is unchanged. At the same time, through a series of innovative mechanisms, it achieves high precision target detection. Specifically, there are these points:
The anchor-free design of the model avoids the complex calculation and hyperparameter setting related to the anchor frame, reduces the computation and memory consumption, and thus improves the generalization ability of the model.
The model adopts a full convolutional network, which can process input images of any size without clipping or scaling the images, thus improving the adaptability of the model.
The model realizes target detection and positioning by predicting the distance between each pixel point and the target boundary box. This pixel-level prediction method improves the accuracy of the target boundary box.
A new “center-ness” branch is introduced to predict the deviation between pixels and the corresponding bounding box center, which is used to reduce the proportion of low-quality detection bounding boxes and improve the detection accuracy.
3. Materials
At present, there are few fish data sets in multiple scenarios, most of which are data in a single scenario, such as the underwater image data set (UTDAC) [
4], natural light underwater exploration data set (RUOD) [
5], DeepFish [
36], LifeCLEF [
37], FishNet [
38], etc. The relevant information of specific relevant data sets is shown in
Table 2.
There is much relevant data, but various data sets are more or less flawed, such as DeepFish and Fish4Knowledge data sets, where the data size is large enough, but the label is not specific to fish categories but fish; the UTDAC, LifeCLEF, and SUIM data sets, which are also large enough to be labeled according to specific fish categories, but only have 4, 10, or 8 different species, with fewer target species, and cannot provide good classification results. Fish in the seagrass habitats data set meet the previous requirements, but its scenario is too simple and not the best choice. The above mentioned relevant data represent the legend in
Figure 3.
Our data set comes from a wide range of sources. By searching online resources or cooperating with fishery agencies to obtain public data sets, we adopted a self-production method to construct a training set by adding labels to fish images of different species and different scenarios for data enhancement processing. Specific data sets can be used for model training and performance verification, and the data set contains fish images in multiple scenarios, with diversity and complexity. Fish images also include images with no fish targets and only partial fish targets. To add labels to fish images, the fish in the image is selected by using the smallest rectangular box, and then the distance between the center point of the smallest rectangular box and the four sides is marked as the position mark of the fish image, and the category of fish in the image is marked. Data enhancement is used to process each image by means of flipping, scaling, random noise, color transformation, Mosaic, etc., to improve the generalization ability of the model and reduce the overfitting probability. These data sets provide rich samples for model training.
A total of three data sets were used in our experiment, namely Fish30, Fish52, and Lahatan. Fish30 is the key data set of our experiment, and its data distribution is shown in
Figure 4. Data sets Fish52 and Lahatan are mainly used for comparative experiments to verify the effect of our model. These data sets are faced with such challenges as blurred pixels, too high a similarity between the foreground and background, fish species diversity, occlusion, a large difference in target size, etc. However, they also make up for the shortcomings of the aforementioned data sets. In order to further improve the quality of the data set, improve the training effect of the model, reduce the probability of overfitting, and improve the generalization ability of the model, we carried out a series of data enhancement operations on the data set, such as flipping, scaling, random noise, color transformation, Mosaic, etc.
6. Discussions
With the increase in population, land resources cannot meet the needs of human beings, and marine resources are vital to human beings. When marine resources are exploited, excessive human behavior can disturb the marine environment and reduce the efficiency of operations.The automatic operation of underwater detection equipment such as AUVs is conducive to the rational exploitation, research, and protection of marine living resources. Currently, the research in this field is still facing many problems in data sets, models, and applications. At the same time, there are many research directions in this field that can improve the current situation, and the following aspects are mainly discussed here:
Data set: Firstly, there are fewer fishery-related multi-scene fish data sets at present, and most of them are single-scene data; secondly, a large amount of image information is extracted from video frames at present, but drawing corresponding labeling information for these images is also a tricky problem; lastly, the scene of this type of data set is highly dynamic, and how to filter the noise contained in the images is a major difficulty. In the future, improvements can be made on the basis of existing techniques to minimize manually labeled features and expand the number of training data sets, such as pre-detection using the existing model weights and then filtering by hand.
Model: Improving the generalization ability of the model is one of the most difficult tasks in fishery detection, i.e., how to reduce the difference between the model effect on the training set and the test set, and the task is even more difficult in the special scenario of specific fish detection. In the future, model-related techniques such as migration learning, weakly supervised learning, and knowledge distillation can be used for enhancement, using migration learning techniques to avoid re-training the model on a new data set and to obtain the optimal value of the weights at the time of migration; using weakly supervised learning techniques to reduce the use of samples with labels; and using knowledge distillation techniques to reduce the parameters of the model and make the model more lightweight.
Application: The “intelligent fishery” has penetrated into all aspects of the marine industry chain, regarding how to further develop the specific “fish detection” task in the “intelligent fishery” and how to integrate big data analytics, remote control, remote monitoring, and data management. How to further integrate big data analysis, remote control, aquaculture methods, and the intelligent Internet of Things is also a major difficulty. In the future, classification, detection, segmentation, counting, and other tasks can be integrated to establish an intelligent analysis platform based on fishing catches so as to achieve the intelligent sensing of fishery catches and forecasting of fishing grounds.
Overall, research related to fishery resources is still at an early stage and still faces many problems, but there are many related research areas. In the future, it is important to explore and develop more effective cross-domain adaptive algorithms, to mine more domain-invariant information, to further improve the accuracy of cross-domain detection, to embed the proposed method into an intelligent fish detection system in order to quickly adapt to the fish detection tasks in different scenarios so as to make the intelligent detection equipment more rapid and versatile, and to enable the relevant practitioners to obtain the categories of the relevant species within a certain area in order to guide the subsequent related work; therefore, this study has strong practicality.
7. Conclusions
In this paper, we propose a multi-scale, multi-level, multi-stage cross-domain feature fusion discriminative model TMFD (triple the multi-scale/multi-layer/multi-stage fish detection) for fish detection in multi-scenarios. Specifically, the model extends the three output channels of the FCOS model backbone, and, in order to minimize the loss of a large number of features from the backbone output after 1*1 convolution, the MCB (multiple convolution batch normalization) module is added at the connection. Meanwhile, in order to enhance the extraction ability of non-rigid fish with multi-scale and multi-pose changes, we propose our MMCFPN (multi-stage, multi-level, and cross-domain feature pyramid network) structure in the neck part, which not only extends the multi-stage up and down sampling operation but also introduces the feature information of different stages, as well as the information of different layers, which, in turn, enhances the network discriminability. In the neck fusion process of the model, we introduce a Q and K binary fusion attention mechanism, DBMFormer (DPConv combines binary additive attention with MLP Former), which further processes the features after fusion and strengthens the features. In addition, in the detection head part, in order to avoid mutual interference among classification, localization, and regression tasks, we decouple the three sub-tasks so that they independently complete their corresponding feature tasks. The excellent target detection of our model is demonstrated by comparison and ablation experiments on multiple data sets, which show that good performance can be obtained in new target domains without any additional labeling. The proposed algorithm is shown to outperform similar models through a series of experiments on multiple data sets from different scenarios, indicating that the proposed algorithm is beneficial for assessing fish species diversity and aquaculture as well as other fishery activities. In addition, it contributes to ecological monitoring and marine biodiversity studies. In the future, the model can be further designed toward being lightweight while maintaining detection accuracy and integrating multiple tasks, such as classification, detection, segmentation, and counting, to establish an intelligent analysis platform based on fishing catch to achieve the intelligent sensing of fishery catch and fishery forecast, which can then be applied to a wider range of fields.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}