1. Introduction
Covert channels in computer systems exploit shared resources to transmit information covertly between processes. Traditional cache-based covert channels often suffer from low throughput and high error rates due to the unpredictable nature of cache access times and system interference. Covert channels between cross-core sender and receiver processes are noisier and harder to establish because the two processes must rely on shared microarchitectural elements, such as the last-level cache (LLC), to communicate. This setup introduces several challenges, including timing jitter from the cache coherence protocols, interference from concurrent system activity on other cores, and difficulties in tightly synchronizing the sender and the receiver. These factors make it harder to reliably measure timing differences, increasing the likelihood of decoding errors and reducing the overall throughput. Earlier investigations by [
1,
2,
3] laid the groundwork for understanding covert channels by analyzing the MESI (Modified, Exclusive, Shared, Invalid) cache coherence protocol’s effects on last-level caches (LLCs). Their approaches primarily relied on accessing a single cache line per bit transmission with a normal page size without incorporating huge pages.
Building upon this foundational research, our method introduces the use of huge pages and facilitates access to multiple cache lines concurrently. This novel approach is designed to enhance both the accuracy and throughput of covert channels, capitalizing on the combined benefits of prefetching and huge pages.
For a cross-core covert channel, the sender and receiver processes are on different cores. Only the shared cache between the sender and the receiver is the LLC. Cache coherence events provide a mechanism to signal or encode the data from a receiver to a sender. A sender within a software enclave such as an Intel SGX enclave may have access to private data of value to the receiver. All of the information channels are typically monitored in a secure domain such as a software enclave [
4,
5,
6,
7] or a secure world domain of an ARM TrustZone [
8,
9]. These covert channels avoid such dynamic information channel monitoring to exfiltrate secret data. How such secret data is acquired in the sender domain is not a focus of this paper.
Prefetching plays a critical role in optimizing memory access but serves to activate specific cache coherence events in covert channels. Prefetchers, through instructions such as PREFETCHW, enable data to be proactively loaded into the L1 cache. The PREFETCHW instruction is a software prefetch hint available in x86 architectures that brings a cache line into the processor’s cache hierarchy in anticipation of a write [
10]. This proactive behavior reduces the memory access latency, improves cache utilization, and interacts with the MESI (Modified, Exclusive, Shared, Invalid) cache coherence protocol to maintain data consistency across cores. For instance, PREFETCHW can transition cache lines to the modified state, preparing them for faster subsequent write operations while maintaining coherence. These operations enable side-channel and covert-channel vulnerabilities through observable changes in cache states. Covert channels, by leveraging the interplay between prefetching and cache coherence protocols, can exploit these microarchitectural optimizations to improve their effectiveness [
1].
Huge pages, on the other hand, address memory management challenges by significantly reducing the number of Translation Lookaside Buffer (TLB) entries required for address translation. With larger page sizes such as 2 MB or 1 GB, a TLB entry covers a broader range of memory addresses, minimizing TLB misses and reducing the address translation overhead. This optimization is particularly effective for memory-intensive applications with spatial locality, as it lowers the latency and improves system efficiency by decreasing the frequency of page table walks and translations. Spatial locality also is likely to reduce the page fault frequency, further improving the performance. Additionally, huge pages are commonly employed in cryptographic systems and secure data transmission to improve the performance and predictability when handling secret or sensitive data, making them a natural fit for covert communication channels that rely on timing stability.
The combination of prefetching and huge pages amplifies these individual benefits, leading to enhanced covert channel efficiency. Huge pages facilitate more effective prefetchers, enabling data fetching across larger contiguous memory regions with fewer interruptions driven by page faults. This integration ensures faster address translations, higher cache hit rates, and a reduced latency, resulting in a significantly improved throughput and accuracy in covert channels. Our methodology constructs a cross-core covert channel by exploiting prefetch-induced cache coherence transitions, specifically using the PREFETCHW instruction to trigger measurable state changes in L1 caches. It further introduces multi-line encoding, wherein messages are encoded by accessing varying numbers of cache lines in a huge-page-backed memory region. This enables more robust and high-bandwidth transmission. Our proposed approach capitalizes on the strengths of prefetching and huge pages to enhance the covert channel performance, demonstrating notable improvements in the throughput and accuracy while addressing associated challenges in a controlled computing environment.
2. Related Work
Microarchitectural side channels have long been used for covert communication. Prior works such as Prime+Probe, Flush+Reload, and Spectre-family attacks demonstrate how cache occupancy and speculation artifacts can be exploited [
11,
12].
Our work is closely related to the “Adversarial Prefetch” attack by Zhang et al. [
1], which showed that
PREFETCHW can leak the coherence state of a cache line, enabling high-throughput covert channels over single-line access patterns. We build on this idea, generalizing to multi-line prefetching and integrating huge page memory mappings.
Recent studies further extend covert channels’ capacity and stealth:
PrefetchX (Zhang et al., 2023) [
13] discovers a cross-core channel via the XPT prefetcher shared among cores, achieving 1.7 MB/s on Intel.
BandwidthBreach (Barth et al., 2023) [
14] establishes covert channels through LFB/SQ contention in the memory pipeline, achieving over 10 Mbps.
Write+Sync Covert Channels (Kumar et al., 2023) [
15] demonstrate durable-write-based channels exploiting
fsync() barriers on disk, effective even under strong cache defenses.
SgxPectre Attacks [
16] exploit speculative execution vulnerabilities in SGX to leak enclave secrets, demonstrating how transient execution can be used to bypass SGX’s isolation guarantees. These highlight the importance of microarchitectural analysis in trusted computing.
Compared to these, our channel uniquely combines huge page access, multi-line prefetching, and TEE compatibility via AMD SEV-SNP. Our throughput and accuracy trends (up to 88%) compare favorably while maintaining low detectability and leveraging coherence transitions observable even under cloud virtualization.
3. Background
3.1. The Software Prefetcher
A software prefetcher is a mechanism that allows a program to explicitly request the fetching of data from memory into the cache before it is accessed [
17]. The purpose is to hide the memory latency by ensuring that data is already available in the cache when needed by the CPU. Software prefetching is typically initiated by inserting special prefetch instructions (e.g., PREFETCH in x86 or PLD in ARM) into the program code. These instructions act as hints to the processor that specific memory locations will likely be accessed soon, prompting the prefetcher to load the data into the appropriate cache level [
18].
The mechanism of software prefetching involves several steps. First, programmers or compilers strategically place prefetch instructions at points in the code where the memory access patterns are predictable, such as in loops that iterate over large datasets. For instance, in a loop processing an array, a prefetch instruction can be placed a few iterations ahead to ensure data is available when needed. Once executed, these instructions trigger the processor to fetch the specified memory location from main memory into the cache. On x86 architectures, instructions like PREFETCHW are used to prepare cache lines for future writes, while PREFETCHT0 brings data into the L1 cache. Similarly, ARM architectures utilize PLD for data prefetching and PLI for prefetching instructions. The fetched data is then stored in a specified cache level, such as L1, L2, or L3, depending on the type of prefetch instruction used. This operation is non-blocking, meaning it does not stall the CPU while waiting for the data to be fetched; the processor continues executing other instructions, allowing the prefetcher to asynchronously load the data into the cache [
19].
Software prefetching can handle both read and write operations. For example, the
__builtin_prefetch instruction in x86 architectures is versatile and explicitly prepares cache lines for future writes by transitioning them to the modified state within the MESI protocol [
20]. Prefetching does not alter the data itself; it merely ensures that the data is readily available in the cache for subsequent operations, thereby enhancing the efficiency without compromising data integrity.
The advantages of software prefetching are significant. It reduces the memory latency by preloading data into the cache, thus minimizing delays when the data is accessed [
21]. By ensuring frequently accessed data is present at the appropriate cache level, it improves cache utilization and reduces cache misses. This also minimizes pipeline stalls caused by memory access delays, leading to smoother instruction execution. Software prefetching is particularly effective in workloads with predictable access patterns, such as matrix operations prevalent in AI/ML applications, image processing, and large-scale numerical simulations [
17]. By leveraging software prefetching effectively, programmers and compilers can achieve substantial performance gains in memory-intensive applications.
In our baseline tests in
Section 4.2, enabling software prefetching reduced the average memory access latency and provided a performance improvement of approximately 13%.
3.2. Huge Pages
A huge page is a memory management feature in modern operating systems that allows the mapping of large, contiguous memory regions using a single page table entry. Unlike the standard memory page size, which is typically 4 KB, huge pages can have much larger sizes, such as 2 MB or 1 GB, depending on the system architecture and configuration. By mapping larger memory regions with fewer TLB entries, huge pages offer significant performance and efficiency advantages for memory-intensive applications [
22,
23].
The mechanism of huge pages starts with their integration into the virtual memory system. Operating systems allocate memory regions to huge pages by reserving contiguous blocks of physical memory. These regions are then mapped to virtual addresses through page table entries, significantly reducing the number of entries required for large datasets [
21]. For example, a 2 MB huge page replaces 512 standard 4 KB pages in the page table, reducing the frequency of page table walks and address translations.
Huge pages are particularly effective in minimizing Translation Lookaside Buffer (TLB) misses. The TLB is a hardware cache that stores recently used virtual-to-physical address mappings, and it has a limited number of entries. By using huge pages, a single TLB entry can map a much larger memory region. It reduces the likelihood of TLB misses, leading to an improved performance. This reduction in TLB pressure is especially advantageous for workloads with large memory footprints, such as databases, high-performance computing (HPC) applications, and virtualization [
24].
Another benefit of huge pages is an improved memory access performance. With fewer page table entries and reduced TLB misses, the latency associated with memory access is significantly decreased. This enhancement is critical for memory-intensive tasks that rely on rapid access to large datasets. Additionally, huge pages optimize cache utilization by enabling better spatial locality. Larger contiguous memory mappings align with prefetching and caching mechanisms, ensuring that data is fetched and utilized more efficiently [
25]. This spatial locality also leads to lower page fault rates.
However, huge pages are not without limitations. One significant drawback is the potential for increased memory fragmentation [
26]. Since huge pages require large contiguous memory blocks, their allocation can lead to physical memory fragmentation, making it harder for the operating system to find suitable free blocks for small-page allocations. This may reduce the memory allocation flexibility and efficiency for other processes, particularly those that rely on frequent or dynamic small memory allocations. Moreover, managing huge pages can be complex and may require administrative privileges to configure. In some cases, huge pages are “pinned”, meaning they cannot be swapped out, which can reduce the flexibility of memory management. Similarly, if the application does not have enough spatial locality to support huge pages, this could lead to significant thrashing, degrading the program’s performance.
Typical applications that leverage huge pages include databases like Oracle and PostgreSQL, which benefit from reduced TLB misses during operations on large datasets [
27]. High-performance computing workloads and virtualization systems also use huge pages to optimize memory access patterns and minimize latency. Similarly, large-scale machine learning and AI applications rely on huge pages to handle their substantial memory requirements efficiently [
21].
For example, on Linux systems, huge pages can be enabled and configured using the hugepages subsystem or libraries like libhugetlbfs [
23]. The standard page size of 4 KB can be replaced with 2 MB huge pages (default for x86) or even 1 GB pages, depending on the hardware support and system configuration. By enabling huge pages, developers and system administrators can unlock substantial performance improvements for memory-bound applications [
23].
Our baseline evaluation in
Section 4.2 shows that using huge pages reduced the average memory access latency, resulting in a 22% improvement. When combined with software prefetching, the memory latency decreased by 24%, indicating a synergistic effect from both techniques.
3.3. The Cache Architecture and Coherence Protocols: MESI
Modern x86 processors feature a hierarchical cache architecture consisting of L1, L2, and L3 caches. The L1 and L2 caches are fast and private to each CPU core and handle requests rapidly. The L3 cache, or the last-level cache (LLC), is shared among cores, slower, and larger, operating on fixed-size data blocks known as cache lines.
Memory access in this hierarchical architecture begins with the CPU checking the L1 data cache for the requested data. If the data is found (a cache hit), it is retrieved rapidly. If the data is not in the L1 cache (a cache miss), the search proceeds to the L2 cache and subsequently to the L3 cache if necessary. When the data is not available at any cache level, it is fetched from the main memory, incurring significant latency. This process highlights the critical role of the cache hierarchy in reducing memory access times and enhancing the overall system performance.
Many modern Intel processors use an extension of the MESI protocol, such as MESIF for an Intel(R) Core(TM) i5-6500 CPU. Cache coherence protocols like MESI (Modified, Exclusive, Shared, Invalid) are crucial for maintaining data consistency across caches in multi-core processors. This protocol helps to ensure that multiple cores can manage shared data without integrity or consistency issues by transitioning cache lines through various states based on access patterns and data ownership changes:
Modified (M): The cache line is present only in one core cache, has been modified (dirty), and is not in sync with the LLC.
Exclusive (E): The cache line is present only in one core cache, has not been modified, and is exclusive to that cache.
Shared (S): The cache line is present in multiple core caches but has not been modified, reflecting uniformity across caches.
Invalid (I): The cache line is not valid in any core cache.
This hierarchical architecture works in tandem with the MESI protocol to optimize both the performance and consistency, ensuring efficient data sharing and synchronization across multi-core systems.
3.4. Contention-Based and State-Based Cross-Core Cache Attacks
Contention-based attacks, also known as stateless attacks, involve passively observing the latency in accessing specific cache hardware components, such as the ring interconnect or L1 cache ports, to infer the victim’s activity.
State-based attacks, on the other hand, involve manipulating the state of cache lines or sets. In this type of attack, the attacker deliberately sets the cache to a particular state and allows the victim to operate, potentially altering this state [
2,
3]. The attacker then re-examines the cache to deduce the victim’s actions based on the changes in cache states. State-based attacks are also known as eviction-based or stateful attacks and are more prevalent in research and applications of cache-based side channels.
Our focus is on these stateful applications, particularly those that manipulate the cache states to infer data transmission or changes due to other processes’ activities.
3.5. Cache Coherence Covert Channels
Covert channels exploit these coherence protocols by manipulating the state of cache lines to create detectable timing variations that can encode and transmit information secretly:
1. State-Based Timing Differences: Access times vary significantly based on the state of the cache line. For instance, a line in the ‘modified’ state in one core’s cache being read by another core will result in a longer latency, as the line must be fetched from the owning core’s cache and updated in the LLC and the requesting core’s cache.
2. Prefetching and Coherence State Manipulation: Prefetch instructions (e.g., PREFETCHW) are used to deliberately alter the state of a cache line. This instruction can prefetch data into a cache and set it to ‘modified’, preparing it for faster subsequent write operations but also changing the coherence state detectably, which can be exploited in a covert channel to signal a ‘1’ or ‘0’ based on whether the prefetch operation took more time (indicating a state change) or less time (indicating no state change).
4. The Design of a Multi-Line Prefetch Covert Channel with Huge Pages
4.1. An Overview of the Multi-Line Prefetch Attack Implementation
The multi-line prefetch covert channel represents an advanced microarchitectural technique leveraging the timing behavior of the PREFETCHW instruction to establish covert channel communication. This enhanced implementation significantly extends the capabilities of the original attack [
1] by introducing multi-line encoding and decoding, enabling a higher bandwidth and more flexible communication compared to the original approach, which could only encode a single bit of information per iteration.
Our attack model involves two main participants, a sender and a receiver, both implemented as regular user-space (i.e., unprivileged) processes without special permissions, running on separate CPU cores of the same physical processor. These two processes collaborate to establish a covert channel via shared memory and cache coherence effects. The sender and the receiver can be launched on separate physical cores using tools such as taskset. Furthermore, these processes can share data, such as through shared libraries or page deduplication. This setup mirrors prior attacks, ensuring shared memory access while maintaining isolation between processes. Additionally, the sender and the receiver must agree on predefined channel protocols, including synchronization mechanisms, core allocation, data encoding, and error correction protocols. These agreements are critical for maintaining the consistency and accuracy of the covert channel.
When huge pages are enabled, the multi-line prefetch covert channel gains significant advantages, particularly in scenarios involving n cache lines. Huge pages reduce TLB misses by mapping larger memory regions with fewer entries, enabling the prefetcher to operate more efficiently. This optimization allows the sender to access multiple cache lines within the same page, reducing latency and improving throughput. The larger contiguous memory provided by huge pages enhances the precision of timing measurements, leading to better accuracy and reduced error rates. Furthermore, the combination of huge pages and multi-line prefetching ensures that more data can be encoded and decoded in fewer iterations, thereby increasing the bandwidth and stealth of the attack.
We outline below the key assumptions of our threat model that enable this covert channel:
The Shared Last-Level Cache (LLC): The sender and the receiver share the same LLC (e.g., reside on the same processor or within the same virtual machine), enabling them to observe coherence traffic.
Privilege Level and Isolation: In our primary setup, both the sender and the receiver are unprivileged user-space processes running on separate CPU cores. However, our threat model also supports scenarios where the sender operates within a secure execution environment—such as an AMD SEV-encrypted virtual machine—as long as the sender and the receiver share the same last-level cache (LLC). The shared LLC enables shared cache coherence events, which in turn enable the covert channel. A broader discussion of TEE platforms, including SGX and TrustZone, is provided in
Section 6.
Access to Huge Pages and Prefetch Instructions: Both parties are assumed to have access to huge pages (e.g., via mmap() with MAP_HUGETLB) and the ability to invoke prefetch instructions such as __builtin_prefetch(). These capabilities are available in modern Linux systems with the appropriate configuration.
4.2. Baseline Performance Comparison with Prefetching and Huge Pages
To establish a baseline for evaluating the performance impact of huge pages and software prefetching, we measure the average memory access latency over a 32 KB region (comprising 512 cache lines, each 64 bytes in size). As shown in Algorithm 1, we test four configurations: with and without huge pages and with and without software prefetching. The resulting latency measurements are summarized in
Table 1.
| Algorithm 1 Timing measurement per cache line |
- 1:
for all lines in memory buffer do - 2:
if prefetching enabled then - 3:
Prefetch(line) - 4:
end if - 5:
read_start_time ← ReadTime() - 6:
Read(line) - 7:
read_end_time ← ReadTime() - 8:
elapsed_time ← elapsed_time + read_end_time - read_start_time ▹Accumulate(elapsed_time) - 9:
end for
|
Prefetching Only: Applying software prefetching without huge pages results in a 12% latency reduction. The prefetch instruction (__builtin_prefetch()) helps bring the cache lines closer to the processor ahead of access, thereby reducing stalls.
Huge Pages Only: Enabling huge pages alone reduces the average access latency by approximately 14% compared to that at the baseline. This is primarily due to the reduced TLB pressure and improved memory translation efficiency provided by 2 MB page mappings.
Combined Optimization: The combination of huge pages and prefetching yields the lowest average latency (3.07 cycles). This configuration effectively leverages both a reduced TLB pressure from huge pages and improved cache readiness from prefetching, making it the most efficient strategy for minimizing the access latency in our setup.
4.3. Setup and Configuration
System Configuration: We utilize a local machine with an Intel(R) Core(TM) i5-6500 CPU operating at a maximum clock speed of 3.60 GHz with the Ubuntu 24.04 OS. The system supports prefetching and utilizing huge pages, enhancing the performance and memory management capabilities.
The Software Environment: We develop sender and receiver programs that operate on the same physical machine to eliminate external interference. The programs are implemented in C using compiler-supported prefetching instructions, such as __builtin_prefetch in GCC, to manipulate the cache states.
Huge Page Setup: To enhance the memory access patterns and overall performance, we configured the system to use 2 MB huge pages by enabling the Linux hugepages subsystem. This included resizing the shared file to 2 MB; updating the mmap system call with the MAP_HUGETLB flag to allocate memory backed by huge pages; and mounting the hugetlbfs filesystem to support these allocations.
4.4. Multi-Line Encoding for Flexible Communication
In this improved implementation, messages are encoded by selectively accessing n cache lines during each iteration, leading to -bit transmissions. Each accessed cache line’s contents do not matter. It is the count of accessed cache lines that encodes information and not the actual cache line contents. From a domain of 512 cache lines, if cache lines are accessed, the encoded value is m, leading to or 9-bit message transmission—in summary, the number of accessed lines is the message, rather than the contents of the cache lines. This coarser encoding leads to better noise tolerance. This multi-line encoding significantly increases the bandwidth compared to that under the binary encoding in traditional prefetch implementations. The count of accessed lines corresponds to a specific message, enhancing the flexibility of the encoding mechanism. For example,
Accessing one cache line encodes Message 1.
Accessing two cache lines encodes Message 2.
Accessing n cache lines encodes Message n.
4.5. The Fine-Grained Decoding Mechanism
The receiver measures the timing of PREFETCHW operations across all n cache lines and decodes the message by comparing the measured latencies to pre-calibrated thresholds. For example,
If the measured timing exceeds T1 but is less than T2, it corresponds to Message 1 (one cache line accessed).
If the timing exceeds T2 but is less than T3, it corresponds to Message 2 (two cache lines accessed).
This fine-grained decoding allows the receiver to infer multi-bit data, improving the efficiency and accuracy in covert communication.
4.6. The Workflow for Multi-Line Encoding and Decoding
The Sender Workflow:
Wait for the receiver: The sender waits for receiver_done_flag to ensure that the receiver has processed the previous iteration.
The sender encodes a value by accessing cache lines for . For example, to transmit the value 3, the sender accesses three cache lines. In order to amplify the signal further, for cache accesses, we access m buckets of cache lines instead, where each bucket consists of b cache lines. Hence, the total number of cache lines accessed to encode a value m is then . This also places another constraint that , which in our case is 512 lines. We experimented with bucket sizes , which yielded as the best choice for the accuracy.
Time operation: The sender uses rdtscp() for precise timing.
Signal completion: The sender updates receiver_done_flag to notify the receiver to start decoding.
The Receiver Workflow:
Wait for the sender: The receiver waits for receiver_done_flag which indicates that the sender has completed its encoding.
Decode the message: The receiver measures the timing of its PREFETCHW operations across all 512 L1 cache lines and decodes the message by comparing the measured timings against the calibrated thresholds (T1 to Tn). The timing differences are influenced by the cache coherence protocol and the state transitions of the cache lines. When the PREFETCHW instruction is executed, it modifies the state of the cache line to M (modified). The latency observed during this operation depends on whether the state of the cache line is M or S (shared):
If the sender has not accessed the cache line, it remains in the M state when the receiver prefetches again. In this scenario, the PREFETCHW operation does not cause any state change and completes quickly.
If the sender accessed the cache line, the state transitions to S. When the receiver prefetches the same cache line, the PREFETCHW operation needs to inform the LLC to invalidate the copy in the sender’s private cache and transition the state back to M. This additional step increases the latency.
For example, in one experiment, the receiver observed that the PREFETCHW operation took approximately 130 cycles when the state transitioned from S to M, as the LLC had to invalidate the sender’s copy of the cache line. In contrast, when the cache line remained in the M state, the PREFETCHW operation completed in around 70 cycles since no state change was required. These timing differences are exploited by the receiver to infer whether the sender accessed the cache line, enabling it to infer the number of sender-accessed cache lines, which, divided by the bucket size b, decodes the message accurately.
Store the decoded message: The receiver stores the decoded message for further processing or logging.
Signal readiness: The receiver sets receiver_done_flag to notify the sender to start the next iteration.
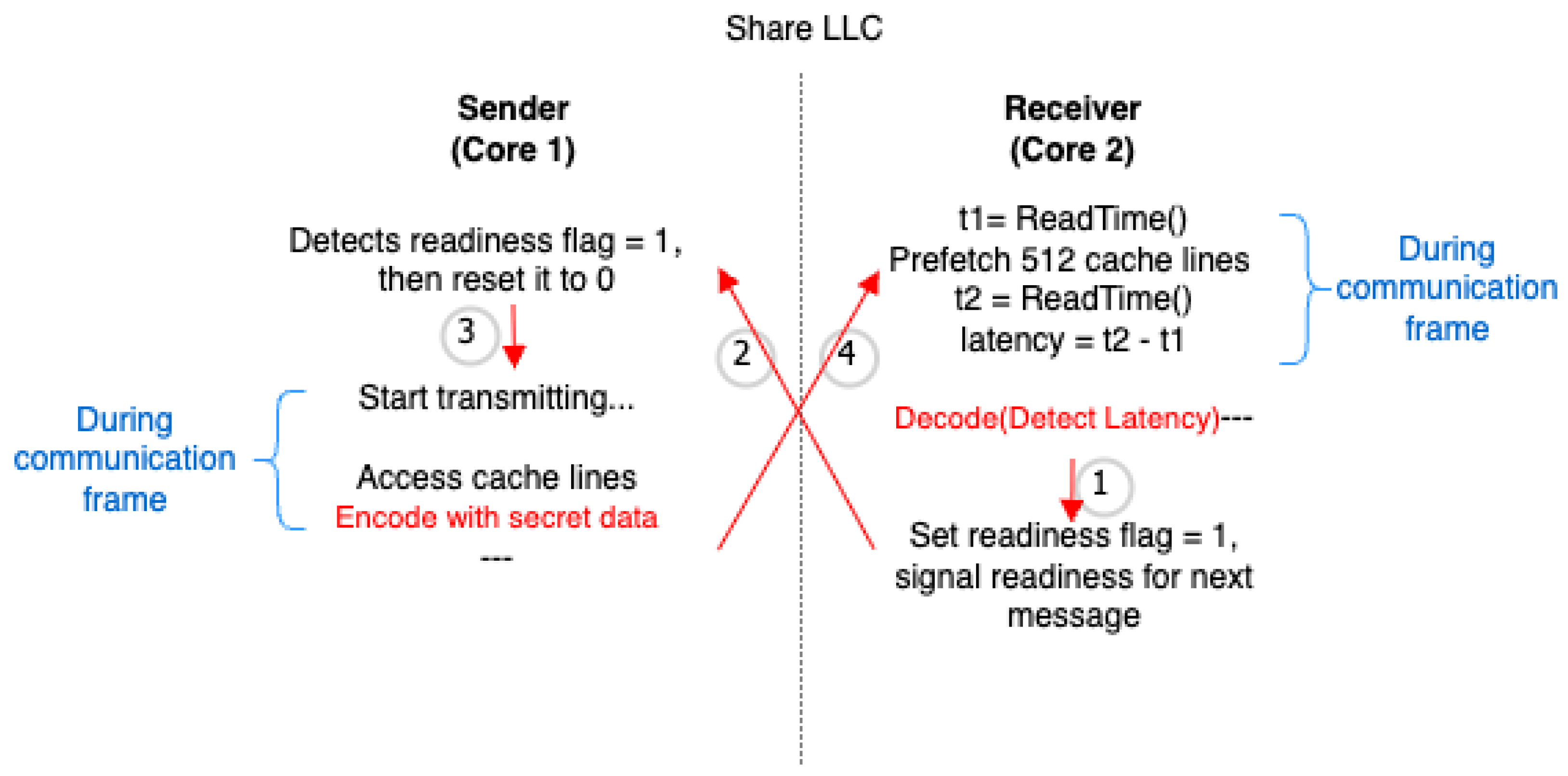
The protocol is shown in
Figure 1 and Algorithm 2. The sequence of interactions (Labeled Edges) is 1. The receiver sets receiver_done_flag = 1 after the initial prefetch measurement. 2. The sender detects that receiver_done_flag = 1 and resets it to 0. 3. The sender accesses memory lines (encoded with secret data) during config.interval. 4. The receiver prefetches memory lines and measures the timing (affected by the sender’s cache state). 5. The receiver sets receiver_done_flag = 1 to signal readiness for the next message.
| Algorithm 2 Covert channel communication via prefetch-based encoding |
- 1:
Shared Variables: volatile int receiver_done_flag = 0 ▹ Synchronization flag CACHE_BLOCK_SIZE = 64 ▹ L1 cache line is 64 bytes - 2:
procedureSender: running in core 1 - 3:
while *receiver_done_flag == 0 do - 4:
usleep(0.1) ▹ Poll with light sleep to reduce CPU usage - 5:
end while - 6:
*receiver_done_flag - 7:
start_t ← cc_sync() - 8:
lines_to_access ← secret_message * N ▹ N is bucket size - 9:
while rdtscp() −start_t<config.intervaldo▹ config.interval as a communication frame: within that frame, one message is sent. - 10:
for to lines_to_access− 1 do - 11:
Access memory at config.addr + i * CACHE_BLOCK_SIZE - 12:
end for - 13:
end while - 14:
end procedure - 15:
- 16:
procedureReceiver: running in core 2 - 17:
while *receiver_done_flag == 1 do - 18:
usleep(0.1) - 19:
end while - 20:
start_t ← cc_sync() - 21:
while rdtscp() −start_t< config.interval do - 22:
t1 ← rdtscp() - 23:
for to 511 do ▹ Prefetch all L1 cache lines - 24:
Prefetch memory at config.addr + j * CACHE_BLOCK_SIZE - 25:
end for - 26:
t2 ← rdtscp() - 27:
total_time - 28:
Decode message: - 29:
if total_time > T1 then - 30:
decoded_message ← 1 - 31:
else if total_time > T2 then - 32:
decoded_message ← 2 - 33:
⋮ - 34:
else - 35:
decoded_message ← n - 36:
end if - 37:
end while - 38:
receiver_done_flag ← 1 ▹ Allow sender to proceed - 39:
end procedure
|
An Alternative Encoding Approach:
In addition to the shared-memory read-only configuration, we explored a second encoding approach where both the sender and the receiver were granted write permissions to the shared memory. In this configuration, the receiver observes longer latencies during PREFETCHW operations due to state transitions from I (invalid) to M (modified), instead of the S to M transition in the read-only setup. This change occurs because the sender writes to the shared memory, transitioning cache lines to the I state from the receiver’s perspective. When the receiver executes PREFETCHW, the coherence protocol must perform additional operations to bring the line back into the M state, resulting in a higher timing overhead.
While this alternative provides a slightly higher decoding accuracy due to the more pronounced timing gap between accessed and unaccessed lines, it results in a lower throughput because of the increased latency in the decoding phase. Therefore, the choice between these two configurations—read-only versus writable shared memory—represents a trade-off between accuracy and the transmission speed.
4.7. Synchronization and Timing Optimizations
Lightweight Flag-Based Coordination:
The sender and the receiver synchronize using a shared memory flag (e.g., receiver_done_flag) to coordinate the encoding and decoding of each message. This approach avoids race conditions while minimizing busy waiting. To improve timing precision, both parties poll this flag while adaptively adjusting their polling intervals based on a locally maintained timestamp obtained via rdtscp(). This hybrid approach balances responsiveness and CPU efficiency, using short delays (e.g., usleep(0.1)) to avoid excessive spinning.
Limitations in Secure Environments:
In our current setting, both the sender and the receiver operate outside of secure enclaves, allowing for unrestricted access to high-resolution timers such as
rdtscp(). However, in trusted execution environments like Intel SGX and AMD SEV, access to precise timers is either restricted or unavailable. This makes
rdtscp-based synchronization infeasible for enclave-resident senders wishing to transmit sensitive data covertly. In these scenarios, we consider using
clock_gettime(CLOCK_MONOTONIC) as a viable alternative for cross-core timing measurement. It provides stable wall-clock timestamps and is accessible even in virtualized environments. We adopt this approach in our AMD SEV evaluation. Although
clock_gettime() has lower precision than that in hardware cycle counters, it avoids the issues associated with virtualized
rdtscp() and delivers consistent results. We also explored loop-based counters [
28,
29], which estimate the timing by counting instruction iterations; however, they are highly susceptible to noise from interrupts, context switches, and scheduling variability in multi-tenant or virtualized environments. These interrupts are asynchronous and unpredictable. This uncertainty in the location and timing of interrupts results in significant variance in the loop counter timing. These significant timing fluctuations over multiple runs make such methods unreliable for the precise latency discrimination required in covert channel decoding.
Semaphore-Based Alternatives and Trade-Offs:
In such restricted environments, semaphores or barriers provide viable alternatives for synchronization. These primitives block the receiver until signaled by the sender, thus avoiding the need for polling and enabling more efficient CPU usage. However, these mechanisms typically rely on atomic operations or memory fences, which introduce additional microarchitectural side effects such as cache line invalidation and memory ordering constraints. Such effects may interfere with the prefetch timing behavior and degrade the performance and accuracy of timing-based covert channels. As a result, while semaphores offer an enclave-compatible solution, their influence on the cache state must be carefully considered when designing prefetch-based transmission mechanisms.
5. Results
Throughput and Accuracy
To evaluate the efficiency of our multi-line encoding covert channel, we measured both the throughput and accuracy across different page sizes and encoding strategies. As shown in
Table 2, the read-only multi-line encoding achieved a throughput of approximately 4623 KB/s with 4 KB pages and up to 4940 KB/s with 2 MB huge pages, with an accuracy of up to 81.23%. The write-access encoding, which leveraged
PREFETCHW to induce transitions from the
I to
M state rather than
S to
M, demonstrated a slightly higher precision at 83.34%, although with a slightly lower throughput—4345 KB/s on 4 KB pages and 4828 KB/s with 2 MB huge pages.
Compared to the original single-line encoding approach from prior work [
1], which achieves a throughput of only 822 KB/s and transmits just a single bit per iteration, our multi-line encoding achieves up to a 4940 KB/s throughput and transmits 9 bits per iteration—representing a 6× increase in the bandwidth capacity. The original design cannot convey meaningful data efficiently due to its limited capacity. In contrast, our approach can encode and transmit 9 bits per iteration by accessing multiple cache lines, allowing for the efficient transmission of complex messages. Moreover, if greater decoding accuracy is desired, a bucket-based method can be employed: for example, transmitting message “1” by accessing 10 lines in one iteration, message “2” by accessing 20 lines, and so on. This technique trades throughput for enhanced resilience to noise and improved decoding reliability, offering flexibility between performance and accuracy.
While the reference paper [
1] achieved a reported accuracy of 96.2% using the single-line encoding scheme, our local reproduction under varying experimental conditions revealed a broader accuracy range of 60–80%. This divergence in the results suggests potential sensitivity to environmental factors not fully replicated in our setup. To uphold transparency and avoid overstating the outcomes, we have opted to omit the accuracy metrics for [
1]’s results from the table, as they may not reliably reflect the scheme’s performance in generalized scenarios.
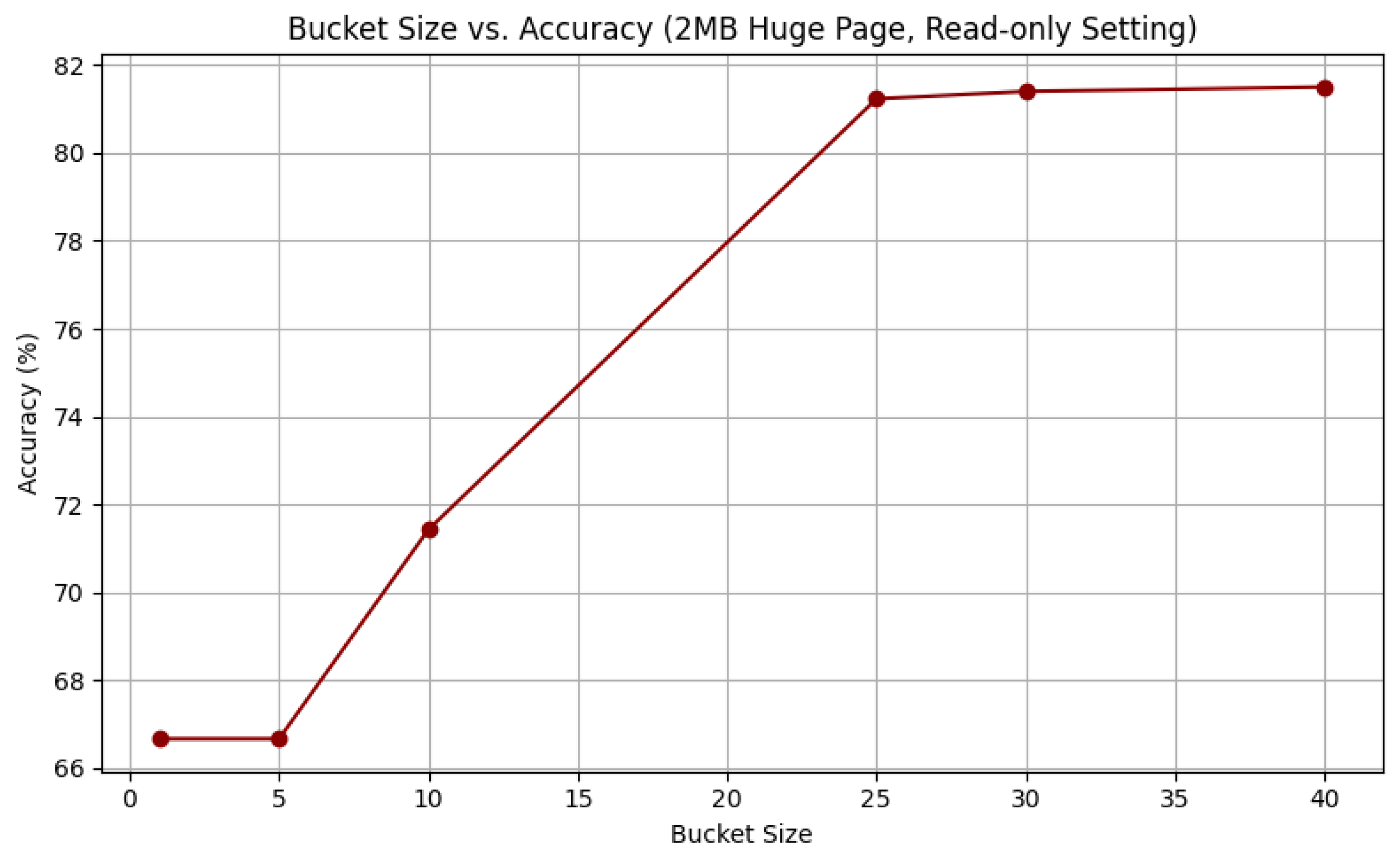
We further evaluated the influence of the bucket size on the decoding accuracy under the read-only 2 MB huge page setting. Our experiments show that as the bucket size increases, the accuracy improves up to a point and then plateaus. Specifically, with a bucket size of 1 or 5, the accuracy remains at 66.67%; increasing the bucket size to 10 improves the accuracy to 71.43%; and at a bucket size of 25, we achieve the peak accuracy of 81.23%. Further increases in the bucket size beyond 25 yield no significant improvements, with the accuracy remaining stable at 81.23%. A bucket size of
b introduces redundancy into the encoding. The timing of a coherence event is above or below a statistical threshold at the receiver to indicate an encoded 1 or 0. Many system-level aspects determine this statistical model—how many other processes are active and what else may engender an aliased coherence event, timer accuracy, or jitter, among many others. Once a certain level of redundancy resulting in a robust statistical threshold is reached, an additional bucket size
b does not overcome any additional noise, resulting in a saturated accuracy. This suggests that a moderate bucket size provides a good balance between throughput and accuracy.
Figure 2 illustrates the relationship between bucket size and accuracy.
A performance comparison of high-capacity encodings: We further explored the trade-off between accuracy and throughput when transmitting messages of different lengths and cache line counts. The experiments in this section were conducted in the 2 MB huge page read-only setting.
Table 3 compares two schemes: (1) transmitting 10-bit messages using 1024 cache lines in a single iteration and (2) transmitting 9-bit messages twice using 512 cache lines each time. The 10-bit scheme demonstrates a higher overall accuracy due to a lower bit error rate, while the 9+9-bit scheme provides a higher raw throughput but at the cost of an increased error probability, resulting in a reduced chance of correctly decoding all bits.
These results indicate that if robustness and successful full-message decoding are the priorities, the 10-bit scheme with more cache lines is preferable. However, when maximizing the bandwidth is critical and some errors are acceptable (or can be corrected), the 9+9-bit scheme may be beneficial.
To provide a more holistic evaluation of each encoding strategy, we introduce a composite metric that combines both the throughput and decoding accuracy to compute the effective bandwidth in KB/s. This metric estimates the number of correct bits transmitted per second, capturing the real-world utility of the covert channel under noisy conditions.
For each scheme, we compute
This reveals that while the 9+9-bit scheme achieves a higher raw throughput, its effective bandwidth (factoring in accuracy) also remains superior to that in the 10-bit scheme. However, the 10-bit scheme retains an advantage in scenarios requiring reliable single-round decoding (e.g., short-lived channels with no retransmission). The choice ultimately depends on whether the application prioritizes raw speed or guaranteed correctness.
The adoption of huge pages further enhanced the throughput and stability. Huge pages reduce TLB misses and maintain consistent memory access timing, benefiting both accuracy and stealth. Moreover, using varied numbers of cache line accesses per iteration increases the unpredictability of the access patterns, improving the stealth against side-channel detection mechanisms. Unlike traditional binary encoding, our method minimizes observable LLC misses and system-level anomalies, making it more resilient against detection through performance monitoring tools.
Overall, the multi-line encoding approach not only provides a higher throughput and accuracy but also expands the covert channel’s capacity for efficient, robust, and stealthy data exfiltration.
6. Trusted Execution Environment (TEE) Support and Feasibility
Trusted execution environments (TEEs) provide hardware-isolated contexts for secure code execution. In this section, we evaluate the feasibility of implementing our covert channel in various TEE platforms—Intel SGX, ARM TrustZone (with OP-TEE), and AMD SEV/SEV-SNP—with a focus on their support for huge pages and cache coherence behavior.
6.1. Intel SGX
Intel SGX provides secure enclaves using a dedicated region of physical memory known as the Enclave Page Cache (EPC), strictly limited to 4 KB pages. Huge page mapping into SGX enclaves is not supported due to SGX’s hardware-enforced memory protection model. Although enclaves lack access to high-resolution timing instructions such as rdtscp, this limitation does not affect our covert channel design since only the sender needs to reside in the enclave, while the timing measurements are made by the receiver outside the enclave in unprivileged space.
While speculative execution attacks like the Foreshadow [
30] setup include an “unmap trick” that transiently exposes non-EPC pages to speculative execution, if this transient access is sufficient to trigger cache coherence state transitions, it could theoretically enable a MESI-based side channel similar to ours, although in a limited or less reliable form.
6.2. ARM TrustZone with OP-TEE
The ARM architecture supports large page mappings via MMU configuration. However, OP-TEE, the commonly used secure-world OS, defaults to 4 KB pages. Configuring huge pages in OP-TEE requires kernel-level modification and system-level support.
More fundamentally, ARM’s prefetch instruction (PRFM) operates as a non-coherent cache hint. It does not trigger inter-core coherence traffic or cause cache state transitions that are visible across cores. As a result, issuing PRFM from one core does not influence the cache state of that memory line in another core’s private cache. This behavior contrasts with x86 prefetching instructions like PREFETCHW, which can induce cross-core coherence transitions (e.g., to the modified or owned states), making them observable via timing differences.
Because ARM prefetching does not generate observable coherence activity, it cannot be leveraged to modulate shared cache line states in a way detectable by a receiver on another core [
31]. Therefore, under the standard configurations, ARM TrustZone cannot support our cache-coherence-based covert channel design.
6.3. AMD SEV and SEV-SNP
AMD SEV and SEV-SNP extend x86 virtualization with full memory encryption and integrity protection while maintaining compatibility with native x86 memory and cache management. Crucially, SEV supports huge pages (e.g., 2 MB, 1 GB) transparently to the guest OS [
32]. This enables our covert channel design without requiring architectural modifications.
Furthermore, AMD’s MOESI coherence protocol enables PREFETCHW from one core to induce a modified (M) or owned (O) state in another core’s cache, a property exploited in our experiments. Using Google Cloud’s Confidential virtual machine (VM) instances, which feature SEV-enabled AMD EPYC CPUs, we demonstrate the practicality of our covert channel with both the sender and the receiver co-resident on a single VM, running on separate physical cores.
The availability of coherent prefetching, the high-resolution timers clock_gettime() or rdtscp(), and huge pages makes SEV the most suitable TEE for this attack.
6.4. Summary
In conclusion, AMD SEV provides the best balance of hardware features and virtualization transparency to evaluate the feasibility and impact of huge-page-aware prefetch-based covert channels in a real-world TEE deployment. Its support for native huge pages and x86 cache coherence behavior—including observable effects from instructions like PREFETCHW—makes it an ideal platform for exploring covert communication across cores within an encrypted VM.
We implement and evaluate our covert channel design on AMD SEV in the following section, demonstrating both the feasibility and performance characteristics in a realistic threat model setting.
7. AMD SEV Covert Channel Evaluation
To further evaluate our covert channel implementation in a real-world TEE scenario, we conducted experiments on AMD SEV VMs deployed on Google Cloud Confidential Compute instances. We focused on testing the multi-line encoding performance under varying sender access patterns (write or read) and memory configurations (with and without huge pages). Each test used 10 rounds per configuration.
Initially, we experimented with using the rdtscp() instruction to measure the latency, consistent with our approach on the local Intel machine. However, we observed that prefetching 512 cache lines on the AMD SEV VM took only ~4700 cycles, compared to ~49,000 cycles on a local Intel i5 processor—more than a 10× discrepancy. This large gap is not due to architectural performance differences but stems from virtualization: rdtscp() is emulated or virtualized in cloud environments like SEV VMs, yielding an inflated timing precision or inaccurate cycle counts.
As a result, we adopted clock_gettime(CLOCK_MONOTONIC) to ensure consistent and stable wall-clock timing. This syscall-based method returns the elapsed time since boot, measured in nanoseconds, and is unaffected by CPU frequency scaling or virtualized performance counters. Although this wall-clock-based method has a lower granularity than that of hardware cycle counters, it avoids the artifacts introduced by virtualized timestamp counters (TSCs). Interestingly, this approach reported even faster timing (e.g., ~920 ns for 512 cache lines prefetching), roughly 20× faster than Intel’s rdtscp-based measurements.
We considered alternate software-based timing techniques, such as loop-based counters or instruction delays, but these proved less reliable due to noisy scheduling, interrupts, and a lack of deterministic scaling under different system loads. Therefore, for our SEV evaluation, we selected clock_gettime() as the most consistent and portable option for cross-core timing measurements.
Latency measurements using
clock_gettime() were converted into CPU cycles based on a 2.45 GHz base frequency.
Table 4 summarizes the average receiver-side prefetch latency when the sender reads or writes 50 lines in each configuration. When huge pages are enabled, the memory page size is 2 MB; otherwise, the system defaults to the standard 4 KB page size.
As shown in the table, the latency measurements on the AMD SEV VM (e.g., 920.9–1063.9 ns or ~2256.2–2606.5 cycles) were much lower than those on our local Intel testbed (~50,000 cycles). This discrepancy can be attributed to time counter virtualization in cloud VMs. While less precise in absolute terms, this timing still preserved the relative trends: increasing the number of lines accessed increased the receiver latency, and huge page usage consistently reduced the timing overhead.
We observed that write-access encoding yields significantly clearer timing distinctions in AMD’s MOESI coherence model due to the state transitions to the modified (M) state. Conversely, sender reads do not result in detectable cache state transitions on AMD—since prefetching transitions to the owned (O) state, not modified (M)—leading to no observable timing difference.
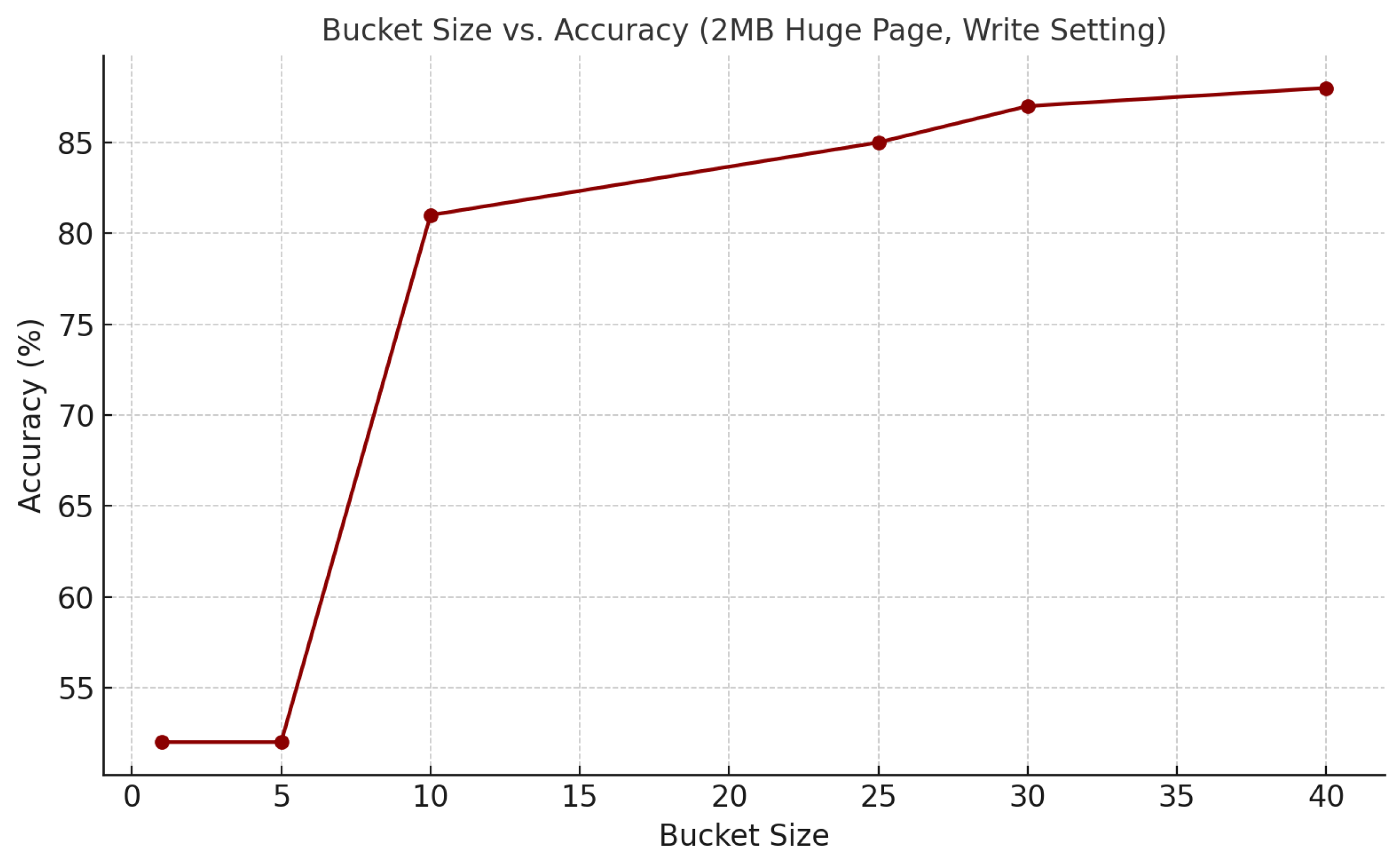
We studied the decoding accuracy further, as we did before for the Intel local machine, using bucket sizes of 5, 10, 25, 30, and 40 lines with sender write access on an AMD SEV VM.
Figure 3 shows that the decoding accuracy improves with an increasing bucket size, up to 88.03% for a size of 40 lines.
These results show that AMD SEV-SNP platforms can practically support our covert channel, especially under configurations where the sender writes to shared memory and the receiver executes prefetch operations. This affirms the importance of cache state transitions and coherence protocol behaviors in covert channel construction across TEE platforms. Our findings suggest that future attacks could focus on triggering write-induced coherence transitions or explore alternative microarchitectural features that amplify side-channel observability.
8. Discussion
Our evaluation demonstrates that the proposed multi-line prefetch-based covert channel significantly outperforms previous single-line encoding schemes in its throughput. However, several avenues remain for further enhancements of the channels’ reliability, robustness, and stealthiness.
Accuracy Optimization:
While our current implementation achieves an up to 83.34% decoding accuracy with write-access encoding and 81.23% with read-only encoding, the accuracy could be improved further through several techniques. First, tuning the synchronization intervals between the sender and the receiver could mitigate the timing drift and system noise that degrade the decoding precision. Second, our current use of a bucket-based message encoding strategy—where each message corresponds to a specific number of accessed cache lines—already improves the robustness by reducing the decoding ambiguity. Increasing the bucket size further (i.e., using larger groups of cache line accesses per message) can improve the accuracy, especially under noisy conditions, at the expense of a reduced throughput.
Research on AMD SEV:
We also evaluated the decoding accuracy on AMD SEV VMs with 2 MB huge pages under write-access encoding. The results demonstrate a consistent increase in accuracy with larger bucket sizes, reaching up to 88.03%. This confirms the effectiveness of the bucket-based strategy in virtualized TEEs. Write access causes observable coherence-induced latency changes, allowing for higher reliability in detection even under cloud-based timing variability.
Future research on AMD SEV platforms could explore dynamic channel adaptation strategies to maintain the decoding accuracy under varying system loads and noise conditions. For instance, runtime adjustment of the bucket sizes or synchronization intervals could improve the robustness in multi-tenant cloud environments. Additionally, as SEV-SNP introduces stricter integrity protections and memory access controls, it would be valuable to evaluate whether covert channels based on cache coherence events remain practical under these constraints. Investigating the interaction between SEV’s memory encryption and microarchitectural behaviors—such as cache sharing and prefetch activity—could offer deeper insights into the resilience or detectability of such attacks in evolving confidential computing infrastructures.
Machine-Learning-Based Decoding: Integrating a lightweight machine learning model for classification of the timing traces could enhance the decoding accuracy further, especially in noisy or unpredictable environments. By training the model on the observed timing patterns associated with different line access counts or cache states, the receiver can distinguish between valid message values and false positives caused by system activity or cache noise better [
33,
34,
35,
36].
Expanding Coherence Exploits:
Our current design focuses on leveraging the MESI cache coherence protocol, primarily through read and write operations that trigger transitions from the shared (S) state to the modified (M) state, as well as from the invalid (I) state to the modified (M) state. Future work could investigate a broader range of MESI state transitions, including the exclusive (E) state, which may display distinct timing characteristics or variations in the coherence traffic patterns. These additional behaviors could potentially enhance the bandwidth of the covert channel, the improve stealth by reducing observable system events, and offer greater flexibility in encoding strategies.
Cross-Platform Considerations:
While our implementation and evaluation focus on Linux due to its flexible support for huge pages, prefetch instructions (e.g., __builtin_prefetch()), and high-resolution timing via rdtscp or clock_gettime(), it is important to briefly consider other major operating systems. On Windows, large pages can be enabled using the VirtualAlloc() API with specific flags, and although user-space access to precise timing sources is more restricted, covert channels leveraging shared caches have still been demonstrated in prior work. On macOS, the situation is more constrained: strict sandboxing, limited access to low-level timing mechanisms, and Apple Silicon’s distinct memory and cache architecture pose challenges for direct translation of our method. Nonetheless, the fundamental principles of cross-core coherence and timing-based side channels remain relevant, and future work may explore adaptations of this channel to Windows or macOS with the appropriate privilege levels and architectural adjustments.
9. Conclusions
In this work, we present a high-throughput, cache-based covert channel leveraging multi-line encoding strategies and the MESI cache coherence protocol. By encoding messages across multiple cache lines per iteration and utilizing both read-only and write-access patterns, our approach significantly improves upon the prior single-line encoding techniques. Notably, our implementation achieves an up to 4940 KB/s throughput with 2 MB huge pages and attains decoding accuracies of 81.23% (read-only) and 83.34% (write-based), outperforming prior single-line Prefetch+Prefetch attacks that are limited to 822 KB/s and binary messages.
We extended our implementation of the multi-line covert channel to AMD SEV VMs to assess the feasibility in a TEE with hardware support for memory encryption and huge pages. Our results show that write-based encoding yields clear timing variations, enabling accurate decoding even in virtualized environments. Using huge pages provides further latency reductions and improved timing consistency, enhancing both the throughput and stealth.
Despite the timing imprecision in virtualized environments, overall trends such as a rising latency with a larger bucket size remain observable, confirming our scheme’s practicality. Our AMD implementation showed up to an 88.03% accuracy with a bucket size of 40-line writes and demonstrated that write encoding outperforms read encoding due to MOESI-induced state changes.
We demonstrate that huge pages enhance the channel stability and performance, and our encoding method supports richer message transmissions—up to 9 bits per iteration—while retaining low detectability. Furthermore, we explore the trade-offs between throughput and accuracy using a bucket-based encoding method, and we identify tuning opportunities such as synchronization timing and bucket size adjustment.
Future directions include applying machine learning models to improving the decoding robustness, experimenting with other cache state transitions (e.g., E to M, I to E), and evaluating more sophisticated cache activities such as atomic operations or flushes. These extensions could increase the stealth, bandwidth, and adaptability of covert communication in shared-memory systems further.





{kind=link}
{kind=link}
{kind=link}