

BPAP: FPGA Design of a RISC-like Processor for Elliptic Curve Cryptography Using Task-Level Parallel Programming in High-Level Synthesis


Abstract
1. Introduction
- We implement and show how High-Level Synthesis and the task-level parallel programming paradigm can be used to design a microprocessor-like unit capable of performing point addition and point doubling
- We present our novel architecture where the processor can execute each instruction in the point addition/doubling formula for an entire batch of points in order to efficiently time-share the resources
- As our point arithmetic processor is completely implemented in HLS C++ and its design is modular, it can be easily templated and customized to support different other elliptic curves, field sizes, and point operations formulas
- We present a point multiplication scheduler unit capable of processing batches of multiple points, and overlapping multiple batches concurrently between the point addition and point doubling units
- We detail how the out-of-the-box libraries of Vitis HLS, such as hls::task, hls::stream, and hls::stream_of_blocks can be used to efficiently implement the point addition and point multiplication designs
2. Background
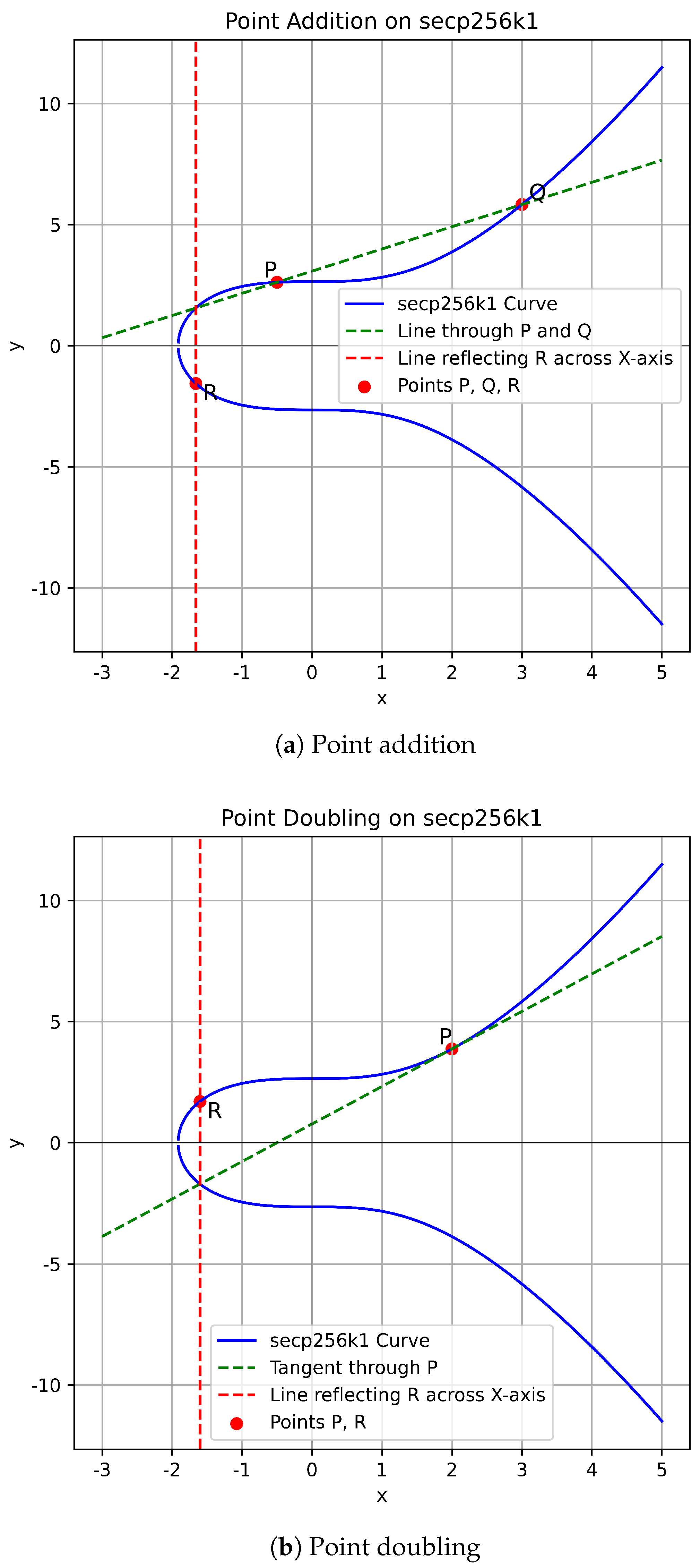
2.1. ECC and Point Operations
- Select two distinct points P and Q on the elliptic curve.
- Draw a straight line passing through P and Q.
- Identify the third point of intersection with the elliptic curve, denoted as R.
- Reflect R across the x-axis to obtain the result P + Q.
- Select a point P on the elliptic curve.
- Draw the tangent line at point P.
- Identify the second point of intersection with the elliptic curve, denoted as R.
- Reflect R across the x-axis to obtain the result 2P.
| Algorithm 1 Double-and-add for point multiplication | |
| Input: Point P, scalar s in binary form with m bits Let be a point at infinity for to 0 do | |
| ▹ Point doubling | |
| if then | |
| ▹ Point addition | |
| end if end for Return R | |
2.2. FPGAs and High-Level Synthesis
3. Related Work
4. HLS Abstract Parallel Programming
| Listing 1. Code example of using the hls::task library with Vitis HLS. |
void funcA(hls::stream<int>&in, hls::stream<int> &out1, hls::stream<int> &out2) {
int data = in.read();
if(data%2){
out1.write(data+1);
out2.write(data+2);
}else{
out1.write(data+2);
out2.write(data+1);
}
}
void funcB(hls::stream<int> &in, hls::stream<int> &out) {
out.write(in.read() >> 1);
}
void funcC(hls::stream<int> &in, hls::stream<int> &out) {
out.write(in.read() << 1);
}
void funcD(hls::stream<int> &in1, hls::stream<int> &in2, hls::stream<int> &out) {
out.write(in1.read() + in2.read());
}
void top(hls::stream<int> &in, hls::stream<int> &out) {
hls_thread_local hls::stream<int> s1;
hls_thread_local hls::stream<int> s2;
hls_thread_local hls::stream<int> s3;
hls_thread_local hls::stream<int> s4;
hls_thread_local hls::task t1(funcA,in,s1,s2);
hls_thread_local hls::task t2(funcB,s1,s3);
hls_thread_local hls::task t3(funcC,s2,s4);
hls_thread_local hls::task t4(funcD,s3,s4,out);
}
|
| Listing 2. Code example of using the hls::stream_of_blocks library with Vitis HLS. |
typedef int buf[N];
void producer (hls::stream_of_blocks<buf> &s) {
for (int i = 0; i < M; i++) {
// Allocation of hls::write\_lock acquires the block for the producer
hls::write_lock<buf> b(s);
for (int j = 0; j < N; j++)
s[j] = ...;
// Deallocation of hls::write\_lock releases the block for the consumer
}
}
void consumer(hls::stream_of_blocks<buf> &s) {
for (int i = 0; i < M; i++) {
// Allocation of hls::read\_lock acquires the block for the consumer
hls::read_lock<buf> b(s);
for (int j = 0; j < N; j++)
int t = s[j];
// Deallocation of hls::read\_lock releases the block for the producer
}
}
void top(...) {
hls::stream_of_blocks<buf> s;
producer(s);
consumer(s);
}
|
5. Design of Point Processing Units
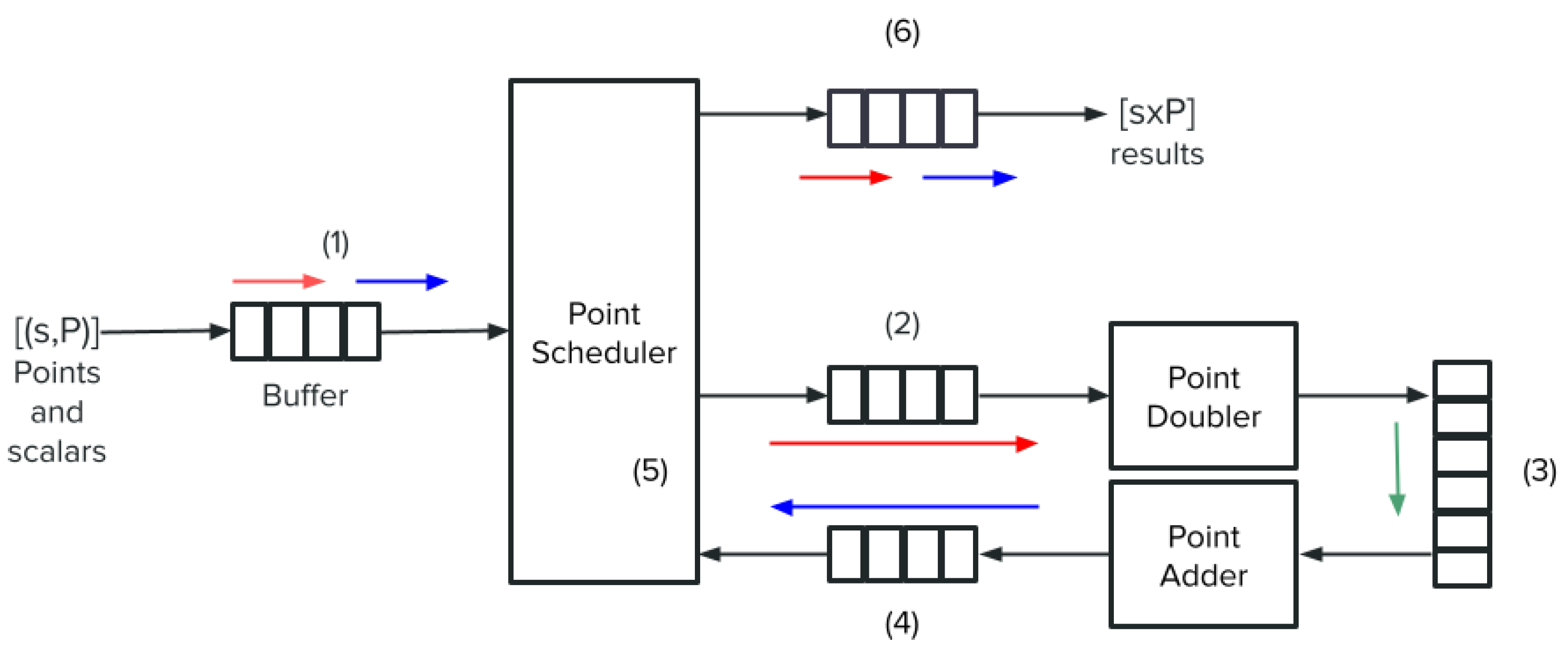
5.1. Point Multiplication Scheduler
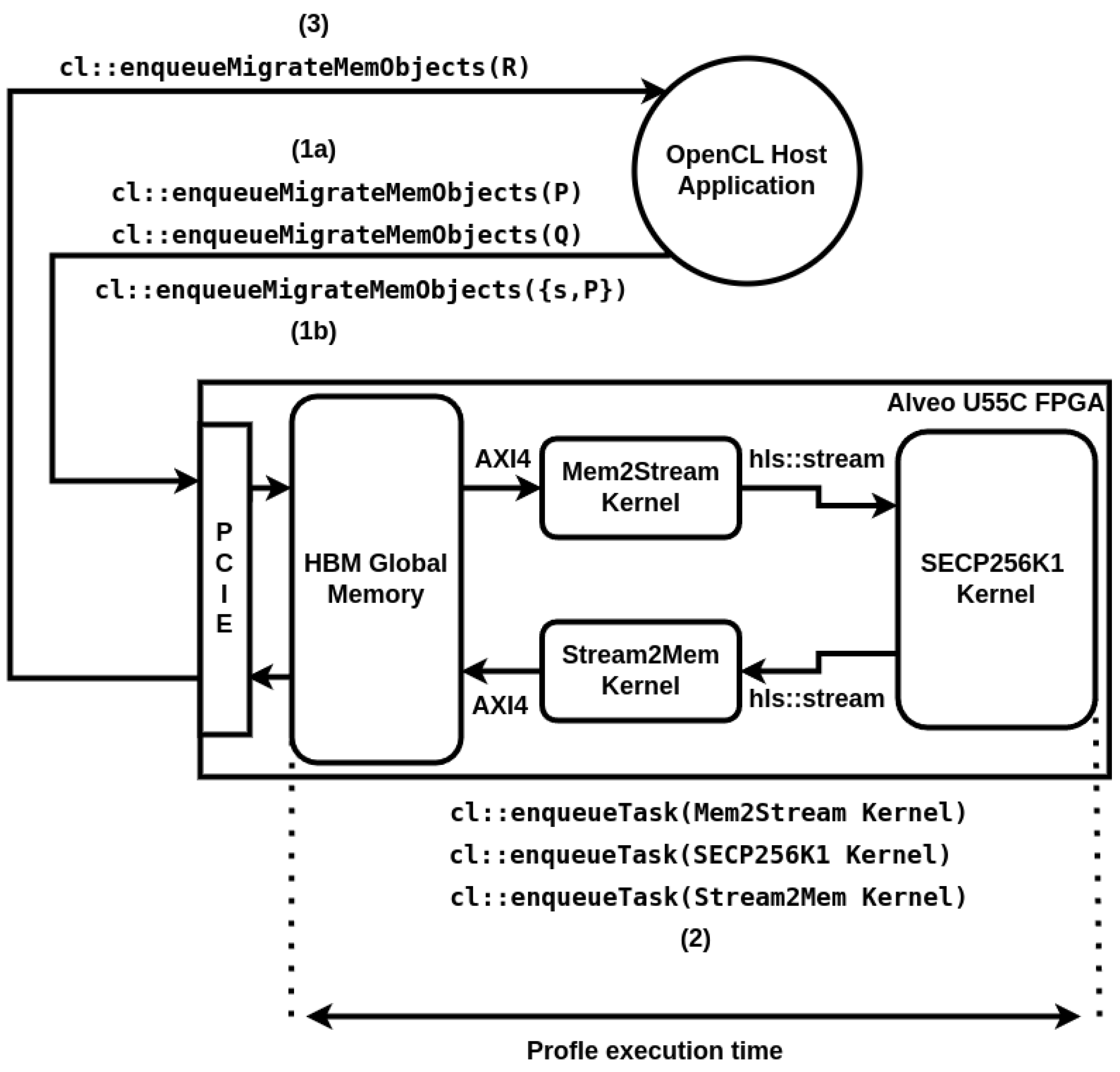
- (1)
- When ready, the point scheduler will read two batches of N pairs of points and scalars, where N can be 8/16/32/64. The points are read in their affine form, so one pair will have a total of 768 bits: two 256-bit coordinates and one 256-bit scalar. As we want to conserve resources, we use a single 256-bit hls::stream interface for streaming each pair.
- (2)
- When the point double unit is ready, the point scheduler sends the first batch to it through two 256-bit hls::stream interfaces. One interface is used to stream the original pairs inside the batch, as we need the unmodified points P for the point addition operation, and we also need the current value of the scalar s. The second interface streams the intermediate point R, which will become our result. This point is also streamed as a pair of three 256-bit values, which represent the three coordinates in the Jacobian system. In the first iteration of the double-and-add algorithm, R is streamed with initial values for all points in a batch. The unit doubles R at each encounter.
- (3)
- When the point doubler finishes the first batch of points, and the point adder unit is/becomes free, it streams through two 256-bit hls::stream interfaces as well the and R pairs of 256-bit values. The point adder will use both R and P values to update R, but only based on the most significant bit of the scalar s, in which case it should be ‘1’. Otherwise, for an MSB of ‘0’, R is not modified. In the meantime, when the point doubler finishes sending the first batch of points to the point adder, it can start reading and processing the second batch from the point scheduler.
- (4)
- Once the point adder finishes the first batch, it forwards it back to the point scheduler unit, similar to the point doubler, using two hls::stream interfaces: one for the pair and one for point R. As mentioned before, point R is updated only if MSB of s is ‘1’; otherwise, R is streamed with the same values it comes with. For the pair, point P is not modified, but scalar s is shifted to the left by one bit so that at the next encounter, the point adder can check the next MSB. This is applied to all scalars in a batch. Similarly to point doubler, once the first batch si dispatched, the point adder is ready to receive the second batch from point doubler immediately.
- (5)
- The point scheduler waits for the first batch to come back, and as soon as data are available on the hls::stream interfaces connected to point adder, it forwards the batch of pairs immediately to the interfaces connected to point doubler, which in turn can start reading them when it becomes free. Once the first batch is dispatched, it proceeds similarly with the second batch and keeps it until point doubler can take it. The point scheduler has an internal counter, which is incremented after both batches are dispatched to the point doubler. This process of cycling the two batches through the two point arithmetic units is repeated 255 times, as described in Algorithm 1 (excluding the initial cycle in which R starts with initial values).
- (6)
- After the internal counter of the point scheduler reaches the 256 iterations, the point scheduler will forward the two batches, one by one, through the output interface, which is a single 256-bit hls::stream interface that will stream the result point R with its three 256-bit coordinates in the Jacobian system. The point scheduler dispatches the first batch as soon as it is available on the interface connected to the point adder, and afterward, it proceeds similarly once the second batch is also available. After dispatching the last batch, it immediately forwards a new pair of batches, if available, repeating the entire flow starting from point (1).
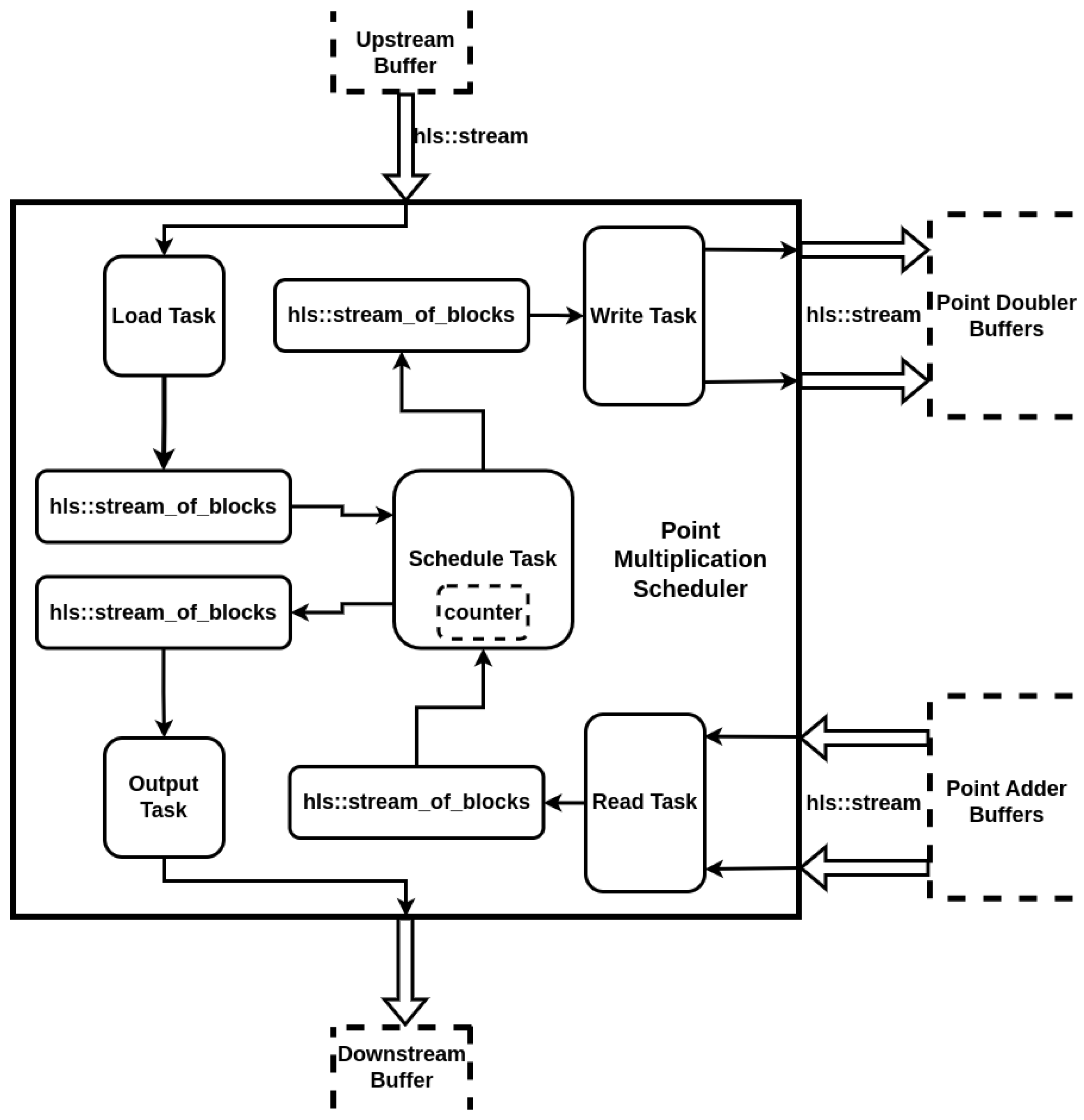
- With the Schedule and Write Task either free or occupied dispatching blocks of data, the Read Task will see data available on its interface from the point adder, so it can acquire a lock first on its channel with the Schedule Task as the Schedule Task is either free or busy sending blocks of data on its other channel connected to the Write Task
- When the Schedule Task is free, it will be able to acquire a read lock on the channel connected to the Read Task only when the Read Task finishes an iteration out of (we have two batches that need to be read) of writing. While the Read Task reads the next block of data, it has to release the write lock of the channel, meaning that the Schedule Task can now acquire it and read the block of data.
- As the Schedule Task finishes reading a block of data, it will release the channel connected to the Read Task and acquire the channel connected to the Write task to dispatch the fresh block of data. This allows now the Read Task to write lock the channel again to push the next block of data.
- After the Schedule Task finishes pushing its current block of data to the channel connected to the Write Task, it has to release it in order to return to the channel connected to the Read Task to get a new block of data. This means that the Write Task can now read lock the channel and read the block of data in order to push it to its stream interface connected to the point double buffers.
- As the Write Task finishes reading a block of data, it has to release it as well in a move to push it to the stream interface, meaning that the Schedule Task can write lock it again in order to push a new block of data.
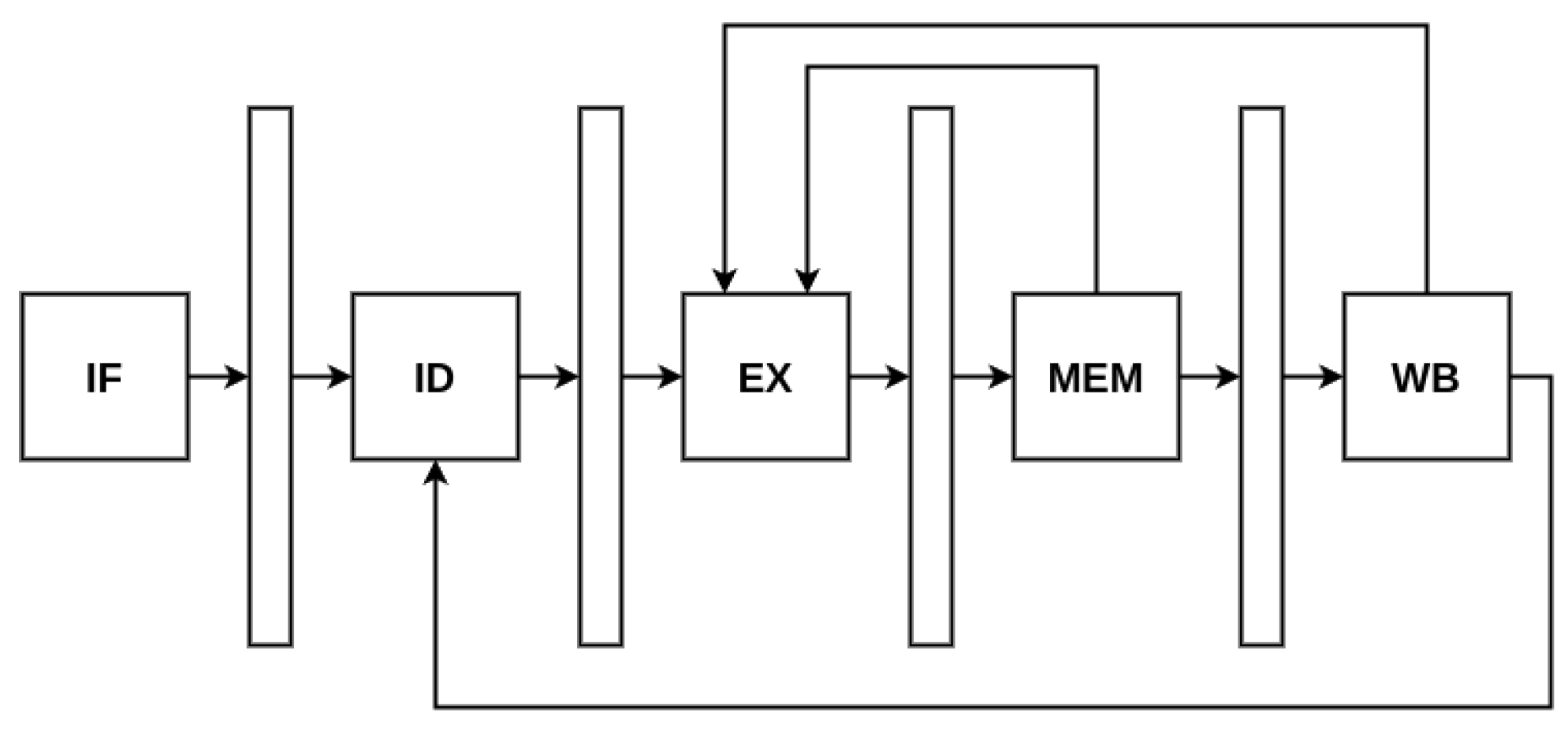
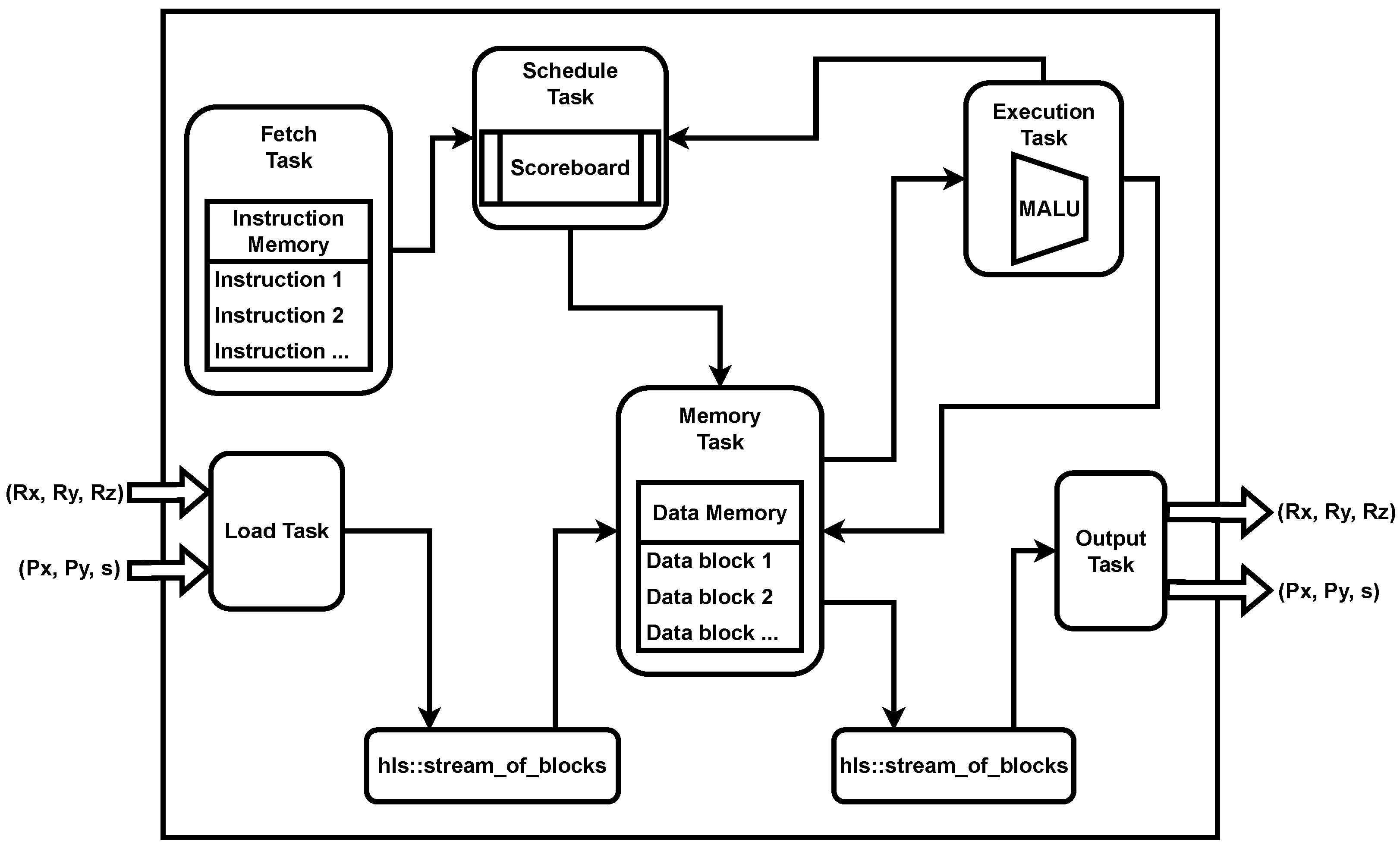
5.2. Point Arithmetic Processor
- Read any new results being completed from the Execution Task and update the scoreboard accordingly (mark the result address as being free)
- If there is an instruction being stalled, verify the updated scoreboard and see if it can be released (in which case we mark the result address as being busy until we obtain its result), otherwise return and wait for the Execution Task
- If no instruction has been blocked, then read the new instruction coming from the Fetch Task and verify if it can be released immediately based on the scoreboard or needs to be stalled. If it can be released, then we will mark its result address as busy.
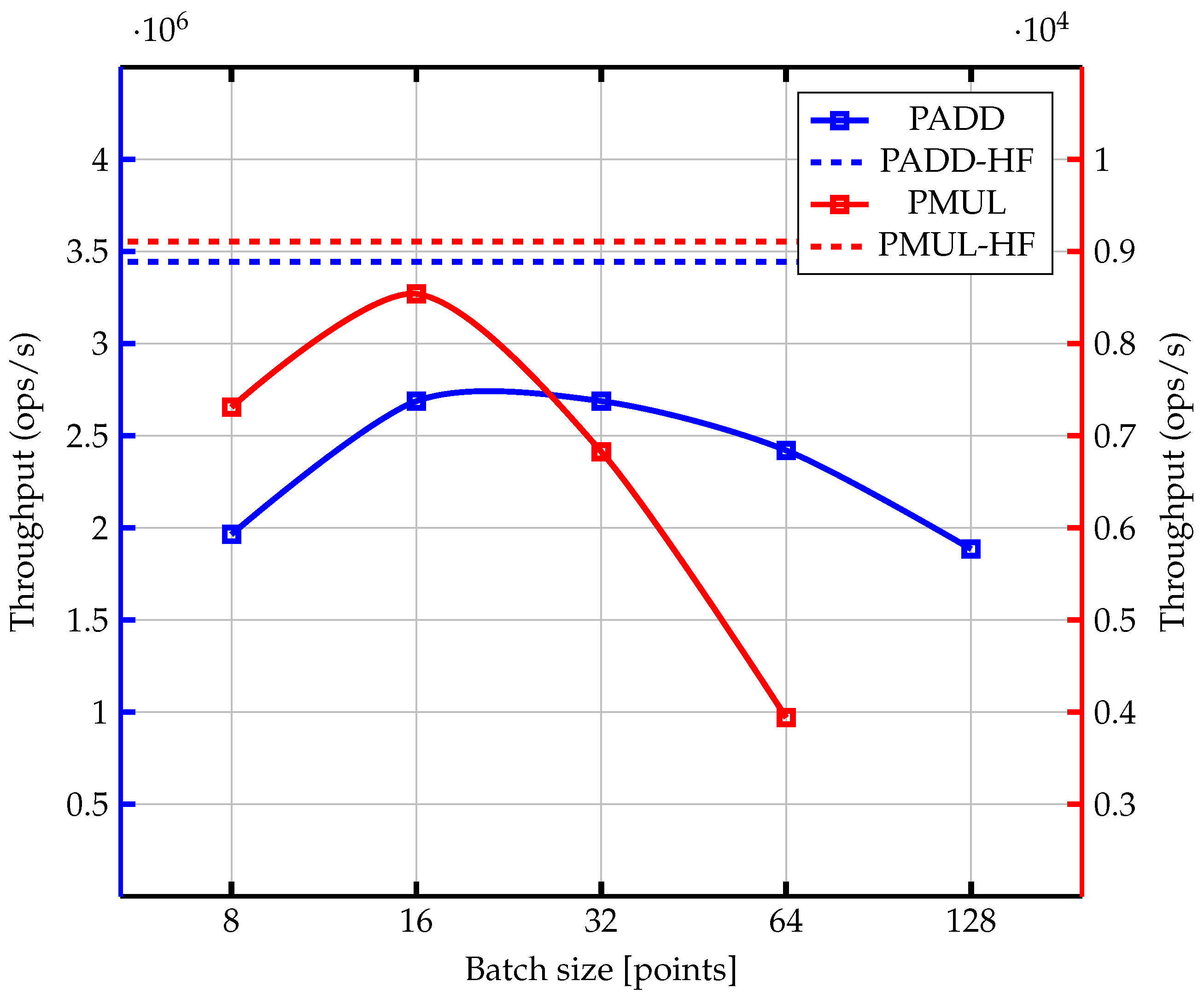
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, J. Digital signature and hash algorithms used in Bitcoin and Ethereum. In Proceedings of the Third International Conference on Machine Learning and Computer Application (ICMLCA 2022), Shenyang, China, 16–18 December 2022; SPIE: St Bellingham, WA, USA, 2023. [Google Scholar]
- Šimunić, S.; Bernaca, D.; Lenac, K. Verifiable computing applications in blockchain. IEEE Access 2021, 9, 156729–156745. [Google Scholar] [CrossRef]
- Ferraiolo, H.; Regenscheid, A. Cryptographic Algorithms and Key Sizes for Personal Identity Verification; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2023. [Google Scholar]
- Alshahrani, H.; Islam, N.; Syed, D.; Sulaiman, A.; Al Reshan, M.S.; Rajab, K.; Shaikh, A.; Shuja-Uddin, J.; Soomro, A. Sustainability in Blockchain: A Systematic Literature Review on Scalability and Power Consumption Issues. Energies 2023, 16, 1510. [Google Scholar] [CrossRef]
- Pote, S.; Sule, V.; Lande, B. Arithmetic of Koblitz Curve Secp256k1 Used in Bitcoin Cryptocurrency Based on One Variable Polynomial Division. In Proceedings of the 2nd International Conference on Advances in Science & Technology (ICAST), Bahir Dar, Ethiopia, 2–4 August 2019. [Google Scholar]
- Ifrim, R.; Loghin, D.; Popescu, D. Baldur: A Hybrid Blockchain Database with FPGA or GPU Acceleration. In Proceedings of the 1st Workshop on Verifiable Database Systems, Seattle, WA, USA, 23 June 2023. [Google Scholar] [CrossRef]
- Kapoor, V.; Abraham, V.S.; Singh, R. Elliptic curve cryptography. ACM Ubiquity 2008, 9, 1–8. [Google Scholar] [CrossRef]
- Hankerson, D.; Menezes, A.J.; Vanstone, S. Guide to Elliptic Curve Cryptography; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Bitcoin. Secp256k1. 2018. Available online: https://archive.ph/uBDlQ (accessed on 20 February 2025).
- Sun, X.; Yu, F.R.; Zhang, P.; Sun, Z.; Xie, W.; Peng, X. A survey on zero-knowledge proof in blockchain. IEEE Netw. 2021, 35, 198–205. [Google Scholar] [CrossRef]
- Johnson, D.; Menezes, A.; Vanstone, S. The elliptic curve digital signature algorithm (ECDSA). Int. J. Inf. Secur. 2001, 1, 36–63. [Google Scholar] [CrossRef]
- Bos, J.W. Constant time modular inversion. J. Cryptogr. Eng. 2014, 4, 275–281. [Google Scholar] [CrossRef]
- Setiadi, I.; Kistijantoro, A.I.; Miyaji, A. Elliptic curve cryptography: Algorithms and implementation analysis over coordinate systems. In Proceedings of the 2015 2nd International Conference on Advanced Informatics: Concepts, Theory and Applications (ICAICTA), Chonburi, Thailand, 19–22 August 2015. [Google Scholar] [CrossRef]
- Trimberger, S.M.S. Three Ages of FPGAs: A Retrospective on the First Thirty Years of FPGA Technology: This Paper Reflects on How Moore’s Law Has Driven the Design of FPGAs Through Three Epochs: The Age of Invention, the Age of Expansion, and the Age of Accumulation. IEEE Solid-State Circuits Mag. 2018, 10, 16–29. [Google Scholar] [CrossRef]
- Nane, R.; Sima, V.M.; Pilato, C.; Choi, J.; Fort, B.; Canis, A.; Chen, Y.T.; Hsiao, H.; Brown, S.; Ferrandi, F.; et al. A survey and evaluation of FPGA high-level synthesis tools. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2015, 35, 1591–1604. [Google Scholar] [CrossRef]
- Cong, J.; Lau, J.; Liu, G.; Neuendorffer, S.; Pan, P.; Vissers, K.; Zhang, Z. FPGA HLS Today: Successes, Challenges, and Opportunities. ACM Trans. Reconfigurable Technol. Syst. 2022, 15, 51. [Google Scholar] [CrossRef]
- Dzurenda, P.; Ricci, S.; Hajny, J.; Malina, L. Performance Analysis and Comparison of Different Elliptic Curves on Smart Cards. In Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST), Calgary, AB, Canada, 28–30 August 2017. [Google Scholar] [CrossRef]
- Awaludin, A.M.; Larasati, H.T.; Kim, H. High-speed and unified ECC processor for generic Weierstrass curves over GF(p) on FPGA. Sensors 2021, 21, 1451. [Google Scholar] [CrossRef]
- Agrawal, R.; Yang, J.; Javaid, H. Efficient FPGA-based ECDSA Verification Engine for Permissioned Blockchains. In Proceedings of the 2022 IEEE 33rd International Conference on Application-specific Systems, Architectures and Processors (ASAP), Gothenburg, Sweden, 12–14 July 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Mehrabi, M.A.; Doche, C.; Jolfaei, A. Elliptic curve cryptography point multiplication core for hardware security module. IEEE Trans. Comput. 2020, 69, 1707–1718. [Google Scholar] [CrossRef]
- Huynh, H.T.; Dang, T.P.; Hoang, T.T.; Pham, C.K.; Tran, T.K. An Efficient Cryptographic Accelerators for IoT System Based on Elliptic Curve Digital Signature. In Proceedings of the International Conference on Intelligent Systems and Data Science, Can Tho, Vietnam, 11–12 November 2023; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Tran, T.K.; Dang, T.P.; Hoang, T.T.; Pham, C.K.; Huynh, H.T. Optimizing ECC Implementations Based on SoC-FPGA with Hardware Scheduling and Full Pipeline Multiplier for IoT Platforms. In Proceedings of the International Conference on Intelligence of Things, Ho Chi Minh City, Vietnam, 25–27 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 299–309. [Google Scholar]
- AMD-Xilinx. Vitis Accelerated Libraries. 2023. Available online: https://github.com/Xilinx/Vitis_Libraries (accessed on 20 February 2025).
- Waterman, A.; Lee, Y.; Patterson, D.A.; Asanović, K. The RISC-V Compressed Instruction Set Manual, Version 1.7. EECS Department, University of California, Berkeley, UCB/EECS-2015-157. 2015. Available online: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2015/EECS-2015-209.pdf (accessed on 20 February 2025).
- Eyupoglu, C. Performance analysis of karatsuba multiplication algorithm for different bit lengths. Procedia-Soc. Behav. Sci. 2015, 195, 1860–1864. [Google Scholar] [CrossRef]
- Boutros, A.; Eldafrawy, M.; Yazdanshenas, S.; Betz, V. Math Doesn’t Have to be Hard: Logic Block Architectures to Enhance Low-Precision Multiply-Accumulate on FPGAs. In Proceedings of the FPGA’19: The 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; pp. 94–103. [Google Scholar] [CrossRef]
- Galbraith, S.D.; Lin, X.; Scott, M. Endomorphisms for Faster Elliptic Curve Cryptography on a Large Class of Curves. In Proceedings of the Advances in Cryptology-EUROCRYPT 2009; Joux, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Hamburg, M. Faster Montgomery and double-add ladders for short Weierstrass curves. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 189–208. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Verilog/VHDL | HLS C++ |
|---|---|---|
| Abstraction Level | Low (RTL) | High (Algorithmic) |
| Development Speed | Slower | Faster |
| Debugging | Complex | Easier (Software-like) |
| Performance | Highly Optimized | May Require Optimization |
| Hardware Control | Fine-grained | Higher-level |
| Learning Curve | Steep | Moderate |
| BPAP Kernel–Point Addition | ||||||
|---|---|---|---|---|---|---|
| Design | Batch Size (Points) | Freq. (MHz) | LUTs | FFs | BRAMs | DSPs |
| PADD-B8 | 8 | 300 | 34,801 | 41,454 | 38 | 144 |
| PADD-B16 | 16 | 300 | 35,434 | 42,293 | 38 | 144 |
| PADD-B32 | 32 | 300 | 39,180 | 44,160 | 38 | 144 |
| PADD-B64 | 64 | 271 | 40,024 | 44,777 | 38 | 144 |
| PADD-B128 | 128 | 210 | 46,713 | 48,455 | 46 | 144 |
| PADD-HFB16 | 16 | 385 | 35,434 | 42,293 | 38 | 144 |
| Point Multiplication Kernel | ||||||
| Design | Batch Size (Points) | Freq. (MHz) | LUTs | FFs | BRAMs | DSPs |
| PMUL-B8 | 8 | 300 | 79,578 | 91,946 | 166 | 288 |
| PMUL-B16 | 16 | 300 | 81,109 | 93,733 | 166 | 288 |
| PMUL-B32 | 32 | 244 | 102,887 | 96,675 | 346 | 288 |
| PMUL-B64 | 64 | 141 | 159,218 | 100,168 | 1066 | 288 |
| PMUL-HFB16 | 16 | 320 | 81,109 | 93,733 | 166 | 288 |
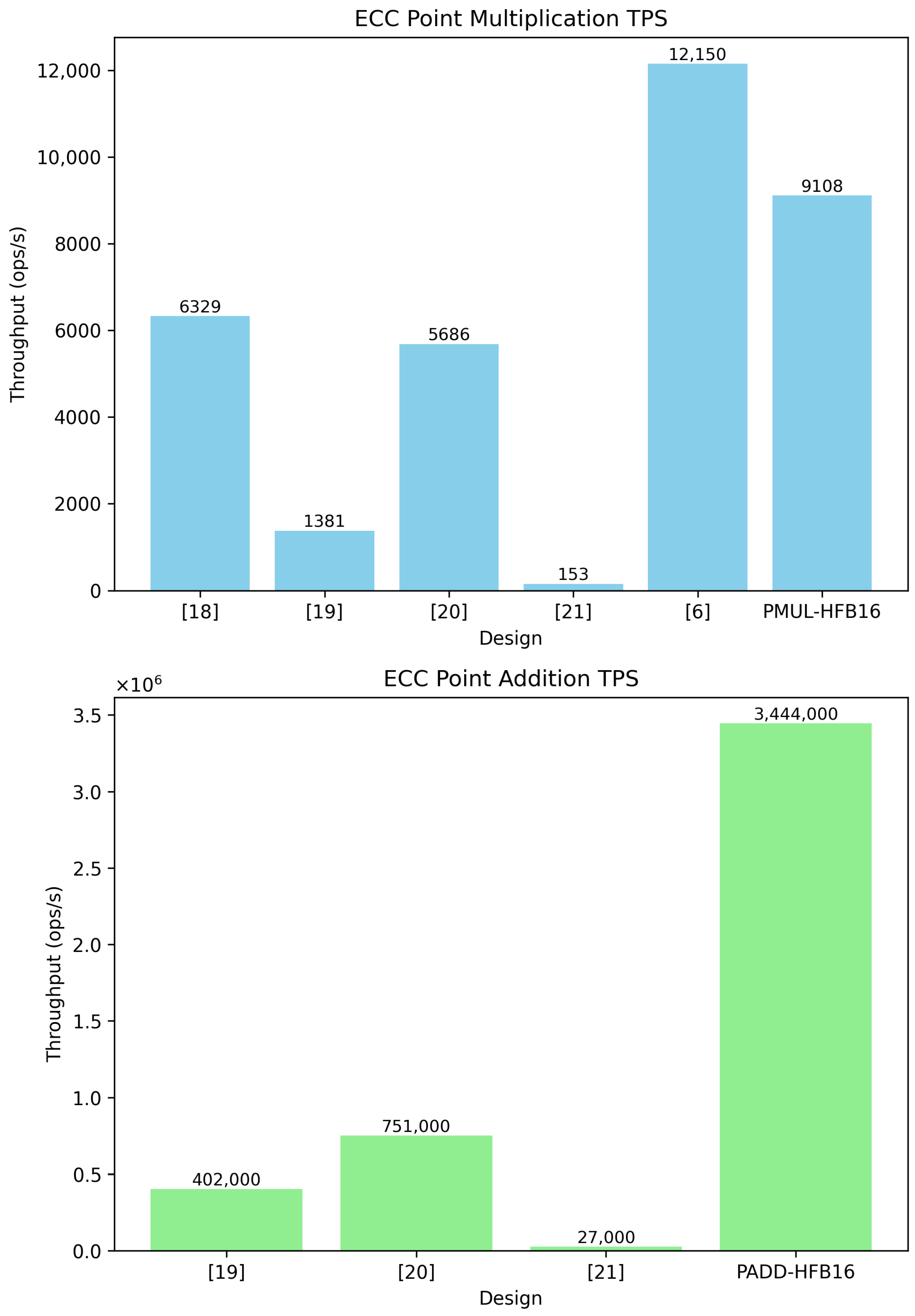
| ECC Point Multiplication Comparison | ||||
|---|---|---|---|---|
| Design | FPGA Platform | Freq. (MHz) | Area | TPS (ops/s) |
| [18] | Virtex-7 | 204 | 22,703 LUTs 12,511 FFs 15 BRAMS 136 DSPs | 6329 |
| [19] | Alveo U250 | 250 | N/A | 1381 |
| [20] | Virtex UltrascalePlus | 181 | 49,780 LUTs 29,742 FFs 560 DSPs | 5686 |
| [21] | Statix 10 | 78 | 17k ALMs | 153 |
| [6] | Alveo U45N | 125 | 91,647 LUTs 53,921 FFs 816 DSPs | 12,150 |
| PMUL-HFB16 (This work) | Alveo U55C | 320 | 81,109 LUTs 93,733 FFs 166 BRAMS 288 DSPs | 9108 |
| ECC Point Addition comparison | ||||
| Design | FPGA Platform | Freq. (MHz) | Area | TPS (ops/s) |
| [19] | Alveo U250 | 250 | N/A | 0.402 |
| [20] | Virtex UltrascalePlus | 181 | N/A | 0.751 |
| [21] | Cyclone V | 30 | N/A | 0.027 |
| PADD-HFB16 (This work) | Alveo U55C | 385 | 35,434 LUTs 42,293 FFs 38 BRAMs 144 DSPs | 3.444 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ifrim, R.; Popescu, D. BPAP: FPGA Design of a RISC-like Processor for Elliptic Curve Cryptography Using Task-Level Parallel Programming in High-Level Synthesis. Cryptography 2025, 9, 20. https://doi.org/10.3390/cryptography9010020
Ifrim R, Popescu D. BPAP: FPGA Design of a RISC-like Processor for Elliptic Curve Cryptography Using Task-Level Parallel Programming in High-Level Synthesis. Cryptography. 2025; 9(1):20. https://doi.org/10.3390/cryptography9010020
Chicago/Turabian StyleIfrim, Rares, and Decebal Popescu. 2025. "BPAP: FPGA Design of a RISC-like Processor for Elliptic Curve Cryptography Using Task-Level Parallel Programming in High-Level Synthesis" Cryptography 9, no. 1: 20. https://doi.org/10.3390/cryptography9010020
APA StyleIfrim, R., & Popescu, D. (2025). BPAP: FPGA Design of a RISC-like Processor for Elliptic Curve Cryptography Using Task-Level Parallel Programming in High-Level Synthesis. Cryptography, 9(1), 20. https://doi.org/10.3390/cryptography9010020