

Faster Spiral: Low-Communication, High-Rate Private Information Retrieval


Abstract
1. Introduction
Our Contribution
- First, we found that the noise introduced by query expansion would impact the subsequent plaintext–plaintext multiplications and ciphertext–ciphertext multiplications. Therefore, we add a modulus switching towards those expanded ciphertexts and ciphertexts. In this way, we propose a Residue Number System (RNS) variant of Spiral.
- Secondly, we apply two existing techniques called the composite algorithm [19] and approximate decomposition [15]. The former is used to execute the algorithm on a composite modulus of two -friendly moduli. The latter is first proposed for the torus variant of and samples in TFHE [15] and it works well in our protocol.
2. Preliminary
2.1. Notations
2.2. Lattice-Based Encryptions
2.3. Useful Algorithms
2.3.1. Plaintext–Ciphertext Multiplication
2.3.2. Ciphertext–Ciphertext Multiplication
2.3.3. Key-Switching
- (). Given an ciphertext and key-switching key as input, the algorithm outputs an ciphertext by computingand outputting accordingly.
2.3.4. Expansion
2.3.5. Conversion from (s) to
2.4. Private Information Retrieval
- Setup (): This phase is run one time per database. Particularly, the client receives nothing and the server receives a database of size . The server can preprocess to generate some public things, e.g., preprocess the database to a preprocessed , thus it can accelerate the online computation.
- Keygen: The client generates a public and secret key pair . Next, the client sends the public key to the server while privately storing the corresponding secret key . Generally speaking, the usually consists of some key-switching keys and the is used for encryption and decryption.
- Query (): Once given an indice , the client computes an online query and sends the query to the server.
- Response : Input, an online query and the public key from the client, and preprocessed , the server computes a response and sends it back to the client.
- Recover : Input an answer and the secret key , the client outputs the desired record d.
2.4.1. Correctness
2.4.2. Security
2.5. Spiral Protocol
2.5.1. Setup and Keygen Phase
2.5.2. Query Generation Phase
2.5.3. Response Phase
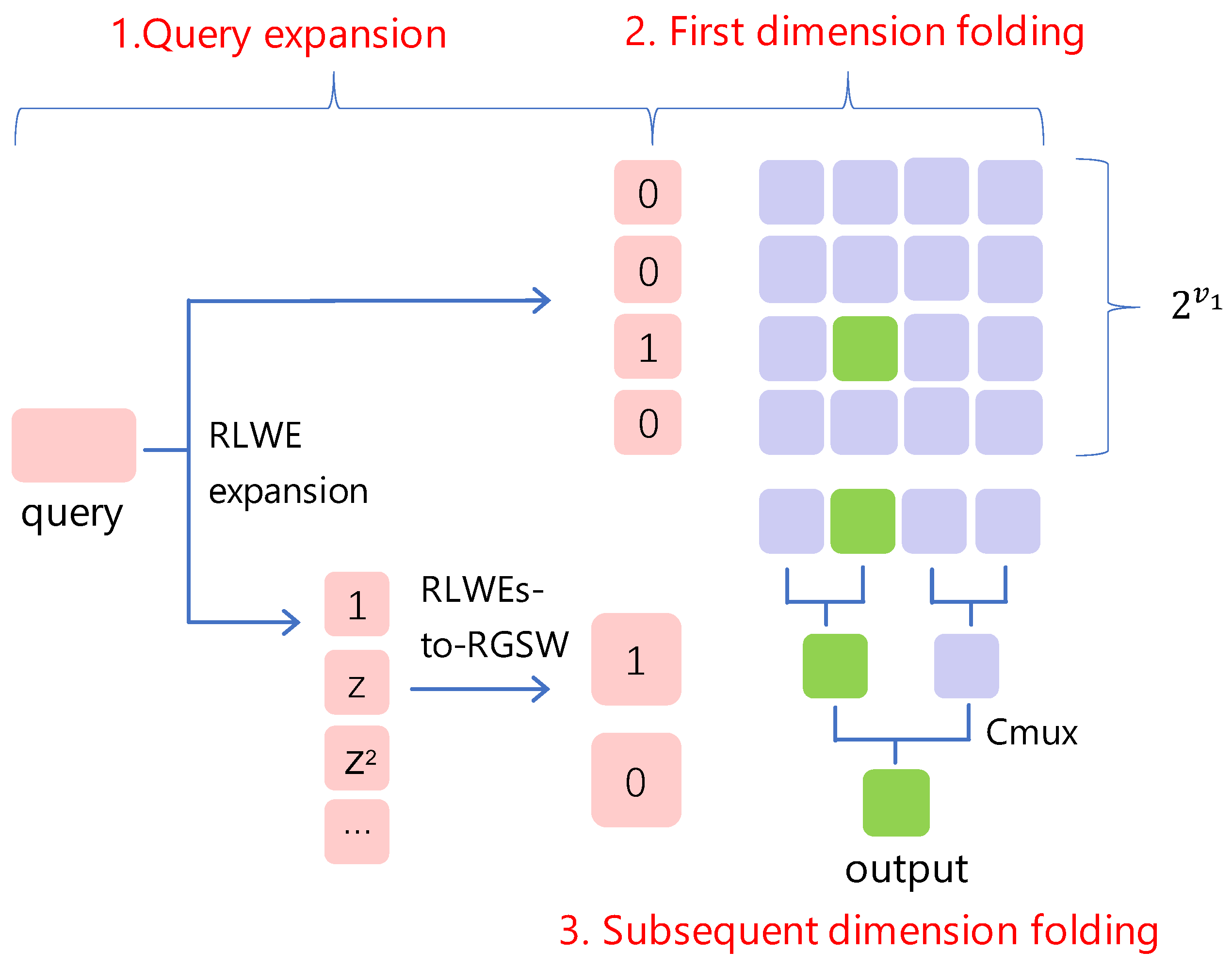
- (Query expansion). Once it receives the online query , the server expands it to a series of ciphertexts that can be divided into two groups. The first group consists of ciphertexts that only the u-th ciphertext encrypts as 1 and the remaining encrypt as 0. The second group consists of ciphertexts, which are the input of the s-to- algorithm. The sever converts these ciphertexts belonging to the second group to cipertexts that encrypt .
- (First dimension folding). Once given ciphertexts, that only one of them encrypts as 1 and the others encrypt as 0, the server can do plaintext–ciphertext multiplications and ciphertext–ciphertext additions for each column in the database. For each column, the server obtains one ciphertext. Consequently, the output ciphertexts encrypt the u-th row of the database.
- (Subsequent dimension folding). Once given ciphertexts (generated in the first dimension-folding phase) and ciphertexts (generated in the query expansion phase), the server evaluates many homomorphic functions, i.e., for . Consequently, the server outputs one ciphertext that encrypts the desired record, and relays it to the client.
2.5.4. Recover Phase
3. Our Improvement
3.1. RNS Variant of Spiral
3.2. Improvement by Composite Algorithm
3.3. Improvement by Approximate Decomposition
4. The Full Protocol
4.1. The Description of Full Protocol
4.1.1. Setup Phase
4.1.2. Keygen Phase
4.1.3. Query Generation Phase
4.1.4. Response Phase
- (Query expansion). Upon receiving the online query , the server first expands it to two ciphertextsFor the property of the expansion algorithm, we know that .Then, the server continues to expand them toWe further know that and .For each , computewhere is an ciphertexts vector.For the property of the s-to- algorithm, we know that .The server performs modulus-switching operations for all expanded ciphertexts and ciphertexts , asConsequently, consists of ciphertexts that only the u-th ciphertext encrypts as 1 and the remaining encrypt as 0, while consists of cipertexts that encrypt .Remark 2.There are two main differences from the original Spiral in the query generation and query expansion phases. The first one is that we work on a bigger ring instead of ring , and we implement the modulus switching algorithm towards those expanded ciphertexts before the first dimension-folding phase. The other is that we use the composite algorithm and approximate decomposition, instead of the standard algorithm and exact decomposition in the original Spiral.
- (First dimension folding). Once given ciphertexts that only one of them encrypts as 1 and the others encrypt as 0, the server can do plaintext–ciphertext multiplications and ciphertext–ciphertext additions for each column of database. For each column, the server obtains one ciphertext, and the output ciphertexts encrypt the u-th row of the database.For each , the server computeswhere is the bit decomposition of j, i.e., .In total, there are plaintext–ciphertext multiplications and ciphertext–ciphertext additions.
- (Subsequent dimension folding). Once given ciphertexts and ciphertexts generated in the first dimension-folding phase, the server can do a ciphertext–ciphertext function, i.e., for . Specifically, inputing two ciphertexts , , and an ciphertext where , the is defined asFor each , let ;For each , the server computesFinally, let . In order to reduce the communication, the server computes a modulus switchingwhere and are two smaller moduli compared with q. Using two unequal moduli contributes to a smaller ciphertext size compared with the original modulus switching which uses one modulus. Finally, the server relays it to the client.Remark 3.There is no difference in the first dimension-folding phase compared with Spiral. In the subsequent dimension-folding phase, we use the composite algorithm and approximate decomposition.
4.1.5. Recover Phase
4.2. Additional Analysis
4.3. Pack and Stream Variant
5. Implementation and Evaluation
5.1. Parameter Selection
5.1.1. Lattice Parameters
5.1.2. Parameters Compared with Spiral
5.2. Concrete Performances for Our PIR Protocol
5.2.1. Compared with Spiral and Prior Works
5.2.2. Compared with KsPIR
6. Recent Works
6.1. -Based PIR Protocols
6.2. Efficient Sublinear PIR Protocols
6.3. Keyword PIR Protocols
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Correctness and Security
Appendix A.2. Heuristic Noise Analysis
Appendix A.2.1. Query Expansion Phase
Appendix A.2.2. First Dimension-Folding Phase
Appendix A.2.3. Second Dimension-Folding Phase
References
- Chor, B.; Goldreich, O.; Kushilevitz, E.; Sudan, M. Private Information Retrieval. In Proceedings of the 36th FOCS, Milwaukee, WI, USA, 23–25 October 1995; IEEE Computer Society Press: Washington, DC, USA, 1995; pp. 41–50. [Google Scholar] [CrossRef]
- Angel, S.; Setty, S.T.V. Unobservable Communication over Fully Untrusted Infrastructure. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2016, Savannah, GA, USA, 2–4 November 2016; Keeton, K., Roscoe, T., Eds.; USENIX Association: Berkeley, CA, USA, 2016; pp. 551–569. [Google Scholar]
- Angel, S.; Chen, H.; Laine, K.; Setty, S.T.V. PIR with Compressed Queries and Amortized Query Processing. In Proceedings of the 2018 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 21–23 May 2018; IEEE Computer Society Press: Washington, DC, USA, 2018; pp. 962–979. [Google Scholar] [CrossRef]
- Trieu, N.; Shehata, K.; Saxena, P.; Shokri, R.; Song, D. Epione: Lightweight Contact Tracing with Strong Privacy. IEEE Data Eng. Bull. 2020, 43, 95–107. [Google Scholar]
- Kogan, D.; Corrigan-Gibbs, H. Private Blocklist Lookups with Checklist. In Proceedings of the USENIX Security 2021, Virtual, 11–13 August 2021; Bailey, M., Greenstadt, R., Eds.; USENIX Association: Berkeley, CA, USA, 2021; pp. 875–892. [Google Scholar]
- Henzinger, A.; Hong, M.M.; Corrigan-Gibbs, H.; Meiklejohn, S.; Vaikuntanathan, V. One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval. In Proceedings of the USENIX Security 2023, Anaheim, CA, USA, 9–11 August 2023; Calandrino, J.A., Troncoso, C., Eds.; USENIX Association: Berkeley, CA, USA, 2023; pp. 3889–3905. [Google Scholar]
- Wu, D.J.; Zimmerman, J.; Planul, J.; Mitchell, J.C. Privacy-Preserving Shortest Path Computation. In Proceedings of the NDSS 2016, San Diego, CA, USA, 21–24 February 2016; The Internet Society: Reston, VA, USA, 2016. [Google Scholar] [CrossRef]
- Kushilevitz, E.; Ostrovsky, R. Replication is NOT Needed: SINGLE Database, Computationally-Private Information Retrieval. In Proceedings of the 38th FOCS, Miami Beach, FL, USA, 19–22 October 1997; IEEE Computer Society Press: Washington, DC, USA, 1997; pp. 364–373. [Google Scholar] [CrossRef]
- Melchor, C.A.; Barrier, J.; Fousse, L.; Killijian, M. XPIR: Private Information Retrieval for Everyone. Proc. Priv. Enhancing Technol. 2016, 2016, 155–174. [Google Scholar] [CrossRef]
- Ali, A.; Lepoint, T.; Patel, S.; Raykova, M.; Schoppmann, P.; Seth, K.; Yeo, K. Communication-Computation Trade-offs in PIR. In Proceedings of the USENIX Security 2021, Virtual, 11–13 August 2021; Bailey, M., Greenstadt, R., Eds.; USENIX Association: Berkeley, CA, USA, 2021; pp. 1811–1828. [Google Scholar]
- Mughees, M.H.; Chen, H.; Ren, L. OnionPIR: Response Efficient Single-Server PIR. In Proceedings of the ACM CCS 2021, Virtual, 15–19 November 2021; Vigna, G., Shi, E., Eds.; ACM Press: New York, NY, USA, 2021; pp. 2292–2306. [Google Scholar] [CrossRef]
- Menon, S.J.; Wu, D.J. SPIRAL: Fast, High-Rate Single-Server PIR via FHE Composition. In Proceedings of the 2022 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 22–26 May 2022; IEEE Computer Society Press: Washington, DC, USA, 2022; pp. 930–947. [Google Scholar] [CrossRef]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the 41st ACM STOC, Bethesda, MD, USA, 31 May–2 June 2009; Mitzenmacher, M., Ed.; ACM Press: New York, NY, USA, 2009; pp. 169–178. [Google Scholar] [CrossRef]
- Gentry, C.; Halevi, S. Compressible FHE with Applications to PIR. In Proceedings of the TCC 2019, Nuremberg, Germany, 1–5 December 2019; Hofheinz, D., Rosen, A., Eds.; Part II, LNCS. Springer: Cham, Switzerland, 2019; Volume 11892, pp. 438–464. [Google Scholar] [CrossRef]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. Faster Fully Homomorphic Encryption: Bootstrapping in Less Than 0.1 Seconds. In Proceedings of the ASIACRYPT 2016, Hanoi, Vietnam, 4–8 December 2016; Cheon, J.H., Takagi, T., Eds.; Part I, LNCS. Springer: Berlin/Heidelberg, Germany, 2016; Volume 10031, pp. 3–33. [Google Scholar] [CrossRef]
- Li, B.; Micciancio, D.; Raykova, M.; Schultz, M. Hintless Single-Server Private Information Retrieval. In Proceedings of the CRYPTO 2024, Santa Barbara, CA, USA, 18–22 August 2024; Reyzin, L., Stebila, D., Eds.; Part IX, LNCS. Springer: Cham, Switzerland, 2024; Volume 14928, pp. 183–217. [Google Scholar] [CrossRef]
- Menon, S.J.; Wu, D.J. YPIR: High-Throughput Single-Server PIR with Silent Preprocessing. In Proceedings of the USENIX Security 2024, Philadelphia, PA, USA, 14–16 August 2024; Balzarotti, D., Xu, W., Eds.; USENIX Association: Berkeley, CA, USA, 2024. [Google Scholar]
- Luo, M.; Liu, F.H.; Wang, H. Faster FHE-Based Single-Server Private Information Retrieval. In Proceedings of the ACM CCS 2024, Salt Lake City, UT, USA, 14–18 October 2024; ACM Press: New York, NY, USA, 2024; pp. 1405–1419. [Google Scholar] [CrossRef]
- Li, Z.; Liu, Y.; Lu, X.; Wang, R.; Wei, B.; Chen, C.; Wang, K. Faster Bootstrapping via Modulus Raising and Composite NTT. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2024, 2024, 563–591. [Google Scholar] [CrossRef]
- Luo, M.; Wang, M. Faster Spiral: Low-Communication, High-Rate Private Information Retrieval. 2024. Available online: https://github.com/mmingluo/fspiral (accessed on 16 February 2025).
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. In Proceedings of the 37th ACM STOC, Baltimore, MD, USA, 22–24 May 2005; Gabow, H.N., Fagin, R., Eds.; ACM Press: New York, NY, USA, 2005; pp. 84–93. [Google Scholar] [CrossRef]
- Lyubashevsky, V.; Peikert, C.; Regev, O. On Ideal Lattices and Learning with Errors over Rings. In Proceedings of the EUROCRYPT 2010, French Riviera, France, 30 May–3 June 2010; Gilbert, H., Ed.; LNCS. Springer: Berlin/Heidelberg, Germany, 2010; Volume 6110, pp. 1–23. [Google Scholar] [CrossRef]
- Bos, J.W.; Costello, C.; Ducas, L.; Mironov, I.; Naehrig, M.; Nikolaenko, V.; Raghunathan, A.; Stebila, D. Frodo: Take off the Ring! Practical, Quantum-Secure Key Exchange from LWE. In Proceedings of the ACM CCS 2016, Vienna, Austria, 24–28 October 2016; Weippl, E.R., Katzenbeisser, S., Kruegel, C., Myers, A.C., Halevi, S., Eds.; ACM Press: New York, NY, USA, 2016; pp. 1006–1018. [Google Scholar] [CrossRef]
- Bos, J.W.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Kyber: A CCA-Secure Module-Lattice-Based KEM. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy, EuroS&P 2018, London, UK, 24–26 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 353–367. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. Cryptology ePrint Archive, Paper 2012/144. 2012. Available online: https://eprint.iacr.org/2012/144 (accessed on 1 December 2024).
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. In Proceedings of the ITCS 2012, Cambridge, MA, USA, 8–10 January 2012; Goldwasser, S., Ed.; ACM: New York, NY, USA, 2012; pp. 309–325. [Google Scholar] [CrossRef]
- Ducas, L.; Micciancio, D. FHEW: Bootstrapping Homomorphic Encryption in Less Than a Second. In Proceedings of the EUROCRYPT 2015, Sofia, Bulgaria, 26–30 April 2015; Oswald, E., Fischlin, M., Eds.; Part I, LNCS. Springer: Berlin/Heidelberg, Germany, 2015; Volume 9056, pp. 617–640. [Google Scholar] [CrossRef]
- Brakerski, Z.; Vaikuntanathan, V. Efficient Fully Homomorphic Encryption from (Standard) LWE. In Proceedings of the 52nd FOCS, Palm Springs, CA, USA, 22–25 October 2011; Ostrovsky, R., Ed.; IEEE Computer Society Press: Washington, DC, USA, 2011; pp. 97–106. [Google Scholar] [CrossRef]
- Ahmad, I.; Yang, Y.; Agrawal, D.; Abbadi, A.E.; Gupta, T. Addra: Metadata-private voice communication over fully untrusted infrastructure. In Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2021, Virtual, 14–16 July 2021; Brown, A.D., Lorch, J.R., Eds.; USENIX Association: Berkeley, CA, USA, 2021. [Google Scholar]
- Albrecht, M.R.; Player, R.; Scott, S. On the concrete hardness of learning with errors. J. Math. Cryptol. 2015, 9, 169–203. [Google Scholar] [CrossRef]
- Kim, A.; Polyakov, Y.; Zucca, V. Revisiting Homomorphic Encryption Schemes for Finite Fields. In Proceedings of the ASIACRYPT 2021, Virtual, 6–10 December 2021; Tibouchi, M., Wang, H., Eds.; Part III, LNCS. Springer: Cham, Switzerland, 2021; Volume 13092, pp. 608–639. [Google Scholar] [CrossRef]
- Seiler, G. Faster AVX2 Optimized NTT Multiplication for Ring-LWE Lattice Cryptography. Cryptology ePrint Archive, Paper 2018/039. 2018. Available online: https://eprint.iacr.org/2018/039 (accessed on 1 December 2024).
- Micciancio, D.; Peikert, C. Trapdoors for Lattices: Simpler, Tighter, Faster, Smaller. In Proceedings of the EUROCRYPT 2012, Cambridge, UK, 15–19 April 2012; Pointcheval, D., Johansson, T., Eds.; LNCS. Springer: Berlin/Heidelberg, Germany, 2012; Volume 7237, pp. 700–718. [Google Scholar] [CrossRef]
- Alperin-Sheriff, J.; Peikert, C. Faster Bootstrapping with Polynomial Error. In Proceedings of the CRYPTO 2014, Santa Barbara, CA, USA, 17–21 August 2014; Garay, J.A., Gennaro, R., Eds.; Part I, LNCS. Springer: Berlin/Heidelberg, Germany, 2014; Volume 8616, pp. 297–314. [Google Scholar] [CrossRef]
- Boemer, F.; Kim, S.; Seifu, G.; de Souza, F.D.M.; Gopal, V. Intel HEXL: Accelerating Homomorphic Encryption with Intel AVX512-IFMA52. In Proceedings of the 9th on Workshop on Encrypted Computing & Applied Homomorphic Cryptography, Virtual, Republic of Korea, 15 November 2021. Cryptology ePrint Archive Paper 2021/420. [Google Scholar]
- Menon, S.J.; Wu, D.J. SPIRAL: Fast, High-Rate Single-Server PIR via FHE Composition. 2023. Available online: https://github.com/menonsamir/spiral/commit/361ee4 (accessed on 1 December 2024).
- Chen, H.; Laine, K.; Player, R. Simple Encrypted Arithmetic Library-SEAL v2.1. In Proceedings of the FC 2017 Workshops, Sliema, Malta, 7 April 2017; Brenner, M., Rohloff, K., Bonneau, J., Miller, A., Ryan, P.Y.A., Teague, V., Bracciali, A., Sala, M., Pintore, F., Jakobsson, M., Eds.; LNCS. Springer: Cham, Switzerland, 2017; Volume 10323, pp. 3–18. [Google Scholar] [CrossRef]
- Zhou, M.; Park, A.; Shi, E.; Zheng, W. Piano: Extremely Simple, Single-Server PIR with Sublinear Server Computation. Cryptology ePrint Archive, Paper 2023/452. 2023. Available online: https://eprint.iacr.org/2023/452 (accessed on 1 December 2024).
- Patel, S.; Seo, J.Y.; Yeo, K. Don’t be Dense: Efficient Keyword PIR for Sparse Databases. In Proceedings of the USENIX Security 2023, Anaheim, CA, USA, 9–11 August 2023; Calandrino, J.A., Troncoso, C., Eds.; USENIX Association: Berkeley, CA, USA, 2023; pp. 3853–3870. [Google Scholar]
- Celi, S.; Davidson, A. Call Me by My Name: Simple, Practical Private Information Retrieval for Keyword Queries. In ACM CCS 2024; ACM Press: New York, NY, USA, 2024; pp. 4107–4121. [Google Scholar] [CrossRef]
- Mahdavi, R.A.; Kerschbaum, F. Constant-weight PIR: Single-round Keyword PIR via Constant-weight Equality Operators. In Proceedings of the USENIX Security 2022, Boston, MA, USA, 10–12 August 2022; Butler, K.R.B., Thomas, K., Eds.; USENIX Association: Berkeley, CA, USA, 2022; pp. 1723–1740. [Google Scholar]

{kind=link}
| Protocols | d | n | (, , ) | (, , ) | (, , ) | Server Time | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Spiral | 8 | 2048 | 2 | < | 1883 ms | |||||
| Ours | 18 | 4096 | 1 | < | 1222 ms |
| Database 1 | Metric | FastPIR [29] | Spiral [12] | SpiralPack [12] | SpiralPack Stream [12] | KsPIR [18] | Ours | Ours-Stream |
|---|---|---|---|---|---|---|---|---|
256B (256 MB) | Server storage | - | 13.3 MB | 13.5 MB | - | 8.8 MB | 6.7 MB | - |
| Server prepro. | 2.1 s | 9.8 s | 8.2 s | 8.2 s | 4.5 s | 2.6 s | 2.6 s | |
| Server resp. | 1832 ms | 1883 ms | 1339 ms | 602 ms | 246 ms | 1222 ms | 427 ms | |
| Query size | 1 MB | 14 KB | 14 KB | 8.3 MB | 140 KB | 40 KB | 4.8 MB | |
| Response size | 64 KB | 20 KB | 20 KB | 20 KB | 26 KB | 26 KB | 30 KB | |
| Through. | 140 MB/s | 136 MB/s | 191 MB/s | 425 MB/s | 1041 MB/s | 236 MB/s | 749 MB/s | |
| Client comp. | 12 ms | 11 ms | 1 ms | 378 ms | 7.7 ms | 2.2 ms | 53 ms | |
8 KB (2 GB) | Server storage | - | 13.8 MB | 14 MB | - | 9.1 MB | 6.7 MB | - |
| Server prepro. | 16.3 s | 101 s | 89 s | 90 s | 37.1 s | 29.6 s | 31.6 s | |
| Server resp. | 8932 ms | 6013 ms | 4998 ms | 3332 ms | 1641 ms | 3645 ms | 2223 ms | |
| Query size | 8 MB | 14 KB | 14 KB | 15.8 MB | 140 KB | 40 KB | 8.6 MB | |
| Response size | 64 KB | 20 KB | 20 KB | 20 KB | 26 KB | 26 KB | 30 KB | |
| Through. | 229 MB/s | 341 MB/s | 410 MB/s | 615 MB/s | 1248 MB/s | 632 MB/s | 1152 MB/s | |
| Client comp. | 68 ms | 43 ms | 1 ms | 717 ms | 7.8 ms | 2.2 ms | 160 ms | |
8 KB (8 GB) | Server storage | - | 15.5 MB | 15.4 MB | - | 9.3 MB | 6.7 MB | - |
| Server prepro. | 68.9 s | 535 s | 410 s | 492 s | 186 s | 166 s | 119 s | |
| Server resp. | 35.6 s | 24.9 s | 13.9 s | 11.6 s | 6.9 s | 14.2 s | 5.4 s | |
| Query size | 32 MB | 14 KB | 14 KB | 30 MB | 140 KB | 40 KB | 14.7 MB | |
| Response size | 64 KB | 20 KB | 20 KB | 20 KB | 26 KB | 26 KB | 90 KB | |
| Through. | 230 MB/s | 329 MB/s | 589 MB/s | 706 MB/s | 1187 MB/s | 649 MB/s | 1896 MB/s | |
| Client comp. | 286 ms | 91 ms | 1 ms | 1.5 s | 8.2 ms | 2.2 ms | 158 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, M.; Wang, M. Faster Spiral: Low-Communication, High-Rate Private Information Retrieval. Cryptography 2025, 9, 13. https://doi.org/10.3390/cryptography9010013
Luo M, Wang M. Faster Spiral: Low-Communication, High-Rate Private Information Retrieval. Cryptography. 2025; 9(1):13. https://doi.org/10.3390/cryptography9010013
Chicago/Turabian StyleLuo, Ming, and Mingsheng Wang. 2025. "Faster Spiral: Low-Communication, High-Rate Private Information Retrieval" Cryptography 9, no. 1: 13. https://doi.org/10.3390/cryptography9010013
APA StyleLuo, M., & Wang, M. (2025). Faster Spiral: Low-Communication, High-Rate Private Information Retrieval. Cryptography, 9(1), 13. https://doi.org/10.3390/cryptography9010013