1. Introduction
Shor demonstrated that solving both the integer factorization problem (IFP) and the discrete logarithm problem (DLP) is theoretically tractable in polynomial time [
1]. Both Rivest–Shamir–Adleman (RSA) public-key cryptography and elliptic curve cryptography (ECC) are widely used, and their security depends on the IFP and DLP, respectively. In recent years, research and development of quantum computers have progressed rapidly. For example, noisy intermediate-scale quantum computers are already in practical use. Since system migration takes time in general, preparation for migration to PQC is a significant issue. Research, development, and standardization projects for post-quantum cryptography (PQC) are ongoing within these contexts. The PQC standardization process was started by the National Institute of Standards and Technology (NIST) in 2016 [
2]. Several cryptosystems have been proposed for the NIST PQC project, including lattice-based, code-based, and hash-based cryptosystems. The multivariate public-key cryptosystem (MPKC) is one of the cryptosystems proposed for the NIST PQC project. At the end of the third round, NIST selected four candidates to be standardized, as shown in
Table 1, and moved four candidates to the fourth-round evaluation, as shown in
Table 2. Moreover, NIST issued a request for proposals of digital signature schemes with short signatures and fast verification [
3]. MPKCs are often more efficient than other public-key cryptosystems, primarily digital signature schemes, as described in the subsequent paragraph; therefore, researching the security of MPKCs is still important.
An MPKC is basically an asymmetric cryptosystem that has a trapdoor one-way multivariate (quadratic) polynomial map
over a finite field
. Let
:
a (quadratic) polynomial map whose inverse can be computed easily, and two randomly selected invertible affine linear maps
and
. The secret key consists of
,
, and
. The public key consists of the composite map
:
such that
. The public key can be regarded as a set
of
m (quadratic) polynomials in
n variables:
where each
is a non-linear (quadratic) polynomial.
Multivariate quadratic (MQ) problem: Find a solution such that the system of (quadratic) polynomial equations:
Then, the MQ problem is closely related to the attack that forges signatures for the MPKC.
Isomorphism of polynomials (IP) problem: Let and be two polynomial maps from to . Find two invertible affine linear maps : and : such that .
Then, the IP problem is closely related to the attack for finding secret keys for the MPKC.
One of the most well-known public-key cryptosystems based on multivariate polynomials over a finite field was proposed by Matsumoto and Imai [
12]. Patarin [
13] later demonstrated that the Matsumoto–Imai cryptosystem is insecure, proposed the hidden field equation (HFE) public-key cryptosystem by repairing their cryptosystems [
14] and designed the Oil and Vinegar (OV) scheme [
15]. There are several variations of the HFE and OV schemes, e.g., Kipnis et al. proposed the unbalanced OV (UOV) scheme [
16] as described in
Section 2.5.
Several MPKCs were proposed for the NIST PQC project [
17], e.g., G
eMSS [
18], LUOV [
19], MQDSS [
20], and Rainbow [
21] MPKCs. Ding et al. found a forgery attack on LUOV [
22], and Kales and Zaverucha found a forgery attack on MQDSS [
23]. At the end of the second round, NIST selected Rainbow as a third-round finalist and moved G
eMSS to an alternate candidate [
24].
MinRank problem: Let
r be a positive integer and
k matrices
. Find
such that
and
The MinRank problem can be reduced to the MQ problem [
25,
26,
27]. By solving the MinRank problem, Tao et al. found a key recovery attack on G
eMSS [
28], and Beullens found a key recovery attack on Rainbow [
29,
30].
NIST reported that a third-round finalist of the digital signature scheme, Rainbow, had the property that its signing and verification were efficient, and the signature size was very short [
31]. Beullens et al. also demonstrated that the (U)OV scheme performed comparably to the algorithms selected by NIST [
32].
As noted above, the security of an MPKC is highly dependent on the hardness of the MQ problem because multivariate polynomial equations are transformed into MQ polynomial equations by increasing the number of variables and equations. To break a cryptosystem, we translate its underlying algebraic structure into a system of multivariate polynomial equations. There are three well-known algebraic approaches to solving the MQ problem: the extended linearization (XL) algorithm proposed by Courtois et al. [
33] and the F4 and F5 algorithms proposed by Faugère [
34,
35]. The XL algorithm is described in
Section 2.2. Gröbner bases algorithm is described in
Section 2.3 and
Section 3.1 and the F4 algorithm is described in
Section 3.2.
In addition to the theoretical evaluations of the computational complexity, practical evaluations are also crucial in the research of cryptography, e.g., such as many efforts addressing the RSA [
36], ECC [
37], and Lattice challenges [
38]. The Fukuoka MQ challenge project [
39,
40] was started in 2015 to evaluate the security of the MQ problem. In this project, the MQ problems were classified into encryption and digital signature schemes. Each scheme was then classified into three categories according to the number of quadratic equations (
m), the number of variables (
n), and the characteristic of the finite field. The encryption schemes were classified into types I to III, which correspond to the condition where
over
,
, and
, respectively. The digital-signature schemes were classified into types IV to VI, which correspond to the condition where
over
,
, and
, respectively. Up to the time of writing this paper, all the best records in the Fukuoka MQ challenge, except type IV, have been set by variant algorithms of both the XL and F4 algorithms. For example, the authors improved the F4-style algorithm and set new records of both type II and III, as described below, but a variant of the XL algorithm later surpassed the record of type III.
The F4 algorithm proposed by Faugère is an improvement of Buchberger’s algorithm for computing Gröbner bases [
41,
42], as described in
Section 3.2. In Buchberger’s algorithm, it is fundamental to compute the S-polynomial of two polynomials, as described in
Section 3.1. The critical pair is defined by a set of data (two polynomials, the least common multiple (
) of their leading terms, and two associated monomials required to compute the S-polynomial, as described in
Section 2.3. The F4 algorithm computes many S-polynomials simultaneously using Gaussian elimination. A variant of the F4 algorithm involving these matrix operations is referred to as an F4-style algorithm in this paper. There are several variants of the F4-style algorithm. For example, Joux and Vitse [
43] designed an efficient variant algorithm to compute Gröbner bases for similar polynomial systems. Additionally, Makarim and Stevens [
44] proposed a variant M4GB algorithm that could reduce the leading and lower terms of a polynomial. Using the M4GB algorithm, they set the best record for the Fukuoka MQ challenge of type VI with up to 20 equations (
), at the time of writing this paper.
Recently, Ito et al. [
45] also proposed a variant algorithm that could solve the Fukuoka MQ challenge for both types II and III, with up to 37 equations (
), and set the best record of type II at the time of writing. In their paper, the following selection strategy for critical pairs was proposed: (a) a set of critical pairs is partitioned into smaller subsets
such that
; (b) Gaussian elimination is performed for an associated Macaulay matrix composed of each subset; and (c) the remaining subsets are omitted if some S-polynomials are reduced to zero. Herein, we refer to the subdividing method as (a) and the removal method as (c). Their strategy was then validated only under the following two situations: systems of MQ polynomial equations associated with encryption schemes, i.e., the
case and the
case. Thus, in this paper, we propose several types of partitions related to the subdividing method and focus on their validity for solving systems of MQ polynomial equations associated with digital-signature schemes, i.e., the
case. We evaluate the performance of the proposed methods for the
case only because we focus on evaluating the performance of the proposed methods. In other words, before executing the F4-style algorithm combined with the proposed methods, we assume that random values or specific values have already been substituted for some
variables in the system, according to the hybrid approach [
46].
Our contribution. In general, the size of a matrix affects the computational complexity of Gaussian elimination. Reducing the number of critical pairs is essential because they determine the size of the Macauley matrix. First, we propose three basic subdividing methods SD1, SD2, and SD3, which have different types of partitions for a set of critical pairs. Then, we integrate both the proposed subdividing methods and the removal method into the OpenF4 library [
47] and compare their software performance with that of the original library using similar settings to those of types V and VI of the Fukuoka MQ challenge, i.e.,
over
and
over
. To validate the removal method, we then verify that neither a temporary base nor critical pair of a higher degree arises from unused critical pairs in omitted subsets. Here,
denotes the highest degree of critical pairs appearing in the Gröbner bases computation or the F4-style algorithm. The process by which the degree of a critical pair reaches
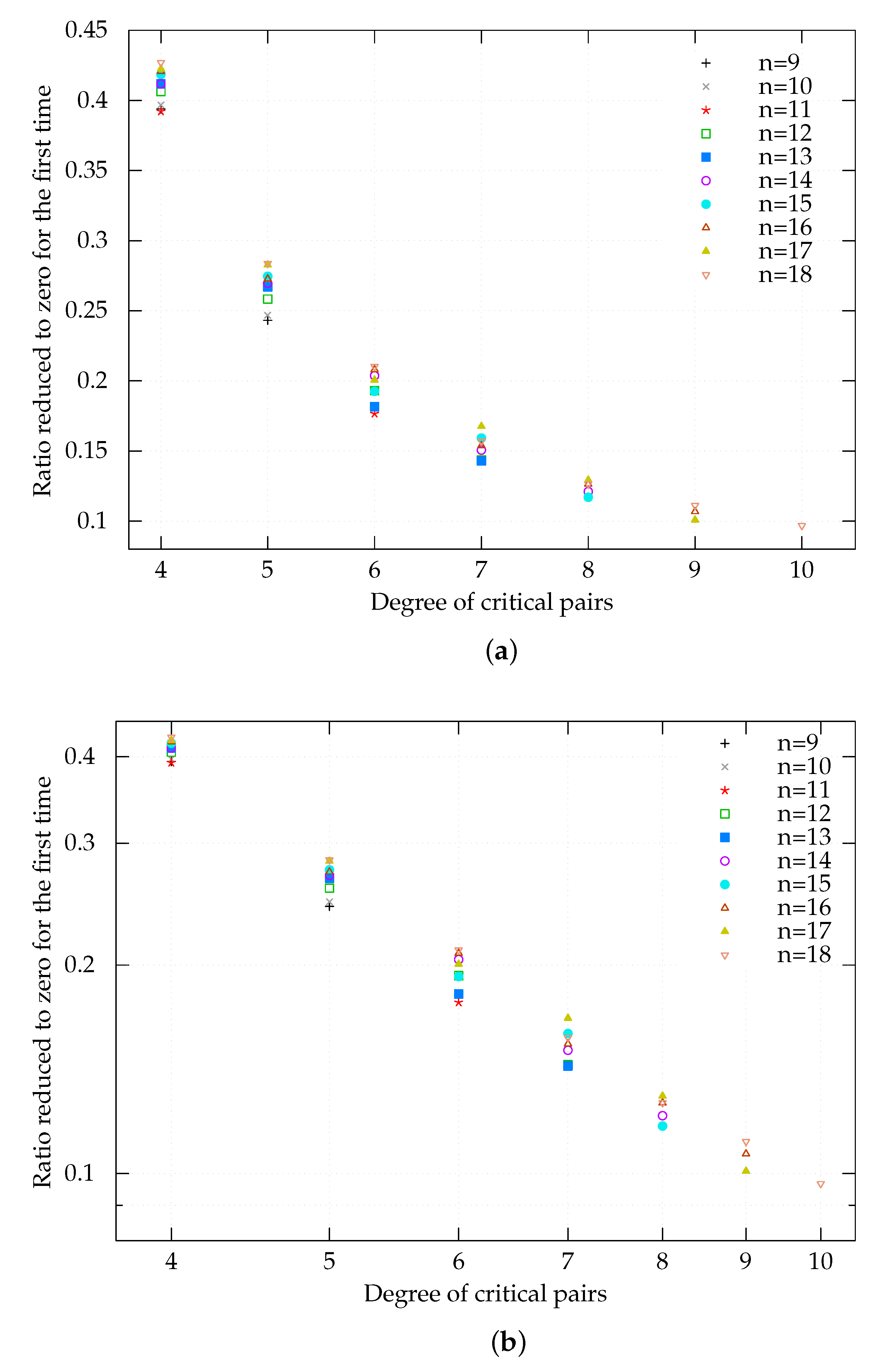
for the first time is referred to as the first half, and the remaining process is referred to as the second half. Then, our experiments show that a combination of two different basic methods (i.e., SD3 followed by SD1) is faster than all other methods because of the difference between the first and second halves of the computation. Finally, our experiments show that the number of critical pairs that generate a reduction to zero for the first time is approximately constant under the condition where
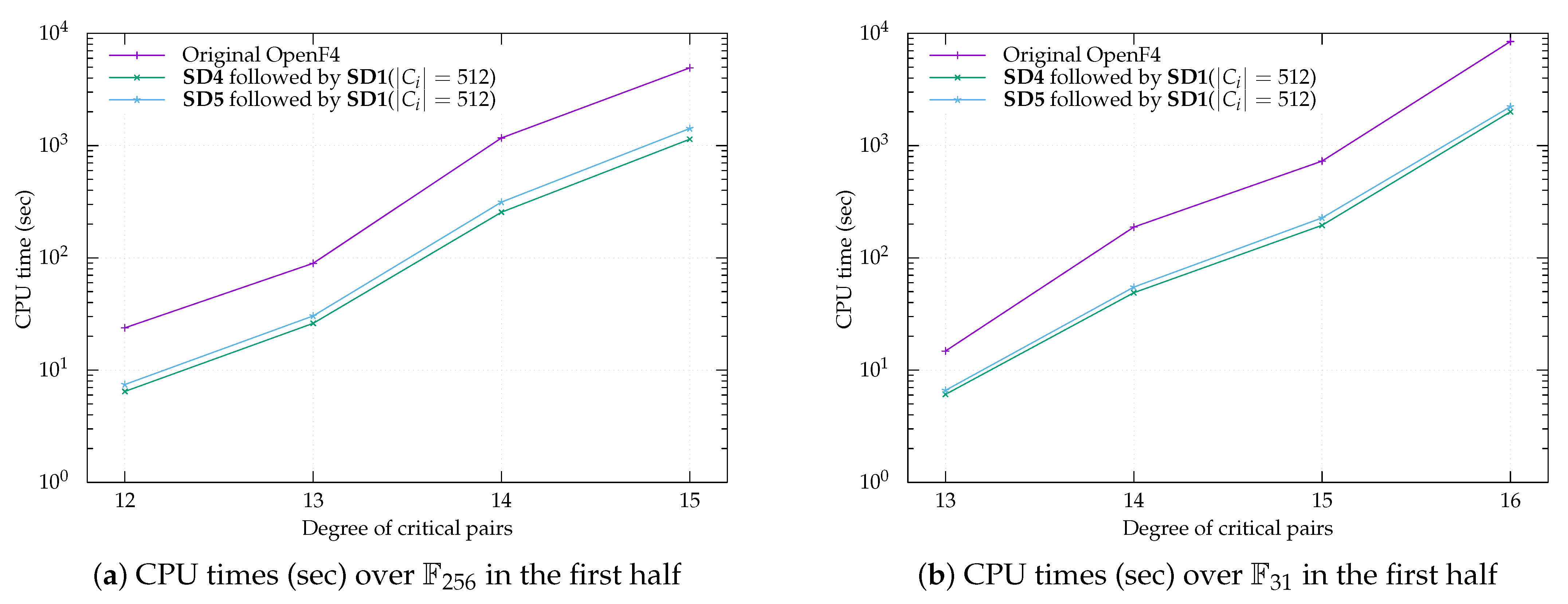
in the sense that a similar number is obtained with a high probability. We also propose two derived subdividing methods (SD4 and SD5) for the first half. The experimental results show that SD4 followed by SD1 is the fastest method and SD5 is as fast as SD4, as long as
over
and
over
hold. Moreover, we propose an extrapolation outside the scope of the experiments for further research. Our findings make a unique contribution toward improving the security evaluation of MPKC.
Organization. The remainder of this paper is organized as follows. First, we introduce basic notations and preliminaries in
Section 2. Next, we present background to Gröbner bases computation in
Section 3. Then, we describe the proposed method in
Section 3.4. Afterward, we present the performance result of the proposed method in
Section 4. Finally, the paper is concluded in
Section 5.
2. Preliminaries
In the following, we define the notations and terminology used in this paper.
2.1. Notations
Let be the set of all natural numbers, the set of all integers, the set of all non-negative integers, and a finite field with q elements. denotes a polynomial ring of n variables over , i.e., .
A monomial is defined by a product , where the is an element of . Furthermore, denotes the set of all monomials in , i.e., . For and , we call the product a term and c the coefficient of u. denotes the set of all terms, i.e., . For a polynomial, for and , denotes the set , and denotes the set .
The total degree of is defined by the sum , which is denoted by . The total degree of f is defined by and is denoted by .
Definition 1. A total order ≺ on is called a monomial order if the following conditions hold:
- (i)
s, t, , t ⪯ s ⇒ ⪯ ,
- (ii)
∀, 1 ⪯ t.
Here, if or holds, then we denote .
Definition 2. The degree reverse lexicographical order ≺ is defined by For example, in
,
The degree reverse lexicographical order ≺ is fixed throughout this paper as a monomial order.
For a polynomial , denotes the leading monomial of f, i.e., , and denotes the leading term of f, i.e., . In addition, denotes the corresponding coefficient for . A polynomial f is called monic if .
For a subset , denotes the set of leading monomials of polynomials , i.e., .
For two monomials and where and , their corresponding least common multiple (LCM) and the greatest common divisor (GCD) are defined as where , and where .
For two subsets A and B, is defined if holds for and .
2.2. The XL Algorithm
Let D be the parameter of the XL algorithm. Let be a set of polynomials over a finite field . The XL algorithm executes the following steps:
Multiply: Generate all the products () with .
Multiply: Consider each monomial in of degree as a new variable and perform Gaussian elimination on the linear equation obtained in step 1. The ordering on the monomials must be such that all the terms containing one variables (say ) are eliminated last.
Solve: Assume that step 2 yields at least one univariate equation in the power of . Solve this equation over .
Repeat: Simplify the equations and repeat the process to find the values of the other variables.
Step 1 is regarded as the construction of the Macaulay matrix with the ordering specified in step 2, as described in
Section 3.2. It is difficult to estimate the parameter
D in advance. The computational complexity of the XL algorithm is roughly
where
n is the number of variables and
is the linear algebra constant [
48].
2.3. Gröbner Bases
The concept of Gröbner bases was introduced by Buchberger [
49] in 1979. Computing Gröbner bases is a standard tool for solving simultaneous equations. This section presents the definitions and notations used in Gröbner bases. Methods to compute Gröbner bases are explained in
Section 3.
Here, denotes an ideal generated by a subset . is called a basis of an ideal I if holds. We refer to G as Gröbner bases of I if for all there exists such that . To compute Gröbner bases, we need to compute polynomials called S-polynomials.
Here, let and . It is said that f is reducible by G if there exist and such that . Thus, we can eliminate from f by computing , where c is the coefficient of u in f. In this case, g is said to be a reductor of u. If f is not reducible by G, then f is said to be a normal form of G. Repeatedly reducing f using a polynomial of G to obtain a normal form is referred to as normalization, and the function normalizing f using G is represented by .
For example, let and . First, the term in f is divisible by and is obtained. Next, the term in is divisible by and is obtained. Finally, is the normal form of f by G since is not reducible by G.
A critical pair of two polynomials
is defined by the tuple (
,
,
,
,
)
such that
For example, let . and . We have . Then, and .
For a critical pair p of , , , and denote , , , , and , respectively.
The S-polynomial,
(or
), of a critical pair
p of
is defined as follows:
and denote and , respectively.
2.4. MQ Problem
Let
F be a subset
, and let
be a quadratic polynomial (i.e.,
). The MQ problem is to compute a common zero
for a system of quadratic polynomial equations defined by
F, i.e.,
The MQ problem is discussed frequently in terms of MPKCs because representative MPKCs, e.g., UOV, Rainbow, and GeMSS, use quadratic polynomials. These schemes are signature schemes and employ a system of MQ polynomial equations under the condition where .
The computation of Gröbner bases is a fundamental tool for solving the MQ problem. If , the system of F tends to have no solution or exactly one solution. If the system of F has no solution, can be obtained as a Gröbner basis of . If it has a solution, , can be obtained as Gröbner bases of . Thus, it is easy to obtain the solution of the system of F from the Gröbner bases of .
If
, it is generally necessary to compute Gröbner bases concerning lexicographic order using a Gröbner -basis conversion algorithm, e.g., FGLM [
50]. Another method is to convert the system associated with
F to a system of multivariate polynomial equations by substituting random values for some variables and then computing its Gröbner bases. The process is repeated with other random values if there is no solution. This method is called the hybrid approach and typically substitutes random values for
variables. Hence, it is important to solve the MQ problem with
.
2.5. The (Unbalanced) Oil and Vinegar Signature Scheme
Let be a finite field. Let o, , , and . For a message to be signed, we define a signature of y as follows.
2.5.1. Key Generation
The secret key consists of two parts:
The public key is the following m quadratic equations:
- (i)
Let .
- (ii)
Compute .
- (iii)
We have
m quadratic equations in
n variables:
2.5.2. Signature Generation
- (i)
We generate
such that (
1) holds.
- (ii)
Compute where .
2.5.3. Signature Verification
If (
2) is satisfied, then we find a signature
x of
y valid.
If (
2) is solved, then we find another solution
. Thus, we can find another signature
of
y. Therefore, the difficulty of forging signatures can be related to the difficulty of the MQ problem.
3. Materials and Methods
In this section, we introduce three algorithms to compute Gröbner bases: the Buchberger-style algorithm, the algorithm proposed by Faugère, and the -style algorithm proposed by Ito et al., which is the primary focus of this paper.
3.1. Buchberger-Style Algorithm
In 1979, Buchberger introduced the concept of Gröbner bases and proposed an algorithm to compute them. He found that Gröbner bases can be computed by repeatedly generating S-polynomials and reducing them. Algorithm 1 describes the Buchberger-style algorithm to compute Gröbner bases. First, we generate a polynomial set
G and a set of critical pairs
P from the input polynomials
F. We then repeat the following steps until
P is empty: one critical pair
p from
P is selected, an S-polynomial
s is generated,
s is reduced to the polynomial
h by
G, and
G and
P are updated from
if
h is a nonzero polynomial. The Update function (Algorithm 2) is frequently used to update
G and
P, omitting some redundant critical pairs [
51]. If a polynomial
h is reduced to zero, then
G and
P are not updated; thus, the critical pair that generates an S-polynomial to be reduced to zero is redundant. Here, the critical pair selection method that selects the pair with the lowest
(referred to as the normal strategy) is frequently employed. If the degree reverse lexicographic order is used as a monomial order, then the critical pair with the lowest degree is naturally selected under the normal strategy.
| Algorithm 1 Buchberger-style algorithm |
Input:.
Output: A Gröbner bases of .
- 1:
- 2:
fordo - 3:
Update - 4:
end for - 5:
whiledo - 6:
- 7:
an element of P - 8:
- 9:
- 10:
- 11:
if then - 12:
Update - 13:
end if - 14:
end while - 15:
returnG
|
| Algorithm 2 Update |
Input:, P is a set of critical pairs, and .
Output: and .
- 1:
- 2:
, - 3:
whiledo - 4:
an element of C, - 5:
if or then - 6:
- 7:
end if - 8:
end while - 9:
- 10:
fordo - 11:
if or - 12:
or - 13:
then - 14:
- 15:
end if - 16:
end for - 17:
- 18:
return
|
3.2. -Style Algorithm
The F4 algorithm, which is a representative algorithm for computing Gröbner bases, was proposed by Faugère in 1999, and it reduces S-polynomials simultaneously. Herein, we present an F4-style algorithm with this feature.
Here, let
G be a subset of
. A matrix in which the coefficients of polynomials in
G are represented as corresponding to their monomials is referred to as a Macaulay matrix of
G.
G is said to be a row echelon form if
and
for all
. The F4-style algorithm reduces polynomials by computing row echelon forms of Macaulay matrices. For example, let
as in the fourth paragraph of
Section 2.3. We use
and
to compute
. The Macaulay matrix
M of
is given as follows:
In addition, a row echelon form
of
M is given as follows:
We can obtain from .
The F4-style algorithm is described in Algorithm 3. The main process is described in lines 5 to 14, where some critical pairs are selected using the Select function (Algorithm 4), and the polynomials of the pairs are reduced using the Reduction function (Algorithm 5). The Select function selects critical pairs with the lowest degree on the basis of the normal strategy. In particular, the F4-style algorithm selects all critical pairs with the lowest degree. It takes the subset
of
P and integer
d so that
and
. The Reduction function collects reductors to reduce the polynomials and computes the row echelon form of the polynomial set. In addition, the Simplify function (Algorithm 6) determines the reductor with the lowest degree from the polynomial set obtained during the computation of the Gröbner bases.
| Algorithm 3 F4-style algorithm |
Input:.
Output: A Gröbner basis of .
- 1:
- 2:
fordo - 3:
Update - 4:
end for - 5:
whiledo - 6:
- 7:
Select - 8:
- 9:
- 10:
- 11:
for do - 12:
Update - 13:
end for - 14:
end while - 15:
returnG
|
| Algorithm 4 Select |
Input:.
Output:: and .
- 1:
- 2:
- 3:
return
|
| Algorithm 5 Reduction |
Input:, and , where .
Output: and .
- 1:
- 2:
- 3:
Done - 4:
while Done do - 5:
an element of Done - 6:
Done ← Done - 7:
if s.t. divides u then - 8:
- 9:
- 10:
- 11:
end if - 12:
end while - 13:
row echelon form of H - 14:
- 15:
return
|
| Algorithm 6 Simplify |
Input:, and , where .
Output:.
- 1:
for list of divisors of u do - 2:
if s.t. then - 3:
row echelon form of - 4:
an element of s.t. - 5:
if then - 6:
return - 7:
else - 8:
return - 9:
end if - 10:
end if - 11:
end for - 12:
return
|
The computational complexity of the F4-style algorithm can be evaluated from above by the same order of magnitude as that of Gaussian elimination of the Macaulay matrix. The size of the Macaulay matrix of degree
D is bounded above by the number of monomials of degree
, which is equal to
The computational complexity of Gaussian elimination is bounded above by
if the matrix size is
N (
is the linear algebra constant).
denotes the highest degree of critical pairs appearing in the Gröbner bases computation. Then, the computational complexity of the F4-style algorithm is roughly
We can reduce the computational complexity by omitting redundant critical pairs.
3.3. The Algorithm Proposed by Ito et al.
Redundant critical pairs do not necessarily vanish after applying the Update function. Here, we introduce a method to omit many redundant pairs. We assume that the degree reverse lexicographic order is employed as a monomial order, and the normal strategy is used as the pair selection strategy in the Gröbner bases computation. When solving the MQ problem in the Gröbner bases computation, in many cases, the degree
d of the critical pairs changes, as described below.
Herein, the computation until the degree of the selected pair becomes is referred to as the first half. In the first half of the computation, many redundant pairs are reduced to zero. When solving the MQ problem, Ito et al. found that if a critical pair of degree d is reduced to zero, all pairs of degree d stored at that time are also reduced to zero with a high probability. Thus, redundant critical pairs can be efficiently eliminated by ignoring all stored pairs of degree d after the critical pairs of degree d are reduced to zero. Algorithm 7 introduces the above method into Algorithm 3. In Algorithm 7, is the set of pairs with the lowest degree d that are not tested. The subset contains critical pairs selected from , and refers to new polynomials obtained by reducing . If the number of new polynomials is less than the number of selected pairs , a reduction to zero has occurred, and then is deleted.
| Algorithm 7 F4-style algorithm proposed by Ito et al. |
Input:.
Output: A Gröbner basis of .
- 1:
- 2:
fordo - 3:
Update - 4:
end for - 5:
whiledo - 6:
Select - 7:
if then - 8:
- 9:
end if - 10:
while do - 11:
- 12:
a subset of - 13:
- 14:
- 15:
- 16:
for do - 17:
Update - 18:
end for - 19:
if s.t. then - 20:
break - 21:
end if - 22:
if and then - 23:
- 24:
end if - 25:
end while - 26:
end while - 27:
returnG
|
Note that Ito et al. stated that the proposed method was valid for MQ problems associated with encryption schemes, i.e., of type , but other MQ problems, including those of type , were not discussed. Moreover, they set the number of selected pairs to 256 to divide . Hence, they did not guarantee that this subdividing method is optimal.
3.4. Proposed Methods
We explain the subdividing methods and the removal method in
Section 3.4.1 and
Section 3.4.2, respectively. The proposed methods were integrated into the F4-style algorithm as described in Algorithm 8. The OpenF4 library was used for these implementations. The OpenF4 library is an open-source implementation of the F4-style algorithm and, thus, is suitable for this purpose.
| Algorithm 8 F4-style algorithm integrating the proposed methods |
Input:.
Output: A basis of .
- 1:
- 2:
fordo - 3:
Update - 4:
end for - 5:
while
do - 6:
Select - 7:
- 8:
while do - 9:
- 10:
SubDividePd - 11:
for do - 12:
- 13:
- 14:
- 15:
- 16:
for do - 17:
Update - 18:
end for - 19:
- 20:
if then - 21:
- 22:
break - 23:
end if - 24:
end for - 25:
end while - 26:
end while - 27:
returnG
|
| Algorithm 9 SubDividePd |
Input: and .
Output: - 1:
(disjoint union) s.t. for - 2:
return
|
As mentioned above, the SelectPd function serves to select a subset of all the critical pairs at each step for the reduction part of the F4-style algorithm. Ito et al. proposed a method where they subdivide into smaller subsets as described in Algorithm 9, and perform the Reduction and Update functions for each set consecutively when no S-polynomials are reduced to zero during the reduction. On the other hand, if some S-polynomials reduce to zero during the reduction of a set for the first time, this method ignores the remaining sets and removes them from all the critical pairs.
The authors confirmed that their method was effective in solving the MQ problems under the condition where and only and they did not mention other types, especially , or other subdividing methods.
In our experiments, as described in
Section 4.1, we generated the MQ problems (
) with random polynomial coefficients to have at least one solution in the same manner as the Fukuoka MQ challenges ([
40], Algorithm 2 and Step 4 of Algorithm 1), and we assumed that
for all input polynomials
because such polynomials are obtained with non-negligible probability for experimental purposes. Taking a change in variables into account, the probability is exactly
. For example, it is close to 1 for
and
.
3.4.1. Subdividing Methods
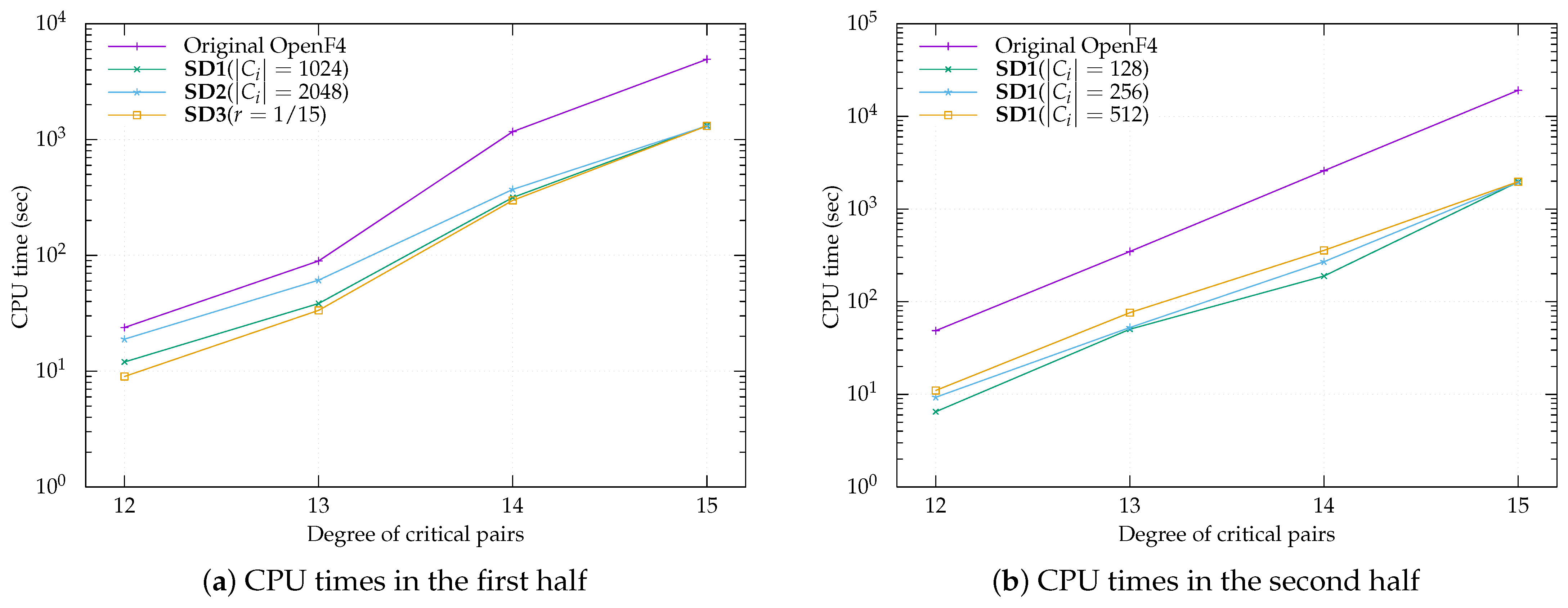
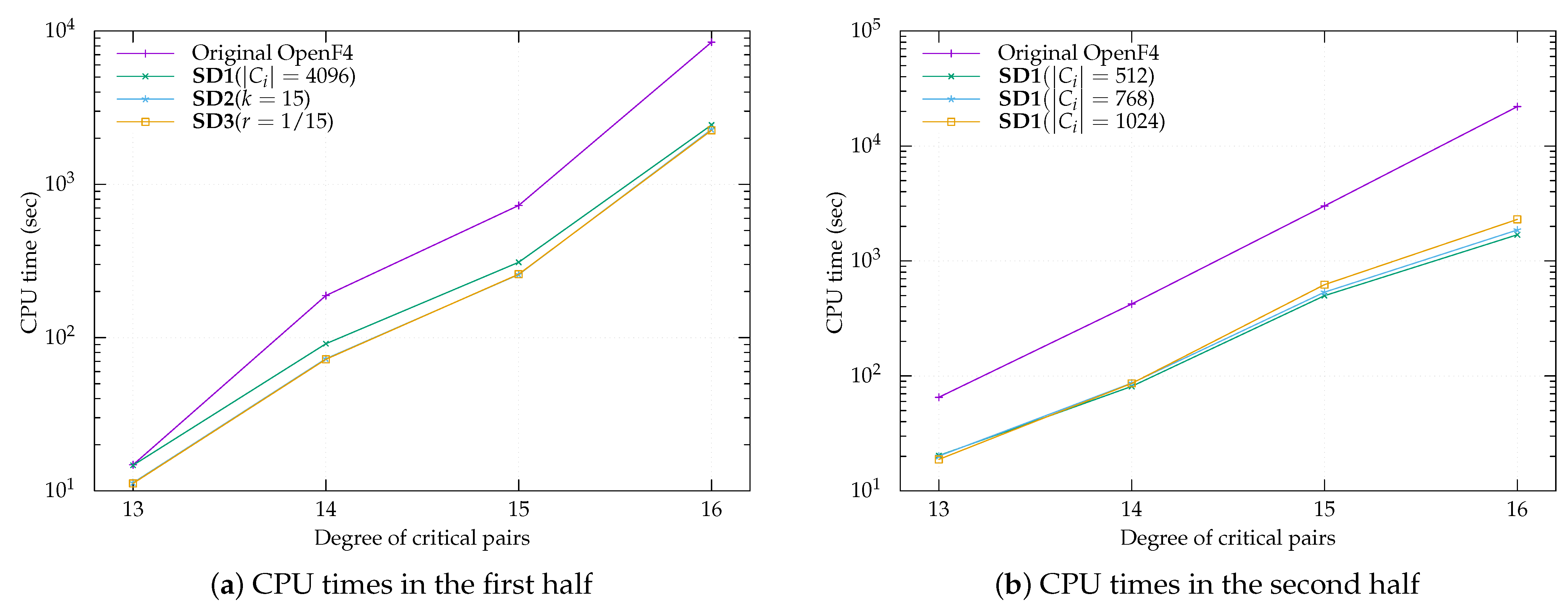
To solve the MQ problems, Ito et al. fixed the number of elements of each to 256, i.e., . In our experiments, we propose three types of subdividing methods:
- SD1:
The number of elements in () is fixed except .
We set , 256, 512, 768, 1024, 2048, and 4096.
- SD2:
The number of subdivided subsets is fixed.
We set , 10, and 15.
- SD3:
The fraction of elements to be processed in the remaining element in is fixed; i.e., and for .
We set , , and .
Furthermore, we propose two subdividing methods based on SD1 in
Section 4.2.
3.4.2. A Removal Method
It is important to skip redundant critical pairs in the -style algorithm because it takes extra time to compute reductions of larger matrix sizes. To solve the MQ problems that are defined as systems of m quadratic polynomial equations over n variables, Ito et al. experimentally confirmed that once a reduction to zero occurs for some critical pairs in , nothing but a reduction to zero will be generated for all subsequently selected critical pairs in P in the case of or with the number of polynomials and the number of variables .
We checked Hypothesis 1 through computational experiments.
Hypothesis 1. If a Macaulay matrix composed of critical pairs has some reductions to zero, i.e., in line 15 in Algorithm 8 with the normal strategy, then all remaining critical pairs s.t. will be reduced to zero with a high probability.
The difference between a measuring algorithm and a checking algorithm is as follows: in the algorithm measuring the software performance of the OpenF4 library and our methods, as defined in Algorithm 8, once a reduction to zero occurs, the remaining critical pairs in are removed. In other words, in such an algorithm, a new next is selected immediately after a reduction to zero. On the other hand, in the algorithm checking Hypothesis 1 as described above, we need to continue reducing all remaining critical pairs and monitor whether reductions to zero are consecutively generated after the first one. However, because the behavior of the checking algorithm needs to match that of the measuring one, every internal state just before processing the remaining critical pairs in the checking algorithm is reset to the state immediately after a reduction to zero.
To check Hypothesis 1, we solved the MQ problems of random coefficients over for the condition where and using Algorithm 8 with SD1. Due to processing times, a hundred samples and fifty samples were generated for each problem for and , respectively. Furthermore, of SD1 was fixed to 1, 16, 32, 256, and 512 for ; ; ; ; and , respectively.
Our programs were terminated normally with about probability. Thus, the experiments showed that Hypothesis 1 was valid with about probability. The remaining events, which coincided with a probability of approximately 0.1, corresponded to an OpenF4 library’s warning concerning the number of temporary basis. Although the warning was output, neither temporary basis (i.e., an element in G, in line 17 of Algorithm 8) nor a critical pair of higher degree arose from unused critical pairs in omitted subsets. Moreover, all outputs of all problems contained the initial values with no errors.
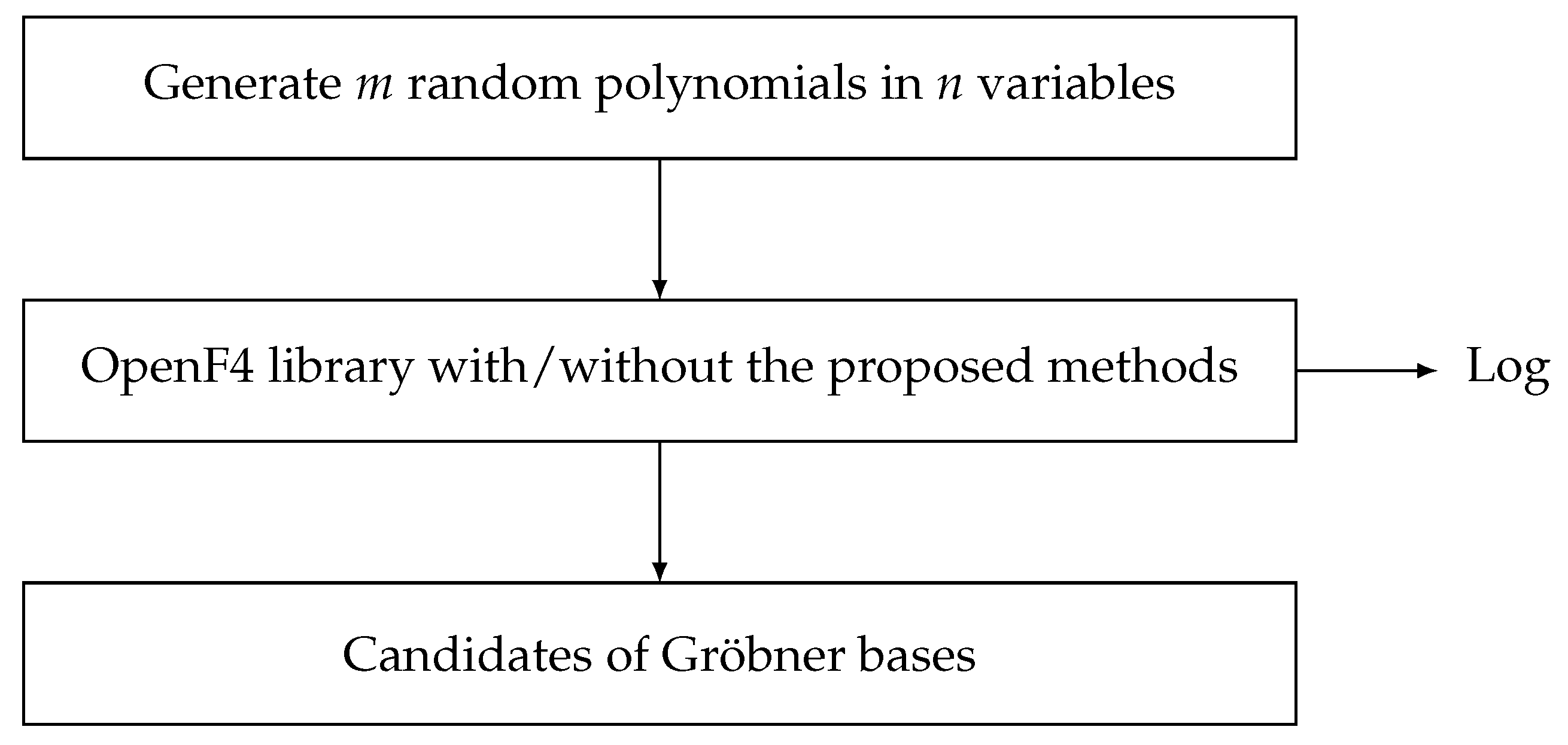
3.5. System Architecture
Our experiments were performed on the following systems as shown in
Table 3 and
Table 4. In the case of
and
in
Appendix A1, our experiments were performed as shown in
Table 4.
Our software diagram was as shown in
Figure 1.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




