
Shift Register, Reconvergent-Fanout (SiRF) PUF Implementation on an FPGA


Abstract
:1. Introduction
- 1.
- A novel delay-based PUF architecture that reduces undesirable bias by distributing components of the sensitized paths over a wide region of the FPGA using shifters, MUXs and logic gate networks.
- 2.
- A hazard-free by-construction logic gate netlist that leverages reconvergent-fanout to add uncertainty regarding which of the inputs of logic gates on the sensitized path dominate the path timing and determine the overall path delay.
- 3.
- A calibration method that post-processes the measured digitized path delays to reduce both environmentally-induced changes in path delay and those introduced by global process variation effects.
- 4.
- An entropy enhancing method that uniformly and randomly distributes within-die delay variations, and maximizes the number of bits available for secret keys and authentication operations.
Background
- Leveraging within-die delay variations that occur in the series combination of LUT, switches and wires within the FPGA fabric.
- Utilizing shift register paths, MUXs and reconvergent-fanout to distribute the structural components of sensitized paths over a wide region of the FPGA fabric as a means of reducing bias effects that exist within localized regions.
- Simplifying design pre-characterization, constraints and challenge generation while maintaining an exponentially large CRP space
- Enabling control over path length using a modular architecture, which provides the opportunity to tune signal-to-noise levels to meet statistical quality targets for reliability, uniqueness and randomness in the generated keys and bitstrings.
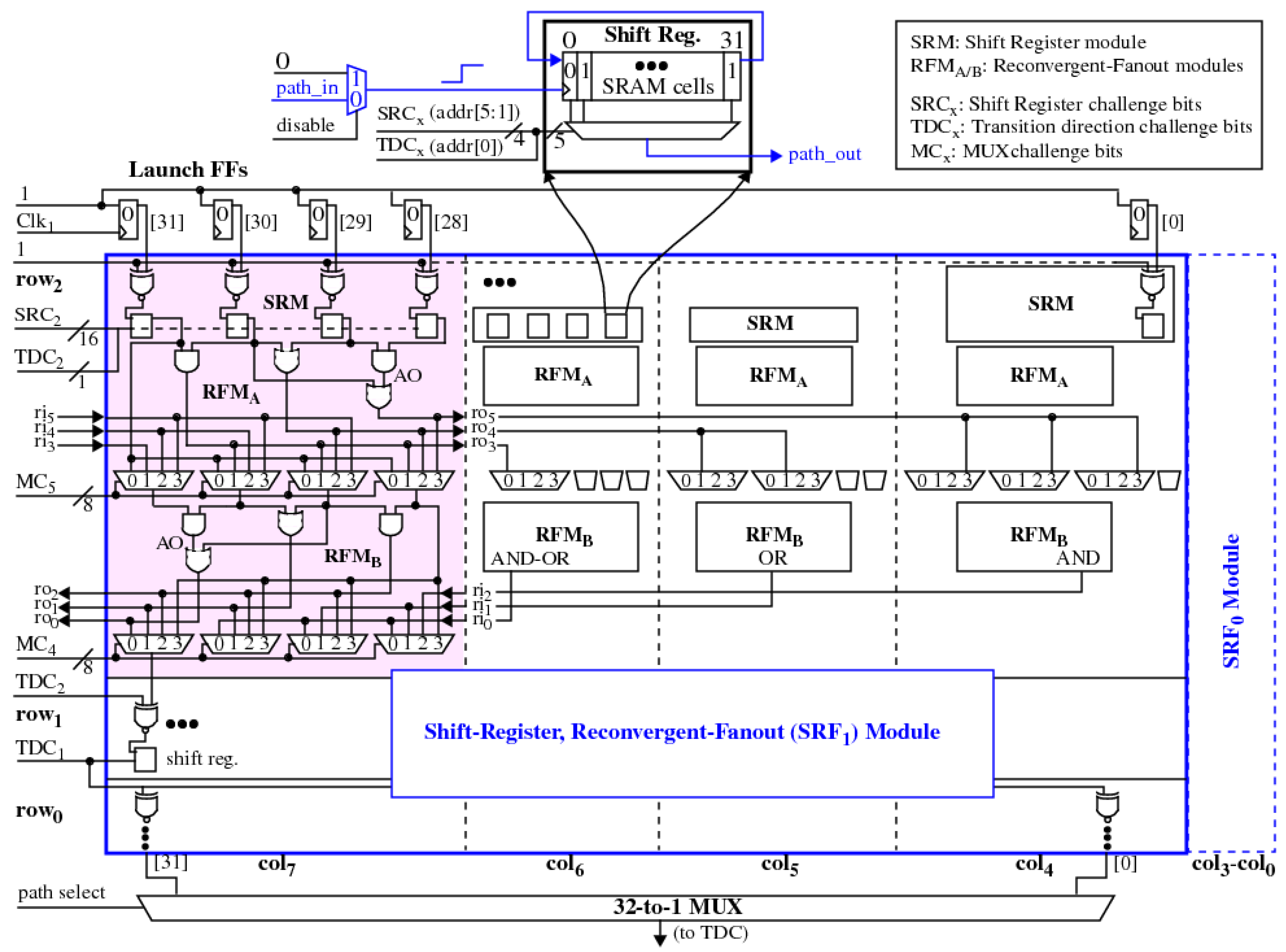
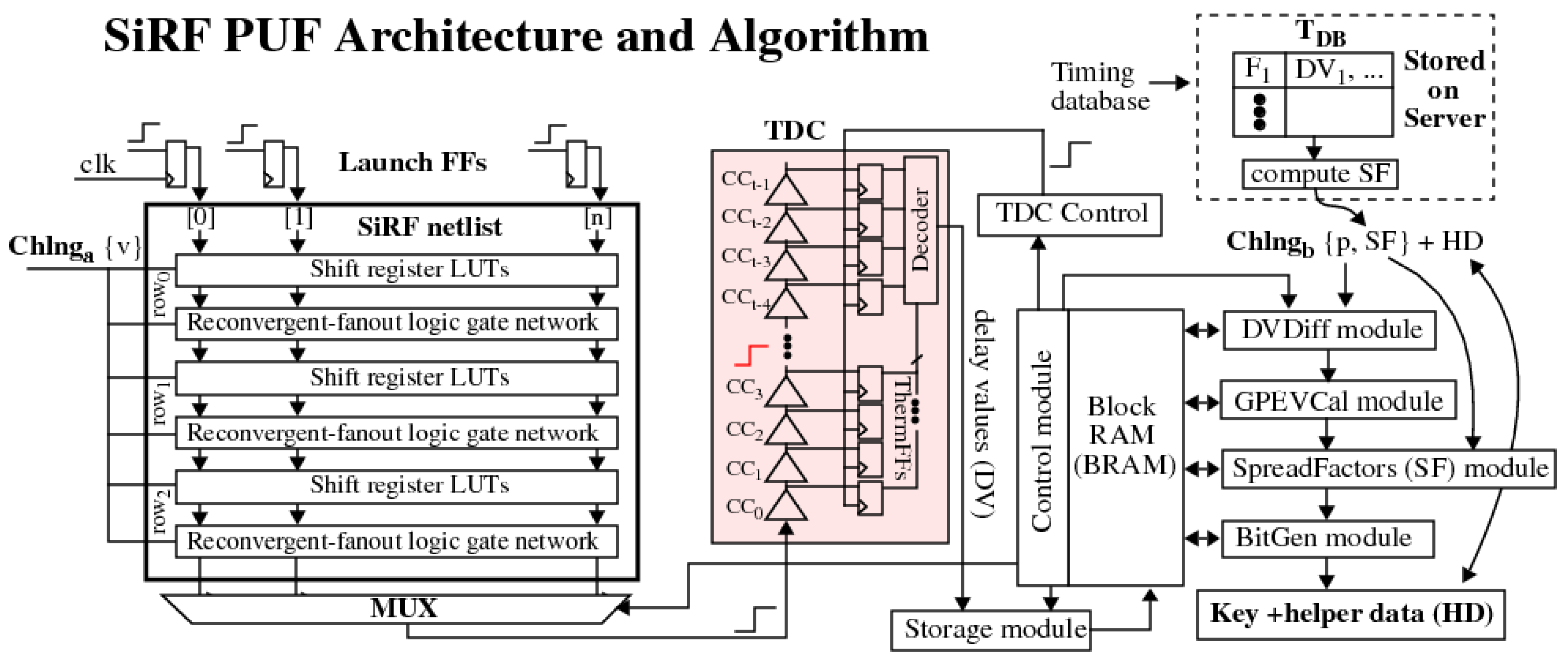
2. SiRF Design
3. The SiRF PUF Algorithm
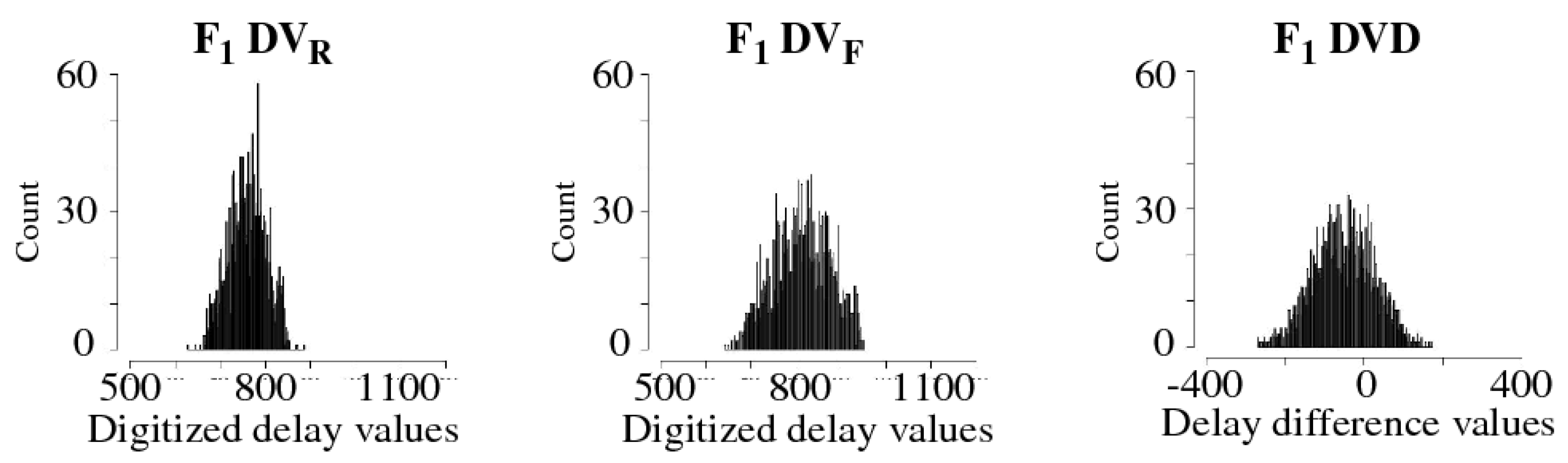
3.1. Difference Module
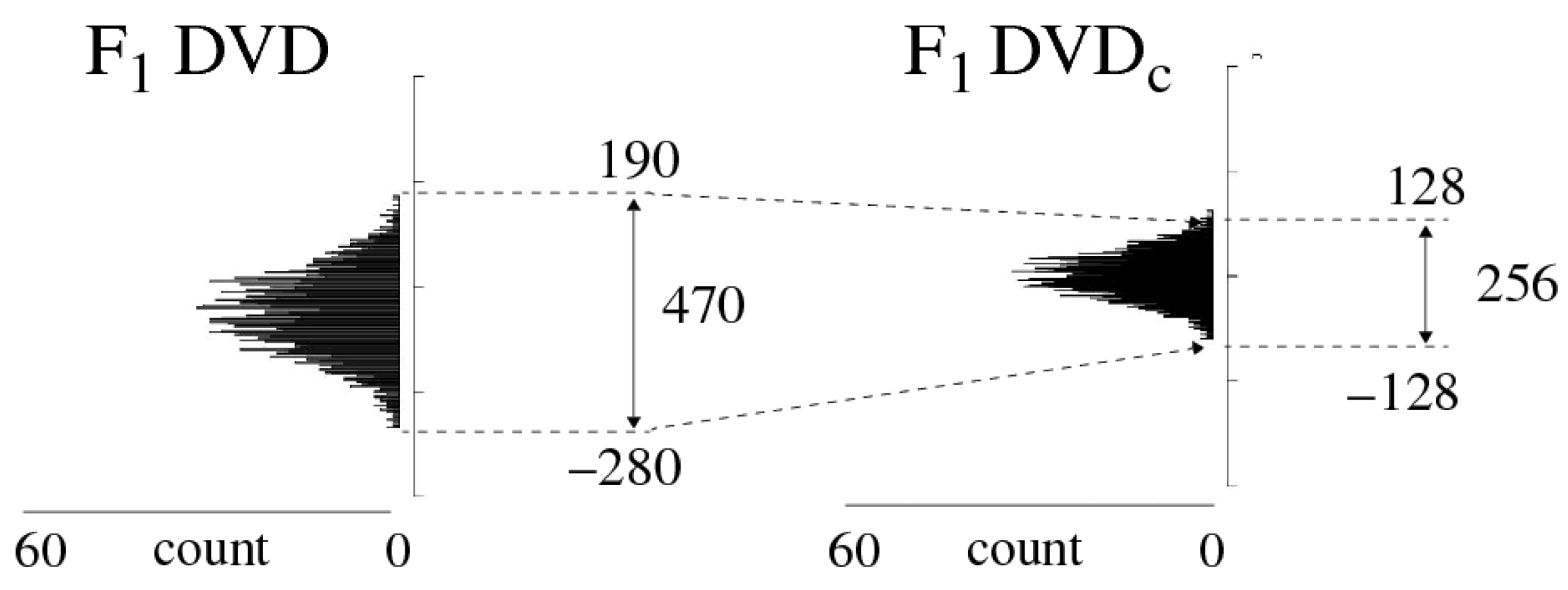
3.2. GPEVCal Module
3.3. SpreadFactors Module
3.4. BitGen Module
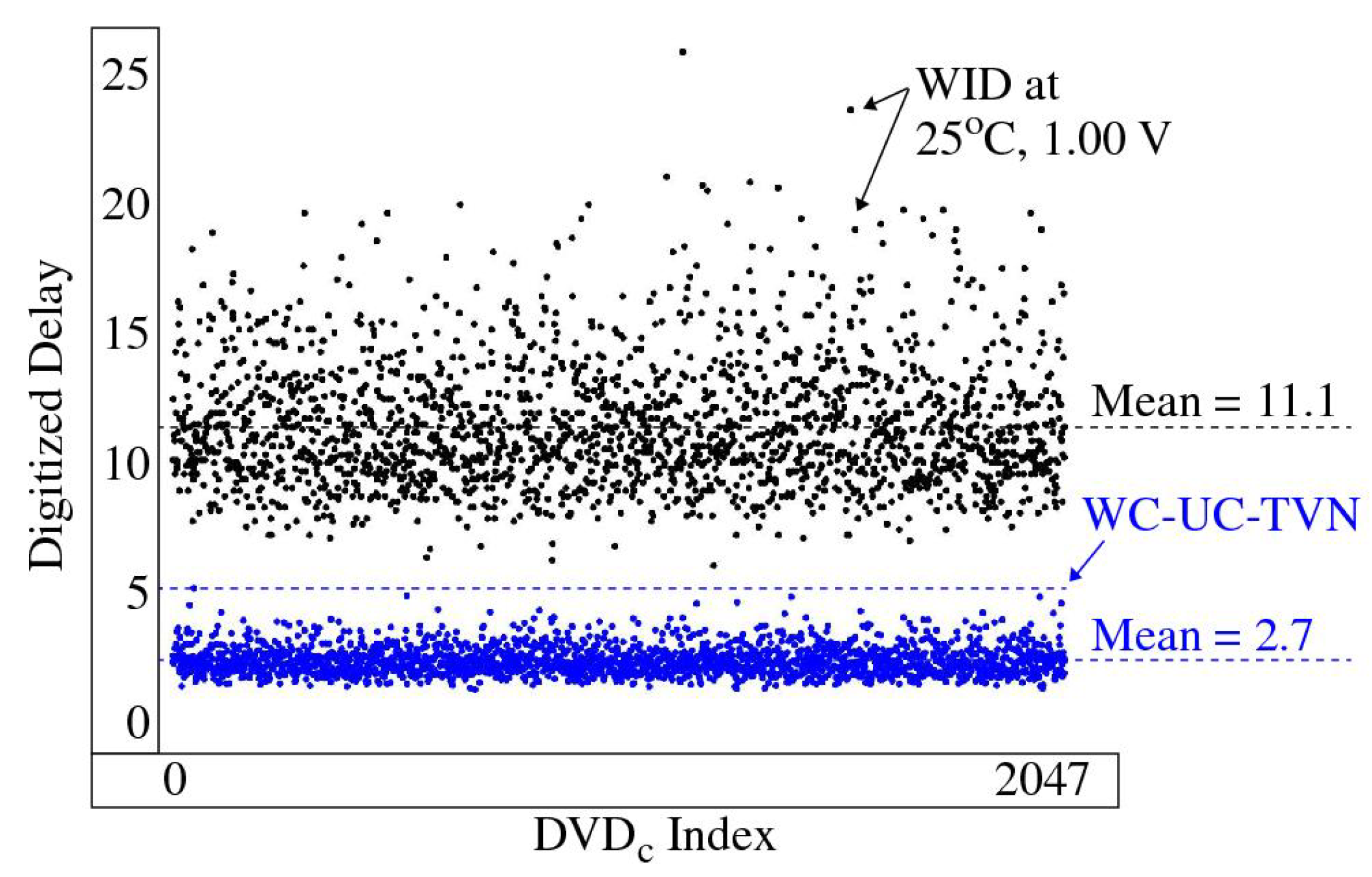
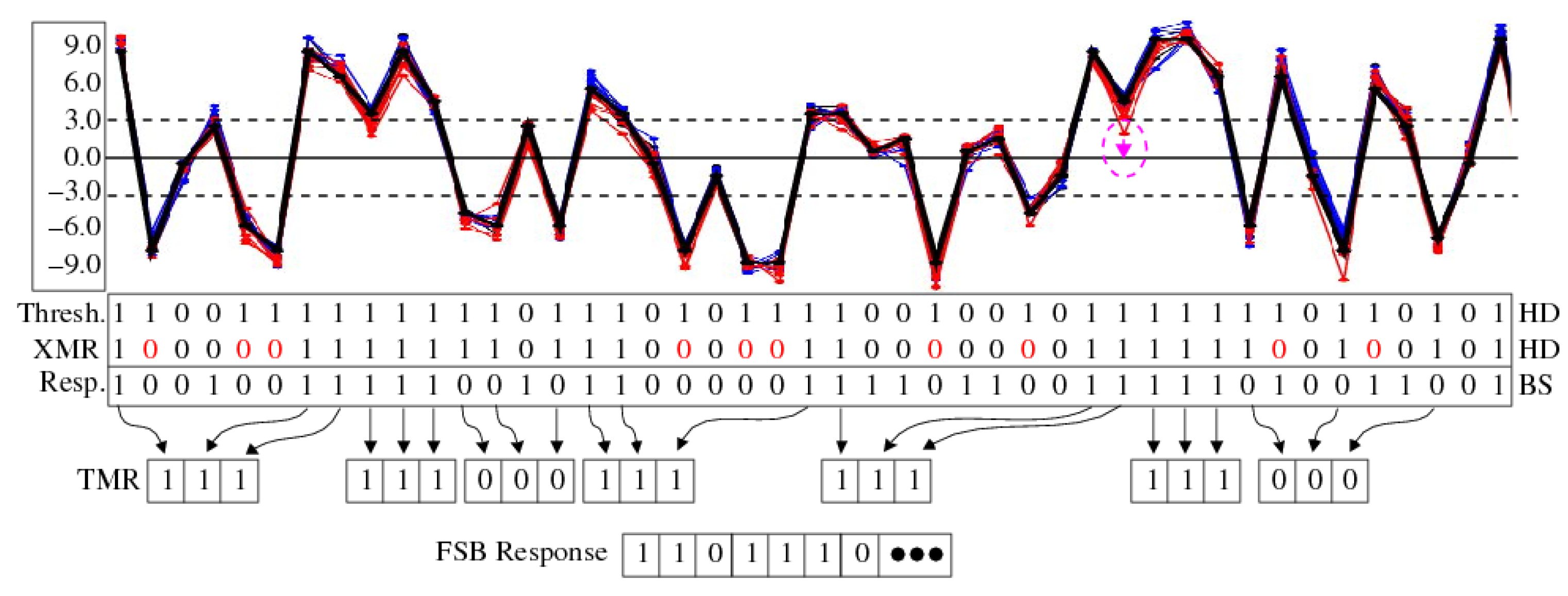
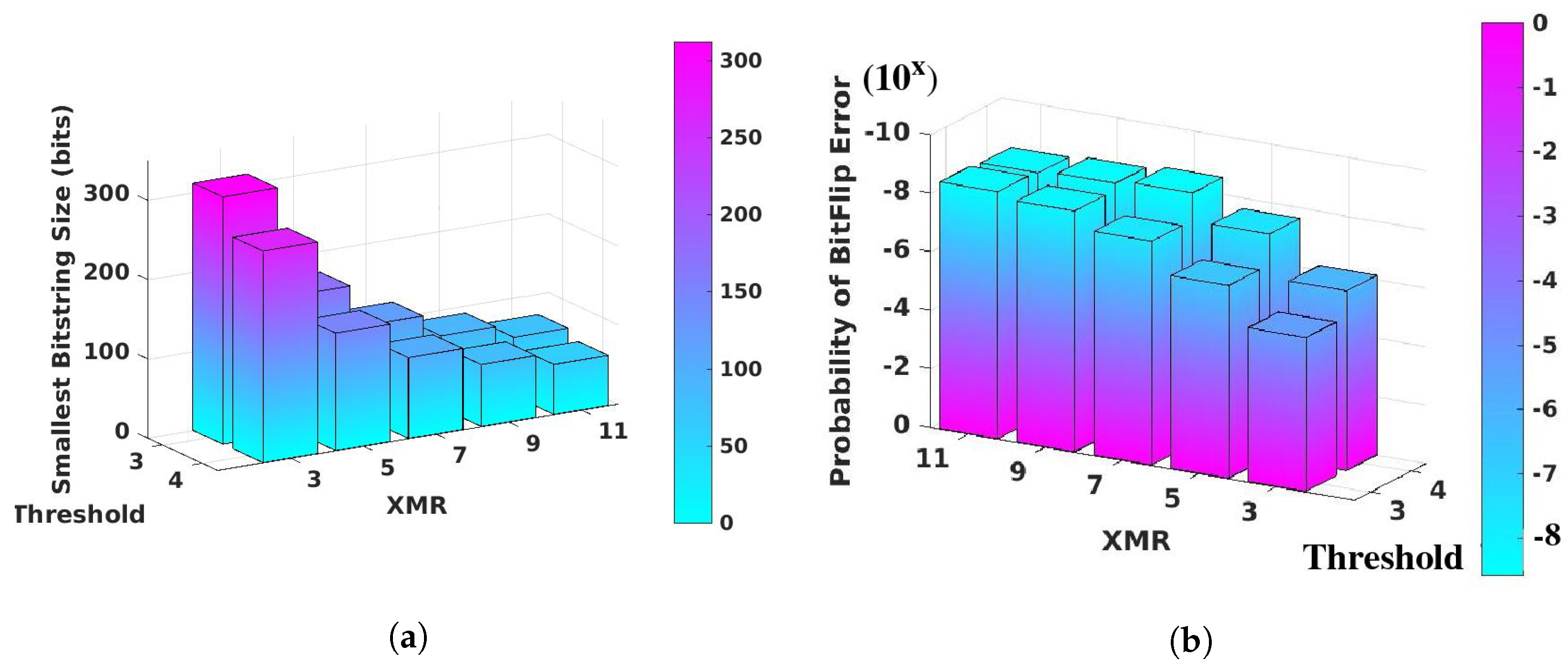
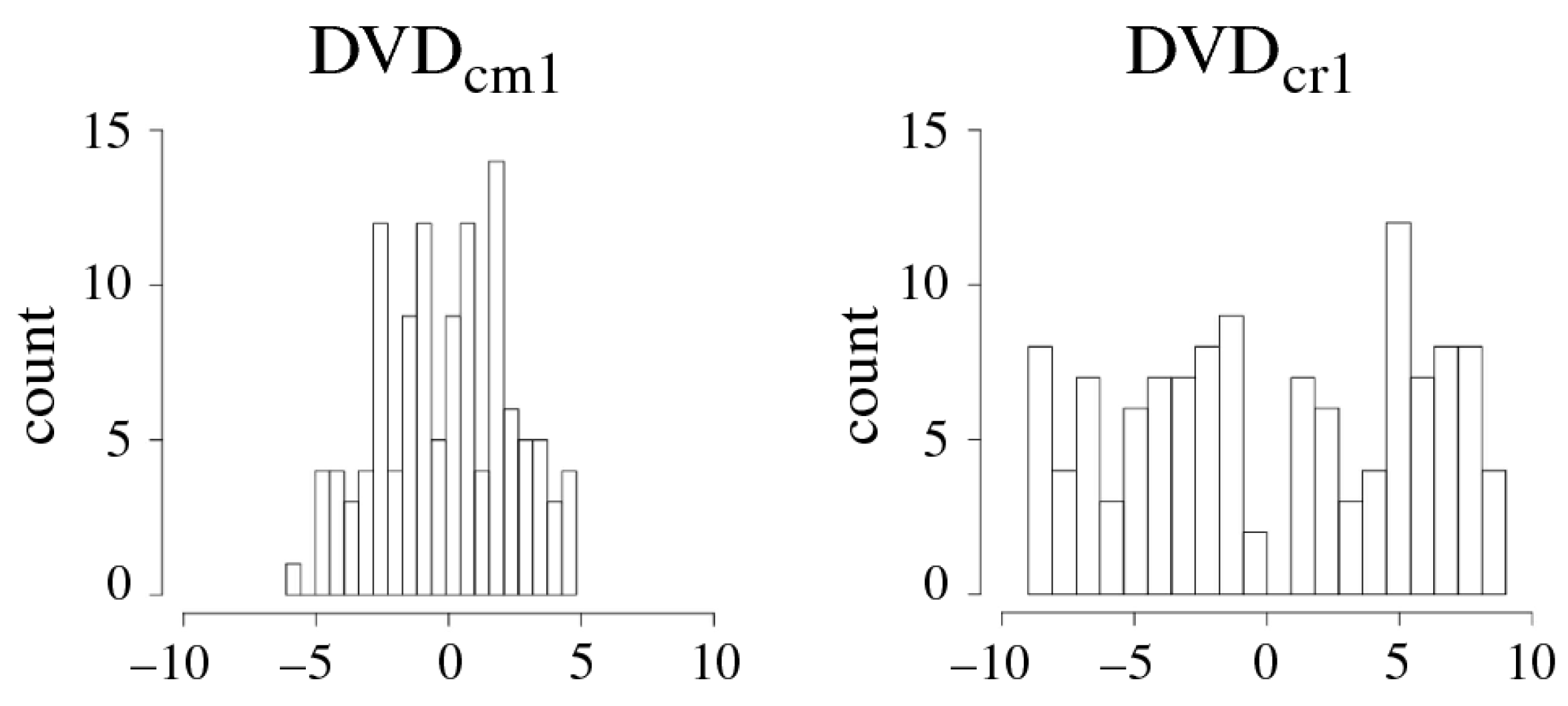
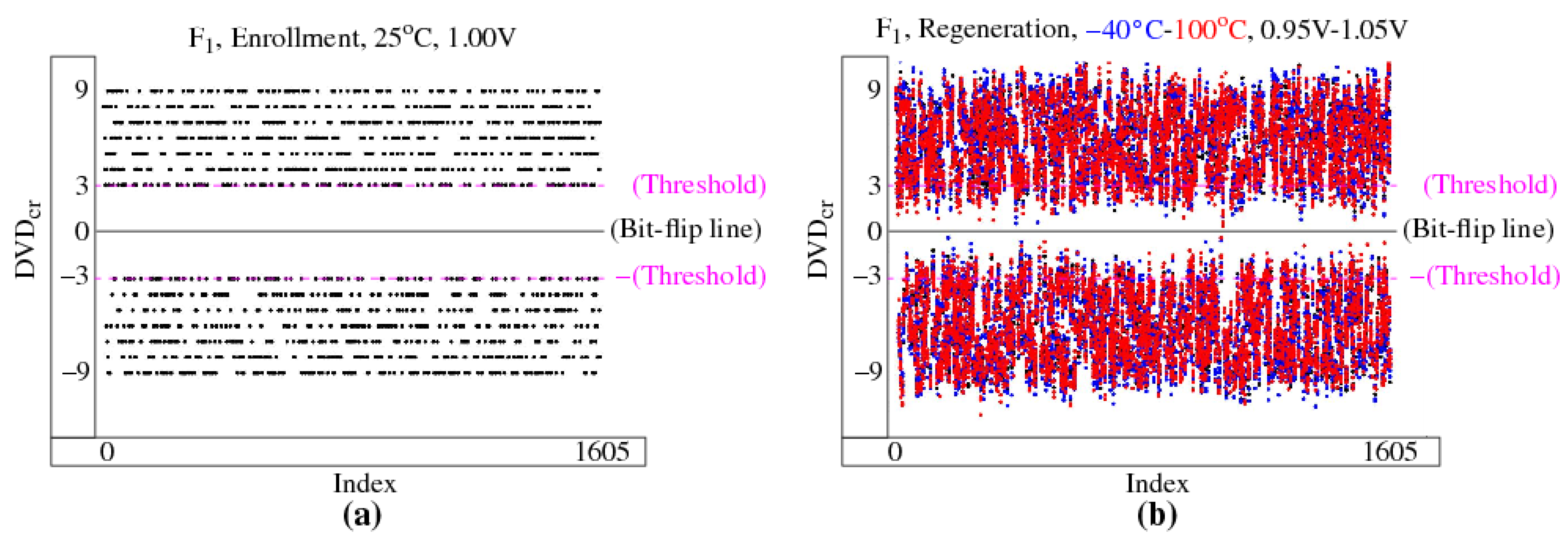
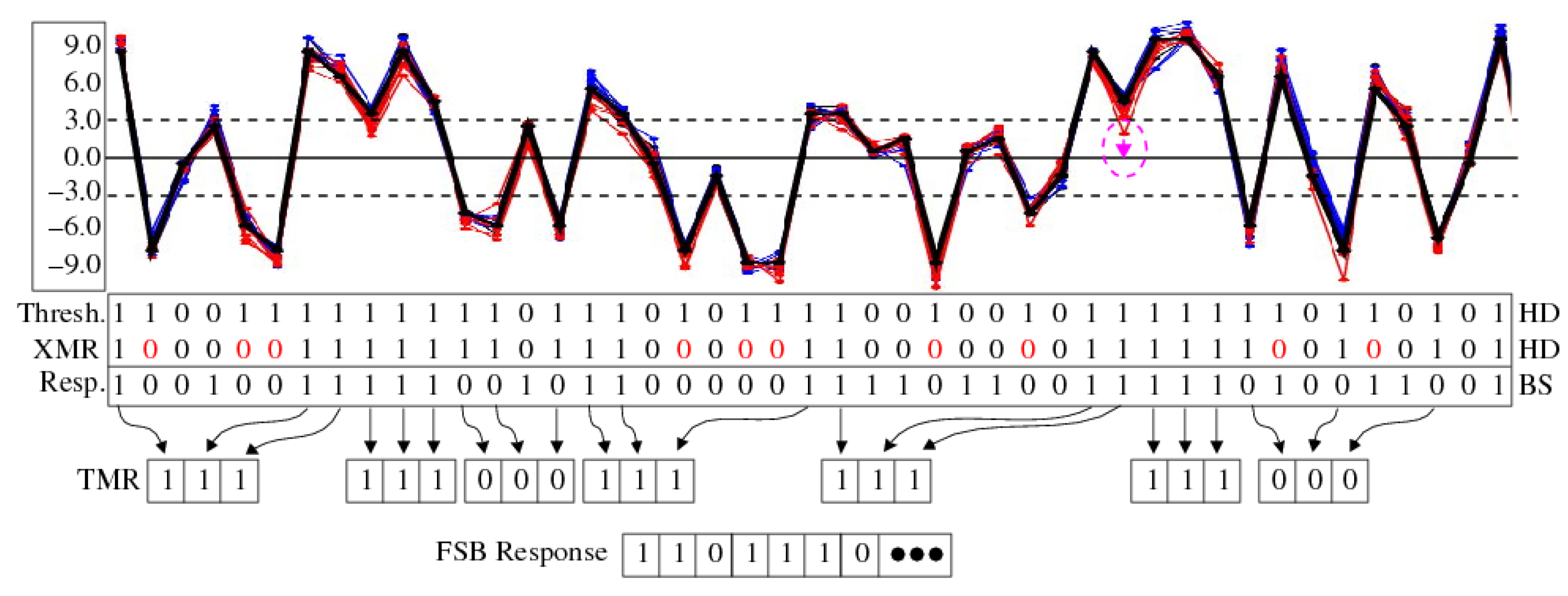
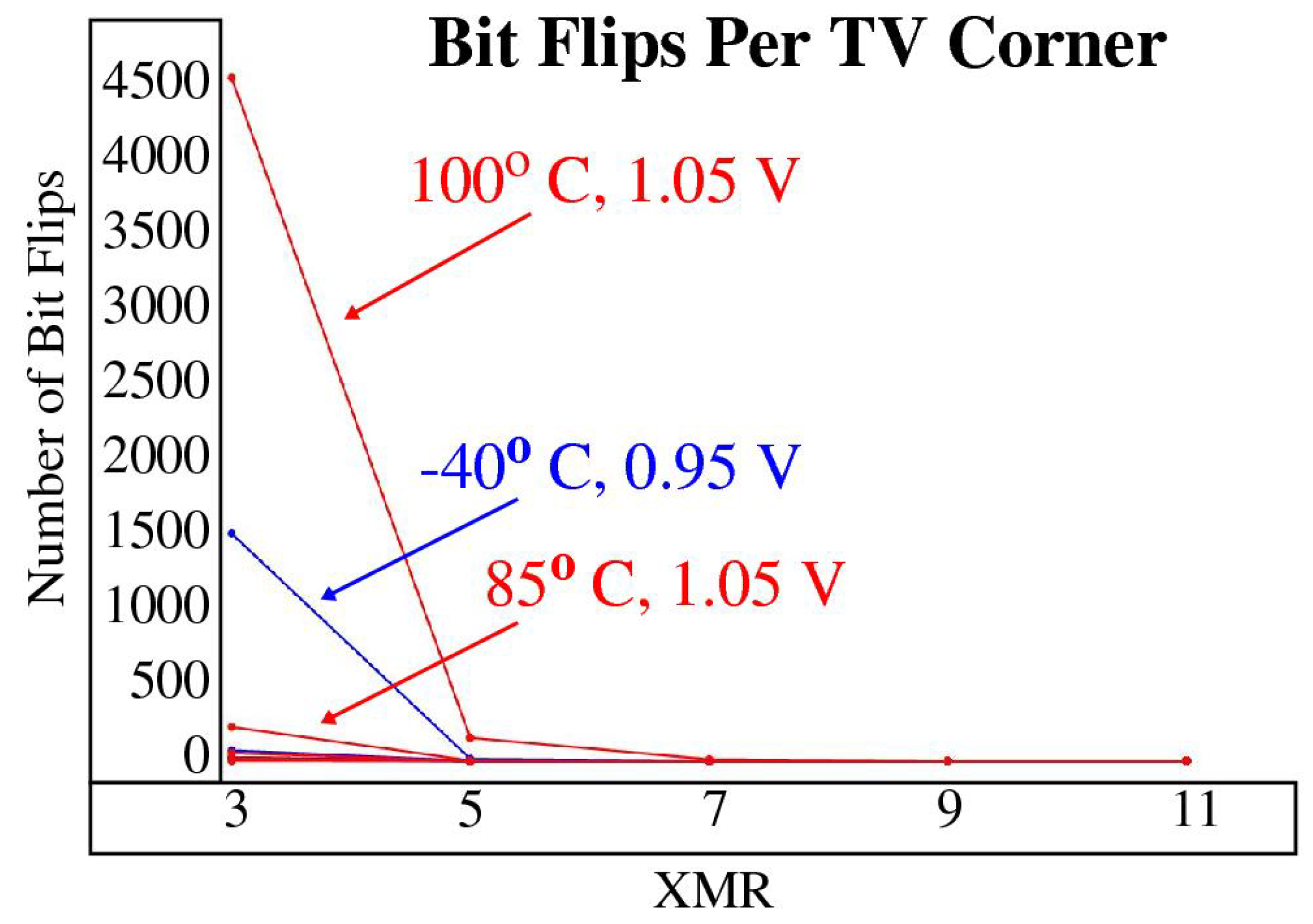
3.4.1. XMR Reliability Enhancement
3.4.2. XMR Applications
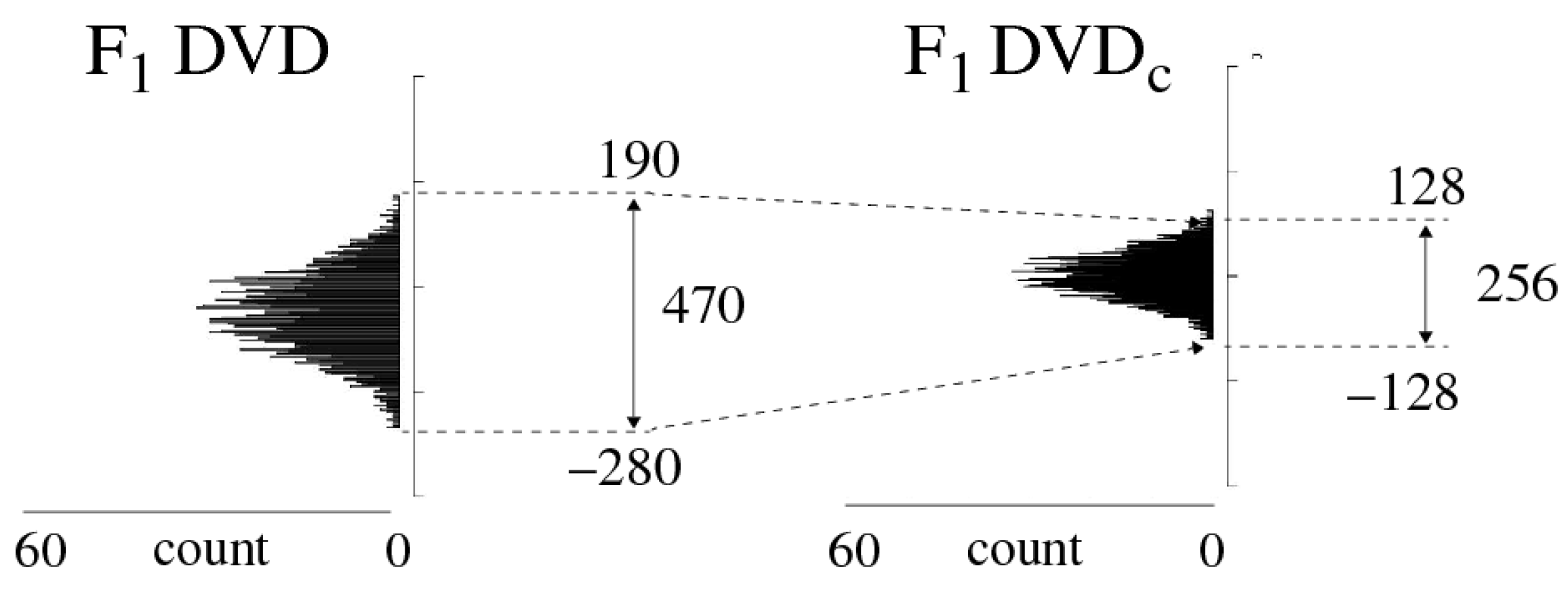
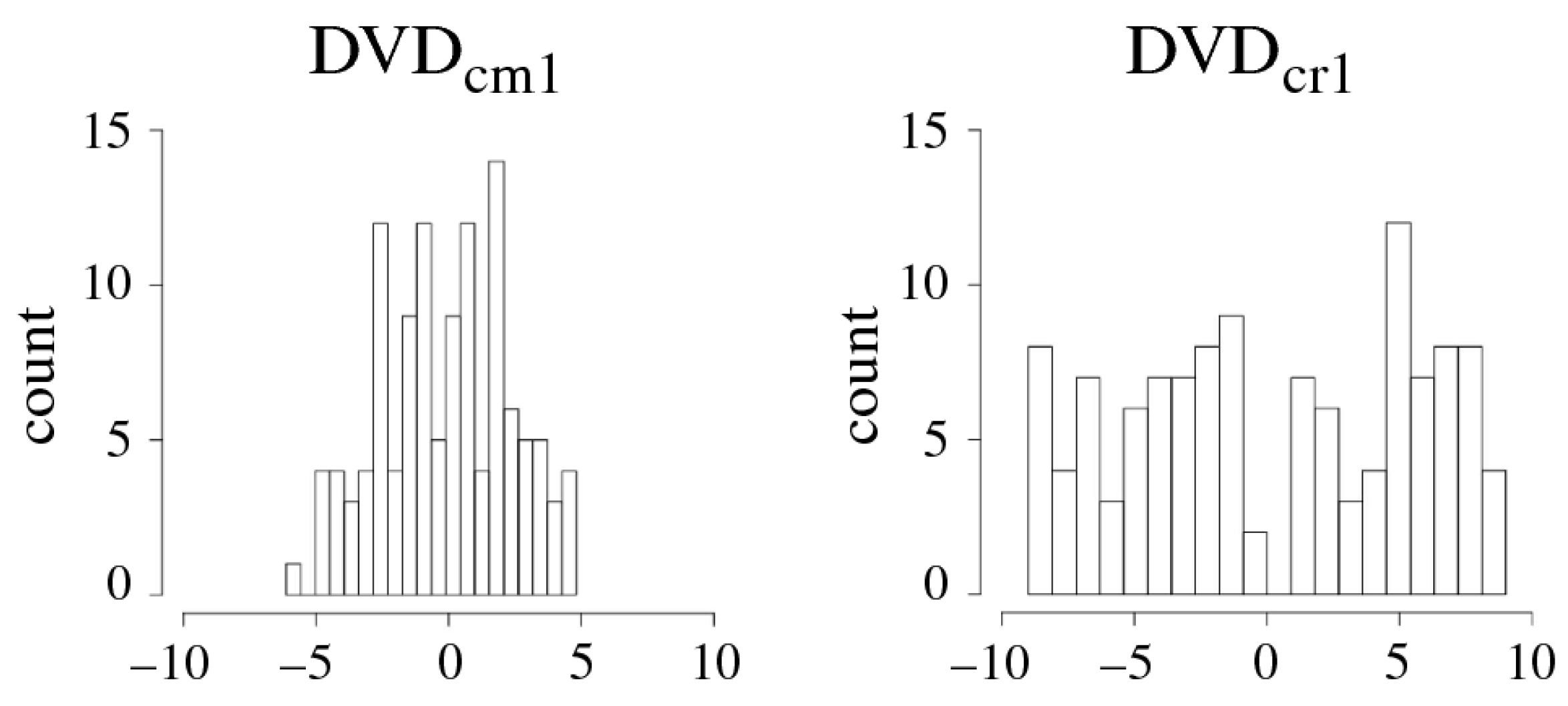
3.4.3. DV Characterization and Challenge Selection
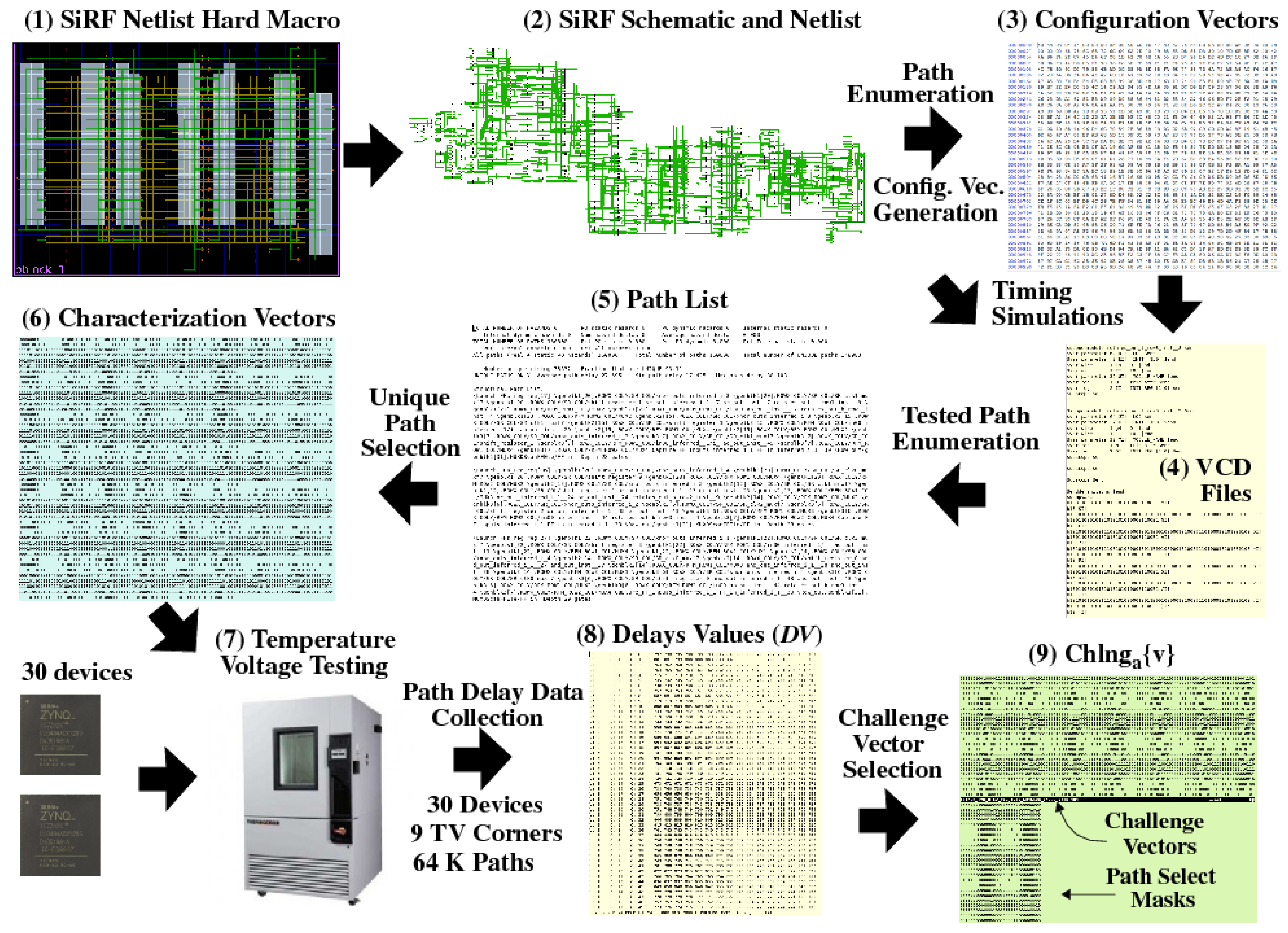
- 1.
- Behavioral VHDL describing the SiRF PUF is processed into a hard macro using the Xilinx Vivado CAD tool flow. No placement or routing constaints are utilized.
- 2.
- A SiRF netlist and standard delay format (SDF) file is extracted from the hard macro.
- 3.
- All possible paths through the netlist are enumerated using a C program and subsets of these paths are used as input to another C program, which determines the configuration vectors required to sensitize (test) the paths in the selected subsets.
- 4.
- Timing simulations are carried out using the configuration vectors to produce value-change-dump (VCD) files. VCD files record the switching (transition) activity on all nodes within the netlist as the configuration vectors are applied.
- 5.
- The VCD files and netlist are analyzed by a third C program to create a list of paths that are sensitized using the configuration vectors (Path List). Note that each configuration vector sensitizes multiple paths and it is likely that any given path may be tested more than once by the vectors.
- 6.
- The uniquely sensitized paths from the Path List are identified using a fourth C program and the configuration vectors needed to test them are identified. The configuration vectors produced by this process are called Characterization Vectors.
- 7.
- The Characterization Vectors are applied to a sample of at least 30 devices at each of the TV corners. The testing process produces DV files for the target paths.
- 8.
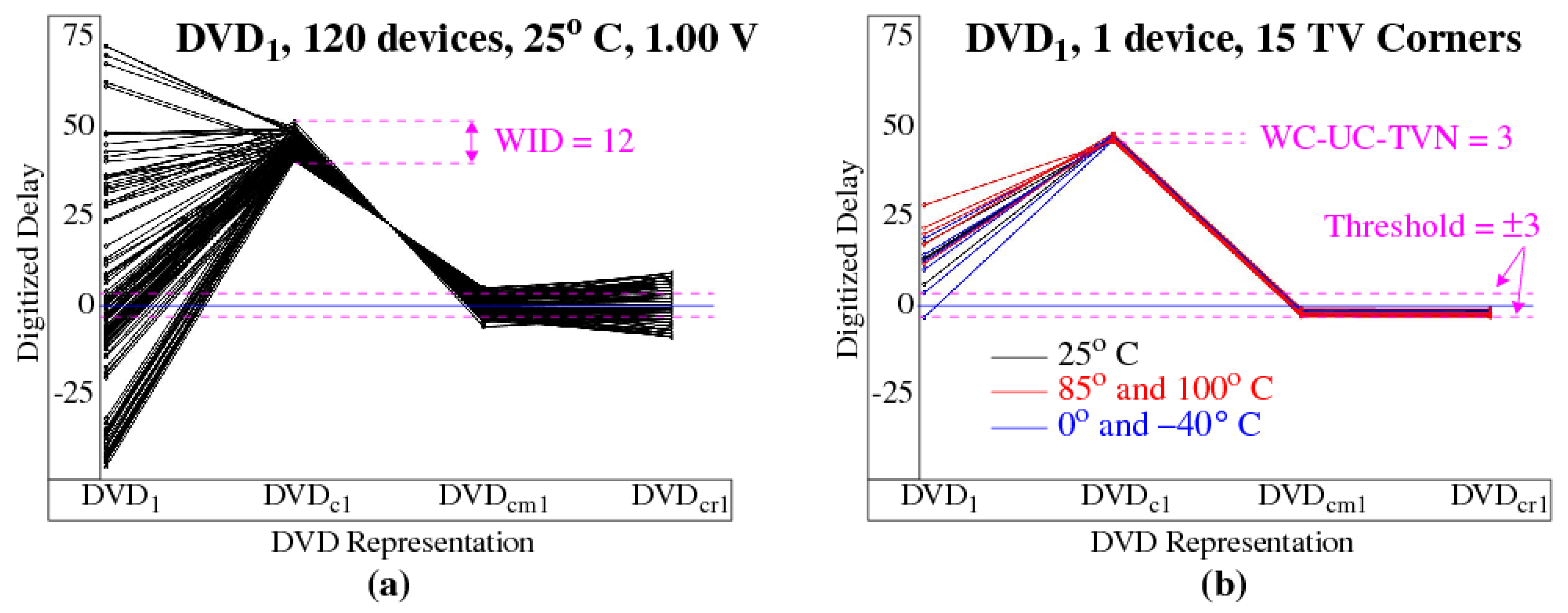
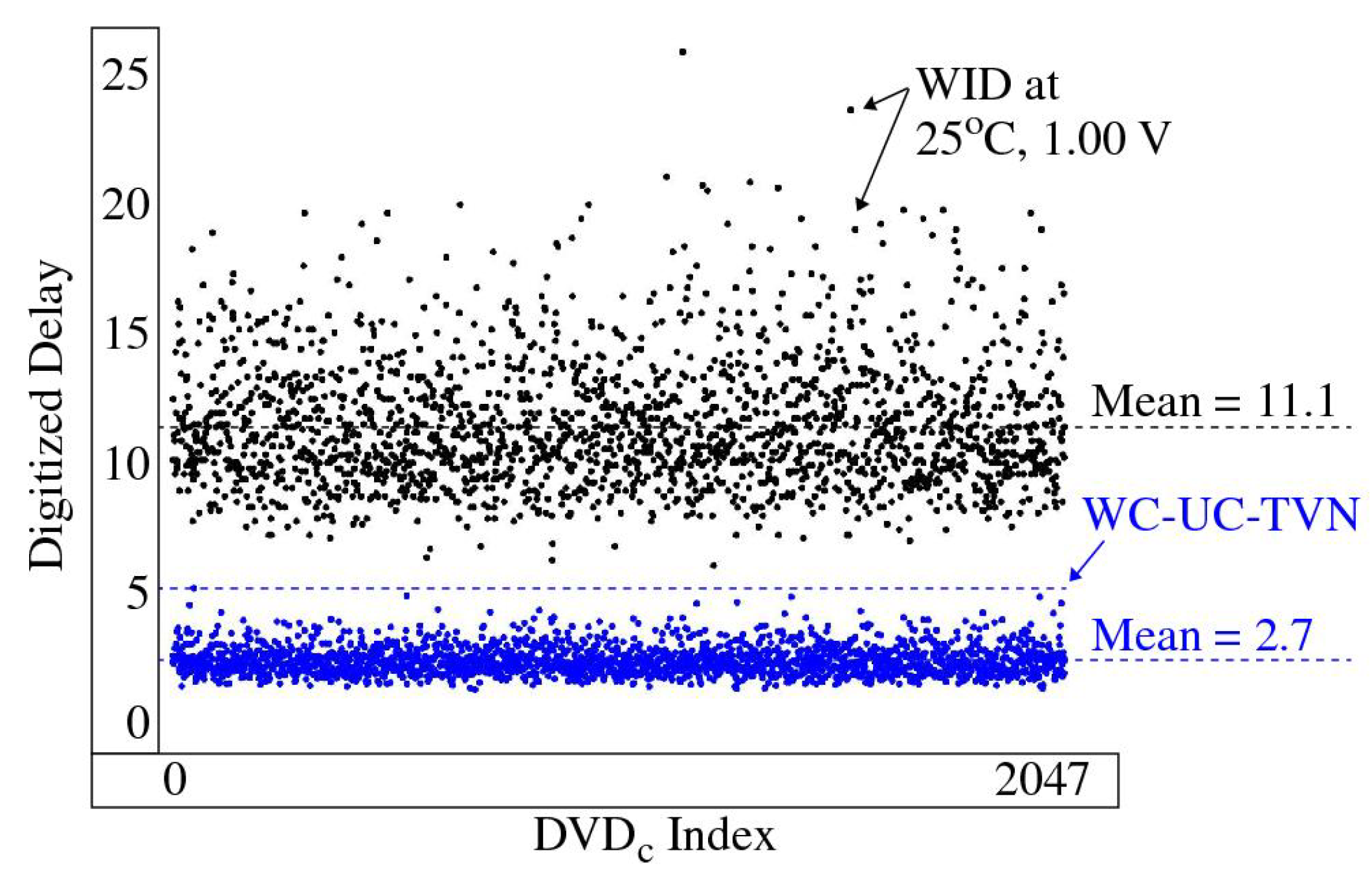
- The DV are analyzed by a fifth C program, which selects sets of compatible paths characterized as having upper and lower bounds on UC-TVNoise and WID, respectively.
4. Experimental Results
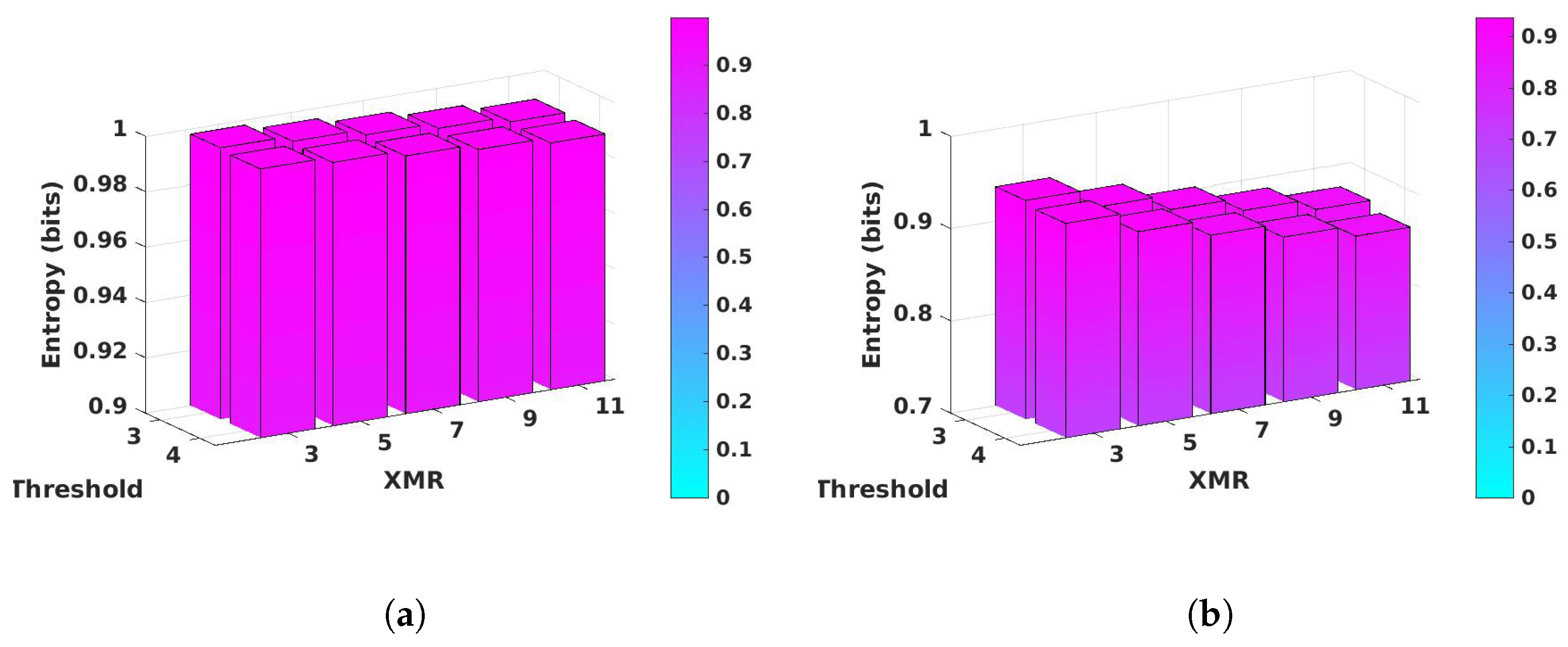
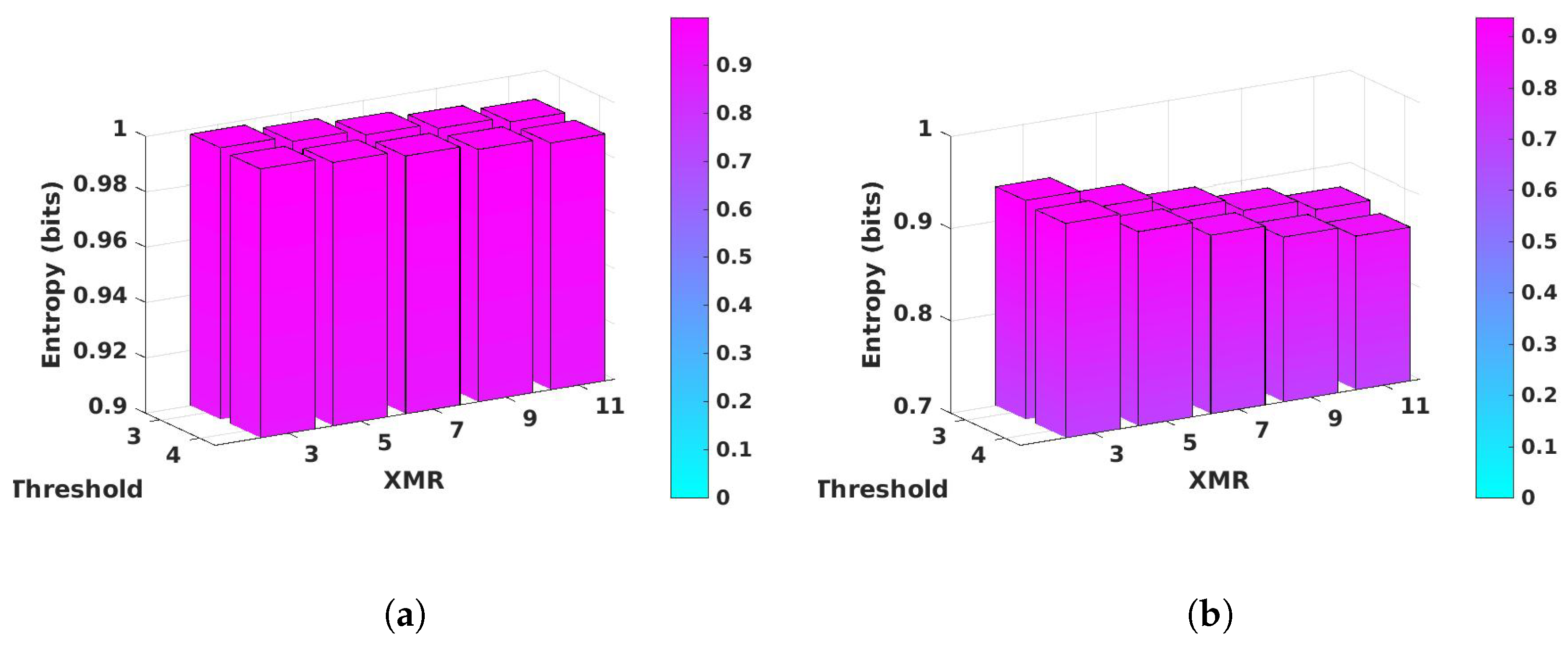
4.1. Entropy and Min-Entropy Analysis
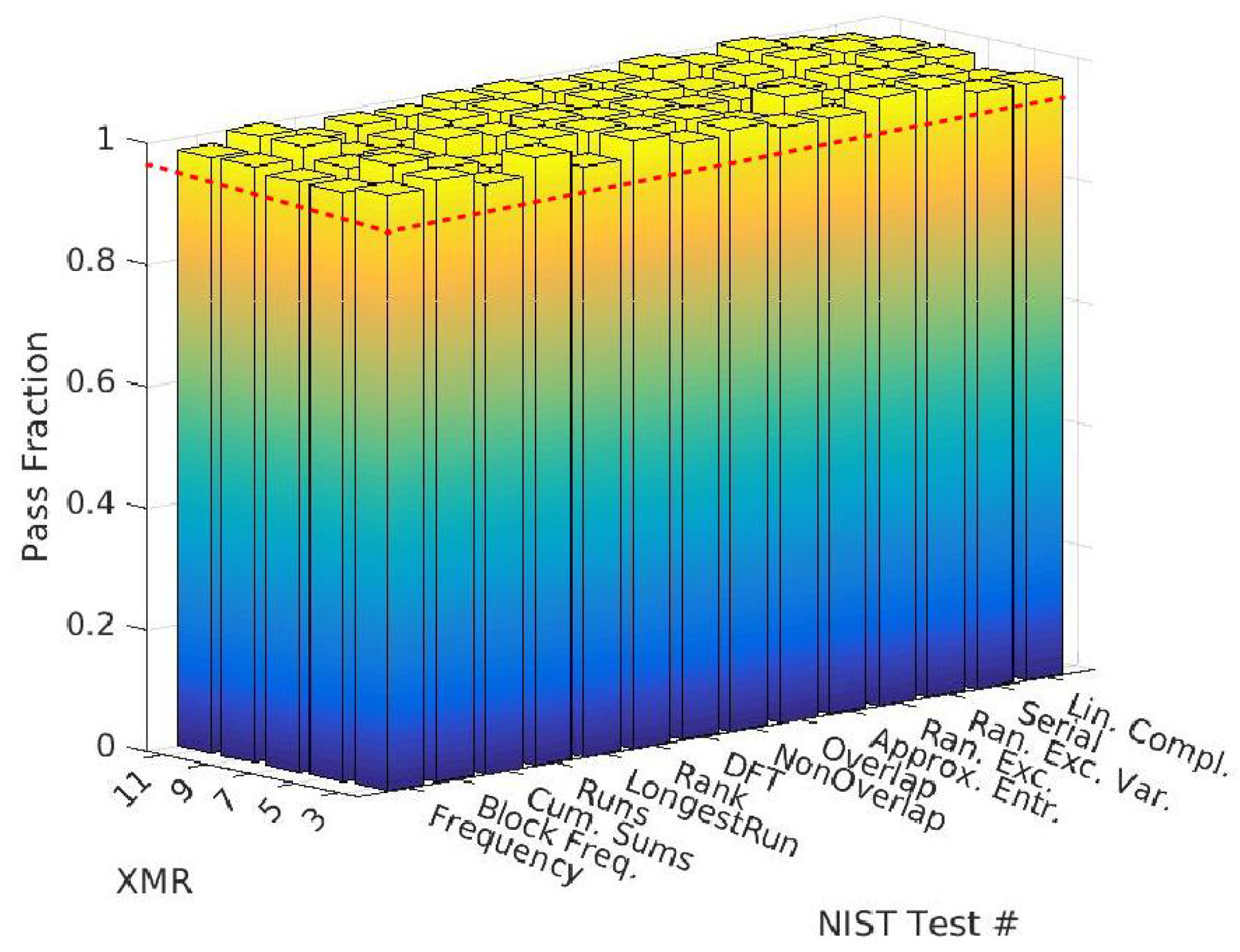
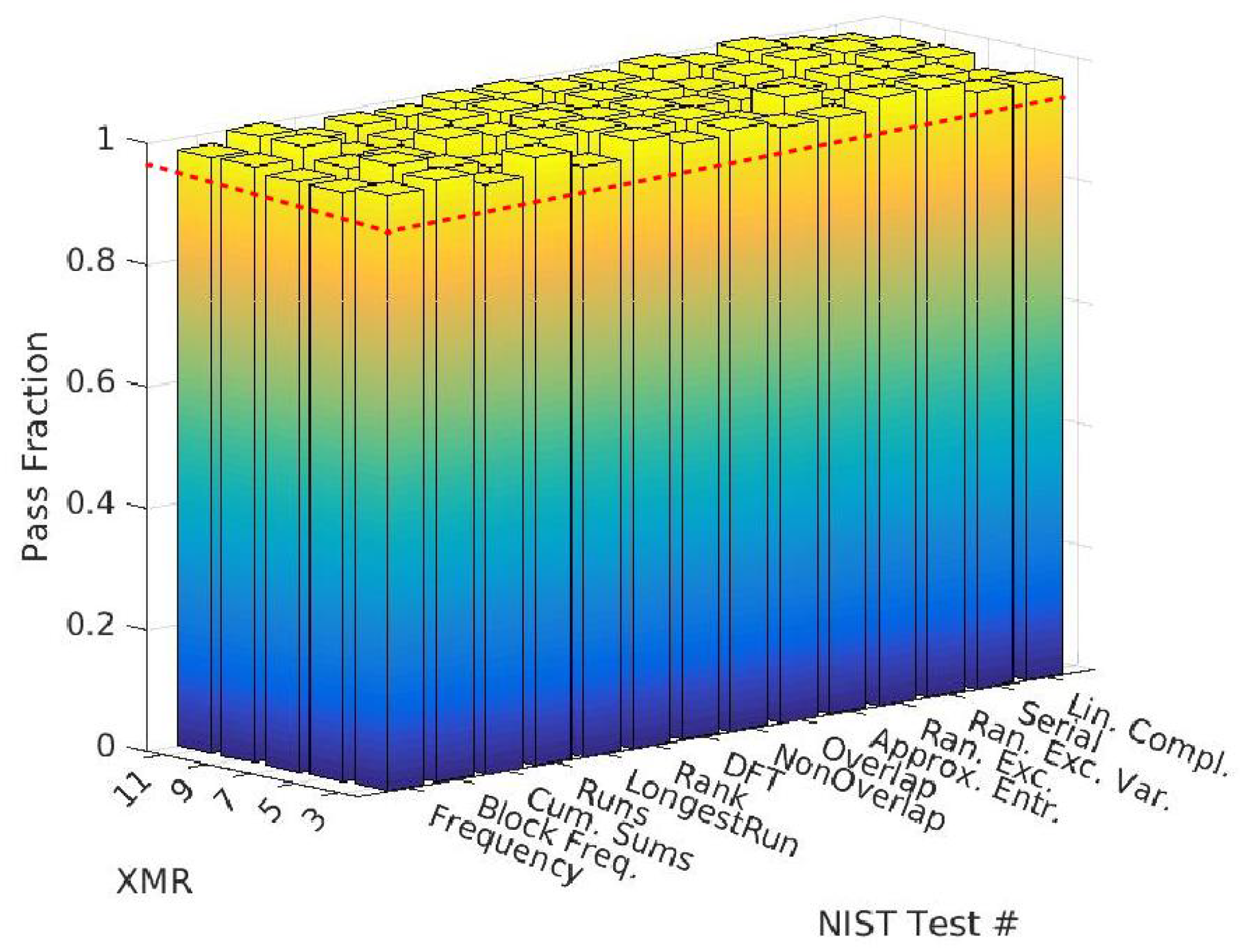
4.2. NIST Statistical Test Results
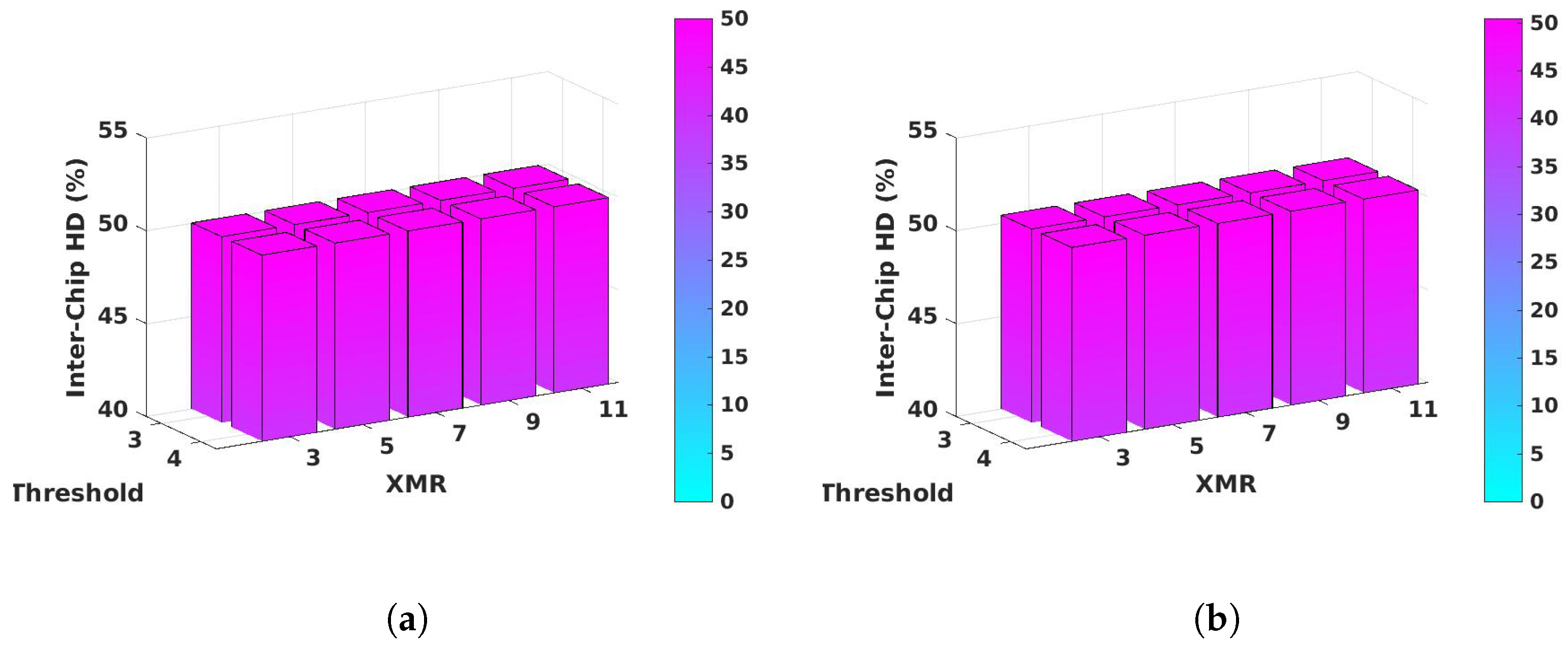
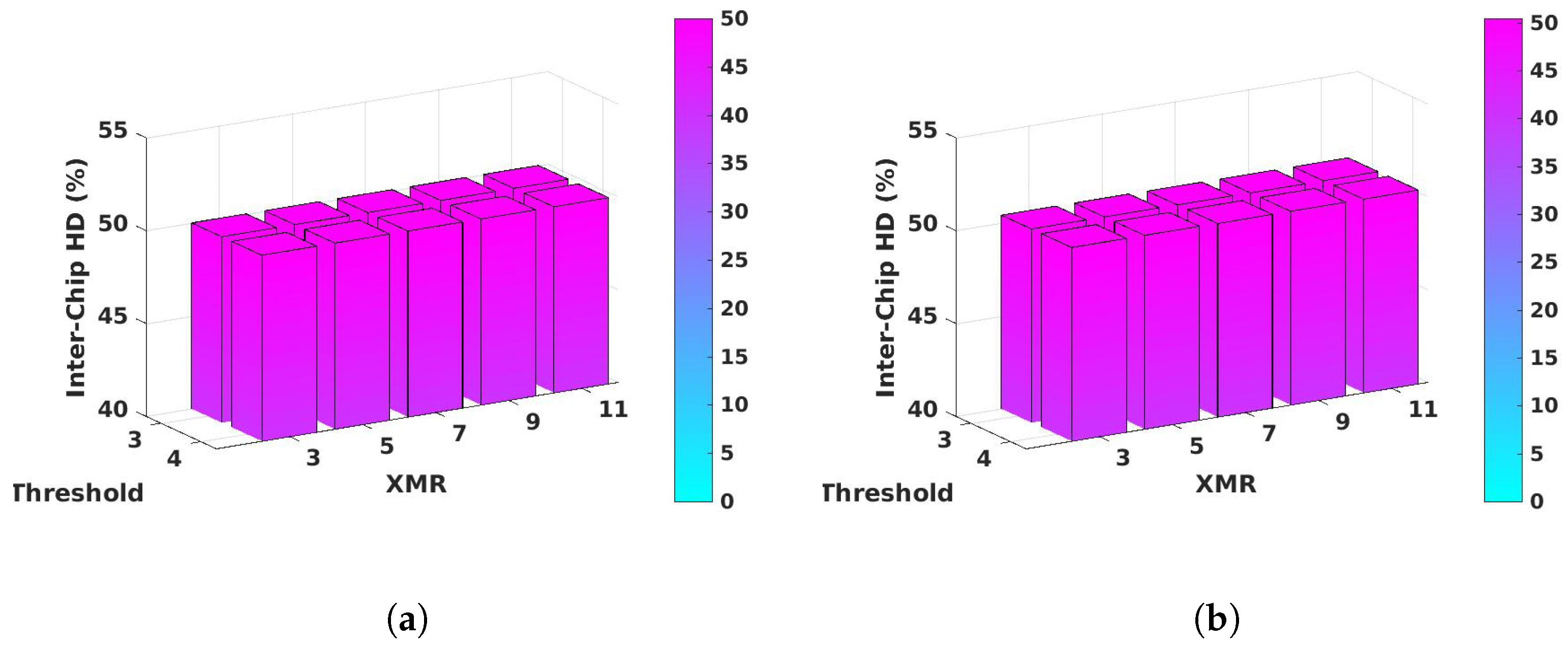
4.3. Inter-Chip Hamming Distance Analysis
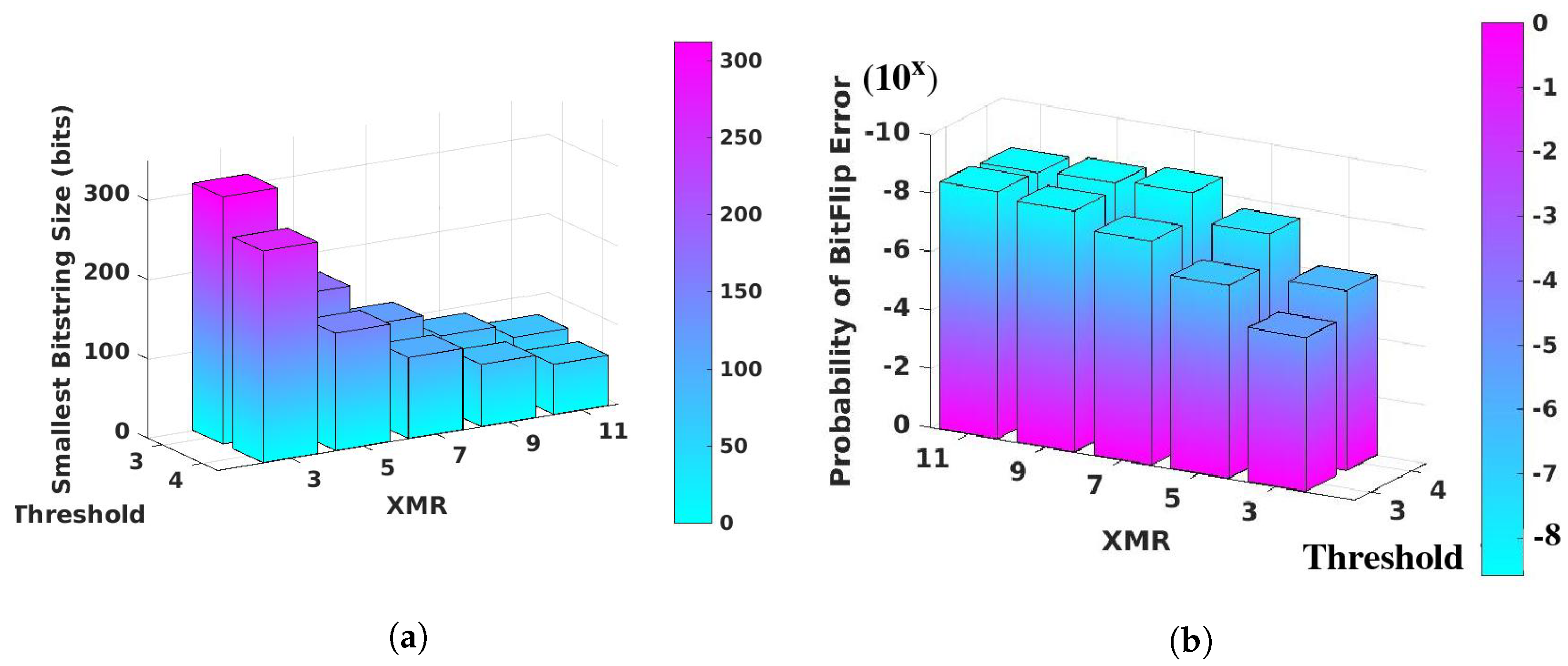
4.4. FSB Response Bitstring Size Analysis
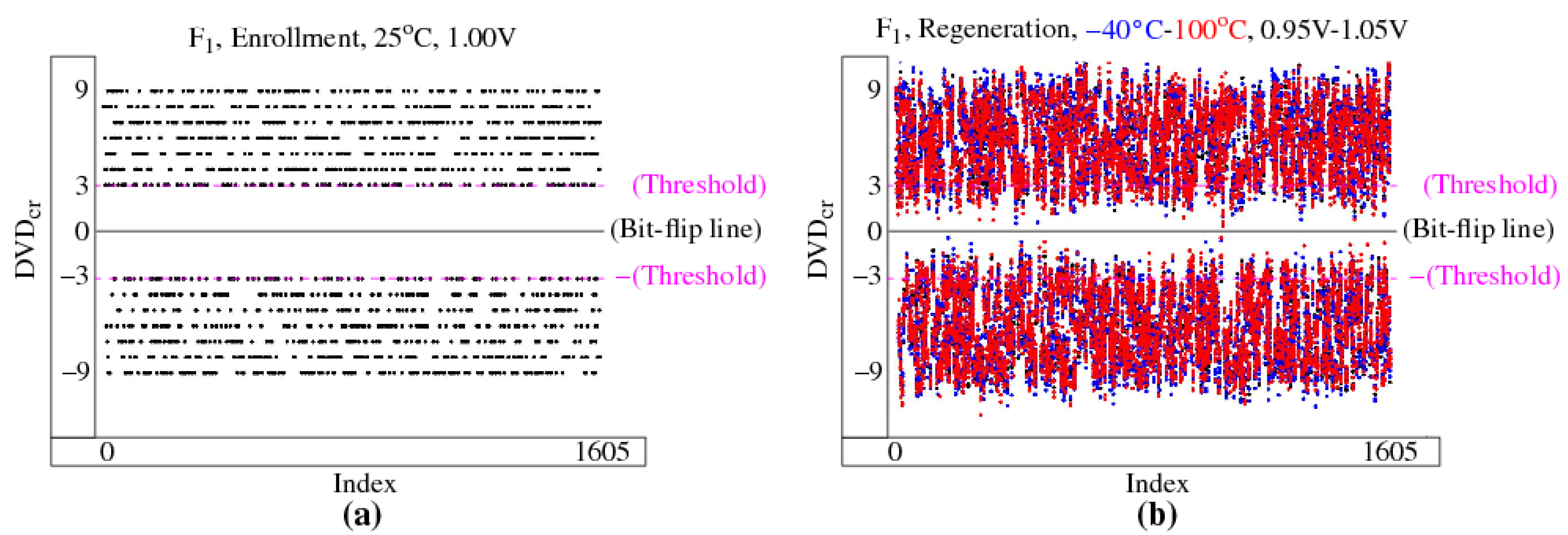
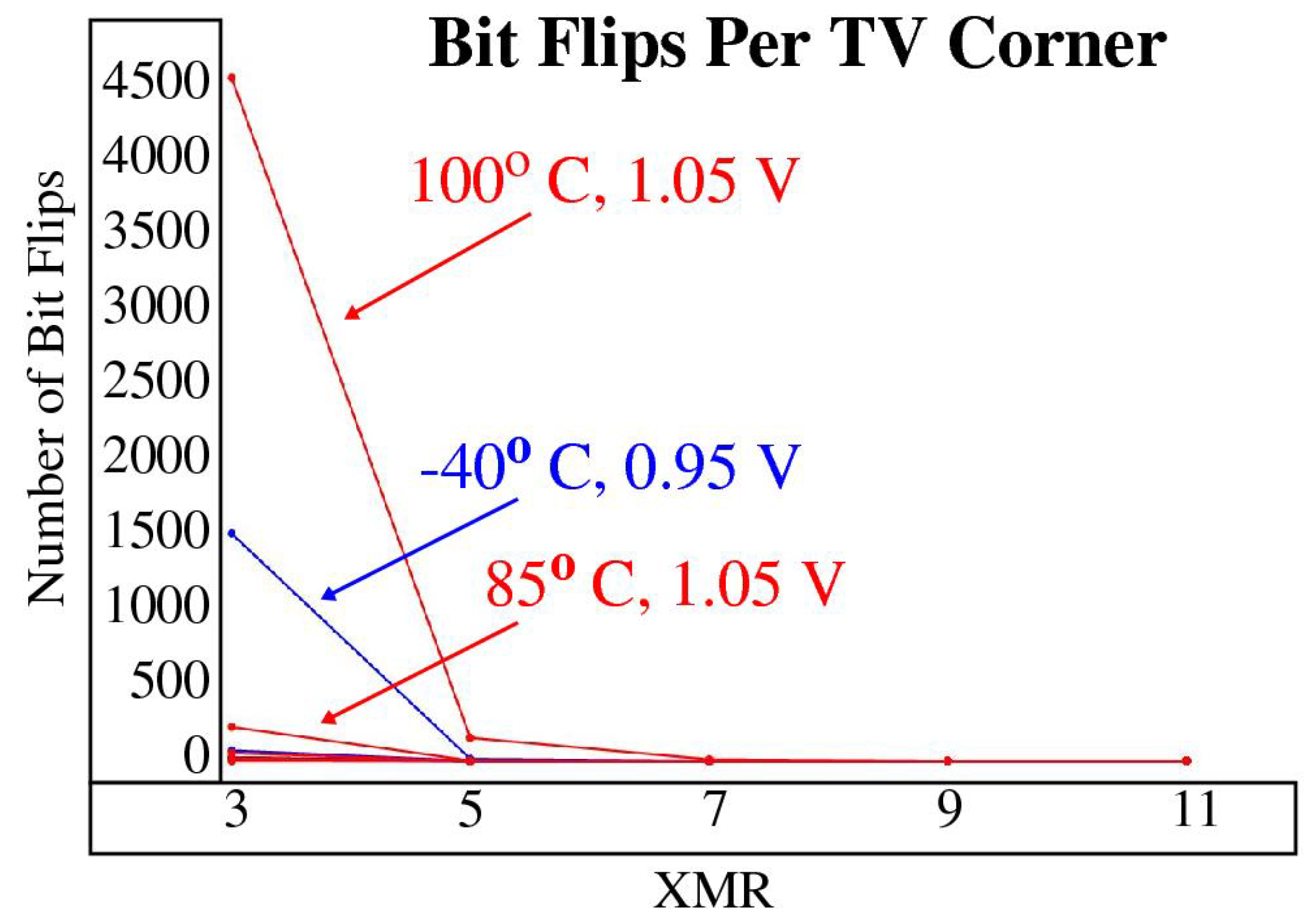
4.5. Reliability Analysis
5. Implementation Characteristics
5.1. Resource Utilization and Power
5.2. Performance Analysis
5.3. Challenge-Response-Pair (CRP) Analysis
6. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lofstrom, K.; Daasch, W.; Taylor, D. IC identification circuit using device mismatch. In Proceedings of the 2000 IEEE International Solid-State Circuits Conference, Digest of Technical Papers (Cat. No.00CH37056), San Francisco, CA, USA, 9 February 2000; pp. 372–373. [Google Scholar] [CrossRef]
- Gassend, B.; Clarke, D.; van Dijk, M.; Devadas, S. Silicon Physical Random Functions; Association for Computing Machinery: New York, NY, USA, 2002. [Google Scholar] [CrossRef]
- Lee, J.; Lim, D.; Gassend, B.; Suh, G.; van Dijk, M.; Devadas, S. A technique to build a secret key in integrated circuits for identification and authentication applications. In Proceedings of the 2004 Symposium on VLSI Circuits, Digest of Technical Papers (IEEE Cat. No. 04CH37525), Honolulu, HI, USA, 17–19 June 2004; pp. 176–179. [Google Scholar] [CrossRef] [Green Version]
- Suh, G.E.; Devadas, S. Physical unclonable functions for device authentication and secret key generation. In Proceedings of the 2007 44th ACM/IEEE Design Automation Conference, San Diego, CA, USA, 4–8 June 2007; pp. 9–14. [Google Scholar]
- Su, Y.; Holleman, J.; Otis, B. A 1.6 pJ/bit 96% Stable Chip-ID Generating Circuit using Process Variations. In Proceedings of the 2007 IEEE International Solid-State Circuits Conference. Digest of Technical Papers, San Francisco, CA, USA, 11–15 February 2007; pp. 406–611. [CrossRef]
- Guajardo, J.; Kumar, S.S.; Schrijen, G.J.; Tuyls, P. FPGA Intrinsic PUFs and Their Use for IP Protection. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2007, Vienna, Austria, 10–13 September 2007; Paillier, P., Verbauwhede, I., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 63–80. [Google Scholar]
- Helinski, R.; Acharyya, D.; Plusquellic, J. A physical unclonable function defined using power distribution system equivalent resistance variations. In Proceedings of the 2009 46th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 26–31 July 2009; pp. 676–681. [Google Scholar] [CrossRef]
- Kamal, K.; Muresan, R. Capacitive physically unclonable function. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Maes, R.; Tuyls, P.V.I. Intrinsic PUFs from flip-flops on reconfigurable devices. In Proceedings of the 3rd Benelux Workshop on Information and System Security (WISSec 2008), Eindhoven, The Netherlands, 13–14 November 2008; Volume 17. [Google Scholar]
- Kumar, S.S.; Guajardo, J.; Maes, R.; Schrijen, G.J.; Tuyls, P. Extended Abstract: The Butterfly PUF Protecting IP on every FPGA. In Proceedings of the Hardware-Oriented Security and Trust Workshop (HOST2008), Anaheim, CA, USA, 9 June 2008; pp. 67–70. [Google Scholar] [CrossRef] [Green Version]
- Marchand, C.; Bossuet, L.; Mureddu, U.; Bochard, N.; Cherkaoui, A.; Fischer, V. Implementation and Characterization of a Physical Unclonable Function for IoT: A Case Study With the TERO-PUF. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 97–109. [Google Scholar] [CrossRef] [Green Version]
- Della Sala, R.; Bellizia, D.; Scotti, G. A Novel Ultra-Compact FPGA PUF: The DD-PUF. Cryptography 2021, 5, 23. [Google Scholar] [CrossRef]
- Della Sala, R.; Bellizia, D.; Scotti, G. A Lightweight FPGA Compatible Weak-PUF Primitive Based on XOR Gates. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 2972–2976. [Google Scholar] [CrossRef]
- Gu, C.; Murphy, J.; O’Neill, M. A unique and robust single slice FPGA identification generator. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, VIC, Australia, 1–5 June 2014; pp. 1223–1226. [Google Scholar] [CrossRef]
- Gu, C.; Chang, C.-H.; Liu, W.; Hanley, N.; Miskelly, J.; O’Neill, M. A large-scale comprehensive evaluation of single-slice ring oscillator and PicoPUF bit cells on 28-nm Xilinx FPGAs. J. Cryptogr. Eng. 2021, 11, 227–238. [Google Scholar] [CrossRef]
- Huang, Z.; Li, L.; Chen, Y.; Li, Z.; Wang, Q.; Jiang, X. RPPUF: An Ultra-Lightweight Reconfigurable Pico-Physically Unclonable Function for Resource-Constrained IoT Devices. Electronics 2021, 10, 3039. [Google Scholar] [CrossRef]
- Huang, J.; Lach, J. IC Activation and User Authentication for Security-Sensitive Systems. In Proceedings of the Workshop on Hardware-Oriented Security and Trust, Anaheim, CA, USA, 9 June 2008; pp. 79–83. [Google Scholar]
- Aarestad, J.; Ortiz, P.; Acharyya, D.; Plusquellic, J. HELP: A hardware-embedded delay PUF. IEEE Des. Test 2013, 30, 17–25. [Google Scholar] [CrossRef]
- Che, W.; Martin, M.; Pocklassery, G.; Kajuluri, V.K.; Saqib, F.; Plusquellic, J. A Privacy-Preserving, Mutual PUF-Based Authentication Protocol. Cryptography 2017, 1, 3. [Google Scholar] [CrossRef]
- Che, W.; Kajuluri, V.K.; Martin, M.; Saqib, F.; Plusquellic, J. Analysis of Entropy in a Hardware-Embedded Delay PUF. Cryptography 2017, 1, 8. [Google Scholar] [CrossRef] [Green Version]
- Che, W.; Kajuluri, V.K.; Saqib, F.; Plusquellic, J. Leveraging Distributions in Physical Unclonable Functions. Cryptography 2017, 1, 17. [Google Scholar] [CrossRef] [Green Version]
- Sauer, M.; Raiola, P.; Feiten, L.; Becker, B.; Rührmair, U.; Polian, I. Sensitized path PUF: A lightweight embedded physical unclonable function. In Proceedings of the 2017 Design, Automation Test in Europe Conference Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 680–685. [Google Scholar] [CrossRef]
- Tiri, K.; Verbauwhede, I. A logic level design methodology for a secure DPA resistant ASIC or FPGA implementation. In Proceedings of the 2004 Design, Automation and Test in Europe Conference and Exhibition, Paris, France, 16–20 February 2004; Volume 1, pp. 246–251. [Google Scholar] [CrossRef] [Green Version]
- Owen, D., Jr.; Heeger, D.; Chan, C.; Che, W.; Saqib, F.; Areno, M.; Plusquellic, J. An autonomous, self-authenticating, and self-contained secure boot process for field-programmable gate arrays. Cryptography 2018, 2, 15. [Google Scholar] [CrossRef]
- Ju, J.; Chakraborty, R.; Lamech, C.; Plusquellic, J. Stability analysis of a physical unclonable function based on metal resistance variations. In Proceedings of the 2013 IEEE International Symposium on Hardware-Oriented Security and Trust (HOST), Austin, TX, USA, 2–3 June2013; pp. 143–150. [Google Scholar] [CrossRef]
- Heeger, D.; Plusquellic, J. Analysis of IoT Authentication Over LoRa. In Proceedings of the 2020 16th International Conference on Distributed Computing in Sensor Systems (DCOSS), Marina del Rey, CA, USA, 25–27 May 2020; pp. 458–465. [Google Scholar] [CrossRef]
- A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications. Available online: https://nvlpubs.nist.gov/nistpubs/legacy/sp/nistspecialpublication800-22r1a.pdf (accessed on 10 September 2022).
- ZedBoard. Available online: https://www.xilinx.com/products/boards-and-kits/1-8dyf-11.html (accessed on 10 September 2022).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | SiRF Engine Utilization | Netlist Utilization | Available | Utilization % |
|---|---|---|---|---|
| LUT | 5842 | 796 | 17,600 | 37.72 |
| LUTRAM | 60 | 96 | 6000 | 2.60 |
| FF | 4377 | 32 | 35,200 | 12.53 |
| BRAM | 5 | - | 60 | 8.33 |
| DSP | 2 | - | 80 | 2.50 |
| BUFG | 2 | - | 32 | 6.25 |
| XMR | Run Time (s) | Number of Iterations |
|---|---|---|
| 3 | 1.40 | 1 |
| 5 | 1.50 | 2 |
| 7 | 1.58 | 3 |
| 9 | 1.58 | 3 |
| 11 | 1.67 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plusquellic, J. Shift Register, Reconvergent-Fanout (SiRF) PUF Implementation on an FPGA. Cryptography 2022, 6, 59. https://doi.org/10.3390/cryptography6040059
Plusquellic J. Shift Register, Reconvergent-Fanout (SiRF) PUF Implementation on an FPGA. Cryptography. 2022; 6(4):59. https://doi.org/10.3390/cryptography6040059
Chicago/Turabian StylePlusquellic, Jim. 2022. "Shift Register, Reconvergent-Fanout (SiRF) PUF Implementation on an FPGA" Cryptography 6, no. 4: 59. https://doi.org/10.3390/cryptography6040059
APA StylePlusquellic, J. (2022). Shift Register, Reconvergent-Fanout (SiRF) PUF Implementation on an FPGA. Cryptography, 6(4), 59. https://doi.org/10.3390/cryptography6040059