1. Introduction
Many papers deal with side-channel attacks ([
1,
2,
3,
4]). However, the digital systems have become so complex that one cannot speak about only one side-channel, but many of them, such as: protocol-level (e.g., error rates in post-quantum cryptography (PQC), code-based), cache-attack, simple power analysis (SPA), differential power analysis (DPA), etc. They are generally addressed individually. For example, a scientific paper will show how to best break one given countermeasure using one attack, in a precise context. However, seldom is there a big picture of evaluating a fully-fledged implementation end-to-end.
Now, from a designer’s or an evaluator’s standpoint, the goal is to get rid of all the leakages, and/or have full coverage. In practice, leakage detection can appear in two flavors:
There can be two scenarios for verification that can be distinguished as:
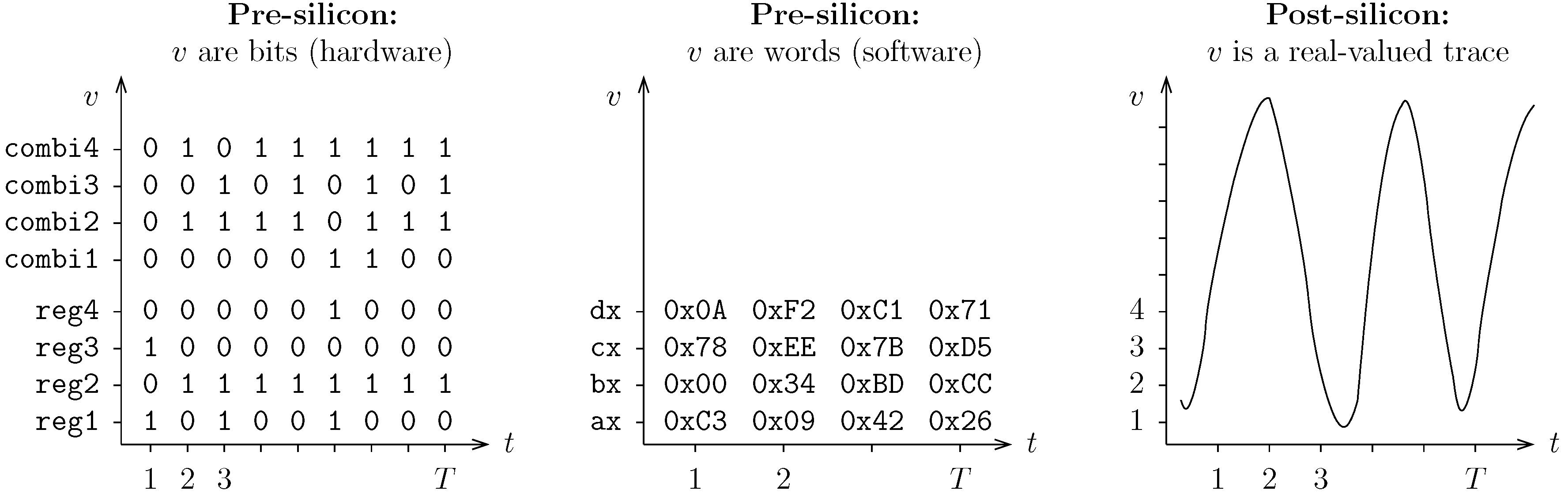
The developer has the two views: correspondence is ensured with a DWARF (Debugging With Attributed Record Formats) file.
It is useful to consider side-channel mitigation under the prism of the SNR (signal-to-noise ratio) metric, defined in [
6] (§ 4.3.2, p. 73): either a signal is reduced or noise is added. Both are not exclusive. Supportive technologies are balancing and random masking. The current consensus is that:
Biases in the control flow can be spotted very easily; hence, control flow (instructions) shall not depend on the secret;
Whereas data leakage cannot usually be extracted in one go; therefore, random masking is suitable.
One apparent drawback of this approach is that once the control flow has been balanced, the traces are already well aligned for subsequent statistical analysis of the data leakage. However, this issue shall rather be considered as an advantage: from the developer’s standpoint the burden of trace alignment is relieved, and therefore the developer can focus on real activity, namely, leakage analysis, in ideal conditions. From the lab evaluator’s standpoint, the alignment is indeed an issue, but it is not the core protection, and resynchronization techniques do exist (cross-correlation, dynamic time warping (DTW), etc.) and/or some analyses are invariant in the time offsets (frequency domain analysis, convolutional neural networks or CNN [
7], recurrent neural networks with connectionist temporal classification loss [
8], etc.). Therefore, in the rest of the paper, we assume a progression of the analysis in two steps: horizontal and then vertical.
1.1. Illustrations
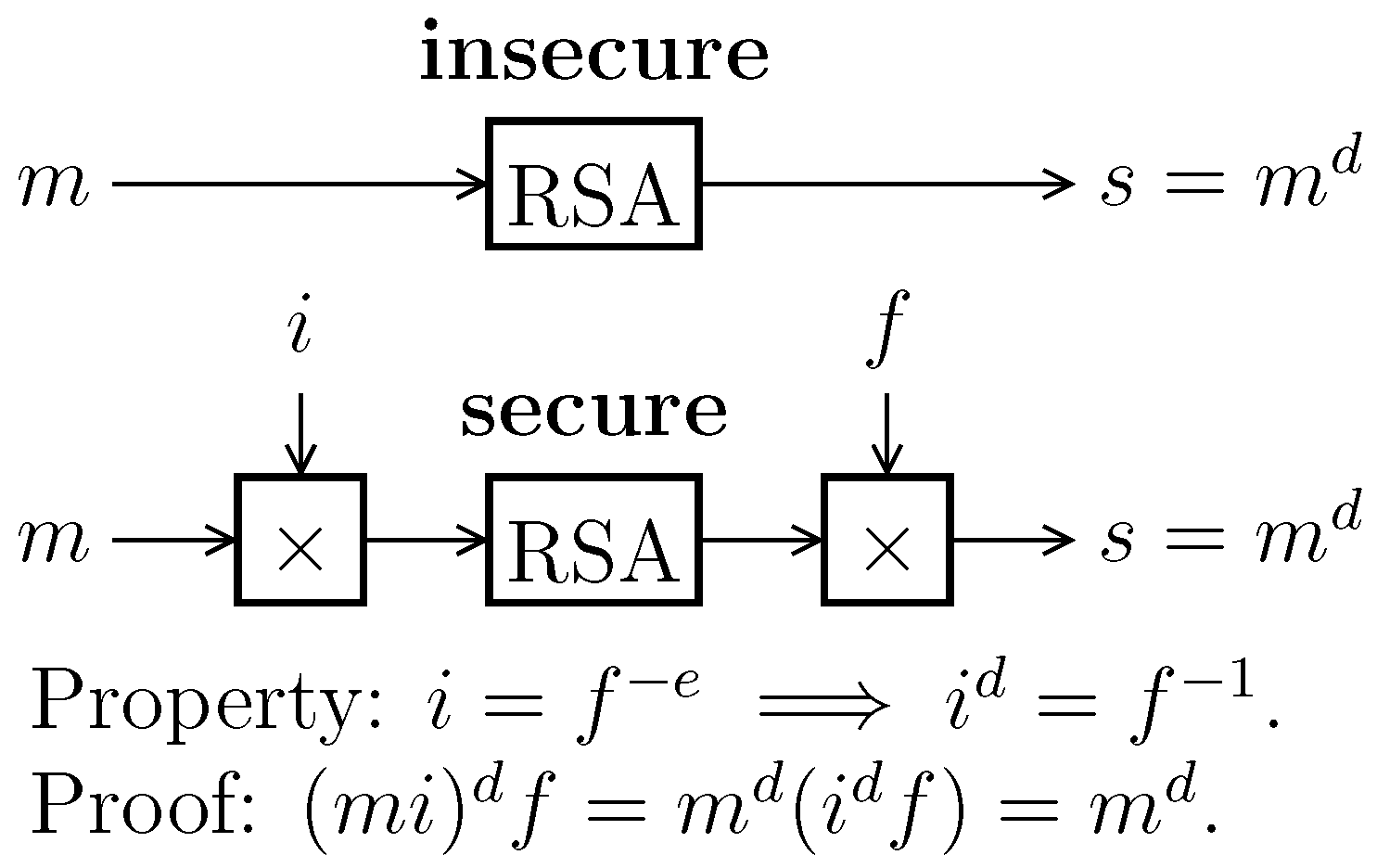
We illustrate the article briefly with symmetric cryptography (AES), and in more detail with asymmetric cryptography (RSA). The RSA implementation is protected with masking, namely, exponent blinding and base blinding (also illustrated in
Figure 1).
1.2. Contributions
As our contributions in this paper, we propose:
A methodology to analyze leakages based on a partitioning of the studied algorithm.
Symbolic (in whitebox context) and dynamic (in blackbox context) horizontal leakage detection, and their repair (a topic that is seldom addressed).
A new strategy for vertical leakage detection (in the case of aligned traces), which does not need any determination of sensitive variables to some constant. Additionally, this strategy leverages a two-step algorithm which first selects the points of interests (that depend on the key), and second, checks whether they are properly masked.
This paper is basically revisiting comprehensive side-channel analysis on software implementations, showing how to detect, diagnose and then repair them in an interactive manner. Typically, we show that the number of fixes to apply to an implementation of mbedTLS RSA is such that the final overhead in terms of performances is about clock cycles. Only after this fix is applied, vertical analyses can follow (indeed, vertical analyses assume that traces are aligned). When traces are not aligned, blinding is ineffective. In this respect, the novel method we put forward allows one to detect sensible samples which are unmasked, with an algorithm that is universal, in that it does not require the tester to set input parameters to some arbitrary constant values (which is the state-of-the-art in ISO/IEC 17825).
1.3. Related Works
There have been some works in this direction. In [
2], the authors explain how it is possible to automatically fix detected timing and cache-timing vulnerabilities in order to reach a constant time implementation of the code-under-test through a series of transformations that operate on the basic blocks. This approach seems interesting; however, the sensitivity propagation method would inevitably catch false positives, for which fixes will be automatically deployed and will add unnecessary overhead to the code.
In [
3], the authors present a tool, which they call SLEAK, whose goal is to automate the analysis against side-channel attack (SCA) vulnerabilities of software implementations. They present a case study on a symmetric algorithm (AES) against vertical attacks. The paper, however, does not address the constant-time feature of the algorithm under test or how to deal with non-constant time implementations (which is challenging, e.g., for the implementations that use shuffling countermeasures). Besides, the presented approach is based on iterations that consider leakages related to each bit of the secret. This may decrease the performance of the evaluation.
In [
4], the authors present a “DATA” framework, whose goal is to detect attacks that exploit cache, DRAM and branch predictions. Their approach consists of recording address access patterns in software with different inputs, and performing a differential analysis in order to find dependency on the secret.
1.4. Scope of This Paper
The goal of this paper is to present an extensive methodology to evaluate cryptographic software in front of horizontal and vertical attacks. Those are threats for software that is designed to conceal secrets. Notice that we aim to detect vulnerabilities in such a way that the implementation can be fixed. Therefore, we will be considering an iterative approach whereby the evaluation results allow one to fix the identified vulnerabilities. We are not interested in attacks, but rather in a methodology to either pinpoint issues or to prove that the software is free from flaws.
1.5. Assumptions
Firstly, we assume that the studied code is correct, i.e., that it contains no bugs. For instance, OpenSSL has several CVEs (common vulnerabilities and exposures), including buffer overflows, etc. Even post-quantum cryptography is prone to bugs, such as the underflow in the BIKE decapsulation algorithm (327 CVEs found in
https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=openssl).
Secondly, we assume that the secrets to be protected are the inputs to the algorithm, and not the outputs. In some (rare) cases, the secrets are the outputs, which makes the analysis more complex (the tainting especially cannot be achieved). Examples are the key generation algorithms, or even the encapsulation algorithms, which yield a so-called shared secret.
1.6. Methodology
The search for vulnerability unfolds in three steps:
Partitioning of inputs into four classes: inputs from the user, algorithm constants, private keys and randomization.
Identification of horizontal leakages, which enables their correction.
Identification of vertical leakages, which enables their correction.
2. Input Partitioning
The inputs of any cryptographic algorithm can be classified into four categories, depending on whether they are public or private, and whether they are fixed or variable. The taxonomy is provided in
Table 1.
Let us notice that the randomness (or asks) can be part of the algorithm’s specifications, such as in digital signatures (which shall not yield twice the same signature, even when signing twice the same message). However, the randomness can also be a means to implement the algorithm in an unpredictable way, so that the attacker fails to correlate a (secret dependent) model to internal values. Such randomness is also referred to as random masking or blinding, and is usually considered only a little effective against effective attacks (which are better off protected by balancing the operations). On the contrary, masking is the preferred technique to protect against vertical attacks, where intermediate values shall be protected.
Examples of parameters are provided in
Table 2.
3. Horizontal Leakage
3.1. Description of the Leak
Horizontal leakage consists of temporal variations which can be monitored while the algorithm is running. The observation can be external, e.g., by monitoring the time or even the power profile. Alternatively, it can be internal, by checking whether a line of cache is required by the (victim) cryptographic program, which can be asserted by concurrently trying to access the same line of cache. The time taken by the attacker process depends upon whether the victim is actually using it or not. Notice that cache-related attacks are preferably executed on a platform with an operating system, since the attacker can deploy, in parallel, one or several attacks to probe the shared cache (at least its timing behavior). However, this situation is not required. Indeed, the attacker can measure externally that the cryptographic code evicts itself (or not) while trying to load far (or close) data/code, relative to the current position.
There are two reasons for horizontal leakage: conditional code and conditional data access (read or write). Control-flow (resp. data-flow) leakage can be prevented by disabling the instruction (resp. data) cache. Indeed, without cache, there is no longer any observable hit/miss pattern in terms of time, nor is there the possibility for an attacker to flush lines of cache to test the time it takes to access any address.
3.2. Identification of the Leak
In a whitebox scenario, leaks are identified by a traversal of the source code abstract syntax tree (AST). The AST vertices are tainted: instructions are termed sensitive if they manipulate a sensitive variable —that is, a variable which depends on any secret .
The tainting algorithm analyzes only a dependence relationship, but can be refined to analyze values. For instance, when a sensitive variable is affecting a constant or a non-sensitive variable, then it is no longer sensitive. Some user-level annotations can also help, for instance, removing the sensitivity from a variable which is the output of a hash function, since there is no way to recover a preimage (computationally speaking). Still, such a sensitive variable equal to a hash value shall remain sensitive if the attack can be perpetrated only knowing the hash value (it is useless for the attacker to know the preimage). Such a situation occurs while analyzing HMAC (hashed message authentication code) functions [
13].
Vulnerabilities are merely identified as the encounter of a sensitive variable with:
A conditional instruction, such as , or
A conditional indirection, such as .
In the context of blackbox analysis, the binary code is exercised under a debugger (GNU Debugger or GDB in our case) under constants , and , but varying . Then, the detection occurs as follows:
We refer to this as the GDB methodology. Notice that this methodology is the same as that already employed by practitioners, using valgrind. In this methodology, instead of varying , it is left uninitialized. This is possible in C language. By default, compilers might assign a zero value to , but in general the actual initialization is undefined. Such code is not executed in the nominal environment, but is handed over to valgrind. The tool will tag specifically uninitialized variables, and will precisely report warning upon:
whose condition is uninitialized. Thus, assuming that the only uninitialized variables in the code are , namely, the secrets intentionally not set, the warnings reported by valgrind will exactly coincide with those emitted by the proposed GDB methodology.
3.3. Examples on mbedTLS
3.3.1. AES
It is well-known that the vanilla AES exhibits both control-flow and data-flow leakages. Namely:
The xtime function contains an statement on the MSB (most significant bit) of the output of SubBytes. This leak is traditionally fixed by replacing the test with a Boolean selection;
The SubBytes look-up can be resolved by an exhaustive access.
Vulnerable code and repaired code (constant-time code) are demonstrated in Algorithms A1 and A2 (
Appendix A).
3.3.2. RSA
Two variants of RSA are shown in
Table 2: either with or without CRT (Chinese remainder theorem). We note that with more secret variables, more vulnerabilities are found.
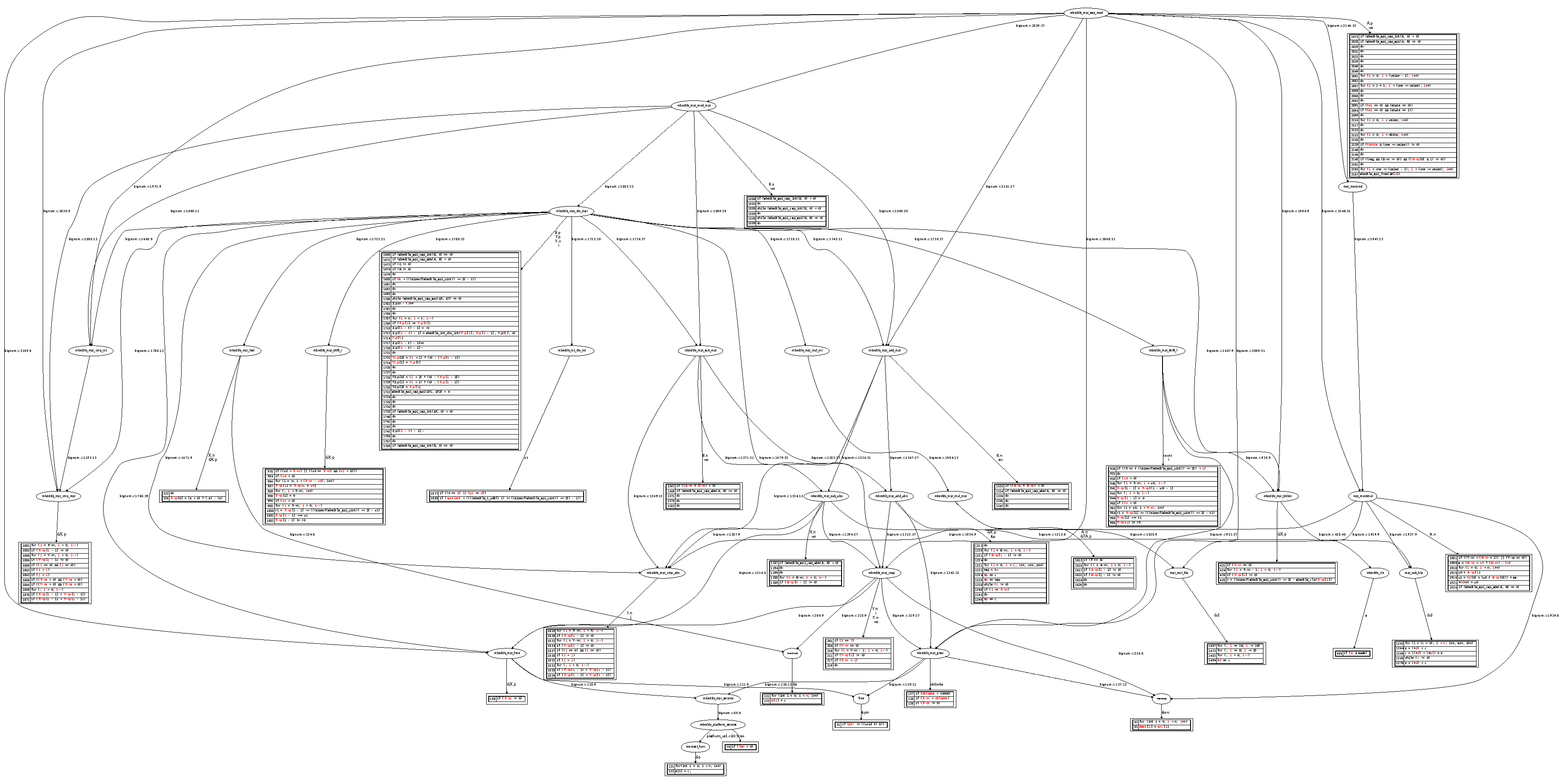
The initial list of vulnerabilities is fairly large, as shown in
Figure 2 (using a representation as that already introduced in [
14]). The leakage graph in the figure reads as follows. The entry point is the function represented at the top of the tree. Internal sub-function calls are indicated as ovals below it. The annotations on the edges represent the propagation path of the master secret
to the sensitive variable
which triggers the non-constant timing issue. The rectangle boxes contain all the lines of code within one function which are vulnerable.
The static analysis tool allows one to detect lines of code that might leak horizontally which might otherwise be exploited by SPA or cache-timing attacks. Fixing those vulnerabilities results in a constant-time implementation.
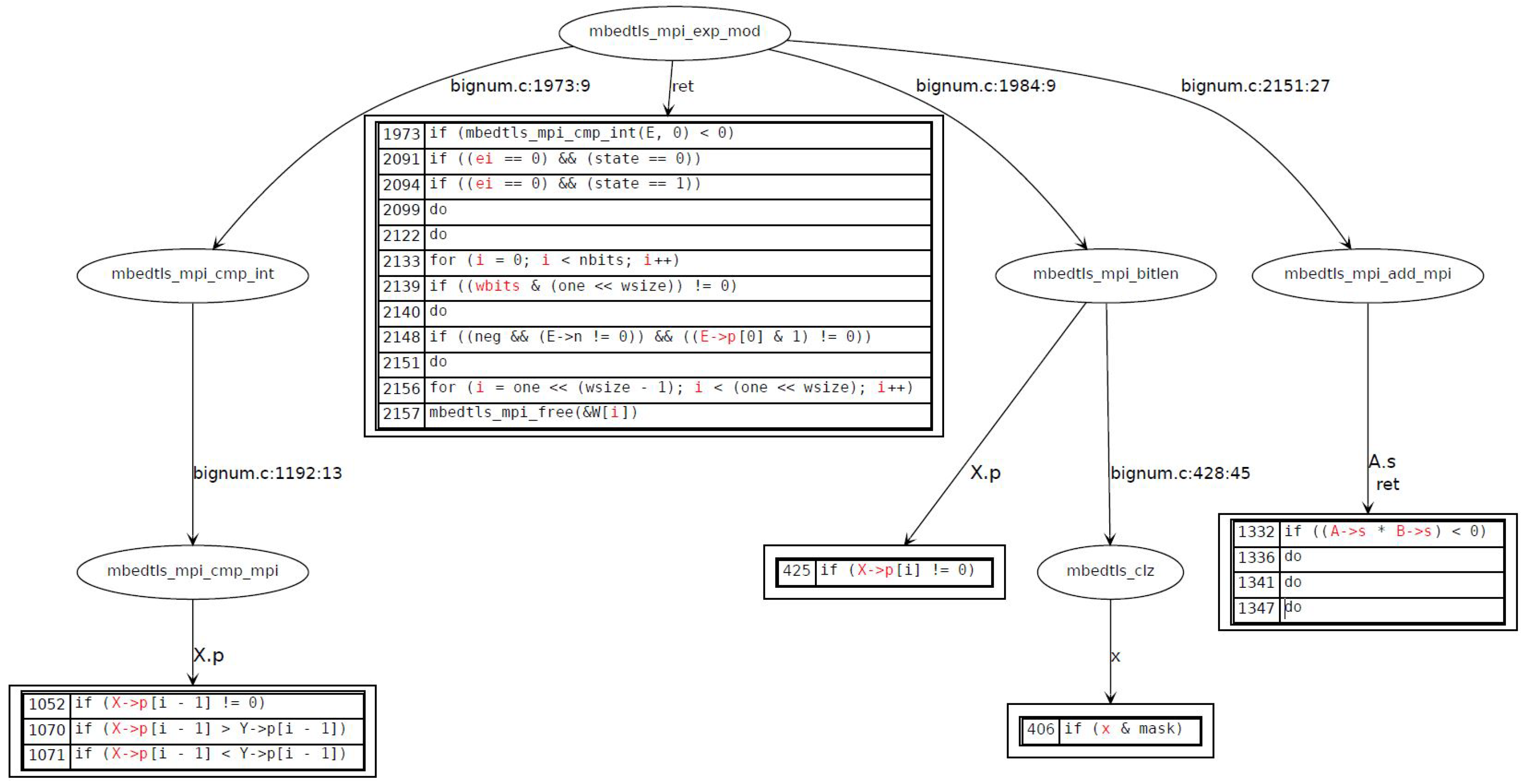
In order to illustrate this, we take the example of an RSA signature in which the target security-sensitive function is the modular exponentiation. Tagging the exponent (respectively the base) uncovers potential vulnerabilities that induce non-constant time behavior of modular exponentiation that depends on the exponent (and respectively the base). Non-constant-time vulnerabilities that were revealed by the static analysis tool applied to sliding window modular exponentiation of
mbedTLS for the exponent are illustrated in
Figure 3 and are summarized as follows:
V1: Conditional branches that depend on the length of the exponent. The exponent length is used in order to compute the width of the window to be used in the computation.
V2: Conditional branch (while loop) that depends upon the length of the exponent.
V3: Conditional branches that depend upon the ith bit of the exponent in order to skip the leading zeros of the exponent (leading zeros do not have to be processed). This approach allows one to optimize the execution time of the modular exponentiation by simply skipping all MSB set to zero.
V4: Conditional branches that depend upon the ith bit of the exponent in order to slide the window and always start the window with a MSB set to one. This approach make available two optimizations: a first optimization in the execution time of the modular exponentiation, and a second optimization in the precomputation of the windows (since we always start with the MSB set to one, we only need to precompute half of the windows).
V5: Table access that depends upon the window value.
V6: Conditional branch in the processing of the remaining bits (out of window bits) in a square and multiply fashion.
In order to make the mbedTLS implementation of modular exponentiation we address these vulnerabilities one by one (in the above order).
Fix for V1 and V2: In order to make the modular exponentiation constant time, the solution would be to fix the length of the exponent.
Fix for V3 and V4: The solution for V3 and V4 is to process the leading zeros and the sliding of the window, and process all windows in the same way. This results in dropping the mentioned optimizations (that makes the implementation non-constant time) in favor of a fixed exponent length and fixed window implementation. The costs of the fix are to spend time processing the windows that does not impact the final result and to precompute all windows (as a window value in this case will not necessarily begin with an MSB equal to one).
Fix for V5: In order to make the table access indistinguishable from an attacker, the solution would be to access all the elements and keep only the desired ones. This comes at a huge cost, as one has to access all precomputed windows before performing the multiplication.
Fix for V6: The square and multiply algorithm is used to deal with the remaining bits. From one SPA trace, an attacker can deduce the value of less than
bits of the exponent. Knowing only
of the exponent is not critical. However, if the attacker repeats the attack many times, he will collect a set of
n equations that gives some information about the secret. The relations are of the form:
where
and
are the unknown random value (of 224 bits) and the recovered exponent at the step where the remaining bits are processed. To our best knowledge, no algebraic attack has been published in this sense.
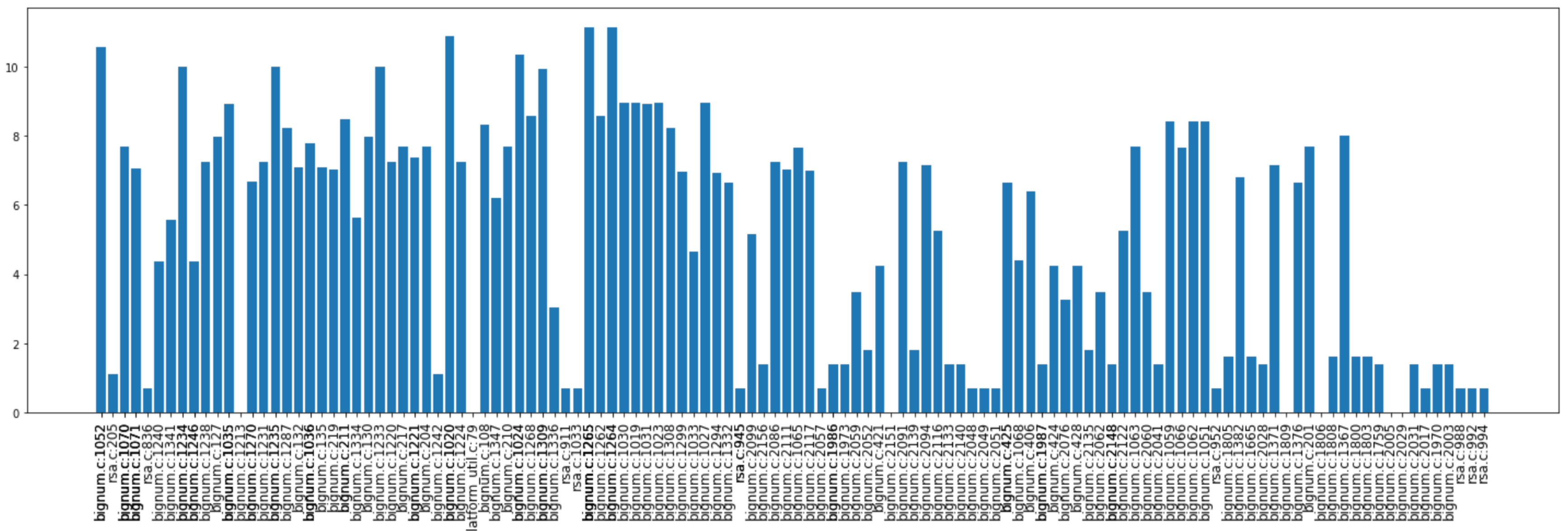
Not all those vulnerabilities are called the same amount of times when the code is executed dynamically. A count of all occurrences is represented in
Figure 4, obtained by a concrete evaluation under a debugger.
An analysis of the vulnerabilities has been conducted and the results are summarized in
Table 3. Our selected repair methods are also indicated. They can be divided into two categories:
Automatable countermeasures, which apply a stereotyped strategy (here: Boolean selection);
Non-automatable countermeasures, which require an algorithmic change (contrast Algorithm A5 to Algorithm A6).
The asterisk (*) in
Table 3 indicates that this is not our preferred option. Indeed, if the code still searches for the secret exponent MSB position, then, for subsequent vertical leakage analysis, traces are not aligned. Therefore, we opt to have the exponentiation be fixed/constant time.
The asterisks pair (**) in
Table 3 suggests that the test is removed. Indeed, it serves the purpose of the determination of the sign of the result, in the case where the input is negative. Now, in RSA, all the computations can be carried out on positive numbers; hence, the elimination of the test is harmless. Instead, keeping the test would also have been fine, as our testbenches never call RSA on a negative message (=basis).
The vulnerabilities listed in
Table 3 are classified as pertaining to “exponentiation” or “arithmetic”. Big number computation is indeed structured as a stack, where exponentiation is built on top of some basic arithmetic operations. The leaks occurring in the exponentiation are the most straightforward to flags by the attacker (attacks including SPA, machine-learning, etc.). Attacks at the arithmetic level are more complex, and require a precise analysis of the underlying mathematics. Nonetheless, despite the leakage in the arithmetic code, it is only indirectly linked to the leakage of the secret exponent, of which some exploits are known, such as extra-reduction [
18]. Still, it is an open problem to know whether the amount of carries in a multiplication allows one to recover information about the secret exponent.
3.4. Performance
In this section, we study the impacts of the non-constant timing vulnerabilities on the performances. Those are illustrated in
Table 4.
In
Table 4 the impact on the execution time of the modular exponentiation is shown (in mean clock cycles). The impact was measured and compared on six different versions, each one implementing more protections than the others (
refers to a version implementing fixes against the vulnerability
), except for
(for which fixing the vulnerability
allows one to skip a call to the function “mbedtls_mpi_bitlen” which results in a faster implementation). All subsequent versions of the modular exponentiation were more time consuming. This came as no surprise, as fixing some of the vulnerabilities (e.g.,
and
) requires useless access to some elements of a table (for which we observe the most impact).

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}