Automating Privacy Compliance Using Policy Integrated Blockchain


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Underlying Technologies
3.1. Hyperledger Fabric Blockchain
- Fabric is permissioned: The nodes participating in the ledger are linked based on identities provided by the modular membership service provider, which in our case will be the Cloud provider.
- Fabric nodes have roles: the implementation of Hyperledger Fabric stipulates that the ledger consist of nodes with task-based roles, for example, clients who can submit transaction proposals, peers can validate or execute such transaction proposals, and Ordering Service Nodes, which maintain the total order of the Fabric. These characteristics were needed to make sure the same node which proposes a transaction does not get to validate and execute the transaction. This is imperative to disallow client nodes from executing and validating transactions on their own.
- Fabric Performance: In Hyperledger Fabric, the delay between transaction proposal, validation and ledger update is similar to the running time of primary-backup replication of data entity in replicated databases with synchronization through middleware [28]. Low Latency is another reason for us choosing the Hyperledger Fabric. Based on the research by Androulaki et al. [29], for block-sizes under 2 MB, 3 K transactions per second throughput with close to 900 ms latencies had been achieved. For our case, the block-sizes were in the range of 0.5–1 MB (including all PII data fields), and the comparable throughput and latency were 3.5 K transactions per second and 100 ms respectively. As per their research, latency tends to run higher with an increase in block-size beyond 2 MB, but the throughput does not get affected as much.
3.2. Semantic Web
4. Results and Discussion
- Create and populate Knowledge graph: We used Semantic Web technologies to build a knowledge graph or ontology to capture all the key elements of policy documents. Semantic Web allows us to translate text-based policy documents into machine processable graph datasets. For the first phase of the project, we have concentrated on data privacy policies. Section 4.1 describes this ontology in detail. We are also building knowledge graphs for regulatory policies like EU GDPR and PCI DSS that are available in reference [32]. Using text extraction techniques, we populated our knowledge graph with privacy policies from the ACL COLING dataset [33].
- Identify key Data Operations: We identified the key data operations that would need to be tracked to ensure policy compliance. Section 4.2 describes the various data operations that are monitored and included in our framework design.
- Data Compliance BlockChain: We next built a system using Semantic Web, NLP/Text Extraction and Hyperledger Fabric blockchain to capture each data operation, identified in phase 2, after validating the operation against the policies captured in phase 1. Section 4.3 describes this in detail. Our current implementation is designed for one instance involving all the stakeholders. We are currently extending this work to include multiple consumer and provider organizations sharing the same service.
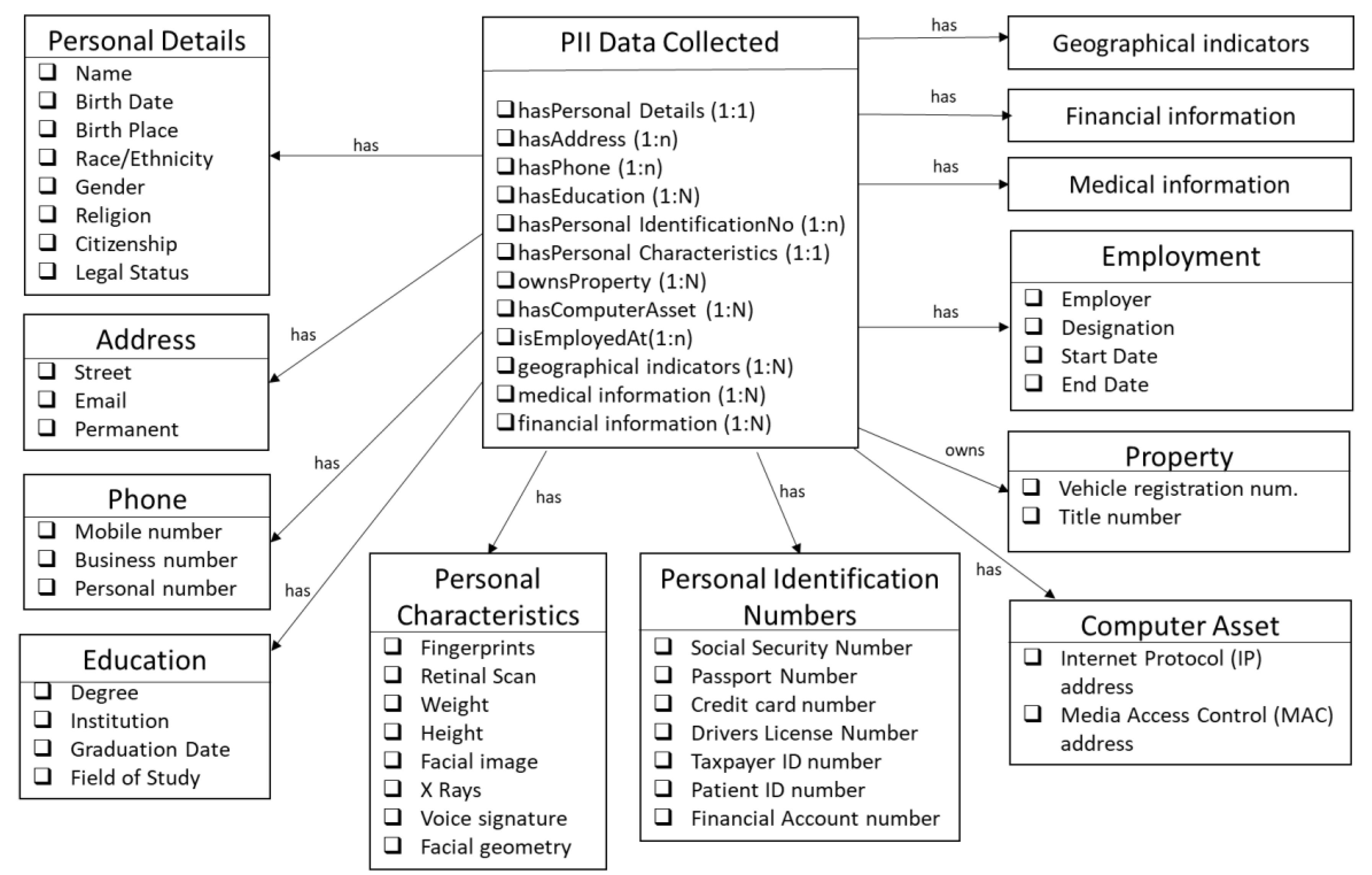
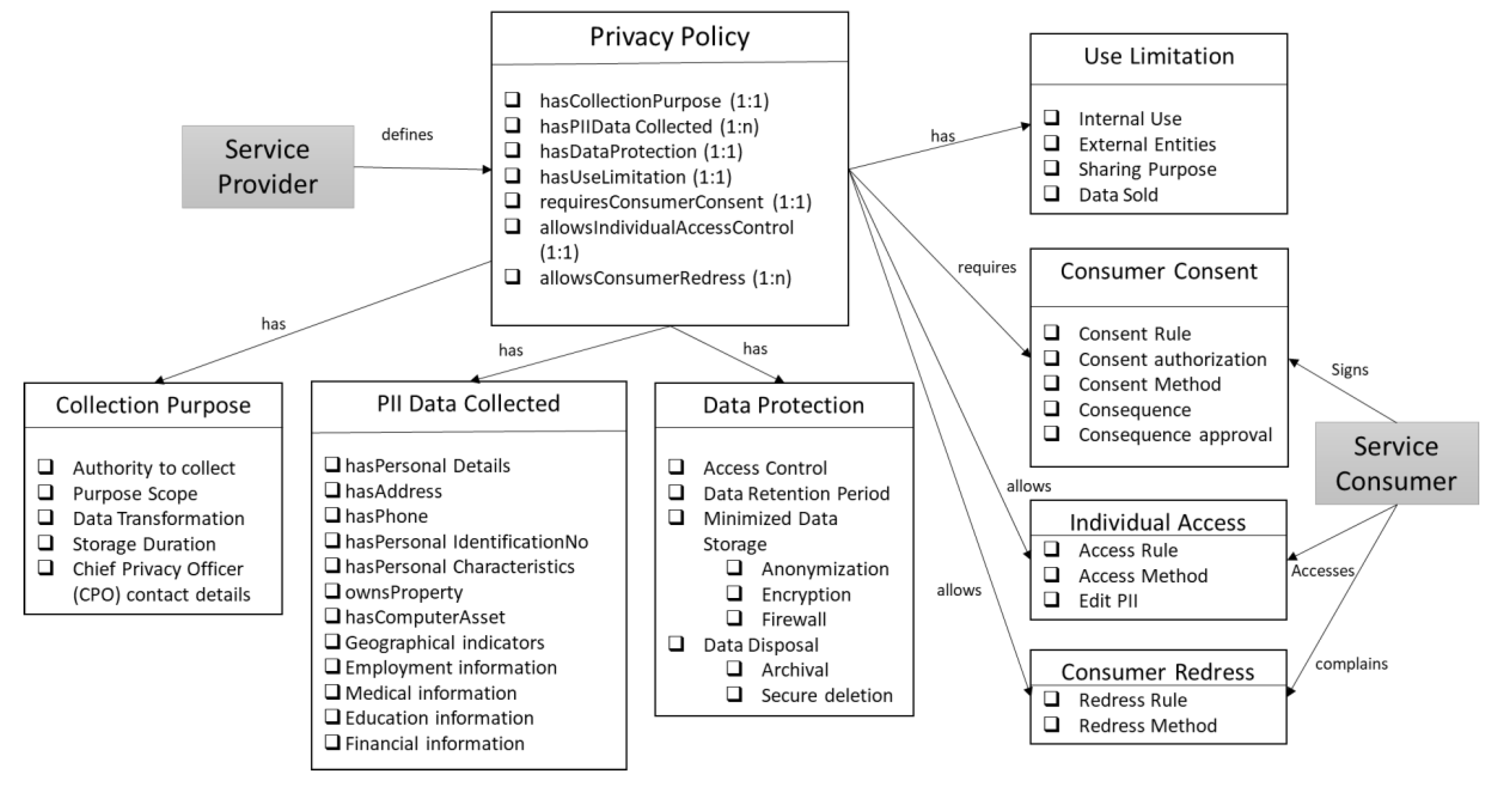
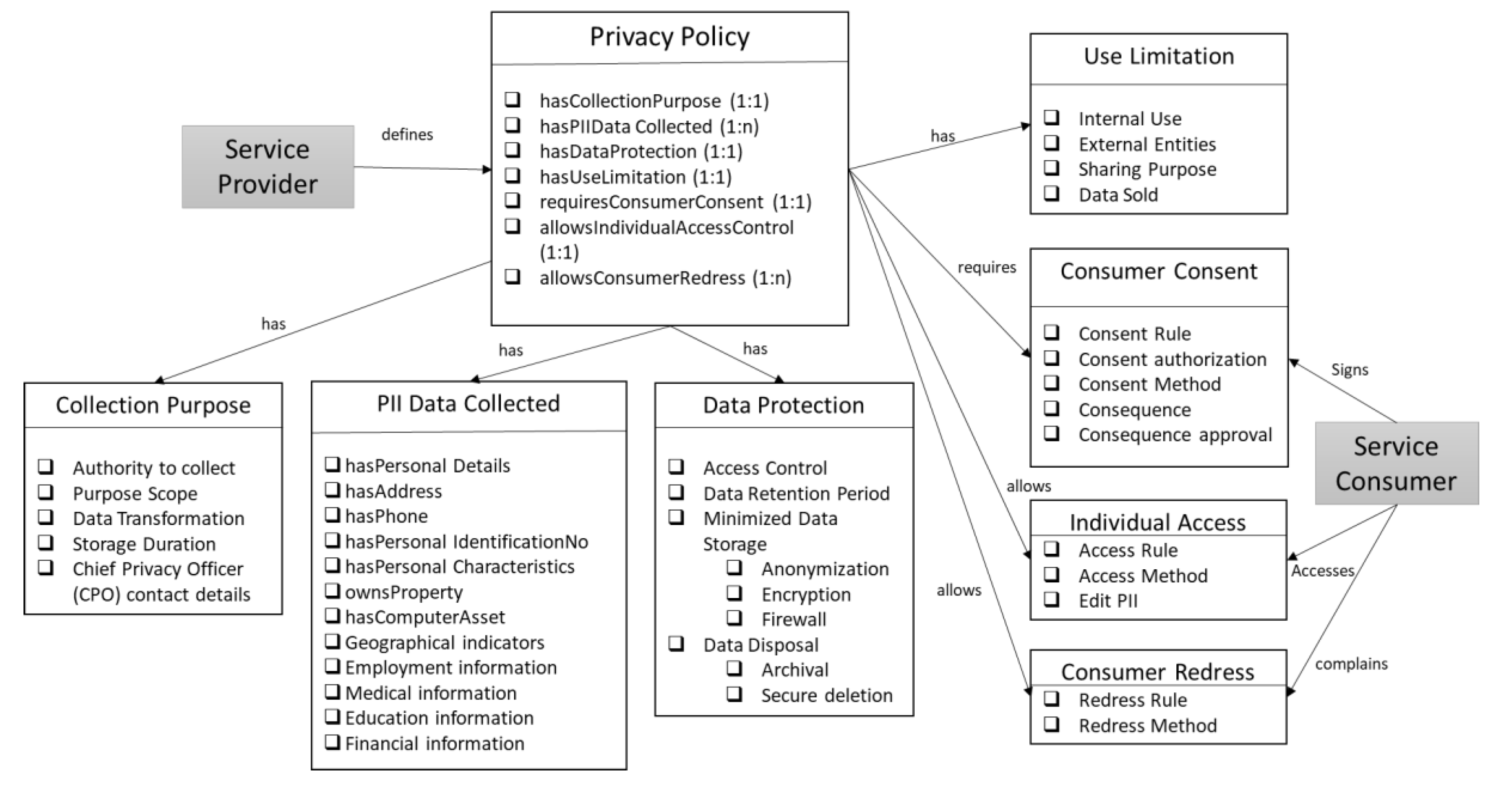
4.1. Knowledge Graph for Data Privacy Policy
4.1.1. Privacy Controls included in Ontology
- Authority to Collect: The service provider should determine and document the legal authority that permits the collection, use, maintenance, and sharing of personally identifiable information (PII), if required by regulatory and compliance bodies.
- Purpose Specification Control: The organization describes the purpose(s) for which personally identifiable information (PII) is collected, used, maintained, and shared in its privacy notices.
- Privacy Notice: The organization
- Dissemination of Privacy Program Information:
- Minimization of personally identifiable information control: The organization -
- Data Retention and Disposal Control: Organization -
- Minimization of PII used in testing, training, and research control: The organization:
- Consent Control: The organization:
- Individual Access Control: The organization:
- Redress Control: The organization:
- Internal Use: The organization uses PII internally only for the authorized purpose(s) identified in the Privacy Act and/or in public notices.
- Information Sharing with Third Parties: The organization:
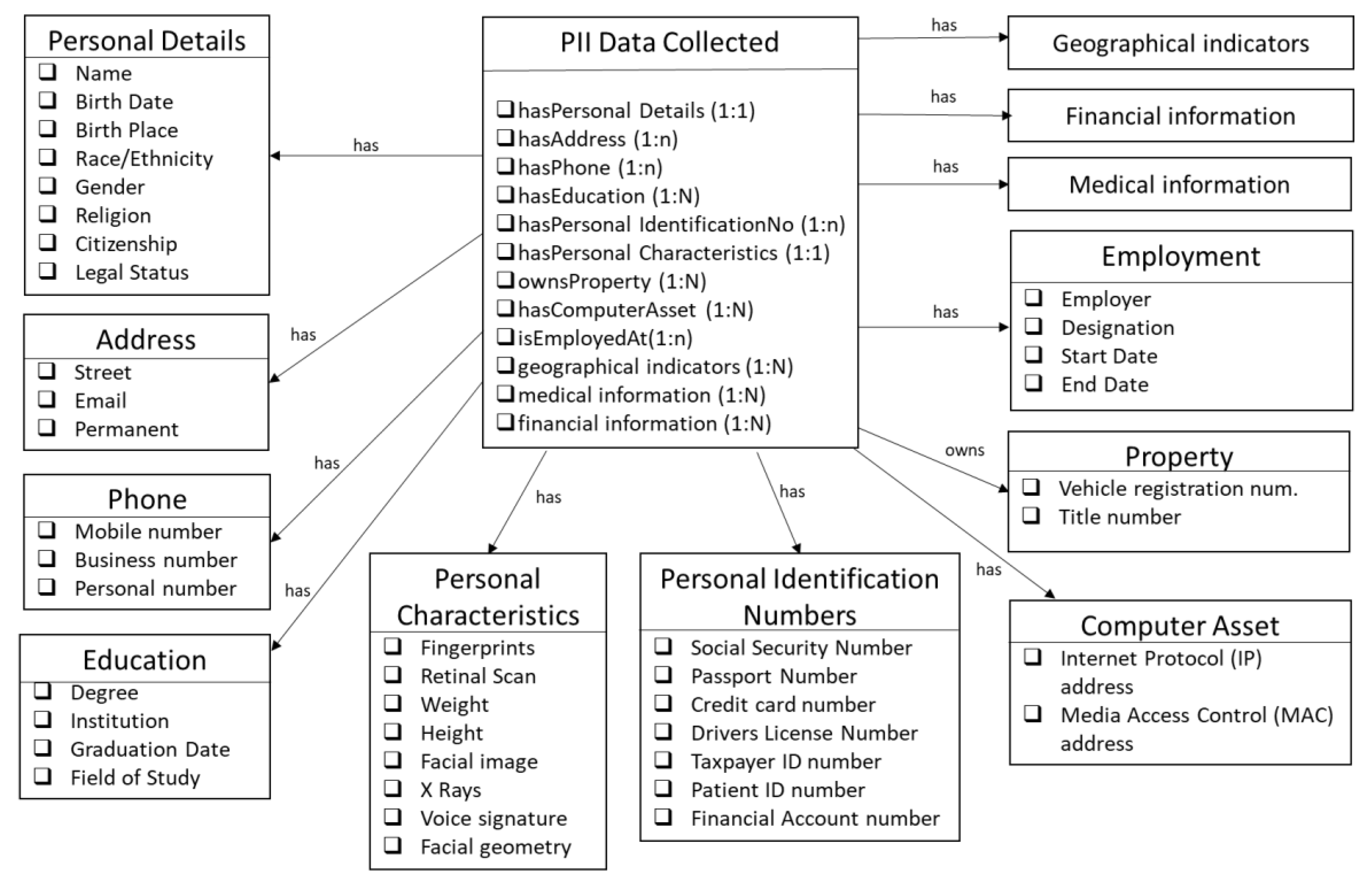
4.1.2. Privacy Ontology Classes
4.2. Data Operations
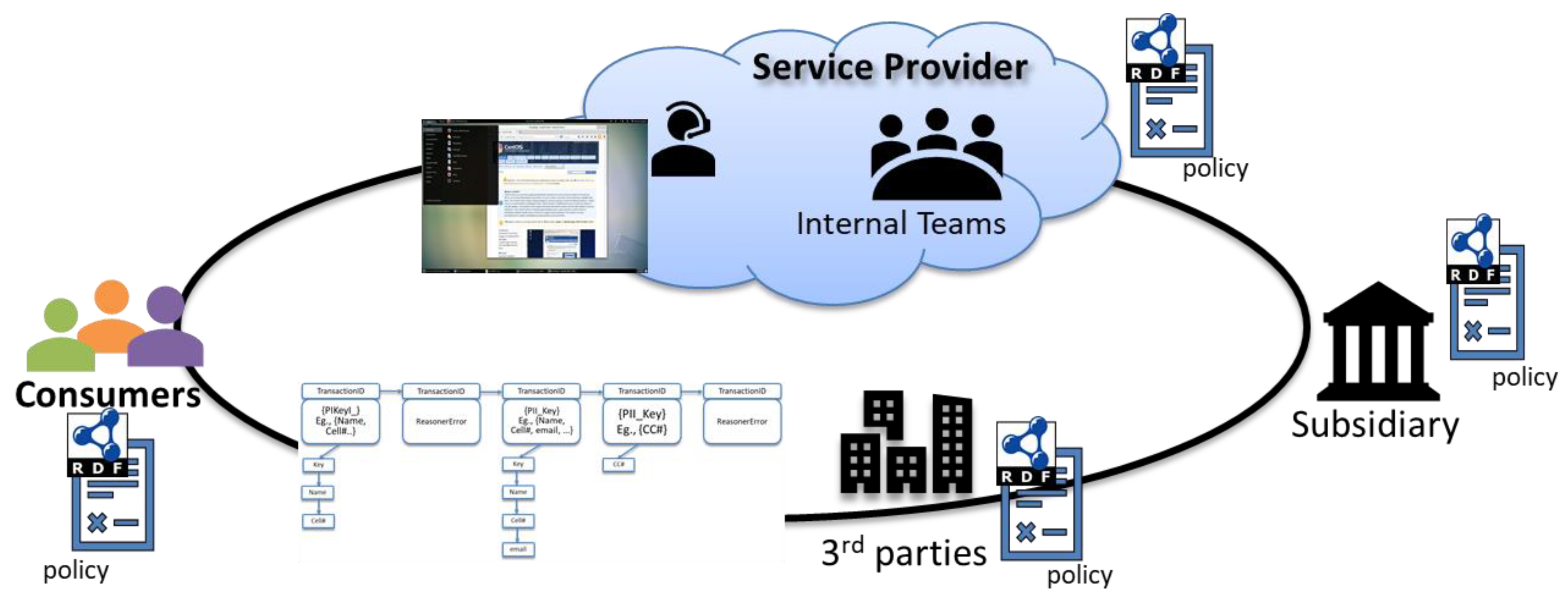
- Data Acquisition: In a cloud-computing environment, we define data acquisition by the transactions that create new data points that are directly provided by the user and stored by the system. These new data points are created only when a new user comes to an agreement with the cloud service provider and its associated business affiliates and trusted third parties. The transactions are between the cloud-based service provider and the end-user, where the end-user provides the data and the service provider stores this data. The data points captured by the system must fall under the purview of the privacy policy.
- Data Generation: When a transaction uses existing data points or conjures new data points from them, it is treated as an instance of data generation. The generation of new data points must come from the existing data entities that were provided by the user. For example, generating Age from date of birth (which is provided by the user), or generating user-class (such as credit-risk) from a combination of data entities (such as credit score and annual income). These new data points generated by the system must fall under the purview of the privacy policy that the end-user and the owner of the system that generated the data is a signatory to. The transactions are usually undertaken by the cloud-based service provider, trusted 3rd parties and subsidiaries of the service provider.
- Data manipulation: This refers to any transaction which acts upon any previously stored data and morphs the data entity permanently. Examples of such transaction would be changes in credit score, home address, phone number, etc. These changes can be performed by any of the signatories under the privacy policy.
- Data distribution: Data distribution on the cloud includes all transactions that result in the sharing of the user data by the service provider with other signatories in the privacy policy. This kind of transaction mostly deals with the sharing of data amongst various parties which are bound by the same privacy policies. For example, a cloud-based service provider (such as Instagram) might share a user’s browsing pattern with another service provider (such as an advertising service).
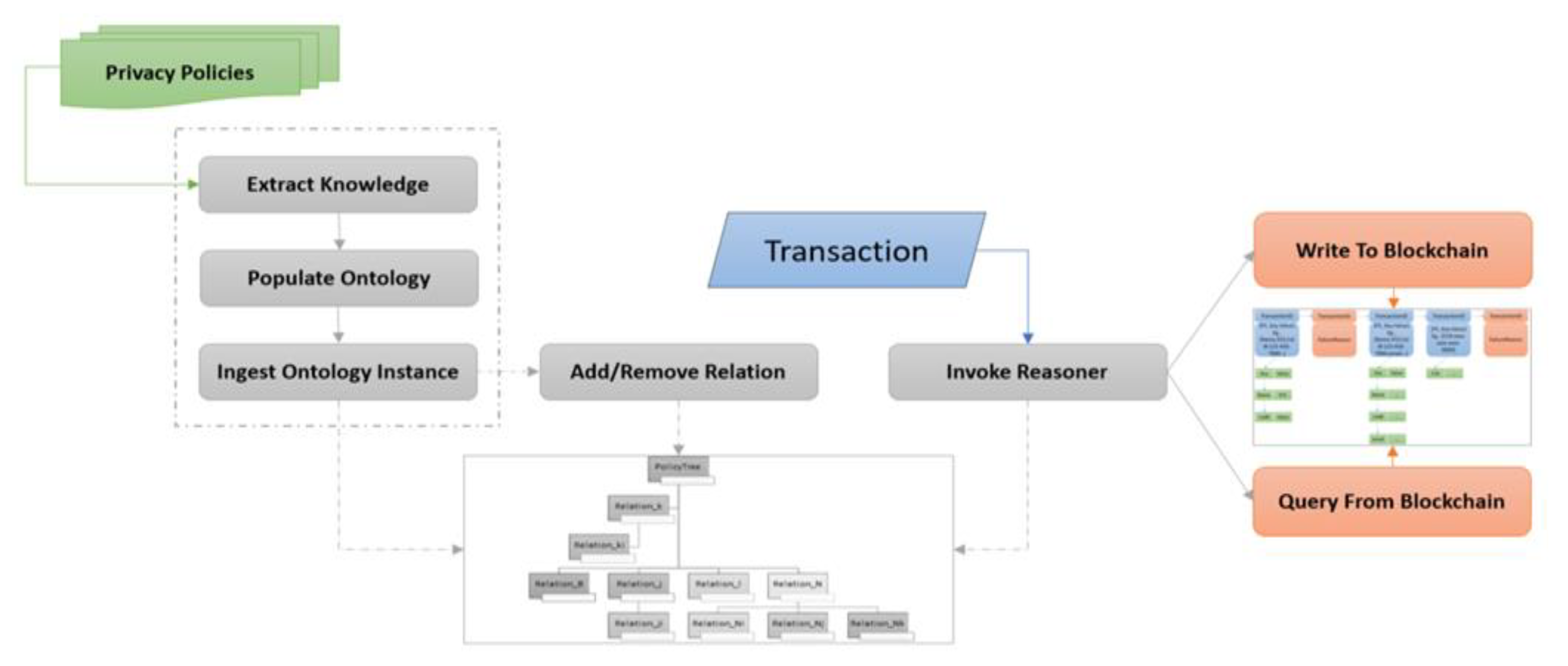
4.3. LinkShare: Data Compliance BlockChain
5. System Evaluation
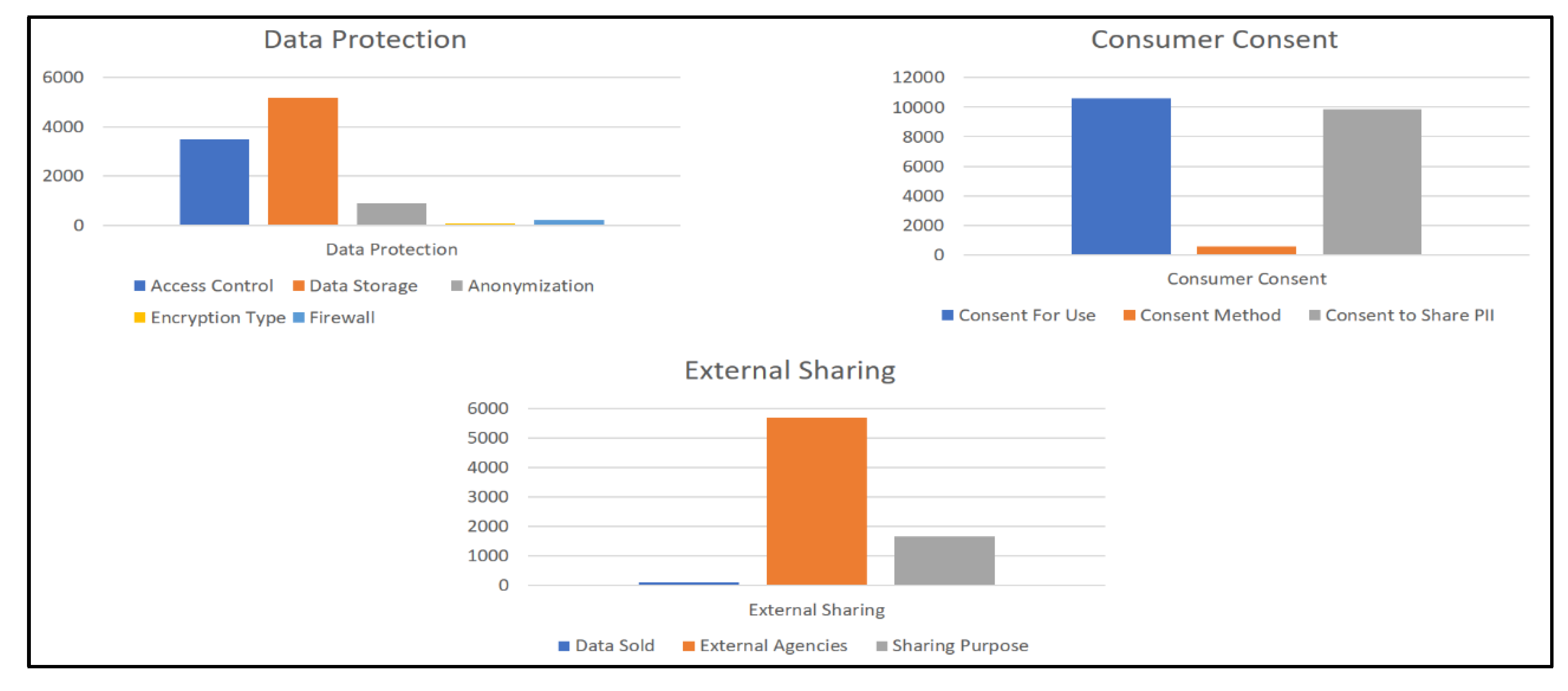
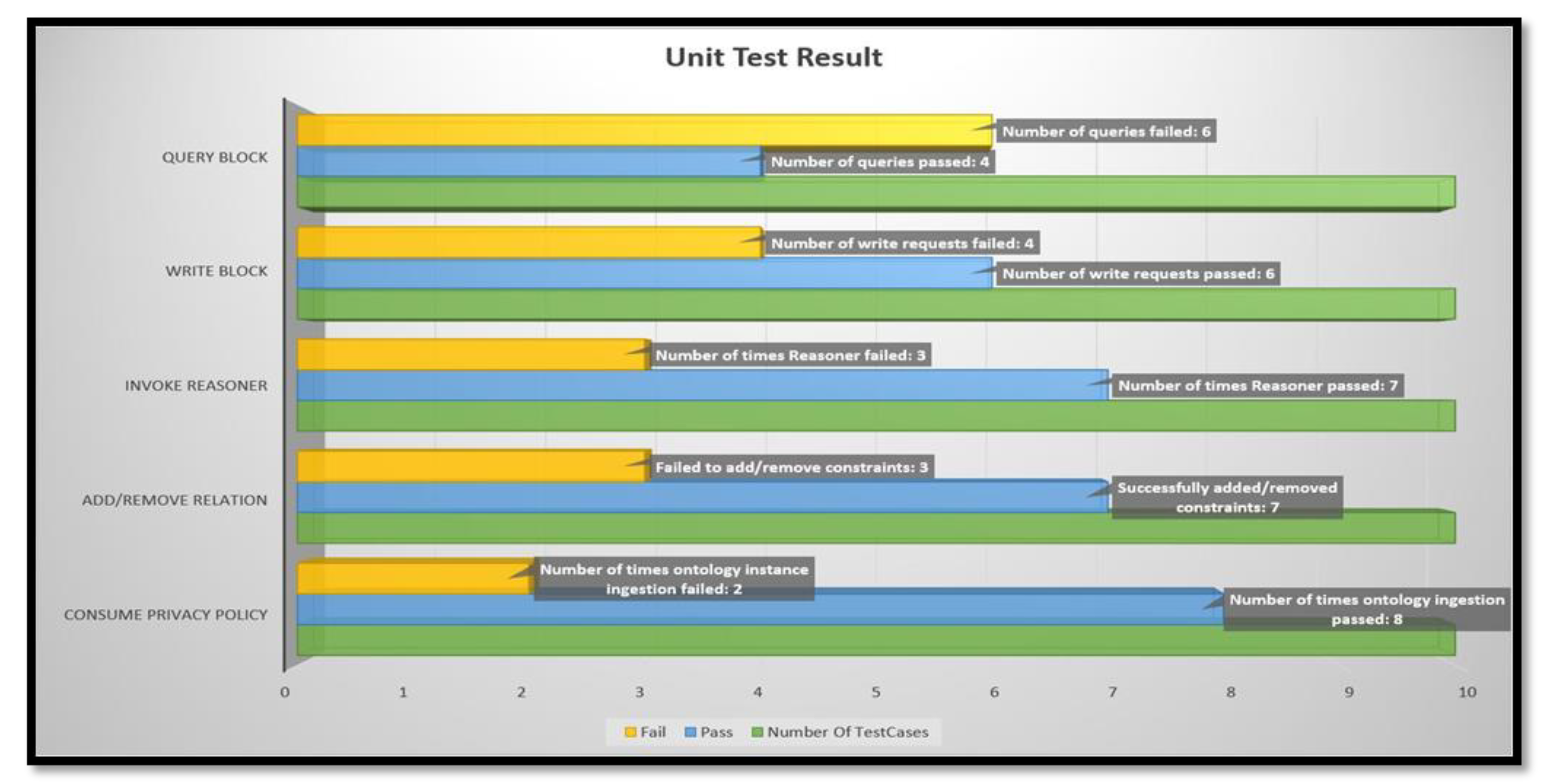
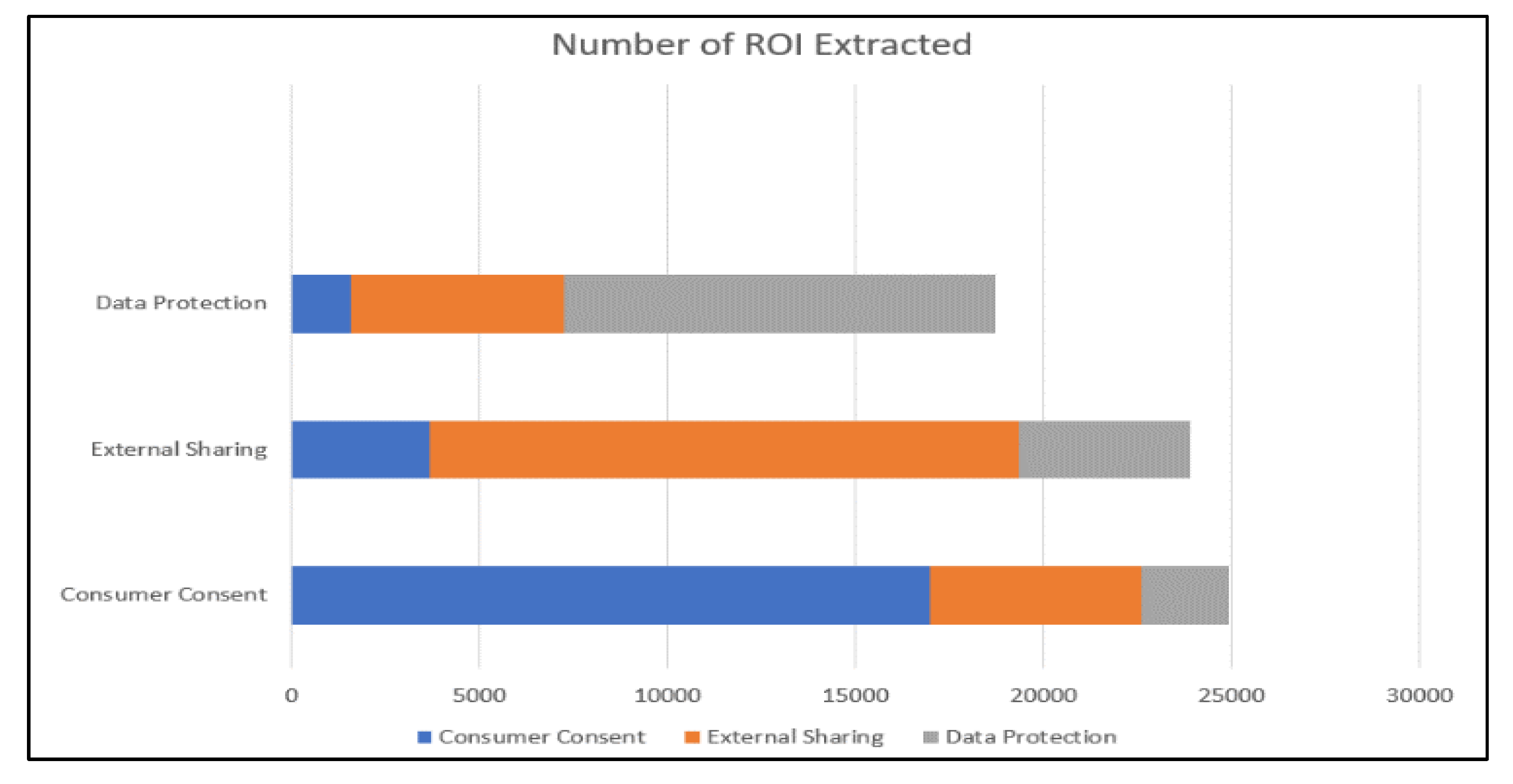
5.1. Extraction Results
- Consumer Consent: “If you are visiting the Services from outside the United States your data will be transferred to and stored in our servers in the U.S. By using the Services, you consent to our collection and use of your data as described in this Privacy Policy.”
- External Sharing: “By using the Services or providing us with any information you consent to the transfer and storage of your information including Personal Information to registered third parties as set forth in this SEA Privacy Policy.”
- Data Protection: “The data protection laws in the United States may differ from those of the country in which you are located, and your Personal Information may be subject to access requests from governments courts or law enforcement in the United States according to laws of the United States.”
5.2. Transaction Processing
- (i)
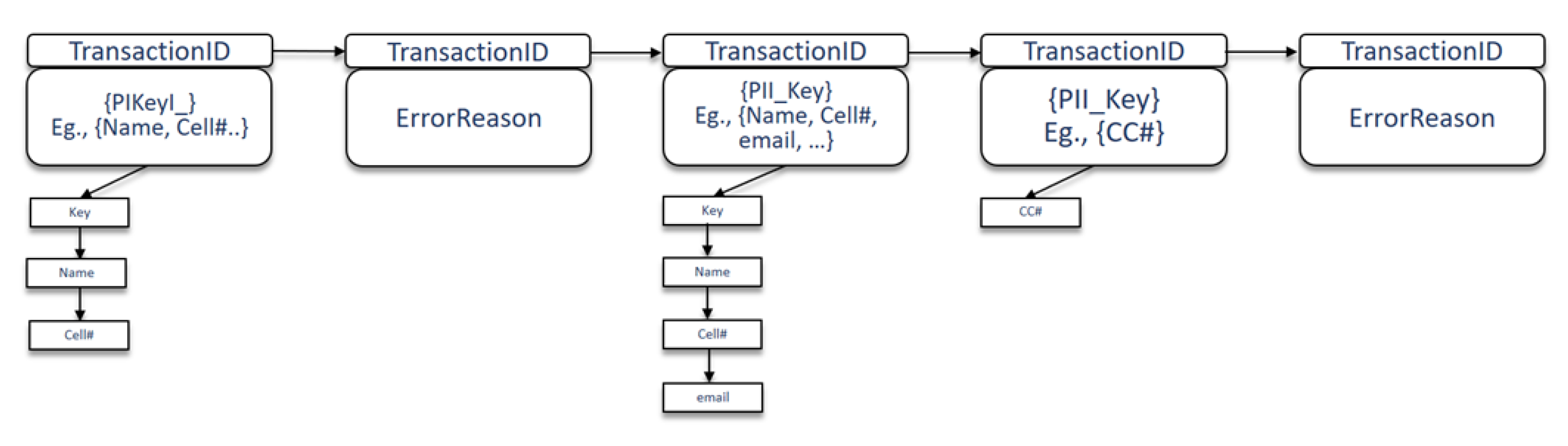
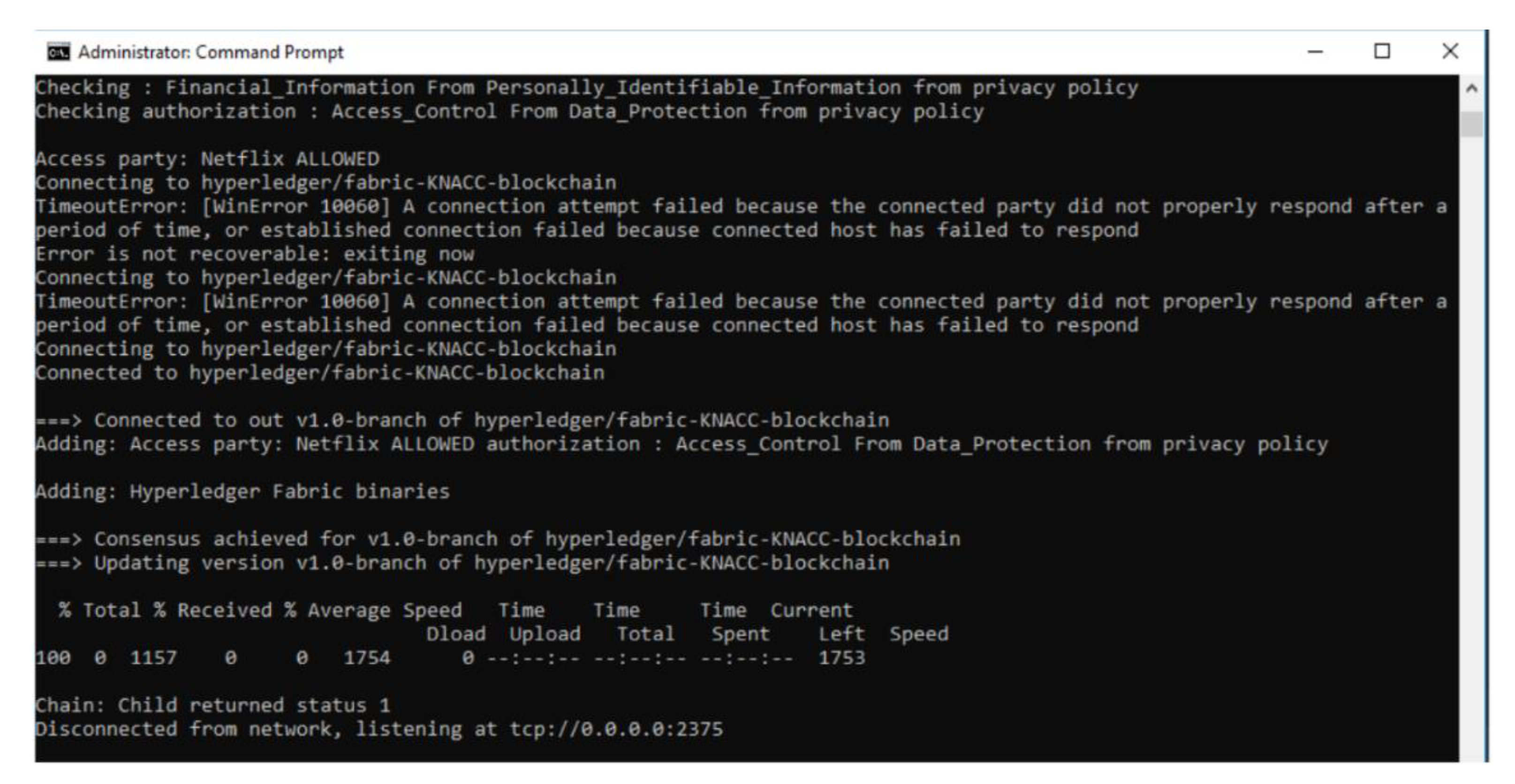
- Data sharing is permitted: Here, depending upon the PII fields present in the data transaction, and based on the policies that allow such PII to be a valid part of the data transaction, the reasoner will deem the data transaction to be valid and proceed to perform Write operation on blockchain with the PII fields and transaction ID. For example, consider a use case of NetFlix acquiring a new customer {PII fields: FirstName, LastName, Date of Birth and Address}, the execution of this scenario in the prototype is shown in Figure 8.
- (ii)
- Data sharing is partially permitted: Here, depending upon the PII fields present in the data transaction, and based on the policies that allow such PII to be a part of the data transaction but not wholly involved, the reasoner will still deem the data transaction to be valid since it is the default selection and proceed to perform Write operation on blockchain with the PII fields and transaction ID. E.g., consider a use case of sharing some PII data by the service provider (Netflix) with trusted 3rd party {PII fields: FirstName, LastName, CreditCardNumber}, the execution of this scenario in the prototype system is shown in Figure 9.
- (iii)
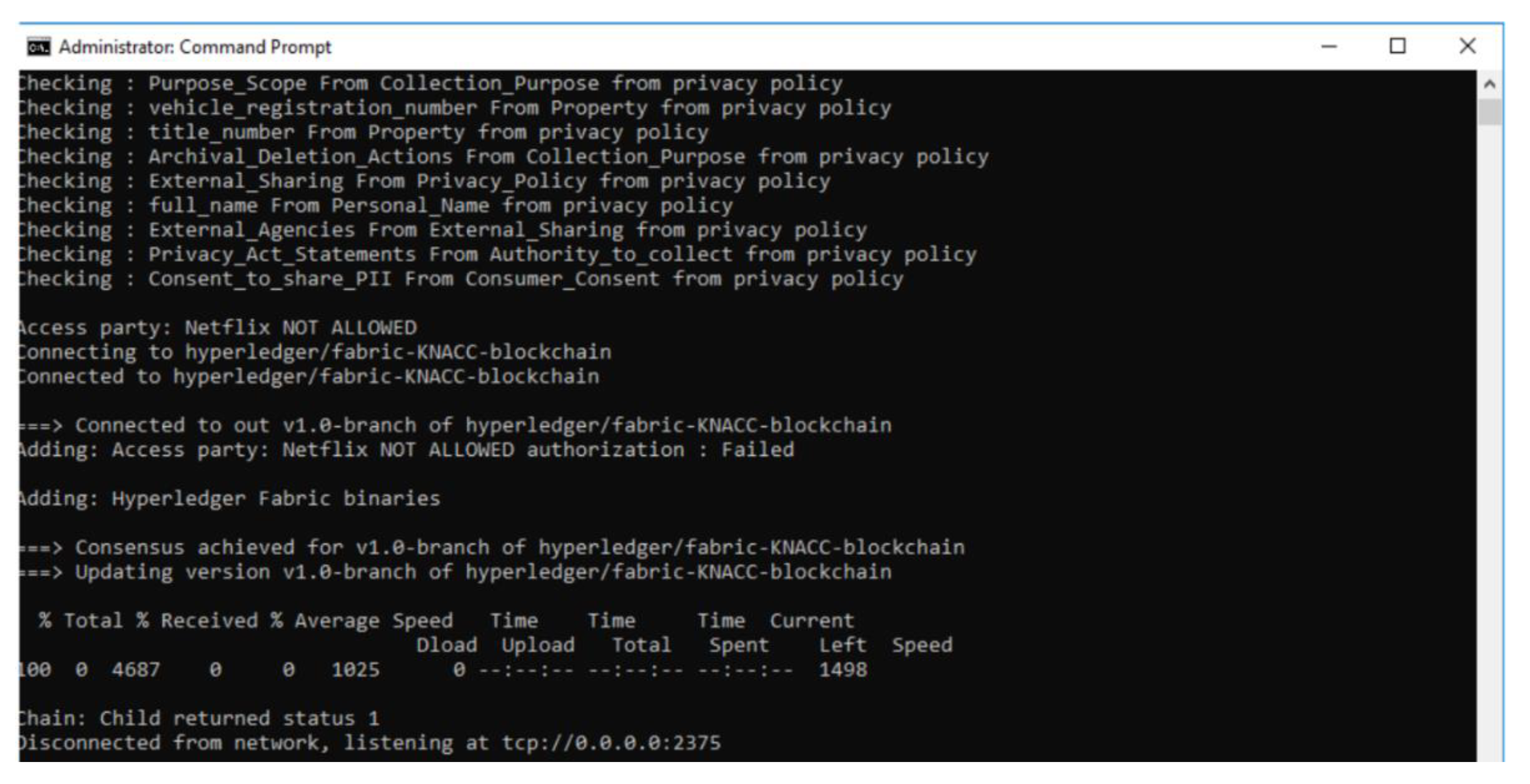
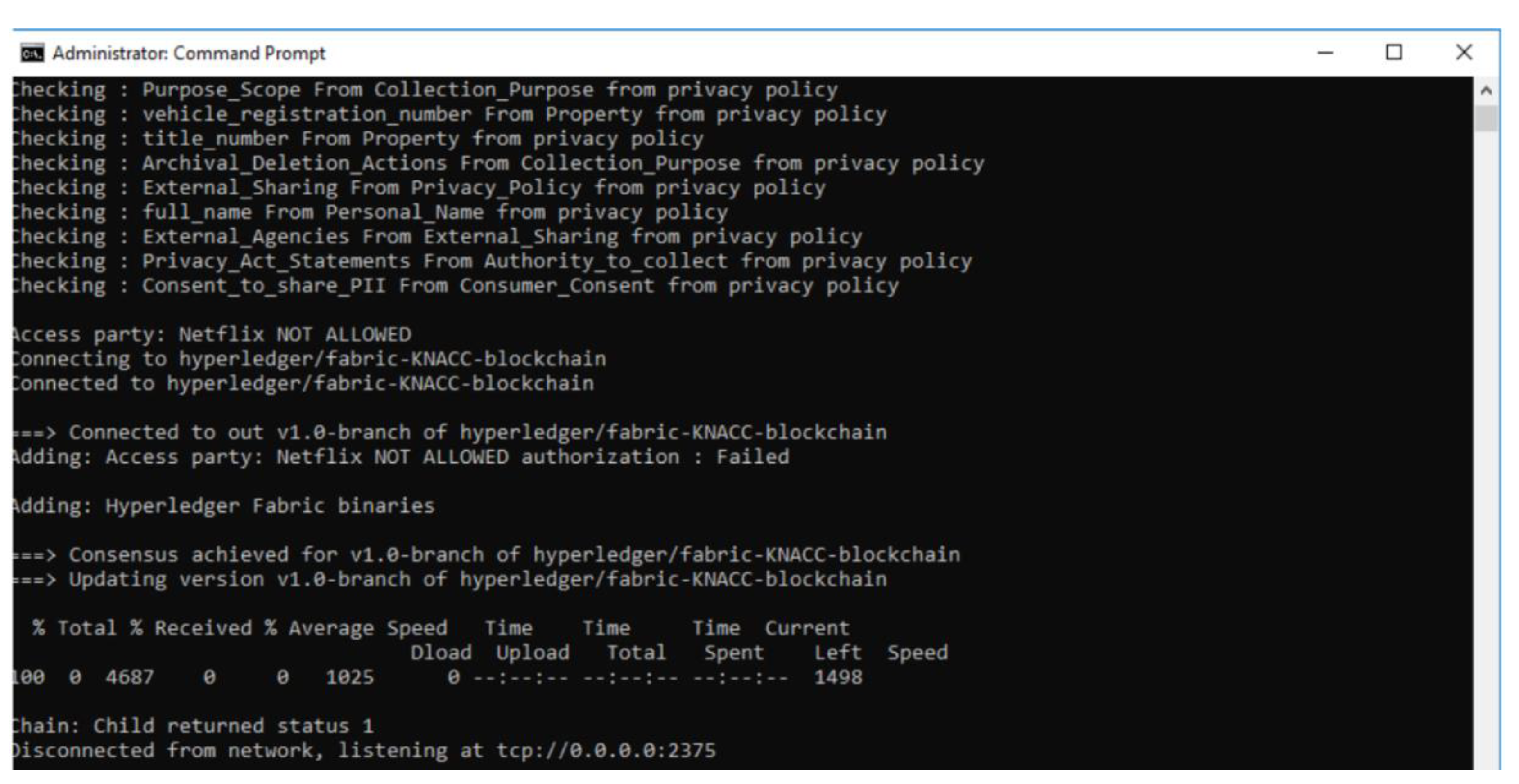
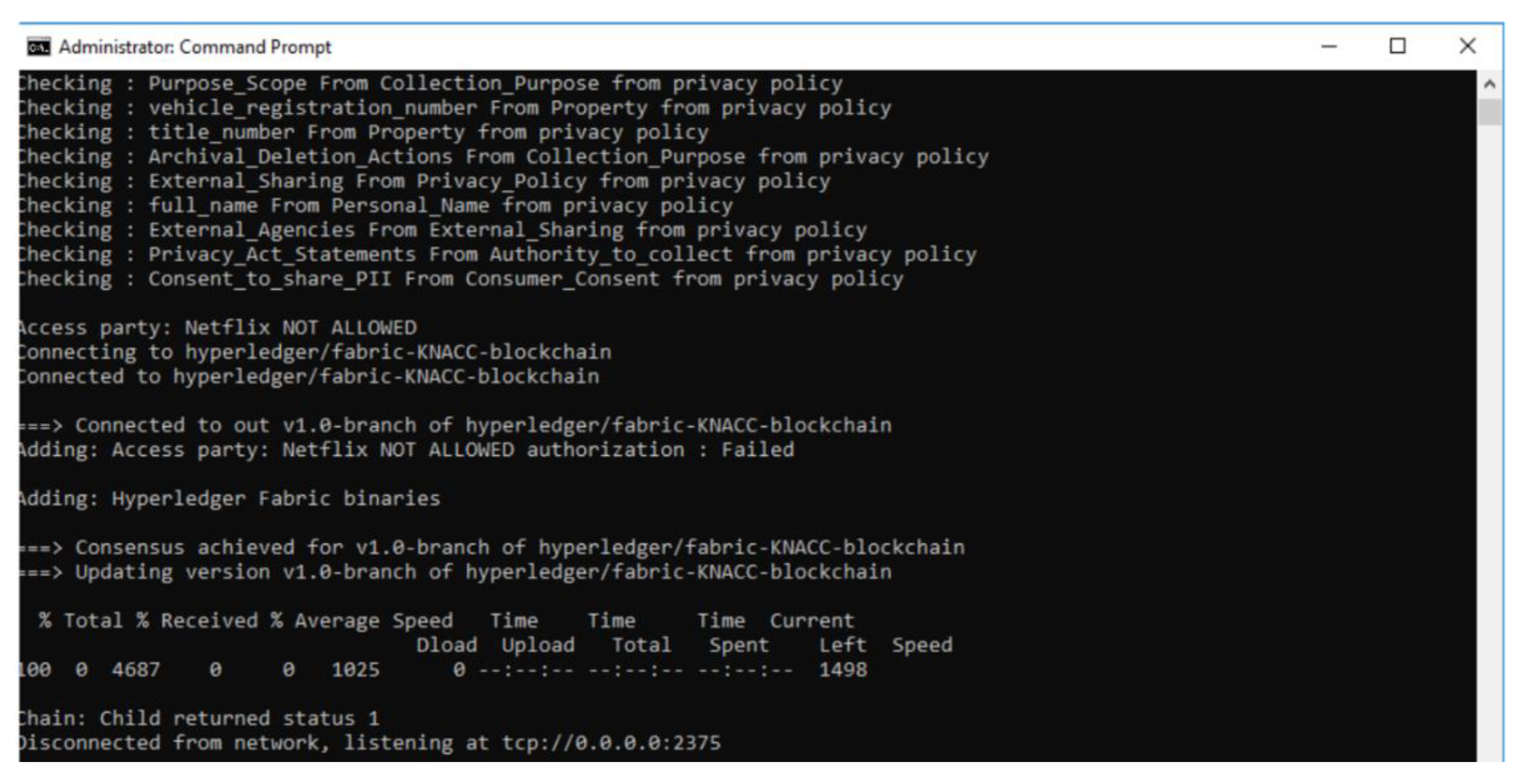
- Data sharing is not permitted: Here, depending upon the PII fields present in the data transaction, and based on the policies that do not allow such PII fields to be a valid part of the data transaction, the reasoner will deem the data transaction to be invalid and proceed to perform a Write operation on blockchain with the transaction ID and FailureReason. This reason acts as part of the Provenance of the system. E.g., for a use case of sharing PII data by the service provider (Netflix) with trusted 3rd party, the execution of this scenario is not permitted by the prototype system as shown in Figure 10.
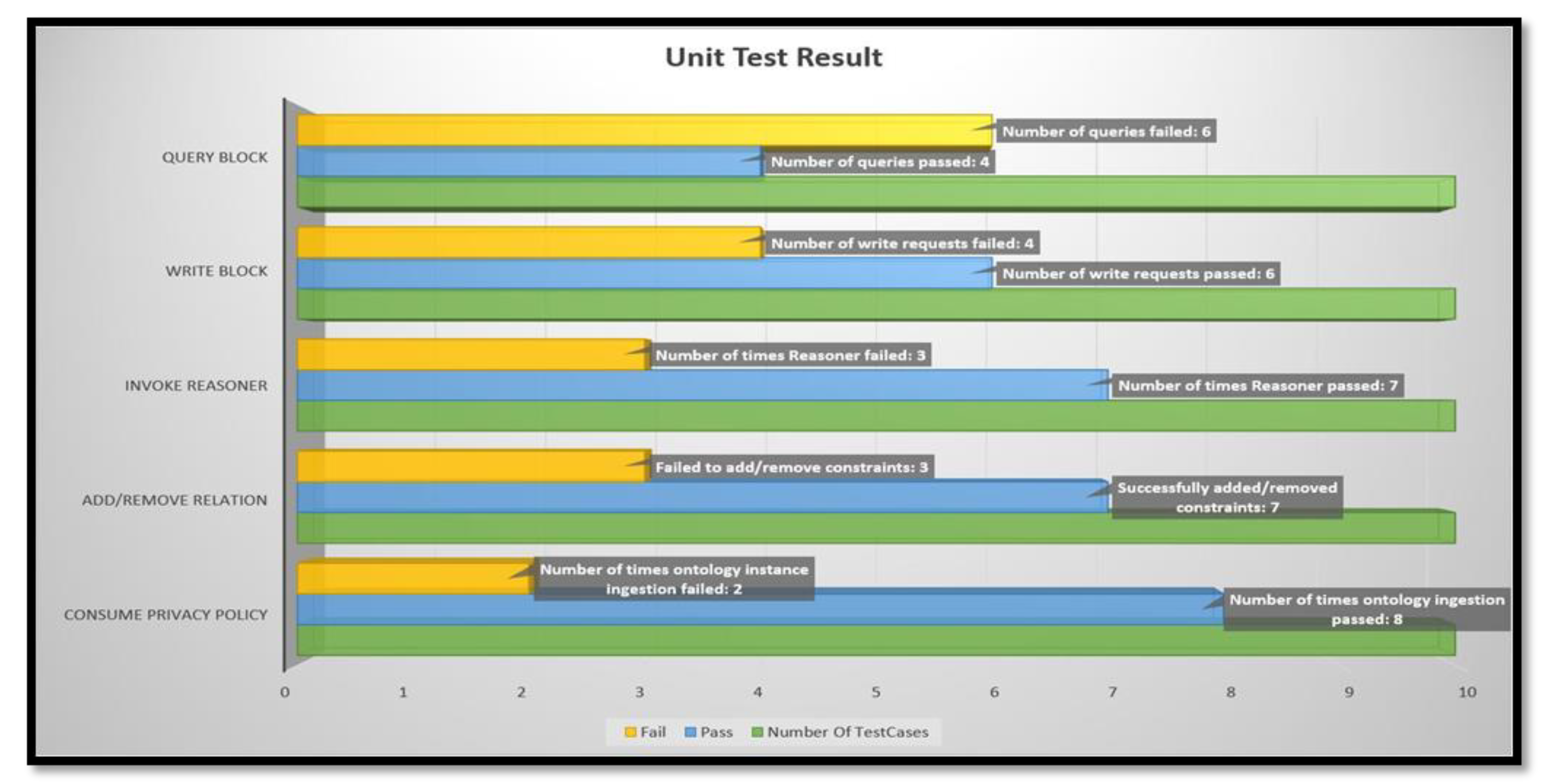
5.3. Performance
- (i)
- experiment duration: 100 s: this is set to take into account the request generation, reasoner result and write to blockchain time;
- (ii)
- the Service Providers/End-User ratio: 1:1—current implementation;
- (iii)
- each Service Providers registered 1 randomly generated End-User;
- (iv)
- each Service Provider sent a randomly generated transaction to write request with Key-Value pair and
- (v)
- each End-User sent a new randomly-generated query request every 10 s.
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Joshi, K.P.; Yesha, Y.; Finin, T. Automating Cloud Services Life Cycle through Semantic Technologies. IEEE Trans. Serv. Comput. 2014, 7, 109–122. [Google Scholar] [CrossRef]
- Gupta, A.; Mittal, S.; Joshi, K.P.; Pearce, C.; Joshi, A. Streamlining Management of Multiple Cloud Services. In Proceedings of the 2016 IEEE 9th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 2–27 July 2016; pp. 481–488. [Google Scholar]
- Mittal, S.; Joshi, K.P.; Pearce, C.; Joshi, A. Automatic extraction of metrics from SLAs for cloud service management. In Proceedings of the 2016 IEEE International Conference on Cloud Engineering (IC2E), Berlin, Germany, 4–8 April 2016; pp. 139–142. [Google Scholar]
- Joshi, K.; Gupta, A.; Mittal, S.; Pearce, C.; Joshi, A.; Finin, T. Semantic Approach to Automating Management of Big Data Privacy Policies. In Proceedings of the IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016. [Google Scholar]
- Banerjee, A.; Joshi, K.P. Link before you share: Managing privacy policies through blockchain. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4438–4447. [Google Scholar]
- Kim, H.; Laskowski, M. Toward an Ontology-Driven Blockchain Design for Supply-Chain Provenance, Intelligent Systems in Accounting, Finance and Management; Wiley Online Library: New York, NY, USA, 2018; pp. 18–27. [Google Scholar]
- TOVE Ontologies. Available online: http://www.eil.utoronto.ca/theory/enterprise-modelling/tove/ (accessed on 4 February 2019).
- Zyskind, G.; Nathan, O.; Pentland, A. Decentralizing Privacy: Using Blockchain to Protect Personal Data. In Proceedings of the 2015 IEEE Security and Privacy Workshops, San Jose, CA, USA, 21–22 May 2015; pp. 180–184. [Google Scholar]
- Kosba, A.; Miller, A.; Shi, E.; Wen, Z.; Papamanthou, C. Hawk: The Blockchain Model of Cryptography and Privacy-Preserving Smart Contracts. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 839–858. [Google Scholar]
- Sutton, A.; Samavi, R. Blockchain Enabled Privacy Audit Logs. In The Semantic Web—ISWC 2017, ISWC 2017, Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10587. [Google Scholar]
- Zhang, N.J.; Todd, C. A privacy agent in context-aware ubiquitous computing environments. In CMS 2006. LNCS; Leitold, H., Markatos, E.P., Eds.; Springer: Heidelberg, Germany, 2006; Volume 4237, pp. 196–205. [Google Scholar]
- Byun, J.; Li, N. Purpose based access control of complex data for privacy protection. In Proceedings of the Tenth ACM Symposium on Access Control Models and Technologies, Vienna, Austria, 1–3 June 2015; ACM: New York, NY, USA, 2005. [Google Scholar]
- de Montjoye, Y.V.; Shmueli, E.; Wang, S.S.; Pentlan, A.S. openPDS: Protecting the privacy of metadata through safeanswers. PLOS ONE 2014, 9, e98790. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Hoang, D.B. Novel Data Protection Model in Healthcare Cloud. In Proceedings of the 2011 IEEE 13th International Conference on High Performance Computing and Communications (HPCC), Banff, AB, Canada, 2–4 September 2011; pp. 550–555. [Google Scholar]
- OAuth Protocol. Available online: https://tools.ietf.org/html/rfc6749 (accessed on 4 February 2019).
- Belaazi, M.; Rahmouni, H.B.; Bouhoula, A. An Ontology Regulating Privacy Oriented Access Controls. In Proceedings of the International Conference on Risks and Security of Internet and Systems (CRiSIS 2015), Mytilene, Greece, 20–22 July 2015. [Google Scholar]
- Jansen, W.; Grance, T. NIST SP 800-144 Guidelines on Security and Privacy in Public Cloud Computing. Available online: http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-144.pdf (accessed on 4 February 2019).
- NIST SP 800-53. Available online: http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-53r4.pdf (accessed on 4 February 2019).
- NIST Special Publication 800-122, Guide to Protecting the Confidentiality of Personally Identifiable Information (PII). Available online: http://csrc.nist.gov/publications/nistpubs/800-122/sp800-122.pdf (accessed on 4 February 2019).
- Regulation 2016/679 of the European Parliament. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32016R0679 (accessed on 21 January 2019).
- European Commission, Protection of Personal Data. Available online: https://ec.europa.eu/info/law/law-topic/data-protection_en (accessed on 4 February 2019).
- Privacy Alliance. Available online: http://www.privacyalliance.org/resources/ppguidelines/ (accessed on 4 February 2019).
- Federal Trade Commission (FTC). Available online: https://www.ftc.gov/tips-advice/business-center/privacy-and-security (accessed on 4 February 2019).
- Beesley, C. 7 Considerations for Crafting an Online Privacy Policy. U.S.S.B.A. (United States Small Business Administration). Available online: https://www.sba.gov/blogs/7-considerations-crafting-online-privacy-policy (accessed on 4 February 2019).
- The Truth about Blockchain, Harvard Business Reviews. Available online: https://hbr.org/2017/01/the-truth-about-blockchain (accessed on 4 February 2019).
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Consulted 2012, 28, 2008. [Google Scholar]
- Hyperledger Project. Available online: https://www.hyperledger.org/ (accessed on 4 February 2019).
- Kemme, B.; Alonso, G. A new approach to developing and implementing eager database replication protocols. ACM Trans. Database Sys. 2000, 25, 333–379. [Google Scholar] [CrossRef]
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; De Caro, A.; Enyeart, D.; Ferris, C.; Laventman, G.; Manevich, Y.; et al. Hyperledger fabric: A distributed operating system for permissioned blockchains. In Proceedings of the Thirteenth EuroSys Conference (EuroSys ’18), Porto, Portugal, 23–26 April 2018. [Google Scholar]
- Lassila, O.; Swick, R. Resource Description Framework (RDF) Model and Syntax Specification. WWW Consortium. 1999. Available online: https://www.w3.org/TR/1999/REC-rdf-syntax-19990222/ (accessed on 4 February 2019).
- McGuinness, D.; van Harmelen, F. OWL Web Ontology Language Overview. W3C Recommendation, World Wide Web Consortium. 2004. Available online: https://www.w3.org/TR/owl-features/ (accessed on 4 February 2019).
- Elluri, L.; Nagar, A.; Joshi, K.P. An Integrated Knowledge Graph to Automate GDPR and PCI DSS Compliance. In Proceedings of the IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- ACL COLING Dataset. Available online: https://usableprivacy.org/data (accessed on 4 February 2019).
- Lieberman, J.; Singh, R.; Goad, C. W3C Geospatial Ontologies. Available online: https://www.w3.org/2005/Incubator/geo/XGR-geo-ont/ (accessed on 4 February 2019).
- Joshi, K. Ontology for Data Privacy Policy. Available online: http://ebiquity.umbc.edu/resource/html/id/370/Ontology-for-DataPrivacy-Policy (accessed on 4 February 2019).
- State Laws related to Internet Privacy. Available online: http://www.ncsl.org/research/telecommunications-and-informationtechnology/state-laws-related-to-internet-privacy.aspx (accessed on 4 February 2019).
- EDM Council. Financial Industry Business Ontology (FIBO). Available online: https://spec.edmcouncil.org/fibo/ (accessed on 4 February 2019).
- Finin, T.; Joshi, A.; Kagal, L.; Niu, J.; Sandhu, R.; Winsborough, W.; Thuraisingham, B. ROWLBAC—Representing Role Based Access Control in OWL. In Proceedings of the 13th Symposium on Access Control Models and Technologies, Estes Park, CO, USA, 11–13 June 2008. [Google Scholar]
- Sharma, N.K.; Joshi, A. Representing Attribute Based Access Control Policies in OWL. In Proceedings of the ICSC, Laguna Hills, CA, USA, 4–6 February 2016. [Google Scholar]






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joshi, K.P.; Banerjee, A. Automating Privacy Compliance Using Policy Integrated Blockchain. Cryptography 2019, 3, 7. https://doi.org/10.3390/cryptography3010007
Joshi KP, Banerjee A. Automating Privacy Compliance Using Policy Integrated Blockchain. Cryptography. 2019; 3(1):7. https://doi.org/10.3390/cryptography3010007
Chicago/Turabian StyleJoshi, Karuna Pande, and Agniva Banerjee. 2019. "Automating Privacy Compliance Using Policy Integrated Blockchain" Cryptography 3, no. 1: 7. https://doi.org/10.3390/cryptography3010007
APA StyleJoshi, K. P., & Banerjee, A. (2019). Automating Privacy Compliance Using Policy Integrated Blockchain. Cryptography, 3(1), 7. https://doi.org/10.3390/cryptography3010007