
How to Make AlphaGo’s Children Explainable

Abstract
:1. Introduction
2. What Is an Explainable Baduk (Go, Weiqi) Player?
The AI’s principal variation (the most advantageous sequence of play) can give information about a better way of playing, but how much a human can infer from it depends on the player. An AI cannot explain why it plays its moves beyond giving an estimated winning probability and possibly a score estimation, but humans cannot generate these numbers on their own. The AI’s output is generally the most useful for a human if the AI’s idea was originally conceivable for the human, but depends on an important key move or realization later in the sequence to truly work. More often, however, an AI chooses its moves by its superior whole-board judgement, which is difficult to explain in human terms.Ref. [20] (Section 4.2) (Emphasis added)
Ultra-weakly solved: The result of perfect play is known, but not the strategy. For example Hex, where a simple mathematical proof shows that the first player wins, but we do not know how to achieve that result.Weakly solved: Perfect result and strategy are known from the starting position. Checkers is solved this way; therefore, there are still positions for which we do not know the perfect result.Strongly solved: For all legal board positions, we know the perfect result and we can demonstrate a sequences of moves leading to that.Ref. [20] (Section 7.1)
The combinatorial complexity of the game prohibits us from having answers to these questions with a brute-force method. How far are the current Go engines from perfect play? There are some indirect ways to measure that distance, e.g., the added value of the tree search to the raw output of the policy network [21]. The current AIs are certainly not at perfect play yet, as omniscient neural networks would have only three distinct output win rate probabilities of 0%, 50%, and 100% for all board positions. Talking in terms of probabilities other than these three values is admitting ignorance.Ref. [20] (Section 7.1)
3. Who Is Afraid of Making AlphaGo Explainable? An Apparent Paradox
Our program, AlphaGo Zero, differs from AlphaGo Fan and AlphaGo Lee 12 in several important aspects. First and foremost, it is trained solely by self-play reinforcement learning, starting from random play, without any supervision or use of human data. Second, it only uses the black and white stones from the board as input features. Third, it uses a single neural network, rather than separate policy and value networks. Finally, it uses a simpler tree search that relies upon this single neural network to evaluate positions and sample moves, without performing any Monte-Carlo rollouts. To achieve these results, we introduce a new reinforcement learning algorithm that incorporates look ahead search inside the training loop, resulting in rapid improvement and precise and stable learning. Further technical differences in the search algorithm, training procedure and network architecture are described in Methods.
AlphaGo Zero is the program described in this paper. It learns from self-play reinforcement learning, starting from random initial weights, without using rollouts, with no human supervision, and using only the raw board history as input features. It uses just a single machine in the Google Cloud with 4 TPUs (AlphaGo Zero could also be distributed but we chose to use the simplest possible search algorithm).Ref. [16] (p. 360)
However, we should not conclude that the crucial step was taken when the last version of AlphaGo, i.e., AlphaGo Master, was transformed into AlphaGo Zero. For, according to [16], AlphaGo Master “uses the same neural network architecture, reinforcement learning algorithm, and MCTS algorithm as described in” it (ibid.). Of course, it was immediately pointed out that “it uses the same handcrafted features and rollouts as AlphaGo Lee 12 and training was initialised by supervised learning from human data” (ibid.). What was happening in AlphaGo Master, about which DeepMind has never published a separate paper? Although there is no explicit mention made, the big difference between AlphaGo Master and its earlier versions, i.e., AlphaGo Fan and AlphaGo Lee, must be that the former no longer has policy and value networks as the latter did. [16] is so anxious to emphasize that AlphaGo Zero discovered a remarkable level of Go knowledge during its self-play training process. This included fundamental elements of human Go knowledge, and also non-standard strategies beyond the scope of traditional Go knowledge.Ref. [16] (p. 357)
(An Apparent Paradox) By making AlphaGo less explainable, DeepMind made the explainability of AI the focal issue of our time once and for all.3
XAI has set itself an ambitious goal of making autonomous AI systems succeed in responding to requests for explanations of its own states, behaviours and outputs. The need for XAI has arisen from perceiving current ML as opaque or even representing solely behaviouristic black-box learning models that are in some sense incomprehensible and ill-motivated in their actions and intentions.Ref. [5] (p. 2)
4. How to Resolve the Apparent Paradox
4.1. The Apparent Paradox in the Suspicious Mind
- 1.
- AlphaGo had two separate neural networks, i.e., Policy network and Value network. (Fact)
- 2.
- The functioning of the policy network is like abduction. (My assumption)
- 3.
- The functioning of the value network is like IBE. (My assumption)
- 4.
- AlphaGo Master, AlphaGo Zero and AlphaGo’s other children have only one neural network by integrating the policy and value networks. (Fact)
- 5.
- Insofar as there was a division of labor between the policy and value networks, it was in principle possible to make sense of AlphaGo’s strategic moves or decision making processes. (My assumption seemingly shared by DeepMind)
- 6.
- Therefore, the policy network is functioning as an abducer, while the value network is doing IBE. [from lines 2 and 3]
- 7.
- Since there is no longer such a division of labor in AlphaGo Zero and AlphaGo’s other children, it becomes a harder task to understand their workings. (Corollary of 5)
- 8.
- In other words, AlphaGo and AlphGo’s other children are less explainable than AlphaGo. [from lines 5, 6, and 7]
- 9.
- It was DeepMind’s deliberate decision to give up the separation of policy and value networks. (Fact)
- 10.
- AlphaGo’s children far outweigh AlphaGo in strength, and are thereby less explainable. (My assumption)
“compensating by selecting those positions more intelligently, using the policy network, and evaluating them more precisely, using the value network—an approach that is perhaps closer to how humans play”Ref. [15] (p. 489) (Emphases added)
4.2. Abduction and IBE
It is common in contemporary discussions of IBE to link abduction to IBE in some way, either to directly equate IBE with abduction, or to trace IBE back to Peirce, or at least to use “IBE” and “abduction” interchangeably.
While Peirce’s notion of abduction is often cited as the intellectual forbearer of IBE, this view has been rejected by a great number of commentators.
(1) Is classifying abduction compatible with the search for the logical form of abduction, and (2) could there be any non-explanatory abduction? If abduction is just IBE, the problem of the logical form of abduction is nothing other than that of the logical form of IBE. If abduction is IBE, there would be no more mind-boggling for non-explanatory abduction: How could there be any “Non-explanatory IBE”?
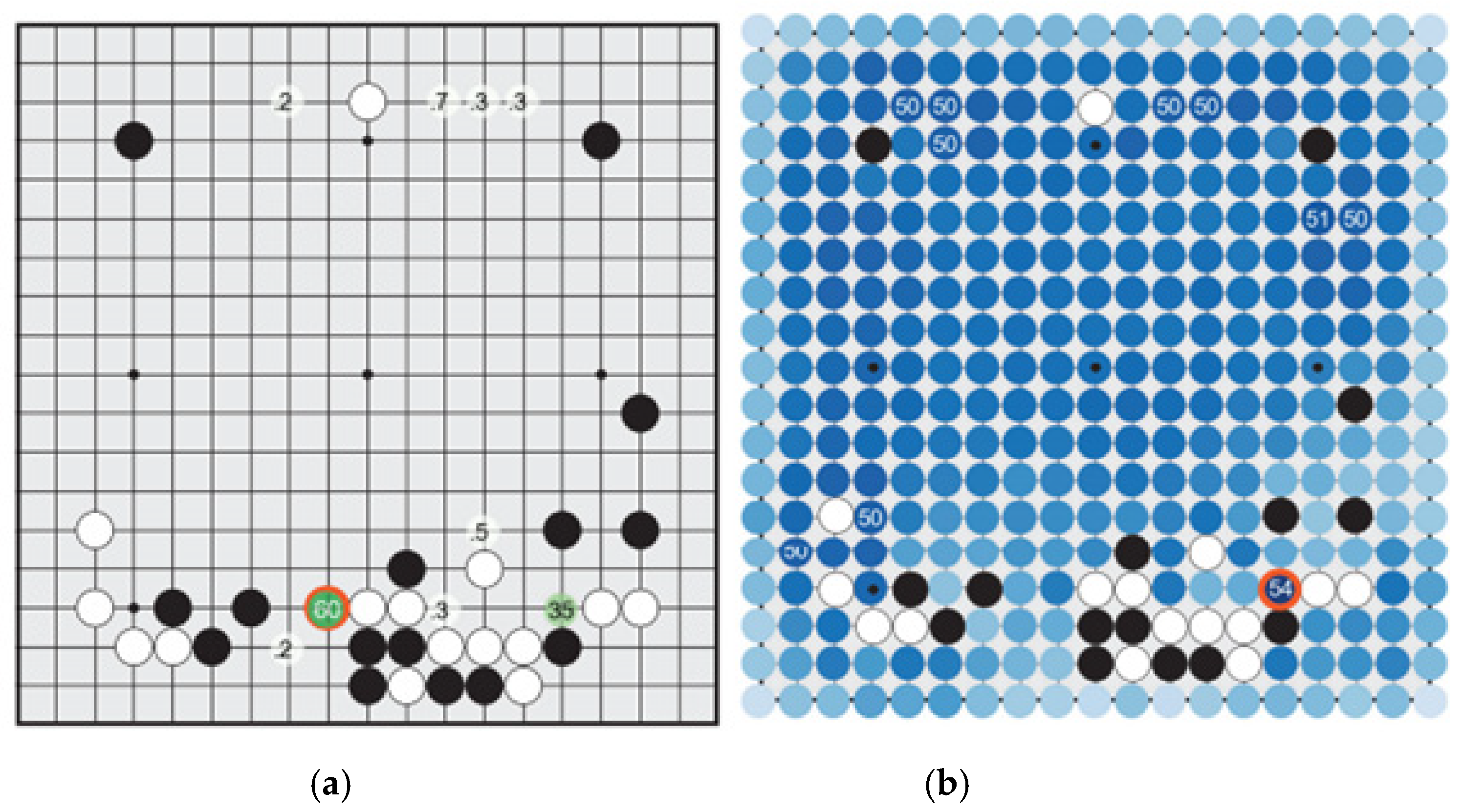
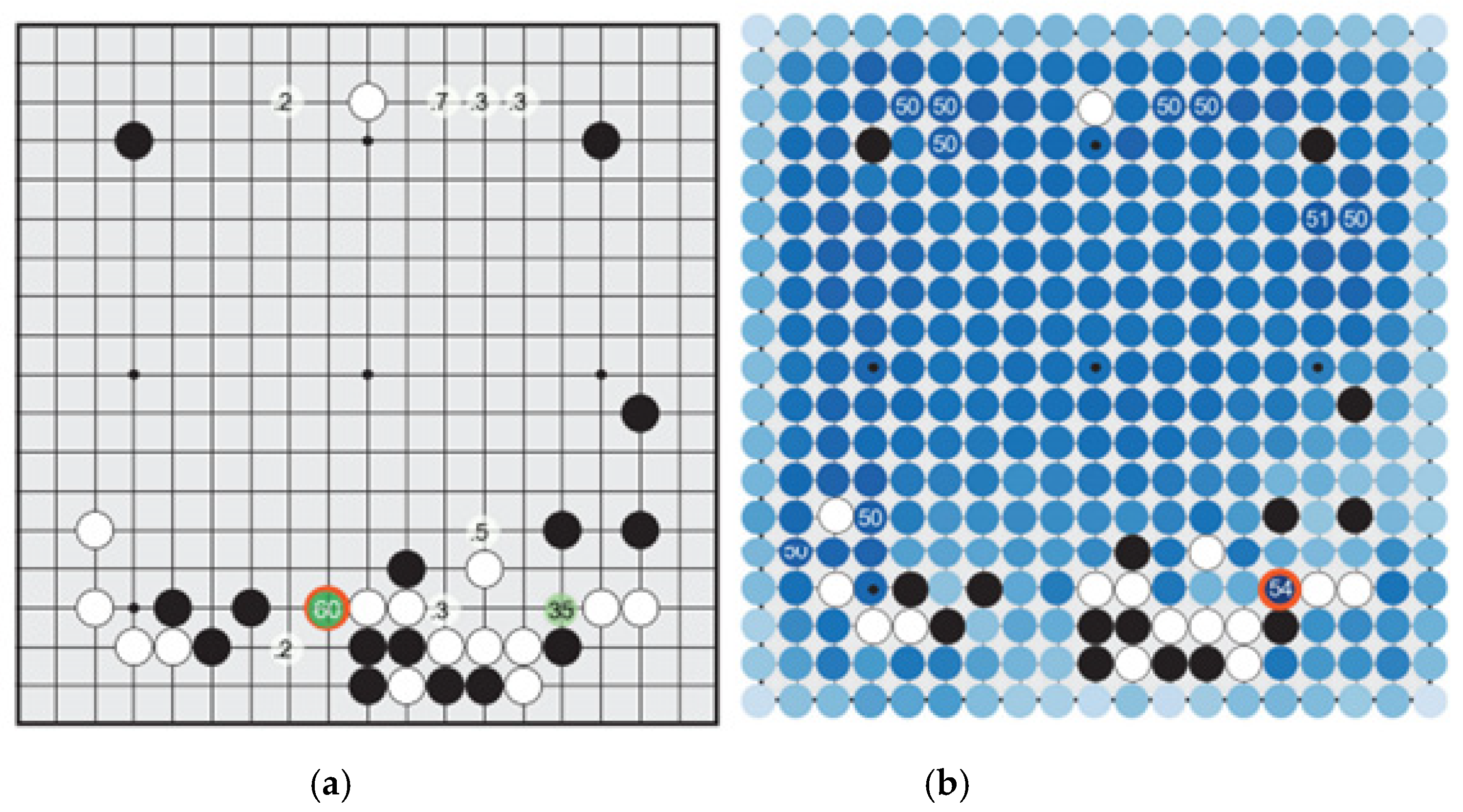
What is most shocking is that there is a dazzling contrast between the policy network and the value network. In the policy network shown in Figure 1a, the focus is on the move that scored 60 and the move scored 35. For, all the other moves scored less than 1. AlphaGo’s judgment that humans prefer the former move to the latter move seems correct. It could be the case that most Baduk players, including the advanced ones, would play the former move without serious consideration. The move not only guarantees ample territory but also promises to secure sente. For, Black can capture two White stones by ladder, unless White responds to Black’s move that scored 60. Even if one considers the invading move in the right bottom corner that scored 35, it would rarely be executed, since it is not so attractive. For, as shown in Figure 2 [sic], though it is a quite nice move destroying White’s territory in the right bottom corner, it is not a fatal move threatening White’s group. There is even a worry due the uncertainty involved in case White counterattacks by thrusting a wedging move, which was in fact the choice Fan Hui made in the actual game. Now, we can see that in the value network shown in Figure 1b [sic] the invading move in the right bottom corner got the highest score 54, and there are many other moves that scored 50, while the hane move in the bottom side got extremely low evaluation even failing to get serious consideration.Ref. [25] (pp. 134–136)
A narrow use of the term “induction” covers only generalization from some to all, but the broader use covers any inference that differs from deduction in introducing uncertainty. There are many such kinds of induction ranging from analogy to statistical inference, but one of the most common goes by the name “inference to the best explanation”.
Arguably, the typical tasks for which machine learning systems consisting of backpropagation algorithms are trained fit the schema of inductive reasoning rather more closely than that of abductive reasoning. Training an A.I. machine learner to distinguish images of cats from those of dogs, for instance, seems to be a cognitive task more closely aligned with generalization than with explanation. Nonetheless, any such implementation of an algorithmic process to fulfill such a task may be understood as being abductive in principle to the degree that the trained network is intended to function successfully with regard to new data that is sufficiently dissimilar to its original training data. The trained network as a whole may in this respect be understood as a type of abductive hypothesis with respect to the successful fulfillment of relevantly similar tasks. Of course, the network itself does not understand itself in this way, but external trainers and collaborators might very well see things in such a light.Ref. [51] (p. 10)
4.3. Criticism of the Implicit Assumptions of the Apparent Paradox
5. Further Reflections on Abduction and IBE in the AlphaGo Experiment
5.1. Abduction and IBE in the Single Neural Network of AlphaGo’s Children
- (1)
- All of them are from the surviving elements of the previous policy network.
- (2)
- Some of them are from the remnants of the policy network, and others are from the ever existing value network component.
- (3)
- All of them are from the value network component.
To separate the contributions of architecture and algorithm, we compared the performance of the neural network architecture in AlphaGo Zero with the previous neural network architecture used in AlphaGo Lee …. Four neural networks were created, using either separate policy and value networks, as in AlphaGo Lee, or combined policy and value networks, as in AlphaGo Zero; and using either the convolutional network architecture from AlphaGo Lee or the residual network architecture from AlphaGo Zero. Each network was trained to minimise the same loss function … using a fixed data-set of self-play games generated by AlphaGo Zero after 72 h of self-play training. Using a residual network was more accurate, achieved lower error, and improved performance in AlphaGo by over 600 Elo. Combining policy and value together into a single network slightly reduced the move prediction accuracy, but reduced the value error and boosted playing performance in AlphaGo by around another 600 Elo. This is partly due to improved computational efficiency, but more importantly the dual objective regularises the network to a common representation that supports multiple use cases.Ref. [16] (pp. 356–357) (Emphases added)
5.2. Abduction and IBE from the Perspective of Human/Computer Interaction in Baduk
One evidently nice outcome is that we secured a novel question: When is a strategy in games? By asking “When?” rather than “What?”, we can give a fair hearing to the players in the formation, evaluation, and revision of the strategies.…One of the most urgent question to raise must be this: Does AlphaGo have any strategy?…How are we to explain such a rapid and unbelievable success of AlphaGo? What was the secret of success of Google DeepMind in developing AlphaGo? Of course, we need to examine carefully which component of AlphaGo was the crucial factor: Monte-carlo method, reinforcement learning, deep learning, machine learning, or what? But one thing evident is that even the DeepMind does not know exactly how AlphaGo achieved all the victories. If so, we have to ask whether AlphaGo has any strategy in playing games of Baduk. In answering this question, what I discuss here can be a point of departure.Ref. [40] (p. 1169)
AlphaGo Zero discovered a remarkable level of Go knowledge during its self-play training process. This included fundamental elements of human Go knowledge, and also non-standard strategies beyond the scope of traditional Go knowledge.Ref. [16] (p. 357)
Humankind has accumulated Go knowledge from millions of games played over thousands of years, collectively distilled into patterns, proverbs and books. In the space of a few days, starting tabula rasa, AlphaGo Zero was able to rediscover much of this Go knowledge, as well as novel strategies that provide new insights into the oldest of games.Ref. [16] (p. 358)
5.3. More Philosophical Issues from Abduction and IBE in Human/Computer Interaction
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | See also Pumperla and Ferguson’s interesting remarks on the great success of AlphaGo Zero: “To us, the most astonishing thing about AlphaGo Zero is how it does more with less. Inmany ways, AGZ is much simpler than the original AlphaGo. No more handcraftedfeature planes. No more human game records. No more Monte Carlo rollouts. Insteadof two neural networks and three training processes, AlphaGo Zero used one neural network and one training process.” [24] (p. 290) |
| 2 | The following excerpts should be enough for following the discussion of DeepMind’s characterization of AlphaZero contrasted with AlphaGo programs: “1. AlphaGo Fan is the previously published program 12 that played against Fan Hui in October 2015. … 2. AlphaGo Lee is the program that defeated Lee Sedol 4–1 in March, 2016. It was previously unpublished but is similar in most regards to AlphaGo Fan 12. However, we highlight several key differences to facilitate a fair comparison. First, the value network was trained from the outcomes of fast games of self-play by AlphaGo, rather than games of self-play by the policy network; this procedure was iterated several times—an initial step towards the tabula rasa algorithm presented in this paper. Second, the policy and value networks were larger than those described in the original paper … 3. AlphaGo Master is the program that defeated top human players by 60–0 in January, 2017 34. It was previously unpublished but uses the same neural network architecture, reinforcement learning algorithm, and MCTS algorithm as described in this paper. However, it uses the same handcrafted features and rollouts as AlphaGo Lee 12 and training was initialised by supervised learning from human data. 4. AlphaGo Zero …”. [16] (p. 360). (The point 4 is cited in the main text.) |
| 3 | It is my presumption that DeepMind’s demonstration of the power consists of a dramatic series of events: (1) AlphaGo Fan’s winning against a professional Baduk player, i.e., Fan Hui, (2) AlphaGo Lee’s victory against Lee Sedol, (3) AlphaGo Master’s perfect winning against 60 top level professional Baduk players on internet, and (4) AlphaGo Zero’s winning against Ke Jie, the current world champion. Not any one of these events but the entire series of them made the explainability of AI the focal issue of our time once and for all. |
| 4 | Whether the imaginary suspicion is justified or not, we have more than enough reasons to be interested in philosophical issues embedded in XAI. For example, according to Medianovskyi and Pietarinen, “[t]he theoretical issues affecting XAI thus reflect long-standing issues in the philosophy of language, science and communication”. [5] (p. 3) |
| 5 | One anonymous reviewer made a penetrating criticism against the argument sketched in Section 3. Right now, it is simply beyond my ability to respond to the criticism. So, please gently allow me to report it: “It seems that there is an equivocation: the argument sketched in Section 3 suggests that the strong integration of policy and value networks in post-AlphaGo systems made those systems less explainable (which seems quite plausible) and that because that design choice was made by DeepMind, the loss of explainability is “intentional”; but in the same section, such “intentionality” is also conceived as if it were _essentially_ a decision about explainability. If the loss of explainability were simply an unintended consequence of this design choice (isn’t this indeed plausible? if not, why not?), then is the second sense of “intentionality” warranted? At the very least, this question should probably be addressed explicitly.” |
| 6 | My assumptions 2 and 3 will continuously be discussed in the following, and my assumption 10 will be discussed in broader context in Section 5. |
| 7 | One anoymous reviewer rightly pointed out the need to define abduction and IBE. In order not to prejudge the issue, however, I would ask the readers to compare Cabrera’s presentation of IBE as “four-step argument schema” with the usual shema for Peircean abduction. [37] |
| 8 | Minnameier’s opinion is widely shared. Cabrera’s list could be expanded by including, e.g., 45, 46, 47, and even 48. (See [38] (pp. 29–34.)) |
| 9 | We may note that, inasmuch as prediction is a standard issue in philosophy of science, we have very good reasons to expect fruitful results from the study of prediction in human/computer games of Baduk. Magnani’s inquiries on anticipation as a kind of abduction in human and machine cognition could be one of the rare precedents in that direction of research [52,53,54,55]. In that sense, the abrupt disappearance of the policy network in AlphaGo’s mechanism is unfortunate. |
| 10 | According to Medianovskyi and Pietarinen [5], induction has been the paradigm of machine learning (ML): “Instead of broadening the theoretical base of the types of reasoning, ML has stuck to its guns of induction and founded even the otherwise promising newcomer of self-supervised learning on just the same modalities of inductive reasoning” [5] (pp. 1–2). So, it might even be possible to strengthen the suspicion gainst DeepMind’s decision to combine the policy and value networks into a single neural network. |
| 11 | What I have in mind could be exemplified well by using the different versions of AlphaGo and their human opponent. Lee Sedol was confronting AlphaGo Lee rather than AlphaGo Fan, and Ke Jie was confronting AlphaGo Zero rather than AlphaGo Lee. It could have been nicer if those human players could have been fully informed of how much progress their AI opponents had achieved. |
References
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Doran, D.; Schulz, S.; Besold, T.R. What does explainable AI really mean? A new conceptualization of perspectives. arXiv 2017, arXiv:1710.00794. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a Rigorous Science of Interpretable Machine Learning. 2017. Available online: https://arxiv.org/abs/1702.08608 (accessed on 19 May 2022).
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Medianovskyi, K.; Pietarinen, A.-V. On Explainable AI and Abductive Inference. Philosophies 2022, 7, 35. [Google Scholar] [CrossRef]
- Schubbach, A. Judging machines: Philosophical aspects of deep learning. Synthese 2019, 198, 1807–1827. [Google Scholar] [CrossRef] [Green Version]
- Zednik, C. Will machine learning yield machine intelligence? In Proceedings of the 3rd Conference on Philosophy and Theory of Artificial Intelligence, Leeds, UK, 4–5 November 2017; Springer: Cham, Switzerland; pp. 225–227. [Google Scholar]
- Zednik, C. Solving the Black Box Problem: A Normative Framework for Explainable Artificial Intelligence. Philos. Technol. 2021, 34, 265–288. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, R.R.; Clancey, W.J.; Mueller, S.T. Explaining AI as an Exploratory Process: The Peircean Abduction Model. arXiv 2020, arXiv:2009.14795v2. [cs.AI]. [Google Scholar]
- Burrell, J. How the machine ‘thinks’: Understanding opacity in machine learning algorithms. Big Data Soc. 2016, 3, 205395171562251. [Google Scholar] [CrossRef]
- Cappelen, H.; Dever, J. Making AI Intelligible: Philosophical Foundations; Oxford University Press: Oxford, UK, 2021. [Google Scholar]
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl.-Based Syst. 2021, 214, 106685. [Google Scholar] [CrossRef]
- Montavon, G.; Samek, W.; Müller, K.-R. Methods for interpreting and understanding deep neural networks. Digit. Signal Processing 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Ras, G.; van Gerven, M.; Haselager, P. Explanation methods in deep learning: Users, values, concerns and challenges. In Explainable and Interpretable Models in Computer Vision and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2018; pp. 19–36. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McGrath, T.; Kapishnikov, A.; Tomašev, N.; Pearce, A.; Hassabis, D.; Kim, B.; Paquet, U.; Kramnik, V. Acquisition of Chess Knowledge in AlphaZero. arXiv 2021, arXiv:2111.09259v1. [cs.AI]. [Google Scholar]
- Thornton, J.M.; Laskowski, R.A.; Borkakoti, N. AlphaFold heralds a data-driven revolution in biology and medicine. Nat. Med. 2021, 27, 1666–1671. [Google Scholar] [CrossRef] [PubMed]
- Egri-Nagy, A.; Törmänen, A. The Game Is Not over Yet—Go in the Post-AlphaGo Era. Philosophies 2020, 5, 37. [Google Scholar] [CrossRef]
- Egri-Nagy, A.; Törmänen, A. Derived metrics for the game of Go—Intrinsic network strength assessment and cheat-detection. In Proceedings of the Eighth International Symposium on Computing and Networking (CANDAR), Naha, Japan, 24–27 November 2020. [Google Scholar]
- Kasparov, G. Deep Thinking: Where Machine Intelligence Ends and Human Creativity Begins; John Murray: London, UK, 2017. [Google Scholar]
- Hsu, F.-H. Behind Deep Blue: Building the Computer That Defeated the World Chess Champion; Princeton University Press: Princeton, NJ, USA, 2002. [Google Scholar]
- Pumperla, M.; Ferguson, K. Deep Learning and the Game of Go; Manning: Shelter Island, NY, USA, 2019. [Google Scholar]
- Park, W.; Kim, S.; Kim, G.; Kim, J. AlphaGo’s Decision Making. J. Appl. Log.—IFCoLog J. Log. Appl. 2019, 6, 105–155. [Google Scholar]
- Harman, G. The inference to the best explanation. Philos. Rev. 1965, 74, 88–95. [Google Scholar] [CrossRef]
- Thagard, P. The best explanation: Criteria for theory choice. J. Philos. 1978, 75, 76–92. [Google Scholar] [CrossRef]
- Lycan, W.G. Judgement and Justification; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar]
- Barnes, E. Inference to the loveliest explanation. Synthese 1995, 103, 251–277. [Google Scholar] [CrossRef]
- Lipton, P. Inference to the Best Explanation, 2nd ed.; Routledge: New York, NY, USA, 2004. [Google Scholar]
- Douven, I. “Abduction”, The Stanford Encyclopedia of Philosophy; Zalta, E.N., Ed.; Spring: Berlin/Heidelberg, Germany, 2021; Available online: https://plato.stanford.edu/entries/abduction/ (accessed on 17 May 2022).
- Minnameier, G. Peirce-suit of truth—Why inference to the best explanation and abduction ought not to be confused. Erkenntnis 2004, 60, 75–105. [Google Scholar] [CrossRef]
- McKaughan, D. From Ugly Duckling to Swan: C. S. Peirce, Abduction, and the Pursuit of Scientific Theories. Trans. Charles S. Peirce Soc. Q. J. Am. Philos. 2018, 4, 446–468. [Google Scholar]
- Campos, D. On the Distinction between Peirce’s Abduction and Lipton’s Inference to the Best Explanation. Synthese 2009, 180, 419–442. [Google Scholar] [CrossRef]
- McAuliffe, W. How did Abduction Get Confused with Inference to the Best Explanation? Trans. Charles S. Peirce Soc. 2015, 51, 300–319. [Google Scholar] [CrossRef]
- Park, W. On Classifying Abduction. J. Appl. Log. 2015, 13, 215–238. [Google Scholar] [CrossRef]
- Cabrera, F. Inference to the Best Explanation—An Overview. In Handbook of Abductive Cognition; Magnani, L., Ed.; Springer: Dordrecht, The Netherlands, 2022; Available online: http://philsci-archive.pitt.edu/20363/1/Inference%2Bto%2Bthe%2BBest%2BExplanation%2B-%2BAn%2BOverview%2BPenultimate%20Draft.pdf (accessed on 17 March 2022).
- Park, W. Abduction in Contect: The Conjectural Dynamics of Scientific Reasoning; Springer: Berlin, Germany, 2017. [Google Scholar]
- Park, W. Enthymematic Interaction in Baduk. In Logical Foundations of Strategic Reasoning, Special Issue of Journal of Applied Logics—IFCoLog Journal of Logics and their Applications; Park, W., Woods, J., Eds.; College Publications: London, UK, 2018; Volume 5, pp. 1145–1167. [Google Scholar]
- Park, W. When Is a Strategy in Games? In Logical Foundations of Strategic Reasoning, Special Issue of Journal of Applied Logics—IFCoLog Journal of Logics and their Applications; Park, W., Woods, J., Eds.; College Publications: London, UK, 2018; Volume 5, pp. 1169–1203. [Google Scholar]
- Park, W. On Abducing the Axioms of Mathematics. In Abduction in Cognition and Action: Logical Reasoning, Scientific Inquiry, and Social Practice, Sapere; Shook, J., Paavola, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2021; pp. 161–175. [Google Scholar]
- Park, W. What Proto-logic Could not be. Axiomathes 2021. Available online: https://doi.org/10.1007/s10516-021-09582-3XXX (accessed on 17 March 2022). [CrossRef]
- Minnameier, G. Abduction, Selection, and Selective Abduction. In Model-Based Reasoning in Science and Technology. Models and Inferences: Logical, Epistemological, and Cognitive Issues, Sapere; Magnani, L., Casadio, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 309–318. [Google Scholar]
- Minnameier, G. Forms of abduction and an inferential taxonomy. In Springer Handbook of Model-Based Reasoning; Magnani, L., Bertolotti, T., Eds.; Springer: Berlin, Germany, 2016; pp. 175–195. [Google Scholar]
- Magnani, L. Abductive Cognition: The Epistemological and Eco-Cognitive Dimensions of Hypothetical Ewasoning; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Woods, J. Errors of Reasoning: Naturalizing the Logic of Inference; College Publications: London, UK, 2013. [Google Scholar]
- Mackonis, A. Inference to the Best Explanation, Coherence and Other Explanatory Virtues. Synthese 2013, 190, 975–995. [Google Scholar] [CrossRef]
- Hintikka, J. What is abduction? The fundamental problem of contemporary epistemology. Trans. Charles S. Peirce Soc. 1998, 34, 503–533. [Google Scholar]
- Harman, G. Thought; Princeton University Press: Princeton, NJ, USA, 1973. [Google Scholar]
- Thagard, P. Naturalizing Logic: How Knowledge of Mechanisms Enhances Inductive Inference. Philosophies 2021, 6, 52. [Google Scholar] [CrossRef]
- Gangle, R. Backpropagation of Spirit: Hegelian Recollection and Human-A.I. Abductive Communities. Philosophies 2022, 7, 36. [Google Scholar] [CrossRef]
- Magnani, L. Playing with anticipations as abductions. Strategic reasoning in an eco-cognitive perspective. In Logical Foundations of Strategic Reasoning, Special Issue of Journal of Applied Logic—IfColog Journal of Logics and their Applications; Park, W., Woods, J., Eds.; College Publications: London, UK, 2018; Volume 5, pp. 1061–1092. [Google Scholar]
- Magnani, L. AlphaGo, Locked Strategies, and Eco-Cognitive Openness. Philosophies 2019, 4, 8. [Google Scholar] [CrossRef] [Green Version]
- Magnani, L. Anticipations as Abductions in Human and Machine Cognition: Deep Learning: Locked and Unlocked Capacities. Postmod. Open. 2020, 11, 230–247. [Google Scholar] [CrossRef]
- Magnani, L. Human Abductive Cognition Vindicated: Computational Locked Strategies, Dissipative Brains, and Eco-Cognitive Openness. Philosophies 2022, 7, 15. [Google Scholar] [CrossRef]
- Paglieri, F.; Woods, J. Enthymematic parsimony. Synthese 2011, 178, 461–501. [Google Scholar] [CrossRef]
- Paglieri, F.; Woods, J. Enthymemes: From reconstruction to understanding. Argumentation 2011, 25, 127–139. [Google Scholar] [CrossRef] [Green Version]
- Hui, F. Commentary on DeepMind Challenge Match between Lee Sedol and AlphaGo. 2016. Available online: https://deepmind.com/research/alphago/ (accessed on 25 December 2017).
- Carruthers, P. Human and Animal Minds: The Consciousness Questions Laid to Rest; Oxford University Press: Oxford, UK, 2019; Introduction. [Google Scholar]
- Park, W. How to Learn Abduction from Animals? From Avicenna to Magnani. In Model-Based Reasoning in Science and Technology: Theoretical and Cognitive Issues; Magnani, L., Ed.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 207–220. [Google Scholar]

{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, W. How to Make AlphaGo’s Children Explainable. Philosophies 2022, 7, 55. https://doi.org/10.3390/philosophies7030055
Park W. How to Make AlphaGo’s Children Explainable. Philosophies. 2022; 7(3):55. https://doi.org/10.3390/philosophies7030055
Chicago/Turabian StylePark, Woosuk. 2022. "How to Make AlphaGo’s Children Explainable" Philosophies 7, no. 3: 55. https://doi.org/10.3390/philosophies7030055
APA StylePark, W. (2022). How to Make AlphaGo’s Children Explainable. Philosophies, 7(3), 55. https://doi.org/10.3390/philosophies7030055