
Lexicalised Locality: Local Domains and Non-Local Dependencies in a Lexicalised Tree Adjoining Grammar


Abstract
:1. Introduction
2. Main Tenets of the TAG Formalism
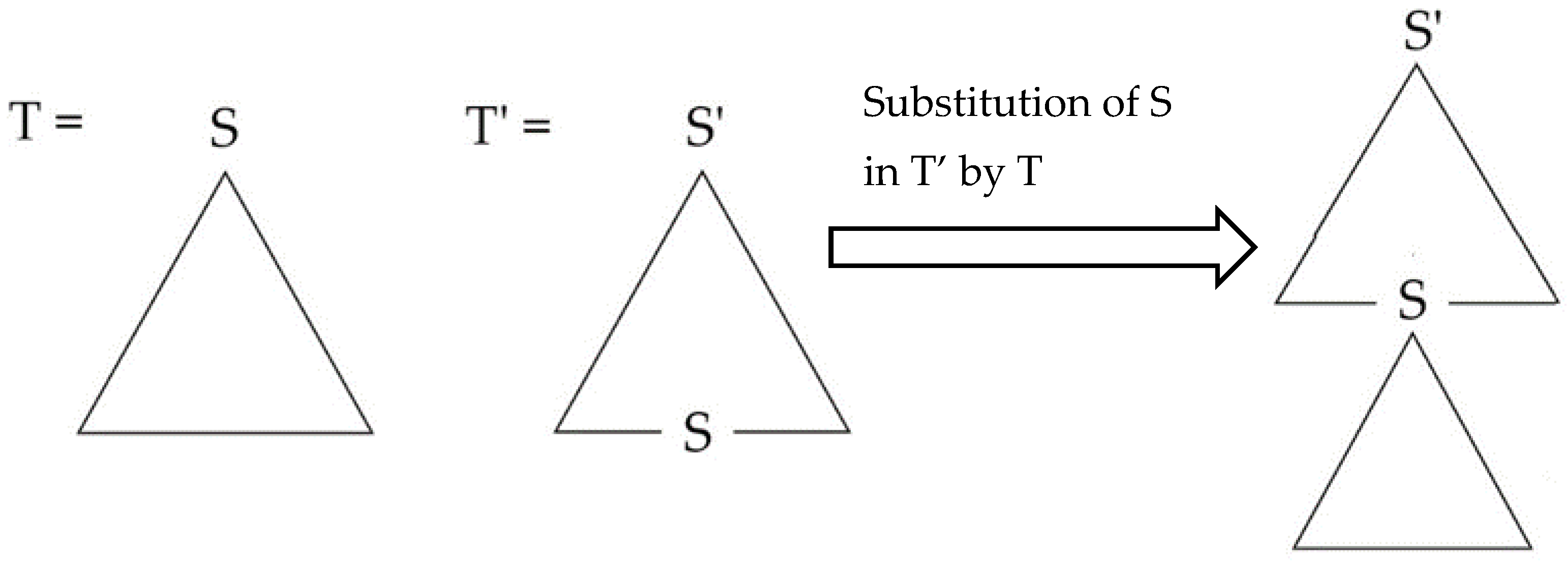
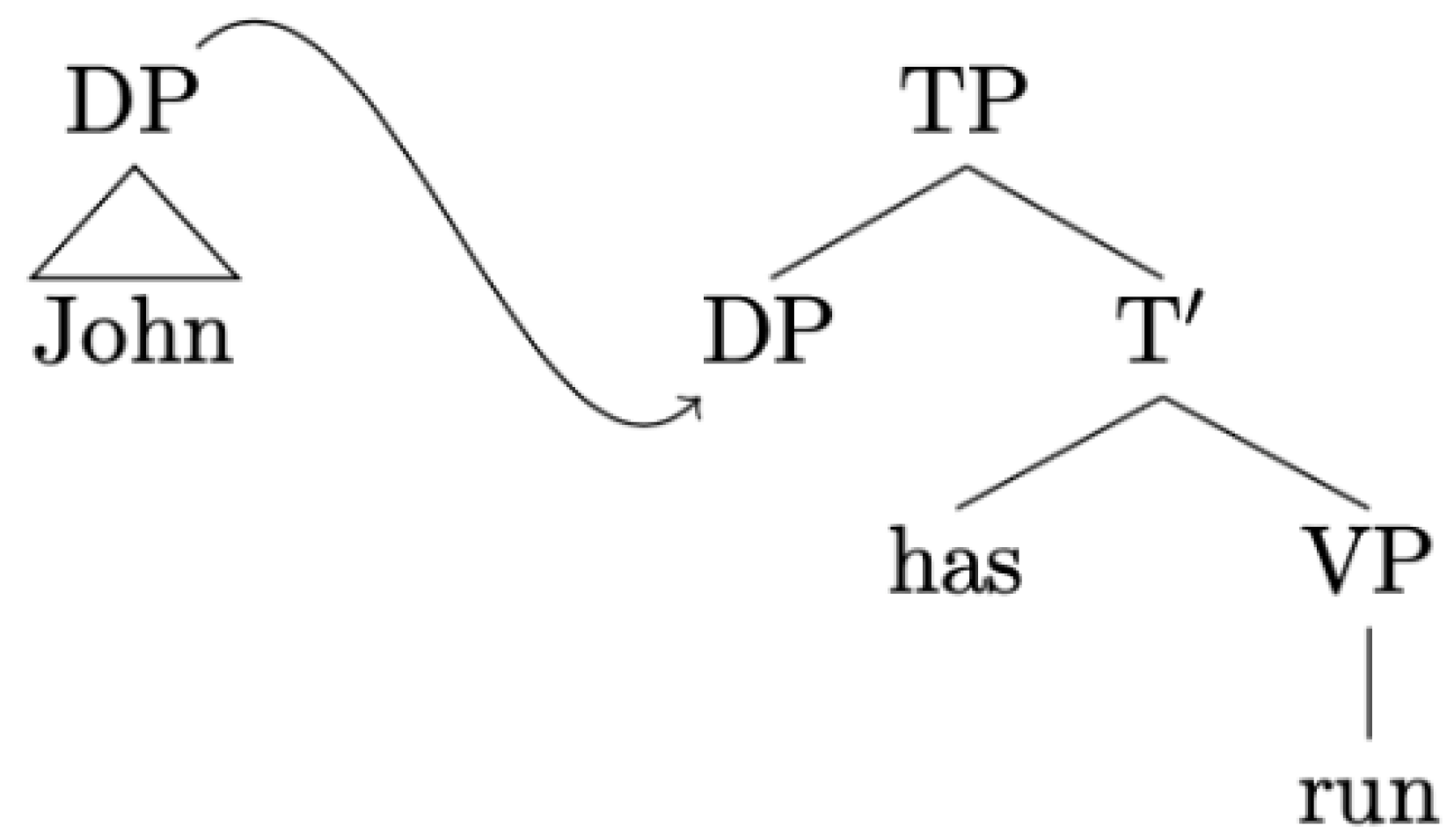
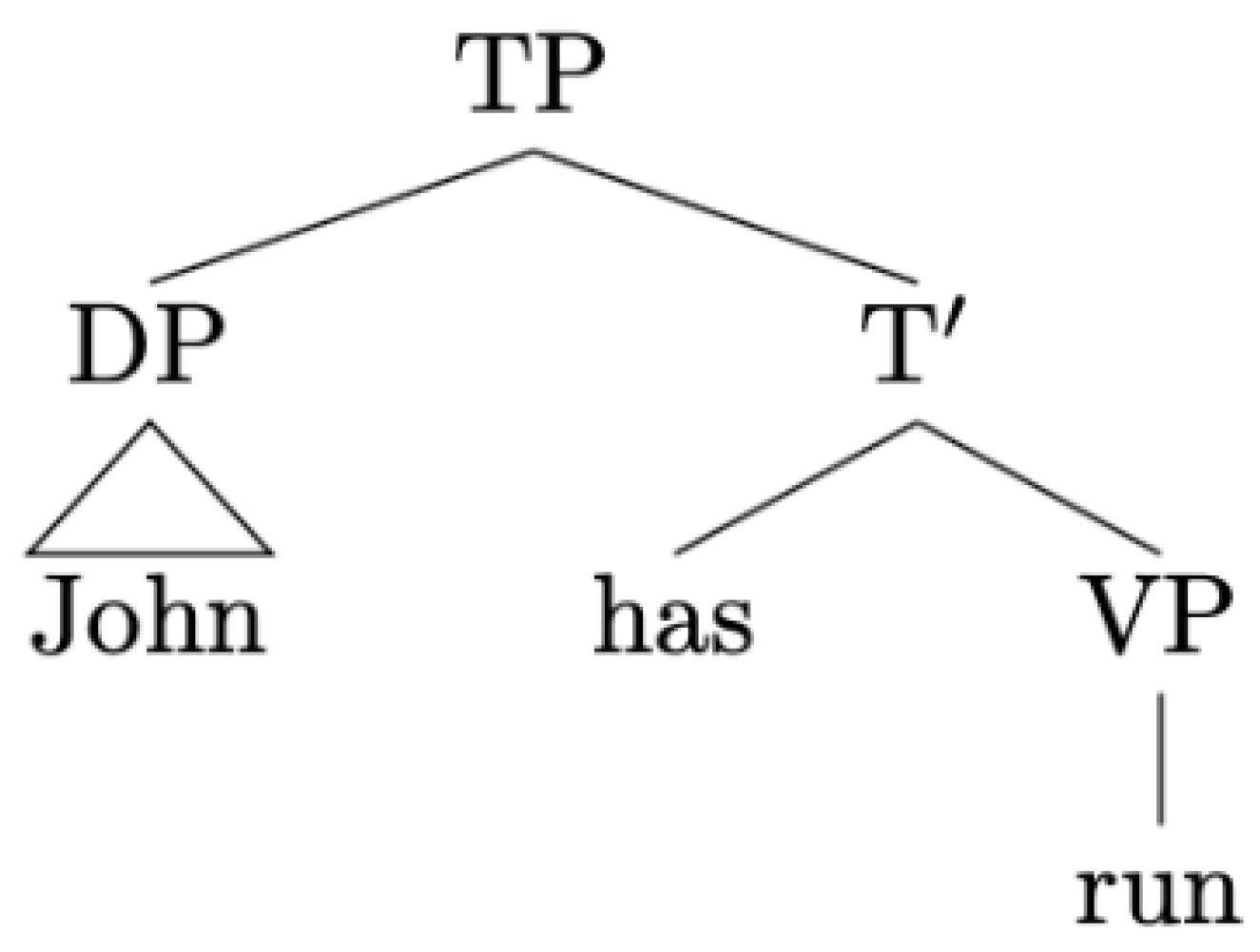
- Substitution: let T be a tree with root S and T’ a tree with root S’ and a node labelled S in its frontier. Substitution inserts T into the frontier of T’ at S. In other words, this operation can be conceived of as the rewriting of a node at the frontier of a piece of structure as another piece of structure. In this sense, substitution is a tail-recursive procedure. Substitution is diagrammed in Figure 3.Figure 3. Substitution.
![Philosophies 06 00070 g003]()
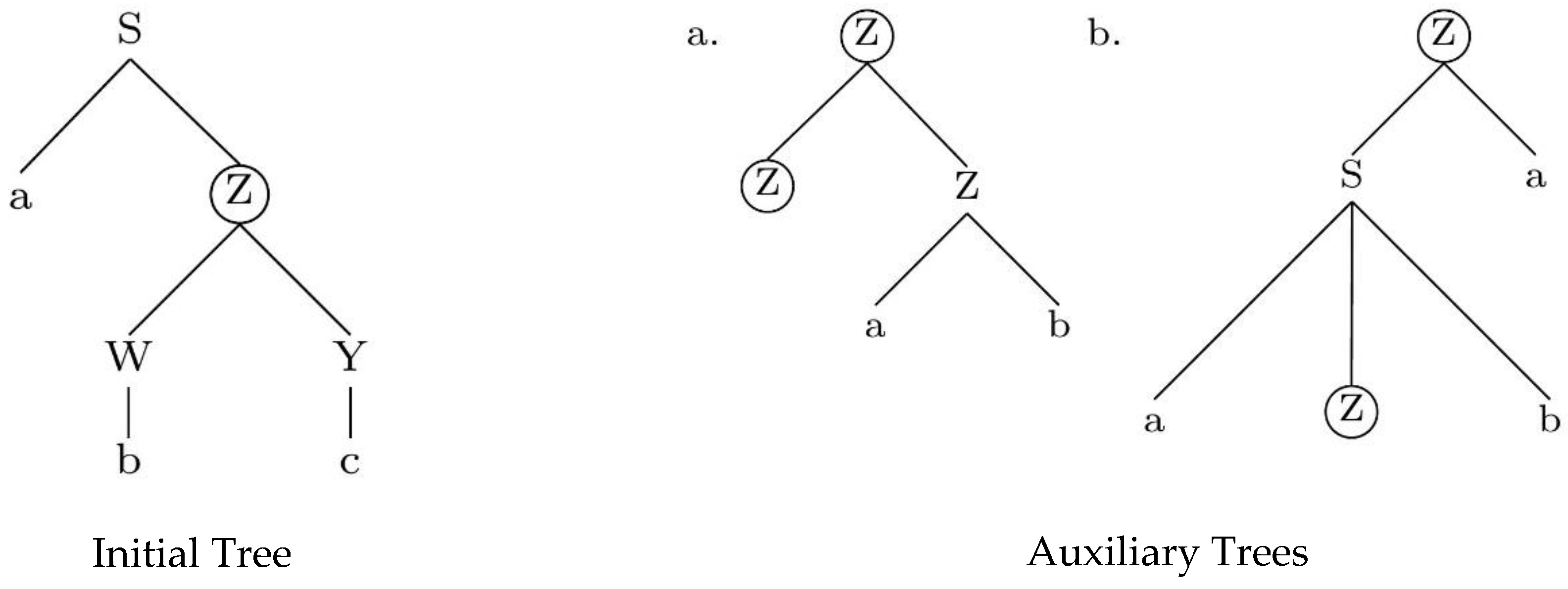
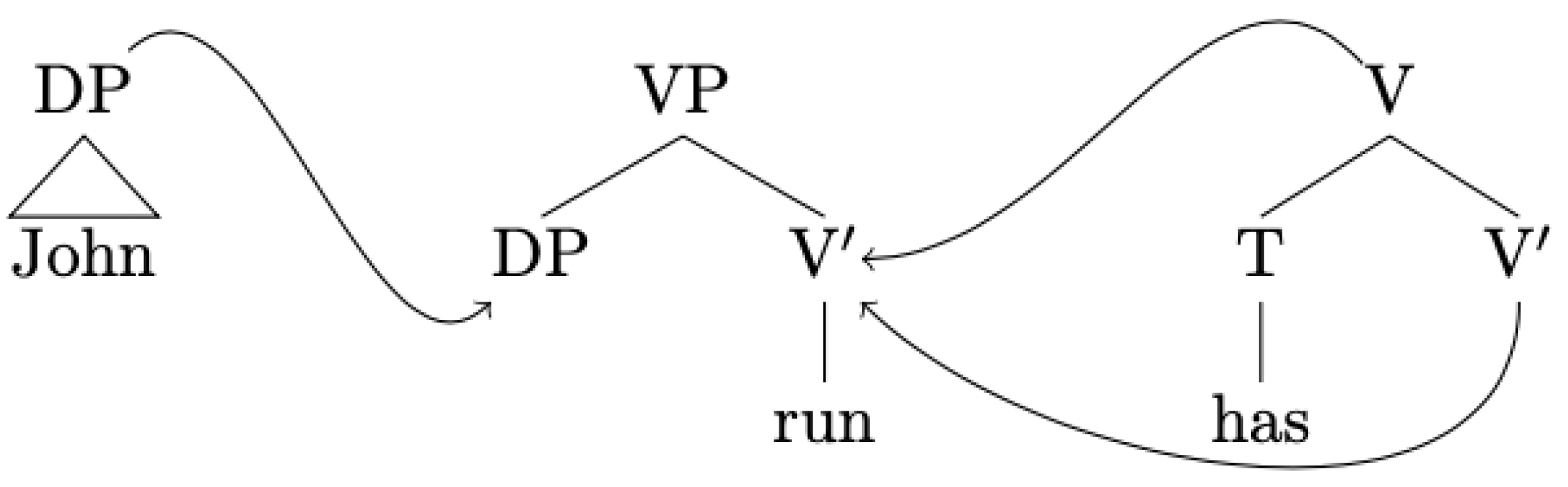
- Adjoining: in this case, a piece of structure, the auxiliary tree, is inserted into a designated node (the adjoining site) in the initial tree. In other words, the operation of adjoining rewrites a node by “shoehorning” a piece of structure (i.e., the auxiliary tree) inside another structure (i.e., the initial tree). The auxiliary tree must have two distinguished nodes at its frontier (node Z in (Figure 4)), namely the root node and the foot node, which must carry the same label as each other, and which also must be the same label as the target for adjunction in the initial tree (here, that label is Z). Note that the foot node can be the daughter of the root node (as in the auxiliary tree (Figure 4a)) or show up much lower in the structure (as in the auxiliary tree (Figure 4b)).Figure 4. Initial and auxiliary trees. Auxiliary tree (a) features a recursive foot node immediately dominated by the root; auxiliary tree (b) features a foot node not immediately dominated by the root.Figure 4. Initial and auxiliary trees. Auxiliary tree (a) features a recursive foot node immediately dominated by the root; auxiliary tree (b) features a foot node not immediately dominated by the root.
![Philosophies 06 00070 g004]()
Conditions Imposed on TAG Derivations
- Condition on Elementary Tree Minimality (CETM): the heads in an elementary tree must form part of the extended projection (in the sense of [23]) of a lexical head. As a result, the lexical array underlying an elementary tree must include a lexical head and may include any number of functional heads that are associated with that lexical head, see [19] (p. 151).
- Non-local Dependency Corollary: Non-local dependencies always reduce to local ones once the recursive structure is factored out [21] (p. 237).
“TAG is a formal system that combines elementary trees, but it is not a linguistic theory and imposes no constraints upon the nature of […] elementary trees”.
- What is the format of elementary trees? (Or, in other words, how many nodes does an extended projection need, and what are those nodes?).
- How do non-local dependencies reduce to local ones? What exactly is a “local” dependency?
3. What Is Inside an Elementary Tree?
- A predicative basic expression p.
- Temporal and aspectual modifiers of p (e.g., functional auxiliaries, in [34]).
- Nominal arguments of p (subjects, objects).
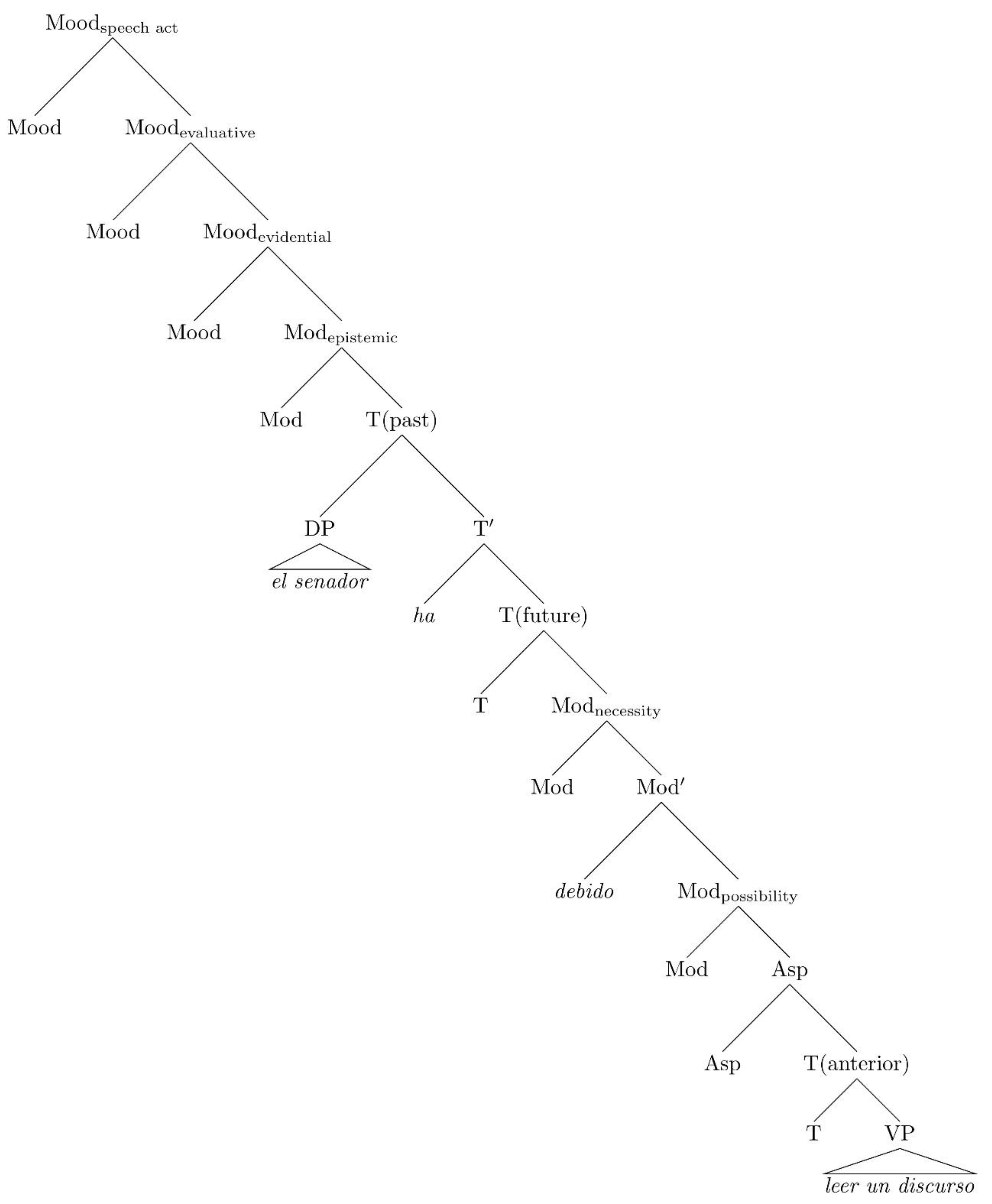
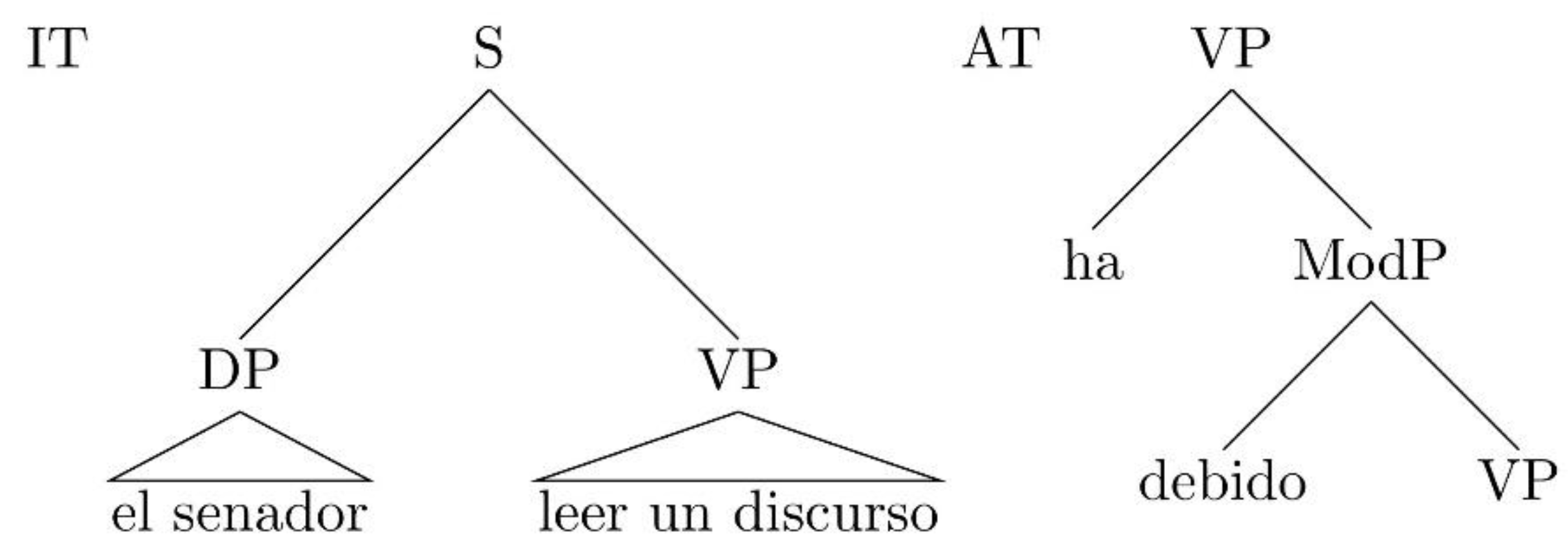
3.1. Elementary Trees in Spanish Auxiliary Chains
| El | senador | debería | leer | un | discurso. | (1) |
| The | senator | must-COND | read-INF | a | speech. | |
| The senator should read a speech. | ||||||
| El | senador | ha | debido | leer | un | discurso. | (2) |
| The | senator | have-3SG-AUX-PRF | must-PART | read-INF | a | speech. | |
| The senator has had to read a speech. | |||||||
| El | senador | ha | leído | un | discurso. | (3) |
| The | senator | has-3sg-Aux-Prf | read-part | a | speech. | |
| The senator has read a speech. | ||||||
| El | senador | ha | debido | leer | un | discurso, | pero | (4) |
| The | senator | have-3SG-AUX.PERF | must-PART | read-INF | a | speech, | but | |
| no | lo | ha | hecho | |||||
| NEG | CL-ACC | have.3SG-AUX-PERF | do-part. | |||||
| “The senator has had to read a speech, but he hasn’t done so” | ||||||||
| El | senador | va a | poder | leer | un | discurso. | (5) |
| The | senator | goes-to.3SG-AUX-FUT | be able to-INF | read-INF | a | speech. | |
| “The senator will be able to read a speech” | |||||||
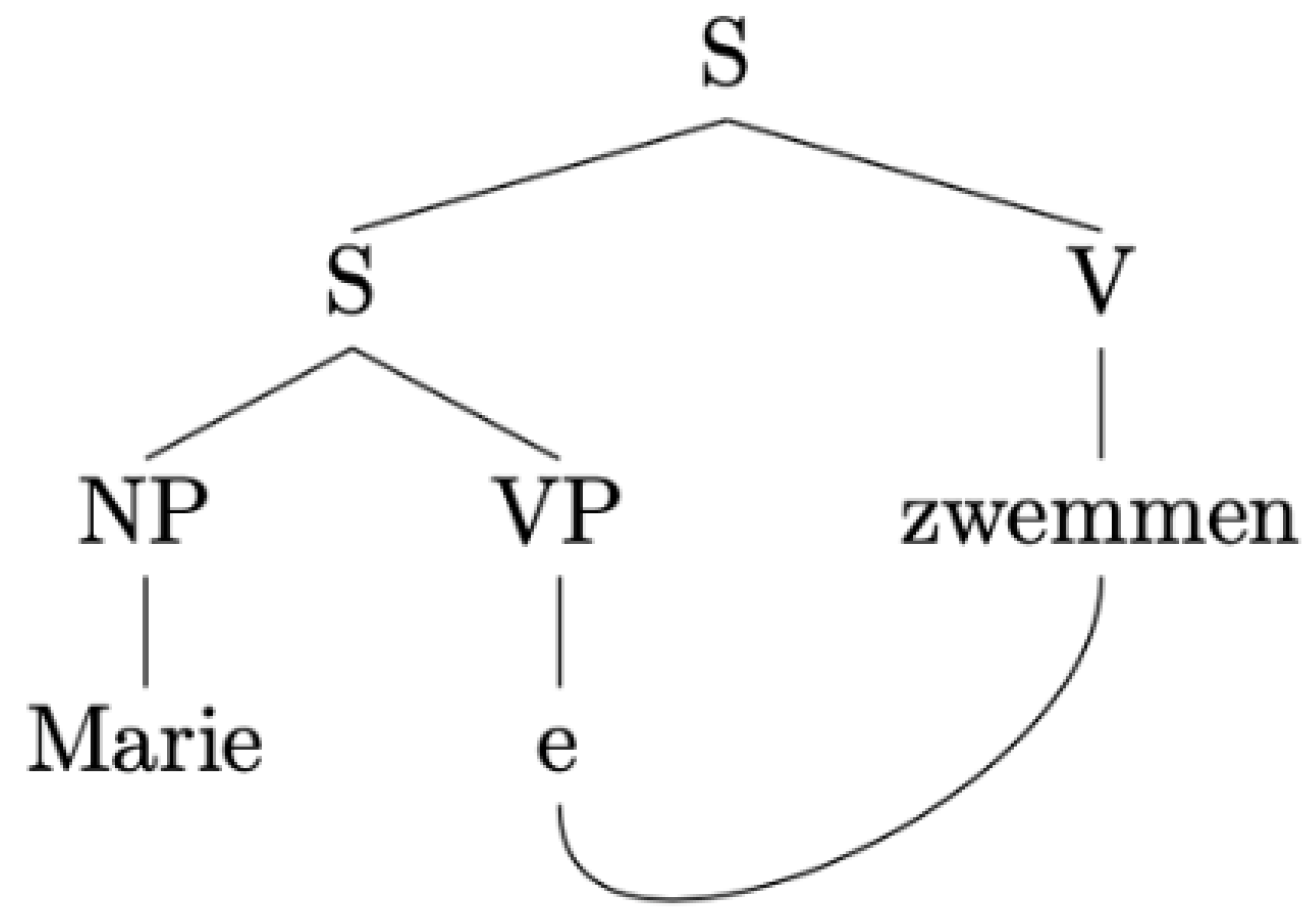
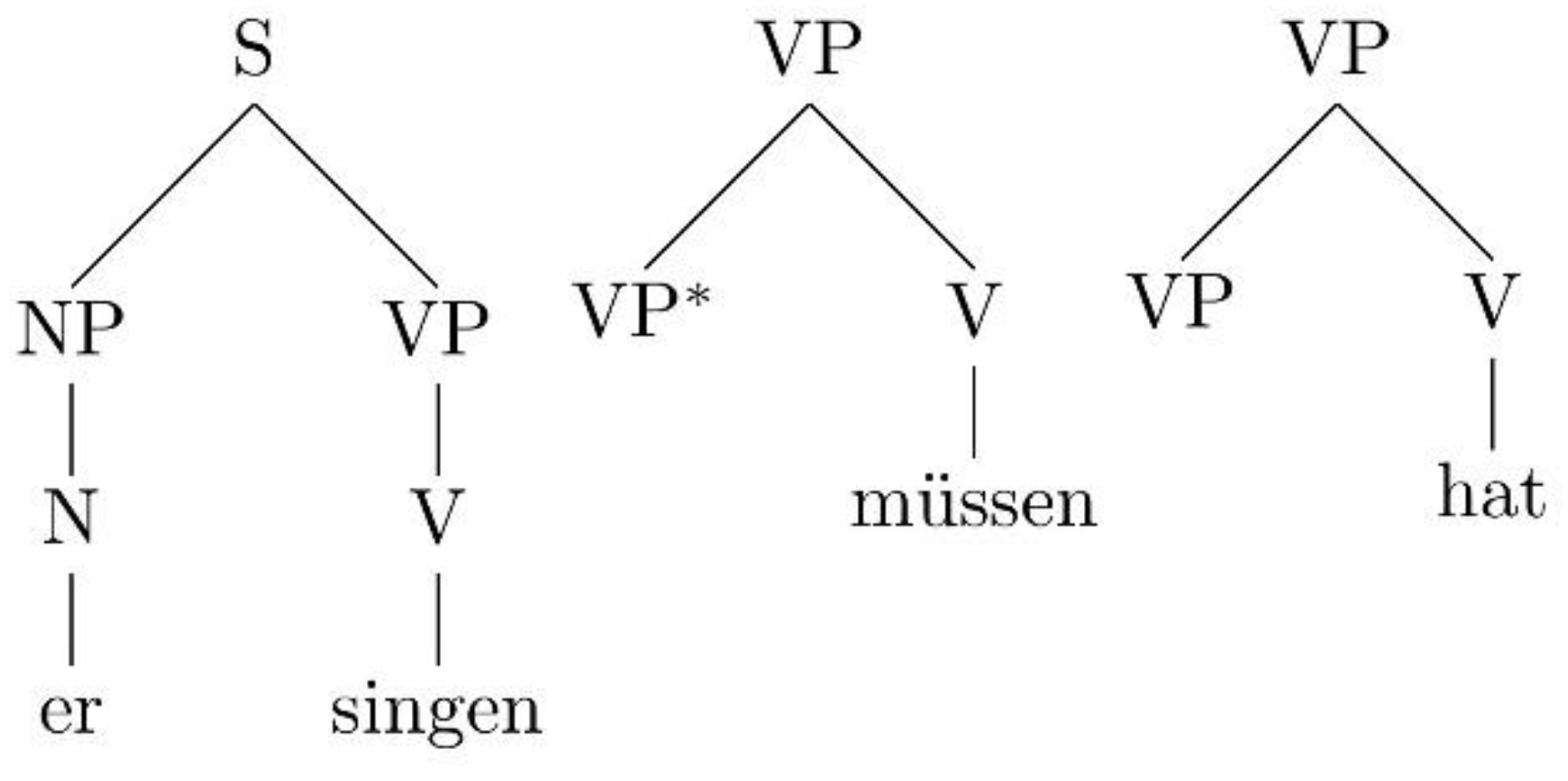
3.2. German Modals: Different Elementary Trees?
- V1]S V2
- …e1][V1 V2]V (German)
- …e1][V2 V1]V (Dutch)
| a. … | dat | Jan [PRO [ | een | huis | kopen]VP]S | wil (D-Structure.) | (6) |
| that | Jan | a | house | buy | wants.3SG | ||
| b. … | dat | Jan [PRO [ | een | huis e] VP]S | wil | kopen (VR) | |
| that | Jan | a | house | want.3SG | buy | ||
| “that Jan wants to buy a house” | |||||||
| a.… | dass | Hans | Peter | Marie | schwimmen | lassen | sah (Germ.) | (7) |
| that | Hans | Peter | Marie | swim | let | saw.3SG-PST | ||
| “that Hans saw Peter let Marie swim” | ||||||||
| b.… | dat | Jan | Piet | Marie | zag | laten | zwemmen (Dut.) | |
| that | Jan | Piet | Marie | saw.3SG-PST | let | swim | ||
| “that Jan saw Piet let Marie swim” | ||||||||
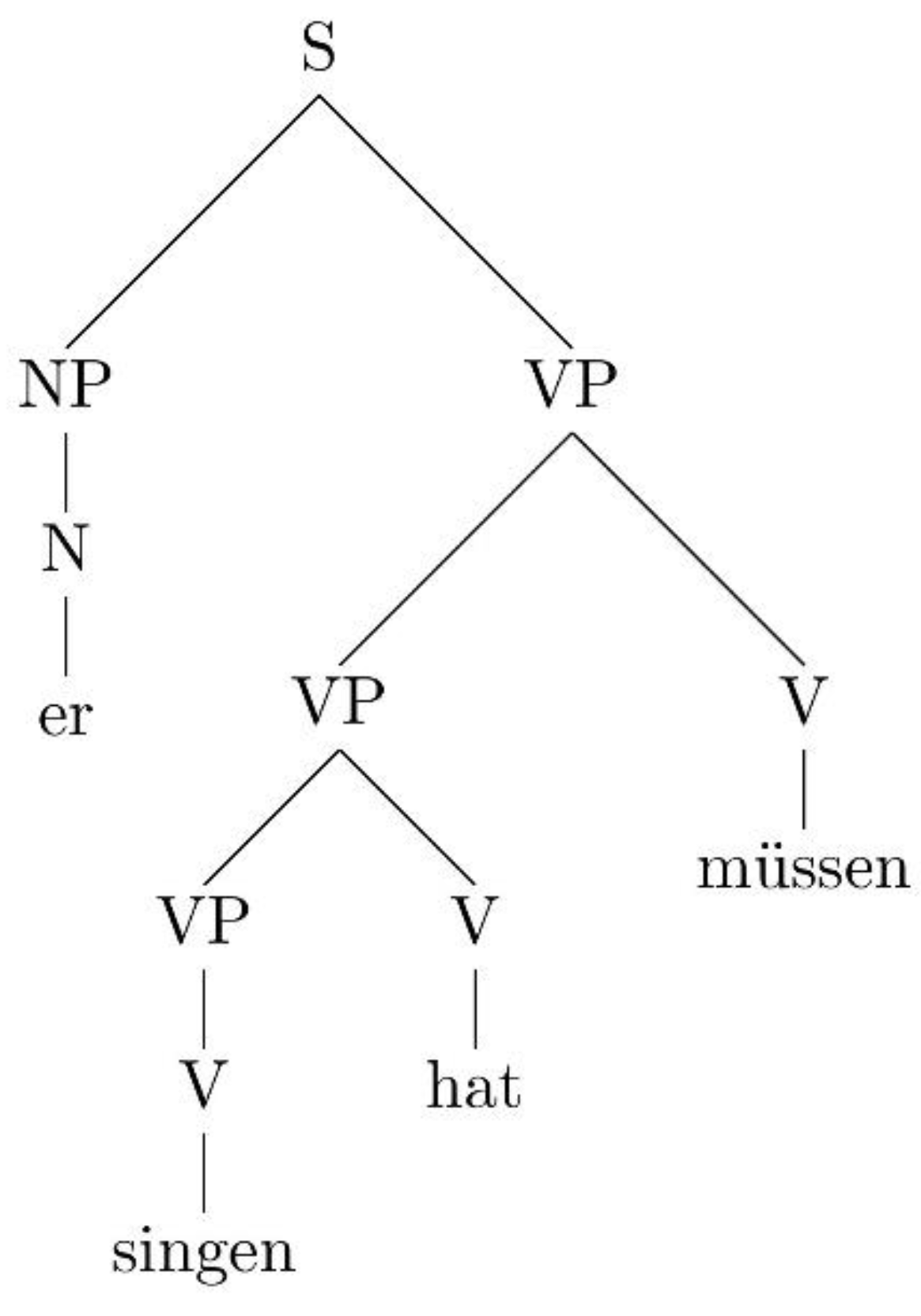
| a.… | dass | er | singen | hat | müssen | (8) |
| that | he | sing | has | have-to-INF | ||
| “that he had to sing” | ||||||
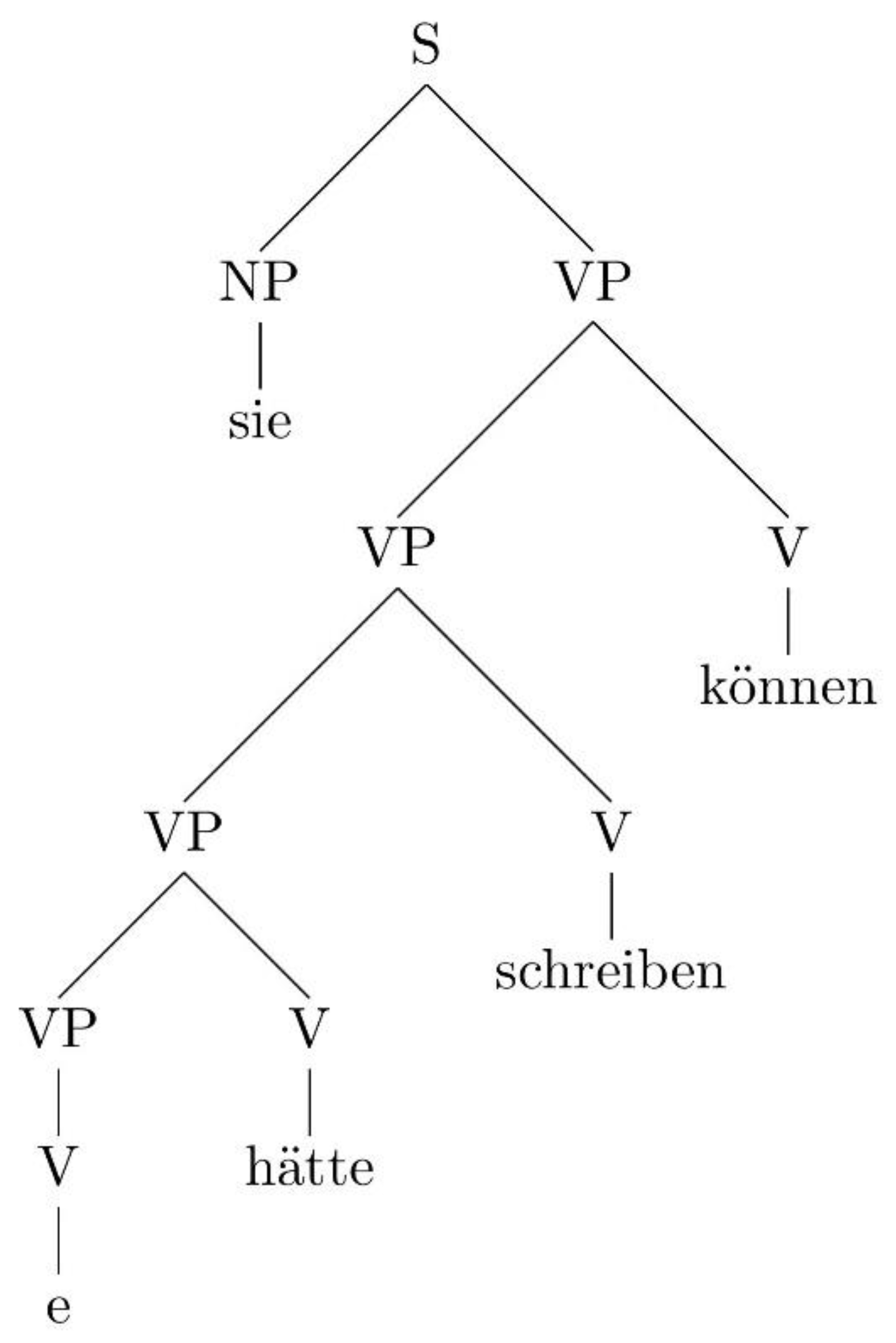
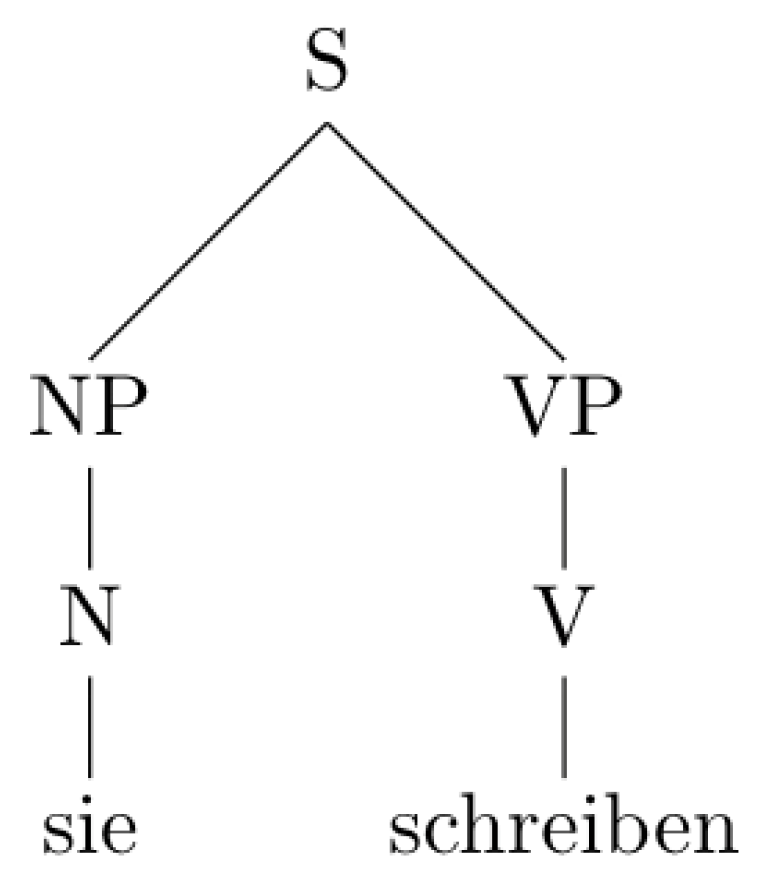
| b.… | dass | sie | hätte | schreiben | können | |
| that | she | have-SUBJ | write | be-able-to | ||
| “that she could have written” | ||||||
“The set of elementary trees in the grammar of a language is the only locus of cross-linguistic differences, imposing substantial restrictions on the kind of variation that we will find crosslinguistically”.
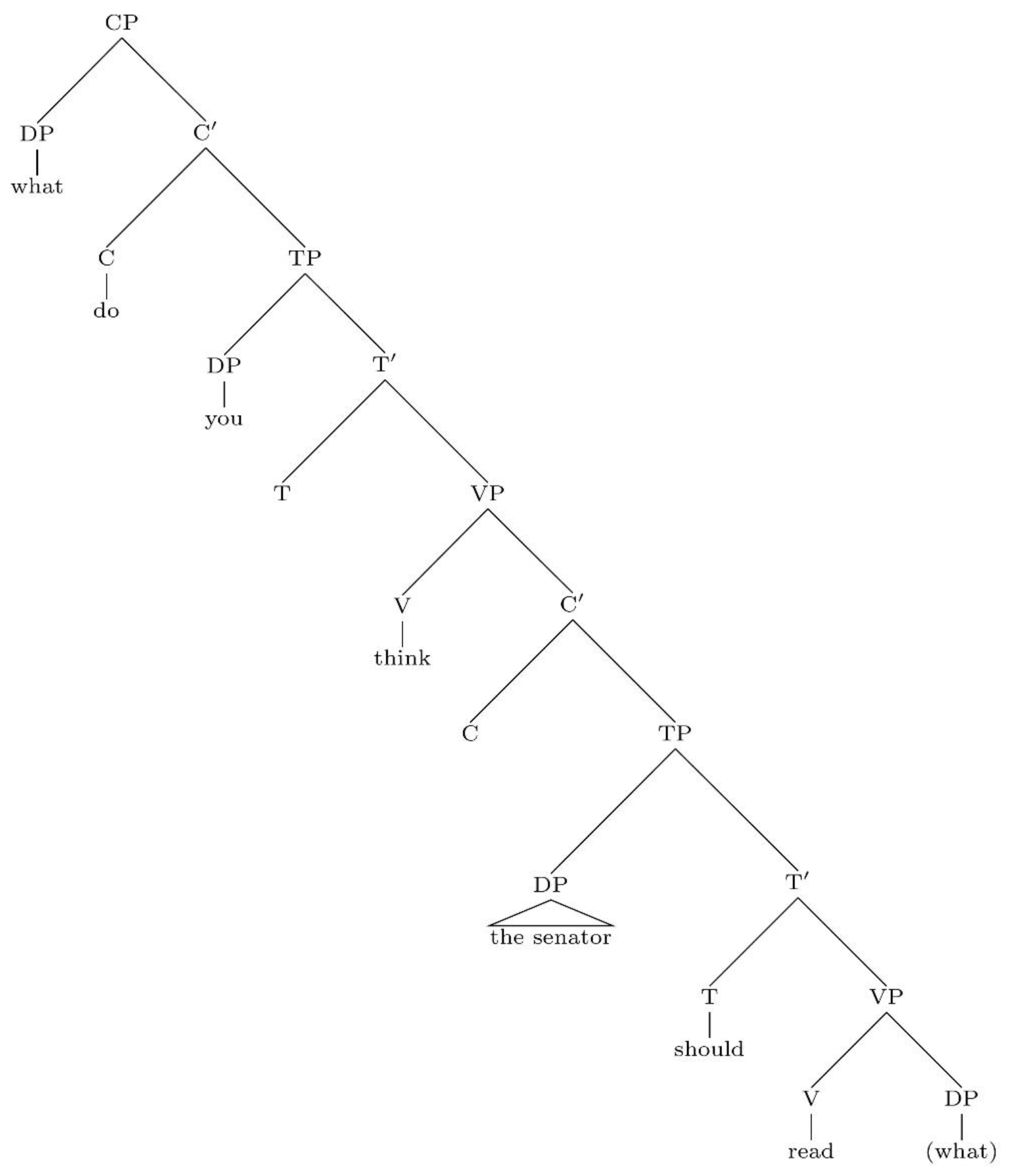
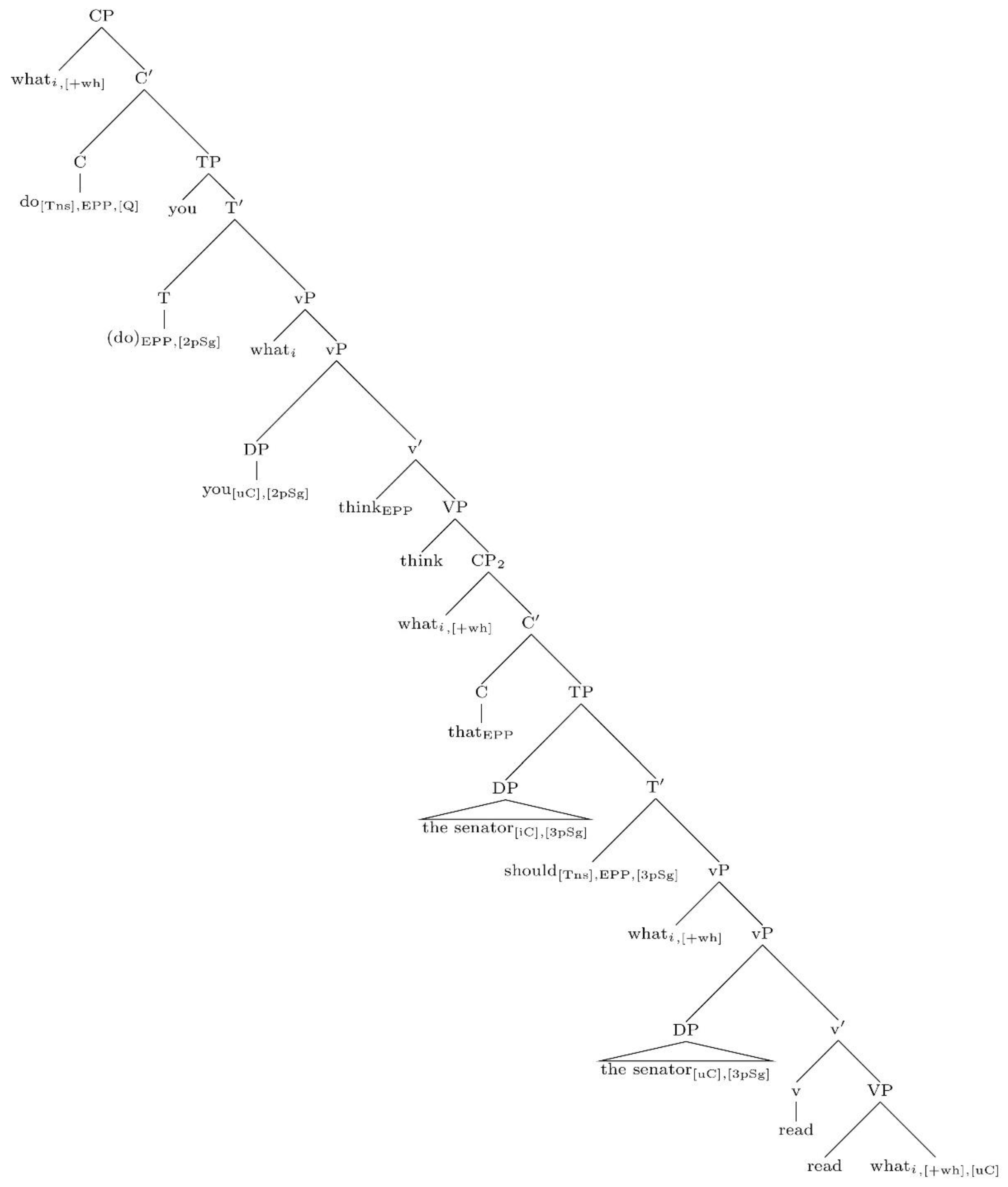
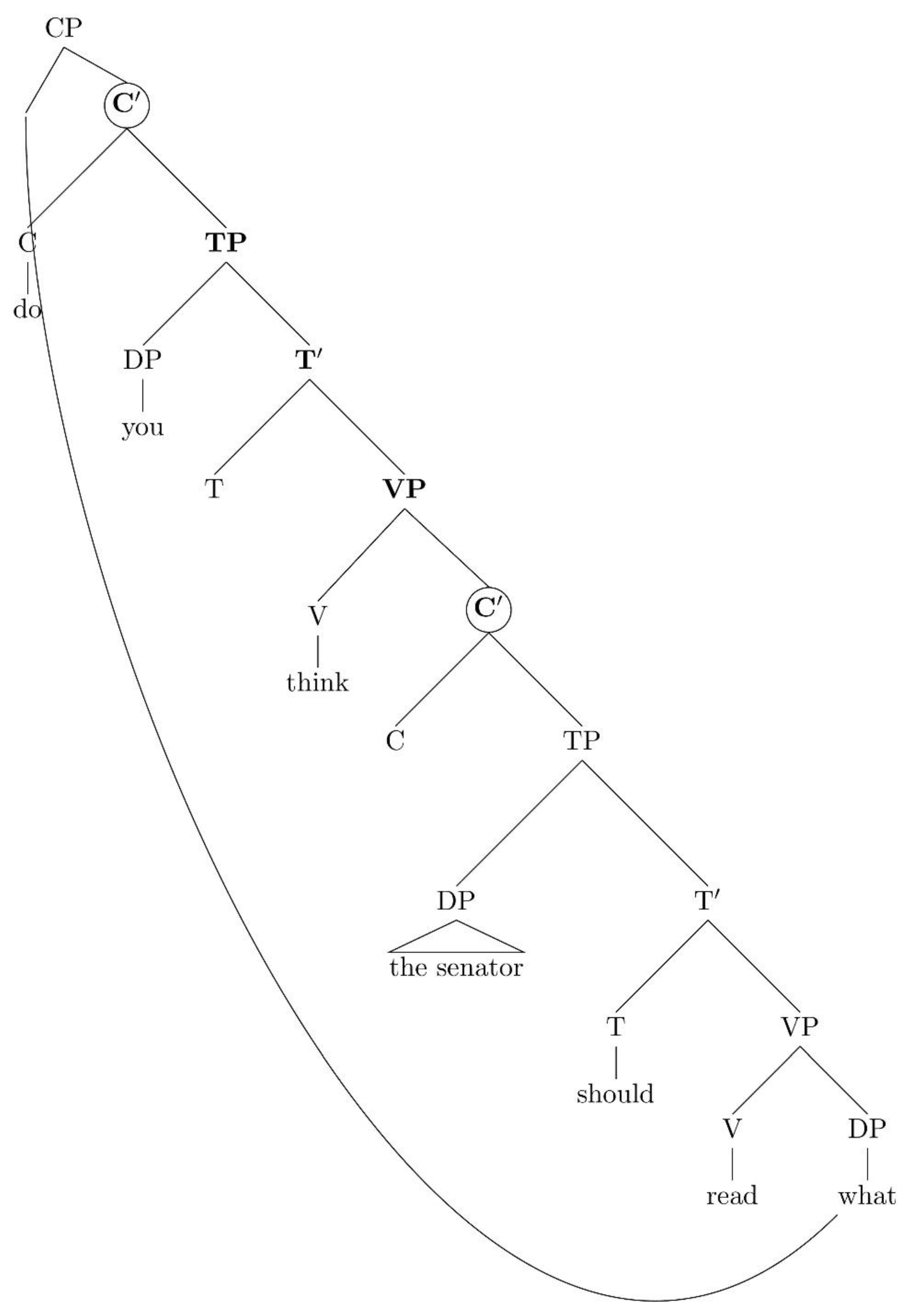
4. Locality and the Definition of Dependencies
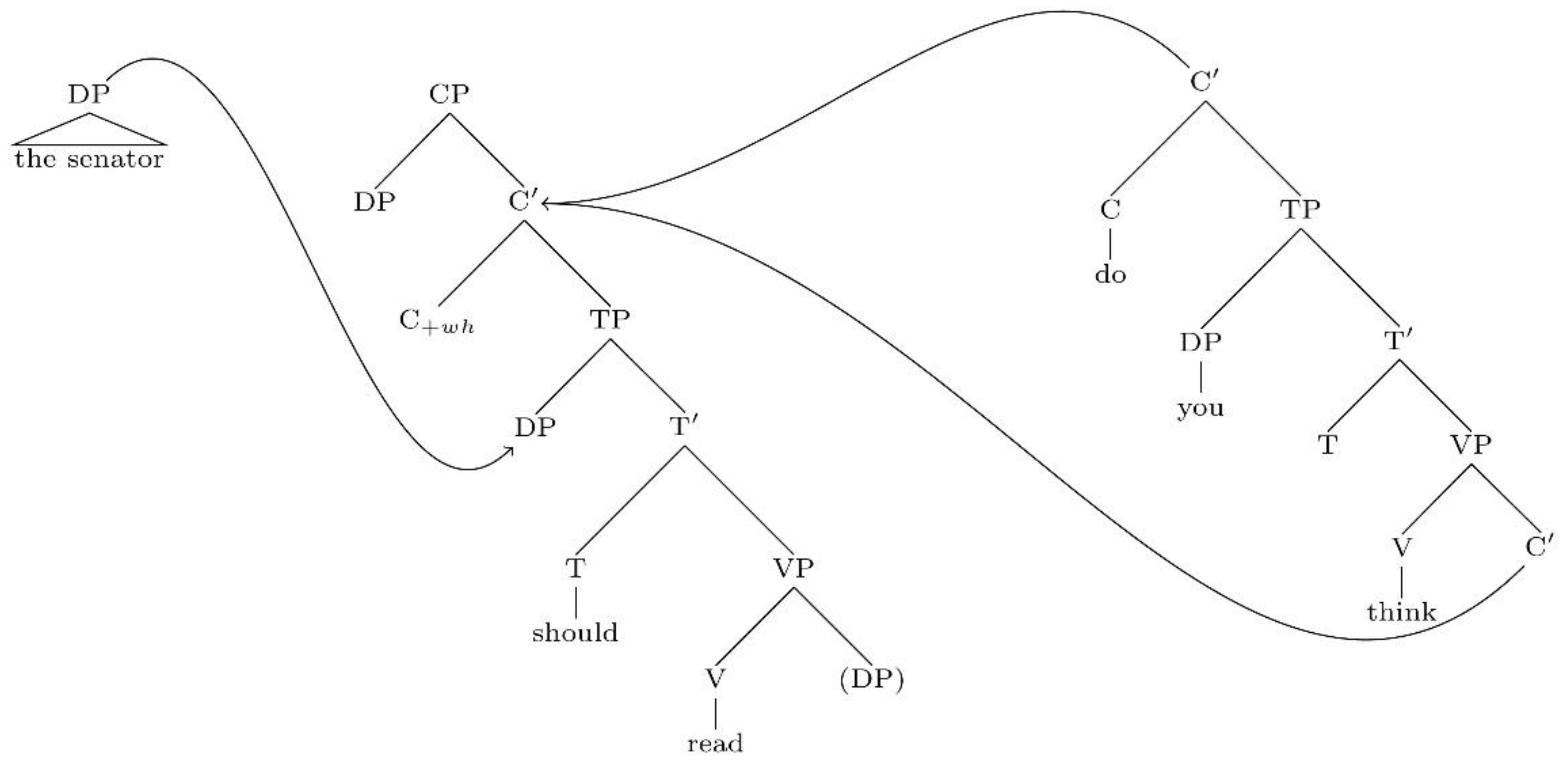
- The extended projection of the lexical verb read.
- The extended projection of the lexical verb think.
- The extended projection of the noun senator.
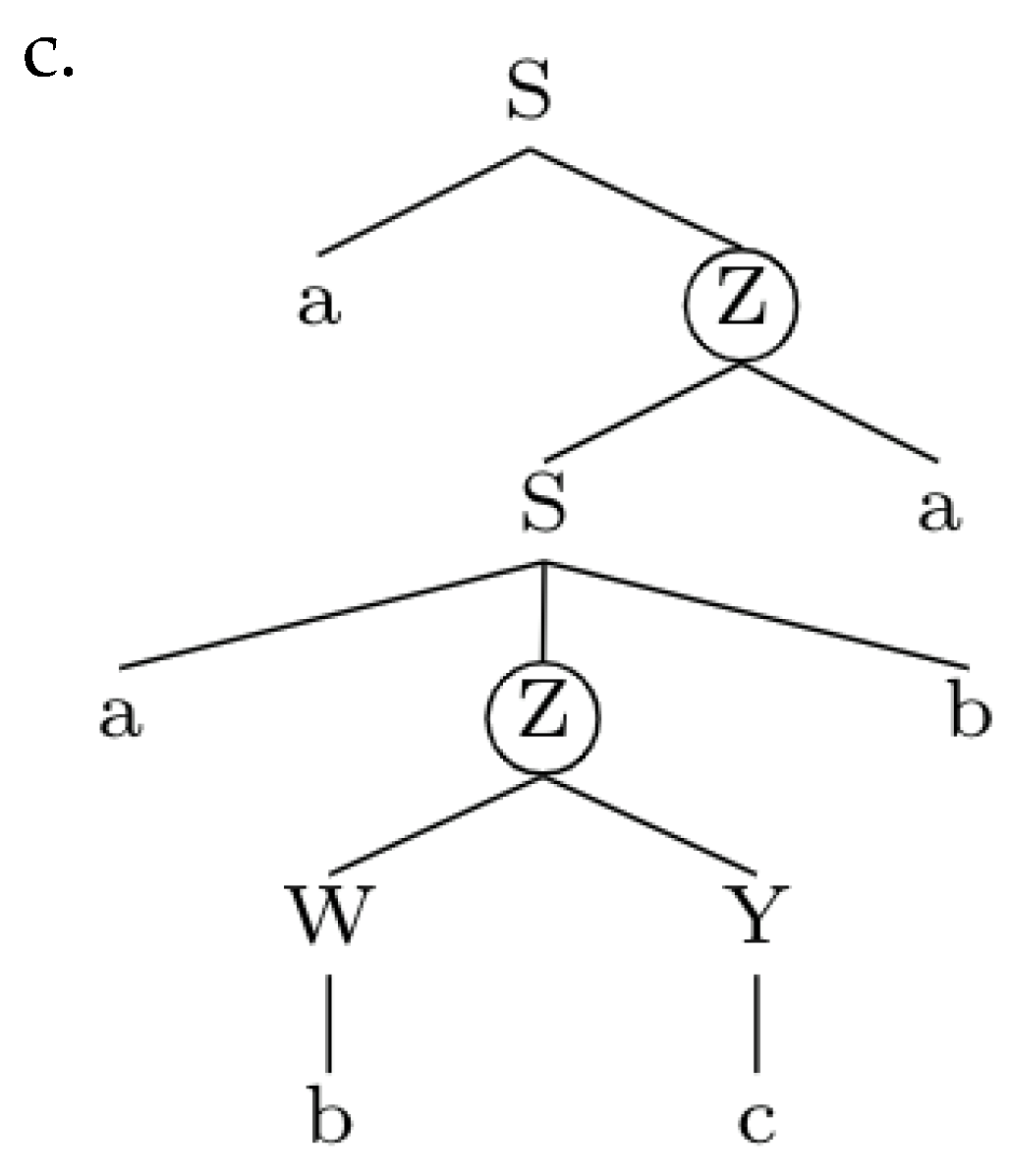
Each node in the tree has a unique address obtained by applying a Gorn tree addressing scheme.
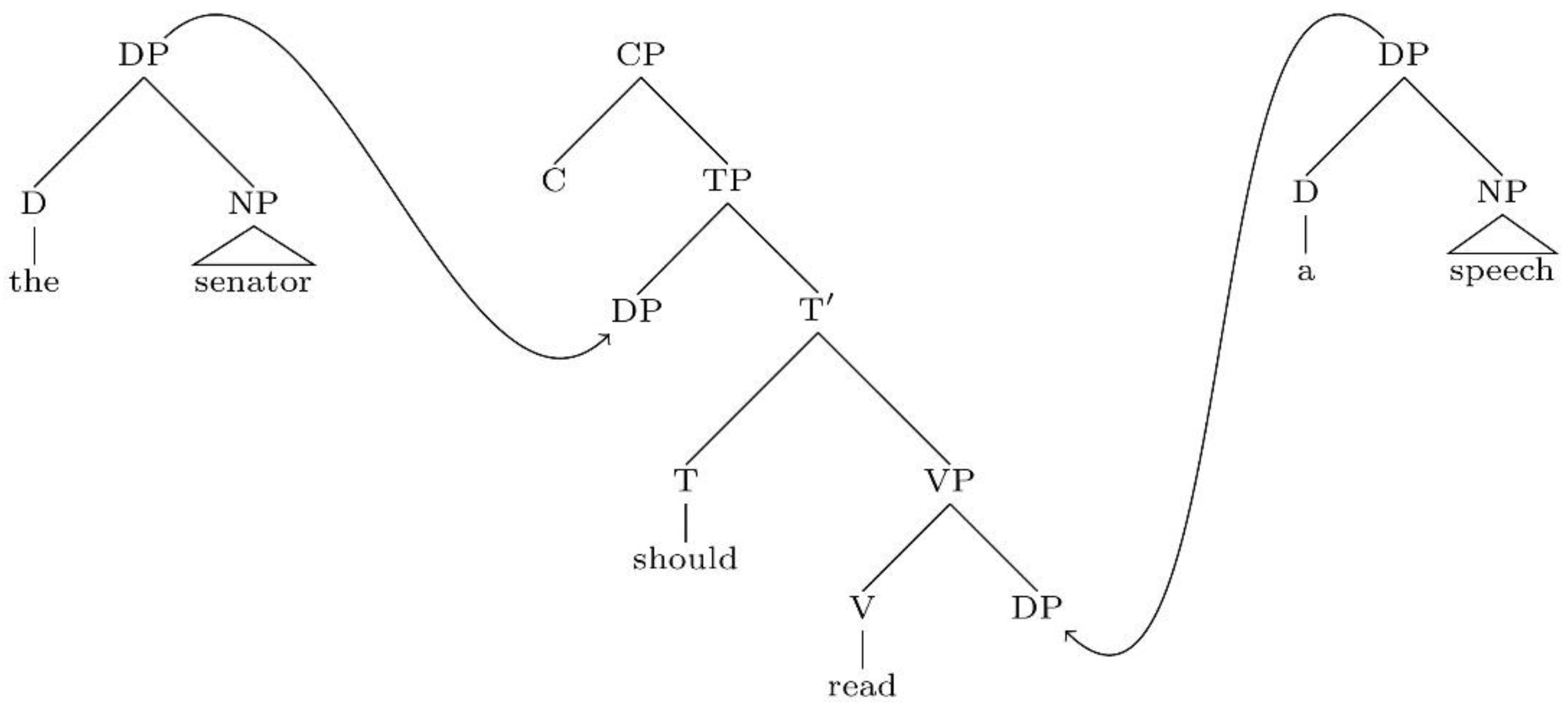
“The movement of NPi to position NPj (where A and B are the contents of these nodes) in (30) yields (31) as a derived constituent structure.(30) … NPj … NPi …| |A B(31) … NPi … NPi …| |B eIn this view, NPi and its contents are copied at position NPj, deleting NPj and A, and the identity element e is inserted as the contents of (in this case, the righthand) NPi, deleting B under identity.”
- “a.
- b.
- c.
- d.
“Independent operations of the Copy + Merge theory of movement:
- a.
- b.
- c.
- d.
5. Conclusions
- The inclusiveness condition, in its strict interpretation, is always respected.
- Problems pertaining to the distinction between copies and repetitions do not arise: copies are formalised as multiple visits to the same node in a strictly ordered walk through a graph, whereas repetitions are instances of distinct nodes (with the same morpho-phonological exponent) in a walk through a graph.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| 1 | |
| 2 | This system, as it is based on two binary dimensions, predicts the existence of four kinds of syntactic categories:
|
| 3 | Strictly speaking, we also want to define a unit where there is no syntactic position between ha and debido, in the light of paradigms such as the following [77,80]:
“What has the senator had to read?” |
| 4 | A reviewer objects that restricting scope relations to elementary trees may be problematic, for example, in NPI licensing in multi-clausal structures, such as:
However, unlike our Spanish example, it is not derived by adjunction; it is derived by substitution:
[S they ate anything].
The resulting structural description thus allows for scope relations to be read off a monotonic syntactic configuration (regardless of whether NEG originates in the embedded clause and NEG-raises or not). For the determination of scope relations it is essential to consider whether the tree composition operation that has applied is substitution (which yields tail-recursive structures in English clausal complementation) or adjunction. |
| 5 | Importantly, this does not mean that TAGs are incompatible with successive cyclic movement. If there are occurrences of a wh in intermediate positions, then we need to assume that there is a dependency to be defined within an adjoined elementary tree. English does not seem to provide evidence of intermediate landing sites in cases of unbounded wh-movement, but other languages do (e.g., by spelling-out copies or dummy wh-pronouns in intermediate locations). What this system allows us to dispense with are tokens of a syntactic object required only by formal reasons, without there being any semantic or phonological effect (this may, of course, vary across languages as it is part of the definition of elementary trees). Frank [21], p. 237, allows objects to move to the edge of an elementary tree (his system allows for singulary transformations) and then, from there, it may be further reordered by operations at the target of adjunction. Detailed discussion about aspects of successive cyclicity in LTAGs was provided in [19], e.g., scope reconstruction. |
| 6 | This proposal also has parallels in computer languages. In programming languages, such as Python, expressions are assigned addresses, which are accessed in the execution of a program by means of variables. It is even possible to access the memory address by means of a specific function, id(…). It is also possible to create local variables, which get created every time a function is called and erased when the function returns an output; this kind of operation would be analogous to the procedure to create copies in movement operations (since the copy is created and stored only temporarily, to be merged later in order to satisfy some featural requirement). In this case, we need two “spaces”: the “shell” (where the program is executed) and the list of objects in memory (which contains the address, type and value assigned to each variable). |
References
- Bach, E. An Introduction to Transformational Grammars; Holt, Rinehart & Winston: New York, NY, USA, 1964. [Google Scholar]
- Ross, J.R. Constraints on Variables in Syntax. Ph.D. Thesis, MIT, Cambridge, MA, USA, 1967. [Google Scholar]
- Chomsky, N.; Halle, M. The Sound Pattern of English; Harper & Row: New York, NY, USA, 1968. [Google Scholar]
- Chomsky, N. Barriers; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Larson, R. On the double object construction. Linguist. Inq. 1988, 19, 335–391. [Google Scholar]
- Pollock, J.-Y. Verb Movement, Universal Grammar, and the Structure of IP. Linguist. Inq. 1989, 20, 365–424. [Google Scholar]
- Chomsky, N. Minimalist Inquiries: The Framework. In Step by Step—Essays in Minimalist Syntax in Honor of Howard Lasnik; Martin, R., Michaels, D., Uriagereka, J., Eds.; MIT Press: Cambridge, MA, USA, 2000; pp. 89–155. [Google Scholar]
- Cinque, G. Adverbs and Functional Heads: A Cross-Linguistic Perspective; OUP: Oxford, UK, 1999. [Google Scholar]
- Cinque, G. ‘Restructuring’ and Functional Structure. In Restructuring and Functional Heads. The Cartography of Syntactic Structures; Cinque, G., Ed.; OUP: Oxford, UK, 2004; Volume 4, pp. 132–192. [Google Scholar]
- Cinque, G.; Rizzi, L. The Cartography of Syntactic Structures. StIL. 2008, Volume 2. Available online: http://www.ciscl.unisi.it/doc/doc_pub/cinque-rizzi2008-The_cartography_of_Syntactic_Structures.pdf (accessed on 13 June 2020).
- Cinque, G.; Rizzi, L. Rizzi, Functional Categories and Syntactic Theory. Annu. Rev. Linguist. 2016, 2, 139–163. [Google Scholar]
- Chomsky, N. Derivation by Phase. In Ken Hale: A Life in Language; Kenstowicz, M., Ed.; MIT Press: Cambridge, MA, USA, 2001; pp. 1–52. [Google Scholar]
- Richards, M. Deriving the Edge: What’s in a Phase? Syntax 2011, 14, 74–95. [Google Scholar] [CrossRef]
- Boeckx, C. Phases beyond explanatory adequacy. In Phases: Developing the Framework; Gallego, A., Ed.; Mouton de Gruyter: Berlin, Germany, 2012; pp. 45–66. [Google Scholar]
- Chomsky, N. The Logical Structure of Linguistic Theory. Mimeographed, MIT. 1955. Available online: http://alpha-leonis.lids.mit.edu/wordpress/wp-content/uploads/2014/07/chomsky_LSLT55.pdf (accessed on 30 July 2018).
- Chomsky, N. Transformational Analysis. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 1955. [Google Scholar]
- Joshi, A.; Levy, L.; Takahashi, M. Tree adjunct grammars. J. Comput. Syst. Sci. 1975, 10, 136–163. [Google Scholar] [CrossRef] [Green Version]
- Joshi, A.K. Tree adjoining grammars: How much context-sensitivity is required to provide reasonable structural descriptions. In Natural Language Parsing; Dowty, D., Karttunen, L., Zwicky, A., Eds.; CUP: Cambridge, MA, USA, 1985; pp. 206–250. [Google Scholar]
- Frank, R. Phrase Structure Composition and Syntactic Dependencies; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Stabler, E. The epicenter of linguistic behavior. In Language down the Garden Path; Sanz, M., Laka, I., Tanenhaus, M., Eds.; OUP: Oxford, UK, 2013; pp. 316–323. [Google Scholar]
- Frank, R. Tree adjoining grammar. In The Cambridge Handbook of Generative Syntax; den Dikken, M., Ed.; CUP: Cambridge, MA, USA, 2013; pp. 226–261. [Google Scholar]
- Frank, R. Phase theory and Tree Adjoining Grammar. Lingua 2006, 116, 145–202. [Google Scholar] [CrossRef]
- Grimshaw, J. Locality and Extended Projection. In Lexical Specification and Insertion; Coopmans, P., Everaert, M., Grimshaw, J., Eds.; John Benjamins: Amsterdam, The Netherlands, 2000; pp. 115–133. [Google Scholar]
- Abney, S.P. The English Noun Phrase in Its Sentential Aspect. Ph.D. Thesis, MIT, Cambridge, MA, USA, 1987. [Google Scholar]
- Frank, R.; Kulick, S.; Vijay-Shanker, K. Monotonic c-command: A new perspective on tree adjoining grammars. Grammars 2002, 3, 151–173. [Google Scholar] [CrossRef]
- Gazdar, G.; Klein, E.; Pullum, G.K.; Sag, I.A. Generalised Phrase Structure Grammar; Blackwell: Oxford, UK, 1985. [Google Scholar]
- Bresnan, J. Lexical Functional Syntax, 1st ed.; Wiley Blackwell: Oxford, UK, 2001. [Google Scholar]
- XTAG Group. A Lexicalized TAG for English; Technical Report; University of Pennsylvania: Pennsylvania, PA, USA, 2001; Available online: https://repository.upenn.edu/cgi/viewcontent.cgi?article=1020&context=ircs_reports (accessed on 13 June 2020).
- Joshi, A.K.; Schabes, Y. Tree-Adjoining Grammars and Lexicalized Grammars. Tech. Rep. (CIS). 1991, p. 445. Available online: http://repository.upenn.edu/cis_reports/445 (accessed on 22 April 2019).
- Hegarty, M. Deriving Clausal Structure in Tree Adjoining Grammar; University of Pennsylvania: Pennsylvania, PA, USA, 1993. [Google Scholar]
- Rambow, O. Mobile Heads and Strict Lexicalization. Master’s Thesis, University of Pennsylvania, Pennsylvania, PA, USA, 1993. [Google Scholar]
- Krivochen, D.G.; García Fernández, L. On the position of subjects in Spanish periphrases: Subjecthood left and right. Boreal. Int. J. Hisp. Linguist. 2019, 8, 1–33. [Google Scholar] [CrossRef]
- Krivochen, D.G.; García Fernández, L. Variability in syntactic-semantic cycles: Evidence from auxiliary chains. In Interface-Driven Phenomena in Spanish: Essays in Honor of Javier Gutiérrez-Rexach; González-Rivera, M., Sessarego, S., Eds.; Routledge: London, UK, 2020; pp. 145–168. [Google Scholar]
- Bravo, A.; García Fernández, L.; Krivochen, D.G. On Auxiliary Chains: Auxiliaries at the Syntax-Semantics Interface. Borealis 2015, 4, 71–101. [Google Scholar] [CrossRef] [Green Version]
- Huddleston, R.; Pullum, G. The Cambridge Grammar of the English Language; CUP: Cambridge, MA, USA, 2002. [Google Scholar]
- May, R. Logical Form: Its Structure and Derivation; MIT Press: Cambridge, MA, USA, 1985. [Google Scholar]
- Fabb, N. Three squibs on auxiliaries. In MIT Working Papers in Linguistics, Volume 5. Papers in Grammatical Theory; Haïk, I.Y., Massam, D., Eds.; Department of Linguistics and Philosophy: Cambridge, MA, USA, 1983; pp. 104–120. [Google Scholar]
- Epstein, S.D. Un-Principled Syntax and the Derivation of Syntactic Relations. In Working Minimalism; Epstein, S., Hornstein, N., Eds.; MIT Press: Cambridge, MA, USA, 1999; pp. 317–345. [Google Scholar]
- Chomsky, N. The Minimalist Program; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Chomsky, N. The UCLA Lectures. University of Arizona, Tucson, AZ, USA. 2020. Available online: https://ling.auf.net/lingbuzz/005485 (accessed on 11 July 2020).
- Evers, A. The Transformational Cycle in Dutch and Germany; Indiana University Linguistics Club: Indiana, IN, USA, 1975. [Google Scholar]
- Den Besten, H.; Edmonson, J. The verbal complex in continental West Germanic. In On the Formal Syntax of the Westgermania; Abraham, W., Ed.; John Benjamins: Amsterdam, The Netherlands, 1983; pp. 155–216. [Google Scholar]
- Haegeman, L.; van Riemsdijk, H. Verb Projection Raising, Scope, and the Typology of Rules Affecting Verbs. Linguist. Inq. 1986, 17, 417–466. [Google Scholar]
- Wurmbrand, S. Verb clusters, verb raising, and restructuring. In The Blackwell Companion to Syntax; Everaert, M., van Riemsdijk, H., Eds.; Blackwell: Oxford, UK, 2017. [Google Scholar]
- Kroch, A.; Santorini, B. The derived constituent structure of the West-Germanic verb-raising construction. In Principles and Parameters in Comparative Grammar; Freidin, R., Ed.; MIT Press: Cambridge, MA, USA, 1991; pp. 269–338. [Google Scholar]
- Altmann, G. Prolegomena to Menzerath’s law. Glottometrika 1980, 2, 1–10. [Google Scholar]
- Adger, D.; Svenonius, P. Features in minimalist syntax. In The Oxford handbook of linguistic Minimalism; Boeckx, C., Ed.; OUP: Oxford, UK, 2011; pp. 27–51. [Google Scholar]
- Panagiotidis, P. Towards a (Minimalist) Theory of Features. University of Cyprus, Nicosia, Cyprus. 2021. Available online: https://ling.auf.net/lingbuzz/005615 (accessed on 15 February 2021).
- Krivochen, D.G. Copies and Tokens: Displacement Revisited. Studia Linguist. 2015, 70, 250–296. [Google Scholar] [CrossRef]
- Gärtner, H.-M. Generalized Transformations and Beyond. Reflections on Minimalist Syntax; Akademie Verlag: Berlin, Germany, 2002. [Google Scholar]
- Collins, C.; Groat, E. Distinguishing Copies and Repetitions. 2018. Available online: http://ling.auf.net/lingbuzz/003809 (accessed on 7 May 2021).
- Gärtner, H.-M. Copies from ‘Standard Set Theory’. 2020. Available online: https://ling.auf.net/lingbuzz/005942 (accessed on 10 September 2020).
- Sampson, G. The Single Mother Condition. J. Linguist. 1975, 11, 1–11. [Google Scholar] [CrossRef]
- Citko, B. On the Nature of Merge: External Merge, Internal Merge, and Parallel Merge. Linguist. Inq. 2005, 36, 475–496. [Google Scholar] [CrossRef]
- Levine, R.D. Right node (non-)raising. Linguist. Inq. 1985, 16, 492–497. [Google Scholar]
- McCawley, J.D. Parentheticals and Discontinuous Constituent Structure. Linguist. Inq. 1982, 13, 91–106. [Google Scholar]
- Johnson, K. Toward a Multidominant Theory of Movement. Lectures Presented at ACTL, University College. June 2016. Available online: https://people.umass.edu/kbj/homepage/Content/Multi_Movement.pdf (accessed on 16 August 2020).
- Kroch, A.; Joshi, A.K. The Linguistic Relevance of Tree Adjoining Grammar; Technical report MS-CS-85-16; Department of Computer and Information Sciences, University of Pennsylvania: Philadelphia, PA, USA, 1985. [Google Scholar]
- Peter, S.; Ritchie, R. Phrase-Linking Grammar. University of Texas at Austin: Austin, TX, USA, 1981. [Google Scholar]
- Postal, P. On some rules that are not successive-cyclic. Linguist. Inq. 1972, 3, 211–222. [Google Scholar]
- Boeckx, C.; Grohmann, K.K. Barriers and Phases: Forward to the Past? Presented in Tools in Linguistic Theory 2004 (TiLT) Budapest (16–18 May 2004). Available online: http://people.umass.edu/roeper/711-05/Boexce%20barriers+phases%20tilt_bg_ho.pdf (accessed on 26 April 2018).
- Sarkar, A.; Joshi, A.K. Handling Coordination in a Tree Adjoining Grammar; Technical Report; University of Pennsylvania: Philadelphia, PA, USA, 1997. [Google Scholar]
- Sutherland, W. Introduction to Metric and Topological Spaces, 2nd ed.; OUP: Oxford, UK, 2009. [Google Scholar]
- Searcóid, M. Metric Spaces; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Krivochen, D.G. Towards a Theory of Syntactic Workspaces: Neighbourhoods and Distances in a Lexicalised Grammar. 2021. Available online: https://ling.auf.net/lingbuzz/005689 (accessed on 6 May 2021).
- Krivochen, D.G. Syntax on the Edge: A Graph-Theoretic Analysis of English (and Spanish) Sentence Structure. Under Review. 2018. Available online: https://ling.auf.net/lingbuzz/003842 (accessed on 6 May 2021).
- Gorn, S. Handling the growth by definition of mechanical languages. In Proceedings of the Spring Joint Computer Conference, Atlantic City, NJ, USA, 18–20 April 1967; pp. 213–224. [Google Scholar] [CrossRef]
- MacFarlane, J. Logical constants. In The Stanford Encyclopedia of Philosophy. 2017. Available online: http://plato.stanford.edu/archives/fall2015/entries/logical-constants/ (accessed on 18 March 2021).
- Schmerling, S.F. Sound and Grammar: Towards a Neo-Sapirian Theory of Language; Brill: Leiden, The Netherlands, 2018. [Google Scholar]
- García Fernández, L.; Krivochen, D.G.; Martín Gómez, F. Los elementos intermedios en las perífrasis verbales. Lingüística Española Actual 2021. [Google Scholar]
- Karttunen, L. Syntax and semantics of questions. Linguist. Philos. 1977, 1, 3–44. [Google Scholar] [CrossRef]
- Hamblin, C.L. Questions in Montague English. Found. Lang. 1973, 10, 41–53. [Google Scholar]
- Montague, R. The proper treatment of quantification in ordinary English. In Approaches to Natural Language; Hintikka, J., Moravcsik, J., Suppes, P., Eds.; Reidel: Dordrecht, The Netherlands, 1973; pp. 221–242. [Google Scholar]
- Reinhart, T. Wh-in situ in the framework of the minimalist program. Nat. Lang. Semant. 1998, 6, 29–56. [Google Scholar] [CrossRef]
- Fiengo, R. On Trace Theory. Linguist. Inq. 1977, 8, 35–61. [Google Scholar]
- Chomsky, N. Some Puzzling Foundational Issues: The Reading Program. Catalan J. Linguist. 2019, 263–285. [Google Scholar] [CrossRef] [Green Version]
- Torrego, E. On Inversion in Spanish and Some of Its Effects. Linguist. Inq. 1984, 15, 103–129. [Google Scholar]
- Uriagereka, J. Multiple Spell-Out. In Derivations: Exploring the Dynamics of Syntax; Routledge: London, UK, 2002; pp. 45–65. [Google Scholar]
- Nunes, J. Linearization of Chains and Sidewards Movement; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- García Fernández, L.; Krivochen, D.G. Dependencias no locales y cadenas de verbos auxiliares. Verba 2019, 46, 207–244. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krivochen, D.G.; Padovan, A. Lexicalised Locality: Local Domains and Non-Local Dependencies in a Lexicalised Tree Adjoining Grammar. Philosophies 2021, 6, 70. https://doi.org/10.3390/philosophies6030070
Krivochen DG, Padovan A. Lexicalised Locality: Local Domains and Non-Local Dependencies in a Lexicalised Tree Adjoining Grammar. Philosophies. 2021; 6(3):70. https://doi.org/10.3390/philosophies6030070
Chicago/Turabian StyleKrivochen, Diego Gabriel, and Andrea Padovan. 2021. "Lexicalised Locality: Local Domains and Non-Local Dependencies in a Lexicalised Tree Adjoining Grammar" Philosophies 6, no. 3: 70. https://doi.org/10.3390/philosophies6030070
APA StyleKrivochen, D. G., & Padovan, A. (2021). Lexicalised Locality: Local Domains and Non-Local Dependencies in a Lexicalised Tree Adjoining Grammar. Philosophies, 6(3), 70. https://doi.org/10.3390/philosophies6030070