1. Introduction
“That evening he was lucky”: what do we mean by this? It is even weirder when we say: “the luck turned”. Does this mean that we could be visited by fortune? Or that some people are luckier than others on certain days? Of course, we cannot rule out the fact that some people may bias the chances of success simply by cheating. Yet, is there any way to assess the dispersion of chances among gamblers (or just the fraction of cheaters)?
This kind of question is part of the field of probability calculus, which aims at determining the relative likelihoods of events (for a nice historical introduction to probability theory, see [
1]). Probability calculus started during the summer of 1654 with the correspondence between Pascal and Fermat precisely on the elementary problems of gambling [
2]. Symmetry arguments are at the heart of this calculus: for example, for an unbiased coin, the two results—heads or tails—are a priori equivalent and therefore, have the same probability of occurrence of
. This is why it is not anecdotal that Pascal wanted to give his treatise the “astonishing” title “Geometry of Chance”. Another illustration of the power of symmetry arguments is the tour de force of Maxwell who managed to calculate the velocity distribution of particles in idealized gases [
3]. At the time when he derived what is since called the Maxwell–Boltzmann distribution, there was no possibility to measure this distribution. It was almost 60 years before Otto Stern could achieve the first experimental verification of this distribution [
4], around the same time when he confirmed with Walther Gerlach the existence of the electron spin [
5], for which he won the Nobel Prize in 1944. The agreement between theoretical and experimental distributions was surprisingly good. Since its invention in the middle of the 17th century, probability calculus has accompanied most if not all new fields of science, especially since the beginning of the 20th century with the burst of genetics and quantum physics up to the most recent developments of quantum cognition [
6], not to mention its countless applications in finance and economy.
In probability theory, events are usually associated with random variables that are measurable. For example, in the heads or tails game, heads may be associated with and tails with . Then, for a given number of draws, one can count the number of times the heads are flipped. This number is between and and the ratio is the frequency of the heads. If the coin is unbiased, this frequency fluctuates around when the game ( draws for each game) is played many times. Importantly, the frequency is observed ex post, i.e., after the game is played; the mean frequency is used as a measure of probability of getting a head. This is the usual way of assessing probabilities in the frequentist perspective of statistics. Remember that assessing probabilities for anticipating the outcome of future events is the very purpose of statistics. However, it is not always possible to deduce probabilities from frequency measurements. For example, suppose that each coin is tossed only once. Can we still assess the dispersion of chances among gamblers?
Dispersion of chances is far from being limited to gamblers. Disease risk is another area where people may be and actually are unequal for genetic or environmental reasons. In this case, the result of a “draw” is whether or not you have a disease . The “game” is then limited to one “draw” per person. Of course, the mean probability to become ill can still be observed. Yet, can we assess the dispersion of disease risks? Then, if so, how can we? As a last emblematic example, we mention social opportunities. Measuring inequality of opportunity is a crucial issue with considerable political stakes, though it is extremely difficult to assess. On this last point, we postpone the in-depth study of the measure of unequal opportunities to a further work.
In all these examples, be it gambling, disease, or social opportunity, the ex ante chances are themselves random variables that cannot be deduced from frequency measurements nor be induced by symmetry arguments. They are hidden variables. Nevertheless, we argue here that the probability distribution function (pdf) of the ex ante chances can be assessed and we propose some tools to (i) first
test the existence of some dispersion of chances in the population; (ii) then,
infer the pdf of the ex ante chances; and (iii) explore more specifically the relevance of those tools to and their consequences in the field of chronic diseases, i.e., diseases that occur at various ages and persist throughout life [
7]. Importantly, we do not assume any hypothetical functional form for the pdf of chances and then infer its parameters by Bayesian inference as is usually carried out. Here, we first test the inequality of chances in the population, then infer the functional form of the pdf by means of the principle of maximum entropy.
2. A Simple Draw Is Not Enough
Let us first assume that there is a sample of
people tossing a coin and that each of them has a probability
to win (hence,
to lose). In an unbiased game, all the
are identical and equal to
. Imagine that some gamblers are luckier, others less fortunate—hence, some
are greater than
, others less than
. This means that the
are random variables that are drawn from a probability distribution
that is different from
, where
is the Dirac delta function. Let
and
be the mean and variance of
. Let us assume now that each individual plays
times. The result of each draw
of the individual
is a random variable
, either
in cases of success or
in cases of failure. This is a Bernoulli process: for each
, the random variables
are i.i.d. (independent, identically distributed, i.e., the probability of success
is the same for the
draws of
). Let us define
as the score over
draws. It is the number of times the individual
has won. Given the risk
,
is a random variable that follows a binomial distribution
. The mean and the variance of
for a given risk
are
Once every individual has played times, we obtain an estimation of the distribution of the random variables as a histogram over the values . These random variables are independent but non-identically distributed, as the are different from one individual to another.
Just as the
are drawn from the distribution
, the
are the realizations of a random variable
(which takes the
discrete values
). The underlying distribution is no longer only on the random variable
, but on the joint probability of
and
. Thus, the marginal probability distribution function of
is given as follows:
where
is expected value of
with the probability distribution of
,
; and
is the binomial coefficient “
choose
”, i.e., the number of k-combinations of
. The mean of
is
where
is the expected value of
with the probability distribution of
,
(S); and
is the conditional expected value of
for a given underlying probability
, i.e., the Bernoulli distribution. Since
is the mean of the distribution
,
and the variance of
is
where
hence
and
Now, we recall the first two moments of
, given its mean
and its variance
so that
Equation (3) gives the variance of the score as a function of the variance of . In the following for the sake of clarity, we will refer to as the dispersion of chances.
Note that within the limit , the probability distribution of the random variable converges to the distribution .
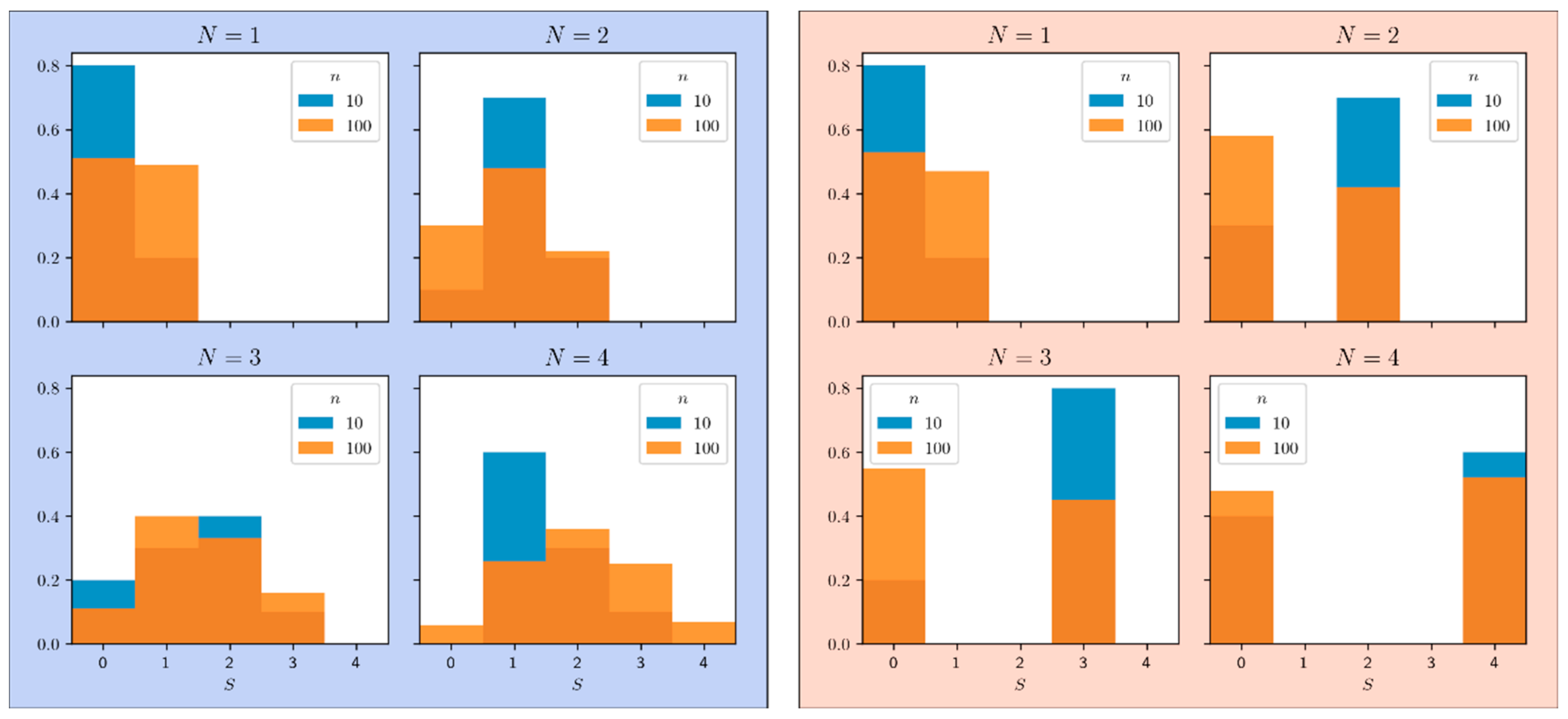
We simulated two populations of
gamblers each drawing
times. Both populations have the same mean chance of gain
. However, in the first population, the chance distribution is
where there is no dispersion of chances, i.e.,
. In contrast, in the second population, the chance distribution is
where the dispersion is maximal, i.e.,
. The histograms are plotted in
Figure 1 for a number
of gamblers ranging from
to
and a number
of draws ranging from
to
. Equation (3) shows that if
the variance
does not depend on the dispersion of chances
. As a matter of fact, when
, the gains are either
or
so that the histogram of gains has only two bins, one at
, the other at
. The mean of gains is
and the variance is
. Neither the mean nor the variance depends on the dispersion of chances
. Moreover, according to Equation (1), the histogram of gains itself depends only on the mean of the distribution
:
The histogram of gains, therefore, cannot provide information on the dispersion of chances, as shown in
Figure 1 for the case
where the histograms for
and
are indistinguishable. This means that
a simple draw is not enough to extract the variance of
from the histogram of gains; multiple draws are necessary, though are they sufficient?
3. A Statistical Test of the Dispersion of Chances
We then note in
Figure 1 that the histogram of gains for two draws (
has three bins, one at
, the second at
and the third at
, with the following values:
Hence, the histogram of gains now depends on (and only on) both the mean and the variance of . Note that Equation (5) shows that , since ; moreover, is maximal when . For three or more draws, we could also have access to higher order moments of . Nevertheless, the minimum condition for the presence of a probability dispersion is that the variance of is non-zero. We therefore propose to design a statistical test that will be able to discriminate between both following hypotheses:
Null hypothesis : everybody has the same probability of gain. This means that whose mean is and dispersion .
Alternative hypothesis : has the same mean but there is some dispersion of chances among the population, so that some people are luckier than others; hence, has a non-zero dispersion .
According to , the mean of draws is and the variance is , whereas according to , the mean of draws is also but the variance is . Hence, if the variance grows linearly with , then all individuals have the same probability of success. If, on the contrary, grows quadratically with , then not all individuals have the same chance of success. We can, therefore, rephrase our hypothesis test as the following alternative based on the dependence of the variance on the number of draws:
Null hypothesis : the variance grows linearly with .
Alternative hypothesis : the variance grows quadratically with .
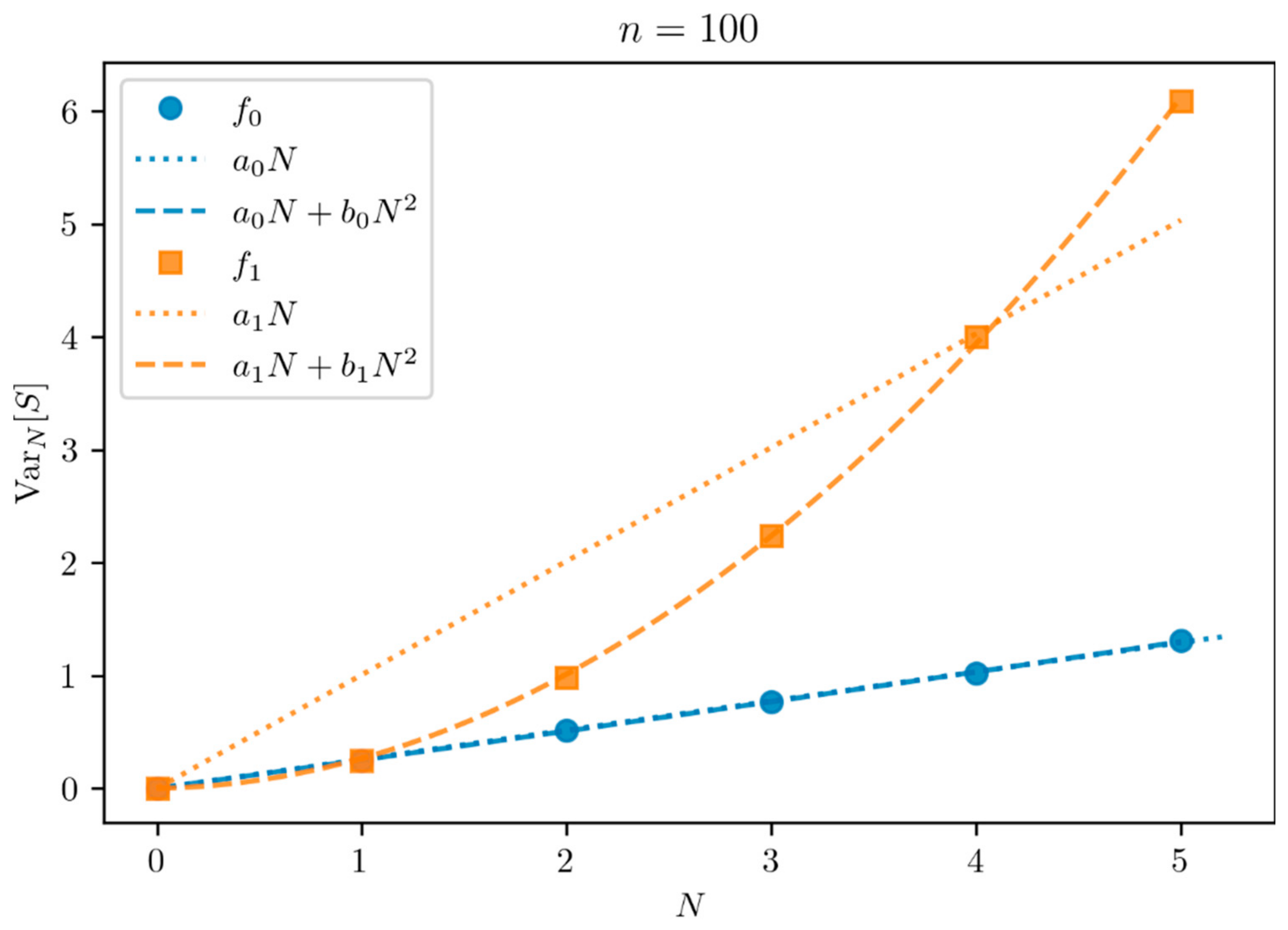
Figure 2 shows how the variance of
varies as a function of the number of draws
for two typical distributions of mean
:
with zero dispersion and
with maximum dispersion
. The distribution
(resp.
) illustrates the case of a variance growing linearly (resp. quadratically) with
.
A relevant statistical test is needed to discriminate between the two hypotheses and , or at least to reject the null hypothesis . Moreover, in the remainder of this paper, we are particularly interested in the case . It is then necessary to reformulate our hypotheses because it becomes difficult to discriminate the quadratic behavior from the linear behavior with only three points. Therefore, we rephrase our hypothesis test, based on the fact that the number of draws is limited to :
Null hypothesis : the variance of reads , i.e., .
Alternative hypothesis : the variance of reads with .
To estimate the variance of
from a sample of
individuals, the unbiased variance estimator is used:
where
is the mean estimator
The estimation of the variance of , , from a sample of finite size is subject to statistical fluctuations. Thus, our hypotheses become:
Null hypothesis : is compatible with 0 considering the error bars, i.e., the standard deviation of .
Alternative hypothesis : .
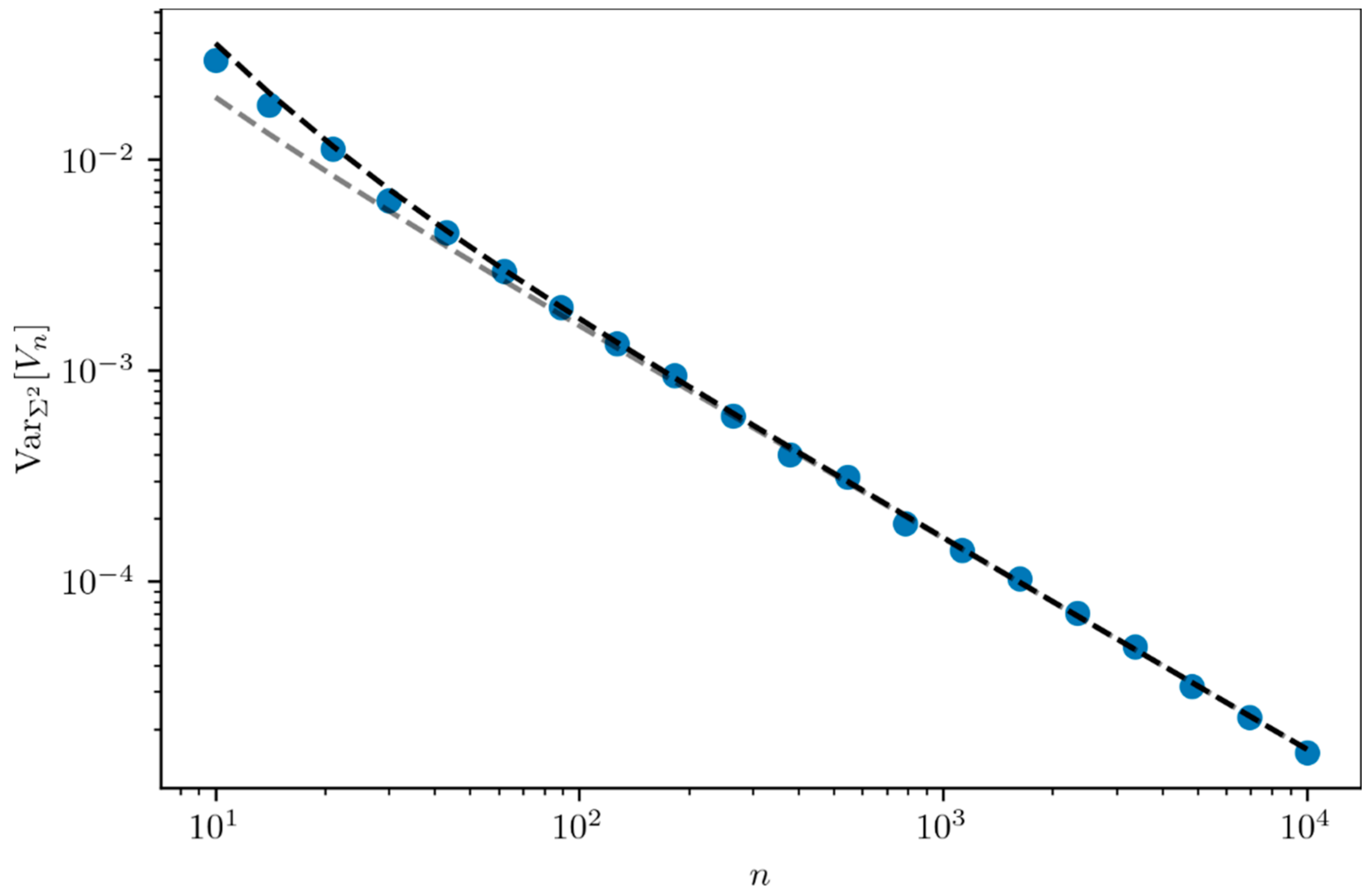
The variance of
reads (see
Appendix A)
where
. Its asymptotic expression for
reads
Figure 3 compares the expression of the variance
(black dashed line) obtained in Equation (7) and its asymptotic expression (grey dashed line) in Equation (8) with simulations (blue dots) and shows good agreement.
It can be noted that the distribution of
tends towards a normal distribution
of mean
and variance
. Now, we wish to estimate the probability of having obtained a value as high as
under the null hypothesis
, i.e., the
p-value. Since
follows a normal distribution, the
p-value can be expressed as follows
where
and
are, respectively, the error function and the complementary error function. By posing
and
as the mean and the variance of
under the null hypothesis
, i.e.,
, we have
Within the limit of large sample sizes
, one can write using, again,
:
In the context of
Figure 2 restricted to the case
and
, the estimated variance
for the distribution
(of mean
and dispersion
) leads to
, i.e., a
p-value of
. This allows us to reject the null hypothesis in this case.
4. Dispersion of Disease Risks for Twins
Inequality in disease risk is a major public health issue [
8,
9]. Of course, part of this inequality is known to depend on genetic and environmental factors. At the turn of the 2000s, a new approach called genome wide association studies (GWAS) was designed to characterize the genetic predisposition to a chronic disease [
10]. GWAS are supposed to find in particular the genes involved in a given disease, and among these genes, the variants most at risk, i.e., the DNA sequences of a given gene that are more represented in the people affected by the disease. Such variants characterize the genetic predisposition to the disease. The mean frequency that an individual will become ill in a given population, specified by genetic and environmental factors, can then be measured. As usual, this frequency can be used as a measure of the probability of becoming ill. However, can we assess the dispersion of disease risk, if only it exists, in this specific population? More generally, is there any way to assess the dispersion of risk in a more objective manner, without any a priori assumption on presumed risk factors? Here comes into play a providential help from the existence of twins. Identical twins, also called monozygotic (MZ) twins, have the same genome, shared the same fetal environment and, generally, share the same living conditions. Therefore, they are most likely to also share the same probability of becoming ill, whatever the disease. Identical twins are, therefore, like a player betting twice. This is much related to the gambling question addressed above for
(two draws). Indeed, as both twins have the same probability
of having disease
, the status—healthy or ill—of each of the two twins is equivalent, respectively, to the outcome—loss or gain—of each of the two draws by one and the same gambler. In this situation, probability
is called a
risk. Let
be the probability distribution function of the risk of having disease
in the population. We define the random variable
as above, i.e.,
if both twins are healthy,
if only one of the two twins is ill and
if both twins are ill. The mean
and variance of
are given by Equations (2) and (3), respectively, hence for
Then, if
is significantly greater than
, which amounts to carrying out the hypothesis test presented in the above section, we can conclude that there is some dispersion of the disease risk. As we will see below, the dispersion is in fact unusually large. However, before that, let us calculate the twin concordance rate of the disease
. In genetics, the twin concordance rate is the probability
that a twin is affected given that his/her co-twin is affected:
hence
Note that
is equal to the probandwise concordance rate, which is known to best assess the twin concordance rate [
11].
Using Equations (4) and (6), we can also reformulate the concordance rate of twins in terms of the moments of the distribution
:
Note we can generalize the concordance rate for a
-tuple:
Using Equations (6) and (10), we obtain
Thus, the relative risk
is equal to
The twin concordance rate can also be computed using the probability density function
restricted to the population of
affected people. Let
be the joint probability of an individual to have a risk
and to be in the state
. According to Bayes’ theorem, also known as the theorem of the probability of causes since it was independently rediscovered by Laplace [
12], we write
hence
Then,
is the distribution of the risk
in the population of affected people
Now, by definition, we have
and by noting that
, we also have
This leads to the following expression of the risk distribution function among affected people
Note that
is the so-called “size-biased law” of the risk
of becoming ill. Size-biased laws are found in many contexts, notably rare events [
13], Poisson point processes [
14] or familial risk of disease [
15].
The mean risk in the affected population is then
where
is the expected value of
among affected people, with the probability distribution
. Using Equation (11), we obtain
which proves that the mean risk in the affected population is equal to the twin concordance rate.
We proceed now to evaluate the functional form of the distribution
. Using the prevalence and the twin concordance rate of the disease
, we have access to, and only to, the mean
and dispersion
of
. The principle of maximum entropy then provides us with the least arbitrary distribution [
16,
17]. Dowson and Wragg proved [
18] that in the class
of absolutely continuous probability distributions on
with given first and second moments (i.e., given mean and variance), there exists a distribution in
which maximizes the entropy
and the corresponding density function
on
is a truncated normal distribution
, which may be either bell-shaped or U-type. Dowson and Wragg show that when
and
, which is usual for most if not all chronic diseases (unpublished results), the distribution
is U-type (see
Appendix B). This distribution, which will be simply denoted
in the following, can then be written
with
The imaginary error function
can be expressed using the Dawson function
Therefore,
can finally be written
It is straightforward to express
and
in terms of the parameters
and
:
Inverting this system of equations to obtain the risk distribution function of the disease in terms of and is a bit trickier and requires a numerical solver. In the next section, we show the outcome of this general formalism for one specific chronic disease, namely Crohn’s disease.
5. Application to Crohn’s Disease (CD)
Crohn’s disease (CD) is one of the most well-documented chronic diseases, particularly in the field of genetics [
19]. Its prevalence
and twin concordance rate
are [
20]:
Then, the twin relative risk is
hence
which means that
The dispersion of the risk of being affected is, therefore, huge for CD.
It is now necessary to calculate the
p-value according to Equation (9) in order to be able to reject (or not) our null hypothesis
. To do this, we first need to estimate the number of twin pairs
that remains unknown in the Swedish study [
20]. Nevertheless, the number of twin pairs with at least one affected twin is known and equal to
, where
and
are the number of discordant and concordant twin pairs, respectively [
20]. We can reconstruct the sample size
that would have been needed to obtain
and
, with probabilities
and
:
By using Equations (5) and (6), we obtain the following sample size
Equation (9) is used by calculating within the limit of large sample sizes . This results in , which allows us to reject the null hypothesis with the .
It is then legitimate to calculate the parameters
and
of the truncated normal distribution
, which maximizes the entropy
given the mean
and the dispersion
. Solving the system of Equations (14) and (15) for
and
gives
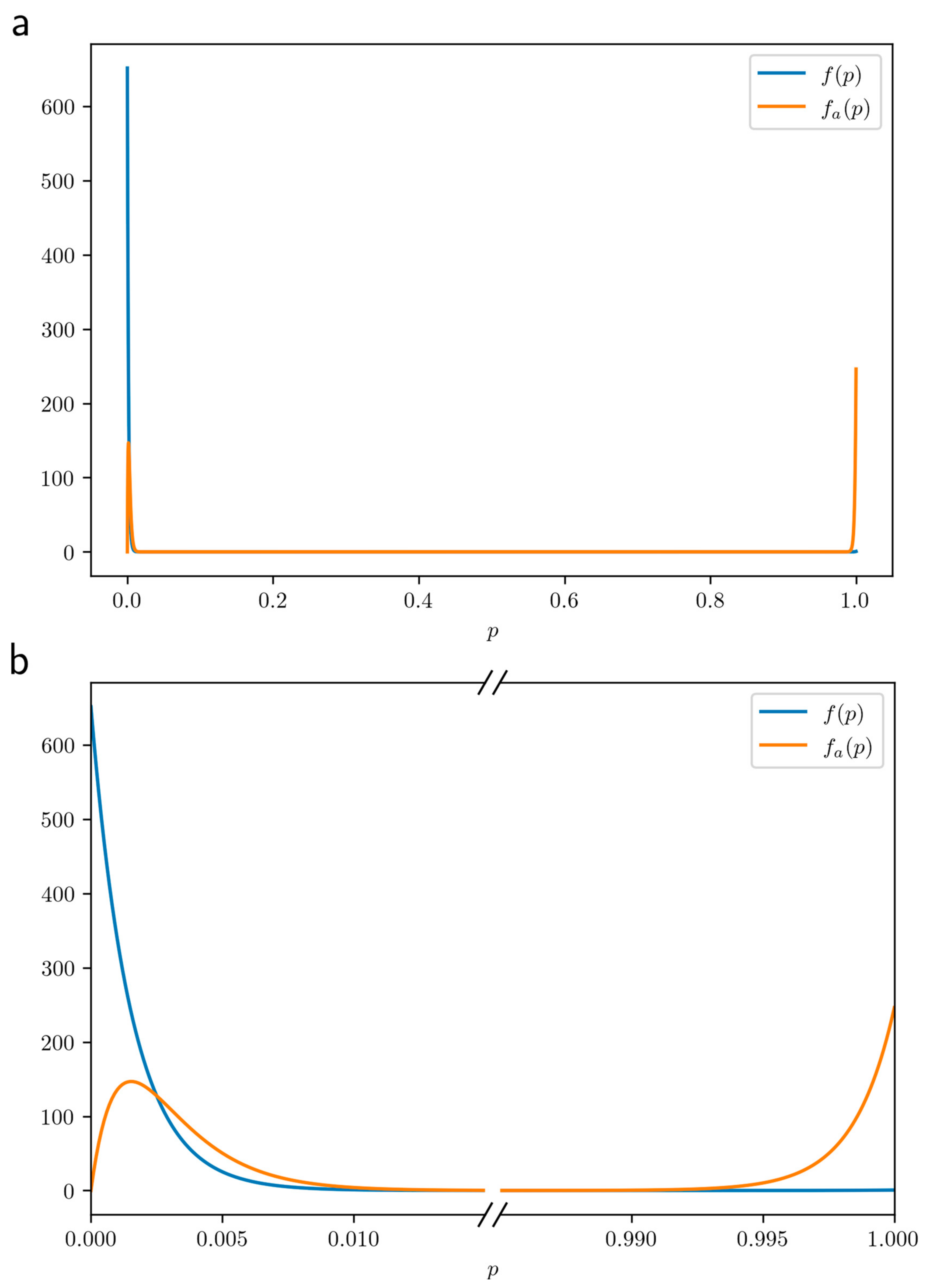
Both probability distribution functions
and
for CD are plotted in
Figure 4a and zoomed in in
Figure 4b. Quite remarkably, the probability density function
in the population of affected people has two narrow peaks, one close to
and the other one close to
. This means that there are two quite separate categories of people who become ill: in the left peak (close to
), people are at very low risk, but still
have been unlucky to become ill, whereas in the right peak (close to
), people are at extremely high risk, hence
are unlucky a priori, and indeed, were bound to become ill. Not having any luck (to become ill
because of high risk) or to have been unlucky (to become ill
despite low risk), that is the question!
Finally, we note that concordant twins are very likely to be in the right peak, whereas discordant twins are in the left one. Indeed, when two MZ twins have their common risk
in the left peak, their probability of being concordant is extremely low, of the order of the mean of
restricted to the left peak of
, which is of the order of
. On the contrary, when two MZ twins have their common risk
in the right peak, their probability to be concordant is extremely high, of the order of
. Interestingly enough, the fraction of people in the right peak (area under the curve) is
, quite similar to the (probandwise) twin concordance rate of
[
20]. This strongly suggests that concordant twins for a given disease both have a strong predisposition for this disease, whereas discordant twins both have no particular predisposition.
6. Conclusions
Assessing the inequality of chances in a given population is a critical problem that has several issues, notably health and social opportunity. Starting with the simple heads or tails game, we have shown that, although hidden variables such as ex ante chances of gamblers (possibly cheating) cannot be assessed, their distribution can actually be assessed whenever multiple draws are available. For this purpose, we have proposed a hypothesis test to evidence the inequality of chances in a given population, then infer the functional form of the probability distribution function of the ex ante chances by means of the principle of maximum entropy, which gives the least arbitrary distribution given the mean and variance of the probability distribution function.
We applied this methodology to chronic diseases and found that the distribution of the risk of becoming ill is usually a U-type truncated normal distribution. We have computed the parameters of this U-type distribution in the case of Crohn’s disease using the prevalence and the twin concordance rate of this pathology. Moreover, we have found that the risk distribution function among affected people is bimodal with two narrow peaks, one corresponding to people with no liable risk factor and the other one to people genetically or environmentally destined to become ill. An interesting consequence is that concordant twins for a given disease both have a strong predisposition for that disease, while discordant twins both have no particular predisposition.
One should still not over-interpret the results, as they still rely only on estimates of the prevalence and the twin concordance rate of the disease. It can be thought of as the best possible interpretation in terms of distribution, based on the available information. Nevertheless, maximizing the entropy of the risk distribution function leads to significantly different conclusions than more arbitrary distributions such as, for example, beta-distributions [
21].
Twins provide a unique means to play twice at the lottery of diseases. Of course, twins are all the more relevant to assess ex ante chances as they share the same environmental factors. In the same vein, “social twins” or more generally “social clones” would be of great help in assessing inequality of opportunities. However, controlling the environment of such social clones would be rather challenging as the issue of choice comes into play, which may change people’s lives with the same opportunities. Assessing the inequality of opportunities is, therefore, one of the most delicate, almost completely open, issues.
Pascal could never complete his treatise “Geometry of Chance”. This never-ending treatise is still being written, as evidenced in this Special Issue.



{kind=link}
{kind=link}
{kind=link}
{kind=link}



