1. Introduction
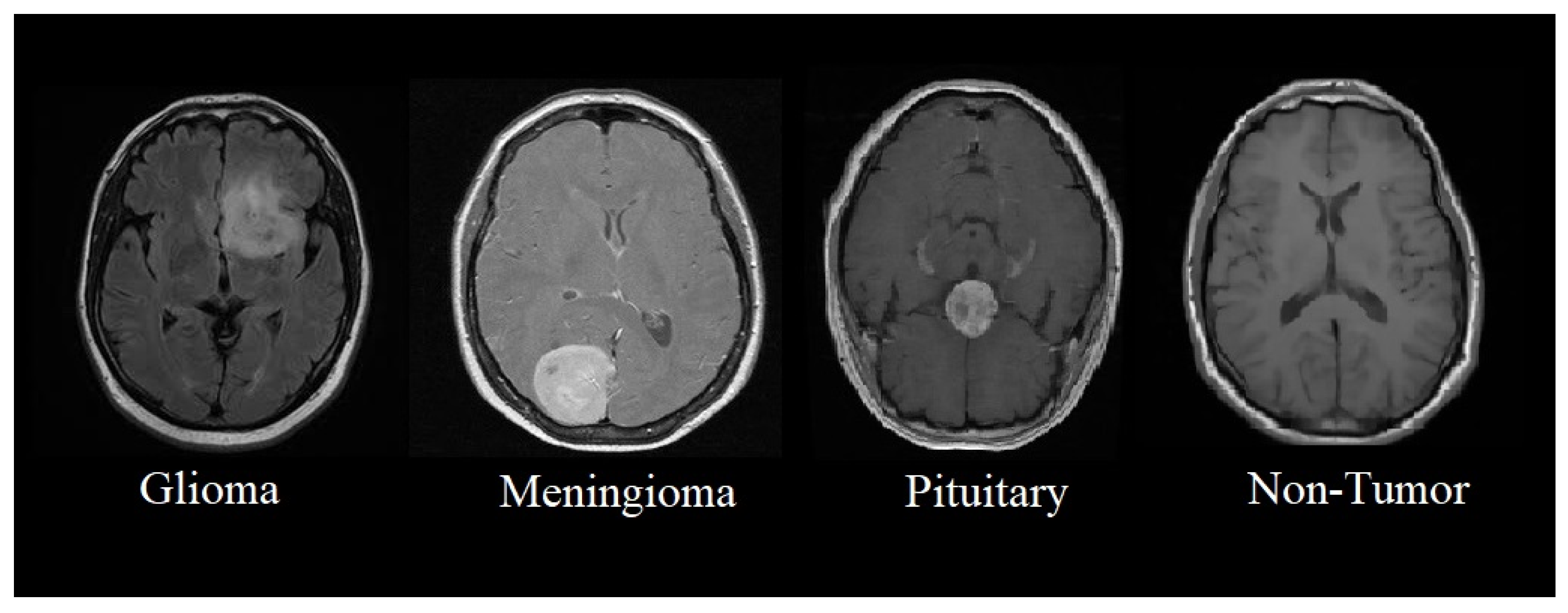
Brain tumors are masses formed due to the abnormal growth of lesions inside human brains that directly affect the functionality of brains for controlling voluntary and involuntary processes [
1]. It is a life-threatening and leading disease toward cancer mortality worldwide [
2]. According to data from the International Agency for Research on Cancer 2012, brain tumors are the 22nd most common form of tumor. However, it is 12th in terms of the mortality rate [
3]. According to Cancer Statistics 2019, there has been an increase in deaths caused by different types of cancer, including brain cancer [
4]. A report published by World Health Organization (WHO) estimated that 9.6 million fatalities were caused by diagnosed cancer around the globe in 2019 [
5]. In [
6], 296,851 new cases of brain tumors and other spinal tumors were reported worldwide in 2018. In 2017, among all types of tumors, brain and other spinal cord tumors were the leading cause of death in men below 40 and women below 20 years of age [
7]. Furthermore, the survival rate of the patient decreases with age. The survival rate for adults above 40 is about 21 percent [
8].
Neuroimaging is a powerful non-invasive tool for finding abnormalities in the brain. Computerized Tomography (CT) scans and MRIs are the two most commonly used neuroimaging techniques for brain tumor diagnosis [
9,
10]. The advantage of using MRI over a CT scan in brain imaging is that not only does it provide a better tissue contrast, but it also does so without the use of radiation [
11]. MRI uses strong magnetic fields and radio waves to analyze the anatomy and physiological processes of a body. Therefore, MRI is a strong tool for detecting diseases and anatomical anomalies in a body. It has a wide range of applications in medical imaging. For example, cardiovascular MRI is used for structural analysis of the heart. Musculoskeletal MRI is used to assess the spine, joint diseases, and soft tissue tumors. Similarly, brain MRI is used to detect neurological diseases such as tumors, clots, etc. [
12]. However, detecting a tumor in a brain MRI is difficult and requires an expert to examine the images to determine the presence of a tumor. It is also imperative to detect and identify the type of tumor. Therefore, Machine Learning (ML) has become a widely used paradigm for detecting tumors in several body parts, including brain tumor detection in MRI [
13], liver tumor classification [
14], breast tumor detection [
15], etc. Hence, a robust solution is needed to utilize a Computer Vision (CV) technology that can accurately detect and identify the presence of a tumor in an MRI.
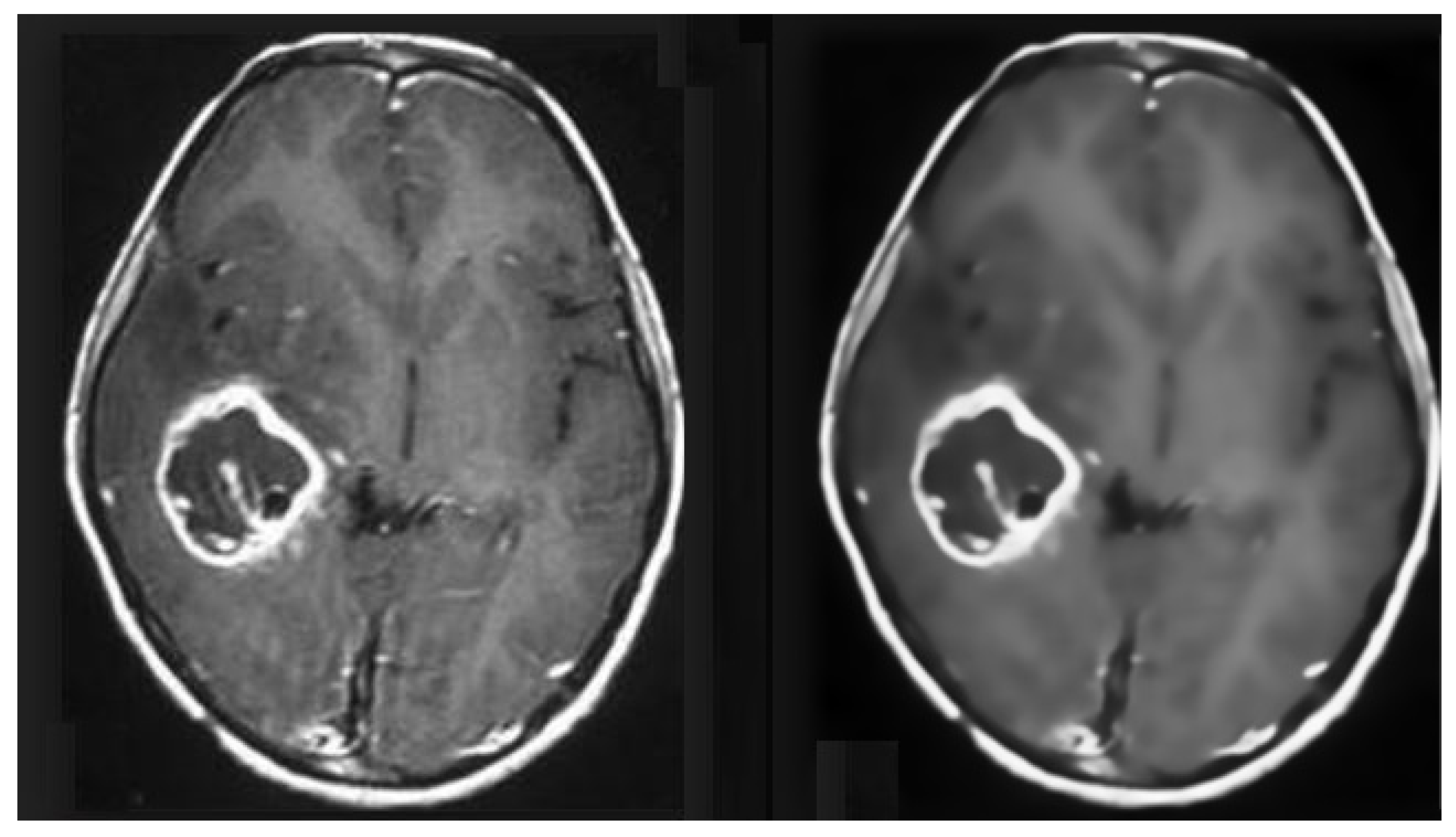
MRIs suffer from the inherited problem of being vulnerable to noise [
16,
17]. Getting the desired image resolution decreases the Signal to Noise Ratio (SNR) [
18]. Noise can occur in any listed processing phase: acquisition, compression, pre-processing, storage, transmission, and/or reproduction. The transformation of MRI images into magnitude images changes the Gaussian distribution into a Rician distribution [
19]. The presence of noise in the MRIs makes it difficult to perform any further image processing techniques on these images [
20]. Therefore, there is a need for noise removal as pre-processing to pass the pre-processed images to the ML classifier for accurate tumor detection. Several techniques have been used to denoise the MRIs [
21]. However, denoising filters also affect the level of detail in the images, which affects the classification process. Hence, FSNLM [
22] is employed to perform noise removal, but it has a comparatively low processing cost. This technique uses fuzzy logic to find segments in the image that are similar to the noisy pixel and use these segments to find the noise-less pixel.
ML techniques have been proven promising for identifying and classifying a brain tumor in MRI images [
23]. Therefore, developing an accurate classification model to detect a brain tumor in MRI images is quite possible. However, conventional ML techniques: Support Vector Machine (SVM) [
24], k-Nearest Neighbor (KNN) [
25], Decision Tree (DT) [
26], Random Forest (RF) [
27], etc., require a lot of knowledge of the input images so that useful features can be extracted from them. Deep Learning (DL) techniques have recently revolutionized ML by automatically extracting features from MRI images [
28]. Convolutional Neural Networks (CNNs) are widely used DL techniques that perform automatic feature extraction, making them suitable for image classification and object detection problems [
29,
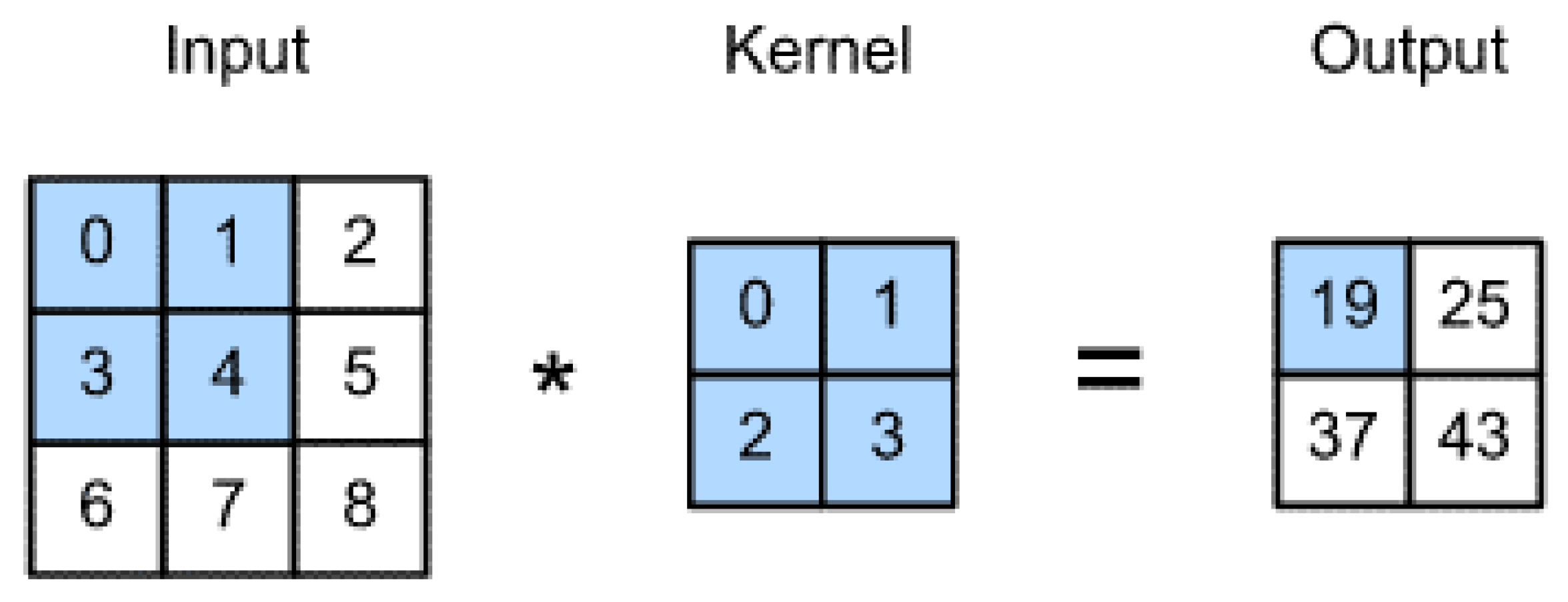
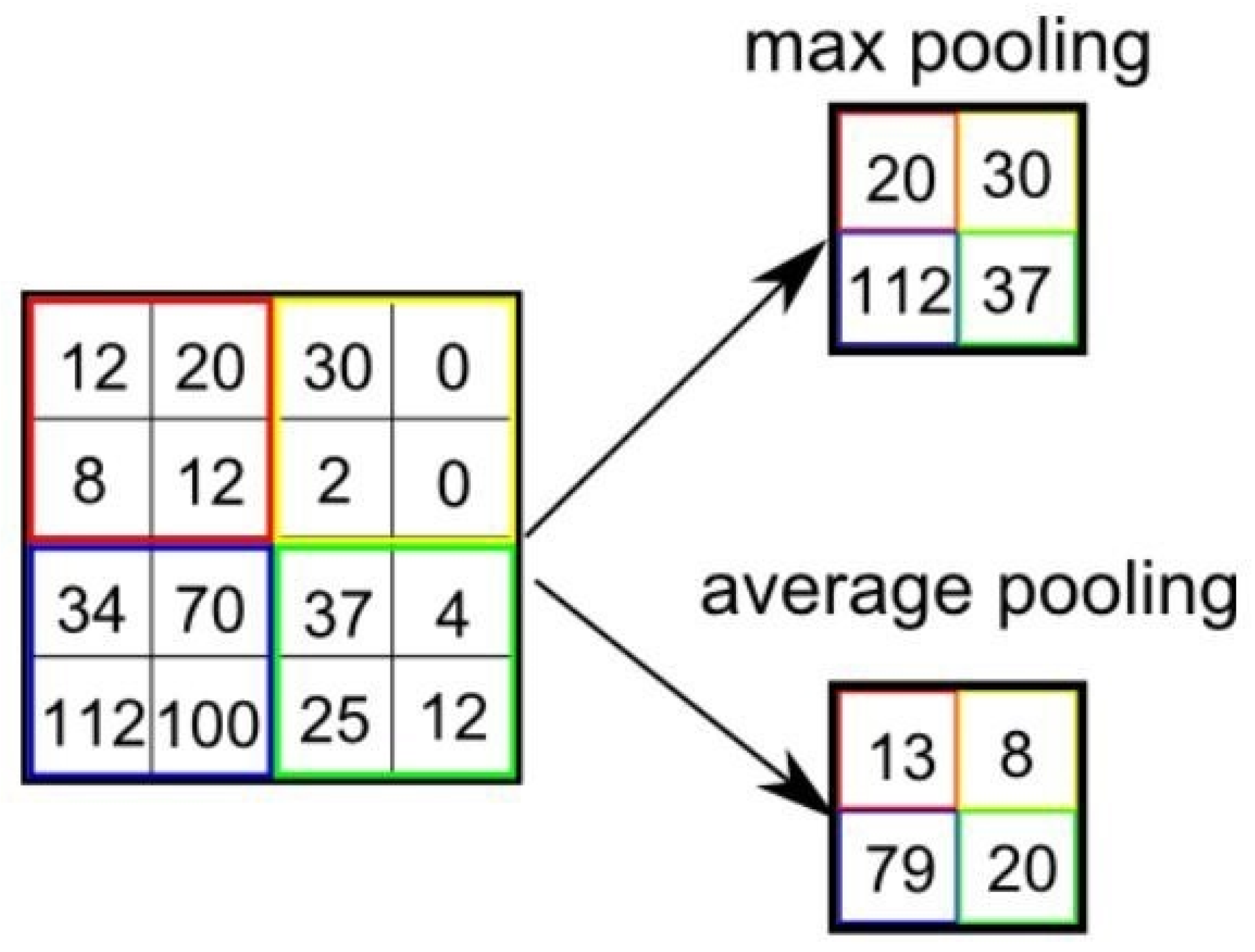
30]. A CNN performs a series of convolutional, non-linearity, and pooling operations on the input images to extract the useful features from given images. These features are then used for object detection, segmentation, or image classification. Moreover, the traditional CNN model requires a huge amount of training samples to produce effective classification results. Therefore, our research study focuses on transfer learning that allows pre-training a CNN model on a vast image dataset and then reusing the resulting parameters of a model for a similar task with specific samples.
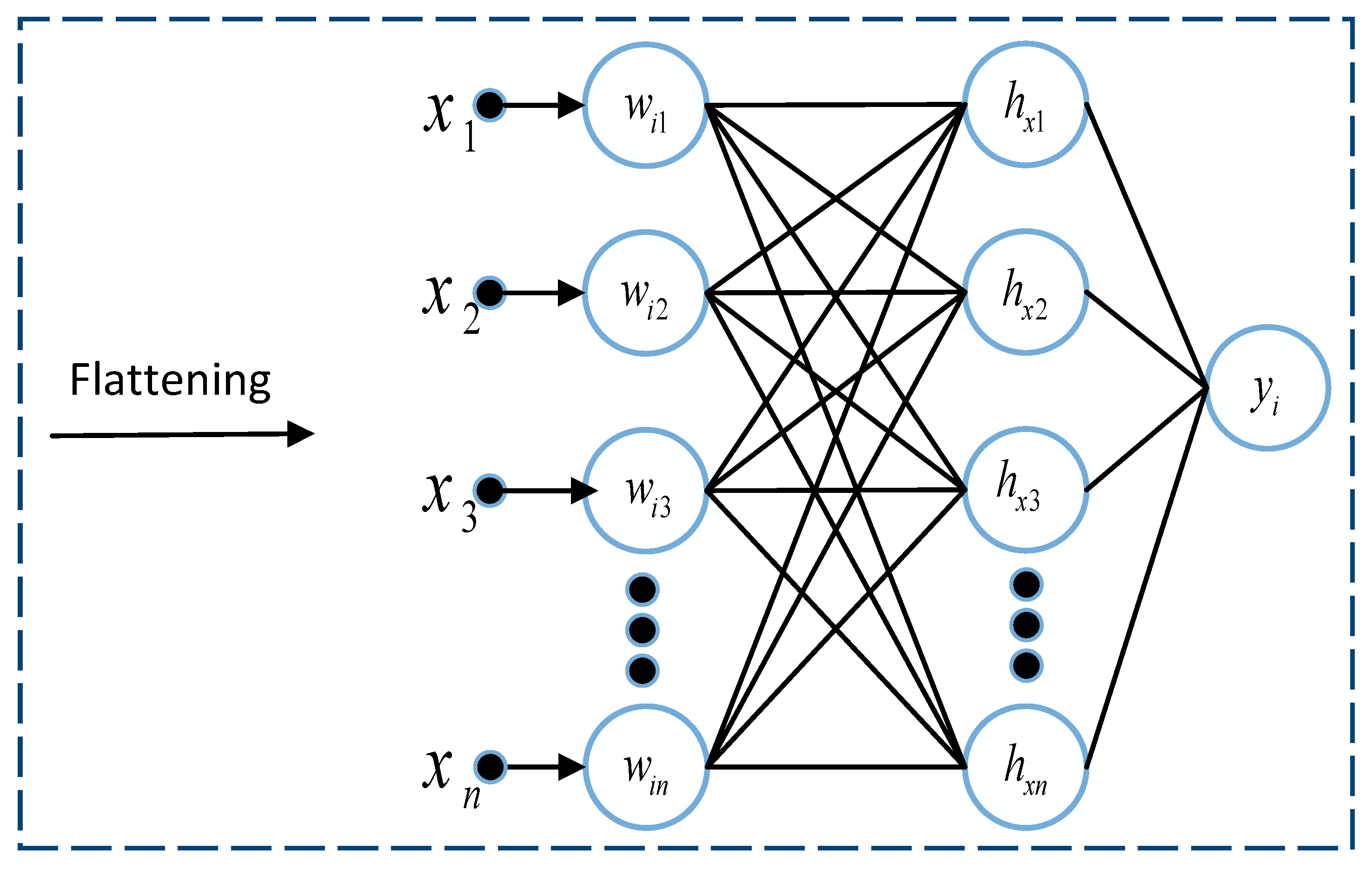
The transfer learning approach is very effective for training a DL architecture from scratch when training samples are small, causing a biased and over-fitted DL model. Several pre-trained models, such as GoogleNet, AlexNet, ResNet, and VGG, were originally designed for different brain tumor classification tasks [
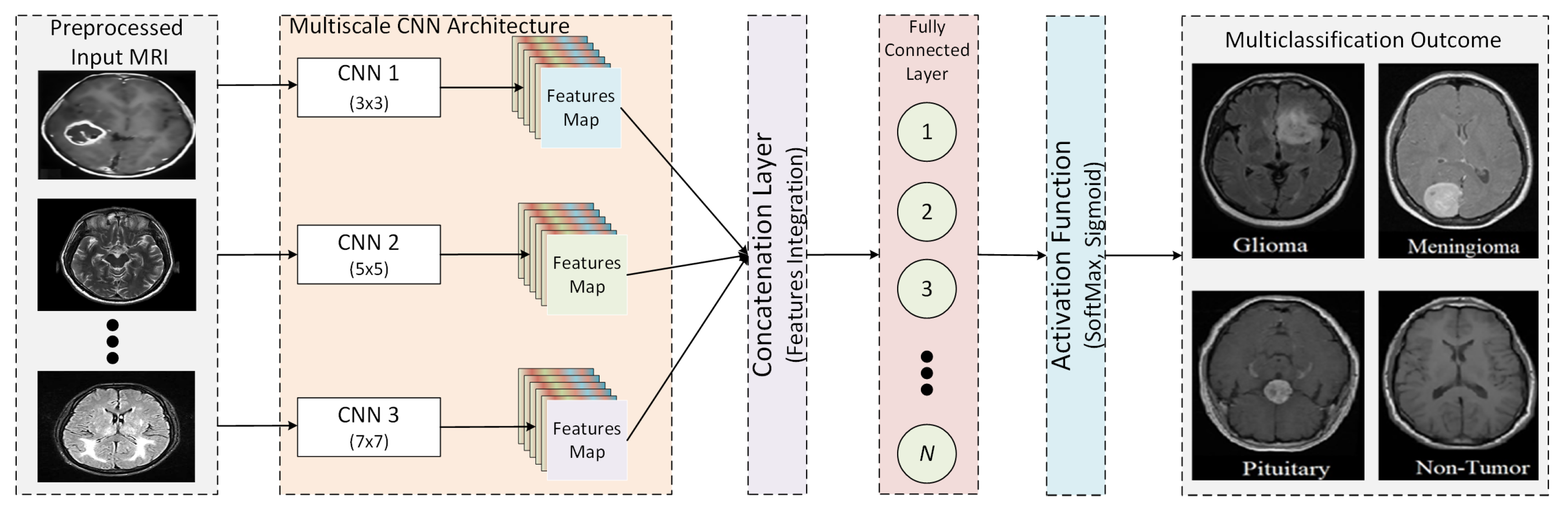
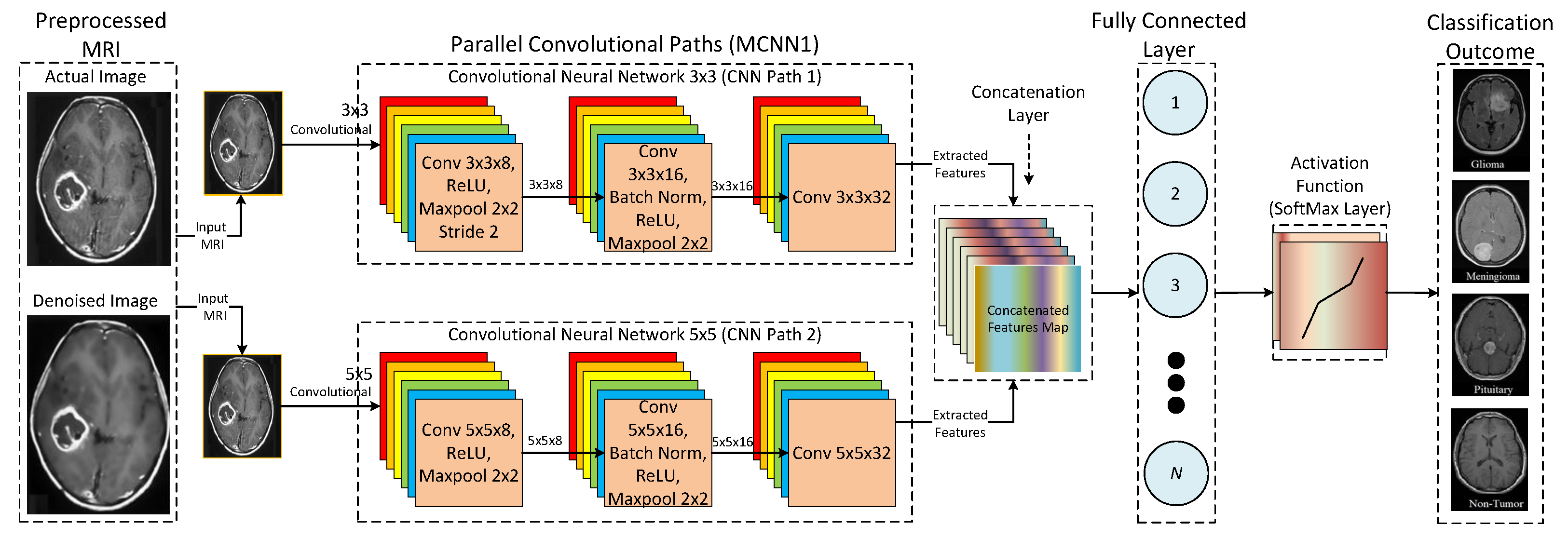
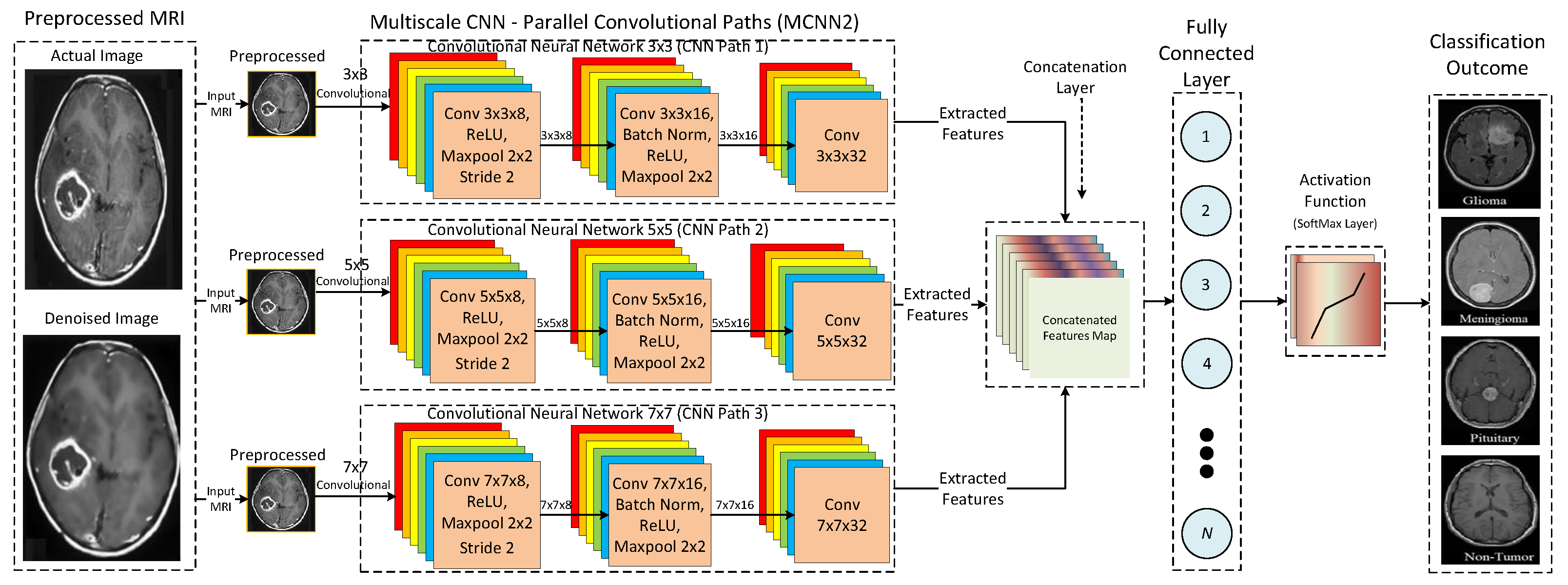
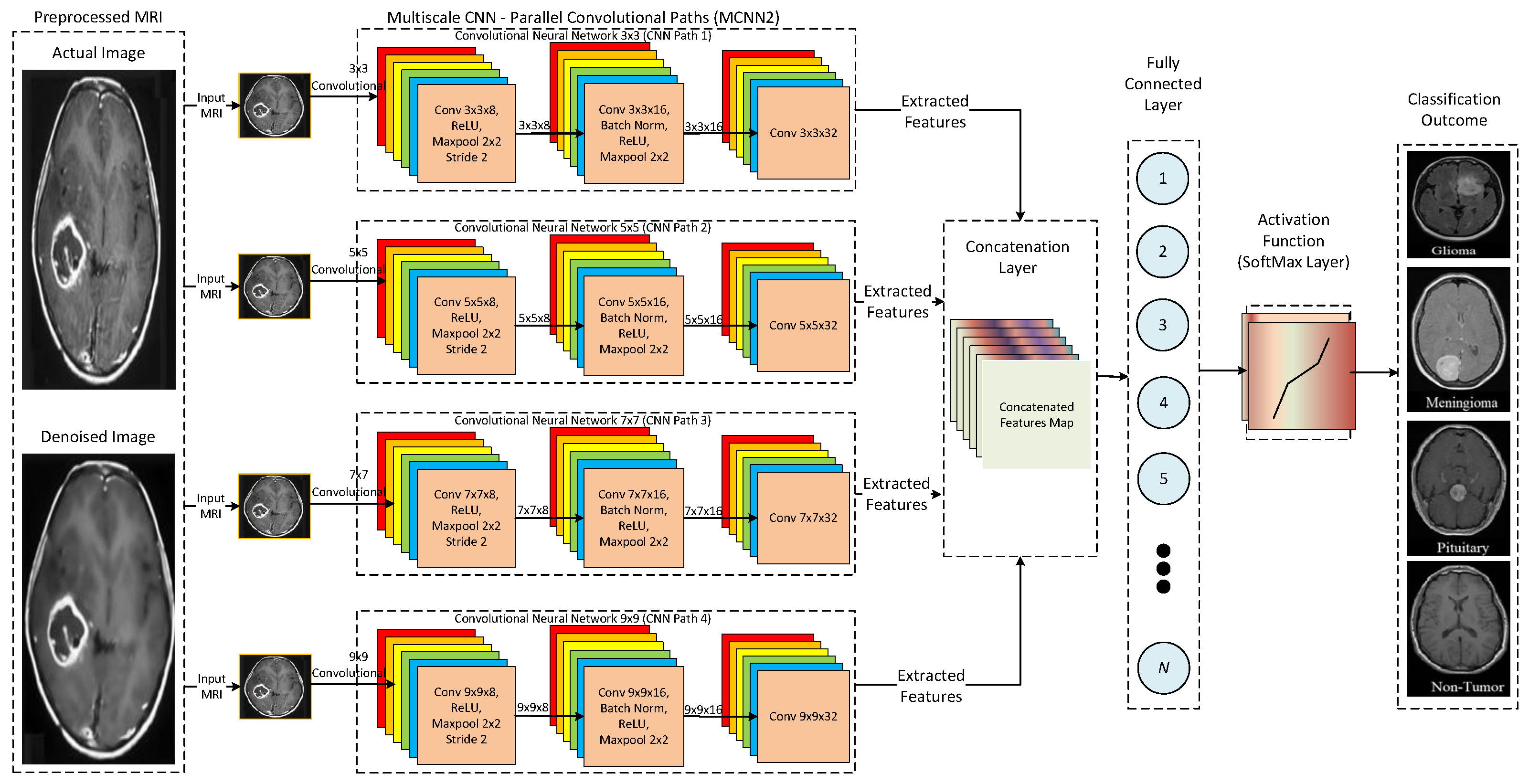
31]. However, these architectures have a large number of trainable parameters and hence require a lot of computational resources. Furthermore, the size of the convolution kernel governs the features extracted by the CNN. Using a single kernel restricts the extractions of a wider range of features from the input images. Therefore, utilizing more than one kernel for a single convolution is imperative. Hence, our study proposes a multi-scale CNN model to enhance the performance and efficiency of traditional CNN architectures.
The notable contributions of the proposed research study are as follows:
The impact of convolutional scaling is evaluated for the varying tumor size, shape, and location on the classification performance of CNN.
An empirical scale-based multi-scale CNN architecture is proposed to outperform the state-of-the-art CNN architectures in terms of effectiveness and efficiency.
The proposed multi-scale CNN model is tested on noisy and denoised images, concluding that noise affects the CNN classifier accuracy.
Furthermore, a detailed comparative analysis is presented to evaluate the accuracy and efficiency of the proposed research study.
The remaining structure of the proposed study is ordered as follows:
Section 2 describes the theoretical background of the computer-aided diagnosis of brain tumor MRIs.
Section 3 discusses the proposed model for brain tumor detection.
Section 4 consists of the experimental environment, experimental results, and performance analysis.
Section 5 presents a comparative analysis to evaluate the accuracy and efficiency of proposed and existing approaches.
Section 6 concludes the proposed research study, and possible future directions are also suggested for research in this field.
4. Experimental Results and Analysis
This section presents the experimental environment, evaluation metrics, experimental results, and analysis. First, an experimental environment of the proposed research study is presented. Second, different evaluation metrics are discussed to evaluate the performance of proposed and conventional DL architectures. Third, experimental results of proposed and state-of-the-art techniques such as AlexNet and Renset18 are discussed. Finally, comparative analyses show the impact of the proposed multi-scale CNN model over traditional CNN architectures.
4.1. Experimental Environment
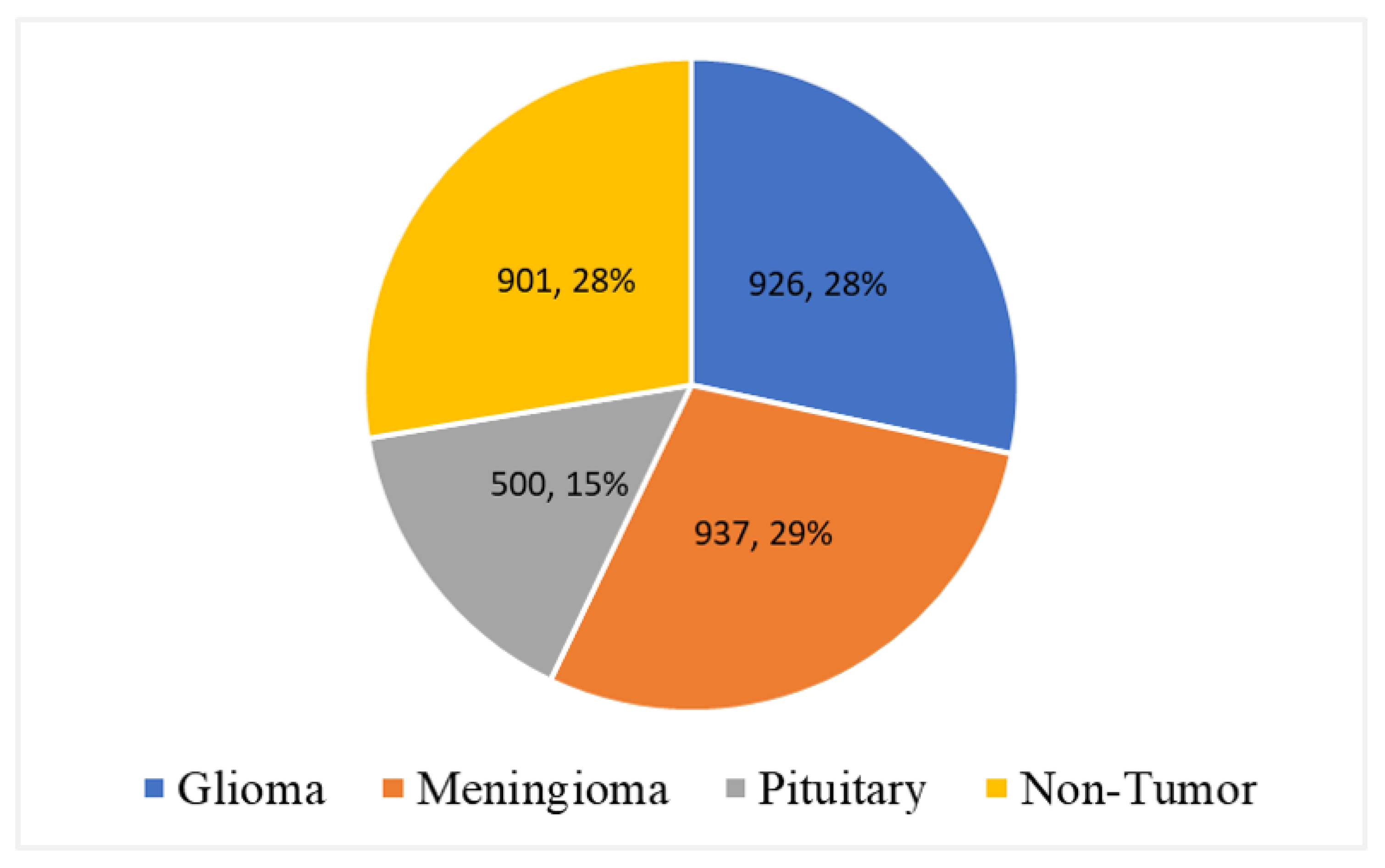
The experiments are performed using Matlab R2020b on two MRI datasets: original and denoised images, to understand the effect of noise on the performance of the proposed multi-scale CNN models.
Table 2 gives the specification of the systems on which all the experiments were performed. Furthermore, a dataset is divided into training and testing sample sets. The k-fold validation strategy is utilized to ensure the quality of the results. Moreover, the k-fold (i.e., k = 10) cross-validation method is used to ensure the generalization and fast convergence of the proposed multi-scale CNN models.
4.2. Evaluation Measures
For performance evaluation of the proposed model, four evaluation measures were used: accuracy, precision, recall, and F1-score [
88]. These measures are calculated with the help of the confusion matrix.
Table 3 shows an example of a confusion matrix for a binary classification problem.
Where , , , and indicate instances that were actually true and correctly predicted true; shows instances that were actually negative and correctly predicted negative. Similarly, indicates instances that were actually positive but falsely predicted negative; shows the instance that was actually negative but falsely predicted positive.
Based on the confusion matrix, different evaluation measures are constructed, such as accuracy, precision, recall, and F1-score.
Accuracy is defined as the ratio between the correctly predicted instances (true positive) and the total number of instances
N. Accuracy is expressed for the aforementioned multi-classification problem as shown in Equation (
5).
Precision is defined as “out of all the actual positives, how many were correctly predicted as positive”. For multi-classification, it is defined for class label
i as the sum over the
ith row of the confusion matrix. Precision is expressed in Equation (
6).
where
M represents a matrix,
i is defined for rows (predicted label), and
j is defined for columns (actual label).
Similarly, recall is defined as “out of all the predicted positives, how many are actually positive”. For the multi-classification problem, it is calculated for the class label
ith as the sum over columns of the confusion matrix. The recall is expressed in Equation (
7).
Furthermore, the F1-score is defined as the harmonic mean of precision and recall. The F1-score is expressed in Equation (
8).
4.3. Experimental Results and Performance Analysis
This section presents the experimental results of the proposed and state-of-the-art DL architectures. In this research study, experiments were performed in four different stages.
In the first stage, the raw images were used for classification by all models.
In the second stage, the images were denoised using an FSNLM filter and were classified using all models.
In the third stage, an artificial noise of magnitude 0.05 was added to the original images. These noisy images were then classified using all models.
Finally, images with artificial noise were denoised using an FSNLM filter and sent to the classifiers.
4.3.1. Original (Raw) MRI Data
In this stage, the proposed and existing DL architectures are employed on an original set of MRI data.
Table 4 shows the accuracy, precision, recall (aka sensitivity), specificity, and F1-score of the five classification models on the original MRI dataset. The classification results indicate that the proposed MCNN2 model yields higher accuracy than other listed DL architectures. Furthermore, the classification results of the proposed MCNN2 model are significantly higher than the existing AlexNet architecture. Similarly, the classification performance of the proposed MCNN2 model is slightly higher compared to the ResNet architecture. Moreover, it shows that the proposed MCNN2 gives high specificity compared to other listed models. Based on the evaluation results, it is concluded that the proposed MCNN2 model gives an accurate classification rate on original MRI data compared to other DL architectures.
4.3.2. Denoised Images Dataset
Next,
Table 5 shows the classification results of the five classification models on the denoised images dataset. The classification results indicate that the proposed MCNN2 model gives superior performance compared to the AlexNet, ResNet, and other CNN architectures. Furthermore, the classification results of the proposed MCNN2 using denoised images are much better than the existing AlexNet architecture. It is also found that the performance of MCNN2 in terms of specificity is better than conventional CNN architectures. Similarly, it is also evident that the proposed MCNN2 model performed slightly better than the ResNet architecture. The evaluation results concluded that the proposed MCNN2 model gives high classification performance on denoised image data compared to other DL architectures.
4.3.3. Synthetic Noise Based Dataset
Although some noise is present in the original images, the level of noise is very low. To deeply observe the effect on noise, a synthetic noise of 0.05 magnitude was added to the original images. These images were then classified using all five classifiers.
Table 6 shows the classification results of all the classifiers on images with synthetic noise. The classification results using synthetic noise indicate that the proposed MCNN2 model performed significantly well compared to the AlexNet architecture. The resulting analysis shows that the proposed MCCN2 model improved accuracy by 6.73%, precision by 8.34%, recall by 5.44%, specificity by 7.65%, and F1-score by 6.91% compared to the AlexNet architecture. Furthermore, the classification results of the proposed MCNN2 were slightly better than the existing AlexNet architecture. The classification results using artificial noise data concluded that the proposed MCNN2 model gives high classification performance compared to the listed DL architectures.
4.3.4. Synthetic Noise Removed
In the final stage, the images from dataset 3 are denoised using an FSNLM filter to remove the synthetic noise.
Table 7 shows the classification results of these images. The evaluation analysis indicates that the MCNN2 gives higher accuracy, recall, and F1-score than AlexNet, ResNet, and other multi-scale CNN architectures. Furthermore, the ResNet architecture gives a high precision of 0.92301 compared to other DL architectures. Moreover, MCNN2 gives a slightly better specificity of 0.89671 than ResNet. Hence, our MCNN2 architecture yields high performance and outperforms state-of-the-art DL techniques.
5. Comparative Analysis
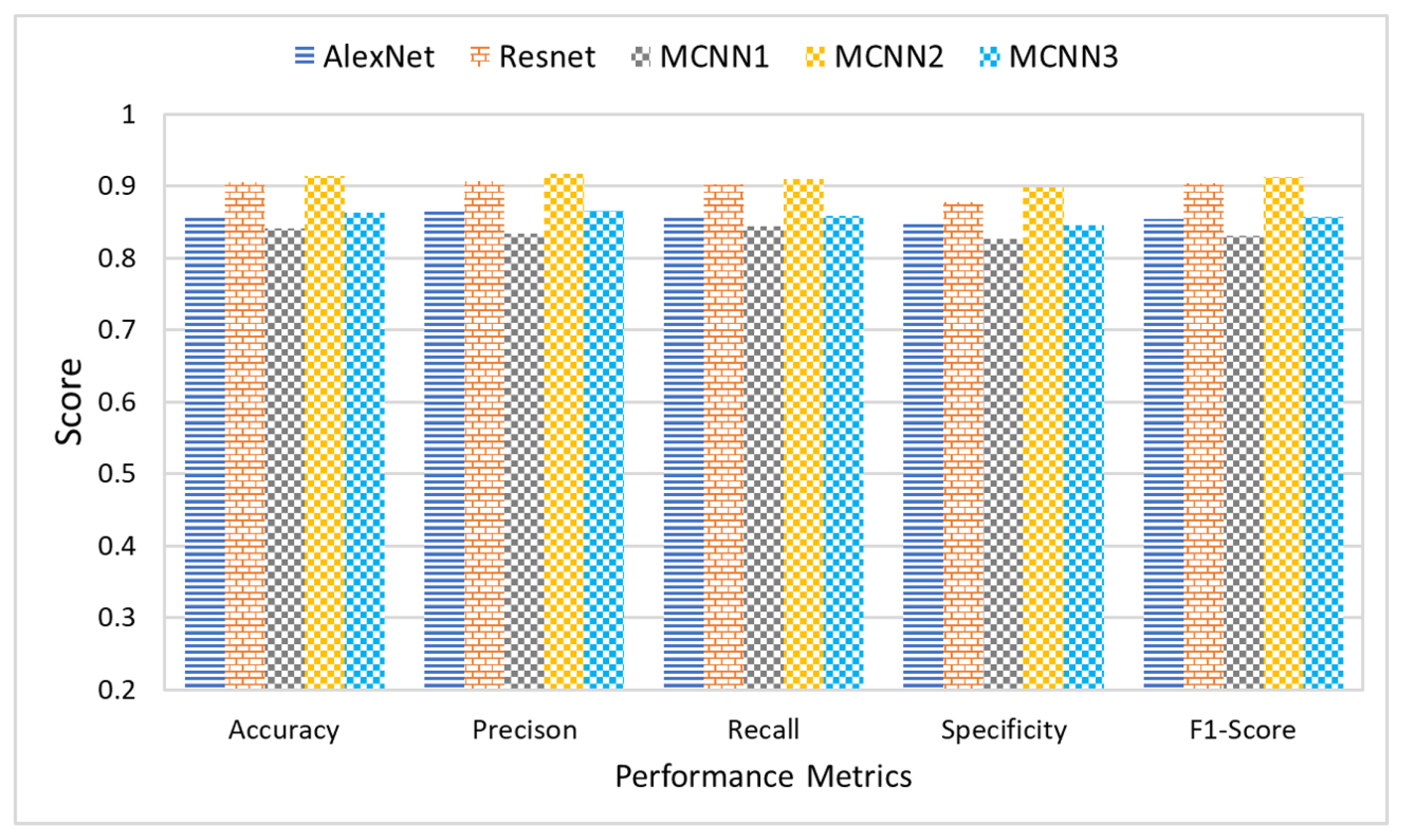
This section presents a comparative analysis to show the effectiveness and significance of the proposed research study. This research study proposes three different multi-scale architectures for brain MRI classification. The proposed architectures are named MCNN1, MCNN2, and MCNN3 and have 2, 3, and 4 parallel convolution paths, respectively. For performance evaluation, the proposed architectures’ classification results were compared with state-of-the-art CNN models, AlexNet and ResNet, using measures of accuracy, precision, recall, and F1-score. Accuracy was normalized between 0 and 1 to make it easier to present. The experiments were performed on four different datasets, each having a different level of noise.
Figure 12 shows the average accuracy, precision, recall, and F1-score of the five classification models across the four different datasets. The comparison of the results indicated that the proposed architecture, MCNN2, performed better than state-of-the-art methods in all the evaluation measures. MCNN2 was able to classify the MRIs with an accuracy of 91.2% and an F1-score of 0.91%, which is higher than not only the other two proposed models but also the state-of-the-art techniques such as ResNet and AlexNet. Not only does the proposed model give better classification, but it does so at a lower computational cost. AlexNet and ResNet 18 have approximately 61 million and 11 million trainable parameters, respectively [
89]; MCNN2 uses only around 1.8 million trainable parameters.
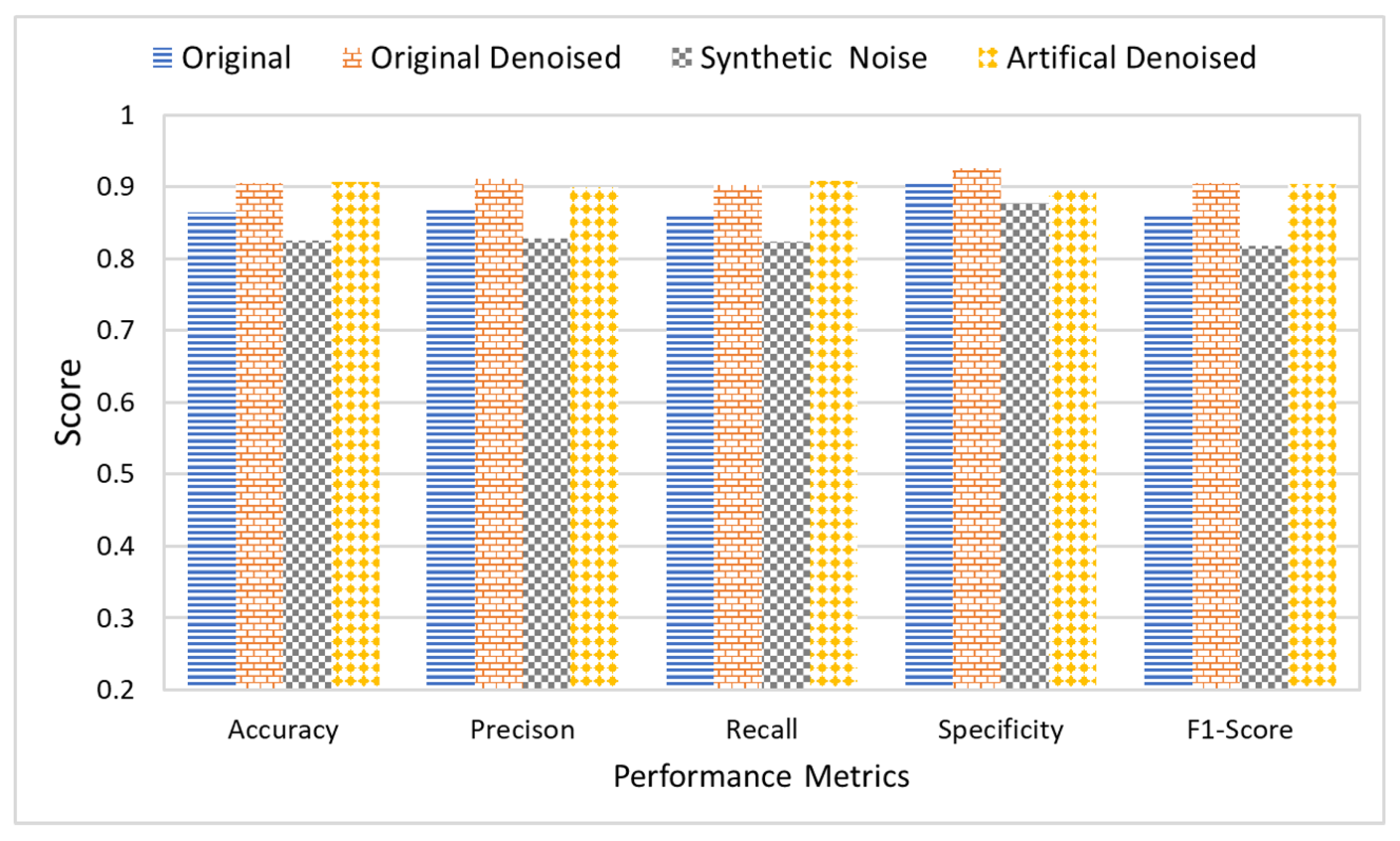
Furthermore, the research study also studied the effect of noise on the classification results. For this purpose, all five classifiers were applied to the dataset in four different stages. Each stage had a different level of noise in the images. The original images with naturally existing noise were used in the first stage. In the second stage, images were denoised using an FSNLM filter. In the third stage, artificial Rician noise was added to the original image dataset. Finally, the images with artificial noise were denoised using an FSNLM filter in the fourth stage.
Figure 13 shows the average classification results of all the classifiers on each of the datasets. The results indicate that the presence of noise adversely affects the classification results. While the original images produced decent results, they had some noise. However, when the images were denoised, it improved performance. Furthermore, adding artificial noise to the images resulted in a decline in performance of the classifiers. However, removing the noise from these images recovered the performance.
Moreover,
Table 8 presents a comparative analysis to evaluate the efficiency of the proposed multi-scale approaches with state-of-the-art architectures, such as ResNet and AlexNet. The efficiency of the proposed and existing models is evaluated based on trainable parameters (weights and biases). The comparative analysis shows that our proposed multi-scale approaches require a small number of trainable parameters to extract features compared to ResNet and AlexNet. Our proposed multi-scale approaches drastically reduce the number of trainable parameters to extract features. The comparative analysis shows that the total number of trainable parameters for the proposed MCNN1, MCNN2, and NCNN3 is 3.443%, 8.191%, and 15.966% of the ResNet architecture. Similarly, it is also found that the total number of trainable parameters for the proposed MCNN1, MCNN2, and MCNN3 is 0.635%, 1.511%, and 2.946% of AlexNet. Hence, our proposed multi-scale approaches enhance efficiency for tumor detection in brain MRIs compared to the existing models such as ResNet and AlexNet [
89].


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}