



Rosette Trajectory MRI Reconstruction with Vision Transformers
 , ,
, ,  and
and
Abstract
1. Introduction
1.1. MRI, Cartesian and Non-Cartesian
1.2. Cartesian K-Space MRI Reconstruction Methods
1.3. Non-Cartesian K-Space MRI Reconstruction Methods
1.4. The Rosette Trajectory
2. Materials and Methods
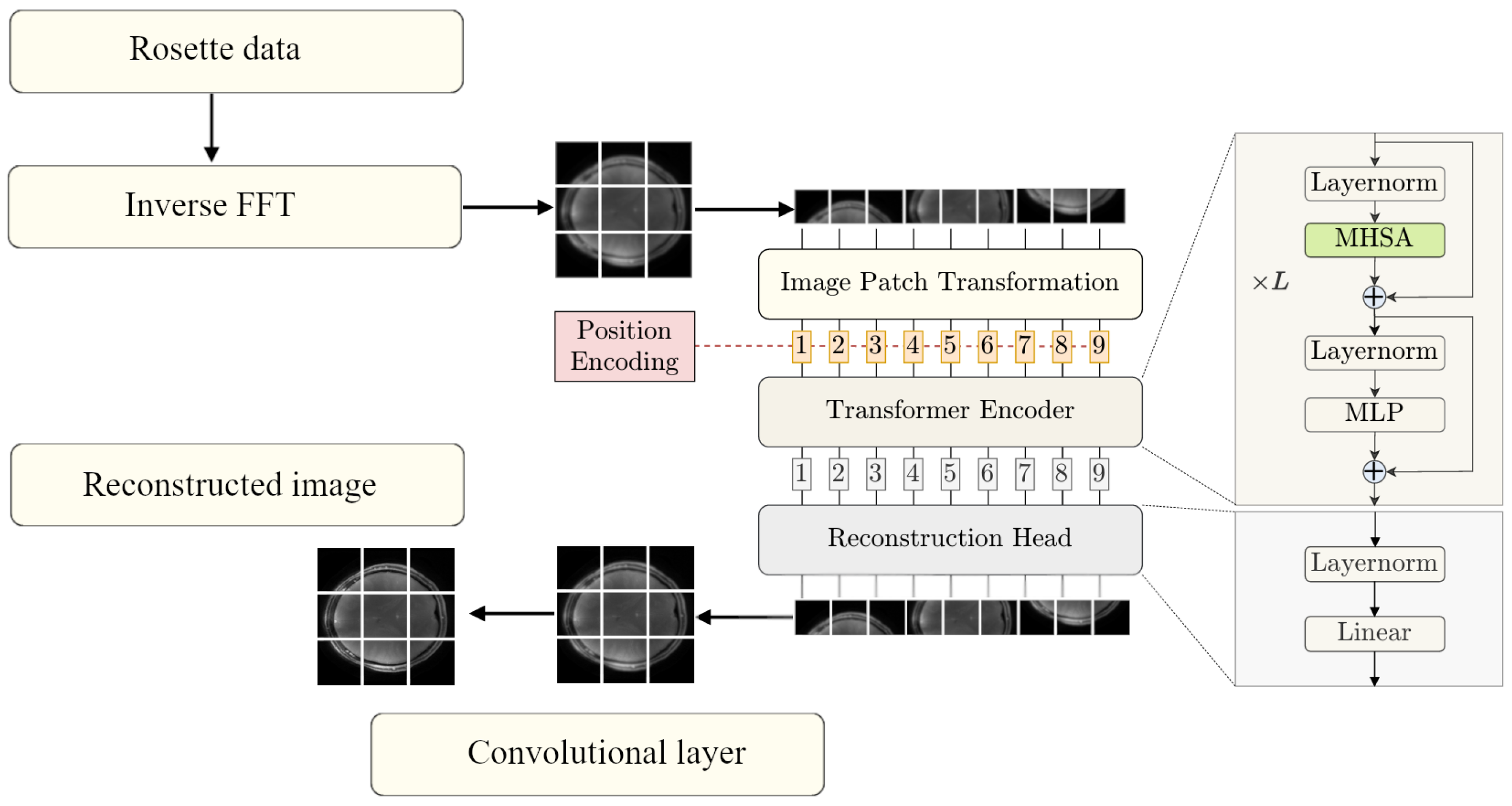
2.1. Method Overview
2.2. Vision Transformer
2.3. Dataset and Preprocessing
- Repetition time (TR): 2.4 s;
- Echo time (TE) (dual): 1 and 9 milliseconds;
- Acceleration factor: 4;
- Total petals: 189;
- : 1000/m;
- : 400 Hz;
- : 400 Hz;
- Nominal in-plane resolution: 0.468 mm;
- Slice thickness: 2 mm;
- Flip angle: 7 degrees;
- Image resolution: 512 × 512.
- Random horizontal flip, probability = 0.5;
- Random vertical flip, probability = 0.5;
- Random rotation, 0 to 180 degrees;
- Color jitter, brightness/contrast/saturation, range = 0.8 to 1.2;
- Random resized crop, scale = 0.3 to 1.1.
2.4. Evaluation Methods
- The structural similarity index measure (SSIM) measures image similarity between a reference image and a processed image [36]. Higher scores are preferred.
- Normalized root mean square error (NRMSE) in the context of image quality is the square root of the mean squared error [37] between two images normalized by the sum of the observed values. Lower error is preferred.
- Normalized mutual information (NMI) measures shared information, where the scale between no mutual information and full correlation is given as 0 to 1 [38].
- Relative contrast is the ratio between the difference in maximum and minimum intensity and the sum of the same values.
- Peak signal-to-noise ratio (PSNR) measures the ratio between the maximum possible pixel value and the noise power [39]. Higher PSNR values indicate better image quality.
- Shannon entropy quantifies the information content of an image using a measure of uncertainty [40].
- The entropy focus criterion (EFC) provides an estimate of corruption and blurring in terms of energy—lower values are preferred [41].
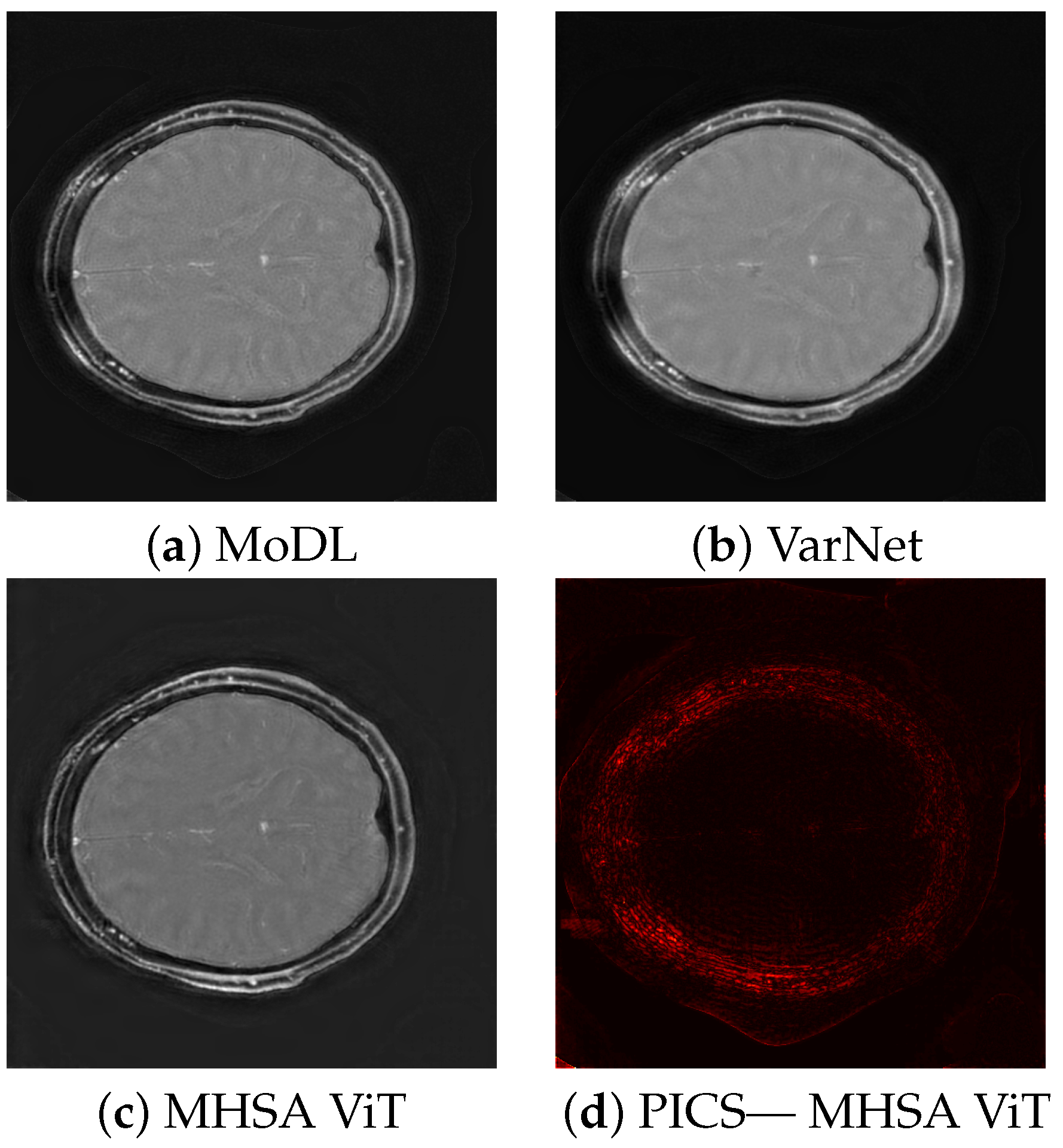
2.5. Visualization
2.6. Training Procedure
3. Results
3.1. Image Scores
3.2. Network Runtime Performance
3.3. Noise Independence
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Geethanath, S.; Vaughan, J.T., Jr. Accessible magnetic resonance imaging: A review. J. Magn. Reson. Imaging 2019, 49, e65–e77. [Google Scholar] [CrossRef] [PubMed]
- Moratal, D.; Vallés-Luch, A.; Martí-Bonmatí, L.; Brummer, M.E. k-Space tutorial: An MRI educational tool for a better understanding of k-space. Biomed. Imaging Interv. J. 2008, 4, e15. [Google Scholar] [CrossRef] [PubMed]
- Gallagher, T.A.; Nemeth, A.J.; Hacein-Bey, L. An introduction to the Fourier transform: Relationship to MRI. Am. J. Roentgenol. 2008, 190, 1396–1405. [Google Scholar] [CrossRef] [PubMed]
- Hollingsworth, K.G. Reducing acquisition time in clinical MRI by data undersampling and compressed sensing reconstruction. Phys. Med. Biol. 2015, 60, R297. [Google Scholar] [CrossRef]
- Wright, K.L.; Hamilton, J.I.; Griswold, M.A.; Gulani, V.; Seiberlich, N. Non-Cartesian parallel imaging reconstruction. J. Magn. Reson. Imaging 2014, 40, 1022–1040. [Google Scholar] [CrossRef]
- Geethanath, S.; Reddy, R.; Konar, A.S.; Imam, S.; Sundaresan, R.; Ramesh Babu, D.R.; Venkatesan, R. Compressed Sensing MRI: A Review. Crit. Rev. Biomed. Eng. 2013, 41, 183–204. [Google Scholar] [CrossRef]
- Ye, J.C. Compressed sensing MRI: A review from signal processing perspective. BMC Biomed. Eng. 2019, 1, 8. [Google Scholar] [CrossRef]
- Pal, A.; Rathi, Y. A review and experimental evaluation of deep learning methods for MRI reconstruction. J. Mach. Learn. Biomed. Imaging 2022, 1, 1. [Google Scholar] [CrossRef]
- Zhang, H.M.; Dong, B. A review on deep learning in medical image reconstruction. J. Oper. Res. Soc. China 2020, 8, 311–340. [Google Scholar] [CrossRef]
- Chen, Y.; Schönlieb, C.B.; Liò, P.; Leiner, T.; Dragotti, P.L.; Wang, G.; Rueckert, D.; Firmin, D.; Yang, G. AI-based reconstruction for fast MRI—A systematic review and meta-analysis. Proc. IEEE 2022, 110, 224–245. [Google Scholar] [CrossRef]
- Liang, D.; Cheng, J.; Ke, Z.; Ying, L. Deep magnetic resonance image reconstruction: Inverse problems meet neural networks. IEEE Signal Process. Mag. 2020, 37, 141–151. [Google Scholar] [PubMed]
- Chandra, S.S.; Bran Lorenzana, M.; Liu, X.; Liu, S.; Bollmann, S.; Crozier, S. Deep learning in magnetic resonance image reconstruction. J. Med. Imaging Radiat. Oncol. 2021, 65, 564–577. [Google Scholar] [PubMed]
- Montalt-Tordera, J.; Muthurangu, V.; Hauptmann, A.; Steeden, J.A. Machine learning in magnetic resonance imaging: Image reconstruction. Phys. Medica 2021, 83, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Hammernik, K.; Klatzer, T.; Kobler, E.; Recht, M.P.; Sodickson, D.K.; Pock, T.; Knoll, F. Learning a variational network for reconstruction of accelerated MRI data. Magn. Reson. Med. 2018, 79, 3055–3071. [Google Scholar] [CrossRef]
- Lv, J.; Zhu, J.; Yang, G. Which GAN? A comparative study of generative adversarial network-based fast MRI reconstruction. Philos. Trans. R. Soc. 2021, 379, 20200203. [Google Scholar]
- Zhou, B.; Schlemper, J.; Dey, N.; Salehi, S.S.M.; Sheth, K.; Liu, C.; Duncan, J.S.; Sofka, M. Dual-domain self-supervised learning for accelerated non-Cartesian MRI reconstruction. Med. Image Anal. 2022, 81, 102538. [Google Scholar]
- Fessler, J.A. On NUFFT-based gridding for non-Cartesian MRI. J. Magn. Reson. 2007, 188, 191–195. [Google Scholar]
- Wang, S.; Xiao, T.; Liu, Q.; Zheng, H. Deep learning for fast MR imaging: A review for learning reconstruction from incomplete k-space data. Biomed. Signal Process. Control. 2021, 68, 102579. [Google Scholar] [CrossRef]
- Sriram, A.; Zbontar, J.; Murrell, T.; Defazio, A.; Zitnick, C.L.; Yakubova, N.; Knoll, F.; Johnson, P. End-to-end variational networks for accelerated MRI reconstruction. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; Proceedings, Part II 23. Springer: Berlin/Heidelberg, Germany, 2020; pp. 64–73. [Google Scholar]
- Aggarwal, H.K.; Mani, M.P.; Jacob, M. MoDL: Model-based deep learning architecture for inverse problems. IEEE Trans. Med. Imaging 2018, 38, 394–405. [Google Scholar]
- Lin, K.; Heckel, R. Vision Transformers Enable Fast and Robust Accelerated MRI. In Proceedings of the 5th International Conference on Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022; Konukoglu, E., Menze, B., Venkataraman, A., Baumgartner, C., Dou, Q., Albarqouni, S., Eds.; PMLR: New York, NY, USA, 2022; Volume 172, pp. 774–795. [Google Scholar]
- Parvaiz, A.; Khalid, M.A.; Zafar, R.; Ameer, H.; Ali, M.; Fraz, M.M. Vision Transformers in medical computer vision—A contemplative retrospection. Eng. Appl. Artif. Intell. 2023, 122, 106126. [Google Scholar]
- Chen, Z.; Chen, Y.; Xie, Y.; Li, D.; Christodoulou, A.G. Data-consistent non-Cartesian deep subspace learning for efficient dynamic MR image reconstruction. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), IEEE, Kolkata, India, 28–31 March 2022; pp. 1–5. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2021; pp. 10012–10022. [Google Scholar]
- Shen, X.; Özen, A.C.; Sunjar, A.; Ilbey, S.; Sawiak, S.; Shi, R.; Chiew, M.; Emir, U. Ultra-short T2 components imaging of the whole brain using 3D dual-echo UTE MRI with rosette k-space pattern. Magn. Reson. Med. 2023, 89, 508–521. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Yang, R.; Zhang, C.; Zhang, J.; Jia, S.; Zhou, Z. Analysis of generalized rosette trajectory for compressed sensing MRI. Med. Phys. 2015, 42, 5530–5544. [Google Scholar] [CrossRef] [PubMed]
- Villarreal, C.X.; Shen, X.; Alhulail, A.A.; Buffo, N.M.; Zhou, X.; Pogue, E.; Özen, A.C.; Chiew, M.; Sawiak, S.; Emir, U.; et al. An accelerated PETALUTE MRI sequence for in vivo quantification of sodium content in human articular cartilage at 3T. Skelet. Radiol. 2024, 54, 601–610. [Google Scholar]
- Bucholz, E.K.; Song, J.; Johnson, G.A.; Hancu, I. Multispectral imaging with three-dimensional rosette trajectories. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2008, 59, 581–589. [Google Scholar] [CrossRef] [PubMed]
- Mahmud, S.Z.; Denney, T.S.; Bashir, A. Feasibility of spinal cord imaging at 7 T using rosette trajectory with magnetization transfer preparation and compressed sensing. Sci. Rep. 2023, 13, 8777. [Google Scholar]
- Alcicek, S.; Craig-Craven, A.R.; Shen, X.; Chiew, M.; Ozen, A.; Sawiak, S.; Pilatus, U.; Emir, U. Multi-site ultrashort echo time 3D phosphorous MRSI repeatability using novel rosette trajectory (PETALUTE). bioRxiv 2024, 2024, 579294. [Google Scholar]
- Bozymski, B.; Shen, X.; Özen, A.; Chiew, M.; Thomas, M.A.; Clarke, W.T.; Sawiak, S.; Dydak, U.; Emir, U. Feasibility and comparison of 3D modified rosette ultra-short echo time (PETALUTE) with conventional weighted acquisition in 31P-MRSI. Sci. Rep. 2025, 15, 6465. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN hybrid deep neural network for semantic segmentation of very-high-resolution remote sensing imagery. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–20. [Google Scholar]
- Nossa, G.; Monsivais, H.; Hong, S.; Park, T.; Erdil, F.S.; Shen, X.; Özen, A.C.; Ilbey, S.; Chiew, M.; Steinwurzel, C.; et al. Submillimeter fMRI Acquisition using a dual-echo Rosette-k-space trajectory at 3T. In Proceedings of the International Society for Magnetic Resonance in Medicine (ISMRM), Toronto, ON, Canada, 20–25 May 2023. [Google Scholar]
- Blumenthal, M.; Luo, G.; Schilling, M.; Holme, H.C.M.; Uecker, M. Deep, deep learning with BART. Magn. Reson. Med. 2023, 89, 678–693. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Hodson, T.O. Root mean square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. Discuss. 2022, 2022, 1–10. [Google Scholar]
- Studholme, C.; Hill, D.L.; Hawkes, D.J. An overlap invariant entropy measure of 3D medical image alignment. Pattern Recognit. 1999, 32, 71–86. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar]
- Tsai, D.Y.; Lee, Y.; Matsuyama, E. Information entropy measure for evaluation of image quality. J. Digit. Imaging 2008, 21, 338–347. [Google Scholar]
- Atkinson, D.; Hill, D.L.; Stoyle, P.N.; Summers, P.E.; Keevil, S.F. Automatic correction of motion artifacts in magnetic resonance images using an entropy focus criterion. IEEE Trans. Med. Imaging 1997, 16, 903–910. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Smith, L.N.; Topin, N. Super-convergence: Very fast training of neural networks using large learning rates. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, SPIE, Baltimore, MD, USA, 7–8 May 2019; Volume 11006, pp. 369–386. [Google Scholar]
- Lin, D.J.; Johnson, P.M.; Knoll, F.; Lui, Y.W. Artificial Intelligence for MR Image Reconstruction: An Overview for Clinicians. J. Magn. Reson. Imaging 2021, 53, 1015–1028. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1002/jmri.27078 (accessed on 10 November 2024).
- Mescheder, L.; Geiger, A.; Nowozin, S. Which training methods for GANs do actually converge? In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3481–3490. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technique | Advantages | Disadvantages |
|---|---|---|
| IFFT [3] |
|
|
| CS [4,6] |
|
|
| VarNet [14,19], MoDL [20] |
|
|
| ViT [21,24] |
|
|
| Metric | Formula |
|---|---|
| SSIM | |
| NRMSE | |
| NMI | |
| Relative Contrast | |
| PSNR | |
| Shannon Entropy | |
| EFC |
| Method | SSIM ↑ | NRMSE ↓ | PSNR ↑ | NMI ↑ | R. Contrast | Shannon | EFC ↓ |
|---|---|---|---|---|---|---|---|
| Reference | - | - | - | - | 0.332 | 3.840 | 2.960 |
| VarNet | 0.944 | 0.322 | 22.740 | 0.598 | 0.430 | 5.003 | 4.023 |
| MoDL | 0.987 | 0.060 | 37.248 | 0.616 | 0.472 | 4.861 | 3.429 |
| Vision T. | |||||||
| Non-aug. MHSA | 0.974 | 0.048 | 40.134 | 0.501 | 0.441 | 4.697 | 3.244 |
| Aug. MHSA (X1) | 0.975 | 0.040 | 42.124 | 0.510 | 0.445 | 4.672 | 3.280 |
| Aug. MHSA (X3) | 0.980 | 0.033 | 43.799 | 0.536 | 0.445 | 4.631 | 3.245 |
| Aug. WBSA (X3) | 0.980 | 0.037 | 42.685 | 0.544 | 0.439 | 4.663 | 3.285 |
| Metric | MHSA(X3) vs. MoDL | MHSA(X3) vs. VarNet | WBSA(X3) vs. MoDL | WBSA(X3) vs. VarNet | MHSA(X3) vs. WBSA(X3) | MHSA X3 vs. X1 |
|---|---|---|---|---|---|---|
| SSIM | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p > 0.0083 | p < 0.0083 |
| NRMSE | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 |
| PSNR | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 |
| NMI | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 |
| Shannon | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p > 0.0083 | p > 0.0083 |
| EFC | p < 0.0083 | p < 0.0083 | p < 0.0083 | p < 0.0083 | p > 0.0083 | p < 0.0083 |
| Network | Total CPU Time (Hours:Minutes:Seconds) | Max GPU Memory Used (MB) |
|---|---|---|
| VarNet (10 slices) | 00:06:58 | 2785 |
| VarNet (20 slices) | 00:13:51 | |
| VarNet (estimate for 128 slices) | 01:28:00 | |
| VarNet (estimate for 512 slices) | 05:54:00 | |
| MoDL (10 slices) | 00:07:05 | 6369 |
| MoDL (20 slices) | 00:14:08 | |
| MoDL (estimate for 128 slices) | 01:30:00 | |
| MoDL (estimate for 512 slices) | 06:00:00 | |
| MHSA ViT (10 slices) | 00:00:45 | 4895 |
| MHSA ViT (20 slices) | 00:01:25 | |
| MHSA ViT (estimate for 128 slices) | 00:09:00 | |
| MHSA ViT (estimate for 512 slices) | 00:36:00 | |
| WBSA ViT (10 slices) | 00:01:09 | 4895 |
| WBSA ViT (20 slices) | 00:01:26 | |
| WBSA ViT (estimate for 128 slices) | 00:10:00 | |
| WBSA ViT (estimate for 512 slices) | 00:37:00 |
| ViT | Gaussian Variance | SSIM ↑ | NRMSE ↓ | PSNR ↑ | NMI ↑ |
|---|---|---|---|---|---|
| MHSA | 0.732 | 0.151 | 29.377 | 0.199 | |
| MHSA | 0.917 | 0.090 | 34.078 | 0.308 | |
| MHSA | 0.944 | 0.063 | 37.389 | 0.360 | |
| MHSA | 0.970 | 0.041 | 41.582 | 0.460 | |
| MHSA | No noise | 0.980 | 0.033 | 43.799 | 0.536 |
| WBSA | 0.745 | 0.118 | 31.702 | 0.200 | |
| WBSA | 0.822 | 0.203 | 27.471 | 0.259 | |
| WBSA | 0.955 | 0.053 | 39.139 | 0.385 | |
| WBSA | 0.974 | 0.041 | 41.509 | 0.484 | |
| WBSA | No noise | 0.980 | 0.037 | 42.685 | 0.544 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yalcinbas, M.F.; Ozturk, C.; Ozyurt, O.; Emir, U.E.; Bagci, U. Rosette Trajectory MRI Reconstruction with Vision Transformers. Tomography 2025, 11, 41. https://doi.org/10.3390/tomography11040041
Yalcinbas MF, Ozturk C, Ozyurt O, Emir UE, Bagci U. Rosette Trajectory MRI Reconstruction with Vision Transformers. Tomography. 2025; 11(4):41. https://doi.org/10.3390/tomography11040041
Chicago/Turabian StyleYalcinbas, Muhammed Fikret, Cengizhan Ozturk, Onur Ozyurt, Uzay E. Emir, and Ulas Bagci. 2025. "Rosette Trajectory MRI Reconstruction with Vision Transformers" Tomography 11, no. 4: 41. https://doi.org/10.3390/tomography11040041
APA StyleYalcinbas, M. F., Ozturk, C., Ozyurt, O., Emir, U. E., & Bagci, U. (2025). Rosette Trajectory MRI Reconstruction with Vision Transformers. Tomography, 11(4), 41. https://doi.org/10.3390/tomography11040041