
Vehicle Behavior Discovery and Three-Dimensional Object Detection and Tracking Based on Spatio-Temporal Dependency Knowledge and Artificial Fish Swarm Algorithm

Abstract
1. Introduction
- The apparent features of the target object change significantly between frames, and the large variation in the feature distribution law leads to a large search space for feature matching between frames [4].
- In the complex motion scene of the target vehicle, the behaviors of the target vehicle and various interfering objects are intertwined. The target vehicle motion driving law changes complexity during occlusion, which leads to a sharp decline in tracking accuracy [5].
- We propose a graph neural network-based method with multi-feature learning to explore the coordinated change law of the target object’s position, direction, and speed; mine the spatio-temporal dependence knowledge in the coordinated change of the target object’s motion; and improve the graph node aggregation feature discrimination.
- We propose a graph neural network-based method with multi-source feature interweaving, exploring the interweaving motion law of the target object and neighboring moving objects and iteratively updating the graph node features through multi-source feature aggregation to mine the relationship between neighboring data samples.
- Finally, a graph neural network-based method with environmental interaction and collaboration is proposed to explore the interaction and collaboration rules between the target object and the traffic environment. The proposed method can accurately calibrate and stably track the target object under severe or continuous occlusion.
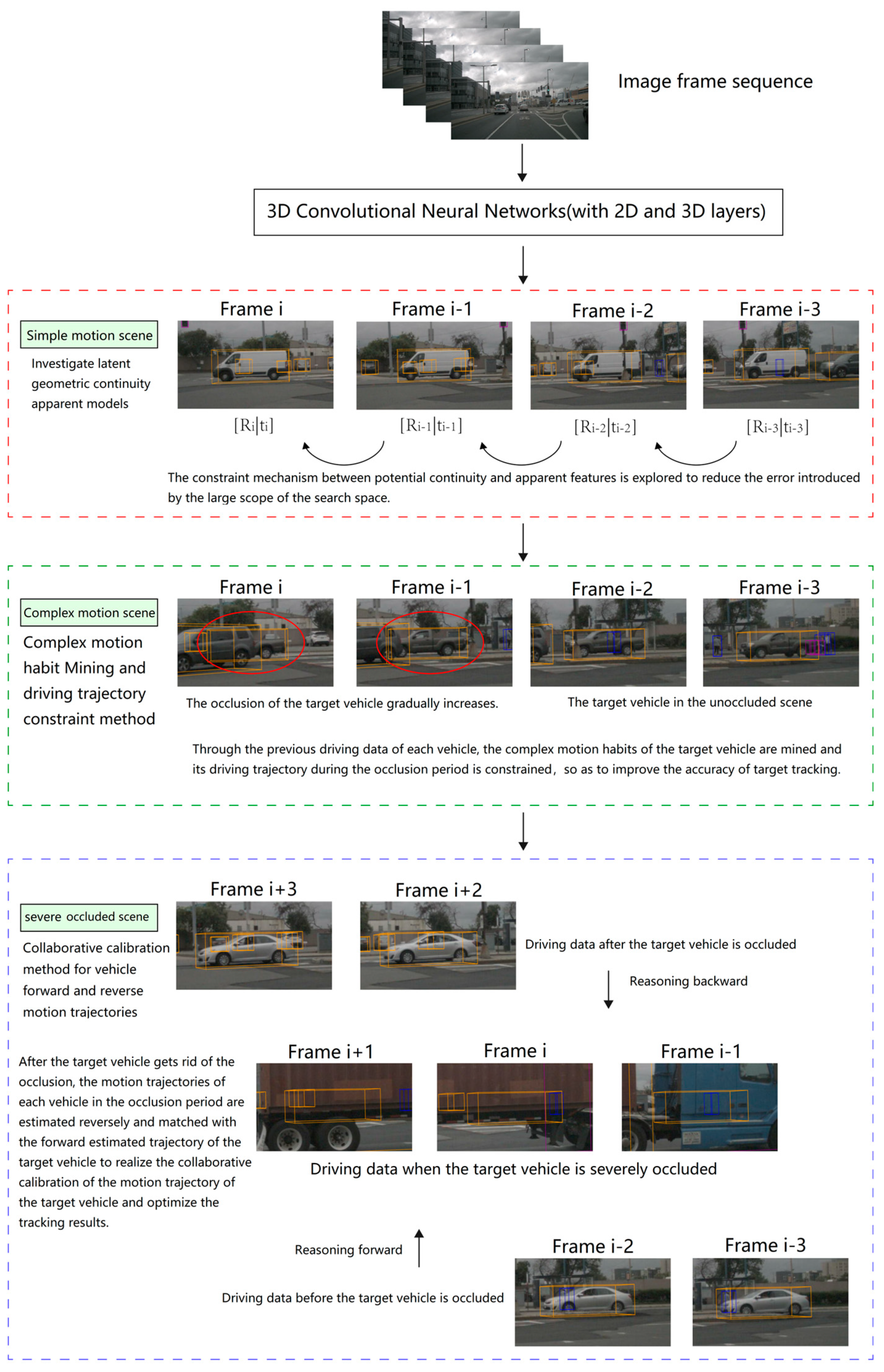
- Starting from the simple motion of the target object, the potential geometric consistency in the rotation and translation transformation of the target is found, and the target structure knowledge and context information are shared. Compared with the appearance features in occluded scenes, the latent geometric consistency features based on rotation and translation transformation are more discriminative.
- Using the complex motion of the target object, the interweaving motion behavior between the target and its neighboring interference objects is studied. Using the previous motion data of the target, the knowledge of the target motion behavior is mined, and the motion trajectory of the target during the occlusion period is constrained, which is helpful to stably track the 3D bounding box of the target during the occlusion period and, after getting rid of the occlusion, to accurately determine its size, position, and orientation. It can provide reliable motion planning clues for automatic driving systems and auxiliary driving systems to ensure driving safety.
2. Objectives
3. Related Work
3.1. Three-Dimensional Object Detection from Single-View Images
3.2. Three-Dimensional Object Detection and Tracking from Multi-View Images
3.3. 3D Object Detection and Tracking in Complex-Occlusion Scenes
- Apparent models of latent geometric continuity;
- 2.
- Complex motion habit Mining and driving trajectory constraint method;
- 3.
- Collaborative calibration of vehicle forward and reverse motion trajectories and artificial fish swarm algorithm.
- The continuity assumption of translation and rotation transformation behavior of vehicle objects between video frames is introduced, the constraint mechanism between latent geometric continuity and appearance characteristics is explored, and the latent geometric continuity appearance model is established to reduce the error introduced by the large search space;
- Using the past driving data of each vehicle, the complex motion habits of the target vehicle are mined, and its driving trajectory during the occlusion period is constrained accordingly to improve the target tracking accuracy;
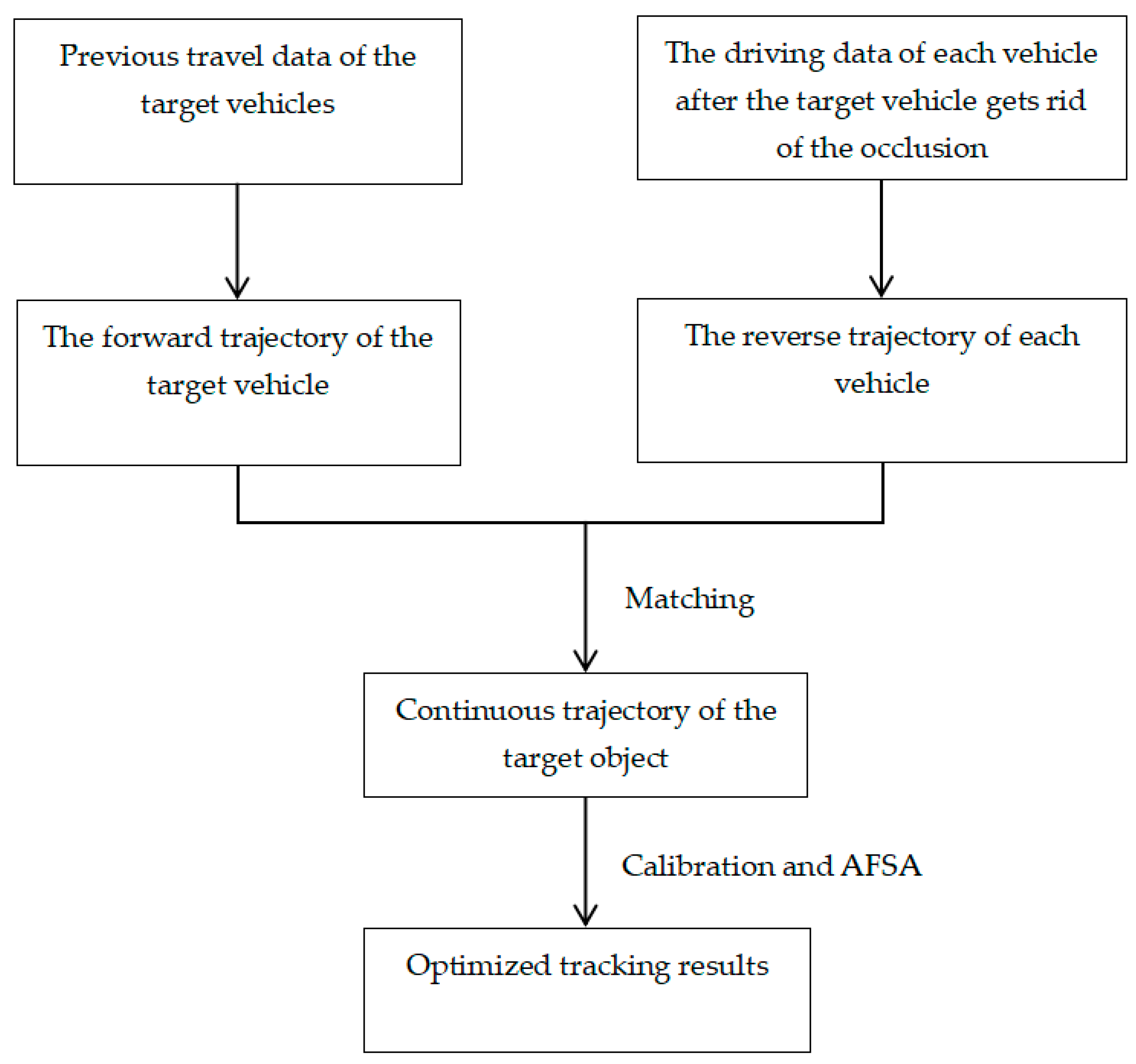
- After the target vehicle gets rid of the occlusion, the motion trajectory of each vehicle in the occlusion period is estimated in the reverse direction and matched with the forward estimated trajectory of the target vehicle. The tracking result is optimized by combining the artificial fish swarm algorithm.
4. Materials and Methods
4.1. Investigate Latent Geometric Continuity Apparent Models
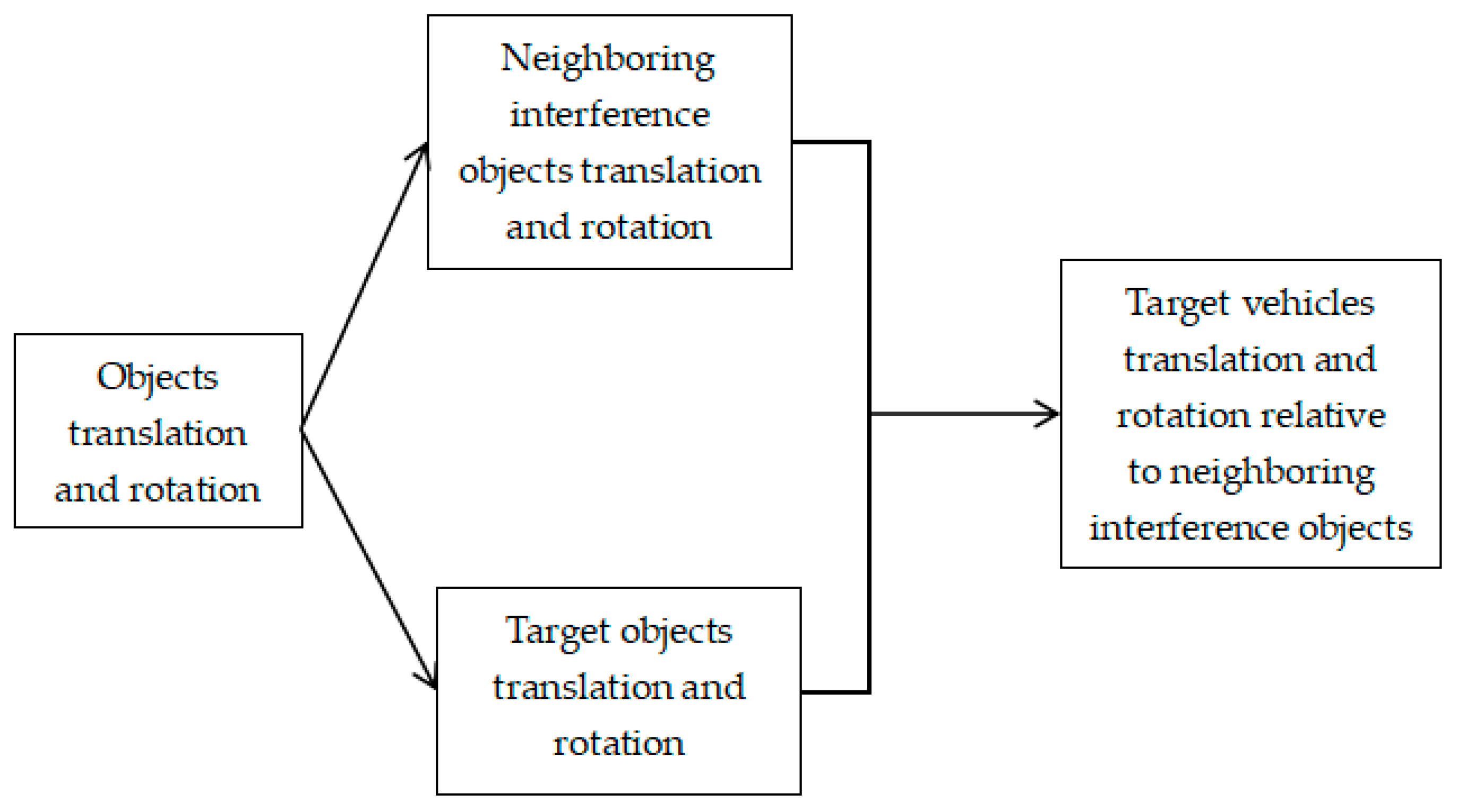
4.2. Complex Motion Habit Mining and Driving Trajectory Constraint Method
4.3. Collaborative Calibration Method for Vehicle forward and Reverse Motion Trajectories
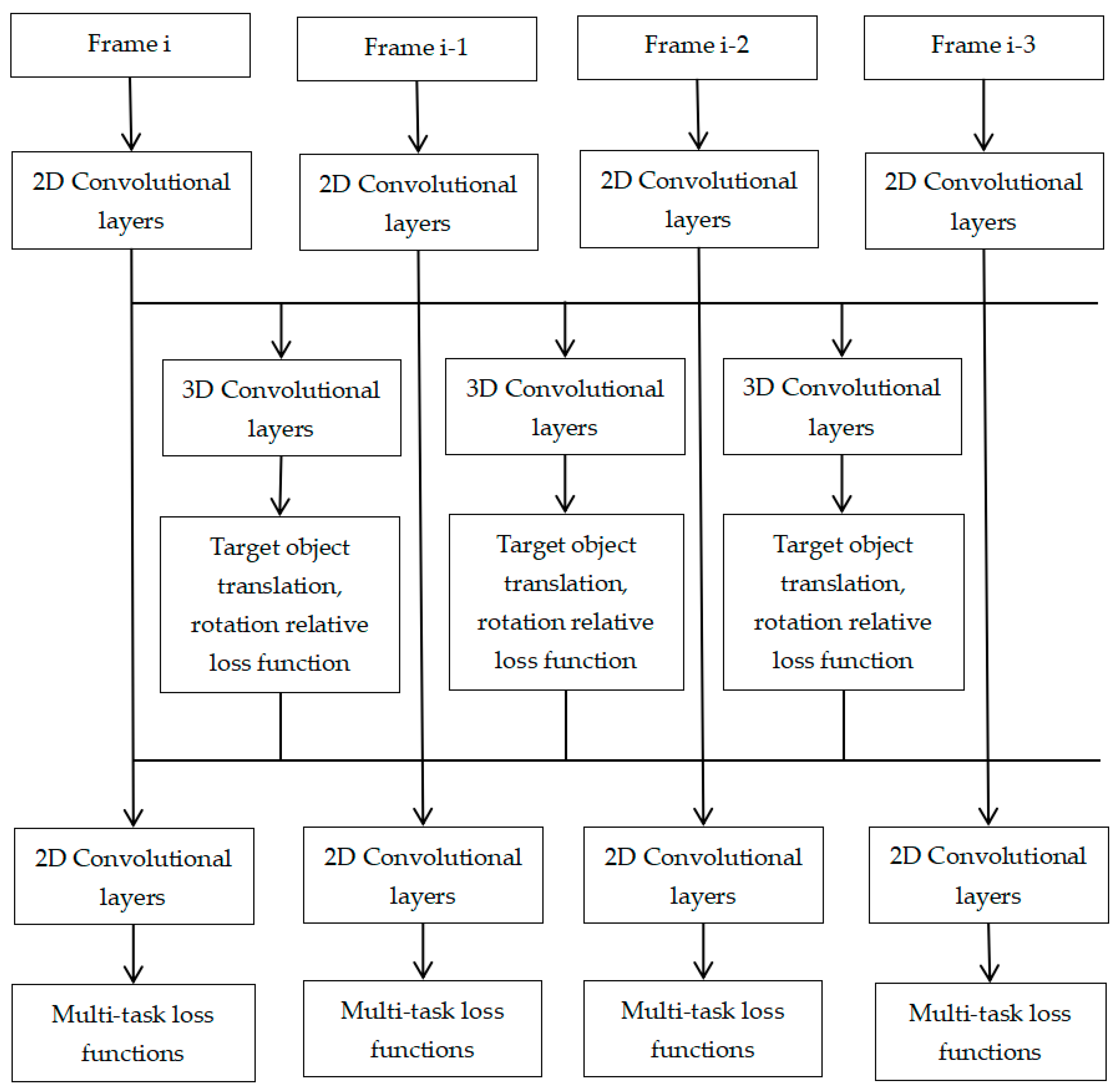
4.4. Apparent Models of Latent Geometric Continuity
- Architecture Design of 3D Convolutional Neural Networks;
- 2.
- Keypoint-based Multi-task Convolutional Neural Networks;
- 3.
- Interframe target object space geometric constraint model.
4.5. Complex Motion Habit-Mining and Driving-Trajectory Constraint Method
4.6. Collaborative Calibration and AFSA Method for Vehicle forward and Reverse Motion Trajectories
5. Experiment
5.1. Experimental Data
5.2. Experimental Environment
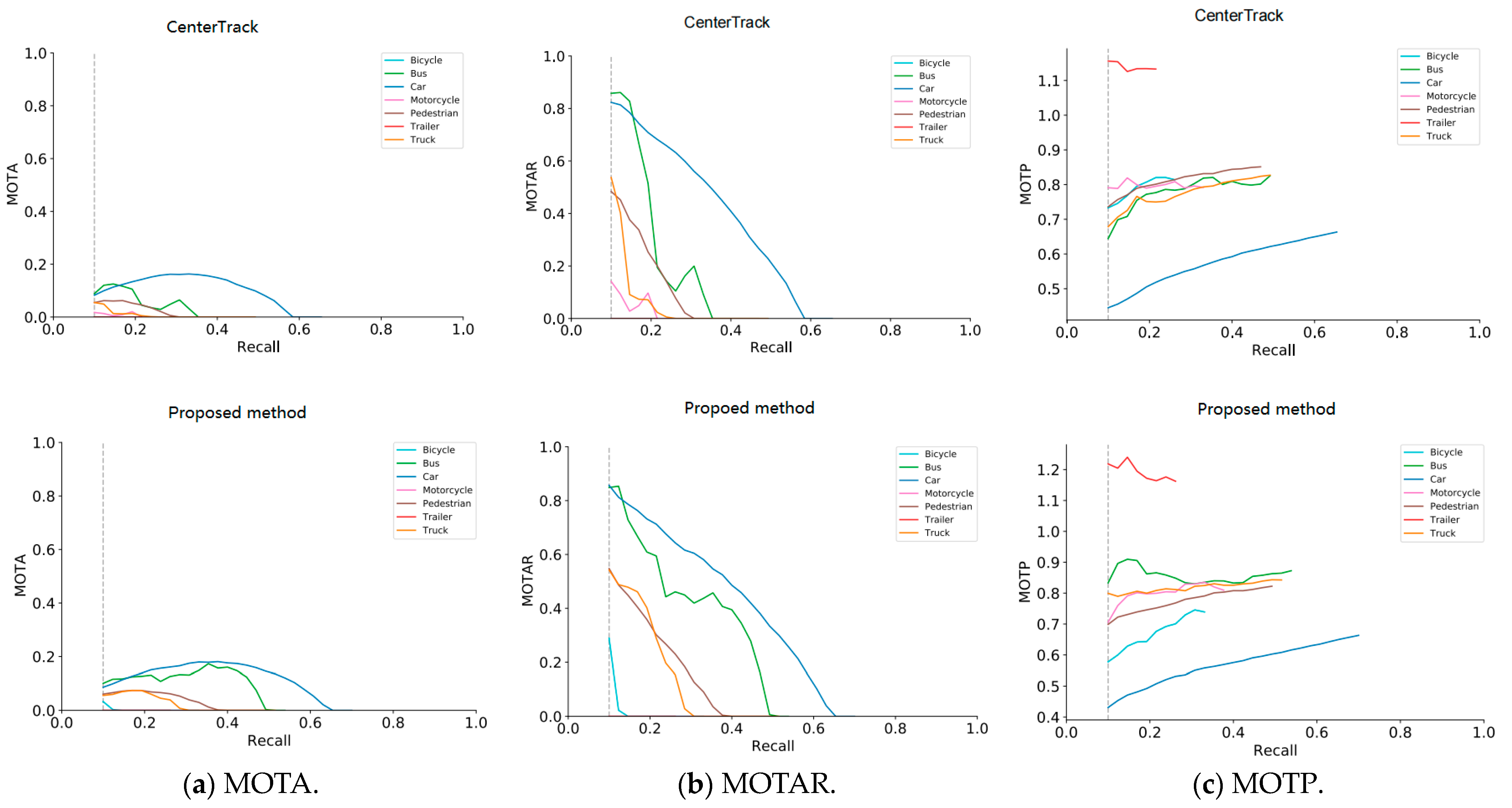
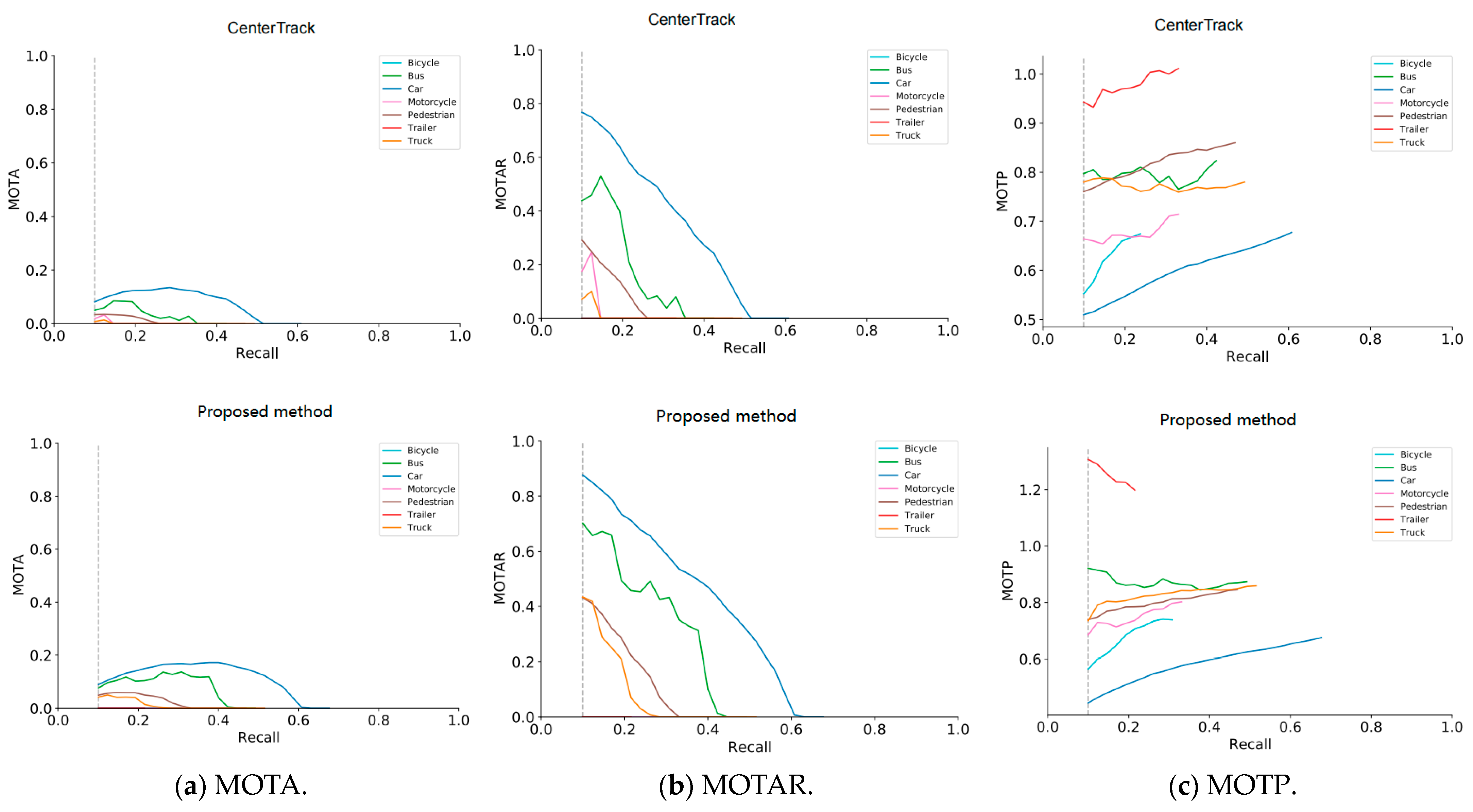
5.3. Experimental Result
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Singh, S. Traffic Safety Facts Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey; National Center for Statistics and Analysis: Washington DC, USA, 2023. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 954–960. [Google Scholar]
- He, J.; Chen, Y.; Wang, N.; Zhang, Z. 3D Video Object Detection with Learnable Object-Centric Global Optimization. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 131–139. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. In Proceedings of the 2021 IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 1104–1112. [Google Scholar]
- Li, B.; Ouyang, W.; Sheng, L.; Zeng, X.; Wang, X. Gs3d: An efficient 3d object detection framework for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1019–1028. [Google Scholar]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3d object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking Objects as Points. arXiv 2020, arXiv:2004.01177. [Google Scholar]
- Wu, Y. Monocular Instance Level 3D Object Reconstruction based on Mesh R-CNN. In Proceedings of the 2020 5th International Conference on Information Science, Computer Technology and Transportation, Shenyang, China, 13–15 November 2020; pp. 1–6. [Google Scholar]
- Zheng, X.; Chen, F.; Lou, L.; Cheng, P.; Huang, Y. Real-Time Detection of Full-Scale Forest Fire Smoke Based on Deep Convolution Neural Network. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Chabot, F.; Chaouch, M.; Rabarisoa, J.; Teuliere, C.; Chateau, T. Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2040–2049. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3d bounding box estimation using deep learning and geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 7074–7082. [Google Scholar]
- Chen, Y.; Liu, S.; Shen, X.; Jia, J. DSGN: Deep Stereo Geometry Network for 3D Object Detection. arXiv 2020, arXiv:2001.03398. [Google Scholar]
- Zhao, Q.; Zhang, L.; Liu, L.; Shuchang, B.; Yong, C.; Han, L. Swarm Motion of Underwater Robots Based on Local Visual Perception. In Proceedings of the 2023 8th International Conference on Automation, Control and Robotics Engineering, Singapore, 17–19 November 2023; pp. 11–17. [Google Scholar]
- Li, X.; Xia, X.; Hu, Z.; Han, B.; Zhao, Y. Intelligent Detection of Underwater Fish Speed Characteristics Based on Deep Learning. In Proceedings of the 2021 5th Asian Conference on Artificial Intelligence Technology, Haikou, China, 29–31 October 2021; pp. 31–37. [Google Scholar]
- Suwajanakorn, S.; Snavely, N.; Tompson, J.J.; Norouzi, M. Discovery of latent 3d keypoints via endto-end geometric reasoning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 3–8 December 2018; pp. 2059–2070. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Knight, W. The Next Big Step for AI? Understanding Video. Available online: https://www.technologyreview.com/s/609651/the-next-big-step-for-ai-understanding-video/ (accessed on 6 December 2017).
- Mozaffari, S.; Al-Jarrah, O.Y.; Dianati, M.; Jennings, P.; Mouzakitis, A. Deep Learning-based Vehicle Behaviour Prediction for Autonomous Driving Applications: A Review. arXiv 2019, arXiv:1912.11676. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 7291–7299. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Nashville, TN, USA, 11 October 2021; pp. 483–499. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 4903–4911. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Su, H.; Qi, C.R.; Li, Y.; Guibas, L.J. Render for cnn: Viewpoint estimation in images using cnns trained with rendered 3d model views. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2686–2694. [Google Scholar]
- Tulsiani, S.; Malik, J. Viewpoints and keypoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1510–1519. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Kim, M.; Alletto, S.; Rigazio, L. Similarity mapping with enhanced siamese network for multiobject tracking. arXiv 2016, arXiv:1609.09156. [Google Scholar]
- Wang, B.; Wang, L.; Shuai, B.; Zuo, Z.; Liu, T.; Luk Chan, K.; Wang, G. Joint learning of convolutional neural networks and temporally constrained metrics for tracklet association. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27–30 June 2016; pp. 1–8. [Google Scholar]
- Zhang, S.; Gong, Y.; Huang, J.B.; Lim, J.; Wang, J.; Ahuja, N.; Yang, M.H. Tracking persons-of-interest via adaptive discriminative features. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 415–433. [Google Scholar]
- Moghaddam, M.; Charmi, M.; Hassanpoor, H. A robust attribute-aware and real-time multi-target multi-camera tracking system using multi-scale enriched features and hierarchical clustering. J. Real-Time Image Process. 2022, 20, 45. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computer Configuration | |
|---|---|
| CPU | Intel Core i7-7700 |
| GPU | NVIDIA GeForce RTX 3070 |
| Memory | 32 G |
| Operating System | Ubuntu 16.04 |
| AMOTA | AMOTP | MOTAR | MT | ML | IDS | FP | FN | |
|---|---|---|---|---|---|---|---|---|
| CenterTrack | 0.068 | 1.543 | 0.332 | 538 | 4231 | 2962 | 15,733 | 73,573 |
| Ours | 0.098 | 1.49 | 0.297 | 635 | 4080 | 2415 | 16,738 | 70,544 |
| Mapillary + AB3D | GDLG | CenterTrack | CaTracker | Buffalo Vision | ProTracker | Ours (without AFSA) | Ours (with AFSA) | |
|---|---|---|---|---|---|---|---|---|
| AMOTA | 0.018 | 0.045 | 0.046 | 0.053 | 0.059 | 0.072 | 0.072 | 0.073 |
| AMOTP | 1.790 | 1.819 | 1.543 | 1.611 | 1.490 | 1.628 | 1.490 | 1.489 |
| MOTAR | 0.091 | 0.242 | 0.231 | 0.168 | 0.244 | 0.256 | 0.355 | 0.349 |
| MOTA | 0.020 | 0.050 | 0.043 | 0.041 | 0.048 | 0.058 | 0.069 | 0.069 |
| MOTP | 0.903 | 0.970 | 0.753 | 0.779 | 0.781 | 0.785 | 0.753 | 0.727 |
| MT | 499 | 448 | 573 | 769 | 675 | 729 | 855 | 867 |
| ML | 4700 | 4094 | 5235 | 4587 | 4835 | 4808 | 4710 | 4713 |
| FAF | 356.753 | 211.536 | 75.945 | 84.284 | 81.302 | 60.914 | 58.919 | 58.471 |
| TP | 25,943 | 29,198 | 26,544 | 33,937 | 32,325 | 32,245 | 33,957 | 33,971 |
| FP | 113,596 | 40,742 | 17,574 | 24,574 | 26,003 | 17,957 | 19,984 | 19,974 |
| FN | 83,202 | 78,327 | 89,214 | 81,171 | 83,070 | 83,314 | 81,978 | 81,974 |
| IDS | 10,420 | 12,040 | 3807 | 4457 | 4170 | 4006 | 3902 | 3841 |
| FRAG | 4403 | 4138 | 2645 | 3169 | 3157 | 2935 | 2762 | 2744 |
| TID | 1.414 | 4.705 | 2.057 | 1.953 | 2.177 | 2.306 | 2.301 | 2.127 |
| LGD | 3.351 | 5.926 | 3.819 | 3.765 | 4.088 | 4.023 | 4.053 | 4.065 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Li, Q. Vehicle Behavior Discovery and Three-Dimensional Object Detection and Tracking Based on Spatio-Temporal Dependency Knowledge and Artificial Fish Swarm Algorithm. Biomimetics 2024, 9, 412. https://doi.org/10.3390/biomimetics9070412
Chen Y, Li Q. Vehicle Behavior Discovery and Three-Dimensional Object Detection and Tracking Based on Spatio-Temporal Dependency Knowledge and Artificial Fish Swarm Algorithm. Biomimetics. 2024; 9(7):412. https://doi.org/10.3390/biomimetics9070412
Chicago/Turabian StyleChen, Yixin, and Qingnan Li. 2024. "Vehicle Behavior Discovery and Three-Dimensional Object Detection and Tracking Based on Spatio-Temporal Dependency Knowledge and Artificial Fish Swarm Algorithm" Biomimetics 9, no. 7: 412. https://doi.org/10.3390/biomimetics9070412
APA StyleChen, Y., & Li, Q. (2024). Vehicle Behavior Discovery and Three-Dimensional Object Detection and Tracking Based on Spatio-Temporal Dependency Knowledge and Artificial Fish Swarm Algorithm. Biomimetics, 9(7), 412. https://doi.org/10.3390/biomimetics9070412