Abstract
The Artificial Electric Field Algorithm (AEFA) stands out as a physics-inspired metaheuristic, drawing inspiration from Coulomb’s law and electrostatic force; however, while AEFA has demonstrated efficacy, it can face challenges such as convergence issues and suboptimal solutions, especially in high-dimensional problems. To overcome these challenges, this paper introduces a modified version of AEFA, named mAEFA, which leverages the capabilities of Lévy flights, simulated annealing, and the Adaptive s-best Mutation and Natural Survivor Method (NSM) mechanisms. While Lévy flights enhance exploration potential and simulated annealing improves search exploitation, the Adaptive s-best Mutation and Natural Survivor Method (NSM) mechanisms are employed to add more diversity. The integration of these mechanisms in AEFA aims to expand its search space, enhance exploration potential, avoid local optima, and achieve improved performance, robustness, and a more equitable equilibrium between local intensification and global diversification. In this study, a comprehensive assessment of mAEFA is carried out, employing a combination of quantitative and qualitative measures, on a diverse range of 29 intricate CEC’17 constraint benchmarks that exhibit different characteristics. The practical compatibility of the proposed mAEFA is evaluated on five engineering benchmark problems derived from the civil, mechanical, and industrial engineering domains. Results from the mAEFA algorithm are compared with those from seven recently introduced metaheuristic algorithms using widely adopted statistical metrics. The mAEFA algorithm outperforms the LCA algorithm in all 29 CEC’17 test functions with 100% superiority and shows better results than SAO, GOA, CHIO, PSO, GSA, and AEFA in 96.6%, 96.6%, 93.1%, 86.2%, 82.8%, and 58.6% of test cases, respectively. In three out of five engineering design problems, mAEFA outperforms all the compared algorithms, securing second place in the remaining two problems. Results across all optimization problems highlight the effectiveness and robustness of mAEFA compared to baseline metaheuristics. The suggested enhancements in AEFA have proven effective, establishing competitiveness in diverse optimization problems.
1. Introduction
Metaheuristic optimization algorithms have recently garnered significant attention and become a focal point for many computer science and engineering researchers. They are increasingly prevalent across various domains, including numerical optimization [1,2], cloud computing [3], neural networks [4], feature selection [5,6], classification [7], clustering [8], predicting chemical activities [9], text document clustering [10], and face detection & recognition [11].
Examples of metaheuristic algorithms include Genetic Algorithms (GA) [12], CMAES) [13], Cuckoo Search Optimization (CS) [14], the Harmony Search (HS) Algorithm [15], Artificial Bee Colony (ABC) [16], the Krill Herd Algorithm (KHA) [17], the Ant Lion Optimizer (ALO) [18], Moth-flame Optimization (MFO) [19], the Crow search Algorithm (CSA) [20], the Whale Optimizer Algorithm (WOA) [21], the Lightning Search Algorithm (LSA) [22], the Salp Swarm Algorithm (SSA) [23], Harris Hawks Optimization (HHO) [24], Virus Colony Search (VCS) [25], and the Snake Optimizer (SO) [26].
Metaheuristics (MHs) typically adopt strategies from swarm intelligence (SI), evolutionary algorithms (EA), physics-based principles, and human-based concepts. EAs are inspired by biological behaviors, while SI draws on food foraging, mutation, territorial fights, and mating behaviors. Physics laws and human behavior also influence optimizer development [27]. Consequently, these refined algorithms are increasingly applied to effectively address challenges in engineering design optimization, yielding more promising solutions.
Despite the wide range of problem-solving capabilities offered by metaheuristics, the “No free Lunch” hypothesis suggests that no single MH can provide the best solution for every complex problem [28]. Each optimization problem requires a specific strategy to be effectively addressed [29].
While solving complex engineering problems, metaheuristics may have drawbacks such as slow convergence and being trapped in local search domains, resulting in higher computational costs [30]. To address these limitations, researchers have devised hybridized, modified, and enhanced MHs that incorporate more beneficial attributes. A few examples include the Hybrid Grey Wolf and Crow Search [31], Hybrid Heat Transfer and Passing Vehicle Search [32], Hybrid Artificial Hummingbird-Simulated Annealing [33], Modified Symbiotic Organisms Search [34], Modified Marine Predator Algorithm [35], Improved Ant Colony Optimization [36], and Improved Salp Swarm Algorithm [37]. To create effective MHs, a balance between global diversification and local intensification is crucial. Both exploration and exploitation phases are important in finding superior solutions and achieving results in the least amount of time. Despite numerous hybrid MHs being implemented in engineering design optimization over the last few decades, the quest for even more potent methods is ongoing. This field continues to evolve and presents new challenges for researchers to address.
The Artificial Electric Field Algorithm (AEFA) is a recent population-based algorithm proposed by Anita and Yadav [38] that is inspired by the electrostatic force of Coulomb’s law. AEFA has been successfully employed in many applications such as photovoltaics [39], fuel cell estimation [40], the economic load dispatch problem [41], non-linear system modeling [42], the quadratic assignment problem [43], soil shear [44], and wind turbine allocation [45].
In addition, many researchers have introduced different variants of AEFA algorithms. For example, Izci et al. [46] hybridized AEFA with the Nelder–Mead simplex. Likewise, Petwal and Rani [47] developed a multiobjective version of AEFA. They strengthened AEFA by adding polynomial mutation and bounded exponential crossover operators. A novel set of velocity and position bounds has been proposed by Anita et al. [48] to address engineering problems. Anita and Yadav [49] developed a discrete AEFA for high-order graph matching. Furthermore, a detailed study of stability and exploratory abilities was presented in [50].
Kahraman et al. [51] introduce a novel approach called the Natural Survivor Method (NSM), devised as a model for population management mirroring natural processes, taking into account environmental variables and analytical relationships. Within the NSM framework, scores reflecting individuals’ adaptability to their natural surroundings are computed to identify survivors. Additionally, the update mechanism in this proposed method is constructed based on NSM scores rather than traditional fitness values.
Although AEFA has demonstrated effectiveness in addressing intricate engineering problems, it exhibits a notable susceptibility to converging toward suboptimal solutions. The iterative process of population size selection poses challenges, as optimal sizes vary across different problems. Like any other algorithm, AEFA demonstrates a moderate convergence rate, potentially requiring more time than alternative algorithms to reach an optimal solution. Moreover, the efficacy of AEFA is notably contingent on parameter choices, including the number of particles, electric charge, and inertia. AEFA performance may be limited on large-scale problems due to high computational complexity. Moreover, AEFA may face premature convergence issues, particularly in multimodal optimization problems. Furthermore, if the algorithm focuses too much on exploration, it may sacrifice exploitation, and vice versa, thus striking a balance between global diversification and local intensification is crucial for optimizing performance. Hybridizing AEFA with other algorithms or the inclusion of performance improvement strategies can result in faster convergence, higher precision, and greater robustness [52]. As AEFA is a relatively new optimizer, there is great potential for uncovering new improvements that can further enhance its efficiency and performance.
The objective of this research was to enhance the performance of the existing AEFA algorithm by addressing its limitations, with a focus on achieving faster convergence, increased accuracy, and improved robustness. To achieve these goals, a modified version of AEFA named modified AEFA (mAEFA) is introduced based on two techniques: Lévy flights and Simulated Annealing (SA). The first operator is used to increase randomness and the second is used to increase exploitation.
This study offers the following significant contributions:
- The Lévy flight distribution mechanism is incorporated to increase the search space of AEFA and improve the exploration potential of the algorithm. This integration aims to prevent the algorithm from getting trapped in local optima, thereby contributing to an overall improvement in performance;
- A simulated annealing mechanism is integrated with AEFA to improve search exploitation by allowing the algorithm to accept solutions that are worse than the current best solution with a certain probability, which helps to avoid getting stuck in local optima and explore other areas of the search space. This can lead to finding better solutions that may have been missed otherwise. Therefore, hybridizing simulated annealing into an algorithm can lead to improved performance and robustness;
- A thorough evaluation of mAEFA performance, utilizing both quantitative and qualitative methods, is carried out on a variety of complex CEC 2017 constraint benchmarks with varying characteristics;
- The behavior of mAEFA is evaluated and compared to 12 prevalent MH approaches on five engineering benchmark problems drawn from diverse fields.
The rest of this paper is structured as follows: Section 2 discusses recent work on metaheuristics and Section 3 introduces the original AEFA. Section 4 presents the suggested modified version of AEFA. Section 5 details the results of the conducted statistical tests and respective discussion, and Section 6 concludes the paper, including outlining future directions.
2. Related Work
The Lévy flight (LF) mechanism is a popular choice for researchers aiming to bolster the optimization efficacy of algorithms, spanning diverse research domains such as control system design [53], wind speed forecasting [54], and high-dimensional optimization problems [55]. Characterized by random steps, the application of LF enables optimization algorithms to navigate the vicinity of existing solutions, while intermittent significant leaps mitigate the risk of entrapment within local minima. For instance, Zhang et al. [56] recently demonstrated that LF enhances particle diversity within PSO, thereby refining the accuracy of lithium-ion battery State-of-Health prediction. Similarly, Hussien et al. [57] noted the efficacy of LF-based Transient Search Optimization in augmenting the transient response of terminal voltages within islanded microgrids. Furthermore, Barua et al. [58] amalgamated the LF strategy with the Arithmetic Optimization Algorithm to address various engineering optimization challenges. Their findings underscore the hybrid algorithm’s superior optimization capabilities, requiring fewer evaluations and surpassing several established algorithms in performance benchmarks.
Simulated annealing (SA) is an MH extensively employed to enhance the search capability of optimization algorithms [59]. Distinguished by its probabilistic jump feature, inspired by the physical process of annealing solids, SA effectively mitigates the risk of stagnation in local optima, facilitating the attainment of global optima. For example, Xu et al. [60] endeavored to enhance the Whale Optimization Algorithm by integrating it with SA, yielding superior optimization performance and stability across multiple dimensional problems compared to alternative algorithms such as WOA, GWO, and PSO. Similarly, Fontes et al. [61] employed a hybrid of SA and PSO for tackling the job shop scheduling problem, achieving high-quality solutions within reasonable computation times. In another study, Sajjad et al. [62] noted that the incorporation of SA notably enhanced the convergence of the multiobjective Grasshopper Algorithm when applied to problem solving in IoT applications.
The performance of population-based metaheuristic algorithms is significantly influenced by the size, nature, and diversity of the initial population, as well as the number of iterations. Agushaka et al. [63] observed that BA performed better with larger population sizes, while GWO, WOA, BOA, MS, and LSHADE-cnEpSin benefited from more iterations. Conversely, MFO, LSHADE, EHO, and HHO showed optimal performance with balanced population sizes and iterations. Kazimipour et al. [64] categorize population initialization techniques based on randomness, compositionality, and generality aspects. While random number generators are commonly used for initialization, their limitations have prompted researchers to explore alternative distributions, such as Latin Hypercube Sampling (LHS), to enhance efficiency [65]. Quasirandom sequences like Halton, Sobol, and Faure have demonstrated effectiveness in uniformly covering the search space, as seen in PSO and Global Best PSO. Chaotic sequences have also shown promise in initializing populations in CS and BFO, despite concerns about computational complexity. Hybridization with other metaheuristic algorithms, like the Greedy Randomized Adaptive Search Procedure (GRASP) and Metropolis–Hastings (MH), has the potential for improving initialization schemes, though scalability and time complexity are challenges. Leveraging ad hoc knowledge of the problem domain, as seen in the Bat Algorithm (BA), and innovative approaches such as patch environments and quasi-opposition-based learning in CS, aim to improve algorithm efficacy. Each method presents unique advantages and challenges, highlighting the importance of selecting suitable initialization strategies tailored to the problem domain and available computational resources [63,64,65].
The MH process involves two main steps: selection of solution candidates from the population and determination of the search direction. Selection methods are vital in MHs and are categorized into three types: non-deterministic, deterministic, and probabilistic [66]. Non-deterministic methods randomly select solution candidates to enhance search diversity. Deterministic methods consider fitness values, selecting the best candidates to guide the search towards successful positions. Probabilistic methods combine characteristics of both elitist and random methods, with examples including the roulette wheel and tournament methods. New selection methods, such as Fitness–Distance balance (FDB) [66], Fitness–Distance-Constraint (FDC) [67], Adaptive FDB [68], and Dynamic FDB [69], address specific challenges in MH search.
3. Artificial Electric Field Algorithm
The Artificial Electric Field Algorithm (AEFA) is a recent population-based metaheuristic algorithm that mimics Coulomb’s electrostatic force law [38]. Coulomb’s electrostatic law states that the force between any two charged particles is inversely proportional to the distance squared between the particles and directly proportional to their charge product.
Particles can migrate/move in the search space. With the help of the electrostatic force, particles are able to interact with each other (either repulsion or attraction).
In AEFA, one only considers the attraction force, which means that particle with the highest charge will absorb other particles with lower charges. The objective function in AEFA is the candidate solution (particle) charges and the agent fitness value. To mathematically model the electric force, the following steps are used.
The position of i-th agent can be given as , where is the position of i-th agent at d-dimension.
The position of the best agent (solution) obtained by any particle, i, at any time, t, denoted as , is given by the following Equation (1)
where is the position of the personal best particle. is the position of the best charged particle determined based on fitness. The best objective value via all particles is given as .
To calculate the total force that is acting on agent i at time t, the following equation is used
where is a random number between 0 and 1, N refers to the number of search agents, and refers to resultant force that affect on the i-th agent.
The acceleration of the i-th agent at d dimension can be calculated using Newton’s second law of motion as below
and represent the charges and electric field of the particle, and refers to particle mass. The velocity and position of particles can be updated using the two following equations:
where is a random number belongs to the interval . The particles’ charge can be obtained using fitness functions and assuming that each particle has the same charge.
4. Proposed Algorithm
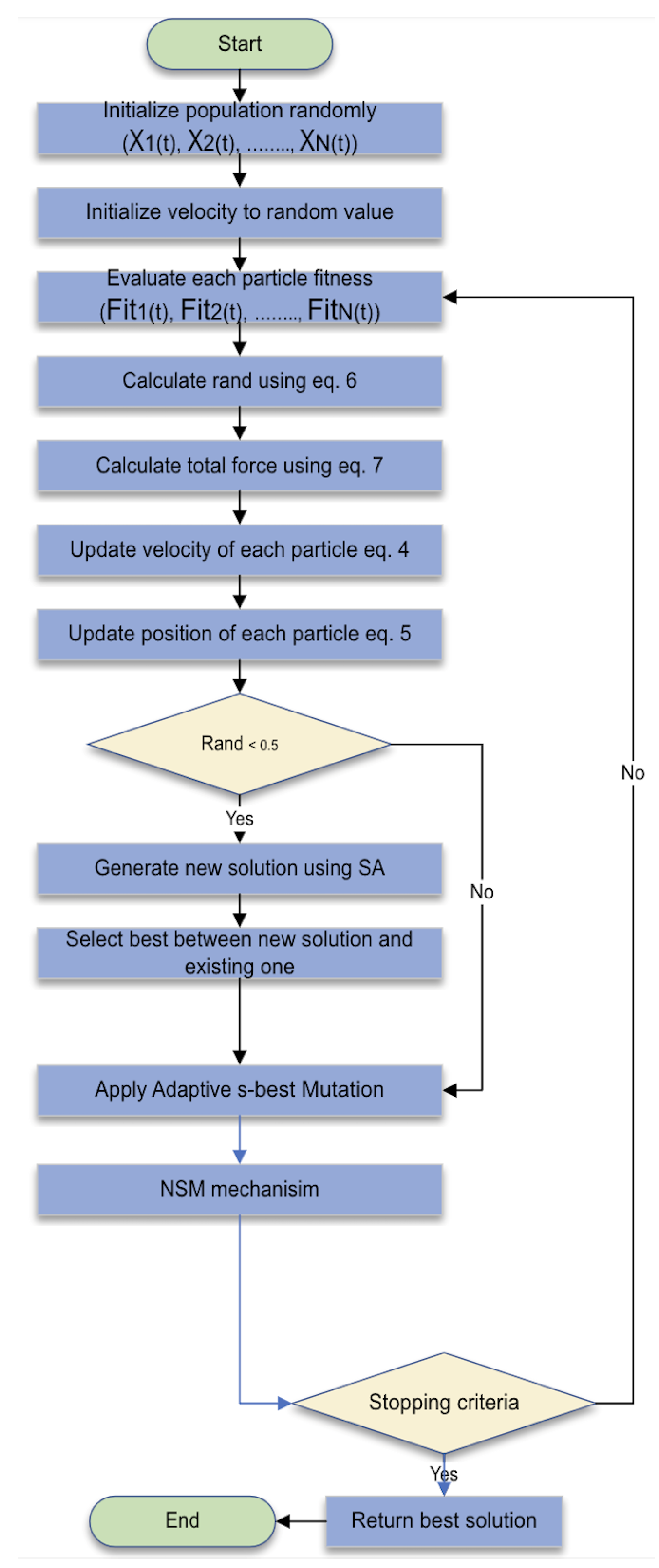
Despite the success and the power of AEFA, it has many drawbacks, as it may become stuck in local optima or have slow convergence, especially in high-dimensional and complex problems. This paper suggests an improved version of AEFA called modified AEFA (mAEFA) that tries to overcome the limitation of the original algorithm using two techniques, Lévy flights and Simulated Annealing, in each updating process. The flow chart is given in Figure 1.
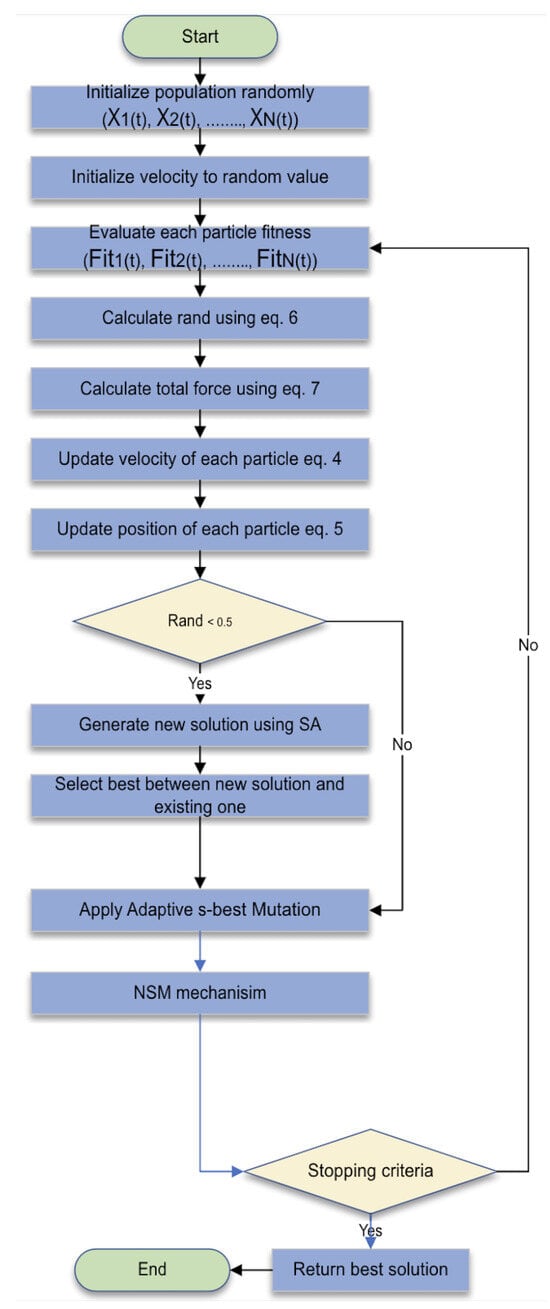
Figure 1.
mAEFA flow chart.
4.1. Lévy Flights
Randomization has a great emphasis and effect in algorithms as it prevents them from falling in local optimal regions/areas. The Lévy flight mechanism has been successfully implemented and employed in many algorithms. In this version, we used Lévy flight to generate a random vector instead of the vector given in Equation (2) and use it to calculate the force as follows:
where is a random number between 0 and 1 and D is the problem dimension. This will provide the search agent with a high opportunity to cover the entire search space.
4.2. Simulated Annealing
Simulated Annealing (SA) is a single-solution metaheuristic algorithm developed by Kirkpatrick et al. [70] that can be considered as an extension of the hill climbing technique. SA use a certain probability in accepting a worse solution to be able to avoid local optima. SA use Boltzmann probability, , where is the difference between solutions and T refers to a temperature parameter.
SA is employed here to enhance the exploitation abilities of the AEFA. In this paper, we used SA to generate a new solution and update the current agent if the new solution is better than the current one. Here, T is equal to , where N is the number of agents.
4.3. Adaptive S-Best Mutation
The equilibrium between exploration and exploitation stands out as a crucial aspect determining an algorithm’s effectiveness in search capability. In the original AEFA algorithm, the absence of a gradual transition from exploration to exploitation results in new solutions being generated from the current solution without any discernible bias. To address this limitation, we introduce the s-best mutation approach, where S represents the top-ranked solution based on its fitness. This mutation strategy randomly selects one solution from the top S candidates to generate new solutions. The range of potential solutions is controlled by variables , and . Through this approach, each new solution, indexed as i, is derived by either mutating the current solution or randomly mutating any solution selected from the top S candidates. The parameter S decreases non-linearly over time, enabling a broad exploration of the search space initially, gradually shifting towards a focus on solutions closer to the global optimum. This straightforward approach enhances diversity at the onset of generations, facilitating effective exploration, while transitioning towards exploitation as generations progress. During the exploitation phase, the algorithm concentrates on a narrower range of solutions surrounding the global best. The s-best mutation scheme operates as follows:
where signifies the agent derived from the top agents, differing from the deterministic best solution. Additionally, the individuals and represent two distinct agents randomly selected from the entire generation, meeting the criteria that , and neither is equal to the current agent. F denotes a constant and real-value factor typically chosen to be between 0 and 1, and r is linearly decreased as specified as follows:
where T signifies the maximum iteration number, t represents the current time, and N denotes the size of the population. Therefore, larger values of S are associated with earlier solutions, facilitating effective exploration. Conversely, as generations progress, S diminishes to foster exploitation enhancements.
4.4. NSM Operator
The survivor-selection process based on NSM scores operates according to a model that analytically connects the three described criteria. According to this model, the solution candidate that contributes more to the diversity of the mating pool and population compared to its competitors, while also achieving a better fitness value for the objective function, will survive. Within the NSM framework, the survivor is determined as the one that obtains the best score according to these three criteria.
5. Experimental Results and Discussion
To evaluate the proposed mAEFA method, this study employs the CEC’17 test suite, consisting of 30 functions commonly used to assess MHs [71]. Five engineering problems are also used for evaluation. The objective is to assess the search capability and convergence behavior of the proposed method. Given the stochastic nature of MHs, the experiments are conducted 30 times to account for randomness and observe result variations across runs.
Several newly developed algorithms are employed for comparison with the suggested mAEFA. These algorithms consist of the Coronavirus Herd Immunity Optimizer (CHIO) [72], Gravitational Search Algorithm (GSA) [73], Smell Agent Optimization (SAO) [74], Grasshopper Optimisation Algorithm (GOA) [75], Particle Swarm Optimization (PSO) [76], Liver Cancer Algorithm (LCA) [77], and basic AEFA [38]. For fairness in comparing algorithms, all were executed on the same hardware system to solve the CEC’17 test suite. The experiments were standardized with a maximum of 500 iterations. MATLAB 2021 served as the programming language for all algorithms, operating on a 64-bit Windows 8.1 system with an i7 Core and 8 GB RAM.
5.1. Experimental Series 1: CEC’17
5.1.1. Comparing mAEFA with State-of-Art Algorithms
CEC’17 includes functions representing diverse, complex, and dynamic optimization problems, commonly used for evaluating algorithm effectiveness. This study assesses the mAEFA algorithm using these functions, gaining insights into its effectiveness. Furthermore, it’s worth noting that each experiment is constrained by a maximum evaluation limit of 50,000 iterations. The setup entails employing 30 agents within a 30-dimensional space, as delineated in Table 1. Throughout the entirety of the experimentation, MATLAB2021 is utilized as the programming language, operating on a 64-bit Windows 8.1 platform. Table 2 presents the 30 functions, classified into four sets: F1 to F3 represents the unimodal set, F4 to F10 represents the multimodal set, F11 to F20 represents the hybrid set, and F21 to F30 represents the composition set. F2 is excluded from the evaluation process, leaving a total of 29 functions utilized to evaluate the mAEFA algorithm and other algorithms. The search range for all test functions, as indicated in Table 2, spans from −100 to 100, with a dimensionality of 30. In order to test and validate the enhanced version of mAEFA, we conducted a comparison with the original AEFA as well as six other distinct algorithms: CHIO, GSA, SAO, GOA, PSO, and LCA. The parameter seetinbg of each algorithm is given in Table 3.

Table 1.
Experiments parameters settings.
Table 2.
Benchmark functions.
Table 3.
Metaheuristic algorithms parameters settings.
The evaluation was based on the calculation of the average and standard deviation.
The comparison results are presented in Table 4. It is evident from the table that the developed algorithm (mAEFA) ranks first in 20 out of the 29 functions. Additionally, mAEFA obtains the second-best results in four functions and the third-best result in three functions. In contrast, GSA ranks first in only five functions, while AEFA achieves the best results in only four functions. Among the majority of the CEC’17 29 test functions, the algorithms that exhibit the lowest performance are SAO, GOA, LCA, and CHIO.
Table 4.
Statistical outcomes comparing mAEFA against various other metaheuristics on CEC’17 benchmark functions.
To validate the effectiveness of mAEFA, the statistical results of the nonparametric Wilcoxon rank-sum (WRS) test are presented in Table 5. This test helps determine the significance of the differences between mAEFA and other algorithms measured with a p-value of ≤0.05. Based on the results, the mAEFA algorithm demonstrates superior performance compared to the LCA algorithm across all 29 test functions. It also outperforms SAO and GOA in 28 functions, CHIO in 27 functions, PSO in 25 functions, GSA in 24 functions, and AEFA in 17 functions, showcasing better results in each case.
Table 5.
Wilcoxon rank-sum test results for the comparative algorithms against the proposed mAEFA using CEC’17 benchmark functions, where a = 0.05 and Dim = 30.
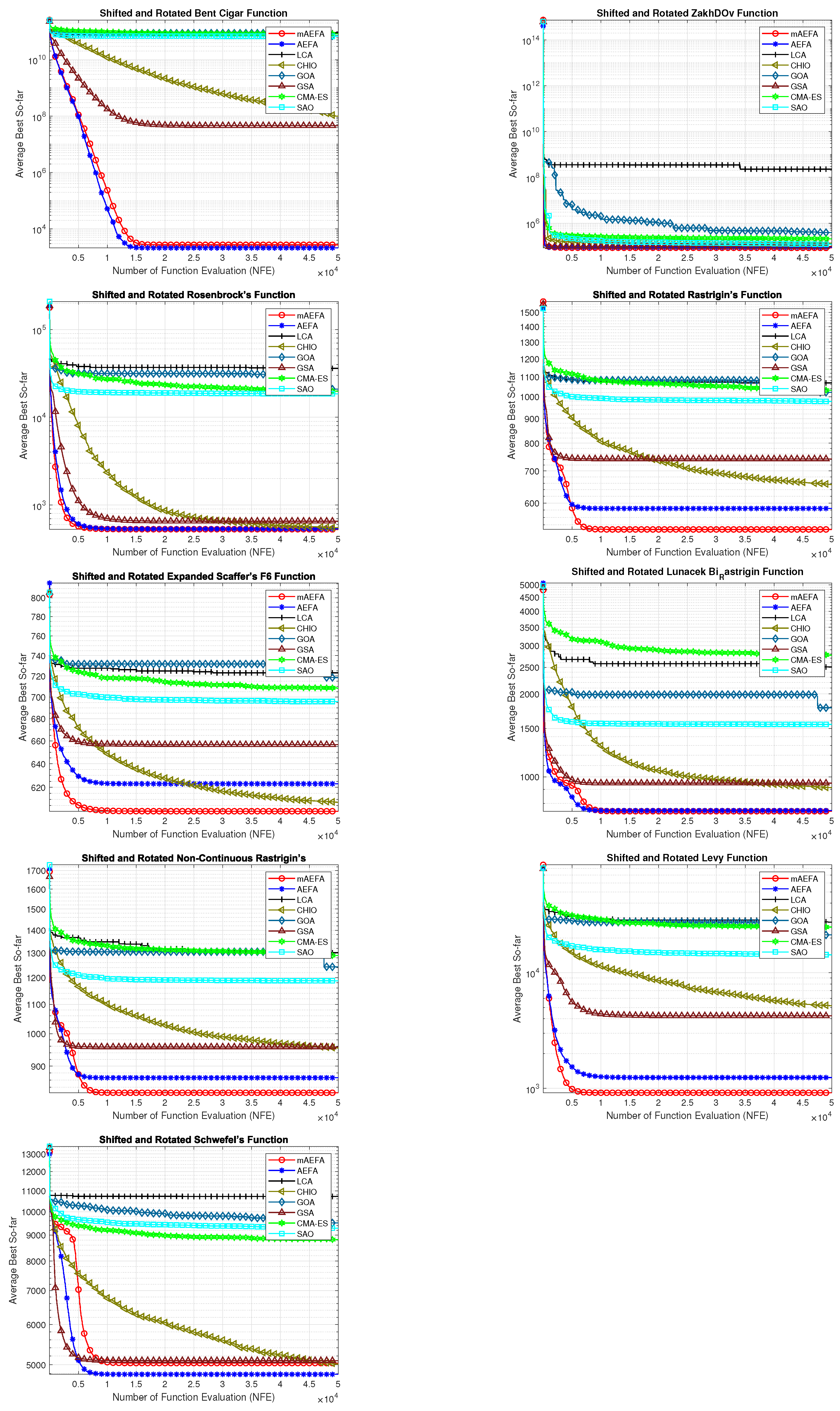
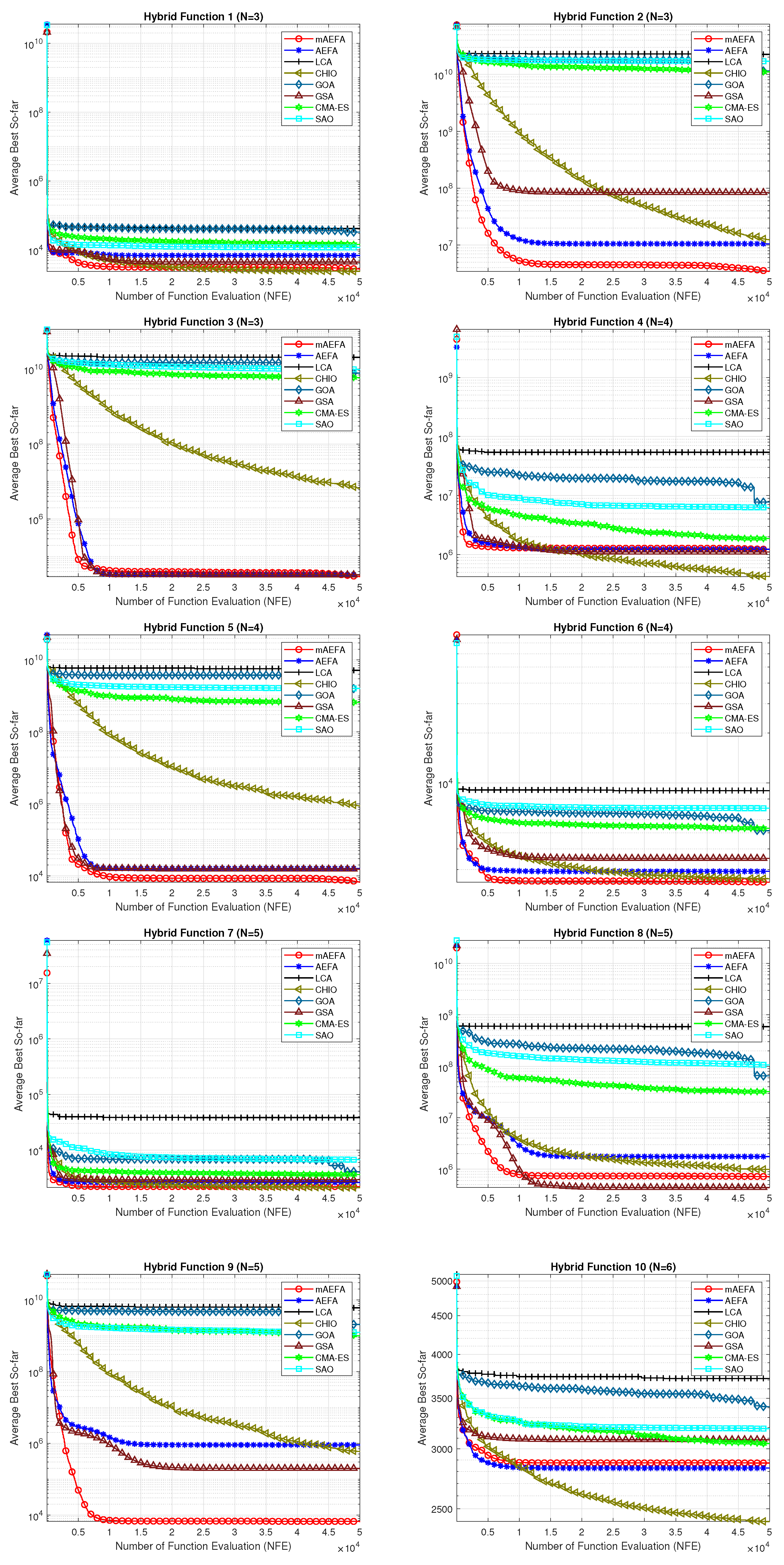
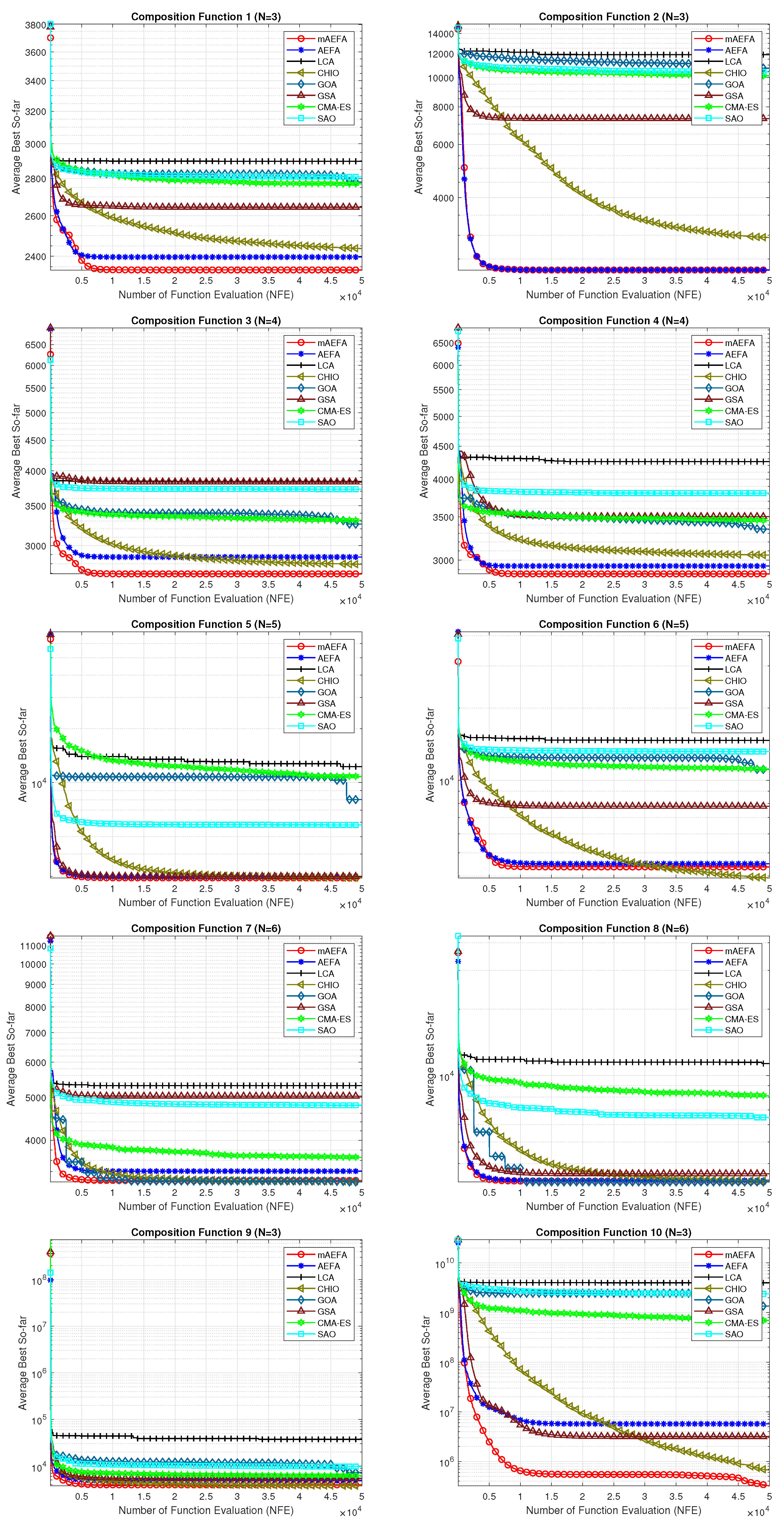
The convergence behavior of the proposed mAEFA algorithm, along with the other compared algorithms, applied to the CEC’17 functions is depicted in Figure 2, Figure 3 and Figure 4. It can be observed that mAEFA demonstrates rapid convergence for F3–F6, F8, F11–F14, F16, F17, F19, F21, F23, F24, and F27–30 compared to the classical AEFA algorithm. Additionally, mAEFA on average depicted better convergence behavior relative to the other algorithms in most of the CEC test suite benchmarks. The mAEFA algorithm demonstrates a balanced exploration–exploitation trade-off, evident in its convergence plots, showcasing both faster convergence and the discovery of optimal solutions during the search process.
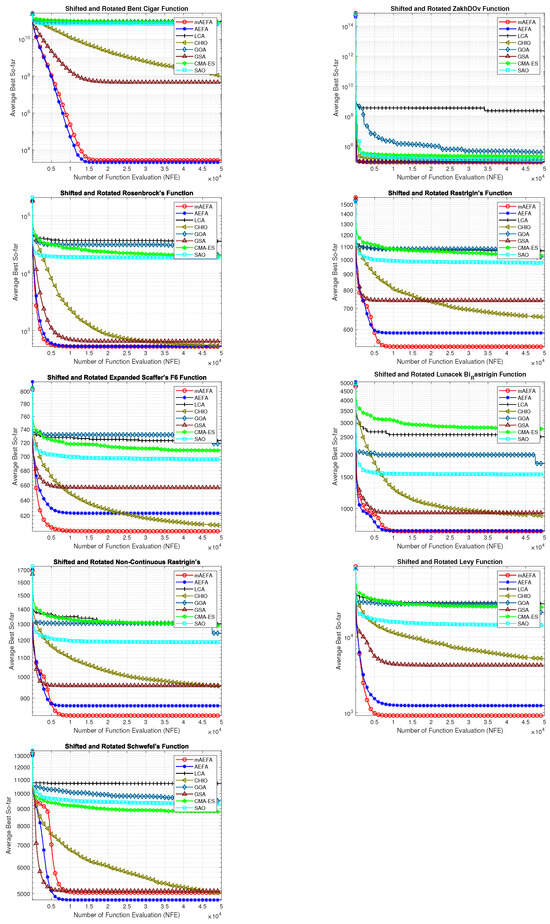
Figure 2.
Graphical representation of convergence curves for functions ranging from F1 to F10 using CEC’17 with a dimensionality of 30.
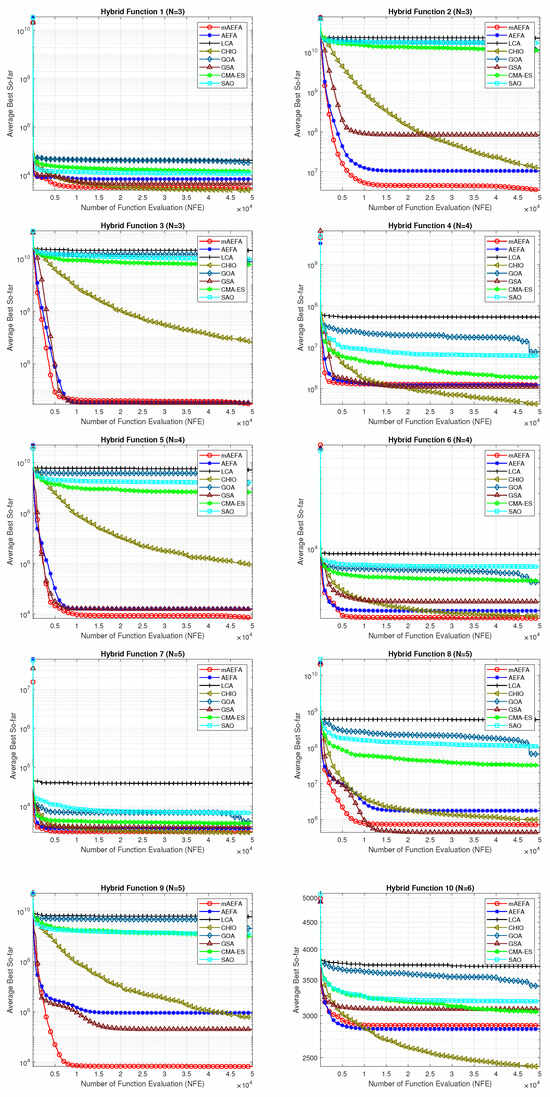
Figure 3.
Graphical representation of convergence curves for functions ranging from F11 to F20 using CEC’17 with a dimensionality of 30.
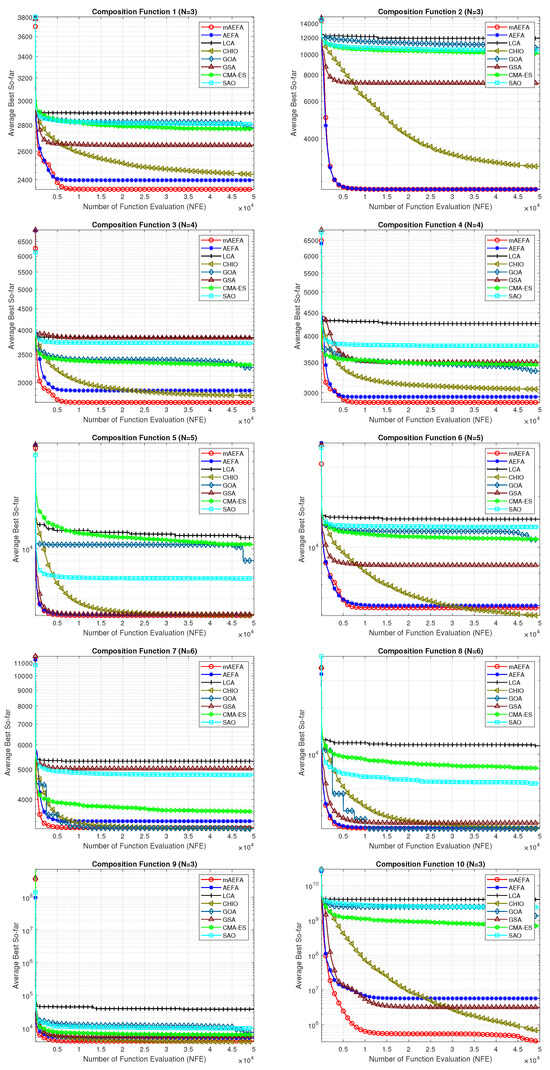
Figure 4.
Graphical representation of convergence curves for functions ranging from F21 to F30 using CEC’17 with a dimensionality of 30.
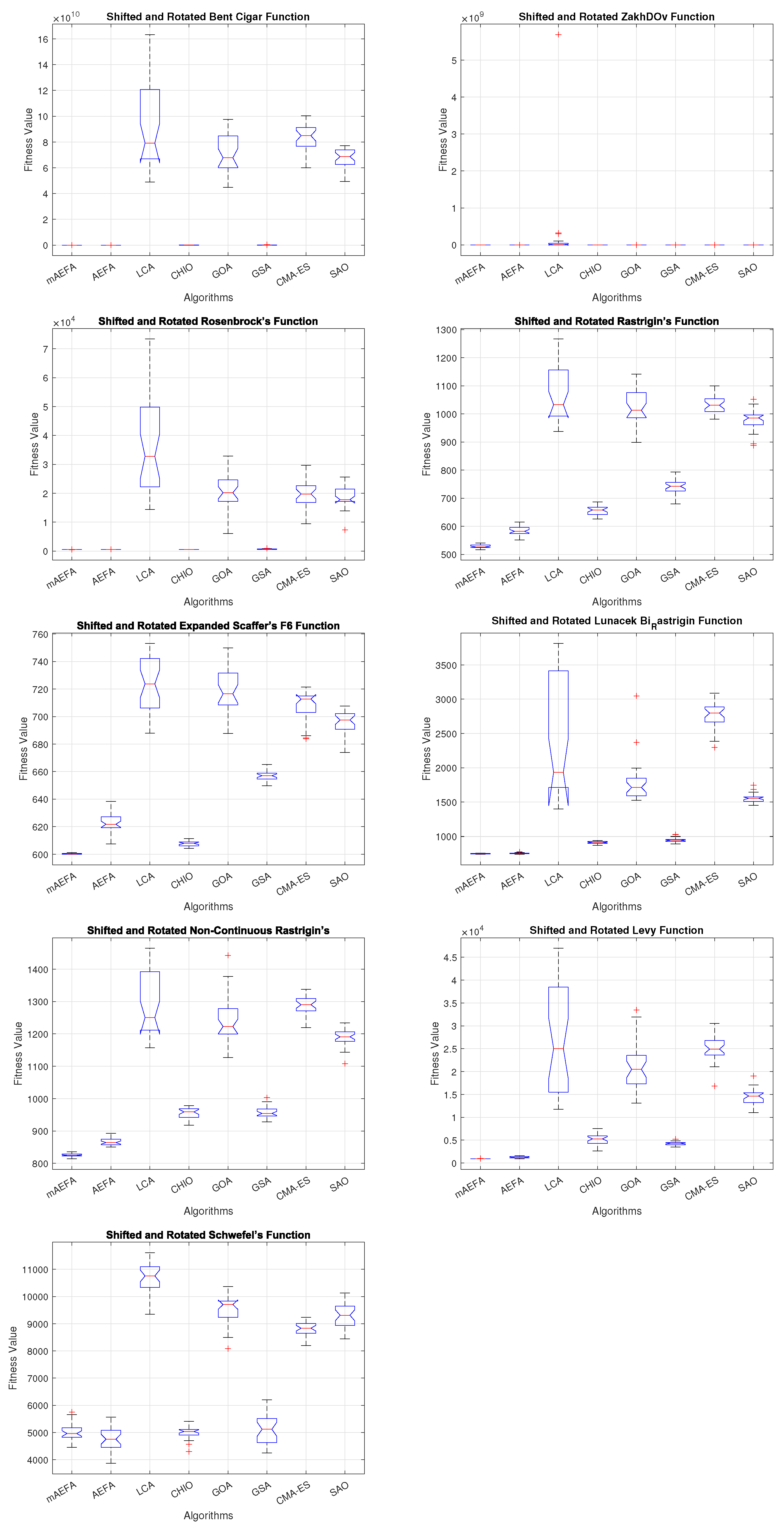
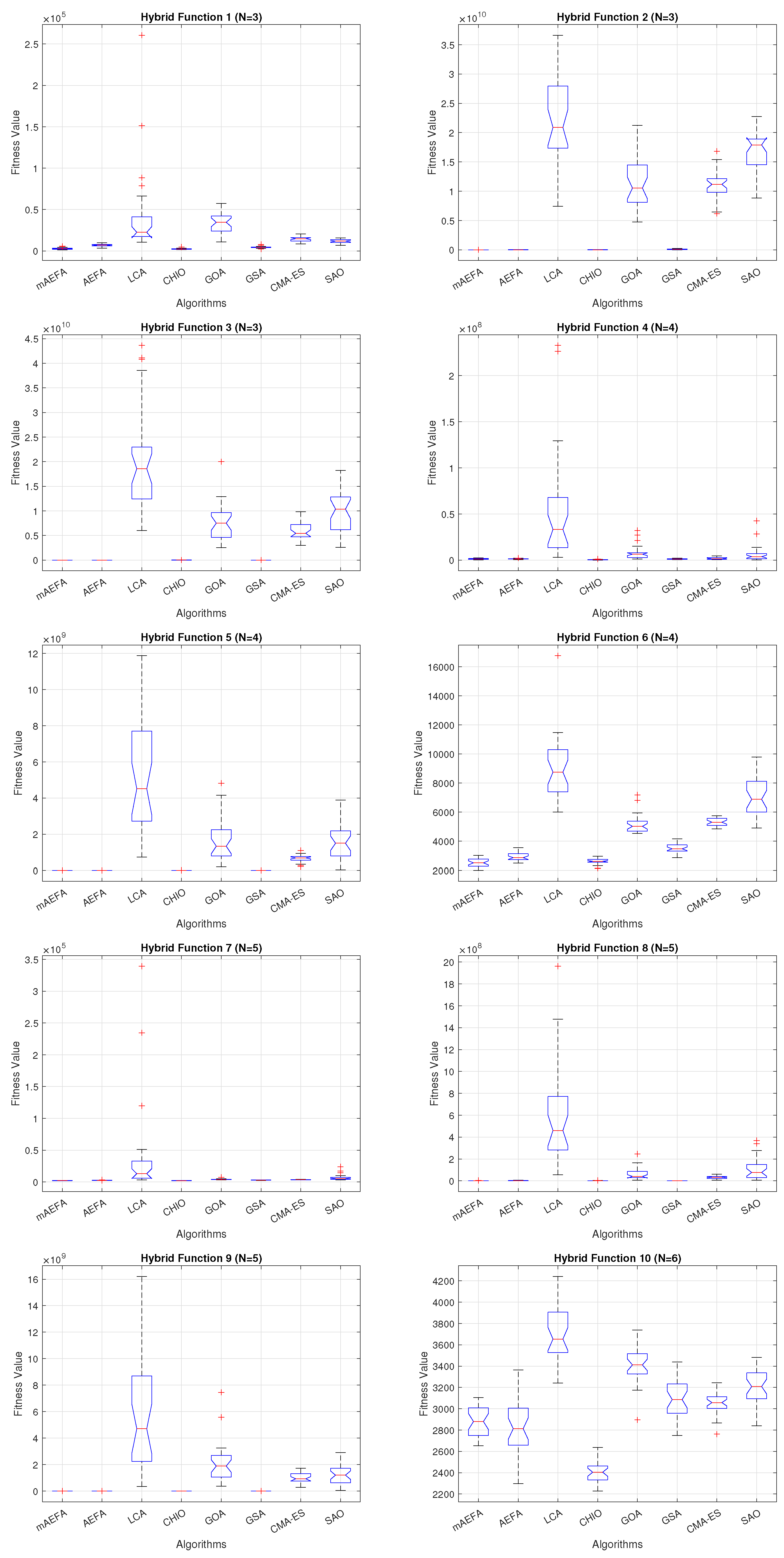
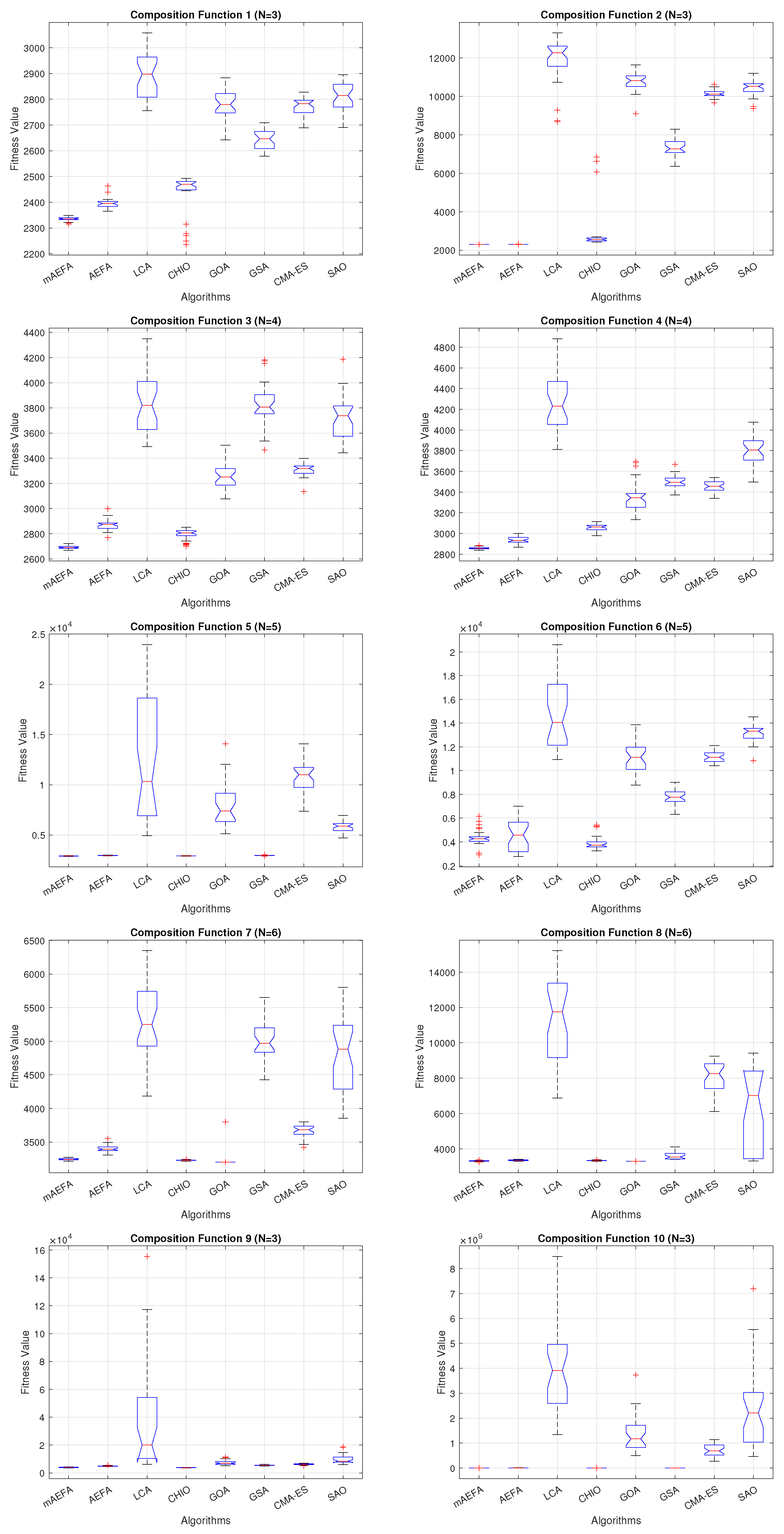
Additionally, Figure 5, Figure 6 and Figure 7 shows box plots for the proposed algorithm and the other compared algorithms, highlighting the distribution of results and the degree of proximity and similarity across multiple runs. The box plot is utilized to represent the minimum, maximum, and mean values for each algorithm. Box plots serve as an effective visual representation for presenting the performance values obtained in the 1st, 2nd, and 3rd] quarters of the experiment. A horizontal line within the box denotes the median value, while the whiskers extending outside indicate the variability beyond the upper and lower quartiles. Ideally, smaller box sizes and lower variability are preferred. Figure 5, Figure 6 and Figure 7 illustrate box plots for mAEFA for the majority of the functions, displaying narrow boxes with the lowest median and variability.
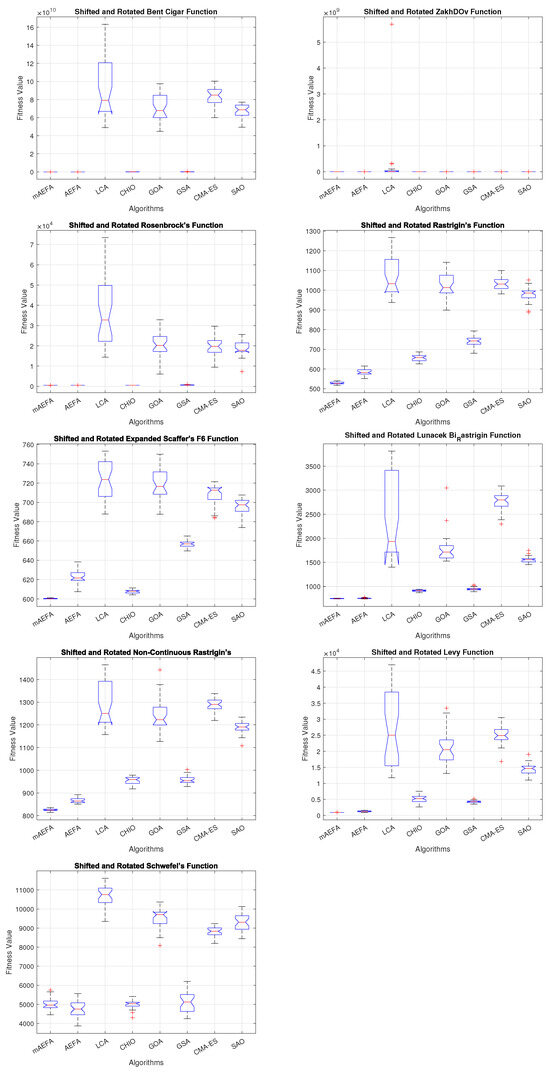
Figure 5.
Box plots illustrating the distribution of results for functions spanning from F1 to F10 using CEC’17 with a dimensionality of 30.
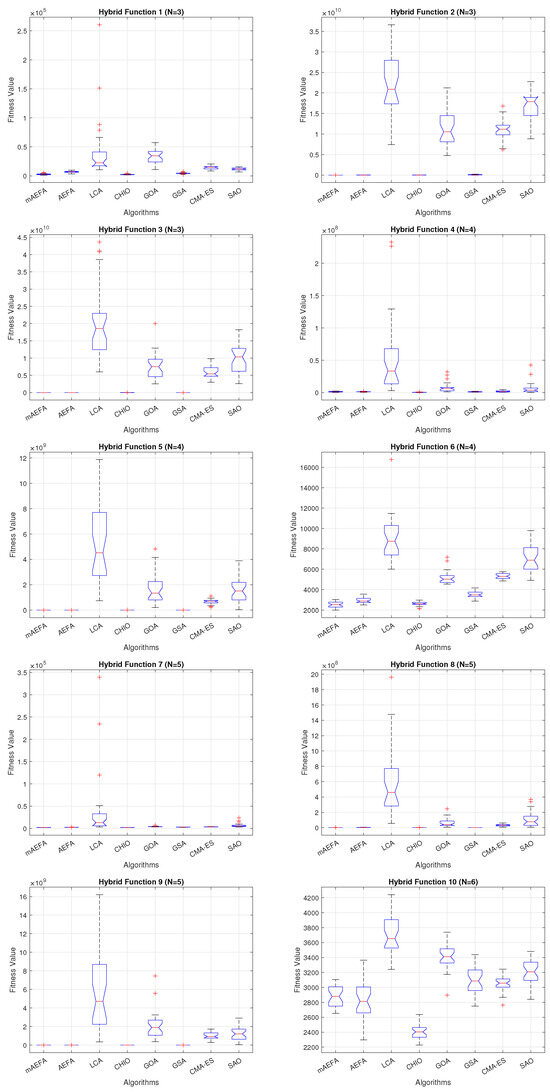
Figure 6.
Box plots illustrating the distribution of results for functions spanning from F11 to F20 using CEC’17 with a dimensionality of 30.
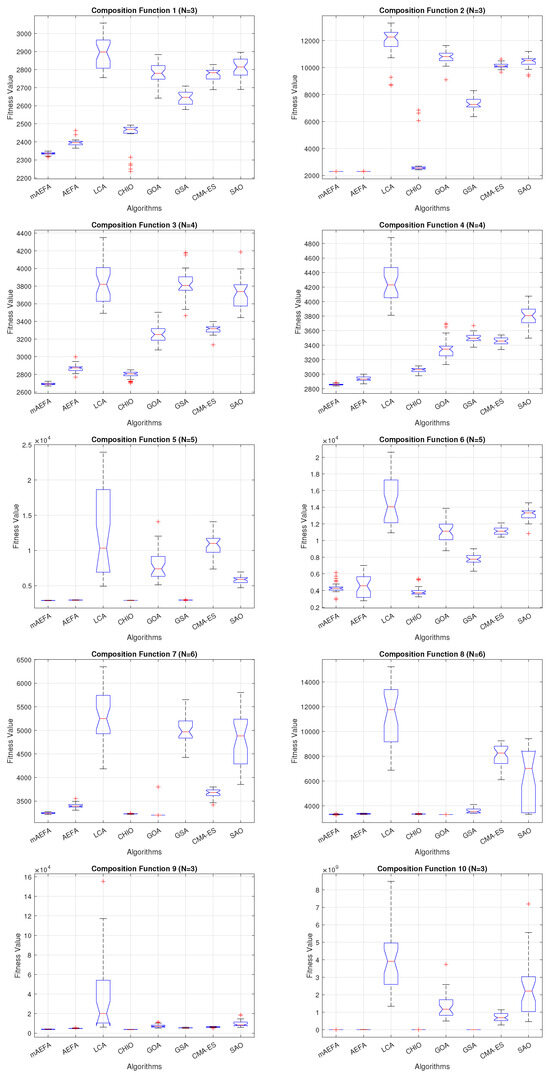
Figure 7.
Box plots illustrating the distribution of results for functions spanning from F21 to F30 using CEC’17 with a dimensionality of 30.
5.1.2. Comparing mAEFA with Fitness–Distance Balance Variants
In this subsection we compare mAEFA with two other FDB variants, namely FDB-SOS [66] and dfDB-MRFO [69]. Table 6 presents the statistical analysis results in terms of minimum, maximum, average, and standard deviation values, along with the ranks of the algorithms. Upon examination, mAEFA consistently outperforms the other variants across several functions, as evidenced by its lower minimum and average values, as well as its higher ranks in most cases. For example, in functions F5–F9, , F21–F24, and F26, mAEFA demonstrates superior performance with lower minimum and average values compared to dfDB-MRFO and FDB-SOS, resulting in higher ranks. Additionally, mAEFA shows competitive performance in other functions, such as , , , , and , where it achieves comparable results to the other variants. Overall, the comparative analysis suggests that mAEFA exhibits favorable performance across a range of benchmark functions compared to dfDB-MRFO and FDB-SOS. These findings underscore the efficacy of mAEFA as a competitive algorithm for solving optimization problems, particularly in the context of the functions analyzed in this study.
Table 6.
Statistical outcomes comparing mAEFA against FDB variants on CEC’17 benchmark functions.
5.2. Experimental Series 2: Engineering Problems
In this section, we explore five distinct engineering challenges to assess the effectiveness of the proposed solution in dealing with problems that involve constraints. The following constraint problems, which are commonly encountered and widely utilized, have been considered: speed reducer design (SRD), pressure vessel design (PVD), cantilever beam design (CBD) and the multi-product batch plant (MPBP) problem, and Industrial Refrigeration System Optimal Design.
5.2.1. Speed Reducer Design Problem
This problem involves optimization with the objective of minimizing the weights associated with various design elements. The optimization process incorporates constraints related to gear teeth, stress, deflection ratios of bending, surface, and shafts [78]. The SRD is based on seven design variables () that aim to minimize the weight. These variables represent face width, teeth module, pinion teeth number, the length of the first shaft between the bearings, the length of the second shaft between the bearings, and the diameters of the first and second shafts.
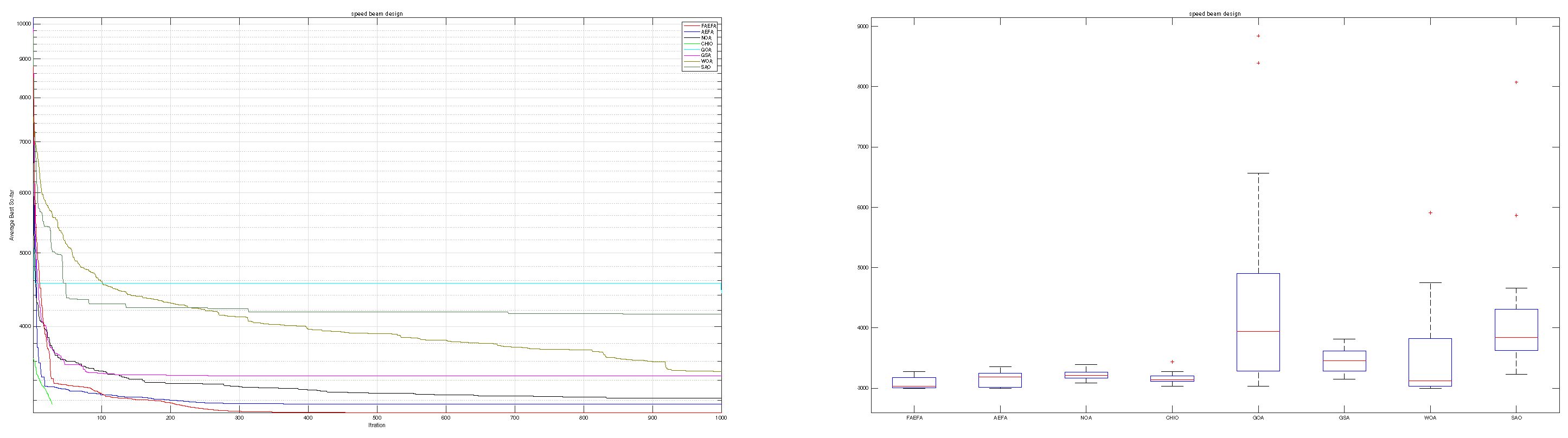
The mAEFA algorithm attains the top rank with a significantly low standard deviation, as indicated by the results in Table 7. Furthermore, Table 8 illustrates its competitive performance across all seven variables, underscoring the noteworthy differentiation of mAEFA in comparison to alternative algorithms. Figure 8 illustrates a distinct divergence in convergence patterns among the algorithms, where mAEFA exhibits superior convergence by attaining exceptionally low values in the final iteration of the search process.
Table 7.
Statistical outcomes comparing mAEFA against other metaheuristics applied to speed reducer design.
Table 8.
Results of mAEFA versus other metaheuristics on speed reducer design.

Figure 8.
Speed reducer design.
5.2.2. Pressure Vessel Design Problem
The PVD problem, introduced by Kannan and Kramer [79], is the second engineering design problem in this study, assessing the effectiveness of the proposed mAEFA. This problem revolves around optimizing the cost associated with PVD, aiming to minimize it. The cost is determined by four design variables: , which represent shell thickness, head thickness, inner radius, and cylinder length, respectively. Hashim et al. [80] provide an extensive description of the mathematical model for this problem. The PVD problem’s mathematical model can be defined using the following set of equations.
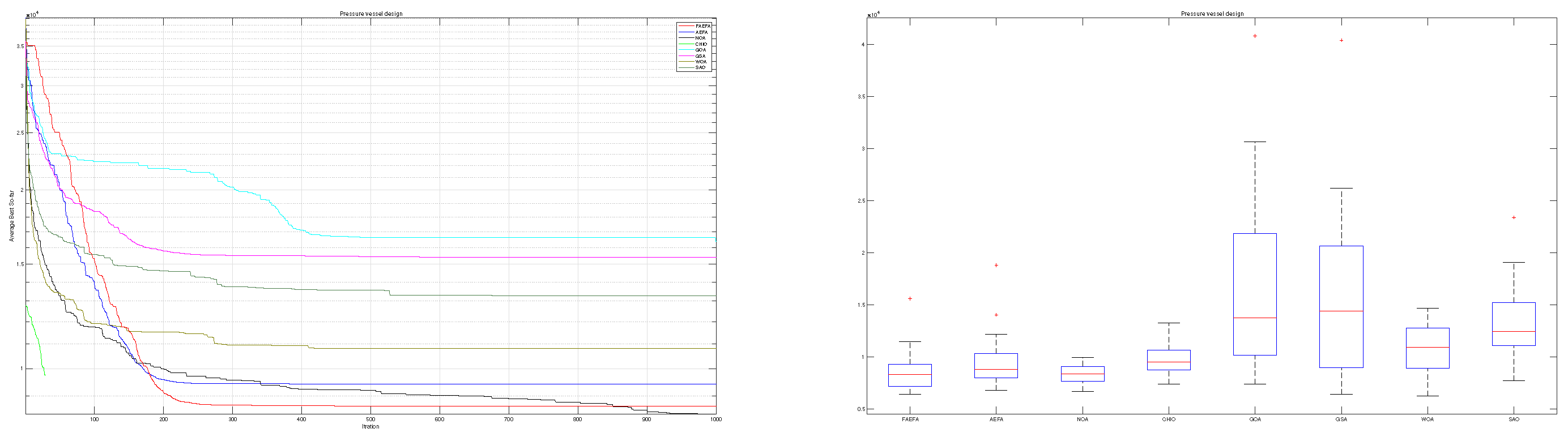
According to the findings presented in Table 9, the mAEFA algorithm obtains the first rank with a minimum mean value of 6412.152. Figure 9 demonstrates comparable behavior across all algorithms, with mAEFA consistently achieving minimum values during the later iterations. Table 10 presents the variable values obtained by each algorithm for this specific problem. Notably, mAEFA achieves competitive values for and , and it secures the second-lowest value for . Table 10 clearly indicates that mAEFA surpasses all algorithms, except for the LCA algorithm, indicating a substantial difference in its performance.
Table 9.
Statistical results of mAEFA versus other metaheuristics on pressure vessel design problem.

Figure 9.
Pressure vessel design problem.
Table 10.
Statistical results of mAEFA compared with other algorithms on pressure vessel design problem.
5.2.3. Multi-Product Batch Plant Problem
In the MPBP problem, the production process begins after the customer submits their order, with each order representing a specific product. Throughout production, the batch size for each order remains constant. Each order is assigned due dates and release dates. At each stage, there are dedicated processing units that exclusively operate within that stage. The objective of this problem is to minimize the makespan, considering additional constraints such as unallowed unit assignments, order due dates, release dates, and storage issues. The problem’s formulation is delineated by Equations (12)–(23), with Equation (12) addressing the constraint related to order assignment, ensuring that each order (i) can only be processed on a single unit (j) at a specific step (s).
Equations (13)–(15) reveal unit order sequencing, with Equations (13) and (15) indicating a singular first order for each unit j, and Equation (12) depicting sequence constraints for different orders i and i′ on the same unit j.
Equations (16) and (17) represent unit assignment constraints. When integer variables or are activated, it implies that orders and i must be processed on the same unit j.
Equations (16)–(19) represent order timing constraints. Equation (18) pertains to timing constraints within one order’s various steps, while Equation (19) addresses timing constraints for multiple orders on the same unit. Additionally, when considering unit release time or order release time , Equations (20) and (21) come into play. Equation (22) is applicable for cases involving due date .
The goal is to minimize the makespan, and the objective function is defined as follows:
Meeting all constraints is straightforward except for Equation (22) when minimizing the makespan with metaheuristic algorithms. To accommodate Equation (22), a penalty function is employed, and Equations (24) and (25) are utilized to calculate the objective function in this study:
Equation (24) defines the penalty function, which is employed to penalize violations in Equation (25). When the completion time of each order exceeds its respective due date, Equation (24) comes into effect, leading to a reduction in the objective value in Equation (25).
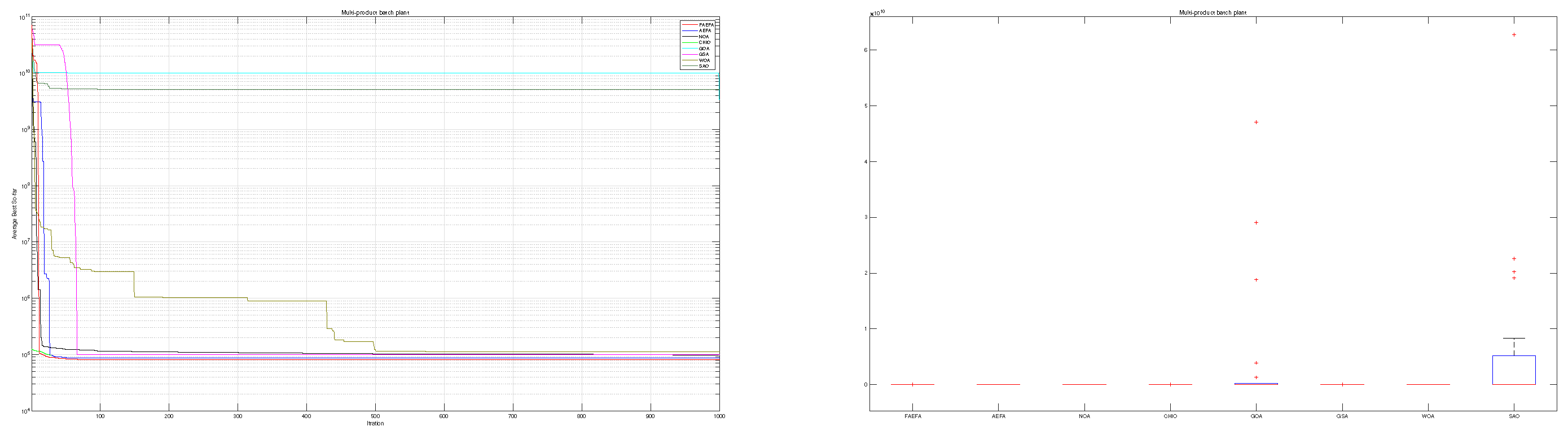
According to the data presented in Table 11, the mAEFA algorithm secures the first position in terms of statistical ranking amongst all compared algorithms. Table 12 showcases that mAEFA attains competitive results across various problem variables. Figure 10 depicts that mAEFA, alongside some other algorithms, demonstrates similar convergence behavior reaching minimum values. However, both CHIO and SAO exhibit premature convergence behavior, indicating a tendency to get trapped in local minima.
Table 11.
Statistical results of mAEFA versus other metaheuristics on multi-product batch plant problem.
Table 12.
Results of mAEFA versus other metaheuristics on multi-product batch plant problem.
Figure 10.
Multi-product batch plant problem.
5.2.4. Industrial Refrigeration System Optimal Design
A refrigeration system utilizes coolant to decrease the temperature of a hot stream, going through three distinct phases. Each phase incorporates a heat exchanger on one side and a boiling cooler on the other. The pumping current is determined by the heat exchanger’s surface area. Moreover, the boiling temperature for the refrigerant is established at the start of each phase. Designing an efficient cooling system entails calculating the surface areas of the three surfaces of the liquid cooling heat exchanger.
The refrigeration system is designed to dissipate 4186.8 J/kg°C of heat while pumping a flow rate of 10,800 kg per hour from an initial temperature of 10 °C to −55 °C. Operating for a minimum of 300 days per year, the refrigeration system’s key parameters include a refrigerant latent heat () of 232.600 J/Kg and an overall heat transfer coefficient of 1130 J/s m2 °C. The primary design objective is to minimize the cost of the three steps, as specified by Equation (26).
The optimization aims to obtain competitive values for design variables, including fluid temperatures, heat exchange area, and liquid refrigerant addition rates in each step, with a focus on minimizing costs. The optimization process places significant emphasis on the temperature of the liquid refrigerant in each step, described as follows:
The temperature of the incoming fluid to the system is 10 °C, denoted as , while the temperature of the outgoing fluid from the system is −55 °C, represented as . It is essential for the output temperature at each step to be higher than the temperature of the refrigerant. As a result, the conditions for the design variables can be expressed as shown in Equations (28)–(33).
The log mean temperature difference at stage i is:
The energy balance over refrigerant is:
is the penalty factor, where is the ratio of heat flow, J/s. The energy balance over the fluid is:
where is the specific heat of fluid, J/kg°C and V is the hot fluid pump ratio, kg/hr.
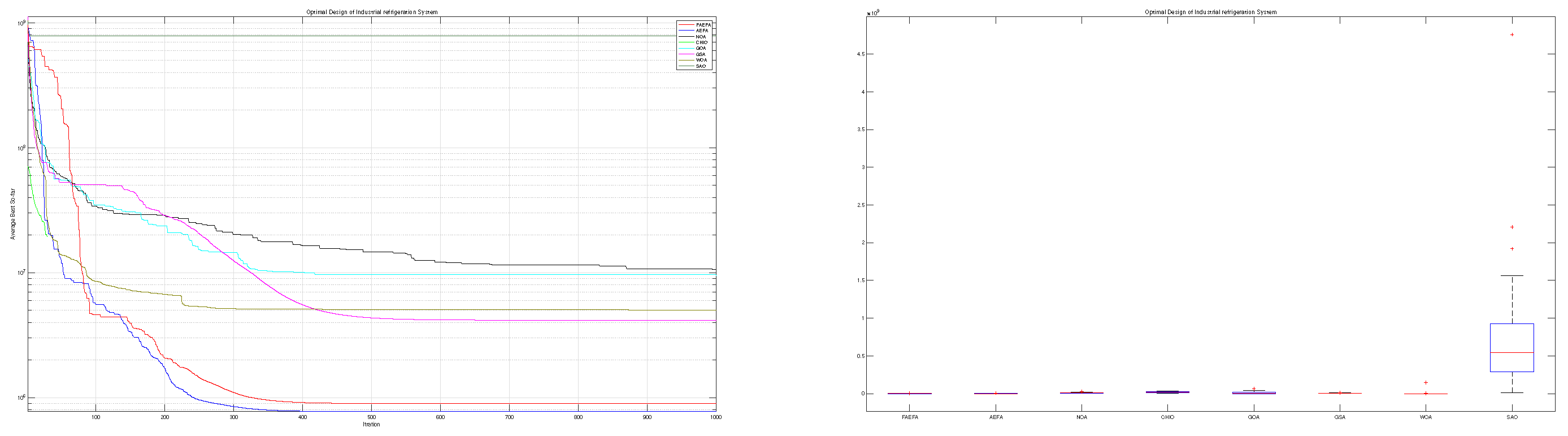
Based on the findings presented in Table 13, the proposed mAEFA algorithm achieves a competitive rank when compared to other algorithms. Additionally, as indicated in Table 14, mAEFA attains the smallest values for the majority of the problem variables and the best solution in comparison to other algorithms. Table 14 demonstrates that mAEFA yields significant results in comparison to all other algorithms. Convergence behavior, as depicted in Figure 11, varies among the algorithms in their approach towards the optimal solution. Notably, mAEFA demonstrates a favourable convergence pattern, reaching minimum values in later search iterations.
Table 13.
Statistical results of mAEFA versus other metaheuristics on design of industrial refrigeration system.
Table 14.
Results of mAEFA versus other metaheuristics on design of industrial refrigeration system.

Figure 11.
Optimal design of Industrial refrigeration system.
6. Conclusions and Future Work
The main contributions of this research work can be summarized as follows:
- A modified mAEFA approach is developed by combining the original AEFA algorithm with Lévy flights, simulated annealing, and Adaptive s-best Mutation and Natural Survivor Method (NSM) mechanisms. The mAEFA utilizes Lévy flights distribution to enhance exploration and convergence, while the simulated annealing approach assists in avoiding local optima;
- The performance of the mAEFA algorithm is scrutinized on various benchmark functions and engineering design problems. Comparative analysis with popular metaheuristics demonstrates the superiority and competitiveness of mAEFA;
- In solving composite CEC’17 benchmark functions, mAEFA shows superior performance compared to other algorithms under comparison, except for specific functions. In unimodal, multimodal, and composite CEC’17 functions, mAEFA is either superior, equal, or ranked second among compared algorithms, with faster convergence observed;
- Box plot analysis and Wilcoxon rank-sum test results further validate the superiority and robustness of mAEFA over comparative algorithms in CEC’17 test functions;
- Performance testing of mAEFA on five engineering design problems demonstrates its superior capability to effectively solve practical optimization problems compared to other algorithms.
Nonetheless, similar to other metaheuristic algorithms, mAEFA faces limitations in solving all optimization problems across different domains, as highlighted by the No Free Lunch theorem. In future research, we aim to validate the effectiveness of the proposed mAEFA by testing it on more intricate continuous and discrete optimization problems. Moreover, there is potential to apply this algorithm to address various problems in diverse fields such as cloud task scheduling, image segmentation, engineering design, air quality prediction, finance, material science, and environmental sciences, among others.
In the future, a multiobjective version of the developed algorithm can be designed to tackle multiobjective problems. Furthermore, the authors intend to use the same combination to test other metaheuristic algorithms.
Author Contributions
Conceptualization, A.G.H. and F.A.H.; Methodology, A.G.H., S.K. and F.A.H.; Software, A.G.H. and F.A.H.; Validation, A.G.H. and A.P.; Formal analysis, A.G.H.; Investigation, A.G.H. and F.A.H.; Resources, A.G.H. and G.H.; Data curation, A.G.H. and G.H.; Writing—original draft, A.G.H., S.K., F.A.H., G.H. and A.P.; Writing—review & editing, A.G.H., A.P. and A.G.H.; Visualization, A.G.H. and F.A.H.; Supervision, A.P. and G.H.; Project administration, A.P. and G.H.; Funding acquisition, A.G.H. and A.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Data are available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- García-Martínez, C.; Gutiérrez, P.D.; Molina, D.; Lozano, M.; Herrera, F. Since CEC 2005 competition on real-parameter optimisation: A decade of research, progress and comparative analysis’s weakness. Soft Comput. 2017, 21, 5573–5583. [Google Scholar] [CrossRef]
- Mernik, M.; Liu, S.H.; Karaboga, D.; Črepinšek, M. On clarifying misconceptions when comparing variants of the artificial bee colony algorithm by offering a new implementation. Inf. Sci. 2015, 291, 115–127. [Google Scholar] [CrossRef]
- Abdullahi, M.; Ngadi, M.A.; Dishing, S.I.; Ahmad, B.I.E. An efficient symbiotic organisms search algorithm with chaotic optimization strategy for multi-objective task scheduling problems in cloud computing environment. J. Netw. Comput. Appl. 2019, 133, 60–74. [Google Scholar] [CrossRef]
- Faris, H.; Mirjalili, S.; Aljarah, I. Automatic selection of hidden neurons and weights in neural networks using grey wolf optimizer based on a hybrid encoding scheme. Int. J. Mach. Learn. Cybern. 2019, 10, 2901–2920. [Google Scholar] [CrossRef]
- Chen, Y.P.; Li, Y.; Wang, G.; Zheng, Y.F.; Xu, Q.; Fan, J.H.; Cui, X.T. A novel bacterial foraging optimization algorithm for feature selection. Expert Syst. Appl. 2017, 83, 1–17. [Google Scholar] [CrossRef]
- Alweshah, M.; Khalaileh, S.A.; Gupta, B.B.; Almomani, A.; Hammouri, A.I.; Al-Betar, M.A. The monarch butterfly optimization algorithm for solving feature selection problems. Neural Comput. Appl. 2020, 34, 11267–11281. [Google Scholar] [CrossRef]
- Fathi, H.; AlSalman, H.; Gumaei, A.; Manhrawy, I.I.; Hussien, A.G.; El-Kafrawy, P. An Efficient Cancer Classification Model Using Microarray and High-Dimensional Data. Comput. Intell. Neurosci. 2021, 2021, 7231126. [Google Scholar] [CrossRef]
- Kumar, Y.; Dahiya, N.; Malik, S.; Yadav, G.; Singh, V. Chemical Reaction-Based Optimization Algorithm for Solving Clustering Problems. In Natural Computing for Unsupervised Learning; Springer: Cham, Switzerland, 2019; pp. 147–162. [Google Scholar]
- Houssein, E.H.; Hosney, M.E.; Oliva, D.; Mohamed, W.M.; Hassaballah, M. A novel hybrid Harris hawks optimization and support vector machines for drug design and discovery. Comput. Chem. Eng. 2020, 133, 106656. [Google Scholar] [CrossRef]
- Bezdan, T.; Stoean, C.; Naamany, A.A.; Bacanin, N.; Rashid, T.A.; Zivkovic, M.; Venkatachalam, K. Hybrid fruit-fly optimization algorithm with k-means for text document clustering. Mathematics 2021, 9, 1929. [Google Scholar] [CrossRef]
- Besnassi, M.; Neggaz, N.; Benyettou, A. Face detection based on evolutionary Haar filter. Pattern Anal. Appl. 2020, 23, 309–330. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Hansen, N.; Müller, S.D.; Koumoutsakos, P. Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (CMA-ES). Evol. Comput. 2003, 11, 1–18. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Geem, Z.W.; Kim, J.H.; Loganathan, G.V. A new heuristic optimization algorithm: Harmony search. Simulation 2001, 76, 60–68. [Google Scholar] [CrossRef]
- Karaboga, D.; Ozturk, C. A novel clustering approach: Artificial Bee Colony (ABC) algorithm. Appl. Soft Comput. 2011, 11, 652–657. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Alavi, A.H. Krill herd: A new bio-inspired optimization algorithm. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 4831–4845. [Google Scholar] [CrossRef]
- Assiri, A.S.; Hussien, A.G.; Amin, M. Ant Lion Optimization: Variants, hybrids, and applications. IEEE Access 2020, 8, 77746–77764. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Askarzadeh, A. A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Comput. Struct. 2016, 169, 1–12. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Shareef, H.; Ibrahim, A.A.; Mutlag, A.H. Lightning search algorithm. Appl. Soft Comput. 2015, 36, 315–333. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Li, M.D.; Zhao, H.; Weng, X.W.; Han, T. A novel nature-inspired algorithm for optimization: Virus colony search. Adv. Eng. Softw. 2016, 92, 65–88. [Google Scholar] [CrossRef]
- Hashim, F.A.; Hussien, A.G. Snake Optimizer: A novel meta-heuristic optimization algorithm. Knowl.-Based Syst. 2022, 242, 108320. [Google Scholar] [CrossRef]
- Yıldız, B.S.; Kumar, S.; Panagant, N.; Mehta, P.; Sait, S.M.; Yildiz, A.R.; Pholdee, N.; Bureerat, S.; Mirjalili, S. A novel hybrid arithmetic optimization algorithm for solving constrained optimization problems. Knowl.-Based Syst. 2023, 271, 110554. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Shayanfar, H.; Gharehchopogh, F.S. Farmland fertility: A new metaheuristic algorithm for solving continuous optimization problems. Appl. Soft Comput. 2018, 71, 728–746. [Google Scholar] [CrossRef]
- Anosri, S.; Panagant, N.; Champasak, P.; Bureerat, S.; Thipyopas, C.; Kumar, S.; Pholdee, N.; Yıldız, B.S.; Yildiz, A.R. A Comparative Study of State-of-the-art Metaheuristics for Solving Many-objective Optimization Problems of Fixed Wing Unmanned Aerial Vehicle Conceptual Design. Arch. Comput. Methods Eng. 2023, 30, 3657–3671. [Google Scholar] [CrossRef]
- Arora, S.; Singh, H.; Sharma, M.; Sharma, S.; Anand, P. A new hybrid algorithm based on grey wolf optimization and crow search algorithm for unconstrained function optimization and feature selection. IEEE Access 2019, 7, 26343–26361. [Google Scholar] [CrossRef]
- Kumar, S.; Tejani, G.G.; Pholdee, N.; Bureerat, S.; Mehta, P. Hybrid heat transfer search and passing vehicle search optimizer for multi-objective structural optimization. Knowl.-Based Syst. 2021, 212, 106556. [Google Scholar] [CrossRef]
- Yildiz, B.S.; Mehta, P.; Sait, S.M.; Panagant, N.; Kumar, S.; Yildiz, A.R. A new hybrid artificial hummingbird-simulated annealing algorithm to solve constrained mechanical engineering problems. Mater. Test. 2022, 64, 1043–1050. [Google Scholar] [CrossRef]
- Kumar, S.; Tejani, G.G.; Mirjalili, S. Modified symbiotic organisms search for structural optimization. Eng. Comput. 2019, 35, 1269–1296. [Google Scholar] [CrossRef]
- Houssein, E.H.; Mahdy, M.A.; Fathy, A.; Rezk, H. A modified Marine Predator Algorithm based on opposition based learning for tracking the global MPP of shaded PV system. Expert Syst. Appl. 2021, 183, 115253. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Zhao, H. An improved ant colony optimization algorithm based on hybrid strategies for scheduling problem. IEEE Access 2019, 7, 20281–20292. [Google Scholar] [CrossRef]
- Tubishat, M.; Idris, N.; Shuib, L.; Abushariah, M.A.; Mirjalili, S. Improved Salp Swarm Algorithm based on opposition based learning and novel local search algorithm for feature selection. Expert Syst. Appl. 2020, 145, 113122. [Google Scholar] [CrossRef]
- Yadav, A. AEFA: Artificial electric field algorithm for global optimization. Swarm Evol. Comput. 2019, 48, 93–108. [Google Scholar]
- Selem, S.I.; El-Fergany, A.A.; Hasanien, H.M. Artificial electric field algorithm to extract nine parameters of triple-diode photovoltaic model. Int. J. Energy Res. 2021, 45, 590–604. [Google Scholar] [CrossRef]
- Houssein, E.H.; Hashim, F.A.; Ferahtia, S.; Rezk, H. An efficient modified artificial electric field algorithm for solving optimization problems and parameter estimation of fuel cell. Int. J. Energy Res. 2021, 45, 20199–20218. [Google Scholar] [CrossRef]
- Anita; Yadav, A.; Kumar, N. Application of artificial electric field algorithm for economic load dispatch problem. In Proceedings of the International Conference on Soft Computing and Pattern Recognition, Hyderabad, India, 13–15 December 2019; Springer: Cham, Switzerland, 2019; pp. 71–79. [Google Scholar]
- Janjanam, L.; Saha, S.; Kar, R.; Mandal, D. Volterra filter modelling of non-linear system using Artificial Electric Field algorithm assisted Kalman filter and its experimental evaluation. ISA Trans. 2020, 125, 614–630. [Google Scholar] [CrossRef]
- Anita; Yadav, A.; Kumar, N.; Kim, J.H. Development of Discrete Artificial Electric Field Algorithm for Quadratic Assignment Problems. In Proceedings of the International Conference on Harmony Search Algorithm, Istanbul, Turkey, 22–24 April 2020; Springer: Singapore, 2020; pp. 411–421. [Google Scholar]
- Cao, M.T.; Hoang, N.D.; Nhu, V.H.; Bui, D.T. An advanced meta-learner based on artificial electric field algorithm optimized stacking ensemble techniques for enhancing prediction accuracy of soil shear strength. Eng. Comput. 2020, 38, 2185–2207. [Google Scholar] [CrossRef]
- Naderipour, A.; Abdul-Malek, Z.; Mustafa, M.W.B.; Guerrero, J.M. A multi-objective artificial electric field optimization algorithm for allocation of wind turbines in distribution systems. Appl. Soft Comput. 2021, 105, 107278. [Google Scholar] [CrossRef]
- Izci, D.; Ekinci, S.; Orenc, S.; Demirören, A. Improved artificial electric field algorithm using Nelder-Mead simplex method for optimization problems. In Proceedings of the 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Istanbul, Turkey, 22–24 October 2020; pp. 1–5. [Google Scholar]
- Petwal, H.; Rani, R. An Improved Artificial Electric Field Algorithm for Multi-Objective Optimization. Processes 2020, 8, 584. [Google Scholar] [CrossRef]
- Yadav, A.; Kumar, N. Artificial electric field algorithm for engineering optimization problems. Expert Syst. Appl. 2020, 149, 113308. [Google Scholar]
- Yadav, A. Discrete artificial electric field algorithm for high-order graph matching. Appl. Soft Comput. 2020, 92, 106260. [Google Scholar]
- Sajwan, A.; Yadav, A. A study of exploratory and stability analysis of artificial electric field algorithm. Appl. Intell. 2022, 52, 10805–10828. [Google Scholar] [CrossRef]
- Kahraman, H.T.; Katı, M.; Aras, S.; Taşci, D.A. Development of the Natural Survivor Method (NSM) for designing an updating mechanism in metaheuristic search algorithms. Eng. Appl. Artif. Intell. 2023, 122, 106121. [Google Scholar] [CrossRef]
- Hertz, A.; Werra, D.d. Using tabu search techniques for graph coloring. Computing 1987, 39, 345–351. [Google Scholar] [CrossRef]
- Ekinci, S.; Izci, D. Enhanced reptile search algorithm with Lévy flight for vehicle cruise control system design. Evol. Intell. 2023, 16, 1339–1351. [Google Scholar] [CrossRef]
- Syama, S.; Ramprabhakar, J.; Anand, R.; Guerrero, J.M. A hybrid extreme learning machine model with lévy flight chaotic whale optimization algorithm for wind speed forecasting. Results Eng. 2023, 19, 101274. [Google Scholar] [CrossRef]
- He, Q.; Liu, H.; Ding, G.; Tu, L. A modified Lévy flight distribution for solving high-dimensional numerical optimization problems. Math. Comput. Simul. 2023, 204, 376–400. [Google Scholar] [CrossRef]
- Zhang, B.; Liu, W.; Cai, Y.; Zhou, Z.; Wang, L.; Liao, Q.; Fu, Z.; Cheng, Z. State of health prediction of lithium-ion batteries using particle swarm optimization with Levy flight and generalized opposition-based learning. J. Energy Storage 2024, 84, 110816. [Google Scholar] [CrossRef]
- Hussien, A.M.; Hasanien, H.M.; Qais, M.H.; Alghuwainem, S. Hybrid Transient Search Algorithm with Levy Flight for Optimal PI Controllers of Islanded Microgrids. IEEE Access 2024, 12, 15075–15092. [Google Scholar] [CrossRef]
- Barua, S.; Merabet, A. Lévy Arithmetic Algorithm: An enhanced metaheuristic algorithm and its application to engineering optimization. Expert Syst. Appl. 2024, 241, 122335. [Google Scholar] [CrossRef]
- Pashaei, E.; Pashaei, E. Hybrid binary COOT algorithm with simulated annealing for feature selection in high-dimensional microarray data. Neural Comput. Appl. 2023, 35, 353–374. [Google Scholar] [CrossRef]
- Xu, R.; Zhao, C.; Li, J.; Hu, J.; Hou, X. A hybrid improved-whale-optimization–simulated-annealing algorithm for trajectory planning of quadruped robots. Electronics 2023, 12, 1564. [Google Scholar] [CrossRef]
- Fontes, D.B.; Homayouni, S.M.; Gonçalves, J.F. A hybrid particle swarm optimization and simulated annealing algorithm for the job shop scheduling problem with transport resources. Eur. J. Oper. Res. 2023, 306, 1140–1157. [Google Scholar] [CrossRef]
- Sajjad, F.; Rashid, M.; Zafar, A.; Zafar, K.; Fida, B.; Arshad, A.; Riaz, S.; Dutta, A.K.; Rodrigues, J.J. An efficient hybrid approach for optimization using simulated annealing and grasshopper algorithm for IoT applications. Discov. Internet Things 2023, 3, 7. [Google Scholar] [CrossRef]
- Agushaka, J.O.; Ezugwu, A.E.; Abualigah, L.; Alharbi, S.K.; Khalifa, H.A.E.W. Efficient initialization methods for population-based metaheuristic algorithms: A comparative study. Arch. Comput. Methods Eng. 2023, 30, 1727–1787. [Google Scholar] [CrossRef]
- Kazimipour, B.; Li, X.; Qin, A.K. A review of population initialization techniques for evolutionary algorithms. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 2585–2592. [Google Scholar]
- Tharwat, A.; Schenck, W. Population initialization techniques for evolutionary algorithms for single-objective constrained optimization problems: Deterministic vs. stochastic techniques. Swarm Evol. Comput. 2021, 67, 100952. [Google Scholar] [CrossRef]
- Kahraman, H.T.; Aras, S.; Gedikli, E. Fitness-distance balance (FDB): A new selection method for meta-heuristic search algorithms. Knowl.-Based Syst. 2020, 190, 105169. [Google Scholar] [CrossRef]
- Ozkaya, B.; Kahraman, H.T.; Duman, S.; Guvenc, U. Fitness-Distance-Constraint (FDC) based guide selection method for constrained optimization problems. Appl. Soft Comput. 2023, 144, 110479. [Google Scholar] [CrossRef]
- Duman, S.; Kahraman, H.T.; Kati, M. Economical operation of modern power grids incorporating uncertainties of renewable energy sources and load demand using the adaptive fitness-distance balance-based stochastic fractal search algorithm. Eng. Appl. Artif. Intell. 2023, 117, 105501. [Google Scholar] [CrossRef]
- Kahraman, H.T.; Bakir, H.; Duman, S.; Katı, M.; Aras, S.; Guvenc, U. Dynamic FDB selection method and its application: Modeling and optimizing of directional overcurrent relays coordination. Appl. Intell. 2022, 52, 4873–4908. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Wu, G.; Mallipeddi, R.; Suganthan, P.N. Problem Definitions and Evaluation Criteria for the CEC 2017 Competition on Constrained Real-Parameter Optimization; Technical Report; National University of Defense Technology: Changsha, China; Kyungpook National University: Daegu, Republic of Korea; Nanyang Technological University: Singapore, 2017. [Google Scholar]
- Al-Betar, M.A.; Alyasseri, Z.A.A.; Awadallah, M.A.; Abu Doush, I. Coronavirus herd immunity optimizer (CHIO). Neural Comput. Appl. 2021, 33, 5011–5042. [Google Scholar] [CrossRef]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A gravitational search algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Salawudeen, A.T.; Mu’azu, M.B.; Yusuf, A.; Adedokun, A.E. A Novel Smell Agent Optimization (SAO): An extensive CEC study and engineering application. Knowl.-Based Syst. 2021, 232, 107486. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Houssein, E.H.; Oliva, D.; Samee, N.A.; Mahmoud, N.F.; Emam, M.M. Liver Cancer Algorithm: A novel bio-inspired optimizer. Comput. Biol. Med. 2023, 165, 107389. [Google Scholar] [CrossRef]
- Mezura-Montes, E.; Coello, C.A.C. Useful infeasible solutions in engineering optimization with evolutionary algorithms. In Proceedings of the Mexican International Conference on Artificial Intelligence, Monterrey, Mexico, 14–18 November 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 652–662. [Google Scholar]
- Kannan, B.; Kramer, S.N. An augmented Lagrange multiplier based method for mixed integer discrete continuous optimization and its applications to mechanical design. J. Mech. Des. 1994, 116, 405–411. [Google Scholar] [CrossRef]
- Hashim, F.A.; Hussain, K.; Houssein, E.H.; Mabrouk, M.S.; Al-Atabany, W. Archimedes optimization algorithm: A new metaheuristic algorithm for solving optimization problems. Appl. Intell. 2021, 51, 1531–1551. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).