Previous research has demonstrated that when Transformer is directly applied to multidimensional time series data, there are issues of mutual interference and noise between data of different dimensions. In light of the aforementioned issues, this paper proposes a multi-channel network traffic anomaly detection model, MTC-Net, which combines Transformer with a convolutional neural network (CNN) [
23]. The model decomposes the network traffic sequence into multiple one-dimensional time series and introduces the Patch strategy, which enables the model to achieve the best performance in terms of both local feature sensitivity and global feature capturing ability. The backbone network incorporates essential elements, including the Transformer encoder and CNN, as illustrated in
Figure 1.
3.1. Design of Model Architecture
The network traffic sequence is a multi-channel signal, and each Transformer input token can be represented by data from a single channel or multiple channels. In this context, channel independence signifies that each input token contains information from a single channel only. To enhance the model’s capacity to discern local features, we propose the incorporation of the Patch strategy. This strategy employs the concept of image segmentation, whereby images are divided into smaller units (patches), as a means of processing sequence data. In MTC-Net, the term “Patch” denotes the partitioning of each sub-sequence into a series of discrete segments of a fixed length. These segments are then employed as input tokens for the Transformer, enabling the effective capture of short-term dependencies and local patterns within the sequence [
24].
In MTC-Net, the network traffic data are divided into multiple sub-sequences, each of which is encoded with Transformer. This process is an effective means of capturing potential dependencies in sequences, both short-term and long-term. Furthermore, the incorporation of positional encoding guarantees that the model is able to accurately comprehend the sequence ordering of these sub-sequences during processing. The aforementioned encoding enables the model to demonstrate enhanced resilience and precision in the context of network attacks characterised by long-range dependencies, such as DDoS attacks.
3.1.1. Patch Strategy and Channel Independence
A network traffic sequence is a multi-channel signal, and each Transformer input token can be represented by data from a single channel or multiple channels. Channel mixing refers to the process of combining vectors representing all sequence features into a single embedding space, thereby mixing the information. This is in contrast to channel independence, which implies that each input token only contains information from a single channel [
25]. To enhance the model’s capacity to discern local features, we propose the introduction of the Patch strategy. This strategy employs the concept of image segmentation, whereby images are divided into smaller units (patches), as a means of processing sequence data. In MTC-Net, the term “Patch” denotes the partitioning of each sub-sequence into a series of discrete segments of a fixed length. These segments are then employed as input tokens for the Transformer, thereby achieving channel independence. This approach facilitates the effective capture of short-term dependencies and local patterns within the sequence.
The introduction of this strategy offers multiple advantages. Firstly, the Patch strategy reduces the number of tokens entered into the Transformer each time, thus reducing the computational complexity. Secondly, the positional encoding ensures that the sequential information of the sequences is preserved. Thirdly, the application of the Patch strategy allows the model to better detect local anomalies in network traffic [
26], such as in the attack patterns that occur with high frequency within a short period of time. This approach can be employed to identify network traffic anomalies characterised by local irregularities.
3.1.2. Combining Convolutional Neural Networks (CNNs)
Following the implementation of the Transformer encoder, we introduce a convolutional neural network (CNN) for the purpose of reducing the dimensionality of the data set and facilitating the extraction of additional features. The CNN is capable of handling high-dimensional data sets and of capturing local patterns with great efficacy. The convolution operation enables the CNN to effectively identify local features in the data, while the pooling operation facilitates the reduction in feature dimensions. This avoids the accumulation of excessive data dimensions in the input classification header, thereby enhancing the robustness of the model.
In MTC-Net, each sub-sequence is processed by both the Transformer and CNN, resulting in the generation of a feature vector. Subsequently, the feature vectors of all sub-sequences are merged to create a comprehensive feature representation, which is then input to the fully connected layer. This allows for the integration of features extracted from all channels, facilitating the final classification operation. This combination enables the model to capture global dependencies and extract key local features, thereby significantly enhancing the accuracy and robustness of anomaly detection.
This design offers several significant advantages. The Patch strategy enables the model to reduce the length of the input sequence, thereby reducing the computational complexity and improving computational efficiency. This allows MTC-Net to maintain a low level of computational resource usage when processing large data sets.
The introduction of the Transformer encoder enables the model to effectively capture long temporal dependencies, which is a significant advancement in the field of machine learning. This is particularly crucial for anomaly detection in network traffic data, as certain anomalous behaviours may manifest themselves as minor alterations over an extended timespan. Consequently, accurate detection can only be achieved through the analysis of long time series.
The modular design of MTC-Net allows for flexibility in processing, with each Patch capable of independent operation and channel independence ensuring scalability. This adaptability to data sets of varying sizes and application scenarios is a key advantage of MTC-Net.
3.2. MTC-Net
At present, there are still a relatively limited number of studies that can effectively address the problem of network traffic sequence modelling, and thus there is a large gap in this field. Transformer has emerged as a powerful option in network traffic sequence modelling research due to its inherent ability to process sequence data and capture complex relationships between elements at different locations in the sequence.
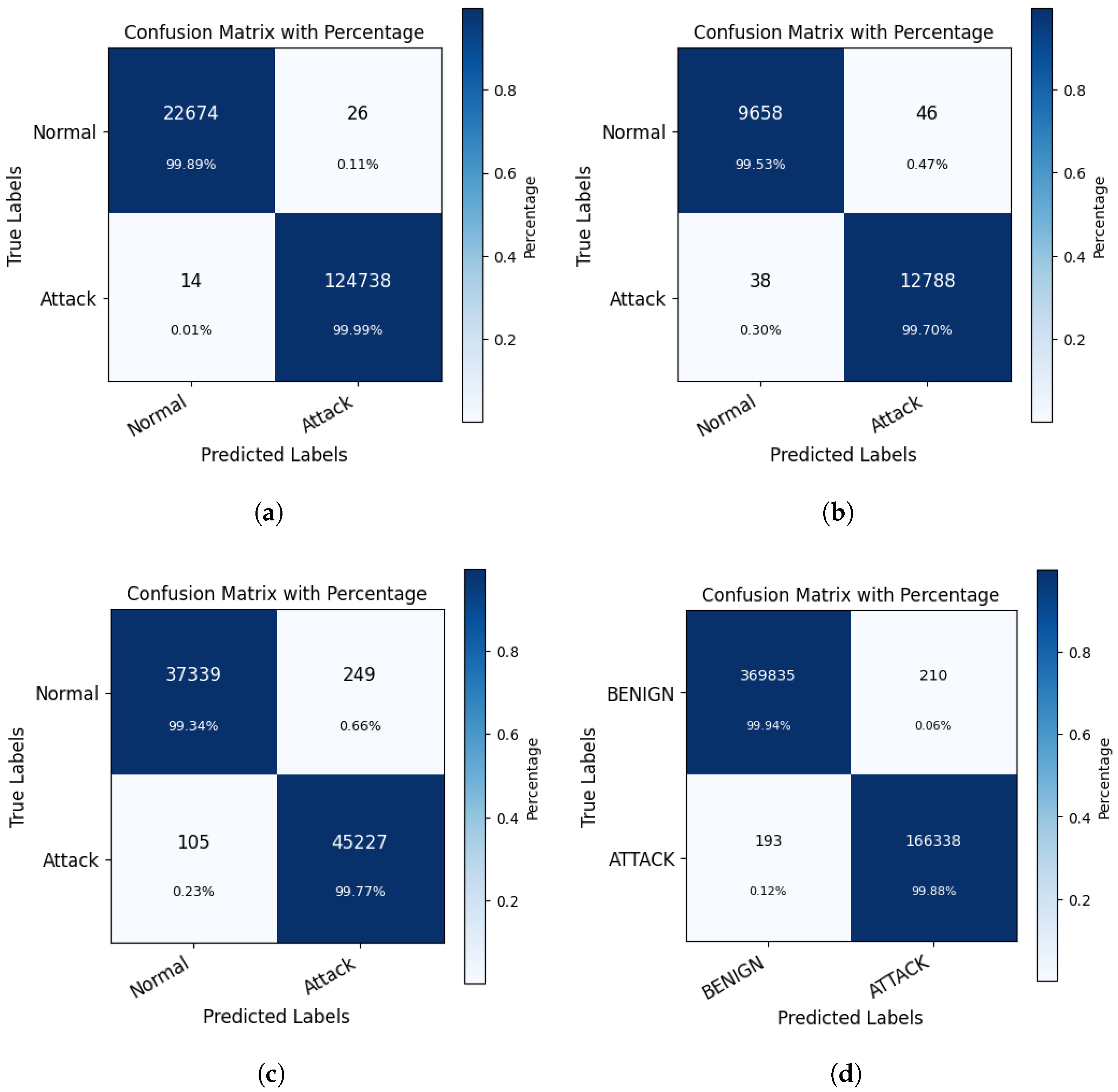
In our study, we propose a deep neural network for network traffic anomaly detection, called MTC-Net, as shown in
Figure 1. MTC-Net consists of three main modules: a data processing module, a Transformer–CNN (
TC) module, and an output prediction module.
First, we pre-process the original network traffic data set to ensure the high quality of the input data. Taking the CIC-IDS2017 data set as an example, the pre-processing mainly consists of the following three steps:
Attribute numerisation: First, the string type attributes in the data set are converted to numeric types. This step ensures that the data can be correctly processed and understood by the model.
Data normalisation: To normalise the data set, a min-max normalisation method is used, which maps the value ranges of all variables to between 0 and 1. This helps to eliminate the negative effects of differences in the magnitude of different variables on model training, thus improving the convergence speed and performance of the model.
Timestamp extraction and serialisation: We extract the raw timestamp information from the data set for additional temporal embedding before the sequence is fed into the model, and use full-connectivity embedding directly for data sets without timestamp information. Timestamps are key time series data that can help the model to capture temporal dependencies and sequential information. After pre-processing the data, we perform a serialisation operation on the processed data set to generate the flow-serialised data.
Finally, we obtain the original sequence L: with window size L, where each is a vector of dimension M. Then, we need to embed the sequence and then feed the sequence into the mesh. First, we need to split the sequence into M sub-sequences and input each sub-sequence as a channel into the TC module for individual feature extraction.
In the TC module, we first process the sub-sequence , reshape the sequence according to the step size S, and generate the sequence of length W. In the process, each Patch can be chosen to overlap or not. Here, P denotes the number of patches generated. By using patches, the number of input tokens can be reduced from L to about . This reduces the space and time complexity of the attention weighting with respect to . Immediately after that, the sequences are mapped into a D-dimensional high-dimensional potential space, , using a projection layer via a trainable linear projection, . To capture temporal relationships and local features in the sequences, we introduce learnable additional positional encodings to ensure that the model is able to understand the order of the Patch, thus enhancing the model’s ability to understand the data.
The processed sub-sequences are fed into the Transformer layer separately. In the multi-head attention mechanism, each head,
, transforms the input into query matrix
, key matrix
and value matrix
, and then obtains the attention output:
As shown in
Figure 1, the output structure is fed into the feed-forward neural network (FFN) using residual connection and regularisation operations, and another residual connection is performed. To further extract the effective features and reduce the dimension of the expanded features, after processing by Transformer, we feed the output into the convolutional neural network (CNN) for convolution operation, and perform Max Pooling on the convolved result.
denotes the elements of the convolution output feature matrix;
X denotes the input feature map;
W denotes the convolution kernel;
b denotes the bias term;
M and N are the convolution kernel height and width, respectively.
denotes the element of the pooled output feature matrix;
Y denotes the input feature map after convolution;
and are the starting positions of the pooling window;
M and N are the height and width of the pooling window, respectively.
We combine the outputs of all the sub-sequences processed by the TC module to obtain a complete sequence, , for the next classification operation. By integrating the outputs of the sub-sequences processed by the TC module, the model fully exploits the information of each channel and transforms this information into outputs through the fully connected layer to obtain the final prediction results.







{kind=link}
{kind=link}
{kind=link}
{kind=link}