
An Angular Acceleration Based Looming Detector for Moving UAVs


Abstract
1. Introduction
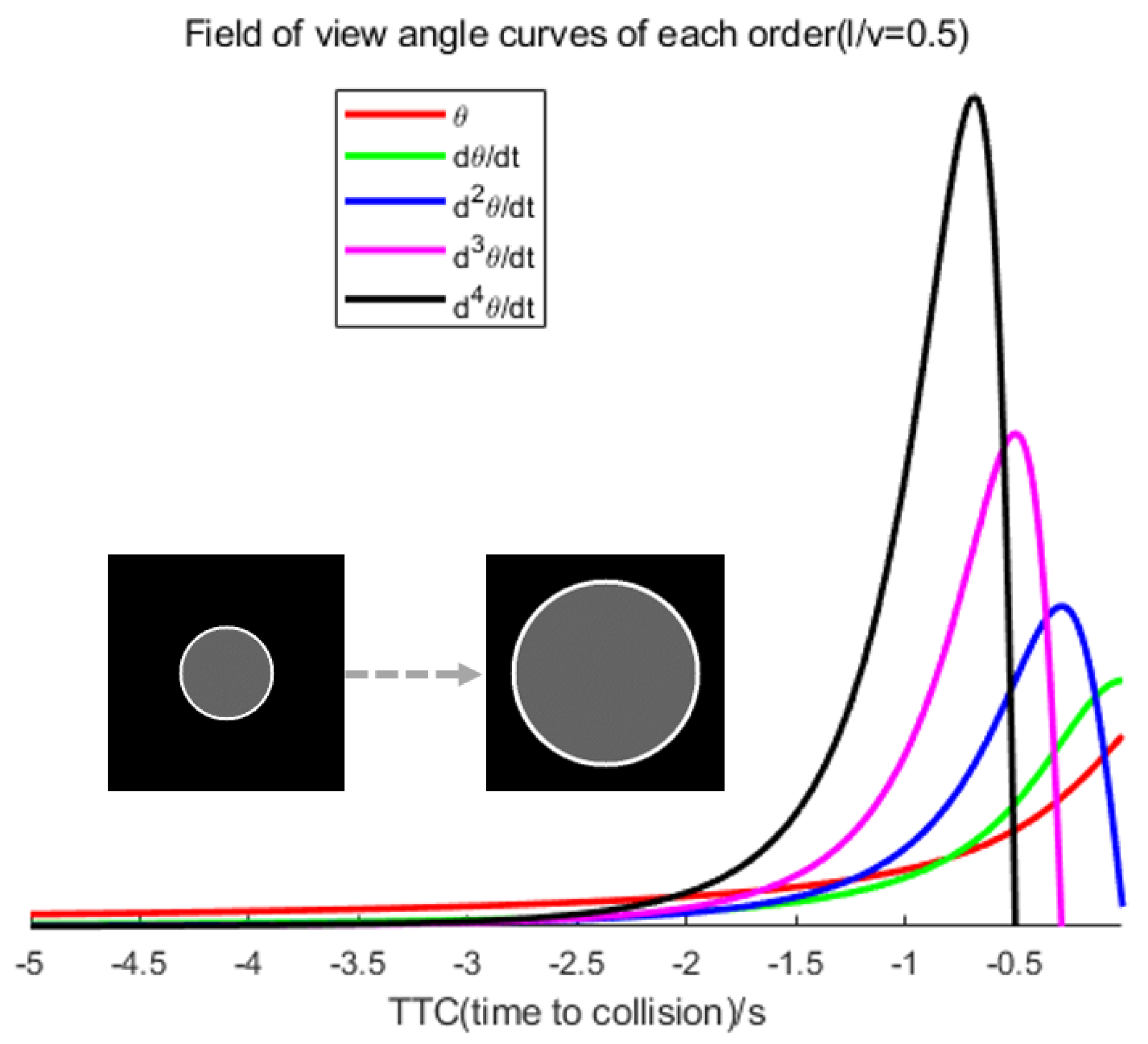
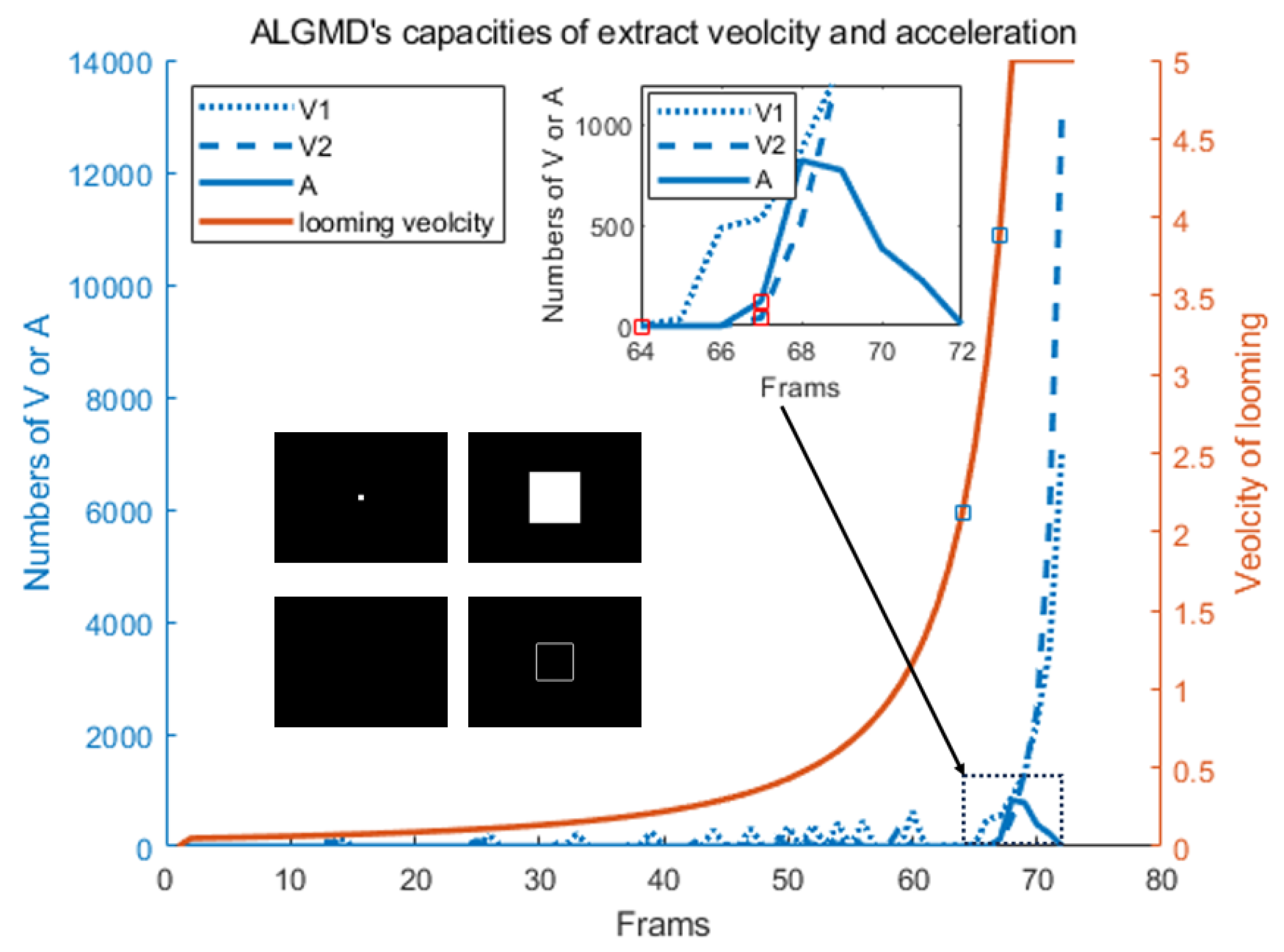
- We deduce that there exist peaks in the curves of the high-order (≥2) differentials of the angular size of a looming object. In particular, the peaks of these curves occur earlier as the differential order increases. This suggests that it is worth increasing the alarming TTC of a looming detection model by introducing higher-order information on the angular size.
- Based on the D-LGMD model, which is an angular velocity-focused algorithm, we introduce the angular acceleration cues, intending to increase sensibility and acquire an earlier alarm time before a collision.
- We have conducted a systematic analysis and comparison of the performance of the proposed A-LGMD model with various other bionic looming detection models in different scenarios. The experimental results demonstrate that the proposed model has a distinct tendency toward looming objects in the observer’s motion and is capable of fulfilling the collision detection task of UAVs.
2. Related Work
2.1. Looming Visual Cues
2.2. Bionic Looming Detection Algorithms
2.3. LGMD Neuron Properties and Model Applications
3. Method
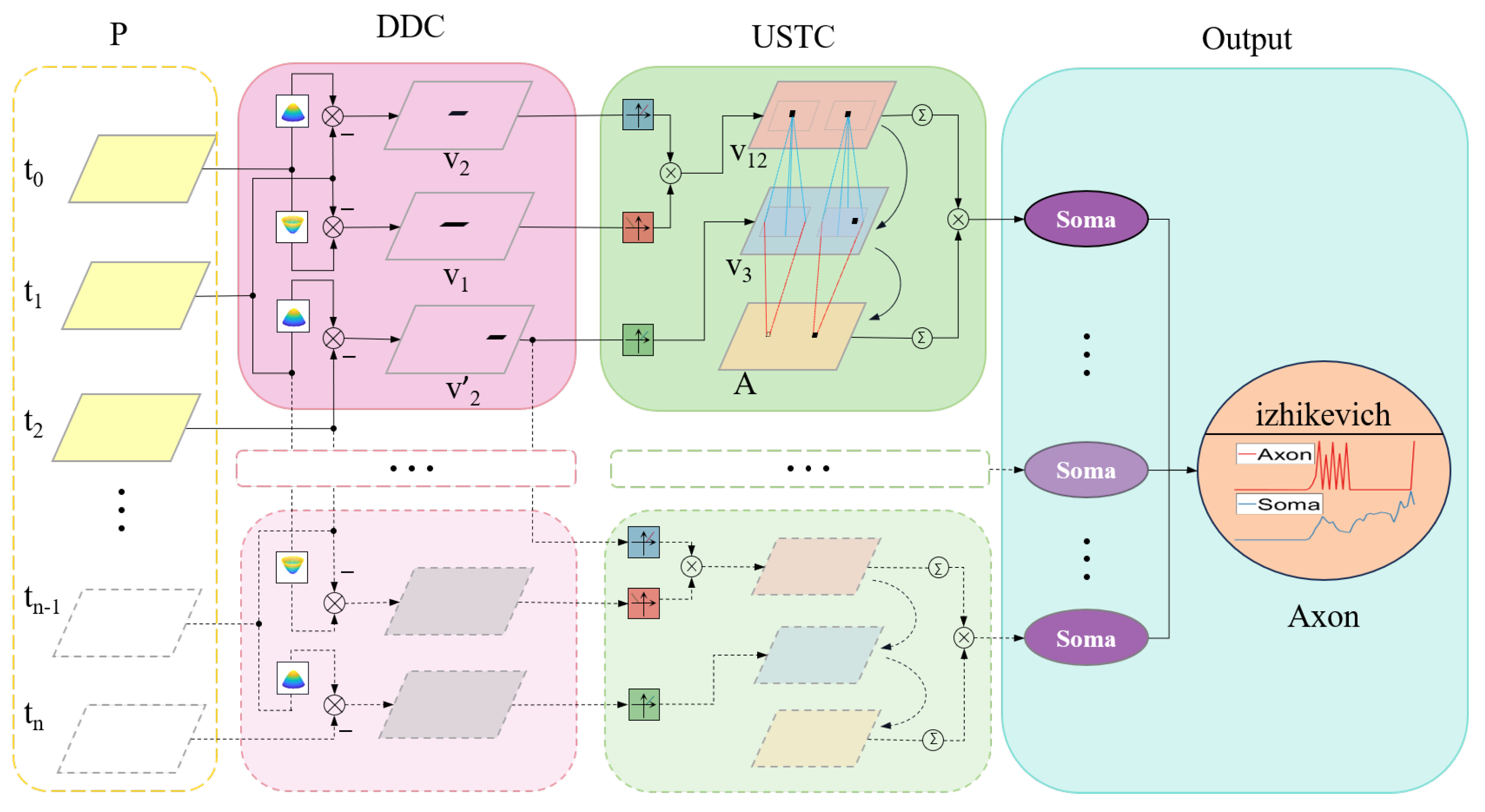
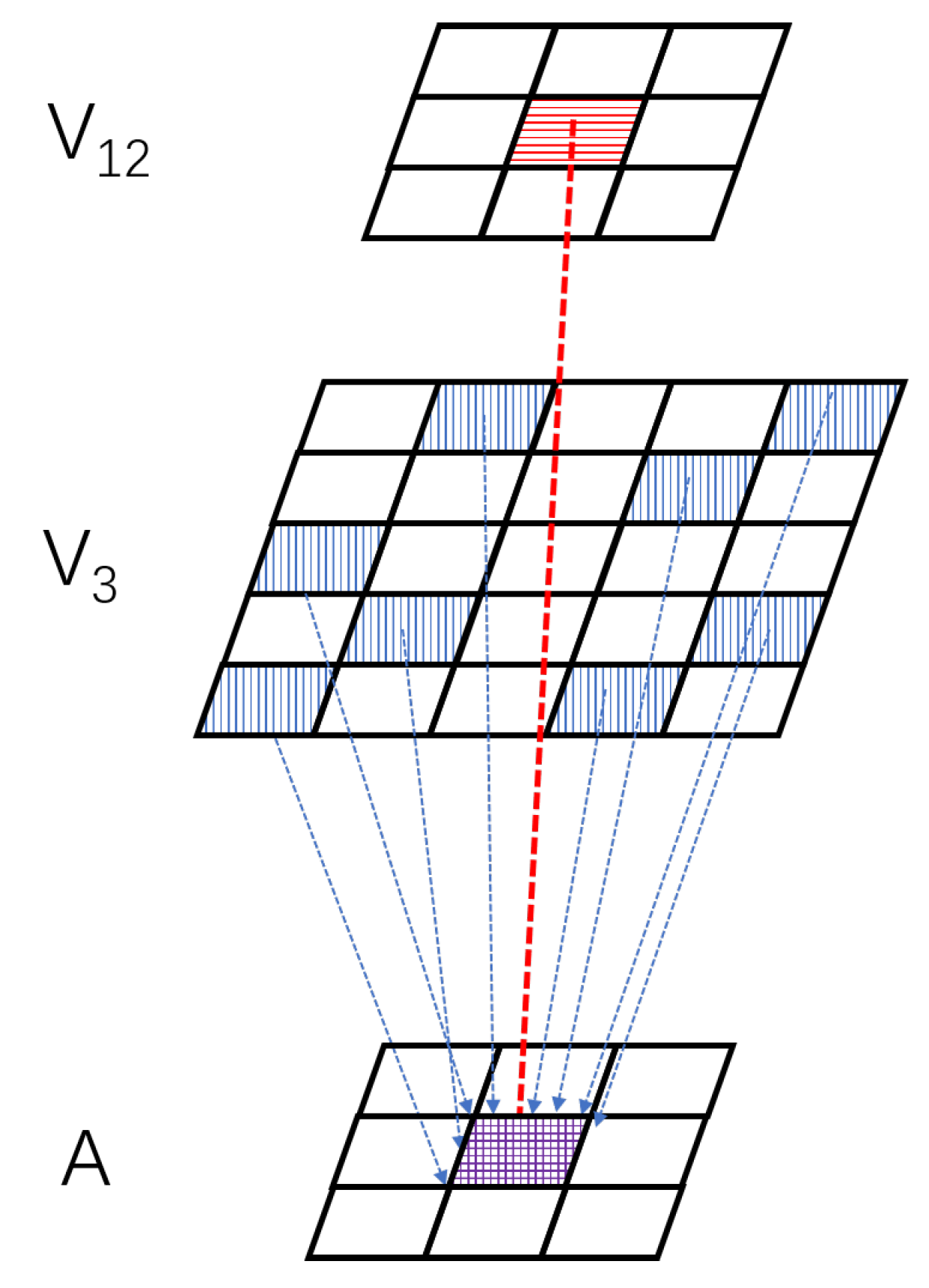
3.1. Mechanism and Schematic
- Dual-channel extraction of angular velocity from images;
- The activation of angular velocity information is delayed, allowing for the aggregation of angular acceleration information;
- Multiple cues for looming stimuli are fused, and warning signals are triggered by peaks.
3.2. Photoreceptor Layer
3.3. Distribution Dual-Channel Layer
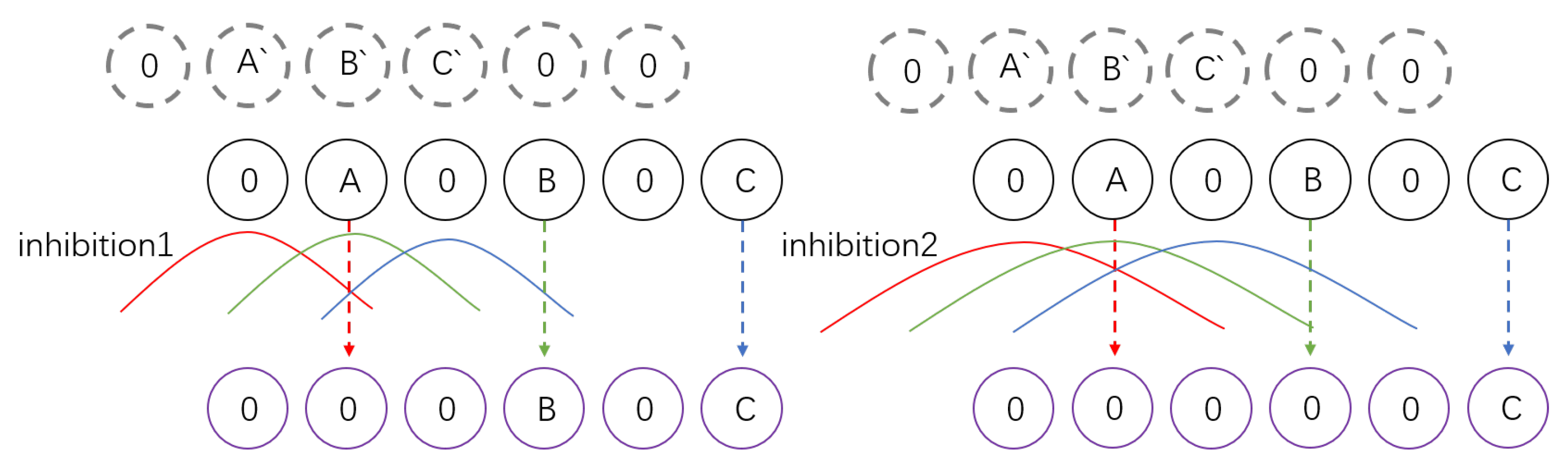
3.4. Ultra-Spatiotemporal Connection Layer
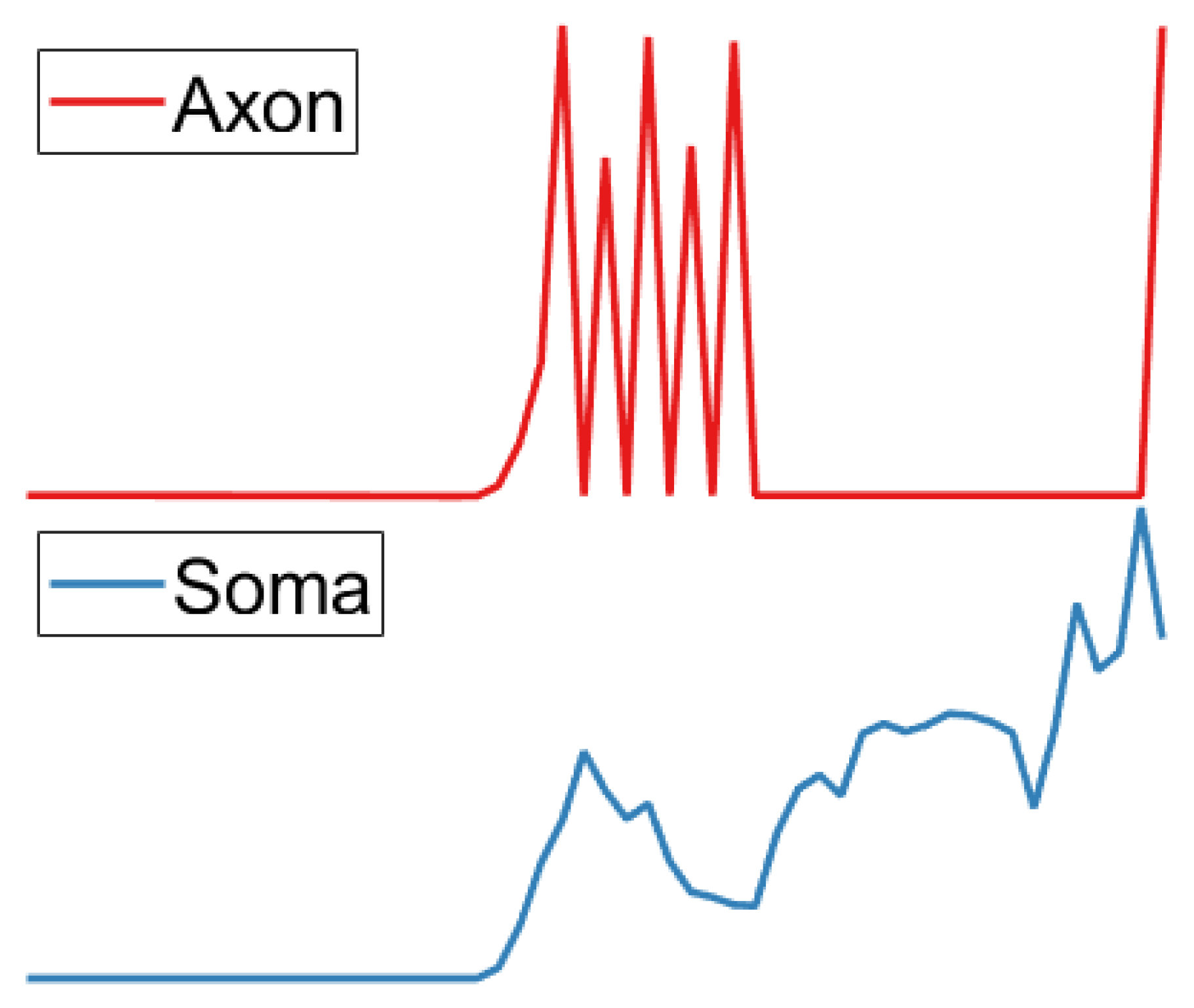
3.5. Soma Layer
3.6. Axon Layer
4. Experiments and Results
4.1. Experimental Set-up
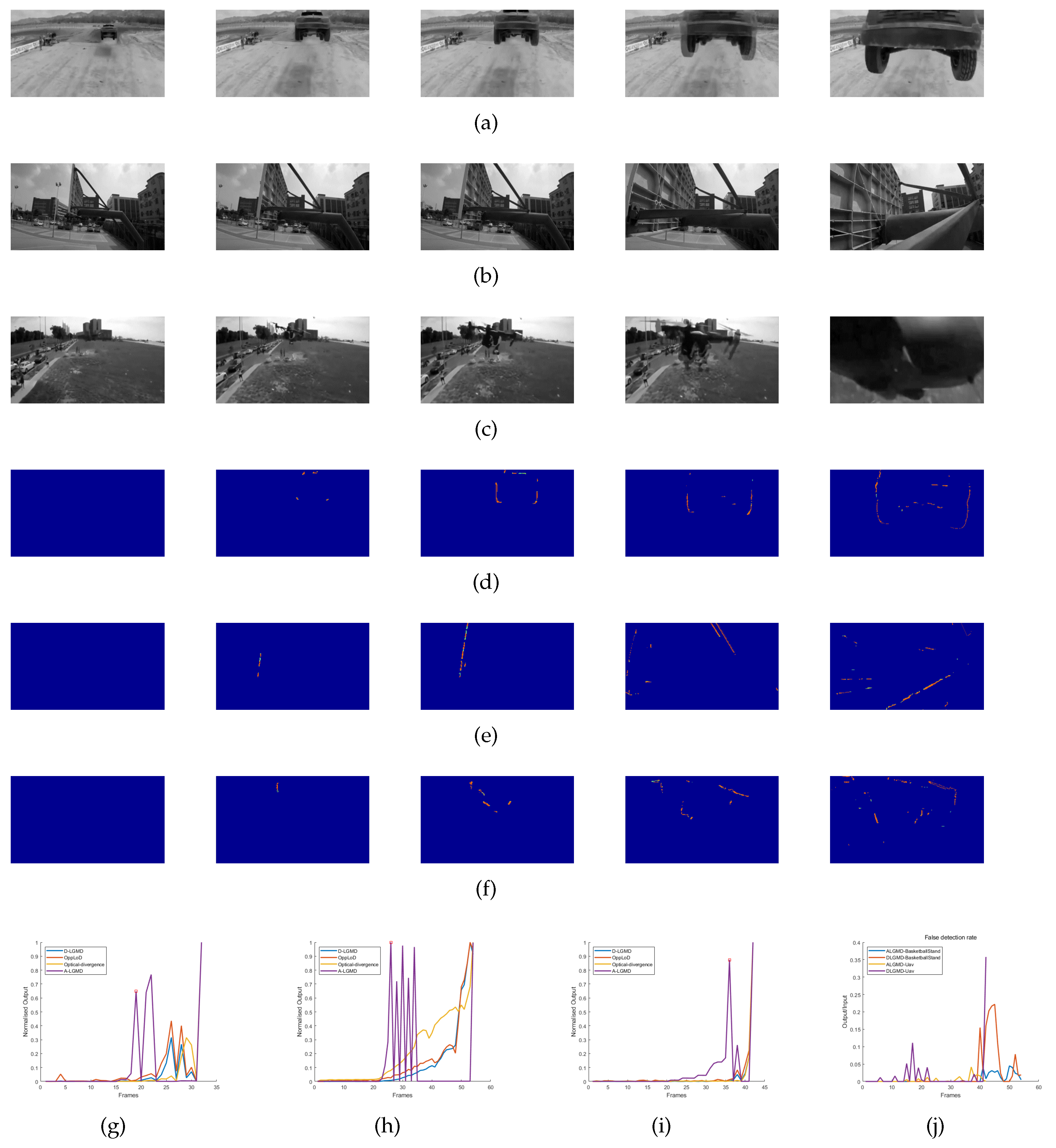
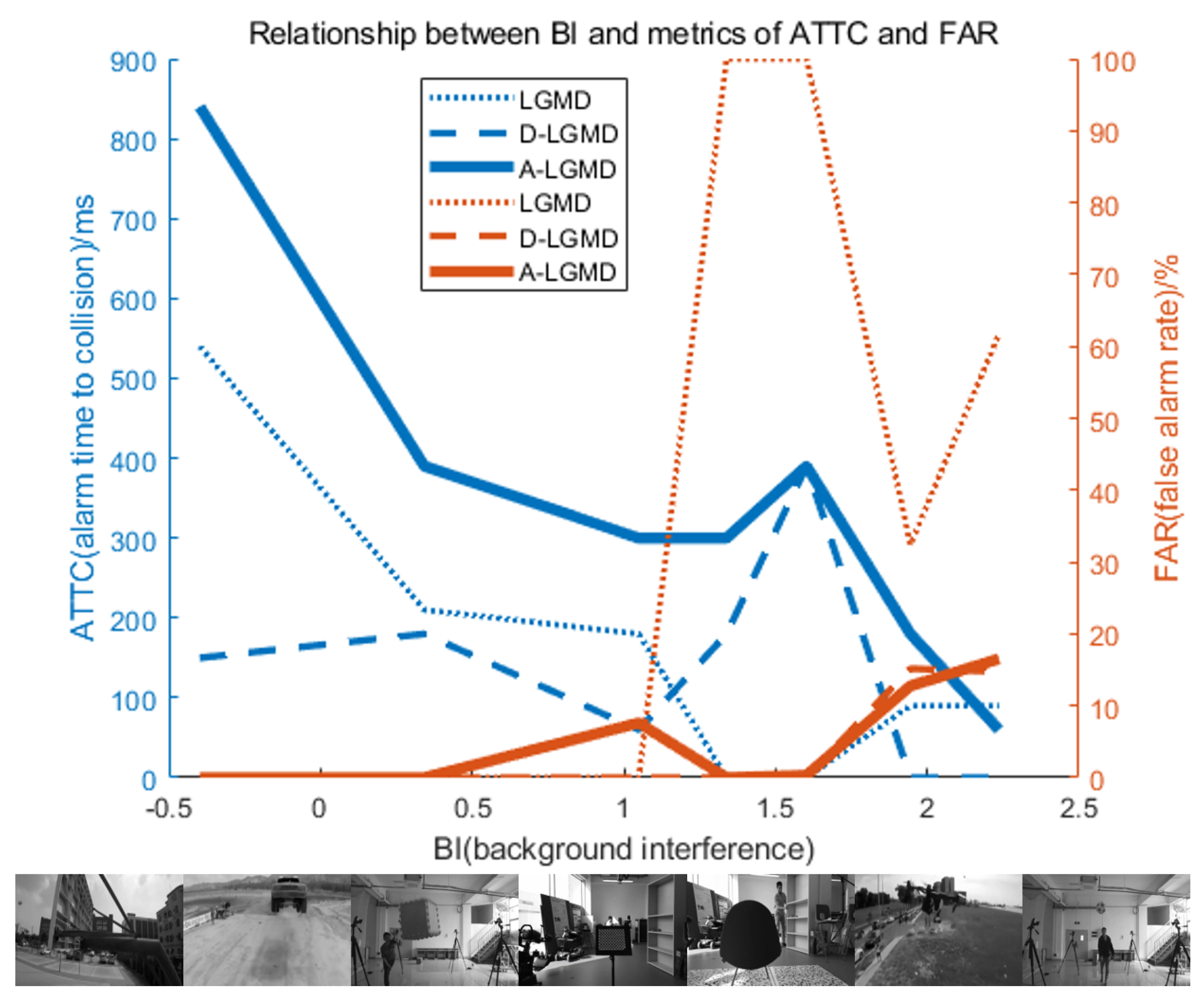
4.2. Model Characteristic Analysis
4.3. Real UAV Experiment
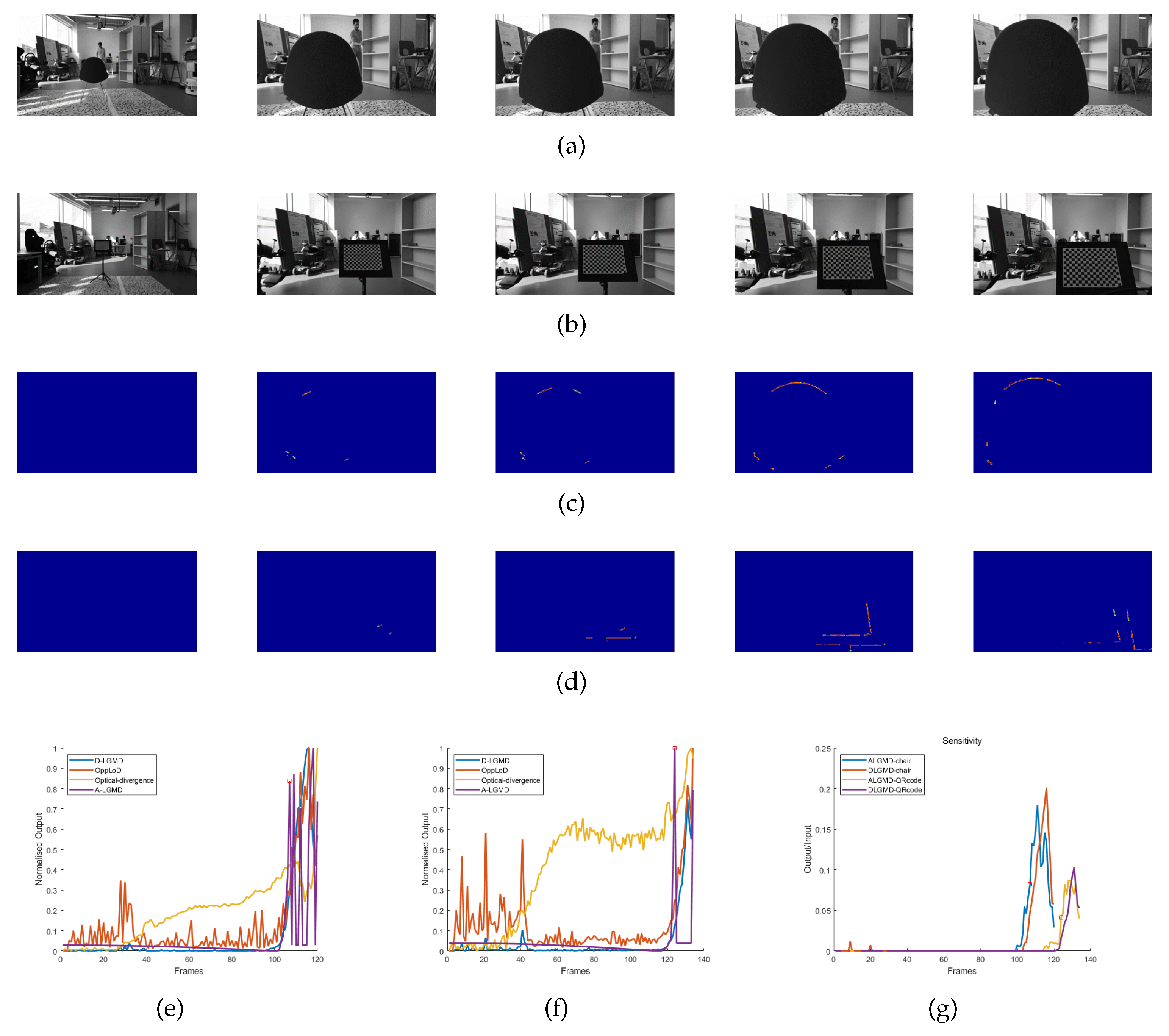
4.3.1. Indoor Simulated Collision Flight Experiments
4.3.2. Outdoor Real Collision Tests
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
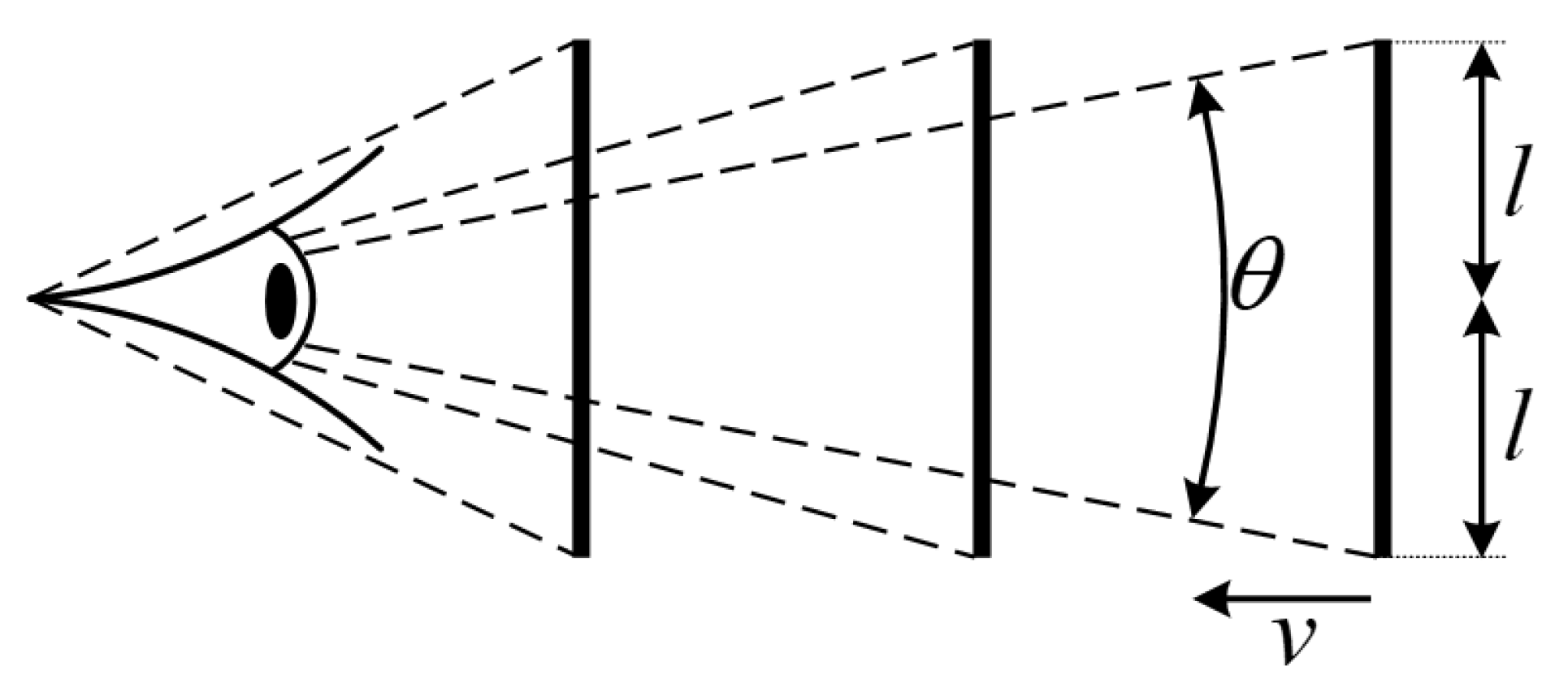
Appendix A. Problem Formulation

References
- Bachrach, A.; He, R.; Roy, N. Autonomous flight in unknown indoor environments. Int. J. Micro Air Veh. 2009, 1, 217–228. [Google Scholar] [CrossRef]
- Xiang, Y.; Zhang, Y. Sense and avoid technologies with applications to unmanned aircraft systems: Review and prospects. Prog. Aerosp. Sci. 2015, 74, 152–166. [Google Scholar]
- Zhou, B.; Li, Z.; Kim, S.; Lafferty, J.; Clark, D.A. Shallow neural networks trained to detect collisions recover features of visual loom-selective neurons. eLife 2022, 11, e72067. [Google Scholar] [CrossRef] [PubMed]
- Rind, F.C.; Simmons, P.J. Orthopteran DCMD neuron: A reevaluation of responses to moving objects. I. Selective responses to approaching objects. J. Neurophysiol. 1992, 68, 1654–1666. [Google Scholar] [CrossRef] [PubMed]
- Temizer, I.; Donovan, J.C.; Baier, H.; Semmelhack, J.L. A Visual Pathway for Looming-Evoked Escape in Larval Zebrafish. Curr. Biol. 2015, 25, 1823–1834. [Google Scholar]
- Sato, K.; Yamawaki, Y. Role of a looming-sensitive neuron in triggering the defense behavior of the praying mantis Tenodera aridifolia. J. Neurophysiol. 2014, 25, 671–683. [Google Scholar]
- Gabbiani, F.; Krapp, H.G.; Laurent, G. Computation of Object Approach by a Wide-Field, Motion-Sensitive Neuron. J. Neurosci. 1999, 19, 1122–1141. [Google Scholar] [CrossRef] [PubMed]
- Rind, F.C. Motion detectors in the locust visual system: From biology to robot sensors. Microsc. Res. Tech. 2002, 56, 256–269. [Google Scholar] [CrossRef] [PubMed]
- Rind, F.C.; Simmons, P.J. Seeing what is coming: Building collision-sensitive neurones. Trends Neurosci. 1999, 22, 215–220. [Google Scholar] [CrossRef]
- Yakubowski, J.M.; Mcmillan, G.A.; Gray, J.R. Background visual motion affects responses of an insect motion-sensitive neuron to objects deviating from a collision course. Physiol. Rep. 2016, 4, e12801. [Google Scholar] [CrossRef]
- Yue, S.; Rind, F.C. Collision detection in complex dynamic scenes using an LGMD-based visual neural network with feature enhancement. IEEE Trans. Neural Netw. 2006, 17, 705–716. [Google Scholar]
- Fotowat, H.; Gabbiani, F. Collision Detection as a Model for Sensory-Motor Integration. Annu. Rev. Neurosci. 2011, 34, 1. [Google Scholar] [CrossRef]
- Wang, Y.; Frost, B.J. Time to collision is signaled by neurons in the nucleus rotundus of pigeons. Nature 1992, 356, 236–238. [Google Scholar] [CrossRef] [PubMed]
- O’Shea, M.; Rowell, C. The neuronal basis of a sensory analyser, the acridid movement detector system. II. response decrement, convergence, and the nature of the excitatory afferents to the fan-like dendrites of the LGMD. J. Exp. Biol. 1976, 65, 289–308. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Wang, H.; Bellotto, N.; Hu, C.; Peng, J.; Yue, S. Enhancing LGMD’s Looming Selectivity for UAV With Spatial-Temporal Distributed Presynaptic Connections. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 2539–2553. [Google Scholar] [CrossRef] [PubMed]
- Klapoetke, N.C.; Nern, A.; Peek, M.Y.; Rogers, E.M.; Breads, P.; Rubin, G.M.; Reiser, M.B.; Card, G.M. Ultra-selective looming detection from radial motion opponency. Nature 2017, 551, 237–241. [Google Scholar] [CrossRef] [PubMed]
- Biggs, F.; Guedj, B. Non-Vacuous Generalisation Bounds for Shallow Neural Networks. In Proceedings of the International Conference on Machine Learning, Baltimore, MA, USA, 17–23 July 2022. [Google Scholar]
- Shuang, F.; Zhu, Y.; Xie, Y.; Zhao, L.; Xie, Q.; Zhao, J.; Yue, S. OppLoD: The Opponency based Looming Detector, Model Extension of Looming Sensitivity from LGMD to LPLC2. arXiv 2023, arXiv:2302.10284. [Google Scholar] [CrossRef]
- Reiser, M.B.; Dickinson, M.H. Drosophila fly straight by fixating objects in the face of expanding optic flow. J. Exp. Biol. 2010, 213, 1771–1781. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Rind, F.C.; Bramwell, D. Neural network based on the input organization of an identifiedneuron signaling impending collision. J. Neurophysiol. 1996, 75, 967–985. [Google Scholar] [CrossRef] [PubMed]
- Fu, Q.; Yue, S. Modelling lgmd2 visual neuron system. In Proceedings of the 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Lei, F.; Peng, Z.; Liu, M.; Peng, J.; Cutsuridis, V.; Yue, S. A Robust Visual System for Looming Cue Detection Against Translating Motion. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8362–8376. [Google Scholar] [CrossRef]
- Graham, L. How not to get caught. Nat. Neurosci. 2002, 5, 1256–1257. [Google Scholar] [CrossRef]
- Silva, A.C.; Mcmillan, G.A.; Santos, C.P.; Gray, J.R. Background complexity affects response of a looming-sensitive neuron to object motion. J. Neurophysiol. 2015, 113, 218–231. [Google Scholar] [CrossRef][Green Version]
- Fotowat, H.; Harrison, R.R.; Gabbiani, F. Multiplexing of motor information in the discharge of a collision detecting neuron during escape behaviors. Neuron 2011, 69, 147–158. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Arvin, F.; Yue, S. Development of a bio-inspired vision system for mobile micro-robots. In Proceedings of the Joint IEEE International Conferences on Development and Learning and Epigenetic Robotics, Genoa, Italy, 13–16 October 2014; pp. 81–86. [Google Scholar]
- Izhikevich, E. Which model to use for cortical spiking neurons? IEEE Trans. Neural Netw. 2004, 15, 1063–1070. [Google Scholar] [CrossRef] [PubMed]
- Cuntz, H.; Borst, A.; Segev, I. Optimization principles of dendritic structure. Theor. Biol. Med. Model. 2007, 4, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Cuntz, H.; Forstner, F.; Borst, A.; Häusser, M.; Morrison, A. One Rule to Grow Them All: A General Theory of Neuronal Branching and Its Practical Application. PLoS Comput. Biol. 2010, 6, e1000877. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Mandel, H.B.; Fitzgerald, J.E.; Clark, D.A. Asymmetric ON-OFF processing of visual motion cancels variability induced by the structure of natural scenes. eLife Sci. 2019, 8, e47579. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value |
|---|---|---|
| r1 | Slow inhibitory kernel’s radius in Equation (8) | 1 |
| r2 | Fast inhibitory kernel’s radius in Equation (8) | 2 |
| k1 | Activation function’s threshold in Equation (12) | 0.03 |
| k2 | Activation function’s threshold in Equation (12) | 0.1 |
| k3 | Activation function’s threshold in Equation (10) | 0.1 |
| a | Izhikevich model’s constants in Equation (14) | 0.02 |
| b | Izhikevich model’s constantsl in Equation (14) | 0.2 |
| c | Izhikevich model’s constants in Equation (15) | −65 |
| d | Izhikevich model’s constants in Equation (16) | 2 |
| Image Sequence | Background Complexity | Attitude Motion | Object Texture | Image Resolution | Collision Frame | Example of Frame Sequence |
|---|---|---|---|---|---|---|
| Compound Looming | None | None | White pixel | 240*320 | 72 | None |
| Group 1 | Cluttered Surroundings | Pitch Accelerating | Pure Color Chair | 240*320 | 120 | [3,104,107,111,115] |
| Group 2 | Cluttered Surroundings | Pitch Accelerating | Gridding Pattern | 240*320 | 134 | [3,120,124,129,134] |
| Group 3 | Simple Surroundings | Static | Moving SUV | 240*320 | 32 | [3,17,19,24,26] |
| Group 4 | Cluttered Surroundings | Low Speed Forward | Basketball Stands | 240*320 | 54 | [3,24,26,40,54] |
| Group 5 | Cluttered Surroundings | High Speed Forward | Flying UAV | 240*320 | 42 | [3,32,36,40,42] |
| Image Sequence | D-LGMD | OppLoD | Optical Divergence | A-LGMD |
|---|---|---|---|---|
| Group 1 | 390 | False | 690 | 390 |
| Group 2 | 180 | False | False | 300 |
| Group 3 | 180 | 210 | 180 | 390 |
| Group 4 | 150 | 150 | 570 | 840 |
| Group 5 | 0 | 0 | 0 | 180 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Xie, Q.; Shuang, F.; Yue, S. An Angular Acceleration Based Looming Detector for Moving UAVs. Biomimetics 2024, 9, 22. https://doi.org/10.3390/biomimetics9010022
Zhao J, Xie Q, Shuang F, Yue S. An Angular Acceleration Based Looming Detector for Moving UAVs. Biomimetics. 2024; 9(1):22. https://doi.org/10.3390/biomimetics9010022
Chicago/Turabian StyleZhao, Jiannan, Quansheng Xie, Feng Shuang, and Shigang Yue. 2024. "An Angular Acceleration Based Looming Detector for Moving UAVs" Biomimetics 9, no. 1: 22. https://doi.org/10.3390/biomimetics9010022
APA StyleZhao, J., Xie, Q., Shuang, F., & Yue, S. (2024). An Angular Acceleration Based Looming Detector for Moving UAVs. Biomimetics, 9(1), 22. https://doi.org/10.3390/biomimetics9010022