1. Introduction
As robotics advance, human-robot integration and human-robot interaction (HRI) have emerged as new research directions. To enable robots to seamlessly integrate into human daily life, it is essential to study HRI technology, especially physical human-robot interaction (pHRI) [
1]. One of the main research challenges is how to make robots learn the skills to interact with humans more effectively. A popular research topic is to make robots learn collaborative skills through an imitative learning approach. This approach allows robots to generalize a skill or task by imitating it, thus avoiding complex expert programming [
2,
3]. Common imitation learning methods include the Hidden Markov Model (HMM) [
4], the Gaussian Mixture Model (GMM) [
5], the Dynamical Movement Primitives (DMP) [
6], the Probabilistic Movement Primitives (ProMP) [
7], and the Kernelized Movement Primitives (KMP) [
8], etc.
Learning skills from demonstration samples is similar to a martial arts practitioner imitating a master’s movements, and a proficient student can acquire various features from the master’s demonstrations. Likewise, researchers expect robots to learn more features from the demonstration samples. To address robot skill learning, researchers have proposed the concept of dual-space feature learning [
9], where dual space usually refers to the task space and the joint space of the robot. Task space is a description of robot actions in Cartesian coordinates, and joint space is a description of robot actions in terms of joint angles. To perform complex and demanding tasks, the robot needs to learn different characteristics of skillful actions from both task space and joint space perspectives [
10,
11,
12]. For example, when a robot imitates a human to generate the motion of writing brush characters, it should not only match the end-effector trajectory to the writing specification, but also adjust the joint posture to resemble the human’s. Another example is when the robot operates in a dynamic environment where obstacles or targets may change their positions or orientations. By integrating the learned knowledge of both task space and joint space from demonstrations, the robot can adapt its motion to the changing situation and avoid collisions or reach the desired goal. Therefore, the learning algorithm should extract and fuse both end-effector and joint posture features from the demonstrated action.
These requirements are not only in the field of skill imitation learning but also in the field of HRI where it is desirable for the robot to learn more action features. In our previous work [
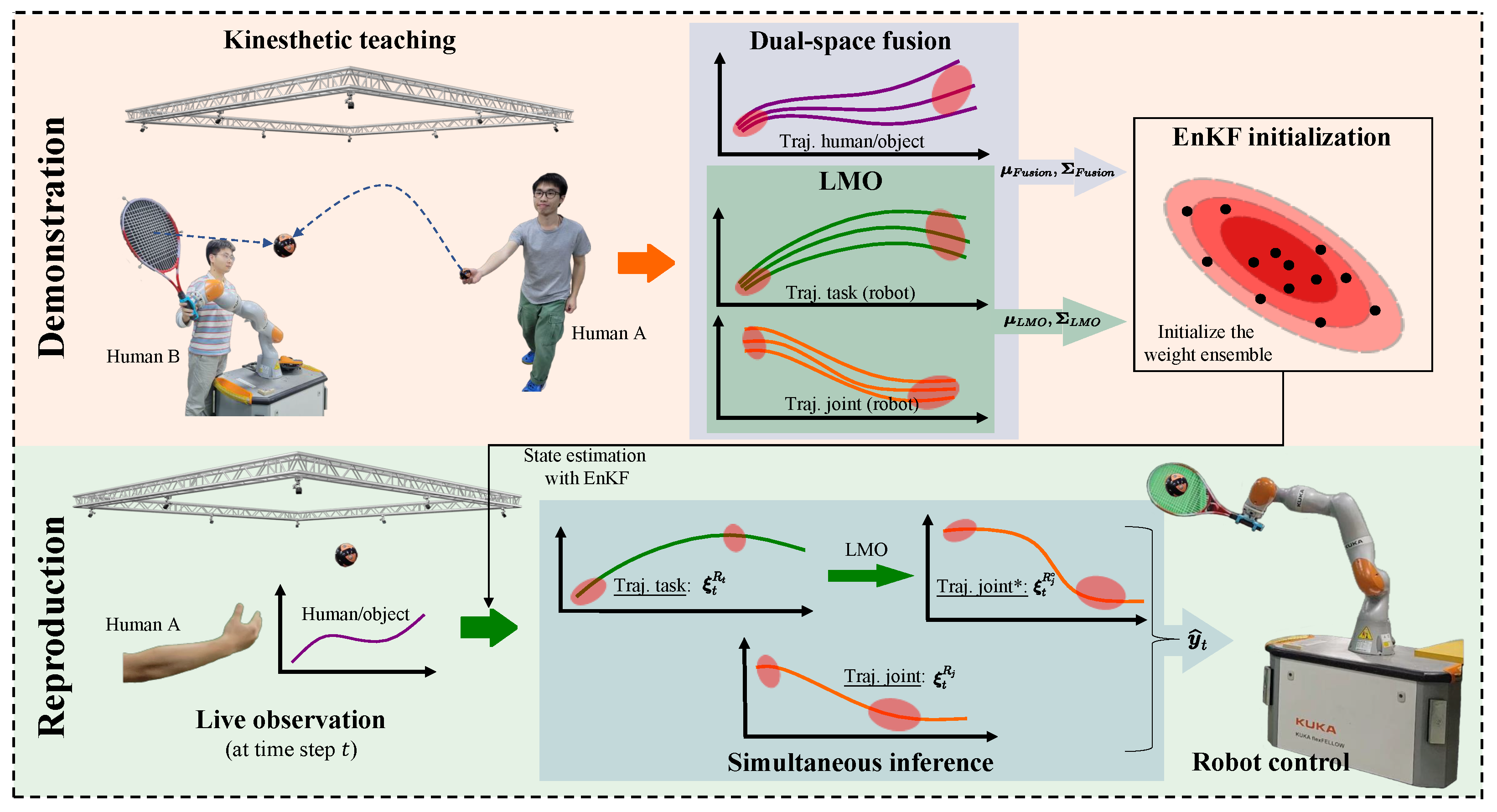
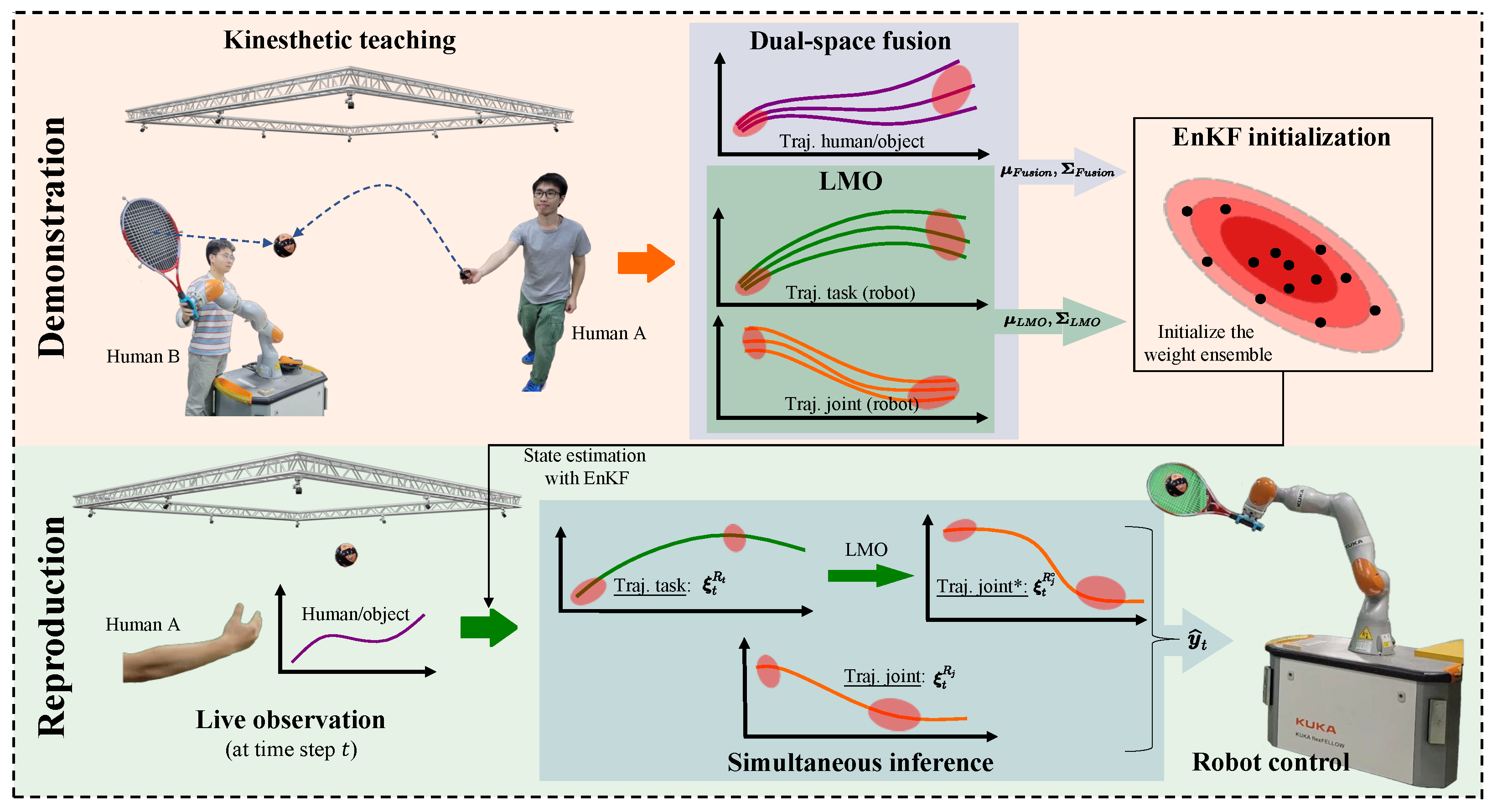
13], we proposed a method for simultaneous generalization and probabilistic fusion of dual-space trajectories, which enables the robot to simultaneously satisfy the dual-space constraints in an HRI task. We demonstrated the feasibility of the method through experiments in which UR5 followed a human-held object. This case required that the robot end-effector followed the target object in the task space, whereas the joint pose needed to move in a specific pattern so as to bypass the box next to it. However, the approach relies on the robot model and requires high computation of the robot Jacobian matrix for each time step. Therefore, in this paper, we extend our previous work and propose a method that does not rely on a robot model, making it more general. In addition, the learning of multiple features is essentially the establishment and inference of a multidimensional model, and with an increase in model dimensionality, the computational performance of the algorithm will be affected to some extent. Therefore, this paper carries out further research and enhancement on the real-time performance of the HRI method. The overview of the proposed framework is shown in
Figure 1. Furthermore, our contributions are mainly threefold:
A physical human-robot interaction method with dual-space (task space and joint space) features fusion is proposed, which improves the accuracy of the inferred trajectories in both spaces.
We also propose a data-driven linear mapping operator for mapping from task space to joint space, which does not rely on robot models and time-consuming Jacobian computation, and is suitable for HRI scenarios especially those involving high-dimensional modeling.
We present a unified probabilistic framework for integrating dual-space trajectories fusion, linear mapping operator and phase estimation, which scales particularly well with high dimensionality of the task and reduces the inference computation.
The rest of the paper is organized as follows. We begin by reviewing the previous related work on motion generation methods and spaces fusion in the field of HRI in
Section 2. In
Section 3,
Section 4 and
Section 5, we outline the methodology of our framework including dual-space fusion, linear mapping operator, phase estimation, and the unified framework. We review and discuss our experimental setups and results in
Section 6. Finally, we conclude our work in
Section 7.
2. Related Work
The primary problem in pHRI is generating robot motion by observing human motion. Amor et al. [
14] proposed Interaction Primitives (IP) based on DMP for modeling the relationship between human and robot. IP is to fit the human trajectory and the robot trajectory separately using the DMP method, then combine the DMP parameters of the two trajectories, and finally observe the human trajectory and infer and predict the robot trajectory. IP has been applied to multiple scenarios [
15,
16]. However, this method only models the spatial uncertainty in the human-robot interaction process and does not model the temporal uncertainty. Therefore, it is difficult to avoid the problem of time synchronization in its interaction process. At the same time, methods based on the DMP framework need to select the type and number of basis functions. As the dimension increases, the number of basis functions also increases, and the complexity of the inference calculation process also increases. Huang et al. proposed KMP [
8] to take the human motion sequence as the input state and directly predict the robot trajectory. Similar to the KMP method, Silvério et al. [
17] performed HRI through Gaussian Process (GP), which also avoided the problem of time synchronization, but this method did not consider the covariance and model generalization of multi-dimensional trajectories. Vogt et al. [
18,
19] used GMM and HMM to model the interaction between humans and humans, and proposed the Interactive Meshes (IMs) method, which mapped the spatiotemporal relationship of teaching motion to the interaction between humans and robots. Wang et al. [
20] utilized a Gaussian Process (GP) dynamics model to infer human intention based on human behavior and applied it to ping-pong robots. Ikemoto et al. [
21] applied GMM to the scenario of physical contact between humanoid robots and humans. Although these works use many mature theories to solve the problems of temporal and spatial uncertainty involved in robot learning, they almost all consider a single spatial feature, either joint space or task space, without involving the fusion of both. Therefore, when the task involves multiple spatial requirements, such as considering joint avoidance during robot trajectory tracking [
22,
23], these methods are not competent.
Dual-space trajectories fusion refers to learning the movement features of different spaces in demonstrations by fusing the movements of a robot’s task space and joint space, and the purpose is to complete the robot operation tasks under the joint constraints of both spaces. In the field of HRI, most current works only focus on the single space of robotics, e.g., Chen et al. proposed an HRI framework in joint space without constraining the task space [
24]. Li et al. [
25] proposed a topology-based motion generalization method for the general motion generation problem, which maintains the spatial relationship between different parts of a robot or between different agents with a topology representation; the configuration prior (joint space) is preserved in the generated motion, and the target position (task space) of the end-effector also can also be realized by applying certain constraint. However, the process of generating these two space features is separative and there is no fusion essentially. Calinon et al. [
22] used the relative distance trajectory between the robot and the object as the task space trajectory and modeled it. Specifically, the task space trajectory and joint space trajectory of the robot in the demonstrations are modeled with GMM separately. Then Gaussian Mixture Regression (GMR) is leveraged to obtain the probability distribution of the two spatial trajectories, and finally Gaussian features are used to fuse the two trajectories.Schneider et al. [
26] adopted a similar way to perform dual-space feature learning of robot trajectories, but replaced the modeling method of GMM and GMR with Heteroscedastic Gaussian Processes (HGP) [
27,
28]. However, Calinon and Schneider’s work did not perform joint modeling of the two spatial trajectories, and could not achieve synchronous generalization of the two spaces. Its essence is still to generalize the joint space trajectory. In addition, their method cannot guarantee that the generalization directions of different spatial trajectories are consistent, which means that the generalization result for one space may not be beneficial to another space. To this end, Huang et al. [
29] presented a work for solving the problem of dual-space synchronous generalization. They considered the generalization of task space while using null space to generalize robot joint space trajectory, but they did not consider the problem of interaction between humans and robots, and could not be used for real-time interaction scenarios.
Regarding the real-time performance of those methods, KMP can model the trajectory uncertainty outside the range of the demonstrations, and the kernel function processing method in the KMP inference process is similar to the Heteroscedastic Gaussian Process, its computational complexity is
. It cannot adapt well in the case of long trajectory sequences and has poor real-time performance. Campbell et al. proposed Bayesian Interaction Primitives (BIP) [
30] and the improved BIP [
31] inspired by the related method of robot pose estimation and update in Simultaneous Localization and Mapping (SLAM). Specifically, BIP is essentially based on the work of Amor et al. [
14] and Maeda et al. [
32], and applies Extended Kalman Filter (EKF) to the phase estimation of Interaction Primitives, making the phase estimation of Interaction Primitives and Bayesian inference [
33] process synchronized, and improving computational efficiency. The time complexity of the time alignment method in the original IP framework is
, BIP removes the extra time alignment process, reducing the interaction inference time by 66%.
As shown in
Table 1, most of the existing research on pHRI or skill learning focuses on either task space or joint space, but not both. Moreover, few methods can achieve dual-space fusion and generalization, as well as meet the real-time interaction requirements. However, the existing methods have advanced in modeling spatial and temporal uncertainties, phase estimation, and other related theories, which can provide guidance for our further exploration.
3. Preliminaries: Probabilistic Fusion in Task Space and Joint Space
3.1. Simultaneous Generalization of Dual Space
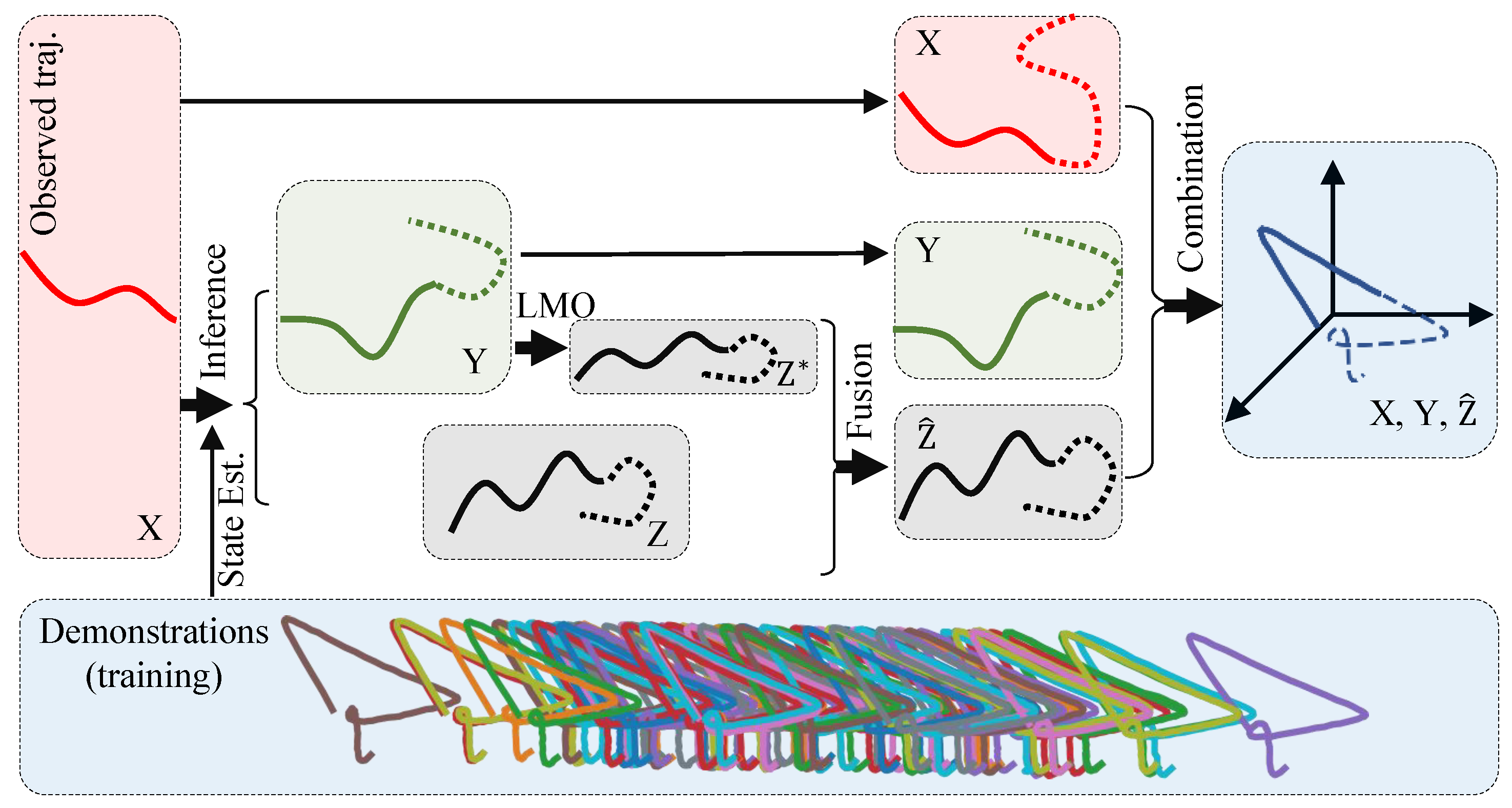
The goal of the simultaneous generalization of dual space is to enable the robots (the controlled agent in pHRI) to learn the features of the motion trajectories in dual space. This enables the robot to perform complex tasks, such as tracking a target object while avoiding obstacles. To achieve the simultaneous generalization of dual space, two components are needed: the learning phase and the inference phase. The former aims to learn the features of trajectories in dual space. The latter aims to generate the robot’s motion trajectories in dual space based on the observed human motion trajectories.
In the learning phase, we propose a probabilistic fusion model of task space and joint space, inspired by IP [
14]. This model encodes the human and robot motion trajectories with basis functions and models their spatial and temporal uncertainty with probabilistic weights. We define the joint trajectory of human and robot
as a sequence of sensor observations of length
T. Here,
is a sequence of human movement trajectories with
degrees of freedom. For a time step
t, we denote
as the human trajectory at that time step, or simply
for brevity.
is a sequence of robot movement trajectories with the number of degrees of freedom
at time step
t.
is the trajectory point of the robot in task space at time step
t,
is the trajectory point of the robot in joint space, and
and
are the numbers of degrees of freedom of the two space trajectories.
The sequence for each degree of freedom is linearly fitted using
B basis functions containing Gaussian white noise. This fitting method is derived from DMP:
where
is the vector composed of
B Gaussian basis functions,
is the weight corresponding to the basis function, and
is the corresponding Gaussian white noise.
The joint weight matrix
is obtained by fitting using Equation (
1). It is assumed that the weights learned from each demo follow a Gaussian distribution, i.e.,
, and the Gaussian parameters
and
can be obtained from multiple demos by Maximum Likelihood Estimation (MLE), where
D is the sum of the dimensions of the human movement trajectories and the robot dual space movement trajectories, and
B is the number of Gaussian basis functions. Furthermore, it is important to note that
captures the correlation among human motion trajectories, robot motion trajectories in task space, and robot motion trajectories in joint space.
In the inference process of HRI, we use the weights learned from the learning phase as prior information. We observe the human motion trajectory
from the beginning of the interaction to time
and update the entire weight matrix using Bayesian recursive inference.
Then, we use the
and
components of the inferred weight matrix
to generate the robot motion trajectories in dual space according to Equation (
1). So for an observation time step
, we denote the generated task space trajectory as
, and the joint space trajectory as
, where
and
represent robot task space and robot joint space, respectively.
3.2. Kinematics-Based Linear Mapping
We have obtained two control trajectories for the robot in both task space and joint space until now, but, in fact, we only need one controller to control the motion of the robot. Therefore, a mapping from task space to joint space for the trajectory is required, and then fusing the two joint space trajectories into one in the form of probability distributions. The most common mapping method in robotics is inverse kinematics with a kind of Jacobian matrix. So, based on the kinematic relationship of the robot, the task space trajectory sequence is linearly and iteratively mapped into the joint space.
Assume that the trajectory point
at each time step
t (
), follows a Gaussian distribution, i.e.,
, and obviously the parameters
and
can be obtained by performing a linear transformation (Equation (
1)) on the updated weight distribution
, as well as the original and mapped joint space trajectory point
and
. The new trajectory obtained from the kinematics-based mapping is denoted as
, and the update formula of a point of the new trajectory at time step
t is:
where
is the pseudo-inverse of the robot Jacobian matrix
at time step
t, and
is the derivative of
. Since
follows a Gaussian distribution,
does so as well, i.e.,
. In addition, the observed joint angle
at the time step of
is taken as the initial value of the iteration, that is
.
3.3. Probabilistic Fusion
From the above iterative mapping method, two kinds of movement trajectories in robot joint space can be obtained, one of which is the robot joint space trajectory sequence obtained by direct extrapolation from the human action sequence , and the other is the joint space sequence mapped from the robot task space trajectory . At time step t, there are and .
and can be regarded as two probability estimates obtained from the same space (joint space) for the same observation object (human motion sequence ). Therefore, the trajectory sequence and are two estimation results of the same estimation object (joint space control trajectory, denoted by ), whereas contains the information of task space feature generalization, contains the information of joint space feature generalization, and by fusing the two feature information at each time step, we can obtain the control trajectory that contains the features of both spaces.
The two estimates are considered to be independent of each other, and the distributions of the two trajectory estimates are fused at each time step
t with Bayesian estimation:
At time step
t, the control trajectory of the robot in the joint space follows a Gaussian distribution
, with:
Finally, we obtain the robot control trajectory , which includes the fusion features of both task space and joint space.
4. Kinematics-Free Linear Mapping Method
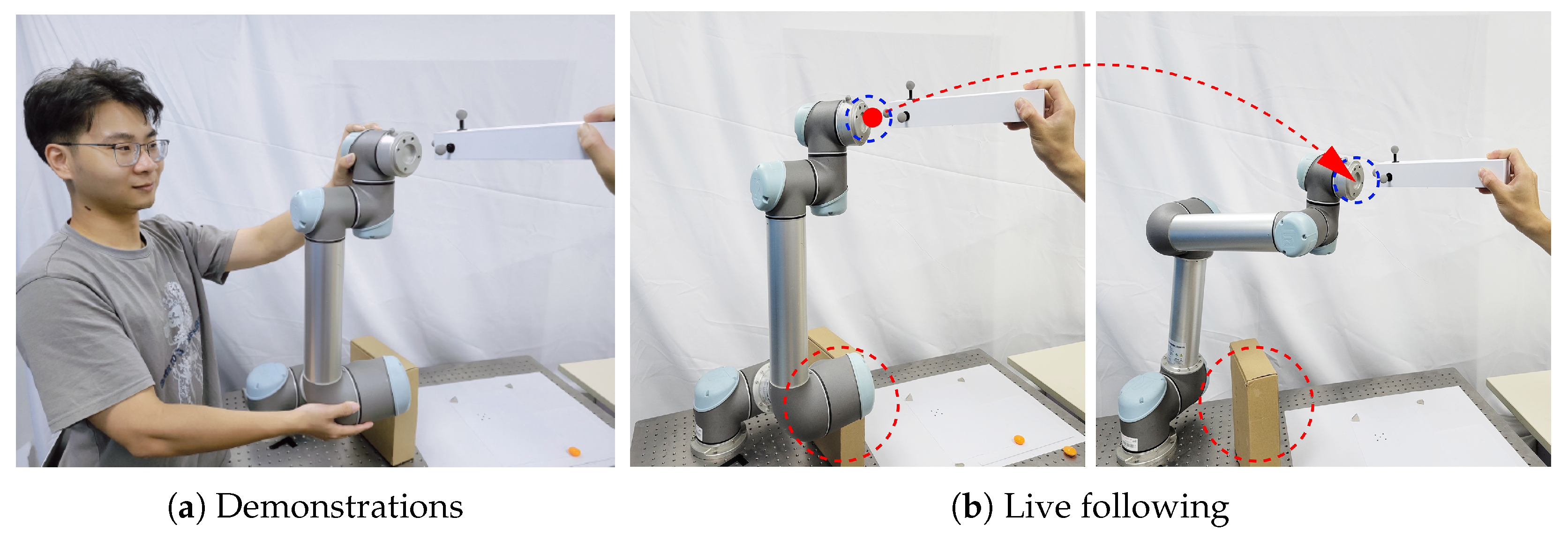
The mapping relationship between task space and joint space in the last subsection is derived from the robot kinematic model and relies on the Jacobian matrix computed from the robot model. We would like to make the application of the dual-space probabilistic fusion method in robot interaction skill learning more flexible and extend it to more non-kinematic scenarios. For example, we can map and fuse only a part of the interaction data in task space or joint space, or we can apply the method to other spatial fusion tasks that do not involve task space or joint space. However, the computation of the Jacobian matrix in inverse kinematics is time-consuming, so it is not suitable for HRI tasks with high real-time requirements. In this part, we will introduce a linear mapping operator (LMO) for this purpose.
4.1. Linear Mapping Operators
We propose a linear mapping approach between two spaces based on Jacobian-like matrices, which are defined as operators that act on data (displacement) vectors. We generalize the notion of dual-space mapping beyond the conventional task and joint spaces and introduce two abstract function spaces, denoted as space A and space B. Assume that, given demonstration samples, we can learn a time-varying LMO denoted as for each time step t of HRI, such that it maps vectors from space A to space B, i.e., .
A possible way to model and estimate the LMO (
) is to treat it as a dynamical system that varies over time. However, this approach may not capture the exact nature of the operator, because it may involve different mapping spaces and nonlinear or discrete transformations in the complex case of dynamical parameters. Therefore, we do not assume a specific mathematical model for the operator but rather regard it as a time-varying parameter to be estimated. There have been many studies on the estimation of time-varying system parameters, e.g., Cui et al. [
35] used the Kalman Filter (KF) method to estimate the system state, Kim et al. [
36] used the Extension Kalman Filter (EKF) method to estimate the nonlinear system, and Campbell et al. [
30] applied the EKF to the trajectory weight inference of Interaction Primitives in HRI. We propose a framework using the Kalman estimation to jointly express the linear mapping operator and the robot interaction trajectory inference.
4.2. Modeling of Linear Mapping Operators
Let
,
, and
be the time-dependent state sequences corresponding to
,
, and
, respectively. For an HRI process with a time length of T, the trajectories corresponding to
,
, and
can be denoted as
,
,
, respectively. The mathematical relationship between
,
, and
is expressed as follows:
which denotes the trajectory point of space B mapped into space A at time step
t, i.e.,
, where
,
,
, where
m and
n is the number of dimensions of space A and space B, respectively, (a more specified definition for an HRI system is introduced in
Section 3.1). The above equation can obtain:
Although
is the linear mapping relationship between two spaces, it is assumed to be a nonlinear dynamic system itself, and needs to be linearly approximated by Taylor expansion or Taylor series, and its expansion order affects the accuracy of model establishment. Theoretically, the higher the expansion order, the higher the mapping accuracy of the model, but it will also bring about a decrease in inference efficiency. Let
o be the order of linear mapping operator expansion, then
can be discretized and expressed as:
where
and
is the first and sencond partial derivative of
with respect to
t, respectively, marked as
(or
) and
(or
). At time step
t, we assume that the coefficients of each term in the series follows a Gaussian distribution, i.e.,
. Therefore, we can estimate the linear mapping operator by estimating the parameters of its finite expansion orders.
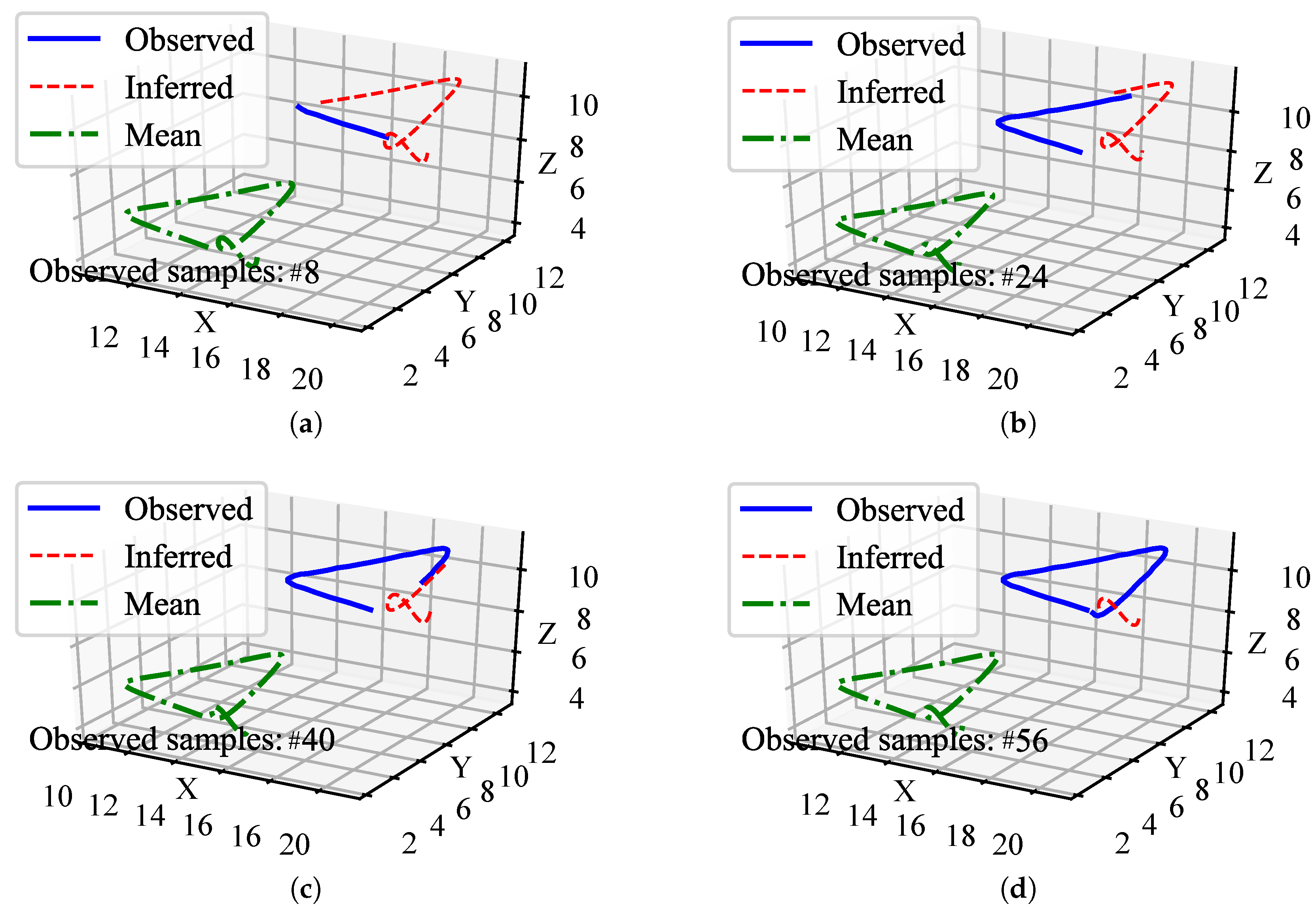
In practical applications, we need to learn from the demonstrations to obtain the parameters of the LMO. By observing the demonstration sample data at a certain observation frequency (120Hz in our demonstrations), we can obtain the human and robot motion data sequences in HRI. The LMO at each interaction time step in the demonstration sample is obtained by Equation (
8). The initial value of the model is the mean of the initial LMO in the training sample.
At an observation frequency, the LMO of each sample is discretized at each time step t. For example, for the first two orders, we have , , where both and follows a Gaussian distribution, i.e., , .
4.3. Inference of Linear Mapping Operators
We adopt a nonlinear KF framework that follows the Bayesian estimation process to infer the LMO and the dual-space weights jointly. If only considering the fusion model and LMO, the state matrix of the model at time
t is given by:
where
is the vectorized form of
(
i is the order of the expansion,
), i.e.,
;
is the joint weight of human and robot motions in two spaces, and
;
is the sum of the dimensions of the interaction primitive weights; and
B is the number of basis functions.
The estimation process aims to compute the probability of the state matrix given an observation sequence
, and its conditional probability density function follows a Gaussian distribution
; we have:
where
and
. The observation object sequence is the HRI trajectory; that is,
,
.
Bayesian filtering methodology consists of two components: the state transition model and the measurement model. Based on the linear approximation assumption of the linear mapping operator in Equation (
10), we can establish the following state transition model for its vectorized form at each time step
t:
where
And then we have the measurement model:
and the partial derivative of
with respect to the weight vector
is:
Finally, by combining the measurement model and the state transition model with the Bayesian filtering methodology, the expansion parameters of the LMO are updated continuously by observing the trajectories of human/object.
5. Dual Space and Time Simultaneous Inference with EnKF
The previous two sections mainly focused on generating robot motions based on human motion trajectories; that is, modeling and inferring the spatial uncertainty of robot motion. Spatial uncertainty estimation is the process of inferring the motion state of the robot at each moment. By using the spatial uncertainty inference in the previous sections, we can obtain the robot’s motion trajectory at any interaction time step. However, the robot does not know which point on the trajectory it should move to at this time. Therefore, we need to model and infer the temporal uncertainty of robot motion, which is essentially modeling and estimating the phase factor of the robot’s current stage; that is, phase estimation [
32].
We draw inspiration from the BIP method, which extends the Kalman Filter to perform spatiotemporal synchronization inference, and we propose an inference method that can infer the phase, the linear mapping operator, and the dual-space trajectory weights simultaneously.
5.1. Spacetime Joint Modeling
In line with the modeling idea of this paper, the phase estimation problem can be formulated as how to find or estimate the value of at the current time step t. We assume that the phase of the demonstration is a constant-speed change process, and for a sample of length T, its phase velocity , and let be the average phase velocity obtained from the demonstrations.
We define the complete state matrix as follows, by concatenating the phase and phase velocity:
where
and
are the phase and phase velocity at time
t, respectively;
is the parameter of the LMO;
is the weight of the dual-space trajectories point. We initialize the phase estimation as follows:
To integrate phase estimation into the probabilistic inference of spatial trajectory, Equation (
18) can be rewritten as:
The above process couples the phase estimation and the recursive state estimation of the dual-space trajectory weights. However, most of the existing studies use DTW to achieve phase estimation, which has a time complexity of
[
14]; DTW needs to query and compare the entire observed trajectory sequence at each time step, so it requires extra computational overhead for phase estimation while performing trajectory inference. We combine phase estimation with state recursion, which can avoid this extra overhead; for the overall algorithm, the two phase factors (
) introduced actually only increase two dimensions on the state matrix (Equation (
19)), which has negligible impact on the overall state estimation dimension.
5.2. Spacetime Synchronization Inference
The linear mapping operator and the dual-space weights increase the dimension of the state matrix significantly. If we use the EKF inference method, we need to maintain a large covariance matrix at all times, and this high-dimensional matrix operation will bring more computational overhead. Therefore, we use the ensemble Kalman Filter (EnKF) inference method to handle the high-dimensional problem. EnKF does not need to maintain the covariance matrix like EKF, but uses an ensemble to simulate the state uncertainty.
The core idea of EnKF is as follows: we use an ensemble of dimension
E to approximate the state prediction with the Monte Carlo method, where the sample mean of the ensemble is
, and the sample covariance matrix is
. Each element of the ensemble is obtained by the state transition model, and is perturbed by stochastic process noise:
where
denotes the prior of the state at time
t obtained from time
. When
E approaches infinity, the ensemble will effectively simulate the covariance calculation result of Equation (
16). In the scenarios of pHRI, each element in the ensemble comes from the demonstration in the training dataset. The state ensemble is transformed to the measurement space through the nonlinear observation equation, and the error between each element and the sample mean in the ensemble is calculated:
Then, the new covariance matrix is:
The Kalman gain is calculated as follows:
The ensemble is updated and the measurement results with random noise are considered:
when
, the ensemble can accurately represent the error covariance of the optimal state estimation [
37]. The measurement noise is calculated by the following:
Equations (
22)–(
29) describe the complete filtering process. In the scenarios of pHRI, we combine them with the EnKF mentioned above to implement the simultaneous generalization and probabilistic fusion of robot motion trajectories in dual space. The pseudocode of integrating dual-space trajectories, LMO, and phase estimation is presented in Algorithm 1.
| Algorithm 1: Dual-space fusion algorithm for real-time pHRI task. |
![Biomimetics 08 00497 i001]() |
7. Conclusions
This paper proposes a probabilistic dual-space (task space and joint space) feature fusion for real-time physical human-robot interaction. We conducted several qualitative and quantitative experiments and analyses to validate our effectiveness. Notably, we achieved:
A pHRI method that considers the dual-space features of the robot. The dual-space trajectory inference fusion method proposed in this paper addresses the limitation of the original IP, which can only perform single-space generalization. By applying our method with two datasets of a UR5 and a KUKA iiwa7 robot, we reduce the trajectory inference error of the proposed method by more than 33% in both spaces. In addition, we demonstrate the applicability of the proposed method to different robots by verifying it with two datasets of robots with different DoFs. Moreover, the inferred results satisfy both task space and joint space constraints and can meet real-time inference interaction requirements.
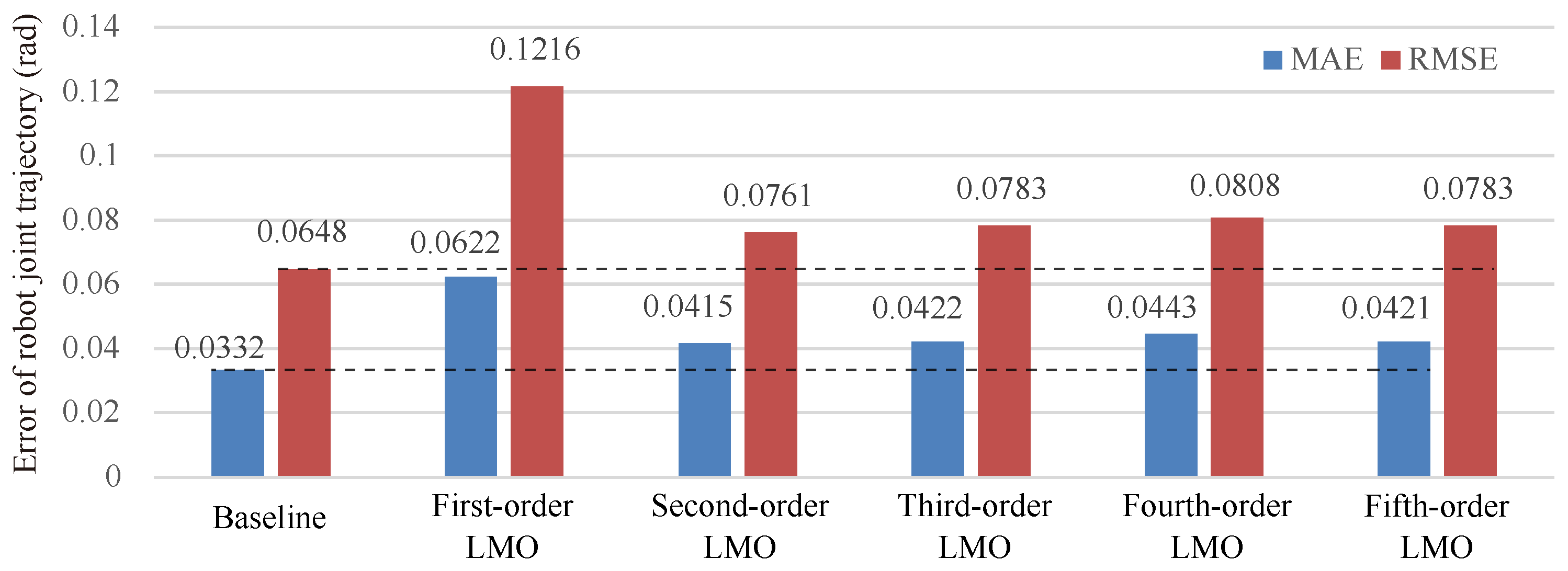
A dual-space linear mapping method that does not depend on the robot model. We propose a method to learn and infer the linear mapping relationship between different spaces from demonstrations. Through the three-dimensional handwriting trajectory experiment, we verify the feasibility of integrating the linear mapping operator into the dual-space synchronous inference framework. With the UR5 dataset experiment, we examine the influence of the expansion order of the linear mapping operator on the trajectory inference accuracy, and we show that increasing the order of the mapping operator within a certain range can improve the inference trajectory accuracy. In the experiment, the trajectory MAE obtained by the second-order LMO is close to that obtained by the kinematic mapping.
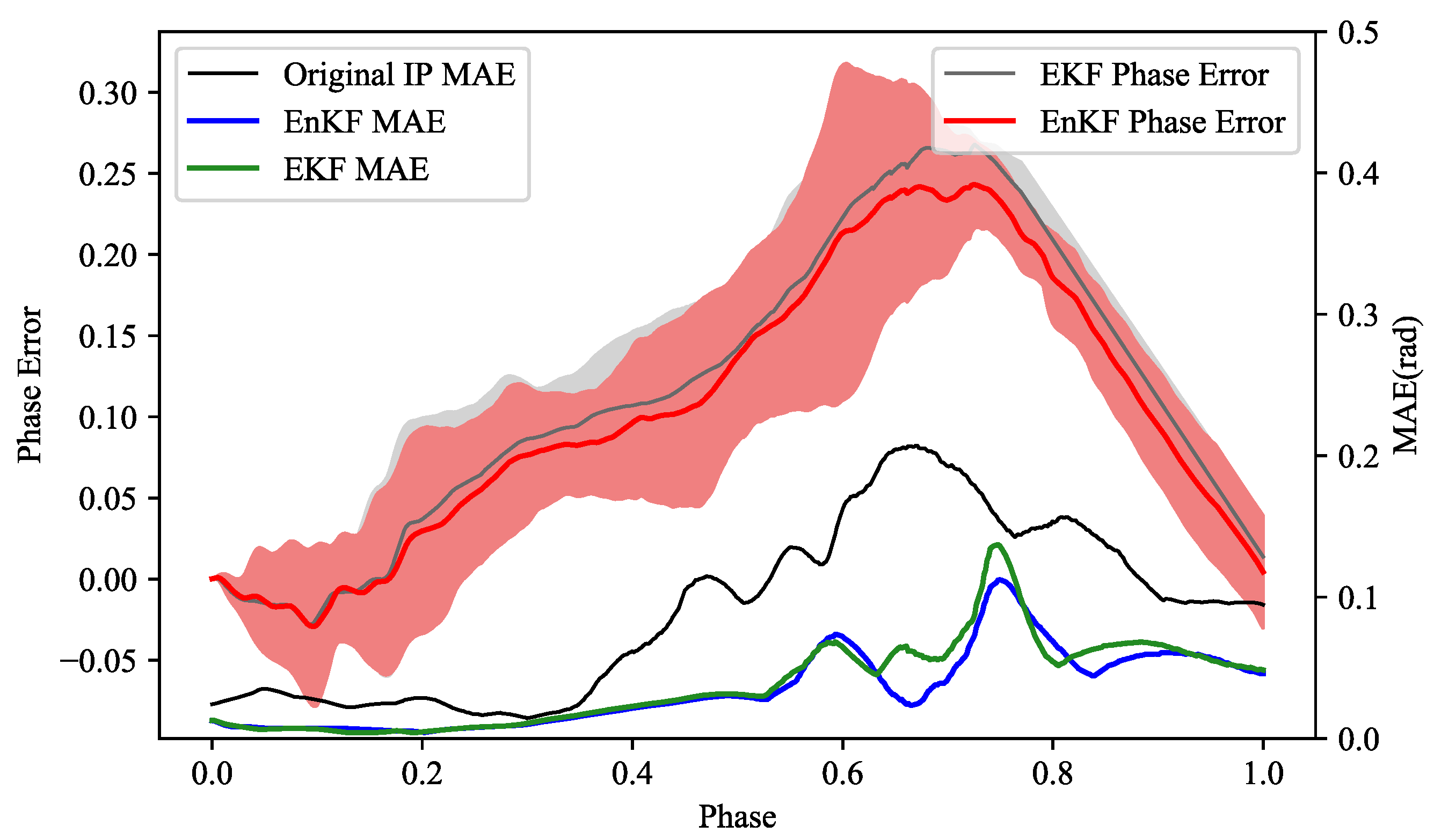
We integrate phase estimation into the Kalman Filter framework to realize a method for spatiotemporal synchronous inference, which reduces the inference hierarchy. Based on the idea of ensemble sampling, we use ensemble Kalman Filter inference to solve the high-dimensional inference problem caused by dual-space inference. The experiments show that our improvements maintain the accuracy superiority of dual-space feature learning, and that the overall computational efficiency is 54.87% higher than EKF.
Our method learns both the task space and joint space features of the demonstration, enabling it to handle scenarios that require both target position and configuration, especially for real-time tasks. As humanoid robots and related technologies become more integrated into people’s daily lives, our method can be applied to service robots to generate motions that satisfy simultaneous constraints on multiple robot joint spaces and task spaces, such as robot anthropomorphic writing, dancing, sign language imitation and communication, greeting, etc. These tasks not only depend on the position of the robot’s hand (end-effector), but also on whether the robot’s configuration (shape) is human-like. In the future, we will explore using our method to learn more feature fusion, such as speed, acceleration, force, etc., so that the generated motion exhibits more human-like characteristics, enhancing its applicability in practical HRI and improving the interaction efficiency and human acceptance of robots.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}