
CBMC: A Biomimetic Approach for Control of a 7-Degree of Freedom Robotic Arm


Abstract
:1. Introduction
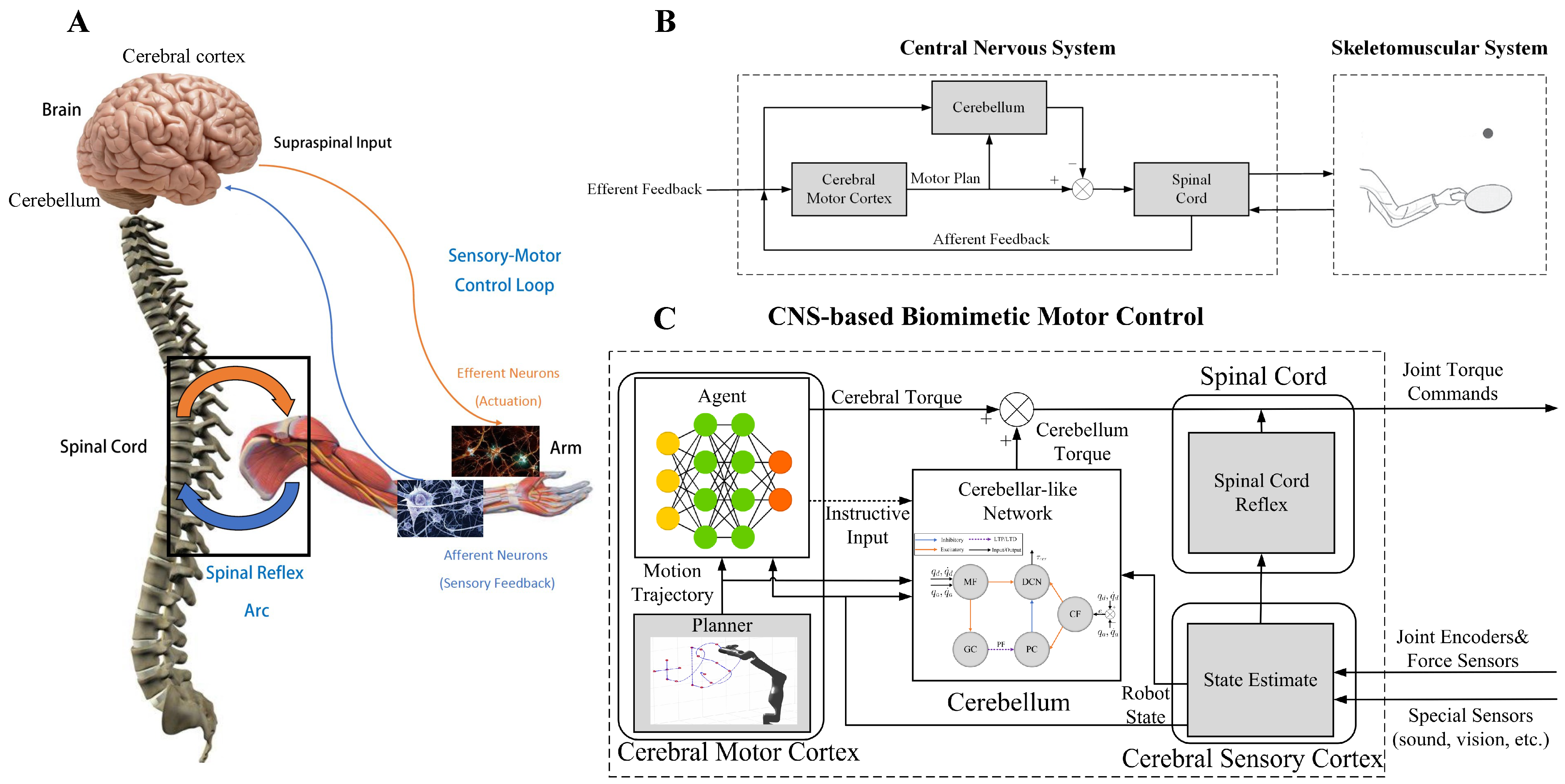
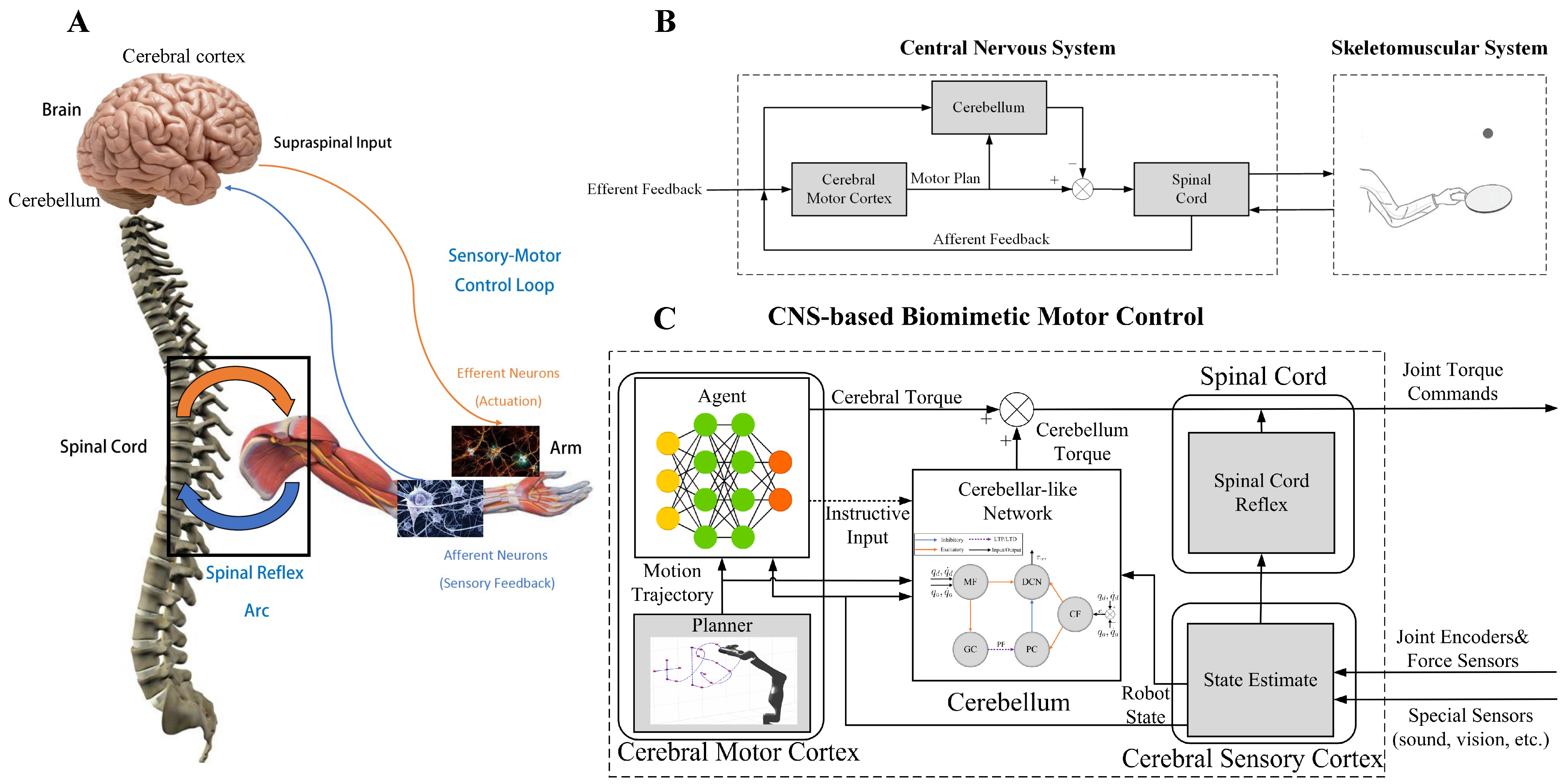
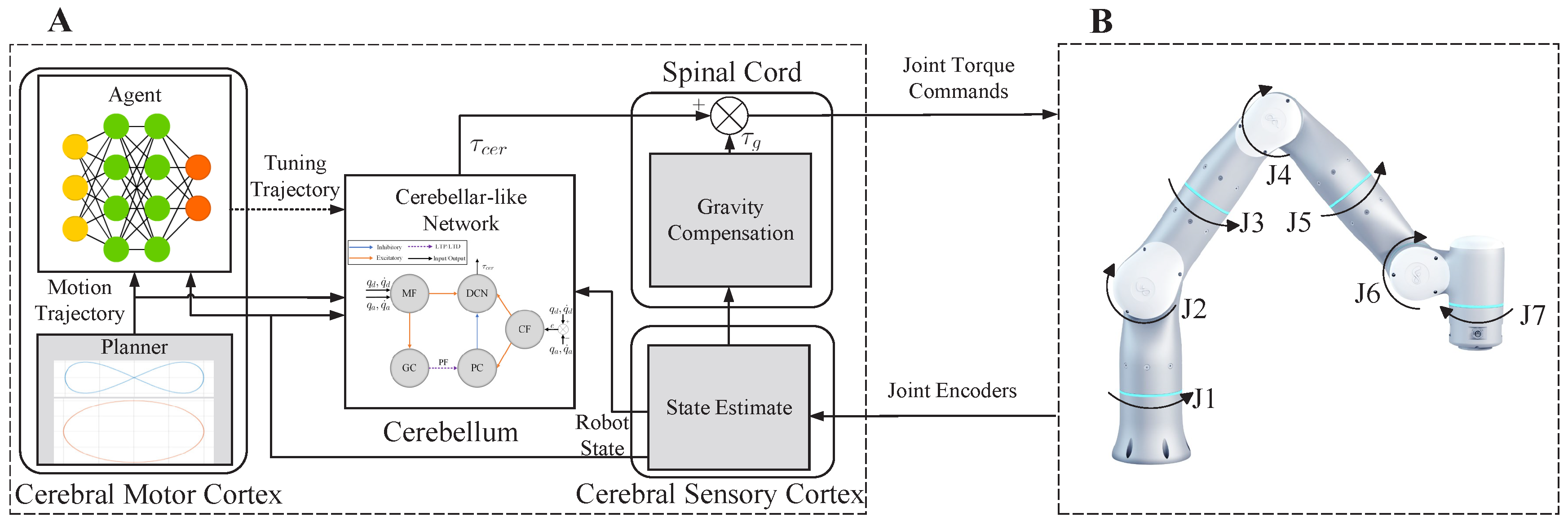
- We propose a system model of the CNS-based Biomimetic Motor Control (CBMC) inspired by the human control loop for issues in control.
- A proposed implementation of this model involves utilizing an SNN for the cerebellum module, which is supervised by an ANN in the cerebral motor cortex module. This implementation is then applied to the control of a 7-DoF robotic arm.
2. CBMC: A Biomimetic Control Approach
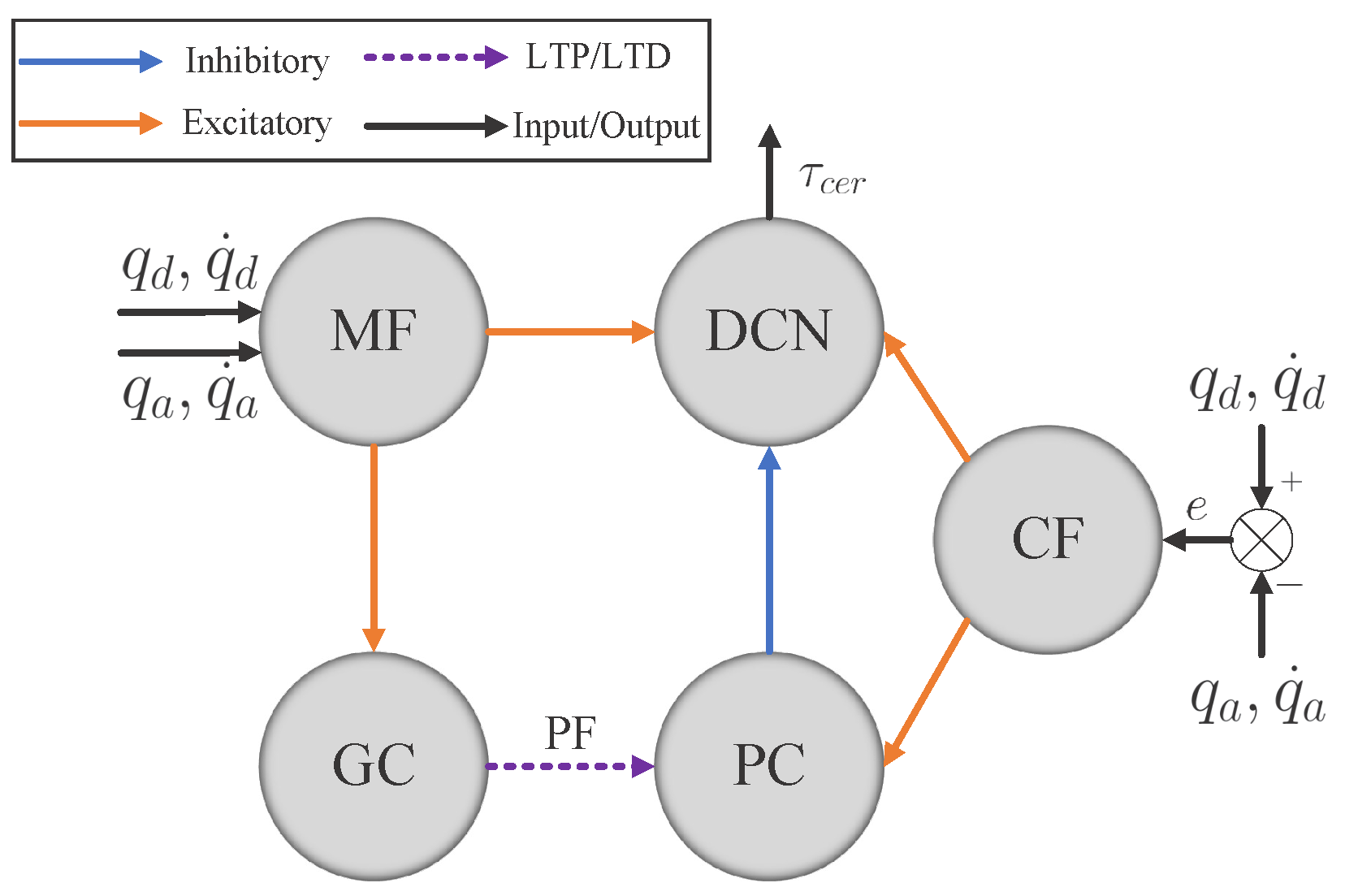
2.1. Cerebellum Module
2.1.1. Neuron Model
2.1.2. Synaptic Plasticity Model
2.1.3. Network Structure
2.2. Cerebral Motor Cortex Module
2.2.1. Learning Mechanism
2.2.2. Supervision to the Cerebellum
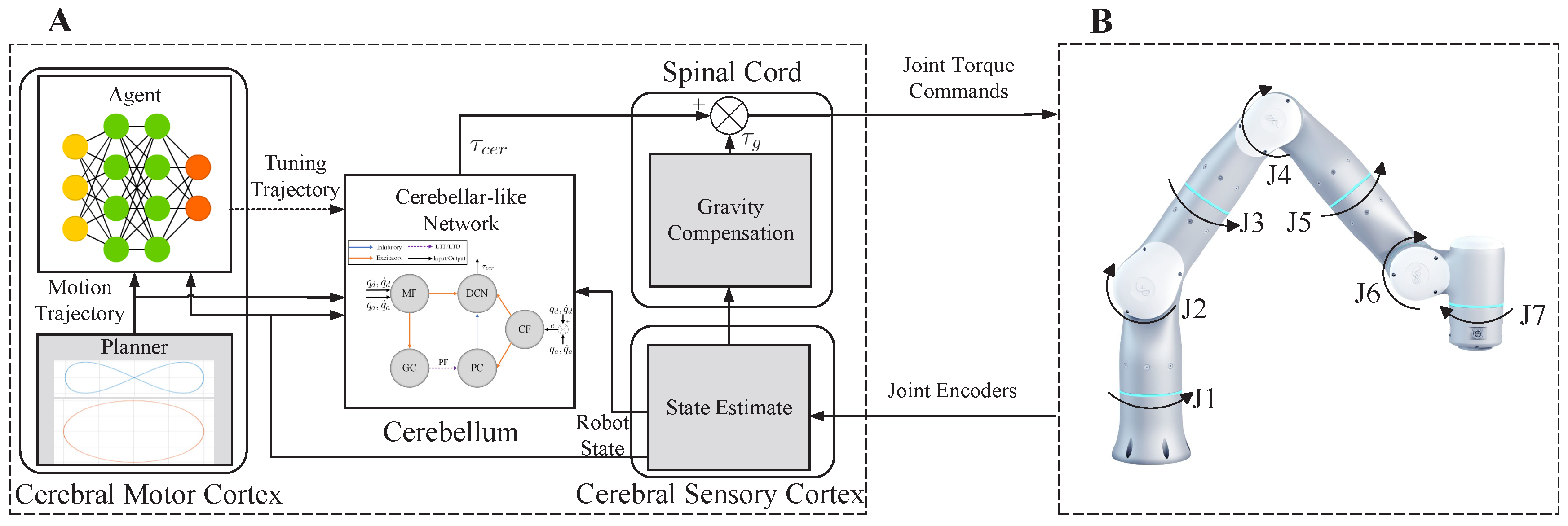
3. Case Study: Trajectory Tracking Control of a 7-DoF Robotic Arm
3.1. Control Framework
3.2. Implementation of CBMC
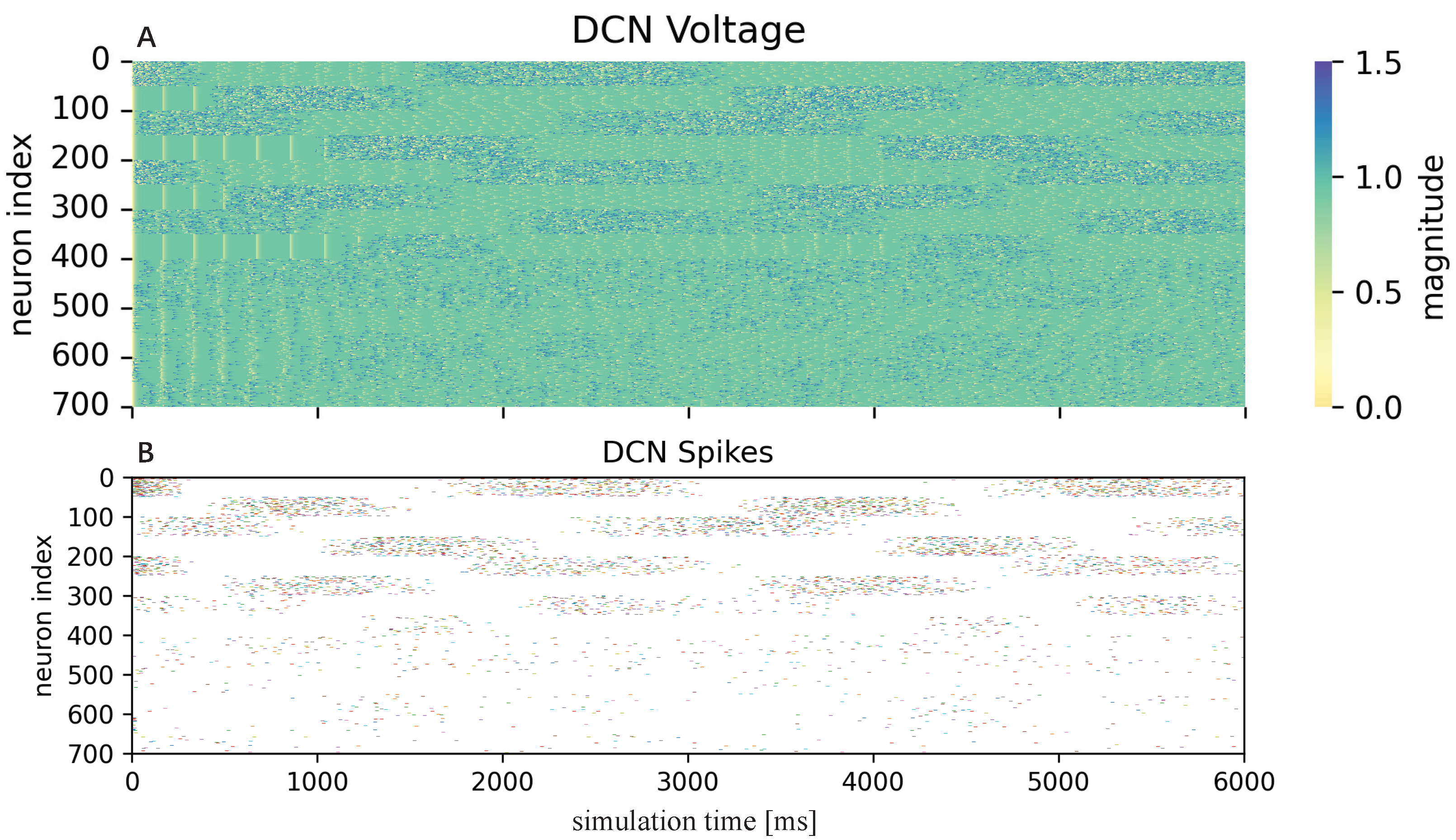
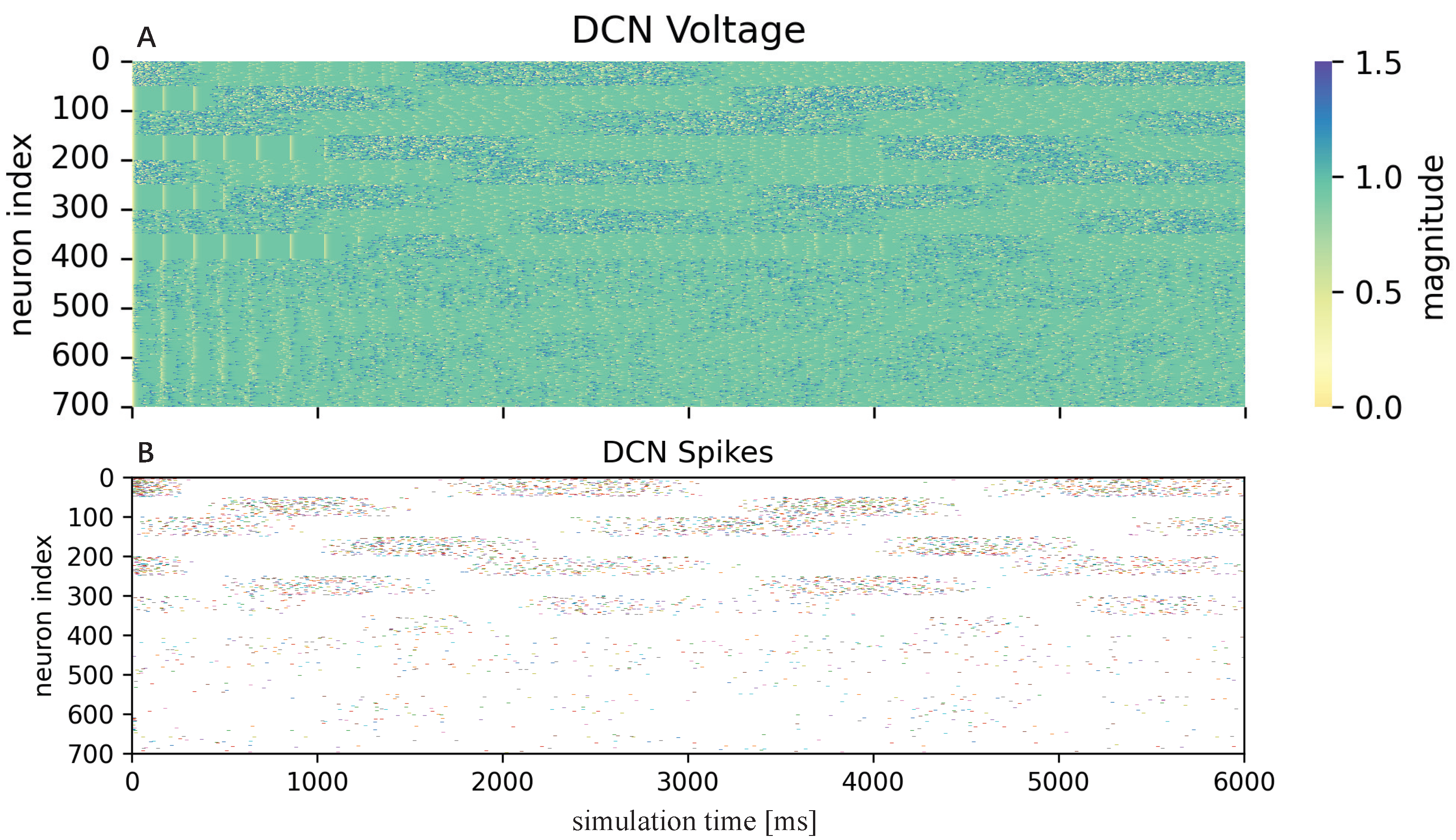
3.2.1. Cerebellum-like SNN
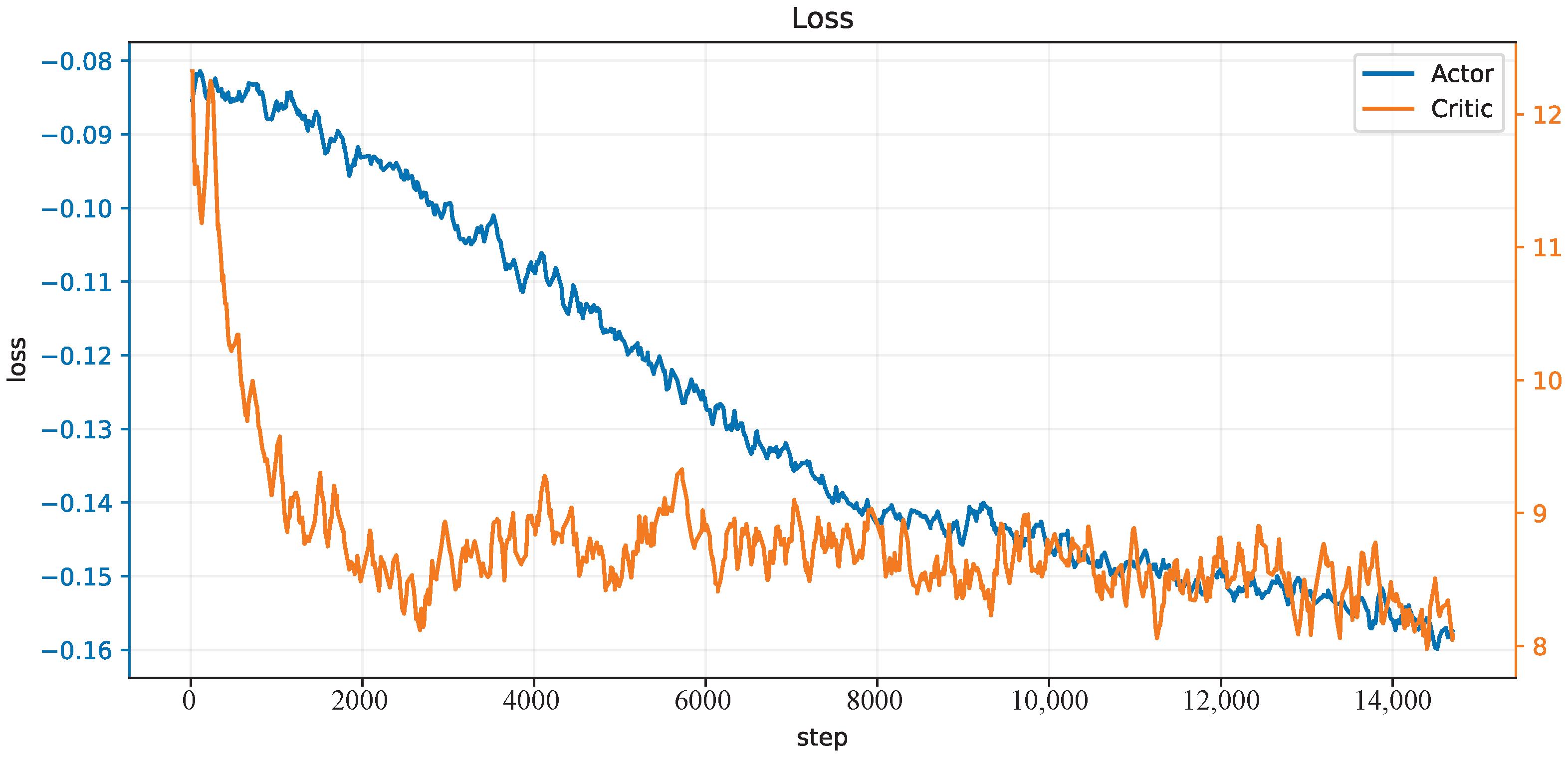
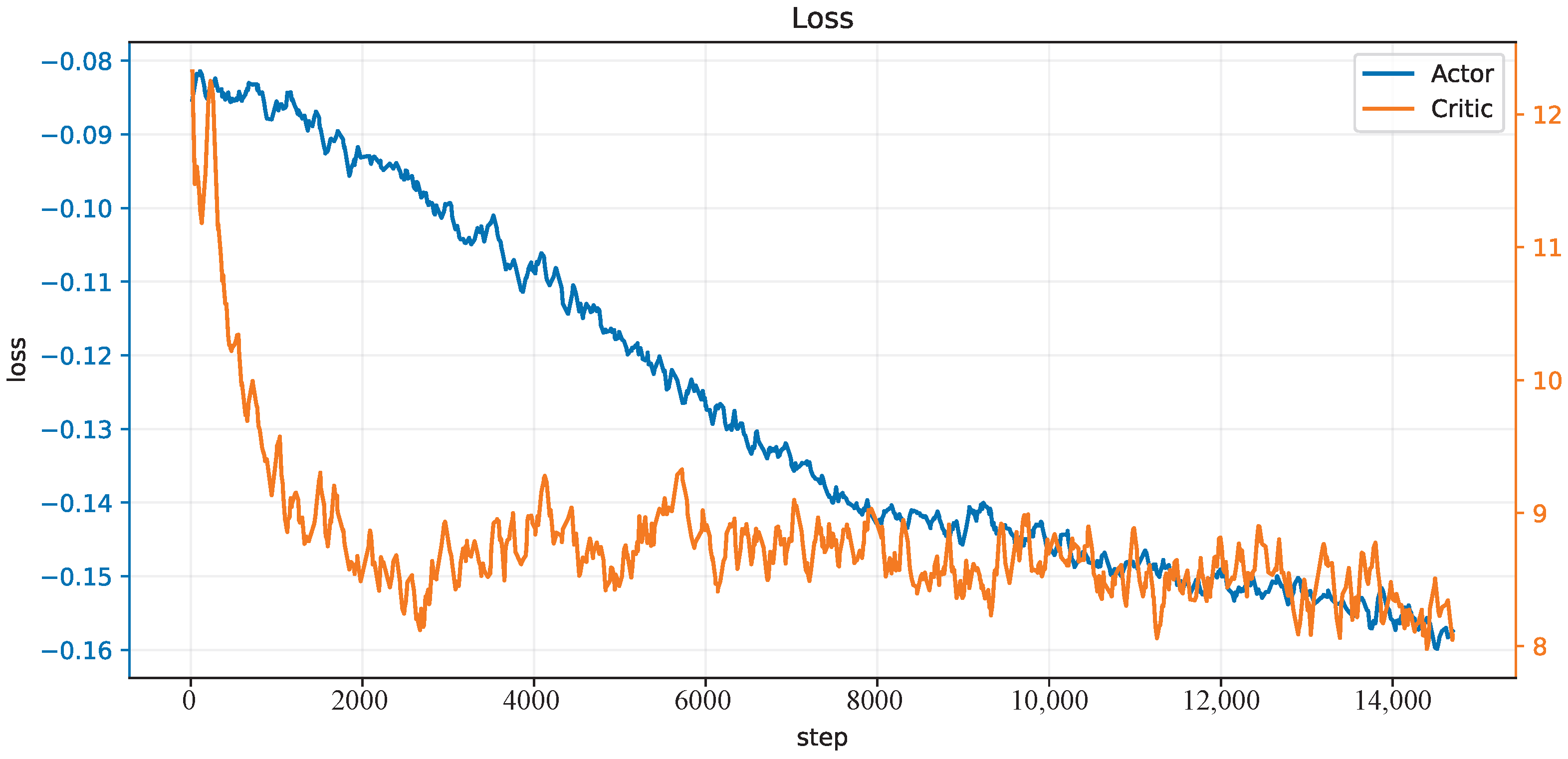
3.2.2. CMCM with Deep Deterministic Policy Gradient
| Algorithm 1 Learning algorithm of CBMC |
|
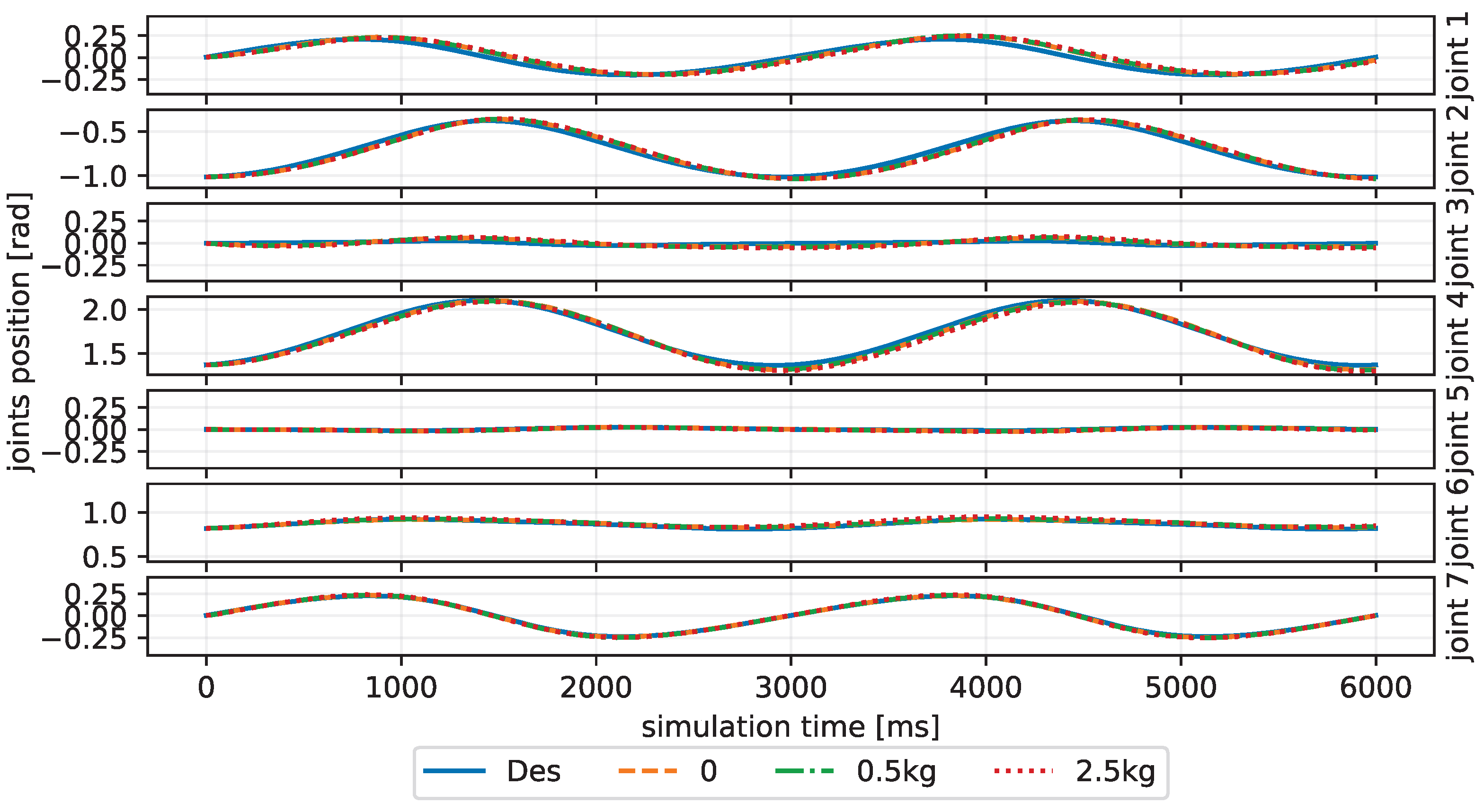
3.3. Experiment Settings
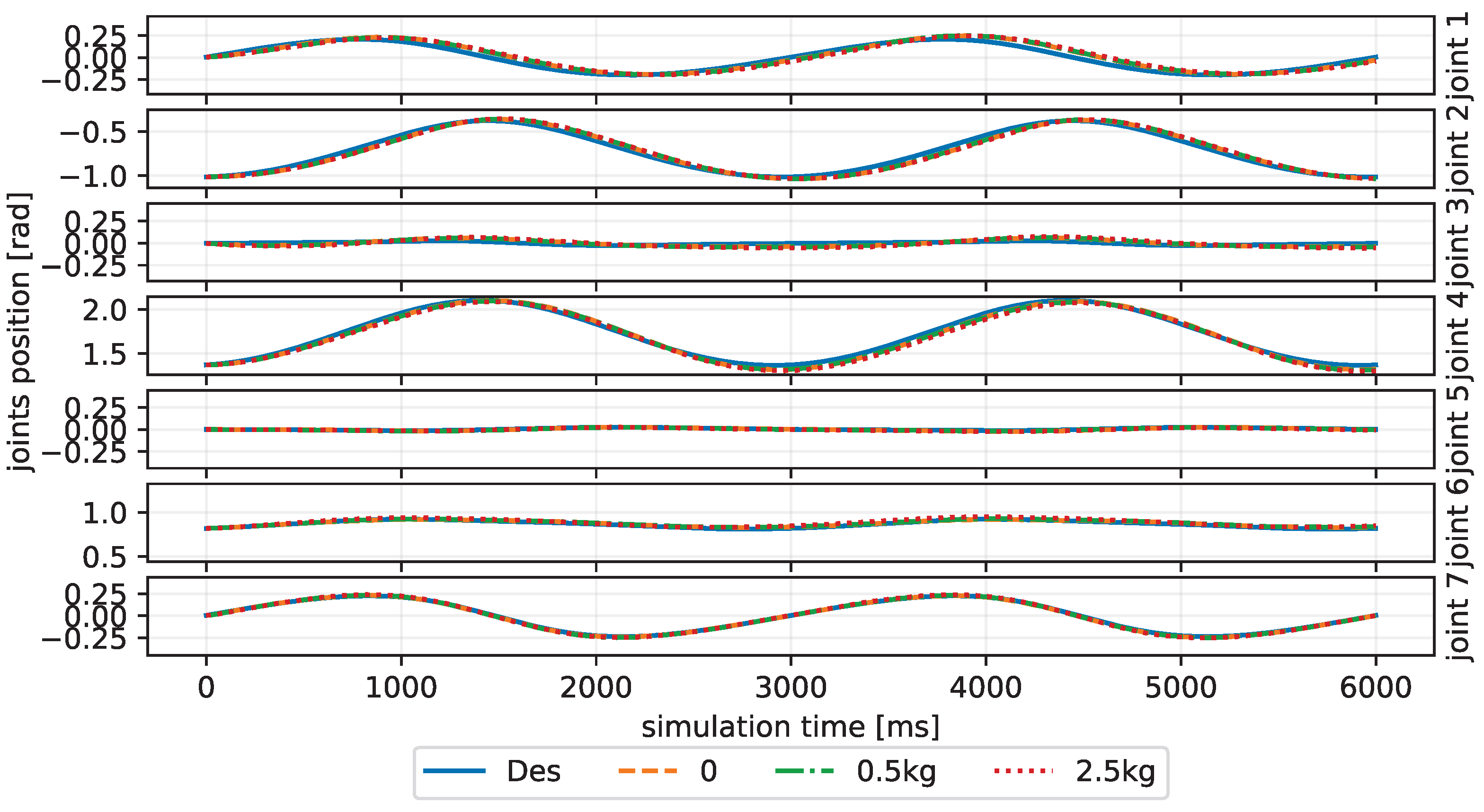
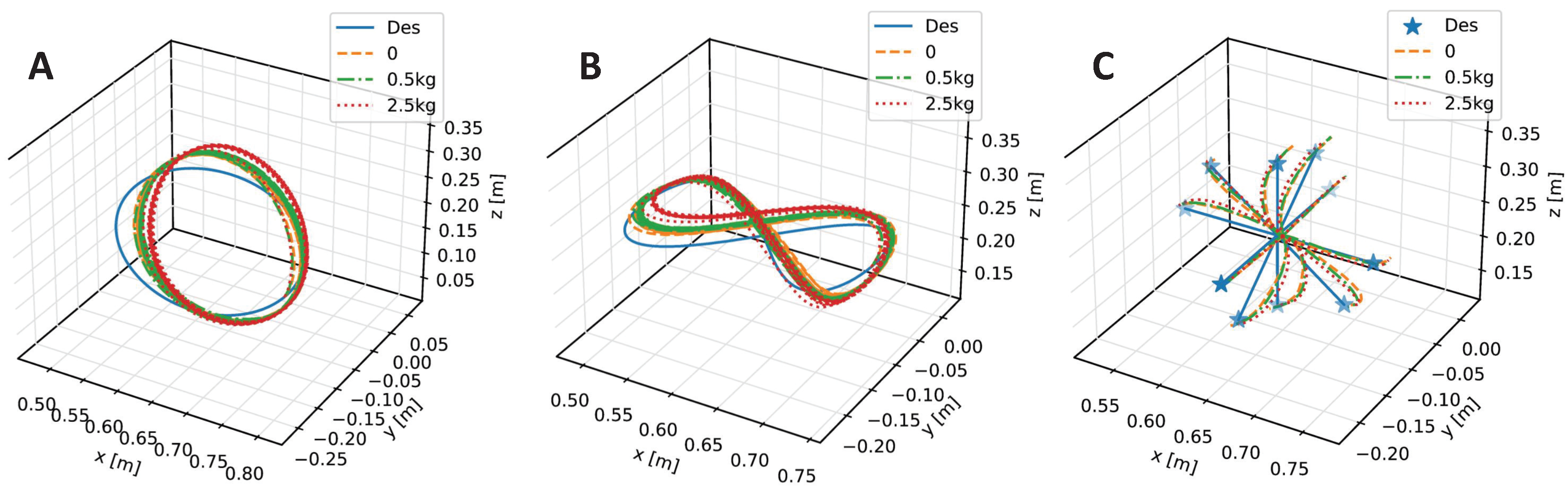
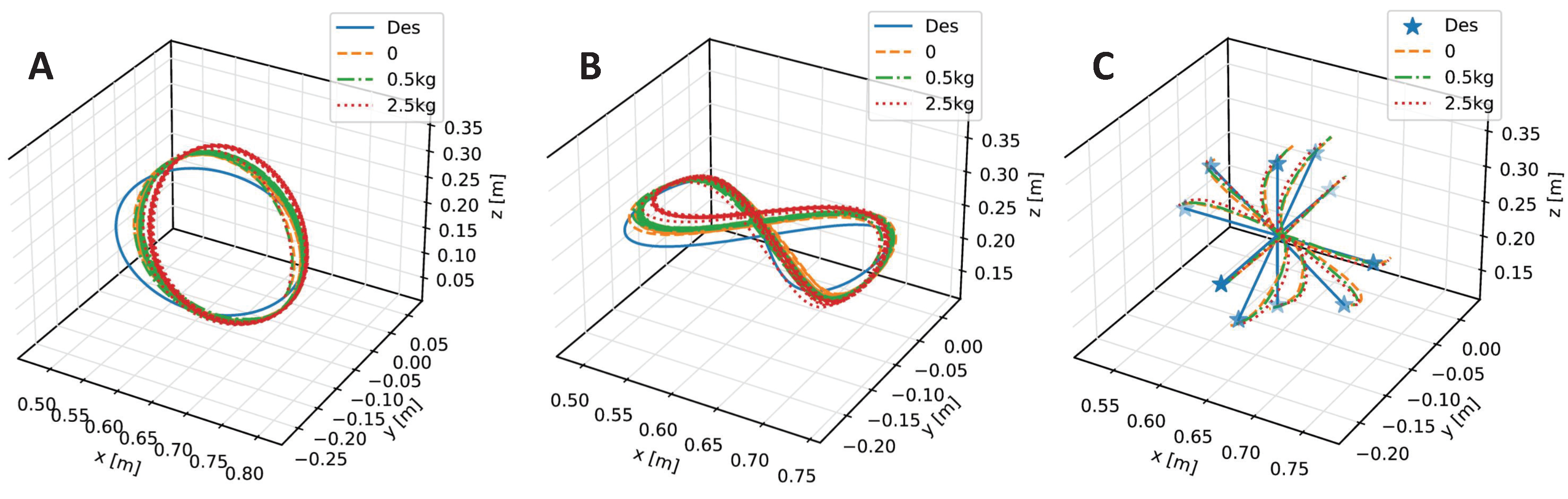
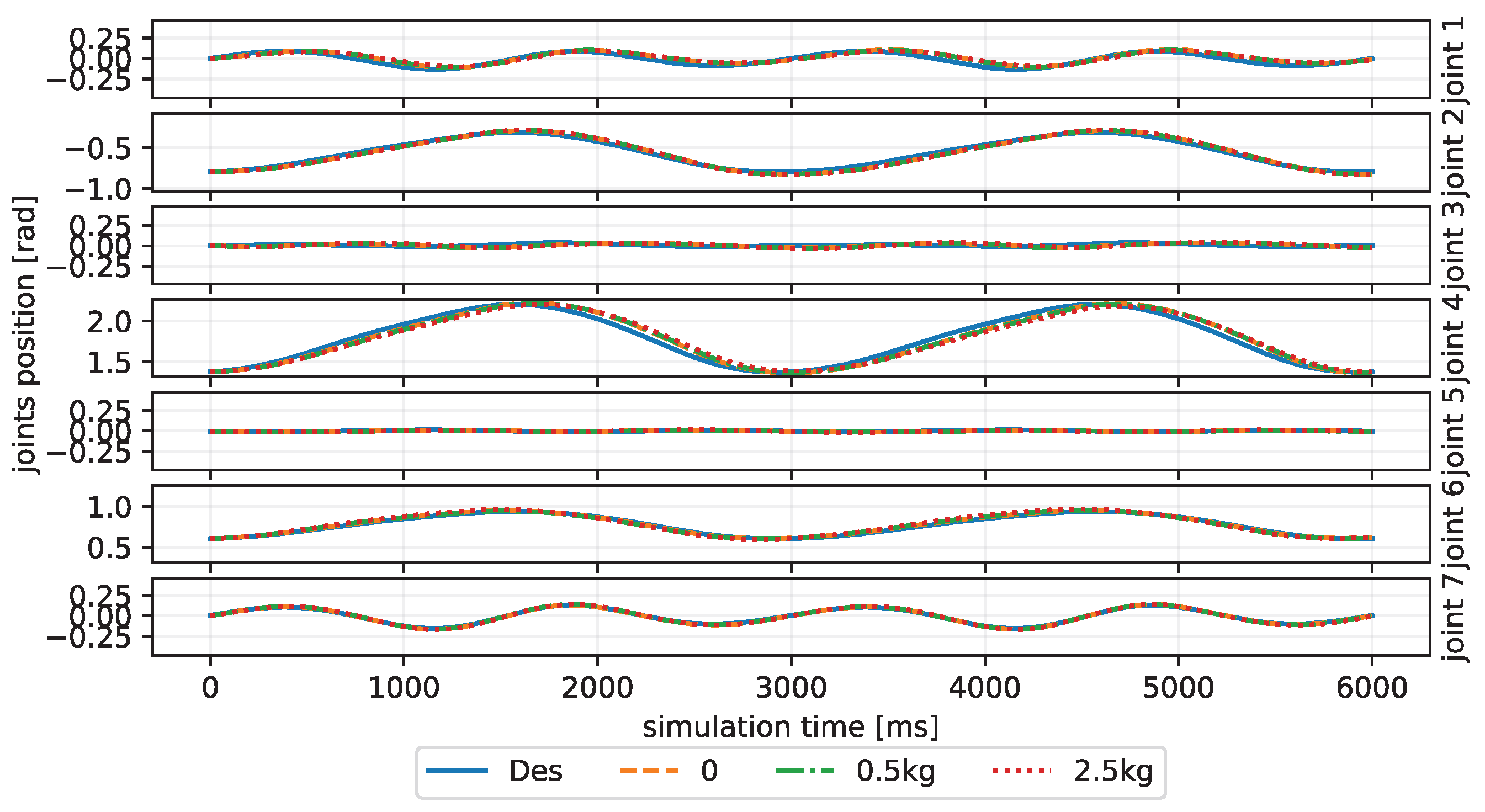
4. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DoF | Degree of Freedom |
| ANN | artificial neuron network |
| CNS | central nervous system |
| CBMC | CNS-based Biomimetic Motor Control |
| SNN | spiking neural network |
| RL | reinforcement learning |
| STDP | spiking timing-dependent plasticity |
| CMCM | cerebral motor cortex module |
| LIF | Leaky-Integrate-and-Fire |
| MF | mossy fiber |
| GC | granule cell |
| CF | climbing fiber |
| PC | Purkinje cell |
| DCN | deep cerebellar nuclei |
| PF | parallel fiber |
References
- Chaoui, H.; Sicard, P.; Gueaieb, W. ANN-Based Adaptive Control of Robotic Manipulators with Friction and Joint Elasticity. IEEE Trans. Ind. Electron. 2009, 56, 3174–3187. [Google Scholar] [CrossRef]
- He, W.; Dong, Y. Adaptive Fuzzy Neural Network Control for a Constrained Robot Using Impedance Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1174–1186. [Google Scholar] [CrossRef]
- Wang, F.; Liu, Z.; Chen, C.L.P.; Zhang, Y. Adaptive neural network-based visual servoing control for manipulator with unknown output nonlinearities. Inf. Sci. 2018, 451–452, 16–33. [Google Scholar] [CrossRef]
- Salloom, T.; Yu, X.; He, W.; Kaynak, O. Adaptive Neural Network Control of Underwater Robotic Manipulators Tuned by a Genetic Algorithm. J. Intell. Robot. Syst. 2020, 97, 657–672. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, Z.; Wen, G. Adaptive neural network control with optimal number of hidden nodes for trajectory tracking of robot manipulators. Neurocomputing 2019, 350, 136–145. [Google Scholar] [CrossRef]
- Pham, D.T.; Nguyen, T.V.; Le, H.X.; Nguyen, L.V.; Thai, N.H.; Phan, T.A.; Pham, H.T.; Duong, A.H. Adaptive neural network based dynamic surface control for uncertain dual arm robots. Int. J. Dyn. Control 2019, 8, 824–834. [Google Scholar] [CrossRef]
- Liu, Z.; Peng, K.; Han, L.; Guan, S. Modeling and Control of Robotic Manipulators Based on Artificial Neural Networks: A Review. Iran. J. Sci. Technol. Trans. Mech. Eng. 2023, 1–41. [Google Scholar] [CrossRef]
- Chadderdon, G.L.; Neymotin, S.A.; Kerr, C.C.; Lytton, W.W. Correction: Reinforcement Learning of Targeted Movement in a Spiking Neuronal Model of Motor Cortex. PLoS ONE 2013, 8, e47251. [Google Scholar] [CrossRef]
- Spüler, M.; Nagel, S.; Rosenstiel, W. A spiking neuronal model learning a motor control task by reinforcement learning and structural synaptic plasticity. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Bouganis, A.; Shanahan, M. Training a spiking neural network to control a 4-dof robotic arm based on spike timing-dependent plasticity. In Proceedings of the The 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Chen, X.; Zhu, W.; Dai, Y.; Ren, Q. A bio-inspired spiking neural network for control of a 4-dof robotic arm. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 616–621. [Google Scholar]
- DeWolf, T.; Patel, K.; Jaworski, P.; Leontie, R.; Hays, J.; Eliasmith, C. Neuromorphic control of a simulated 7-DOF arm using Loihi. Neuromorphic Comput. Eng. 2023, 3, 014007. [Google Scholar] [CrossRef]
- Carrillo, R.R.; Ros, E.; Boucheny, C.; Olivier, J.M.C. A real-time spiking cerebellum model for learning robot control. Biosystems 2008, 94, 18–27. [Google Scholar] [CrossRef]
- Abadia, I.; Naveros, F.; Garrido, J.A.; Ros, E.; Luque, N.R. On robot compliance: A cerebellar control approach. IEEE Trans. Cybern. 2019, 51, 2476–2489. [Google Scholar] [CrossRef] [PubMed]
- Abadía, I.; Naveros, F.; Ros, E.; Carrillo, R.R.; Luque, N.R. A cerebellar-based solution to the nondeterministic time delay problem in robotic control. Sci. Robot. 2021, 6, eabf2756. [Google Scholar] [CrossRef] [PubMed]
- Van Der Smagt, P.; Arbib, M.A.; Metta, G. Neurorobotics: From vision to action. In Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 2069–2094. [Google Scholar]
- Swinnen, S.P.; Vangheluwe, S.; Wagemans, J.; Coxon, J.P.; Goble, D.J.; Van Impe, A.; Sunaert, S.; Peeters, R.; Wenderoth, N. Shared neural resources between left and right interlimb coordination skills: The neural substrate of abstract motor representations. Neuroimage 2010, 49, 2570–2580. [Google Scholar] [CrossRef]
- Bhat, A. A Soft and Bio-Inspired Prosthesis with Tactile Feedback; Carnegie Mellon University: Pittsburgh, PA, USA, 2017. [Google Scholar]
- Ponulak, F.; Kasinski, A. Introduction to spiking neural networks: Information processing, learning and applications. Acta Neurobiol. Exp. 2011, 71, 409–433. [Google Scholar]
- Hodgkin, A.L.; Huxley, A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952, 117, 500. [Google Scholar] [CrossRef] [PubMed]
- Burkitt, A.N. A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input. Biol. Cybern. 2006, 95, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Stein, R.B. A theoretical analysis of neuronal variability. Biophys. J. 1965, 5, 173–194. [Google Scholar] [CrossRef]
- Bing, Z.; Meschede, C.; Röhrbein, F.; Huang, K.; Knoll, A.C. A survey of robotics control based on learning-inspired spiking neural networks. Front. Neurorobot. 2018, 12, 35. [Google Scholar] [CrossRef]
- Gerstner, W.; Kistler, W.M. Mathematical formulations of Hebbian learning. Biol. Cybern. 2002, 87, 404–415. [Google Scholar] [CrossRef]
- Albus, J.S. A new approach to manipulator control: The cerebellar model articulation controller (CMAC). J. Dyn. Sys. Meas. Control 1975, 97, 220–227. [Google Scholar] [CrossRef]
- Schweighofer, N. Computational Models of the Cerebellum in the Adaptive Control of Movements; University of Southern California: Los Angeles, CA, USA, 1995. [Google Scholar]
- Holroyd, C.B.; Coles, M.G.H. The neural basis of human error processing: Reinforcement learning, dopamine, and the error-related negativity. Psychol. Rev. 2002, 109, 679–709. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction. IEEE Trans. Neural Netw. 2005, 16, 285–286. [Google Scholar] [CrossRef]
- Nagaraj, A.; Sood, M.; Patil, B.M. A Concise Introduction to Reinforcement Learning in Robotics. arXiv 2022, arXiv:2210.07397. [Google Scholar]
- Sun, X.; O’Shea, D.J.; Golub, M.D.; Trautmann, E.M.; Vyas, S.; Ryu, S.I.; Shenoy, K.V. Cortical preparatory activity indexes learned motor memories. Nature 2022, 602, 274–279. [Google Scholar] [CrossRef]
- Fang, W.; Chen, Y.; Ding, J.; Chen, D.; Yu, Z.; Zhou, H.; Timothée, M.; Tian, Y. SpikingJelly. 2020. Available online: https://github.com/fangwei123456/spikingjelly (accessed on 18 April 2023).
- Yuan, R.; Duan, Q.; Tiw, P.J.; Li, G.; Xiao, Z.; Jing, Z.; Yang, K.; Liu, C.; Ge, C.; Huang, R.; et al. A calibratable sensory neuron based on epitaxial VO2 for spike-based neuromorphic multisensory system. Nat. Commun. 2022, 13, 3973. [Google Scholar] [CrossRef]
- Xiang, S.; Zhang, T.; Jiang, S.; Han, Y.; Zhang, Y.; Du, C.; Guo, X.; Yu, L.; Shi, Y.; Hao, Y. Spiking SiamFC++: Deep Spiking Neural Network for Object Tracking. arXiv 2022, arXiv:2209.12010. [Google Scholar]
- Liu, G.; Deng, W.; Xie, X.; Huang, L.; Tang, H. Human-Level Control through Directly-Trained Deep Spiking Q-Networks. IEEE Trans. Cybern. 2022, 1–12. [Google Scholar] [CrossRef]
- Morrison, A.; Diesmann, M.; Gerstner, W. Phenomenological models of synaptic plasticity based on spike timing. Biol. Cybern. 2008, 98, 459–478. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.M.O.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujita, Y.; Nagarajan, P.; Kataoka, T.; Ishikawa, T. ChainerRL: A Deep Reinforcement Learning Library. J. Mach. Learn. Res. 2021, 22, 3557–3570. [Google Scholar]
- Coumans, E.; Bai, Y. PyBullet, a Python Module for Physics Simulation for Games, Robotics and Machine Learning. 2016–2021. Available online: http://pybullet.org (accessed on 21 May 2022).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | GC | PC | DCN |
|---|---|---|---|
| 0 | 0 | 0 | |
| 1.0 | 5.0 | 1.5 | |
| 50 | 60 | 12 |
| Synapses | ||||
|---|---|---|---|---|
| value | 0.25 | 0.0028 | 0.45 | −0.5 |
| Trajectory | No Payload | 0.5 kg | 2.5 kg |
|---|---|---|---|
| Inclined Circle | |||
| Eight-Like Trajectory | |||
| Target Reaching |
| Methods | No Payload | 0.5 kg | 2.5 kg |
|---|---|---|---|
| No CMCM | |||
| CBMC | |||
| PD | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Pang, Y.; Wang, Y.; Han, X.; Li, Q.; Zhao, M. CBMC: A Biomimetic Approach for Control of a 7-Degree of Freedom Robotic Arm. Biomimetics 2023, 8, 389. https://doi.org/10.3390/biomimetics8050389
Li Q, Pang Y, Wang Y, Han X, Li Q, Zhao M. CBMC: A Biomimetic Approach for Control of a 7-Degree of Freedom Robotic Arm. Biomimetics. 2023; 8(5):389. https://doi.org/10.3390/biomimetics8050389
Chicago/Turabian StyleLi, Qingkai, Yanbo Pang, Yushi Wang, Xinyu Han, Qing Li, and Mingguo Zhao. 2023. "CBMC: A Biomimetic Approach for Control of a 7-Degree of Freedom Robotic Arm" Biomimetics 8, no. 5: 389. https://doi.org/10.3390/biomimetics8050389
APA StyleLi, Q., Pang, Y., Wang, Y., Han, X., Li, Q., & Zhao, M. (2023). CBMC: A Biomimetic Approach for Control of a 7-Degree of Freedom Robotic Arm. Biomimetics, 8(5), 389. https://doi.org/10.3390/biomimetics8050389