



Explainable AI: A Neurally-Inspired Decision Stack Framework
 , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Background
2. Explainable AI
3. Current State-of-the-Art Explainable AI Methods and Approaches
3.1. Intrinsic vs. Post-Hoc: The Criterion of Structure
3.2. Blackbox vs. Whitebox vs. Greybox Approaches: The Criterion of Transparency in Design
3.3. Local vs. Global: The Criterion of Scope
3.4. Model Specific vs. Model Agnostic: The Criterion of Agnosticity
3.5. Supervision-Based Methods
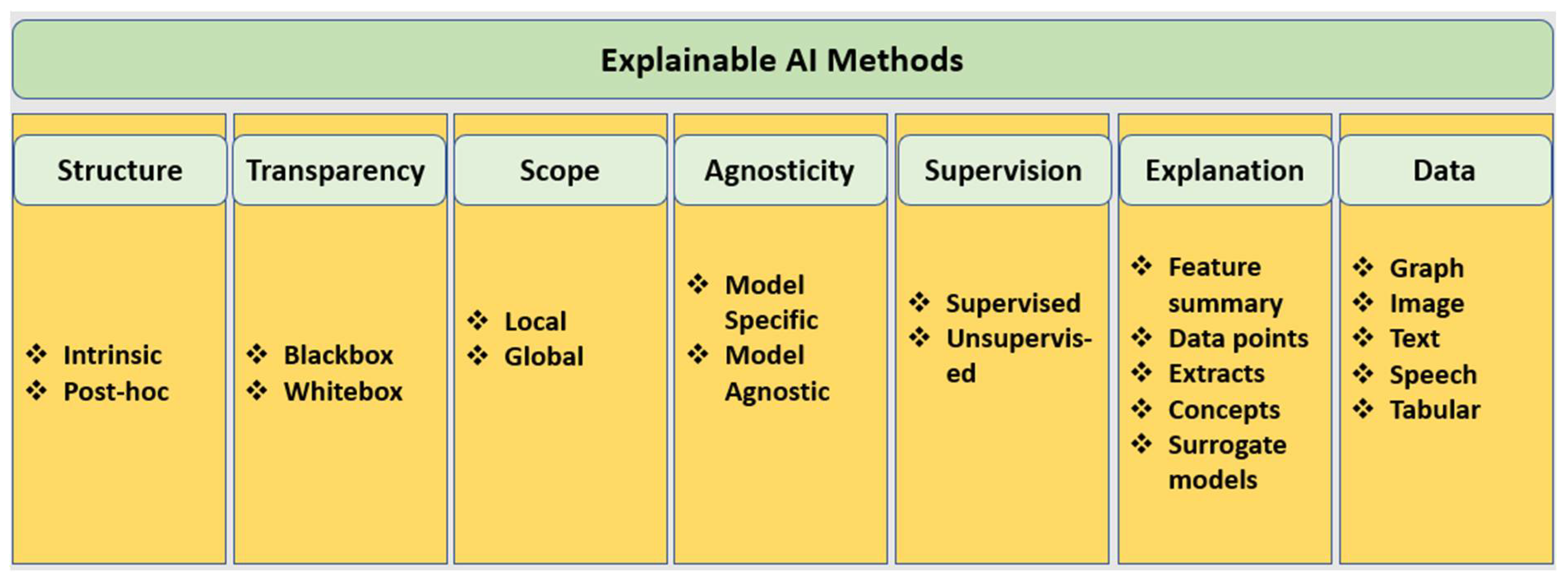
3.6. Explanation Type-Based Methods
3.7. Data Type-Based Methods
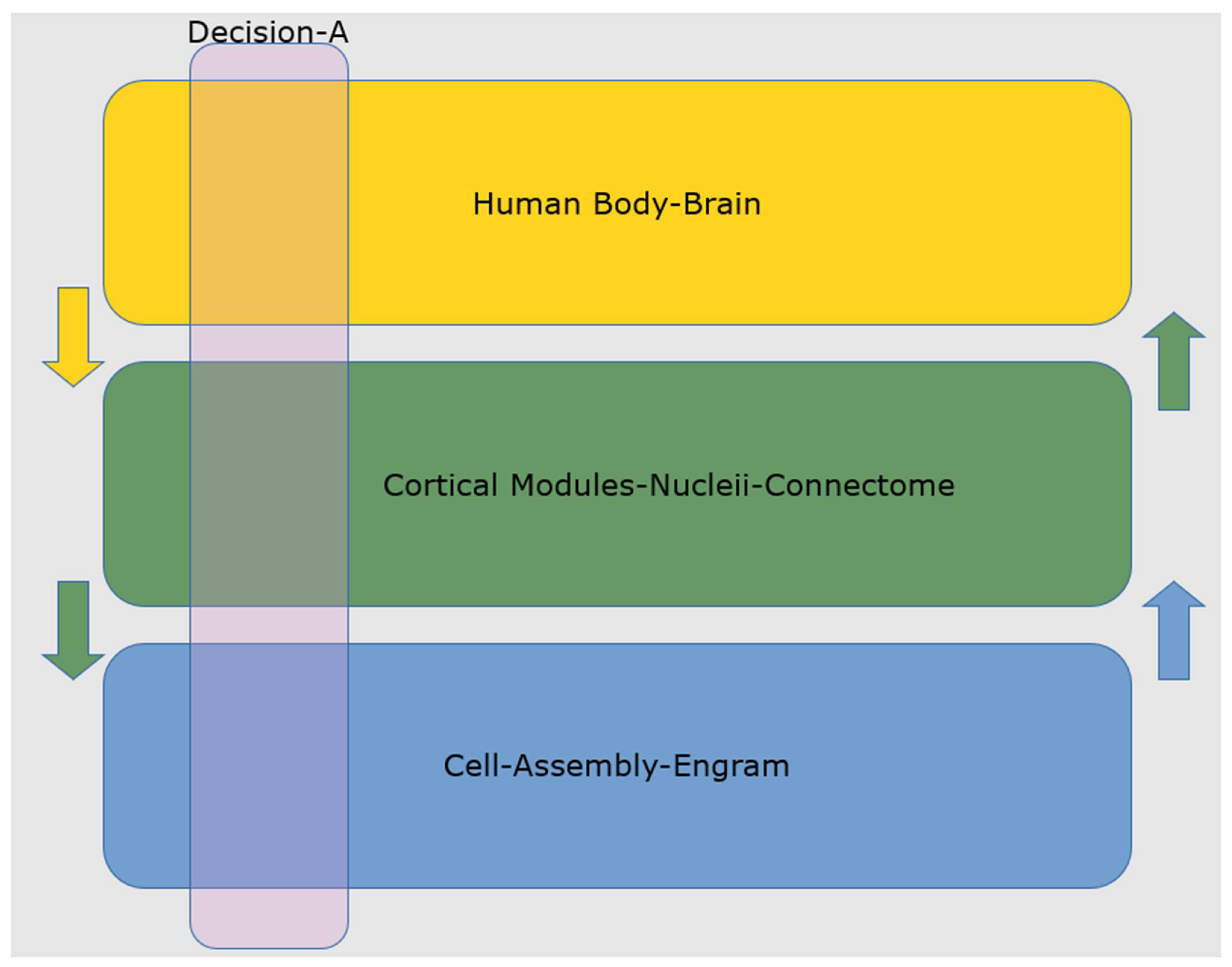
4. Existence Proof: The Lessons from Neuroscience
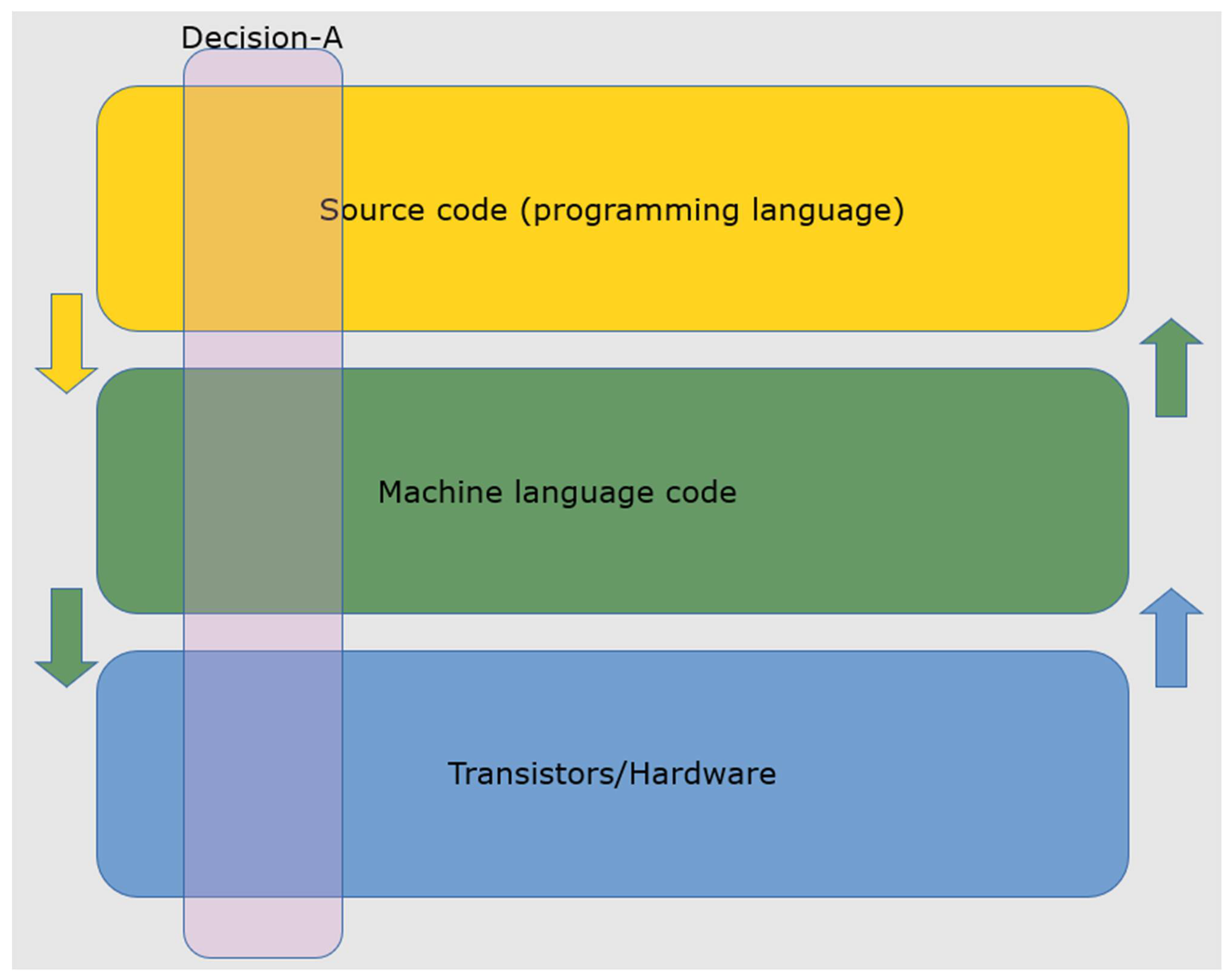
5. Non-AI Machine Decision Stacks
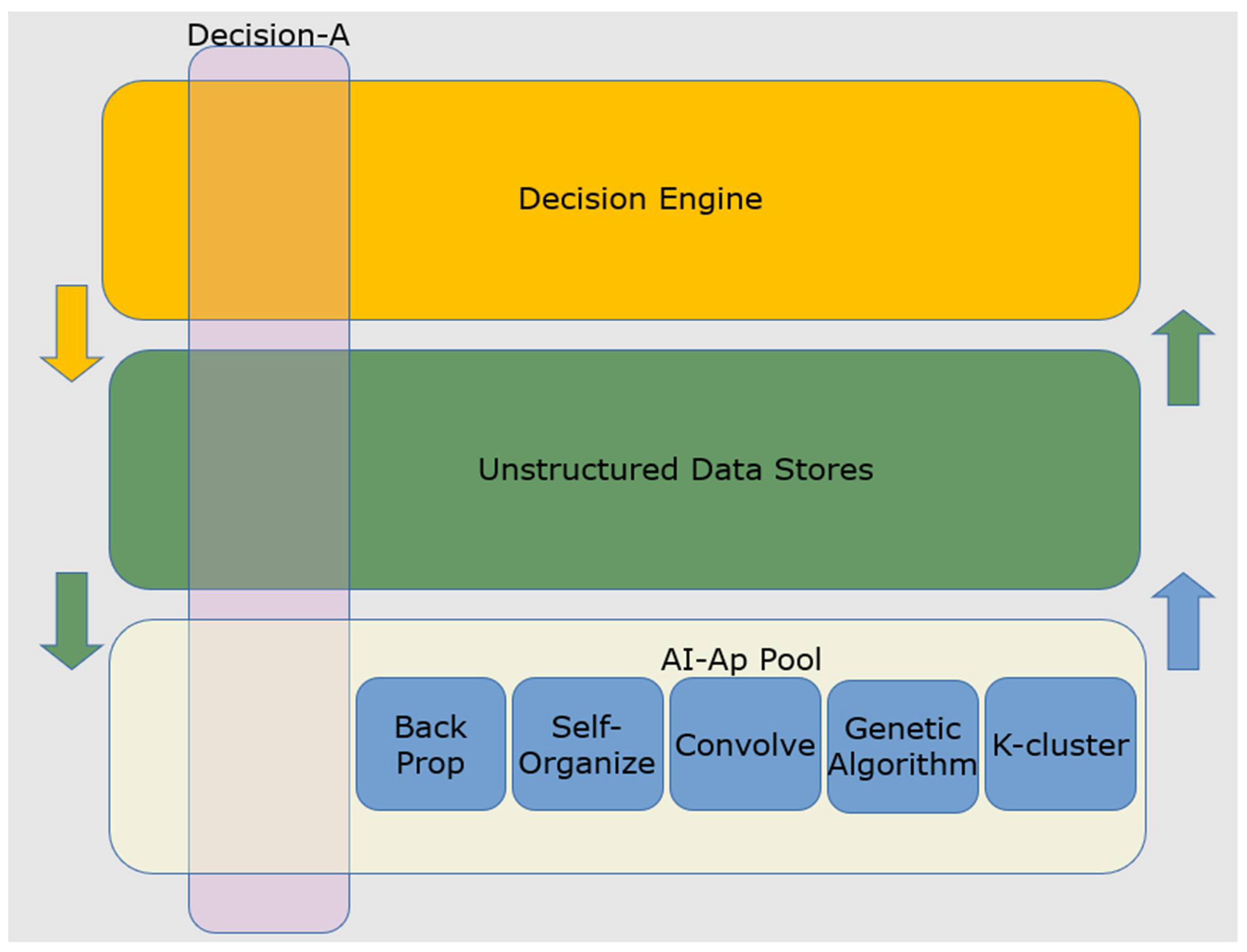
6. Explaining AI Failures: Towards an AI Decision-Stack
7. The Neurally inspired Framework
8. Existing Explainable AI Methods and Our Framework
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Gelles, D. Boeing 737 Max: What’s Happened after the 2 Deadly Crashes. The New York Times. 22 March 2019. Available online: https://www.nytimes.com/interactive/2019/business/boeing-737-crashes.html (accessed on 13 August 2022).
- Krichmar, J.L.; Severa, W.; Khan, M.S.; Olds, J.L. Making BREAD: Biomimetic Strategies for Artificial Intelligence Now and in the Future. Front. Neurosci. 2019, 13, 666. [Google Scholar] [CrossRef] [PubMed]
- Cowen, T. Average Is Over: Powering America Beyond the Age of the Great Stagnation; Penguin Group: New York, NY, USA, 2013. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the Game of Go without Human Knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Tesla Driver in Fatal “Autopilot” Crash Got Numerous Warnings: U.S. Government-Reuters. Available online: https://uk.reuters.com/article/us-tesla-crash-idUKKBN19A2XC (accessed on 21 August 2019).
- Friedman, J.A.; Zeckhauser, R. Assessing Uncertainty in Intelligence. Intell. Natl. Secur. 2012, 27, 824–847. [Google Scholar] [CrossRef]
- More Efficient Machine Learning Could Upend the AI Paradigm. MIT Technology Review. Available online: https://www.technologyreview.com/2018/02/02/145844/more-efficient-machine-learning-could-upend-the-ai-paradigm/ (accessed on 13 August 2022).
- Liu, X.; Ramirez, S.; Pang, P.T.; Puryear, C.B.; Govindarajan, A.; Deisseroth, K.; Tonegawa, S. Optogenetic Stimulation of a Hippocampal Engram Activates Fear Memory Recall. Nature 2012, 484, 381–385. [Google Scholar] [CrossRef] [PubMed]
- Fellows, L.K. The Neuroscience of Human Decision-Making Through the Lens of Learning and Memory. Curr. Top. Behav. Neurosci. 2018, 37, 231–251. [Google Scholar] [CrossRef]
- Gunning, D.; Aha, D. DARPA’s Explainable Artificial Intelligence (XAI) Program. AI Mag. 2019, 40, 44–58. [Google Scholar] [CrossRef]
- Wallace, N.; Castro, D. The Impact of the EU’s New Data Protection Regulation on AI. Center for Data Innovation. 2018. Available online: https://www2.datainnovation.org/2018-impact-gdpr-ai.pdf (accessed on 27 March 2018).
- Goodman, B.; Flaxman, S. European Union Regulations on Algorithmic Decision-Making and a “Right to Explanation”. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef]
- Rossini, P.M.; Burke, D.; Chen, R.; Cohen, L.G.; Daskalakis, Z.; Di Iorio, R.; Di Lazzaro, V.; Ferreri, F.; Fitzgerald, P.B.; George, M.S.; et al. Non-Invasive Electrical and Magnetic Stimulation of the Brain, Spinal Cord, Roots and Peripheral Nerves: Basic Principles and Procedures for Routine Clinical and Research Application. An Updated Report from an I.F.C.N. Committee. Clin. Neurophysiol. 2015, 126, 1071–1107. [Google Scholar] [CrossRef]
- Yibo, C.; Hou, K.; Zhou, H.; Shi, H.; Liu, X.; Diao, X.; Ding, H.; Li, J.; de Vaulx, C. 6LoWPAN Stacks: A Survey. In Proceedings of the 2011 7th International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, China, 23–25 September 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Clancey, W.J. From GUIDON to NEOMYCIN and HERACLES in Twenty Short Lessons. AI Mag. 1986, 7, 40. [Google Scholar] [CrossRef]
- Moore, J.D.; Swartout, W.R. Pointing: A Way Toward Explanation Dialogue. In Proceedings of the 8th National Conference on Artificial Intelligence, Boston, MA, USA, 29 July–3 August 1990; Shrobe, H.E., Dietterich, T.G., Swartout, W.R., Eds.; AAAI Press; The MIT Press: Cambridge, MA, USA, 1990; Volume 2, pp. 457–464. [Google Scholar]
- Biran, O.; Cotton, C. Explanation and Justification in Machine Learning: A Survey. In Proceedings of the IJCAI-17 Workshop on Explainable AI (XAI), Melbourne, Australia, 20 August 2017; Volume 8, pp. 8–13. [Google Scholar]
- Paudyal, P. Should AI Explain Itself? Or Should We Design Explainable AI so that It Doesn’t Have to. Medium. Available online: https://towardsdatascience.com/should-ai-explain-itself-or-should-we-design-explainable-ai-so-that-it-doesnt-have-to-90e75bb6089e (accessed on 13 August 2022).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Angwin, J.; Larson, J.; Mattu, S.; Kirchner, L. Machine Bias. ProPublica. Available online: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing?token=Tu5C70R2pCBv8Yj33AkMh2E-mHz3d6iu (accessed on 13 August 2022).
- Kirsch, A. Explain to Whom? Putting the User in the Center of Explainable AI. In Proceedings of the First International Workshop on Comprehensibility and Explanation in AI and ML 2017 Co-Located with 16th International Conference of the Italian Association for Artificial Intelligence (AI*IA 2017), Bari, Italy, 14 November 2017. [Google Scholar]
- Mueller, S.T.; Hoffman, R.R.; Clancey, W.; Emrey, A.; Klein, G. Explanation in Human-AI Systems: A Literature Meta-Review, Synopsis of Key Ideas and Publications, and Bibliography for Explainable AI. arXiv 2019. [Google Scholar] [CrossRef]
- Wang, D.; Yang, Q.; Abdul, A.; Lim, B.Y. Designing Theory-Driven User-Centric Explainable AI. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, CHI ’19, Scotland, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–15. [Google Scholar] [CrossRef]
- Hoffman, R.R.; Mueller, S.T.; Klein, G.; Litman, J. Metrics for Explainable AI: Challenges and Prospects. arXiv 2019. [Google Scholar] [CrossRef]
- Sheh, R.; Monteath, I. Defining Explainable AI for Requirements Analysis. Künstl Intell. 2018, 32, 261–266. [Google Scholar] [CrossRef]
- Kim, T.W. Explainable Artificial Intelligence (XAI), the Goodness Criteria and the Grasp-Ability Test. arXiv 2018. [Google Scholar] [CrossRef]
- Adler, P.; Falk, C.; Friedler, S.A.; Nix, T.; Rybeck, G.; Scheidegger, C.; Smith, B.; Venkatasubramanian, S. Auditing Black-Box Models for Indirect Influence. Knowl. Inf. Syst. 2018, 54, 95–122. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Floridi, L. Why a Right to Explanation of Automated Decision-Making Does Not Exist in the General Data Protection Regulation. Int. Data Priv. Law 2017, 7, 76–99. [Google Scholar] [CrossRef]
- Hayes, B.; Shah, J.A. Improving Robot Controller Transparency Through Autonomous Policy Explanation. In Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, HRI ’17, Vienna, Austria, 6–9 March 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 303–312. [Google Scholar] [CrossRef] [Green Version]
- Fallon, C.K.; Blaha, L.M. Improving Automation Transparency: Addressing Some of Machine Learning’s Unique Challenges. In Augmented Cognition: Intelligent Technologies; Schmorrow, D.D., Fidopiastis, C.M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; pp. 245–254. [Google Scholar] [CrossRef]
- What Does It Mean to Ask for an “Explainable” Algorithm? Available online: https://freedom-to-tinker.com/2017/05/31/what-does-it-mean-to-ask-for-an-explainable-algorithm/ (accessed on 14 August 2022).
- Bengio, Y.; Lecun, Y.; Hinton, G. Deep Learning for AI. Commun. ACM 2021, 64, 58–65. [Google Scholar] [CrossRef]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A Brief Survey on History, Research Areas, Approaches and Challenges. In Natural Language Processing and Chinese Computing; Tang, J., Kan, M.-Y., Zhao, D., Li, S., Zan, H., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 563–574. [Google Scholar] [CrossRef]
- Holzinger, A.; Saranti, A.; Molnar, C.; Biecek, P.; Samek, W. Explainable AI Methods—A Brief Overview. In xxAI-Beyond Explainable AI, Proceedings of the International Workshop on Extending Explainable AI Beyond Deep Models and Classifiers, Vienna, Austria, 18 July 2020; Revised and Extended, Papers; Holzinger, A., Goebel, R., Fong, R., Moon, T., Müller, K.-R., Samek, W., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2022; pp. 13–38. [Google Scholar] [CrossRef]
- Lipton, Z.C. The Mythos of Model Interpretability. arXiv 2017. [Google Scholar] [CrossRef]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable Artificial Intelligence: A Survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar] [CrossRef]
- Madsen, A.; Reddy, S.; Chandar, S. Post-Hoc Interpretability for Neural NLP: A Survey. ACM Comput. Surv. 2022. [Google Scholar] [CrossRef]
- Zhang, Y.; Weng, Y.; Lund, J. Applications of Explainable Artificial Intelligence in Diagnosis and Surgery. Diagnostics 2022, 12, 237. [Google Scholar] [CrossRef]
- Yera, R.; Alzahrani, A.A.; Martínez, L. Exploring Post-Hoc Agnostic Models for Explainable Cooking Recipe Recommendations. Knowl. Based Syst. 2022, 251, 109216. [Google Scholar] [CrossRef]
- Pintelas, E.; Livieris, I.E.; Pintelas, P. A Grey-Box Ensemble Model Exploiting Black-Box Accuracy and White-Box Intrinsic Interpretability. Algorithms 2020, 13, 17. [Google Scholar] [CrossRef] [Green Version]
- Grau, I.; Sengupta, D.; Lorenzo, M.M.G. Grey-Box Model: An Ensemble Approach for Addressing Semi-Supervised Classification Problems. 2016. Available online: https://kulak.kuleuven.be/benelearn/papers/Benelearn_2016_paper_45.pdf (accessed on 13 August 2022).
- Loyola-González, O. Black-Box vs. White-Box: Understanding Their Advantages and Weaknesses from a Practical Point of View. IEEE Access 2019, 7, 154096–154113. [Google Scholar] [CrossRef]
- Taherkhani, N.; Sepehri, M.M.; Khasha, R.; Shafaghi, S. Ranking Patients on the Kidney Transplant Waiting List Based on Fuzzy Inference System. BMC Nephrol. 2022, 23, 31. [Google Scholar] [CrossRef] [PubMed]
- Zaitseva, E.; Levashenko, V.; Rabcan, J.; Krsak, E. Application of the Structure Function in the Evaluation of the Human Factor in Healthcare. Symmetry 2020, 12, 93. [Google Scholar] [CrossRef]
- Nazemi, A.; Fatemi Pour, F.; Heidenreich, K.; Fabozzi, F.J. Fuzzy Decision Fusion Approach for Loss-given-Default Modeling. Eur. J. Oper. Res. 2017, 262, 780–791. [Google Scholar] [CrossRef]
- Zaitseva, E.; Levashenko, V.; Kvassay, M.; Deserno, T.M. Reliability Estimation of Healthcare Systems Using Fuzzy Decision Trees. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems, Gdansk, Poland, 11–14 September 2016; pp. 331–340. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Fuzzy Set and Possibility Theory-Based Methods in Artificial Intelligence. Artif. Intell. 2003, 148, 1–9. [Google Scholar] [CrossRef]
- Garibaldi, J.M. The Need for Fuzzy AI. IEEE/CAA J. Autom. Sin. 2019, 6, 610–622. [Google Scholar] [CrossRef]
- Robnik-Šikonja, M.; Kononenko, I. Explaining Classifications for Individual Instances. IEEE Trans. Knowl. Data Eng. 2008, 20, 589–600. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, F.; Zou, J.; Petrosian, O.L.; Krinkin, K.V. XAI Evaluation: Evaluating Black-Box Model Explanations for Prediction. In Proceedings of the 2021 II International Conference on Neural Networks and Neurotechnologies (NeuroNT), Saint Petersburg, Russia, 16 June 2021; 2021; pp. 13–16. [Google Scholar] [CrossRef]
- Aliramezani, M.; Norouzi, A.; Koch, C.R. A Grey-Box Machine Learning Based Model of an Electrochemical Gas Sensor. Sens. Actuators B Chem. 2020, 321, 128414. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From Local Explanations to Global Understanding with Explainable AI for Trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Machlev, R.; Heistrene, L.; Perl, M.; Levy, K.Y.; Belikov, J.; Mannor, S.; Levron, Y. Explainable Artificial Intelligence (XAI) Techniques for Energy and Power Systems: Review, Challenges and Opportunities. Energy AI 2022, 9, 100169. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems—NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking Inside the Black Box: Visualizing Statistical Learning with Plots of Individual Conditional Expectation. arXiv 2014. [Google Scholar] [CrossRef]
- Danesh, T.; Ouaret, R.; Floquet, P.; Negny, S. Interpretability of Neural Networks Predictions Using Accumulated Local Effects as a Model-Agnostic Method. In Computer Aided Chemical Engineering; Montastruc, L., Negny, S., Eds.; 32 European Symposium on Computer Aided Process Engineering; Elsevier: Amsterdam, The Netherlands, 2022; Volume 51, pp. 1501–1506. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and Practice of Explainable Machine Learning. Front. Big Data 2021, 4, 688969. [Google Scholar] [CrossRef] [PubMed]
- Sairam, S.; Srinivasan, S.; Marafioti, G.; Subathra, B.; Mathisen, G.; Bekiroglu, K. Explainable Incipient Fault Detection Systems for Photovoltaic Panels. arXiv 2020. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Trans. Syst. Man Cybern. Part C 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Ancona, M.; Ceolini, E.; Öztireli, C.; Gross, M. Gradient-Based Attribution Methods. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Samek, W., Montavon, G., Vedaldi, A., Hansen, L.K., Müller, K.-R., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 169–191. [Google Scholar] [CrossRef]
- Lei, T.; Barzilay, R.; Jaakkola, T. Rationalizing Neural Predictions. arXiv 2016. [Google Scholar] [CrossRef]
- Jain, S.; Wiegreffe, S.; Pinter, Y.; Wallace, B.C. Learning to Faithfully Rationalize by Construction. arXiv 2020. [Google Scholar] [CrossRef]
- Esmaeili, B.; Wu, H.; Jain, S.; Bozkurt, A.; Siddharth, N.; Paige, B.; Brooks, D.H.; Dy, J.; Meent, J.-W. Structured Disentangled Representations. In Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, Okinawa, Japan, 16–18 April 2019; Proceedings of Machine Learning Research. pp. 2525–2534. [Google Scholar]
- Palczewska, A.; Palczewski, J.; Marchese Robinson, R.; Neagu, D. Interpreting Random Forest Classification Models Using a Feature Contribution Method. In Integration of Reusable Systems; Bouabana-Tebibel, T., Rubin, S.H., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2014; pp. 193–218. [Google Scholar] [CrossRef]
- Tolomei, G.; Silvestri, F.; Haines, A.; Lalmas, M. Interpretable Predictions of Tree-Based Ensembles via Actionable Feature Tweaking. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 465–474. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. Proc. AAAI Conf. Artif. Intell. 2018, 32. [Google Scholar] [CrossRef]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). arXiv 2018. [Google Scholar] [CrossRef]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.-J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. arXiv 2016. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [Google Scholar] [CrossRef]
- Welling, S.H.; Refsgaard, H.H.F.; Brockhoff, P.B.; Clemmensen, L.H. Forest Floor Visualizations of Random Forests. arXiv 2016. [Google Scholar] [CrossRef]
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mané, D.; Fritz, D.; Krishnan, D.; Viégas, F.B.; Wattenberg, M. Visualizing Dataflow Graphs of Deep Learning Models in TensorFlow. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Hendricks, L.A.; Hu, R.; Darrell, T.; Akata, Z. Grounding Visual Explanations. arXiv 2018. [Google Scholar] [CrossRef]
- Pawelczyk, M.; Haug, J.; Broelemann, K.; Kasneci, G. Learning Model-Agnostic Counterfactual Explanations for Tabular Data. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 3126–3132. [Google Scholar] [CrossRef]
- de Bruijn, H.; Warnier, M.; Janssen, M. The Perils and Pitfalls of Explainable AI: Strategies for Explaining Algorithmic Decision-Making. Gov. Inf. Q. 2022, 39, 101666. [Google Scholar] [CrossRef]
- Antoniadi, A.M.; Du, Y.; Guendouz, Y.; Wei, L.; Mazo, C.; Becker, B.A.; Mooney, C. Current Challenges and Future Opportunities for XAI in Machine Learning-Based Clinical Decision Support Systems: A Systematic Review. Appl. Sci. 2021, 11, 5088. [Google Scholar] [CrossRef]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, Methods, and Applications in Interpretable Machine Learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and Explainability of Artificial Intelligence in Medicine. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef]
- Alcorn, M.A.; Li, Q.; Gong, Z.; Wang, C.; Mai, L.; Ku, W.-S.; Nguyen, A. Strike (with) a Pose: Neural Networks Are Easily Fooled by Strange Poses of Familiar Objects. arXiv 2019. [Google Scholar] [CrossRef]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Visual Classification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1625–1634. [Google Scholar] [CrossRef]
- Su, J.; Vargas, D.V.; Kouichi, S. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Computat. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Fatal Tesla Self-Driving Car Crash Reminds Us That Robots Aren’t Perfect. IEEE Spectrum. Available online: https://spectrum.ieee.org/fatal-tesla-autopilot-crash-reminds-us-that-robots-arent-perfect (accessed on 13 August 2022).
- Racial Bias Found in Algorithms That Determine Health Care for Millions of Patients-IEEE Spectrum. Available online: https://spectrum.ieee.org/racial-bias-found-in-algorithms-that-determine-health-care-for-millions-of-patients (accessed on 13 August 2022).
- Newman, J. Explainability Won’t Save AI; Brookings: Washington, DC, USA, 2021. [Google Scholar]
- Bansal, N.; Agarwal, C.; Nguyen, A. SAM: The Sensitivity of Attribution Methods to Hyperparameters 2020. Poster. Available online: https://bnaman50.github.io/SAM/CVPR_2020_SAM_Poster.pdf (accessed on 13 August 2022).
- Explainable AI Won’t Deliver. Here’s Why.|HackerNoon. Available online: https://hackernoon.com/explainable-ai-wont-deliver-here-s-why-6738f54216be (accessed on 14 August 2022).
- 7 Revealing Ways AIs Fail. IEEE Spectrum. Available online: https://spectrum.ieee.org/ai-failures (accessed on 14 August 2022).
- Medical Imaging AI Software Is Vulnerable to Covert Attacks. IEEE Spectrum. Available online: https://spectrum.ieee.org/medical-imaging-ai-software-vulnerable-to-covert-attacks (accessed on 14 August 2022).
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2014. [Google Scholar] [CrossRef]
- Nantais, J. Does Your Data Science Project Actually Do What You Think It Does? Medium. Available online: https://towardsdatascience.com/internal-validity-in-data-science-c44c1a2f194f (accessed on 14 August 2022).
- Bansal, N.; Agarwal, C.; Nguyen, A. SAM: The Sensitivity of Attribution Methods to Hyperparameters. arXiv 2020. [Google Scholar] [CrossRef]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. SmoothGrad: Removing Noise by Adding Noise. arXiv 2017. [Google Scholar] [CrossRef]
- Olds, J. Ideas Lab for Imagining Artificial Intelligence and Augmented Cognition in the USAF of 2030; George Mason University: Arlington, VA, USA, 2019; p. 134. Available online: https://apps.dtic.mil/sti/pdfs/AD1096469.pdf (accessed on 22 August 2019).
- Vosskuhl, J.; Strüber, D.; Herrmann, C.S. Non-Invasive Brain Stimulation: A Paradigm Shift in Understanding Brain Oscillations. Front. Hum. Neurosci. 2018, 12, 211. [Google Scholar] [CrossRef]
- Zrenner, C.; Belardinelli, P.; Müller-Dahlhaus, F.; Ziemann, U. Closed-Loop Neuroscience and Non-Invasive Brain Stimulation: A Tale of Two Loops. Front. Cell. Neurosci. 2016, 10, 92. [Google Scholar] [CrossRef] [PubMed]
- Pollok, B.; Boysen, A.-C.; Krause, V. The Effect of Transcranial Alternating Current Stimulation (TACS) at Alpha and Beta Frequency on Motor Learning. Behav. Brain Res. 2015, 293, 234–240. [Google Scholar] [CrossRef]
- Antal, A.; Nitsche, M.A.; Kincses, T.Z.; Kruse, W.; Hoffmann, K.-P.; Paulus, W. Facilitation of Visuo-Motor Learning by Transcranial Direct Current Stimulation of the Motor and Extrastriate Visual Areas in Humans. Eur. J. Neurosci. 2004, 19, 2888–2892. [Google Scholar] [CrossRef]
- Zaehle, T.; Sandmann, P.; Thorne, J.D.; Jäncke, L.; Herrmann, C.S. Transcranial Direct Current Stimulation of the Prefrontal Cortex Modulates Working Memory Performance: Combined Behavioural and Electrophysiological Evidence. BMC Neurosci. 2011, 12, 2. [Google Scholar] [CrossRef]
- Bartolotti, J.; Bradley, K.; Hernandez, A.E.; Marian, V. Neural Signatures of Second Language Learning and Control. Neuropsychologia 2017, 98, 130–138. [Google Scholar] [CrossRef] [PubMed]
- Anggraini, D.; Glasauer, S.; Wunderlich, K. Neural Signatures of Reinforcement Learning Correlate with Strategy Adoption during Spatial Navigation. Sci. Rep. 2018, 8, 10110. [Google Scholar] [CrossRef] [PubMed]
- Heekeren, H.R.; Marrett, S.; Bandettini, P.A.; Ungerleider, L.G. A General Mechanism for Perceptual Decision-Making in the Human Brain. Nature 2004, 431, 859–862. [Google Scholar] [CrossRef] [PubMed]
- Hsu, M.; Bhatt, M.; Adolphs, R.; Tranel, D.; Camerer, C.F. Neural Systems Responding to Degrees of Uncertainty in Human Decision-Making. Science 2005, 310, 1680–1683. [Google Scholar] [CrossRef] [Green Version]
- Dudai, Y. The Neurobiology of Consolidations, or, How Stable Is the Engram? Annu. Rev. Psychol. 2004, 55, 51–86. [Google Scholar] [CrossRef]
- Ramirez, S.; Liu, X.; Lin, P.-A.; Suh, J.; Pignatelli, M.; Redondo, R.L.; Ryan, T.J.; Tonegawa, S. Creating a False Memory in the Hippocampus. Science 2013, 341, 387. [Google Scholar] [CrossRef]
- Sandberg, A. Energetics of the Brain and AI. arXiv 2016. [Google Scholar] [CrossRef]
- Debugging Tools for High Level Languages-Satterthwaite-1972-Software: Practice and Experience-Wiley Online Library. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1002/spe.4380020303 (accessed on 14 August 2022).
- Yao, X. Evolving Artificial Neural Networks. Proc. IEEE 1999, 87, 1423–1447. [Google Scholar] [CrossRef]
- Bowers, J.S. On the Biological Plausibility of Grandmother Cells: Implications for Neural Network Theories in Psychology and Neuroscience. Psychol. Rev. 2009, 116, 220–251. [Google Scholar] [CrossRef]
- Janssen, M.; Kuk, G. The Challenges and Limits of Big Data Algorithms in Technocratic Governance. Gov. Inf. Q. 2016, 33, 371–377. [Google Scholar] [CrossRef]
- Wan, A. What Explainable AI Fails to Explain (and How We Fix that). Medium. Available online: https://towardsdatascience.com/what-explainable-ai-fails-to-explain-and-how-we-fix-that-1e35e37bee07 (accessed on 15 August 2022).
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Joshi, K. Deep Dive into Explainable AI: Current Methods and Challenges. Arya-xAI 2022. Available online: https://medium.com/arya-xai/deep-dive-into-explainable-ai-current-methods-and-challenges-2e9912d73136 (accessed on 1 February 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.S.; Nayebpour, M.; Li, M.-H.; El-Amine, H.; Koizumi, N.; Olds, J.L. Explainable AI: A Neurally-Inspired Decision Stack Framework. Biomimetics 2022, 7, 127. https://doi.org/10.3390/biomimetics7030127
Khan MS, Nayebpour M, Li M-H, El-Amine H, Koizumi N, Olds JL. Explainable AI: A Neurally-Inspired Decision Stack Framework. Biomimetics. 2022; 7(3):127. https://doi.org/10.3390/biomimetics7030127
Chicago/Turabian StyleKhan, Muhammad Salar, Mehdi Nayebpour, Meng-Hao Li, Hadi El-Amine, Naoru Koizumi, and James L. Olds. 2022. "Explainable AI: A Neurally-Inspired Decision Stack Framework" Biomimetics 7, no. 3: 127. https://doi.org/10.3390/biomimetics7030127
APA StyleKhan, M. S., Nayebpour, M., Li, M.-H., El-Amine, H., Koizumi, N., & Olds, J. L. (2022). Explainable AI: A Neurally-Inspired Decision Stack Framework. Biomimetics, 7(3), 127. https://doi.org/10.3390/biomimetics7030127