Evaluation of Mixed Deep Neural Networks for Reverberant Speech Enhancement




Abstract
:1. Introduction
2. Problem Statement
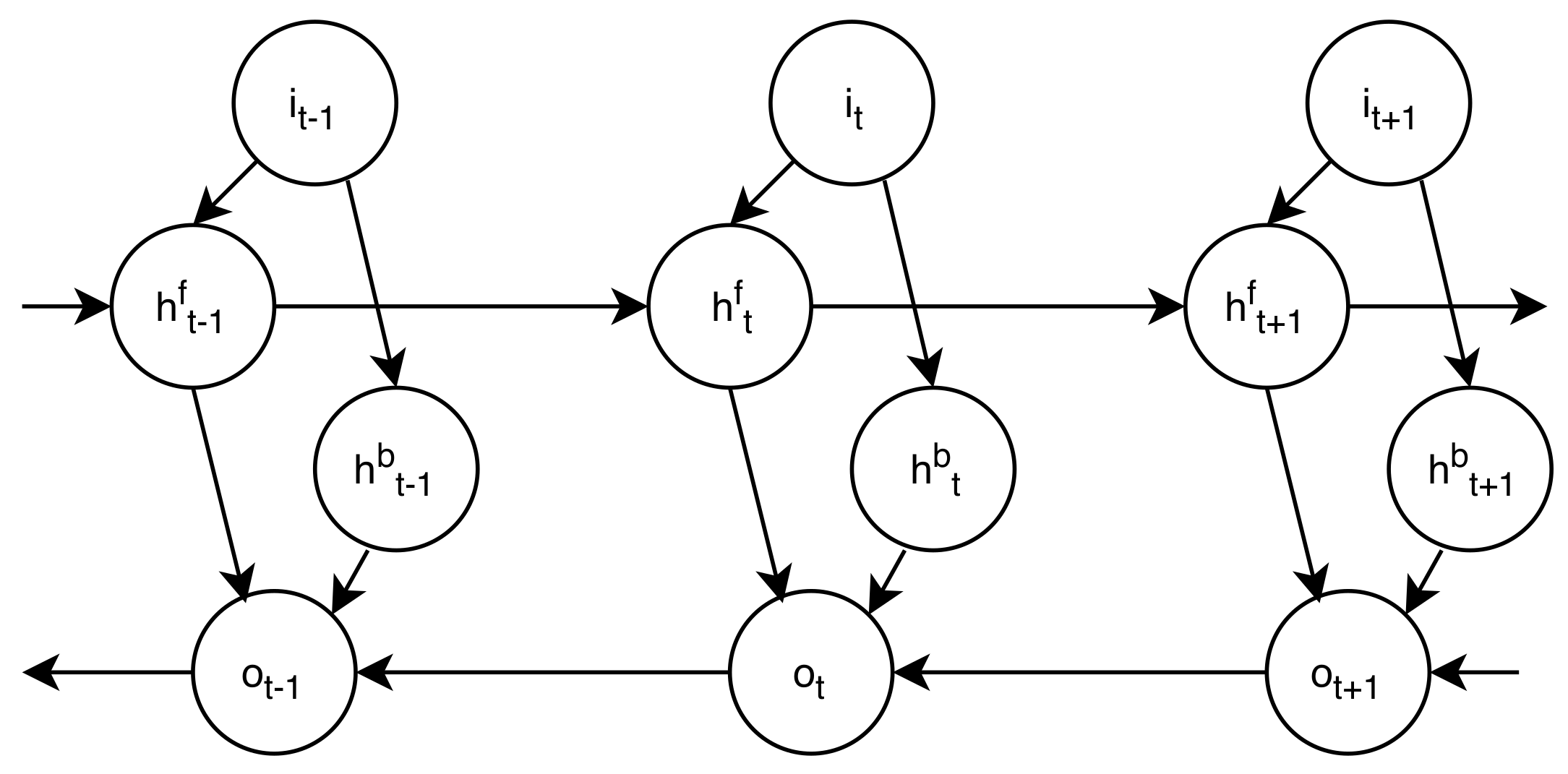
3. Autoencoders of BLSTM Networks
4. Experimental Setup
- Selection of conditions: Given the large number of impulse responses contemplated in the databases, we randomly chose five reverberated speech conditions. Each of the conditions has the corresponding clean version in the database.
- Extraction of features and input-output correspondence: A set of parameters was extracted from the reverberated and clean audio files. Those of the reverberated files were used as inputs to the networks, while the corresponding clean functions were the outputs.
- Training: During training, the weights of the networks were adjusted as the parameters with reverberation and clean were presented to the network. As usual in recurrent neural networks, the updating of the values of the internal weights was carried out using the back-propagation algorithm through time. In total, 210 expressions were used for each condition (approximately 70% of the total database) to train each case. The details and equations of the algorithm followed can be found in [34].
- Validation: After each training step, the sum of the squared errors within the validation set of approximately 20% of the statements was calculated, and the weights of the network were updated in each improvement.
- Test: A subset of 50 phrases, selected at random (about 10% of the total number of phrases in the database), was chosen for the test set, for each condition. These phrases were not part of the training process, to provide independence between training and testing.
4.1. Database
4.2. Feature Extraction
4.3. Evaluation
- Perceptual evaluation of speech quality (PESQ): This measure uses a model to predict the subjective quality of speech, as defined in ITU-T P.862.ITU recommendation. The results are in the range , where 4.5 corresponds to the signal enhanced perfectly. PESQ is calculated as [37]:where is the average disturbance and is the asymmetric perturbation. The were chosen to optimize PESQ in the measurement of general speech quality.
- Sum of squared errors (sse): This is the most common metric for the validation set error during the training process of a neural network. It is defined as:where is the known value of the outputs and is the approximation made by the network.
- Time per epoch: This refers to the time it takes for an iteration of the training process.
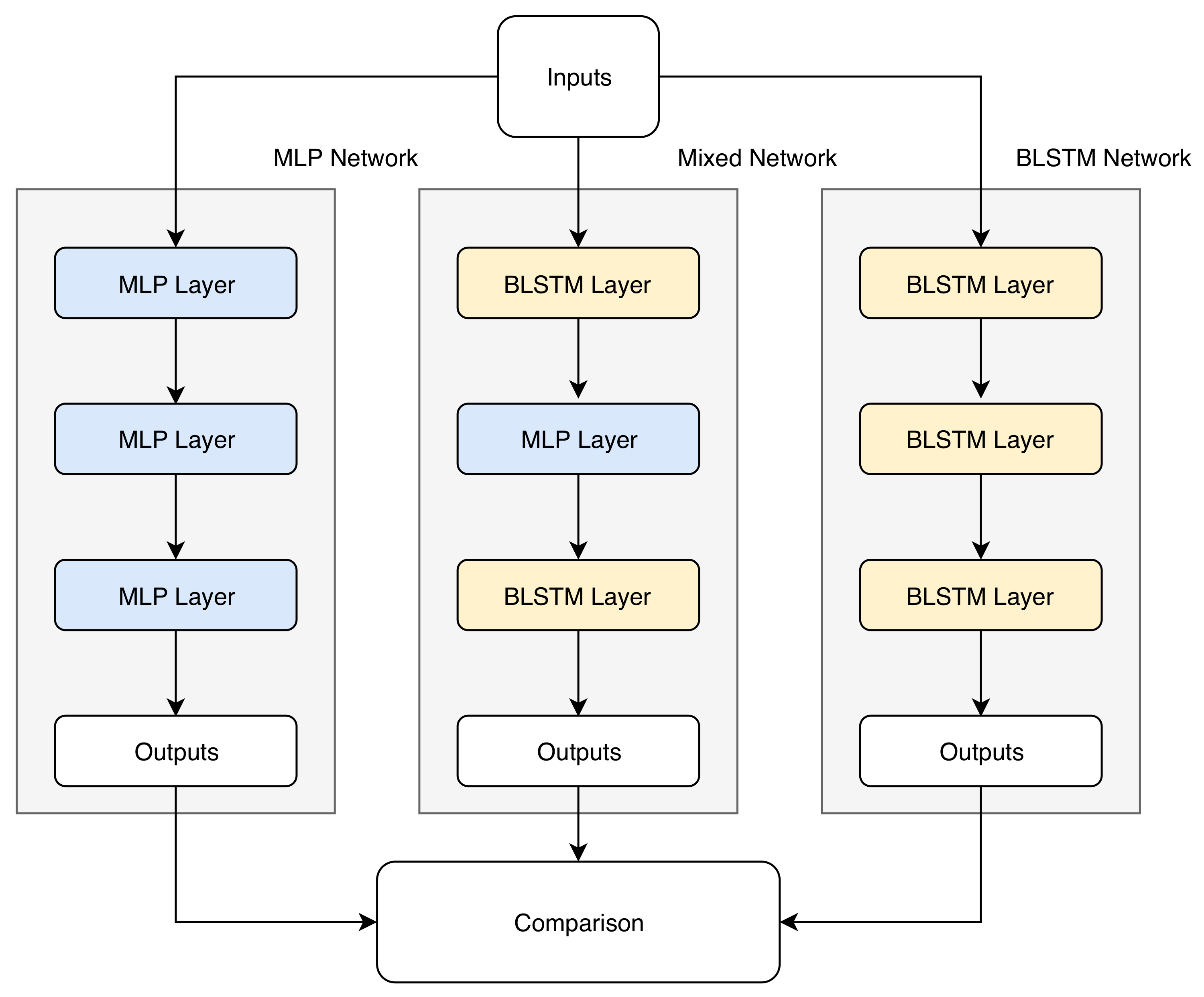
4.4. Experiments
- BLSTM–BLSTM–BLSTM
- BLSTM–BLSTM–MLP
- BLSTM–MLP–BLSTM
- BLSTM–MLP–MLP
- MLP–BLSTM–BLSTM
- MLP–BLSTM–MLP
- MLP–MLP–BLSTM
- MLP–MLP–MLP
5. Results and Discussion
- MARDY, Lecture Room and Artificial Room: Only two of the mixed configurations present results that do not significantly differ statistically with the base system. These mixed networks are BLSTM–BLSTM–MLP and MLP–BLSTM–BLSTM.
- Ace Building: In this case, three combinations of hidden layers present results that do not differ significantly from the base case.
- Meeting Room: This is a particular case, because the combination BLSTM-BLSTM-MLP is the one that presents the best result, although the improvement is not significant compared to the base system. On the other hand, MLP–BLSTM–BLSTM, BLSTM–MLP–BLSTM, and MLP–BLSTM–MLP present results that do not differ significantly from the base system.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BLSTM | Bidirectional Long Short-term Memory Neural Network |
| DNN | Deep Neural Network |
| LSTM | Long Short-term Memory Neural Network |
| MEMS | Microelectromechanical System |
| MFCC | Mel Frequency Cepstral Coefficients |
| MLP | Multi-Layer Perceptron |
| PESQ | Perceptual Evaluation of Speech Quality |
| RNN | Recurrent Neural Network |
| SNR | Signal-to-noise Ratio |
| TTS | Text-to-Speech Synthesis |
References
- Weninger, F.; Watanabe, S.; Tachioka, Y.; Schuller, B. Deep recurrent de-noising auto-encoder and blind de-reverberation for reverberated speech recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4623–4627. [Google Scholar]
- Weninger, F.; Geiger, J.; Wöllmer, M.; Schuller, B.; Rigoll, G. Feature enhancement by deep LSTM networks for ASR in reverberant multisource environments. Comput. Speech Lang. 2014, 28, 888–902. [Google Scholar] [CrossRef]
- Narayanan, A.; Wang, D. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In Proceedings of the 2013 IEEE International Conference onAcoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–30 May 2013; pp. 7092–7096. [Google Scholar]
- Bagchi, D.; Mandel, M.I.; Wang, Z.; He, Y.; Plummer, A.; Fosler-Lussier, E. Combining spectral feature mapping and multi-channel model-based source separation for noise-robust automatic speech recognition. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 496–503. [Google Scholar]
- Hansen, J.H.; Pellom, B.L. An effective quality evaluation protocol for speech enhancement algorithms. In Proceedings of the Fifth International Conference on Spoken Language Processing, Sydney, Australia, 30 November–4 December 1998. [Google Scholar]
- Du, J.; Wang, Q.; Gao, T.; Xu, Y.; Dai, L.R.; Lee, C.H. Robust speech recognition with speech enhanced deep neural networks. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Han, K.; He, Y.; Bagchi, D.; Fosler-Lussier, E.; Wang, D. Deep neural network based spectral feature mapping for robust speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Maas, A.L.; Le, Q.V.; O’Neil, T.M.; Vinyals, O.; Nguyen, P.; Ng, A.Y. Recurrent neural networks for noise reduction in robust ASR. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, Oregon, 9–13 September 2012. [Google Scholar]
- Deng, L.; Li, J.; Huang, J.T.; Yao, K.; Yu, D.; Seide, F.; Seltzer, M.L.; Zweig, G.; He, X.; Williams, J.D.; et al. Recent advances in deep learning for speech research at Microsoft. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP, Vancouver, BC, Canada, 26–31 May 2013; Volume 26, p. 64. [Google Scholar]
- Healy, E.W.; Yoho, S.E.; Wang, Y.; Wang, D. An algorithm to improve speech recognition in noise for hearing-impaired listeners. J. Acoust. Soc. Am. 2013, 134, 3029–3038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Coto-Jiménez, M.; Goddard-Close, J. LSTM Deep Neural Networks Postfiltering for Enhancing Synthetic Voices. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1860008. [Google Scholar] [CrossRef]
- Coto-Jiménez, M. Robustness of LSTM Neural Networks for the Enhancement of Spectral Parameters in Noisy Speech Signals. In Proceedings of the Mexican International Conference on Artificial Intelligence, Guadalajara, Mexico, 22–27 October 2018; Springer: New York, NY, USA, 2018; pp. 227–238. [Google Scholar]
- Kumar, A.; Florencio, D. Speech enhancement in multiple-noise conditions using deep neural networks. arXiv 2016, arXiv:1605.02427. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Vincent, E.; Watanabe, S.; Nugraha, A.A.; Barker, J.; Marxer, R. An analysis of environment, microphone and data simulation mismatches in robust speech recognition. Comput. Speech Lang. 2017, 46, 535–557. [Google Scholar] [CrossRef] [Green Version]
- Feng, X.; Zhang, Y.; Glass, J. Speech feature denoising and dereverberation via deep autoencoders for noisy reverberant speech recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 1759–1763. [Google Scholar]
- Ishii, T.; Komiyama, H.; Shinozaki, T.; Horiuchi, Y.; Kuroiwa, S. Reverberant speech recognition based on denoising autoencoder. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013; pp. 3512–3516. [Google Scholar]
- Zhao, Y.; Wang, Z.Q.; Wang, D. Two-Stage Deep Learning for Noisy-Reverberant Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 53–62. [Google Scholar] [CrossRef] [PubMed]
- Dong, H.; Supratak, A.; Pan, W.; Wu, C.; Matthews, P.M.; Guo, Y. Mixed Neural Network Approach for Temporal Sleep Stage Classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 26, 4–5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sakar, C.O.; Polat, S.O.; Katircioglu, M.; Kastro, Y. Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and LSTM recurrent neural networks. Neural Comput. Appl. 2018, 31, 1–16. [Google Scholar] [CrossRef]
- Jiang, C.; Chen, Y.; Chen, S.; Bo, Y.; Li, W.; Tian, W.; Guo, J. A Mixed Deep Recurrent Neural Network for MEMS Gyroscope Noise Suppressing. Electronics 2019, 8, 181. [Google Scholar] [CrossRef] [Green Version]
- Qummar, S.; Khan, F.G.; Shah, S.; Khan, A.; Shamshirband, S.; Rehman, Z.U.; Khan, I.A.; Jadoon, W. A Deep Learning Ensemble Approach for Diabetic Retinopathy Detection. IEEE Access 2019, 7, 150530–150539. [Google Scholar] [CrossRef]
- Shamshirband, S.; Rabczuk, T.; Chau, K.W. A Survey of Deep Learning Techniques: Application in Wind and Solar Energy Resources. IEEE Access 2019, 7, 164650–164666. [Google Scholar] [CrossRef]
- Babaee, E.; Anuar, N.B.; Abdul Wahab, A.W.; Shamshirband, S.; Chronopoulos, A.T. An overview of audio event detection methods from feature extraction to classification. Appl. Artif. Intell. 2017, 31, 661–714. [Google Scholar] [CrossRef]
- Naylor, P.A.; Gaubitch, N.D. Speech Dereverberation; Springer Science & Business Media: New York, NY, USA, 2010. [Google Scholar]
- Fan, Y.; Qian, Y.; Xie, F.L.; Soong, F.K. TTS synthesis with bidirectional LSTM based recurrent neural networks. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Zen, H.; Sak, H. Unidirectional long short-term memory recurrent neural network with recurrent output layer for low-latency speech synthesis. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4470–4474. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Jaitly, N.; Mohamed, A.R. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Olomouc, Czech Republic, 8–13 December 2013; pp. 273–278. [Google Scholar]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Proceedings of the International Conference on Artificial Neural Networks, Warsaw, Poland, 11–15 September 2005; Springer: New York, NY, USA, 2005; pp. 799–804. [Google Scholar]
- Gers, F.A.; Schraudolph, N.N.; Schmidhuber, J. Learning precise timing with LSTM recurrent networks. J. Mach. Learn. Res. 2002, 3, 115–143. [Google Scholar]
- Wöllmer, M.; Eyben, F.; Schuler, B.; Rigoll, G. A multi-stream ASR framework for BLSTM modeling of conversational speech. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; p. 4861. [Google Scholar]
- Coto-Jimenez, M.; Goddard-Close, J.; Di Persia, L.; Rufiner, H.L. Hybrid Speech Enhancement with Wiener filters and Deep LSTM Denoising Autoencoders. In Proceedings of the 2018 IEEE International Work Conference on Bioinspired Intelligence (IWOBI), San Carlos, CA, USA, 18–20 July 2018; pp. 1–8. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Networks Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valentini-Botinhao, C. Reverberant Speech Database for Training Speech Dereverberation Algorithms and TTS Models; University of Edinburgh: Edinburgh, UK, 2016. [Google Scholar] [CrossRef]
- Erro, D.; Sainz, I.; Navas, E.; Hernáez, I. Improved HNM-based vocoder for statistical synthesizers. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Rix, A.W.; Hollier, M.P.; Hekstra, A.P.; Beerends, J.G. Perceptual Evaluation of Speech Quality (PESQ) The New ITU Standard for End-to-End Speech Quality Assessment Part I–Time-Delay Compensation. J. Audio Eng. Soc. 2002, 50, 755–764. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Condition | Network (Hidden Layers) | sse | Time per Epoch (s) |
|---|---|---|---|
| MARDY | BLSTM–BLSTM–BLSTM | 201.34 * | 50.6 |
| BLSTM–BLSTM–MLP | 204.39 | 33.3 | |
| BLSTM–MLP–BLSTM | 210.81 | 33.5 | |
| BLSTM–MLP–MLP | 218.91 | 15.9 | |
| MLP–BLSTM–BLSTM | 204.82 | 36.1 | |
| MLP–BLSTM–MLP | 256.32 | 18.6 | |
| MLP–MLP–BLSTM | 216.46 | 18.8 | |
| MLP–MLP–MLP | 400.34 | 1.2 | |
| Lecture Room | BLSTM–BLSTM–BLSTM | 213.12 | 74.9 |
| BLSTM–BLSTM–MLP | 214.35 | 48.8 | |
| BLSTM–MLP–BLSTM | 221.88 | 49.3 | |
| BLSTM–MLP–MLP | 229.22 | 23.2 | |
| MLP–BLSTM–BLSTM | 212.34 * | 52.8 | |
| MLP–BLSTM–MLP | 226.39 | 27.7 | |
| MLP–MLP–BLSTM | 230.85 | 27.6 | |
| MLP–MLP–MLP | 360.41 | 1.8 | |
| Artificial Room | BLSTM–BLSTM–BLSTM | 88.47 * | 55.5 |
| BLSTM–BLSTM–MLP | 90.37 | 36.5 | |
| BLSTM–MLP–BLSTM | 93.61 | 36.6 | |
| BLSTM–MLP–MLP | 104.23 | 17.4 | |
| MLP–BLSTM–BLSTM | 92.18 | 39.5 | |
| MLP–BLSTM–MLP | 108.56 | 20.6 | |
| MLP–MLP–BLSTM | 111.13 | 20.5 | |
| MLP–MLP–MLP | 170.61 | 1.3 | |
| ACE Building | BLSTM–BLSTM–BLSTM | 207.32 * | 73.8 |
| BLSTM–BLSTM–MLP | 210.17 | 45.8 | |
| BLSTM–MLP–BLSTM | 214.29 | 46.1 | |
| BLSTM–MLP–MLP | 212.54 | 21.6 | |
| MLP–BLSTM–BLSTM | 208.04 | 49.2 | |
| MLP–BLSTM–MLP | 221.28 | 25.6 | |
| MLP–MLP–BLSTM | 220.13 | 25.8 | |
| MLP–MLP–MLP | 333.60 | 1.7 | |
| Meeting Room | BLSTM–BLSTM–BLSTM | 197.37 | 69.9 |
| BLSTM–BLSTM–MLP | 199.03 | 45.7 | |
| BLSTM–MLP–BLSTM | 204.68 | 45.8 | |
| BLSTM–MLP–MLP | 217.52 | 21.6 | |
| MLP–BLSTM–BLSTM | 196.90 * | 49.6 | |
| MLP–BLSTM–MLP | 206.03 | 25.7 | |
| MLP–MLP–BLSTM | 214.28 | 25.9 | |
| MLP–MLP–MLP | 363.19 | 1.7 |
| Condition | Network (Hidden Layers) | PESQ | Significative Difference | p-Value |
|---|---|---|---|---|
| MARDY | BLSTM-BLSTM-BLSTM | 2.30 | - | - |
| BLSTM–BLSTM–MLP | 2.31 * | no | 0.715 | |
| BLSTM–MLP–BLSTM | 2.27 | yes | 0.003 | |
| BLSTM–MLP–MLP | 2.19 | yes | 6.648 × 10 | |
| MLP–BLSTM–BLSTM | 2.28 | no | 0.147 | |
| MLP–BLSTM–MLP | 2.08 | yes | 1.965 × 10 | |
| MLP–MLP–BLSTM | 2.24 | yes | 0.000 | |
| MLP–MLP–MLP | 1.94 | yes | 0.000 | |
| Lecture Room | BLSTM–BLSTM–BLSTM | 2.28 * | - | - |
| BLSTM–BLSTM–MLP | 2.21 | no | 0.095 | |
| BLSTM–MLP–BLSTM | 2.22 | yes | 0.0034 | |
| BLSTM–MLP–MLP | 2.20 | yes | 1.729 × 10 | |
| MLP–BLSTM–BLSTM | 2.27 | no | 0.199 | |
| MLP–BLSTM–MLP | 2.21 | yes | 9.635 × 10 | |
| MLP–MLP–BLSTM | 2.20 | yes | 9.617 | |
| MLP–MLP–MLP | 2.00 | yes | 0.000 | |
| Artificial Room | BLSTM–BLSTM–BLSTM | 3.18 * | - | - |
| BLSTM–BLSTM–MLP | 3.17 | no | 1.000 | |
| BLSTM–MLP–BLSTM | 3.14 | yes | 0.002 | |
| BLSTM–MLP–MLP | 3.12 | yes | 6.650 × 10 | |
| MLP–BLSTM–BLSTM | 3.17 | no | 1.000 | |
| MLP–BLSTM–MLP | 3.06 | yes | 1.965 × 10 | |
| MLP–MLP–BLSTM | 3.08 | yes | 2.695 × 10 | |
| MLP–MLP–MLP | 2.90 | yes | 0.000 | |
| ACE Building | BLSTM–BLSTM–BLSTM | 2.37 * | - | - |
| BLSTM–BLSTM–MLP | 2.35 | no | 0.068 | |
| BLSTM–MLP–BLSTM | 2.35 | no | 0.147 | |
| BLSTM–MLP–MLP | 2.32 | yes | 4.22 × 10 | |
| MLP–BLSTM–BLSTM | 2.36 | no | 0.474 | |
| MLP–BLSTM–MLP | 2.33 | yes | 0.026 | |
| MLP–MLP–BLSTM | 2.33 | yes | 0.008 | |
| MLP–MLP–MLP | 2.08 | yes | 0.000 | |
| Meeting Room | BLSTM–BLSTM–BLSTM | 2.28 | - | - |
| BLSTM–BLSTM–MLP | 2.29 * | no | 0.147 | |
| BLSTM–MLP–BLSTM | 2.24 | no | 0.060 | |
| BLSTM–MLP–MLP | 2.23 | yes | 0.002 | |
| MLP–BLSTM–BLSTM | 2.28 | no | 0.474 | |
| MLP–BLSTM–MLP | 2.25 | no | 0.715 | |
| MLP–MLP–BLSTM | 2.20 | yes | 0.001 | |
| MLP–MLP–MLP | 2.0 | yes | 1.960 × 10 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutiérrez-Muñoz, M.; González-Salazar, A.; Coto-Jiménez, M. Evaluation of Mixed Deep Neural Networks for Reverberant Speech Enhancement. Biomimetics 2020, 5, 1. https://doi.org/10.3390/biomimetics5010001
Gutiérrez-Muñoz M, González-Salazar A, Coto-Jiménez M. Evaluation of Mixed Deep Neural Networks for Reverberant Speech Enhancement. Biomimetics. 2020; 5(1):1. https://doi.org/10.3390/biomimetics5010001
Chicago/Turabian StyleGutiérrez-Muñoz, Michelle, Astryd González-Salazar, and Marvin Coto-Jiménez. 2020. "Evaluation of Mixed Deep Neural Networks for Reverberant Speech Enhancement" Biomimetics 5, no. 1: 1. https://doi.org/10.3390/biomimetics5010001
APA StyleGutiérrez-Muñoz, M., González-Salazar, A., & Coto-Jiménez, M. (2020). Evaluation of Mixed Deep Neural Networks for Reverberant Speech Enhancement. Biomimetics, 5(1), 1. https://doi.org/10.3390/biomimetics5010001