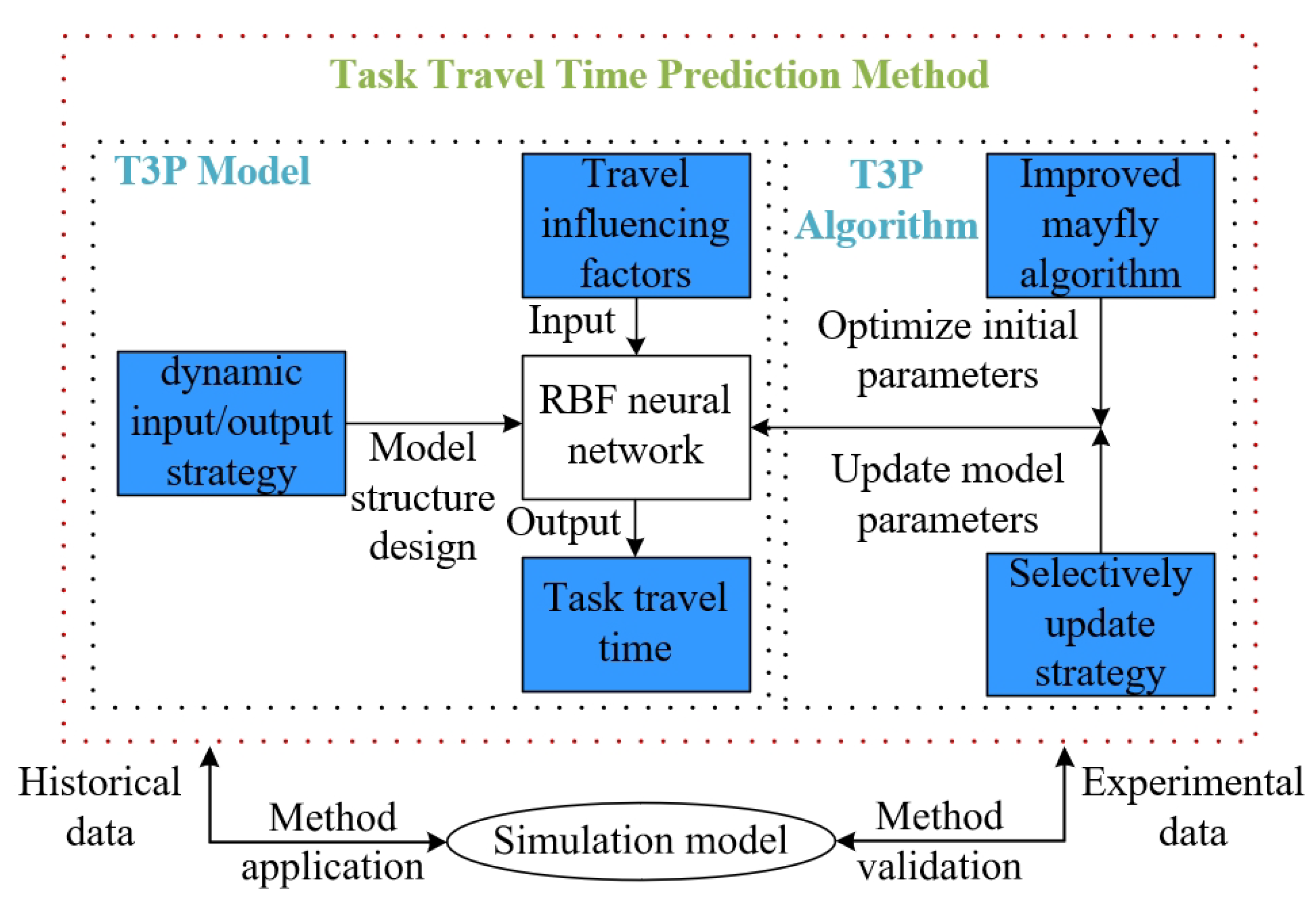
3.1. T3P Model
The commonly-used neural networks include the back propagation (BP) neural network and the RBF neural network. It has been proved that the RBF neural network has stronger and faster nonlinear fitting ability than the BP neural network [
37]. The RBF neural network offers many advantages, such as simple structure, fast convergence speed, and the ability to approximate any nonlinear function [
38]. Therefore, this paper constructs a T3P model based on the RBF neural network. While neural networks, particularly RBF networks, have been extensively applied in task prediction, their application to heterogeneous AGV systems has been limited. Heterogeneous AGV systems, characterized by diverse vehicle types, variable task demands, and dynamic traffic flow environments, present unique challenges for T3P. The novelty of this study lies in the development of the T3P model, which combines the characteristics of heterogeneous AGV systems with RBF neural networks to address these challenges. The proposed model dynamically adapts to changes in task assignments, traffic flow, and AGV states, improving prediction accuracy in heterogeneous AGV systems.
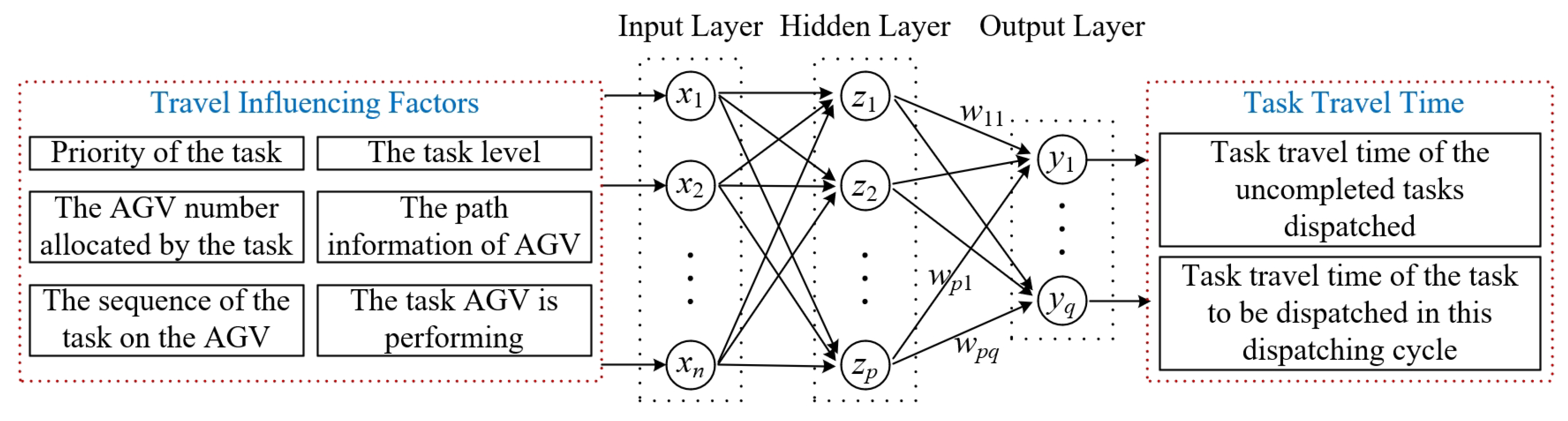
Based on the network structure of a typical RBF neural network, the topology structure of the T3P model is further determined according to the characteristics of a heterogeneous AGV system and the requirements of the problem in this paper. The input layer
, hidden layer
, and output layer
of the network can be represented by the following matrix:
where
denote the number of neurons in the input layer, hidden layer, and output layer, respectively. Based on the heuristic guidelines summarized in [
39], the number of hidden nodes
p is determined as
.
The topology structure of the T3P model proposed in this paper is shown in
Figure 3. In order to ensure the certainty of the model topology, a dynamic input/output strategy is used to determine
n and
q. Specifically, to
, the total number of elements
n is the product of the maximum number
of tasks possible in the system and the number
l of travel-influencing factors. To
, the size of q is equal to
of tasks in the system.
The input layer represents the tasks, the traffic load of paths, and the load of the AGVs in the system at a given time. In , the set of every l elements from the front to the back represents travel-influencing factors of a task. These factors include the priority of the task, the AGV number assigned by the task, the sequence of the task on the AGV, the path information of AGV, the task that AGV is performing, and the task level (the uncompleted tasks that have been dispatched or the tasks to be dispatched in this dispatching cycle). Moreover, considering the dimensional influence between the travel-influencing factors, the input matrix must be normalized before being put into the RBF network for parameter update. The output layer represents the task travel time in the system. Tasks include the uncompleted tasks dispatched or the task to be dispatched in this dispatching cycle.
3.2. T3P Algorithm
The conventional RBF neural network does not introduce additional parameters in the whole training process. It only adjusts the initial weight, the centers and widths of the basis functions, and deviations according to the training samples. Consequently, it is prone to fall into the local optima. Moreover, the prediction performance of the RBF neural network is affected by the parameters of the weight, and the center and width of the hidden layer. When the initial parameters are randomly selected, the solution process tends to fall into a local extreme point, leading to deviation from the optimal parameters and a low-performance network model. Furthermore, the dimensions of the input layer, the output layer, and the weight parameters in the conventional RBF neural network are all fixed on the updating stage during the network training process. In contrast, the distribution tasks in the AGV system are updated in real time and the task number changes dynamically. If the input/output variables of the RBF neural network are set according to the real-time data in the system, the dimensions of variables and parameters in the RBF neural network will change irregularly. It makes the T3P model too complicated to solve. To address these challenges, this study proposes the following enhancements to the traditional RBF neural network.
(1) K-means algorithm is used to determine the center and width of the basis functions, and an IMA is developed to optimize the initial weights of the RBF neural network. On the one hand, the K-means method is simple and easy to implement. It can reduce the computational load of the RBF neural network algorithm while approaching to the optimal value as close as possible [
40]. In our model, the K-means algorithm is used to determine the center and width of the basis functions in the RBF neural network. Specifically, K-means is applied to cluster the input data, where the centroids of the clusters are used as the centers of the radial basis functions, and the spread of each cluster is used to define the width of the corresponding basis function. On the other hand, the mayfly algorithm (MA) is a new intelligent optimization algorithm with advantages in terms of convergence rate and speed [
41,
42]. However, the conventional MA is prone to fall into the local optima in the later stage. Therefore, The IMA algorithm, an enhanced variant of the standard mayfly algorithm, is utilized to optimize the parameters of the RBF neural network for better prediction accuracy.
(2) A selective updating strategy is designed by dynamically selecting partial weight parameters to update. The model topology is fixed, while the dimensions of input/output variables and internal parameters change under the upper limitation, which is determined by the maximum number of tasks possible in the AGV system. The practical task number in the AGV system varies at different moments. If the practical task number is smaller than the upper limitation, some remaining (the upper limitation minus the practical task number) rows of the input matrix are all meaningless or invalid data. Since the invalid data cannot describe any system characteristics, updating the weight parameters according to the invalid data during the training process not only wastes training time but also brings negative effects to the model accuracy. Hence, the selective update strategy is designed to select the valid data in the input rows for parameter training while disregarding the invalid data in the remaining rows. The strategy promises to improve the training efficiency and prediction accuracy of the RBF neural network simultaneously.
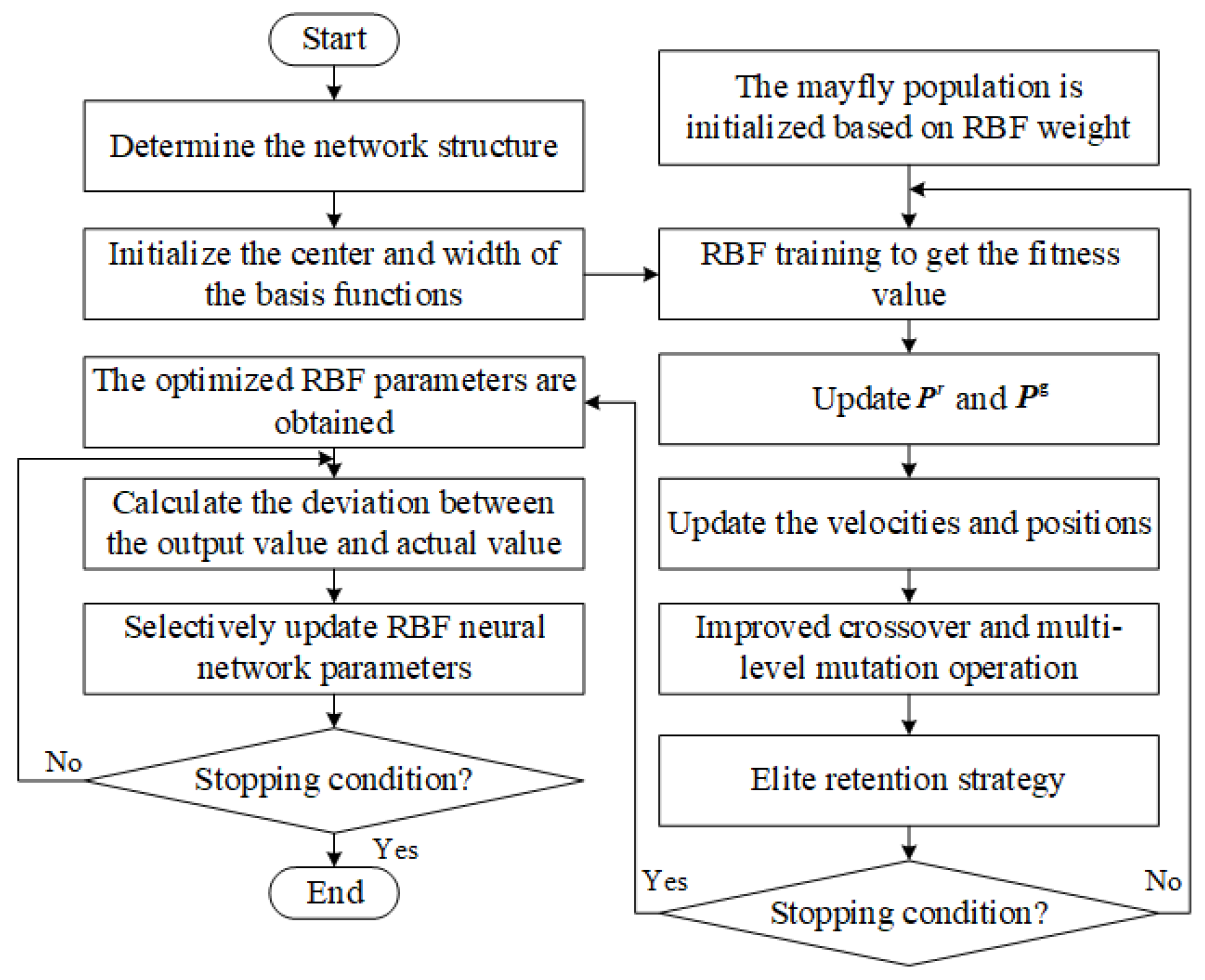
The flowchart of the IMA-SURBF algorithm is shown in
Figure 4. The detailed algorithm steps are as follows.
Step1: Initialize RBF neural network parameters. To accurately reflect the sample’s real situation and ensure the precision of the prediction model, this paper uses the K-means algorithm to initialize the center and width of the basis function.
Step2: Determine the initial weight .
Step2.1: Initialize the mayfly population. To obtain the solution space of the weight, each mayfly individual’s position is used to represent a weight solution. Further, the dimension of the weight denotes the dimension of the mayfly individual vector. Then, the size of male and female populations is set to , and the serial number of each mayfly individual is marked as . The position and velocity of each male mayfly individual are initialized. Similarly, the position and velocity of each female mayfly individual are also initialized. Furthermore, represents the best position found by the rth mayfly that had ever been visited, and denotes the global best position. Finally, the range of position and speed values, along with the maximum iteration number , are set.
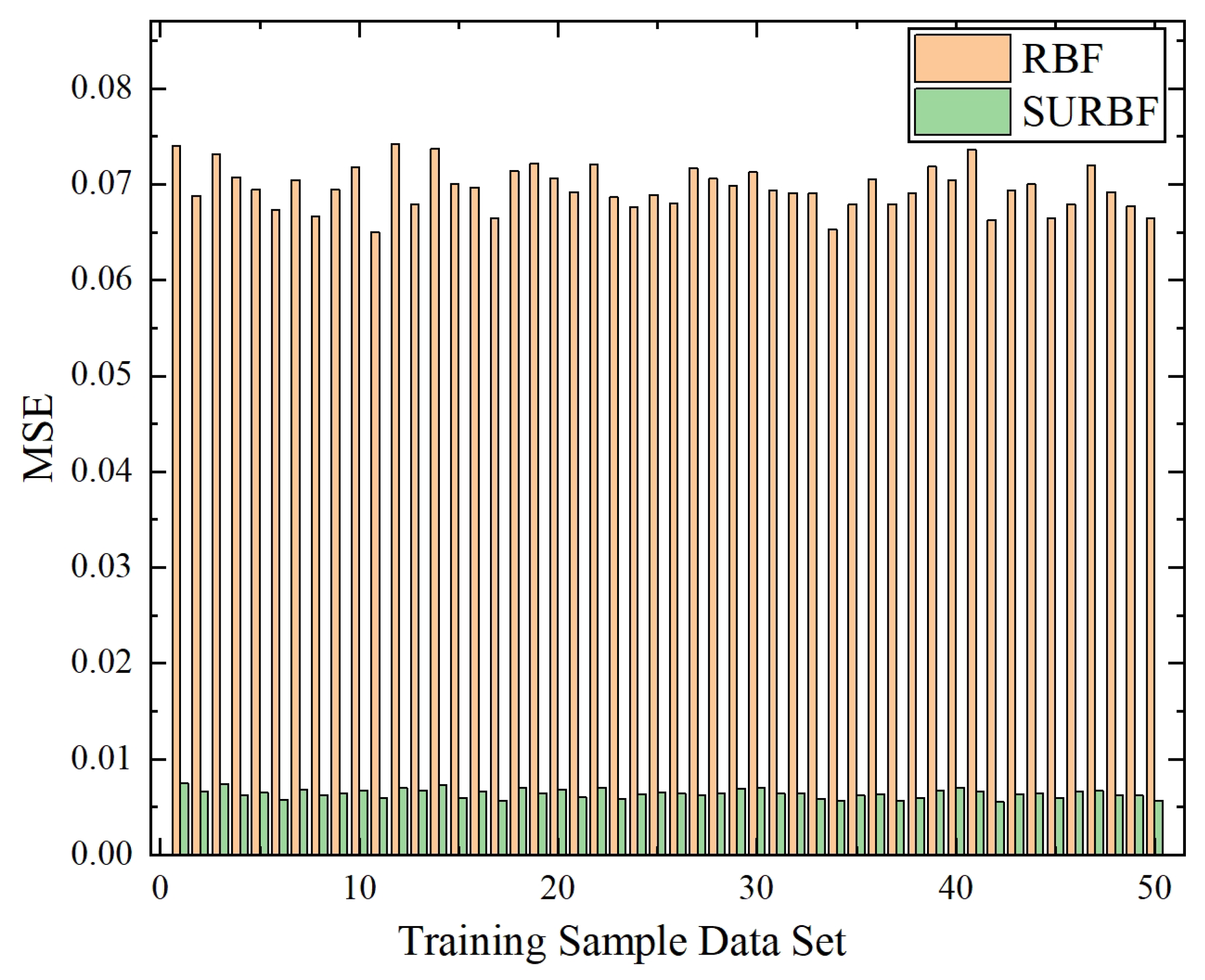
Step2.2: Calculate the fitness value. For each individual mayfly, it is firstly decoded into the weights of the neural network. Then, a complete neural network is constructed with the weights obtained by decoding, and the center and width are determined using the K-means algorithm. Thirdly, the neural network is trained by using the sample data. Finally, the mean square error (MSE) obtained by network training is used as the fitness value of the individual mayfly.
Step2.3: Update and . The current fitness value of the rth mayfly is compared with its historical optimal fitness value. If the current fitness value is better, the optimal position and fitness value of the rth mayfly are updated. Then the global optimal mayfly individual and position are updated.
Step2.4: Update velocities and positions.
Movement of male mayflies: Assuming
is the current position of
rth mayfly in the search space at time step
s, the current position is changed by adding a velocity,
, to the next position. This can be formulated as
When the fitness value of rth mayfly is less than the fitness value of
, the velocity is calculated as
where
is the velocity of
rth mayfly in dimension
at time step
s,
is the position of
rth mayfly in dimension
t at time step
s,
and
are positive attraction constants used to scale the contribution of the cognitive and social component, respectively.
is a fixed visibility coefficient, used to limit a mayfly’s visibility to others, while
is the Cartesian distance between
and
, and
is the Cartesian distance between
and
. The squared distances
and
are used inside the exponential functions to model Gaussian-like decay of attraction strength [
43].
When the fitness value of rth mayfly is better than the fitness value of
, the velocity is calculated as
where
d is the nuptial dance coefficient and
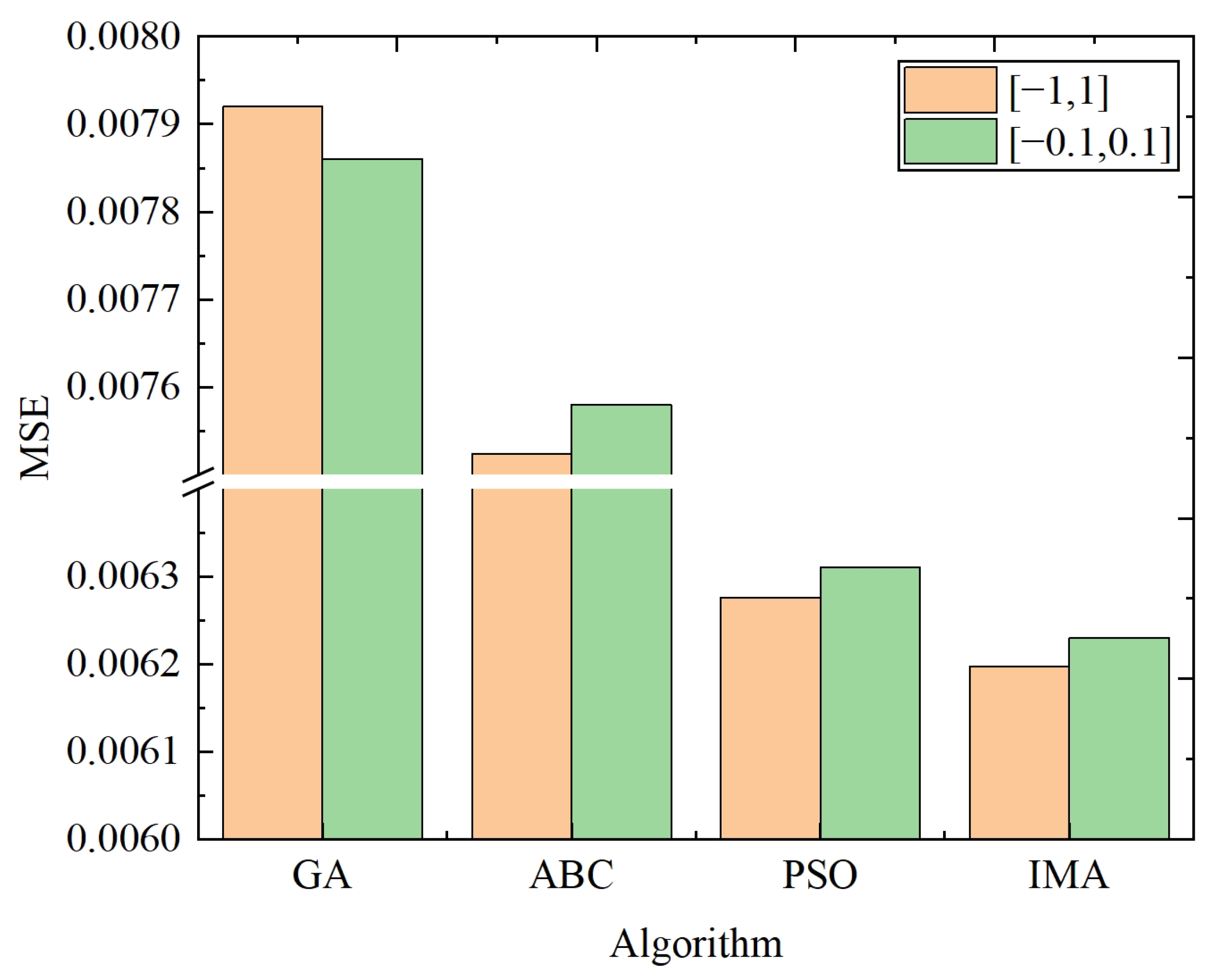
is a random value in the range [−1, 1].
Movement of female mayflies: Assuming
is the current position of female mayfly
r in the search space at time step
s, the current position is changed by adding a velocity
to the next position, i.e.,
The velocity of female mayfly is defined by different equations according to the fitness value of male mayfly. When the fitness value of the
rth female mayfly is better than that of the
rth male mayfly, the velocity is defined by Equation (
6); otherwise, Equation (
7) is used:
where
is the velocity of
rth female mayfly in dimension
at time step
s,
is the position of
rth female mayfly in dimension
t at time step
s,
is the Cartesian distance between male and female mayflies, and
is a random walk coefficient.
Step2.5: Improved crossover operation. The crossover operation according to Equation (
8) has the limitation that is not easy to escape local optima. To enhance the population diversity, an improved crossover operation is proposed for the MA. The main steps of improved crossover operation are presented in Algorithm 1, as illustrated in
Figure 5.
where
is the male parent,
is the female parent, and
L is a random value within a specific range.
| Algorithm 1 Improved crossover operation |
| Input: Male and female populations, Number of offspring , crossover probability |
| output: offspring populations |
- 1:
for to do //Crossover operator of mayfly algorithm - 2:
Select a male parent and female parent based on the fitness function - 3:
and are calculated according to Equation ( 8) //The second crossover operation - 4:
Randomly select a male parent and female parent - 5:
- 6:
while do - 7:
Randomly select a crossover site from D sites - 8:
The crossover site of the is assigned to , and the remaining sites are assigned to the site of the is assigned to , and the remaining sites are assigned to - 9:
- 10:
end while - 11:
end for
|
Step2.6: Multi-level mutation operation. In order to prevent the algorithm from falling into a local optimum, the mutation operation of genetic algorithm is introduced. However, the single-level mutation operation, performing the mutation operation only once, has a small search range, and is not easy to jump out of local optimums. Therefore, this paper proposes a multi-level mutation operation; the main steps of the multi-level mutation are displayed in Algorithm 2, which is illustrated in
Figure 6.
| Algorithm 2 Multi-level mutation operation |
| Input: Male and female populations, , mutation probability , Threshold of multiple mutation f |
| output: offspring populations
|
- 1:
Create a variable to record the optimal fitness value in all previous iterations - 2:
Create a variable to record how many generations of optimal fitness values have not changed - 3:
for to do - 4:
Randomly select a parent //Single-level mutation operation - 5:
Genetic algorithm mutation operation based on mutation probability - 6:
if then //Multi-level mutation operation - 7:
The individual formed by the single mutation is used as the parent to perform the mutation operation again. - 8:
end if - 9:
end for - 10:
The optimal offspring is selected from the offspring of single-level mutation and multi-level mutation as the offspring of this mutation operation. - 11:
Calculate the optimal fitness value of this round of iteration - 12:
if then - 13:
- 14:
else - 15:
- 16:
- 17:
end if
|
Step2.7: Elite retention strategies. The updated male population and the first half of the mutated offspring population were merged into a new male population. The individuals of the new male population were sorted by fitness, and the optimal individuals were selected as the next generation of male population. Similarly, the updated female population and the second half of the mutated offspring population are merged, and the fitness values are sorted and screened to obtain the next generation of female population.
Step2.8: Stopping condition judgment for initial parameters. If the stopping condition is satisfied, the global optimal solution is obtained based on the fitness values of all mayfly individuals. Then, the global optimal solution is transformed into the initial weight of the RBF neural network. Afterward, the sample is used to start the neural network training. If the stopping condition is not satisfied, it proceeds to step2.2.
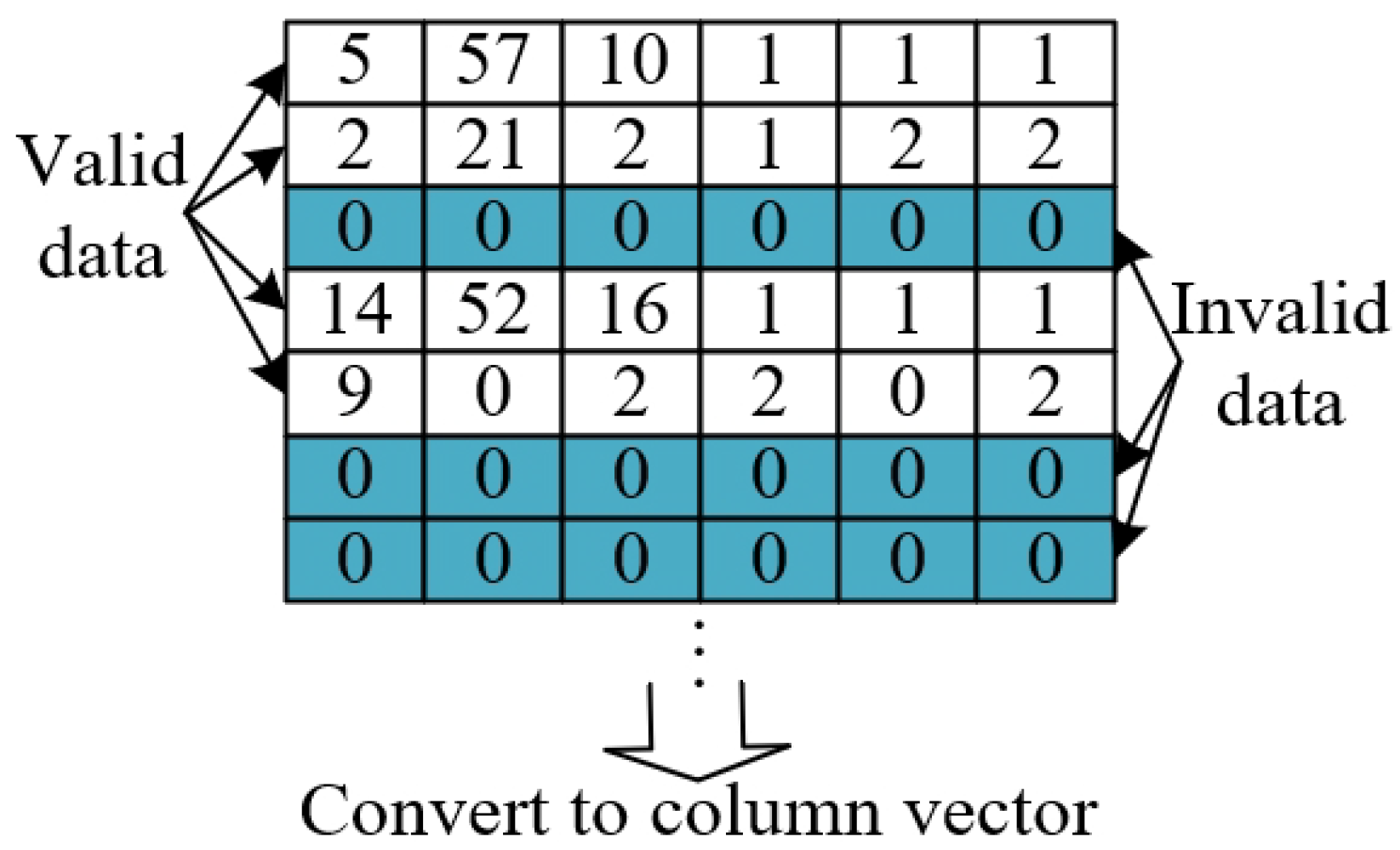
Step3: Selective update strategy. When a sample is provided for the network training at each time, the data in the sample should be classified into valid data and invalid data, as shown in
Figure 7. The subsequent step involves integrating the valid data into the neural network, calculating the output value based on the input sample, the center, width of the network, and the weight parameters. Moreover, the MSE value of network prediction for this sample is calculated by comparing with the actual output value. Finally, the weight parameters are updated selectively by means of the gradient descent method. It is noteworthy that only the weight parameters corresponding to the valid data are updated. The main steps of the selective update strategy are displayed in Algorithm 3.
| Algorithm 3 Selective update strategy for RBF neural network |
| Input: Input sample , true output , centers , widths , weights , learning rate |
| output: Updated weights |
- 1:
// Step1: Sample validity check - 2:
if then // (i.e., all elements of x are zero) - 3:
// x is an invalid data - 4:
// No forward computation or parameter update - 5:
// Keep weights unchanged - 6:
return unchanged - 7:
else - 8:
// x is a valid data - 9:
// Proceed to forward propagation and selective update
- 10:
// Step2: Forward pass and error computation - 11:
for to p do - 12:
Compute RBF activation: - 13:
end for - 14:
for to q do - 15:
Compute output: - 16:
Compute error: - 17:
end for
- 18:
// Step3: Selective gradient update - 19:
for to q do - 20:
for to p do - 21:
Compute gradient: - 22:
Update weight: - 23:
end for - 24:
end for - 25:
return Updated weights - 26:
end if
|
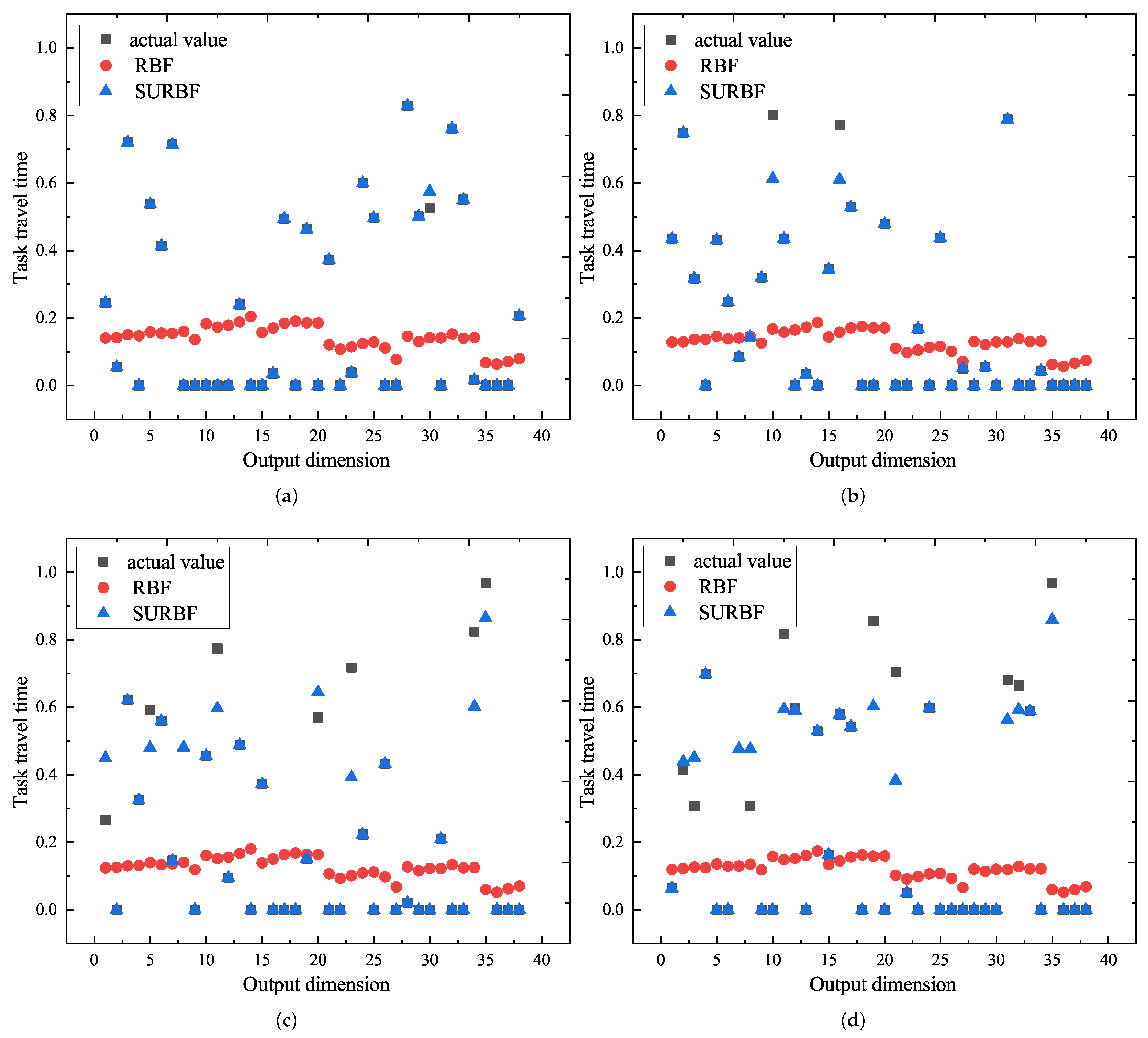
Step4: Stopping condition judgment for network training. If the stopping condition is satisfied, the neural network has completed the training process. Then, the test samples are used to test the performance of the neural network. After that, the real-time information of the AGV system is put into the RBF neural network to predict the task travel time. When the neural network is used to predict, only the valid data is adopted to calculate the MSE value and the prediction travel time. If the stopping condition is not satisfied, the algorithm goes to Step3 to continue the iterative optimization process.
Although the detailed algorithmic steps and flowchart in
Figure 4 provide a comprehensive explanation, the full process of the IMA-SURBF algorithm remains computationally intricate. Therefore, to enhance readability and offer a structured overview,
Table 2 summarizes the key steps, hyperparameters, outputs, and computational complexity across each phase of the algorithm.






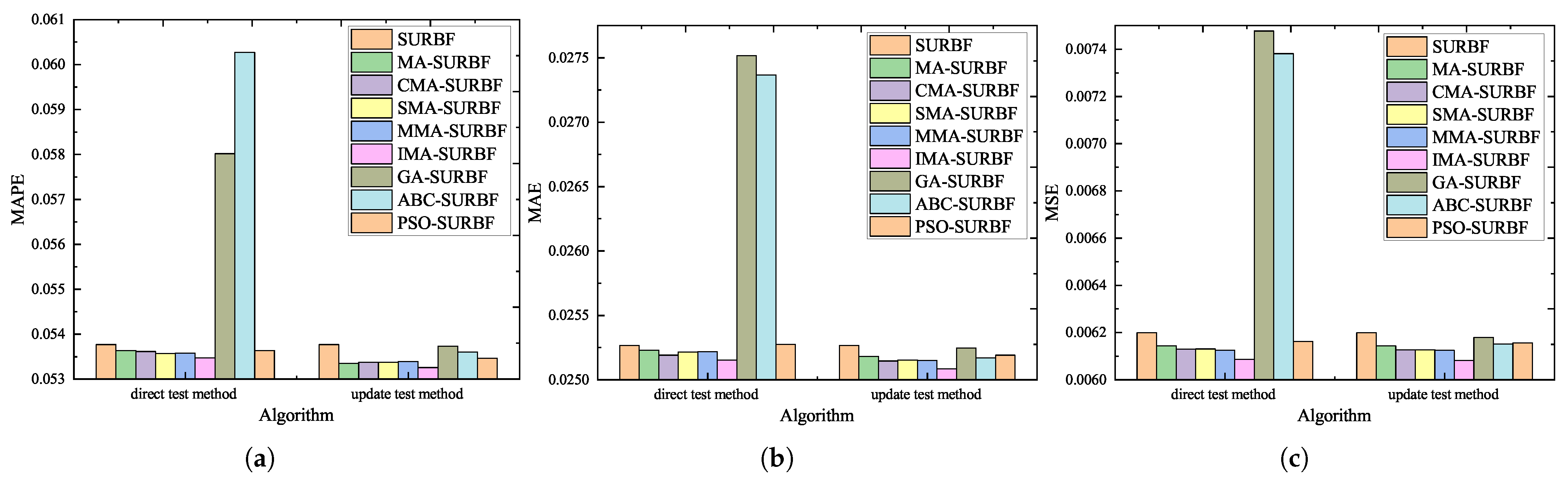

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}