1. Introduction
Multiple sequence alignment (MSA) is a fundamental pillar in bioinformatics, which allows for the comparison and analysis of biological sequences (DNA, RNA, proteins) to uncover key information about their function, evolution, and molecular structure. The importance of MSA lies in its role as the foundation for essential tasks such as phylogenetic analysis, protein structure and function prediction, and searching genomic databases [
1]. The bacterial foraging algorithm (Bacterial Foraging Optimization, BFOA) is a bioinspired optimization method that simulates the foraging behavior of bacteria. Its importance lies in its ability to efficiently, adaptively, and robustly solve complex optimization problems [
2,
3,
4,
5,
6,
7], often outperforming other nature-inspired algorithms [
8]. The BFOA has been previously applied to the MSA problem through hybrid methodologies and multi-objective variations [
9,
10,
11,
12,
13]. In this context, we present a novel strategy based on constructing a list of every aminoacidic or DNA pair from each alignment matrix and successive parallel BLOSUM evaluation of this list, which utilizes logarithmic scores: Each place in the evaluation matrix represents a log-odds score, which compares the probability of two amino acids aligning by homology, such as an evolutionary relationship, versus aligning by chance. This makes it possible to distinguish biologically plausible substitutions from random coincidences.
The main steps in the BFOA are as follows [
14]:
Chemotaxis: Bacteria move through the search space by alternating between random and straight-line movements, following gradients to explore and exploit the environment. Swarming: Bacteria communicate and form groups, which helps to guide the population toward promising regions in the search space. Reproduction: After several chemotaxis steps, the best-performing bacteria reproduce, while the worst-performing ones are removed, thereby maintaining a constant population size. Elimination and Dispersal: Randomly, some bacteria are eliminated and dispersed to new locations, which helps to avoid getting stuck in local optima and maintains diversity.
These steps are repeated in cycles, allowing the algorithm to explore the solution space efficiently and find optimal (or near-optimal) solutions. This algorithm has been improved and adapted for various applications, such as feature selection, scheduling, and image segmentation, through introducing adaptive step sizes, enhanced swarming mechanisms, and even hybrid strategies [
15]. It should be noted that tuning the BFOA process before any hybridization is essential. In terms of efficiency, adequate hardware and software resources are necessary when running optimization algorithms, as these resources directly impact the algorithm’s efficiency, speed, and ability to solve complex problems. The availability and type of hardware influence the performance, scalability, and accuracy of optimization algorithms [
16]. In this context, parallelism is significant when running optimization algorithms as it allows multiple computations to be performed simultaneously, leading to substantial improvements in speed, efficiency, and the ability to solve larger or more complex problems. Leveraging parallelism can drastically reduce the time required for computation and enhance the quality of solutions in optimization tasks [
17,
18].
As stated above, MSA is an essential problem that is still under research. It is a computationally complex problem, as the number of possible alignments grows exponentially with the number and length of the sequences. This makes an exhaustive search for the best solution unfeasible [
19] as sequences may present insertions, deletions, mutations, and highly divergent regions, making it challenging to identify homologous positions and obtain accurate alignments, especially among distant sequences [
20]. There are two main strategies to tackle this problem: progressive pairwise alignment [
21] and complete multiple alignment of the sequence matrix. In this work, we implement the second option as it provides more transparency regarding the algorithm’s capabilities in the considered task. Regarding the complexity of MSA, especially when using the sum-of-pairs (SP) scoring method, it is NP-complete. This means that finding the exact optimal alignment is computationally intractable as the number of sequences increases [
22]. The MSA problem can be described as follows:
Given a set of n sequences S = {s1, s2, ..., sₙ}, where each sequence sᵢ has a length lᵢ, the goal is to find an alignment that maximizes the similarity among all sequences simultaneously. The alignment can be represented as a matrix A of dimensions n × m, where m is the length of the final alignment, and each element aᵢⱼ can be a character from the genetic alphabet Adenine, Cytosine, Guanine, and Thymine (A, C, G, T) or a gap (-), mathematically represented as ε.
The objective function typically seeks to maximize the following:
where
w(aᵢₖ,
aⱼₖ) is the scoring function for aligned characters, and
k represents the position in the alignment.
The scoring function generally considers the following:
Matches: w(x,x) = α (positive value);
Mismatches: w(x,y) = β (negative value);
Gaps: w(x,ε) = w(ε,x) = γ (penalty).
The problem’s computational complexity is
O(lⁿ), where l is the average length of the sequences. This problem can also be formulated in terms of the minimization of the sum-of-pairs (SP) score:
where
d(sᵢ,
sⱼ) is the distance between each pair of aligned sequences.
As stated before, this problem is NP-complete, meaning that there is no efficient algorithm which is guaranteed to find the optimal solution for an arbitrary number of sequences.
A hypothetical alignment matrix of four genetic sequences could have three alignment cases: match, mismatch, and gap.
2. Materials and Methods
As described above, the BFOA implements four optimization steps. Accordingly, the interaction of bacteria is expressed as a function g():
where
cell denotes the bacterium at the time of the evaluation iteration, and
other refers to a neighboring cell. The parameters
dattr and
wattr are coefficients of attraction, and the parameters
hrepel and
wrepel are related to repulsion. Finally,
S is the number of cells in the population, and
P is the number of dimensions in the optimization problem.
Appendix A provides the pseudocode for a general implementation of the BFOA.
2.1. The Developed BFOA
In this work, we developed a BFOA using the Python programming language. The main advantage of this strategy is the parallelization of the main cycles in the optimization process. The algorithm starts the main class in the parallel_BFOA.py document; it starts the execution by importing the other necessary classes in the different documents, in addition to the multiprocessing, numpy, and copy libraries. Once all the tools used in this class have been imported, the variables indicating the number of bacteria that will make up the initial population, the number of iterations of the optimization cycle, and the range of tumbling are initialized. A list containing the genetic sequences that represent the bacteria is initialized. Next, the fastaReader class is used, which is responsible for abstracting the genetic sequences and their names, which are later saved in variables that are finally passed to the main class. As the genetic sequences and their names are stored in a FASTA file, it is necessary to pass the relative or global path of said document.
The variables dattr, wattr, hrepel, and wrepel are initialized. The Manager class is then referenced by saving it in a variable, creating a multiprocessing instance. Manager() is an object in the multiprocessing library for parallel processing. The number of sequences that will be aligned and printed on the console is saved in a variable. To start the parallel multithreading process, a list containing a shared list is created using the manager.list() method, which can be modified by multiple processes in parallel, as well as another shared list with the names of the streams. Finally, a shared list called NFE is initialized, containing the evaluation results for the bacteria.
Two methods are created: One initializes the population of bacteria, in which the genetic sequences are loaded into a list named bacterium that is restarted in each cycle according to the number of iterations previously defined; however, before that, it is added to an array called a population that contains all the new lists of bacteria. The second method is printPopulation which, as its name indicates, helps to print the sequences of the bacteria in the population on the console. Lists shared between parallel processes are initialized. Each list represents a table of bacterial model data:
blosumScore: Alignment scores according to the BLOSUM.
tablaAtract, tablaRepel: Forces of attraction and repulsion between bacteria.
tablaInteraction: Sum of Attract and Repel tables.
tablaFitness: Total evaluation for each bacterium.
granListaPares: List of amino acid pairs in each alignment.
NFE: List of amino acid pairs in each alignment.
The resetLists method, as its name implies, re-initializes all shared lists and creates a new manager. It is used in each algorithm iteration to prevent the accumulation of old data. The following method in the class is the cuadra method, which ensures that all sequences have the same length, filling the shorter ones with “-” (gaps) to avoid future indexing errors in subsequent operations. The “column-clean” method goes through the sequence matrix and eliminates the columns formed of only gaps, relying on the “gapCulmn” (which detects this type of column) and “deleteCulmn” (which removes the column) methods.
The class also has methods for the evaluation of the bacteria, supported by two methods and the class
evaluadorBlosum, which assesses the row and returns a grade based on the alignment and number of gaps in the sequences. The BLOcks SUbstitution Matrix (BLOSUM) refers to a family of amino acid substitution matrices derived from conserved local alignments (“building blocks”) of related proteins, without assuming an explicit evolutionary model [
23]. In this work, we implement the widely used BLOSUM62. In the
creaTablasAtractRepel method, the threads from
ThreadPoolExecutor are used to calculate the attraction and repulsion in parallel, resulting in a score. With this score, using the “
creaTablaFitness” method, a final score can be calculated for each bacterium by adding the score calculated using
evaluatorBlosum and its interactions with other bacteria. In the end, the best bacteria (evaluated with the
getBest method) are selected, while the worst ones are eliminated (with the
replaceWorst method) and are replaced with copies of the bacteria that were best evaluated.
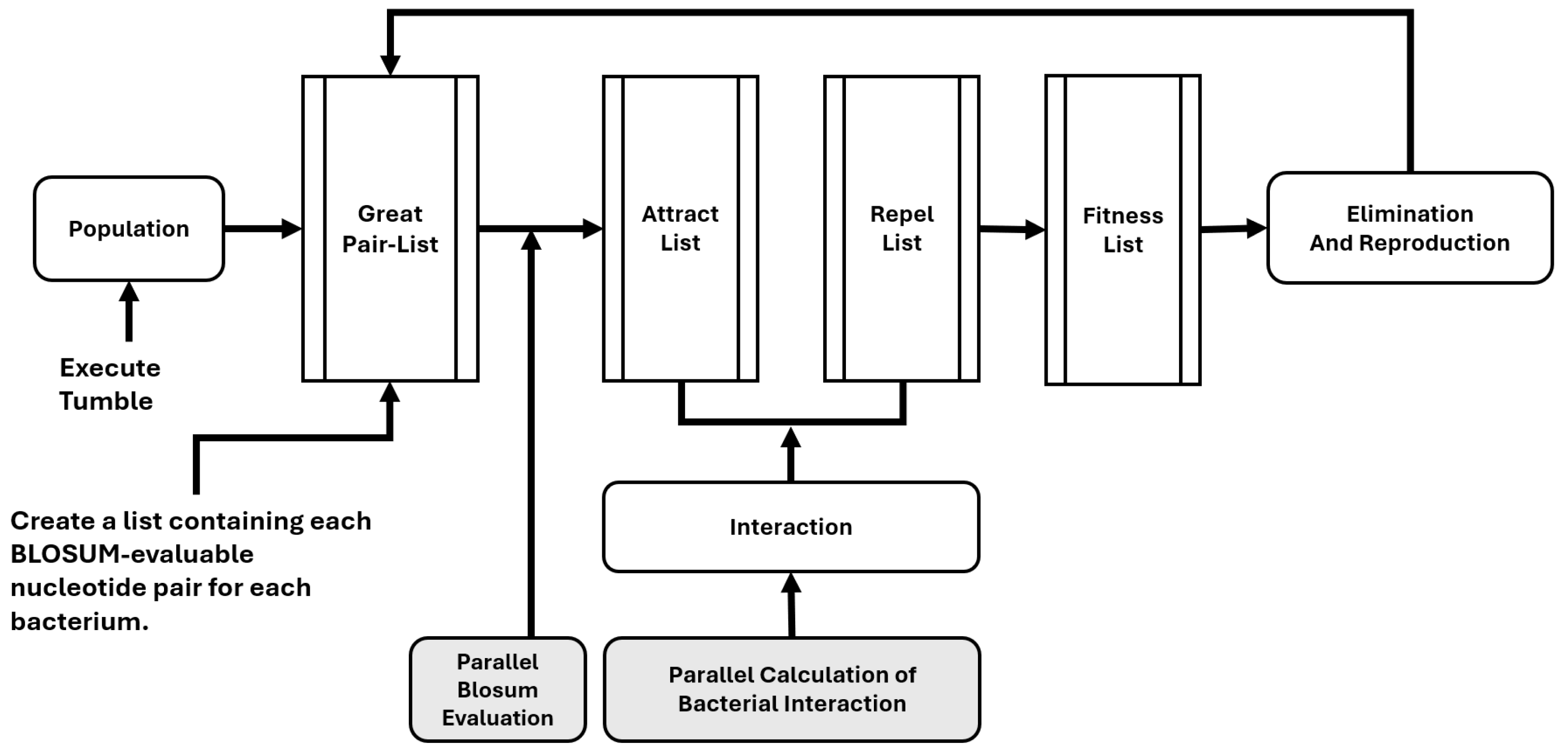
Figure 1 presents a diagram of the developed algorithm. The primary strategy for parallelization is using lists as “notebooks” where the parallel process can write simultaneously, with each register corresponding to a different bacterium from the population. We parallelized tasks in Python using
multiprocessing.Pool(), which significantly improves computational efficiency by distributing workloads across the CPU cores, allowing for a reduction in execution time. Due to its scalability, it is particularly advantageous for computationally intensive applications, including large-scale data processing and modeling. The Python code is available for download. As described above, constructing a list of evaluable pairs is the main characteristic of this BFOA approach. In this way, the algorithm builds a list of every amino acid pair from each column in the matrix for a given set of sequences to be aligned. Then, the BLOSUM evaluation is performed on the parallel resources. This approach provides a more rapid evaluation and successive chemotaxis process, as the BLOSUM evaluation proceeds simultaneously with the other processes in the alignment matrix.
In a hypothetical scenario designed to illustrate the computational demands of multiple sequence alignment, we considered the case of 100 alignment matrices, each comprising 100 sequences of 100 amino acids in length. All unique pairs of amino acids must be evaluated using the BLOSUM for each column within these matrices. The binomial coefficient C(100, 2) gives the number of unique pairs per column, resulting in 4950 pairwise comparisons for each column. Given that each matrix contains 100 columns, this leads to 495,000 comparisons per matrix. When extended to 100 such matrices, the total number of pairwise evaluations required reaches 49,500,000. Supposing a hypothetical evaluation time of 1 millisecond per pairwise comparison, under a sequential processing regime, the total computation time for all matrices would amount to approximately 13.75 h. However, the adoption of parallel processing strategies can dramatically reduce this time. For instance, utilizing 16 processing cores would decrease the total computation time to approximately 52 min, while employing 128 cores reduces it to just 7 min. This linear scaling demonstrates the substantial efficiency gains which are achievable through parallelization. However, in practice, the number of iterations and the successive alignment evaluation after each mutation influence the processing time. Finally, with the evaluation results, the attraction and repulsion lists (capturing the interaction process) are built in parallel for the fitness calculation.
2.2. Genetic Sequences
The genetic sequences used in this work were downloaded from the NCBI [
24] database. All genetic sequences are related to human health, particularly that in older persons.
Appendix B outlines the four sets of genetic sequences: set A is described in
Appendix B.1, the set B is described in
Appendix B.2, the set C in
Appendix B.3, and the set D in
Appendix B.4. Additionally, a detailed length comparison is provided in
Table A1,
Table A2,
Table A3 and
Table A4.
2.3. Performance Evaluation Metrics
The metrics of interest for the purposes of performance comparison were as follows: (1) The fitness is a numeric representation of a bacterium’s capacity to efficiently reach better solutions to the alignment problem. It is essential to point out that Equation (3) describes the fitness calculation. The other evaluation metrics include (2) the processing time (t), which is widely used as a comparison metric among optimization algorithms, and (3) the number of function evaluations (NFE), which is the number of times that the functions must be evaluated by the algorithm to reach the corresponding result; more specifically, the algorithm counts the calculation of each attraction or repulsion among the bacteria in the population. In the case of finding an indel (i.e., a pair of characters where one of them is a gap), the algorithm imposed a penalty of 0.1 on the BLOSUM evaluation process.
2.4. Hardware Resources
Every test run of the algorithm developed in this work was performed using a multi-core supercomputer with 1 Tbyte storage for hosting data, 128 cores divided into four nodes, and 192 GB of RAM.
2.5. Algorithm Initialization
The population is a sensitive parameter that is critical in the optimization process. The number of bacteria in the set of schemes varies from 8 to 120, depending on the given scheme. Also, the tumbling process is defined as the number of gap insertions. The initialization of this parameter varies from 100 to 330, also depending on the given scheme. Furthermore, the BFOA implements the attraction and repulsion parameters. In this work, the initialization involved varying the wrep parameter from 0.001 to 0.002, and in the final phase, it was set to 1. Regarding the alignment matrix, the initialization consists of the insertion of gaps corresponding to the tumble parameter. All the parameters are initialized in each of the 30 algorithm runs. Generally, each scheme represents a distinct initialization scenario.
2.6. Experiment
To explore the performance of the BFOA, we designed a three-phase experiment. The first phase involved an empirical exploration based on schemes of BFOA parameters, where the first approach provided data from one alignment made under each scheme for the genetic sequences from Set A. Subsequently, in the second phase, we used the rest of the genetic and/or protein sequences to perform alignments in a 30-run scheme. Finally, the third phase was configured taking into consideration the results from the first and second phases. The details of each phase are described below.
In the first phase, we tested the performance of the BFOA and the developed parallel process using Set A of sequences to perform alignment and compare the algorithm’s results. For this purpose, we established an experiment to compare the values of the previously described evaluation metrics. We configured the 4 test schemes described in
Table 1, where the algorithm’s parameters were changed at different levels to determine those with which the algorithm performed best. It is worth noting that each scheme (from A to D) presents differing tumbling, bacteria, and iteration settings while maintaining identical attraction and repulsion parameters. With this strategy, we expected to observe differences in performance regarding the parameters mentioned, which are known to relate directly to the computational effort. After that, scheme K was incorporated, as described below.
In the second phase, we chose new parameters based on the results from the first phase. In particular, we changed (a) the
wrep parameter from 0.001 to 0.002 to increase the strength with which bacteria repel each other; (b) the population size to 120 bacteria and the tumbles to 200; and (c) the number of iterations to 33 during optimization. This set of parameters was named scheme K. We also included the
swim process in the algorithm, which consists of deleting random gaps to avoid sequences with gap saturation. For clarity, we named this algorithm BFOAd (for the gap deletion process). Finally, we incorporated three sets of sequences for performance comparison among the BFOA vs. BFOAd, each in a 30-run process.
Table 2 details the second phase of the experiment. The number of random gaps deleted in the BFOAd was 50.
The comparison consisted of the statistical discrimination of mean values using the Mann–Whitney U test for cases with atypical values and a non-normal distribution, while the Shapiro–Wilk test was used to determine those with a normal distribution. Additionally, a t-test was performed to compare differences. Then, the Cohen test was carried out to assess the effect size.
Finally, the third phase included the development of the well-known Genetic Algorithm for performance comparison. Additionally, the bacterial foraging algorithm was modified into a new version called BFOAdtp, which primarily incorporated an elitism operator to enhance fitness.
3. Results
As previously described, the results correspond to the three-phase experiment, with the first phase exploring the algorithm’s performance and the second phase involving 30 runs, with the parameters having been empirically adjusted based on the results obtained in the first phase.
3.1. First Phase
Presenting the results of the experiment’s first phase,
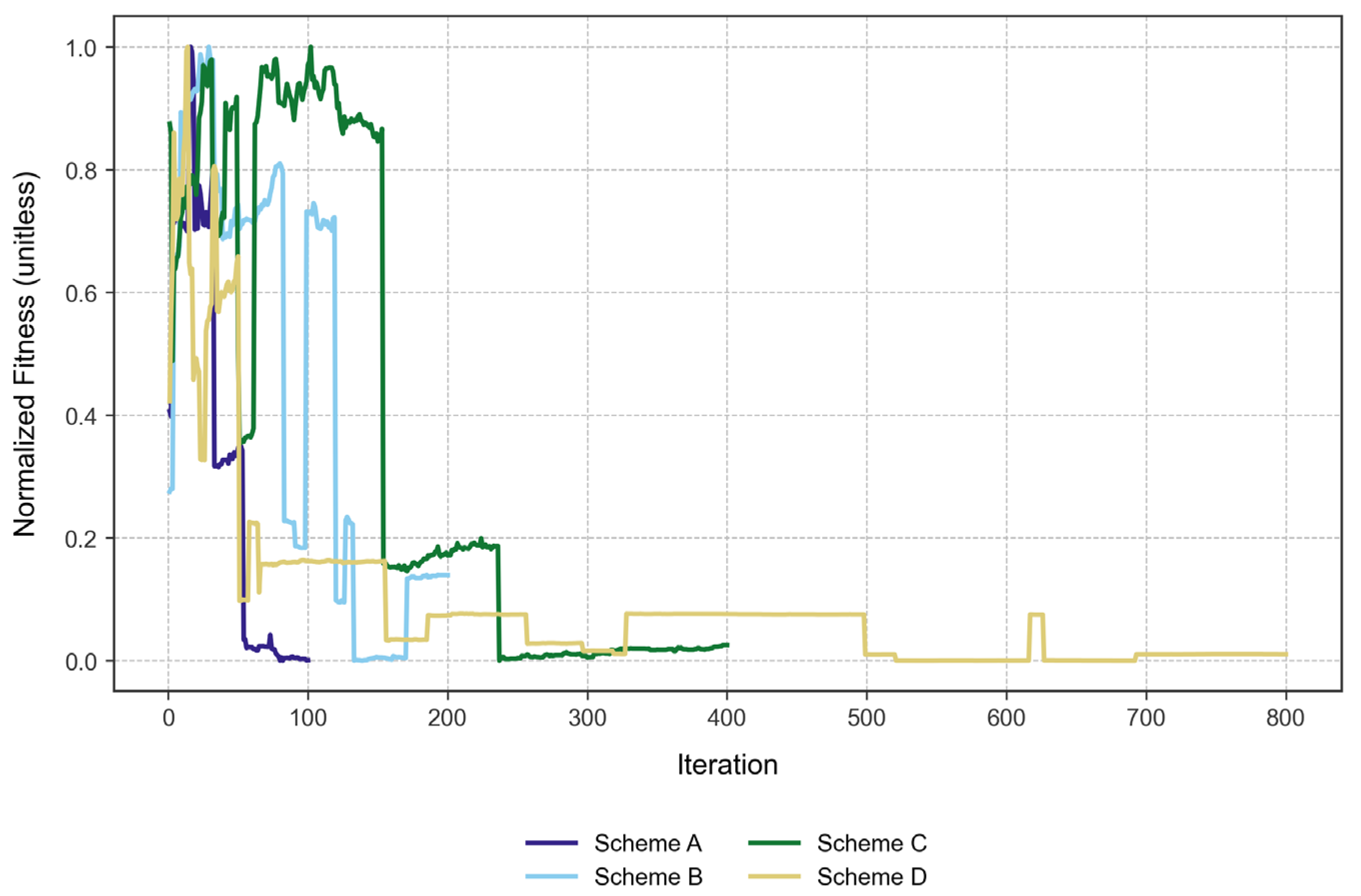
Table 3 displays the best fitness value achieved by the algorithm, as well as the NFE and time in seconds (t). Scheme D performed the best in terms of fitness value; however, it sacrificed time and had an increased NFE value. As described above, the higher the fitness value, the better.
On the other hand, we found that the solutions obtained with the algorithm tended to worsen from an iteration number of approximately 150. As a representation of this occurrence, we normalized the fitness values from each scheme and obtained
Figure 2.
This observation may provide justification for stopping the algorithm before its fitness value starts to worsen, as the genetic sequences may reach a gap-saturated status since the algorithm reports the best bacteria from the given iteration without elitism. This process permits the worsening of the solutions through iterations and serves as an exploration of the algorithm’s performance.
In terms of convergence, we found that scheme D converged the fastest, reaching 95% of its best fitness within just 13 iterations. This is interesting, as Scheme D also had the most demanding parameters (i.e., more bacteria, more iterations), but it found reasonable solutions quickly. Scheme A reached 95% of its best fitness within 16 iterations, showing rapid convergence despite being the simplest scheme. Finally, scheme B took 22 iterations, while scheme C took 25 to reach the same threshold. As such, these two schemes converged more slowly than schemes A and D.
The convergence speed does not strictly increase with the complexity of the scheme. While Scheme D was the most complex and converges fastest, Scheme A (the simplest) also converged rapidly. Schemes B and C were intermediate in complexity and took longer to converge; this could be due to the larger search space or the algorithm exploring more before settling.
3.2. Second Phase
In this part of the work, we compared the performance of the BFOA and BFOAd with respect to the alignment of three sets of sequences (B, C, D) using scheme K and a 30-run experiment for comparison. The performance metrics were the same as in the previous phase, namely, fitness, NFE, and time (t).
Table 4 details the statistical results.
The most remarkable statistical feature is the considerable variability and occasional high performance of the BFOAd on Set B. However, the BFOAd achieved better fitness values on all three sets in comparison to the BFOA. This suggests that the BFOAd may have potential for exceptional results. The standard deviation of the BFOAd in fitness values is also higher in Sets C and D, which describes the variability in the solutions found, especially in Set D. The computational time and number of function evaluations (NFE) were higher across all datasets, about 10–18% slower than the BFOA. However, more extensive swimming may also lead to a more time-consuming process.
The BLOSUM score—which measures biological alignment quality—was higher for the BFOA on all datasets, especially Set B, where the BFOAd’s score was observed to decrease dramatically. The relative performance ratios confirmed that the only dramatic difference was in fitness for Set B, where the BFOAd sometimes found much better solutions. However, this came with a loss in biological quality (i.e., BLOSUM score) and much higher variability. From a computational efficiency perspective, the BFOA and BFOAd are very similar, with the BFOAD being marginally more demanding in time but not in the number of evaluations.
Table 5 describes the statistically significant differences between the BFOA and BFOAd applied to the sequence sets in terms of the fitness, time, and NFE metrics.
First, it can be observed that the BFOAd was significantly slower and required more function evaluations (NFE) than the BFOA on all datasets. The Cohen’s d values for these metrics were enormous, indicating that the difference is statistically significant and relevant in practice. Regarding fitness, the differences were small or unimportant, and, in some cases, the BFOA performed slightly better. This suggests that the BFOA is more efficient and maintains or improves the quality of solutions, while the BFOAd does not justify its higher computational cost. Additionally, the Cohen’s d values reinforce this interpretation: practical differences are essential in efficiency but negligible in solution quality. The collected data are available for download and further analysis. Finally,
Table 6 presents a compact side-by-side comparison of the three key metrics of the BFOA and BFOAd. The execution time in seconds of the BFOAd is an order of magnitude longer than that of the BFOA for every dataset. The NFE of the BFOAd shows that it consistently requires 2–3× more evaluations than the BFOA to reach its final solution. The fitness is improved for the BFOAd only in Set B.
As a general summary,
Figure 3 compares the convergence behaviors of the BFOA and BFOAd versus the NFE, across all three datasets (i.e., Set B, Set C, and Set D) in a single panel.
Across all datasets, both algorithms showed rapid initial improvement, followed by a slower approach to their best solutions. For Set C and Set D, the BFOA generally achieved better (lower) fitness values than the BFOAd, especially in the early and middle stages of optimization. In Set B, the performance of the BFOAd was better.
3.3. Third Phase
We found a high variance in the fitness value from the previous phase, which may be due to the way the BFOA calculates the fitness value, considering the interaction between each bacterium and the others in the population with the BLOSUM score, as described in Equation (3). Also, the gap deletion process in the BFOAd increased the variability in the alignment matrices of the bacterial population.
Thus, we developed a third version of the BFOA, named BFOAdtp, based on the results of the previous phases. The configured changes are as follows: (a) The BLOSUM evaluation values were normalized for greater biological significance. (b) The elitism operator was incorporated to keep the N best bacteria in the population. Also, (c) we developed an improved bacteria substitution method, where the best bacteria of each iteration were discarded if they were not better than the best bacteria of the previous iteration. And finally, (d) the wrep value was changed to 1 to increase the degree of the algorithm’s bacterial dispersion and exploration. Regarding the NFE, we updated the count process to correspond to the evaluation of each bacterium’s alignment matrix, since the BFOA and BFOAd were counting evaluation functions for each repulsion and attraction interaction.
A Genetic Algorithm (GA or AG) was developed for performance comparison. This well-known optimization method from John Holland, based on evolutionary principles, has proven effective in challenging problems like Multiple Sequence Alignment (MSA). The parameters of both algorithms and the experiment scheme are described in
Table 7.
Set B of genetic sequences was used for a performance comparison of the GA vs. BFOAdtp, with an interest in the fitness and NFE metrics.
For data clarification and performance visualization, we calculated the z-score from the fitness metric of the 30 runs. Every fitness measurement
fk,
t from each run becomes
Raw GA and BFOA fitness numbers differ in magnitude and variance. Converting each run to a z-score erases the scale differences, which enables us to overlay and average runs fairly. The curves in
Figure 4 show how far, in standardized units, each algorithm climbs over time. A higher z-score is a direct measure of quality progress.
We found that in the last 50 iterations, the BFOAdtp remains approximately 0.4 σ above the GA, which means that, relative to its own variability, the BFOAdtp achieves solutions that are several tenths of a standard deviation better on average. Additionally, the GA rises quickly but plateaus near +1 σ. In contrast, the BFOAdtp continues to climb well past that point, indicating a stronger exploitation phase that persists in extracting gains after the GA has stalled. However, both algorithms start below their run means. Yet, the BFOA begins closer (≈ –0.3 σ), while the GA plunges to about –0.8 σ, considering that a smaller negative offset implies more promising initial solutions and less risk of a poor early population. Finally, we found greater run-to-run consistency because each run was standardized before averaging, and a smoother BFOAdtp trajectory indicates lower volatility across the 30 runs. The GA exhibits sharper swings in the first 40 generations, suggesting a stronger dependence on random starting conditions.
Regarding the NFE metric, both algorithms record it as an accumulated counter that increases by eight evaluations per step in the BFOA and by eight in the AG (16 → 24 → 32 → …), so every run shows practically identical NFE values at the same iteration or generation index. However, the GA started with sixteen counts, while the BFOAdtp started with eight due to the first selection process. For comparison, using this metric, we took the best fitness achieved by both the AG and BFOAdtp for each run (
n = 60). Then, the median was calculated and defined as the threshold of interest (
tHi). Then, we discarded the runs that never reached
tHi, that is, twenty-four from the AG and one from the BFOAdtp were discarded because they would not provide information for NFE comparison.
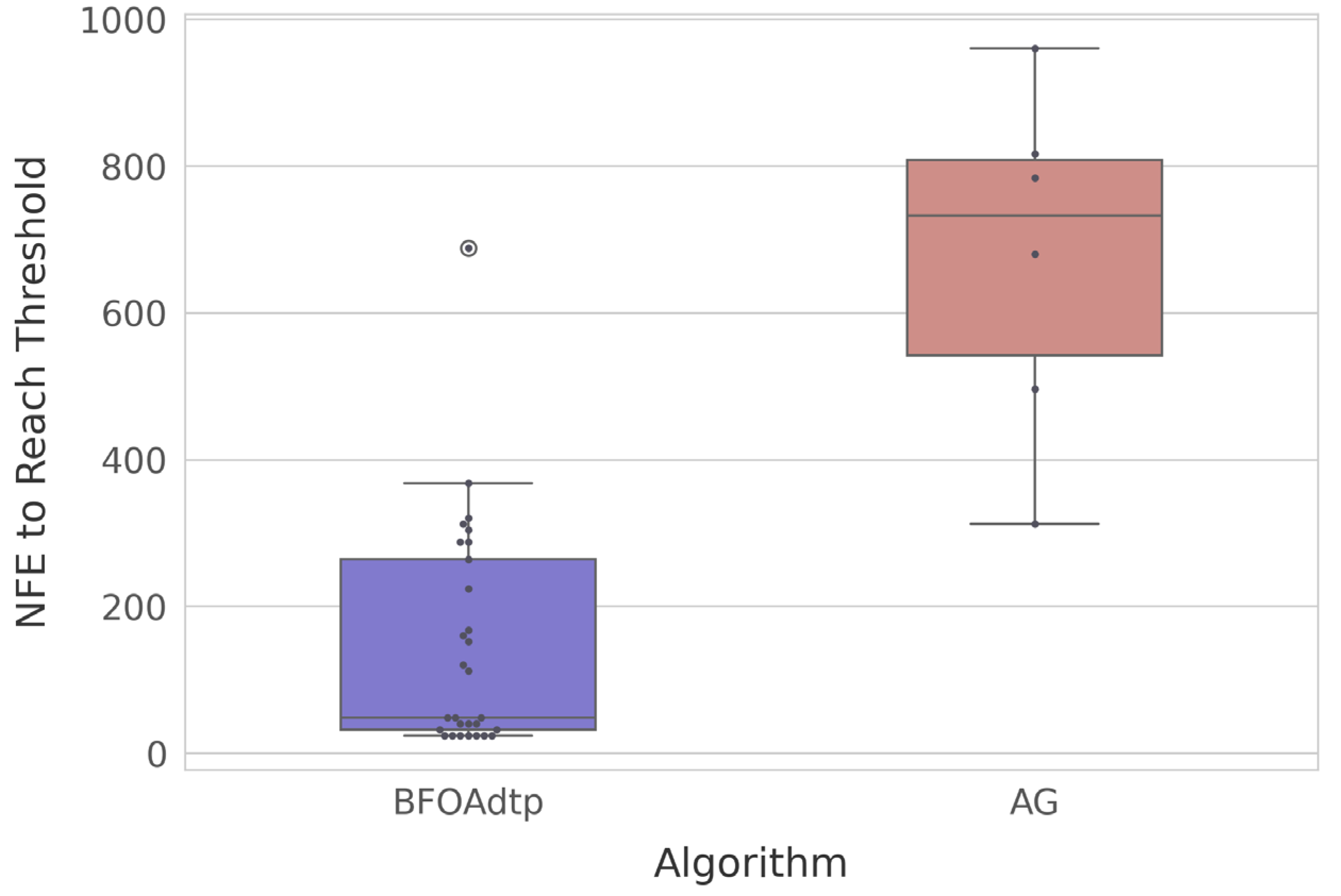
Figure 5 shows a boxplot of the NFE values required to reach the threshold.
Each dot represents a run that successfully reached the fitness threshold; the colored box and whiskers summarize the distribution of the NFE at the moment of success. We found that the BFOAdtp achieves the target in dramatically fewer evaluations: median NFE ≈ 80, with 75% of runs below NFE ≈ 200. Only one run fails to appear because it never hit the threshold. On the other hand, the AG manages to reach the goal in just six runs, all of which require an NFE value of between ≈approximately 300 and ≈approximately 1000. Thus, the BFOAdtp requires an order of magnitude fewer evaluations to achieve the same quality level, thereby saving computational time and energy.
5. Conclusions
The present study shows that the bacterial foraging algorithm is an effective alternative for tackling the Multiple Sequence Alignment (MSA) problem. Across four Alzheimer-related datasets, the BFOAdtp achieved significantly better fitness values than its comparator variants, demonstrating better performance. However, the three developed bacterial algorithms showed improvement, as the basic BFOA provided the first approach but yielded a high NFE value and poor fitness achievement. Then, the BFOAd version incorporated a swim process that deleted gaps from the alignment matrix. Finally, the third version, BFOAdtp, incorporated elitism and showed better performance compared to the well-known Genetic Algorithm. The use of t-tests and Mann–Whitney tests in the second phase confirmed statistical significance. The parallel design consistently reduced the execution time while preserving alignment quality, underscoring its computational efficiency. The list-based population handling enabled scalable performance over a range of problem sizes, and the alignments are suitable for immediate biological relevance to phylogenetic analyses and drug design research. Future work will focus on hybrid affinity heuristics to accelerate chemotaxis, evaluating the algorithm on larger metagenomic datasets, extending parallelization to distributed computing environments, and developing a sequence preprocessing stage that detects conserved domains in the alignment matrix to yield biologically richer results. Additionally, the fitness, NFE, and time showed a contrasting panorama.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}