

An Unsupervised Fusion Strategy for Anomaly Detection via Chebyshev Graph Convolution and a Modified Adversarial Network
Abstract
1. Introduction
- (I)
- An unsupervised deep graph network is provided for the prediction of time series.
- (II)
- The network architecture performs using a graph of time samples to consider the connections in the time distribution of samples.
- (III)
- A fusion of graph networks and generative adversarial networks is proposed to improve the performance of the graph network.
- (IV)
- A modified cost function is provided for the adversarial part of the network architecture to obtain efficient weights for the network with fast convergence and achieve desired results with a low number of iterations.
- (V)
- The adversarial part works utilizing one-dimensional convolutional layers.
2. Materials and Methods
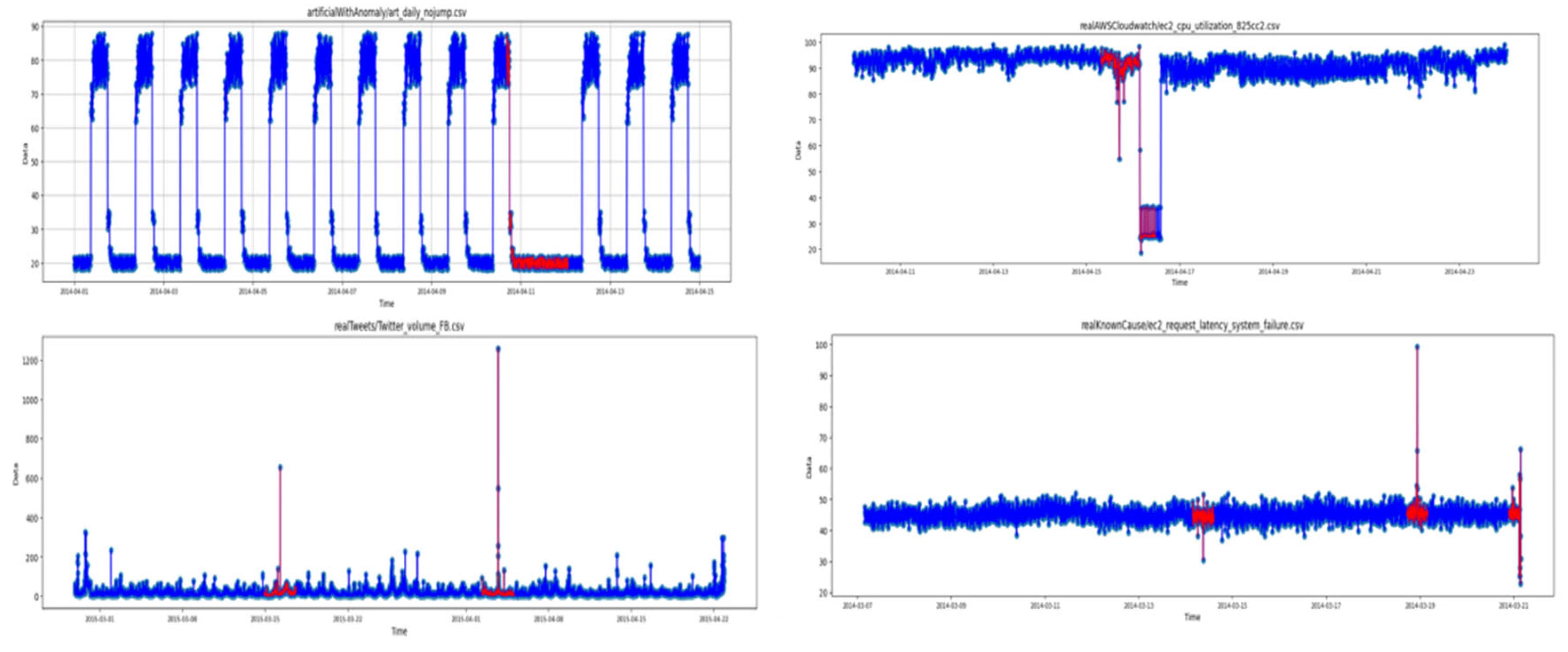
2.1. Numenta Benchmark Database
2.2. Algorithms Used
2.2.1. GANs
2.2.2. Convolutional Neural Network and Graph Theory
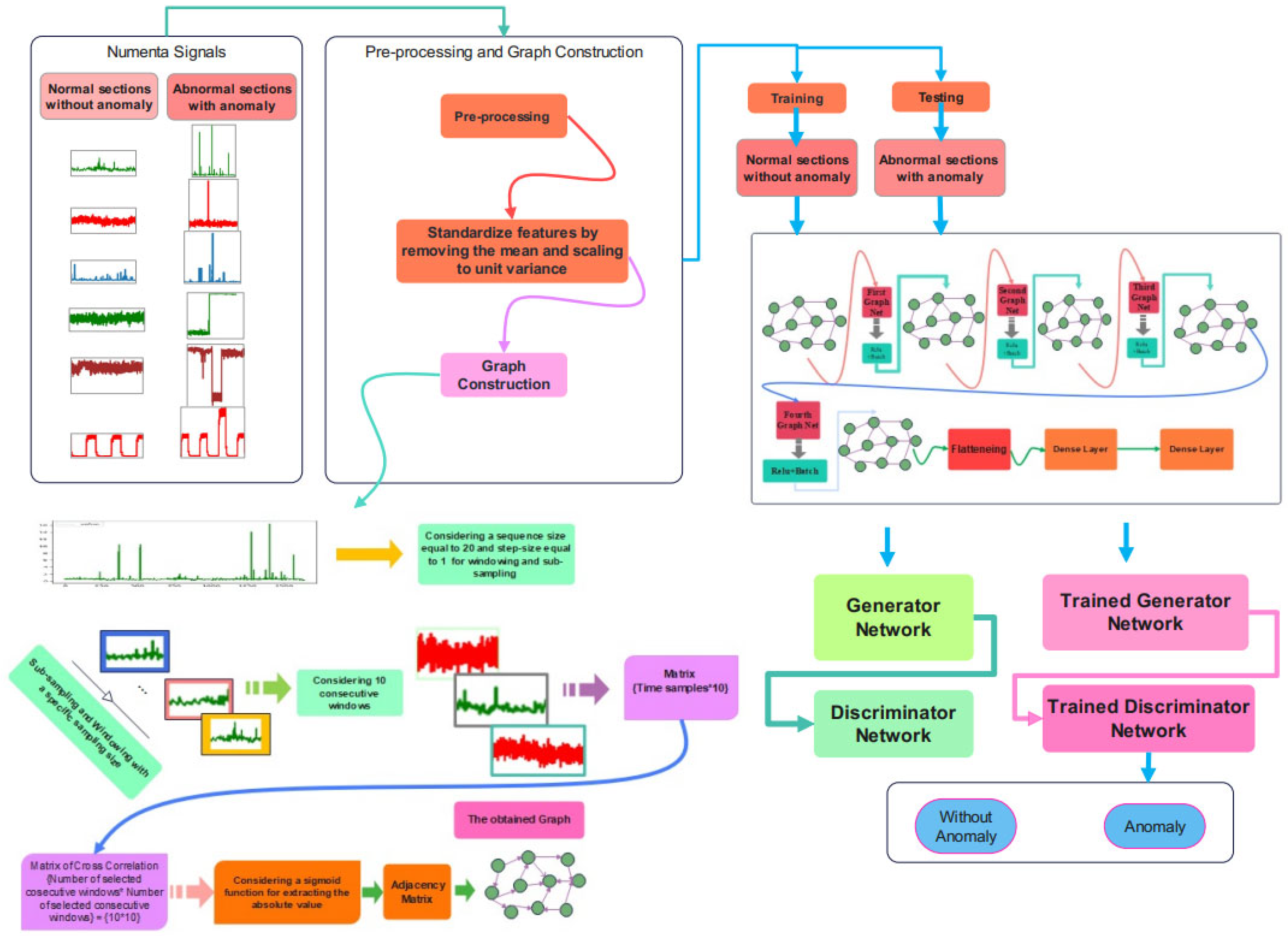
3. Proposed Model
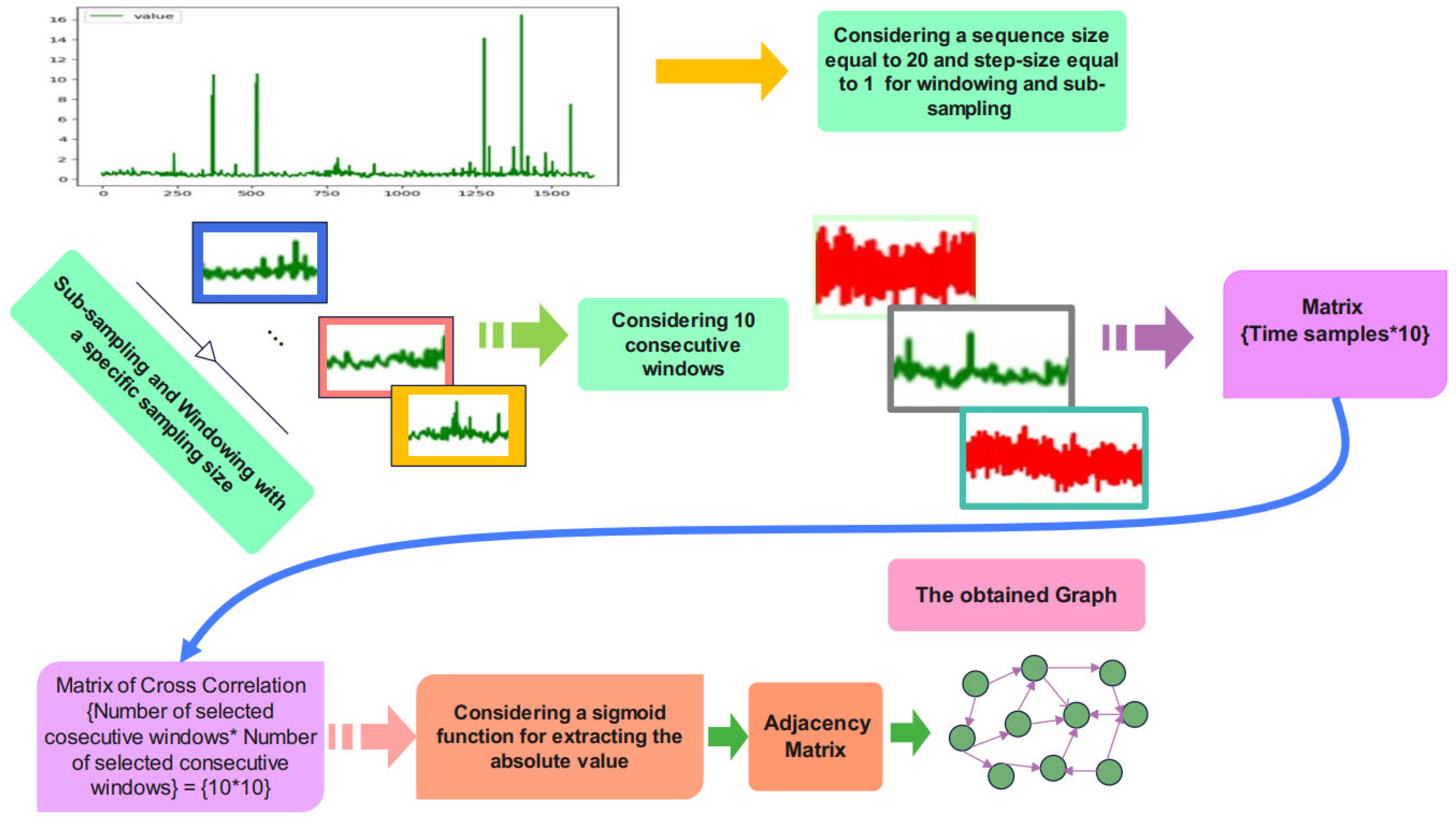
3.1. Pre-Processing Stage
3.2. Graph Construction
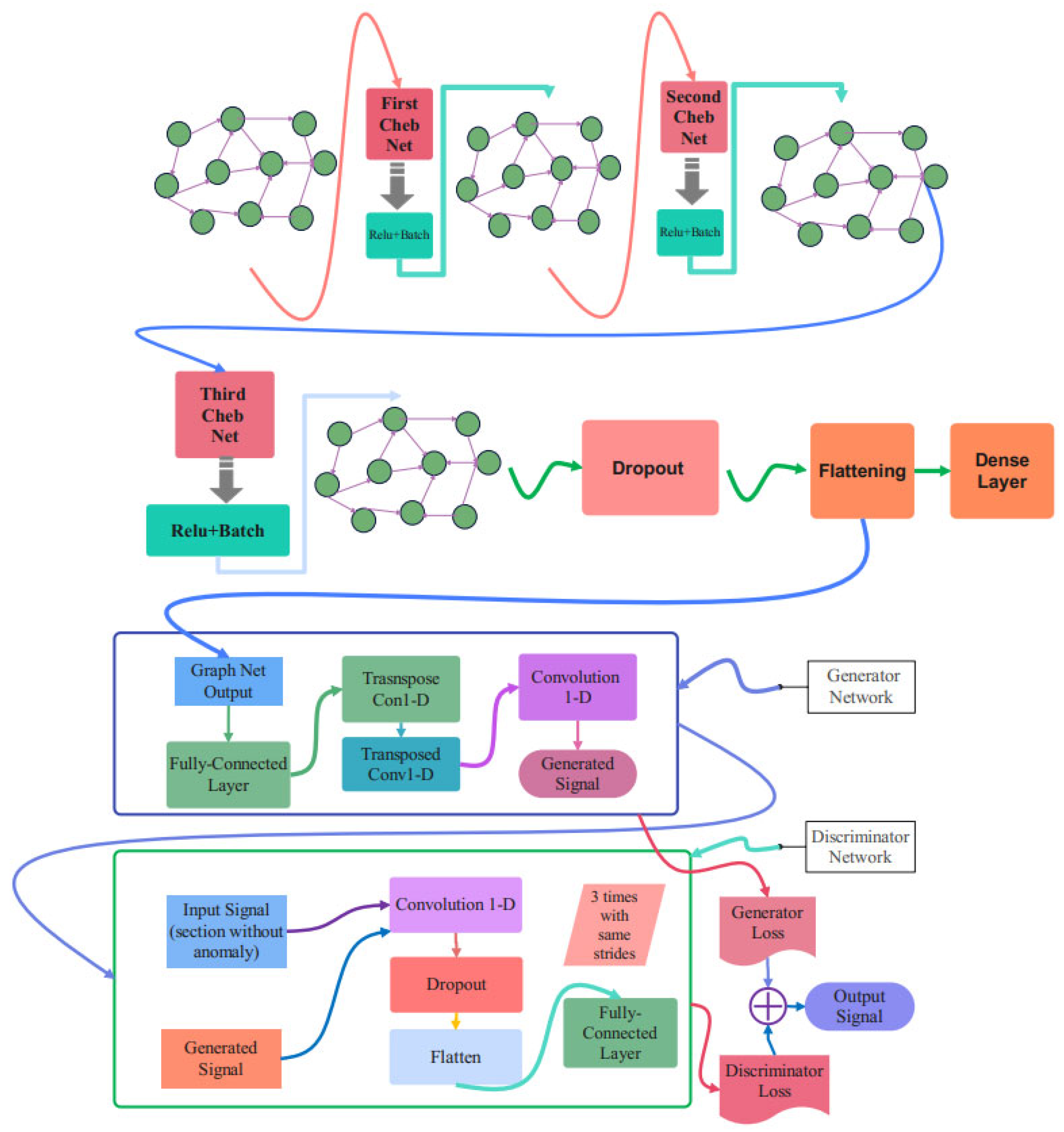
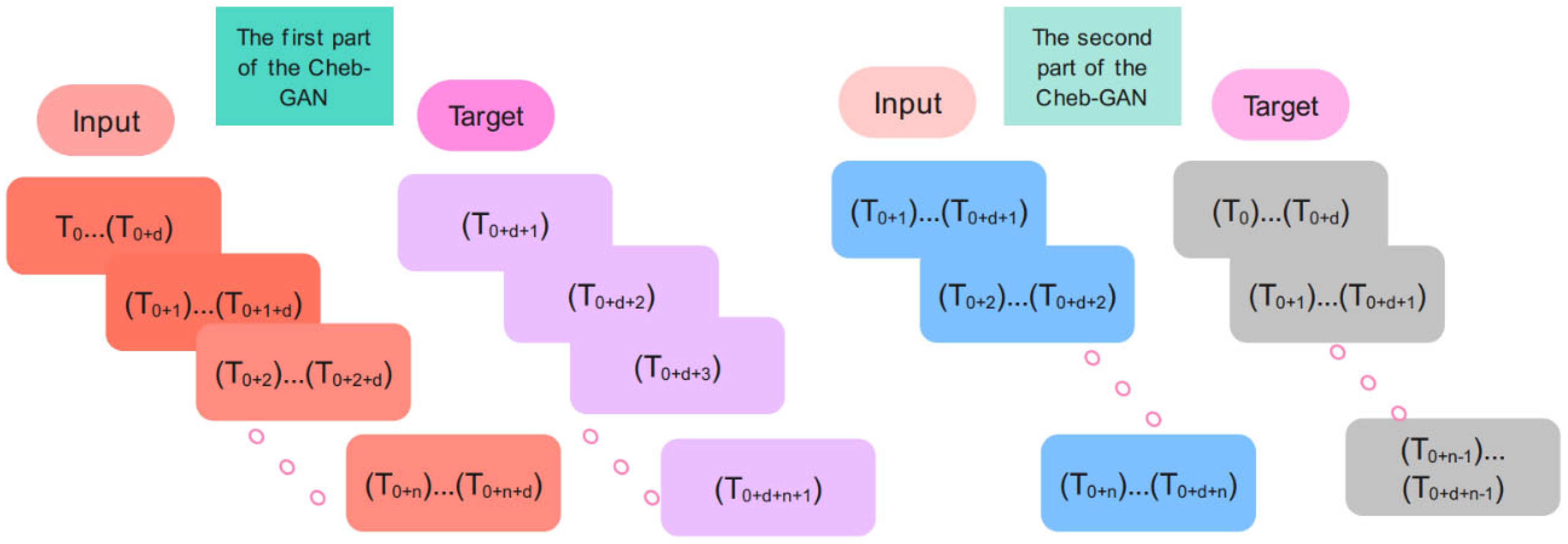
3.3. Proposed Chebyshev Convolution-Based Modified Adversarial Network (Cheb-MA)
3.4. Proposed Cheb-MA Architecture
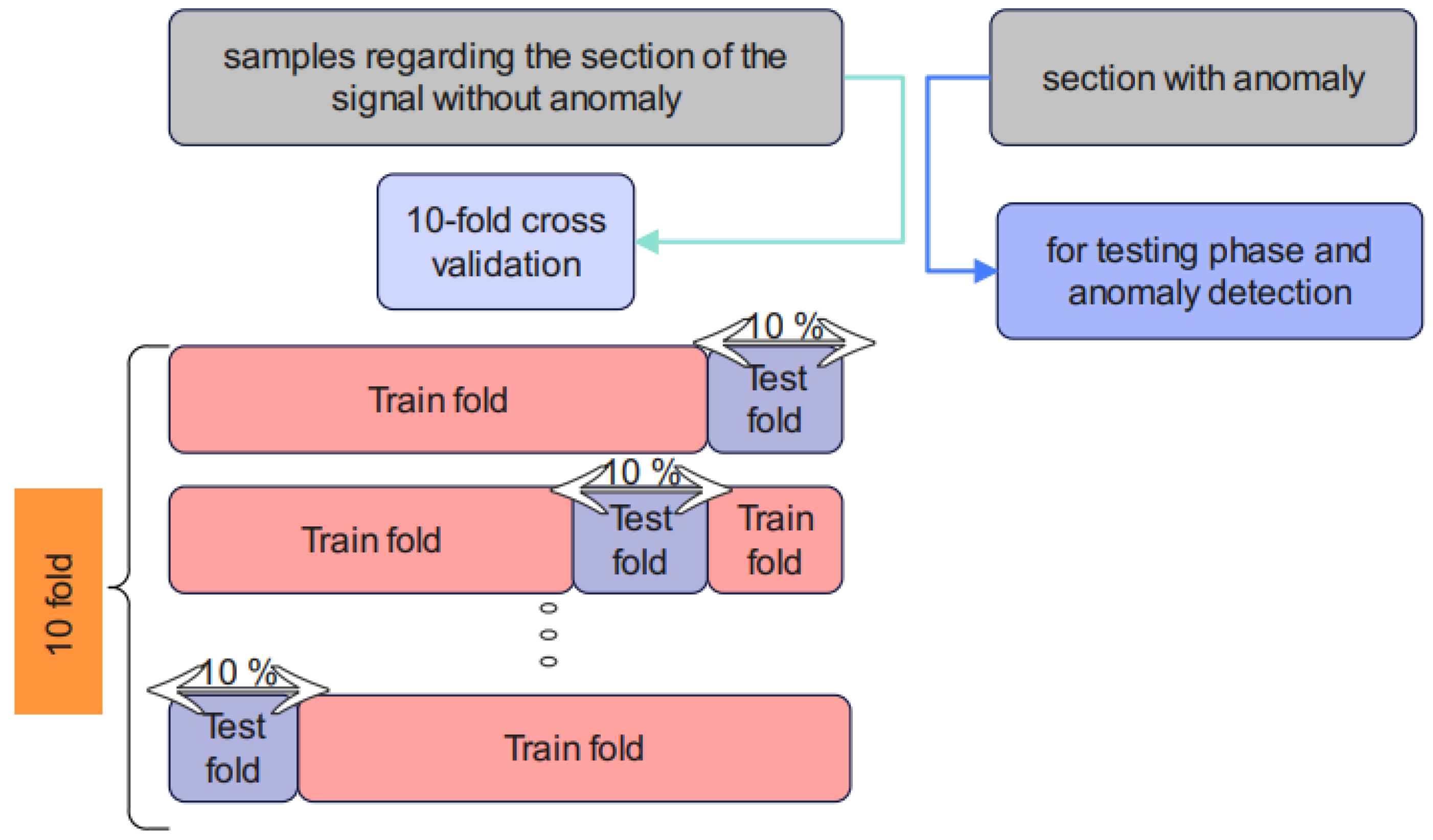
3.5. Training and Evaluation of the Unsupervised Cheb-MA
| Algorithm 1 Proposed method. |
| Chebyshev convolution-based modified adversarial network (Cheb-MA) Input: (1) Multichannel EEG signal X. (2) Window size, striding size, (modifying coefficient of the adversarial network). (3) Coefficient for modified adversarial network. (4) Train and Test Sequence Xtrain and Xtest. Output: Train Target and Test Target Initialize the model parameters. Repeat according to the 10-fold cross-validation: 1: Compute the correlation coefficient of the X in Xtrain. 2: Obtain the adjacency matrix W via using the sigmoid function for the result of step 1. 3: Compute the normalized Laplacian matrix . 4: Calculate the Chebyshev polynomials. 5: Compute the output of the three Chebyshev convolution layers and regularize using the Relu operator. 6: Calculate the Dense layer. 7: Update the weights of the layers using cross-entropy as loss function. 8: Impose the result onto the generator and discriminator part. 9: Update the weights of the layers using modified cost function: Generator: Discriminator: 10: Calculate the predictions for the constructed graphs according to Xtest using the trained Cheb-MA. Stop criterion: Until either a maximum number of iterations or efficient accuracy is acquired. |
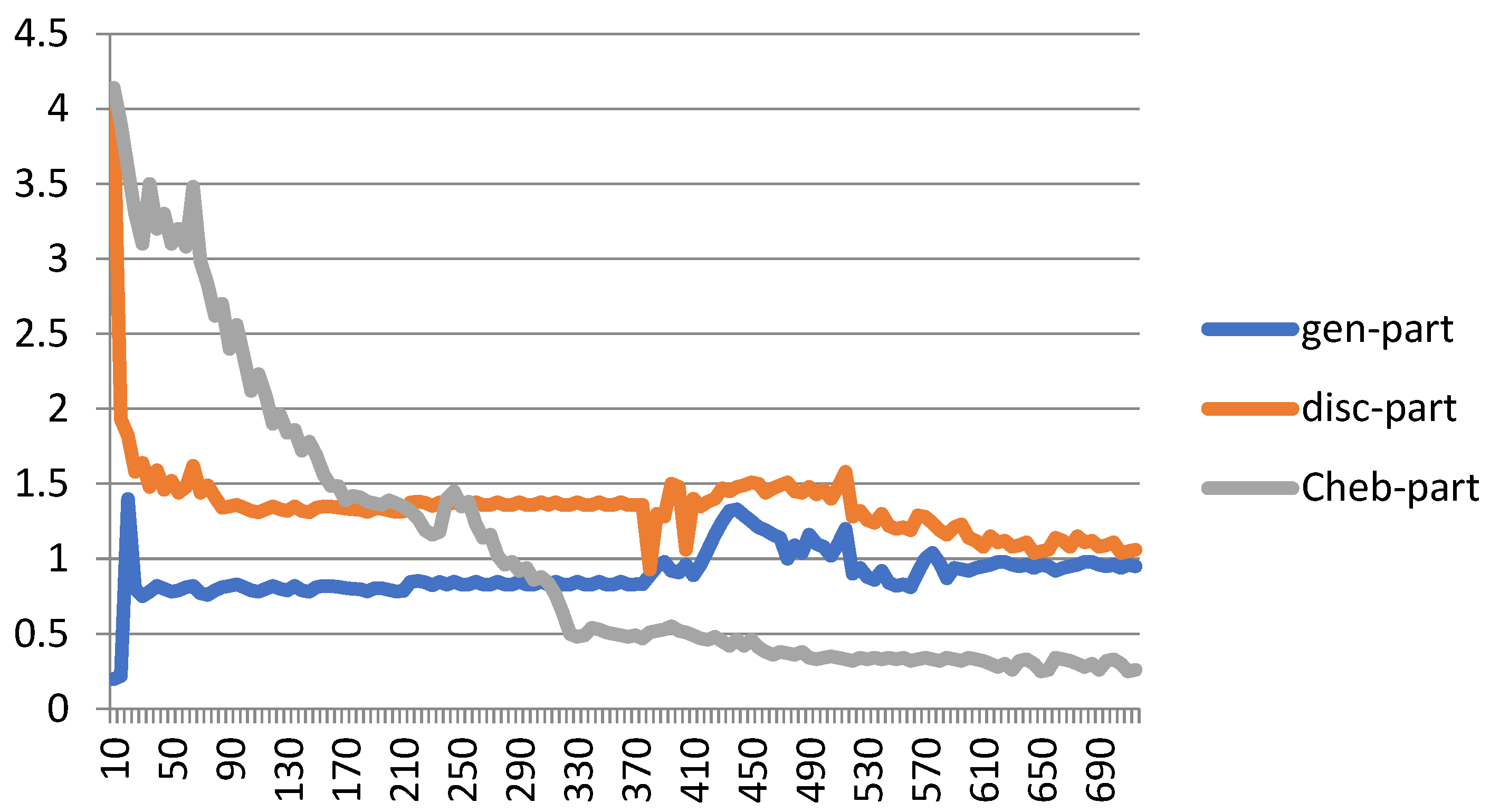
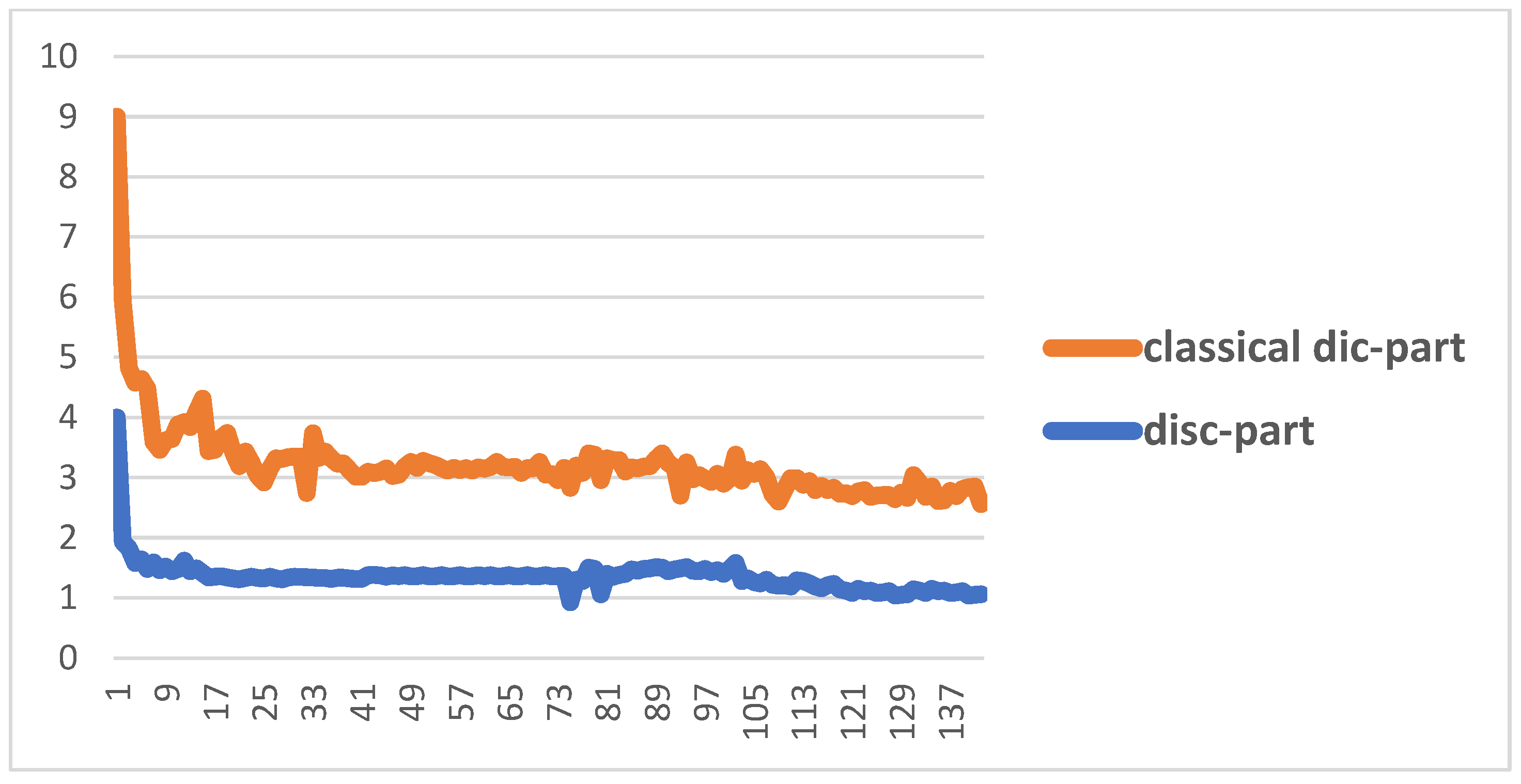
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Mikuni, V.; Nachman, B. High-dimensional and permutation invariant anomaly detection. SciPost Phys. 2024, 16, 062. [Google Scholar] [CrossRef]
- Shiva, K.; Etikani, P.; Bhaskar, V.V.S.R.; Mittal, A.; Dave, A.; Thakkar, D.; Kanchetti, D.; Munirathnam, R. Anomaly detection in sensor data with machine learning: Predictive maintenance for industrial systems. J. Electr. Syst. 2024, 20, 454–462. [Google Scholar]
- Palakurti, N.R. Challenges and future directions in anomaly detection. In Practical Applications of Data Processing, Algorithms, and Modeling; IGI Global: Hershey, PA, USA, 2024; pp. 269–284. [Google Scholar] [CrossRef]
- Li, J.; Liu, Z. Attribute-weighted outlier detection for mixed data based on parallel mutual information. Expert Syst. Appl. 2024, 236, 121304. [Google Scholar] [CrossRef]
- Maged, A.; Lui, C.F.; Haridy, S.; Xie, M. Variational AutoEncoders-LSTM based fault detection of time-dependent high dimensional processes. Int. J. Prod. Res. 2024, 62, 1092–1107. [Google Scholar] [CrossRef]
- Belis, V.; Odagiu, P.; Aarrestad, T.K. Machine learning for anomaly detection in particle physics. Rev. Phys. 2024, 12, 100091. [Google Scholar] [CrossRef]
- Iqbal, A.; Amin, R. Time series forecasting and anomaly detection using deep learning. Comput. Chem. Eng. 2024, 182, 108560. [Google Scholar] [CrossRef]
- Ibrahim, M.; Badran, K.M.; Hussien, A.E. Artificial intelligence-based approach for Univariate time-series Anomaly detection using Hybrid CNN-BiLSTM Model. In Proceedings of the 2022 13th International Conference on Electrical Engineering (ICEENG), Cairo, Egypt, 29–31 March 2022; pp. 129–133. [Google Scholar]
- Wu, T.; Ortiz, J. Rlad: Time series anomaly detection through reinforcement learning and active learning. arXiv 2021, arXiv:2104.00543. [Google Scholar]
- Hong, A.E.; Malinovsky, P.P.; Damodaran, S.K. Towards attack detection in multimodal cyber-physical systems with sticky HDP-HMM based time series analysis. Digit. Threat: Res. Pract. 2024, 5, 1–21. [Google Scholar] [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International Conference on Information Processing in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2017; pp. 146–157. [Google Scholar]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-supervised anomaly detection via adversarial training. In Proceedings of the Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part III 14. Springer: Berlin/Heidelberg, Germany, 2019; pp. 622–637. [Google Scholar]
- Zenati, H.; Romain, M.; Foo, C.-S.; Lecouat, B.; Chandrasekhar, V. Adversarially learned anomaly detection. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 727–736. [Google Scholar]
- Chen, R.-Q.; Shi, G.-H.; Zhao, W.-L.; Liang, C.-H. A joint model for IT operation series prediction and anomaly detection. Neurocomputing 2021, 448, 130–139. [Google Scholar] [CrossRef]
- Qin, J.; Gao, F.; Wang, Z.; Wong, D.C.; Zhao, Z.; Relton, S.D.; Fang, H. A novel temporal generative adversarial network for electrocardiography anomaly detection. Artif. Intell. Med. 2023, 136, 102489. [Google Scholar] [CrossRef]
- Liu, Q.; Paparrizos, J. The Elephant in the Room: Towards A Reliable Time-Series Anomaly Detection Benchmark. Adv. Neural Inf. Process. Syst. 2025, 37, 108231–108261. [Google Scholar]
- Hamon, M.; Lemaire, V.; Nair-Benrekia, N.E.Y.; Berlemont, S.; Cumin, J. Unsupervised Feature Construction for Anomaly Detection in Time Series—An Evaluation. arXiv 2025, arXiv:2501.07999. [Google Scholar]
- Wang, F.; Jiang, Y.; Zhang, R.; Wei, A.; Xie, J.; Pang, X. A Survey of Deep Anomaly Detection in Multivariate Time Series: Taxonomy, Applications, and Directions. Sensors 2025, 25, 190. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Liu, D.; Alnegheimish, S.; Cuesta-Infante, A.; Veeramachaneni, K. Tadgan: Time series anomaly detection using generative adversarial networks. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 33–43. [Google Scholar]
- Xu, L.; Zheng, L.; Li, W.; Chen, z.; song, w.; deng, y.; chang, y.; xiao, j.; yuan, b. nvae-gan based approach for unsupervised time series anomaly detection. arXiv 2021, arXiv:2101.02908. [Google Scholar]
- Lavin, A.; Ahmad, S. Evaluating real-time anomaly detection algorithms—The numenta anomaly benchmark. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (icmla), Miami, FL, USA, 9–11 December 2015; pp. 38–44. [Google Scholar]
- Ahmadirad, Z. The Beneficial Role of Silicon Valley’s Technological Innovations and Venture Capital in Strengthening Global Financial Markets. Int. J. Mod. Achiev. Sci. Eng. Technol. 2024, 1, 9–17. [Google Scholar] [CrossRef]
- Zarean Dowlat Abadi, J.; Iraj, M.; Bagheri, E.; RabieiPakdeh, Z.; Dehghani Tafti, M.R. A Multiobjective Multiproduct Mathematical Modeling for Green Supply Chain Considering Location-Routing Decisions. Math. Probl. Eng. 2022, 2022, 7009338. [Google Scholar] [CrossRef]
- Askarzadeh, A.; Kanaanitorshizi, M.; Tabarhosseini, M.; Amiri, D. International Diversification and Stock-Price Crash Risk. Int. J. Financ. Stud. 2024, 12, 47. [Google Scholar] [CrossRef]
- Gudarzi Farahani, Y.; Mirarab Baygi, S.A.; Abbasi Nahoji, M.; Roshdieh, N. Presenting the Early Warning Model of Financial Systemic Risk in Iran’s Financial Market Using the LSTM Model. Int. J. Financ. Manag. Account. 2026, 11, 29–38. [Google Scholar] [CrossRef]
- Roshdieh, N.; Farzad, G. The Effect of Fiscal Decentralization on Foreign Direct Investment in Developing Countries: Panel Smooth Transition Regression. Int. Res. J. Econ. Manag. Stud. IRJEMS 2024, 3, 133–140. [Google Scholar] [CrossRef]
- Nezhad, K.K.; Ahmadirad, Z.; Mohammadi, A.T. The Dynamics of Modern Business: Integrating Research Findings into Practical Management; Nobel Science: Maharashtra, India, 2024. [Google Scholar]
- Ahmadirad, Z. The Banking and Investment in the Future: Unveiling Opportunities and Research Necessities for Long-Term Growth. Int. J. Appl. Res. Manag. Econ. Account. 2024, 1, 34–41. [Google Scholar] [CrossRef]
- Sadeghi, S.; Marjani, T.; Hassani, A.; Moreno, J. Development of Optimal Stock Portfolio Selection Model in the Tehran Stock Exchange by Employing Markowitz Mean-Semivariance Model. J. Financ. Issues 2022, 20, 47–71. [Google Scholar] [CrossRef]
- Ahmadirad, Z. Evaluating the Influence of AI on Market Values in Finance: Distinguishing Between Authentic Growth and Speculative Hype. Int. J. Adv. Res. Humanit. Law 2024, 1, 50–57. [Google Scholar] [CrossRef]
- Dokhanian, S.; Sodagartojgi, A.; Tehranian, K.; Ahmadirad, Z.; Moghaddam, P.K.; Mohsenibeigzadeh, M. Exploring the Impact of Supply Chain Integration and Agility on Commodity Supply Chain Performance. World J. Adv. Res. Rev. 2024, 22, 441–450. [Google Scholar] [CrossRef]
- Ahmadirad, Z. The Effects of Bitcoin ETFs on Traditional Markets: A Focus on Liquidity, Volatility, and Investor Behavior. Curr. Opin. 2024, 4, 697–706. [Google Scholar] [CrossRef]
- Khorsandi, H.; Mohsenibeigzadeh, M.; Tashakkori, A.; Kazemi, B.; Khorashadi Moghaddam, P.; Ahmadirad, Z. Driving Innovation in Education: The Role of Transformational Leadership and Knowledge Sharing Strategies. Curr. Opin. 2024, 4, 505–515. [Google Scholar] [CrossRef]
- Azadmanesh, M.; Roshanian, J.; Georgiev, K.; Todrov, M.; Hassanalian, M. Synchronization of Angular Velocities of Chaotic Leader-Follower Satellites Using a Novel Integral Terminal Sliding Mode Controller. Aerosp. Sci. Technol. 2024, 150, 109211. [Google Scholar] [CrossRef]
- Mohammadabadi, S.M.S.; Zawad, S.; Yan, F.; Yang, L. Speed Up Federated Learning in Heterogeneous Environments: A Dynamic Tiering Approach. IEEE Internet Things J. 2025, 12, 5026–5035. [Google Scholar] [CrossRef]
- Khatami, S.S.; Shoeibi, M.; Salehi, R.; Kaveh, M. Energy-Efficient and Secure Double RIS-Aided Wireless Sensor Networks: A QoS-Aware Fuzzy Deep Reinforcement Learning Approach. J. Sens. Actuator Netw. 2025, 14, 18. [Google Scholar] [CrossRef]
- Barati Nia, A.; Moug, D.M.; Huffman, A.P.; DeJong, J.T. Numerical Investigation of Piezocone Dissipation Tests in Clay: Sensitivity of Interpreted Coefficient of Consolidation to Rigidity Index Selection. In Cone Penetration Testing 2022: Proceedings of the 5th International Symposium on Cone Penetration Testing (CPT’22); Gottardi, G., Tonni, L., Eds.; CRC: Boca Raton, FL, USA, 2022; pp. 282–287. [Google Scholar] [CrossRef]
- Mahdavimanshadi, M.; Anaraki, M.G.; Mowlai, M.; Ahmadirad, Z. A Multistage Stochastic Optimization Model for Resilient Pharmaceutical Supply Chain in COVID-19 Pandemic Based on Patient Group Priority. In Proceedings of the 2024 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 3 May 2024; pp. 382–387. [Google Scholar] [CrossRef]
- Nawaser, K.; Jafarkhani, F.; Khamoushi, S.; Yazdi, A.; Mohsenifard, H.; Gharleghi, B. The Dark Side of Digitalization: A Visual Journey of Research Through Digital Game Addiction and Mental Health. IEEE Eng. Manag. Rev. 2024, 1, 1–27. [Google Scholar] [CrossRef]
- Afsharfard, A.; Jafari, A.; Rad, Y.A.; Tehrani, H.; Kim, K.C. Modifying Vibratory Behavior of the Car Seat to Decrease the Neck Injury. J. Vib. Eng. Technol. 2023, 11, 1115–1126. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef] [PubMed]
- He, M.; Wei, Z.; Wen, J.-R. Convolutional neural networks on graphs with chebyshev approximation, revisited. Adv. Neural Inf. Process. Syst. 2022, 35, 7264–7276. [Google Scholar]
- Ali, P.J.M.; Faraj, R.H.; Koya, E.; Ali, P.J.M.; Faraj, R.H. Data normalization and standardization: A technical report. Mach. Learn. Tech. Rep. 2014, 1, 1–6. [Google Scholar]
- Aparna, R.; Chithra, P. Role of windowing techniques in speech signal processing for enhanced signal cryptography. Adv. Eng. Res. Appl. 2017, 5, 446–458. [Google Scholar]
- Anguita, D.; Ghelardoni, L.; Ghio, A.; Oneto, L.; Ridella, S. The ‘K’ in K-Fold Cross Validation. In Proceedings of the European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 25–27 April 2012; Volume 102, pp. 441–446. [Google Scholar]
- Ahmad, S.; Lavin, A.; Purdy, S.; Agha, Z. Unsupervised real-time anomaly detection for streaming data. Neurocomputing 2017, 262, 134–147. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar]
- Burnaev, E.; Ishimtsev, V. Conformalized density-and distance-based anomaly detection in time-series data. arXiv 2016, arXiv:1608.04585. [Google Scholar]
- Guha, S.; Mishra, N.; Roy, G.; Schrijvers, O. Robust random cut forest based anomaly detection on streams. In Proceedings of the International Conference on Machine Learning (PMLR), New York, NY, USA, 20–22 June 2016; pp. 2712–2721. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Numenta | Category | Subset | Time Sample | Number of Anomalies | Train Length | Test Length |
|---|---|---|---|---|---|---|
| 1 | AdExchange | AdEx1 | 1600 | 184 | 1000 | 600 |
| 2 | KnownCause | Cause1 | 5184 | 530 | 4000 | 1200 |
| 3 | KnownCause | Cause2 | 4032 | 346 | 3000 | 1000 |
| 4 | Tweets | Twitter1 | 15,840 | 1582 | 10,000 | 5840 |
| 5 | Tweets | Twitter2 | 15,840 | 1588 | 10,000 | 5840 |
| 6 | Tweets | Twitter3 | 15,840 | 1580 | 10,000 | 5840 |
| 7 | Tweets | Twitter4 | 15,840 | 1593 | 10,000 | 5840 |
| 8 | AWS | AWS1 | 4032 | 343 | 3000 | 1032 |
| 9 | AWS | AWS2 | 4032 | 403 | 3000 | 1032 |
| 10 | AWS | AWS3 | 4032 | 403 | 3000 | 1032 |
| 11 | Artificial | Art1 | 4032 | 403 | 3000 | 1032 |
| 12 | Artificial | Art2 | 4032 | 403 | 3000 | 1032 |
| 13 | Artificial | Art3 | 4032 | 403 | 3000 | 1032 |
| 14 | Artificial | Art4 | 4032 | 403 | 3000 | 1032 |
| Numenta | Category | Subset | Anomaly Slice | Numenta | Category | Subset | Anomaly Slice |
|---|---|---|---|---|---|---|---|
| 1 | AdExchange | AdEx1 | Slice (347,380) Slice (729,769) Slice (1256,1296) Slice (1381,1421) | 8 | AWS | AWS1 | Slice (1526,1868) |
| 2 | Known Cause | Cause1 | Slice (2243,2507) Slice (2877,3141) | 9 | AWS | AWS2 | Slice (1437,1839) |
| 3 | Known Cause | Cause2 | Slice (2014,2148) Slice (3328,3462) Slice (3956,4031) | 10 | AWS | AWS3 | Slice (3374,3776) |
| 4 | Tweets | Twitter1 | Slice (4614,5404) Slice (9926,10,716) | 11 | Artificial | Art1 | Slice (2679,3081) |
| 5 | Tweets | Twitter2 | Slice (1235,1631) Slice (2920,3316) Slice (4761,5157) Slice (9087,9483) | 12 | Artificial | Art2 | Slice (2787,3189) |
| 6 | Tweets | Twitter3 | Slice (1796,2190) Slice (3538,3932) Slice (9598,9992) Slice (11,409,11,803) | 13 | Artificial | Art3 | Slice (2787,3189) |
| 7 | Tweets | Twitter4 | Slice (2872,3402) Slice (5800,6330) Slice (7768,8298) | 14 | Artificial | Art4 | Slice (2787,3189) |
| Layer | Layer Name | Activation Function | Dimension of Weight Array | Dimension of Bias | Number of Parameters |
|---|---|---|---|---|---|
| 1 | Chebyshev convolution layer | ReLU | [1, 20, 20] | [20] | 420 |
| 2 | Batch normalization | - | [20] | [20] | 40 |
| 3 | Chebyshev convolution layer | ReLU | [1, 20, 20] | [20] | 420 |
| 4 | Batch normalization | - | [20] | [20] | 40 |
| 5 | Chebyshev convolution layer | ReLU | [1, 20, 10] | [5] | 205 |
| 6 | Batch normalization | - | [10] | [10] | 20 |
| 7 | Dense layer | - | [100, 1] | [1] | 101 |
| Layer | Layer Name | Activation Function | Output Dimension | Size of Kernel | Stride Shape | Number of Kernels | Number of Weights |
|---|---|---|---|---|---|---|---|
| 2 | Dense | LeakyReLU (alpha = 0.1) | (1, 20) | 2000 | |||
| 3 | Reshape | (1, 20,1) | 0 | ||||
| 4 | Transposed Convolution 1-D | LeakyReLU (alpha = 0.1) | (1, 20, 8) | 1 × 4 | 1 × 1 | 8 | 256 |
| 5 | Transposed Convolution 1-D | LeakyReLU (alpha = 0.1) | (1, 20, 8) | 1 × 4 | 1 × 1 | 8 | 256 |
| 6 | Transposed Convolution 1-D | LeakyReLU (alpha = 0.1) | (1, 20, 1) | 1 × 4 | 1 × 1 | 1 | 4 |
| Layer | Layer Name | Activation Function | Output Dimension | Size of Kernel | Strides | Number of Kernels | Number of Weights |
|---|---|---|---|---|---|---|---|
| 1 | Convolution 1-D | LeakyReLU (alpha = 0.1) | (1, 20, 4) | 1 × 4 | 1 × 1 | 4 | 20 |
| 2 | Dropout (0.3) | (1, 20,4) | 0 | ||||
| 3 | Convolution 1-D | LeakyReLU (alpha = 0.1) | (1, 10, 4) | 1 × 4 | 1 × 1 | 4 | 68 |
| 4 | Dropout (0.3) | (1, 10,4) | 0 | ||||
| 5 | Convolution 1-D | LeakyReLU (alpha = 0.1) | (1, 5, 4) | 1 × 4 | 1 × 1 | 4 | 68 |
| 6 | Dropout (0.3) | (1, 5, 4) | 0 | ||||
| 7 | Flatten | (1, 20) | 0 | ||||
| 8 | Dense | (1, 1) | 21 |
| Parameters | Search Scope | Optimal Value |
|---|---|---|
| Optimizer of first part | Adam, SGD | SGD |
| Cost function of first part | MSE, Cross-Entropy | Cross-Entropy |
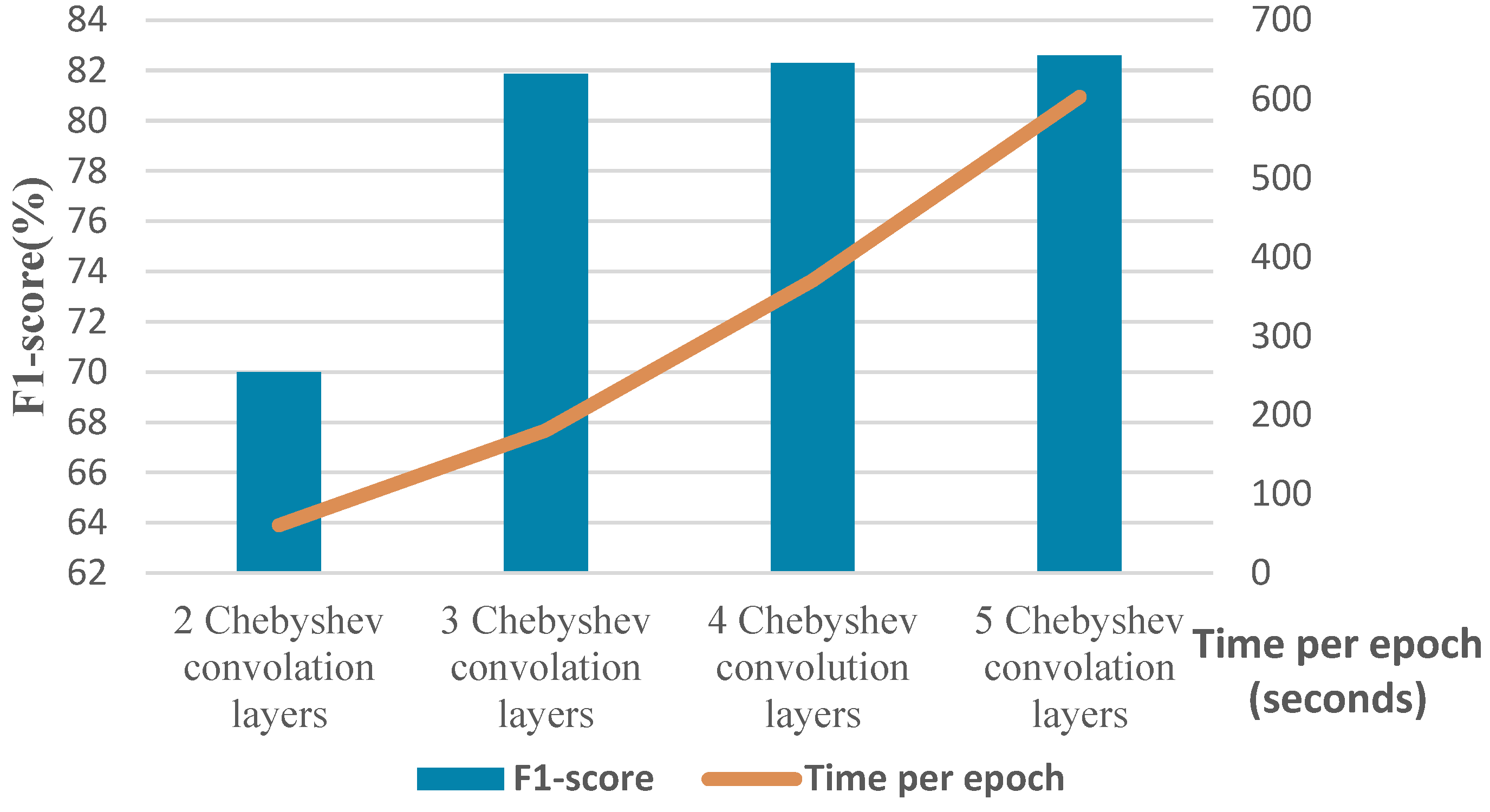
| Number of Chebyshev convolutional layers | 2, 3, 4 | 3 |
| Learning rate of first part | 0.1, 0.01, 0.001 | 0.001 |
| Window size | 15, 20, 25, 30 | 20 |
| Optimizer of MA | Adam, SGD | Adam |
| Learning rate of MA | 0.01, 0.001, 0.0001, 0.00001 | 0.0001 |
| Number of transposed 1D-convolution layers of generator of MA | 2, 3, 4 | 4 |
| Number of 1D-convolution layers of discriminator of MA part | 2, 3, 4 | 3 |
| Dataset | Cheb-MA | GNN | LSTM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | Accuracy | Precision | Recall | F1 | Accuracy | Precision | Recall | F1 | |
| Art 1 | 87.08 | 88 | 93 | 90 | 92.01 | 85.9 | 91.31 | 88 | 84.32 | 84.36 | 93.3 | 88.6 |
| Art 2 | 86.2 | 85.3 | 86.4 | 85.84 | 85.36 | 82.06 | 85.4 | 83.69 | 85.23 | 81 | 83.4 | 82.3 |
| Art 3 | 90.09 | 87 | 88.2 | 87.59 | 89 | 84.36 | 85 | 84.67 | 89 | 82 | 82.65 | 82.32 |
| Art 4 | 82.2 | 64.69 | 92.3 | 76.06 | 80.2 | 64 | 91.31 | 75.48 | 78.6 | 63.2 | 90.02 | 73.65 |
| AdEx 1 | 89.37 | 79.5 | 76 | 78 | 78 | 72.9 | 86.7 | 79.11 | 75.3 | 67 | 77.2 | 71.64 |
| AWS 1 | 95.27 | 76.2 | 73 | 74.46 | 93 | 73 | 68 | 70 | 94.22 | 75 | 69.3 | 71.87 |
| AWS 2 | 96.8 | 78.66 | 86 | 82.2 | 91.3 | 74.9 | 84.5 | 79.33 | 90.89 | 78 | 83 | 80.4 |
| Cause 1 | 91.64 | 78.66 | 86 | 82.2 | 91.3 | 78 | 83 | 80.4 | 90.77 | 74.9 | 84.5 | 79.33 |
| Cause 2 | 91.51 | 74 | 70 | 71.9 | 90.23 | 69.3 | 75 | 71.87 | 90.46 | 68 | 73 | 70 |
| Tweet 1 | 94.06 | 80.4 | 82.8 | 80.98 | 93.88 | 73.11 | 85.9 | 78.96 | 93.09 | 72.90 | 88.4 | 79.2 |
| Tweet 2 | 94.23 | 93.2 | 91.2 | 91.89 | 93.52 | 87.5 | 73.5 | 79.3 | 92.8 | 85.6 | 69.3 | 76.1 |
| Tweet 3 | 94.02 | 90.2 | 90.82 | 90.51 | 93.2 | 77 | 91 | 83.4 | 92.75 | 72.04 | 84.8 | 77.5 |
| Tweet 4 | 92.8 | 74.3 | 76.9 | 75.6 | 91.62 | 75 | 79.6 | 77.2 | 91.06 | 73.4 | 74.6 | 73.8 |
| Average | 91.17 | 80.77 | 84.04 | 82.09 | 89.4 | 76.69 | 83.09 | 79.33 | 88.34 | 75.18 | 81.03 | 77.43 |
| Dataset | Cheb-MA | GNN | LSTM | Average Cheb-MA (%) | Average GNN (%) | Average LSTM (%) |
|---|---|---|---|---|---|---|
| Art 1 | 81.38 | 76.42 | 76.42 | 75.26 | 71.82 | 71.32 |
| Art 2 | 81.3 | 79.2 | 79.3 | |||
| Art 3 | 79.6 | 75.3 | 74.23 | |||
| Art 4 | 58.77 | 56.36 | 55.36 | |||
| AdEx 1 | 80.43 | 67.8 | 62.9 | 80.43 | 67.8 | 62.9 |
| AWS 1 | 80.49 | 80.4 | 79.33 | 78.54 | 78.5 | 75.51 |
| AWS 2 | 76.6 | 76.6 | 71.7 | |||
| Cause 1 | 71.09 | 68.20 | 65.3 | 80.82 | 77.1 | 72.74 |
| Cause 2 | 90.56 | 86.79 | 80.18 | |||
| Tweet 1 | 82.5 | 81.3 | 79.7 | 83.59 | 73.84 | 70.03 |
| Tweet 2 | 96.8 | 76.66 | 70.6 | |||
| Tweet 3 | 75.2 | 68.8 | 62.53 | |||
| Tweet 4 | 79.89 | 68.6 | 67.3 | |||
| Average | 79.72 | 73.81 | 70.5 |
| Method | NAB Score (%) |
|---|---|
| Cheb-MA | 79.72 |
| GNN | 73.8 |
| LSTM [48] | 70.5 |
| ARTime [18] | 74.9 |
| Numenta HTM [45] | 70.5–69.7 |
| KNN CAD [49] | 58.0 |
| Random Cut Forest [50] | 51.7 |
| Method | F1-Score |
|---|---|
| Cheb-MA | 82.09 |
| GNN | 79.33 |
| LSTM [48] | 77.43 |
| TadGAN [16] | 70.2 |
| Arima [51] | 60.9 |
| DeepAR [52] | 56.8 |
| Test 1 | Test 2 | Test 3 | Test 4 | Test 5 | |
|---|---|---|---|---|---|
| Cheb-MA | 93.17% | 89.42% | 92.52% | 92.46% | 88.28% |
| GNN | 89.4% | 88.56% | 89.84% | 87.23% | 91.97% |
| LSTM | 87.23% | 88.56% | 87.43% | 89.12% | 89.36% |
| Cheb-MA, GNN | 3.77 | 0.86 | 2.68 | 5.23 | 3.69 |
| t | T = (50.5) × 3.246/1.61 = 4.50 | ||||
| p-value < 0.02 | p-value < 0.05 | p-value < 0.1 | p-value < 0.15 | p-value < 0.2 | |
| 4.5 > 2.77 | 4.5 > 2.13 | 4.5 > 1.53 | 4.5 > 1.19 | 4.5 > 0.94 | |
| Cheb-MA, LSTM | 5.94 | 0.86 | 5.09 | 3.34 | 1.08 |
| t | t = (50.5 × 3.26)/2.28 = 3.19 | ||||
| p-value < 0.02 | p-value < 0.05 | p-value < 0.1 | p-value < 0.15 | p-value < 0.2 | |
| 3.19 > 2.77 | 3.19 > 2.13 | 3.19 > 1.53 | 3.19 > 1.19 | 3.19 > 0.94 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manafi, H.; Mahan, F.; Izadkhah, H. An Unsupervised Fusion Strategy for Anomaly Detection via Chebyshev Graph Convolution and a Modified Adversarial Network. Biomimetics 2025, 10, 245. https://doi.org/10.3390/biomimetics10040245
Manafi H, Mahan F, Izadkhah H. An Unsupervised Fusion Strategy for Anomaly Detection via Chebyshev Graph Convolution and a Modified Adversarial Network. Biomimetics. 2025; 10(4):245. https://doi.org/10.3390/biomimetics10040245
Chicago/Turabian StyleManafi, Hamideh, Farnaz Mahan, and Habib Izadkhah. 2025. "An Unsupervised Fusion Strategy for Anomaly Detection via Chebyshev Graph Convolution and a Modified Adversarial Network" Biomimetics 10, no. 4: 245. https://doi.org/10.3390/biomimetics10040245
APA StyleManafi, H., Mahan, F., & Izadkhah, H. (2025). An Unsupervised Fusion Strategy for Anomaly Detection via Chebyshev Graph Convolution and a Modified Adversarial Network. Biomimetics, 10(4), 245. https://doi.org/10.3390/biomimetics10040245