
Speed Up of Volumetric Non-Local Transform-Domain Filter Utilising HPC Architecture


Abstract
:1. Introduction
- Application of parallel version of BM4D algorithm to many-core architectures and combination of multi and many-core HW and proving the scalability tests.
- Comparison of the algorithm with DL-based approaches.
- Testing the algorithm as a pre-processing stage before volume rendering.
2. Materials and Methods
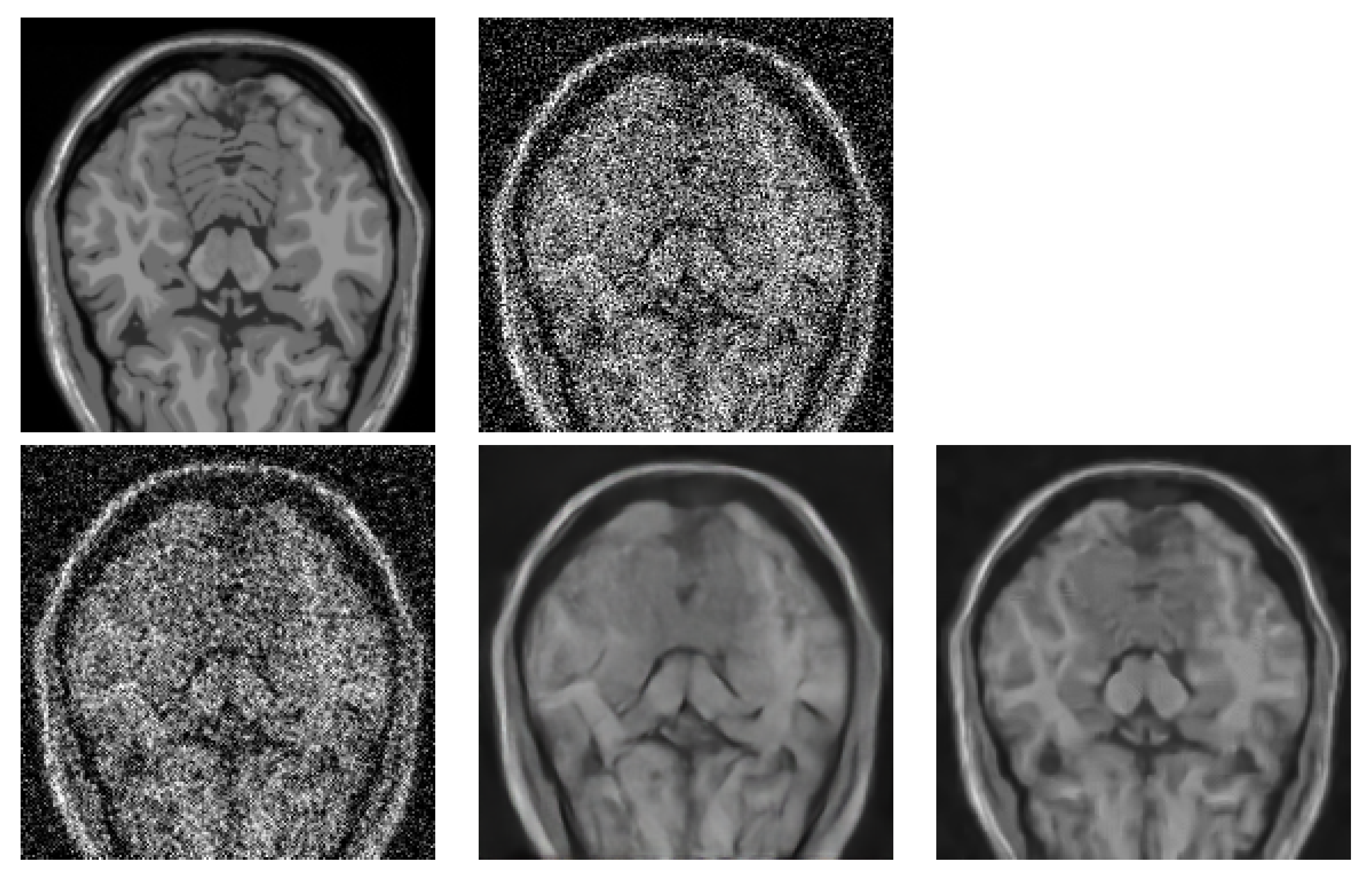
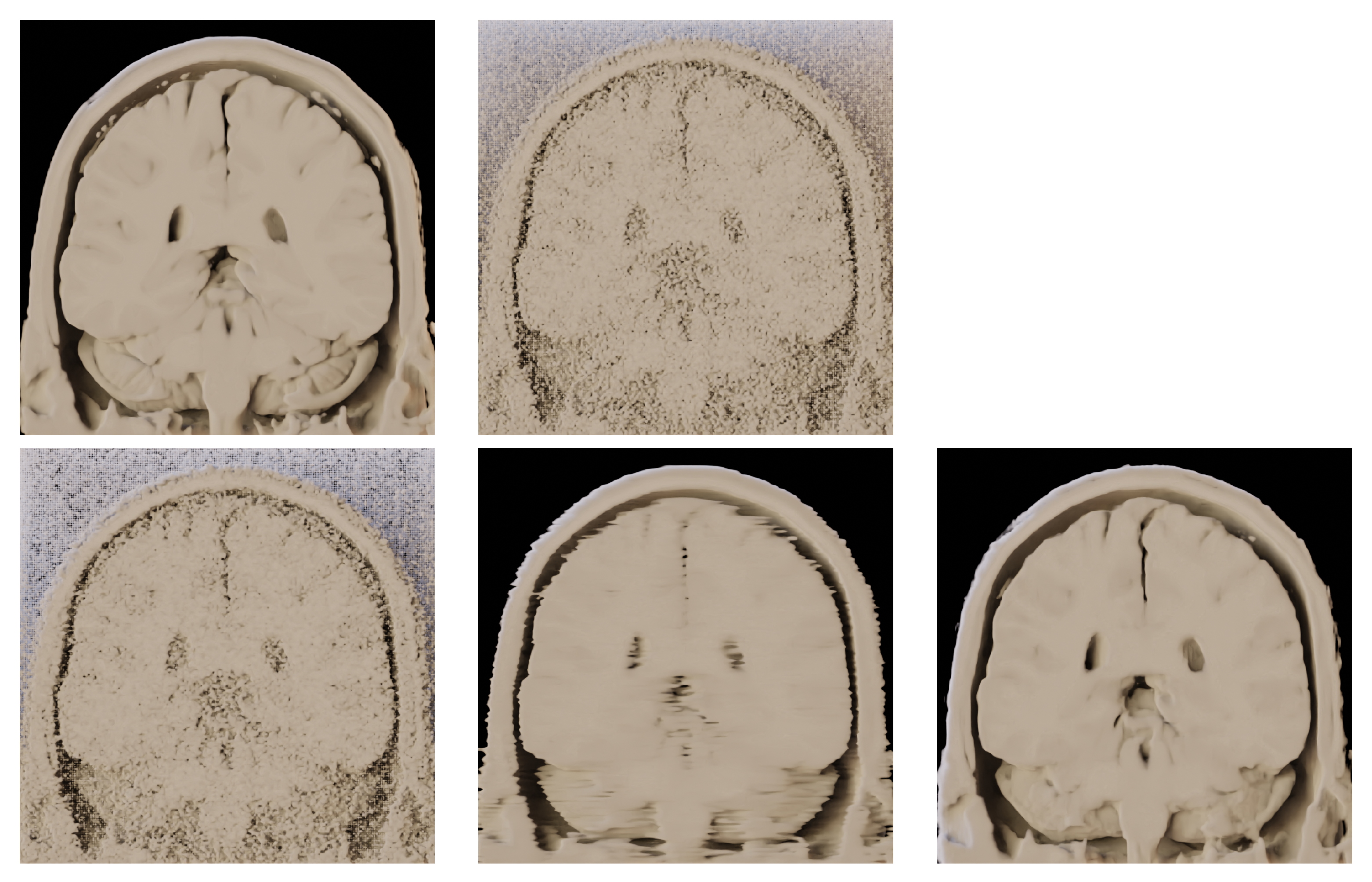
2.1. Explanation of BM4D Algorithm
| Algorithm 1: Four-dimensional transformation from spatial to sparse domain. |
 |
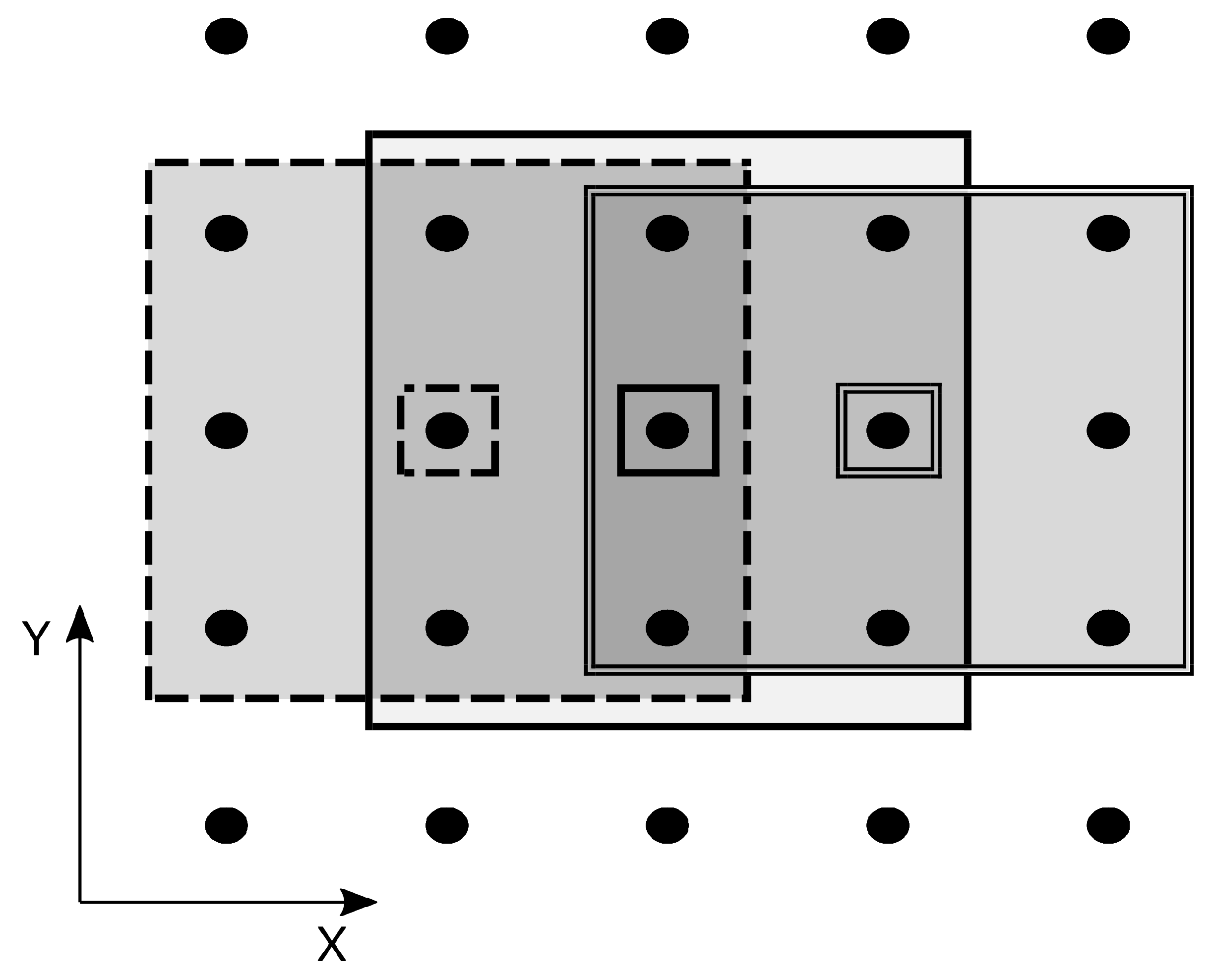
2.2. Parallelisation Concept
2.3. Practical Realisation of the Parallel Filter Implementation
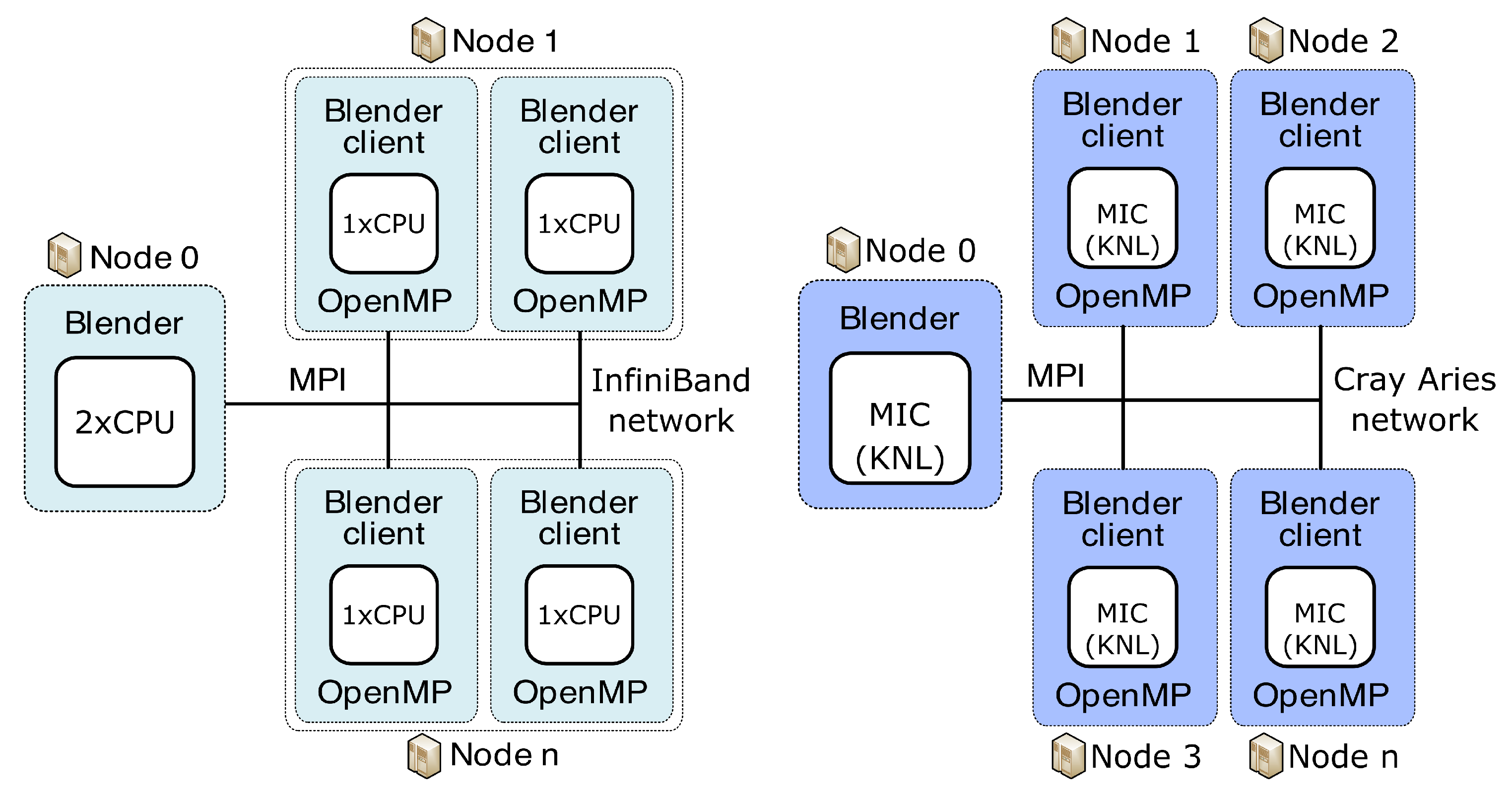
2.4. Utilised HPC Resources and Test Data
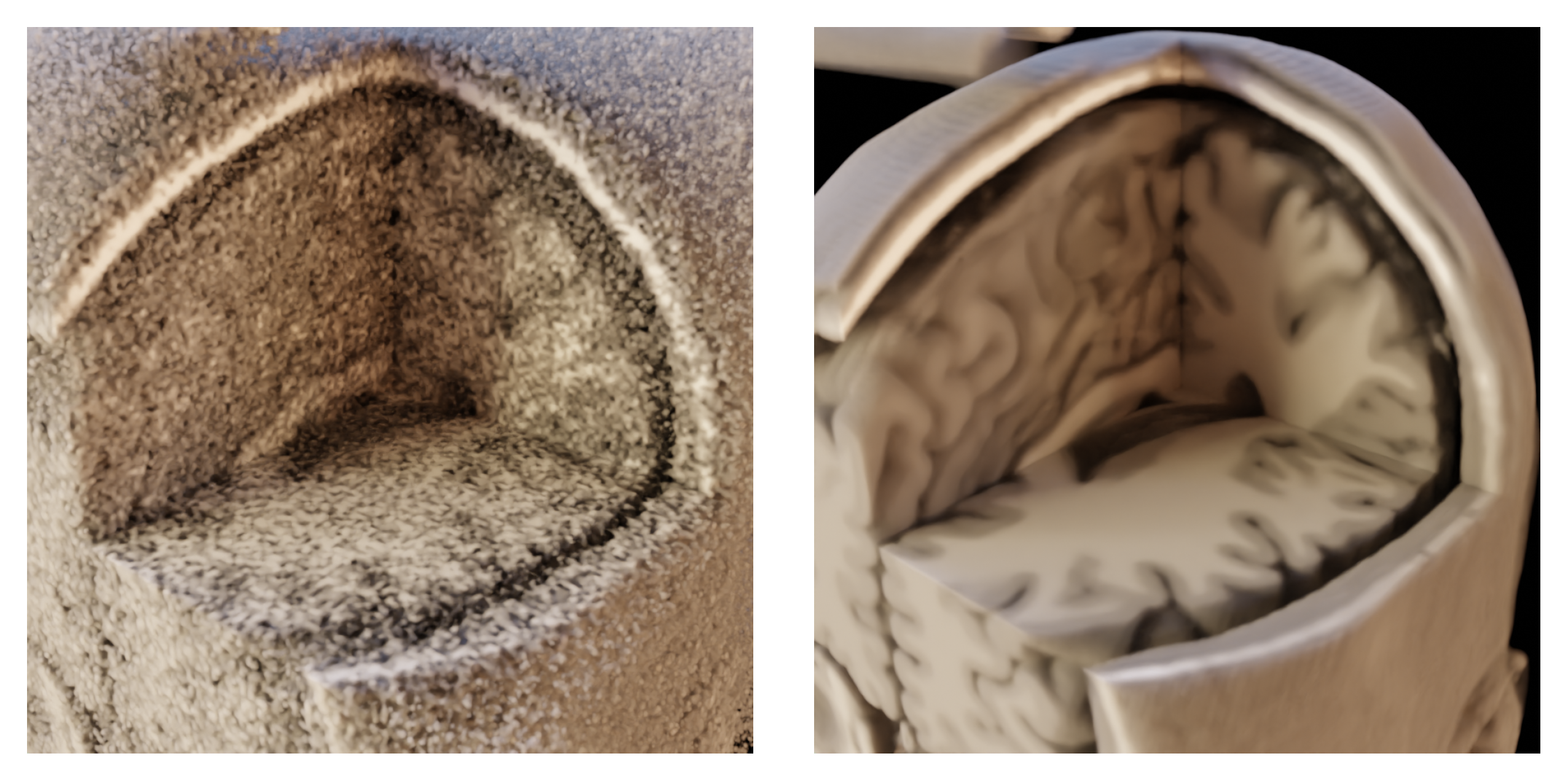
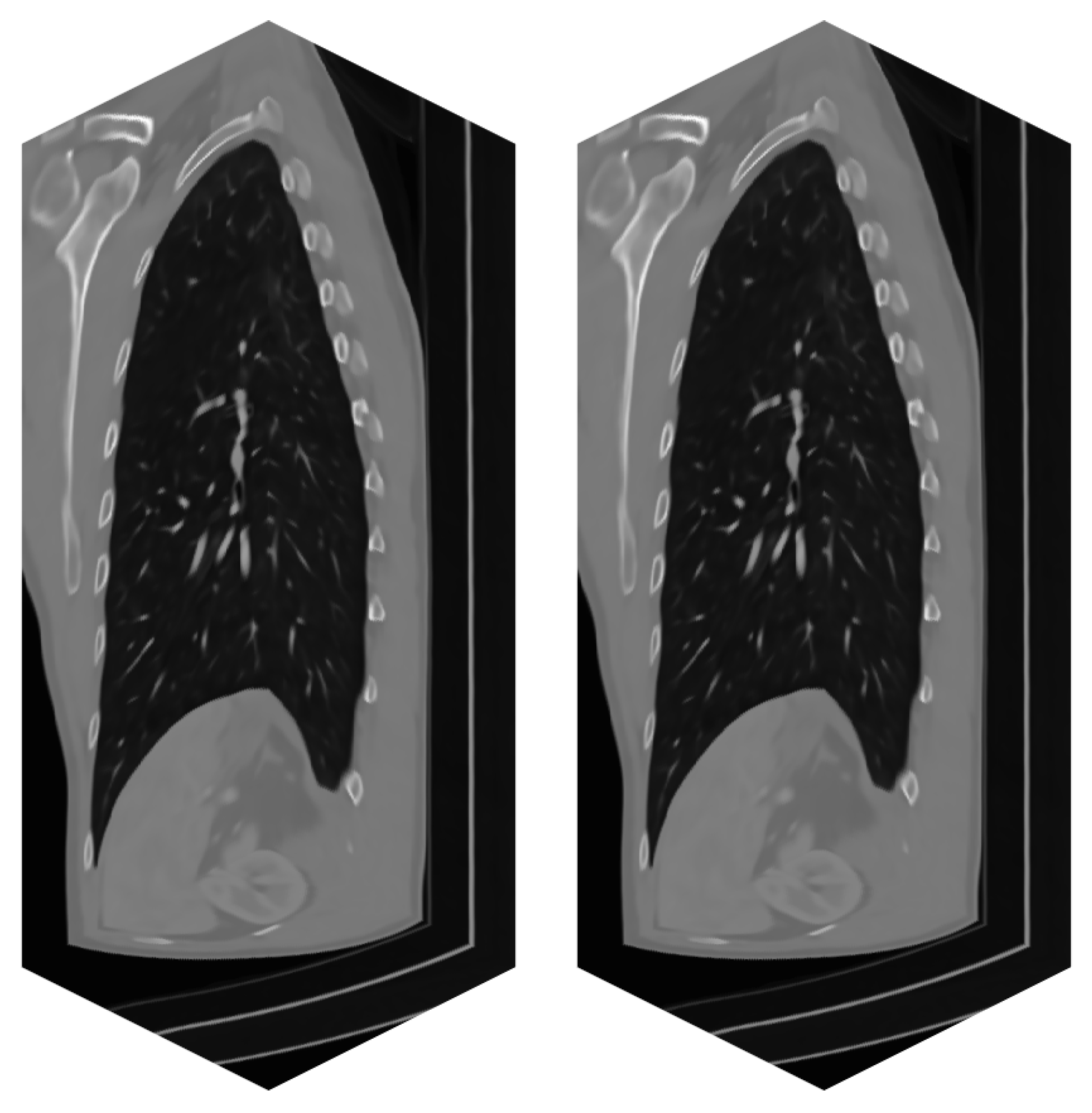
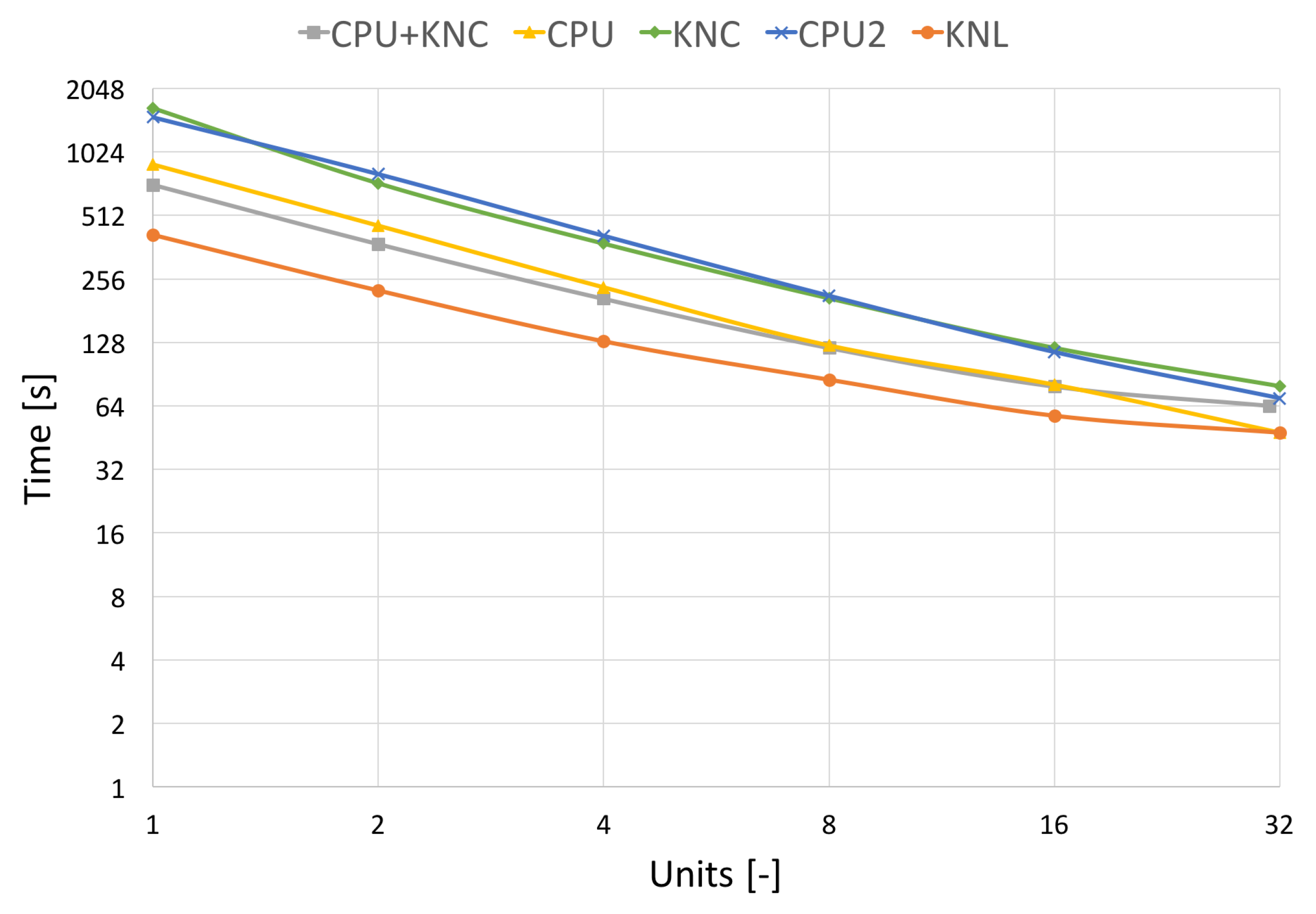
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CT | Computed Tomography |
| MRI | Magnetic Resonance Imaging |
| DL | Deep Learning |
| HPC | High-Performance Computing |
| CPU | Central Processing Unit |
| MIC | Many Integrated Core |
| OpenMP | Open Multi-Processing |
| MPI | Message Passing Interface |
| NUMA | Non-Uniform Memory Access |
| KNC | Knights Corner |
| KNL | Knights Landing |
References
- Haddad, R.A.; Akansu, A.N. A Class of Fast Gaussian Binomial Filters for Speech and Image Processing. IEEE Trans. Signal Process. 1991, 39, 723–727. [Google Scholar] [CrossRef]
- Martin-Fernandez, M.; Villullas, S. The em method in a probabilistic wavelet-based MRI denoising. Comput. Math. Methods Med. 2015, 2015, 182659. [Google Scholar] [CrossRef] [PubMed]
- Boulfelfel, D.; Rangayyan, R.; Hahn, L.; Kloiber, R. Three-dimensional restoration of single photon emission computed tomography images. IEEE Trans. Nucl. Sci. 1994, 41, 1746–1754. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J. A non-local algorithm for image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising with block-matching and 3D filtering. In Proceedings of the SPIE—The International Society for Optical Engineering, San Jose, CA, USA, 16–18 January 2006; Volume 6064. [Google Scholar]
- Manjon, J.V.; Coupe, P.; Buades, A.; Louis Collins, D.; Robles, M. New methods for MRI denoising based on sparseness and self-similarity. Med. Image Anal. 2012, 16, 18–27. [Google Scholar] [CrossRef] [PubMed]
- Manjon, J.V.; Coupe, P.; Marti-Bonmati, L.; Collins, D.L.; Robles, M. Adaptive non-local means denoising of MR images with spatially varying noise levels. J. Magn. Reson. Imaging 2010, 31, 192–203. [Google Scholar] [CrossRef] [PubMed]
- Coupe, P.; Yger, P.; Prima, S.; Hellier, P.; Kervrann, C.; Barillot, C. An optimized blockwise nonlocal means denoising filter for 3-D magnetic resonance images. IEEE Trans. Med. Imaging 2008, 27, 425–441. [Google Scholar] [CrossRef] [PubMed]
- Coupe, P.; Hellier, P.; Prima, S.; Kervrann, C.; Barillot, C. 3D wavelet subbands mixing for image denoising. Int. J. Biomed. Imaging 2008, 2008, 590183. [Google Scholar] [CrossRef] [PubMed]
- Maggioni, M.; Katkovnik, V.; Egiazarian, K.; Foi, A. Nonlocal transform-domain filter for volumetric data denoising and reconstruction. IEEE Trans. Image Process. 2013, 22, 119–133. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Zhang, Y.; Kalra, M.K.; Lin, F.; Chen, Y.; Liao, P.; Zhou, J.; Wang, G. Low-Dose CT with a residual encoder-decoder convolutional neural network. IEEE Trans. Med. Imaging 2017, 36, 2524–2535. [Google Scholar] [CrossRef] [PubMed]
- Intel. Intel® Open Image Denoise. 2023. Available online: https://www.openimagedenoise.org (accessed on 1 July 2023).
- NVIDIA. NVIDIA OptiX™ AI-Accelerated Denoiser. 2023. Available online: https://developer.nvidia.com/optix-denoiser (accessed on 1 July 2023).
- Usui, K.; Ogawa, K.; Goto, M.; Sakano, Y.; Kyougoku, S.; Daida, H. Quantitative evaluation of deep convolutional neural network-based image denoising for low-dose computed tomography. Vis. Comput. Ind. Biomed. Art 2021, 4, 21. [Google Scholar] [CrossRef] [PubMed]
- Dabov, K.; Foi, A.; Egiazarian, K. Video denoising by sparse 3D transform-domain collaborative filtering. In Proceedings of the 2007 15th European Signal Processing Conference, Poznań, Poland, 3–7 September 2007; pp. 145–149. Available online: https://webpages.tuni.fi/foi/GCF-BM3D/ (accessed on 1 July 2023).
- Strakos, P.; Jaros, M.; Karasek, T. Speed up of Volumetric Non-local Transform-Domain Filter. In Proceedings of the Fifth International Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering, Pecs, Hungary, 30–31 May 2017. [Google Scholar] [CrossRef]
- Cocosco, C.A.; Kollokian, V.; Kwan, R.K.S.; Evans, A.C. BrainWeb: Online Interface to a 3D MRI Simulated Brain Database. NeuroImage. 1997. Available online: http://brainweb.bic.mni.mcgill.ca/brainweb/ (accessed on 1 July 2023).
- blender.org—Home of the Blender Project—Free and Open 3D Creation Software. 2023. Available online: https://www.blender.org/ (accessed on 1 July 2023).
- MPI Forum. 2023. Available online: http://mpi-forum.org/ (accessed on 1 July 2023).
- Home—OpenMP. 2023. Available online: http://www.openmp.org/ (accessed on 1 July 2023).
- Salomon—Hardware Overview—IT4Innovations Documentation. 2023. Available online: https://docs.it4i.cz/salomon/hardware-overview/ (accessed on 1 July 2023).
- Anselm—Hardware Overview—IT4Innovations Documentation. 2023. Available online: https://docs.it4i.cz/anselm/hardware-overview/ (accessed on 1 July 2023).
- HLRN Website. 2023. Available online: https://www.hlrn.de/supercomputer-e/hlrn-iii-system/ (accessed on 1 July 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Stage | ||
|---|---|---|---|
| Hard Thresholding | Wiener Filtering | ||
| Cube size | L | 4 | 5 |
| Group size | M | 32 | |
| Step | 3 | ||
| Search-cube size | 11 | ||
| Similarity thr. | 24.6 | 6.7 | |
| Shrinkage thr. | 2.8 | Not applicable | |
| Method | Quality Measure | ||
|---|---|---|---|
| PSNR | SSIM | RMSE | |
| None | 13.663 | 0.617 | 0.208 |
| RED-CNN | 15.770 | 0.716 | 0.163 |
| OIDN | 22.235 | 0.902 | 0.078 |
| BM4D | 23.547 | 0.921 | 0.067 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strakos, P.; Jaros, M.; Riha, L.; Kozubek, T. Speed Up of Volumetric Non-Local Transform-Domain Filter Utilising HPC Architecture. J. Imaging 2023, 9, 254. https://doi.org/10.3390/jimaging9110254
Strakos P, Jaros M, Riha L, Kozubek T. Speed Up of Volumetric Non-Local Transform-Domain Filter Utilising HPC Architecture. Journal of Imaging. 2023; 9(11):254. https://doi.org/10.3390/jimaging9110254
Chicago/Turabian StyleStrakos, Petr, Milan Jaros, Lubomir Riha, and Tomas Kozubek. 2023. "Speed Up of Volumetric Non-Local Transform-Domain Filter Utilising HPC Architecture" Journal of Imaging 9, no. 11: 254. https://doi.org/10.3390/jimaging9110254
APA StyleStrakos, P., Jaros, M., Riha, L., & Kozubek, T. (2023). Speed Up of Volumetric Non-Local Transform-Domain Filter Utilising HPC Architecture. Journal of Imaging, 9(11), 254. https://doi.org/10.3390/jimaging9110254