
Multi-Camera Multi-Person Tracking and Re-Identification in an Operating Room


Abstract
:1. Introduction
2. Related Work
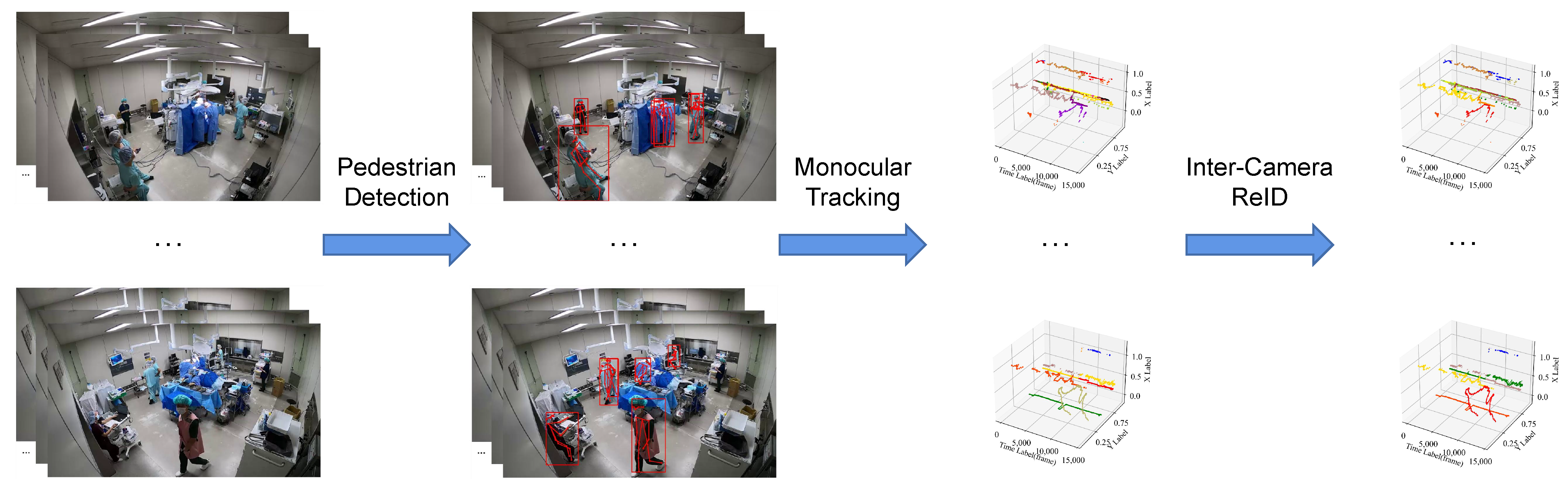
3. Method Framework
3.1. Pose Estimation and Bounding Box Detection
3.2. Monocular Tracking
3.3. Inter-Camera ReID
4. Experiments
4.1. Dataset
4.2. Implementation of Models
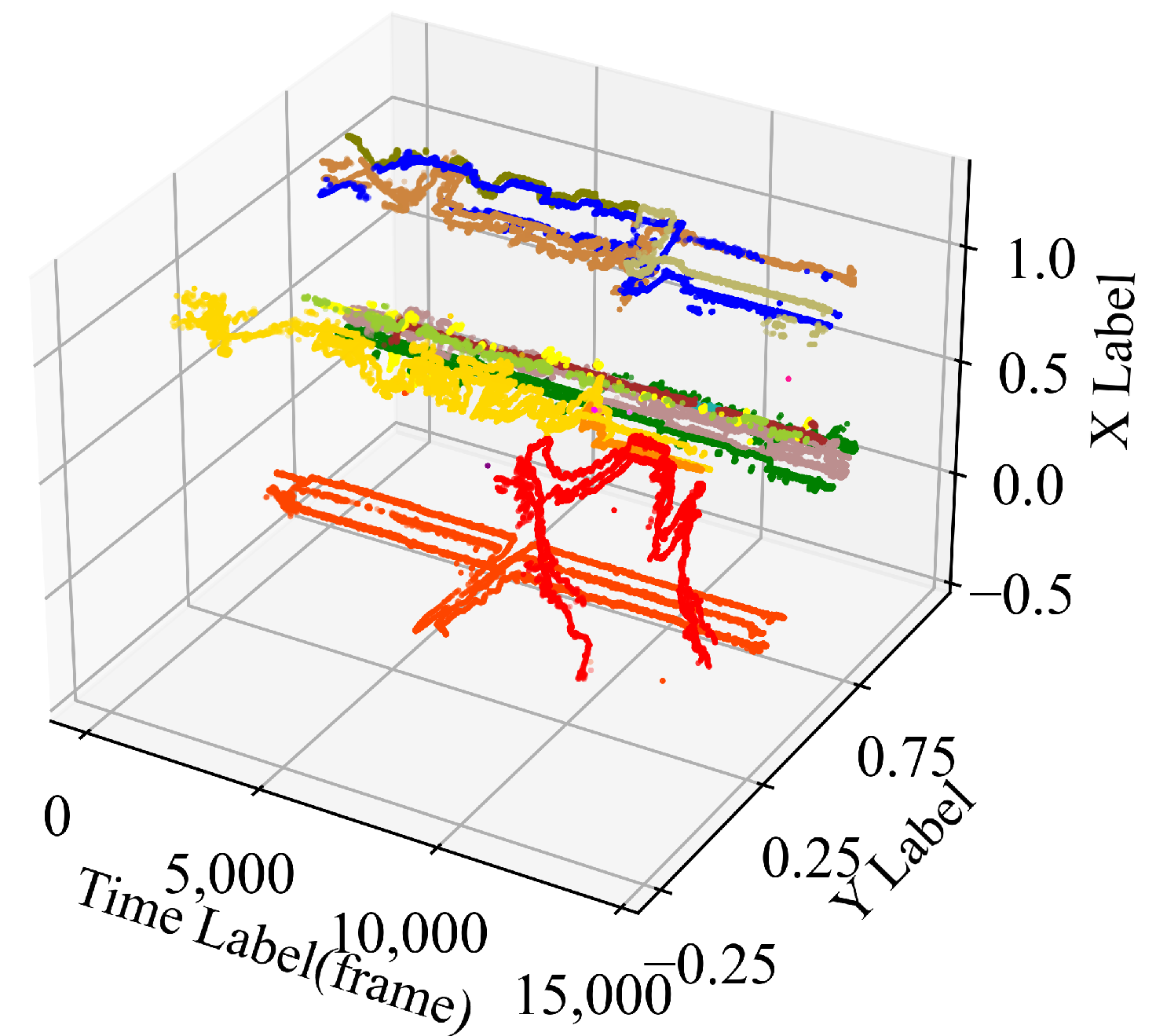
4.3. Tracking and ReID Performance Evaluation
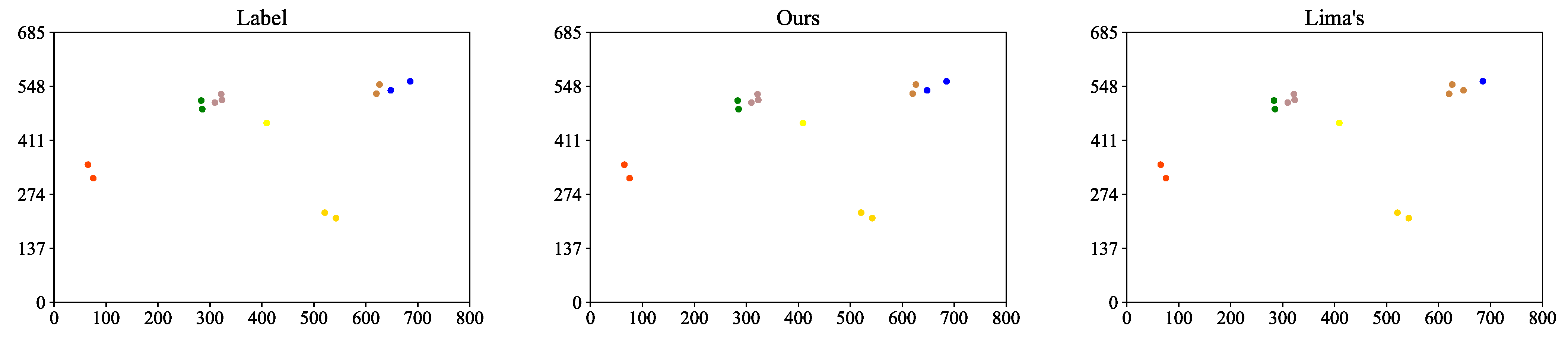
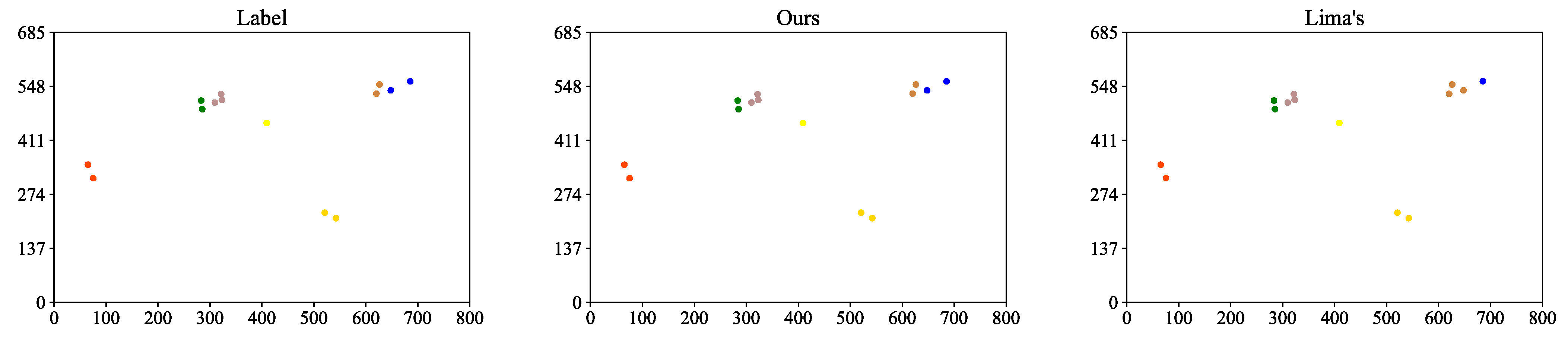
4.4. Discussion and Comparison of ReID
4.5. Limitation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MCMP | Multi-camera multi-person |
| ReID | Re-identification |
| CNNs | Convolutional neural networks |
| DBSCAN | Density-based spatial clustering of applications with noise |
| MOTA | Multiple object tracking accuracy |
| IDF | Identification F |
| NMI | Normalized mutual information |
References
- Kitaguchi, D.; Takeshita, N.; Matsuzaki, H.; Takano, H.; Owada, Y.; Enomoto, T.; Oda, T.; Miura, H.; Yamanashi, T.; Watanabe, M.; et al. Real-time automatic surgical phase recognition in laparoscopic sigmoidectomy using the convolutional neural network-based deep learning approach. Surg. Endosc. 2020, 34, 4924–4931. [Google Scholar] [CrossRef] [PubMed]
- Srivastav, V.; Issenhuth, T.; Kadkhodamohammadi, A.; de Mathelin, M.; Gangi, A.; Padoy, N. MVOR: A multi-view RGB-D operating room dataset for 2D and 3D human pose estimation. arXiv 2018, arXiv:1808.08180. [Google Scholar]
- Liu, W.; Bao, Q.; Sun, Y.; Mei, T. Recent advances in monocular 2d and 3d human pose estimation: A deep learning perspective. arXiv 2021, arXiv:2104.11536. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Wang, X.; Liu, W.; Zeng, W. Voxeltrack: Multi-person 3d human pose estimation and tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), 2022; early access. [Google Scholar]
- Yang, Y.; Ren, Z.; Li, H.; Zhou, C.; Wang, X.; Hua, G. Learning dynamics via graph neural networks for human pose estimation and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8074–8084. [Google Scholar]
- Ota, M.; Tateuchi, H.; Hashiguchi, T.; Ichihashi, N. Verification of validity of gait analysis systems during treadmill walking and running using human pose tracking algorithm. Gait Posture 2021, 85, 290–297. [Google Scholar] [CrossRef] [PubMed]
- Hassaballah, M.; Kenk, M.A.; Muhammad, K.; Minaee, S. Vehicle detection and tracking in adverse weather using a deep learning framework. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4230–4242. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, X.; Liang, W.; Zeng, Z.; Yan, Z. Deep-Learning-Enhanced Multitarget Detection for End–Edge–Cloud Surveillance in Smart IoT. IEEE Internet Things J. 2021, 8, 12588–12596. [Google Scholar] [CrossRef]
- Chen, K.; Song, X.; Zhai, X.; Zhang, B.; Hou, B.; Wang, Y. An integrated deep learning framework for occluded pedestrian tracking. IEEE Access 2019, 7, 26060–26072. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Y.J.; Weng, X.; Kitani, K. Wide-baseline multi-camera calibration using person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13134–13143. [Google Scholar]
- Lu, Y.; Shu, Y. Custom Object Detection via Multi-Camera Self-Supervised Learning. arXiv 2021, arXiv:2102.03442. [Google Scholar]
- Quach, K.G.; Nguyen, P.; Le, H.; Truong, T.D.; Duong, C.N.; Tran, M.T.; Luu, K. Dyglip: A dynamic graph model with link prediction for accurate multi-camera multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13784–13793. [Google Scholar]
- Li, Y.J.; Weng, X.; Xu, Y.; Kitani, K.M. Visio-Temporal Attention for Multi-Camera Multi-Target Association. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9834–9844. [Google Scholar]
- Alzantot, M.; Youssef, M. UPTIME: Ubiquitous pedestrian tracking using mobile phones. In Proceedings of the 2012 IEEE Wireless Communications and Networking Conference (WCNC), Paris, France, 1–4 April 2012; pp. 3204–3209. [Google Scholar]
- Jiang, Y.; Li, Z.; Wang, J. Ptrack: Enhancing the applicability of pedestrian tracking with wearables. IEEE Trans. Mob. Comput. 2018, 18, 431–443. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Z.; Luo, H.; Pu, H.; Tan, J. Multi-person multi-camera tracking for live stream videos based on improved motion model and matching cascade. Neurocomputing 2022, 492, 561–571. [Google Scholar] [CrossRef]
- Han, W.; Dong, X.; Khan, F.S.; Shao, L.; Shen, J. Learning to fuse asymmetric feature maps in siamese trackers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16570–16580. [Google Scholar]
- Liu, Y.; Yin, J.; Yu, D.; Zhao, S.; Shen, J. Multiple people tracking with articulation detection and stitching strategy. Neurocomputing 2020, 386, 18–29. [Google Scholar] [CrossRef]
- Stadler, D.; Beyerer, J. Improving multiple pedestrian tracking by track management and occlusion handling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10958–10967. [Google Scholar]
- Fabbri, M.; Brasó, G.; Maugeri, G.; Cetintas, O.; Gasparini, R.; Ošep, A.; Calderara, S.; Leal-Taixé, L.; Cucchiara, R. MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking? In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10849–10859. [Google Scholar]
- Liu, J.; Shi, X. Research on Person Reidentification Method Fusing Direction Information in Multi-camera Pedestrian Tracking Problem. J. Phys. Conf. Ser. 2021, 1871, 012068. [Google Scholar] [CrossRef]
- Xu, J.; Bo, C.; Wang, D. A novel multi-target multi-camera tracking approach based on feature grouping. Comput. Electr. Eng. 2021, 92, 107153. [Google Scholar] [CrossRef]
- Wang, G.; Wang, Y.; Zhang, H.; Gu, R.; Hwang, J.N. Exploit the connectivity: Multi-object tracking with trackletnet. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 482–490. [Google Scholar]
- Nguyen, D.M.; Henschel, R.; Rosenhahn, B.; Sonntag, D.; Swoboda, P. LMGP: Lifted Multicut Meets Geometry Projections for Multi-Camera Multi-Object Tracking. arXiv 2021, arXiv:2111.11892. [Google Scholar]
- Kohl, P.; Specker, A.; Schumann, A.; Beyerer, J. The mta dataset for multi-target multi-camera pedestrian tracking by weighted distance aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1042–1043. [Google Scholar]
- Lima, J.P.; Roberto, R.; Figueiredo, L.; Simoes, F.; Teichrieb, V. Generalizable multi-camera 3d pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1232–1240. [Google Scholar]
- Li, J.; Wang, C.; Zhu, H.; Mao, Y.; Fang, H.S.; Lu, C. Crowdpose: Efficient crowded scenes pose estimation and a new benchmark. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10863–10872. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Kreiss, S.; Bertoni, L.; Alahi, A. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11977–11986. [Google Scholar]
- Allan, D.; Caswell, T.; Keim, N.; van der Wel, C.M.; Verweij, R. Trackpy: Fast, Flexible Particle-Tracking Toolkit. Available online: http://soft-matter.github.io/trackpy/v0.5.0/index.html (accessed on 5 August 2022).
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bernardin, K.; Elbs, A.; Stiefelhagen, R. Multiple object tracking performance metrics and evaluation in a smart room environment. In Proceedings of the Sixth IEEE International Workshop on Visual Surveillance, in Conjunction with ECCV, Graz, Austria, 13 May 2006; Volume 90. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 17–35. [Google Scholar]
- Csiszár, I. I-divergence geometry of probability distributions and minimization problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| (%) | 74.64 | 87.02 | 92.43 | 87.34 |
| (%) | 79.19 | 80.44 | 100.00 | 79.22 |
| 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | ||
|---|---|---|---|---|---|---|
| (cm) | ||||||
| 40 | 78.71 | 81.53 | 77.85 | 77.85 | 77.85 | |
| 80 | 79.16 | 82.54 | 79.15 | 77.12 | 76.51 | |
| 120 | 79.16 | 85.44 | 81.61 | 77.68 | 77.85 | |
| 160 | 80.25 | 82.62 | 78.91 | 76.14 | 77.93 | |
| 200 | 75.69 | 78.93 | 75.86 | 74.70 | 74.76 | |
| Method | Ours | Lima’s |
|---|---|---|
| (%) | 85.44 | 77.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, H.; Hachiuma, R.; Saito, H.; Takatsume, Y.; Kajita, H. Multi-Camera Multi-Person Tracking and Re-Identification in an Operating Room. J. Imaging 2022, 8, 219. https://doi.org/10.3390/jimaging8080219
Hu H, Hachiuma R, Saito H, Takatsume Y, Kajita H. Multi-Camera Multi-Person Tracking and Re-Identification in an Operating Room. Journal of Imaging. 2022; 8(8):219. https://doi.org/10.3390/jimaging8080219
Chicago/Turabian StyleHu, Haowen, Ryo Hachiuma, Hideo Saito, Yoshifumi Takatsume, and Hiroki Kajita. 2022. "Multi-Camera Multi-Person Tracking and Re-Identification in an Operating Room" Journal of Imaging 8, no. 8: 219. https://doi.org/10.3390/jimaging8080219
APA StyleHu, H., Hachiuma, R., Saito, H., Takatsume, Y., & Kajita, H. (2022). Multi-Camera Multi-Person Tracking and Re-Identification in an Operating Room. Journal of Imaging, 8(8), 219. https://doi.org/10.3390/jimaging8080219