
Indoor Scene Recognition via Object Detection and TF-IDF



Abstract
:1. Introduction
2. Related Work
Indoor Scene Classification
3. Methodology
3.1. Datasets
| Algorithm 1 Pseudocode of the proposed approach. |
|
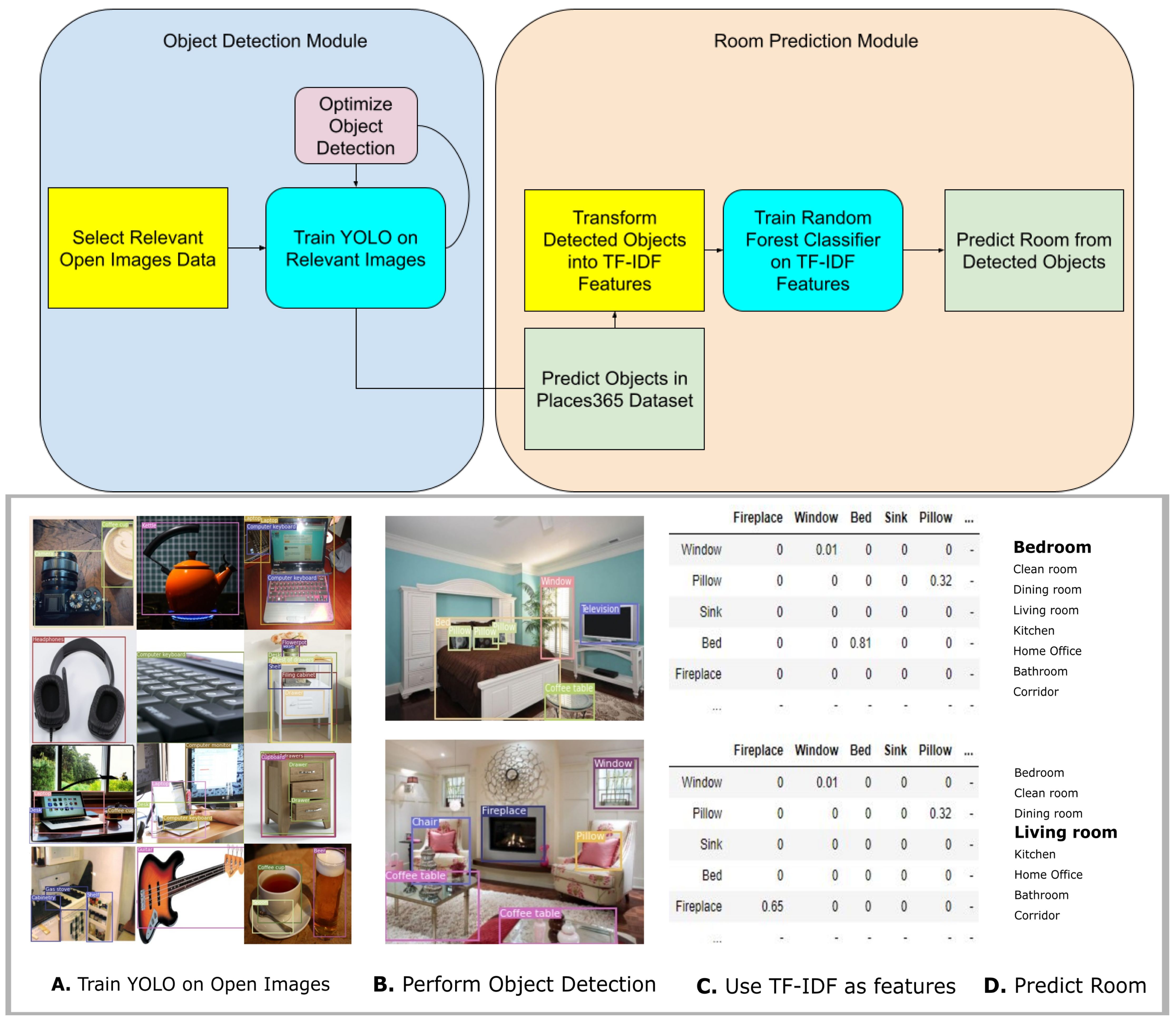
3.2. Object Detection Modules
3.3. Object-Level Scene Classification Module
4. Results
4.1. Evaluating Object Detection
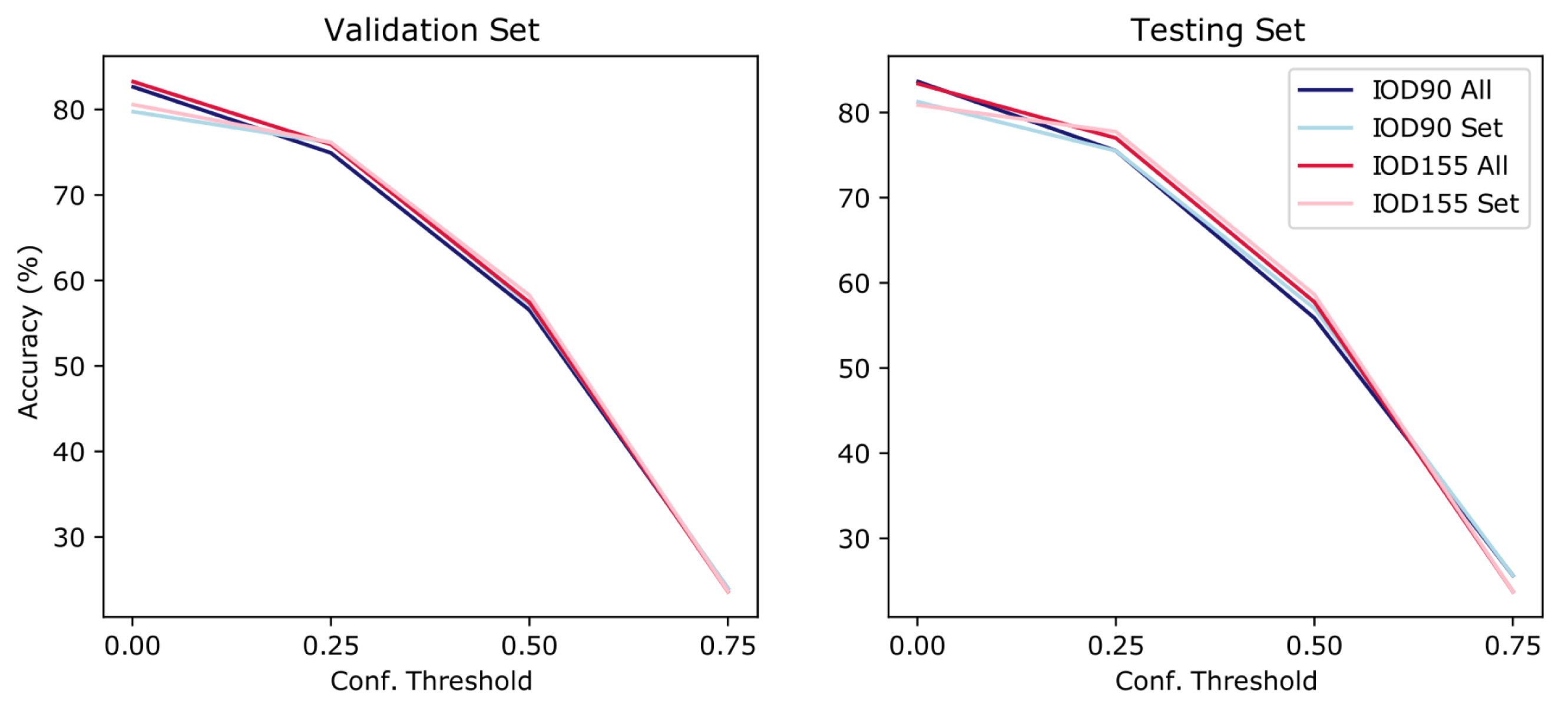
4.2. Scene Classification with IOD90
4.3. Scene Classification with IOD155
4.4. Scene Classification with Semantic Segmentation
4.5. Model Comparisons
4.6. Experimental Settings
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Narasimhan, M.; Wijmans, E.; Chen, X.; Darrell, T.; Batra, D.; Parikh, D.; Singh, A. Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation. arXiv 2020, arXiv:2007.09841. [Google Scholar]
- Othman, K.; Rad, A. An indoor room classification system for social robots via integration of CNN and ECOC. Appl. Sci. 2019, 9, 470. [Google Scholar] [CrossRef] [Green Version]
- Kwon, O.; Oh, S. Learning to use topological memory for visual navigation. In Proceedings of the 20th International Conference on Control, Automation and Systems, Busan, Korea, 13–16 October 2020. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 3357–3364. [Google Scholar]
- Liu, M.; Guo, Y.; Wang, J. Indoor scene modeling from a single image using normal inference and edge features. Vis. Comput. 2017, 33, 1227–1240. [Google Scholar] [CrossRef]
- Chaplot, D.; Gandhi, D.; Gupta, A.; Salakhutdinov, R. Object Goal Navigation using Goal-Oriented Semantic Exploration. arXiv 2020, arXiv:2007.00643. [Google Scholar]
- Zatout, C.; Larabi, S. Semantic scene synthesis: Application to assistive systems. Vis. Comput. 2021, 38, 2691–2705. [Google Scholar] [CrossRef]
- Yang, W.; Wang, X.; Farhadi, A.; Gupta, G.; Mottaghi, R. Visual semantic navigation using scene priors. arXiv 2018, arXiv:1810.06543. [Google Scholar]
- Qaiser, S.; Ali, R. Text mining: Use of TF-IDF to example the relevance of words to documents. Int. J. Comput. Appl. 2018, 181, 975–997. [Google Scholar] [CrossRef]
- Ramos, J. Using TF-IDF to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Piscataway, NJ, USA, 21–24 August 2003; pp. 133–142. [Google Scholar]
- Dadgar, S.; Araghi, M.; Farahani, M. A novel text mining approach based on TF-IDF and support vector machine for news classification. In Proceedings of the IEEE International Conference on Engineering and Technology, Coimbatore, India, 17–18 March 2016; pp. 112–116. [Google Scholar]
- Teder, M.; Mayor-Torres, J.; Teufel, C. Deriving visual semantics from spatial context: An adaptation of LSA and Word2Vec to generate object and scene embeddings from images. arXiv 2009, arXiv:2009:09384. [Google Scholar]
- Chen, B.; Sahdev, R.; Wu, D.; Zhao, X.; Papagelis, M.; Tsotsos, J. Scene Classification in Indoor Environments for Robots using Context Based Word Embeddings. arXiv 2019, arXiv:1908.06422. [Google Scholar]
- Quattoni, A.; Torralba, A. Recognizing indoor scenes. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 413–420. [Google Scholar]
- Matei, A.; Glavan, A.; Talavera, E. Deep learning for scene recognition from visual data: A survey. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Gijón, Spain, 11–13 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 763–773. [Google Scholar]
- Yang, J.; Jiang, Y.G.; Hauptmann, A.; Ngo, C.W. Evaluating bag-of-visual-words representations in scene classification. In Proceedings of the International Workshop on Multimedia Information Retrieval, Bavaria, Germany, 24–29 September 2007; IEEE: Augsburg, Germany, 2007; pp. 197–206. [Google Scholar]
- Wang, L.; Guo, S.; Huang, W.; Xiong, Y.; Qiao, Y. Knowledge guided disambiguation for large-scale scene classification with multi-resolution. CNNs IEEE Trans. Image 2017, 26, 2055–2068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, Y.; Kodagoda, S.; Wang, Y.; Shi, L.; Liu, Y. Understand scene categories by objects: A semantic regularized scene classifier using Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 2318–2325. [Google Scholar]
- Yao, J.; Fidler, S.; Urtasun, R. Describing the scene as a whole: Joint object detection, scene classification and semantic segmentation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 702–709. [Google Scholar]
- Li, L.J.; Su, H.; Li, F.F.; P Xing, E. Object bank: A high- level image representation for scene classification & semantic feature sparsification. In Advances in Neural Information Processing Systems; Carnegie Mellon University: Pittsburgh, PA, USA, 2010; pp. 1378–1386. [Google Scholar]
- Zheng, Y.T.; Neo, S.Y.; Chua, T.S.; Tian, Q. Toward a higher-level visual representation for object-based image retrieval. Vis. Comput. 2009, 25, 13–23. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified real-time object detection. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Evangelopoulos, N.E. Latent semantic analysis. Wiley Interdiscip. Rev. Cogn. Sci. 2013, 4, 683–692. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 1, pp. 770–778. [Google Scholar]
- Simonyan, J. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Zhou, L.; Cen, J.; Wang, X.; Sun, Z.; Lam, T.L.; Xu, Y. Borm: Bayesian object relation model for indoor scene recognition. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Czech Republic, 27 September–1 October 2021; pp. 39–46. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 15 October 2015; pp. 567–576. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miao, B.; Zhou, L.; Mian, A.S.; Lam, T.L.; Xu, Y. Object-to-scene: Learning to transfer object knowledge to indoor scene recognition. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 2069–2075. [Google Scholar]
- Labinghisa, B.A.; Lee, D.M. Indoor localization system using deep learning based scene recognition. Multimed. Tools Appl. 2022. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; Duerig, T.; et al. The open images dataset V4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Jocher, G.; Yolov5. Code Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 July 2021).
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Espinosa Leal, L.; Chapman, A.; Westerlund, M. Reinforcement learning for extended reality: Designing self-play scenarios. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Grand Wailea, HI, USA, 8–11 January 2019. [Google Scholar]
- Espinosa-Leal, L.; Chapman, A.; Westerlund, M. Autonomous industrial management via reinforcement learning. J. Intell. Fuzzy Syst. 2020, 39, 8427–8439. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch; NIPS-Workshop: Long Beach, CA, USA, 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press: New York, NY, USA, 1999. [Google Scholar]
- Heikel, E.; Espinosa-Leal, L. Trained Models and Datasets for Indoor Scene Recognition via Object Detection and TF-IDF. 2022. Available online: https://doi.org/10.5281/zenodo.6792296 (accessed on 1 July 2021). [CrossRef]


{kind=link}
{kind=link}
| Model | Precision | Recall | mAP@.50 | mAP@.50:.95 |
|---|---|---|---|---|
| IOD90 | 0.526 | 0.601 | 0.553 | 0.416 |
| IOD155 | 0.455 | 0.469 | 0.417 | 0.309 |
| Dataset | Top-1 | Top-5 | |||
|---|---|---|---|---|---|
| Val | Test | Val | Test | ||
| ADE20K | |||||
| ResNet18+LSA [12] | 53.77% | - | 75.65% | - | |
| Places365 | |||||
| VGG [28] | 55.24% | 55.19% | 84.91% | 85.01% | |
| ResNet152 [28] | 53.63% | 54.65% | 85.08% | 85.07% | |
| Places365-Home | |||||
| ResNet50 [13] | 83.46% | 92.03% | - | - | |
| ResNet50+Word2Vec [13] | 83.67% | 93.27% | - | - | |
| CBORM [26] | 85.80% | - | - | - | |
| OTS [29] | 85.90% | - | - | - | |
| this work | IOD155 + tfidf | 83.25% | 83.38% | - | - |
| IOD90 + tfidf | 82.53% | 83.63% | - | - | |
| Xception + tfidf | 80.00% | 71.41% | - | - | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heikel, E.; Espinosa-Leal, L. Indoor Scene Recognition via Object Detection and TF-IDF. J. Imaging 2022, 8, 209. https://doi.org/10.3390/jimaging8080209
Heikel E, Espinosa-Leal L. Indoor Scene Recognition via Object Detection and TF-IDF. Journal of Imaging. 2022; 8(8):209. https://doi.org/10.3390/jimaging8080209
Chicago/Turabian StyleHeikel, Edvard, and Leonardo Espinosa-Leal. 2022. "Indoor Scene Recognition via Object Detection and TF-IDF" Journal of Imaging 8, no. 8: 209. https://doi.org/10.3390/jimaging8080209
APA StyleHeikel, E., & Espinosa-Leal, L. (2022). Indoor Scene Recognition via Object Detection and TF-IDF. Journal of Imaging, 8(8), 209. https://doi.org/10.3390/jimaging8080209