
HFM: A Hybrid Feature Model Based on Conditional Auto Encoders for Zero-Shot Learning




Abstract
:1. Introduction
2. Related Work
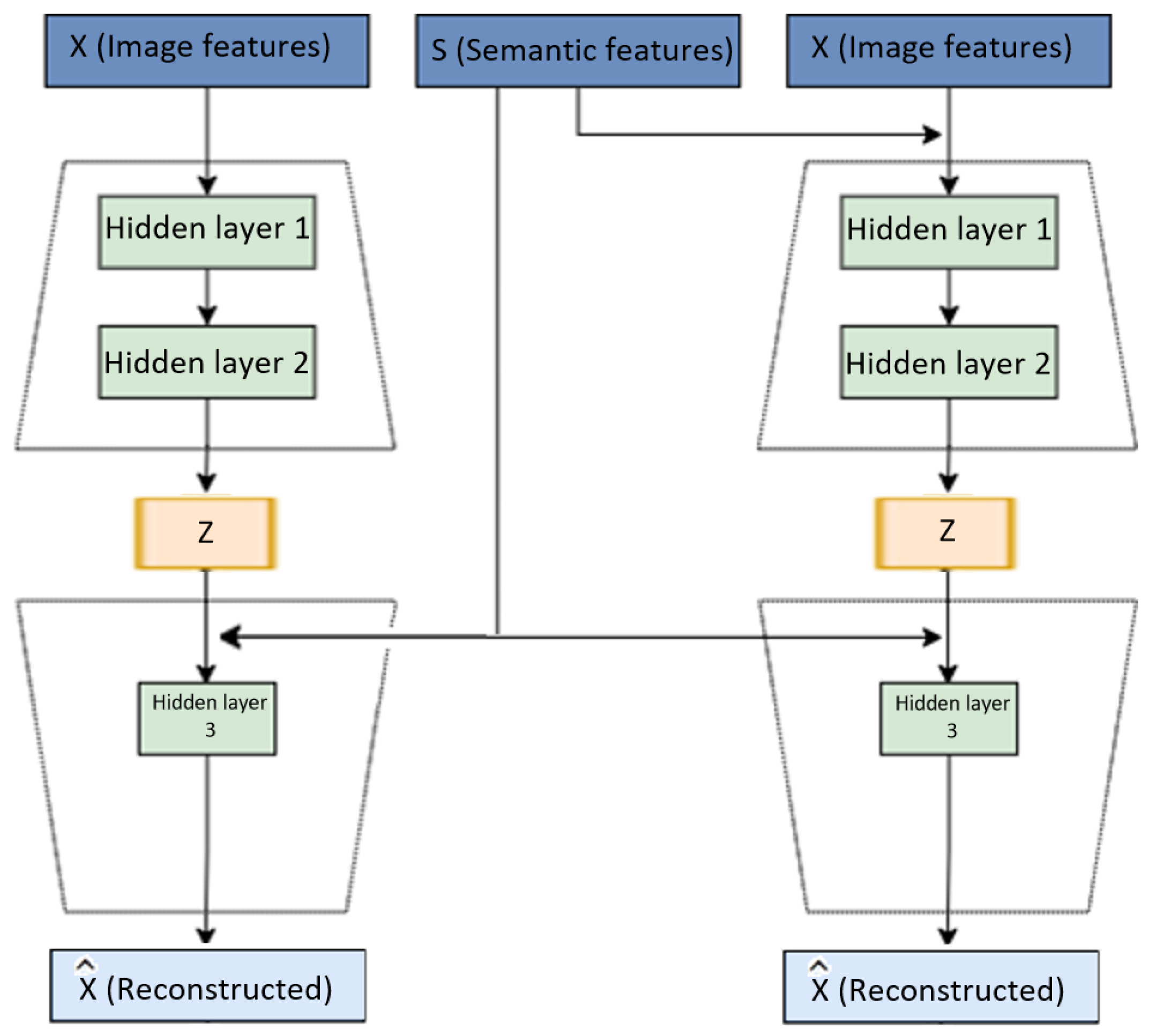
3. A Hybrid Feature Model
3.1. Problem Definition
3.2. Approach
| Algorithm 1 Training |
|
| Algorithm 2 Unseen classes classification |
|
4. Experiments
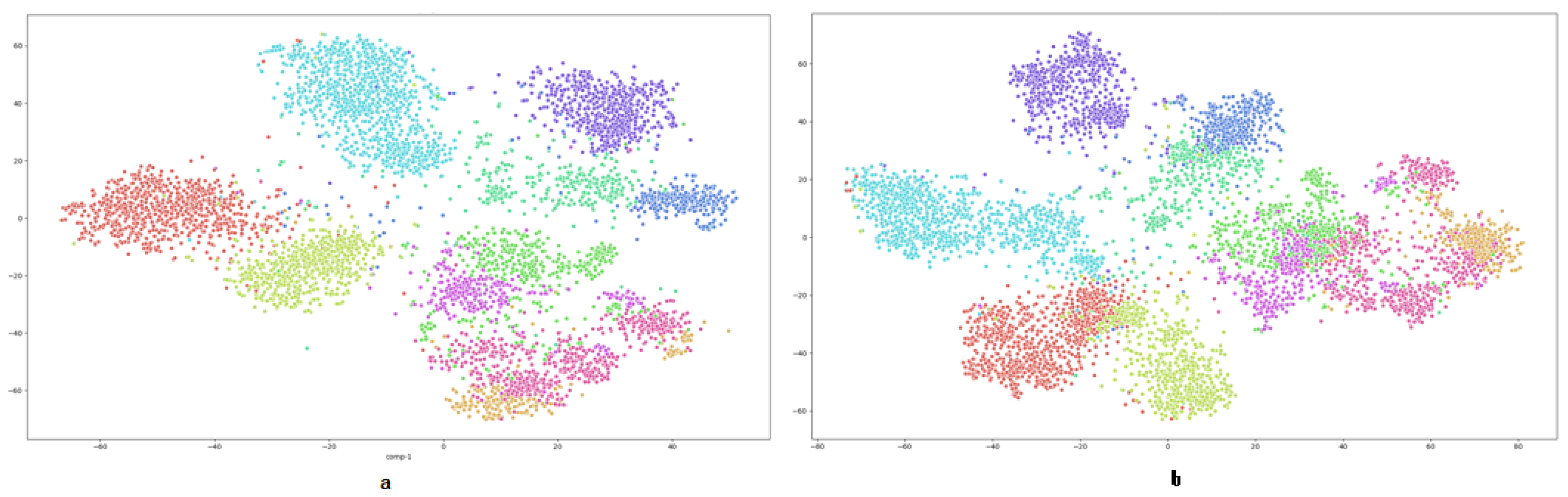
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yan, T.; Li, H.; Sun, B.; Wang, Z.; Luo, Z. Discriminative Feature Mining and Enhancement Network for Low-resolution Fine-grained Image Recognition. IEEE Trans. Circuits Syst. Video Technol. Available online: https://ieeexplore.ieee.org/document/9684445 (accessed on 2 February 2022).
- Shagdar, Z.; Ullah, M.; Ullah, H.; Cheikh, F.A. Geometric Deep Learning for Multi-Object Tracking: A Brief Review. In Proceedings of the 2021 9th European Workshop on Visual Information Processing (EUVIP), Paris, France, 23–25 June 2021; pp. 1–6. [Google Scholar]
- Wu, C.; Li, X.; Guo, Y.; Wang, J.; Ren, Z.; Wang, M.; Yang, Z. Natural language processing for smart construction: Current status and future directions. Autom. Constr. 2022, 134, 104059. [Google Scholar] [CrossRef]
- Ullah, H.; Ahmed, T.U.; Ullah, M.; Cheikh, F.A. IR-SSL: Improved Regularization Based Semi-Supervised Learning For Land Cover Classification. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 874–878. [Google Scholar]
- Aljaloud, A.S.; Ullah, H. IA-SSLM: Irregularity-Aware Semi-Supervised Deep Learning Model for Analyzing Unusual Events in Crowds. IEEE Access 2021, 9, 73327–73334. [Google Scholar] [CrossRef]
- Zhao, T.; Wang, Z.; Masoomi, A.; Dy, J. Deep Bayesian Unsupervised Lifelong Learning. Neural Netw. 2022, 149, 95–106. [Google Scholar] [CrossRef] [PubMed]
- Hunter, R.A.; Pompano, R.R.; Tuchler, M.F. Alternative Assessment of Active Learning. In Active Learning in the Analytical Chemistry Curriculum; ACS Publications: New York, NY, USA, 2022; pp. 269–295. [Google Scholar]
- Biederman, I. Recognition-by-components: A theory of human image understanding. Psychol. Rev. 1987, 94, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Min, S.; Yao, H.; Xie, H.; Wang, C.; Zha, Z.J.; Zhang, Y. Domain-aware visual bias eliminating for generalized zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12664–12673. [Google Scholar]
- Han, Z.; Fu, Z.; Chen, S.; Yang, J. Contrastive embedding for generalized zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2371–2381. [Google Scholar]
- Zhang, J.; Li, Q.; Geng, Y.A.; Wang, W.; Sun, W.; Shi, C.; Ding, Z. A zero-shot learning framework via cluster-prototype matching. Pattern Recognit. 2022, 124, 108469. [Google Scholar] [CrossRef]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Attribute-based classification for zero-shot visual object categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 453–465. [Google Scholar] [CrossRef] [PubMed]
- Norouzi, M.; Mikolov, T.; Bengio, S.; Singer, Y.; Shlens, J.; Frome, A.; Corrado, G.S.; Dean, J. Zero-shot learning by convex combination of semantic embeddings. arXiv 2013, arXiv:1312.5650. [Google Scholar]
- Gao, R.; Hou, X.; Qin, J.; Shen, Y.; Long, Y.; Liu, L.; Zhang, Z.; Shao, L. Visual-Semantic Aligned Bidirectional Network for Zero-Shot Learning. IEEE Trans. Multimed. Available online: https://ieeexplore.ieee.org/document/9693152 (accessed on 2 February 2022).
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Annadani, Y.; Biswas, S. Preserving semantic relations for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7603–7612. [Google Scholar]
- Vyas, M.R.; Venkateswara, H.; Panchanathan, S. Leveraging Seen and Unseen Semantic Relationships for Generative Zero-Shot Learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 70–86. [Google Scholar]
- Socher, R.; Ganjoo, M.; Manning, C.D.; Ng, A. Zero-shot learning through cross-modal transfer. Adv. Neural Inf. Process. Syst. 2013, 26, 1–10. [Google Scholar]
- Zhang, L.; Sung, F.; Liu, F.; Xiang, T.; Gong, S.; Yang, Y.; Hospedales, T.M. Actor-critic sequence training for image captioning. arXiv 2017, arXiv:1706.09601. [Google Scholar]
- Akata, Z.; Reed, S.; Walter, D.; Lee, H.; Schiele, B. Evaluation of output embeddings for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2927–2936. [Google Scholar]
- Xian, Y.; Akata, Z.; Sharma, G.; Nguyen, Q.; Hein, M.; Schiele, B. Latent embeddings for zero-shot classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 69–77. [Google Scholar]
- Romera-Paredes, B.; Torr, P. An embarrassingly simple approach to zero-shot learning. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: New York, NY, USA, 2015; pp. 2152–2161. [Google Scholar]
- Akata, Z.; Perronnin, F.; Harchaoui, Z.; Schmid, C. Label-embedding for image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1425–1438. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Xiang, T.; Gong, S. Learning a deep embedding model for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2021–2030. [Google Scholar]
- Xian, Y.; Sharma, S.; Schiele, B.; Akata, Z. f-vaegan-d2: A feature generating framework for any-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10275–10284. [Google Scholar]
- Narayan, S.; Gupta, A.; Khan, F.S.; Snoek, C.G.; Shao, L. Latent embedding feedback and discriminative features for zero-shot classification. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 479–495. [Google Scholar]
- Mishra, A.; Krishna Reddy, S.; Mittal, A.; Murthy, H.A. A generative model for zero shot learning using conditional variational autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2188–2196. [Google Scholar]
- Changpinyo, S.; Chao, W.L.; Gong, B.; Sha, F. Synthesized classifiers for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5327–5336. [Google Scholar]
- Kodirov, E.; Xiang, T.; Gong, S. Semantic autoencoder for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3174–3183. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Zhang, T.; Yang, Z.; Li, D. Stochastic simulation of deltas based on a concurrent multi-stage VAE-GAN model. J. Hydrol. 2022, 607, 127493. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Bowman, S.R.; Vilnis, L.; Vinyals, O.; Dai, A.M.; Jozefowicz, R.; Bengio, S. Generating sentences from a continuous space. arXiv 2015, arXiv:1511.06349. [Google Scholar]
- Zhao, S.; Song, J.; Ermon, S. Towards deeper understanding of variational autoencoding models. arXiv 2017, arXiv:1702.08658. [Google Scholar]
- Chen, R.T.; Li, X.; Grosse, R.B.; Duvenaud, D.K. Isolating sources of disentanglement in variational autoencoders. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Patterson, G.; Hays, J. Sun attribute database: Discovering, annotating, and recognizing scene attributes. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2751–2758. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-Ucsd Birds-200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Xian, Y.; Schiele, B.; Akata, Z. Zero-shot learning-the good, the bad and the ugly. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 211–26 July 2017; pp. 4582–4591. [Google Scholar]
- Bursztein, E.; Chollet, F.; Jin, H.; Watson, M.; Zhu, Q.S. Keras: The Python Deep Learning API. Available online: https://keras.io (accessed on 2 February 2022).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 2 February 2022).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chao, W.L.; Changpinyo, S.; Gong, B.; Sha, F. An empirical study and analysis of generalized zero-shot learning for object recognition in the wild. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Amsterdam, The Netherlands, 2016; pp. 52–68. [Google Scholar]
- Xian, Y.; Lorenz, T.; Schiele, B.; Akata, Z. Feature generating networks for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5542–5551. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Liu, B.; Dong, Q.; Hu, Z. Zero-shot learning from adversarial feature residual to compact visual feature. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 1–12 February 2020; Volume 34, pp. 11547–11554. [Google Scholar]
- Liu, Y.; Zhou, L.; Bai, X.; Huang, Y.; Gu, L.; Zhou, J.; Harada, T. Goal-oriented gaze estimation for zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3794–3803. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CUB | AwA1 | AwA2 | SUN |
|---|---|---|---|---|
| DAP [12] | 40.0 | 44.1 | 46.1 | 39.9 |
| IAP [12] | 24.0 | 35.9 | 35.9 | 19.4 |
| ConSE [13] | 34.3 | 45.6 | 44.5 | 38.8 |
| CMT [18] | 34.6 | 39.5 | 37.9 | 39.9 |
| SSE [19] | 43.9 | 60.1 | 61.0 | 51.5 |
| DeViSE [15] | 52.0 | 54.2 | 59.7 | 56.5 |
| SJE [20] | 53.9 | 65.6 | 61.9 | 53.7 |
| LATEM [21] | 49.3 | 55.1 | 55.8 | 55.3 |
| ESZSL [22] | 53.9 | 58.2 | 58.6 | 54.5 |
| ALE [23] | 54.9 | 59.9 | 62.5 | 58.1 |
| SYNC [28] | 55.6 | 54.0 | 46.6 | 56.3 |
| SAE [29] | 33.3 | 53.0 | 54.1 | 40.3 |
| Relation Net [30] | 55.6 | 68.2 | 64.2 | - |
| DEM [24] | 51.7 | 68.4 | 67.1 | 61.9 |
| f-VAEGAN-D2 [25] | 61.0 | — | 71.1 | 64.7 |
| TF-VAEGAN [26] | 64.9 | — | 72.2 | 66.0 |
| CVAE [27] | 52.1 | 71.4 | 65.8 | 61.7 |
| HFM (Ours) | 69.5 | 65.0 | 65.5 | 53.8 |
| Model | CUB | AwA1 | AwA2 | SUN |
|---|---|---|---|---|
| DAP [12] | 3.3 | 0.0 | 0.0 | 7.2 |
| IAP [12] | 0.4 | 4.1 | 1.8 | 1.8 |
| ConSE [13] | 3.1 | 0.8 | 1.0 | 11.6 |
| CMT [18] | 8.7 | 15.3 | 15.9 | 13.3 |
| SSE [19] | 14.4 | 12.9 | 14.8 | 4.0 |
| DeViSE [15] | 32.8 | 22.4 | 27.8 | 20.9 |
| SJE [20] | 33.6 | 19.6 | 14.4 | 19.8 |
| LATEM [21] | 24.0 | 13.3 | 20.0 | 19.5 |
| ESZSL [22] | 21.0 | 12.1 | 11.0 | 15.8 |
| ALE [23] | 34.4 | 27.5 | 23.9 | 26.3 |
| SYNC [28] | 19.8 | 16.2 | 18.0 | 13.4 |
| SAE [29] | 13.6 | 3.5 | 2.2 | 11.8 |
| Relation Net [30] | 47.0 | 46.7 | 45.3 | — |
| DEM [24] | 29.2 | 47.3 | 45.1 | 25.6 |
| f-VAEGAN-D2 [25] | 53.6 | — | 63.5 | 41.3 |
| TF-VAEGAN [26] | 58.1 | — | 66.6 | 43.0 |
| CVAE [27] | 34.5 | 47.2 | 51.2 | 26.7 |
| HFM (Ours) | 43.4 | 61.6 | 63.4 | 29.7 |
| Dataset | Autoencoder1 | Autoencoder2 | Both |
|---|---|---|---|
| AWA1 | 63.6 | 60.0 | 65.0 |
| AWA2 | 58.6 | 58.4 | 65.5 |
| CUB | 68.5 | 58.9 | 69.5 |
| SUN | 50.6 | 51.4 | 53.8 |
| Dataset | Seen | Unseen | Harmonic Mean |
|---|---|---|---|
| AWA1 | 75.7 | 52.0 | 61.6 |
| AWA2 | 80.9 | 49.7 | 63.4 |
| CUB | 57.9 | 34.7 | 43.4 |
| SUN | 75.3 | 18.5 | 29.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Machot, F.; Ullah, M.; Ullah, H. HFM: A Hybrid Feature Model Based on Conditional Auto Encoders for Zero-Shot Learning. J. Imaging 2022, 8, 171. https://doi.org/10.3390/jimaging8060171
Al Machot F, Ullah M, Ullah H. HFM: A Hybrid Feature Model Based on Conditional Auto Encoders for Zero-Shot Learning. Journal of Imaging. 2022; 8(6):171. https://doi.org/10.3390/jimaging8060171
Chicago/Turabian StyleAl Machot, Fadi, Mohib Ullah, and Habib Ullah. 2022. "HFM: A Hybrid Feature Model Based on Conditional Auto Encoders for Zero-Shot Learning" Journal of Imaging 8, no. 6: 171. https://doi.org/10.3390/jimaging8060171
APA StyleAl Machot, F., Ullah, M., & Ullah, H. (2022). HFM: A Hybrid Feature Model Based on Conditional Auto Encoders for Zero-Shot Learning. Journal of Imaging, 8(6), 171. https://doi.org/10.3390/jimaging8060171