
upU-Net Approaches for Background Emission Removal in Fluorescence Microscopy


Abstract
1. Introduction
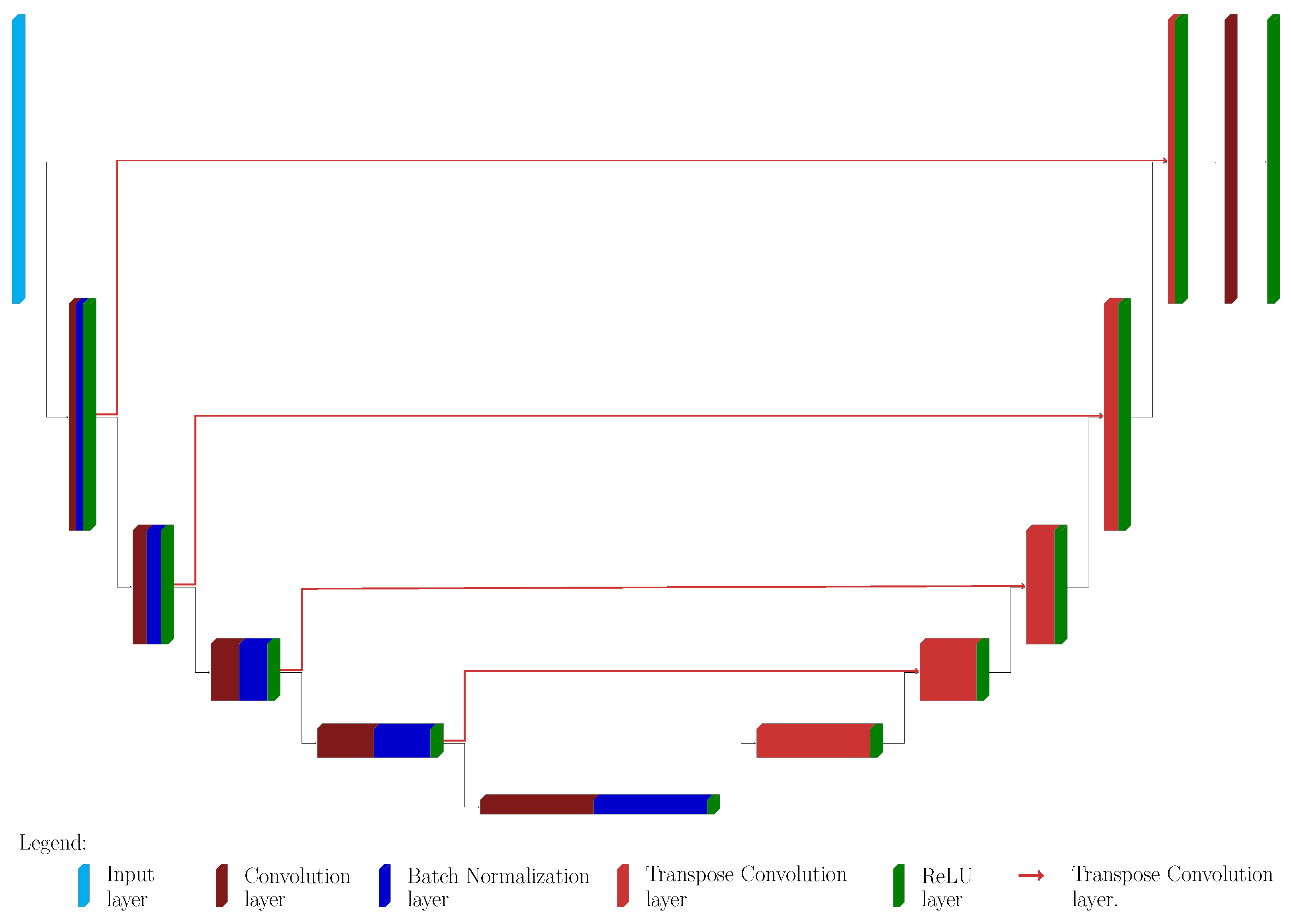
2. upU-net Architecture
- A convolution 2D layer, with stride 2 (in both dimensions) and padding 1 (in both dimensions). The boundary conditions are set to symmetric, excluding the image edge.
- A batch normalization layer.
- A ReLU layer.
- An up–convolution layer. The scope of this type of layer is to increase the size of the input, and the last one will provide data of the same size as the input.
- A ReLU layer.
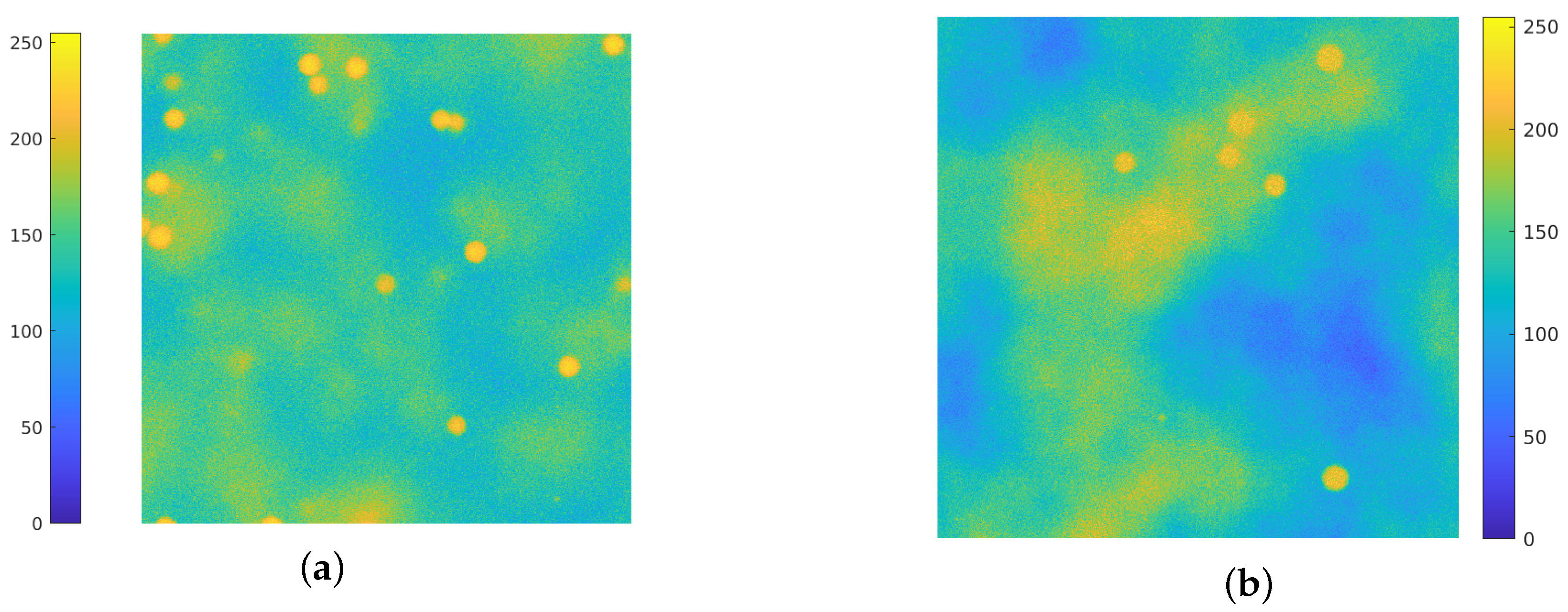
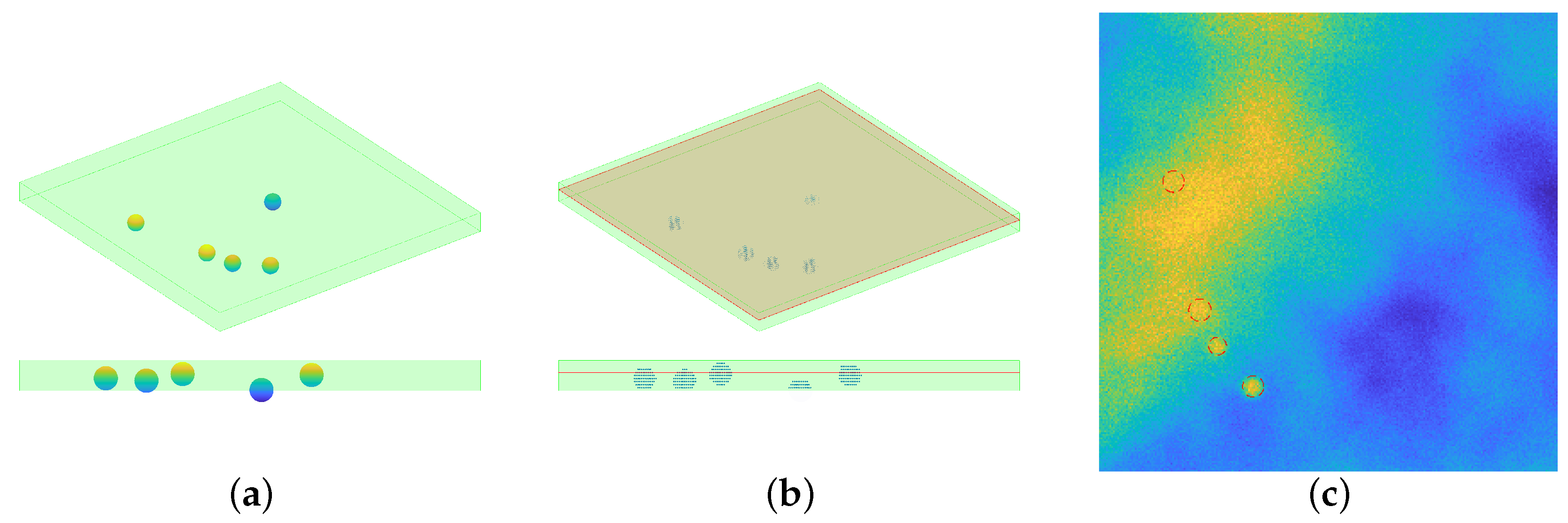
3. Data Generation
- Gaussian noise is added following the procedure depicted in [61]: a multivalued random Gaussian variable is generated, then a noise level is chosen. Being g the noise–free image, the perturbed one is thenwhere denotes the Frobenius norm. In this way, one has that .
- Poisson noise is added, using built-in functions of the software used (see Section 4 for details).
4. Results
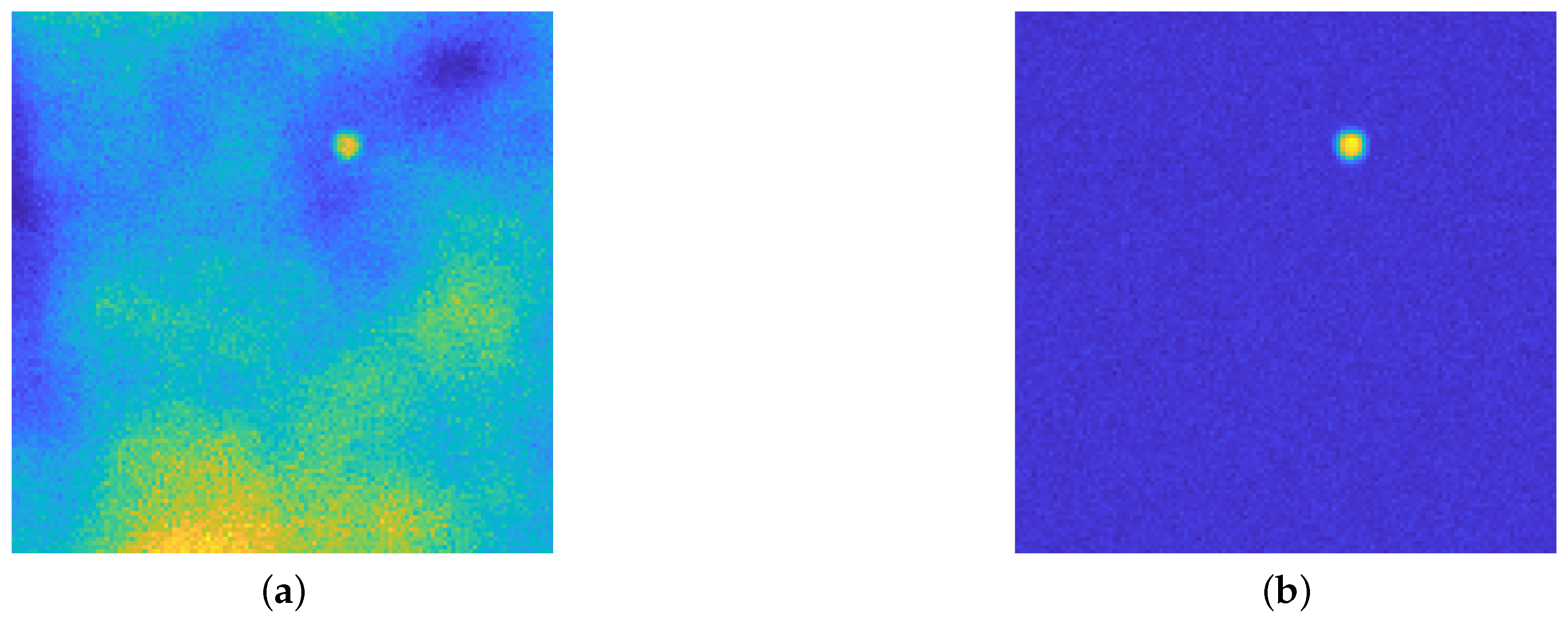
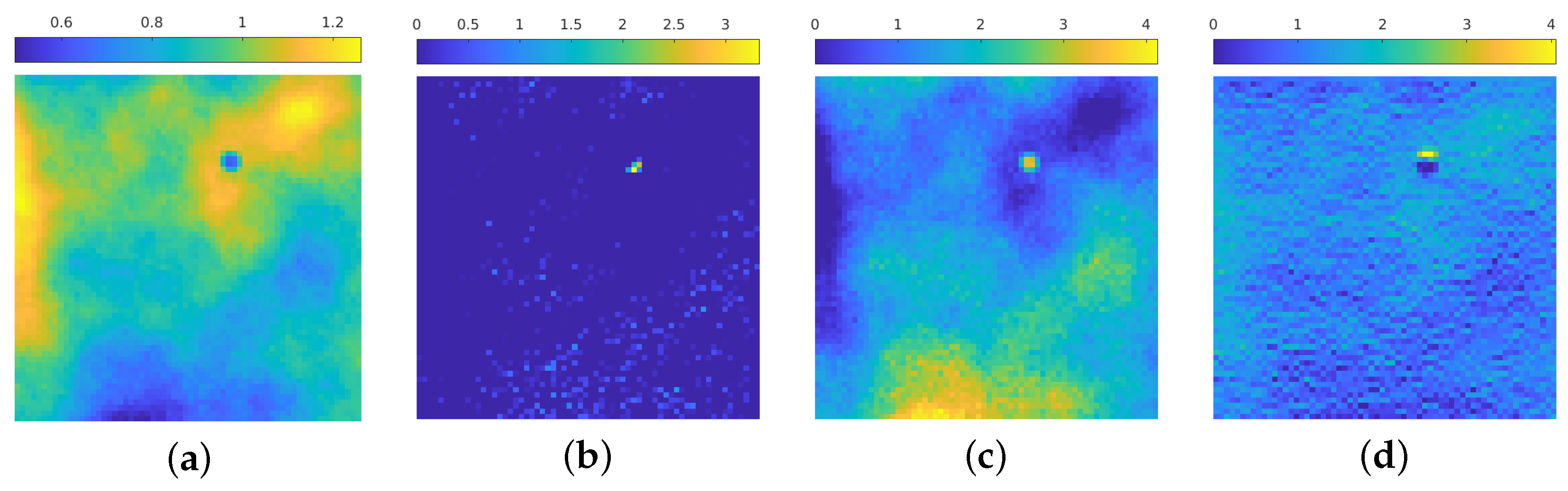
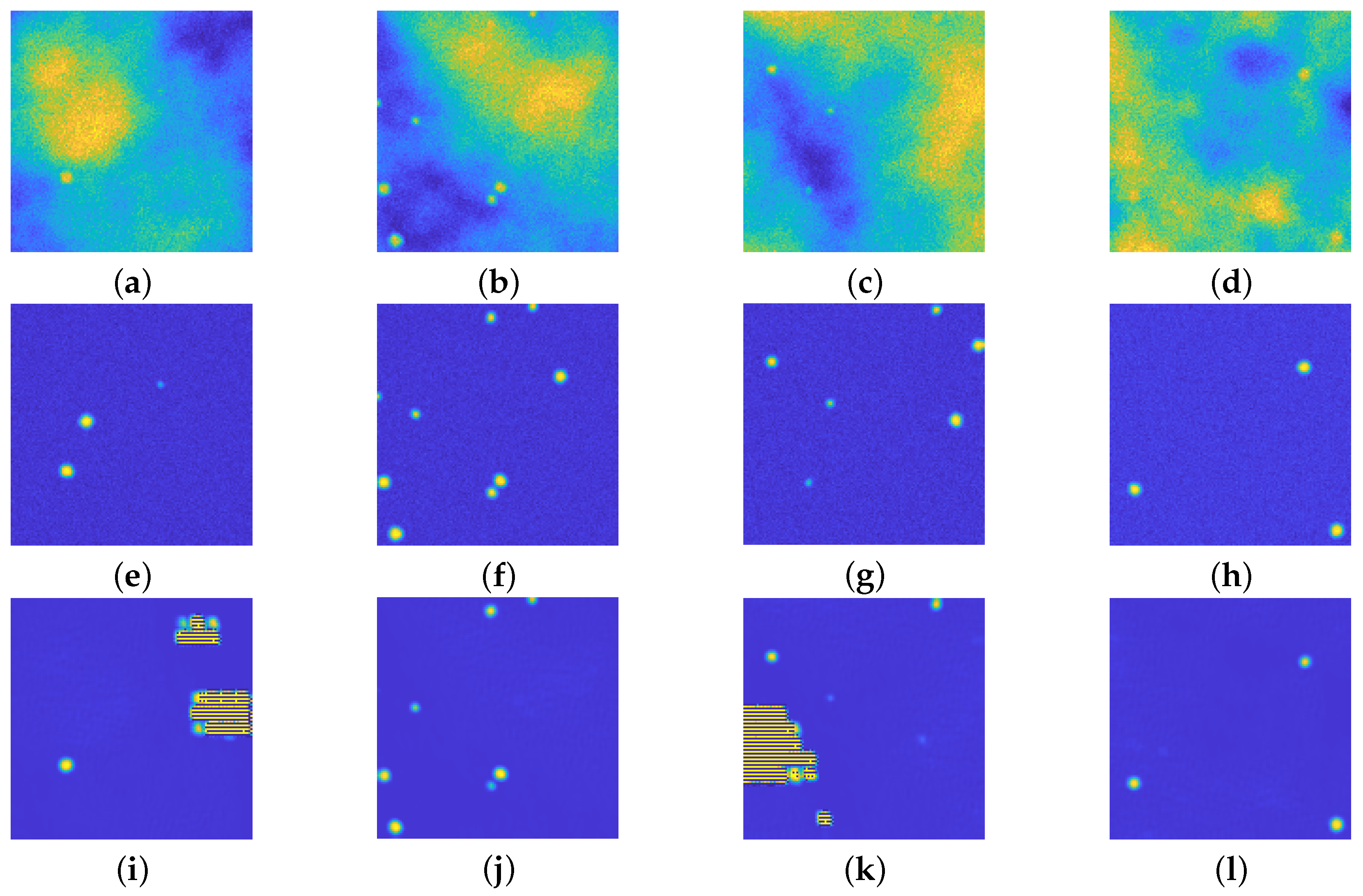
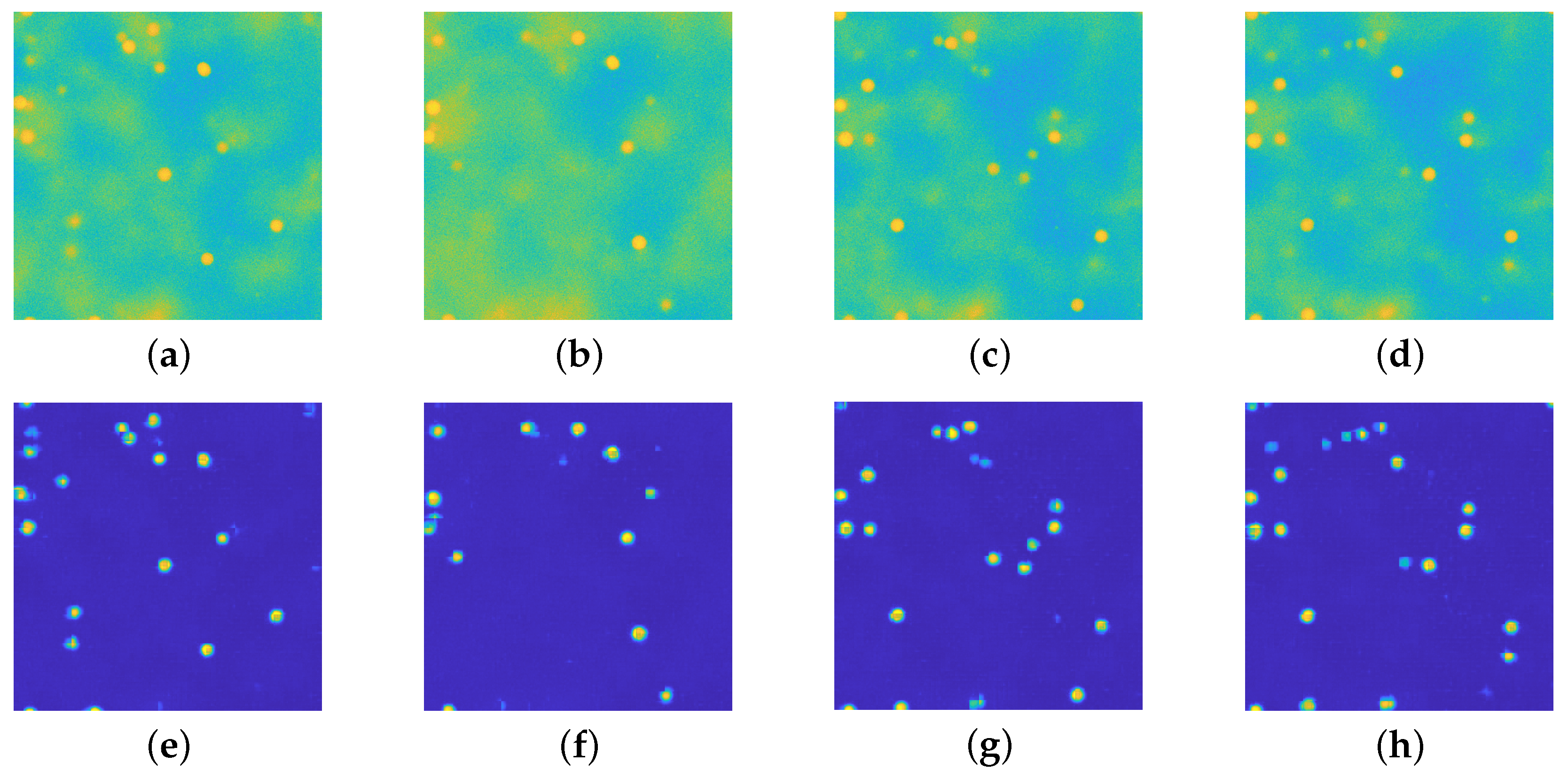
4.1. Assessing the Performance of upU-net
- 5 blocks in the contracting part, each one containing a 2D convolution layer, a batch normalization, and a ReLU layer (see Figure 2). The number of filters in the first block is 8, then it is doubled in each subsequent block.
- 5 blocks in the expansive path, consisting of an up–convolution layer and a ReLU layer. The number of filters starts from 128 and then it is halved, mimicking the structure of the contracting path.
- 5 up-convolution layers that connect the relative blocks in the two paths.
- A final 1D convolution layer for merging all the filtered data, coupled with the last ReLU layer.
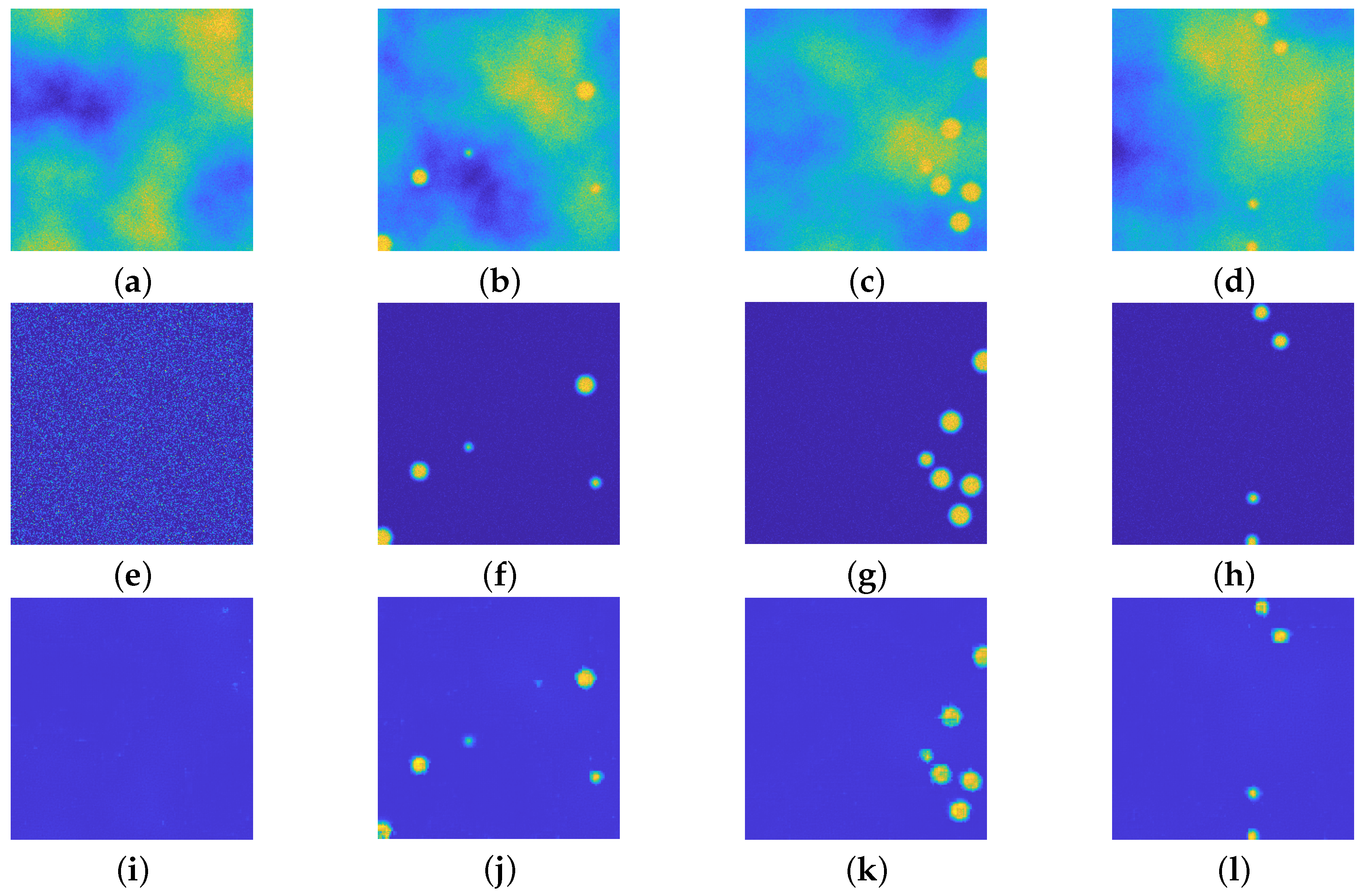
4.2. Comparison with Classical U-net
- a convolution layer
- a ReLU layer
- a batch normalization layer
- a convolution layer
- a ReLU layer
- a batch normalization layer
- a max-pooling layer
- an upconvolution layer
- a ReLU layer
- a concatenation layer, for connecting with the relative encoding part
- a convolution layer
- a ReLU layer
- a batch normalization layer
- a convolution layer
- a ReLU layer
- a batch normalization layer
4.3. upU-net for Different Radius Particles
4.4. upU-net for Particle Estimation Task
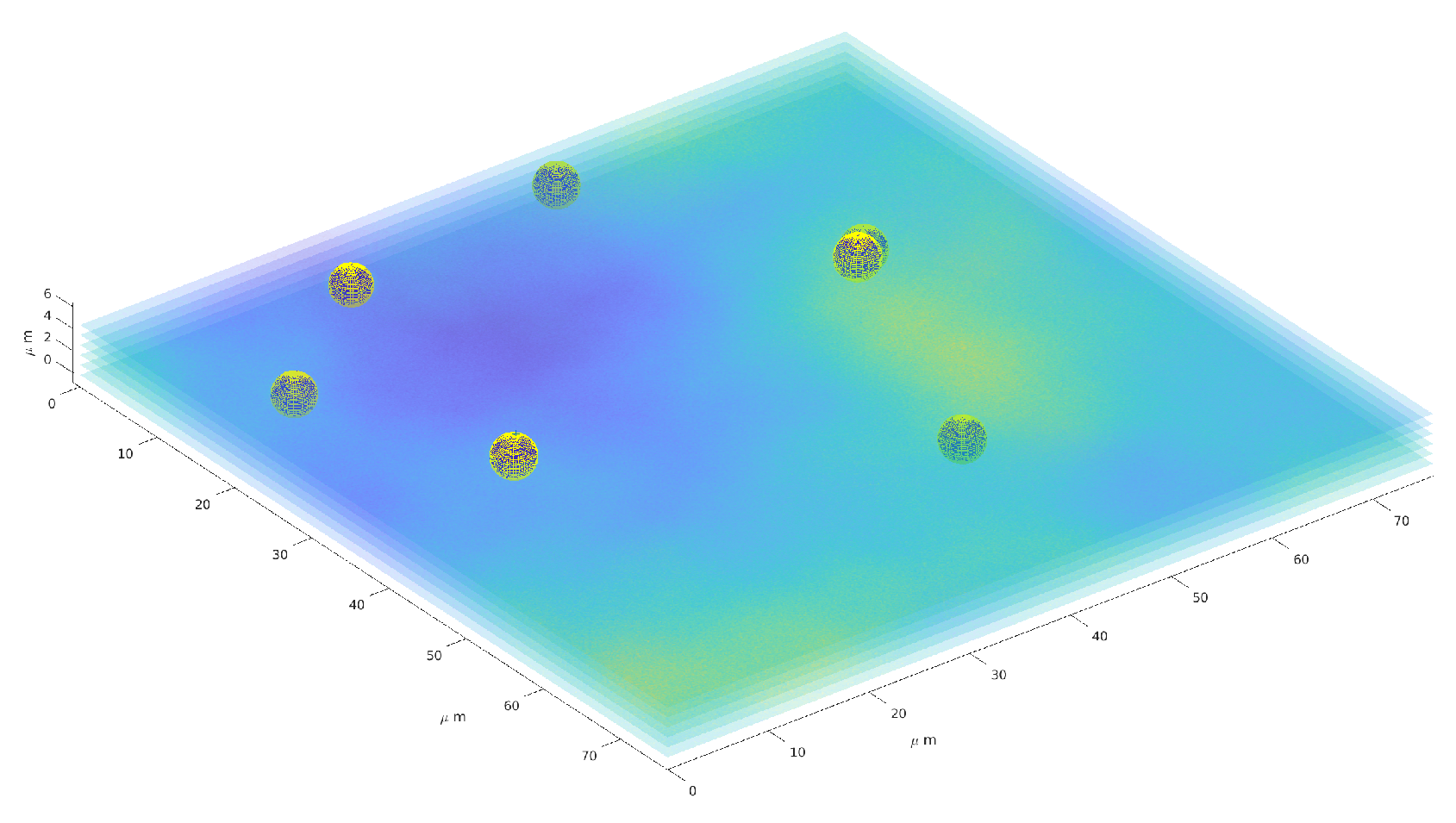
4.5. Volume Reconstruction
- Apply to each frame the up–UNet, in order to remove the noise artifacts.
- Apply the procedure in [66] to the restored array.
4.6. Real Dataset
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bertero, M.; Boccacci, P.; Desiderà, G.; Vicidomini, G. Image deblurring with Poisson data: From cells to galaxies. Inverse Probl. 2009, 25, 123006. [Google Scholar] [CrossRef]
- Bertero, M.; Boccacci, P.; Ruggiero, V. Inverse Imaging with Poisson Data; IOP Publishing: Bristol, UK, 2018; pp. 2053–2563. [Google Scholar]
- Bechensteen, A.; Rebegoldi, S.; Aubert, G.; Blanc-Féraud, L. ℓ2—ℓ0 optimization for single molecule localization microscopy. In Proceedings of the Imaging and Applied Optics 2018 (3D, AO, AIO, COSI, DH, IS, LACSEA, LS&C, MATH, pcAOP), Orlando, FL, USA; Optica Publishing Group: Orlando, FL, USA, 2018; p. MW2D.1. [Google Scholar]
- Benfenati, A.; Ruggiero, V. Image regularization for Poisson data. J. Phys. Conf. Ser. 2015, 657, 012011. [Google Scholar] [CrossRef]
- di Serafino, D.; Landi, G.; Viola, M. Directional TGV-Based Image Restoration under Poisson Noise. J. Imaging 2021, 7, 99. [Google Scholar] [CrossRef]
- Pragliola, M.; Calatroni, L.; Lanza, A.; Sgallari, F. Residual Whiteness Principle for Automatic Parameter Selection in ℓ2—ℓ2 Image Super-Resolution Problems. In Proceedings of the International Conference on Scale Space and Variational Methods in Computer Vision, Lège-Cap Ferret, France, 16–20 May 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 476–488. [Google Scholar]
- Benfenati, A.; Chouzenoux, E.; Pesquet, J.C. Proximal approaches for matrix optimization problems: Application to robust precision matrix estimation. Signal Process. 2020, 169, 107417. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Bonettini, S.; Benfenati, A.; Ruggiero, V. Primal-dual first order methods for total variation image restoration in presence of poisson noise. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4156–4160. [Google Scholar]
- Cascarano, P.; Sebastiani, A.; Comes, M.C.; Franchini, G.; Porta, F. Combining Weighted Total Variation and Deep Image Prior for natural and medical image restoration via ADMM. In Proceedings of the 2021 21st International Conference on Computational Science and Its Applications (ICCSA), Cagliari, Italy, 13–16 September 2021; pp. 39–46. [Google Scholar]
- Nasonov, A.; Krylov, A. An Improvement of BM3D Image Denoising and Deblurring Algorithm by Generalized Total Variation. In Proceedings of the 2018 7th European Workshop on Visual Information Processing (EUVIP), Tampere, Finland, 26–28 November 2018; pp. 1–4. [Google Scholar]
- Benfenati, A.; Camera, A.L.; Carbillet, M. Deconvolution of post-adaptive optics images of faint circumstellar environments by means of the inexact Bregman procedure. Astron. Astrophys. 2016, 586, A16. [Google Scholar] [CrossRef]
- Benfenati, A.; Causin, P.; Lupieri, M.G.; Naldi, G. Regularization Techniques for Inverse Problem in DOT Applications. J. Phys. Conf. Ser. 2020, 1476, 012007. [Google Scholar] [CrossRef]
- Zhang, M.; Desrosiers, C. High-quality Image Restoration Using Low-Rank Patch Regularization and Global Structure Sparsity. IEEE Trans. Image Process. 2019, 28, 868–879. [Google Scholar] [CrossRef]
- Bevilacqua, F.; Lanza, A.; Pragliola, M.; Sgallari, F. Nearly Exact Discrepancy Principle for Low-Count Poisson Image Restoration. J. Imaging 2022, 8, 1. [Google Scholar] [CrossRef]
- Zanni, L.; Benfenati, A.; Bertero, M.; Ruggiero, V. Numerical Methods for Parameter Estimation in Poisson Data Inversion. J. Math. Imaging Vis. 2015, 52, 397–413. [Google Scholar] [CrossRef]
- Benfenati, A.; Ruggiero, V. Inexact Bregman iteration with an application to Poisson data reconstruction. Inverse Probl. 2013, 29, 065016. [Google Scholar] [CrossRef]
- Benfenati, A.; Ruggiero, V. Inexact Bregman iteration for deconvolution of superimposed extended and point sources. Commun. Nonlinear Sci. Numer. Simul. 2015, 20, 882–896. [Google Scholar] [CrossRef]
- Cadoni, S.; Chouzenoux, E.; Pesquet, J.C.; Chaux, C. A block parallel majorize-minimize memory gradient algorithm. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3194–3198. [Google Scholar]
- Cascarano, P.; Comes, M.C.; Mencattini, A.; Parrini, M.C.; Piccolomini, E.L.; Martinelli, E. Recursive Deep Prior Video: A super resolution algorithm for time-lapse microscopy of organ-on-chip experiments. Med Image Anal. 2021, 72, 102124. [Google Scholar] [CrossRef]
- Liu, J.; Sun, Y.; Xu, X.; Kamilov, U.S. Image Restoration Using Total Variation Regularized Deep Image Prior. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7715–7719. [Google Scholar]
- Cascarano, P.; Piccolomini, E.L.; Morotti, E.; Sebastiani, A. Plug-and-Play gradient-based denoisers applied to CT image enhancement. Appl. Math. Comput. 2022, 422, 126967. [Google Scholar] [CrossRef]
- Puybareau, É.; Carlinet, E.; Benfenati, A.; Talbot, H. Spherical Fluorescent Particle Segmentation and Tracking in 3D Confocal Microscopy. In Proceedings of the Mathematical Morphology and Its Applications to Signal and Image Processing, Fontainebleau, France, May 15–17 2019; Burgeth, B., Kleefeld, A., Naegel, B., Passat, N., Perret, B., Eds.; Springer International Publishing: Cham, Swizerland, 2019; pp. 520–531. [Google Scholar]
- Josephson, L.L.; Swan, J.W.; Furst, E.M. In situ measurement of localization error in particle tracking microrheology. Rheol. Acta 2018, 57, 793–800. [Google Scholar] [CrossRef]
- Chu, K.K.; Mojahed, D.; Fernandez, C.M.; Li, Y.; Liu, L.; Wilsterman, E.J.; Diephuis, B.; Birket, S.E.; Bowers, H.; Solomon, G.M.; et al. Particle-Tracking Microrheology Using Micro-Optical Coherence Tomography. Biophys. J. 2016, 111, 1053–1063. [Google Scholar] [CrossRef]
- Godinez, W.J.; Rohr, K. Tracking Multiple Particles in Fluorescence Time-Lapse Microscopy Images via Probabilistic Data Association. IEEE Trans. Med. Imaging 2015, 34, 415–432. [Google Scholar] [CrossRef]
- Gardill, A.; Kemeny, I.; Li, Y.; Zahedian, M.; Cambria, M.C.; Xu, X.; Lordi, V.; Gali, A.; Maze, J.R.; Choy, J.T.; et al. Super-Resolution Airy Disk Microscopy of Individual Color Centers in Diamond. arXiv 2022, arXiv:2203.11859. [Google Scholar]
- Richter, V.; Piper, M.; Wagner, M.; Schneckenburger, H. Increasing Resolution in Live Cell Microscopy by Structured Illumination (SIM). Appl. Sci. 2019, 9, 1188. [Google Scholar] [CrossRef]
- Kim, B. DVDeconv: An Open-Source MATLAB Toolbox for Depth-Variant Asymmetric Deconvolution of Fluorescence Micrographs. Cells 2021, 10, 397. [Google Scholar] [CrossRef]
- Jezierska, A.; Chouzenoux, E.; Pesquet, J.C.; Talbot, H. A primal-dual proximal splitting approach for restoring data corrupted with poisson-gaussian noise. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 1085–1088. [Google Scholar]
- Novák, T.; Gajdos, T.; Sinkó, J.; Szabó, G.; Erdélyi, M. TestSTORM: Versatile simulator software for multimodal super-resolution localization fluorescence microscopy. Sci. Rep. 2017, 7, 951. [Google Scholar] [CrossRef]
- Flier, B.M.; Baier, M.; Huber, J.; Müllen, K.; Mecking, S.; Zumbusch, A.; Wöll, D. Single molecule fluorescence microscopy investigations on heterogeneity of translational diffusion in thin polymer films. Phys. Chem. Chem. Phys. 2011, 13, 1770–1775. [Google Scholar] [CrossRef]
- Abdellah, M.; Bilgili, A.; Eilemann, S.; Markram, H.; Schürmann, F. A Computational Model of Light-Sheet Fluorescence Microscopy using Physically-based Rendering. In Proceedings of the Eurographics (Posters), Los Angeles, CA, USA, 7–9 August 2015; pp. 15–16. [Google Scholar]
- Carles, G.; Zammit, P.; Harvey, A.R. Holistic Monte-Carlo optical modelling of biological imaging. Sci. Rep. 2019, 9, 15832. [Google Scholar] [CrossRef]
- Lu, X.; Rodenko, O.; Zhang, Y.; Gross, H. Efficient simulation of autofluorescence effects in microscope lenses. Appl. Opt. 2019, 58, 3589–3596. [Google Scholar] [CrossRef]
- Mukamel, E.; Babcock, H.; Zhuang, X. Statistical Deconvolution for Superresolution Fluorescence Microscopy. Biophys. J. 2012, 102, 2391–2400. [Google Scholar] [CrossRef]
- Axelrod, D. Evanescent Excitation and Emission in Fluorescence Microscopy. Biophys. J. 2013, 104, 1401–1409. [Google Scholar] [CrossRef]
- Perlin, K. An image synthesizer. ACM Siggraph Comput. Graph. 1985, 19, 287–296. [Google Scholar] [CrossRef]
- Meraner, A.; Ebel, P.; Zhu, X.X.; Schmitt, M. Cloud removal in Sentinel-2 imagery using a deep residual neural network and SAR-optical data fusion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 333–346. [Google Scholar] [CrossRef]
- Lee, K.Y.; Sim, J.Y. Cloud Removal of Satellite Images Using Convolutional Neural Network With Reliable Cloudy Image Synthesis Model. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3581–3585. [Google Scholar]
- Enomoto, K.; Sakurada, K.; Wang, W.; Fukui, H.; Matsuoka, M.; Nakamura, R.; Kawaguchi, N. Filmy Cloud Removal on Satellite Imagery with Multispectral Conditional Generative Adversarial Nets. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1533–1541. [Google Scholar]
- Štěpka, K.; Matula, P.; Matula, P.; Wörz, S.; Rohr, K.; Kozubek, M. Performance and sensitivity evaluation of 3D spot detection methods in confocal microscopy. Cytom. Part A 2015, 87, 759–772. [Google Scholar] [CrossRef]
- Rolfe, D.J.; McLachlan, C.I.; Hirsch, M.; Needham, S.R.; Tynan, C.J.; Webb, S.E.; Martin-Fernandez, M.L.; Hobson, M.P. Automated multidimensional single molecule fluorescence microscopy feature detection and tracking. Eur. Biophys. J. 2011, 40, 1167–1186. [Google Scholar] [CrossRef]
- Woelk, L.M.; Kannabiran, S.A.; Brock, V.J.; Gee, C.E.; Lohr, C.; Guse, A.H.; Diercks, B.P.; Werner, R. Time-Dependent Image Restoration of Low-SNR Live-Cell Ca2 Fluorescence Microscopy Data. Int. J. Mol. Sci. 2021, 22, 11792. [Google Scholar] [CrossRef]
- Abdolhoseini, M.; Kluge, M.G.; Walker, F.R.; Johnson, S.J. Neuron Image Synthesizer Via Gaussian Mixture Model and Perlin Noise. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 530–533. [Google Scholar]
- Sorokin, D.V.; Peterlík, I.; Ulman, V.; Svoboda, D.; Nečasová, T.; Morgaenko, K.; Eiselleová, L.; Tesařová, L.; Maška, M. FiloGen: A Model-Based Generator of Synthetic 3-D Time-Lapse Sequences of Single Motile Cells With Growing and Branching Filopodia. IEEE Trans. Med. Imaging 2018, 37, 2630–2641. [Google Scholar] [CrossRef]
- Sorokin, D.V.; Peterlík, I.; Ulman, V.; Svoboda, D.; Maška, M. Model-based generation of synthetic 3D time-lapse sequences of motile cells with growing filopodia. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, VIC, Australia, 18–21 April 2017; pp. 822–826. [Google Scholar]
- Ghaye, J.; De Micheli, G.; Carrara, S. Simulated biological cells for receptor counting in fluorescence imaging. BioNanoScience 2012, 2, 94–103. [Google Scholar] [CrossRef]
- Malm, P.; Brun, A.; Bengtsson, E. Papsynth: Simulated bright-field images of cervical smears. In Proceedings of the 2010 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Rotterdam, The Netherlands, 14–17 April 2010; pp. 117–120. [Google Scholar]
- Möckl, L.; Roy, A.R.; Petrov, P.N.; Moerner, W. Accurate and rapid background estimation in single-molecule localization microscopy using the deep neural network BGnet. Proc. Natl. Acad. Sci. USA 2020, 117, 60–67. [Google Scholar] [CrossRef]
- Möckl, L.; Roy, A.R.; Moerner, W.E. Deep learning in single-molecule microscopy: Fundamentals, caveats, and recent developments. Biomed. Opt. Express 2020, 11, 1633–1661. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Swizerland, 2015; pp. 234–241. [Google Scholar]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-Net and Its Variants for Medical Image Segmentation: A Review of Theory and Applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Punn, N.S.; Agarwal, S. Modality specific U-Net variants for biomedical image segmentation: A survey. Artif. Intell. Rev. 2022, 2022, 1–45. [Google Scholar] [CrossRef]
- Long, F. Microscopy cell nuclei segmentation with enhanced U-Net. BMC Bioinform. 2020, 21, 8. [Google Scholar] [CrossRef]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Tran, S.T.; Cheng, C.H.; Nguyen, T.T.; Le, M.H.; Liu, D.G. TMD-Unet: Triple-Unet with Multi-Scale Input Features and Dense Skip Connection for Medical Image Segmentation. Healthcare 2021, 9, 54. [Google Scholar] [CrossRef]
- Fu, C.; Lee, S.; Joon Ho, D.; Han, S.; Salama, P.; Dunn, K.W.; Delp, E.J. Three Dimensional Fluorescence Microscopy Image Synthesis and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Perlin, K. Improving Noise. ACM Trans. Graph. 2002, 21, 681–682. [Google Scholar] [CrossRef]
- Lagae, A.; Lefebvre, S.; Cook, R.; DeRose, T.; Drettakis, G.; Ebert, D.S.; Lewis, J.P.; Perlin, K.; Zwicker, M. State of the Art in Procedural Noise Functions. In Proceedings of the EG 2010–State of the Art Reports; Hauser, H., Reinhard, E., Eds.; Eurographics, Eurographics Association: Norrkoping, Sweden, 2010. [Google Scholar]
- Hansen, P.; Nagy, J.; O’Leary, D. Deblurring Images: Matrices, Spectra, and Filtering; Fundamentals of Algorithms, Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2006. [Google Scholar]
- MatLab. 2022. Available online: https://it.mathworks.com/products/parallel-computing.html (accessed on 13 May 2022).
- MatLab. 2022. Available online: https://www.mathworks.com/products/deep-learning.html (accessed on 13 May 2022).
- Bock, S.; Weiß, M. A Proof of Local Convergence for the Adam Optimizer. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- MatLab. Imnoise Documentation. 2022. Available online: https://it.mathworks.com/help/images/ref/imnoise.html (accessed on 13 May 2022).
- Benfenati, A.; Bonacci, F.; Bourouina, T.; Talbot, H. Efficient Position Estimation of 3D Fluorescent Spherical Beads in Confocal Microscopy via Poisson Denoising. J. Math. Imaging Vis. 2021, 63, 56–72. [Google Scholar] [CrossRef]
- Li, H.; Schwab, J.; Antholzer, S.; Haltmeier, M. NETT: Solving inverse problems with deep neural networks. Inverse Probl. 2020, 36, 065005. [Google Scholar] [CrossRef]
- Aletti, G.; Benfenati, A.; Naldi, G. A Semiautomatic Multi-Label Color Image Segmentation Coupling Dirichlet Problem and Colour Distances. J. Imaging 2021, 7, 208. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benfenati, A. upU-Net Approaches for Background Emission Removal in Fluorescence Microscopy. J. Imaging 2022, 8, 142. https://doi.org/10.3390/jimaging8050142
Benfenati A. upU-Net Approaches for Background Emission Removal in Fluorescence Microscopy. Journal of Imaging. 2022; 8(5):142. https://doi.org/10.3390/jimaging8050142
Chicago/Turabian StyleBenfenati, Alessandro. 2022. "upU-Net Approaches for Background Emission Removal in Fluorescence Microscopy" Journal of Imaging 8, no. 5: 142. https://doi.org/10.3390/jimaging8050142
APA StyleBenfenati, A. (2022). upU-Net Approaches for Background Emission Removal in Fluorescence Microscopy. Journal of Imaging, 8(5), 142. https://doi.org/10.3390/jimaging8050142