1. Introduction
Chess is the one of the most popular board games in the world. Based on the surveys of the Agon Ltd. (2012), approximately 605 million adults play chess regularly [
1], and this number has been exponentially rising since then. Although there are different variants of chess, most of the time it is played between two players. The first player plays with white pieces and the second player with black pieces. In a game, both players make their moves with their pieces in alternate turns until the game ends. During an Over-the-Board (OTB) chess event, both of these players for every match are generally required to record their own and their opponent’s moves on a chess move recording sheet, or chess scoresheet, by hand. These moves are usually recorded in a Standard Algebraic Notation (SAN) [
2]. This is a standard method for recording and describing the moves based on a coordinate system to uniquely identify each square on the chessboard. This particular move recording standard is the most widely used chess notation in the world, adopted by almost all the chess international organization, including the United States Chess Federation (USCF) and the Fédération Internationale des Échecs (FIDE), which oversee all world-class competitions. Furthermore, most books, magazines, newspapers, and online articles use SAN to report chess games and events. In English-speaking countries, a descriptive notation for chess moves used to be popular until about 1980. While a few players still use the descriptive notation, it is no longer recognized by FIDE [
3].
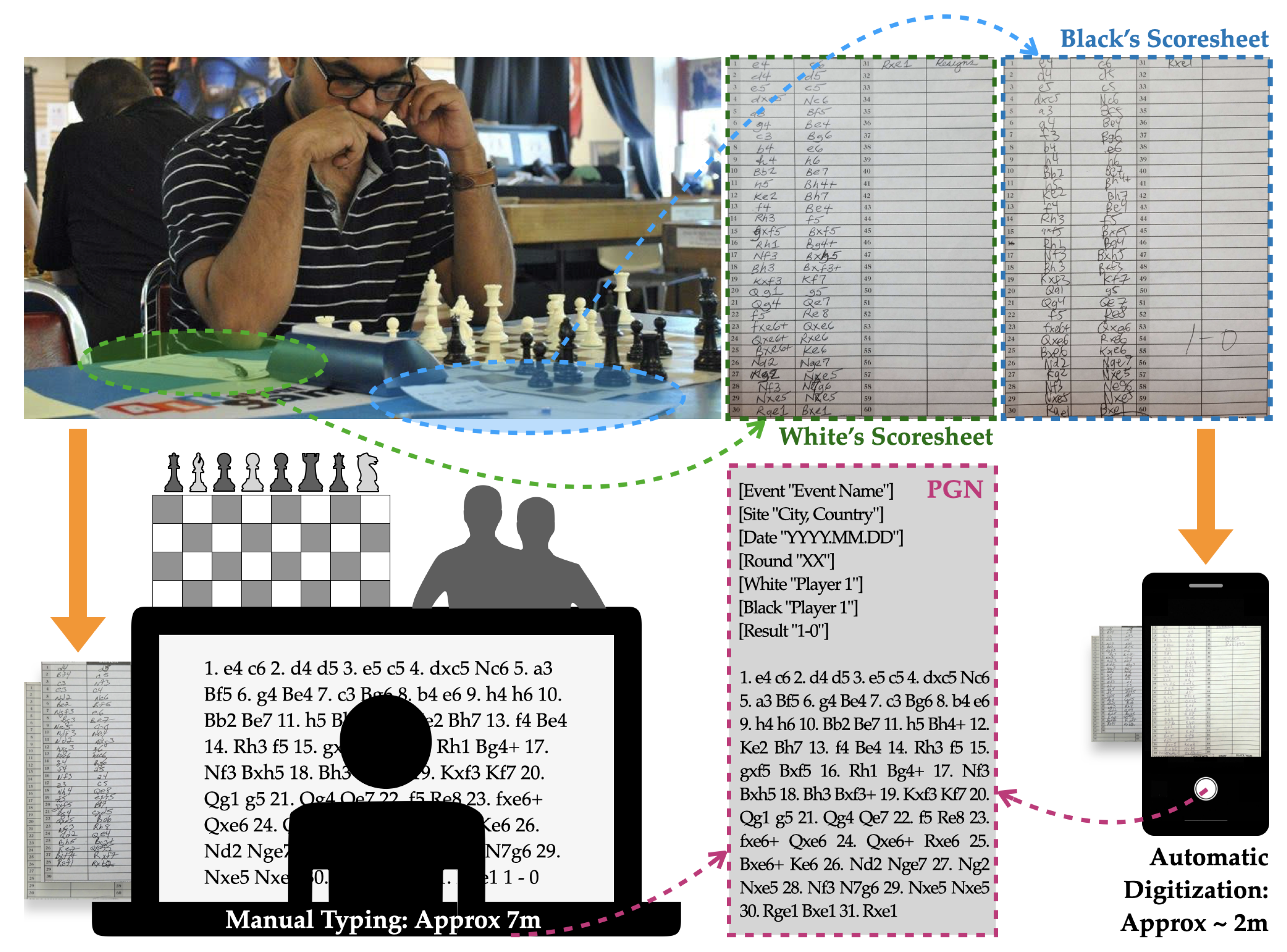
The chess scoresheet contains a sequential move history of the entire game along with information about the players, game format, results, and other details like event name, date, board number, etc. They are useful to keep as official game records, and to settle any disputes that may arise, hence their popularity in competitive settings. Moves are never recorded digitally (unless it is an online event) in an attempt to prevent computer assisted cheating, which is a big issue in the world of chess. This scoresheet system, while secure, leaves the event organizers with hundreds of scoresheets which must be manually digitized into a Portable Game Notation (PGN) file. PGN is a standard plain text format (filename extension is .pgn) for recording chess games and other related information, which allows an easy read by humans as well as easy parsing and generation by computer programs [
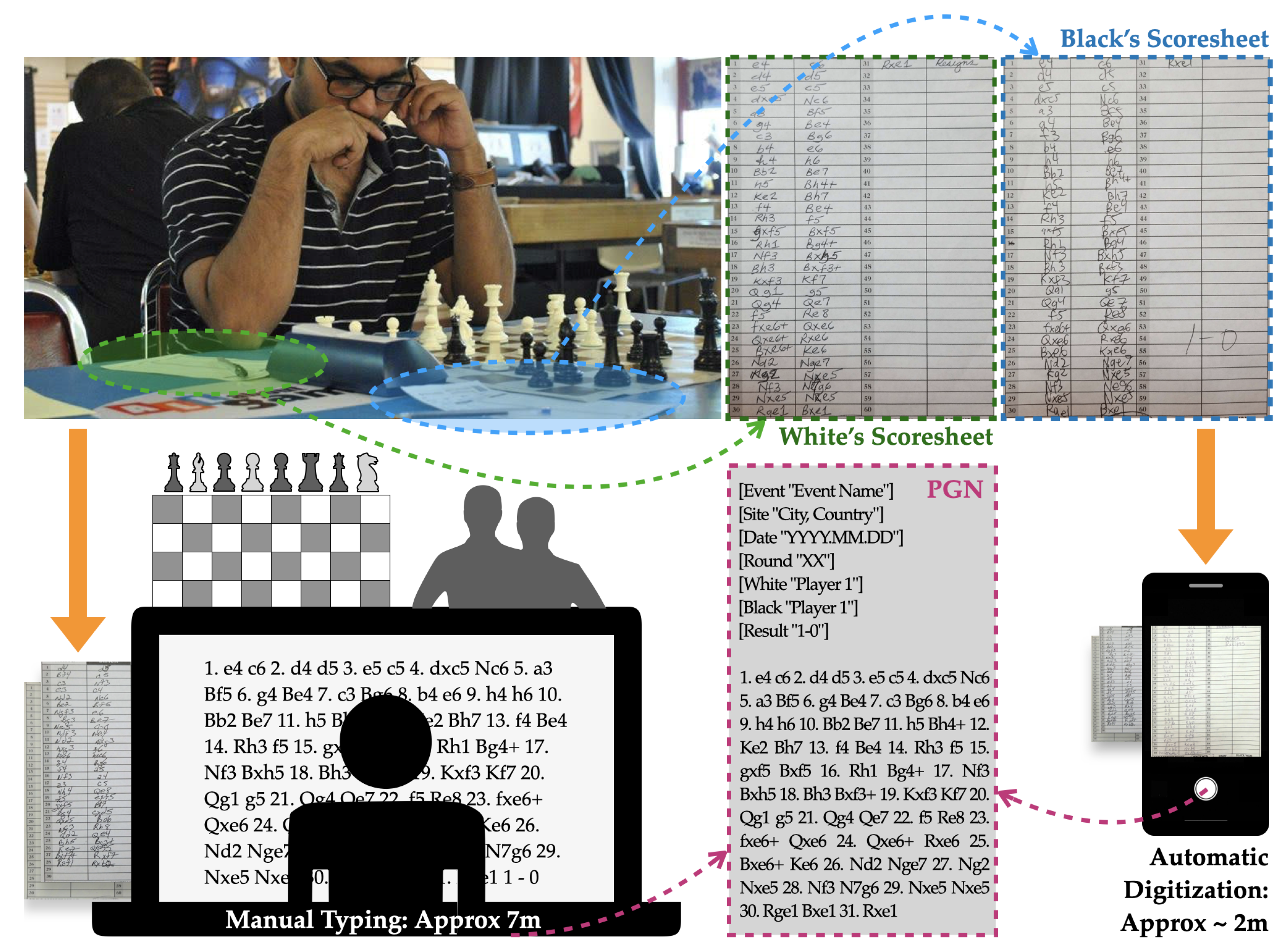
4]. This is the most widely accepted file format for a chess game and is accepted by the majority of the chess programs and engines today. However, the process of converting handwritten scoresheet pages received from the players to PGN files requires extensive time and labor, as organizers must not only type each move, but in the case of a conflict or illegible writing, play out the game on a chess board to infer moves. This is also a stressful and error-prone thing to do, since many conflicts can not easily be fixed without talking with the players. As an alternative to this legacy approach, we propose a deep neural network architecture to perform automatic conversion from pictures of these scoresheets to a PGN text file. In most practical cases, a cellphone camera is an extremely convenient way of collecting data, much more so than a flat-bed scanner. Keeping this in mind, we developed our detection system, from data acquisition to training and testing, to perform digitization on cellphone camera photos.
Figure 1 shows an OTB chess event and potential workflows for manual typing and proposed automatic digitization.
This automatic digitization of chess games from scoresheets also provides a benefit for the players. Often, professional and serious chess players like to analyze all of their games later, on their own or with their other chess players or coaches or with a computer engine. This process helps players to track their growth over time, patterns of common mistakes, missed opportunities and scope of improvement in strategies. Since the process of getting a scoresheet and digitizing manually takes a lot of time and effort, many players tend not to go through this crucial self evaluation and reflection stages of their own OTB games. Therefore, an automated process of digitizing a chess game from scoresheet images not only helps the chess event organizers to officially keep their records, but also helps every ambitious chess player who wants to improve their chess skills by studying their own games.
1.1. Distinguishing Features of Chess Scoresheets
In theory, chess moves could be recognized with a standard offline Latin handwriting recognition system, since chess universally uses Latin symbols. This generic approach has its shortcomings. Chess scoresheets offer many distinguishing features that we can leverage to significantly increase move recognition accuracy, including:
Two scoresheets for each match are available since both players write on their own copy of all the moves played. These copies can be cross referenced for validation.
Chess moves use a much smaller character set than the entire Latin alphabet, allowing only 31 characters as opposed to the 100+ ASCII (American Standard Code For Information Interchange) characters.
Table 1 summarizes the all possible chess move formats allowed in SAN, and
Table 2 shows some examples of how they work.
Traditional post-processing techniques (spell checking, Natural Language Processing or NLP, etc.) do not work. Instead, chess moves can be ruled valid or invalid based on SAN syntax errors or illegality dictated by the game rules.
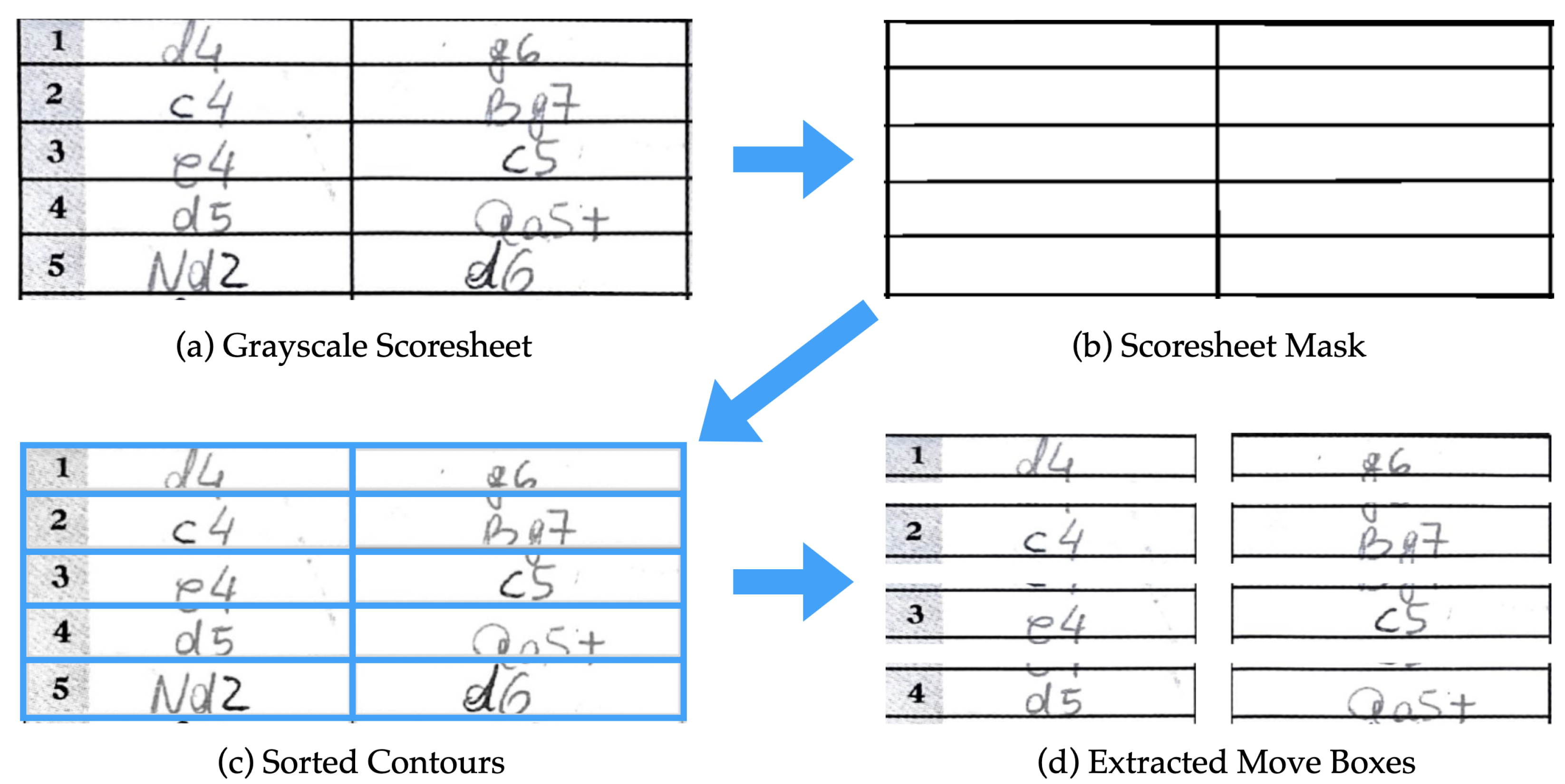
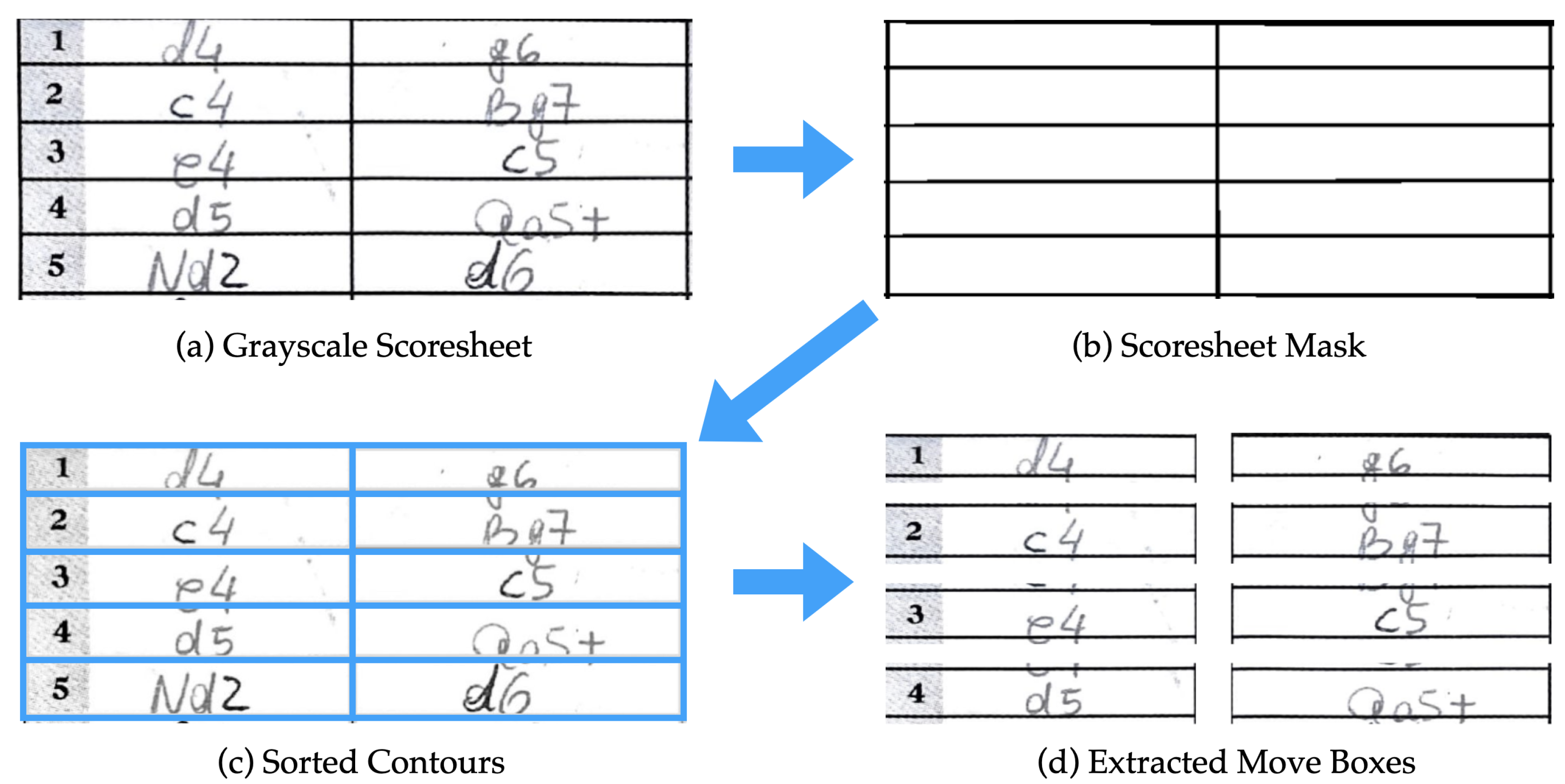
Handwritten moves are contained inside well defined bounding boxes (
Figure 2,
Figure 3 and
Figure 4) with some natural degrees of shift; therefore, the process of individual move segmentation is much simpler than in unconstrained handwriting.
Furthermore, the vast majority of chess moves are 2–5 characters long with only a few rare exceptions, and none are longer than 7 characters. These differences between the generic Latin script and handwritten chess moves make it worthwhile to approach this problem separately, while invoking the traditional wisdom of offline handwriting recognition.
1.2. Related Works
This paper is an extended version of our formal approach presented in [
5], and we found no other academic journal or conference publications for handwritten chess scoresheet recognition at this time of writing. There are some preliminary level works in the form of undergraduate or graduate thesis reports [
6,
7], but they are not quite well-presented or finished enough to be comparable with our approach. In addition, there are some works on typographical chess move reading from books or magazines (e.g., [
8]) which propose ideas for issues like layout fixing and semantic correction, but do not address the problems that can arise from a handwritten scoresheet. Services for digitizing chess scoresheets such as Reine Chess [
9] currently exist, but they require games to be recorded on their proprietary scoresheets with very specific formats; they cannot be applied to existing scoresheet formats, and would require tournaments to alter their structure, causing a variety of problems.
Figure 2 shows sample scoresheets from Reine Chess and from a typical chess event, which demonstrates the differences and limitations of such scannable solutions in a practical scenario. Scoresheet-specific solutions also offer no solution to retroactively digitize scoresheets and cannot be easily applied to other documents.
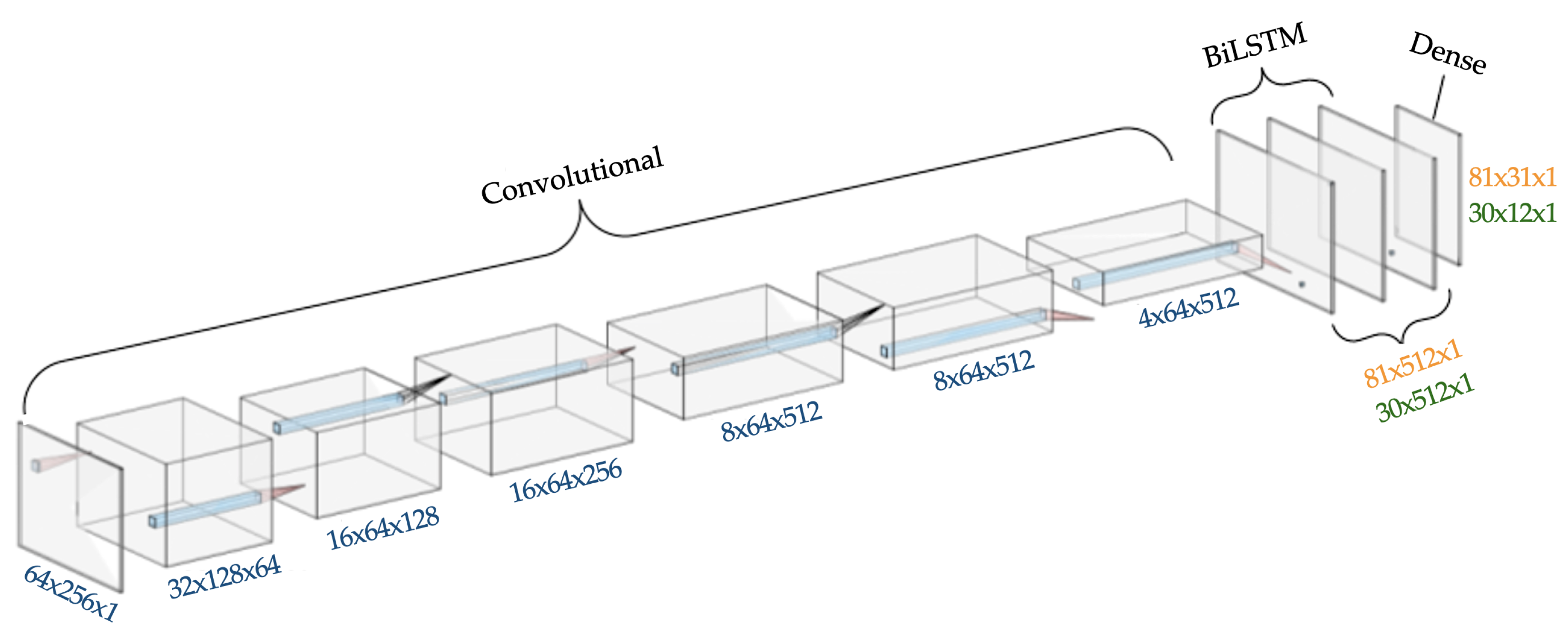
Digitizing chess scoresheets is essentially an offline handwriting recognition problem, and there are many different ways this problem can be approached. One approach, known as character spotting, works by finding the locations and classes of each individual component from a word image. This is a powerful technique but is better suited for more complicated scripts [
10]. Since the chess moves are recorded using a fraction of the Latin alphabet, a segmentation-free whole word recognition, using tools like Recurrent Neural Networks (RNN) or Hidden Markov Models (HMM), can be considered more suitable for this problem. Our choice for this experiment is a convolutional BiLSTM network. BiLSTM or Bi-directional Long Short Term Memory is a variant of a Recurrent Neural Network (RNN), which has been proven to be extremely powerful in offline recognition in recent years. For example, Bruel et al. achieved a 0.6% Character Error Rate (CER) using a BiLSTM network for printed Latin text [
11]. Shkarupa et al. achieved 78% word-level accuracy in classifying unconstrained Latin handwriting on the KNMP Chronicon Boemorum and Stanford CCCC datasets [
12]. Dutta et al. were able to achieve a 12.61% Word Error Rate (WER) when recognizing unconstrained handwriting on the IAM dataset [
13]. Ingle et al. proposed a line recognition based on neural networks without recurrent connections and achieved a comparable training accuracy with LSTM-based models while allowing better parallelism in training and inference [
14]. They also presented methods for building large datasets for handwriting text recognition models. In contrast, Chammas and Mokbel used an RNN to recognize historical text documents demonstrating how to work with smaller datasets [
15]. Sudholt et al. presented a Convolutional Neural Network (CNN), called Pyramidal Histogram of Characters or PHOCNet, to deploy a query based word spotting algorithm from handwritten Latin documents [
16]. Scheidl et al. demonstrated the benefit of training an RNN with the Connectionist Temporal Classification (CTC) loss function using the IAM and Bentham HTR datasets [
17].
Pattern recognition systems are never error-free and often researchers propose systems with human intervention for assistance with certain predictions [
18,
19]. We also used such a strategy that we call semi-autonomous post-processing, which looks for manual help for unresolved cases. Different segmented text recognition approaches for problems like bank check recognition, signature verification, tabular or form based text identification are also relevant to our chess move recognition problem. One notable demonstration for recognizing segmented handwritten text was presented by Su et al. using two RNN classifiers with Histogram of Oriented Gradient (HOG) and traditional geometric features to obtain 93.32% accuracy [
20].
1.3. Overview of the Presented Approach
This paper presents an end-to end system for offline chess scoresheet recognition with a convolutional BiLSTM neural network as an alternative to the existing inefficient method of manual digitization. To accomplish this, we pretrain a deep neural network on an existing Latin handwriting dataset, IAM [
21] and later fine-tune our model with redefined classes and network size adjustments. Each handwritten move is extracted from its scoresheet during pre-processing and passed through the network to generate a prediction. We used post-processing algorithms to restrict the output and improve accuracy, since valid chess moves allow only a limited set of letters, numbers, and symbols (
Table 1 and
Table 2) in specific positions (e.g., moves cannot start with a number, cannot end with a character, etc.). We also utilized the fact that all moves are not legal from a certain board position; therefore, a valid notation can still be an illegal move and can be detected if we can keep track of the pieces on the board. For example, a piece can not move to a square which is already occupied with a piece of the same color, rooks can not move diagonally and a light square Bishop can not land on dark square. There are plenty of chess engines available which already can tell if a move is legal or not. We used one of them, Stockfish 14.1 [
22], in our post-processing. Leveraging the fact that always two scoresheets are available for a game, we proposed two post-processing mechanisms: an autonomous post-processing which outputs a final prediction for the text box after cross-checking with the game’s second scoresheet; and a semi-autonomous post-processing that increases the recognition accuracy to a near human-level by requesting user input for difficult handwriting samples, invalid entries and unsettling conflict cases. Although the semi-autonomous correction is an interrupting process, it can also save hundreds of hours for event organizers and drastically reduce human labor required for digitizing chess games.
We made the Handwritten Chess Scoresheet (HCS) dataset, which we used for our experiments, openly accessible to encourage further research and development [
23]. This dataset contains scoresheets from actual chess events digitized with a cellphone camera and tagged with associated ground truths. This also has some additional data containing only less frequent chess moves to allow a network to be trained more uniformly. The HCS dataset is currently the only publicly available chess scoresheet dataset. As this is an extension of our original work presented in [
5], we present the details of our entire approach highlighting the changes we made and improvements we achieved since our first attempt.
3. The Handwritten Chess Scoresheet (HCS) Dataset
There were no publicly available chess scoresheet image datasets that we could use when we first presented this approach in [
5]. Therefore, we developed our own, the HCS dataset [
23], to train and test our network. This dataset consists of 158 total games, 53 of which had both copies from the players with white and black pieces and the remaining 105 with just one copy, making a total of 211 pages of chess scoresheet images. All the images were digitized using a standard cellphone camera in natural lighting conditions. These images are tightly cropped, and a standard corner detection based transformation is applied to eliminate perspective distortion. The headers and footers were also cropped out from each image in order to maintain player anonymity. The scoresheets were collected from actual chess events; they were not artificially prepared by volunteers. Despite posing challenges for training, identifying handwriting “in the wild” has more generality than identifying text from artificial, pristine images. The data are therefore very diverse, consisting of many different handwriting and scoresheet styles, varieties in ink colors, natural occurrences of crossed-off, rewritten and out-of-the box samples, a few of which are shown in
Figure 11.
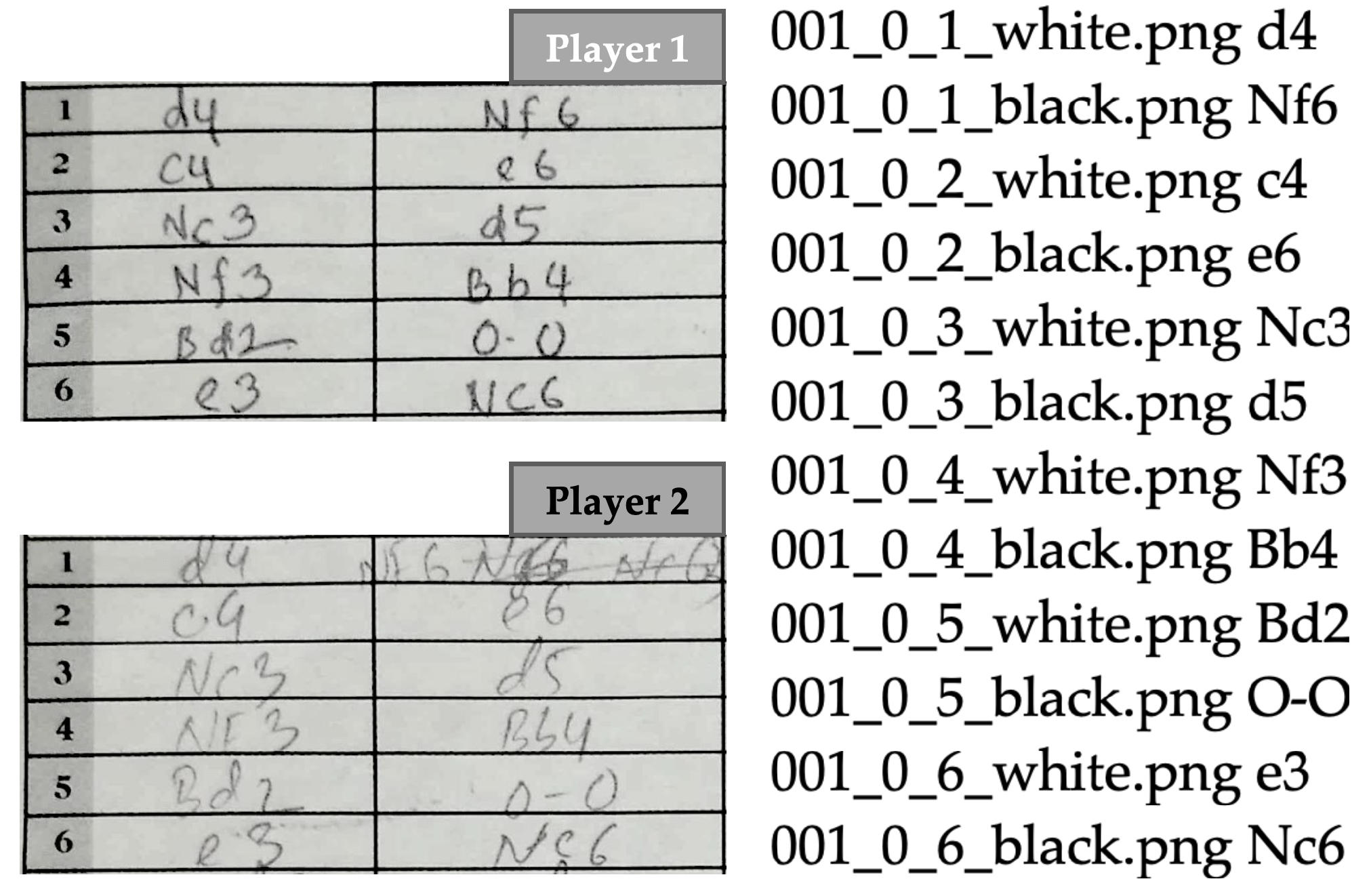
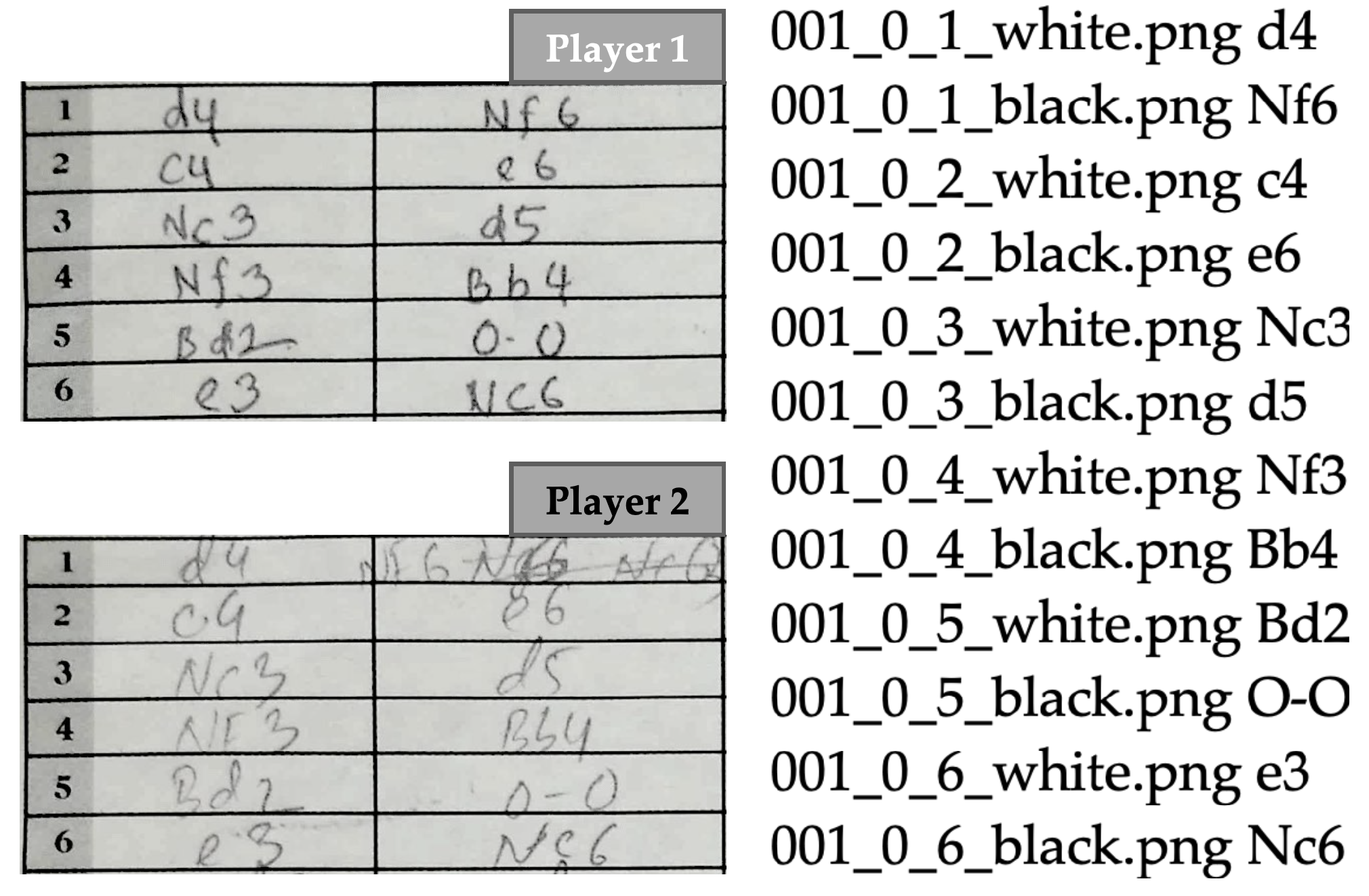
Each scoresheet in the dataset contains 120 text boxes (60 boxes for each player). However, many of these boxes are empty since most chess matches last for far fewer than 60 moves. Omitting the empty boxes, there are approximately 13,810 handwritten chess moves currently in our dataset, with an average of approximately 33 moves (66 for each player) per game. Some of these scoresheets came with a photocopied or carbon copied version as well. These were included in the dataset since such variations of images provide a natural form of data augmentation which can be useful for the training process. We manually created the ground truth version of each game and stored it in a text file. A sample is shown in
Figure 12. Both the images and the ground truth text files are stored with a naming convention given by:
Furthermore, we created an additional dataset to improve the overall balance of our training data. One of the major problems with our first attempt as reported in [
5] was caused by moves that occur rarely. For example, short castles (written as ‘O-O’) are way more common than long castles (written as ‘O-O-O’). This also reflects our dataset as we have around 10 times more samples of castles short than long. Since the network was not well trained with enough data to recognize the long castles, it consistently predicted those as short castles too, which greatly affected the recognition accuracy in our earlier attempt. Other moves like pawn promotions (e.g., ‘f8 = R’) or disambiguating moves (e.g., ‘Nbd7’ or ‘R1f7’ ) are also very rare, and we did not have enough samples in our dataset that is required for a robust training. Therefore, we opted to craft a small dataset of less frequent moves to mitigate this problem. The images of this dataset were not collected from actual games, rather artificially created with the help of volunteer chess players. This contains:
20 samples of long castles or ‘O-O-O’.
20 samples’ pawn promotions from a random file (between ‘a’ and ‘h’) to random promotion pieces (‘Q’, ‘R’, ‘B’ or ‘N’), a few with random events like capture, check, or mate.
20 samples’ random disambiguation moves, 10 from disambiguation files and 10 from disambiguation ranks a few with random events like capture, check, or mate.
A set of sample images from this less frequent moves dataset is shown in
Figure 13. We used the same data augmentation techniques described earlier with this additional dataset as well.
To summarize, this release of the HCS dataset contains:
211 images of scoresheets from 158 unique games collected from actual chess events. Only 53 of these games come with both players’ scoresheet,
60 images of less frequent moves dataset artificially created with the help of volunteer chess players,
8 samples of empty/blank scoresheet images and
25,327 extracted move box images which include 13,810 of written moves and 11,517 of unused blank boxes from the scoresheets.
The HCS dataset is public and free to use for researchers who want to work with similar problems [
23].
4. Training and Results
We used the following set of data for training our BiLSTM network:
161 scoresheet images from our HCS dataset. This includes 28 games where both players’ scoresheets were available and 105 games with single scoresheets. There are 9370 raw move images which with our 10:1 data augmentation scheme expanded into 93,700 training images.
60 additional images of less frequent chess moves from the HCS dataset (described in
Section 2.4 which after augmentation expanded into 600 additional training images.
15 annotated scoresheets or 1160 move images collected from web scraping which after the same augmentation scheme expanded into 11,600 additional training images.
This entire combination gave us a total of 105,900 move images which is a decently sized dataset to obtain a robust training. These data are separated into batches of 32, and trained with a learning rate of 0.0005 using the Adam optimizer for 50 epochs. For testing, we used 25 games or 50 scoresheets, which translates into 1905 testing image pairs or 3810 total move images. This is roughly 15% of our HCS dataset. This test set was composed of data from writers/players unseen by the network during training. Not all of the games in our dataset have unique white and black player copies, which is fine for the network training with our approach. However, since our post-processing pipeline uses a comparison framework from two copies of the same game, the test set is carefully chosen with the games where both white and black player scoresheets are available, which also means that the user needs to submit both scoresheets for a game in order to use our post-processing schemes.
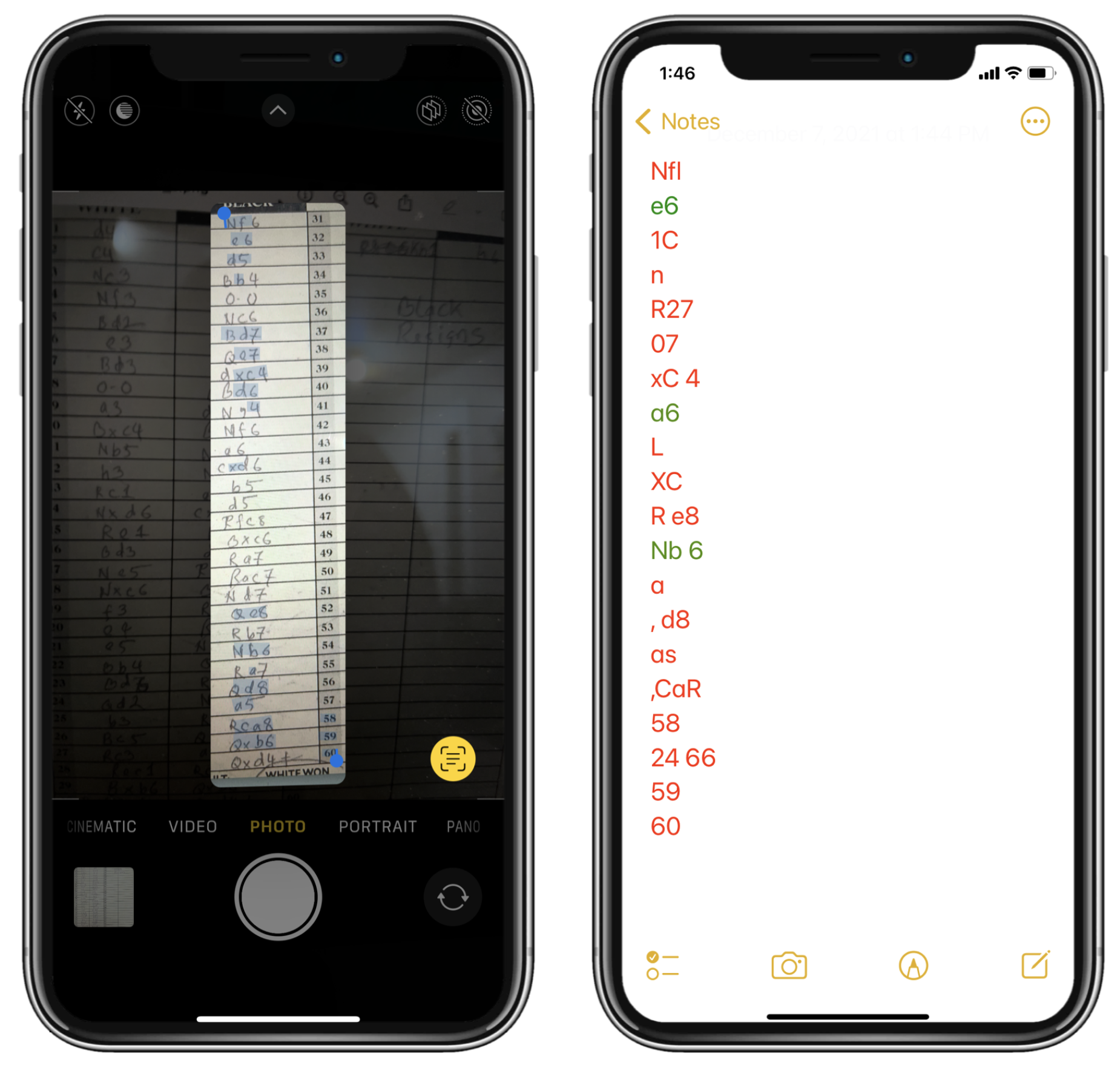
Table 3 presents the performance of our system with different pre and post processing conditions. We used the Live Text as introduced in iOS 15 [
31] and macOS Monterey 12 [
32] by Apple Inc. (California, USA) to its supported devices like iPhones, iPads, Mac computers, etc. to compare our raw move recognition accuracy against an off-the-shelf solution to this problem. The Live Text feature attempts to spot and recognize texts from an image, and generally it works great with handwriting. The move recognition accuracy we obtained with Live Text on a smaller test set is less than 20% compared to the 87.8% of raw recognition accuracy we obtained without any pre or post processing. A sample showing how Live Text struggles to recognize the moves is shown in
Figure 14. This goes to show why a generic offline handwriting recognition solution might not be a viable option for a specialized problem like this.
As can be seen from
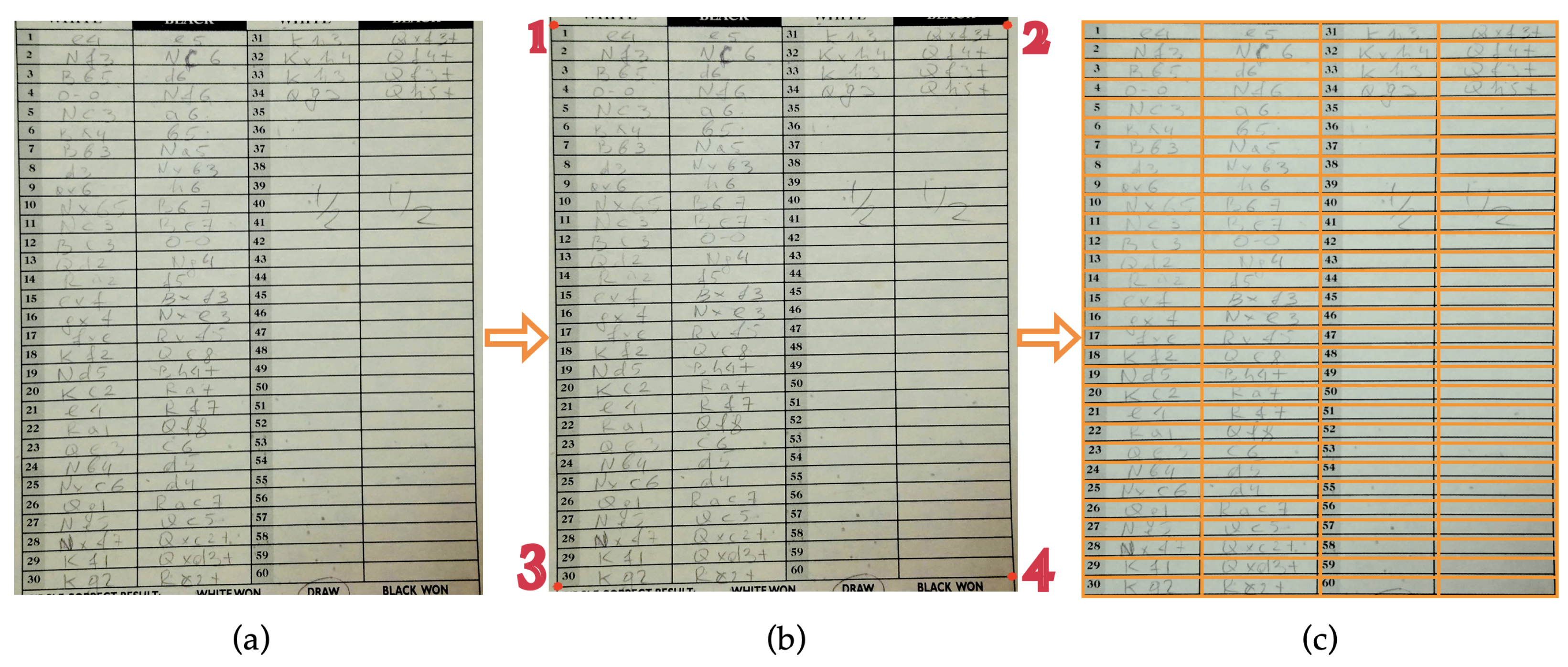
Table 3, the effect of the four-corner-marking preprocessing over our default text box extraction method is fairly small (around 1%) but is consistent across every test scenario. The four-corner-marking approach comes with a cost of convenience, since the user needs to manually mark the corners of a scoresheet table (
Figure 4. Therefore, the default text box extraction method might be more desirable for most practical cases. However, in situations where the absolute best performance out of the system is needed, or maybe with specific types scoresheets where the default text extraction process is not functioning well, the four-corner-marking is a more reliable option for our system.
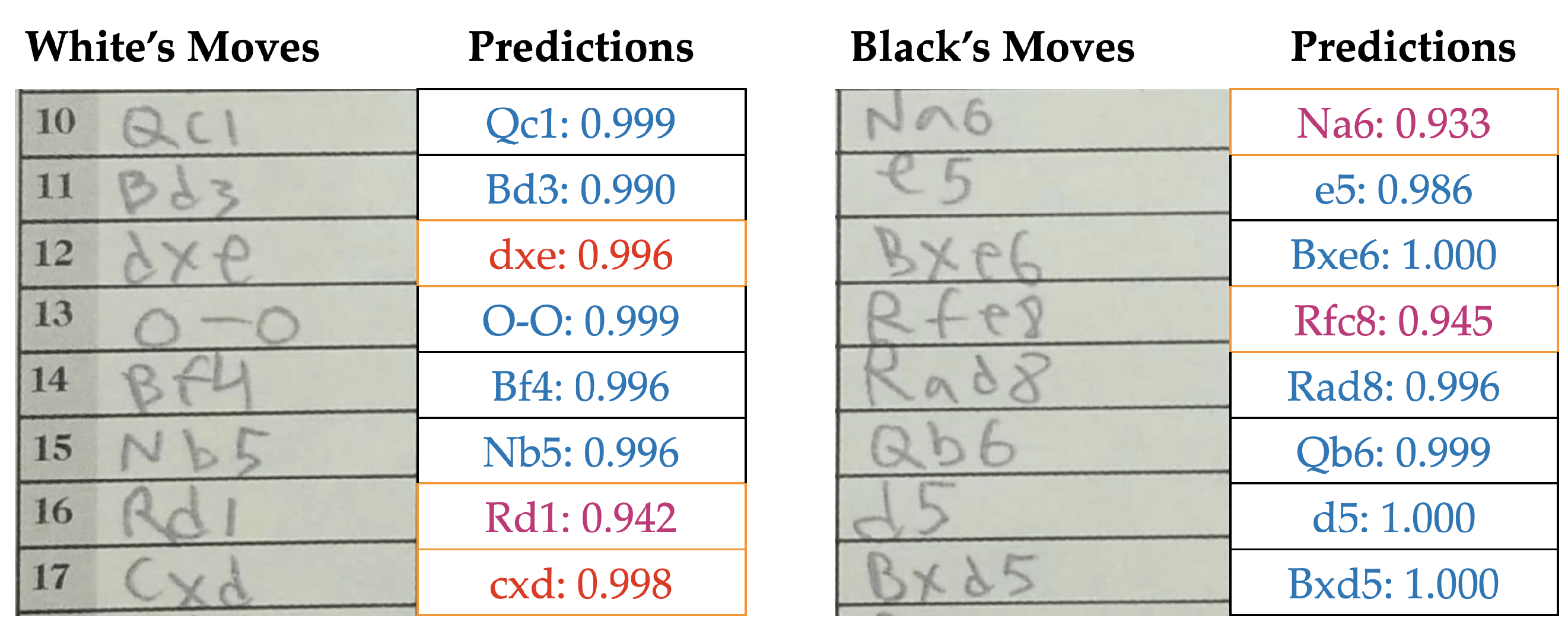
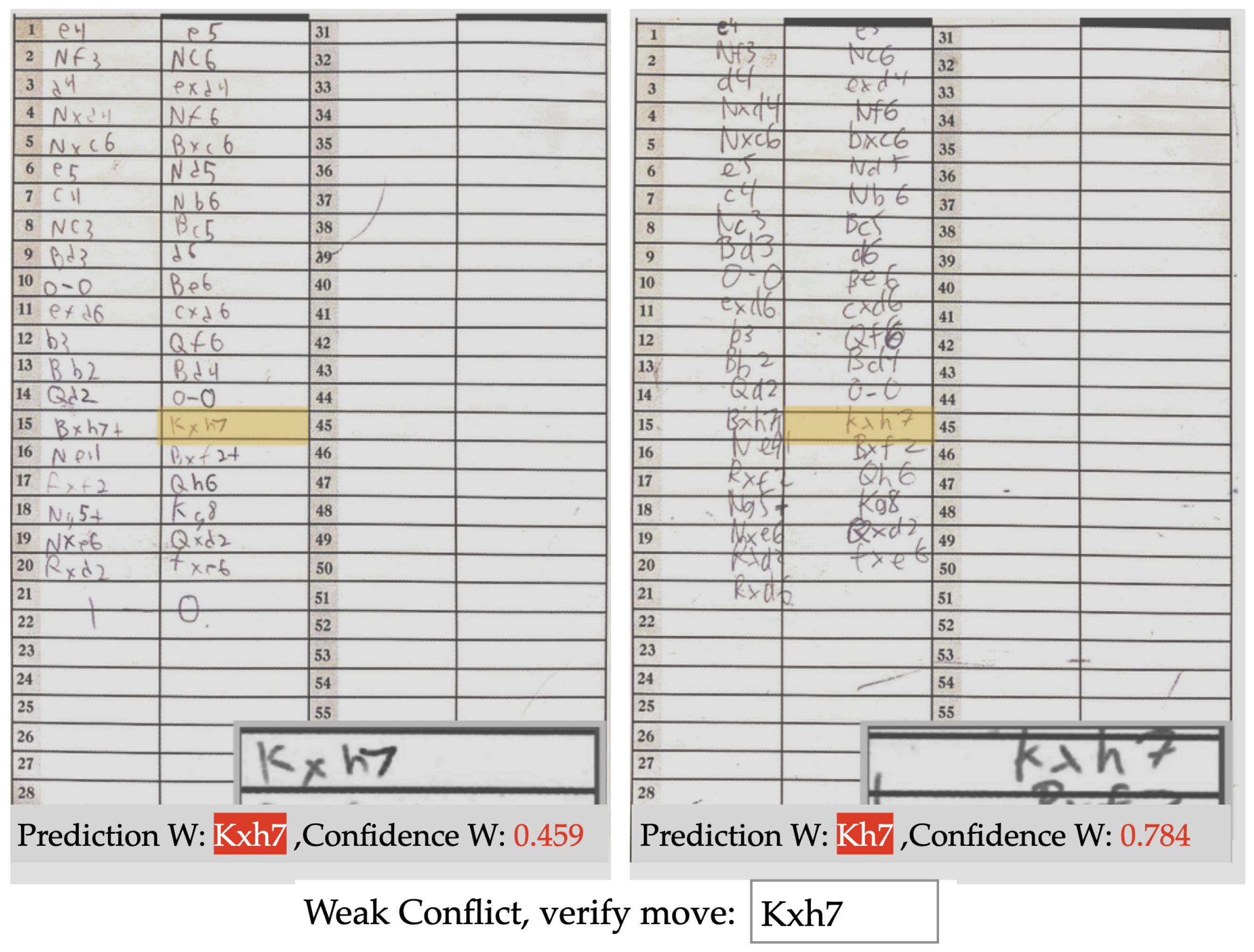
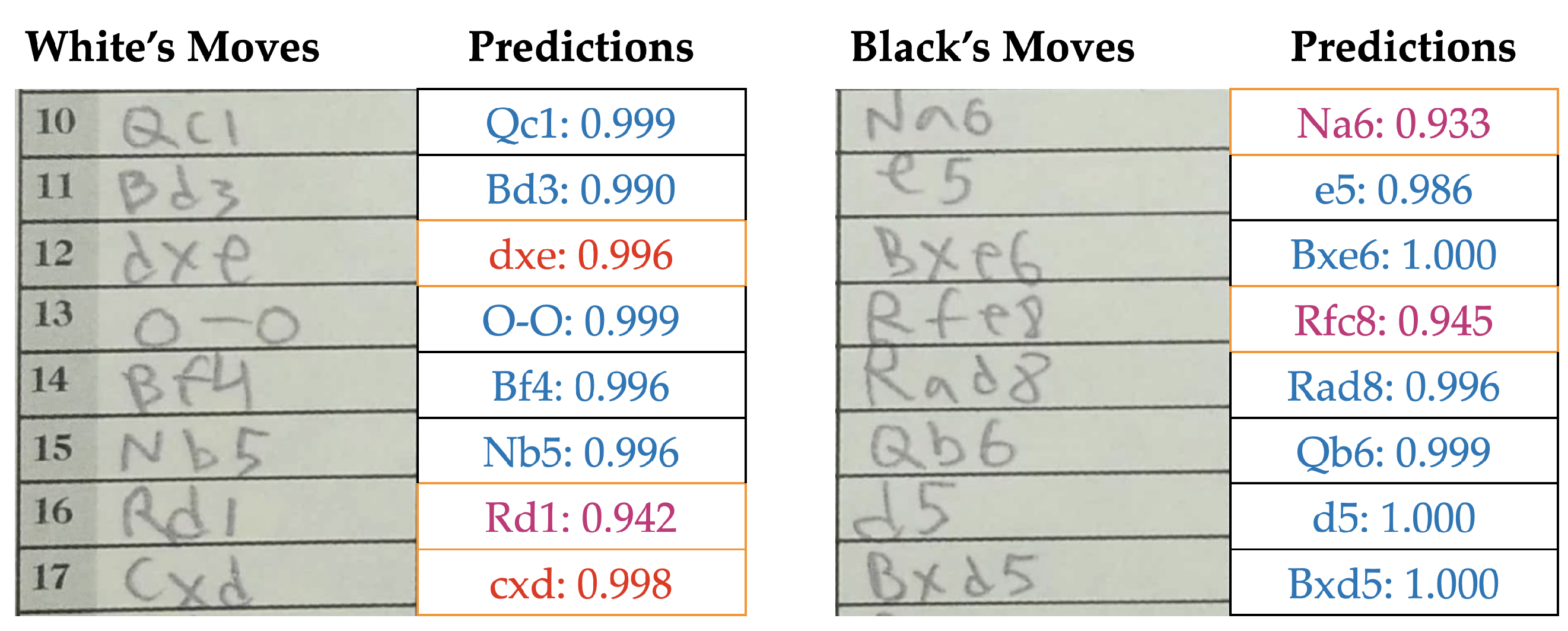
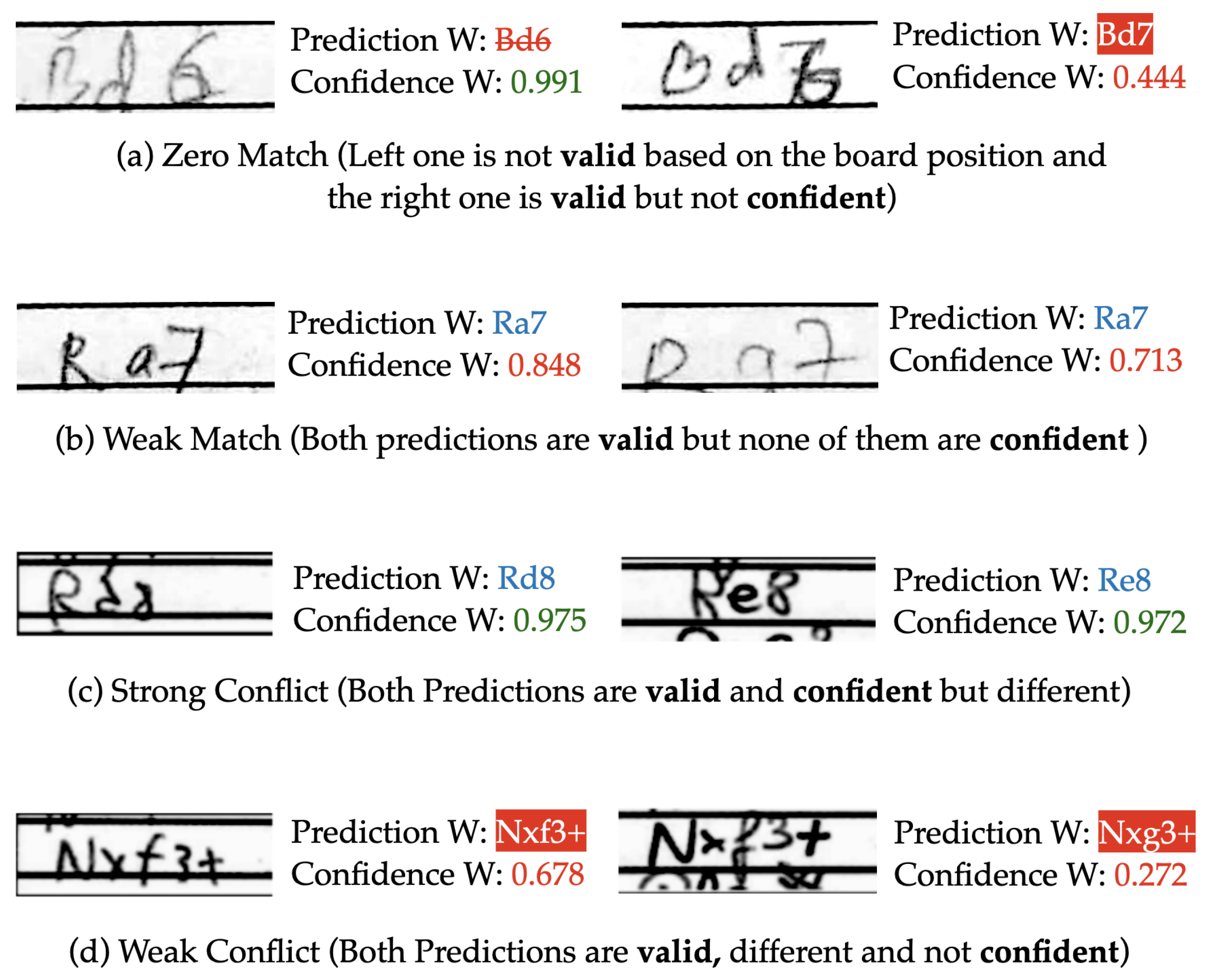
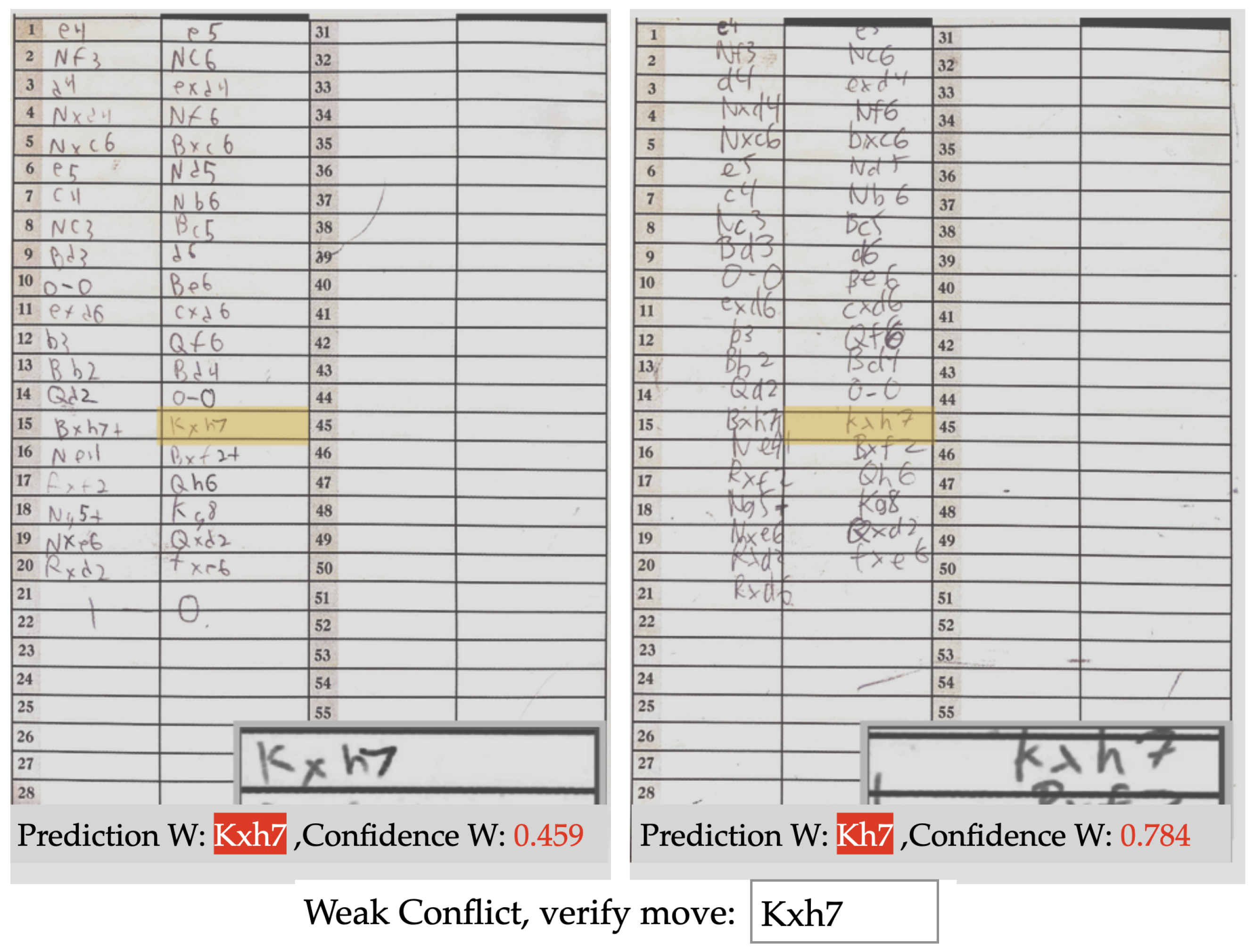
The autonomous post-processing with default text box extraction is an uninterrupted workflow, which gave us a move recognition accuracy of 94.9%. This translates into less than four error cases for a game of average length. This already competes with the legacy approach of pure manual entry with casual human error, especially when recording a lot of games at a stretch. Furthermore, we present the complete scoresheet along with the predictions and their corresponding confidence values. During this presentation, if a move is invalid or illegal, we mark it with red and if the move is legal but below a confidence threshold of 95%, we mark it with magenta. This allows the user to quickly spot, check and correct for any prediction errors or inconsistencies.
Figure 7 shows an example prediction output of our autonomous pipeline.
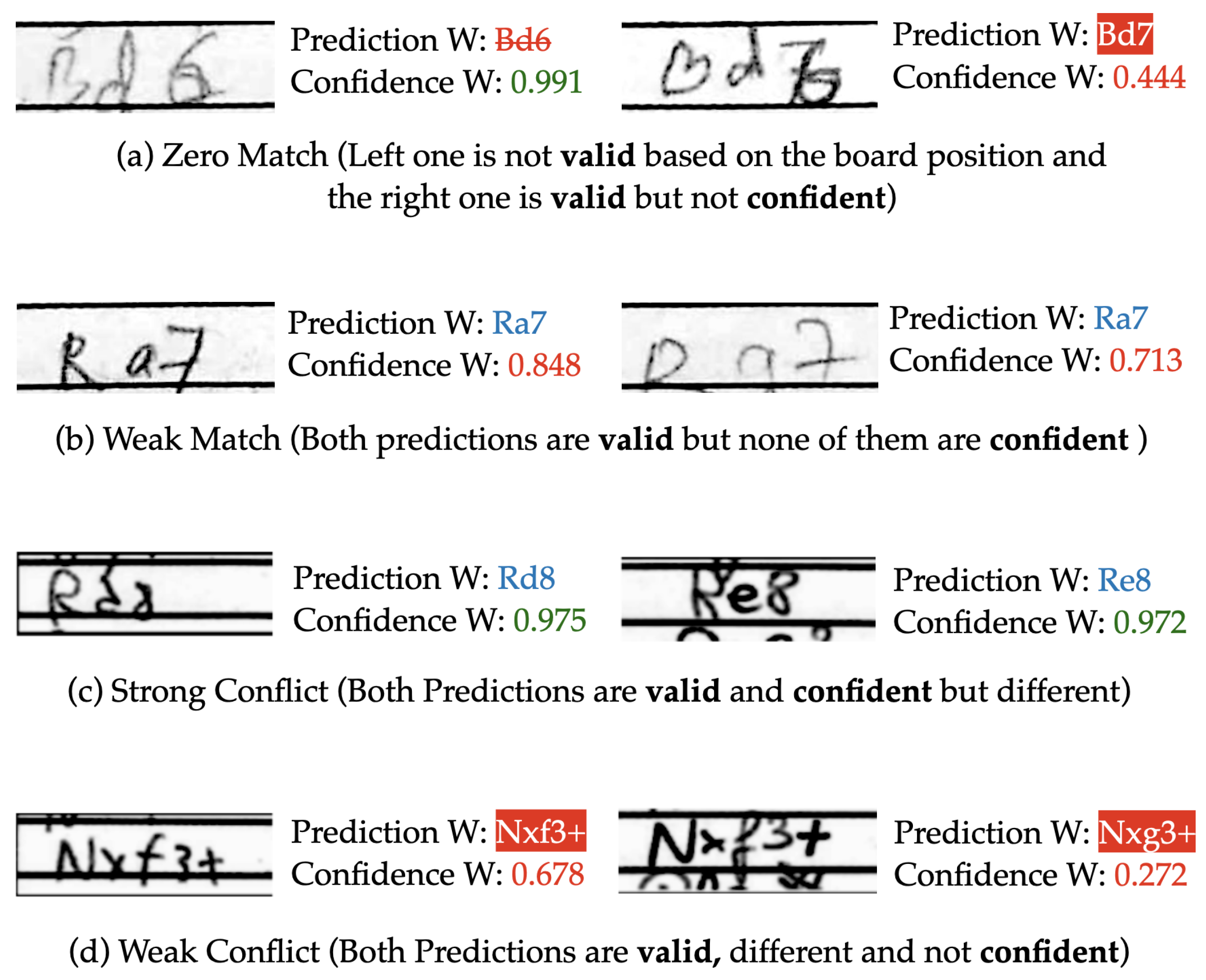
The most drastic improvement is found with the semi-autonomous system with a recognition accuracy of 98.4% (99.1% with four-corner-marking). This is around 11% gain in accuracy, while only requesting user input on 4% of the moves. This means, for a 30 move game ( total moves from both players), a user will be prompted for manual entry 2–3 times on average. In our case, many scoresheets went without any interruption, while, for a few faded and quite illegible scoresheets, it was invoked frequently. The best error rate of 0.9% we obtained out of the system using the four-corner-method combined with semi-autonomous post-processing. This is arguably much better than what we expect from the legacy approach of manual entry. Furthermore, many of these errors are caused when players accidentally write different moves, and one of those moves is above the confidence threshold while the other is not. This means that the user is not prompted for the move (considering both of the moves are valid and legal), and whichever has a higher confidence value is selected. This selection, whether correct or not, is currently counted as an error since the selected move contradicts one of the two samples we have from the players. This error is common, so our true accuracy may be slightly higher than the measured accuracy of 99.1%. Since our current ground truth values are based on the handwriting itself, and not what was played in the game, we may be outputting a prediction which is correct to the game, but not to the handwriting of one scoresheet.
Errors from both autonomous and semi-autonomous systems are primarily caused by incorrect prediction, when the network does not accurately recognize an individual move. These errors generally fall into one of three categories: rare move structures (~20%), illegible writing (~50%), or information lost due to cropping (~30%). Rare or less frequent moves such as pawn promotions, moves involving disambiguation files/ranks, or long castles were a major problem in our first attempt [
5]. While easily recognizable to a human, our real event dataset includes very few (or sometimes no) examples of these move structures, so the network tended towards a simpler and shorter prediction. With the introduction of the less frequent moves dataset as described in
Section 3, the issues with the rare structured moves have been heavily mitigated. Ideally, a larger dataset should reduce this type of error even more. Messy, illegible writing which includes crossed-out or cramped letters (examples shown in
Figure 11) often causes single move errors; however, most of these are solved with our post-processing algorithm. Both the autonomous and semi-autonomous algorithms cross-check both player’s scoresheet, one of which is likely to be written in a better way. Finally, many players do not write a move entirely within its move-box, and this missing information also causes prediction errors.
Along with reporting the excellent performance, we also wanted to quantify the amount of time our different approaches take compared with the time it takes for pure manual entry. In this regard, we collected data by talking with a number of chess event organizers and by involving a number of volunteers to digitize scoresheets using our framework with different pre- and post-processing approaches. The summary of this timing research is presented in
Table 4. Although this is a very small scale research, it should reflect the actual time requirements with a reasonable degree of error. As can be seen, our worst workflow still is twice as fast as best possible cases of manual entry when there are no conflicts or issues with the scoresheets. In addition, these numbers add up pretty quickly for a medium to large tournament. For a chess event with 31 games (e.g., FIDE World Cup 2021), even our most time-consuming workflow can save more than two-and-half hours of manual labor while giving a 99.1% move recognition accuracy. It is tough to estimate how many OTB chess events happen everyday around the globe, but, for sure, that number is a huge one. This implies that our framework or frameworks like this can have a massive impact in the chess world events, let alone the convenience it provides to a player for his/her own growth.
Since, we could not find any similar work reported for handwritten chess scoresheet recognition, and off-the-shelf solutions like Apple’s Live Text are not useful for this problem, we can only compare our work to our former attempt, as presented in [
5]. For the autonomous post-processing, our character recognition accuracy and move recognition accuracy went up by 2.7% and 5.5% respectively. For the semi-autonomous post-processing, we improved our character recognition accuracy and move recognition accuracy by 1.5% and 1.9%, respectively, while the interruption rate went down by 3%. This improvement is caused by a number of things. Firstly, we used more than twice the amount of data. We utilized the Stockfish chess engine to further identify possible errors in detection. Lastly, we crafted an additional dataset for rare occurrence moves which balanced our dataset a little more than our previously used training set. Obviously, the system will become more robust with more data, but there is still room for improvement in post processing. Currently, our evaluation metric is based on what the players wrote, but not what the actual game is. With this approach, if a player mistakenly writes a valid move which is not what he/she played, the move might not be immediately considered as an illegal move. Rather, at a later stage of the game, a contradiction might occur causing an actual true move to be labeled illegal. This problem can be resolved if we can keep track of all probable paths of the game, and at the end we would present the entire game path which causes the least amount of contradictions with what the players wrote in their scoresheets.
5. Conclusions
Although the core of this approach of scoresheet digitization was first presented by us in [
5], we have made a substantial amount of progress since then. We upgraded our dataset and training process, introduced a more reliable preprocessing technique and improved our post-processing pipeline by utilizing a chess engine. Starting with this relatively small HCS dataset, we were able to achieve an accuracy of almost 95% with no human interaction needed other than just to take the photos with his/her cell phone camera. This autonomous approach almost instantly presents the resultant scoresheet to the user with highlights for the low confidence predictions and possible illegal or invalid moves. This also allows the user to quickly correct a few moves if needed. Our semi-autonomous approach increased this accuracy to around 99% with an average of less than three interrupts per game needed for human intervention. Although this accuracy is potentially way better than actual human level performance in most practical scenarios, even a 1% error rate can cause big issues in some sensitive cases. This small gap from a perfect result could be further reduced by getting more data for training and adding more samples of rare occurrence moves whether synthetically or organically. Along with that, a more sophisticated post-processing system could be deployed which not only makes predictions move by move, but presents an entire game with least edit distance required from the series of predictions. With tools from graph theory, it could be possible to determine the fewest number of alterations required in order to have a top-to-bottom valid game—this could take the system accuracy even closer to a 100% accurate system. Another possibility is to utilize the most played moves in a certain position in the post-processing, which could be especially useful in common chess openings. Thanks to the rapid growth in online chess, lots of open source databases are available to get this information. In order to encourage further research and development in this area, we offer our HCS dataset to the public [
23]. We also have a future plan to make this framework openly accessible to the chess community.
The applications of deep learning have been assisting us in countless different ways, and yet almost no meaningful attempt has been made to resolve this seemingly obvious problem of chess scoresheet digitization. The chess world is a gigantic community and the number of events and activities is always growing. A handwriting recognition framework can be particularly useful with chess since players are bound to record moves by hand in order to prevent computer aided cheating. Although the process of digital record keeping with human labor has never been considered as a problem, we do not have to keep the legacy approach when and if the technology allows us to improve. Here, we present an attempt to save thousands of man-hours currently being spent by event organizers to transform chess scoresheets into standard PGN files. While saving a substantial amount of manpower, our framework also makes the record-keeping process extremely convenient and arguably more reliable. Chess scoresheet digitization has a variety of uses from post-game engine analysis to efficient game-publishing, and in most professional and serious events, it is mandatory to keep these records. Therefore, we firmly believe that our presented approach can have a big influence, and potentially revolutionize the chess event management system practiced today.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}