

Colorizing the Past: Deep Learning for the Automatic Colorization of Historical Aerial Images




Abstract
1. Introduction
Data and Paper Contribution
- (a)
- Testing and evaluating the performance of several state-of-the-art and recent deep-learning models to colorize grayscale aerial images;
- (b)
- (c)
- Collecting and sharing a new benchmark dataset for colorizing historical aerial photographs (some 10,000 image patches).
2. Related Works
2.1. User-Guided Approaches
2.2. Deep Learning for Colorization
2.2.1. Convolution Neural Networks (CNNs)
2.2.2. Generative Adversarial Networks (GANs)
2.3. Colorization of Aerial-Scale Images
2.4. Benchmarking Methods
- The joint learning of global and local image priors with the simultaneous classification approach proposed by Iizuka et al. [43];
- The Larsson et al. [22] method, based on the exploitation of both low-level and semantic representations;
- The colorization approach of Zhang et al. [42], addressed as a classification task;
- The NoGAN technique, available in the Deoldify (Antic [57]) and relying on a modified version of U-NET;
- The Instance-Aware colorization method of Su et al. [60], where the architecture leverages a network for extracting object-level and full-image features.
3. Proposed Method
3.1. Color Space
3.2. Proposed Architecture
3.2.1. The U-NET Part
3.2.2. The HyperConnections Part
3.3. Training Data
4. Experiments and Results
4.1. Evaluation Metrics
- (1)
- The ∆E2000 (DeltaE-CIEDE2000) (Equation (9)):
- (2)
- The mean absolute error (MAE) (Equation (10)), i.e., the average of the absolute differences between the observed and predicted color values, defined as follows:
- (3)
- The peak signal-to-noise ratio (PSNR) [72] (Equation (11)), defined as:
- (4)
- The Structural Similarity Index Measure (SSIM) [73] (Equation (12)), defined as:
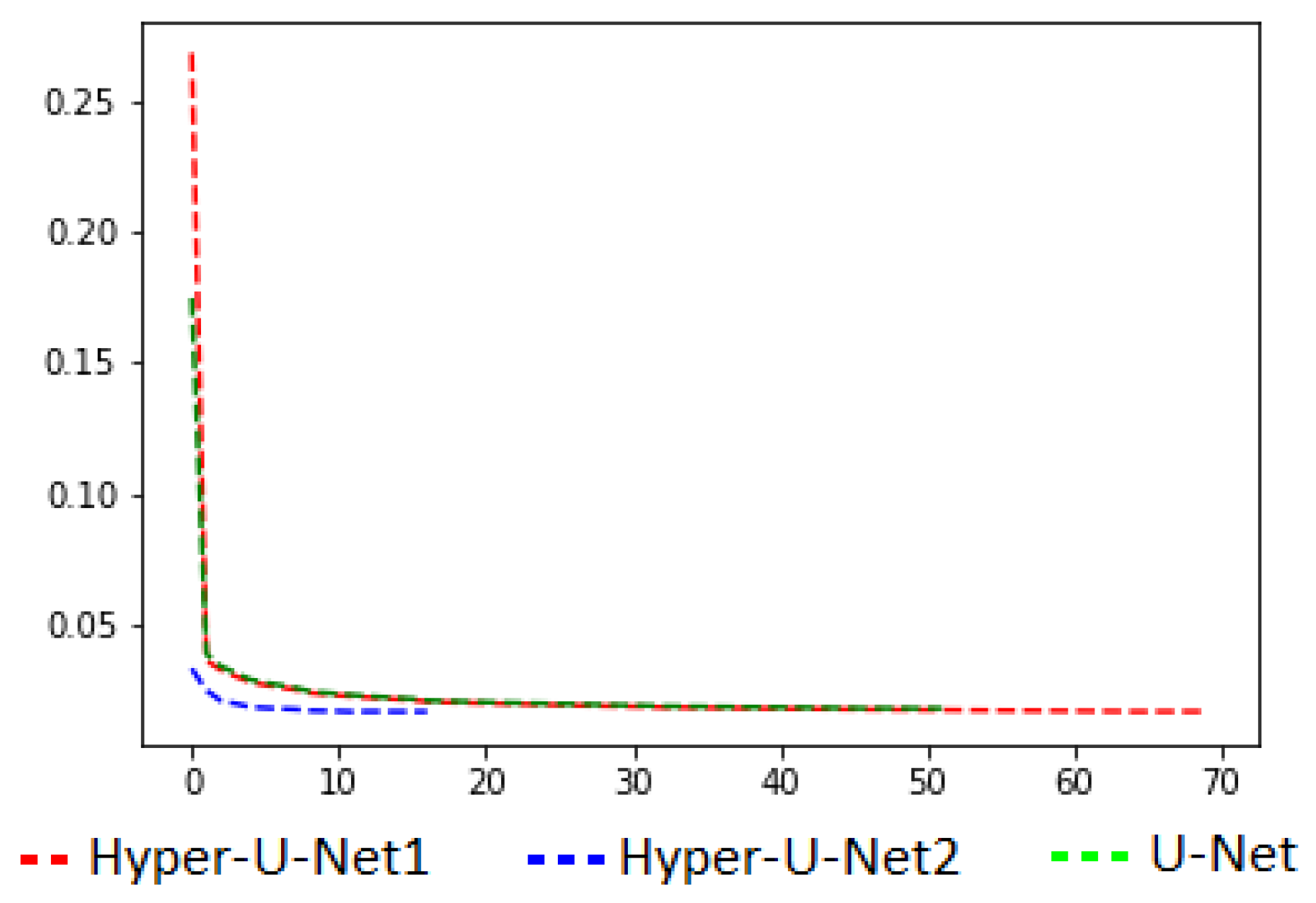
4.2. Ablation Experiment
- (a)
- U-NET: a standard U-NET model trained on our dataset. The model has the same configuration as our Hyper-U-NET, except for the HyperConnections and the last extra three layers;
- (b)
- Hyper-U-NET1: the model proposed in the paper, trained from the beginning on our dataset;
- (c)
- Hyper-U-NET2: unlike the previous case, it is finetuned based on the best model found on the U-NET part.
4.3. Colorization of Historical Aerial Images
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, R.; Zhu, Y.J.; Isola, P.; Geng, X.; Lin, S.A.; Yu, T.; Efros, A.A. Real-time user-guided image colorization with learned deep priors. arXiv preprint 2017, arXiv:1705.02999. [Google Scholar] [CrossRef]
- Kumar, K.S.; Basy, S.; Shukla, N.R. Image Colourization and Object Detection Using Convolutional Neural Networks. Int. J. Psychosoc. Rehabil. 2020, 24, 1059–1062. [Google Scholar]
- Zhao, J.; Han, J.; Shao, L.; Snoek, C.G. Pixelated Semantic Colorization. Int. J. Comput. Vis. 2020, 128, 818–834. [Google Scholar] [CrossRef]
- Lagodzinski, P.; Smolka, B. Colorization of medical images. In Proceedings of the APSIPA ASC 2009: Asia-Pacific Signal and Information Processing Association, 2009 Annual Summit and Conference, Sappora, Japan, 4–7 October 2009; pp. 769–772. [Google Scholar]
- Nida, N.; Sharif, M.; Khan, M.U.G.; Yasmin, M.; Fernandes, S.L. A framework for automatic colorization of medical imaging. IIOAB J. 2016, 7, 202–209. [Google Scholar]
- Khan, M.U.G.; Gotoh, Y.; Nida, N. Medical image colorization for better visualization and segmentation. In Proceedings of the Annual Conference on Medical Image Understanding and Analysis; Springer: Cham, Switzerland, 2017; pp. 571–580. [Google Scholar]
- Jin, X.; Li, Z.; Liu, K.; Zou, D.; Li, X.; Zhu, X.; Zhou, Z.; Sun, Q.; Liu, Q. Focusing on Persons: Colorizing Old Images Learning from Modern Historical Movies. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 1176–1184. [Google Scholar]
- Anwar, S.; Tahir, M.; Li, C.; Mian, A.; Khan, F.S.; Muzaffar, A.W. Image colorization: A survey and dataset. arXiv preprint 2020, arXiv:2008.10774. [Google Scholar]
- Dalal, H.; Dangle, A.; Radhika, M.J.; Gore, S. Image Colorization Progress: A Review of Deep Learning Techniques for Automation of Colorization. Int. J. Adv. Trends Comput. Sci. Eng. 2021, 10. [Google Scholar] [CrossRef]
- Noaman, M.H.; Khaled, H.; Faheem, H.M. Image Colorization: A Survey of Methodolgies and Techniques. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics; Springer: Cham, Switzerland, December 2021; pp. 115–130. [Google Scholar]
- Pierre, F.; Aujol, J.F. Recent approaches for image colorization. In Handbook of Mathematical Models and Algorithms in Computer Vision and Imaging: Mathematical Imaging and Vision; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–38. [Google Scholar]
- Žeger, I.; Grgic, S.; Vuković, J.; Šišul, G. Grayscale image colorization methods: Overview and evaluation. IEEE Access 2021, 9, 113326–113346. [Google Scholar] [CrossRef]
- Chen, S.Y.; Zhang, J.Q.; Zhao, Y.Y.; Rosin, P.L.; Lai, Y.K.; Gao, L. A review of image and video colorization: From analogies to deep learning. Visual Inform. 2022, 9, 1–17. [Google Scholar] [CrossRef]
- Huang, S.; Jin, X.; Jiang, Q.; Liu, L. Deep learning for image colorization: Current and future prospects. Eng. Appl. Artif. Intell. 2022, 114, 105006. [Google Scholar] [CrossRef]
- Poterek, Q.; Herrault, P.A.; Skupinski, G.; Sheeren, D. Deep learning for automatic colorization of legacy grayscale aerial photographs. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2899–2915. [Google Scholar] [CrossRef]
- Dias, M.; Monteiro, J.; Estima, J.; Silva, J.; Martins, B. Semantic segmentation and colorization of grayscale aerial imagery with W-Net models. Expert Syst. 2020, 37, e12622. [Google Scholar] [CrossRef]
- Seo, D.K.; Kim, Y.H.; Eo, Y.D.; Park, W.Y. Learning-based colorization of grayscale aerial images using random forest regression. Appl. Sci. 2018, 8, 1269. [Google Scholar] [CrossRef]
- Farella, E.M.; Morelli, L.; Remondino, F.; Mills, J.P.; Haala, N.; Crompvoets, J. The EuroSDR TIME benchmark for historical aerial images. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2022, XLIII-B2, 1175–1182. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, October 2015; pp. 234–241. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar] [CrossRef]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Learning representations for automatic colorization. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 577–593. [Google Scholar]
- Levin, A.; Lischinski, D.; Weiss, Y. Colorization using optimization. ACM SIGGRAPH Pap. 2004, 23, 689–694. [Google Scholar] [CrossRef]
- Qu, Y.; Wong, T.T.; Heng, P.A. Manga colorization. ACM Trans. Graph. 2006, 25, 1214–1220. [Google Scholar] [CrossRef]
- Sýkora, D.; Dingliana, J.; Collins, S. Lazybrush: Flexible painting tool for hand-drawn cartoons. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, April 2009; Volume 28, pp. 599–608. [Google Scholar]
- Li, S.; Liu, Q.; Yuan, H. Overview of scribbled-based colorization. Art Des. Rev. 2018, 6, 169. [Google Scholar] [CrossRef]
- Huang, Y.C.; Tung, Y.S.; Chen, J.C.; Wang, S.W.; Wu, J.L. An adaptive edge detection based colorization algorithm and its applications. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; ACM: New York, NY, USA, 2005; pp. 351–354. [Google Scholar]
- Yatziv, L.; Sapiro, G. Fast Image and Video Colorization Using Chrominance Blending. IEEE Trans. Image Processing 2006, 15, 1120–1129. [Google Scholar] [CrossRef]
- Luan, Q.; Wen, F.; Cohen-Or, D.; Liang, L.; Xu, Y.Q.; Shum, H.Y. Natural image colorization. In Proceedings of the 18th Eurographics Conference on Rendering Techniques., Goslar, Germany, 25–27 June 2007; Eurographics Association: Goslar, Germany, 2007; pp. 309–320. [Google Scholar]
- Xu, L.; Yan, Q.; Jia, J. A Sparse Control Model for Image and Video Editing. ACM Trans. Graph. 2013, 32, 197. [Google Scholar] [CrossRef]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analogies. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 327–340. [Google Scholar]
- Reinhard, E.; Adhikhmin, M.; Gooch, B.; Shirley, P. Color transfer between images. IEEE Comput. Graph. Appl. 2001, 21, 34–41. [Google Scholar] [CrossRef]
- Welsh, T.; Ashikhmin, M.; Mueller, K. Transferring color to greyscale images. ACM Trans. Graph. 2002, 21, 277–280. [Google Scholar] [CrossRef]
- Di Blasi, G.; Reforgiato, D. Fast colorization of gray images. Eurographics Ital. Chapter 2003, 2003, 1–8. [Google Scholar]
- Li, B.; Zhao, F.; Su, Z.; Liang, X.; Lai, Y.K.; Rosin, P.L. Example-based image colorization using locality consistent sparse representation. IEEE Trans. Image Processing 2017, 26, 5188–5202. [Google Scholar] [CrossRef] [PubMed]
- Gupta, R.K.; Chia, A.Y.-S.; Rajan, D.; Ng, E.S.; Zhiyong, H. Image Colorization Using Similar Images. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 369–378. [Google Scholar]
- Cheng, Z.; Yang, Q.; Sheng, B. Deep colorization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 415–423. [Google Scholar]
- Deshpande, A.; Rock, J.; Forsyth, D. Learning large-scale automatic image colorization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 567–575. [Google Scholar]
- Agrawal, M.; Sawhney, K. Exploring Convolutional Neural Networks for Automatic Image Colorization; Stanford University: Standford, CA, USA, 2016; p. 409. [Google Scholar]
- Hwang, J.; Zhou, Y. Image Colorization with Deep Convolutional Neural Networks; Stanford University: Standford, CA, USA, 2016; Available online: cs231n.stanford.edu/reports/2016/pdfs/219_Report.pdf (accessed on 29 September 2022).
- Nguyen, T.; Mori, K.; Thawonmas, R. Image colorization using a deep convolutional neural network. arXiv preprint 2016, arXiv:1604.07904. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 649–666. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Let There Be Color! Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification. ACM Trans. Graph. 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Royer, A.; Kolesnikov, A.; Lampert, C.H. Probabilistic image colorization. arXiv preprint 2017, arXiv:1705.04258v1. [Google Scholar]
- Guadarrama, S.; Dahl, R.; Bieber, D.; Norouzi, M.; Shlens, J.; Murphy, K. Pixcolor: Pixel recursive colorization. arXiv preprint 2017, arXiv:1705.07208. [Google Scholar]
- Dabas, C.; Jain, S.; Bansal, A.; Sharma, V. Implementation of image colorization with convolutional neural network. Int. J. Syst. Assur. Eng. Manag. 2020, 11, 1–10. [Google Scholar] [CrossRef]
- Pahal, S.; Sehrawat, P. Image Colorization with Deep Convolutional Neural Networks. In Advances in Communication and Computational Technology; Springer: Singapore, 2020; pp. 45–56. [Google Scholar]
- Liu, L.; Jiang, Q.; Jin, X.; Feng, J.; Wang, R.; Liao, H.; Lee, S.J.; Yao, S. CASR-Net: A color-aware super-resolution network for panchromatic image. Eng. Appl. Artif. Intell. 2022, 114, 105084. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Processing Syst. 2014, 27, 2672–2680. [Google Scholar]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv preprint 2014, arXiv:1411.1784. [Google Scholar]
- Hoang, Q.; Nguyen, T.D.; Le, T.; Phung, D. MGAN: Training generative adversarial nets with multiple generators. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Nazeri, K.; Ng, E.; Ebrahimi, M. Image Colorization Using Generative Adversarial Networks. In International Conference on Articulated Motion and Deformable Objects; Springer: Cham, Switzerland, 2018; pp. 85–94. [Google Scholar]
- Cao, Y.; Zhou, Z.; Zhang, W.; Yu, Y. Unsupervised diverse colorization via generative adversarial networks. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2017; pp. 151–166. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2017, 1125–1134. [Google Scholar] [CrossRef]
- Antic, J. Jantic/deoldify: A Deep Learning Based Project for Colorizing and Restoring Old Images (and Video!). 2019. Available online: https://github.com/jantic/DeOldify (accessed on 16 October 2019).
- Mourchid, Y.; Donias, M.; Berthoumieu, Y. Dual Color-Image Discriminators Adversarial Networks for Generating Artificial-SAR Colorized Images from SENTINEL-1. In Proceedings of the MACLEAN: Machine Learning for Earth Observation Workshop (ECML/PKDD 2020), Virtual Conference, 14–18 September 2020. [Google Scholar]
- Vitoria, P.; Raad, L.; Ballester, C. ChromaGAN: Adversarial picture colorization with semantic class distribution. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 2–5 March 2020; pp. 2445–2454. [Google Scholar]
- Su, J.W.; Chu, H.K.; Huang, J.B. Instance-aware image colorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7968–7977. [Google Scholar]
- Du, K.; Liu, C.; Cao, L.; Guo, Y.; Zhang, F.; Wang, T. Double-Channel Guided Generative Adversarial Network for Image Colorization. IEEE Access 2021, 9, 21604–21617. [Google Scholar] [CrossRef]
- Treneska, S.; Zdravevski, E.; Pires, I.M.; Lameski, P.; Gievska, S. GAN-Based Image Colorization for Self-Supervised Visual Feature Learning. Sensors 2022, 22, 1599. [Google Scholar] [CrossRef] [PubMed]
- Song, Q.; Xu, F.; Jin, Y.Q. Radar image colorization: Converting single-polarization to fully polarimetric using deep neural networks. IEEE Access 2017, 6, 1647–1661. [Google Scholar] [CrossRef]
- Liu, H.; Fu, Z.; Han, J.; Shao, L.; Liu, H. Single satellite imagery simultaneous super-resolution and colorization using multi-task deep neural networks. J. Vis. Commun. Image Represent. 2018, 53, 20–30. [Google Scholar] [CrossRef]
- Ballester, C.; Bugeau, A.; Carrillo, H.; Clément, M.; Giraud, R.; Raad, L.; Vitoria, P. Influence of Color Spaces for Deep Learning Image Colorization. arXiv preprint 2022, arXiv:2204.02850. [Google Scholar]
- BT.601. Studio encoding parameters of digital television for standard 4:3 and wide-screen 16:9 aspect ratios; The International Telecommunication Union: Geneva, Switzerland, 2011; p. 624. [Google Scholar]
- Hong, G.; Luo, M.R. New algorithm for calculating perceived colour difference of images. Imaging Sci. J. 2006, 54, 86–91. [Google Scholar] [CrossRef]
- Gupta, P.; Srivastava, P.; Bhardwaj, S.; Bhateja, V. A modified PSNR metric based on HVS for quality assessment of color images. In Proceedings of the 2011 International Conference on Communication and Industrial Application, Kolkata, India, 26–28 December 2011; pp. 1–4. [Google Scholar]
- Yang, Y.; Ming, J.; Yu, N. Color image quality assessment based on CIEDE2000. Adv. Multimed. 2012, 2012, 273723. [Google Scholar] [CrossRef]
- Grečova, S.; Morillas, S. Perceptual similarity between color images using fuzzy metrics. J. Vis. Commun. Image Represent. 2016, 34, 230–235. [Google Scholar] [CrossRef]
- Mokrzycki, W.S.; Tatol, M. Colour difference ∆E-A survey. Mach. Graph. Vis. 2011, 20, 383–411. [Google Scholar]
- Johnson, D.H. Signal-to-noise ratio. Scholarpedia 2006, 1, 2088. [Google Scholar] [CrossRef]
- Brunet, D.; Vrscay, E.R.; Wang, Z. On the mathematical properties of the structural similarity index. IEEE Trans. Image Processing 2011, 21, 1488–1499. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv preprint 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ∆E 2000 ↓ | MAE ↓ | PSNR ↑ | SSIM ↑ | |
|---|---|---|---|---|
| U-NET | 0.797 | 4.315 | 32.9 | 98.32 |
| Hyper-U-NET1 | 0.735 | 4.058 | 33.302 | 98.46 |
| Hyper-U-NET2 | 0.723 | 3.957 | 33.508 | 98.47 |
| Training Time (h) | Prediction Time (s) | Epochs | |
|---|---|---|---|
| U-NET | 15.1 | 0.132 | 47 |
| Hyper-U-NET1 | 30.3 | 0.149 | 65 |
| Hyper-U-NET2 | 20.7 | 0.149 | 12 |
| ∆E 2000 ↓ | MAE ↓ | PSNR ↑ | SSIM ↑ | |
|---|---|---|---|---|
| Iizuka et al. [43] | 1.683 | 10.506 | 26.257 | 0.955 |
| Larsson et al. [22] | 1.777 | 34.309 | 21.273 | 0.913 |
| Zhang et al. [42] | 1.620 | 11.721 | 25.318 | 0.951 |
| Antic [57] | 1.716 | 10.257 | 25.749 | 0.946 |
| Su et al. [60] | 1.604 | 10.413 | 26.200 | 0.949 |
| Our | 0.764 | 3.987 | 33.287 | 0.980 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farella, E.M.; Malek, S.; Remondino, F. Colorizing the Past: Deep Learning for the Automatic Colorization of Historical Aerial Images. J. Imaging 2022, 8, 269. https://doi.org/10.3390/jimaging8100269
Farella EM, Malek S, Remondino F. Colorizing the Past: Deep Learning for the Automatic Colorization of Historical Aerial Images. Journal of Imaging. 2022; 8(10):269. https://doi.org/10.3390/jimaging8100269
Chicago/Turabian StyleFarella, Elisa Mariarosaria, Salim Malek, and Fabio Remondino. 2022. "Colorizing the Past: Deep Learning for the Automatic Colorization of Historical Aerial Images" Journal of Imaging 8, no. 10: 269. https://doi.org/10.3390/jimaging8100269
APA StyleFarella, E. M., Malek, S., & Remondino, F. (2022). Colorizing the Past: Deep Learning for the Automatic Colorization of Historical Aerial Images. Journal of Imaging, 8(10), 269. https://doi.org/10.3390/jimaging8100269