
On the Limitations of Visual-Semantic Embedding Networks for Image-to-Text Information Retrieval




Abstract
:1. Introduction
2. Related Methods
3. Materials and Methods
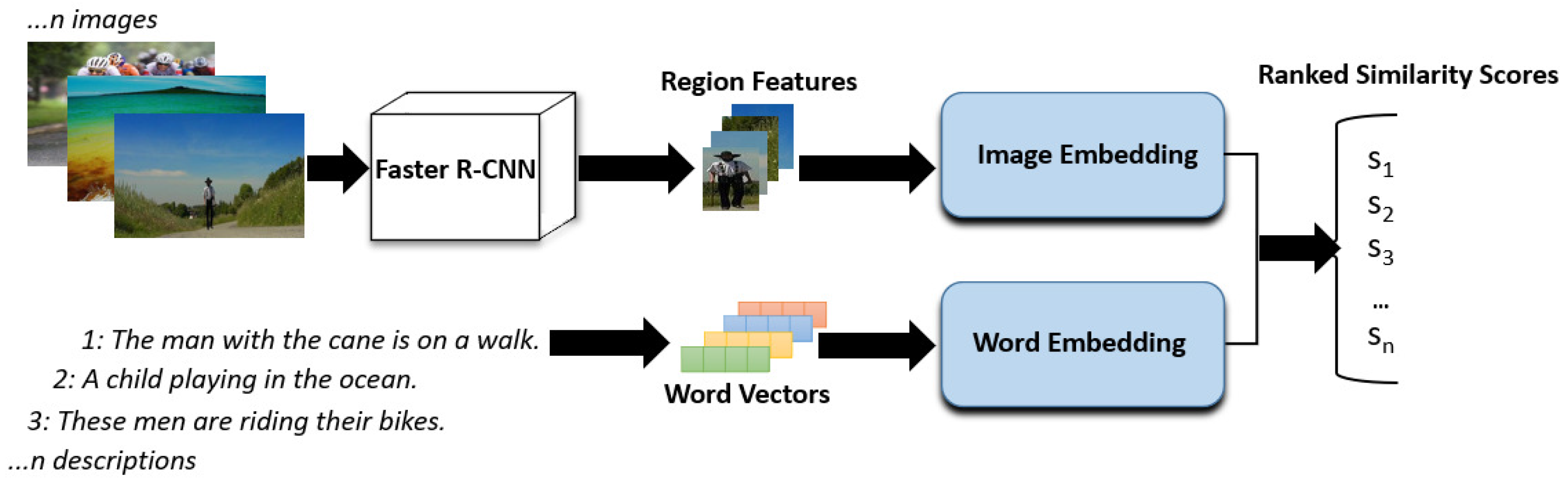
3.1. Dataset and VSE Network Preparation
3.2. Performance Evaluation Measures
3.3. Experiment 1 Methodology for the Comparison of VSE Networks for Image-to-Text Retrieval
3.4. Experiment 2 Methodology for Finding the Limitations of VSE Networks
4. Results
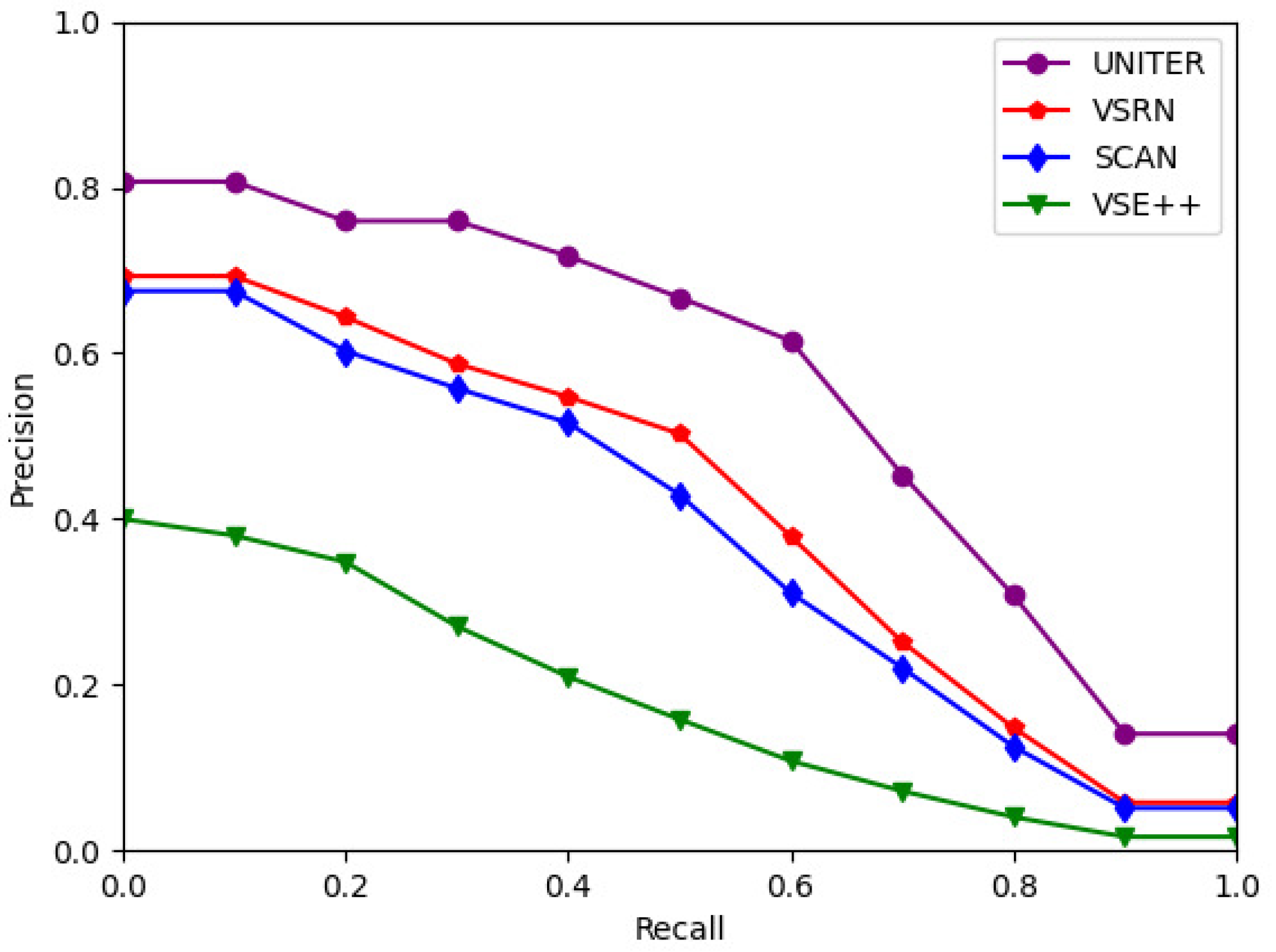
4.1. Results of Experiment 1: Comparison of VSE++, SCAN, VSRN, and UNITER for Image-to-Text Retrieval
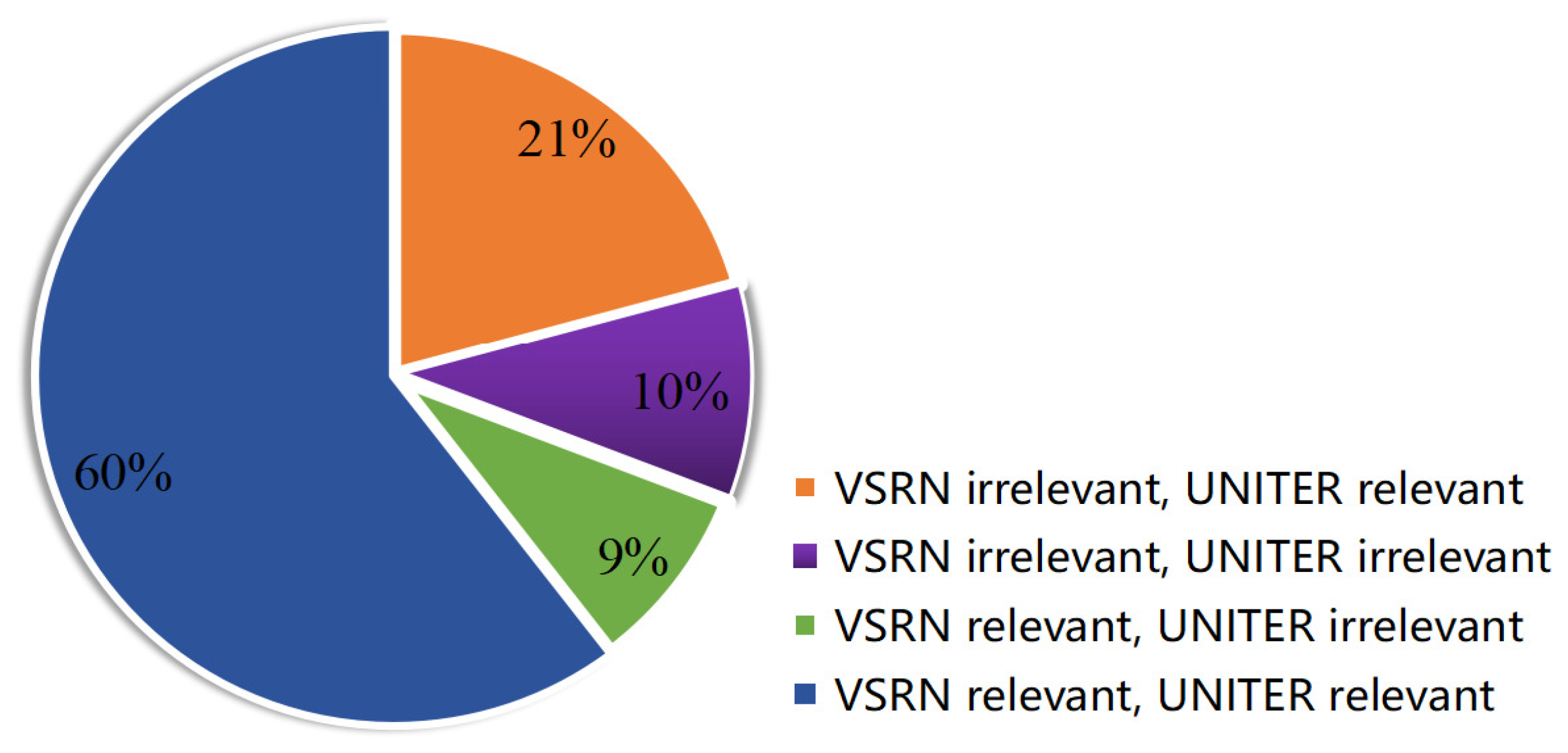
4.2. Results of Experiment 2: Limitations of VSE Networks
4.3. Discussion on the Strengths and Limitations of VSE Networks
- VSRN applies a GRU for global visual reasoning based on the pairwise relations between image regions extracted by GCN. The limitations in group 1 indicate that the performance of global visual reasoning for VSRN still needs to be improved. Compared to VSRN, UNITER benefits from the multi-layers of the transformer, and it has overcome limitation 1. However, the limitation of missing key image objects by VSRN and UNITER indicates that global visual reasoning is still a challenging problem for VSE networks.
- Table 6 shows that none of the networks has the attention mechanisms to achieve detailed visual attention. Misclassified cases of VSRN and UNITER from group 2 limitations reveal that the current VSE networks are not using detailed information for cross-modal information retrieval. However, the matched details between image and text should play a positive role in retrieval, while the unmatched parts should make a negative contribution to matching in further research.
- VSRN performs image–self attention by using GCN to compute the relations between image regions, so the average Precision@1 of VSRN is 1.8% higher than that of SCAN, as shown in Table 6. UNITER applies transformers to achieve image–self, text–self, and image–text attentions, and it outperformed other networks by more than 11% in average Precision@1. Therefore, this progress shows that the extraction of high-level visual semantics can improve the VSE networks. According to the limitations of group 3, as described in Table 5, there is still a need to improve the extraction of visual semantics for VSRN and UNITER, so higher-level visual semantics are necessary to VSE networks. In addition, SCAN outperformed VSE++ by using the stacked cross attention on image–text, where the average Precision@1 was improved by almost 27.5%. UNITER also uses the transformer for image–text attention, thus cross-modal attention is effective in VSE networks. However, cross-modal attention requires the network to iteratively process image and text pairs, and the retrieval time for 1000 queries of SCAN and UNITER is 187.3 seconds and 4379 seconds, respectively, which is too slow for practice.
- Group 4 limitations illustrate that VSE networks still need to perfect the basic functions, such as object detection and recognition, of neural networks. At present, the two-stage VSE networks rely on the reliability of the object detection stage.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VQA | Visual Question Answering |
| VSE | Visual-Semantic Embedding |
| VSE++ | Visual-Semantic Embedding Network ++ |
| SCAN | Stacked Cross-Attention Network |
| PFAN++ | Position-Focused Attention Network |
| VSRN | Visual-Semantic Reasoning Network |
| UNITER | Universal Image–Text Representation |
| GRU | Gated Recurrent Unit |
| GCN | Graph Convolution Network |
References
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. VSE++: Improving visual-semantic embeddings with hard negatives. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; p. 12. [Google Scholar]
- Lee, K.H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked cross attention for image-text matching. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 201–216. [Google Scholar]
- Li, K.; Zhang, Y.; Li, K.; Li, Y.; Fu, Y. Visual semantic reasoning for image-text matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4654–4662. [Google Scholar]
- Chen, Y.C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: Universal image-text representation learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 104–120. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Bai, S.; An, S. A survey on automatic image caption generation. Neurocomputing 2018, 311, 291–304. [Google Scholar] [CrossRef]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6904–6913. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations, Conference Track Proceedings (2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics (Volume 1: Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, H.; Bai, X.; Qian, X.; Ma, L.; Lu, J.; Li, B.; Fan, X. PFAN++: Bi-Directional Image-Text retrieval with position focused attention network. IEEE Trans. Multimed. 2020. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, Conference Track Proceedings (2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar]
- Ordonez, V.; Kulkarni, G.; Berg, T. Im2text: Describing images using 1 million captioned photographs. Adv. Neural Inf. Process. Syst. 2011, 24, 1143–1151. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39, pp. 234–265. [Google Scholar]
- Zuva, K.; Zuva, T. Evaluation of information retrieval systems. Int. J. Comput. Sci. Inf. Technol. 2012, 4, 35. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forty Classes with the Largest Number of Images | |||||
|---|---|---|---|---|---|
| Descriptions | No. of Images | Descriptions | No. of Images | Descriptions | No. of Images |
| unicycle, monocycle | 53 | ballplayer, baseball player | 21 | swimming trunks, bathing trunks | 15 |
| stage | 50 | crutch | 19 | racket, racquet | 14 |
| mountain bike, all-terrain bike off-roader | 43 | miniskirt, mini | 19 | sarong | 14 |
| restaurant, eating house, eating place, eatery | 40 | rugby ball | 19 | volleyball | 14 |
| soccer ball | 29 | library | 18 | lakeside, lakeshore | 14 |
| swing, | 27 | stretcher | 18 | sandbar, sand bar | 14 |
| ski | 26 | maypole | 17 | barbershop | 13 |
| jinrikisha, ricksha, rickshaw | 23 | umbrella | 17 | prison, prison house | 13 |
| cliff, drop, drop-off | 22 | grocery store, grocery food market, market | 16 | accordion, piano accordion squeeze box | 12 |
| horizontal bar, high bar | 21 | jean, blue jean, denim | 16 | croquet ball | 12 |
| Performance Evaluation of Networks: Retrieving any 1 of 5 Relevant Textual Descriptions | ||||
|---|---|---|---|---|
| Network | Average Recall@1 (%) | Average Recall@5 (%) | Average Recall@10 (%) | Average Recall@20 (%) |
| VSE++ | 40.0 | 70.4 | 80.6 | 87.3 |
| SCAN | 67.5 | 90.2 | 94.1 | 97.1 |
| VSRN | 69.3 | 90.2 | 94.2 | 97.1 |
| UNITER | 80.8 | 95.7 | 98.0 | 99.0 |
| Performance Evaluation of Networks: Retrieving 5 of 5 Relevant Textual Descriptions | ||||
|---|---|---|---|---|
| @K | Network |
Average Recall (%) |
Average Precision (%) |
Average -Score (%) |
| 5 | VSE++ | 29.4 | 29.4 | 29.4 |
| SCAN | 47.1 | 47.1 | 47.1 | |
| VSRN | 50.3 | 50.3 | 50.3 | |
| UNITER | 61.5 | 61.5 | 61.5 | |
| 10 | VSE++ | 41.9 | 21.0 | 27.9 |
| SCAN | 62.1 | 31.1 | 41.4 | |
| VSRN | 64.5 | 32.3 | 43.0 | |
| UNITER | 76.4 | 38.2 | 50.9 | |
| 20 | VSE++ | 54.7 | 13.7 | 21.9 |
| SCAN | 73.9 | 18.5 | 29.5 | |
| VSRN | 76.0 | 19.0 | 30.4 | |
| UNITER | 85.5 | 21.4 | 34.2 | |
| 50 | VSE++ | 70.6 | 7.1 | 12.8 |
| SCAN | 85.1 | 8.5 | 15.5 | |
| VSRN | 86.5 | 8.7 | 15.7 | |
| UNITER | 93.2 | 9.3 | 17.0 | |
| 100 | VSE++ | 80.1 | 4.0 | 7.6 |
| SCAN | 90.8 | 4.5 | 8.6 | |
| VSRN | 92.0 | 4.6 | 8.8 | |
| UNITER | 96.0 | 4.8 | 9.2 | |
| Performance on ImageNet Classes Using the Experiment 2 Query Set | |||||
|---|---|---|---|---|---|
| VSRN | UNITER | ||||
|
Topic (Keyword) |
Average Precision@1 (%) |
Average Recall@5 (%) |
Topic (keyword) |
Average Precision@1 (%) |
Average Recall@5 (%) |
| butcher shop, meat market | 20.0 | 14.0 | butcher shop, meat market | 60.0 | 32.0 |
| torch | 27.3 | 21.8 | torch | 45.5 | 32.7 |
| prison, prison house | 53.9 | 35.4 | prison, prison house | 61.5 | 47.7 |
| cowboy hat, ten-gallon hat | 54.6 | 36.4 | cowboy hat, ten-gallon hat | 72.7 | 58.2 |
| accordion, piano accordion, squeeze box | 33.3 | 36.7 | accordion, piano accordion, squeeze box | 75.0 | 51.7 |
| stretcher | 88.9 | 38.9 | stretcher | 55.6 | 43.3 |
| stage | 58.0 | 40.0 | stage | 76.0 | 53.2 |
| crutch | 63.2 | 42.1 | crutch | 84.2 | 46.3 |
| jean, blue jean, denim | 50.0 | 42.5 | jean, blue jean, denim | 81.3 | 57.5 |
| grocery store, grocery, food market, market | 43.8 | 42.5 | grocery store, grocery, food market, market | 68.8 | 52.5 |
| volleyball | 50.0 | 44.3 | volleyball | 85.7 | 60.0 |
| restaurant, eating house, eating place, eatery | 65.0 | 44.5 | restaurant, eating house, eating place, eatery | 80.0 | 57.0 |
| barbershop | 53.9 | 44.6 | barbershop | 92.3 | 53.9 |
| maypole | 64.7 | 45.9 | maypole | 82.4 | 54.1 |
| jinrikisha, ricksha, rickshaw | 69.6 | 47.8 | jinrikisha, ricksha, rickshaw | 82.6 | 60.9 |
| rugby ball | 89.5 | 48.4 | rugby ball | 79.0 | 56.8 |
| military uniform | 41.7 | 35.0 | football helmet | 80.0 | 46.0 |
| miniskirt, mini | 52.6 | 43.2 | basketball | 72.7 | 49.1 |
| pole | 83.3 | 46.7 | soccer ball | 89.7 | 55.2 |
| umbrella | 82.4 | 47.1 | horizontal bar, high bar | 71.4 | 57.1 |
| unicycle, monocycle | 71.7 | 47.2 | moped | 80.0 | 58.0 |
| paddle, boat paddle | 70.0 | 48.0 | cinema, movie theater, movie theatre, movie house, picture palace | 70.0 | 58.0 |
| lakeside, lakeshore | 71.4 | 48.6 | swing | 81.5 | 59.3 |
| ballplayer, baseball player | 81.0 | 49.5 | library | 77.8 | 60.0 |
| fountain | 70.0 | 50.0 | swimming trunks, bathing trunks | 86.7 | 61.3 |
| Summary of Limitations of VSE Networks | ||
|---|---|---|
| No. | Limitation Title | Limitation Description |
| Group 1: The VSE networks do not globally reason with the image scene (limitation 1 only applies to VSRN, limitation 2 applies to VSRN and UNITER) | ||
| 1 | Background issue | The VSE networks cannot accurately recognise the content of the image’s foreground based on its background. |
| 2 | Missing key objects | Key objects, which are important to the image content, are ignored. |
| Group 2: The VSE networks do not give enough attention to the detailed visual information (all limitations apply to VSRN and UNITER) | ||
| 3 | Errors in retrieved descriptions | Details of objects from the retrieved textual descriptions do not match the details of the image. |
| 4 | Partially redundant descriptions | Only part of the retrieved textual description is relevant to the image. |
| 5 | Object counting error | The networks cannot correctly count objects in an image. |
| Group 3: The VSE networks’ capability in extracting the higher-level visual semantics needs to be improved (all limitations apply to VSRN and UNITER) | ||
| 6 | Visual reasoning error | The capability for extracting the higher-level semantics for visual reasoning of the VSE networks is inadequate. |
| 7 | Imprecise descriptions | Retrieved descriptions do not provide enough detail to describe the rich content of images. |
| 8 | Action recognition issue | Actions and postures of objects in retrieved textual descriptions sometimes do not match the image content. |
| Group 4: The basic functions, i.e., object detection and recognition, of neural networks need to be improved (all limitations apply to VSRN and UNITER) | ||
| 9 | Detection error | Some key objects are missed at the object detection stage. |
| 10 | Recognition error | Image object attributes are recognised incorrectly. |
| Comparison of Attention Mechanisms Amongst VSE Networks | |||||||
|---|---|---|---|---|---|---|---|
| Network |
Image–Text Attention |
Image–Self Attention |
Text–Self Attention |
Global Visual Reasoning |
Detailed Visual Attention |
Average Precision@1 (Image-to-Text) |
Retrieval Time |
| VSE++ | None | None | None | None | None | 40.0% | 4.4s |
| SCAN | Stacked Cross | None | None | None | None | 67.5% | 187.3s |
| VSRN | None | GCN | None | GRU | None | 69.3% | 13.6s |
| UNITER | Transformer | Transformer | Transformer | Transformer | None | 80.8% | 4379s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, Y.; Cosma, G.; Fang, H. On the Limitations of Visual-Semantic Embedding Networks for Image-to-Text Information Retrieval. J. Imaging 2021, 7, 125. https://doi.org/10.3390/jimaging7080125
Gong Y, Cosma G, Fang H. On the Limitations of Visual-Semantic Embedding Networks for Image-to-Text Information Retrieval. Journal of Imaging. 2021; 7(8):125. https://doi.org/10.3390/jimaging7080125
Chicago/Turabian StyleGong, Yan, Georgina Cosma, and Hui Fang. 2021. "On the Limitations of Visual-Semantic Embedding Networks for Image-to-Text Information Retrieval" Journal of Imaging 7, no. 8: 125. https://doi.org/10.3390/jimaging7080125
APA StyleGong, Y., Cosma, G., & Fang, H. (2021). On the Limitations of Visual-Semantic Embedding Networks for Image-to-Text Information Retrieval. Journal of Imaging, 7(8), 125. https://doi.org/10.3390/jimaging7080125