A Review on Computer Vision-Based Methods for Human Action Recognition



Abstract
1. Introduction
2. Popular Challenges in Action Recognition Models
2.1. Selection of Training and Testing Data
2.2. Variation in Viewpoint
2.3. Occlusion
2.4. Features Modelling for Action Recognition
2.5. Cluttered Background
2.6. Feature Design Techniques
3. Applications of Action Recognition Models
3.1. Surveillance and Assisted Living
3.2. Healthcare Monitoring
3.3. Entertainment and Games
3.4. Human–Robot Interaction
3.5. Video Retrieval
3.6. Autonomous Driving Vehicles
4. Hand-Crafted Feature Representation for Action Recognition
4.1. Holistic Feature Representation Based Methods
- Recognition based on shape information such as shape masks and the silhouette of the person;
- Recognition based on shape and global motion information.
4.1.1. Shape Information Based Methods
RGB-D Information Based Shape Models
4.1.2. Hybrid Methods Based on Shape and Global Motion Information
4.2. Local Feature Representations Based Methods
RGB-D Information Based Local Features
4.3. Trajectories Based Methods
4.4. Other Feature Representations Based Methods
5. Deep Learning Techniques Based Models
5.1. Unsupervised (Generative) Models
5.2. Supervised (Descriminative) Models
5.3. Multiple Modality Based Methods
5.4. Pose Estimation and Multi-View Action Recognition
6. Conclusions
- data selection: suitable data to capture the action may help to improve performance of action recognition.
- approach of recognition: deep learning based methods achieved superior performance.
- multiple-modal: current research highlighted that multi-modal fusion can efficiently improve the performance.
Author Contributions
Funding
Conflicts of Interest
References
- Yurur, O.; Liu, C.; Moreno, W. A survey of context-aware middleware designs for human activity recognition. IEEE Commun. Mag. 2014, 52, 24–31. [Google Scholar] [CrossRef]
- Ranasinghe, S.; Al Machot, F.; Mayr, H.C. A review on applications of activity recognition systems with regard to performance and evaluation. Int. J. Distrib. Sens. Netw. 2016, 12, 1550147716665520. [Google Scholar] [CrossRef]
- Sztyler, T.; Stuckenschmidt, H.; Petrich, W. Position-aware activity recognition with wearable devices. Pervasive Mob. Comput. 2017, 38, 281–295. [Google Scholar] [CrossRef]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Marr, D.; Vaina, L. Representation and recognition of the movements of shapes. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1982, 214, 501–524. [Google Scholar]
- Hester, C.F.; Casasent, D. Multivariant technique for multiclass pattern recognition. Appl. Opt. 1980, 19, 1758–1761. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, B.K.; Sarma, D.; Bhuyan, M.K.; MacDorman, K.F. Review of constraints on vision-based gesture recognition for human–computer interaction. IET Comput. Vis. 2017, 12, 3–15. [Google Scholar] [CrossRef]
- Dawn, D.D.; Shaikh, S.H. A comprehensive survey of human action recognition with spatio-temporal interest point (STIP) detector. Vis. Comput. 2016, 32, 289–306. [Google Scholar] [CrossRef]
- Meng, M.; Drira, H.; Boonaert, J. Distances evolution analysis for online and offline human object interaction recognition. Image Vis. Comput. 2018, 70, 32–45. [Google Scholar] [CrossRef]
- Ibrahim, M.S.; Muralidharan, S.; Deng, Z.; Vahdat, A.; Mori, G. A hierarchical deep temporal model for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1971–1980. [Google Scholar]
- Cheng, G.; Wan, Y.; Saudagar, A.N.; Namuduri, K.; Buckles, B.P. Advances in human action recognition: A survey. arXiv 2015, arXiv:1501.05964. [Google Scholar]
- Raman, N. Action Recognition in Depth Videos Using Nonparametric Probabilistic Graphical Models. Ph.D. Thesis, Birkbeck, University of London, London, UK, 2016. [Google Scholar]
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-time human pose recognition in parts from single depth images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.V.; Schiele, B. Deepcut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1302–1310. [Google Scholar]
- Chakraborty, B.; Rudovic, O.; Gonzalez, J. View-invariant human-body detection with extension to human action recognition using component-wise HMM of body parts. In Proceedings of the 2008 8th IEEE International Conference on Automatic Face & Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–6. [Google Scholar]
- Kumar, M.N.; Madhavi, D. Improved discriminative model for view-invariant human action recognition. Int. J. Comput. Sci. Eng. Technol. 2013, 4, 1263–1270. [Google Scholar]
- Syeda-Mahmood, T.; Vasilescu, A.; Sethi, S. Recognizing action events from multiple viewpoints. In Proceedings of the IEEE Workshop on Detection and Recognition of Events in Video, Vancouver, BC, Canada, 8 July 2001; pp. 64–72. [Google Scholar]
- Iosifidis, A.; Tefas, A.; Pitas, I. Neural representation and learning for multi-view human action recognition. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–6. [Google Scholar]
- Lv, F.; Nevatia, R. Single view human action recognition using key pose matching and viterbi path searching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Souvenir, R.; Babbs, J. Learning the viewpoint manifold for action recognition. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Rahman, S.A.; Cho, S.Y.; Leung, M. Recognising human actions by analysing negative spaces. IET Comput. Vis. 2012, 6, 197–213. [Google Scholar] [CrossRef]
- Park, S.; Aggarwal, J.K. A hierarchical Bayesian network for event recognition of human actions and interactions. Multimed. Syst. 2004, 10, 164–179. [Google Scholar] [CrossRef]
- Nguyen, N.T.; Phung, D.Q.; Venkatesh, S.; Bui, H. Learning and detecting activities from movement trajectories using the hierarchical hidden Markov model. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 955–960. [Google Scholar]
- Huang, F.; Xu, G. Action recognition unrestricted by location and viewpoint variation. In Proceedings of the 2008 IEEE 8th International Conference on Computer and Information Technology Workshops, Sydney, Australia, 8–11 July 2008; pp. 433–438. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Niebles, J.C.; Wang, H.; Fei-Fei, L. Unsupervised learning of human action categories using spatial-temporal words. Int. J. Comput. Vis. 2008, 79, 299–318. [Google Scholar] [CrossRef]
- Ragheb, H.; Velastin, S.; Remagnino, P.; Ellis, T. Human action recognition using robust power spectrum features. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 753–756. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Laptev, I. On space-time interest points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the CVPR 2008, IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Matikainen, P.; Hebert, M.; Sukthankar, R. Trajectons: Action recognition through the motion analysis of tracked features. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops (ICCV Workshops), Kyoto, Japan, 27 September–4 October 2009; pp. 514–521. [Google Scholar]
- Blasiak, S.; Rangwala, H. A Hidden Markov Model Variant for Sequence Classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence–Volume Volume Two, IJCAI’11, Barcelona, Spain, 16–22 July 2011; pp. 1192–1197. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data; ACM: New York, NY, USA, 2001. [Google Scholar]
- Wu, Z.; Wang, X.; Jiang, Y.G.; Ye, H.; Xue, X. Modeling spatial-temporal clues in a hybrid deep learning framework for video classification. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; ACM: New York, NY, USA, 2015; pp. 461–470. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Gavrilova, M.L.; Wang, Y.; Ahmed, F.; Paul, P.P. Kinect sensor gesture and activity recognition: New applications for consumer cognitive systems. IEEE Consum. Electron. Mag. 2017, 7, 88–94. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Rashidi, P.; Cook, D.J. Keeping the resident in the loop: Adapting the smart home to the user. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2009, 39, 949–959. [Google Scholar] [CrossRef]
- Michael, J.; Mayr, H.C. Creating a domain specific modelling method for ambient assistance. In Proceedings of the 2015 Fifteenth International Conference on Advances in ICT for Emerging Regions (ICTer), Colombo, Sri Lanka, 24–26 August 2015; pp. 119–124. [Google Scholar]
- Brémond, F.; Thonnat, M.; Zúniga, M. Video-understanding framework for automatic behavior recognition. Behav. Res. Methods 2006, 38, 416–426. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Peursum, P.; West, G.; Venkatesh, S. Combining image regions and human activity for indirect object recognition in indoor wide-angle views. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 82–89. [Google Scholar]
- Chang, M.C.; Krahnstoever, N.; Lim, S.; Yu, T. Group level activity recognition in crowded environments across multiple cameras. In Proceedings of the 2010 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August–1 September 2010; pp. 56–63. [Google Scholar]
- Nunez-Marcos, A.; Azkune, G.; Arganda-Carreras, I. Vision-based fall detection with convolutional neural networks. Wirel. Commun. Mob. Comput. 2017, 2017. [Google Scholar] [CrossRef]
- Sree, K.V.; Jeyakumar, G. A Computer Vision Based Fall Detection Technique for Home Surveillance. In Proceedings of the International Conference on Computational Vision and Bio Inspired Computing, Coimbatore, India, 25–26 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 355–363. [Google Scholar]
- Chen, D.; Bharucha, A.J.; Wactlar, H.D. Intelligent video monitoring to improve safety of older persons. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 23–26 August 2007; pp. 3814–3817. [Google Scholar]
- Shotton, J.; Girshick, R.; Fitzgibbon, A.; Sharp, T.; Cook, M.; Finocchio, M.; Moore, R.; Kohli, P.; Criminisi, A.; Kipman, A.; et al. Efficient human pose estimation from single depth images. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2821–2840. [Google Scholar] [CrossRef] [PubMed]
- Kong, Y.; Fu, Y. Max-margin heterogeneous information machine for RGB-D action recognition. Int. J. Comput. Vis. 2017, 123, 350–371. [Google Scholar] [CrossRef]
- Jia, C.; Kong, Y.; Ding, Z.; Fu, Y.R. Latent tensor transfer learning for RGB-D action recognition. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 87–96. [Google Scholar]
- Ryoo, M.; Fuchs, T.J.; Xia, L.; Aggarwal, J.K.; Matthies, L. Robot-centric activity prediction from first-person videos: What will they do to me? In Proceedings of the 2015 10th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Portland, OR, USA, 2–5 March 2015; pp. 295–302. [Google Scholar]
- Koppula, H.S.; Saxena, A. Anticipating human activities using object affordances for reactive robotic response. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 14–29. [Google Scholar] [CrossRef] [PubMed]
- Ramezani, M.; Yaghmaee, F. A review on human action analysis in videos for retrieval applications. Artif. Intell. Rev. 2016, 46, 485–514. [Google Scholar] [CrossRef]
- Ciptadi, A.; Goodwin, M.S.; Rehg, J.M. Movement pattern histogram for action recognition and retrieval. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 695–710. [Google Scholar]
- Li, K.; Fu, Y. Prediction of human activity by discovering temporal sequence patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1644–1657. [Google Scholar] [CrossRef] [PubMed]
- Poppe, R. Vision-based human motion analysis: An overview. Comput. Vis. Image Underst. 2007, 108, 4–18. [Google Scholar] [CrossRef]
- Ramasso, E.; Panagiotakis, C.; Rombaut, M.; Pellerin, D.; Tziritas, G. Human shape-motion analysis in athletics videos for coarse to fine action/activity recognition using transferable belief model. ELCVIA Electron. Lett. Comput. Vis. Image Anal. 2009, 7, 32–50. [Google Scholar] [CrossRef]
- Davis, J.W.; Bobick, A.F. The representation and recognition of human movement using temporal templates. In Proceedings of the 1997 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 928–934. [Google Scholar]
- Zhu, P.; Hu, W.; Li, L.; Wei, Q. Human Activity Recognition Based on R Transform and Fourier Mellin Transform. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 631–640. [Google Scholar]
- Qian, H.; Mao, Y.; Xiang, W.; Wang, Z. Recognition of human activities using SVM multi-class classifier. Pattern Recognit. Lett. 2010, 31, 100–111. [Google Scholar] [CrossRef]
- Al-Faris, M.; Chiverton, J.; Yang, L.; Ndzi, D. Appearance and motion information based human activity recognition. In Proceedings of the IET 3rd International Conference on Intelligent Signal Processing (ISP 2017), London, UK, 4–5 December 2017; pp. 1–6. [Google Scholar]
- Sullivan, J.; Carlsson, S. Recognizing and tracking human action. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2002; pp. 629–644. [Google Scholar]
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-Time Shapes; IEEE: Piscataway, NJ, USA, 2005; pp. 1395–1402. [Google Scholar]
- Yilmaz, A.; Shah, M. Actions sketch: A novel action representation. In Proceedings of the CVPR 2005, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 984–989. [Google Scholar]
- Weinland, D.; Boyer, E. Action recognition using exemplar-based embedding. In Proceedings of the CVPR 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Zhang, Z.; Hu, Y.; Chan, S.; Chia, L.T. Motion context: A new representation for human action recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 817–829. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Hofmann, T. Unsupervised learning by probabilistic latent semantic analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R.; Hebert, M. Event detection in crowded videos. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, ICCV 2007, Rio De Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Ni, B.; Wang, G.; Moulin, P. A Colour-Depth video database for human daily activity recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 6–13. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing actions using depth motion maps-based histograms of oriented gradients. In Proceedings of the 20th ACM international conference on Multimedia, Nara, Japan, 29 October–2 November 2012; ACM: New York, NY, USA, 2012; pp. 1057–1060. [Google Scholar]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time human action recognition based on depth motion maps. J. Real Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. Action recognition from depth sequences using depth motion maps-based local binary patterns. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Beach, HI, USA, 7–8 January 2015; pp. 1092–1099. [Google Scholar]
- Chen, C.; Liu, M.; Zhang, B.; Han, J.; Jiang, J.; Liu, H. 3D Action Recognition Using Multi-Temporal Depth Motion Maps and Fisher Vector. In Proceedings of the IJCAI 2016, New York, NY, USA, 9–15 July 2016; pp. 3331–3337. [Google Scholar]
- El Madany, N.E.D.; He, Y.; Guan, L. Human action recognition using temporal hierarchical pyramid of depth motion map and keca. In Proceedings of the 2015 IEEE 17th International Workshop on Multimedia Signal Processing (MMSP), Xiamen, China, 19–21 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Vieira, A.W.; Nascimento, E.R.; Oliveira, G.L.; Liu, Z.; Campos, M.F. Stop: Space-time occupancy patterns for 3d action recognition from depth map sequences. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 252–259. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2013; pp. 716–723. [Google Scholar]
- Lacoste-Julien, S.; Sha, F.; Jordan, M.I. DiscLDA: Discriminative learning for dimensionality reduction and classification. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 897–904. [Google Scholar]
- Efros, A.A.; Berg, A.C.; Mori, G.; Malik, J. Recognizing Action at a Distance. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; IEEE Computer Society: Washington, DC, USA, 2003; Volume 2, p. 726. [Google Scholar]
- Fathi, A.; Mori, G. Action recognition by learning mid-level motion features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2008, Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Rodriguez, M.D.; Ahmed, J.; Shah, M. Action mach a spatio-temporal maximum average correlation height filter for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2008, Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Ke, Y.; Sukthankar, R.; Hebert, M. Efficient visual event detection using volumetric features. In Proceedings of the Tenth IEEE International Conference on Computer Vision, ICCV 2005, Beijing, China, 17–21 October 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 166–173. [Google Scholar]
- Lu, W.L.; Little, J.J. Simultaneous tracking and action recognition using the pca-hog descriptor. In Proceedings of the The 3rd Canadian Conference on Computer and Robot Vision (CRV’06), Quebec, QC, Canada, 7–9 June 2006; IEEE: Piscataway, NJ, USA, 2006; p. 6. [Google Scholar]
- Schindler, K.; Van Gool, L. Action snippets: How many frames does human action recognition require? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2008, Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Hu, Y.; Cao, L.; Lv, F.; Yan, S.; Gong, Y.; Huang, T.S. Action detection in complex scenes with spatial and temporal ambiguities. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 128–135. [Google Scholar]
- Zhen, X.; Shao, L. Action recognition via spatio-temporal local features: A comprehensive study. Image Vis. Comput. 2016, 50, 1–13. [Google Scholar] [CrossRef]
- Lisin, D.A.; Mattar, M.A.; Blaschko, M.B.; Learned-Miller, E.G.; Benfield, M.C. Combining local and global image features for object class recognition. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05)-Workshops, San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; p. 47. [Google Scholar]
- Wilson, J.; Arif, M. Scene recognition by combining local and global image descriptors. arXiv 2017, arXiv:1702.06850. [Google Scholar]
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior recognition via sparse spatio-temporal features. In Proceedings of the 2nd Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 65–72. [Google Scholar]
- Oikonomopoulos, A.; Patras, I.; Pantic, M. Spatiotemporal salient points for visual recognition of human actions. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2005, 36, 710–719. [Google Scholar] [CrossRef] [PubMed]
- Willems, G.; Tuytelaars, T.; Van Gool, L. An efficient dense and scale-invariant spatio-temporal interest point detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 650–663. [Google Scholar]
- Wong, S.F.; Cipolla, R. Extracting spatiotemporal interest points using global information. In Proceedings of the IEEE 11th International Conference on Computer Vision, ICCV 2007, Rio de Janeiro, Brazil, 14–20 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–8. [Google Scholar]
- Wang, H.; Ullah, M.M.; Klaser, A.; Laptev, I.; Schmid, C. Evaluation of local spatio-temporal features for action recognition. In BMVC 2009-British Machine Vision Conference; BMVA Press: Durham, UK, 2009; pp. 124.1–124.11. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 23–26 August 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 3, pp. 32–36. [Google Scholar]
- Marszalek, M.; Laptev, I.; Schmid, C. Actions in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2009, Miami Beach, FL, USA, 20–26 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 2929–2936. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2005, San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Action recognition by dense trajectories. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3169–3176. [Google Scholar]
- Klaser, A.; Marszałek, M.; Schmid, C. A spatio-temporal descriptor based on 3d-gradients. In Proceedings of the BMVC 2008-19th British Machine Vision Conference, Leeds, UK, 1–4 September 2008. [Google Scholar]
- Scovanner, P.; Ali, S.; Shah, M. A three-dimensional sift descriptor and its application to action recognition. In Proceedings of the 15th ACM international Conference on Multimedia, Augsburg, Germany, 24–29 September 2007; ACM: New York, NY, USA, 2007; pp. 357–360. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rahmani, H.; Mahmood, A.; Huynh, D.Q.; Mian, A. HOPC: Histogram of oriented principal components of 3D pointclouds for action recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 742–757. [Google Scholar]
- Cheng, Z.; Qin, L.; Ye, Y.; Huang, Q.; Tian, Q. Human daily action analysis with multi-view and color-depth data. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 52–61. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y. Random Occupancy Patterns. In SpringerBriefs in Computer Science; Number 9783319045603 in SpringerBriefs in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; pp. 41–55. [Google Scholar]
- Messing, R.; Pal, C.; Kautz, H. Activity recognition using the velocity histories of tracked keypoints. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 104–111. [Google Scholar]
- Sun, J.; Wu, X.; Yan, S.; Cheong, L.F.; Chua, T.S.; Li, J. Hierarchical spatio-temporal context modeling for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2009, Miami Beach, FL, USA, 20–26 June 2009; pp. 2004–2011. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th Intl Joint Conf on Artifical Intelligence (IJCAI), Vancouver, BC, Canada, 24–28 August 1981; pp. 674–679. [Google Scholar]
- Bilinski, P.; Bremond, F. Contextual statistics of space-time ordered features for human action recognition. In Proceedings of the 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance (AVSS), Beijing, China, 18–21 September 2012; pp. 228–233. [Google Scholar]
- Bilinski, P.; Bremond, F. Statistics of pairwise co-occurring local spatio-temporal features for human action recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 311–320. [Google Scholar]
- Bilinski, P.T.; Bremond, F. Video Covariance Matrix Logarithm for Human Action Recognition in Videos. In Proceedings of the IJCAI, Buenos Aires, Argentina, 25–31 July 2015; pp. 2140–2147. [Google Scholar]
- Bilinski, P.; Corvee, E.; Bak, S.; Bremond, F. Relative dense tracklets for human action recognition. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–7. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Zaidenberg, S.; Bilinski, P.; Brémond, F. Towards unsupervised sudden group movement discovery for video surveillance. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 2, pp. 388–395. [Google Scholar]
- Laptev, I.; Lindeberg, T. Local descriptors for spatio-temporal recognition. In Spatial Coherence for Visual Motion Analysis; Springer: Berlin/Heidelberg, Germany, 2006; pp. 91–103. [Google Scholar]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 428–441. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef]
- Atmosukarto, I.; Ghanem, B.; Ahuja, N. Trajectory-based fisher kernel representation for action recognition in videos. In Proceedings of the 2012 21st International Conference on Pattern Recognition (ICPR), Tsukuba Science City, Japan, 11–15 November 2012; pp. 3333–3336. [Google Scholar]
- Jargalsaikhan, I.; Little, S.; Direkoglu, C.; O’Connor, N.E. Action recognition based on sparse motion trajectories. In Proceedings of the 2013 20th IEEE International Conference on Image Processing (ICIP), Melbourne, Australia, 15–18 September 2013; pp. 3982–3985. [Google Scholar]
- Yi, Y.; Lin, Y. Human action recognition with salient trajectories. Signal Process. 2013, 93, 2932–2941. [Google Scholar] [CrossRef]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV, Prague, Czech Republic, 11–14 May 2004; Volume 1, pp. 1–2. [Google Scholar]
- Peng, X.; Wang, L.; Wang, X.; Qiao, Y. Bag of visual words and fusion methods for action recognition: Comprehensive study and good practice. Comput. Vis. Image Underst. 2016, 150, 109–125. [Google Scholar] [CrossRef]
- Zhang, L.; Khusainov, R.; Chiverton, J. Practical Action Recognition with Manifold Regularized Sparse Representations. In Proceedings of the BMVC Workshop, Newcastle, UK, 26 September 2018. [Google Scholar]
- Perronnin, F.; Dance, C. Fisher kernels on visual vocabularies for image categorization. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Oneata, D.; Verbeek, J.; Schmid, C. Action and event recognition with fisher vectors on a compact feature set. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1817–1824. [Google Scholar]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A review on human activity recognition using vision-based method. J. Healthc. Eng. 2017, 2017. [Google Scholar] [CrossRef] [PubMed]
- Kong, Y.; Fu, Y. Human Action Recognition and Prediction: A Survey. arXiv 2018, arXiv:1806.11230. [Google Scholar]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A review of human activity recognition methods. Front. Robot. AI 2015, 2, 28. [Google Scholar] [CrossRef]
- Tripathi, R.K.; Jalal, A.S.; Agrawal, S.C. Suspicious human activity recognition: A review. Artif. Intell. Rev. 2017, 50, 1–57. [Google Scholar] [CrossRef]
- Saif, S.; Tehseen, S.; Kausar, S. A Survey of the Techniques for The Identification and Classification of Human Actions from Visual Data. Sensors 2018, 18, 3979. [Google Scholar] [CrossRef] [PubMed]
- Ikizler, N.; Duygulu, P. Histogram of oriented rectangles: A new pose descriptor for human action recognition. Image Vis. Comput. 2009, 27, 1515–1526. [Google Scholar] [CrossRef]
- Wu, X.; Xu, D.; Duan, L.; Luo, J. Action recognition using context and appearance distribution features. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011. [Google Scholar]
- Eweiwi, A.; Cheema, S.; Thurau, C.; Bauckhage, C. Temporal key poses for human action recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1310–1317. [Google Scholar]
- Kellokumpu, V.; Zhao, G.; Pietikäinen, M. Recognition of human actions using texture descriptors. Mach. Vis. Appl. 2011, 22, 767–780. [Google Scholar] [CrossRef]
- Kliper-Gross, O.; Gurovich, Y.; Hassner, T.; Wolf, L. Motion interchange patterns for action recognition in unconstrained videos. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 256–269. [Google Scholar]
- Jiang, Y.G.; Dai, Q.; Xue, X.; Liu, W.; Ngo, C.W. Trajectory-based modeling of human actions with motion reference points. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 425–438. [Google Scholar]
- Xia, L.; Chen, C.C.; Aggarwal, J. View invariant human action recognition using histograms of 3d joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Wang, C.; Wang, Y.; Yuille, A.L. An approach to pose-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 915–922. [Google Scholar]
- Zanfir, M.; Leordeanu, M.; Sminchisescu, C. The moving pose: An efficient 3d kinematics descriptor for low-latency action recognition and detection. In Proceedings of the IEEE international conference on computer vision, Sydney, Australia, 1–8 December 2013; pp. 2752–2759. [Google Scholar]
- Chaaraoui, A.A.; Climent-Pérez, P.; Flórez-Revuelta, F. Silhouette-based human action recognition using sequences of key poses. Pattern Recognit. Lett. 2013, 34, 1799–1807. [Google Scholar] [CrossRef]
- Rahman, S.A.; Song, I.; Leung, M.K.; Lee, I.; Lee, K. Fast action recognition using negative space features. Expert Syst. Appl. 2014, 41, 574–587. [Google Scholar] [CrossRef]
- Yang, X.; Tian, Y. Effective 3d action recognition using eigenjoints. J. Vis. Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Peng, X.; Zou, C.; Qiao, Y.; Peng, Q. Action recognition with stacked fisher vectors. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 581–595. [Google Scholar]
- Theodorakopoulos, I.; Kastaniotis, D.; Economou, G.; Fotopoulos, S. Pose-based human action recognition via sparse representation in dissimilarity space. J. Vis. Commun. Image Represent. 2014, 25, 12–23. [Google Scholar] [CrossRef]
- Junejo, I.N.; Junejo, K.N.; Al Aghbari, Z. Silhouette-based human action recognition using SAX-Shapes. Vis. Comput. 2014, 30, 259–269. [Google Scholar] [CrossRef]
- Amor, B.B.; Su, J.; Srivastava, A. Action recognition using rate-invariant analysis of skeletal shape trajectories. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Vishwakarma, D.K.; Kapoor, R.; Dhiman, A. A proposed unified framework for the recognition of human activity by exploiting the characteristics of action dynamics. Robot. Auton. Syst. 2016, 77, 25–38. [Google Scholar] [CrossRef]
- Sargano, A.B.; Angelov, P.; Habib, Z. Human action recognition from multiple views based on view-invariant feature descriptor using support vector machines. Appl. Sci. 2016, 6, 309. [Google Scholar] [CrossRef]
- Baumann, F.; Ehlers, A.; Rosenhahn, B.; Liao, J. Recognizing human actions using novel space-time volume binary patterns. Neurocomputing 2016, 173, 54–63. [Google Scholar] [CrossRef]
- Chun, S.; Lee, C.S. Human action recognition using histogram of motion intensity and direction from multiple views. IET Comput. Vis. 2016, 10, 250–257. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, Y.H.; Kim, Y.J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Patrona, F.; Chatzitofis, A.; Zarpalas, D.; Daras, P. Motion analysis: Action detection, recognition and evaluation based on motion capture data. Pattern Recognit. 2018, 76, 612–622. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Smolensky, P. Information Processing in Dynamical Systems: Foundations of Harmony Theory; Technical Report; Colorado University at Boulder Department of Computer Science: Boulder, CO, USA, 1986. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Le, Q.V.; Zou, W.Y.; Yeung, S.Y.; Ng, A.Y. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3361–3368. [Google Scholar]
- Foggia, P.; Saggese, A.; Strisciuglio, N.; Vento, M. Exploiting the deep learning paradigm for recognizing human actions. In Proceedings of the 2014 International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014; pp. 93–98. [Google Scholar]
- Hasan, M.; Roy-Chowdhury, A.K. Continuous learning of human activity models using deep nets. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 705–720. [Google Scholar]
- Ballan, L.; Bertini, M.; Del Bimbo, A.; Seidenari, L.; Serra, G. Effective codebooks for human action representation and classification in unconstrained videos. IEEE Trans. Multimed. 2012, 14, 1234–1245. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Xu, B.; Fu, Y.; Jiang, Y.G.; Li, B.; Sigal, L. Video emotion recognition with transferred deep feature encodings. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; ACM: New York, NY, USA, 2016; pp. 15–22. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Sun, L.; Jia, K.; Yeung, D.Y.; Shi, B.E. Human action recognition using factorized spatio-temporal convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4597–4605. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Sun, L.; Jia, K.; Chan, T.H.; Fang, Y.; Wang, G.; Yan, S. DL-SFA: Deeply-learned slow feature analysis for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 2625–2632. [Google Scholar]
- Lei, J.; Li, G.; Zhang, J.; Guo, Q.; Tu, D. Continuous action segmentation and recognition using hybrid convolutional neural network-hidden Markov model model. IET Comput. Vis. 2016, 10, 537–544. [Google Scholar] [CrossRef]
- Leong, M.C.; Prasad, D.K.; Lee, Y.T.; Lin, F. Semi-CNN Architecture for Effective Spatio-Temporal Learning in Action Recognition. Appl. Sci. 2020, 10, 557. [Google Scholar] [CrossRef]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Ofli, F.; Chaudhry, R.; Kurillo, G.; Vidal, R.; Bajcsy, R. Berkeley MHAD: A comprehensive Multimodal Human Action Database. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision (WACV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 53–60. [Google Scholar]
- Müller, M.; Röder, T.; Clausen, M.; Eberhadt, B.; Krüger, B.; Weber, A. Documentation Mocap Database hdm05; University of Bonn: Bonn, Germany, 2007. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1764–1772. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 816–833. [Google Scholar]
- Park, E.; Han, X.; Berg, T.L.; Berg, A.C. Combining multiple sources of knowledge in deep cnns for action recognition. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–8. [Google Scholar]
- Yu, S.; Cheng, Y.; Su, S.; Cai, G.; Li, S. Stratified pooling based deep convolutional neural networks for human action recognition. Multimed. Tools Appl. 2017, 76, 13367–13382. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in the Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal multiplier networks for video action recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7445–7454. [Google Scholar]
- Töreyin, B.U.; Dedeoğlu, Y.; Çetin, A.E. HMM based falling person detection using both audio and video. In International Workshop Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2005; pp. 211–220. [Google Scholar]
- Al-Faris, M.; Chiverton, J.; Yang, Y.; Ndzi, D. Deep learning of fuzzy weighted multi-resolution depth motion maps with spatial feature fusion for action recognition. J. Imaging 2019, 5, 82. [Google Scholar] [CrossRef]
- Rahmani, H.; Mian, A. 3D action recognition from novel viewpoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1506–1515. [Google Scholar]
- Xiao, Y.; Chen, J.; Wang, Y.; Cao, Z.; Zhou, J.T.; Bai, X. Action recognition for depth video using multi-view dynamic images. Inf. Sci. 2019, 480, 287–304. [Google Scholar] [CrossRef]
- Naeem, H.B.; Murtaza, F.; Yousaf, M.H.; Velastin, S.A. Multiple Batches of Motion History Images (MB-MHIs) for Multi-view Human Action Recognition. Arabian J. Sci. Eng. 2020, 1–16. [Google Scholar] [CrossRef]
- Singh, S.; Velastin, S.A.; Ragheb, H. Muhavi: A multicamera human action video dataset for the evaluation of action recognition methods. In Proceedings of the 2010 Seventh IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Boston, MA, USA, 29 August–1 September 2010; pp. 48–55. [Google Scholar]
- Murtaza, F.; Yousaf, M.H.; Velastin, S.A. Multi-view human action recognition using 2D motion templates based on MHIs and their HOG description. IET Comput. Vis. 2016, 10, 758–767. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Gao, Z.; Zhang, J.; Tang, C.; Ogunbona, P.O. Action recognition from depth maps using deep convolutional neural networks. IEEE Trans. Hum. Mach. Syst. 2016, 46, 498–509. [Google Scholar] [CrossRef]
- Al-Faris, M.; Chiverton, J.; Yang, Y.; David, N. Multi-view region-adaptive multi-temporal DMM and RGB action recognition. Pattern Anal. Appl. 2020. [Google Scholar] [CrossRef]
- Ijjina, E.P.; Mohan, C.K. Human action recognition based on motion capture information using fuzzy convolution neural networks. In Proceedings of the 2015 Eighth International Conference on Advances in Pattern Recognition (ICAPR), Kolkata, India, 4–7 January 2015; pp. 1–6. [Google Scholar]
- Chéron, G.; Laptev, I.; Schmid, C. P-cnn: Pose-based cnn features for action recognition. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3218–3226. [Google Scholar]
- Jhuang, H.; Gall, J.; Zuffi, S.; Schmid, C.; Black, M.J. Towards Understanding Action Recognition. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3192–3199. [Google Scholar]
- Rohrbach, M.; Amin, S.; Andriluka, M.; Schiele, B. A database for fine grained activity detection of cooking activities. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1194–1201. [Google Scholar]
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-Time Shapes. In Proceedings of the 10th IEEE International Conference Comp. Vision (ICCV’05), Beijing, China, 17–21 October 2005; pp. 1395–1402. [Google Scholar]
- Niebles, J.C.; Chen, C.W.; Fei-Fei, L. Modeling temporal structure of decomposable motion segments for activity classification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 392–405. [Google Scholar]
- Reddy, K.K.; Shah, M. Recognizing 50 human action categories of web videos. Mach. Vis. Appl. 2013, 24, 971–981. [Google Scholar] [CrossRef]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Cross-view action modeling, learning and recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–28 June 2014; pp. 2649–2656. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Ni, B.; Wang, G.; Moulin, P. Rgbd-hudaact: A color-depth video database for human daily activity recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 7 November 2011; pp. 1147–1153. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Xiao, X.; Xu, D.; Wan, W. Overview: Video recognition from handcrafted method to deep learning method. In Proceedings of the 2016 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 11–12 July 2016; pp. 646–651. [Google Scholar]
- Hssayeni, M.D.; Saxena, S.; Ptucha, R.; Savakis, A. Distracted driver detection: Deep learning vs handcrafted features. Electron. Imaging 2017, 2017, 20–26. [Google Scholar] [CrossRef]
- Zare, M.R.; Alebiosu, D.O.; Lee, S.L. Comparison of handcrafted features and deep learning in classification of medical x-ray images. In Proceedings of the 2018 Fourth International Conference on Information Retrieval and Knowledge Management (CAMP), Kota Kinabalu, Malaysia, 26–28 March 2018; pp. 1–5. [Google Scholar]
- Georgiou, T.; Liu, Y.; Chen, W.; Lew, M. A survey of traditional and deep learning-based feature descriptors for high dimensional data in computer vision. Int. J. Multimed. Inform. Retrieval 2019, 1–36. [Google Scholar] [CrossRef]
- Zhang, Z.; Tao, D. Slow feature analysis for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 436–450. [Google Scholar] [CrossRef] [PubMed]
- Yue-Hei Ng, J.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 5–12 June 2015; pp. 4694–4702. [Google Scholar]
- Veeriah, V.; Zhuang, N.; Qi, G.J. Differential recurrent neural networks for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4041–4049. [Google Scholar]
- Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. Learning to track for spatio-temporal action localization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3164–3172. [Google Scholar]
- Mahasseni, B.; Todorovic, S. Regularizing long short term memory with 3D human-skeleton sequences for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3054–3062. [Google Scholar]
- Fernando, B.; Gavves, E.; Oramas, J.; Ghodrati, A.; Tuytelaars, T. Rank pooling for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 773–787. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Li, W.; Gao, Z.; Tang, C.; Ogunbona, P.O. Depth pooling based large-scale 3-d action recognition with convolutional neural networks. IEEE Trans. Multimed. 2018, 20, 1051–1061. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Wan, J.; Ogunbona, P.; Liu, X. Cooperative Training of Deep Aggregation Networks for RGB-D Action Recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]





{kind=link}
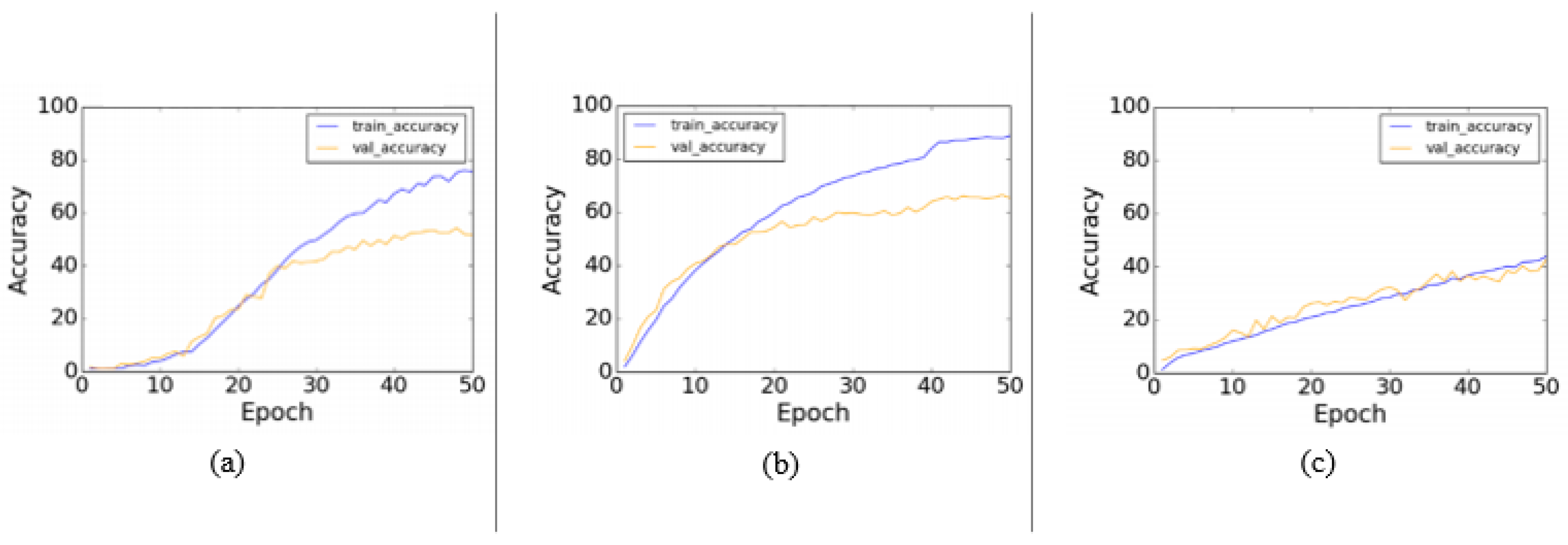{kind=link}
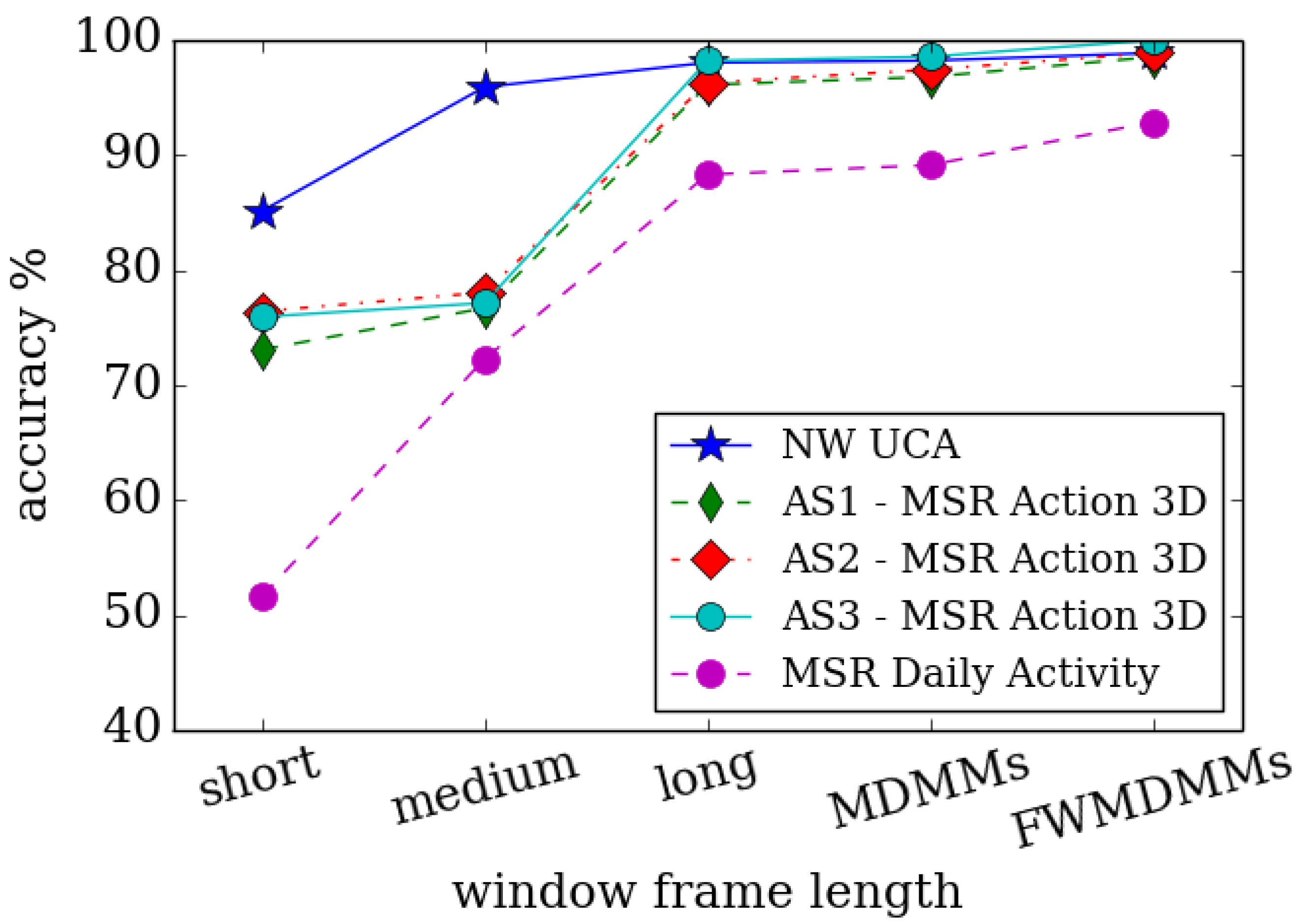{kind=link}
{kind=link}
| Paper | Year | Method | Dataset | Accuracy |
|---|---|---|---|---|
| [136] | 2009 | Space-time volumes | KTH | 89.4 |
| [101] | 2011 | Dense trajectory | KTH | 95 |
| [137] | 2011 | Space-time volumes | KTH | 94.5 |
| UCF sports | 91.30 | |||
| [138] | 2011 | Shape-motion | Weizmann | 100 |
| [139] | 2011 | LBP | Weizmann | 100 |
| [140] | 2012 | bag-of-visual-words | HDMB-51 | 29.2 |
| [141] | 2012 | Trajectory | HDMB-51 | 40.7 |
| [142] | 2012 | HOJ3D + LDA | MSR Action 3D | 96.20 |
| [143] | 2013 | Features (Pose-based) | UCF sports | 90 |
| MSR Action 3D | 90.22 | |||
| [144] | 2013 | 3D Pose | MSR Action 3D | 91.7 |
| [145] | 2013 | Shape Features | Weizmann | 92.8 |
| [111] | 2013 | Dense trajectory | HDMB-51 | 57.2 |
| [146] | 2014 | Shape-motion | Weizmann | 95.56 |
| KTH | 94.49 | |||
| [147] | 2014 | EigenJoints + AME + NBNN | MSR Action 3D | 95.80 |
| [148] | 2014 | Features (FV + SFV) | HDMB-51 | 66.79 |
| Youtube action | 93.38 | |||
| [149] | 2014 | Dissimilarity and sparse representation | UPCV Action dataset | 89.25 |
| [150] | 2014 | Shape features | IXMAS | 89.0 |
| [151] | 2016 | Trajectory | MSR Action 3D | 89 |
| [152] | 2016 | Shape Features | Weizmann | 100 |
| [153] | 2016 | Shape features | IXMAS | 89.75 |
| [154] | 2016 | LBP | IXMAS | 80.55 |
| [155] | 2016 | Motion features | IXMAS | 83.03 |
| [64] | 2017 | MHI | MuHAVi | 86.93 |
| [156] | 2017 | spatio-temporal+HMM | MSR Action 3D | 93.3 |
| MSR Daily | 94.1 | |||
| [157] | 2018 | Joints + KE Descriptor | MSR Action 3D | 96.2 |
| Datasets | RGB | Depth | Skeleton | Samples | Classes |
|---|---|---|---|---|---|
| KTH [98] | ✓ | ✗ | ✗ | 1707 | 12 |
| Weizmann [201] | ✓ | ✗ | ✗ | 4500 | 10 |
| Hollywood2 [99] | ✓ | ✗ | ✗ | 1707 | 12 |
| HMDB51 [27] | ✓ | ✗ | ✗ | 6766 | 51 |
| Olympic Sports [202] | ✓ | ✗ | ✗ | 783 | 16 |
| UCF50 [203] | ✓ | ✗ | ✗ | 6618 | 50 |
| UCF101 [186] | ✓ | ✗ | ✗ | 13,320 | 101 |
| MSR-Action3D [74] | ✗ | ✓ | ✓ | 567 | 20 |
| MSR-Daily Activity [107] | ✓ | ✓ | ✓ | 320 | 16 |
| Northwestern-UCLA [204] | ✓ | ✓ | ✓ | 1475 | 10 |
| Berkeley-MHAD [205] | ✓ | ✓ | ✓ | 861 | 27 |
| UTD-MHAD [205] | ✓ | ✓ | ✓ | 861 | 27 |
| RGBD-HuDaAct [206] | ✓ | ✓ | ✗ | 1189 | 13 |
| NTU RGB+D [207] | ✓ | ✓ | ✓ | 56,880 | 60 |
| Characteristics | Deep Learning Based Models | Hand-Crafted Feature Based Models |
|---|---|---|
| Feature extraction and Representation | Ability to learn features directly from raw data | Pre-process algorithms and /or detectors are needed to discover the most efficient patterns to improve recognition accuracy. |
| Generalisation and Diversity | Automatically extract spatial, temporal and scale, transition invariant features from raw data | Use feature selection and dimensionality reduction methods which are not very generalisable. |
| Data preparation | Data pre-processing and normalisation is not mandatory in deep learning based models to achieve high performance | Usually require comprehensive data pre-processing and normalisation to achieve significant performance. |
| Inter-class and Intra-class | Hierarchical and translational invariant features are obtained from such models to solve this problem | Inefficient in managing such kind of problems. |
| Training and Computation time | Huge amount of data required for training purposes to avoid over-fitting and high computation powerful system with Graphical Processing Unit (GPU) to speed up training | Require less data for training purposes with less computation time and memory usage. |
| Paper | Year | Method | Class of Architecture | Dataset | Accuracy |
|---|---|---|---|---|---|
| [212] | 2012 | ASD features | SFA | KTH | 93.5 |
| [40] | 2013 | Spatio-temporal | 3D CNN | KTH | 90.2 |
| [163] | 2014 | STIP features | Sparse auto-encoder | KTH | 96.6 |
| [32] | 2014 | Two-stream | CNN | HDMB-51 | 59.4 |
| [172] | 2014 | DL-SFA | SFA | Hollywood2 | 48.1 |
| [32] | 2014 | Two-stream | CNN | UCF-101 | 88.0 |
| [213] | 2015 | convolutional temporal feature | CNN-LSTM | UCF-101 | 88.6 |
| [117] | 2015 | TDD Descriptor | CNN | UCF-101 | 91.5 |
| [170] | 2015 | Spatio-Temporal | CNN | UCF-101 | 88.1 |
| [171] | 2015 | Spatio-temporal | 3D CNN | UCF-101 | 90.4 |
| [175] | 2015 | Hierarchical model | RNN | MSR Action3D | 94.49 |
| [214] | 2015 | Differential | RNN | MSR Action3D | 92.03 |
| [215] | 2015 | static and motion features | CNN | UCF Sports | 91.9 |
| [117] | 2015 | TDD Descriptor | CNN | HDMB-51 | 65.9 |
| [170] | 2015 | Spatio-Temporal | CNN | HDMB-51 | 59.1 |
| [216] | 2016 | Spatio-temporal | LSTM-CNN | HDMB-51 | 55.3 |
| [184] | 2016 | Deep Network | CNN | UCF-101 | 89.1 |
| [216] | 2016 | Spatio-temporal | LSTM-CNN | UCF-101 | 86.9 |
| [184] | 2016 | Deep model | CNN | HDMB-51 | 54.9 |
| [173] | 2016 | 3D CNN + HMM | CNN | KTH | 89.20 |
| [179] | 2016 | LRCN | CNN + LSTM | UCF-101 | 82.34 |
| [185] | 2017 | SP-CNN | CNN | HDMB-51 | 74.7 |
| [217] | 2017 | Rank pooling | CNN | HDMB-51 | 65.8 |
| [217] | 2017 | Rank pooling | CNN | Hollywood2 | 75.2 |
| [185] | 2017 | SP-CNN | CNN | UCF-101 | 91.6 |
| [218] | 2018 | DynamicMaps | CNN | NTU RGB+D | 87.08 |
| [219] | 2018 | Cooperative model | CNN | NTU RGB+D | 86.42 |
| [191] | 2019 | Depth Dynamic Images | CNN | UWA3DII | 68.10 |
| [189] | 2019 | FWMDMM | CNN | MSR Daily Activity | 92.90 |
| CNN | NUCLA | 69.10 | |||
| [192] | 2020 | MB-MHI | ResNet | MUHaVi | 83.8 |
| [196] | 2020 | MV-RAMDMM | 3DCNN | MSR Daily Activity | 87.50 |
| 3DCNN | NUCLA | 86.20 | |||
| [174] | 2020 | Semi-CNN | ResNet | UCF-101 | 89.00 |
| Semi-CNN | VGG-16 | UCF-101 | 82.58 | ||
| Semi-CNN | DenseNet | UCF-101 | 77.72 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Faris, M.; Chiverton, J.; Ndzi, D.; Ahmed, A.I. A Review on Computer Vision-Based Methods for Human Action Recognition. J. Imaging 2020, 6, 46. https://doi.org/10.3390/jimaging6060046
Al-Faris M, Chiverton J, Ndzi D, Ahmed AI. A Review on Computer Vision-Based Methods for Human Action Recognition. Journal of Imaging. 2020; 6(6):46. https://doi.org/10.3390/jimaging6060046
Chicago/Turabian StyleAl-Faris, Mahmoud, John Chiverton, David Ndzi, and Ahmed Isam Ahmed. 2020. "A Review on Computer Vision-Based Methods for Human Action Recognition" Journal of Imaging 6, no. 6: 46. https://doi.org/10.3390/jimaging6060046
APA StyleAl-Faris, M., Chiverton, J., Ndzi, D., & Ahmed, A. I. (2020). A Review on Computer Vision-Based Methods for Human Action Recognition. Journal of Imaging, 6(6), 46. https://doi.org/10.3390/jimaging6060046