1. Introduction
Hyperspectral sensors collect data as a set of images with high spatial and spectral resolutions, with each spectral band image being a narrow wavelength range of the electromagnetic spectrum. The large quantities of hyperspectral data present great challenges in storage, transmission, and analysis, as a consequence, data compression is becoming a common process for such imagery. In general, compression can be either lossy or lossless. Lossy compression typically provides lower bit rates but incurs loss on the original data. On the other hand, lossless compression guarantees perfect reconstruction on the original data, albeit with higher bit rates. This work focuses on improving the performance of onboard predictive lossless compression on hyperspectral imagery. The techniques are useful for many precision-demanding applications where strictly no data loss is highly desirable [
1,
2,
3]. Below is a brief survey on the existing work on the subject.
Lossless compression of hyperspectral images has been performed very successfully using prediction-based methods. Context-based Adaptive Lossless Image Codec (3D-CALIC) [
4] and its variant M-CALIC [
5] consider both interband and intraband correlations to reduce prediction errors. The Lookup Table (LUT) approach in [
6] exploits the calibration-induced data correlation specific to hyperspectral imagery to facilitate accuracy prediction. This scheme was enhanced by a Locally Averaged Interband Scaling (LAIS-LUT) approach using a band adaptive quantization factor [
7].
Transform-based approaches such as Discrete Wavelet Transform (DWT) and Principal Component Analysis (PCA), aim to exploit the relations in the spectral and spatial dimensions based on a redundancy reduction transform. The problem of selecting an appropriate signal representation for transform-based compression is equivalent to the feature extraction problem in machine learning. Recently, Wavelet-based Regression Analysis (RWA) [
8,
9] was introduced for lossless compression by exploiting the relationships among wavelet-transformed components, which outperforms the traditional approaches.
Low-complexity filter-based compressors, such as the Fast Lossless (FL) [
10] and Spectral-Oriented Least Squares (SLSQ) [
11], utilize linear models to de-correlate the co-located pixels from different spectral bands. An optimized version of the Fast Lossless (FL) algorithm developed by the NASA Jet Propulsion Laboratory (JPL) has been selected as the core predictor in the new Consultative Committee for Space Data Systems (CCSDS) standard for multispectral and hyperspectral data compression [
12]. Besides, traditional Wiener filter, Kalman filter and least mean square filter, were adopted for hyperspectral image compression. Examples include the Backward Pixel Search (BPS) [
13], Kalman Spectral Prediction (KSP) [
14] and Maximum Correntropy Criterion based Least Mean Square (MCC-LMS) [
15] algorithms. Similar to linear predictors, nonlinear predictors such as Context-based Condition Average Prediction (CCAP) [
16] and Two-Stage Prediction (TSP) [
17] have also brought improvement in compressed bit rates.
High-complexity compressors such as Clustered Differential Pulse Code Modulation (C-DPCM) have been studied in [
18], which partitions the data into several clusters with similar statistics and applies separate least-square optimized linear predictors to different clusters. [
19] presents an Adaptive Prediction Length C-DPCM (C-DPCM-APL) method, which is a brute-force variant of the C-DPCM approach, in that the number of previous bands selected for prediction was determined by a brute-force search ranging from 10 to 200 bands in steps of 10. Two other C-DPCM variants also use a large portion of previous bands for prediction, including the Spectral Relaxation Labeled Prediction (S-RLP) and Spectral Fuzzy Matching Pursuits (S-FMP) in [
20]. However, the computational complexity of these clustering-based compressors is very high.
Recently, Deep-learning based approaches have been widely utilized to lossy and lossless hyperspectral data compression. For lossy compression, [
21,
22,
23,
24] focused on designing deep networks to reconstruct the original imagery with a reasonable loss of information. Those models have an encoder-decoder structure, where representative features are usually extracted by Autoencoder network (AE) or Convolution Neural Network (CNN). Ref. [
25] proposed an onboard CNN-based lossy compressor, where the neural network is pre-trained on other datasets in a ground-based setting. For lossless compression, deep neural networks [
26,
27] and recurrent neural networks (RNN) [
28] have been proposed to compress hyperspectral data by appropriately pre-training the networks.
Nonetheless, the above mentioned deep-learning methods are not suitable for the challenging task of onboard lossless compression of hyperspectral images. The main reason is that deep learning relies on the availability of data from all the spectral bands during the process of training or clustering. However, either the entire original dataset or decompressed dataset is normally not available, or only partially available in many real-time compression applications. Furthermore, a pre-trained model can not in general adapt well for some new datasets, which necessitates model retraining for each new dataset.
To address those limitations, we propose an adaptive filtering-based Concatenated Shallow Neural Network (CSNN) model for predictive lossless compression. The contributions of the proposed method are twofold: (1) The CSNN was designed as an adaptive prediction filter rather than as a training-based network. Thus the model needs not be pre-trained before being used for pixel value calculation. To the best of our knowledge, this might be the first neural network based method requiring no training proposed for hyperspectral data compression. (2) The shallow two-hidden layer structure of the proposed model is capable of capturing both spatial and spectral correlations to provide more accurate pixel prediction, with only a few contexts from four previous bands. Consequently, computational complexity is much lower than other deep-learning based methods.
The rest of the paper is organized as follows.
Section 2 discusses context selection for prediction and provides an information theoretic analysis of the prediction performance.
Section 3 describes the proposed method in detail. Simulation results are given in
Section 4. Finally, conclusions are drawn in
Section 5.
2. Context Selection and Prediction Performance Analysis
Let denotes the pixel value at line x and column y in band z of a hyperspectral image cube. Rather than directly encoding the value of , a predictive compression algorithm uses previously decoded pixel values to compute a predicted pixel value . Then the prediction residual, (), which is the difference between the actual pixel value and its estimate is encoded losslessly using an entropy coder.
2.1. Context Selection
The predictor attempts to exploit correlations between the contexts and the current pixel value. Thus, the first step is to select the contexts appropriately. Typically, the neighboring pixels tend to have correlations. Considering the fact that spectral correlations tend to be much stronger than spatial correlations, the FL and MCC-LMS methods use only spectral contexts, while CCAP, TSP and M-CALIC methods combine spatial context with spectral context for prediction. Following the practice in [
10], as a pre-processing step, we perform a simple local averaging to better exploit the spatial correlations as follows:
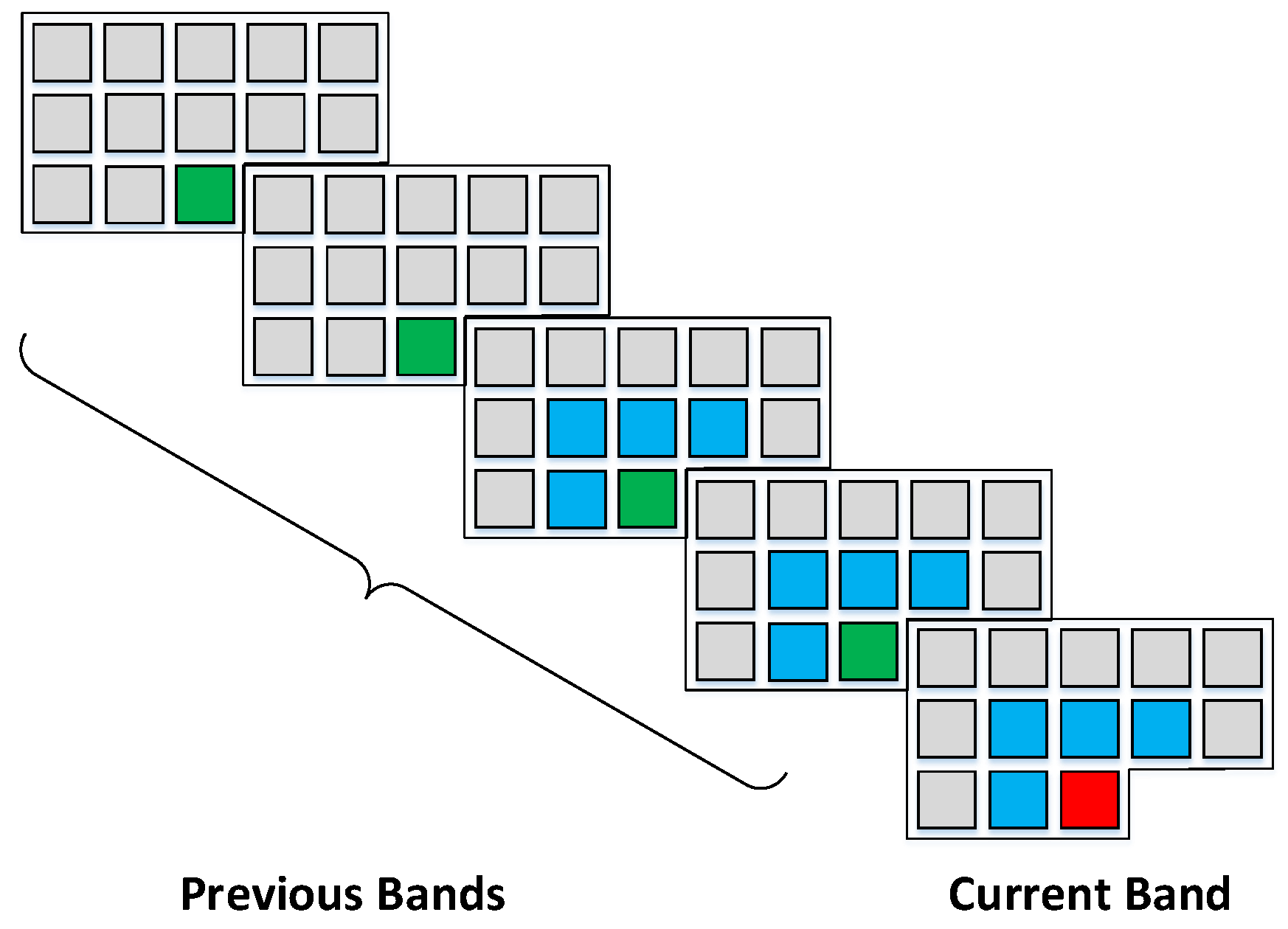
Figure 1 shows an example of context selection. The spatial context was selected from the current band and two previous bands. For each band, four neighboring pixels are reshaped into a 1-D vector
, note the selected pixels are averaged values. Thus, the combined spatial context, denotes as
, is a 3 × 4 matrix. If a pixel reaches the boundary of image, we can still use the four nearest pixels to construct the context vector. For example, four previous pixels are selected as context for pixels in the first row of image:
, we repeat previous pixel values to make the size of context vector equals to four even if
. For pixels in the first column, the spatial context vector becomes
. Similarly, context vector for pixels in the last column of the image can be written as
. Besides, four pixels from previous bands co-located with the current pixel are chosen as the spectral context, denotes as
. Note for prediction of the pixels in the spectral bands where
, we use spatial contexts only.
2.2. Prediction Performance Analysis
The performance of the prediction based algorithms largely depends on the choice of the context. Information theoretic analysis can provide an upper bound on the amount of compression achievable based on the specific context. The analysis employs the concept of conditional entropy, as a measure of information gain, based on a simple model of prediction process [
29].
Let
be a two-dimensional spectral image of the hyperspectral dataset, and
, where
K is the total number of spectral bands in the data cube. We reshape pixel value of
into a vector, then the occurrences of pixels in the vector can be viewed as a random process. For a hyperspectral image having 16 bits/pixel, the first order statistical properties of
is defined in terms of the probabilities
, where
is the set of distinct pixel values in
, with the range
. Then the entropy of the source can be written as [
30]:
where
is the minimum bit rate that lossless compression can possibly achieve using an ideal entropy coder.
The information gain of
can be further reduced by exploiting the first-order statistical information of contexts. The entropy scheme
can be easily extended to conditional entropy of band
given spatial context
and spectral context
:
where
is the conditional probability
. By applying the chain rule, the conditional entropy can be further rewritten as:
The conditional entropy gives the minimum achievable bit rate of
, given the context
and
. In general, by exploiting the spectral and spatial correlation, we will have
.
In practice, as stated in [
14], the conditional entropy estimation becomes very inaccurate when two or more previous bands are used for prediction. It is because the conditional entropy have to estimate the joint entropy by calculating the occurrence frequencies on a very large alphabet space, i.e.,
in our case, where
and
is the number of bands used for selecting spatial and spectral context. As a consequence, a band might not contain enough pixels to provide a statistically meaningful estimation of the probabilities. [
14] proposes to use the bit-planes of
as a set of 16 binary sources to greatly reduce the alphabet size. However, results obtained from the binary source might not be representative of the actual alphabet sources, since the correlations between the bit-planes cannot be ignored. To solve this problem, we propose to use a neural network to extract the features from the selected contexts, which are more representative of the context sources.
3. Proposed Method
The proposed approach was motivated by the state of the art CCSDS-123 standard onboard compressor [
12], which has been proved very efficient in lossless compression [
10,
12]. In CCSDS-123, the core algorithm FL is mainly a gradient-based adaptive filter. The predicted value
and error
can be expressed as:
where the
and
are the weight vector and input context vector. Then the weight vector is updated adaptively based on
:
where
denotes the clipping of the real number to the range
, and
is the sign function defined as
.
is the weight update scaling exponent, and
is the inter-band weight exponent offsets in the range
.
Our goal here is to improve the traditional gradient-based adaptive filter with a neural network. The main idea is that the training a neural network can be interpreted as a nonlinear filtering procedure. Compared to the FL algorithm, the corresponding prediction value and error can be rewritten in a neural network setting:
and
are the designed network and the loss function. Then weights and bias are updated by the batch gradient decent with a small learning rate:
As we can see, the prediction and the updating scheme of the neural network are very similar to the FL algorithm, which indicates that the neural network can play the role of a nonlinear adaptive filter.
With onboard data compression (with limited data for pre-training the network) in mind, we propose a filtering-based concatenated shallow network (CSNN) for predictive lossless compression. The CSNN behaves as an adaptive filter, which updates the network parameters on-the-fly with the incoming batch input. Specifically, the input samples (following a zigzag scanning order) flow through the network for just one time. The prediction error of each sample is recorded simultaneously for further mapping (to non-negative integers) and entropy coding. The weights and biases are adjusted for each batch according to the prediction errors. Algorithm 1 provides more details of the proposed adaptive scheme.
| Algorithm 1 Algorithm for filtering based CSNN adaptive prediction. |
- 1:
Initialize the neural networks. - 2:
Calculate the local sample mean using Equation ( 1). - 3:
for t = 1:N do %% N is the number of batch, and the batch size equals to the number of columns in the spectral band. - 4:
Select the spatial and spectral contexts and for each pixels in batch, and prepare the data pair . - 5:
Extract spatial and spectral features and from the contexts using one-layer shallow neural networks. - 6:
Concatenate the features: . - 7:
Predict the pixel values based on F using Equation ( 11). - 8:
Calculate and record the prediction error for further mapping and coding. - 9:
Calculate the weight updates using Equation ( 13). - 10:
Adjusting the parameters in every batch: . - 11:
end for
|
We design the prediction method in such a way that the training procedure associated with most conventional neural networks based algorithms is not required. The filtering-based network aims to get the losses of each input sample rather than a well-trained network. Also, training a neural network relies on the availability of a large amount of training data, as well as an iterative optimization process of high computational complexity. In contrast, the proposed method filters each input sample only once, with a zigzag scanning order band by band. Thus, the computational time of filtering-based network is significantly lower than the conventional training-based neural network. In a nutshell, the filtering-based CSNN provides a more robust solution for a wide variety of hyperspectral datasets, without any pre-training or prior knowledge needed.
3.1. Concatenated Shallow Neural Network (CSNN)
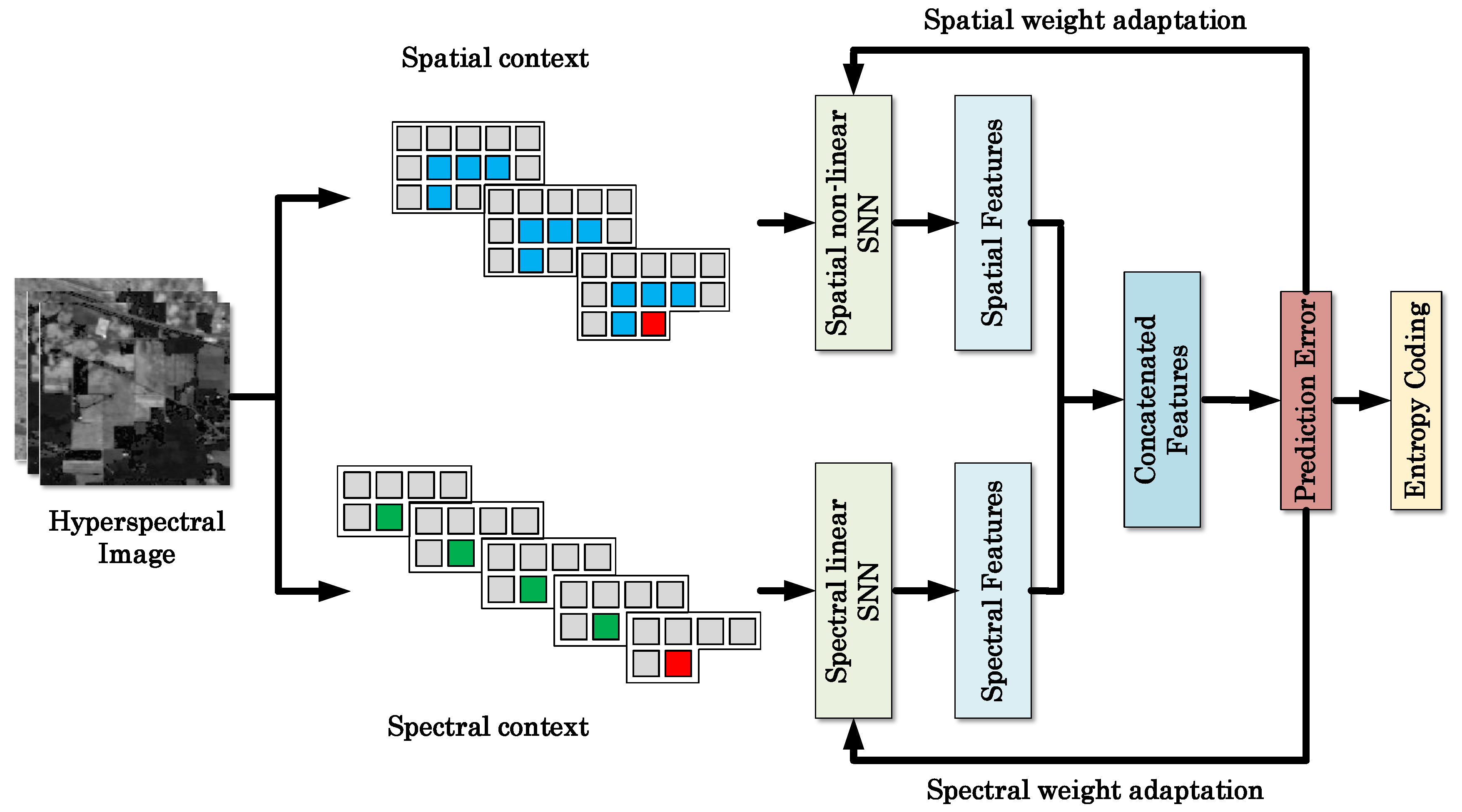
Figure 2 illustrates the framework of the proposed method. The processing flow of the proposed method consists of two channels, i.e., the spatial channel and spectral channel. Both channels extract representative features from the corresponding contexts. The features from these two channels are then combined to obtain the final predicted pixel values.
The spatial contexts and spectral contexts tend to correlate with the current sample pixel to be predicted in a very different way. Conventional prediction methods either directly combine these two types of contexts, or use the spectral contexts only. In this work, we introduce two parallel shallow neural networks to learn the spatial and spectral correlations separately, in light of the good ability of neural networks for many ill-posed tasks.
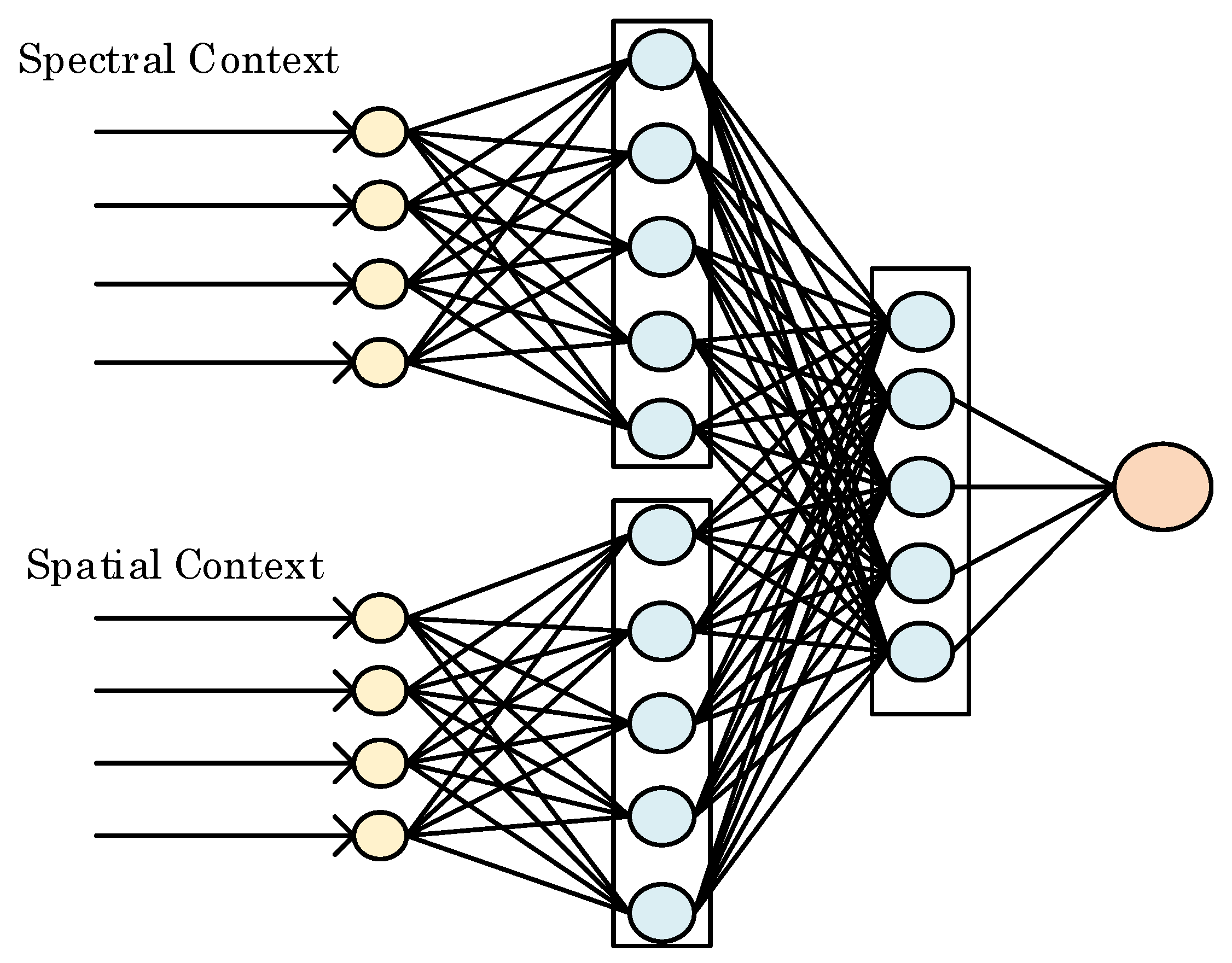
Figure 3 shows the structure of the concatenated shallow neural network for pixel prediction. To extract spatial correlations, the hidden neurons connected with spatial context converts the input into a series of feature maps via a non-linear process,
where
is the extracted spatial features, and
and
denote the corresponding weight and bias. A Rectified Linear Unit,
, is used as the activation function for spatial channel. In this work, a 3 × 4 spatial context matrix is converted to a 1 × 5 feature vector by means of five connected neurons.
For the spectral channel, exactly the same number of hidden neurons are used for extracting the spectral feature, however, the
ReLU activation function is not used here to obtain the spectral feature
below, based on our observation in extensive empirical study that the spectral contexts tend to be correlated in a less non-linear fashion than the spatial contexts.
Similarly,
and
in the equation above denote the corresponding weights and biases.
Note that the neural networks are employed for both channels as opposed to deep neural networks. Although deep networks are capable of capturing high dimensional features, they might suffer from the overfitting problem. To predict a spectral band whose context changes rapidly, optimization of the deep network might be trapped by local optima and thus fail to react promptly. Besides, since a large number of the weights and biases need be adjusted by prediction errors using back propagation, training of deep network may be time consuming.
The extracted features from two channels are concatenated together denote as
. The combined features jointly decide the final predicted pixel value with a linear output layer,
where
and
are the weights and biases for the final layer. Thus, the CSNN model contains two hidden layers: the first hidden layer extracts spatial and spectral features, and the second concatenated hidden layer for final pixel value prediction.
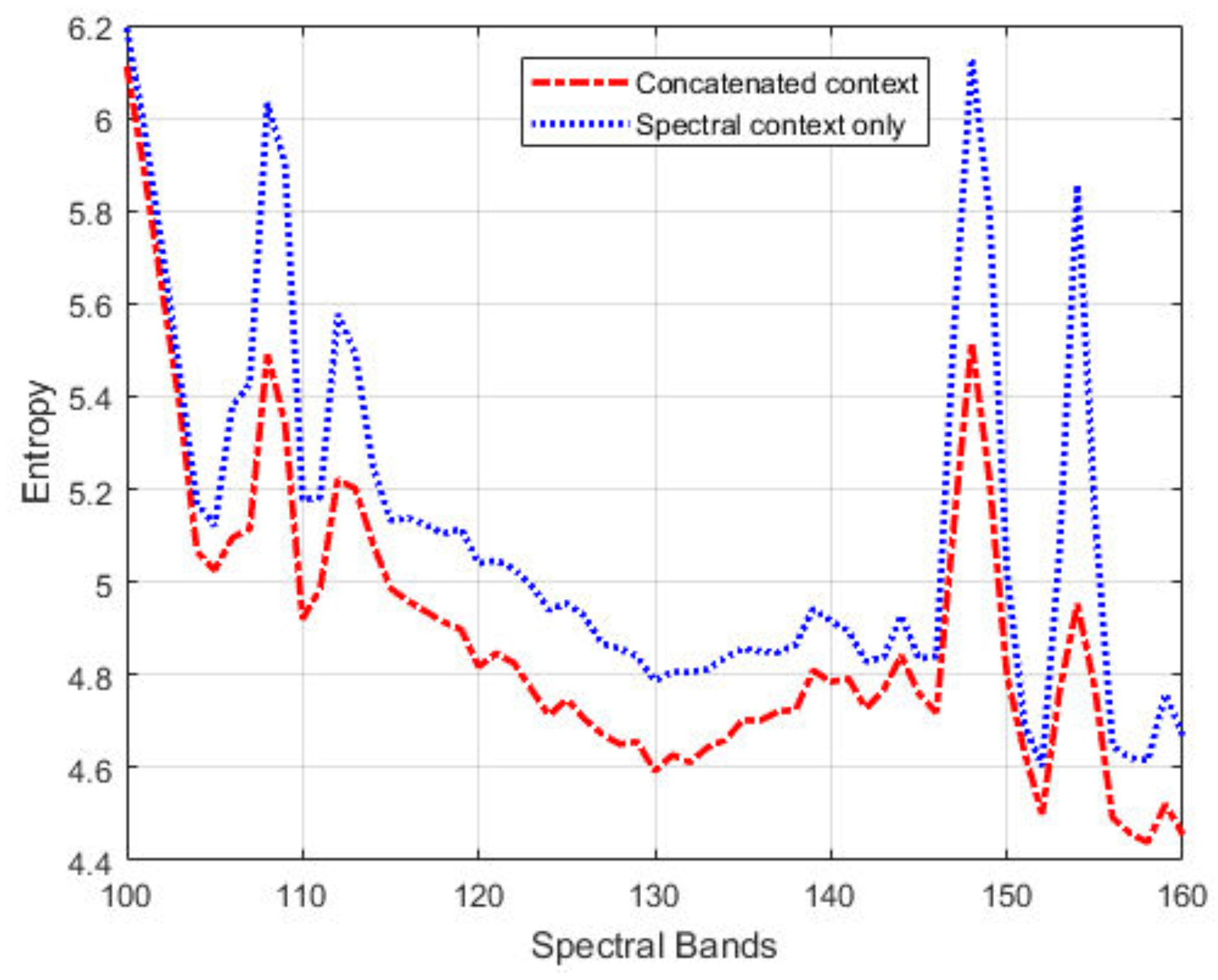
Figure 4 shows the first-order entropies of the prediction residuals for a segment of the IP dataset, with the joint spatial/spectral contexts and spectral contexts only, respectively. We can see that combined contexts allow for more accurate prediction (i.e., low entropy values). The improvement in prediction is especially pronounced for band images with large pixel-intensity variations, for example, entropy reduction by 0.6 bit for band 148 and 0.9 bit for band 154.
The CSNN is a typical end-to-end fully connected neural network, with the weights and biases being updated by the Adadelta optimizer [
31] with the
loss function:
Note that the
loss function was adopted since our study found that it can lead to lower residual entropies than the
loss function, which favors quality assessment based on the mean square errors. If we set
to be the gradient of the parameters at
t-th input data, the update
can be calculated as follows:
where RMS is the root mean square, which is defined as
.
is an exponentially decaying average of the squared gradients:
where
is a decay constant and
is added to the numerator of RMS to ensure progress continues to be made even if the previous updates become small. We set
and
in the simulations. The code of CSNN model can be found at [
32].
3.2. Entropy Coding
After prediction, all the residuals are mapped to non-negative values [
33] and then coded into bitstream losslessly using a Golomb Rice Codec (GRC) [
34]:
where
n refers to the value of the prediction residual. Note GRC is selected as the entropy coder due to its computational efficiency. We observed that arithmetic coding [
35] can offer slightly lower bitrates, albeit at a much higher computational cost.
Besides the GR codewords, there is other side information that needs to be transferred to the decoder in order to recover the original data losslessly. For example, the weights and biases that initialize the neural networks need to be encoded too. Since the CSNN model has less than 20 neurons, such side information becomes negligible and thus it is not included in the total bit rates reported in the following.
4. Simulations Results
We tested the proposed method on five public hyperspectral datasets [
36] and the standard CCSDS test datasets. We selected 20 datasets from the CCSDS test sets with different collecting instruments: Atmospheric Infrared Sounder (AIRS), Airborne Visible/Infrared Imaging Spectrometer (AVIRIS), SWIR Full Spectrum Imager (SFSI), and Compact Airborne Spectrographic Imager (CASI). The test results are compared with the state-of-the-art CCSDS-123 method. Before presenting the results, we first provide a convergence analysis on the proposed model, and discuss the sensitivity of parameter initialization on the compression result.
4.1. Convergence Analysis and Parameter Sensitivity
Deep neural network is the mainstream technique for many machine learning tasks. Despite its success, theoretically explaining why deep neural networks can be efficiently trained in practice using simple gradient-based methods is still an open problem. Filtering the input data by the CSNN model is similar to the training process, which requires optimizing a complex non-convex problem. Over the past few years, much research has been devoted to this problem [
37,
38,
39,
40,
41]. Based on these existing work, we found that the convergence of the neural network is closely related to the choice of hyperparameters such as the number of hidden layers, the number of hidden units and the learning rate. Although training a network seems intractable, [
37] provides some tricks to determine the hyper-parameters in the model.
The convergence of neural networks is studied in [
39,
40]. An early convergence of filtering-based network can provide much smaller prediction loss, and lower compression bitrates as a return. To demonstrate the convergence of filtering-based CSNN model, we perform the filtering-based CSNN on four public hyperspectral datasets:
Indian Pines (IP),
Pavia University (PU),
Salinas (SAL), and
Botswana (BOT).
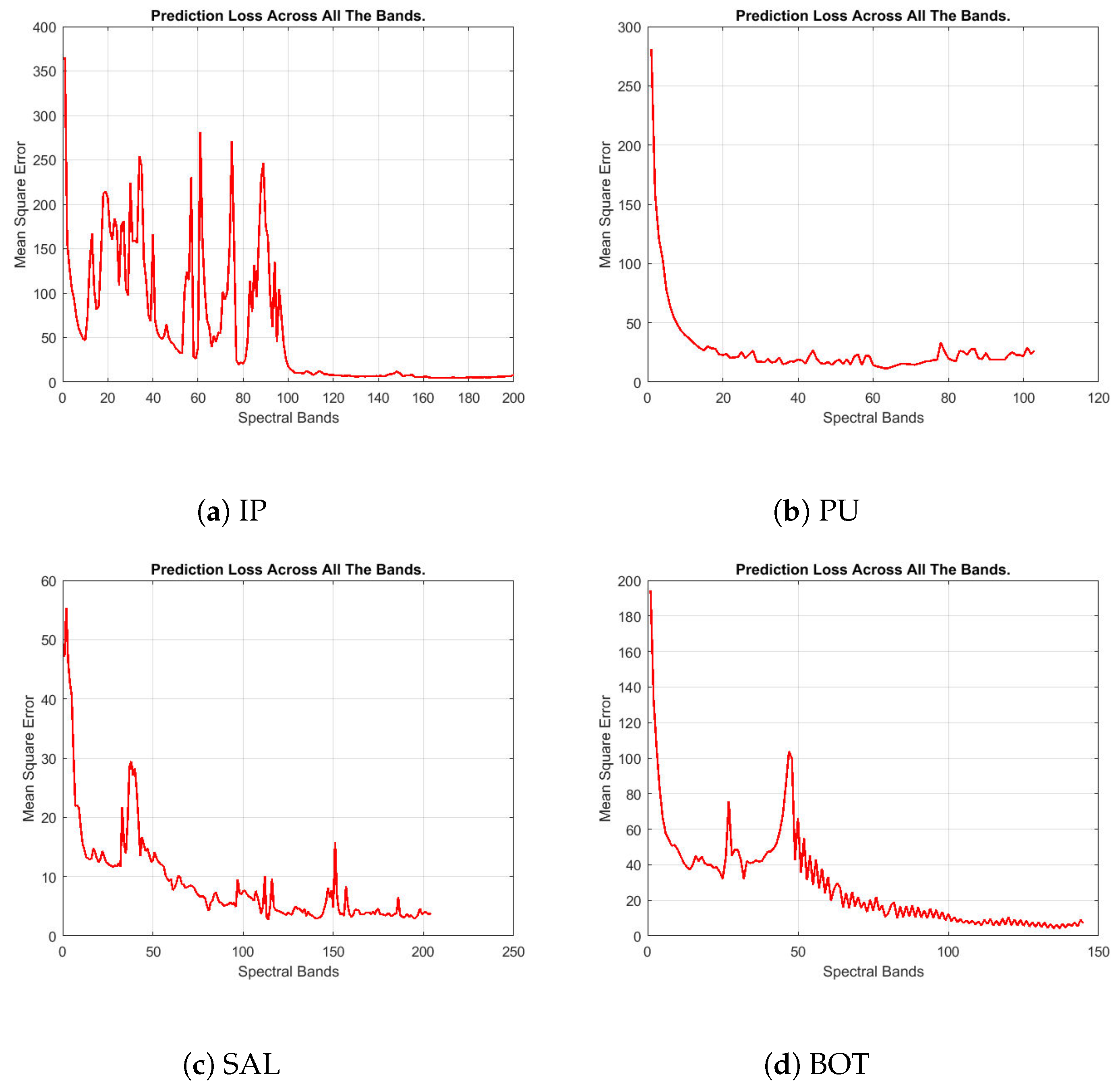
Figure 5 shows the prediction loss in Mean Square Error (MSE) across all the spectral bands.
Clearly, the prediction loss curves of four datasets show convergence to relatively small error values. For example, the losses of the PU dataset decrease to a very low level after filtering the first 20 bands. For other datasets, even if the losses fluctuate intensely at the beginning like IP dataset, the losses converged to small values after half of the data have been filtered. This demonstrates the ability of the proposed CSNN model to find a fairly good solution with only a single iteration on the data. We believe that the similarity (correlation) of data samples among different spectral bands helps accelerate the convergence of the model.
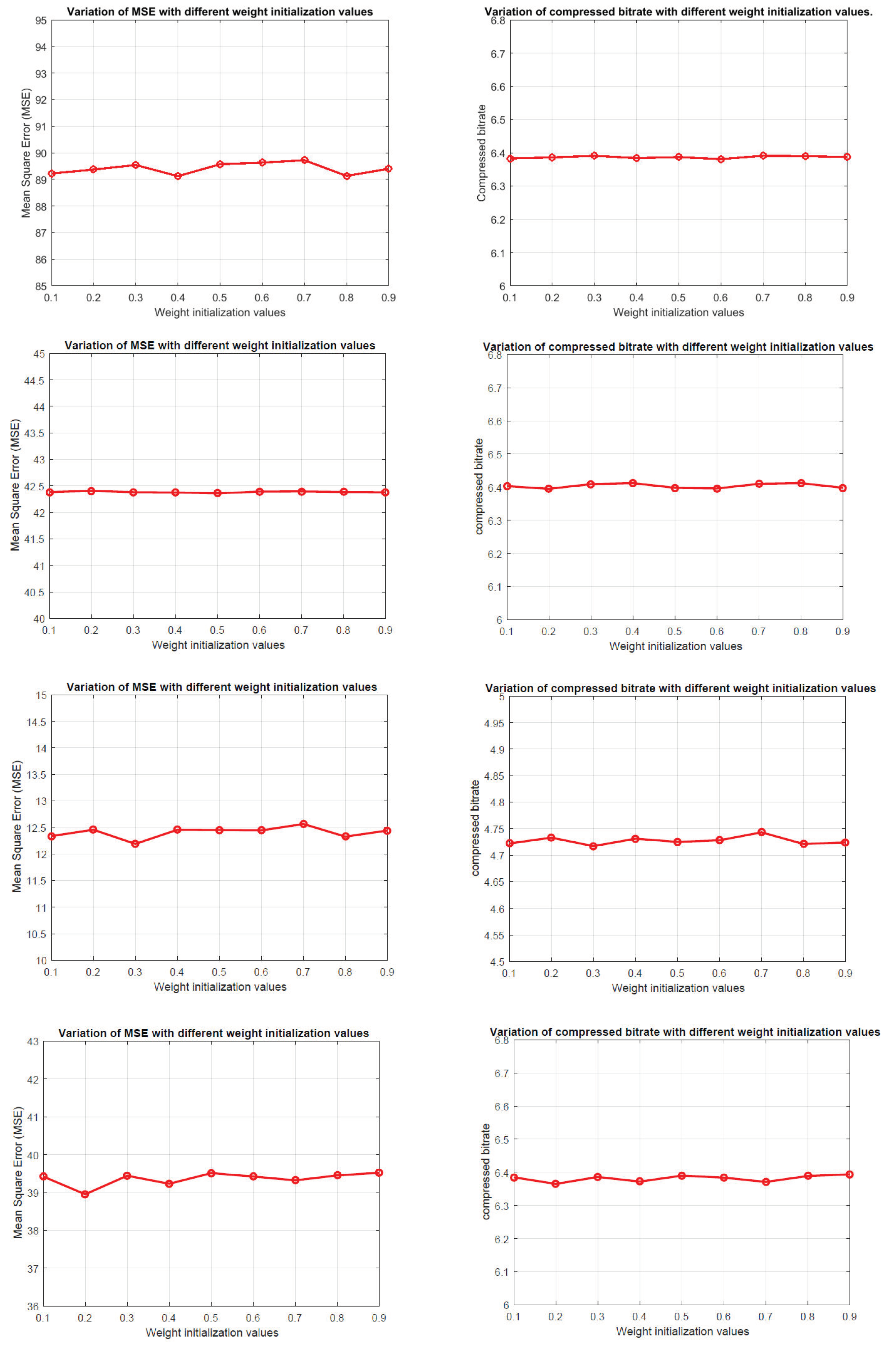
Another factor that can influence the convergence is the initialization of parameters in the network. In our simulations, we select
Xavier initialization [
42], which is one of the most commonly used initialization methods for the neural network. In
Xavier, all the weights initialize independently from a zero-mean, unit variance distribution. It is interesting to see how different weight initialization methods would affect prediction loss and entropy. Thus, we conduct several experiments by assigning network with weight values ranging from 0.1 to 0.9.
Figure 6 shows the variations of MSE values and compression bitrates on four different datasets using proposed method. Note the weight parameters include the weights and biases in each layer.
We can see that the MSE values and compressed bitrates do not appear to be very sensitive to change of weight parameters. For example, the MSE values of IP dataset range from 89 to 90 with different initialized weight values. For other datasets, the value of MSE and bitrate all fluctuated within a small range. The testing results are consistent with the conclusion in [
40], where the gradient-based linear neural network has a strong convergence ability. It also indicates the filtering-based CSNN is robust to the initial condition.
4.2. Simulations on Five Public Hyperspectral Datasets
The five hyperspectral image datasets include IP, PU, SAL, BOT and
Kennedy Space Center (KSC). All these datasets contain 12-bits non-calibrated raw images. More detailed information of these data sets are given in
Table 1.
We select three representative adaptive filtering methods to benchmark the proposed method:
As we can see in
Table 2, the proposed CSNN method achieves the lowest bitrates on all five hyperspectral image datasets, where the LMS method has the highest bitrates. Specifically, the CSNN method improves by nearly 0.2 bit/pixel and 0.25 bit/pixel on average on the FL and MCC-LMS methods, respectively, with a more significant reduction of 0.58 bit/pixel over the LMS method. The CSNN seems to provide more efficient compression by exploiting jointly the spatial and spectral correlations from the contexts.
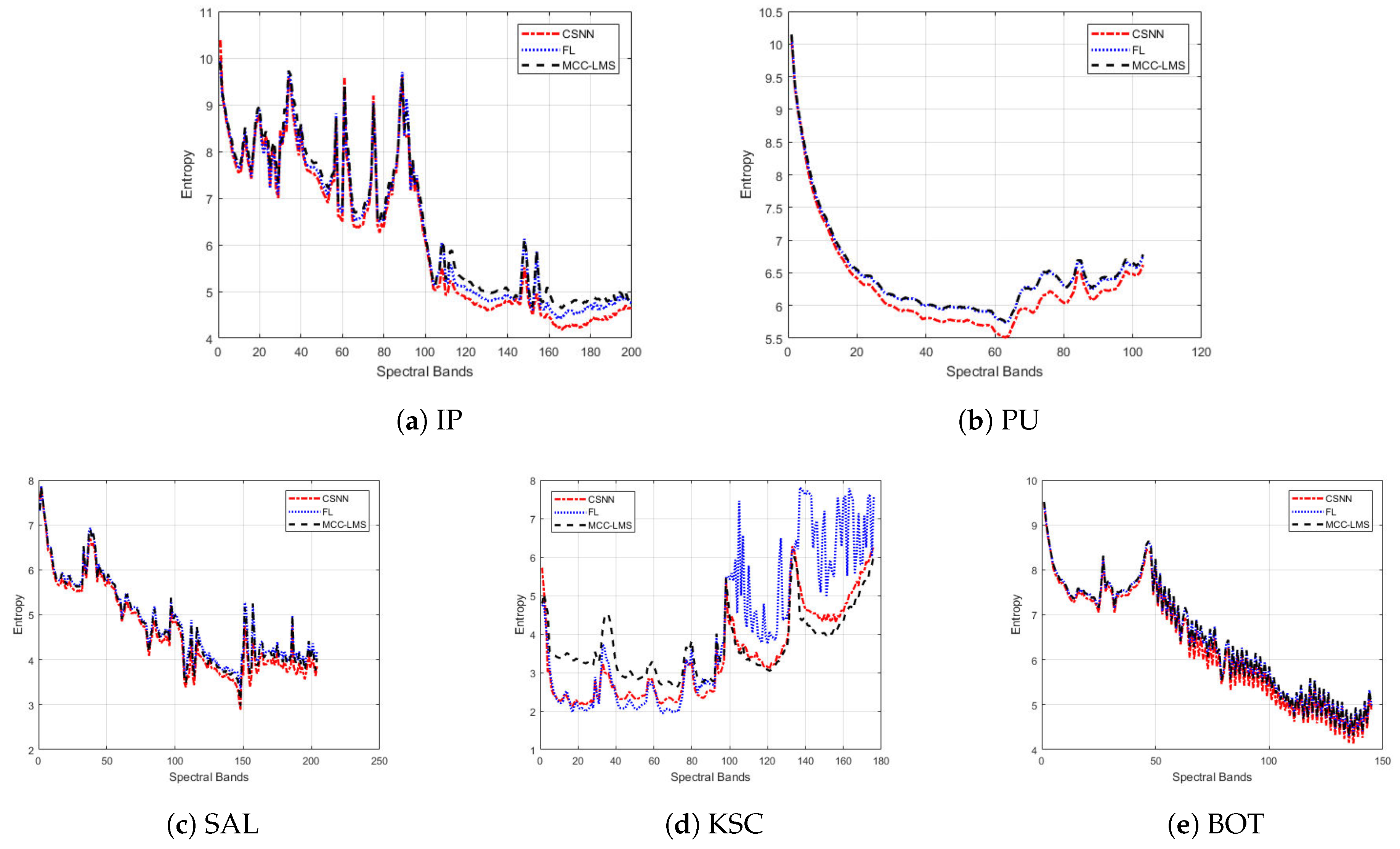
In terms of the prediction residuals,
Figure 7 shows that the CSNN method consistently achieves the lowest entropies on the most of bands of IP, PU, SAL and BOT datasets, with more obvious improvement for the last 50 bands. For example, in
Figure 7b, the curves of the last 50 bands of MCC-LMS and FL methods almost overlap, while the CSNN curve goes much lower. The curves for the KSC dataset in
Figure 7d exhibit significant fluctuations for all three methods. This data set contains a substantial amount of impulse noise, which might cause many sudden changes of the contexts. For example, the residual entropy fluctuates rapidly after band 100. But still, the proposed method seems to be the most stable one among the four methods. By considering also the compression bitrates of the KSC dataset in
Table 2, we can see that the adaptive filtering methods (including the proposed method) are not robust enough to data with noise.
4.3. Simulations on CCSDS Test Datasets
The CCSDS hyperspectral and multispectral test corpus [
43] has been publicly available for hyperspectral images compression testing and evaluation. The corpus includes images from many different instruments. To diversify the testing datasets, we selected 20 hyperspectral datasets from instruments AVIRIS, AIRS, SFSI and CASI for further evaluation of the algorithms. Seven hyperspectral images are from AVIRIS instrument, which includes five 16-bit non-calibrated Yellowstone scenes and two 12-bit scenes. The AIRS instrument has ten scenes, each scene has 1501 spectral bands and 90 lines with a width of 153 pixels. The remaining three images are from instruments SFSI and CASI.
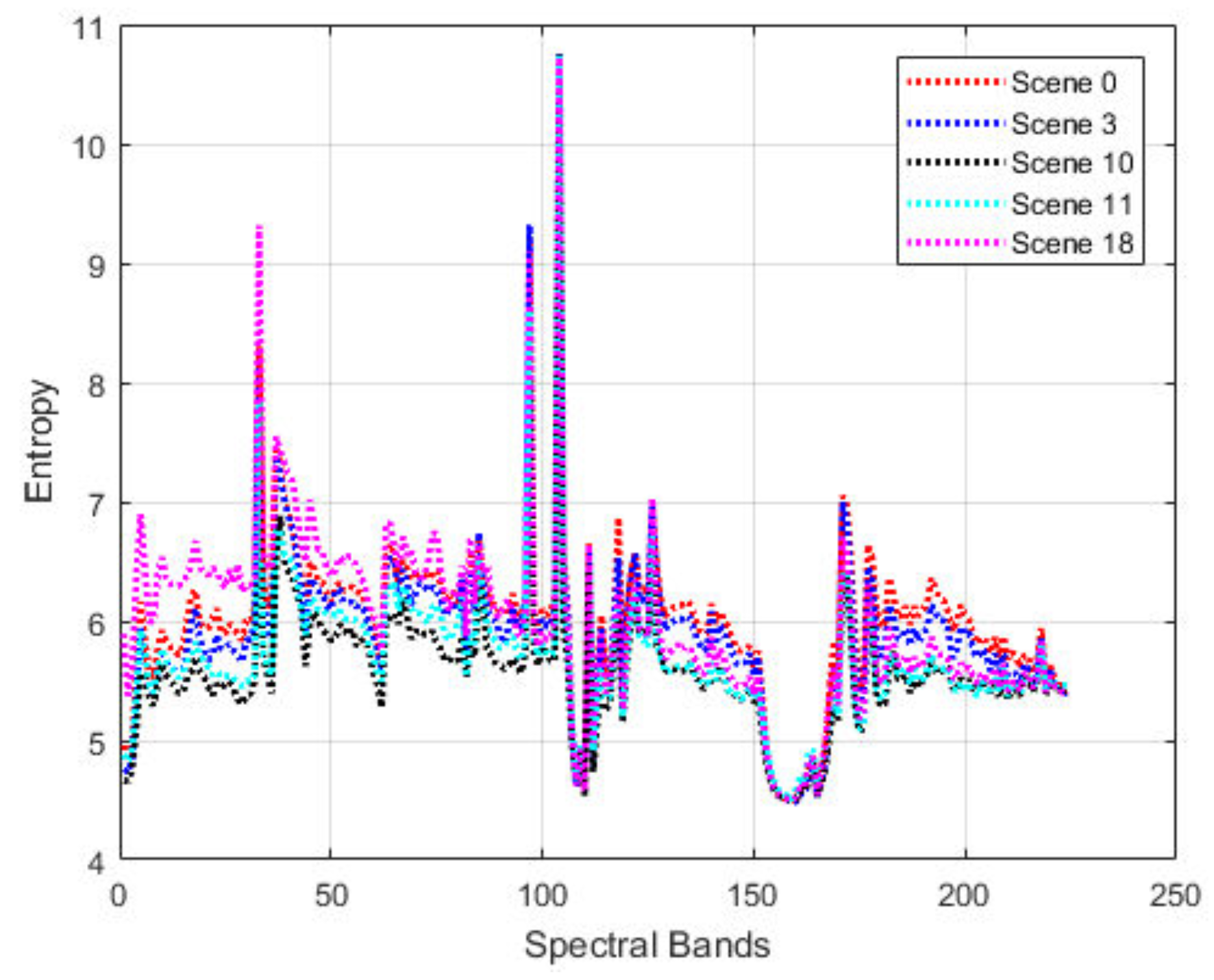
Table 3 provides detailed information about the selected datasets. As an example, The grayscale versions of the five AVIRIS Yellowstone scenes are shown in
Figure 8.
Lossless hyperspectral image compression techniques can be separated into two main categories: transform-based compression and prediction-based compression. Transform-based techniques achieve compression by taking advantage of frequency domain representation of images (e.g., based on wavelet transforms). On the other hand, predictive compression performs directly on pixel domain, followed by entropy coding on the prediction residuals (e.g., by using the Golomb-Rice codes). We selected a total of seven lossless compressors from both categories: JPEG2000 [
3], JPEG-LS [
2], LUT [
6], European Space Agency (ESA) [
44], CCSDS-122 [
45], MCC-LMS [
15], CCSDS-123 [
12]. Note the state-of-the-art predictive compressor CCSDS-123 is also provided for comparison.
Table 4 provides the lossless coding results for all the images in terms of the bit rate (in bpppc). The compression efficiency of each algorithm can be appreciated by observing the degree to which its resulting bit rate falls below the bit depth of the original images. We can see that the overall performance of the proposed filtering-based CSNN method exceeds other state-of-the-art methods included in the comparison.
For 16 bpppc non-calibrated AVIRIS Yellowstone scenes, the filtering-based CSNN model outperforms CCSDS-123 and MCC-LMS by 0.12 bpppc and 0.17 bpppc on average, respectively. When compared with the transform-based compression, the coding gain of CSNN is larger than JPEG2000 and CCSDS-122 by 0.52 bpppc and 0.60 bpppc, respectively.
For 12 bpppc non-calibrated AVIRIS scene (Hawaii and Maine), the coding performance of proposed model is comparable with CCSDS-123. Specifically, the compressed bitrate of CSNN is 0.03 bpppc higher than CCSDS-123, but much lower than other methods. Compared with other 12 bpppc images with different instruments, the Hawaii and Maine scenes have relatively smaller pixel values. For example, the average pixel value of Hawaii and Maine scene is 267.10 and 328.75, respectively. But for AIRS-gran9 image, the average pixel value is 2091. This indicates that the filtering-based CSNN would obtain more compression gain for images with higher pixel values. These results are also consistent with the property of the gradient-based network, where the neural network can make a quick response for large variations in the data. However, linear predictors, such as CCSDS-123, might be more suitable for slowly changing data with small values.
For other images from AIRS, SFSI and CASI instruments, the filtering-based CSNN model also provides superior performance compared to other prominent predictive coding techniques. To summarize, the results show that the proposed filtering-based CSNN yields the best overall achievement as compared to other predictive-based compressors. It offers additional desirable features such as no pre-training involved in compression procedure, thereby making it an appealing approach for lossless hyperspectral image compression.
Figure 9 shows the residual entropy variations of the “Yellow Stone” scenes. It is interesting to observe that five distinct scenes seem to follow a similar trend spectral band around 160 are almost the same. This indicates the robust prediction performance that can be achieved by jointly considering both the spatial and spectral contexts using the proposed method. There is the potential to use transfer learning to exploit such a similarity to further improve the compression performance.
4.4. Computational Complexity
The computation of the proposed CSNN method includes feed-forward propagation and back propagation. Note the filtering of CSNN model is mainly implemented with multiplication of matrices. Assume there are
i nodes in the input layer, corresponding to
i context pixels being fed to the network, and
j and
k denotes the number of nodes in the two hidden layers, and
l denotes the number of nodes in the output layer. In a four-layer neural network, there are three weight matrices to represent weights between these layers. For example,
is a weight matrix with
j rows and
i columns, which contains the weights going from layer
i to layer
j. In a feed forward pass, propagating a sample from layer
i to layer
j takes
time complexity, thus the overall time complexity from the input layer to the output layer becomes
. The back propagation starts from the last layer of the model. Similar to the feed forward pass, the time complexity of the back propagation is given by
. We can see that the computational complexity of the neural network largely depends on the number of hidden layers and the number of nodes in each layer. Also, as shown in Equations (
9) and (
10), activation function is only needed for the spatial channel, with very light computation required for the
function. The computation time for compressing the IP dataset takes 0.8 seconds/band, the experiments were carried out on a Thinkpad laptop with Intel Core i5 CPU and 8GB installed memory, running Windows 7 Professional (64-bit operating system). Note the matrix operations can be greatly parallelized by GPUs to further reduce the computation time.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}