Fusing Appearance and Spatio-Temporal Models for Person Re-Identification and Tracking




Abstract
1. Introduction
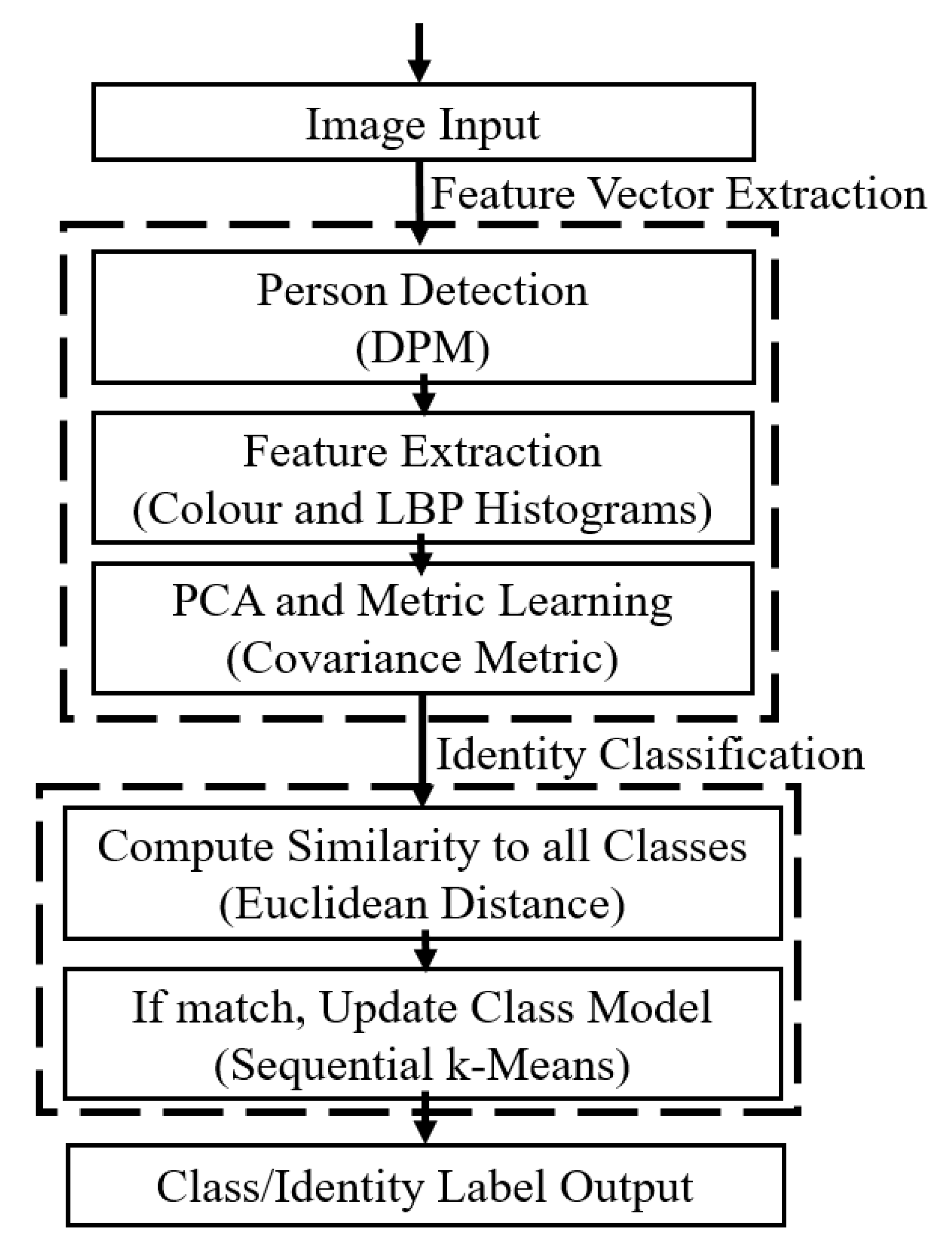
2. Appearance Based Re-Identification
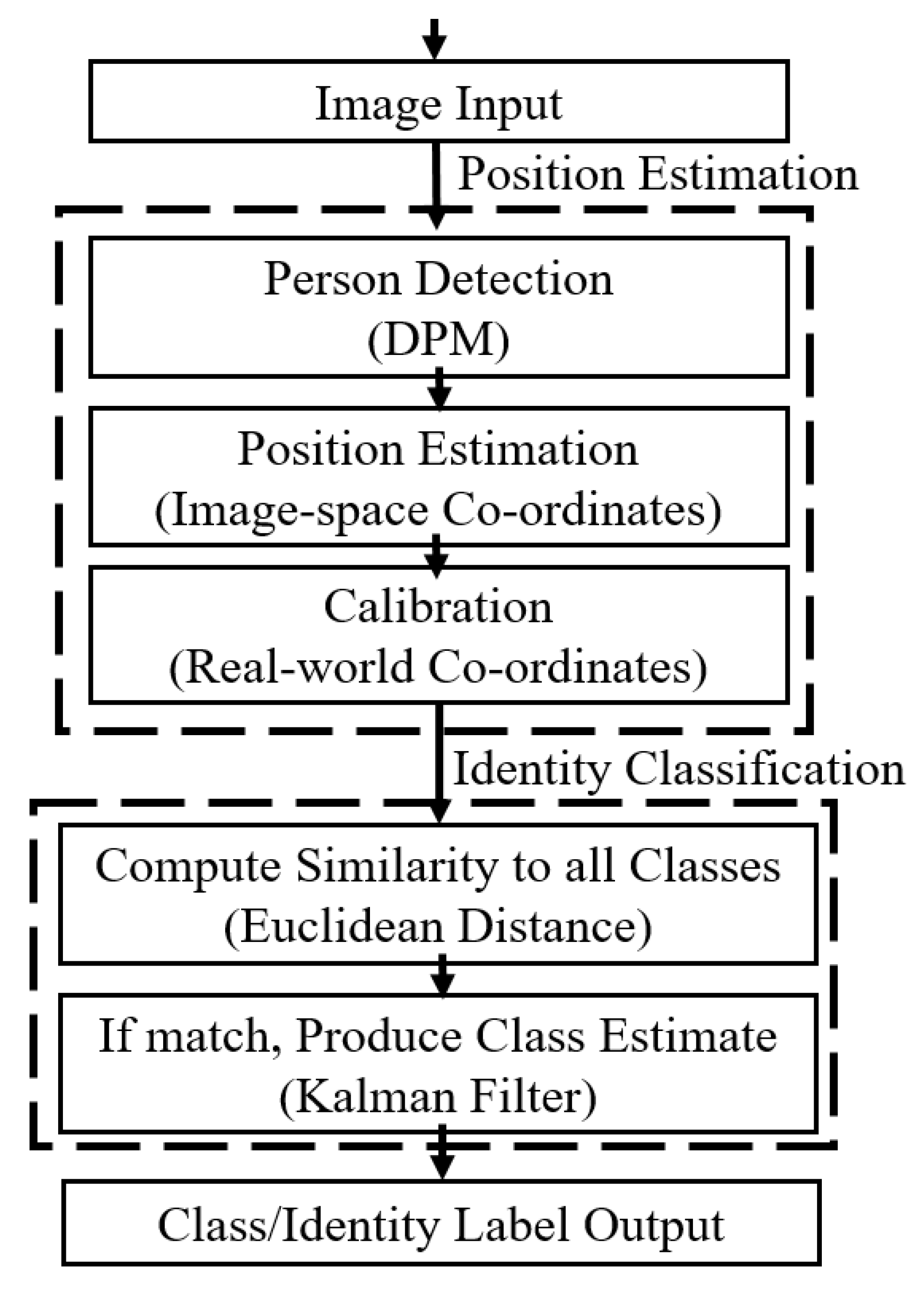
3. Spatio-Temporal Based Tracking
3.1. Calibration and Mapping
3.2. Kalman Filters
4. Rule-Based Model Fusion
4.1. Re-Ranking with Linear Weighting
4.2. Decay Function
4.3. Rule-Based System
4.3.1. Initialising Gallery Models by Camera
| Algorithm 1 Computation and use of , including the rule-based system to cover corner cases. |
| Set a value for each class c |
| 1: for each class c in the gallery C do |
| 2: if ethis camera is seeing the ST model’s top ranked identity for the first time then |
| 3: |
| 4: else if the scaled appearance distance is very close to zero then |
| 5: |
| 6: else |
| 7: {the decay function} |
| 8: Clamp between and |
| 9: end if |
| 10: end for |
| Cover similarity-based corner cases, overwriting previous values if necessary |
| 11: Calculate and {the ratio matrices} |
| 12: Initialise w, , and to False {assume good certainty initially} |
| 13: if {the first and second classes appear similar} then |
| 14: Form a restricted set of classes c where |
| 15: = True {appearance model has low certainty} |
| 16: for each class do |
| 17: |
| 18: end for |
| 19: end if |
| 20: if {the first and second classes are proximate to each other} then |
| 21: Form a restricted set of classes c where |
| 22: = True {spatio-temporal model has low certainty} |
| 23: for each class do |
| 24: |
| 25: end for |
| 26: end if |
| 27: if and {both the appearance and spatio-temporal models are uncertain} then |
| 28: w = True {declare that the final output will have low certainty} |
| 29: end if |
| Calculate the class c with the most similarity to the input person> |
| 30: for each class do |
| 31: |
| 32: end for |
| 33: {Combine the two restricted sets together} |
| 34: Return the highest ranking class c where if else , with to represent the similarity score and w to indicate the certainty on the result |
4.3.2. Scaling Effects
4.3.3. Similar Similarity
| Algorithm 2 Model update and class creation with unsupervised learning. |
| 1: Receive the Similarity Score , the class label c, and the certainty w from model fusion |
| 2: if w is True {if there is low certainty on the result} then |
| 3: Overwrite the class label with −99 to indicate low certainty |
| 4: Do not update the models, do not create a new class |
| 5: else if New Class Threshold {if most similar class is above the threshold} then |
| 6: increment the total number of classes by 1 |
| 7: Create a new class ID |
| 8: Initialise the spatio-temporal model (Kalman Filter) |
| 9: Initialise the appearance model (Sequential k-Means) |
| 10: else |
| 11: Update the spatio-temporal and appearance models for class c |
| 12: end if |
4.4. One-Shot vs. Unsupervised Learning
5. Experimental Results
5.1. Baseline Experiments
5.2. Comparing Person Detection Algorithms
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Wang, X. Intelligent Multi-camera Video Surveillance: A Review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Kumar, S.; Marks, T.K.; Jones, M. Improving person tracking using an inexpensive thermal infrared sensor. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 217–224. [Google Scholar]
- Petrushin, V.A.; Wei, G.; Shakil, O.; Roqueiro, D.; Gershman, V. Multiple-Sensor Indoor Surveillance System. In Proceedings of the Canadian Conference on Computer and Robot Vision (CRV), Quebec City, QC, Canada, 7–9 June 2006; pp. 40–47. [Google Scholar]
- Huh, J.H.; Seo, K. An Indoor Location-Based Control System Using Bluetooth Beacons for IoT Systems. Sensors 2017, 17, 2917. [Google Scholar] [CrossRef] [PubMed]
- Nazare, A.C.; de O. Costa, F.; Schwartz, W.R. Content-Based Multi-Camera Video Alignment using Accelerometer Data. In Proceedings of the International Conference on Advanced Video and Signal-based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018. [Google Scholar]
- Ahmed, E.; Jones, M.; Marks, T.K. An Improved Deep Learning Architecture for Person Re-Identification. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3908–3916. [Google Scholar]
- Li, W.; Du, Q. Gabor-filtering-based nearest regularized subspace for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1012–1022. [Google Scholar] [CrossRef]
- Wu, L.; Wang, Y.; Ge, Z.; Hue, Q.; Li, X. Structured deep hashing with convolutional neural networks for fast person re-identification. Comput. Vis. Image Underst. (CVIU) 2018, 167, 63–73. [Google Scholar] [CrossRef]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. Joint Detection and Identification Feature Learning for Person Search. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 1–26 July 2017; pp. 3415–3424. [Google Scholar]
- Camps, O.; Gou, M.; Hebble, T.; Karanam, S.; Lehmann, O.; Li, Y.; Radke, R.J.; Wu, Z.; Xiong, F. From the Lab to the Real World: Re-identification in an Airport Camera Network. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 540–553. [Google Scholar] [CrossRef]
- Filković, I.; Kalafatić, Z.; Hrkać, T. Deep metric learning for person Re-identification and De-identification. In Proceedings of the International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 30 May–3 June 2016; pp. 1360–1364. [Google Scholar]
- Khan, F.M.; Brémond, F. Person Re-identification for Real-world Surveillance Systems. arXiv 2016, arXiv:1607.05975. [Google Scholar]
- Paisitkriangkrai, S.; Shen, C.; van den Hengel, A. Learning to rank in person re-identification with metric ensembles. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1846–1855. [Google Scholar]
- Chen, A.T.Y.; Biglari-Abhari, M.; Wang, K.I.K. Investigating Fast Re-identification for Multi-camera Indoor Person Tracking. Comput. Electr. Eng. 2019, 77, 273–288. [Google Scholar] [CrossRef]
- Shu, G.; Dehghan, A.; Oreifej, O.; Hand, E.; Shah, M. Part-based multiple-person tracking with partial occlusion handling. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1815–1821. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Pedagadi, S.; Orwell, J.; Velastin, S.; Boghossian, B. Local Fisher discriminant analysis for pedestrian reidentification. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3318–3325. [Google Scholar]
- Ma, B.; Su, Y.; Jurie, F. Covariance Descriptor based on Bio-inspired Features for Person Re-identification and Face Verification. Image Vis. Comput. 2014, 32, 379–390. [Google Scholar] [CrossRef]
- Mahalanobis, P.C. On the generalized distance in statistics. Proc. Natl. Inst. Sci. USA 1936, 2, 49–55. [Google Scholar]
- Yilmaz, A.; Javed, O.; Shah, M. Object Tracking: A Survey. ACM Comput. Surv. 2006, 38, 13-es. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Ma, Y.; Soatto, S.; Kosecka, J.; Sastry, S.S. An Invitation to 3-D Vision: From Images to Geometric Models; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Bishop, G.; Welch, G. An introduction to the Kalman filter. Spec. Interest Group Comput. Graph. Interact. Tech. (SIGGRAPH) 2001, 8, 27599-3175. [Google Scholar]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [PubMed]
- Yan, W.; Weber, C.; Wermter, S. A hybrid probabilistic neural model for person tracking based on a ceiling-mounted camera. J. Ambient Intell. Smart Environ. 2011, 3, 237–252. [Google Scholar] [CrossRef]
- García, J.; Gardel, A.; Bravo, I.; Lázaro, J.L.; Martínez, M.; Rodríguez, D. Directional people counter based on head tracking. IEEE Trans. Ind. Electron. 2013, 60, 3991–4000. [Google Scholar] [CrossRef]
- Gustafsson, F. Particle filter theory and practice with positioning applications. IEEE Aerosp. Electron. Syst. Mag. 2010, 25, 53–82. [Google Scholar] [CrossRef]
- Choi, J.W.; Moon, D.; Yoo, J.H. Robust Multi-person Tracking for Real-Time Intelligent Video Surveillance. Electron. Telecommun. Res. Inst. J. 2015, 37, 551–561. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Kamen, E.W.; Su, J.K. Introduction to Optimal Estimation; Springer: London, UK, 1999. [Google Scholar]
- Zarchan, P.; Musoff, H. Fundamentals of Kalman Filtering: A Practical Approach; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2000. [Google Scholar]
- Liem, M.C.; Gavrila, D.M. Joint multi-person detection and tracking from overlapping cameras. Comput. Vis. Image Underst. (CVIU) 2014, 128, 36–50. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 25, 120–126. [Google Scholar]
- Kuo, C.H.; Nevatia, R. How does person identity recognition help multi-person tracking? In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1217–1224. [Google Scholar]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple People Tracking by Lifted Multicut and Person Re-identification. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3539–3548. [Google Scholar]
- Beyer, L.; Breuers, S.; Kurin, V.; Leibe, B. Towards a Principled Integration of Multi-Camera Re-Identification and Tracking Through Optimal Bayes Filters. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 29–38. [Google Scholar]
- Liu, C.; Change Loy, C.; Gong, S.; Wang, G. POP: Person Re-identification Post-rank Optimisation. In Proceedings of the International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 441–448. [Google Scholar]
- Leng, Q.; Hu, R.; Liang, C.; Wang, Y.; Chen, J. Person re-identification with content and context re-ranking. Multimed. Tools Appl. 2015, 74, 6989–7014. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking Person Re-identification with k-Reciprocal Encoding. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3652–3661. [Google Scholar]
- Karanam, S.; Gou, M.; Wu, Z.; Rates-Borras, A.; Camps, O.; Radke, R.J. A Systematic Evaluation and Benchmark for Person Re-Identification: Features, Metrics, and Datasets. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 523–536. [Google Scholar] [CrossRef]
- Lin, S. Rank Aggregation Methods. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 555–570. [Google Scholar] [CrossRef]
- Pacuit, E. Voting Methods. In The Stanford Encyclopedia of Philosophy; Zalta, E.N., Ed.; Stanford University: Stanford, CA, USA, 2017. [Google Scholar]
- Gehrlein, W.V. Condorcet’s paradox. Theory Decis. 1983, 15, 161–197. [Google Scholar] [CrossRef]
- Hummel, R.A.; Landy, M.S. A Statistical Viewpoint on the Theory of Evidence. IEEE Trans. Patern Anal. Mach. Intell. 1988, 10, 235–247. [Google Scholar] [CrossRef][Green Version]
- Challa, S.; Koks, D. Bayesian and Dempster-Shafer Fusion. Sādhanā 2004, 29, 145–174. [Google Scholar] [CrossRef]
- Anderson, T.W. An Introduction to Multivariate Statistical Analysis; Wiley: New York, NY, USA, 1958. [Google Scholar]
- van der Helm, H.J.; Hische, E.A. Application of Bayes’s theorem to results of quantitative clinical chemical determinations. Clin. Chem. 1979, 25, 985–988. [Google Scholar] [CrossRef]
- Chen, A.T.Y.; Biglari-Abhari, M.; Wang, K.I.K. A Computationally Efficient Pipeline for Camera-based Indoor Person Tracking. In Proceedings of the Image and Vision Computing New Zealand (IVCNZ), Christchurch, New Zealand, 4–6 December 2017. [Google Scholar]
- Figueira, D.; Taiana, M.; Nambiar, A.; Nascimento, J.; Bernardino, A. The HDA+ Data Set for Research on Fully Automated Re-identification Systems. In Proceedings of the European Conference on Computer Vision Workshop (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 241–255. [Google Scholar]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef]
- De Smedt, F.; Goedemé, T. Open framework for combined pedestrian detection. In Proceedings of the International Conference on Computer Vision Theory and Applications (VISIGRAPP), Berlin, Germany, 11–14 March 2015; pp. 551–558. [Google Scholar]
- Nguyen, V.; Ngo, T.D.; Nguyen, K.M.T.T.; Duong, D.A.; Nguyen, K.; Le, D. Re-ranking for person re-identification. In Proceedings of the International Conference on Soft Computing and Pattern Recognition (SoCPaR), Hanoi, Vietnam, 15–18 December 2013; pp. 304–308. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Model | Accuracy (%) | |
|---|---|---|
| One-Shot Learning | Unsupervised Learning | |
| Spatio-temporal Only | 33.3 | 31.7 |
| Appearance Only | 51.9 | 48.8 |
| Both Fused Together | 65.7 | 61.6 |
| Classification Model | Accuracy (%) | |
|---|---|---|
| One-Shot Learning | Unsupervised Learning | |
| Spatio-temporal Only | 34.3 | 30.6 |
| Appearance Only | 53.8 | 47.1 |
| Both Fused Together | 69.4 | 56.7 |
| Person Detection Method | System Accuracy (%) | Computation Time (ms) | Computation Time (fps) |
|---|---|---|---|
| DPM | 63.5 | 102 | 9.8 |
| ACF | 56.7 | 44.8 | 22.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, A.T.-Y.; Biglari-Abhari, M.; Wang, K.I.-K. Fusing Appearance and Spatio-Temporal Models for Person Re-Identification and Tracking. J. Imaging 2020, 6, 27. https://doi.org/10.3390/jimaging6050027
Chen AT-Y, Biglari-Abhari M, Wang KI-K. Fusing Appearance and Spatio-Temporal Models for Person Re-Identification and Tracking. Journal of Imaging. 2020; 6(5):27. https://doi.org/10.3390/jimaging6050027
Chicago/Turabian StyleChen, Andrew Tzer-Yeu, Morteza Biglari-Abhari, and Kevin I-Kai Wang. 2020. "Fusing Appearance and Spatio-Temporal Models for Person Re-Identification and Tracking" Journal of Imaging 6, no. 5: 27. https://doi.org/10.3390/jimaging6050027
APA StyleChen, A. T.-Y., Biglari-Abhari, M., & Wang, K. I.-K. (2020). Fusing Appearance and Spatio-Temporal Models for Person Re-Identification and Tracking. Journal of Imaging, 6(5), 27. https://doi.org/10.3390/jimaging6050027