1. Introduction
Automatic vehicle navigation is typically performed using the global positioning system (GPS). However, GPS-based navigation could become unreliable due to several reasons, such as, interference from other systems, issues with signal strength, limitations in receiver sensitivity, and unavailability of maps. Therefore, it is advantageous to have a back-up system to take over the navigation process in case of such issues. Vision-based navigation is an alternative solution, in which street sign recognition plays a major role. Also, due to improper maintenance and the use of non-contrasting colours, people with vision impairments may find it difficult to read street signs. Automatic street sign recognition can be used to aid such individuals as well.
Street signs typically contain alphanumerical characters, the identification of which has received much focus in recent years, specifically in the context of scanned books and documents [
1,
2,
3,
4]. Street sign recognition, like other similar problems such as license plate and transport route recognition, typically consists of three stages: (i) extraction of the region of interest (ROI) from the image, (ii) segmentation of characters, and (iii) character recognition [
5]. For ROI extraction and character segmentation, researchers use many different methods, the majority of which are based on image thresholding. Classifiers are usually trained for the character recognition task.
A street name detection and recognition method in the urban environment was developed by Parizi et al. [
6]. First, they used Adaboost [
7] to detect the ROI. Then, they used histogram-based text segmentation and scale-invariant feature transform (SIFT) [
8] feature matching for text image classification. An approach for text detection and recognition in road panels was introduced by Gonzalez et al. [
9]. For character text localisation, they used the maximally stable extremal regions (MSER) algorithm [
10]. An algorithm based on HMM was used for word recognition/classification.
In license plate recognition, some researchers used adaptive boosting in conjunction with Haar-like features for training cascade classifiers [
11,
12,
13]. Others used template matching to recognise number plate text [
14,
15,
16,
17]. Dia et al. [
18] proposed a method for character recognition in license plates which was based on histogram projection, fuzzy matching, and dynamic programming. In Hegt et al. [
19], a feature vector was generated from the Hotelling transform [
20] of each character. The charters were then classified based on a distance measure between their Hotelling transformed counterparts and Hotelling transformed prototypes. Others employed feature extraction methods (such as, (LBP) [
21], Haar-like [
22], and bag-of-features (BoF) [
23]) coupled with classifiers (such as artificial neural networks (ANN) [
24,
25,
26], support vector machines (SVM) [
27], and hidden Markov models (HMM) [
28]) for character recognition. Similarly, Leszczuk et al. [
29] introduced a method for the recognition of public transportation route numbers based on optical character recognition (OCR). Intelligence transportation systems use a similar process of segmenting the region of interest from and images and identifying text using optical character recognition to read traffic signs [
1,
2,
3,
5,
29,
30,
31,
32,
33,
34,
35].
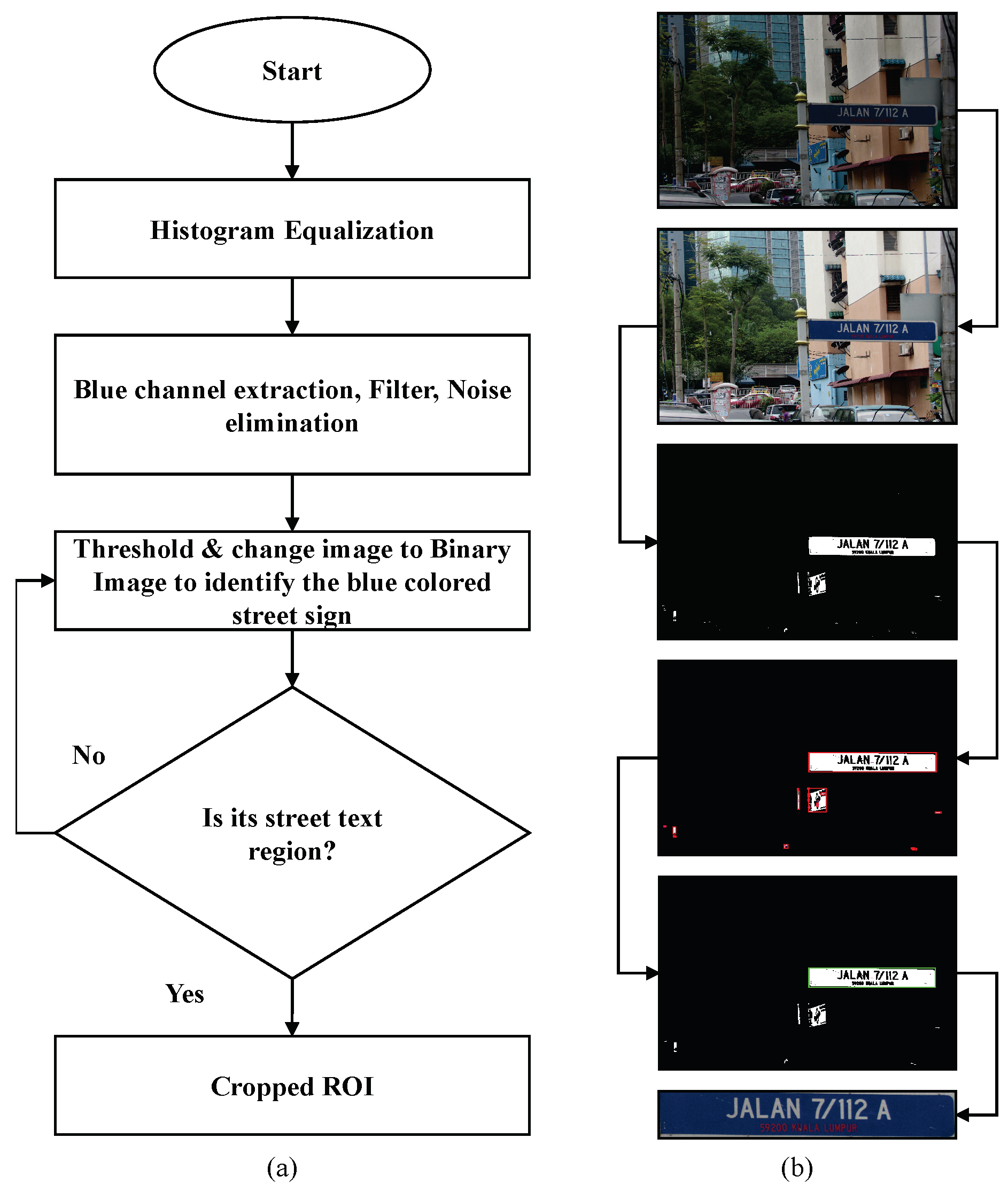
In this paper, we discuss the development of an intelligent identification and interpretation system for Malaysian street signs. The system consists of the following steps: (1) real-time capture of images using a digital camera mounted on the dashboard of a vehicle, (2) segmentation of the street sign from each frame captured by the camera, (3) extraction of characters from the segmented image, (4) identification of the street sign, and (5) presentation of the identified street sign as a verbal message. We showed through experimental results that the proposed method is effective in real-time applications and comparable with other similar existing methods. The remainder of the paper is organised as follows. The proposed methodology for street sign recognition and interpretation is described in
Section 2. The experimental setup and results (including performance comparisons) are discussed in
Section 3.
Section 4 concludes the paper.
3. Experimental Results
To conduct the experiments, a Dell latitude E6420 (Dell Inc., Round Rock, TX, USA) computer running windows 10 professional (64-bit) powered by Intel® Core™ (Intel, Santa Clara, CA, USA) i5 2.5 GHz processor, and 8 GB of RAM (Dell Inc., Round Rock, TX, USA) was used. The system and related experiments were implemented using MATLAB (R2016a) (MathWorks, Natick, MA, USA) image processing, computer vision, and neural network toolboxes.
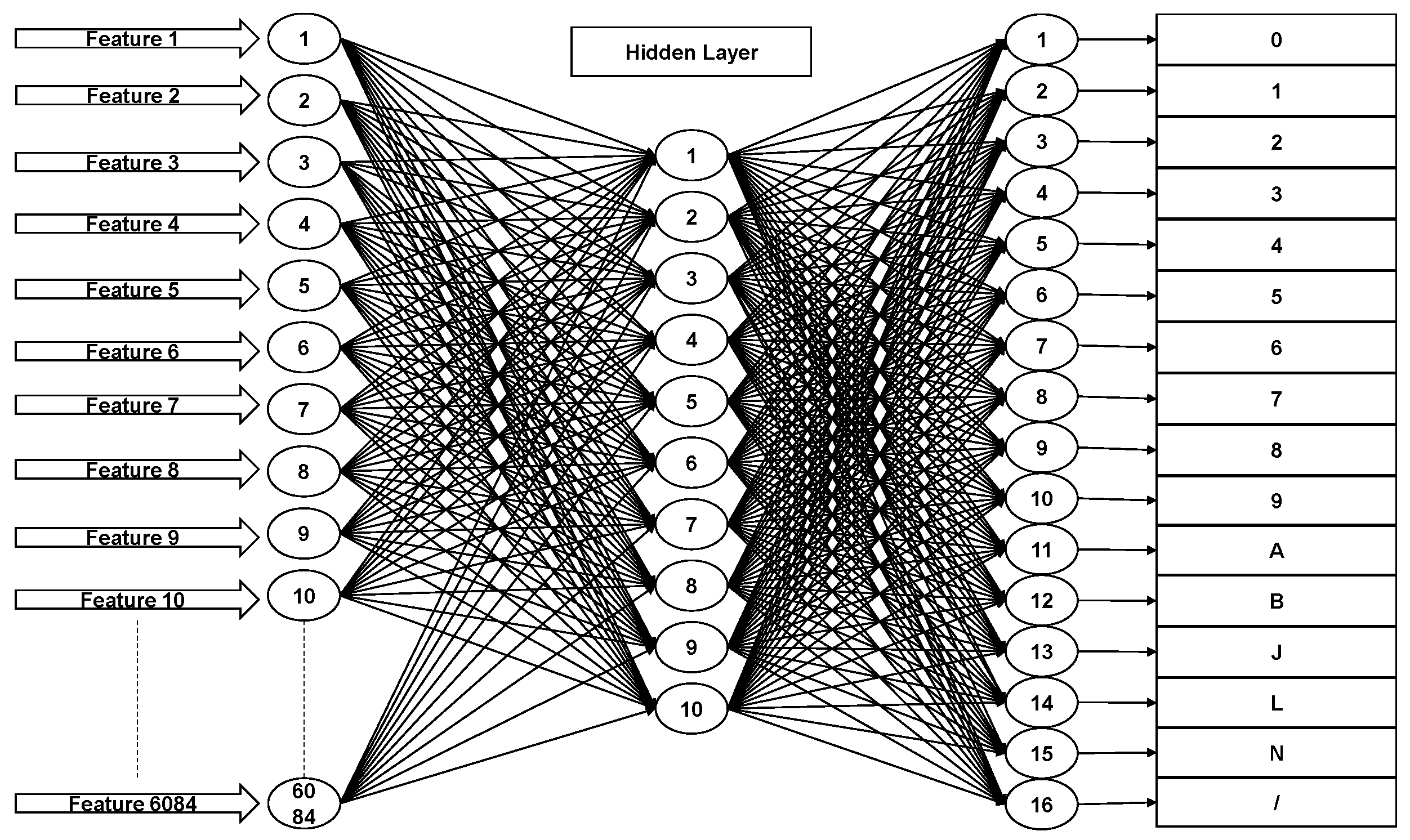
3.1. Training Performance of the Neural Network
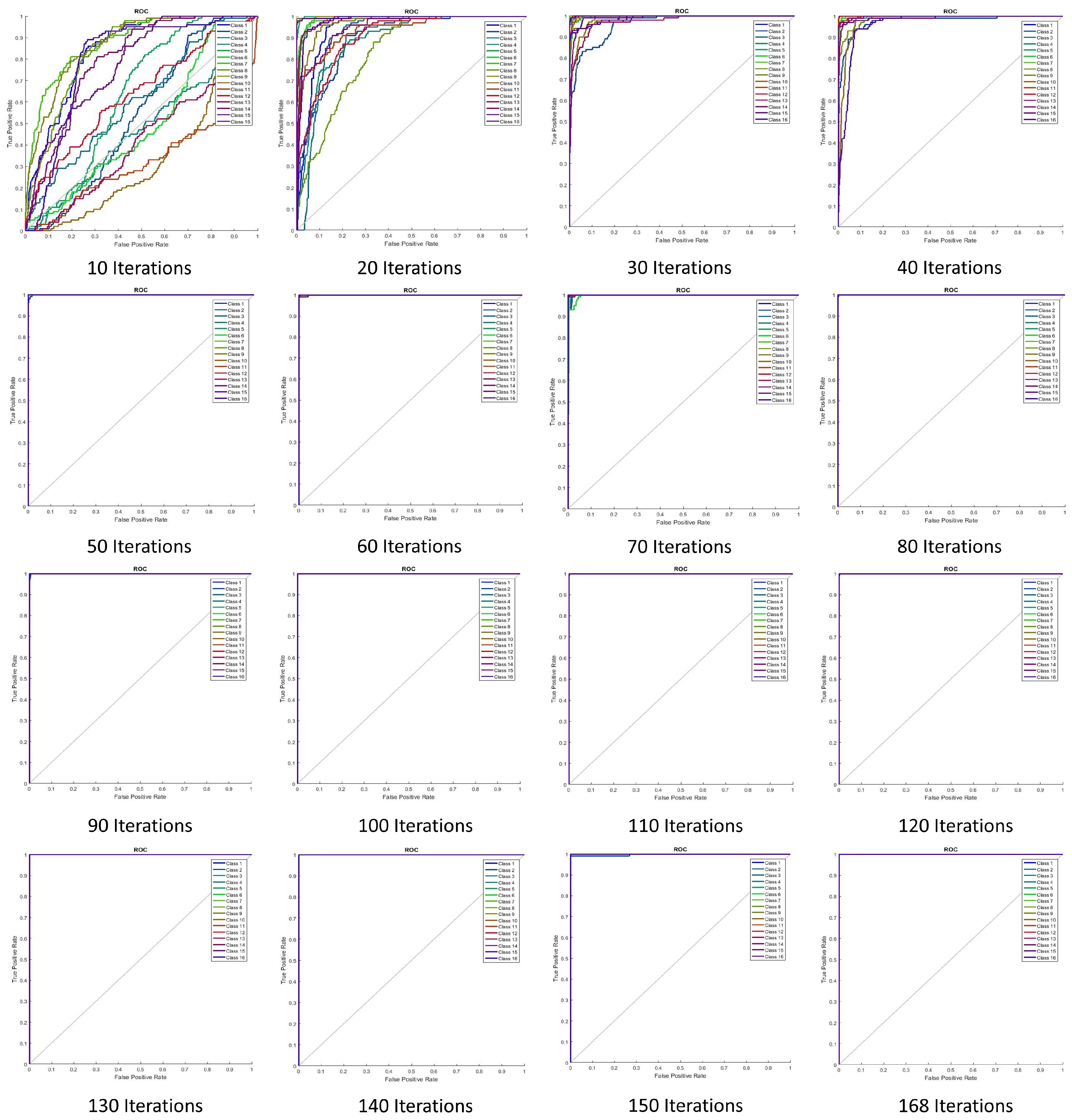
The training performance of the neural network for several training iterations is shown in
Table 2. Training number 16 with 168 iterations provided the best error rate (0%), and as such was considered the optimal training number for the proposed system.
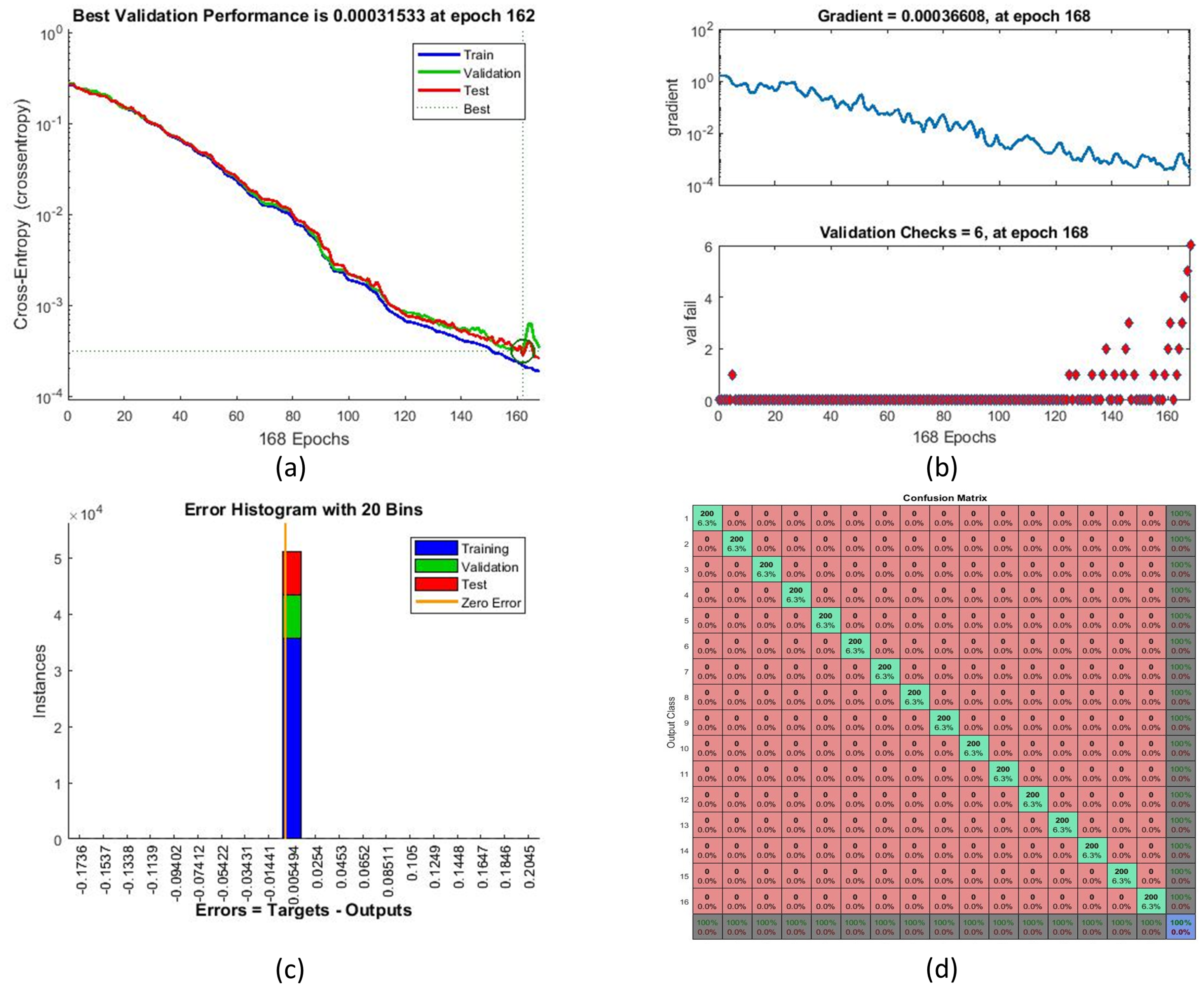
Figure 9 illustrates the training performance with respect to parameters such as cross-entropy error. Receiver operating characteristic (ROC) curves and the performance of ANN training are shown in
Figure 10. Perfect classification results were seen at 168 iterations.
3.2. Performance on Testing Data
Data that had not been used in the training process was used to test the performance of the neural network classifier. The testing dataset was extracted from images of the street sign from Malaysian street signs using the process discussed in
Section 2. Each class contained 100 test samples, resulting in a total of 1600 samples (see
Figure 11).
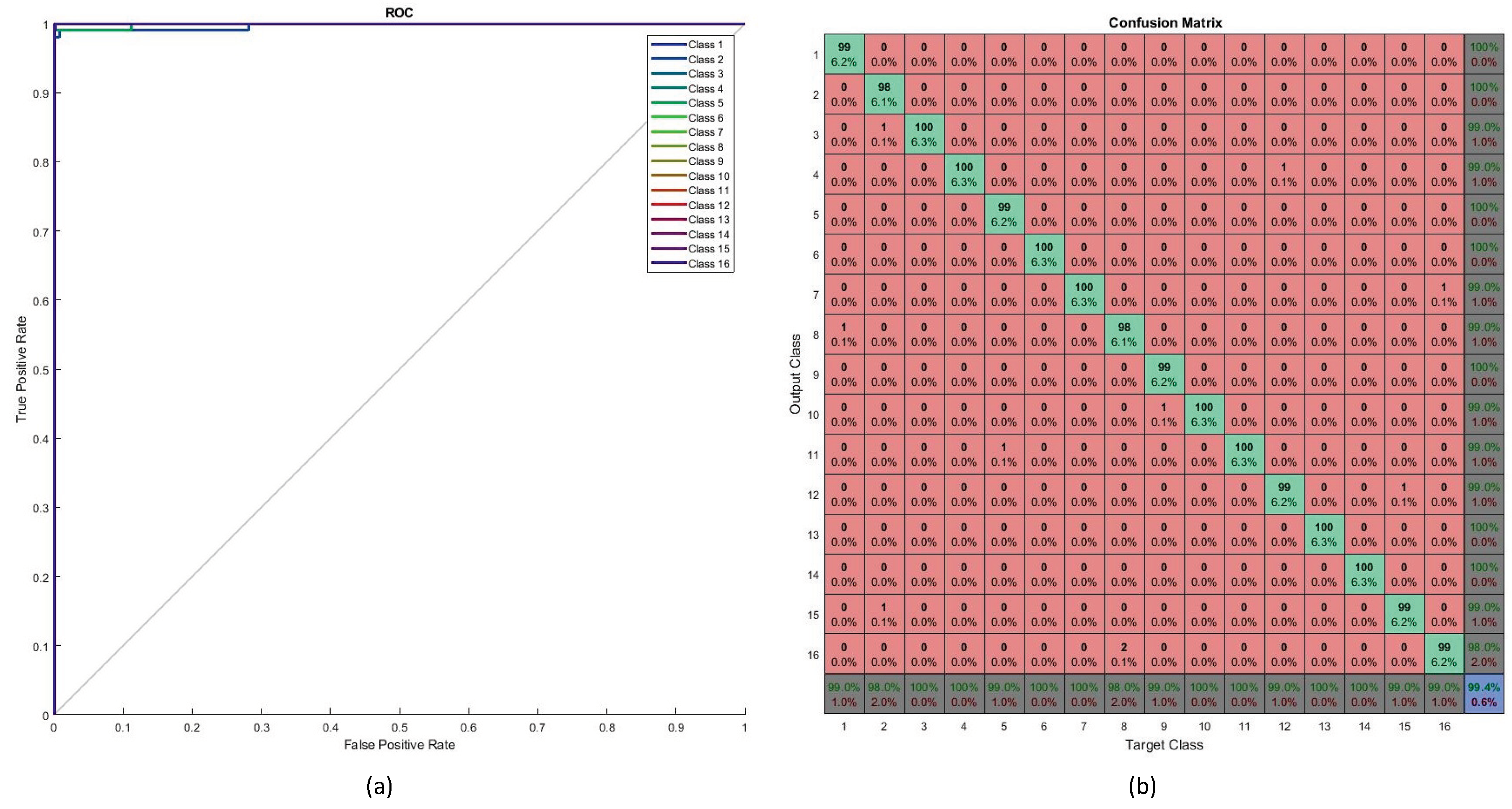
Testing performance is shown in
Figure 12. The ROC curve (as shown in
Figure 12a) determines the values of the area under curve (AUC) for all testing samples (16 classes). Most of the classes achieved perfect AUC as seen from the figure. The confusion matrix for the testing data is shown in
Figure 12b. The overall percentage of correct classification was 99.4%. The highest levels of misclassification were observed in the class pairs of ‘7’ and ‘/’, ‘1’ and ‘7’ and ’2’ and ’N’.
Figure 13 shows some characters that led to miscalssifications.
Testing performance with respect to some common metrics, along with how they were calculated based on the the number of true negative (TN), true positive (TP), false negative (FN), and false positive (FP) classifications, is shown in
Table 3.
3.3. Comparison of ROI Extraction using Different Colour Spaces
To observe if choice of colour space used in the ROI extraction played a significant role in the performance of our method, we compared the original method based on the RGB colour space with those using other colour spaces such as HSV, YCbCr, and CIEL*a*b* [
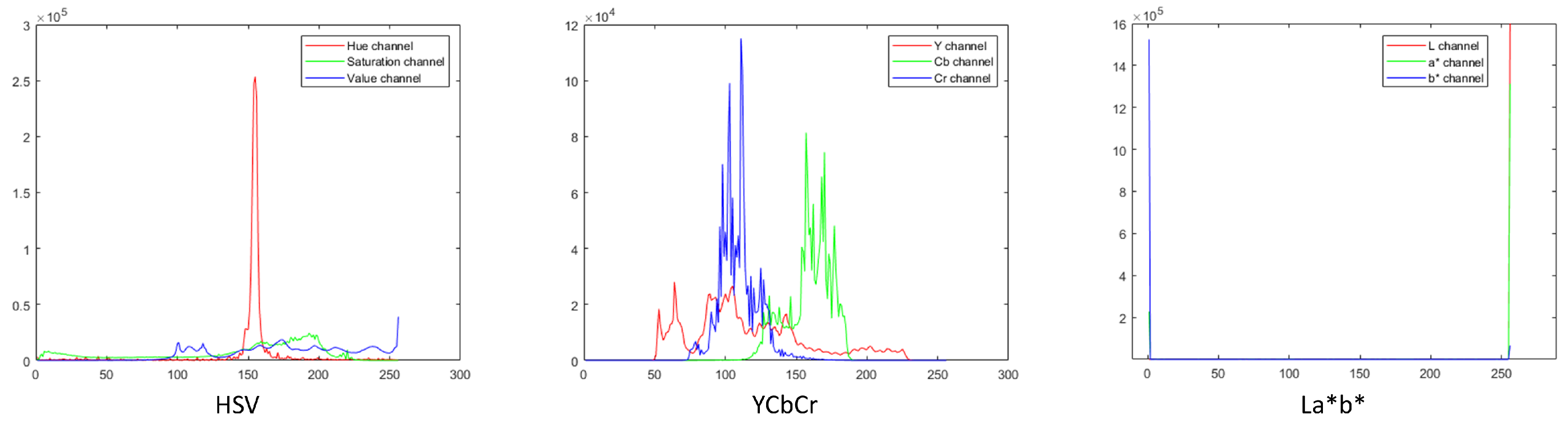
38]. First, we manually cropped 20 images to extract the ROI. Then, we created the colour profiles for these extracted regions in each colour space.
Figure 14 shows the colour profile histograms for HSV, YCbCr, and CIEL*a*b* colour spaces. Next, for each channel in a colour space, we calculated the value range using mean (
) and standard deviation (
) as
. This value range was then used to threshold the ROI from the image. Comparison results with respect to the different ROI extraction methods are shown in
Table 4. As seen from the comparison results, the choice of colour space does not significantly affect the performance of the system.
3.4. Comparison of Different Feature Extraction Methods
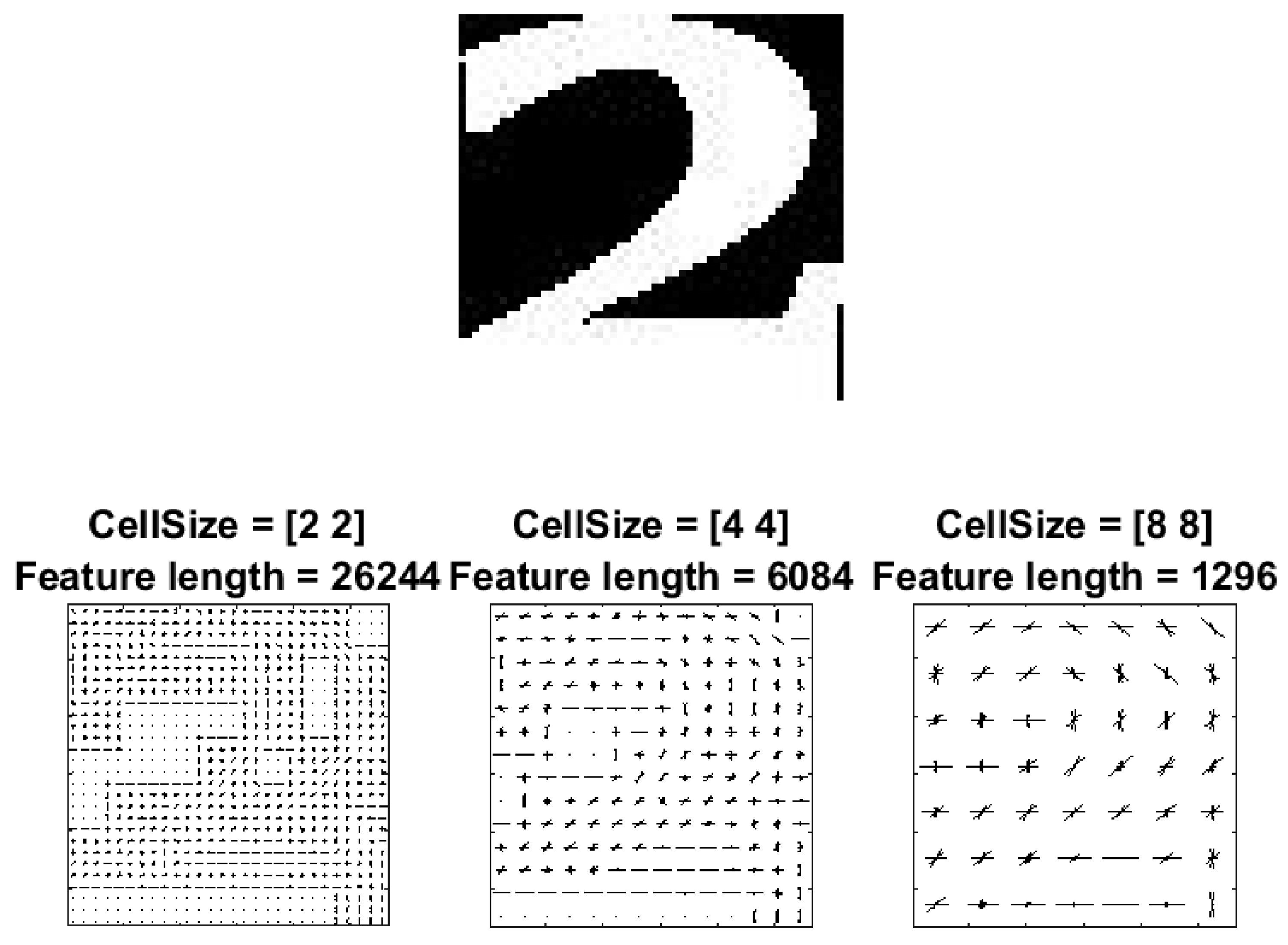
To explore the effect of the feature extraction method, we compared the classification performance when using the original HOG features and some others that are often used in the literature: local binary patterns (LBP) [
21], Haar-like [
22], and bag-of-features (BoF) [
23]. We used our ANN as the classifier. We considered accuracy and average time to extract features across all images to be measures of performance in this comparison.
Table 5 shows the results. From this comparison, we observe that HOG provides the best accuracy and a comparable level of efficiency.
3.5. Comparison with Similar Existing Methods
To evaluate the performance of the proposed method on the Malaysian street sign database, we compared it to some similar existing methods. For example, Kamble et al. [
39] discussed handwritten character recognition using rectangular HOG (R-HOG) feature extraction and used a feed-forward neural network (FFANN) and a support vector machine (SVM) for classification. Su et al. [
40] also investigated the character recognition task in natural scenes. They used convolutional co-occurrence HOG (CHOG) as their feature extractor and SVM as their classifier. Tian et al. [
41] performed text recognition with CHOG and SVM. Boukharouba et al. [
42] classified handwritten digits using a chain code histogram (CCH) [
43] for feature extraction and a SVM for classification. Niu et al. [
44] introduced a hybrid method for recognition of handwritten digits. They used a convolution neural network (CNN) to extract the image features and fed them to a hybrid classifier for classification. Their hybrid classifier contained a CNN and SVM. For the purpose of comparison, we re-implemented these methods and trained and tested them on our database. The pre-processing procedure discussed above was performed to extract text from the images for all compared methods.
Table 6 shows the comparison results.
3.6. Comparison of Methods with Respect to the MNIST Database
To investigate the transferability of the proposed method, we compared its performance with the above methods on a publicly available text image database. For this purpose, we used the modified national institute of standards and technology (MNIST) database [
45]. As this database only contains text images, no pre-processing (as discussed in
Section 2.2) was required. As such, only feature extraction and classification methods were considered here.
Table 7 shows the comparison results. The execution time here refers to the average time (in seconds) for feature extraction and recognition of a single character. We observed that the method discussed in Niu et al. [
44] performed best with respect to classification accuracy. The proposed method was slightly less accurate, but shows the best execution time.
4. Conclusions
In this paper, we presented a system for Malaysian street sign identification and interpretation in real-time. The proposed system consisted of a few steps: image acquisition, extraction of the region of interest (i.e., the street sign) from the image, extraction of text, calculation of features (histogram of oriented gradients) from the text, recognition or classification of the text (using a neural network), and the presentation of the identified text visually and verbally. Experimental results showed high performance levels (including when compared to other similar existing methods), indicating that the proposed system is effective in recognising and interpreting Malaysian street signs.
As such, it can be used as an alternative/backup to GPS-based navigation and as an aid for visually impaired individuals. In future work, we will investigate the use of deep learning techniques in the recognition system. We will also explore how this system can be used for identifying street signs in other countries and under difficult imaging conditions (such as low-lit environments at night). We will also extend it to be used in other similar applications such as license plate detection and traffic sign detection. Furthermore, we will also consider methods to possibly improve detection levels, for example, the removal of deformations (such as that caused by perspective projection) as a pre-processing step.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}